- Linux常用命令
- [root@AAAA7 ~ ]# 代表什么意思?
- 命令行模式下,几个快捷键
- Linux工作在bash平台,bash命令分类:
- compgen -c ->想要知道当前系统支持的所有命令的列表,需要怎么做?
- command
- hostname 显示和设置系统的主机名称
- 修改主机名,永久生效(hostname)three methods
- hostid 打印当前主机的十六进制数字标识
- pwd绝对路径方式显示用户当前工作目录
- pwdx查看Linux程序的工作目录
- envsubst
- dirs显示目录记录
- dir 和ls差不多
- tty:查看当前所属的虚拟终端,并且实现虚拟终端之间的通信?
- 查看所有或当前shell类型:
- 查看Linux系统信息
- watch 以周期性的方式执行给定的指令,指令输出以全屏方式显示
- w、who、whoami、ac
- reboot shutdown poweroff halt(普通用户无法操作)
- 退出当前会话(3种)
- 路径的分类与理解
- date 显示或设置系统时间与日期
- hwclock 硬件时钟访问工具,显示,设置
- time 统计给定命令所花费的总时间
- Bash Shell 的会话超时时间的环境变量
- cal 用于显示当前日历,或者指定日期的日历。
- echo打印shell变量的值,或者直接输出指定的字符串
- tput命令是Linux下的一个用于控制终端输出的工具。它可以设置终端的属性、颜色、光标位置等
- 通过什么命令指定终端命令提示符?
- wc 用来计算数字(行号、单词数、字节数)
- 更改登录信息
- 获取随机字符串或数字
- tr 字符转换命令
- seq 用于产生从某个数到另外一个数之间的所有整数
- eval 将会首先扫描命令行进行所有的替换
- dd 用于复制文件并对原文件的内容进行转换和格式化处理
- getent 用来察看系统的数据库中的相关记录
- 一次性执行多个命令,用分号隔开;
- 排序命令
- 你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
- dirs 如果你的助手想要打印出当前的目录栈,你会建议他怎么做?
- 哪一个bash内置命令能够进行数学运算。
- comm两个文件之间的比较
- diff 在最简单的情况下,比较给定的两个文件的不同
- patch 用于为开放源代码软件安装补丁程序
- diff3 用于比较3个文件
- 更改系统当前语言
- 定义语言环境命令
- 获取文件的文件名或者目录
- wget/curl 下载工具
- 域名查询工具
- ulimit 控制shell程序的资源
- 终端是哪个文件?黑洞是哪个文件?
- ldd 打印程序或者库文件所依赖的共享库列表
- lsmod 用于显示已经加载到内核中的模块的状态信息
- lspci 显示当前主机的所有PCI总线信息,以及所有已连接的PCI设备信息
- mii-tool 用于查看、管理介质的网络接口的状态
- lsusb 用于显示本机的USB设备列表,以及USB设备的详细信息
- convert非常强大的图片处理工具
- 当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
- 文件基于行随机shuf
- jq 可以用来解析json
- parallel用于并行执行多个相近的命令
- 为指定的可执行文件设置特殊权限
Linux常用命令
[root@AAAA7 ~ ]# 代表什么意思?

root:代表当前用户名@:固定GrammarAAAA7:主机名~:当前的工作目录#:代表当前用户为root$:普通用户提示符
Notice:root用户的工作目录默认在/root下,而普通用户的默认工作目录/home/USER
命令行模式下,几个快捷键
-
alt + 鼠标:可以移动命令框 -
shift+ctrl+加号终端字体放大 -
ctrl+减号终端字体缩小 -
ctr+a/e/u/k/w/"XX"YY/:选中要复制的内容,然后按住滚轮,就相当于复制粘贴 -
Ctrl+shift +,打开多个终端/Ctrl+d,删除终端 -
shift+ctrl+N` 快速打开一个终端
-
ctrl+?撤销前一次输入 ctrl+r输入单词搜索历史命令-
ctrl+t前后字符进行替换 -
ctr+a/e/u/k/w/跳到命令行首、行尾、删除光标之前的内容、删除光标之后的内容、删除光标之前的一个单词
在命令模式下:shift+pageup/pagedown,上下翻页
Linux查看命令时:几个快捷
b-->back向文件的首部翻屏
[space] 或者f -->向文件的尾部翻屏
enter-->向文件的尾部翻一行
ctrl+u-->向文件首部翻半屏
ctrl+d-->向文件尾部翻半屏
shift+{pageup|pagedown} --> 翻一屏
G-->跳转至文件尾页
{1G|g} --> 跳转至文件首也
如何实现在文件中查找文件搜索:
/heyword:正向查看关键字
?/keyword:逆向查找关键字
Notice:在使用过程中,若出现多个关键字,使用n查看下一个,使用N返回查看上一个
退出文件查看:q
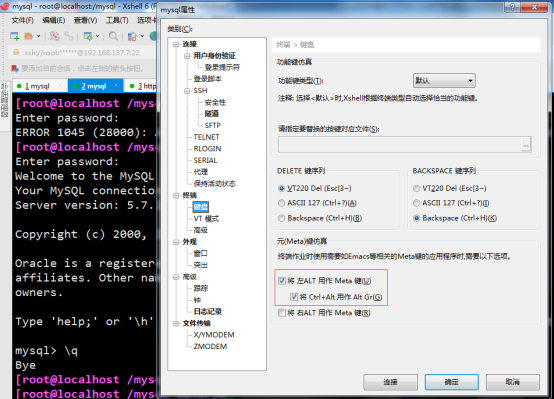
xshell连接服务器下的快捷键
-
ctrl+tab / shift+tab在xshell切换窗口
-
ctrl+d 或者exit或者logout 关闭远程连接
-
alt+r 透视化界面
-
alt+o 打开会话
-
alt+p 打开属性(相当于如果需要新建远程的那个界面)
-
alt+s 显示或隐藏菜单栏(就是就上面的那个所有菜单栏)
-
alt+enter 全屏
-
ctrl+shift+r 重新连接
-
Ctrl + a - 光标移动到行首
-
Ctrl + e - 光标移动到行尾
-
Ctrl + c - 终止当前程序
-
Ctrl + d - 如果光标前有字符则删除,没有则退出当前中断
-
Ctrl + l - 清屏
-
Ctrl + u - 剪切光标以前的字符
-
Ctrl + k - 剪切光标以后的字符
-
Ctrl + y - 复制u/k的内容
-
Ctrl + r - 查找最近用过的命令
-
Ctrl + o --- 查找下面的历史命令
-
Ctrl + p --- 查找上面的历史命令
-
tab - 命令或路径补全
-
Ctrl+shift+c - 复制
-
Ctrl+shift+v - 粘贴
选中该项,在xshell终端上,按住alt + .(点),会查找历史命令的最后一部分参数;相当于!$
Linux工作在bash平台,bash命令分类:
分类:内置命令、外部命令
内置命令:
在bash中内部实现的命令被称为内置命令
外部命令:
通过发行商或者自定义,在文件系统上的某个位置有一个与命令名称相对应的可执行文件
区分命令是内置命令还是外置命令:
type -a echo
#或者
type echo
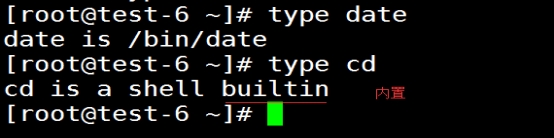
可以进入bin目录里面查看
查看命令帮助
查看内置命令帮助用help
# 语法:help+COMMAND
help cd
查看外部命令帮助用man
man+COMMAND -> man date
man -k "copy files" ->-k使得与cpoy files相关的帮助手册都显示出来了
man的分段机制:

总结:Linux命令Grammar格式及详细信息
所有的命令大致分为:
#COMMAND 选项S ARUMENTS
命令 选项 参数
COMMAND:内置命令、外置命令
选项S:长选项、短选项
长选项:--Keywords
eg:date –- --all
短选项:--Keywords
eg:-a
短选项与长选项的区别:多个短选项可以合并成一个长选项,多个长选项不能合并成一个
[]:可选部分,可以拥有括号内的内容,也可以没有
[A|B|C……]:既可以是A参数表示,又可以是B参数表示,也可以是C参数表示……
{A|B|C……}:代表分组之意,要么B,要么C……
<>:尖括号内的内容“必不可少的”
…:代表同类的内容可以出现多个
清除 bash 历史:

compgen -c ->想要知道当前系统支持的所有命令的列表,需要怎么做?
使用命令compgen -c,可以打印出所有支持的命令列表。
[root@test-6 ~]# compgen -c | wc –l #(查看有多少个)
[root@test-6 ~]# compgen -c > 1.txt #(重定向到1.txt里面)
compgen: compgen [-abcdefgjksuv] [-o 选项] [-A 动作] [-G 全局模式] [-W 词语列表] [-F 函数] [-C 命令] [-X 过滤模式] [-P 前缀] [-S 后缀] [词语]
依据选项显示可能的补完。
意图在能产生可能的补完的 shell 函数内部使用。
如果提供了可选的 WORD 参数,则产生按照 WORD
进行的匹配。
退出状态:
除非使用了无效选项或者错误发生,否则返回成功。
command
command命令调用指定的指令并执行,命令执行时不查询shell函数。command命令只能够执行shell内部的命令
command -v yum
hostname 显示和设置系统的主机名称
hostname命令用于显示和设置系统的主机名称。环境变量HOSTNAME也保存了当前的主机名。
在使用hostname命令设置主机名后,系统并不会永久保存新的主机名,重新启动机器之后还是原来的主机名。如果需要永久修改主机名,需要同时修改/etc/hosts和/etc/sysconfig/network的相关内容
Grammar
hostname(选项)(参数)
选项
- -v:详细信息模式;
-
-a:显示主机别名;
-
-d:显示DNS域名;
-
-f:显示FQDN名称;
-
-i:显示主机的ip地址;
-
-s:显示短主机名称,在第一个点处截断;
-
-y:显示NIS域名。
参数
主机名:指定要设置的主机名。
Living Example
[root@CentOS6 ~]# hostname (显示主机名)
CentOS6.8-min

[root@CentOS6 ~]# hostname -v #(显示详细的信息)
gethostname()=`CentOS6.8-min'
CentOS6.8-min
修改主机名:
# hostname 需要修改后的名字
# exit
扩展:uname -n也可以查看主机名
[root@CentOS6 ~]# uname -n
CentOS6.8-min
修改主机名,永久生效(hostname)three methods
第一种:直接修改配置文件(6版本)
vim /etc/sysconfig/network #编辑主机名,永久生效
第二种:setup命令(6版本)
第三种:hostname 更改后的主机名
hostnamectl/hostname #查看主机名
第一种:直接修改配置文件(7版本)
vim /etc/hostname
第二种:nmtui命令
第三种:hostnamectl set-hostname 命令修改主机名,可永久生效:
[root@localhost ~]# hostnamectl set-hostname Test-7-7
[root@localhost ~]# exit
[root@test-7-7 ~]# (xshell重新连接)
hostid 打印当前主机的十六进制数字标识
hostid命令用于打印当前主机的十六进制数字标识。是主机的唯一标识,是被用来限时软件的使用权限,不可改变。
Grammar
hostid
选项
- --help:显示帮助信息;
- --version:显示版本信息。
Living Example
[root@CentOS6 ~]# hostid
00000000

pwd绝对路径方式显示用户当前工作目录
pwd命令 以绝对路径的方式显示用户当前工作目录。命令将当前目录的全路径名称(从根目录)写入标准输出。全部目录使用/分隔。第一个/表示根目录,最后一个目录是当前目录。执行pwd命令可立刻得知您目前所在的工作目录的绝对路径名称。
语法
pwd(选项)
选项
- --help:显示帮助信息;
- --version:显示版本信息。
实例
[root@localhost ~]# pwd
root
pwdx查看Linux程序的工作目录
在linux实际操作命令中,查看pid的方式有很多种,通过pid找程序路径的方式也有好几个,但是可能大家都忽略的一个很简单也是很实用的命令:pwdx
比如要查找某个java编写的程序运行情况可通过jps命令查看,然后可以通过显示的pid进行程序定位
[root:~ 16:05]# jps # 先使用jps查看当前用户启动的进程
7520 Jps
8994 nacos-server.jar
8516 nacos-server.jar
8843 nacos-server.jar
2204 pamirs-scheduler-console-1.0-SNAPSHOT.jar #查看这个程序为例
4221 Application
847 QuorumPeerMain
24911 jar
[root:~ 16:12]# pwd 2204
/root
[root:~ 16:12]# pwdx 2204
2204: /usr/local/pamirs
[root:~ 16:12]# ll /usr/local/pamirs/
total 87996
drwxrwxrwx 2 root root 4096 Nov 5 11:57 config
-rwxrwxrwx 1 root root 95 Nov 5 11:58 entrypoint.sh
-rwxrwxrwx 1 root root 35528 Nov 5 11:59 nohup.out
-rwxrwxrwx 1 root root 8744 Mar 19 2020
pamirs-schedule-console-zkconfig.txt
-rwxrwxrwx 1 root root 32012148 Feb 24 2020
pamirs-scheduler-console-1.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 29043997 Nov 5 11:42 pamirs.tar.gz
-rwxrwxrwx 1 root root 22068 Mar 19 2020 scheduler.sql
-rw-r--r-- 1 root root 28966487 Nov 5 11:30 xxpamirs.tar.gz
envsubst
envsubst命令将输出内容中的Shell变量替换成变量值
dirs显示目录记录
dirs命令 显示当前目录栈中的所有记录(不带参数的dirs命令显示当前目录栈中的记录)。
dirs始终显示当然目录, 再是堆栈中的内容;即使目录堆栈为空, dirs命令仍然只显示当然目录。
语法
dirs(选项)(参数)
选项
- -c:删除目录栈中的所有记录
-
-l:以完整格式显示
-
-p:一个目录一行的方式显示
-
-v:每行一个目录来显示目录栈的内容,每个目录前加上的编号
-
+N:显示从左到右的第n个目录,数字从0开始
-
-N:显示从右到左的第n个日录,数字从0开始
参数
目录:显示目录堆叠中的记录。
实例
[root@localhost etc]# dirs
/etc
dir 和ls差不多
dir - list directory contents
tty:查看当前所属的虚拟终端,并且实现虚拟终端之间的通信?
[root@test-7 ~]# tty (root用户当前所在的虚拟终端)
/dev/pts/0
[root@test-7 ~]# echo aaaa > /dev/pts/2
(root用户发给/dev/pts/2这个终端)
广播给所有用户:
[root@test-7 ~]# wall "The system will be shut down 10 minutes"
如果不想接收消息:mesg n
如果想接收到消息:mesg y
wall "广播dadkasllfmalsmflas" 这个全部都可以收到
默认开启服务mail:
cat /etc/init/start-ttys.conf #修改终端个数
查看所有或当前shell类型:
[root@test-7 ~]# cat /etc/shells 第一种
/bin/sh
/bin/bash
/sbin/nologin
/usr/bin/sh
/usr/bin/bash
/usr/sbin/nologin
[root@test ~]# chsh --list #第二种
[root@test ~]# chsh -l #第三种
[root@test6 etc]# echo $0 (确定当前的shell)
-bash
[root@test6 etc]# ps -p $$ (确定当前的shell)
PID TTY TIME CMD
1590 pts/0 00:00:00 bash
详看:[chsh 用户管理职添加用户那一块]{.underline}
查看Linux系统信息
1、uname
uname命令 用于打印当前系统相关信息(内核版本号、硬件架构、主机名称和操作系统类型等)
选项:
- -a或--all:显示全部的信息;
- -m或--machine:显示电脑类型;
-
-n或-nodename:显示在网络上的主机名称;
-
-r或--release:显示操作系统的发行编号;
-
-s或--sysname:显示操作系统名称;
-
-v:显示操作系统的版本;
-
-p或--processor:输出处理器类型或"unknown";
-
-i或--hardware-platform:输出硬件平台或"unknown";
-
-o或--operating-system:输出操作系统名称;
-
--help:显示帮助;
-
--version:显示版本信息。
实例:
使用uname命令查看全部信息:
uname -a #显示全部的信息
uname #单独使用uname命令时相当于uname -s
uname -i/uname -m/arch # -> x86_64位系统
uname -r #<==内核版本
uname -n #<==主机名 等于hostname
uname -v
2、查看系统是多少位
# getconf LONG_BIT
64
3、查看当前版本(6、7版本都需要自己安装)
# lsb_release -a #如果没有此命令需要安装redhat-lsb-core包
yum install redhat-lsb-core(安装)
[root@CentOS6 ~]# lsb_release -a
LSB Version:
:base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0-noarch
Distributor ID: CentOS
Description: CentOS release 6.10 (Final)
Release: 6.10
Codename: Final
4、内核版本
# cat /proc/version
Linux version 2.6.32-754.6.3.el6.x86_64
(mockbuild@x86-01.bsys.centos.org) (gcc version 4.4.7 20120313 (Red Hat
4.4.7-23) (GCC) ) #1 SMP Tue Oct 9 17:27:49 UTC 2018
5、系统版本
# cat /etc/issue
CentOS release 6.8 (Final)
Kernel \r on an \m
6、查看版本
# cat /etc/centos-release
CentOS release 6.8 (Final)
7、查看版本
# cat /etc/redhat-release

