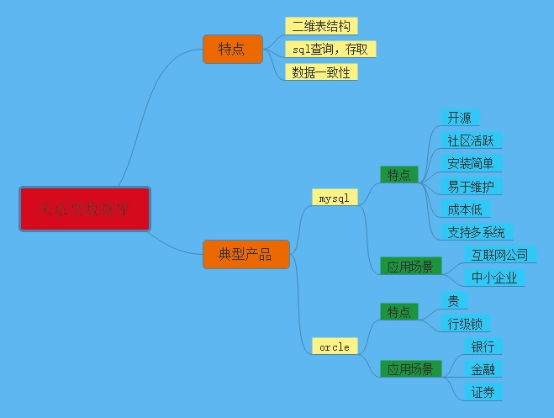
- MySQL理论
- MySQL部署
- MySQL的配置文件 my.cnf详解
- MySQL配置文件参数详解(503)
- MySQL的一些简单优化
- MySQL的启动方式4种
- 数据库注释及退出(3种)
- MySQL多实例
- 数据库重启失败
- 利用mysqladmin添加mysql 的root密码
- 忘记密码的解决方案(4种)
- MySQL命令详解
- MySQL命令补全及查看帮助
- 避免在脚本或命令行中明文传递 MySQL 用户名和密码
- MySQL 配置安全的 SSL/TLS 加密连接
- 查看当前所在的库
- 查看当前用户
- MySQL查看连接数、最大并发数
- MySQL状态情况
- MySQL 5.7之后的performance_schema
- MySQL系统时间
- 了解SQL执行的状(explain)
- MySQL数据文件介绍及存放位置
- MySQL的root用户误删了或只剩下没有任何操作权限的用户?
- MySQL的用户管理、权限管理
- 生产环境如何授权用户权限
- 数据库操作(重点)
- 数据表操作(重点)
- 数据操作(重点)
- 查看数据库的数据大小
- innodb与myisam
- 中文数据问题->字符集1
- 字符集2
- 校对集问题
- web乱码问题
- 数据类型(列类型)
- MySQL记录长度
- 索引
- 列属性
- 字段属性之主键
- 字段属性之自动增长
- 字段属性之唯一键
- 关系
- 范式
- 数据高级操作
- 连接查询
- 联合查询
- 子查询
- 外键 foreign key
- 视图
- 锁的分类:
- 数据库的事务(重要)
- 触发器
- MySQL中的变量
- MySQL的日志管理
MySQL理论
有了这 4 款工具,老板再也不怕我写烂SQL
https://mp.weixin.qq.com/s/HvNdATqq-7XeSLGSXSdqfg
https://mp.weixin.qq.com/s/slpkC2_4nrcffzthSuS8oA
建议将MySQL线下测试版本和线上生产版本保持一致,避免不一致造成错误
数据库的分类
关系型数据库
大部分数据库都是关系型数据,存储的是结构化数据,以关系模型来组织数据。
数据库事务必须具备ACID特性,ACID分别是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
十大主流的关系型数据库 Oracle,Microsoft SQL Server,MySQL(MySQL 是行式存储),MariaDB(MySQL的一个分支),PostgreSQL,DB2,Microsoft Access, SQLite,Teradata,SAP
非关系型数据库
非关系型数据库:指非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。
非关系型数据库以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些时间和空间的开销。
主流非关系数据库:
Redis, MongoDB、Hbase(HBase主要用于大数据领域,MySQL 是行式存储,HBase 是列式存储)
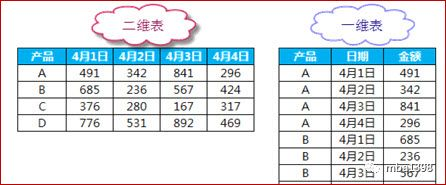
二维表
一维表:第一行为字段名,其他行为数据
二维表:第一行也是字段名,但是可能也是数据的一部分。
简而言之:一维表砍掉一列只是砍掉了表的一个属性,二维表砍掉一列是砍掉了某个属性的一部分,造成数据缺失,因为建议使用一维表来组织数据。
见下图理解:
MySQL中SQL语句的分类
1:数据定义语言(DDL)
用于创建、修改、和删除数据库内的数据结构,如:
- 创建和删除数据库
(CREATE DATABASE || DROP DATABASE); - 创建、修改、重命名、删除表
(CREATE TABLE || ALTER TABLE|| RENAME TABLE||DROP TABLE); - 创建和删除索引
(CREATEINDEX || DROP INDEX);
数据定义语言DDL用来创建数据库中的各种对象、表、视图、索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER/表/视图/索引/同义词/簇;
DDL操作是隐性提交的!不能rollback
2:数据查询语言(DQL)
从数据库中的一个或多个表中查询数据(SELECT),数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件>;
3:数据操作语言(DML)
修改数据库中的数据,包括插入(INSERT)、更新(UPDATE)和删除(DELETE)
4:数据控制语言(DCL)
用于对数据库的访问,如:
- 给用户授予访问权限
(GRANT); - 取消用户访问权限
(REMOKE);
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1) GRANT:授权。
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
回滚---ROLLBACK
回滚命令使数据库状态回到上次最后提交的状态。其格式为:
SQL> ROLLBACK;
3) COMMIT [WORK]:提交。
问:什么时候使用DROP?什么时候使用DELETE?
答:由上可看出,对于结构删除,如数据库删除、表删除、索引删除等当使用DROP;而对于数据的删除则是DELETE.
提交数据有三种类型
在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。
提交数据有三种类型:显式提交、隐式提交及自动提交。下面分别说明这三种类型。
(1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL> COMMIT;
(2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME
(3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,系统将自动进行提交,这就是自动提交。其格式为:
SQL> SET AUTOCOMMIT ON;
MySQL的层次划分:
A、用户请求链接池:
用于与用户实现请求建立链接的线程
B、核心功能层:
解析SQL语句、调用内置函数并实现分析SQL语句是否成立
C、存储引擎层:
数据的存入和查询功能
MySQL部署
建议将MySQL线下测试版本和线上生产版本保持一致,避免不一致造成错误
源码编译安装(5.7)
官网:https://dev.mysql.com/downloads/mysql/5.7.html#downloads
建议:如果没有dba,建议线上用二进制包进行安装
下载mysql源码包:
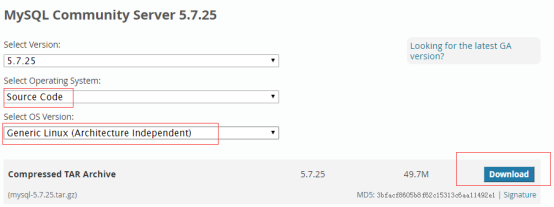
这里下载的是mysql-5.7.25.tar.gz
mysql-5.7.25.tar.gz 和 mysql-boost-5.7.25.tar.gz 是两个不同的 MySQL 软件压缩包,它们之间的差别在于是否包含了 Boost C++ 库的优化或增强功能。
mysql-5.7.25.tar.gz:这是纯粹的 MySQL 5.7.25 版本的软件压缩包,没有采用 Boost C++ 库进行优化或增强。它包含了 MySQL 数据库的核心代码和相关工具,可以用于安装和部署 MySQL 数据库服务。mysql-boost-5.7.25.tar.gz:这个压缩包也是 MySQL 5.7.25 版本的软件,但是它在编译和构建过程中采用了 Boost C++ 库来进行性能优化或者增强功能。Boost C++ 库是一个流行的开源 C++ 库,提供了许多实用的工具和组件,可以用于加速程序运行、增强功能等。在 MySQL 中使用 Boost 库可能会带来更好的性能表现或具有一些额外的功能特性。
因此,如果你对于 MySQL 的性能和功能有特定的需求,并且希望利用 Boost C++ 库的优势,那么你可以选择下载 mysql-boost-5.7.25.tar.gz 压缩包。否则,如果你只需要原始的 MySQL 版本,可以选择下载 mysql-5.7.25.tar.gz 压缩包。
安装cmake:
# yum install ncurses ncurses-devel libaio libaio-devel gcc gcc-c++ -y # 依赖的包
# yum install cmake # 安装cmake
# 或者可以源码安装
# cd /usr/local/src
# wget https://cmake.org/files/v3.5/cmake-3.5.2.tar.gz
# tar -zxvf cmake-3.5.2.tar.gz
# cd cmake-3.5.2
# ./bootstrap
# make -j 8 (-j 8 参数充分利用多核CPU优势,加快编译速度,参数-j后数字为CPU核数,可用`cat /proc/cpuinfo | grep processor | wc -l`进行查看,此数值应小于等于CPU核数,下面用的到编译参数相同)
# make install
# hash -r #命令行指令,用于在 Unix/Linux 系统中刷新已经缓存的命令路径.当你在命令行中输入一个命令时,系统会使用哈希表(hash table)来记录该命令的可执行文件的路径。这样,在下次执行相同命令时,系统就可以快速找到该命令的位置,而不需要每次都进行完整的路径搜索。然而,有时候你可能更新了命令所在的位置或者安装了新的命令,但系统的哈希表并不会自动更新。这时就可以使用 hash -r 命令来强制刷新已经缓存的命令路径,使系统重新查找命令的位置。当你运行 hash -r 命令后,系统会清除当前的命令缓存,并在需要时重新定位命令的路径。这对于确保系统正确找到最新安装的或者更新过的命令非常有用。
# /usr/local/bin/cmake -version
cmake version 3.5.2
CMake suite maintained and supported by Kitware (kitware.com/cmake).
linux平台下要编译安装除gcc和gcc-c++之外,还需要两个开发库:bzip2-devel和python-devel,因此在安装前应该先保证这两个库已经安装:
# yum install gcc gcc-c++ bzip2 bzip2-devel bzip2-libs python-devel -y
如果gcc版本过低,需要升级
# 升级gcc7.3.0,直接复制即可
# cd /usr/local/src
# wget https://mirrors.tuna.tsinghua.edu.cn/gnu/gcc/gcc-7.3.0/gcc-7.3.0.tar.gz
# tar -xvf gcc-7.3.0.tar.gz
# cd gcc-7.3.0
# ./configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --enable-bootstrap
# make -j8
# make -j8 install
# gcc –v
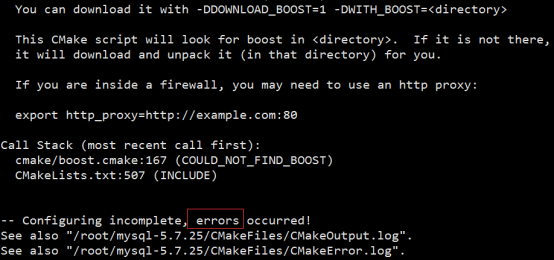
安装boost:
然后是去官网(https://sourceforge.net/projects/boost/files/boost/1.59.0/)下载boost源码包下,解压,按照如下步骤(5.5版本不需要安装boost):(如果你下载的是mysql-boost-5.7.25.tar.gz就不需要下载boost,源码包里面有)
# tar xvzf boost_1_59_0.tar.gz
进入boost_1_59_0目录:
# cd boost_1_50_0
然后是编译安装,boost源码包中有安装脚本,直接用就可以:
# sh ./bootstrap.sh进入boost_1_59_0目录:
# cd boost_1_50_0
然后是编译安装,boost源码包中有安装脚本,直接用就可以:
# sh ./bootstrap.sh
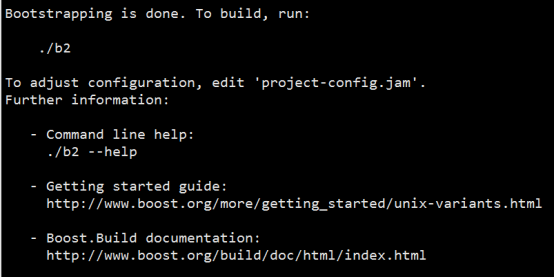
# ./b2 install
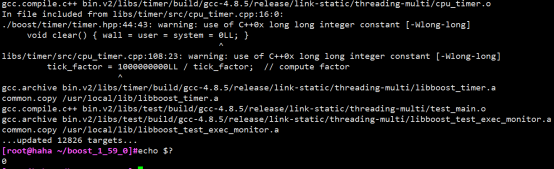
然后编译MySQL:
# wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.25.tar.gz
# tar zxvf /root/mysql-5.7.25.tar.gz
# cat README #MySQL说明
# cat INSTALL #安装说明
# cd mysql-5.7.25 # 进入mysql-5.7.25源码目录下
cmake . -DCMAKE_INSTALL_PREFIX=/usr/local/mysql-5.7.25 \ #MySQL路径
-DMYSQL_UNIX_ADDR=/usr/local/mysql-5.7.25/tmp/mysql.sock \ #套接字路径
-DDEFAULT_CHARSET=utf8mb4 \ #指定默认使用的字符集编码
-DDEFAULT_COLLATION=utf8mb4_unicode_ci \ #设定默认排序规则
-DWITH_EXTRA_CHARSETS=complex \ #指定额外支持的其他字符集编码
-DWITH_READLINE=1 \ #启用readline库支持(提供可编辑的命令行)
-DMYSQL_DATADIR=/usr/local/mysql-5.7.25/data \ #数据存放路径
-DWITH_FEDERATED_STORAGE_ENGINE=1 \
-DWITH_INNOBATED_STORAGE_ENGINE=1 \
-DWITH_BLACKHOLE_STORAGE_ENGINE=1 \
-DWITHOUT_EXAMPLE_STORAGE_ENGINE=1 \
-DWITH_ZLIB=bundled \ #启用libz库支持
-DWITH_SSL=bundled \
-DENABLED_LOCAL_INFILE=1 \ #启用本地数据导入支持
-DENABLE_EMBEDDED_SERVER=1 \
-DENABLE_DOWNLOADS=1 \
-DBUILD_CONFIG=mysql_release \
-DWITH_DEBUG=0 #禁用debug(默认为禁用)
-DWITH_BOOST=/usr/local/boost #指定BOOST依赖的包的路径
# 其实这里最好创建一个build目录,然后进入build目录进行编译
mkdir build && cd build
cmake .. -DBUILD_CONFIG=mysql_release -DCMAKE_INSTALL_PREFIX=/usr/local/mysql-5.7.25 -DMYSQL_DATADIR=/usr/local/mysql-5.7.25/data -DDEFAULT_CHARSET=utf8mb4 -DDEFAULT_COLLATION=utf8mb4_unicode_ci -DWITH_BOOST=../boost/boost_1_59_0 #注意,这里是cmake ..因为mysql源码在build上一级目录。如果是同目录就是cmake .
# cp /usr/include/sys/prctl.h ../include/
# sed -i '24a #include "prctl.h"' ../sql/mysqld.cc
# make -j8
# make -j8 install
# /usr/local/mysql-5.7.25/bin/mysql --version
-DBUILD_CONFIG 是一个在编译 MySQL 时使用的参数,用于指定构建配置选项。
在 MySQL 的源代码中,通常有一个 CMakeLists.txt 文件,用于配置和生成项目的构建系统。-DBUILD_CONFIG 参数可以用来指定不同的构建配置选项,以定制编译过程和生成的可执行文件。
具体的构建配置选项取决于 MySQL 版本和源代码的设置。一些常见的构建配置选项包括:
-DBUILD_CONFIG=mysql_release:这是默认的构建配置选项,用于生成发布版本的 MySQL。它可能包含了一些性能和稳定性方面的优化,并且会禁用一些调试和开发相关的功能。-DBUILD_CONFIG=mysql_debug:这是用于生成调试版本的构建配置选项。它可能会开启更多的调试信息和额外的调试功能,以方便开发人员进行调试和故障排除。-DBUILD_CONFIG=mysql_relwithdebinfo:这是用于生成带有调试信息的优化版本的构建配置选项。它会在编译时进行一些优化,并且保留一些调试信息,旨在在开发和生产环境中取得平衡。- 其他定制的构建配置选项,可能会根据具体情况而变化,例如启用或禁用特定的功能、选择特定的存储引擎等。
需要注意的是,具体的构建配置选项可能会因为不同 MySQL 版本、操作系统环境或个人需求而有所不同。在编译 MySQL 之前,可以参考相关的文档或源代码的说明,了解可用的构建配置选项,并选择适合的配置进行编译。
成功如下:
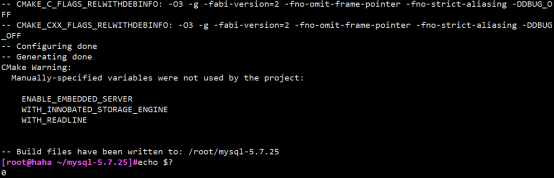
报错如下:
可能没有安装ncurses-devel
yum install ncurses-devel -y
再删除刚才编译生成的CMakeCache.txt文件,然后在进行编译,否则无法进行下一步
[root@haha ~/mysql-5.7.25]# rm -rf CMakeCache.txt
如果报如下错误:
-- Could NOT find Git (missing: GIT_EXECUTABLE)
解决:
yum install git
最后进行安装:
make && make install
# make -j8
# make -j8 install
报错如下:

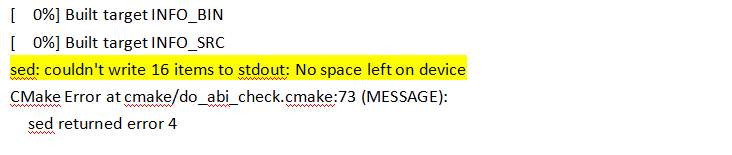
解决方案:由于磁盘空间不足,因此加磁盘后,在make,就it's ok
创建mysql用户:
groupadd mysql
useradd -r -g mysql -c "`date +%Y/%m/%d`, install mysql" -s /bin/false mysql
# useradd -s /sbin/nologin -M -r mysql
# id mysql #查看是否创建成功
创建目录data与tmp:
mkdir -pv /usr/local/mysql-5.7.25/data
链接,为后面版本升级之内的做准备:(不用在指定路径等)
# ln -sv /usr/local/mysql-5.7.25/ /usr/local/mysql
‘/usr/local/mysql’ -> ‘/usr/local/mysql-5.7.25/’
修改权限:
# chown -R mysql.mysql /usr/local/mysql /usr/local/mysql-5.7.25/
修改启动脚本文件:
# cp mysql-5.7.25/support-files/mysql.server /etc/init.d/mysqld #复制启动脚本(在解压包里面复制)
# vim /etc/init.d/mysqld
basedir=/usr/local/mysql #定义mysql程序目录#(最后面不要带斜线)