8、查看版本号
# grep -o "[0-9]\+" /etc/redhat-release | head -1
6
9、输出了系统版本信息
cat /etc/os-release
10、系统版本
cat /etc/system-release
grep -oE "[0-9.]+" /etc/redhat-release
grep -oE "[0-9.]+" /etc/issue
get_IP=$( ip addr | egrep -o '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' | egrep -v "^192\.168|^172\.1[6-9]\.|^172\.2[0-9]\.|^172\.3[0-2]\.|^10\.|^127\.|^255\.|^0\." | head -n 1 )
watch 以周期性的方式执行给定的指令,指令输出以全屏方式显示
watch命令以周期性的方式执行给定的指令,指令输出以全屏方式显示。watch是一个非常实用的命令,基本所有的Linux发行版都带有这个小工具,如同名字一样,watch可以帮你监测一个命令的运行结果,省得你一遍遍的手动运行。
Grammar
watch(选项)(参数)
选项
- -n:指定指令执行的间隔时间(秒);
-
-d:高亮显示指令输出信息不同之处;
-
-t:不显示标题。
参数
指令:需要周期性执行的指令。
Living Example
[root@CentOS6 ~]# watch ss --stplu #(通过套接字实时观察tcp、udp端口)
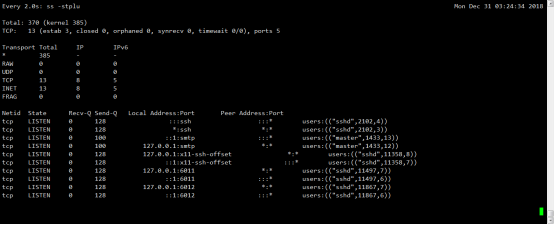
# watch uptime
# watch -t uptime
# watch -d -n 1 netstat -ntlp
# watch -d 'ls -l | fgrep goface' #监测goface的文件
# watch -t -differences=cumulative uptime
# watch -n 60 from #监控mail
# watch -n 1 "df -i;df" #监测磁盘inode和block数目变化情况
FreeBSD和Linux下watch命令的不同,在Linux下,watch是周期性的执行下个程序,并全屏显示执行结果,如:watch -n 1 -d netstat -ant,而在FreeBSD下的watch命令是查看其它用户的正在运行的操作,watch允许你偷看其它terminal正在做什么,该命令只能让超级用户使用。
w、who、whoami、ac
w 显示已经登陆系统的用户列表,并显示用户正在执行的指令
w命令用于显示已经登陆系统的用户列表,并显示用户正在执行的指令。执行这个命令可得知目前登入系统的用户有那些人,以及他们正在执行的程序。单独执行w命令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。
Grammar
w(选项)(参数)
选项
- -h:不打印头信息;
-
-u:当显示当前进程和cpu时间时忽略用户名;
-
-s:使用短输出格式;
-
-f:显示用户从哪登录;
-
-V:显示版本信息。
参数
用户:仅显示指定用户。
Living Example
[root@test6 ~]# w
16:20:35 up 7:50, 2 users, load average: 0.00, 0.01, 0.06
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 sky-20181114odd. 08:31 5.00s 0.17s 0.17s -bash
root pts/1 sky-20181114odd. 16:20 0.00s 0.13s 0.08s w
root tty1 :0 00:40 8:06m 2.99s 2.99s /usr/bin/Xorg :0 -br -verbose -audi
参数解释
load average:分别显示系统在过去1、5、15分总内的平均负载程度
USER:登陆的用户
tty1:表示在本端上面打开的终端;就是串行终端(本端就是服务器本机上面打开的)
pts/1:表示通过xshell等远程工具连接到远端的(远端就是远端的服务器)
FROM:显示用户从何处登陆系统,":0"的显示代表该用户是人X
windows(本地窗口)下,打开文本模式窗口登陆的
LOGIN@:开始登陆的时间
IDLE:用户闲置的时间,这是一个计时器,一旦用户执行任何操作,该计时器便会被重置
JCPU:以终端代号来区分,该终端所有相关的进程的进程执行时,所消耗的CPU时间会显示在这里
PCPU:CPU执行程序消耗的时间
WHAT:用户下在执行的操作
# w mysql #显示mysql用户的相关信息
09:56:23 up 47 min, 2 users, load average: 0.72, 0.28, 0.25
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
who 显示目前登录系统的用户信息
who命令是显示目前登录系统的用户信息。执行who命令可得知目前有那些用户登入系统,单独执行who命令会列出登入帐号,使用的终端机,登入时间以及从何处登入或正在使用哪个X显示器。
Grammar
who(选项)(参数)
选项
- -a:显示所有相关登陆信息
-
-b:显示上一次系统启动信息
-
-d:僵死进程
-
-l:显示系统登陆进程
-
-H或--heading:显示各栏位的标题信息列;
-
-q或--count:只显示登入系统的帐号名称和总人数;
-
-i或-u或--idle:显示闲置时间,若该用户在前一分钟之内有进行任何动作,将标示成"."号,如果该用户已超过24小时没有任何动作,则标示出"old"字符串;
-
-m:此参数的效果和指定"am i"字符串相同;
-
-s:此参数将忽略不予处理,仅负责解决who指令其他版本的兼容性问题;
-
-w或-T或--mesg或--message或--writable:显示用户的信息状态栏;
-
--help:在线帮助;
-
--version:显示版本信息。
参数
文件:指定查询文件。
Living Example
[root@test ~]# who
root pts/0 2018-12-20 14:12 (sky-20181114odd.mshome.net)
root pts/1 2019-11-14 09:10 (gateway)
root pts/2 2019-11-14 09:58 (node01)
[root@test ~]# who -q
root root root
# users=3
[root@test ~]# who -H
NAME LINE TIME COMMENT
root pts/1 2019-11-14 09:10 (gateway)
root pts/2 2019-11-14 09:58 (node01)
root pts/0 2018-12-20 14:12 (sky-20181114odd.mshome.net)
[root@test ~]# who -w
root + pts/0 2018-12-20 14:12 (sky-20181114odd.mshome.net)
whoami 显示当前有效的用户名称,相当于执行id -un命令
whoami命令用于打印当前有效的用户名称,相当于执行id -un命令。
Grammar
whoami(选项)
选项
- --help:在线帮助;
- --version:显示版本信息。
Living Example
[root@localhost ~]# whoami
root
[root@localhost ~]# id -un
root
ac 输出用户连接时间
选项
-d, --daily-totals
为每天输出输出一个总计时间,而不是在结尾输出一大的总计。输出 可能象下面这样:
Jul 3 total 1.17
Jul 4 total 2.10
-a, --all-days
如果我们在输出日总计时使用了此参数,则输出每天的记录,
而不是忽略掉没有登录活动的间隔日。没有此Option时,在这
些间隔日期间自然增长的时间被列在下一天即有登录活动的
那一天的底下。
-p, --individual-totals
为每个用户输出总计时间,并在最后追加一个所有用户的总计时间的
累计值。输出可能象下面这样:
bob 8.06
goff 0.60
[用户列表]
输出的是在用户列表中包括的所有用户的连接时间的总计和值。
用户列表由空格分隔,其中不允许有通配符。
-f, --file filename
从指定文件而不是系统的 /var/log/wtmp 文件中读取记帐信息。
--complain
当 /var/log/wtmp 存在着问题(时间扭曲,丢失记录,
或其他任何问题),输出一个适当的错误信息。
--reboots
重新引导(reboot)记录不是在系统重新引导时写的,而是
在系统重新启动(restart)时写的。所以不可能知道重新引导
的精确的发生时间。用户在系统重新引导时可能已经在系统
上登录了,许多 ac 依据用户(的要求)自动的统计在登录与重
新引导记录之间的时间(尽管所有的这些时间不应是问题,但
系统关机很长的时间时可能就是了)。如果你打算统计这个时
间,就应包括此Option。
*要求对 vanilla ac 的兼容性,就要包含此Option*
--supplants
有时,注销记录没有写出明确的终端,因而
最近的用户的自然增长的时间就不能被计算。如果你打算
包括在一个终端上的从用户登录到下一次登录的时间(尽管
可能是不正确的),就应包括此Option。
*要求对 vanilla ac 的兼容性,就要包含此Option*
--timewarps
一些时候,在 @WTMP_FILE_LOC 文件中的记录可能突然跳回
到了以前的时间而却没有时钟更改记录出现。在这种情况
发生时,不可能知道用户登录了多长时间。如果你打算依据
用户(的要求)统计从登录到时间扭曲之间的时间,就应包括
此Option。
*要求对 vanilla ac 的兼容性,就要包含此Option*
--compatibility
这是上面三种Option的速写,就不用敲三次键盘了。
--tw-leniency num
设置时间扭曲的宽限为 num 秒。在 /var/log/wtmp 文件中
的记录可能轻微的乱了次序(最显著的是当两个登录发生在
一前一后的时期,第二个可能先写了记录)。缺省的值被设置
为60。如果程序Notice到了这个问题,除非使用了--timewarps
Option,否则不把时间赋给用户。
--tw-suspicious num
设置时间扭曲的不信任值为 num 秒. 结果 /var/log/wtmp 文
件中的两个记录超出了这个秒间隔数, 那么在 @WTMP_FILE_LOC
文件中一定存在问题 (或者你的机器已经一年没有使用了).
如果程序Notice到了这个问题,除非使用了--timewarpsOption,
否则不把时间赋给用户。
-y, --print-year
在显示日期的时候输出年份。
-z, --print-zeros
一个任何类别的总计(除了全部总计)是零,还是输出此总计。
缺省时禁止输出是零的总计。
--debug
输出冗余的内部(调试)信息。
-V, --version
在标准输出上输出版本号并退出。
-h, --help
在标准输出上输出使用方法并退出。
reboot shutdown poweroff halt(普通用户无法操作)
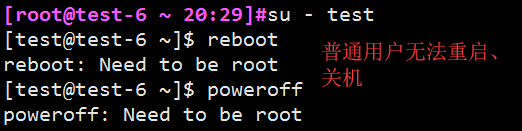
reboot 用来重新启动正在运行的Linux操作系统
Grammar
reboot(选项)
选项
- -w:仅做测试,并不真正将系统重新开机,只会把重开机的数据写入/var/log目录下的wtmp记录文件。
-
-f:强制重新开机,不调用shutdown指令的功能;
-
-d:重新开机时不把数据写入记录文件/var/tmp/wtmp。本参数具有"-n"参数效果;
-
-i:在重开机之前,先关闭所有网络界面;
-
-n:重开机之前不检查是否有未结束的程序;
Living Example
reboot #(重开机。)
reboot -w #(做个重开机的模拟(只有纪录并不会真的重开机))
shutdown 用来系统关机命令
shutdown指令可以关闭所有程序,并依用户的需要,进行重新开机或关机的动作。
Grammar
shutdown(选项)(参数)
参数
[时间]:设置多久时间后执行shutdown指令;
[警告信息]:要传送给所有登入用户的信息。
选项
- -r:shutdown之后重新启动; (相当于重启)
-
-h:将系统关机;
-
-c:取消关机或重启;
-
-k:只是送出信息给所有用户,但不会实际关机;
-
-f:重新启动时不执行fsck;
-
-F:重新启动时执行fsck;
-
-n:不调用init程序进行关机,而由shutdown自己进行;
-
-t<秒数>:送出警告信息和删除信息之间要延迟多少秒。
Living Example
# shutdown -h now (指定现在立刻关机)
指定5分钟后关机,同时送出警告信息给登入用户:
# shutdown +5 "System will shutdown after 5 minutes"
# shutdown –c (停止关机)
广播给所有用户,5分钟后将关机,实际是不会关机
# shutdown -k 5 "System will shutdown after 5 minutes"
poweroff 用来关闭计算机操作系统并且切断系统电源
Grammar
poweroff(选项)
选项
- -w:不真正关闭操作系统,仅在日志文件"/var/log/wtmp"中;
-
-n:关闭操作系统时不执行sync操作;
-
-d:关闭操作系统时,不将操作写入日志文件"/var/log/wtmp"中添加相应的记录;
-
-f:强制关闭操作系统;
-
-i:关闭操作系统之前关闭所有的网络接口;
-
-h:关闭操作系统之前将系统中所有的硬件设置为备用模式。
Living Example
[root@test-7 ~]# poweroff #(立即关闭系统)
[root@test-7 ~]# poweroff --w #(不会关机,仅在日志文件中)
halt 用来关闭正在运行的Linux操作系统。
halt命令会先检测系统的runlevel,若runlevel为0或6,则关闭系统,否则即调用shutdown来关闭系统。
Grammar
halt(选项)
选项
- -d:不要在wtmp中记录;
-
-p:halt之后,执行poweroff;
-
-f:不论目前的runlevel为何,不调用shutdown即强制关闭系统;
-
-i:在halt之前,关闭全部的网络界面;
-
-n:halt前,不用先执行sync;
- -w:仅在wtmp中记录,而不实际结束系统。
Living Example
halt -p #(关闭系统后关闭电源。)
halt -d #(关闭系统,但不留下纪录。)
退出当前会话(3种)
logout 退出当前登录的Shell、logout指令让用户退出系统
logout命令用于退出当前登录的Shell,logout指令让用户退出系统,其功能和login指令相互对应。
Grammar
logout
[root@test-6 ~]# help logout
logout: logout [n]
Exit a login shell.
Exits a login shell with exit status N. Returns an error if not executed
in a login shell.
exit 退出shell,并返回给定值
exit命令同于退出shell,并返回给定值。在shell脚本中可以终止当前脚本执行。执行exit可使shell以指定的状态值退出。若不设置状态值参数,则shell以预设值退出。状态值0代表执行成功,其他值代表执行失败。
Grammar
exit(参数)
参数
返回值:指定shell返回值。
Living Example
#退出当前shell:
[root@localhost ~]# exit
#或者
[root@localhost ~]# logout
在脚本中,进入脚本所在目录,否则退出:
cd $(dirname $0) || exit 1
在脚本中,判断参数数量,不匹配就打印使用方式,退出:
if [ "$#" -ne "2" ]; then
echo "usage: $0 <area> <hours>"
exit 2
fi
在脚本中,退出时删除临时文件:
trap "rm -f tmpfile; echo Bye." EXIT
检查上一命令的退出码:
./mycommand.sh
EXCODE=$?
if [ "$EXCODE" == "0" ]; then
echo "O.K"
fi
kill -9 $$ (这个也可以退出当前shell)
路径的分类与理解
绝对路径:每次都是从根开始的路径
相对路径:从当前工作目录开始的路径
绝对路径: 如/etc/init.d
当前目录和上层目录: ./ ../
主目录: ~/
date 显示或设置系统时间与日期
概述
很多shell脚本里面需要打印不同格式的时间或日期,以及要根据时间和日期执行操作。延时通常用于脚本执行过程中提供一段等待的时间。
日期可以以多种格式去打印,也可以使用命令设置固定的格式。在类UNIX系统中,日期被存储为一个整数,其大小为自世界标准时间(UTC)1970年1月1日0时0分0秒起流逝的秒数。
Grammar
SYNOPSIS
date [OPTION]... [+FORMAT]
date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
date(Option)(参数)
选项
- -s<字符串>:根据字符串来设置日期与时间。字符串前后必须加上双引号;
-
-d<字符串>:显示字符串所指的日期与时间。字符串前后必须加上双引号;
-
-f :调用文件内的时间,一行一行的输出 (文件内的时间必须一行一个时间)
- -R, --rfc-email 按照RFC 5322格式输出,即输出时区信息,例如: Mon, 18 Nov 2019 11:44:50 +0800
- -u:显示GMT;
- --help:在线帮助;
- --version:显示版本信息。
参数
<+时间日期格式>:指定显示时使用的日期时间格式。
日期格式字符串列表
%H 小时,24小时制(00~23)
%M 分钟(00~59)
%S 显示秒(00~59)
%R 显示时分(17:49)
%r 显示时间,12小时制(hh:mm:ss %p)
%X 显示时间的格式(%H:%M:%S 17时44分16秒)
%A 星期的全称(Sunday~Saturday)
%a 星期的简称(Sun~Sat)
%c 日期和时间(2018年12月25日 星期二 17时43分19秒)
%F 日期(2018-12-25) #常用
%T显示时间,24小时制(hh:mm:ss 17:51:09) #常用
%B 月的全称(January~December)
%d 一个月的第几天(01~31)
%j 一年的第几天(001~366)
%m 月份(01~12)
%k 小时,24小时制(0~23)
%I 小时,12小时制(01~12)
%l 小时,12小时制(1~12)
%p 显示出AM或PM
%s 从1970年1月1日00:00:00到目前经历的秒数
%Z 显示时区,日期域(CST)
%h,%b 月的简称(Jan~Dec)
%x,%D 日期(mm/dd/yy)
%w 一个星期的第几天(0代表星期天)
%W 一年的第几个星期(00~53,星期一为第一天)
%y 年的最后两个数字(1999则是99)
Living Example
查看日期
# date
Fri Sep 27 15:04:07 CST 2019
# date -R #附带显示时区
Mon, 18 Nov 2019 11:56:36 +0800
-0800表示西八区,是美国旧金山所在的时区,国家的东八区(+0800)
修改时区(改为上海时区)
所有的时区可以在/usr/share/zoneinfo下找到,设置的本地时区文件在/etc/localtime
第一种修改方法:使用命令修改(使用root确保有权限),根据提示一步步修改就可以了
tzselect
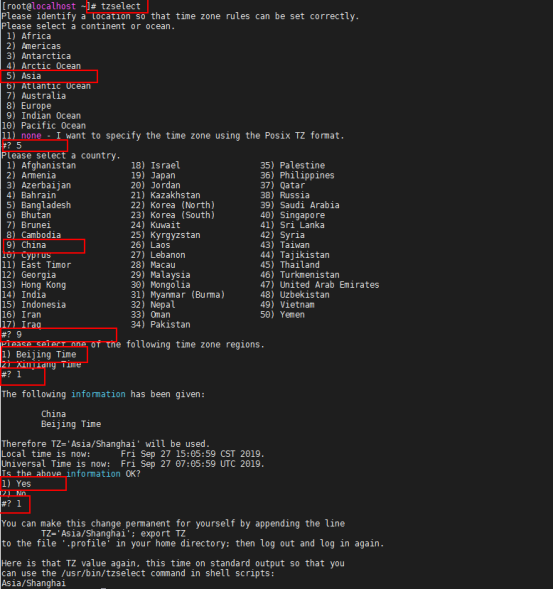
第二种方法:直接复制时区文件,强制软连接至/etc/localtime
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
centos7 查看、修改系统时间、时区
1、查看当前系统时间
# date
Thu Dec 27 15:46:19 CST 2018
2、查看当前时区
# timedatectl status
Local time: Thu 2018-12-27 15:49:12 CST
Universal time: Thu 2018-12-27 07:49:12 UTC
RTC time: Thu 2018-12-27 07:49:10
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: no
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
3、修改时间
# date -s "2018-2-22 19:10:30"
Thu Feb 22 19:10:30 CST 2018
# date
Thu Feb 22 19:10:33 CST 2018
4、修改时区(立即生效)
# timedatectl set-timezone Asia/Shanghai
5、查看硬件时间
# hwclock --show
Thu 27 Dec 2018 04:14:21 PM CST -0.490938 seconds