datadir=/usr/local/mysql/data #定义数据目录#(最后面不要带斜线)
# chmod +x /etc/init.d/mysqld
# sed -i "s#^basedir=#basedir=/usr/local/mysql#g" /etc/init.d/mysqld
# sed -i "s#^datadir=#datadir=/usr/local/mysql/data#g" /etc/init.d/mysqld
# chkconfig --add mysqld


否则启动时会出现这样的错误
添加环境变量:
echo "export PATH=$PATH:/usr/local/mysql/bin" > /etc/profile.d/mysql.sh
source /etc/profile.d/mysql.sh
修改配置文件:
# vim /etc/my.cnf
[client]
port = 3306
socket = /tmp/mysql.sock
default-character-set = utf8mb4
[mysqld]
datadir=/usr/local/mysql/data ##从给定目录读取数据库文件
basedir = /usr/local/mysql
socket=/tmp/mysql.sock ##为MySQL客户程序与服务器之间的本地通信指定一个套接字文件(仅适用于UNIX/Linux系统; 默认设置一般是/var/lib/mysql/mysql.sock文件)
pid-file = /tmp/mysql.pid
user = mysql ##mysqld程序在启动后将在给定UNIX/Linux账户下执行; mysqld必须从root账户启动才能在启动后切换到另一个账户下执行;
bind-address = 0.0.0.0
default-time_zone = '+8:00'
explicit_defaults_for_timestamp=true
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0 ##MySQL数据库及表(仅MyISAM)支持符号链接(symbolic link),即数据库或表可以存储在 ## my.cnf中指定datadir之外的分区或目录。
##要支持符号链接,需要在配置中设置 symbolic-links=1(较新的版本为默认开启)
## https://blog.csdn.net/moxiaomomo/article/details/17092871
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd
[mysqld_safe]
log-error=/tmp/mysql-error.log ##错误日志位置
pid-file=/tmp/mysql.pid ##为mysqld程序指定一个存放进程ID的文件(仅适用于UNIX/Linux系统);
#
# include all files from the config directory
#
!includedir /etc/my.cnf.d
检查 MySQL 配置文件/etc/my.cnf是否存在任何错误或未正确配置的设置。您可以使用以下命令检查配置文件语法是否正确:
mysqld --validate-config
如果配置文件存在格式或语法错误,则必须修复它们才能启动 MySQL 服务
初始化数据库(如果报错误,把data目录删掉、重新初始化):
cd /usr/local/mysql/bin
./mysqld --verbose --help #查看支持的选项
./mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
2019-03-12T06:28:54.991858Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
………………………………………………
2019-03-12T06:28:56.685066Z 0 [Warning] Gtid table is not ready to be used. Table 'mysql.gtid_executed' cannot be opened.
2019-03-12T06:28:56.697949Z 1 [Note] A temporary password is generated for root@localhost: ?/(D5oyUrup7

注意:如果是mysql8,那么需要忽略大小写,那么必须在初始化的时候指定,否则后面无法修改忽略大小写。设置为 1 表示忽略大小写,设置为 0 表示区分大小写。
mysqld --initialize-insecure --lower_case_table_names=1
这将使用指定的 lower_case_table_names 设置值进行初始化。
然后编辑 MySQL 配置文件:打开 MySQL 的配置文件(通常是 my.cnf 或 my.ini),在 [mysqld] 部分中添加或修改以下行:
lower_case_table_names = 1
mysqld --initialize-insecure 是一个 MySQL 5.7 的命令,用于在初始化过程中创建一个没有密码的超级用户。使用 --initialize-insecure 参数可以跳过为 root 用户生成随机密码的步骤。然后登录MySQL后可以用ALTER USER 'root'@'localhost' IDENTIFIED BY '123654';设置一个密码
mysqld --initialize 是 MySQL 5.7 的命令之一,用于执行初始化过程并生成一个随机密码的超级用户。该命令会为 root 用户自动生成一个初始密码。
请注意,在使用 --initialize-insecure 命令进行初始化时,会创建一个默认的不安全的 root 用户账户,强烈建议在生产环境中修改默认密码或禁用不安全的初始化方式。好像语句也需要大写执行
1、使用管理员账户登录 MySQL:使用拥有足够权限的管理员账户(例如 root)登录到 MySQL 服务器。
2、创建用户(如果需要):如果你还没有要授予权限的用户,可以使用以下命令创建用户。将 <username> 替换为你希望创建的用户名,以及 <password> 替换为用户的密码。
CREATE USER '<username>'@'localhost' IDENTIFIED BY '<password>';
这将创建一个具有指定用户名和密码的用户,只能从本地主机连接。
3、授予所有权限:使用以下命令授予用户所有权限。将 <username> 替换为要授予权限的用户名,或者使用通配符 '%' 表示所有用户。如果你希望用户能够从任何主机连接,请将 'localhost' 替换为 '%'。
GRANT ALL PRIVILEGES ON *.* TO '<username>'@'localhost';
这将授予用户对所有数据库、所有表的全部权限。
4、刷新权限:在授予权限后,使用以下命令刷新 MySQL 的权限:
FLUSH PRIVILEGES;
这将使最新的权限更改立即生效。
数据目录已生成默认的相关文件
# ll ../data
total 110652
-rw-r----- 1 mysql mysql 56 May 5 01:53 auto.cnf
-rw-r----- 1 mysql mysql 425 May 5 01:53 ib_buffer_pool
-rw-r----- 1 mysql mysql 12582912 May 5 01:53 ibdata1
-rw-r----- 1 mysql mysql 50331648 May 5 01:53 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 May 5 01:53 ib_logfile1
drwxr-x--- 2 mysql mysql 4096 May 5 01:53 mysql
drwxr-x--- 2 mysql mysql 4096 May 5 01:53 performance_schema
-rw------- 1 mysql mysql 1676 May 5 01:53 private_key.pem
-rw-r--r-- 1 mysql mysql 452 May 5 01:53 public_key.pem
drwxr-x--- 2 mysql mysql 12288 May 5 01:53 sys
MySQL 5.7初始化完后会生成一个临时的密码,A temporary password is generated for root@localhost: ?/(D5oyUrup7
如果想初始化表空间,在后面加上--innodb_data_file_path=ibdata1:1G:autoextend即可
启动MySQL(如果报错,就重启试试,或者查看mysql-error.log文件):
[root@learn html]# /etc/init.d/mysqld start
Starting MySQL.Logging to '/tmp/mysql-error.log'.