6、同步系统时间和硬件时间(系统时间为标准,重启init6/reboot生效)
# hwclock --hctosys
7、本地时间写入硬件时间(立即生效)
# timedatectl set-local-rtc 1
# timedatectl list-timezones # 列出所有时区
# timedatectl set-local-rtc 1 # 将硬件时钟调整为与本地时钟一致, 0 为设置为 UTC 时间
# timedatectl set-timezone Asia/Shanghai # 设置系统时区为上海
其实不考虑各个发行版的差异化, 从更底层出发的话, 修改时间时区比想象中要简单:
# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
时间同步(前提时区正确)
文档:
[root@test ~]# ntpdate time1.aliyun.com
9 Jan 11:20:27 ntpdate[8472]: step time server 203.107.6.88 offset 68577.396644 sec
或者:
[root@test ~]# ntpdate pool.ntp.org
或者:
[root@test ~]# crontab -e
1 */2 * * * /usr/sbin/ntpdate pool.ntp.org
/usr/sbin/ntpdate time1.aliyun.com
echo "#time sync" >> /var/spool/cron/root
echo "1 */2 * * * /usr/sbin/ntpdate time1.aliyun.com >/dev/null 2>&1 " >>/var/spool/cron/root
设定时间:three methods
date -s #设置当前时间,只有root权限才能设置,其他只能查看
(方法1)月/日/年 时:分:秒
# date -s 11/24/2018
2018年 11月 24日 星期六 00:00:00 CST
[root@AAAA7 ~]# date -s "11/24/2018 12:20"
2018年 11月 24日 星期六 12:20:00 CST
# date -s 23:00
2018年 11月 24日 星期六 23:00:00 CST
(方法2)年-月-日 时:分:秒
date -s "2012-05-23 01:01:01" #这样可以设置全部时间
date -s "01:01:01 2012-05-23" #这样可以设置全部时间
(方法3)年月日 时:分:秒
date -s "20120523 01:01:01" #这样可以设置全部时间
date -s "01:01:01 20120523" #这样可以设置全部时间
date -s 20120523 #设置成20120523,这样会把具体时间设置成空00:00:00
date -s 01:01:01 #设置具体时间,不会对日期做更改将时间写入bios避免重启失效。
hwclock -w
当我们进行完 Linux 时间的校时后,还需要以hwclock来更新 BIOS的时间,因为每次重新启动的时候,系统会重新由 BIOS 将时间读出来,所以,BIOS 才是重要的时间依据吶。
调用文件里面的时间一行一行的输出
[root@test6 ~]# echo "2018-10-20 10:20:20" >> time.txt
[root@test6 ~]# cat time.txt
2018-10-10 20:20:20
2018-10-20 10:20:20
[root@test6 ~]# date -f time.txt
2018年 10月 10日 星期三 20:20:20 CST
2018年 10月 20日 星期六 10:20:20 CST
文件内的时间输入错误,输出的时间久会报错
[root@test6 ~]# cat time.txt
2018-10-10 20:20:20 2018-11-11 11:11:11
2018-10-20 10:20:20
[root@test6 ~]# date -f time.txt
date: 无效的日期"2018-10-10 20:20:20 2018-11-11 11:11:11"
2018年 10月 20日 星期六 10:20:20 CST
格式化输出:
[root@test6 ~]# date +"%Y%m%d%H%M%S" (年月日时分秒)
20211125103510
[root@test6 ~]# date +"%Y-%m-%d" (年-月-日)
2009-12-07
[root@test6 ~]# date +%F (年月日)
2018-12-25
[root@test6 ~]# date +"%Y-%m-%d %H:%M:%S" (年月日 时分秒)
2018-12-25 17:40:05
[root@test6 ~]# date +"%F %T" (年月日 时分秒)
2018-12-25 17:46:30
[root@test6 ~]# date +%T (时分秒)
17:51:09
[root@test6 ~]# date +%c (年月日星期几 时分秒)
2018年12月25日 星期二 17时48分14秒
输出昨天日期:
date -d "1 day ago" +"%Y-%m-%d" (红色除了数字是固定格式)
2012-11-19
[root@learn logs]# date -d yesterday +%Y%m%d
20200311
加减操作:
date +%Y%m%d //显示当天年月日
date -d "+1 day" +%Y%m%d //显示前一天的日期(就是明天的日期)
date -d "-1 day" +%Y%m%d //显示后一天的日期(就是昨天的日期)
date -d "-1 month" +%Y%m%d //显示上一月的日期
date -d "+1 month" +%Y%m%d //显示下一月的日期
date -d "-1 year" +%Y%m%d //显示前一年的日期
date -d "+1 year" +%Y%m%d //显示下一年的日期
2秒后输出:
date -d "2 second" +"%Y-%m-%d %H:%M.%S"
2012-11-20 14:21.31
有时需要检查一组命令花费的时间,举例:
#!/bin/bash
start=$(date +%s)
nmap man.linuxde.net &> /dev/null
end=$(date +%s)
difference=$(( end - start ))
echo $difference seconds.
传说中的 1234567890 秒:
date -d "1970-01-01 1234567890 seconds" +"%Y-%m-%d %H:%m:%S"
2009-02-13 23:02:30
普通转格式:
date -d "2009-12-12" +"%Y/%m/%d %H:%M.%S"
2009/12/12 00:00.00
apache格式转换:
date -d "Dec 5, 2009 12:00:37 AM" +"%Y-%m-%d %H:%M.%S"
2009-12-05 00:00.37
格式转换后时间游走:
date -d "Dec 5, 2009 12:00:37 AM 2 year ago" +"%Y-%m-%d %H:%M.%S"
2007-12-05 00:00.37
hwclock 硬件时钟访问工具,显示,设置
hwclock命令是一个硬件时钟访问工具,它可以显示当前时间、设置硬件时钟的时间和设置硬件时钟为系统时间,也可设置系统时间为硬件时钟的时间。
在Linux中有硬件时钟与系统时钟等两种时钟。硬件时钟是指主机板上的时钟设备,也就是通常可在BIOS画面设定的时钟。系统时钟则是指kernel中的时钟。当Linux启动时,系统时钟会去读取硬件时钟的设定,之后系统时钟即独立运作。所有Linux相关指令与函数都是读取系统时钟的设定。
Grammar
hwclock [functions] [选项s]
hwclock(选项)
FUNCTIONS
-
-w, --systohc
-
-r, --show
-
--show:显示硬件时钟的时间与日期;
-
--systohc:将硬件时钟调整为与目前的系统时钟一致;
-
--set --date=<日期与时间>:设定硬件时钟;
-
-s,--hctosys:将系统时钟调整为与目前的硬件时钟一致;
-
--adjust:hwclock每次更改硬件时钟时,都会记录在/etc/adjtime文件中。使用--adjust参数,可使hwclock根据先前的记录来估算硬件时钟的偏差,并用来校正目前的硬件时钟;
-
--debug:显示hwclock执行时详细的信息;
-
--directisa:hwclock预设从/dev/rtc设备来存取硬件时钟。若无法存取时,可用此参数直接以I/O指令来存取硬件时钟;
-
--test:仅测试程序,而不会实际更改硬件时钟;
-
--utc:若要使用格林威治时间,请加入此参数,hwclock会执行转换的工作;
-
-h, --help 显示此帮助并退出
-
-r, --show 读取硬件时钟并打印结果
-
--set 将 RTC 设置为 --date 指定的时间
-
-s, --hctosys 从硬件时钟设置系统时间
-
-w, --systohc 从当前系统时间设置硬件时钟
-
--systz 基于当前时区设置系统时间
-
--adjust 根据自上次时钟设置或调整后的系统漂移来调整 RTC
-
-c, --compare 定期将系统时钟与 CMOS 时钟相比较
-
--getepoch 打印内核的硬件时钟纪元(epoch)值
-
--setepoch 将内核的硬件时钟纪元(epoch)值设置为
-
--epoch 选项指定的值
-
--predict 预测 --date 选项所指定时刻读取到的 RTC 值
-
-V, --version 显示版本信息并退出
选项:
- -u, --utc 硬件时钟保持为 UTC 时间
-
--localtime 硬件时钟保持为本地时间
-
-f, --rtc <文件> 代替默认文件的特殊 /dev/... 文件
-
--directisa 直接访问 ISA 总线,而非 /dev/rtc
-
--badyear 忽略 RTC 年份(由于 BIOS 损坏)
-
--date <时间> 指定要设置的硬件时钟时间
-
--epoch <年> 指定作为硬件纪元(epoch)值起始的年份
-
--noadjfile 不访问 /etc/adjtime;需要使用 --utc 或 --localtime 选项
-
--adjfile <文件> 指定调整文件的路径;
默认为/etc/adjtime
- --test 不更新,只显示将进行什么操作
- -D, --debug 调试模式
Living Example
设置硬件时间要依赖于操作系统时间,具体方法如下:
hwclock --systohc
hwclock --systohc --utc
不加任何参数使用hwclock,可以查看当前的硬件日期和时间。
hwclock
查看clock文件,确认是否设置了UTC:
cat /etc/default/rcS
UTC=yes
在其他一些版本的Linux(如RebHat)中可以这样查看:
cat /etc/sysconfig/clock
ZONE="America/Los_Angeles"
UTC=false
ARC=false
[root@redhat7-min ~]# hwclock -r
2018年12月24日 星期一 23时49分10秒 -0.340414 秒
time 统计给定命令所花费的总时间
time命令用于统计给定命令所花费的总时间。
Grammar
time(参数)
参数
指令:指定需要运行的额指令及其参数。
Living Example
可以看到, cp -r dir1 dir2 实际运行时间 5.81s
$ time cp -r dir1 dir2
real 0m5.810s
user 0m0.032s
sys 0m2.184s
当测试一个程序或比较不同算法时,执行时间是非常重要的,一个好的算法应该是用时最短的。所有类UNIX系统都包含time命令,使用这个命令可以统计时间消耗。例如:
[root@localhost ~]# time ls
anaconda-ks.cfg install.log install.log.syslog satools text
real 0m0.009s
user 0m0.002s
sys 0m0.007s
输出的信息分别显示了该命令所花费的real时间、user时间和sys时间。
-
real时间是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其他进程所占用的时间片,和进程被阻塞时所花费的时间。
-
user时间是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
-
sys时间是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的时间,这也是真正由进程使用的CPU时间。
shell内建也有一个time命令,当运行time时候是调用的系统内建命令,应为系统内建的功能有限,所以需要时间其他功能需要使用time命令可执行二进制文件/usr/bin/time
使用-o选项将执行时间写入到文件中:
/usr/bin/time -o outfile.txt ls
使用-a选项追加信息:
/usr/bin/time -a -o outfile.txt ls
使用-f选项格式化时间输出:
/usr/bin/time -f "time: %U" ls
-f选项后的参数:
| 参数 | 描述 |
|---|---|
| %E | real时间,显示格式为[小时:]分钟:秒 |
| %U | user时间。 |
| %S | sys时间。 |
| %C | 进行计时的命令名称和命令行参数。 |
| %D | 进程非共享数据区域,以KB为单位。 |
| %x | 命令退出状态。 |
| %k | 进程接收到的信号数量。 |
| %w | 进程被交换出主存的次数。 |
| %Z | 系统的页面大小,这是一个系统常量,不用系统中常量值也不同。 |
| %P | 进程所获取的CPU时间百分百,这个值等于user+system时间除以总共的运行时间。 |
| %K | 进程的平均总内存使用量(data+stack+text),单位是KB。 |
| %w | 进程主动进行上下文切换的次数,例如等待I/O操作完成。 |
| %c | 进程被迫进行上下文切换的次数(由于时间片到期)。 |
Bash Shell 的会话超时时间的环境变量
timeout
命令简介:
运行指定的命令,如果在指定时间后仍在运行,则杀死该进程。用来控制程序运行的时间。
使用方法:
timeout [选项] 数字[后缀] 命令 [参数]...
后缀”s”代表秒(默认值),”m”代表分,”h”代表小时,”d”代表天。
选项详解:
长选项必须使用的参数对于短选项时也是必需使用的。
-s, --signal=信号
指定在超时时发送的信号。信号可以是类似"HUP"的信号名或是信号数。
查看"kill -l"以获得信号列表
--help 显示此帮助信息并退出
--version 显示版本信息并退出
如果程序超时则退出状态数为124,否则返回程序退出状态。
如果没有指定信号则默认为TERM 信号。TERM信号在进程没有捕获此信号时杀死进程。
对于另一些进程可能需要使用KILL (9)信号,当然此信号不能被捕获。
示例:
timeout 10 command
解释:如过command命令在10秒内结束,则平安结束,运行超过10秒,将被强行kill掉
TMOUT
在 Linux 中,可以使用 TMOUT 环境变量设置 Bash Shell 的自动注销时间。如果您将 TMOUT 设置为一个正整数,则表示在一段时间(以秒为单位)内没有用户活动时,Bash Shell 将自动注销用户会话,以确保会话安全。
如果您希望在当前 Shell 会话中手动注销用户会话,而不等待自动注销功能生效,可以使用 exit 命令退出当前 Shell。执行该命令后,Shell 会立即注销用户会话并关闭当前 Shell 窗口。
需要注意的是,手动注销用户会话可能会导致其他正在运行的进程突然停止并可能导致数据丢失。因此,建议在手动注销之前先保存所有未保存的数据,并确保没有重要的进程在后台运行。
另外,如果需要在一段时间内暂时禁用 Bash Shell 的自动注销功能,可以将 TMOUT 设置为 0,如下所示:
export TMOUT=0
这将禁用 Bash Shell 的自动注销功能,直到下一次设置为非零值。
在 Linux 中,TIMEOUT 和 TMOUT 都是用于控制 Bash Shell 的会话超时时间的环境变量。它们虽然类似,但是具有不同的作用和含义。
- TIMEOUT 环境变量用于控制命令行输入等待时间。如果将 TIMEOUT 设置为 0,则表示禁用命令行输入等待时间。也就是说,在需要输入内容的情况下,脚本会立即进行下一步操作,而不会等待用户输入。
- TMOUT 环境变量用于设置 Bash Shell 的自动注销时间。如果将 TMOUT 设置为一个正整数,则表示在一段时间(以秒为单位)内没有用户活动时,Bash Shell 将自动注销用户会话,以确保会话安全。如果将 TMOUT 设置为 0,则表示禁用 Bash Shell 的自动注销功能,即用户会话将永远不会自动注销。
因此,二者主要区别在于作用对象和作用范围。TIMEOUT 仅用于控制脚本等交互式命令行程序的输入超时时间,而 TMOUT 则用于控制 Shell 会话的自动注销时间。另外,TMOUT 的作用范围通常比 TIMEOUT 更广,它适用于所有启动 Bash Shell 的终端窗口,而 TIMEOUT 只影响当前终端窗口中的命令行交互。
cal 用于显示当前日历,或者指定日期的日历。
(默认显示当年当月的日历)
Grammar
cal [Options] [[[day] month] year]
cal(Option)(参数)
cal [Option] [[[日] 月] 年]
选项
- -1:显示单月输出;
-
-3:显示上个月、当月和下个月;
-
-y:显示当前年的日历。
-
-s:将星期日作为月的第一天;
-
-m:将星期一作为月的第一天;
-
-j:显示"julian"日期;
-
-V:显示版本信息并退出
-
-h:显示此帮助并退出
参数
-
月:指定月份
-
年:指定年份
Living Example
显示指定月份(日 月 年)
[root@CentOS6 ncdu-1.9]# cal 30 11 2018
十一月 2018
日 一 二 三 四 五 六
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30
----------------------------------------------------------
单独执行cal或者cal -l命令会打印出当前日历:
显示2018年10月的日期
----------------------------------------------------------
[root@CentOS6 ~]# cal -1
十二月 2018
日 一 二 三 四 五 六
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
30 31
echo打印shell变量的值,或者直接输出指定的字符串
echo用法:http://www.zsythink.net/archives/96
echo命令用于在shell中打印shell变量的值,或者直接输出指定的字符串。 linux的echo命令,在shell编程中极为常用,在终端下打印变量value的时候也是常常用到的,因此有必要了解下echo的用法echo命令的功能是在显示器上显示一段文字,一般起到一个提示的作用。
Grammar
echo(选项)(参数)
选项
-n:输出不换行
-E:禁止反斜杠和转义符[默认开启]
-e:激活转义字符。
使用-e选择时,若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
-
\a发出警告声; -
\n换行且光标移至行首; -
\t插入tab; -
\b删除前一个字符; -
\c最后不加上换行符号; -
\f换行但光标仍旧停留在原来的位置; -
\r光标移至行首,但不换行; -
\v与\f相同; -
\\插入\字符; -
\nnn插入nnn(八进制)所代表的ASCII字符;
参数
变量:指定要打印的变量。
Living Example
输出结果不换行符:echo -n
[root@CentOS6 tmp]# echo -n "-n输出不换行"
-n输出不换行[root@CentOS6 tmp]#
激活转义字符:echo -e
[root@CentOS6 tmp]# echo -e "表示激活转义字符,如:\n你\t懂\t了\t吗?"
表示激活转义字符,如:
你 懂 了 吗?
用echo命令打印带有色彩的文字(3种):
1、 echo -e "\033[背景颜色;文字颜色m 要输出的字符 \003[0m"
2、 echo $'\e[0;33m'"要输出的字符"$'\e[0m'
3、 echo -e "\e[背景颜色;文字颜色m要输出的字符\e[0m" # (0m是清除所有格式)
其中\033是ESC健的八进制,\033[即告诉终端后面是设置颜色的参数,显示方式,前景色,背景色均是数字
说明:背景颜色和文字颜色使用数字大小决定,不管顺序
文字色:
[root@CentOS6 tmp]# echo -e "\e[1;31mThis is red text\e[0m"
This is red text

-
\e[1;31m将颜色设置为红色 -
\e[0m将颜色重新置回
颜色码:重置=0,黑色=30,红色=31,绿色=32,黄色=33,蓝色=34,洋红=35,青色=36,白色=37
背景色:
echo -e "\e[1;42mGreed Background\e[0m"
echo -e "\e[0;42mGreed Background\e[0m"

颜色码:重置=0,黑色=40,红色=41,绿色=42,黄色=43,蓝色=44,洋红=45,青色=46,白色=47
文字闪动:
echo -e "\033[37;31;5mMySQL Server Stop...\033[37;31;0m"

红色数字处还有其他数字参数:0 关闭所有属性、1 设置高亮度(加粗)、4 下划线、5 闪烁、7 反显、8 消隐
----------------------------------综合应用-----------------------------------
vim echocolor.sh
#!/bin/bash
##set color##
echoRed() { echo $'\e[0;31m'"$1"$'\e[0m'; }
echoGreen() { echo $'\e[0;32m'"$1"$'\e[0m'; }
echoYellow() { echo $'\e[0;33m'"$1"$'\e[0m'; }
source echocolor.sh && echoRed "red"
source echocolor.sh && echoGreen "green"
source echocolor.sh && echoYellow "Yellow"
补充:0m关闭所有属性,1m设置高亮加粗,5m闪烁,4m下划线
[root@web ~]# echo -e "\033[5;34mhello word\033[0m"
执行后,发现 后期所有输出都是闪烁状态,如何关闭呢? 0m,就关闭
最后的5m改为0m就关闭闪烁状态
字体颜色是30开始,背景颜色是40开始。
在写shell脚本时候,我需要在屏幕同一行上打印内容,比如我要sleep 5
#!/bin/bash
for ((i=5; i>0; i--))
do
echo -ne "Remaining Time: $i seconds\033[0K\r"
sleep 1
done
tput命令是Linux下的一个用于控制终端输出的工具。它可以设置终端的属性、颜色、光标位置等
tput tput 命令将通过 terminfo 数据库对终端会话进行初始化和操作。
terminfo UNIX 系统上的 terminfo 数据库用于定义终端和打印机的属性及功能,包括各设备(例如,终端和打印机)的行数和列数以及要发送至该设备的文本的属性。UNIX 中的几个常用程序都依赖 terminfo 数据库提供这些属性以及许多其他内容,其中包括 vi 和 emacs 编辑器以及 curses 和 man 程序。
常见的tput命令选项和用法如下:
- tput clear:清屏,将当前终端窗口清空,并将光标移动到左上角。
- tput cup <行号> <列号>:将光标移动到指定的行号和列号位置。
- tput bold:设置文本为粗体。
- tput sgr0:重置所有属性,包括颜色、粗体等。
- tput setaf <颜色代码>:设置前景色(文本颜色),颜色代码范围是0-7,分别表示黑、红、绿、黄、蓝、紫、青、白。
- tput setab <颜色代码>:设置背景色,颜色代码范围同上。
- tput lines:获取当前终端窗口的行数。
- tput cols:获取当前终端窗口的列数。
通过使用tput命令,您可以更好地控制终端输出的样式和位置,使您的脚本或程序具有更好的可读性和交互性。
| 参数用途分类 | 参数名 | 参数含义 |
|---|---|---|
| 字符串输出 | ||
| bel | 警铃 | |
| blink | 闪烁模式 | |
| bold | 粗体 | |
| civis | 隐藏光标 | |
| clear | 清屏 | |
| cnorm | 不隐藏光标 | |
| cup | 移动光标到屏幕位置(x,y) | |
| el | 清除到行尾 | |
| el1 | 清除到行首(注意结尾是数字一不是字母l) | |
| smso | 启动突出模式 | |
| rmso | 停止突出模式 | |
| smul | 开始下划线模式 | |
| rmul | 结束下划线模式 | |
| sc | 保存当前光标位置 | |
| rc | 恢复光标到最后保存位置 | |
| sgr0 | 正常屏幕 | |
| rev | 逆转视图 | |
| 数字输出 | ||
| cols | 列数目 | |
| ittab | 设置宽度 | |
| lines | 屏幕行数 | |
| 布尔输出 | ||
| chts | 光标不可见 | |
| hs | 具有状态行 | |
| tput setb no | 设置终端背景色。no的取值:0:黑色、1:蓝色、2:绿色、3:青色、4:红色、5:洋红色、6:黄色、7:白色 | |
| tput setf no | 设置文本的颜色。no的取值:0:黑色、1:蓝色、2:绿色、3:青色、4:红色、5:洋红色、6:黄色、7:白色 | |
| tput ed | 删除当前光标到行尾的内容 |
可以使用infocmp命令检查终端信息(通过制定名称或者不指定名称的方式)
infocmp $TERM
infocmp
cat tputTest.sh
tput clear
echo "触发系统蜂鸣"
tput bel
sleep 1echo "闪烁模式"
tput blink
echo -e "\t闪烁模式测试内容"
sleep 1
tput sgr0
echo "恢复正常屏幕"echo "粗体"
tput bold
echo -e "\t粗体测试内容"
sleep 1
tput sgr0
echo "恢复正常屏幕"echo "隐藏光标"
tput civis
echo -e "\t隐藏光标测试内容"
sleep 1
tput cnorm
echo "恢复正常屏幕"echo "移动光标"
tput cup 10 10
echo -e "\t移动光标测试内容"
sleep 1
tput sgr0
echo "恢复正常屏幕"echo "清屏"
echo -e "\t清屏测试"
sleep 1
tput clearecho "xxxxxxxxxxUxxxxxxxxxx"
tput cup 0 9
sleep 1
tput el1tput cup 1 0
echo "xxxxxxxxxxUxxxxxxxxxx"
tput cup 1 9
sleep 1
tput eltput cup 2 0
echo "突出模式启用"
tput smso
echo -e "\t突出模式启用测试"
sleep 1
tput rmso
echo "停止突出模式测试内容"echo "下划线模式启用"
tput smul
echo -e "\t下划线模式启用测试"
sleep 1
tput rmul
echo "结束下划线模式测试"echo "逆转视图"
tput rev
echo -e "\t逆转视图测试"
sleep 1
tput sgr0
echo "恢复正常屏幕"echo "输出列"
tput cols
echo "输出行"
tput lines
echo "设置背景颜色"
tput setb 1
echo -e "\t测试带背景颜色"
echo "设置前景颜色"
tput setf 4
echo -e "\t测试带前景颜色"
tput sgr0
echo "恢复正常屏幕"
#例如显示系统时钟
#!/bin/bash
#tput clear # 清除屏幕
#tput sc # 记录当前光标位置
#tput rc # 恢复光标到最后保存位置
#tput civis # 光标不可见
#tput cnorm # 光标可见
#tput cup x y # 光标按设定坐标点移动
while true
do
tput sc; # 记录光标位置
echo -ne $(date +'%Y-%m-%d %H:%M:%S') # 显示时间
sleep 1tput rc # 恢复光标到记录位置,不恢复会一直累计显示
done
#文本属性示例
#!/bin/bash
#tput blink # 文本闪烁
#tput bold # 文本加粗
#tput el # 清除到行尾
#tput smso # 启动突出模式
#tput rmso # 停止突出模式
#tput smul # 下划线模式
#tput rmul # 取消下划线模式
#tput sgr0 # 恢复默认终端
#tput rev # 反相终端count=0;
通过什么命令指定终端命令提示符?
\u:显示当前用户账号
\h:显示当前主机名
\W:只显示当前路径最后一个目录
\w:显示当前绝对路径(当前用户目录会以~代替)
$PWD:显示当前全路径
\$:显示命令行’$'或者’#'符号
\#:下达的第几个命令
\d:代表日期,格式为week day month date,例如:"MonAug1"
\t:显示时间为24小时格式,如:HH:MM:SS
\T:显示时间为12小时格式
\A:显示时间为24小时格式:HH:MM
\v:BASH的版本信息
颜色的设置
在PS1中设置字符颜色的格式为:[\e[F;Bm],其中F为字体颜色,编号为30-37,B为背景颜色,编号为40-47。颜色表如下:
F B
30 40 黑色
31 41 红色
32 42 绿色
33 43 黄色
34 44 蓝色
35 45 紫红色
36 46 青蓝色
37 47 白色
设置特殊显示
0 OFF,关闭颜色
1 高亮显示
4 显示下划线
5 闪烁显示
7 反白显示
8 颜色不可见
保存设置(修改配置文件)
通过上面的设置只能改变当前终端的命令行格式,关闭这个终端,在重新打开的一个终端中命令行格式又会恢复到默认的形式。想要永久性的改变终端命令行格式,需要修改.bashrc文件。
写入/etc/profile或/etc/bashrc对全部用户生效;写入~/.bash_profile或~/.bashrc只对当前用户生效。
[root@test ~]# vim ~/.bashrc # 在文件中加入
PS1="[\e[33;40m][\u@\h \w \t]\\$[\e[0m]"
重新加载配置文件或者退出终端重新进入
[root@test ~]# source . ~/.bashrc
这样就可以永久性的改变终端命令行格式了。
Living Example:
# vim /etc/profile (4个中的随机一个即可)
export PS1="[\e[1;35m][\u@\h \w \t]\\$[\e[0m] "
export PS1='[\u@\h \w \#]\\$ '
export PS1="[\e[33;40m][\u@\h \w \t]\\$[\e[0m] " #黄色
sed -i '/export PATH/aexport PS1="\[\\e[1;35m\][\\u@\\h \\w]\\\\$\[\\e[0m\] "' /root/.bash_profile
# 加载
# source /etc/profile
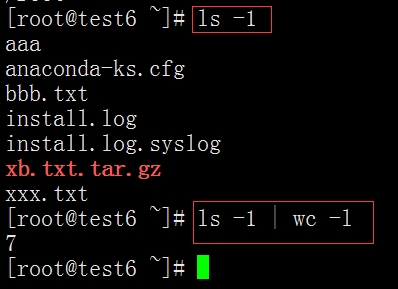
wc 用来计算数字(行号、单词数、字节数)
wc命令用来计算数字。利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
Grammar
wc(选项)(参数)
选项
- -c或--bytes或--chars:只显示Bytes(字节)数;(Notice应该有时候多一位换行符)
-
-m:统计字符数
-
-l或--lines:只显示列数;
-
-w或--words:只显示字数。
-
-L:显示文件中最长的行的长度
参数
文件:需要统计的文件列表。
举例:ls -1 | wc -l(前面这个是-数字1,后面这个是小写字母l,)
更改登录信息
登陆前:vim /etc/issue

登陆后:vim /etc/motd

解释里面的内容:
\d 本地端时间癿日期;
\n 显示主机癿网络名称;
\t 显示本地端时间癿时间;
\r 操作系统癿版本 (相当于 uname -r)
\s 操作系统癿名称
\v 操作系统癿版本
\l 显示第几个终端机接口
\m 显示硬件癿等级 (i386/i486/i586/i686...)
\o 显示 domain name
环境变量:vim ~/.bash_profile (这里面也可以更改登陆信息)
stty 修改终端命令行的相关设置
Grammar
stty (选项) (参数)
选项
- -a:以容易阅读的方式打印当前的所有配置;
- -g:以stty可读方式打印当前的所有配置。
参数
终端设置:指定终端命令行的设置选项。
Living Example
在命令行下,禁止输出大写的方法:
stty iuclc #开启
stty -iuclc #恢复
在命令行下禁止输出小写:
stty olcuc #开启
stty -olcuc #恢复
打印出终端的行数和列数:
stty size
改变Ctrl+D的方法:
stty eof "string"
系统默认是Ctrl+D来表示文件的结束,而通过这种方法,可以改变!
屏蔽显示:
stty -echo #禁止回显
stty echo #打开回显
测试方法:
stty -echo;read;stty echo;read
忽略回车符:
stty igncr #开启
stty -igncr #恢复
定时输入:
timeout_read()
{
timeout=$1
old_stty_settings=`stty -g` #save current settings
stty -icanon min 0 time 100 #set 10seconds,not 100seconds
eval read varname #=read $varname
stty "$old_stty_settings" #recover settings
}
更简单的方法就是利用read命令的-t选项:
read -t 10 varname
快捷键在哪里设置:
stty -a

获取随机字符串或数字
生成随机数:
# echo $[$RANDOM%100] #(100以内的随机数)
# openssl rand -base64 5 #(生成5位随机字符)
y9RcPWc=
# openssl rand -base64 100 | tr -dc '[:alnum:]' | head -c 10
# cat /dev/urandom | tr -dc A-Za-z0-9 | head -c 24 #(生成随机密码,必须指定取多少位,否则一直取,直到服务器崩溃)
获取随机8位字符串:
方法1:
# echo $RANDOM |md5sum |cut -c 1-8
471b94f2
方法2:
# openssl rand -base64 4
vg3BEg==
方法3:
# cat /proc/sys/kernel/random/uuid |cut -c 1-8
ed9e032c
获取随机8位数字:
方法1:
echo $RANDOM | cksum | cut -c 1-8
方法2:
# openssl rand -base64 4 |cksum |cut -c 1-8
38571131
方法3:
# date +%N |cut -c 1-8
69024815
cksum:打印CRC效验和统计字节
tr 字符转换命令
tr命令可以对来自标准输入的字符进行替换、压缩和删除。它可以将一组字符变成另一组字符,经常用来编写优美的单行命令,作用很强大。
Grammar
tr(选项)(参数)
选项
- -c或--complerment:取代所有不属于第一字符集的字符;
-
-d或--delete:删除所有属于第一字符集的字符;
-
-s或--squeeze-repeats:把连续重复的字符以单独一个字符表示;
-
-t或--truncate-set1:先删除第一字符集较第二字符集多出的字符。
参数
-
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数"字符集2"指定转换的目标字符集。但执行删除操作时,不需要参数"字符集2";
-
字符集2:指定要转换成的目标字符集。
Living Example
将输入字符由大写转换为小写:
echo "HELLO WORLD" | tr 'A-Z' 'a-z'
hello world
'A-Z' 和 'a-z'都是集合,集合是可以自己制定的,例如:'ABD-}'、'bB.,'、'a-de-h'、'a-c0-9'都属于集合,集合里可以使用'\n'、'\t',可以可以使用其他ASCII字符。
--------------------------------------------
使用tr删除字符:
echo "hello 123 world 456" | tr -d '0-9'
hello world
--------------------------------------------
将制表符转换为空格:
cat text | tr '\t' ' '
--------------------------------------------
字符集补集,从输入文本中将不在补集中的所有字符删除:
echo "aa.,a 1 b#$bb 2 c*/cc 3 ddd 4 "| tr -d -c '0-9 \n'
1 2 3 4
此例中,补集中包含了数字0~9、空格和换行符\n,所以没有被删除,其他字符全部被删除了。
--------------------------------------------
用tr压缩字符,可以压缩输入中重复的字符:
echo "thissss is a text linnnnnnne." | tr -s ' sn'
this is a text line.
--------------------------------------------
巧妙使用tr做数字相加操作:
echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr '\n' '+') 0 ]
--------------------------------------------
删除Windows文件“造成”的'^M'字符:
cat file | tr -s "\r" "\n" > new_file
或
cat file | tr -d "\r" > new_file
--------------------------------------------
使用方式:
tr '[:lower:]' '[:upper:]'
表示把这个文件内容大写字母变成小写字母,但是原文件里面的内容是没有发生变化的。
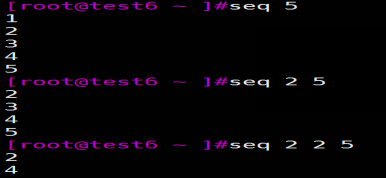
seq 用于产生从某个数到另外一个数之间的所有整数
seq命令用于产生从某个数到另外一个数之间的所有整数。
Grammar
seq [Option]... 尾数
seq [Option]... 首数 尾数
seq [Option]... 首数 增量 尾数
选项
- -f, --format=格式 使用printf 样式的浮点格式
-
-s, --separator=字符串 使用指定字符串分隔数字(默认使用:\n)
-
-w, --equal-width 在列前添加0 使得宽度相同
Living Example
-f选项:指定格式
#seq -f"%3g" 9 11
9
10
11
%后面指定数字的位数 默认是%g,%3g那么数字位数不足部分是空格。
#sed -f"%03g" 9 11
#seq -f"str%03g" 9 11
str009
str010
str011
这样的话数字位数不足部分是0,%前面制定字符串。
-w选项:指定输出数字同宽
seq -w 98 101
098
099
100
101
不能和-f一起用,输出是同宽的。
-s选项:指定分隔符(默认是回车)
seq -s" " -f"str%03g" 9 11
str009 str010 str011
要指定/t做为分隔符号:
seq -s"`echo -e "/t"`" 9 11
指定\n作为分隔符号:
seq -s"`echo -e "\n"`" 9 11
19293949596979899910911
1-10间隔2的数
[root@test tmp]# seq 1 2 10
1
3
5
7
9
eval 将会首先扫描命令行进行所有的替换
eval命令将会首先扫描命令行进行所有的替换,类似于C语言中的宏替换,然后再执行命令,该命令使用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描.
1 测试使用
~$ echo chenyu > 1.txt
~$ puts="cat 1.txt"
~$ eval $puts
chenyu
2 测试使用
[root@VM-16-16-centos ~ 13:18:37]# CMD=whoami
[root@VM-16-16-centos ~ 13:18:39]# echo $CMD
whoami
[root@VM-16-16-centos ~ 13:18:39]# eval $CMD
root
[root@VM-16-16-centos ~ 13:18:42]# n=10
[root@VM-16-16-centos ~ 13:20:05]# echo {0..$n}
{0..10}
[root@VM-16-16-centos ~ 13:20:05]# eval echo {0..$n}
0 1 2 3 4 5 6 7 8 9 10
dd 用于复制文件并对原文件的内容进行转换和格式化处理
dd命令用于复制文件并对原文件的内容进行转换和格式化处理。dd命令功能很强大的,对于一些比较底层的问题,使用dd命令往往可以得到出人意料的效果。
用的比较多的还是用dd来备份裸设备。但是不推荐,如果需要备份oracle裸设备,可以使用rman备份,或使用第三方软件备份,使用dd的话,管理起来不太方便。
建议在有需要的时候使用dd 对物理磁盘操作,如果是文件系统的话还是使用tar backup cpio等其他命令更加方便。另外,使用dd对磁盘操作时,最好使用块设备文件。