[ OK ]
[root@learn html]# cat /tmp/mysql-error.log
或者直接命令行启动服务:
# /usr/local/mysql/bin/mysqld_safe --user=mysql --datadir=/data/mysql/data --defaults-file=/etc/my.cnf & # (指定数据库目录)
# /usr/local/mysql/bin/mysqld_safe --user=mysql 2>&1 > /dev/null &
查看是否正常启动:
# netstat -nutlp | grep mysql
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 20314/mysqld
# ps aux | grep mysql
root 25249 0.0 0.0 113320 1608 pts/1 S 17:06 0:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir=/datamysql --pid-file=/tmp/mysql.pid
mysql 25447 0.1 9.2 1120600 173488 pts/1 Sl 17:06 0:00 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/datamysql --plugin-dir=/usr/local/mysql/lib/plugin --user=mysql --log-error=/datamysql/mysql-error.log --pid-file=/tmp/mysql.pid --socket=/tmp/mysql.sock

登陆mysql:
[root@localhost /mysql 16:09]# mysql -u root -p
Enter password: #输入之前初始化数据库时,生成的随机密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.25
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases; #这里表示已经进入了数据库
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement. #这里报错是正常的,且必须修改密码
mysql> set password = password('666666'); #修改密码
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> alter user 'root'@'localhost' identified by '666666'; #或者这样修改密码
Query OK, 0 rows affected (0.00 sec)
mysql> alter user user() identified by '666666'; #或者这样修改密码user()表示当前用户
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges; #刷新数据库
Query OK, 0 rows affected (0.05 sec)
mysql> quit #退出
Bye
[root@localhost /mysql 16:11]# mysql -u root -p #再次登陆
Enter password: #输入修改后的密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 4
Server version: 5.7.25 Source distribution
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases; #可以操作数据库了
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
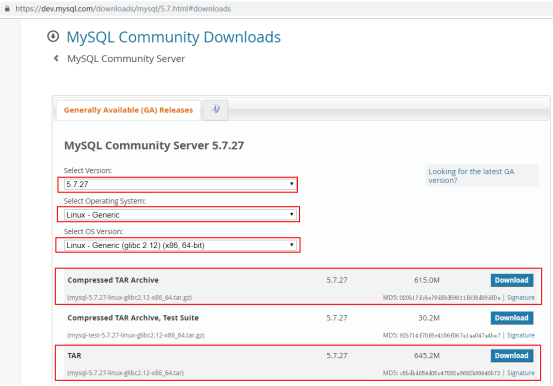
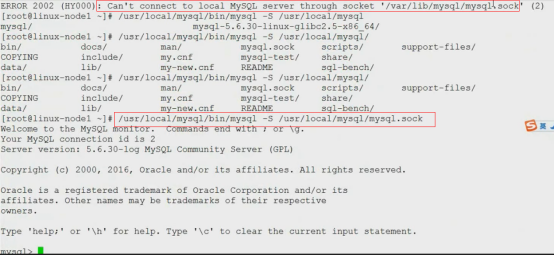
二进制包安装mysql5.6
如果二进制安装mysql5.7,只有初始化数据库时不一样,参数源码安装mysql5.7进行初始化数据库
# vim install_mysql.sh
#!/bin/bash
# desc: mysql自动安装
#创建mysql用户
groupadd mysql
useradd -r -g mysql -c "`date +%Y/%m/%d`, install mysql" -s /bin/false mysql
#下载MySQL二进制文件安装
cd /usr/local/src
wget
https://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.45-linux-glibc2.12-x86_64.tar.gz
# https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.27-linux-glibc2.12-x86_64.tar.gz
# http://mirrors.sohu.com/mysql/MySQL-5.7/mysql-5.7.28-linux-glibc2.12-x86_64.tar.gz
tar zxvf mysql-5.6.45-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
cd /usr/local
ln -s mysql-5.6.45-linux-glibc2.12-x86_64 mysql
mkdir -p /home/mysql
chown -R mysql:mysql mysql mysql-5.6.45-linux-glibc2.12-x86_64 /home/mysql
#初始化mysql
cd mysql
#scripts/mysql_install_db --user=mysql --datadir=/home/mysql
./scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql/ --datadir=/home/mysql
#mv my.cnf /etc/my.cnf
cat > /etc/my.cnf <<EOF
[client]
port = 3306
socket = /tmp/mysql.sock
default-character-set = utf8mb4
[mysql]
prompt="MySQL [\d]> "
no-auto-rehash
[mysqld]
port = 3306
socket = /tmp/mysql.sock
basedir = /usr/local/mysql
datadir = /home/mysql
pid-file = /home/mysql/mysql.pid
user = mysql
bind-address = 0.0.0.0
server-id = 12
default-time_zone = '+8:00'
init-connect = 'SET NAMES utf8mb4'
character-set-server = utf8mb4
skip-name-resolve
#skip-networking
back_log = 300
max_connections = 16077
max_connect_errors = 6000
open_files_limit = 65535
table_open_cache = 1024
max_allowed_packet = 500M
binlog_cache_size = 1M
max_heap_table_size = 8M
tmp_table_size = 128M
read_buffer_size = 2M
read_rnd_buffer_size = 8M
sort_buffer_size = 8M
join_buffer_size = 8M
key_buffer_size = 256M
thread_cache_size = 64
query_cache_type = 1
query_cache_size = 64M
query_cache_limit = 2M
ft_min_word_len = 4
log_bin = mysql-bin
binlog_format = row
expire_logs_days = 7
log_error = /home/mysql/mysql-error.log
slow_query_log = 1
long_query_time = 1
log_queries_not_using_indexes=1
slow_query_log_file = /home/mysql/mysql-slow.log
performance_schema = 0
explicit_defaults_for_timestamp=true
#lower_case_table_names = 1
skip-external-locking
default_storage_engine = InnoDB
innodb_file_per_table = 1
innodb_open_files = 500
innodb_buffer_pool_size = 1024M
innodb_write_io_threads = 4
innodb_read_io_threads = 4
innodb_thread_concurrency = 0
innodb_purge_threads = 1
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 2M
innodb_log_file_size = 32M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 90
innodb_lock_wait_timeout = 120
bulk_insert_buffer_size = 8M
myisam_sort_buffer_size = 64M
myisam_max_sort_file_size = 10G
myisam_repair_threads = 1
interactive_timeout = 28800
wait_timeout = 28800
[mysqldump]
quick
max_allowed_packet = 500M
[myisamchk]
key_buffer_size = 256M
sort_buffer_size = 8M
read_buffer = 4M
write_buffer = 4M
EOF
#centos7启动文件
cat > /usr/lib/systemd/system/mysql.service <<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
Restart=on-failure
#RestartPreventExitStatus=1
#PrivateTmp=false
EOF
#启动mysql
systemctl start mysql
# Loading environment variables
echo "PATH=$PATH:/usr/local/mysql/bin" > /etc/profile.d/mysql.sh
source /etc/profile.d/mysql.sh
# set password
mysqladmin -u root password '666666'
systemctl status mysql
yum安装mysql
2.5.1配置mysql的epel源
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
2.5.2安装rpm包
rpm -ivh mysql-community-release-el7-5.noarch.rpm
#安装这个包后,会获得两个mysql的yum repo源
/etc/yum.repos.d/mysql-community.repo
/etc/yum.repos.d/mysql-community-source.repo
2.5.3安装MySQL 并且启动服务
yum install mysql-server -y
systemctl start mysql
systemctl status mysql
或者用清华源镜像站(这个aarch64,只需要修改你需要的架构就ok):
[mysql]
name=MySQL Community Server
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/mysql-8.0-community-el7-aarch64/
gpgcheck=0
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/RPM-GPG-KEY-mysql
enabled=1
执行以下命令安装 MySQL:
yum install mysql-community-server
依赖如下:
Dependencies Resolved
============================================================================================================================================================================================
Package Arch Version Repository Size
============================================================================================================================================================================================
Installing:
mysql-community-server aarch64 8.0.33-1.el7 mysql 62 M
Installing for dependencies:
mysql-community-client aarch64 8.0.33-1.el7 mysql 16 M
mysql-community-client-plugins aarch64 8.0.33-1.el7 mysql 3.5 M
mysql-community-common aarch64 8.0.33-1.el7 mysql 664 k
mysql-community-icu-data-files aarch64 8.0.33-1.el7 mysql 2.1 M
mysql-community-libs aarch64 8.0.33-1.el7 mysql 1.5 M
Transaction Summary
============================================================================================================================================================================================