Grammar
dd(选项)
选项
-
bs=<字节数>:将ibs(输入)与(输出)设成指定的字节数;
-
cbs=<字节数>:转换时,每次只转换指定的字节数;
-
conv=<关键字>:指定文件转换的方式;
-
count=<区块数>:仅读取指定的区块数;
-
ibs=<字节数>:每次读取的字节数;
-
obs=<字节数>:每次输出的字节数;
-
of=<文件>:输出到文件;
-
seek=<区块数>:一开始输出时,跳过指定的区块数;
-
skip=<区块数>:一开始读取时,跳过指定的区块数;
-
--help:帮助;
- --version:显示版本信息。
Living Example
[root@localhost text]# dd if=/dev/zero of=sun.txt bs=1M count=1
1+0 records in
1+0 records out
1048576 bytes (1.0 MB) copied, 0.006107 seconds, 172 MB/s
[root@localhost text]# du -sh sun.txt
1.0M sun.txt
该命令创建了一个1M大小的文件sun.txt,其中参数解释:
-
if 代表输入文件。如果不指定if,默认就会从stdin中读取输入。
-
of 代表输出文件。如果不指定of,默认就会将stdout作为默认输出。
-
bs 代表字节为单位的块大小。
-
count 代表被复制的块数。
-
/dev/zero 是一个字符设备,会不断返回0值字节(
\0)。
块大小可以使用的计量单位表
| 单元大小 | 代码 |
|---|---|
| 字节(1B) | c |
| 字节(2B) | w |
| 块(512B) | b |
| 千字节(1024B) | k |
| 兆字节(1024KB) | M |
| 吉字节(1024MB) | G |
以上命令可以看出dd命令来测试内存操作速度:
1048576 bytes (1.0 MB) copied, 0.006107 seconds, 172 MB/s
[root@test-6 tmp]# dd if=/dev/zero of=/dev/null bs=1M count=10
10+0 records in
10+0 records out
10485760 bytes (10 MB) copied, 0.00150904 s, 6.9 GB/s
getent 用来察看系统的数据库中的相关记录
长选项的强制或可选参数对对应的短选项也是强制或可选的。
用法: getent [选项...] 数据库 [键 ...]
Get entries from administrative database.
-s, --service=CONFIG 要使用的服务配置
-?, --help 给出该系统求助列表
--usage 给出简要的用法信息
-V, --version 打印程序版本号
支持的数据库: ahosts,ahostsv4 ,ahostsv6, aliases ,ethers ,group, gshadow, hosts, netgroup, networks, passwd, protocols, rpc ,services, shadow,例如:getent protocols , getent services, getent rpc等
例1
# getent hosts baidu.com #从hosts库中得到baidu.com的IP信息
220.181.38.148 baidu.com
39.156.69.79 baidu.com
# getent passwd root #从passwd库中得到账号root信息
root:x:0:0:root:/root:/bin/bash
# 脚本中使用
getent group prometheus >/dev/null || groupadd -r prometheus
getent passwd prometheus >/dev/null || \
useradd -r -g prometheus -d /var/lib/prometheus -s /sbin/nologin \
-c "Prometheus services" prometheus
一次性执行多个命令,用分号隔开;
# cal ; date
排序命令
sort 既可以从特定的文件,也可以从stdin中获取输入。
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。sort命令既可以从特定的文件,也可以从stdin中获取输入。
sort:默认情况下,此命令以首字母中的a-z的顺序进行排序
Grammar:
sort(选项)(参数/指定待排序的文件列表)
选项
- -u:除去重复的行
- -b:忽略每行的空格字符
- -r:逆序来排序
- -n:依照数值的大小排序
- -f:排序时,忽略大小写
- -t<分隔字符>:指定排序时所用的栏位分隔字符-k NUM:已制定字段排序
- -c:检查文件是否已经按照顺序排序
- -R:随机排序
- -d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符
- -i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符
- -m:将几个排序号的文件进行合并
- -M:将前面3个字母依照月份的缩写进行排序
- -o<输出文件>:将排序后的结果存入制定的文件
- +<起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位
Living Example
[root@test-7 ~]# cat /etc/passwd | sort (默认是以字母排序)
[root@test-7 ~]# cat /etc/passwd | sort -t ":" -k 3 (以冒号进行分割,然后以第三个字段的首位进行排序)
[root@test-7 ~]# cat /etc/passwd | sort -t ":" -k 3 (以冒号进行分割,然后以第三个字段的第二位进行排序)
[root@CentOS6 tmp]# cat /var/log/httpd/access_log | cut -d" " -f1 | sort |uniq -c | sort -nr | head (取访问次数前10的IP地址)
uniq 用于报告或忽略文件中的重复行(仅仅针对连续的行才能去重)
uniq命令用于报告或忽略文件中的重复行,一般与sort命令结合使用。
Grammar
uniq(选项)(参数)
选项
- -u:显示未重复的行
-
-c或--count:在每列旁边显示该行重复出现的次数;
-
-d或--repeated:仅显示重复出现的行列;
-
-f<栏位>或--skip-fields=<栏位>:忽略比较指定的栏位;
-
-s<字符位置>或--skip-chars=<字符位置>:忽略比较指定的字符;
-
-w<字符位置>或--check-chars=<字符位置>:指定要比较的字符。
参数
-
输入文件:指定要去除的重复行文件。如果不指定此项,则从标准读取数据;
-
输出文件:指定要去除重复行后的内容要写入的输出文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
Living Example
删除重复行:
uniq file.txt
sort file.txt | uniq
sort -u file.txt
只显示单一行:
uniq -u file.txt
sort file.txt | uniq -u
统计各行在文件中出现的次数:
sort file.txt | uniq -c
在文件中找出重复的行
sort file.txt | uniq -d
sort与uniq的区别
sort -u不是连续的同样内容都会被去掉重复uniq -u仅仅针对连续的行才能去重
你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
使用linux命令disown -r可以将所有正在运行的进程移除。
- -h 标记每个作业标识符,这些作业将不会在shell接收到sighup信号时接收到sighup信号。
-
-a 移除所有的作业。
-
-r 移除运行的作业。
dirs 如果你的助手想要打印出当前的目录栈,你会建议他怎么做?
dirs命令显示当前目录栈中的所有记录(不带参数的dirs命令显示当前目录栈中的记录)。dirs始终显示当然目录, 再是堆栈中的内容;即使目录堆栈为空, dirs命令仍然只显示当然目录。
Grammar
dirs(选项)(参数)
选项
- -c:删除目录栈中的所有记录
-
-l:以完整格式显示
-
-p:一个目录一行的方式显示
-
-v:每行一个目录来显示目录栈的内容,每个目录前加上的编号
-
+N:显示从左到右的第n个目录,数字从0开始
-
-N:显示从右到左的第n个日录,数字从0开始
参数
目录:显示目录堆叠中的记录。
Living Example
[root@localhost etc]# dirs
/etc
使用Linux 命令dirs可以将当前的目录栈打印出来。
[root@localhost ~]# dirs
/usr/share/X11
【附】:目录栈通过pushd popd 来操作。
哪一个bash内置命令能够进行数学运算。
bash shell 的内置命令let可以进行整型数的数学运算。
#! /bin/bash
...
...
let c=a+b
...
...
comm两个文件之间的比较
comm命令 可以用于两个文件之间的比较,它有一些选项可以用来调整输出,以便执行交集、求差、以及差集操作。
-
交集:打印出两个文件所共有的行。
-
求差:打印出指定文件所包含的且不相同的行。
-
差集:打印出包含在一个文件中,但不包含在其他指定文件中的行。
语法
comm [选项]... 文件1 文件2
选项
如果不附带选项,程序会生成三列输出。
第一列包含文件1 特有的行,
第二列包含文件2 特有的行,
第三列包含两个文件共有的行。
-1 不输出文件1 特有的行
-2 不输出文件2 特有的行
-3 不输出两个文件共有的行
- --check-order 检查输入是否被正确排序,即使所有输入行均成对
-
--nocheck-order 不检查输入是否被正确排序
-
--output-delimiter=STR 依照STR 分列
参数
-
文件1:指定要比较的第一个有序文件;
-
文件2:指定要比较的第二个有序文件。
实例:
comm -1 file1 file2 比较两个文件的内容只删除 'file1' 所包含的内容
comm -2 file1 file2 比较两个文件的内容只删除 'file2' 所包含的内容
comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
文本 aaa.txt 内容
[root@localhost text]# cat aaa.txt
aaa
bbb
ccc
ddd
eee
111
222
文本 bbb.txt 内容
[root@localhost text]# cat bbb.txt
bbb
ccc
aaa
hhh
ttt
jjj
两个文件之间的比较,如果没有排序需要带上--nocheck-order参数,没有带上参数将会收到提示,此命令重要之功能在于比较。
comm: 文件2 没有被正确排序
comm: 文件1 没有被正确排序
比较结果
[root@localhost text]# comm --nocheck-order aaa.txt bbb.txt
aaa
bbb
ccc
aaa
ddd
eee
111
222
hhh
ttt
jjj
第一列 第二列 第三列
输出的第一列只包含在aaa.txt中出现的行,第二列包含在bbb.txt中出现的行,第三列包含在aaa.txt和bbb.txt中相同的行。各列是以制表符(\t)作为定界符。
有序比较,先通过 sort 将文件内容排序
[root@localhost ~]# sort aaa.txt > aaa1.txt
[root@localhost ~]# sort bbb.txt > bbb1.txt
有序比较结果:
[root@localhost ~]# comm aaa1.txt bbb1.txt
111
222
aaa
bbb
ccc
ddd
eee
hhh
jjj
ttt
交集、打印两个文件的交集,需要删除第一列和第二列:
[root@localhost text]# comm aaa.txt bbb.txt -1 -2
bbb
ccc
求差、打印出两个文件中不相同的行,需要删除第三列:
[root@localhost text]# comm aaa.txt bbb.txt -3 | sed 's/^\t//'
aaa
aaa
ddd
eee
111
222
hhh
ttt
sed 's/^\t//' #是将制表符\t删除,以便把两列合并成一列。
差集、通过删除不需要的列,可以得到aaa.txt和bbb.txt的差集:
aaa.txt的差集
[root@localhost text]# comm aaa.txt bbb.txt -2 -3
aaa
ddd
eee
111
222
bbb.txt的差集
[root@localhost text]# comm aaa.txt bbb.txt -2 -3
aaa
ddd
eee
111
222
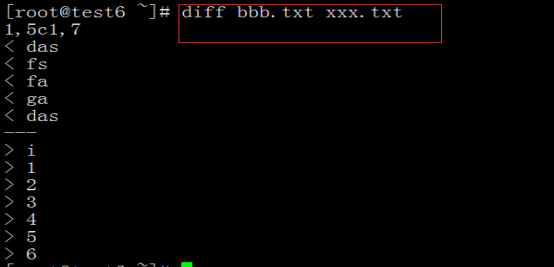
diff 在最简单的情况下,比较给定的两个文件的不同
diff命令在最简单的情况下,比较给定的两个文件的不同。如果使用"-"代替"文件"参数,则要比较的内容将来自标准输入。diff命令是以逐行的方式,比较文本文件的异同处。如果该命令指定进行目录的比较,则将会比较该目录中具有相同文件名的文件,而不会对其子目录文件进行任何比较操作。
Grammar
diff(选项)(参数)
选项
- -u,-U<列数>或--unified=<列数>:以合并的方式来显示文件内容的不同;
- -<行数>:指定要显示多少行的文本。此参数必须与-c或-u参数一并使用;
-
-a或--text:diff预设只会逐行比较文本文件;
-
-b或--ignore-space-change:不检查空格字符的不同;
-
-B或--ignore-blank-lines:不检查空白行;
-
-c:显示全部内容,并标出不同之处;
-
-C<行数>或--context<行数>:与执行"-c-<行数>"指令相同;
-
-d或--minimal:使用不同的演算法,以小的单位来做比较;
-
-D<巨集名称>或ifdef<巨集名称>:此参数的输出格式可用于前置处理器巨集;
-
-e或--ed:此参数的输出格式可用于ed的script文件;
-
-f或-forward-ed:输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处;
-
-H或--speed-large-files:比较大文件时,可加快速度;
-
-l<字符或字符串>或--ignore-matching-lines<字符或字符串>:若两个文件在某几行有所不同,而之际航同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异;
-
-i或--ignore-case:不检查大小写的不同;
-
-l或--paginate:将结果交由pr程序来分页;
-
-n或--rcs:将比较结果以RCS的格式来显示;
-
-N或--new-file:在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录,文件A 若使用-N参数,则diff会将文件A 与一个空白的文件比较;
-
-p:若比较的文件为C语言的程序码文件时,显示差异所在的函数名称;
-
-P或--unidirectional-new-file:与-N类似,但只有当第二个目录包含了第一个目录所没有的文件时,才会将这个文件与空白的文件做比较;
-
-q或--brief:仅显示有无差异,不显示详细的信息;
-
-r或--recursive:比较子目录中的文件;
-
-s或--report-identical-files:若没有发现任何差异,仍然显示信息;
-
-S<文件>或--starting-file<文件>:在比较目录时,从指定的文件开始比较;
-
-t或--expand-tabs:在输出时,将tab字符展开;
-
-T或--initial-tab:在每行前面加上tab字符以便对齐;
-
-v或--version:显示版本信息;
-
-w或--ignore-all-space:忽略全部的空格字符;
-
-W<宽度>或--width<宽度>:在使用-y参数时,指定栏宽;
-
-x<文件名或目录>或--exclude<文件名或目录>:不比较选项中所指定的文件或目录;
-
-X<文件>或--exclude-from<文件>;您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件;
-
-y或--side-by-side:以并列的方式显示文件的异同之处;
-
--help:显示帮助;
-
--left-column:在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容;
-
--suppress-common-lines:在使用-y参数时,仅显示不同之处。
参数
-
文件1:指定要比较的第一个文件;
-
文件2:指定要比较的第二个文件。
Living Example
将目录/usr/li下的文件"test.txt"与当前目录下的文件"test.txt"进行比较,输入如下命令:
diff /usr/li test.txt # 使用diff指令对文件进行比较
上面的命令执行后,会将比较后的不同之处以指定的形式列出,如下所示:
n1 a n3,n4
n1,n2 d n3
其中,字母"a"、"d"、"c"分别表示添加、删除及修改操作。而"n1"、"n2"表示在文件1中的行号,"n3"、"n4"表示在文件2中的行号。
Notice:以上说明指定了两个文件中不同处的行号及其相应的操作。在输出形式中,每一行后面将跟随受到影响的若干行。其中,以<开始的行属于文件1,以>开始的行属于文件2。
说明:更新补丁->可以用diff这个命令查两个文件的不同,patch用于为开放源代码软件安装补丁程序
patch 用于为开放源代码软件安装补丁程序
patch命令被用于为开放源代码软件安装补丁程序。让用户利用设置修补文件的方式,修改,更新原始文件。如果一次仅修改一个文件,可直接在命令列中下达指令依序执行。如果配合修补文件的方式则能一次修补大批文件,这也是Linux系统核心的升级方法之一。
Grammar
patch(选项)(参数)
选项
- -b或--backup:备份每一个原始文件;
-
-p<剥离层级>或--strip=<剥离层级>:设置欲剥离几层路径名称;
-p2参数指定了要去掉补丁路径中的前两个目录层级。例如,如果补丁文件中的路径是a/b/c/file.txt,则去掉前两个目录层级后,最终应用补丁的路径为c/file.txt -
-B<备份字首字符串>或--prefix=<备份字首字符串>:设置文件备份时,附加在文件名称前面的字首字符串,该字符串可以是路径名称;
-
-c或--context:把修补数据解译成关联性的差异;
-
-d<工作目录>或--directory=<工作目录>:设置工作目录;
-
-D<标示符号>或--ifdef=<标示符号>:用指定的符号把改变的地方标示出来;
-
-e或--ed:把修补数据解译成ed指令可用的叙述文件;
-
-E或--remove-empty-files:若修补过后输出的文件其内容是一片空白,则移除该文件;
-
-f或--force:此参数的效果和指定"-t"参数类似,但会假设修补数据的版本为新版本;
-
-F<监别列数>或--fuzz<监别列数>:设置监别列数的最大值;
-
-g<控制数值>或--get=<控制数值>:设置以RSC或SCCS控制修补作业;
-
-i<修补文件>或--input=<修补文件>:读取指定的修补问家你;
-
-l或--ignore-whitespace:忽略修补数据与输入数据的跳格,空格字符;
-
-n或--normal:把修补数据解译成一般性的差异;
-
-N或--forward:忽略修补的数据较原始文件的版本更旧,或该版本的修补数据已使 用过;
-
-o<输出文件>或--output=<输出文件>:设置输出文件的名称,修补过的文件会以该名称存放;
-
-f<拒绝文件>或--reject-file=<拒绝文件>:设置保存拒绝修补相关信息的文件名称,预设的文件名称为.rej;
-
-R或--reverse:假设修补数据是由新旧文件交换位置而产生;
-
-s或--quiet或--silent:不显示指令执行过程,除非发生错误;
-
-t或--batch:自动略过错误,不询问任何问题;
-
-T或--set-time:此参数的效果和指定"-Z"参数类似,但以本地时间为主;
-
-u或--unified:把修补数据解译成一致化的差异;
-
-v或--version:显示版本信息;
-
-V<备份方式>或--version-control=<备份方式>:用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用"-z"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字符串;
-
-Y<备份字首字符串>或--basename-prefix=--<备份字首字符串>:设置文件备份时,附加在文件基本名称开头的字首字符串;
-
-z<备份字尾字符串>或--suffix=<备份字尾字符串>:此参数的效果和指定"-B"参数类似,差别在于修补作业使用的路径与文件名若为src/linux/fs/super.c,加上"backup/"字符串后,文件super.c会备份于/src/linux/fs/backup目录里;
-
-Z或--set-utc:把修补过的文件更改,存取时间设为UTC;
-
--backup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,才备份文件;
-
--binary:以二进制模式读写数据,而不通过标准输出设备;
-
--help:在线帮助;
-
--nobackup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,不要备份文件;
-
--verbose:详细显示指令的执行过程。
Living Example:
[root@myserver ~]# echo "1 2" > m1
[root@myserver ~]# echo "1 2 3" > m2
[root@myserver ~]# diff -u m1 m2 > patch_diff.log
[root@myserver ~]# cat patch_diff.log
--- m1 2023-10-10 14:32:07.630018444 +0800
+++ m2 2023-10-10 14:32:15.180203783 +0800
@@ -1 +1 @@
-1 2
+1 2 3
[root@myserver ~]# patch -b m1 < patch_diff.log #向m1打补丁
patching file m1
[root@myserver ~]# cat m1
1 2 3
[root@myserver ~]# cat m1.orig
1 2
[root@myserver ~]# cat m2
1 2 3
[root@myserver test]# ls
m1 m2 m2.orig patch_diff.log
diff3 用于比较3个文件
diff3命令用于比较3个文件,将3个文件的不同的地方显示到标准输出。
Grammar
diff3(选项)(参数)
选项
- -a:把所有的文件都当做文本文件按照行为单位进行比较,即给定的文件不是文本文件;
-
-A:合并第2个文件和第3个文件之间的不同到第1个文件中,有冲突内容用括号括起来;
-
-B:与选项"-A"功能相同,但是不显示冲突的内容;
-
-e/--ed:生成一个"-ed"脚本,用于将第2个文件和第3个文件之间的不同合并到第1个文件中;
-
--easy-only:除了不显示互相重叠的变化,与选项"-e"的功能相同;
-
-i:为了和system V系统兼容,在"ed"脚本的最后生成"w"和"q"命令。此选项必须和选项"-AeExX3"连用,但是不能和"-m"连用;
- --initial-tab:在正常格式的行的文本前,输出一个TAB字符而非两个空白字符。此选项将导致在行中TAB字符的对齐方式看上去规范。
参数
-
文件1:指定要比较的第1个文件;
-
文件2:指定要比较的第2个文件;
-
文件3:指定要比较的第3个文件。
更改系统当前语言
7版本配置文件所在位置:
原文链接:https:#blog.csdn.net/wo541075754/article/details/89787894
安装语言包(针对centos 7实体机):
# yum install kde-l10n-Chinese #安装中文字符集
更新gitbc包(防止镜像阉割了该包的部分功能):
yum install glibc-common -y && yum reinstall glibc-common -y
设置系统语言包:
localedef -c -f UTF-8 -i zh_CN zh_CN.utf8
# locale -a (查看系统所有支持的语言)
# locale (当前系统的语言)
LANG=zh_CN.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
..............................
LANG表示当前的编码
https:#blog.51cto.com/watchmen/1940609
-
LANG LANG的优先级是最低的,它是所有
LC_*变量的默认值。下方所有以LC_开头变量(不包括LC_ALL)中,如果存在没有设置变量值的变量,那么系统将会使用LANG的变量值来给这个变量进行赋值。如果变量有值,则保持不变,不受影响。可以看到,我们上面示例中的输出中的LC_*变量的值其实就是LANG变量决定的 -
LC_CTYPE 用于字符分类和字符串处理,控制所有字符的处理方式,包括字符编码,字符是单字节还是多字节,如何打印等,这个变量是最重要的。
-
LC_ALL 它不是环境变量,它是一个宏,可通过该变量的设置覆盖所有的
LC_*变量。这个变量设置之后,可以废除LC_*的设置值,使得这些变量的设置值与LC_ALL的值一致,注意,LANG变量不受影响。
优先级级别:
LC_ALL > LC_* > LANG
注意:定义这么多变量在某些情况下是很有用的,例如:当我需要一个能够输入中文的英文环境,我可以把 LC_CTYPE设定成zh_CN.GB18030,而其他所有的项都是en_US.UTF-8
总结:LANG是LC_*的默认值,而LC_ALL比LC_*的优先级都高,设置完LC_ALL之后,会强制重置LC_*的值,如果不将LC_ALL的值重置为空,则无法再去设置LC_*的值
修改系统语言:
在/etc/profile文件中新增:
export LC_ALL=zh_CN.UTF-8
重新加载: source /etc/profile
设置/etc/locale.conf,新增:
LANG="zh_CN.UTF-8"
#LANG=en_US.UTF-8
# cat /etc/locale.conf
LANG="zh_CN.UTF-8" (中文)
#LANG="en_US.UTF-8" (英文)
source /etc/locale.conf #使刚修改的文件生效
# LANG=en_US.UTF-8 (当前shell有效,永久生效需改配置文件)
--------------------------------------------------------------------------
6版本配置文件
[root@test6 init.d]# cat /etc/sysconfig/i18n
LANG="zh_CN.UTF-8"
定义语言环境命令
定义语言环境可以使用localedef命令,比如定义zh_CN.UTF-8,则可以使用:
localedef -c -f UTF-8 -i zh_CN zh_CN.UTF-8
另外,localedef的完整帮助说明如下:
[root]# localedef --help
用法: localedef [选项...] 名称
或: localedef [选项...]
[--add-to-archive|--delete-from-archive] 文件...
或: localedef [选项...] --list-archive [文件]
编译区域规范
输入文件:
- -f, --charmap=FILE Symbolic character names defined in FILE
-
-i, --inputfile=FILE 在 FILE 中找到源定义
-
-u, --repertoire-map=FILE FILE contains mapping from symbolic names to UCS4 values
输出控制:
- -c, --force 即使出现警告消息也创建输出
-
--old-style 创建旧风格表格
-
--posix 严格遵循 POSIX
-
--prefix=PATH 可选的输出文件前缀
-
--quiet 关闭警告和信息消息
-
-v, --verbose 打印更多消息
归档控制:
- --add-to-archive
将由参数命名的区域添加到归档文件中
- -A, --alias-file=FILE 在制作归档文件时参考 locale.alias
文件
-
--delete-from-archive 从归档文件中删除由参数命名的区域
-
--list-archive 列出归档文件的内容
-
--no-archive 不要将新数据添加到归档文件中
-
--replace 替换现有的归档文件内容
-
-?, --help 给出该系统求助列表
-
--usage 给出简要的用法信息
-
-V, --version 打印程序版本号
长选项的强制或可选参数对对应的短选项也是强制或可选的。
获取文件的文件名或者目录
[root@test-6 /]# basename /etc/passwd # (获取文件名)
passwd
[root@test-6 /]# dirname /etc/passwd # (获取目录名)
/etc
wget/curl 下载工具
$ wget http://people.csail.mit.edu/leozhu/paper/cvpr10iCCCP.pdf -O /tmp/leo_paper.pdf # 下载这篇论文,并且保存在指定位置
$ wget -O /tmp/leo_paper.pdf http://people.csail.mit.edu/leozhu/paper/cvpr10iCCCP.pdf # 下载这篇论文,并且保存在指定位置
ps:-O表示下载文件到指定的位置
$ curl -o /tmp/leo_paper.pdf http://people.csail.mit.edu/leozhu/paper/cvpr10iCCCP.pdf # 下载这篇论文,并且保存在指定位置
ps: -o表示下载文件指定的位置
curl -I www.baidu.com #表示返回改网页的头部信息

wget->Linux系统下载文件工具
wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
wget支持HTTP,HTTPS和FTP协议,可以使用HTTP代理。所谓的自动下载是指,wget可以在用户退出系统的之后在后台执行。这意味这你可以登录系统,启动一个wget下载任务,然后退出系统,wget将在后台执行直到任务完成,相对于其它大部分浏览器在下载大量数据时需要用户一直的参与,这省去了极大的麻烦。
用于从网络上下载资源,没有指定目录,下载资源默认为当前目录。wget虽然功能强大,而且使用起来还是比较简单:
支持断点下传功能这一点,也是网络蚂蚁和FlashGet当年最大的卖点,现在,Wget也可以使用此功能,那些网络不是太好的用户可以放心了;
同时支持FTP和HTTP下载方式尽管现在大部分软件可以使用HTTP方式下载,但是,有些时候,仍然需要使用FTP方式下载软件;
支持代理服务器对安全强度很高的系统而言,一般不会将自己的系统直接暴露在互联网上,所以,支持代理是下载软件必须有的功能;
设置方便简单可能,习惯图形界面的用户已经不是太习惯命令行了,但是,命令行在设置上其实有更多的优点,最少,鼠标可以少点很多次,也不要担心是否错点鼠标;程序小,完全免费 程序小可以考虑不计,因为现在的硬盘实在太大了;完全免费就不得不考虑了,即使网络上有很多所谓的免费软件,但是,这些软件的广告却不是我们喜欢的。
语法
wget [参数] [URL地址]
选项
启动参数:
- -V, --version 显示wget的版本后退出
-
-h, --help 打印语法帮助
-
-b, --background 启动后转入后台执行
-
-e, –-execute=COMMAND 执行 `.wgetrc’格式的命令,wgetrc格式参见/etc/wgetrc或~/.wgetrc
记录和输入文件参数:
- -o, --output-file=FILE 把记录写到FILE文件中
-
-a, --append-output=FILE 把记录追加到FILE文件中
-
-d, --debug 打印调试输出
-
-q, --quiet 安静模式(没有输出)
-
-v, --verbose 冗长模式(这是缺省设置)
-
-nv, --non-verbose 关掉冗长模式,但不是安静模式
-
-i, --input-file=FILE 下载在FILE文件中出现的URLs
-
-F, --force-html 把输入文件当作HTML格式文件对待
-
-B, --base=URL 将URL作为在-F -i参数指定的文件中出现的相对链接的前缀
-
--sslcertfile=FILE 可选客户端证书
-
--sslcertkey=KEYFILE 可选客户端证书的KEYFILE
-
--egd-file=FILE 指定EGD socket的文件名
下载参数:
-
--bind-address=ADDRESS 指定本地使用地址(主机名或IP,当本地有多个IP或名字时使用)
-
-t, --tries=NUMBER 设定最大尝试链接次数(0 表示无限制).
-
-O --output-document=FILE 把文档写到FILE文件中
-
-O代表指定输出位置,-O-表示输出到标准输出
-
-nc, --no-clobber 不要覆盖存在的文件或使用.#前缀;不要重复下载已存在的文件 --no-clobber
-
-c, --continue 接着下载没下载完的文件
-
--progress=TYPE 设定进程条标记,具体来说,
--progress=TYPE中的TYPE可以是以下选项之一: -
dot: 默认类型,使用点号 (.) 来表示下载进度,点越多表示下载速度越快。在下载较小的文件时比较适合。 -
bar: 使用进度条来表示下载进度,可以直观地显示已下载数据量和总数据量之间的比例关系。在下载较大的文件时比较适合。 -
meter: 使用带有数字百分比的进度条来表示下载进度,在下载需要时间较长的文件时比较适合。 -
-N, --timestamping 不要重新下载文件除非比本地文件新
- -S, --server-response 打印服务器的回应
- --spider 不下载任何东西
- -T, --timeout=SECONDS 设定响应超时的秒数
- -w, --wait=SECONDS 两次尝试之间间隔SECONDS秒
- --waitretry=SECONDS 在重新链接之间等待1...SECONDS秒
- --random-wait 在下载之间等待0...2*WAIT秒
- -Y, --proxy=on/off 打开或关闭代理
- -Q, --quota=NUMBER 设置下载的容量限制
- --limit-rate=RATE 限定下载输率
目录参数:
- -nd --no-directories 不创建目录;递归下载时不创建一层一层的目录,把所有的文件下载到当前目录
-
-x, --force-directories 强制创建目录
-
-nH, --no-host-directories 不创建主机目录(比如下载的是这个目录下的文件http://xxxx/download/autoinstall,加了-nH就不会创建xxxx这个目录了,而是download/autoinstall目录)
- -P, --directory-prefix=PREFIX 将文件保存到目录PREFIX/...(http://xxxx/download/autoinstall加上
-P./test 那么下载的文件保存的目录就是./download/autoinstall) - --cut-dirs=NUMBER 忽略 NUMBER层远程目录
HTTPS选项参数:
使用wget下载https资源的时候,可能会有证书出错的情况,这时使用--no-check-certificate就可以解决
HTTP 选项参数:
- --http-user=USER 设定HTTP用户名为 USER.
-
--http-passwd=PASS 设定http密码为 PASS
-
-C, --cache=on/off 允许/不允许服务器端的数据缓存 (一般情况下允许)
-
-E, --html-extension 将所有text/html文档以.html扩展名保存
-
--ignore-length 忽略 `Content-Length'头域
-
--header=STRING 在headers中插入字符串 STRING
-
--proxy-user=USER 设定代理的用户名为 USER
-
--proxy-passwd=PASS 设定代理的密码为 PASS
-
--referer=URL 在HTTP请求中包含 `Referer: URL'头
-
-s, --save-headers 保存HTTP头到文件
-
-U, --user-agent=AGENT 设定代理的名称为 AGENT而不是 Wget/VERSION
-
--no-http-keep-alive 关闭 HTTP活动链接 (永远链接)
-
--cookies=off 不使用 cookies
-
--load-cookies=FILE 在开始会话前从文件 FILE中加载cookie
-
--save-cookies=FILE 在会话结束后将 cookies保存到 FILE文件中
FTP 选项参数:
-
-nr, --dont-remove-listing 不移走 `.listing'文件
-
-g, --glob=on/off 打开或关闭文件名的 globbing机制
-
--passive-ftp 使用被动传输模式 (缺省值).
-
--active-ftp 使用主动传输模式
-
--retr-symlinks 在递归的时候,将链接指向文件(而不是目录)
递归下载参数:
- -r, --recursive 递归下载--慎用!
-
-l, --level=NUMBER 最大递归深度 (inf 或 0 代表无穷)
-
--delete-after 在现在完毕后局部删除文件
- -k, --convert-links 转换非相对链接为相对链接;表示将下载的网页里的链接修改为本地链接.(下载整个站点后脱机浏览网页,最好加上这个参数)
-
-K, --backup-converted 在转换文件X之前,将之备份为 X.orig
-
-m, --mirror 等价于 -r -N -l inf -nr
-
-p, --page-requisites 下载网页所需的所有文件
递归下载中的包含和不包含(accept/reject):
-
-A, --accept=LIST 分号分隔的被接受扩展名的列表
-
-R, --reject=LIST 分号分隔的不被接受的扩展名的列表
-
-D, --domains=LIST 分号分隔的被接受域的列表
-
--exclude-domains=LIST 分号分隔的不被接受的域的列表
-
--follow-ftp 跟踪HTML文档中的FTP链接
-
--follow-tags=LIST 分号分隔的被跟踪的HTML标签的列表
-
-G, --ignore-tags=LIST 分号分隔的被忽略的HTML标签的列表
-
-H, --span-hosts 当递归时转到外部主机
-
-L, --relative 仅仅跟踪相对链接;递归时不进入其它主机,如wget -c -r www.xxx.org/ 如果网站内有一个这样的链接:www.yyy.org,不加参数-L,会递归下载www.yyy.org网站
-
-I, --include-directories=LIST 允许目录的列表
-
-X, --exclude-directories=LIST 不被包含目录的列表
-
-np, --no-parent 不要追溯到父目录;递归下载时不搜索上层目录
- wget -S --spider url 不下载只显示过程
参数
URL:下载指定的URL地址。
实例
使用wget下载单个文件
wget http://www.jsdig.com/testfile.zip
以下的例子是从网络下载一个文件并保存在当前目录,在下载的过程中会显示进度条,包含(下载完成百分比,已经下载的字节,当前下载速度,剩余下载时间)。
下载并以不同的文件名保存
wget -O wordpress.zip http://www.jsdig.com/download.aspx?id=1080
wget默认会以最后一个符合/的后面的字符来命令,对于动态链接的下载通常文件名会不正确。
错误:下面的例子会下载一个文件并以名称download.aspx?id=1080保存:
wget http://www.jsdig.com/download?id=1
即使下载的文件是zip格式,它仍然以download.php?id=1080命令。
正确:为了解决这个问题,我们可以使用参数-O来指定一个文件名:
wget -O wordpress.zip http://www.jsdig.com/download.aspx?id=1080
wget限速下载
wget --limit-rate=300k http://www.jsdig.com/testfile.zip
当你执行wget的时候,它默认会占用全部可能的宽带下载。但是当你准备下载一个大文件,而你还需要下载其它文件时就有必要限速了。
使用wget断点续传
wget -c http://www.jsdig.com/testfile.zip
使用wget -c重新启动下载中断的文件,对于我们下载大文件时突然由于网络等原因中断非常有帮助,我们可以继续接着下载而不是重新下载一个文件。需要继续中断的下载时可以使用-c参数。
使用wget后台下载
wget -b http://www.jsdig.com/testfile.zip
Continuing in background, pid 1840.
Output will be written to `wget-log'.
对于下载非常大的文件的时候,我们可以使用参数-b进行后台下载,你可以使用以下命令来察看下载进度:
tail -f wget-log
伪装代理名称下载
wget --user-agent="Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16" http://www.jsdig.com/testfile.zip
有些网站能通过根据判断代理名称不是浏览器而拒绝你的下载请求。不过你可以通过--user-agent参数伪装。
测试下载链接
当你打算进行定时下载,你应该在预定时间测试下载链接是否有效。我们可以增加--spider参数进行检查。
wget --spider URL
如果下载链接正确,将会显示:
Spider mode enabled. Check if remote file exists.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Remote file exists and could contain further links,
but recursion is disabled -- not retrieving.
这保证了下载能在预定的时间进行,但当你给错了一个链接,将会显示如下错误:
# wget --spider url
Spider mode enabled. Check if remote file exists.
HTTP request sent, awaiting response... 404 Not Found
Remote file does not exist -- broken link!!!
你可以在以下几种情况下使用--spider参数:
-
定时下载之前进行检查
-
间隔检测网站是否可用
-
检查网站页面的死链接
-
增加重试次数
wget --tries=40 URL
如果网络有问题或下载一个大文件也有可能失败。wget默认重试20次连接下载文件。如果需要,你可以使用--tries增加重试次数。
下载多个文件
wget -i filelist.txt
首先,保存一份下载链接文件:
cat > filelist.txt
url1
url2
url3
url4
接着使用这个文件和参数-i下载。
镜像网站
wget --mirror -p --convert-links -P ./LOCAL URL
下载整个网站到本地。
- --miror开户镜像下载。
-
-p下载所有为了html页面显示正常的文件。
-
--convert-links下载后,转换成本地的链接。
-P ./LOCAL保存所有文件和目录到本地指定目录。
过滤指定格式下载
wget --reject=gif ur #下载一个网站,但你不希望下载图片,可以使用这条命令。
把下载信息存入日志文件
wget -o download.log URL
不希望下载信息直接显示在终端而是在一个日志文件,可以使用。
限制总下载文件大小
wget -Q5m -i filelist.txt
当你想要下载的文件超过5M而退出下载,你可以使用。注意:这个参数对单个文件下载不起作用,只能递归下载时才有效。
下载指定格式文件
wget -r -A.pdf url
可以在以下情况使用该功能:
-
下载一个网站的所有图片。
-
下载一个网站的所有视频。
-
下载一个网站的所有PDF文件。
可以使用wget来完成ftp链接的下载。
FTP下载
wget ftp-url
wget --ftp-user=USERNAME --ftp-password=PASSWORD url
使用wget匿名ftp下载:
wget ftp-url
使用wget用户名和密码认证的ftp下载:
wget --ftp-user=USERNAME --ftp-password=PASSWORD url
递归下载目录下的内容
wget -c -r -L -np -nc -nH --ignore-tags=robots.txt http://xxxx/download/autoinstall/
访问网站(必须是这个格式,只需要变后面网址)
wget -O- -q www.baidu.com
curl 利用URL规则在命令行下工作的文件传输工具
curl命令 是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、ftp等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
如果系统没有curl可以使用yum install curl安装,也可以下载安装
语法
curl(选项)(参数)
选项
-
-I/--head 只显示传输文档,经常用于测试连接本身
-
-o/--output 把输出写到该文件中,必须输入保存文件名
-
-O/--remote-name 把输出写到该文件中,保留远程文件的文件名
-
-F/--form 模拟表单提交
-
-s/--silent 静默模式,不输出任何东西
-
-S/--show-error 显示错误,在选项 -s 中,当 curl 出现错误时将显示
-
-L/--location 跟踪重定向
-
-f/--fail 不输出错误
-
-n/--netrc 从netrc文件中读取用户名和密码
-
--netrc-选项al 使用 .netrc 或者 URL来覆盖-n
-
--ntlm 使用 HTTP NTLM 身份验证
-
-N/--no-buffer 禁用缓冲输出
-
-p/--proxytunnel 使用HTTP代理
-
--proxy-anyauth 选择任一代理身份验证方法
-
--proxy-basic 在代理上使用基本身份验证
-
--proxy-digest 在代理上使用数字身份验证
-
--proxy-ntlm 在代理上使用ntlm身份验证
-
-P/--ftp-port 使用端口地址,而不是使用PASV
-
-M/--manual 显示全手动
-
-Q/--quote 文件传输前,发送命令到服务器
-
-r/--range 检索来自HTTP/1.1或FTP服务器字节范围
-
--range-file 读取(SSL)的随机文件
-
-R/--remote-time 在本地生成文件时,保留远程文件时间
-
--retry 传输出现问题时,重试的次数
-
--retry-delay 传输出现问题时,设置重试间隔时间
-
--retry-max-time 传输出现问题时,设置最大重试时间
-
--socks4 用socks4代理给定主机和端口
-
--socks5 用socks5代理给定主机和端口
-
-t/--telnet-选项 Telnet选项设置
-
--trace 对指定文件进行debug
-
--trace-ascii Like 跟踪但没有hex输出
-
--trace-time 跟踪/ 详细输出时,添加时间戳
-
-T/--upload-file 上传文件
-
-u/--user 设置服务器的用户和密码
-
-U/--proxy-user 设置代理用户名和密码
-
-V/--version 显示版本信息
-
-w/--write-out [format] 什么输出完成后
-
-x/--proxy 在给定的端口上使用HTT正向代理
-
-X/--request 指定什么命令 例如:-XPOST
-
-y/--speed-time 放弃限速所要的时间。默认为30
-
-Y/--speed-limit 停止传输速度的限制,速度时间\'秒
-
-z/--time-cond 传送时间设置
-
-0/--http1.0 使用HTTP 1.0
-
-1/--tlsv1 使用TLSv1(SSL)
-
-2/--sslv2 使用SSLv2的(SSL)
-
-3/--sslv3 使用的SSLv3(SSL)
-
--3p-quote like -Q for the source URL for 3rd party transfer
-
--3p-url 使用url,进行第三方传送
-
--3p-user 使用用户名和密码,进行第三方传送