Install 1 Package (+5 Dependent packages)
安装完成后,使用以下命令启动 MySQL 服务:
systemctl start mysqld
使用以下命令查看 MySQL 服务状态:
systemctl status mysqld
如果您在安装过程中没有设置 root 密码,请执行以下命令为 root 用户设置密码:
mysql_secure_installation
输入 root 密码并按照提示进行配置和设置。
或者使用初始化密码登录mysql,然后在修改密码,如下操作:
grep password /var/log/mysqld.log | awk -F' ' '{print $NF}'
登录数据库,
# mysql -uroot -p
Enter password: #输入密码
mysql> show databases; -- 必须修改密码才能操作
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
mysql> alter user user() identified by 'Abc@123654';
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> show databases; -- 现在可以正常操作了
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
docker安装mysql8
docker run -itd \
-e MYSQL_ROOT_PASSWORD=123456 \
-p 3306:3306 \
--name test-mysql \
--restart always \
-v /data/mysql:/var/lib/mysql \
-v /etc/localtime:/etc/localtime \
mysql:8.0.12 --default-authentication-plugin=mysql_native_password --lower_case_table_names=1 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --max_connections=3000 --wait_timeout=600 --interactive_timeout=600 --thread_cache_size=50 --sql-mode="STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
=====
-e MYSQL_ROOT_PASSWORD=123456 \ #root密码
-e MYSQL_DATABASE=dnname \ #数据库名
--default-authentication-plugin=mysql_native_password #修改密码策略
--lower_case_table_names=1 #忽略表名大小写
-v /etc/localtime:/etc/localtime \ #解决时区问题。一定要配置
--sql-mode= #修改sql_mode
-e MYSQL_DATABASE=数据库名称
-e MYSQL_USER=应用用户
-e MYSQL_PASSWORD=应用账号密码
-e MYSQL_ROOT_PASSWORD=ROOT账户密码
-e MYSQL_RANDOM_ROOT_PASSWORD=yes # 允许为为 root 用户生成一个随机初始密码并将其打印到stdout
-e MYSQL_ALLOW_EMPTY_PASSWORD=yes # 以允许使用根用户的空白密码启动容器,非常不建议在实践环境中使用该变量
8.1.0使用如下启动
docker run -itd \
-e MYSQL_ROOT_PASSWORD=123456 \
-p 3306:3306 \
--name test-mysql \
--restart always \
--privileged \
-v /data/mysql:/var/lib/mysql \
-v /etc/localtime:/etc/localtime \
mysql:8.1.0 --authentication_policy=caching_sha2_password --lower_case_table_names=1 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --max_connections=3000 --wait_timeout=600 --interactive_timeout=600 --thread_cache_size=50 --sql-mode="STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
如果不加--privileged参数会报错
Entrypoint script for MySQL Server 8.1.0-1.el8 started. ls: cannot access ‘/docker-entrypoint-initdb.d/‘: Operation not permitted
验证
[root@node01 ~]# docker exec -it test-mysql8 /bin/bash
bash-4.4# mysql -V
mysql Ver 8.1.0 for Linux on x86_64 (MySQL Community Server - GPL)
docker-compose部署mysql8
# cat docker-compose.yml
version: "3.9"
services:
mysql:
container_name: mysql
image: mysql
labels:
release: "8"
restart: always
network_mode: "host"
hostname: mysql-server
# docker安全验证,处理错误日志.Docker下运行Mysql报错 mbind: Operation not permitted
security_opt:
- seccomp:unconfined
volumes:
- /data/docker-compose-data/mysql/data:/var/lib/mysql
- /data/docker-compose-data/mysql/log:/var/log/mysql
#- /data/docker-compose-data/mysql/mysql-conf:/etc/mysql/
- /etc/localtime:/etc/localtime
environment:
MYSQL_ROOT_PASSWORD: 123654
command:
#- --default_authentication_plugin=mysql_native_password
- --authentication_policy=mysql_native_password
- --lower_case_table_names=1
- --max_connections=3000
- --wait_timeout=600
- --interactive_timeout=600
- --thread_cache_size=50
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
MySQL的配置文件 my.cnf详解
参考:https://www.docs4dev.com/docs/zh/mysql/5.7/reference/server-system-variables.html
http://www.deituicms.com/mysql8cn/cn/server-administration.html#sysvar_auto_generate_certs
# cat my.cnf
[client]
#port = 3306
#socket = /tmp/mysql.sock
[mysql]
#prompt=[\h][\u]@\d\r:\m:\s>
prompt="[\d] mysql> "
no-auto-rehash
--prompt=name
#参数对于做运维的人来说很重要。我们登入mysql数据库后,mysql的提示符只是一个很简单内容 mysql> ,没有其他任何信息。通过--prompt=name可以自定义提示信息,通过配置显示登入的主机地址,登陆用户名,当前时间,当前数据库schema等待。个人强烈要求加上 登入主机名,登陆用户名,当前库 schema这三项加入提示内容
# mysql -uroot -p --prompt="\\u@\\h : \\d\\r:\\m:\\s>"
#也可以把参数加到my.cnf里面
# vim /etc/my.cnf
[mysql]
prompt="\\u@\\h :\\d\\r:\\m:\\s>"
参考博客:
https://www.cnblogs.com/lzrabbit/p/4298789.html
https://www.cnblogs.com/sunny18/articles/8847472.html
--prompt选项列表,示例脚本中用到的选项已经标红
#!/bin/bash
case $1 in
crm) cmd='mysql -h192.168.1.2 -uroot -proot -P3306 -Dcrm'
;;
*)
echo "数据库变量不存在:$1 仅支持输入 crm"
exit 0
;;
esac
shift 1
$cmd --prompt="[\u@\h:\p(\d) \R:\m:\s] mysql>" --default-character-set=utf8 -A "$@"
\c A counter that increments for each statement you issue
\D 当前日期
\d 当前数据库
\h 数据库主机
\l The current delimiter (new in 5.1.12)
\m 当前时间(分)
\n A newline character
\O The current month in three-letter format (Jan, Feb, …)
\o The current month in numeric format
\P am/pm
\p The current TCP/IP port or socket file 端口号
\R 当前时间(小时)(0–23)
\r 当前时间(小时)(1–12)
\S Semicolon
\s 当前时间(秒)
\t A tab character
\U Your full user_name@host_name account name
\u 数据库用户名
\v The server version
\w The current day of the week in three-letter format (Mon, Tue, …)
\Y The current year, four digits
\y The current year, two digits
_ A space
\ A space (a space follows the backslash)
' Single quote
\" Double quote
\\ A literal “\” backslash character
\x x, for any “x” not listed above
no-auto-rehash
#auto-rehash是自动补全的意思,就像我们在linux命令行里输入命令的时候,使用tab键的功能是一样的,my.cnf示例片段:
[mysql]
prompt="MySQL [\d]> "
auto-rehash
[mysqld]
#port = 3306
#socket = /tmp/mysql.sock
#basedir = /var/lib/mysql
#datadir = /var/lib/mysql/data
#pid-file = /var/lib/data/mysql.pid
#user = mysql
#bind-address = 0.0.0.0
port
#定义mysql的端口
socket
#定义mysql的socket文件
basedir
#定义mysql的路径
datadir
#定义mysql的数据目录
pid-file
#定义mysql的pid文件
user = mysql
#定义mysql的用户
bind-address = 0.0.0.0
#绑定mysql地址
server-id = 1
#表示是本机的序号为1,一般来讲就是master的意思。在配置mysql的主从是必须所使用的。该参数启动会才能使用log-bin参数,否则启动mysql时报pid未找到而启动失败
default-time_zone = '+8:00'
#修改时区, 修改完了记得记得重启msyql
#注意一定要在 [mysqld] 之下加 ,否则会出现 unknown variable 'default-time-zone=+8:00'
init-connect = 'SET NAMES utf8mb4'
#审计功能,参考:https://www.cnblogs.com/zejin2008/p/5756192.html
扩展说明:
1.init-connect只会在连接时执行,不会对数据库产生大的性能影响
2.init-connect是在连接时执行的动作命令,故可以用它来完成其它的功能,如:init_connect='SET autocommit=0'
3.init-connect不会记录拥有super权限的用户记录,为了防止init_connect语句由于语法错误或权限问题而所有用户都登陆不了的情况,保证至少super用户能登陆并修改此值
# Specify the default character set to be UTF-8:
character-set-server = utf8mb4
#设置字符集
collation-server=utf8_bin
#校对集
skip-name-resolve
# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。增加远程连接速度
#但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求
#skip-networking
#开启该选项后就不能远程访问MySQL
#为安全考虑希望指定的IP访问MySQL,可以在配置文件中增加bind-address=IP,前提是关闭skip-networking
back_log = 600
博客参考:https://www.cnblogs.com/mydriverc/p/8296814.html
#修改back_log参数值:由默认的50修改为500.(每个连接256kb, 占用:125M)
back_log=500
查看mysql 当前系统默认back_log值,命令:
show variables like 'back_log';
back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。也就是说,如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。将会报:
unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时.
# back_log值不能超过TCP/IP连接的侦听队列的大小。若超过则无效,查看当前系统的TCP/IP连接的侦听队列的大小命令:cat /proc/sys/net/ipv4/tcp_max_syn_backlog,目前系统为1024。对于Linux系统推荐设置为大于512的整数。
#修改系统内核参数,可以编辑/etc/sysctl.conf去调整它。如:net.ipv4.tcp_max_syn_backlog = 2048,改完后执行sysctl -p 让修改立即生效
# MySQL能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,
# 然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。
# 如果期望在一个短时间内有很多连接,你需要增加它。也就是说,如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,
# 以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
# 另外,这值(back_log)限于您的操作系统对到来的TCP/IP连接的侦听队列的大小。
# 你的操作系统在这个队列大小上有它自己的限制(可以检查你的OS文档找出这个变量的最大值),试图设定back_log高于你的操作系统的限制将是无效的。
secure_file_priv = /data/mysqldata
#该参数指定了用于导入和导出文件操作的目录路径。当用户使用 LOAD DATA INFILE 或 SELECT ... INTO OUTFILE 等语句进行文件操作时,secure_file_priv 参数可以限制操作的目录范围,防止用户访问系统中的敏感文件。只有位于 secure_file_priv 指定的目录或其子目录下的文件可以被读取或写入
max_connections = 1000
# MySQL的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。可以过'conn%'通配符查看当前状态的连接数量,以定夺该值的大小。
但实际MySQL服务器允许的最大连接数16384
max_connect_errors = 6000
# 对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST。
https://www.cnblogs.com/xuegang/archive/2011/08/30/2159782.html
Max_user_connections 与Max_connections 与max_connect_errors
对于连接数的设置,show variables里有三个参数可以对它进行控制,max_connections与max_user_connections以及max_connect_errors。下面对这三个参数相关描述。
max_connections #针对所有的账号所有的客户端并行连接到MYSQL服务的最大并行连接数。简单说是指MYSQL服务能够同时接受的最大并行连接数。
max_user_connections #针对某一个账号的所有客户端并行连接到MYSQL服务的最大并行连接数。简单说是指同一个账号能够同时连接到mysql服务的最大连接数。设置为0表示不限制。
max_connect_errors #针对某一个IP主机连接中断与mysql服务连接的次数,如果超过这个值,这个IP主机将会阻止从这个IP主机发送出去的连接请求。遇到这种情况,需执行flush hosts。
在 show global 里有个系统状态Max_used_connections,它是指从这次mysql服务启动到现在,同一时刻并行连接数的最大值。它不是指当前的连接情况,而是一个比较值。如果在过去某一个时刻,MYSQL服务同时有1000个请求连接过来,而之后再也没有出现这么大的并发请求时,则Max_used_connections=1000.请注意与show variables 里的max_user_connections的区别
open_files_limit = 65535
# MySQL打开的文件描述符限制,默认最小1024;当open_files_limit没有被配置的时候,比较max_connections*5和ulimit -n的值,哪个大用哪个,
# 当open_file_limit被配置的时候,比较open_files_limit和max_connections*5的值,哪个大用哪个。
table_open_cache = 128
# MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。默认值64
# 假定系统有200个并发连接,则需将此参数设置为200*N(N为每个连接所需的文件描述符数目);
# 当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上
max_allowed_packet = 256M
# 接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。
# 该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出。
binlog_cache_size = 1M
# 一个事务,在没有提交的时候,产生的日志,记录到Cache中;等到事务提交需要提交的时候,则把日志持久化到磁盘。默认binlog_cache_size大小32K
max_heap_table_size = 8M
# 定义了用户可以创建的内存表(memory table)的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变
tmp_table_size = 16M
# MySQL的heap(堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。
# 大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。
# 如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySQL同时将增加heap表的大小,可达到提高联接查询速度的效果
read_buffer_size = 2M
# MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。
# 如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能
read_rnd_buffer_size = 8M
# MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,
# MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大
sort_buffer_size = 8M
# MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。
# 如果不能,可以尝试增加sort_buffer_size变量的大小
join_buffer_size = 8M
# 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享
thread_cache_size = 8
# 这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,
# 如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
# 增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。(–>表示要调整的值)
# 根据物理内存设置规则如下:
# 1G —> 8
# 2G —> 16
# 3G —> 32
# 大于3G —> 64
query_cache_size = 8M
#MySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,
# 今后对于同样的SELECT语句(区分大小写),将直接从缓冲区中读取结果。根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率。
# 通过检查状态值'Qcache_%',可以知道query_cache_size设置是否合理:如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,
# 如果Qcache_hits的值也非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小;如果Qcache_hits的值不大,则表明你的查询重复率很低,
# 这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。此外,在SELECT语句中加入SQL_NO_CACHE可以明确表示不使用查询缓冲
query_cache_limit = 2M
#指定单个查询能够使用的缓冲区大小,默认1M
key_buffer_size = 4M
#指定用于索引的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,
# 系统将开始换页并且真的变慢了。对于内存在4GB左右的服务器该参数可设置为384M或512M。通过检查状态值Key_read_requests和Key_reads,
# 可以知道key_buffer_size设置是否合理。比例key_reads/key_read_requests应该尽可能的低,
# 至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE 'key_read%'获得)。注意:该参数值设置的过大反而会是服务器整体效率降低
ft_min_word_len = 4
# 分词词汇最小长度,默认4
transaction_isolation = REPEATABLE-READ
# MySQL支持4种事务隔离级别,他们分别是:
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.
# 如没有指定,MySQL默认采用的是REPEATABLE-READ,ORACLE默认的是READ-COMMITTED
log_bin = mysql-bin
#配置mysql的bin log日志
binlog_format = row
#配置mysql的binlog日志格式,有三种。如果 binlog 格式不为 row,那么在误操作数据后就没有办法做闪回操作,只能老老实实地走备份恢复流程
expire_logs_days = 30
#超过30天的binlog删除
log_timestamps=SYSTEM
#log日志时间变为系统时间
log_error = /data/mysql/mysql-error.log
#错误日志路径
slow_query_log = 1
#开启mysql的慢查询日志
long_query_time = 1
#慢查询时间 超过1秒则为慢查询。# 慢查询日志的时间定义(秒),默认为10秒,多久就算慢查询的日志
log_queries_not_using_indexes=1
# 将所有没有使用带索引的查询语句全部写到慢查询日志中
slow_query_log_file = /data/mysql/mysql-slow.log
#慢查询日志文件路劲
performance_schema = 0
# MySQL 5.5开始新增一个数据库:PERFORMANCE_SCHEMA,主要用于收集数据库服务器性能参数。并且库里表的存储引擎均为PERFORMANCE_SCHEMA,而用户是不能创建存储引擎为PERFORMANCE_SCHEMA的表。MySQL5.5默认是关闭的,需要手动开启,在配置文件里添加:
#[mysqld]
#performance_schema=ON
explicit_defaults_for_timestamp=true
# mysql 中有这样的一个默认行为,如果一行数据中某些列被更新了,如果这一行中有timestamp类型的列,那么这个timestamp列的数据也会被自动更新到更新操作所发生的那个时间点;这个操作是由explicit_defaults_for_timestamp这个变更控制的