-
-4/--ipv4 使用IP4
-
-6/--ipv6 使用IP6
-
-#/--progress-bar 用进度条显示当前的传送状态
-
-a/--append 上传文件时,附加到目标文件
-
-A/--user-agent 设置用户代理发送给服务器
-
-anyauth 可以使用"任何"身份验证方法
-
-b/--cookie cookie字符串或文件读取位置
-
--basic 使用HTTP基本验证
-
-B/--use-ascii 使用ASCII /文本传输
-
-c/--cookie-jar 操作结束后把cookie写入到这个文件中
-
-C/--continue-at 断点续传
-
-d/--data HTTP POST方式传送数据
-
--data-ascii 以ascii的方式post数据
-
--data-binary 以二进制的方式post数据
-
--negotiate 使用HTTP身份验证
-
--digest 使用数字身份验证
-
--disable-eprt 禁止使用EPRT或LPRT
-
--disable-epsv 禁止使用EPSV
-
-D/--dump-header 把header信息写入到该文件中
-
--egd-file 为随机数据(SSL)设置EGD socket路径
-
--tcp-nodelay 使用TCP_NODELAY选项
-
-e/--referer 来源网址
-
-E/--cert 客户端证书文件和密码 (SSL)
-
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
-
--key 私钥文件名 (SSL)
-
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
-
--pass 私钥密码 (SSL)
-
--engine 加密引擎使用 (SSL). "--engine list" for list
-
--cacert CA证书 (SSL)
-
--capath CA目录 (made using c_rehash) to verify peer against (SSL)
-
--ciphers SSL密码
-
--compressed 要求返回是压缩的形势 (using deflate or gzip)
-
--connect-timeout 设置最大请求时间
-
--create-dirs 建立本地目录的目录层次结构
-
--crlf 上传是把LF转变成CRLF
-
-f/--fail 连接失败时不显示http错误
-
--ftp-create-dirs 如果远程目录不存在,创建远程目录
-
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
-
--ftp-pasv 使用 PASV/EPSV 代替端口
-
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
-
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
-
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-
-F/--form 模拟http表单提交数据
-
--form-string 模拟http表单提交数据
-
-g/--globoff 禁用网址序列和范围使用{}和[]
-
-G/--get 以get的方式来发送数据
-
-H/--header 自定义头信息传递给服务器
-
--ignore-content-length 忽略的HTTP头信息的长度
-
-i/--include 输出时包括protocol头信息
-
-I/--head 只显示请求头信息(大写I)
-
-j/--junk-session-cookies 读取文件进忽略session cookie
-
--interface 使用指定网络接口/地址
-
--krb4 使用指定安全级别的krb4
-
-k/--insecure 允许不使用证书到SSL站点
-
-K/--config 指定的配置文件读取
-
-l/--list-only 列出ftp目录下的文件名称
-
--limit-rate 设置传输速度
-
--local-port 强制使用本地端口号
-
-m/--max-time 设置最大传输时间
-
--max-redirs 设置最大读取的目录数
-
--max-filesize 设置最大下载的文件总量
-
-M/--manual 显示全手动
-
-n/--netrc 从netrc文件中读取用户名和密码
-
--netrc-选项al 使用 .netrc 或者 URL来覆盖-n
-
--ntlm 使用 HTTP NTLM 身份验证
-
-N/--no-buffer 禁用缓冲输出
-
-p/--proxytunnel 使用HTTP代理
-
--proxy-anyauth 选择任一代理身份验证方法
-
--proxy-basic 在代理上使用基本身份验证
-
--proxy-digest 在代理上使用数字身份验证
-
--proxy-ntlm 在代理上使用ntlm身份验证
-
-P/--ftp-port 使用端口地址,而不是使用PASV
-
-q 作为第一个参数,关闭 .curlrc
-
-Q/--quote 文件传输前,发送命令到服务器
-
-r/--range 检索来自HTTP/1.1或FTP服务器字节范围
-
--range-file 读取(SSL)的随机文件
-
-R/--remote-time 在本地生成文件时,保留远程文件时间
-
--retry 传输出现问题时,重试的次数
-
--retry-delay 传输出现问题时,设置重试间隔时间
-
--retry-max-time 传输出现问题时,设置最大重试时间
-
-s/--silent 静默模式。不输出任何东西
-
-S/--show-error 显示错误
-
--socks4 用socks4代理给定主机和端口
-
--socks5 用socks5代理给定主机和端口
-
--stderr
-
-t/--telnet-选项 Telnet选项设置
-
--trace 对指定文件进行debug
-
--trace-ascii Like --跟踪但没有hex输出
-
--trace-time 跟踪/详细输出时,添加时间戳
-
-T/--upload-file 上传文件
-
--url Spet URL to work with
-
-u/--user 设置服务器的用户和密码
-
-U/--proxy-user 设置代理用户名和密码
-
-w/--write-out [format] 什么输出完成后
-
-x/--proxy 在给定的端口上使用HTTP代理
-
-X/--request 指定什么命令 (psot、get......)
-
-y/--speed-time 放弃限速所要的时间,默认为30
-
-Y/--speed-limit 停止传输速度的限制,速度时间
实例:
测试端口是否占用,如果没有会显示连接拒绝,反之
[root@localhost logs]# curl 127.0.0.1:1799
[root@localhost logs]# echo $?
0
[root@localhost logs]# curl 127.0.0.1:1794
curl: (7) Failed connect to 127.0.0.1:1794; Connection refused
[root@localhost logs]# echo $?
7
#测试网页返回值[https:#blog.csdn.net/workdsz/article/details/78489101]
# curl -I -m 10 -L -k -o /dev/null -s -w %{http_code} www.baidu.com
Ps:在脚本中,这是很常见的测试网站是否正常的用法
通过-I或者-head可以只打印出HTTP头部信息:
# curl -I "http://www.baidu.com"
get请求:
curl "http://www.baidu.com" # 如果这里的URL指向的是一个文件或者一幅图都可以直接下载到本地
curl -v "http://www.baidu.com" # 显示get请求全过程解析
curl -i "http://www.baidu.com" # 显示全部信息
post请求:
curl -d "param1=value1¶m2=value2" "http://www.baidu.com"
json格式的post请求:
curl -l -H "Content-type: application/json" -X POST -d '{"phone":"13521389587","password":"test"}' http://www.baidu.com/apis/users.json
文件下载:
curl命令可以用来执行下载、发送各种HTTP请求,指定HTTP头部等操作。curl是将下载文件输出到stdout,将进度信息输出到stderr,不显示进度信息使用--silent选项。这条命令是将下载文件输出到终端,所有下载的数据都被写入到stdout。
curl URL --silent
使用选项-O将下载的数据写入到文件,必须使用文件的绝对地址:
curl http://wangchujiang.com/text.iso --silent -O
选项-o将下载数据写入到指定名称的文件中,并使用--progress显示进度条:
curl http://wangchujiang.com/test.iso -o filename.iso --progress
######################################### 100.0%
断点续传
curl能够从特定的文件偏移处继续下载,它可以通过指定一个偏移量来下载部分文件:
curl URL/File -C 偏移量
#偏移量是以字节为单位的整数,如果让curl自动推断出正确的续传位置使用-C -:
curl -C -URL
使用curl设置参照页字符串
参照页是位于HTTP头部中的一个字符串,用来表示用户是从哪个页面到达当前页面的,如果用户点击网页A中的某个连接,那么用户就会跳转到B网页,网页B头部的参照页字符串就包含网页A的URL。使用--referer选项指定参照页字符串:
curl --referer http://www.google.com http://wangchujiang.com
用curl设置cookies,使用--cookie "COKKIES"选项来指定cookie,多个cookie使用分号分隔:
curl http://wangchujiang.com --cookie "user=root;pass=123456"
将cookie另存为一个文件,使用--cookie-jar选项:
curl URL --cookie-jar cookie_file
用curl设置用户代理字符串,有些网站访问会提示只能使用IE浏览器来访问,这是因为这些网站设置了检查用户代理,可以使用curl把用户代理设置为IE,这样就可以访问了。使用--user-agent或者-A选项:
curl URL --user-agent "Mozilla/5.0"
curl URL -A "Mozilla/5.0"
其他HTTP头部信息也可以使用curl来发送,使用-H"头部信息" 传递多个头部信息,例如:
curl -H "Host:wangchujiang.com" -H "accept-language:zh-cn" URL
curl的带宽控制和下载配额
使用--limit-rate限制curl的下载速度:命令中用k(千字节)和m(兆字节)指定下载速度限制。
curl URL --limit-rate 50k
使用--max-filesize指定可下载的最大文件大小:
curl URL --max-filesize bytes
如果文件大小超出限制,命令则返回一个非0退出码,如果命令正常则返回0。
用curl进行认证
使用curl选项 -u 可以完成HTTP或者FTP的认证,可以指定密码,也可以不指定密码在后续操作中输入密码:
curl -u user:pwd http://wangchujiang.com
curl -u user http://wangchujiang.com
axel:多线程下载工具,下载文件时可以替代curl、wget
# yum install axel -y
#axel -n 20 下载的URL
域名查询工具
host 常用的分析域名查询工具
host命令 是常用的分析域名查询工具,可以用来测试域名系统工作是否正常。
语法
host(选项)(参数)
选项
-
-a:显示详细的DNS信息;
-
-c<类型>:指定查询类型,默认值为"IN";
-
-C:查询指定主机的完整的SOA记录;
-
-r:在查询域名时,不使用递归的查询方式;
-
-t<类型>:指定查询的域名信息类型;
-
-v:显示指令执行的详细信息;
-
-w:如果域名服务器没有给出应答信息,则总是等待,直到域名服务器给出应答;
-
-W<时间>:指定域名查询的最长时间,如果在指定时间内域名服务器没有给出应答信息,则退出指令;
-
-4:使用IPv4;
- -6:使用IPv6.
参数
主机:指定要查询信息的主机信息。
实例
[root@localhost ~]# host www.jsdig.com
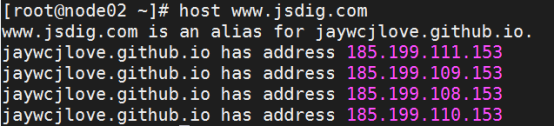
www.jsdig.com这是个不错的网站
[root@localhost ~]# host -a www.jsdig.com
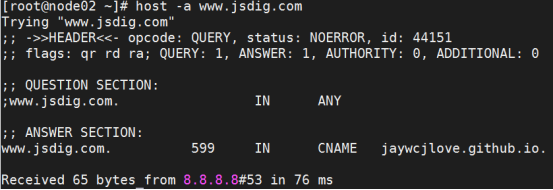
nslookup 查询域名DNS信息的工具
nslookup命令 是常用域名查询工具,就是查DNS信息用的命令。
nslookup4有两种工作模式,即"交互模式"和"非交互模式"。在"交互模式"下,用户可以向域名服务器查询各类主机、域名的信息,或者输出域名中的主机列表。而在"非交互模式"下,用户可以针对一个主机或域名仅仅获取特定的名称或所需信息。
进入交互模式,直接输入nslookup命令,不加任何参数,则直接进入交互模式,此时nslookup会连接到默认的域名服务器(即/etc/resolv.conf的第一个dns地址)。或者输入nslookup
-nameserver/ip。进入非交互模式,就直接输入nslookup 域名就可以了。
语法
nslookup(选项)(参数)
选项
- -sil:不显示任何警告信息。
参数
域名:指定要查询域名。
实例
[root@localhost ~]# nslookup www.jsdig.com
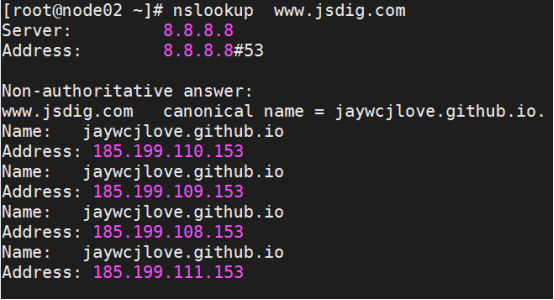
查看DNS服务器:nslookup 然后输入server
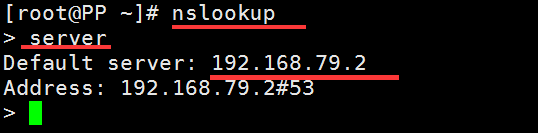
dig 域名查询工具
dig命令 是常用的域名查询工具,可以用来测试域名系统工作是否正常。
语法
dig(选项)(参数)
选项
-
@<服务器地址>:指定进行域名解析的域名服务器;
-
-b
:当主机具有多个IP地址,指定使用本机的哪个IP地址向域名服务器发送域名查询请求; -
-f<文件名称>:指定dig以批处理的方式运行,指定的文件中保存着需要批处理查询的DNS任务信息;
-
-P:指定域名服务器所使用端口号;
-
-t<类型>:指定要查询的DNS数据类型(A记录就是A,其他暂时没有用到过);
-
-x
:执行逆向域名查询; -
-4:使用IPv4;
-
-6:使用IPv6;
-
+short:直接显示域名对应的IP
-
-h:显示指令帮助信息。
参数
-
主机:指定要查询域名主机;
-
查询类型:指定DNS查询的类型;
-
查询类:指定查询DNS的class;
-
查询选项:指定查询选项。
实例
[root@localhost ~]# dig www.jsdig.com
[root@localhost ~]# dig +short www.jsdig.com
ulimit 控制shell程序的资源
还有ulimit -n查看linux系统打开最大的文件描述符,这里默认1024
不修改这里web服务器修改再大也没用,若要用就修改很几个办法,这里说其中一个:
# vim /etc/security/limits.conf #永久生效:写入配置文件
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535
说明:* 代表针对所有用户
noproc 是代表最大进程数
nofile 是代表最大文件打开数
好了,退出当前终端以后重新登录可以看到ulimit -n已经改成了65535
#添加的格式是
#<domain> <type> <item> <value>
域 类型 项目 值
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
为什么要同时有soft和hard这两个限制?这个soft和hard应该是代表两种类型的阀值吧,一定不能超过hard限制,但是可以超过soft限制,有一个hard不就够了么?soft是一个警告值,而hard则是一个真正意义的阀值,超过就会报错。
* soft noproc 655350 #该文件有具体的解释!
临时生效:
ulimit -n 655350
理论概述:
ulimit命令用来限制系统用户对shell资源的访问。如果不懂什么意思,下面一段内容可以帮助你理解:
假设有这样一种情况,当一台 Linux 主机上同时登陆了 10个人,在系统资源无限制的情况下,这 10 个用户同时打开了 500个文档,而假设每个文档的大小有10M,这时系统的内存资源就会受到巨大的挑战。
而实际应用的环境要比这种假设复杂的多,例如在一个嵌入式开发环境中,各方面的资源都是非常紧缺的,对于开启文件描述符的数量,分配堆栈的大小,CPU时间,虚拟内存大小,等等,都有非常严格的要求。资源的合理限制和分配,不仅仅是保证系统可用性的必要条件,也与系统上软件运行的性能有着密不可分的联 系。这时,ulimit可以起到很大的作用,它是一种简单并且有效的实现资源限制的方式。
ulimit 用于限制 shell启动进程所占用的资源,支持以下各种类型的限制:所创建的内核文件的大小、进程数据块的大小、Shell进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开文件描述符的数量、分配堆栈的最大大小、CPU时间、单个用户的最大线程数、Shell进程所能使用的最大虚拟内存。同时,它支持硬资源和软资源的限制。
作为临时限制,ulimit 可以作用于通过使用其命令登录的 shell会话,在会话终止时便结束限制,并不影响于其他 shell会话。而对于长期的固定限制,ulimit 命令语句又可以被添加到由登录 shell读取的文件中,作用于特定的shell 用户。
ulimit 语法
选项:
- -a:显示目前资源限制的设定;
-
-u <程序数目>:用户最多可开启的程序数目;
-
-n <文件数目>:同一时间最多可开启的文件数;
-
-c
:设定core文件的最大值,单位为区块; -
-d <数据节区大小>:程序数据节区的最大值,单位为KB;
-
-f <文件大小>:shell所能建立的最大文件,单位为区块;
-
-H:设定资源的硬性限制,也就是管理员所设下的限制;
-
-m <内存大小>:指定可使用内存的上限,单位为KB;
-
-p <缓冲区大小>:指定管道缓冲区的大小,单位512字节;
-
-s <堆叠大小>:指定堆叠的上限,单位为KB;
-
-S:设定资源的弹性限制;
-
-t
:指定CPU使用时间的上限,单位为秒; -
-v <虚拟内存大小>:指定可使用的虚拟内存上限,单位为KB。

实例
[root@localhost ~]# ulimit -a
core file size (blocks, -c) 0 #core文件的最大值为100 blocks。
data seg size (kbytes, -d) unlimited #进程的数据段可以任意大。
scheduling priority (-e) 0
file size (blocks, -f) unlimited #文件可以任意大。
pending signals (-i) 98304 #最多有98304个待处理的信号。
max locked memory (kbytes, -l) 32 #一个任务锁住的物理内存的最大值为32KB。
max memory size (kbytes, -m) unlimited #一个任务的常驻物理内存的最大值。
open files (-n) 1024 #一个任务最多可以同时打开1024的文件。
pipe size (512 bytes, -p) 8 #管道的最大空间为4096字节。
POSIX message queues (bytes, -q) 819200 #POSIX的消息队列的最大值为819200字节。
real-time priority (-r) 0
stack size (kbytes, -s) 10240 #进程的栈的最大值为10240字节。
cpu time (seconds, -t) unlimited #进程使用的CPU时间。
max user processes (-u) 98304 #当前用户同时打开的进程(包括线程)的最大个数为98304 #ulimit -u的值
virtual memory (kbytes, -v) unlimited #没有限制进程的最大地址空间。
file locks (-x) unlimited #所能锁住的文件的最大个数没有限制。

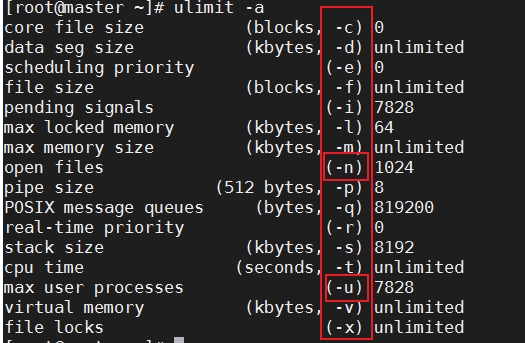
系统调优
如前所述,ulimit -a用来显示当前的各种用户进程限制。
linux对于每个用户,系统限制其最大进程数。为提高性能,可以根据设备资源情况,
设置各linux用户的最大进程数,下面我把某linux用户的最大进程数设为10000个:
ulimit -u 65535
对于需要做许多 socket 连接并使它们处于打开状态的 Java应用程序而言,最好通过使用ulimit -n 65535修改每个进程可打开的文件数,缺省值是1024。
ulimit -n 4096 将每个进程可以打开的文件数目加大到4096,缺省为1024;其他建议设置成无限制(unlimited)的一些重要设置是:
数据段长度:ulimit -d unlimited
最大内存大小:ulimit -m unlimited
堆栈大小:ulimit -s unlimited
CPU 时间:ulimit -t unlimited
虚拟内存:ulimit -v unlimited
暂时地,适用于通过ulimit命令登录 shell 会话期间。
永久地,通过将一个相应的ulimit语句添加到由登录 shell 读取的文件中,
即特定于 shell 的用户资源文件,如:
1) 解除 Linux 系统的最大进程数和最大文件打开数限制:
vim /etc/security/limits.conf
# 添加如下的行
* soft noproc 65535
* hard noproc 65535
* soft nofile 65535
* hard nofile 65535
说明:* 代表针对所有用户
noproc 是代表最大进程数
nofile 是代表最大文件打开数
2) 让 SSH 接受 Login 程式的登入,方便在 ssh 客户端查看 ulimit -a 资源限制:
a、vi /etc/ssh/sshd_config
把 UserLogin 的值改为 yes,并把 # 注释去掉。#这个保证其他的用户也能修改设置
把 UsePAM 的值改为 yes,并把 # 注释去掉
b、重启 sshd 服务:
/etc/init.d/sshd restart
3) 修改所有 linux 用户的环境变量文件:
vim /etc/profile
ulimit -u 65535
ulimit -n 65535
ulimit -d unlimited
ulimit -m unlimited
ulimit -s unlimited
ulimit -t unlimited
ulimit -v unlimited
有时候在程序里面需要打开多个文件,进行分析,系统一般默认数量是1024,(用ulimit -a可以看到)对于正常使用是够了,但是对于程序来讲,就太少了:修改2个文件。
1) vim /etc/security/limits.conf #加上:
* soft noproc 65535
* hard noproc 65535
* soft nofile 65535
* hard nofile 65535
2) /etc/pam.d/login
session required /lib/security/pam_limits.so
**********
另外确保/etc/pam.d/system-auth文件有下面内容
session required /lib/security/$ISA/pam_limits.so
这一行确保系统会执行这个限制。
***********
3) 一般用户的.bash_profile
#ulimit -n 65535
重新登陆ok
4) /proc目录:
1)/proc目录里面包括很多系统当前状态的参数,例如:引用
/proc/sys/fs/file-max
/proc/sys/fs/inode-max
是对整个系统的限制,并不是针对用户的;
2)proc目录中的值可以进行动态的设置,若希望永久生效,可以修改/etc/sysctl.conf文件,例如增加:
fs.file-max=xxx
fs.inode-max=xxx
并使用下面的命令确认:# sysctl -p
分析
soft和hard一起设置才好使
* soft nofile 1000000
* hard nofile 1000000
如果只是设置一个,那么是不起作用的。
啥时候ulimit的设置才生效:退出当前session,重新登录后 或者直接命令行执行
ulimit -n 1000000
ulimit -u unlimited

nofile不能设置unlimited,noproc可以
如果设置
* soft nofile unlimited
* hard nofile unlimited
那么你将被登录拒绝,因为
但是nproc可以的。
检验ssh登录问题的良药-vv
总结
如果遇到这种情况该如何是好
重启进入单用户模式,修改/etc/security/limits.d/90-nproc直接删除
保险的做法是啥
直接用命令行操作,结果只会报错,不会无法登陆
扩展 如果是因为/etc/profile里面加入了exit导致无法登陆
ssh root@xxx -t
然后你就可以输入命令了,这个-t就没有加载profile等软件,可以
sed -i '/exit/d' /etc/profile
然后登陆试试就ok了,亲测过
ulimit -n的最大值是$((2**20))
也就是最大 1048576 多加个1都会报错哦
所以这个地方也引申出来,在互联网程序中,同时处理大概100w已经是顶峰。
也扩展出,同时处理和每秒并发是不同的概念,这个是时空不同而已。
再进一步, nofile的hard绝对不允许超过1048576,soft随意,大不了最大1048576
终端是哪个文件?黑洞是哪个文件?
终端/dev/tty
黑洞文件/dev/null
泡泡机/dev/zero
ldd 打印程序或者库文件所依赖的共享库列表
ldd命令用于打印程序或者库文件所依赖的共享库列表。
语法
ldd(选项)(参数)
选项
-
--version:打印指令版本号;
-
-v:详细信息模式,打印所有相关信息;
-
-u:打印未使用的直接依赖;
-
-d:执行重定位和报告任何丢失的对象;
-
-r:执行数据对象和函数的重定位,并且报告任何丢失的对象和函数;
-
--help:显示帮助信息。
参数
文件:指定可执行程序或者文库。
其他介绍
首先ldd不是一个可执行程序,而只是一个shell脚本
ldd能够显示可执行模块的dependency,其原理是通过设置一系列的环境变量,如下:LD_TRACE_LOADED_OBJECTS、LD_WARN、LD_BIND_NOW、LD_LIBRARY_VERSION、LD_VERBOSE等。当LD_TRACE_LOADED_OBJECTS环境变量不为空时,任何可执行程序在运行时,它都会只显示模块的dependency,而程序并不真正执行。要不你可以在shell终端测试一下,如下:
export LD_TRACE_LOADED_OBJECTS=1
再执行任何的程序,如ls等,看看程序的运行结果。
ldd显示可执行模块的dependency的工作原理,其实质是通过ld-linux.so(elf动态库的装载器)来实现的。我们知道,ld-linux.so模块会先于executable模块程序工作,并获得控制权,因此当上述的那些环境变量被设置时,ld-linux.so选择了显示可执行模块的dependency。
实际上可以直接执行ld-linux.so模块,如:/lib/ld-linux.so.2 --list
program(这相当于ldd program)
# ldd -v `which sshd` | grep wrap :该命令查看该服务是否支持libwrap
lsmod 用于显示已经加载到内核中的模块的状态信息
lsmod命令用于显示已经加载到内核中的模块的状态信息。执行lsmod命令后会列出所有已载入系统的模块。Linux操作系统的核心具有模块化的特性,应此在编译核心时,务须把全部的功能都放入核心。您可以将这些功能编译成一个个单独的模块,待需要时再分别载入。
Grammar
lsmod
Living Example
[root@test-6 ~]# lsmod
Module Size Used by
autofs4 27032 3
8021q 20507 0
…………………………………………
dm_region_hash 12181 1 dm_mirror
dm_log 9930 2 dm_mirror,dm_region_hash
dm_mod 102823 8 dm_mirror,dm_log
Module Size Used by
-
第1列:表示模块的名称。
-
第2列:表示模块的大小。
-
第3列:表示依赖模块的个数。
-
第4列:表示依赖模块的内容。
通常在使用lsmod命令时,都会采用类似lsmod | grep -i ext3这样的命令来查询当前系统是否加载了某些模块。
lspci 显示当前主机的所有PCI总线信息,以及所有已连接的PCI设备信息
lspci命令用于显示当前主机的所有PCI总线信息,以及所有已连接的PCI设备信息。
Grammar
lspci(选项)
选项
- -n:以数字方式显示PCI厂商和设备代码;
-
-t:以树状结构显示PCI设备的层次关系,包括所有的总线、桥、设备以及它们之间的联接;
-
-b:以总线为中心的视图;
-
-d:仅显示给定厂商和设备的信息;
-
-s:仅显示指定总线、插槽上的设备和设备上的功能块信息;
-
-i:指定PCI编号列表文件,而不使用默认的文件;
-
-m:以机器可读方式显示PCI设备信息。
常用选项:
lspci -tv
Living Example
[root@test-6 ~]# lspci
00:00.0 Host bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX Host bridge (rev 01)
00:01.0 PCI bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX AGP bridge (rev 01)
00:15.0 PCI bridge: VMware PCI Express Root Port (rev 01)
………………………………
00:18.7 PCI bridge: VMware PCI Express Root Port (rev 01)
02:00.0 USB controller: VMware USB1.1 UHCI Controller
02:03.0 USB controller: VMware USB2 EHCI Controller
[root@test-6 ~]# lspci -tv
-[0000:00]-+-00.0 Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX Host bridge
+-01.0-[01]--
+-07.0 Intel Corporation 82371AB/EB/MB PIIX4 ISA
+-07.1 Intel Corporation 82371AB/EB/MB PIIX4 IDE
| +-01.0 Intel Corporation 82545EM Gigabit Ethernet Controller (Copper)
| +-02.0 Ensoniq ES1371/ES1373 / Creative Labs CT2518
| \-03.0 VMware USB2 EHCI Controller
+-15.0-[03]--
……………………………………
\-18.7-[22]--
mii-tool 用于查看、管理介质的网络接口的状态
mii-tool命令是用于查看、管理介质的网络接口的状态,有时网卡需要配置协商方式,比如10/100/1000M的网卡半双工、全双工、自动协商的配置。但大多数的网络设备是不用我们来修改协商,因为大多数网络设置接入的时候,都采用自动协商来解决相互通信的问题。不过自动协商也不是万能的,有时也会出现错误,比如丢包率比较高,这时就要我们来指定网卡的协商方式。mii-tool就是能指定网卡的协商方式。下面我们说一说mii-tool的用法。
Grammar
usage: mii-tool [-VvRrwl] [-A media,... | -F media] [interface ...]
选项
- -V 显示版本信息;
-
-v 显示网络接口的信息;
-
-R 重设MII到开启状态;
-
-r 重启自动协商模式;
-
-w 查看网络接口连接的状态变化;
-
-l 写入事件到系统日志;
-
-A 指令特定的网络接口;
-
-F 更改网络接口协商方式;
media: 100baseT4, 100baseTx-FD, 100baseTx-HD, 10baseT-FD, 10baseT-HD,
(to advertise both HD and FD) 100baseTx, 10baseT
Living Example
查看网络接口的协商状态:
[root@localhost ~]# mii-tool -v eth0
eth0: negotiated 100baseTx-FD, link ok
product info: vendor 00:50:ef, model 60 rev 8
basic mode: autonegotiation enabled
basic status: autonegotiation complete, link ok
link partner: 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
注:上面的例子,我们可以看得到是自动协商,注意红字的部份。
更改网络接口协商方式:
更改网络接口的协商方式,我们要用到-F选项,后面可以接100baseT4,100baseTx-FD, 100baseTx-HD, 10baseT-FD, 10baseT-HD等参数;
如果我们想把网络接口eth0改为1000Mb/s全双工的模式应该怎么办呢?
[root@localhost ~]# mii-tool -F 100baseTx-FD
[root@localhost ~]# mii-tool -v eth0
eth0: 100 Mbit, full duplex, link ok
product info: vendor 00:00:00, model 0 rev 0
basic mode: 100 Mbit, full duplex
basic status: link ok
capabilities: 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
advertising: 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
注:是不是已经改过来了?当然,我们也一样用ethtool工具来更改,比如执行下面的命令:
[root@localhost ~]# ethtool -s eth0 speed 100 duplex full
lsusb 用于显示本机的USB设备列表,以及USB设备的详细信息
lsusb命令用于显示本机的USB设备列表,以及USB设备的详细信息。
lsusb命令是一个学习USB驱动开发,认识USB设备的助手,推荐大家使用,如果您的开发板中或者产品中没有lsusb命令可以自己移植一个,放到文件系统里面。
Grammar
lsusb(选项)
选项
- -v:显示USB设备的详细信息;
- -s<总线:设备号>仅显示指定的总线和(或)设备号的设备;
-
-d<厂商:产品>:仅显示指定厂商和产品编号的设备;
-
-t:以树状结构显示无理USB设备的层次;
-
-V:显示命令的版本信息。
Living Example
插入usb鼠标后执行lsusb的输出内容如下:
Bus 005 Device 001: id 0000:0000
Bus 001 Device 001: ID 0000:0000
解释:
Bus 005
表示第五个usb主控制器(机器上总共有5个usb主控制器 --
可以通过命令lspci | grep USB查看
Device 006
表示系统给usb鼠标分配的设备号(devnum),同时也可以看到该鼠标是插入到了第二个usb主控制器
006 usb_device.devnum
/sys/devices/pci0000:00/0000:00:1d.1/usb2/2-2/devnum
ID 15d9:0a37
表示usb设备的ID(这个ID由芯片制造商设置,可以唯一表示该设备)
15d9 usb_device_descriptor.idVendor
0a37 usb_device_descriptor.idProduct
/sys/devices/pci0000:00/0000:00:1d.1/usb2/2-2/idVendor
Bus 002 Device 006: ID 15d9:0a37 Bus 002 Device 001: ID 0000:0000
表示002号usb主控制器上接入了两个设备:
-
一个是usb根Hub -- 001
-
一个是usb鼠标 -- 006
convert非常强大的图片处理工具
[root@CentOS-6-3 ~]# yum install ImageMagick # (图片处理工具)
[root@CentOS-6-3 ~]# convert input.jpg output.png # 转化格式
[root@CentOS-6-3 ~]# convert -flip input.jpg input-flipped.jpg # 左右反转
[root@CentOS-6-3 ~]# convert -resize 50% input.jpg output.jpg # 按照比例resize
[root@CentOS-6-3 ~]# convert -resize 200x100 input.jpg output.jpg # 按照像素resize
当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
bind命令用于显示和设置命令行的键盘序列绑定功能。通过这一命令,可以提高命令行中操作效率。您可以利用bind命令了解有哪些按键组合与其功能,也可以自行指定要用哪些按键组合。
Grammar
bind(选项)
选项
- -d:显示按键配置的内容;
-
-f<按键配置文件>:载入指定的按键配置文件;
-
-l:列出所有的功能;
-
-m<按键配置>:指定按键配置;
-
-q<功能>:显示指定功能的按键;
-
-v:列出目前的按键配置与其功能。
Living Example
bind -x '"\C-l":ls -l' #直接按 CTRL+L 就列出目录
其中keyseq可以使用showkey -a命令来获取:
[root@localhost ~]# showkey -a
Press any keys - Ctrl-D will terminate this program
^[[A 27 0033 0x1b 上
91 0133 0x5b
65 0101 0x41
^[[B 27 0033 0x1b 下
91 0133 0x5b
66 0102 0x42
^[[D 27 0033 0x1b 左
91 0133 0x5b
68 0104 0x44
^[[C 27 0033 0x1b 右
91 0133 0x5b
67 0103 0x43
32 0040 0x20
^M 13 0015 0x0d 字母M
^C 3 0003 0x03 Ctrl-C
^D 4 0004 0x04 Ctrl-D 退出
比如获取F12的字符序列获取方法如下:先按下Ctrl+V,然后按下F12.我们就可以得到F12的字符序列^[[24~。
接着使用bind进行绑定。
[root@localhost ~]# bind ‘”\e[24~":"date"'
Notice:相同的按键在不同的终端或终端模拟器下可能会产生不同的字符序列。
【附】也可以使用showkey -a命令查看按键对应的字符序列。
文件基于行随机shuf
shuf命令是一个在Linux和类Unix系统上使用的命令行工具,用于对输入进行随机排序或随机抽样。它可以从文件或标准输入中读取输入,并将其随机排序后输出到标准输出。
shuf命令的基本语法如下:
shuf [选项] [文件]
常用的选项包括:
-e:指定要随机排序的元素列表,用空格分隔。-n:指定输出的行数。-i:指定一个范围,用于生成整数序列,例如-i 1-10表示生成1到10的整数序列。-r:允许元素重复出现。-o:将输出写入指定的文件,而不是打印到标准输出。
以下是一些示例用法:
1、随机排序整个文件的行:
shuf file.txt
2、从文件中随机抽取3行:
shuf -n 3 file.txt
3、生成1到100之间的10个随机整数:
shuf -i 1-100 -n 10
4、随机排序字符串列表:
shuf -e "apple" "banana" "orange"
# 从文件中随机抽取10行。Notice,到文件比较大时,比 shuf a_file_name | head -n 10 显著快
$ shuf -n 10 a_file_name
jq 可以用来解析json
# 安装
yum install jq -y
# 这个例子中简单的选择了json中的一个键。jq的更多高级用法可以自行查阅文档。
$ echo '{"key1":"value1","key2":"value2"}' | jq '.key2'
"value2"
parallel用于并行执行多个相近的命令
并行下载给定列表中的文件,最大并行度4
$ cat 20urls.list | parallel -j 4 wget -q {}
在ficusdenmark,ficusxi,ficuspi三台机器上,分别占用1,2,3的并行度,来并行(不保证顺序)处理10个任务。
$ parallel --no-notice --sshlogin 1/ficusdenmark,2/ficusxi,3/ficuspi echo "Number {}: Running on \`hostname\`" ::: `seq 1 10`
Number 2: Running on ficusdenmark
Number 4: Running on ficusxi
Number 6: Running on ficuspi
Number 1: Running on ficusxi
Number 3: Running on ficuspi
Number 5: Running on ficuspi
Number 7: Running on ficusdenmark
Number 8: Running on ficusxi
Number 10: Running on ficusxi
Number 9: Running on ficuspi
为指定的可执行文件设置特殊权限
是在Linux系统中使用setcap工具为指定的可执行文件设置特殊权限。
具体来说,setcap命令用于设置文件的特殊能力(capabilities)
特殊能力的参数:
+e表示添加(enable)特殊能力。通过+e参数,你可以将指定的特殊能力添加到文件上。i表示不受继承限制。使用i参数,特殊能力将不会被子进程继承。p表示永久性地保留特殊能力(permanent)。这意味着即使文件拥有者或权限发生变化,特殊能力也将保持不变。
因此,+eip的含义是为文件添加特殊能力并使其不受继承限制。
setcap命令可以为文件设置多种特殊能力(capabilities),以授予程序在不拥有完全超级用户权限的情况下执行某些特定操作的能力。以下是一些常见的特殊能力:
CAP_CHOWN:允许程序更改文件所有权CAP_DAC_OVERRIDE:允许程序忽略文件的DAC(Discretionary Access Control)权限CAP_DAC_READ_SEARCH:允许程序读取和搜索任何文件,无论它们的DAC权限如何CAP_NET_RAW:允许程序发送原始网络数据包CAP_NET_ADMIN:允许程序进行网络管理操作CAP_SYS_ADMIN:允许程序进行系统管理操作CAP_SYS_PTRACE:允许程序跟踪进程
要查看系统支持的特殊能力列表,可以使用man 7 capabilities命令查看Linux手册页。
要查看一个文件是否具有特殊权限,可以使用getcap命令。具体操作如下:
getcap /path/to/file
例如,如果你想查看/opt/py3114/bin/python这个文件是否具有特殊权限,可以执行以下命令:
getcap /opt/py3114/bin/python
如果该文件具有特殊权限,则会显示出该文件的特殊能力;如果该文件没有特殊权限,则不会显示任何信息
设置一个文件具有特殊权限:
setcap cap_net_raw+eip /opt/py3114/bin/python
要取消使用setcap命令设置的特殊权限,可以使用setcap命令的-r参数。具体操作如下:
setcap -r /opt/py3114/bin/python
以上命令将从 /opt/py3114/bin/python 文件中移除之前设置的特殊权限。
要为一个文件同时设置CAP_NET_RAW和CAP_NET_ADMIN特殊能力,可以使用以下命令:
setcap cap_net_raw,cap_net_admin+ep /path/to/file
这将为指定的文件添加CAP_NET_RAW和CAP_NET_ADMIN特殊能力,并将它们设置为生效和永久性保留。
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。