#lower_case_table_names = 1
#创建表名时,不区分大小写
skip-external-locking
#MySQL选项以避免外部锁定。该选项默认开启。如果是单服务器环境,则将其禁用即可,使用如下语句skip-external-locking
default-storage-engine = InnoDB
#默认存储引擎
innodb_file_per_table = 1
# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间
# 独立表空间优点:
# 1.每个表都有自已独立的表空间。
# 2.每个表的数据和索引都会存在自已的表空间中。
# 3.可以实现单表在不同的数据库中移动。
# 4.空间可以回收(除drop table操作处,表空不能自已回收)
# 缺点:
# 单表增加过大,如超过100G
# 结论:
# 共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整:innodb_open_files
innodb_open_files = 500
# 限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。这个值默认是300
innodb_buffer_pool_size = 64M
# InnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.
# 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%。设置越大占用物理内存越大
# 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
# 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
# 所以不要设置的太高.
参考:https://www.cnblogs.com/wanbin/p/9530833.html
innodb_buffer_pool_instances = 1
innodb_write_io_threads = 4
innodb_read_io_threads = 4
# innodb使用后台线程处理数据页上的读写 I/O(输入输出)请求,根据你的 CPU 核数来更改,默认是4
# 注:这两个参数不支持动态改变,需要把该参数加入到my.cnf里,修改完后重启MySQL服务,允许值的范围从 1-64
innodb_thread_concurrency = 0
# 默认设置为 0,表示不限制并发数,这里推荐设置为0,更好去发挥CPU多核处理能力,提高并发量
innodb_purge_threads = 1
# InnoDB中的清除操作是一类定期回收无用数据的操作。在之前的几个版本中,清除操作是主线程的一部分,这意味着运行时它可能会堵塞其它的数据库操作。
# 从MySQL5.5.X版本开始,该操作运行于独立的线程中,并支持更多的并发数。用户可通过设置innodb_purge_threads配置参数来选择清除操作是否使用单
# 独线程,默认情况下参数设置为0(不使用单独线程),设置为 1 时表示使用单独的清除线程。建议为1
innodb_flush_log_at_trx_commit = 2
# 0:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
# 主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile1
# 1:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。
# 2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。
# 每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘
# 默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。
# 设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。
# 总结
# 设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能
innodb_log_buffer_size = 2M
# 此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL开发人员建议设置为1-8M之间
innodb_log_file_size = 2G
# 此参数确定数据日志文件的大小,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间
innodb_log_files_in_group = 3
# 为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3
innodb_max_dirty_pages_pct = 90
# innodb主线程刷新缓存池中的数据,使脏数据比例小于90%
innodb_lock_wait_timeout = 120
# InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒
-------------------------------------
bulk_insert_buffer_size = 8M
# 批量插入缓存大小, 这个参数是针对MyISAM存储引擎来说的。适用于在一次性插入100-1000+条记录时, 提高效率。默认值是8M。可以针对数据量的大小,翻倍增加。
myisam_sort_buffer_size = 8M
# MyISAM设置恢复表之时使用的缓冲区的尺寸,当在REPAIR TABLE或用CREATE INDEX创建索引或ALTER TABLE过程中排序 MyISAM索引分配的缓冲区
myisam_max_sort_file_size = 10G
# 如果临时文件会变得超过索引,不要使用快速排序索引方法来创建一个索引。注释:这个参数以字节的形式给出
myisam_repair_threads = 1
# 如果该值大于1,在Repair by sorting过程中并行创建MyISAM表索引(每个索引在自己的线程内)
interactive_timeout = 28800
# 服务器关闭交互式连接前等待活动的秒数。交互式客户端定义为在mysql_real_connect()中使用CLIENT_INTERACTIVE选项的客户端。默认值:28800秒(8小时)
wait_timeout = 28800
# 服务器关闭非交互连接之前等待活动的秒数。在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,
# 取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)。参数默认值:28800秒(8小时)
# MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQL Server处理完相应的操作后,
# 应该断开连接并释放占用的内存。如果你的MySQL Server有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,
# 最终肯定会达到MySQL Server的连接上限数,这会报'too many connections'的错误。对于wait_timeout的值设定,应该根据系统的运行情况来判断。
# 在系统运行一段时间后,可以通过show processlist命令查看当前系统的连接状态,如果发现有大量的sleep状态的连接进程,则说明该参数设置的过大,
# 可以进行适当的调整小些。要同时设置interactive_timeout和wait_timeout才会生效。
transaction-isolation=READ-COMMITTED
# 确保数据库的全局事务隔离级别已设置为READ-COMMITTED
[mysqldump]
quick
max_allowed_packet = 500M
[myisamchk]
#myisamchk实用程序可以用来获得有关你的数据库表的统计信息或检查、修复、优化他们。参考博客:https://blog.csdn.net/wyzxg/article/details/7303486
key_buffer_size = 256M
sort_buffer_size = 8M
read_buffer = 4M
write_buffer = 4M
| \c | A counter that increments for each statement you issue |
|---|---|
| \D | 当前日期 |
| \d | 当前数据库 |
| \h | 数据库主机 |
| \l | The current delimiter (new in 5.1.12) |
| \m | 当前时间(分) |
| \n | A newline character |
| \O | The current month in three-letter format (Jan, Feb, …) |
| \o | The current month in numeric format |
| \P | am/pm |
| \p | The current TCP/IP port or socket file 端口号 |
| \R | 当前时间(小时)(0–23) |
| \r | 当前时间(小时)(1–12) |
| \S | Semicolon |
| \s | 当前时间(秒) |
| \t | A tab character |
| \U | Your full user_name@host_name account name |
| \u | 数据库用户名 |
| \v | The server version |
| \w | The current day of the week in three-letter format (Mon, Tue, …) |
| \Y | The current year, four digits |
| \y | The current year, two digits |
| _ | A space |
| \ | A space (a space follows the backslash) |
| ' | Single quote |
| \" | Double quote |
| \ | A literal “\” backslash character |
| \x | x, for any “x” not listed above |
检查 MySQL 配置文件 /etc/my.cnf 是否存在任何错误或未正确配置的设置。您可以使用以下命令检查配置文件语法是否正确:
mysqld --validate-config
如果配置文件存在格式或语法错误,则必须修复它们才能启动 MySQL 服务
MySQL配置文件参数详解(503)
阿里云数据库有503个配置
MySQL的一些简单优化
#修改最大连接数
max_connections = 500
#设置默认字符集为utf8mb4
character-set-server=utf8mb4
#查询排序时缓冲区大小,只对order by和group by起作用,可增大此值为16M
sort_buffer_size = 16M
#查询缓存限制,只有1M以下查询结果才会被缓存,以免结果数据较大把缓存池覆盖
query_cache_limit = 1M
#查看缓冲区大小,用于缓存SELECT查询结果,下一次有同样SELECT查询将直接从缓存池返回结果,可适当成倍增加此值
query_cache_size = 16M
#给所有的查询做cache,代表使用缓冲
query_cache_type = 1
#设置以顺序扫描的方式扫描表数据的时候使用缓冲区的大小
read_buffer_size = 8M
#打开文件数限制
open_files_limit = 10240
#修改InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间
innodb_file_per_table = 1
#索引和数据缓冲区大小,一般设置物理内存的60%-70%
innodb_buffer_pool_size = 1G
#缓冲池实例个数,推荐设置4个或8个
innodb_buffer_pool_instances = 8
#2代表只把日志写入到系统缓存区,再每秒同步到磁盘,效率很高
innodb_flush_log_at_trx_commit = 2
#日志缓冲区大小,由于日志最长每秒钟刷新一次,所以一般不用超过16M
innodb_log_buffer_size = 8M
#back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中
back_log = 1024
#thread cache 池中存放的最大连接数
thread_cache_size = 64
#开启慢查询日志
slow_query_log = ON

MySQL的启动方式4种
参考博客:
https://blog.csdn.net/simplemurrina/article/details/80088479
https://blog.csdn.net/alexdamiao/article/details/51498684
mysql的启动方式有4种: mysqld 、mysql_safe 、mysql_multi、service mysql start
1. mysqld:守护进程启动,是mysql的核心程序,用于管理mysql的数据库文件以及用户的请求操作。mysqld可以读取配置文件中的[mysqld]的部分
一般的,我们通过这种方式手动的调用mysqld,如果不是出去调试的目的,我们一般都不这样做。这种方式如果启动失败的话,错误信息只会从终端输出,而不是记录在错误日志文件中,这样,如果mysql崩溃的话我们也不知道原因,所以这种启动方式一般不用在生产环境中,而一般在调试(debug)系统的时候用到
[mysqld]
user = mysql
basedir = /usr/local/mysql
datadir = /data/mysql/mysql_3306/data
port = 3306
socket = /tmp/mysql.sock
event_scheduler = 0
mysqld启动命令:
# bin/mysqld --defaults-file=/etc/my.cnf &
2. mysqld_safe启动:相当于多了一个守护进程,mysqld挂了会自动把mysqld进程拉起来
mysqld_safe是一个启动脚本,该脚本会调用mysqld启动,如果启动出错,会将错误信息记录到错误日志中,mysqld_safe启动mysqld和monitor mysqld两个进程,这样如果出现mysqld进程异常终止的情况,mysqld_safe会重启mysqld进程
1.可以读取的配置部分[mysqld],[server],[myslqd_safe],为了兼容mysql_safe也会读取[safe_mysqld]中的配置
2.调用的mysqld是可以在[mysqld_safe]中用-mysqld, --mysqld-version指定
mysqld_safe启动命令:mysqld_safe --defaluts-file=/etc/my.cnf &
3. serverice mysql start 启动
mysql.server同样是一个启动脚本,调用mysqld_safe脚本。它的执行文件在$MYSQL_BASE/share/mysql/mysql.server和support-files/mysql.server。
主要用于系统的启动和关闭配置
这个启动先要把mysql.server文件复制到/etc/init.d目录下才可以使用
# cp support-files/mysql.server /etc/init.d/mysql
以上三种启动方式用到的参数可以参见下表:
MySQL Startup Scripts and Supported Server Option Groups
| Script | Option Groups |
|---|---|
| mysqld | [mysqld], [server], [mysqld-major_version] |
| mysqld_safe | [mysqld], [server], [mysqld_safe] |
| mysql.server | [mysqld], [mysql.server], [server] |
4. mysqld_multi 启动
是用于管理多实例启动的一个脚本。读取配置文件中的[mysqld_multi],[mysqldN] N需要一个整数,建议用端口号表示,该部分配置会覆盖[mysqld]部分中的配置[mysqld_multi]参数
[mysqld_multi]
mysqld = /usr/local/mysql/bin/mysqld_safe
mysqladmin =/usr/local/mysql/bin/mysqladmin
user= multiadmin
password = multipass
mysqld_multi 启动命令:mysqld_multi start 3306
数据库注释及退出(3种)
注释:
-- 注释信息(记住是两个横线在加一个空格)
/注释信息/
#注释信息
退出:
quit;
exit;
ctrl + c
Ctrl +d
MySQL多实例
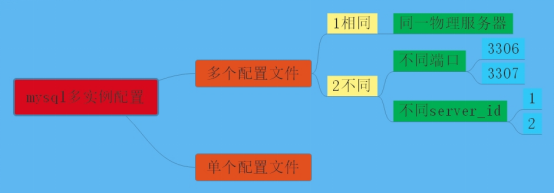
定义:
MySQL多实例就是在一台服务器上同时开启多个不同的服务端口(如:3306,3307),同时运行多个MySQL服务进程,这些服务进程通过不同的服务端口来提供服务(Nginx,apache,memcahe等都可以配置多实例)
作用:
有效利用服务器资源,当单个服务器资源有限时,可以充分利用剩余资源提供跟多的服务。节约服务器资源,当公司资金紧张,但是数据库又需要各自尽量独立的提供服务,而且需要主从复制等技术时,多实例就再好不过了。
MySQL多实例的生产应用场景
很多网络服务都可以配置多实例,例如Nginx,Apache,Haproxy,Redis,memcahe等都可以配置多实例。这在门户网站使用得很广泛。
安装前配置操作,杀掉进程,避免冲突如,删除启动命令
[root@Mysql02 /]# pkill mysqld
[root@Mysql02 /]# ps -ef | grep mysql
root 41567 40868 0 08:44 pts/0 00:00:00 grep mysql
[root@Mysql02 /]# rm -f /etc/init.d/mysqld
[root@Mysql02 /]# mkdir -p /data/{3306,3307}/data
[root@Mysql02 /]# chown -R mysql.mysql /data
[root@Mysql02 /]# tree /data/
/data/
├── 3306
│ └── data
└── 3307
└── data
3306_my.cnf配置文件:
[client]
port = 3306
socket = /data/3306/mysql.sock
[mysql]
no-auto-rehash
[mysqld]
user = mysql
port = 3306
socket = /data/3306/mysql.sock
basedir = /application/mysql
datadir = /data/3306/data
open_files_limit = 1024
back_log = 600
max_connections = 800
max_connect_errors = 3000
table_cache = 614
external-locking = FALSE
max_allowed_packet =8M
sort_buffer_size = 1M
join_buffer_size = 1M
thread_cache_size = 100
thread_concurrency = 2
query_cache_size = 2M
query_cache_limit = 1M
query_cache_min_res_unit = 2k
#default_table_type = InnoDB
thread_stack = 192K
#transaction_isolation = READ-COMMITTED
tmp_table_size = 2M
max_heap_table_size = 2M
long_query_time = 1
#log_long_format
#log-error = /data/3306/error.log
#log-slow-queries = /data/3306/slow.log
pid-file = /data/3306/mysql.pid
log-bin = /data/3306/mysql-bin
relay-log = /data/3306/relay-bin
relay-log-info-file = /data/3306/relay-log.info
binlog_cache_size = 1M
max_binlog_cache_size = 1M
max_binlog_size = 2M
expire_logs_days = 7
key_buffer_size = 16M
read_buffer_size = 1M
read_rnd_buffer_size = 1M
bulk_insert_buffer_size = 1M
#myisam_sort_buffer_size = 1M
#myisam_max_sort_file_size = 10G
#myisam_max_extra_sort_file_size = 10G
#myisam_repair_threads = 1
#myisam_recover
lower_case_table_names = 1
skip-name-resolve
slave-skip-errors = 1032,1062
replicate-ignore-db=mysql
server-id = 1
innodb_additional_mem_pool_size = 4M
innodb_buffer_pool_size = 32M
innodb_data_file_path = ibdata1:128M:autoextend
innodb_file_io_threads = 4
innodb_thread_concurrency = 8
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 2M
innodb_log_file_size = 4M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 90
innodb_lock_wait_timeout = 120
innodb_file_per_table = 0
[mysqldump]
quick
max_allowed_packet = 2M
[mysqld_safe]
log-error=/data/3306/mysql3306.err
pid-file=/data/3306/mysqld.pid
3306_mysql init
port=3306
mysql_user="root"
mysql_pwd="suoning"
CmdPath="/application/mysql/bin"
mysql_sock="/data/${port}/mysql.sock"
#startup function
function_start_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "Starting MySQL...\n"
/bin/sh ${CmdPath}/mysqld_safe --defaults-file=/data/${port}/my.cnf 2>&1 > /dev/null &
else
printf "MySQL is running...\n"
exit
fi
}
#stop function
function_stop_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "MySQL is stopped...\n"
exit
else
printf "Stoping MySQL...\n"
${CmdPath}/mysqladmin -u ${mysql_user} -p${mysql_pwd} -S /data/${port}/mysql.sock shutdown
fi
}
#restart function
function_restart_mysql()
{
printf "Restarting MySQL...\n"
function_stop_mysql
sleep 2
function_start_mysql
}
case $1 in
start)
function_start_mysql
;;
stop)
function_stop_mysql
;;
restart)
function_restart_mysql
;;
*)
printf "Usage: /data/${port}/mysql {start|stop|restart}\n"
esac
3307_my.cnf配置文件:
[client]
port = 3307
socket = /data/3307/mysql.sock
[mysql]
no-auto-rehash
[mysqld]
user = mysql
port = 3307
socket = /data/3307/mysql.sock
basedir = /application/mysql
datadir = /data/3307/data
open_files_limit = 1024
back_log = 600
max_connections = 800
max_connect_errors = 3000
table_cache = 614
external-locking = FALSE
max_allowed_packet =8M
sort_buffer_size = 1M
join_buffer_size = 1M
thread_cache_size = 100
thread_concurrency = 2
query_cache_size = 2M
query_cache_limit = 1M
query_cache_min_res_unit = 2k
#default_table_type = InnoDB
thread_stack = 192K
#transaction_isolation = READ-COMMITTED
tmp_table_size = 2M
max_heap_table_size = 2M
#long_query_time = 1
#log_long_format
#log-error = /data/3307/error.log
#log-slow-queries = /data/3307/slow.log
pid-file = /data/3307/mysql.pid
#log-bin = /data/3307/mysql-bin
relay-log = /data/3307/relay-bin
relay-log-info-file = /data/3307/relay-log.info
binlog_cache_size = 1M
max_binlog_cache_size = 1M
max_binlog_size = 2M
expire_logs_days = 7
key_buffer_size = 16M
read_buffer_size = 1M
read_rnd_buffer_size = 1M
bulk_insert_buffer_size = 1M
#myisam_sort_buffer_size = 1M
#myisam_max_sort_file_size = 10G
#myisam_max_extra_sort_file_size = 10G
#myisam_repair_threads = 1
#myisam_recover
lower_case_table_names = 1
skip-name-resolve
slave-skip-errors = 1032,1062
replicate-ignore-db=mysql
server-id = 3
innodb_additional_mem_pool_size = 4M
innodb_buffer_pool_size = 32M
innodb_data_file_path = ibdata1:128M:autoextend
innodb_file_io_threads = 4
innodb_thread_concurrency = 8
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 2M
innodb_log_file_size = 4M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 90
innodb_lock_wait_timeout = 120
innodb_file_per_table = 0
[mysqldump]
quick
max_allowed_packet = 2M
[mysqld_safe]
log-error=/data/3307/mysql3307.err
pid-file=/data/3307/mysqld.pid
3307_mysql init
#init
port=3307
mysql_user="root"
mysql_pwd="suoning"
CmdPath="/application/mysql/bin"
mysql_sock="/data/${port}/mysql.sock"
#startup function
function_start_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "Starting MySQL...\n"
/bin/sh ${CmdPath}/mysqld_safe --defaults-file=/data/${port}/my.cnf 2>&1 > /dev/null &
else
printf "MySQL is running...\n"
exit
fi
}
#stop function
function_stop_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "MySQL is stopped...\n"
exit
else
printf "Stoping MySQL...\n"
${CmdPath}/mysqladmin -u ${mysql_user} -p${mysql_pwd} -S /data/${port}/mysql.sock shutdown
fi
}
#restart function
function_restart_mysql()
{
printf "Restarting MySQL...\n"
function_stop_mysql
sleep 2
function_start_mysql
}
case $1 in
start)
function_start_mysql
;;
stop)
function_stop_mysql
;;
restart)
function_restart_mysql
;;
*)
printf "Usage: /data/${port}/mysql {start|stop|restart}\n"
esac
增加执行权限
[root@Mysql02 3307]# chmod +x /data/3306/mysql
[root@Mysql02 3307]# chmod +x /data/3307/mysql
[root@Mysql02 3307]# tree /data
/data
├── 3306
│ ├── data
│ ├── my.cnf
│ └── mysql
└── 3307
├── data
├── my.cnf
└── mysql
多实例启动文件的启动MySQL服务实质:
mysqld_safe --defaults-file=/data/3306/my.cnf 2>&1 > /dev/null &
mysqld_safe --defaults-file=/data/3307/my.cnf 2>&1 > /dev/null &
多实例启动文件的停止mysql服务实质:
mysqladmin -u root -p123456 -S /data/3306/mysql.sock shutdown
mysqladmin -u root -p123456 -S /data/3307/mysql.sock shutdown
初始化启动登陆,存放数据路径,自己放自己目录下
cd /application/mysql/scripts/
./mysql_install_db --basedir=/application/mysql/ --datadir=/data/3306/data --user=mysql
./mysql_install_db --basedir=/application/mysql/ --datadir=/data/3307/data --user=mysql

启动mysql并检查端口
/data/3306/mysql start
/data/3307/mysql start
[root@Mysql02 scripts]# netstat -lntup | grep mysql
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 45523/mysqld
tcp 0 0 0.0.0.0:3307 0.0.0.0:* LISTEN 52154/mysqld
授权并检查
[root@Mysql02 scripts]# find /data/ -type f -name "mysql" -exec chmod 700 {} \;
[root@Mysql02 scripts]# find /data/ -type f -name "mysql" -exec chown root.root {} \;
[root@Mysql02 scripts]# find /data/ -type f -name "mysql" -exec ls -l {} \;
-rwx------ 1 root root 1007 Feb 21 08:57 /data/3307/mysql
-rwx------ 1 root root 1007 Feb 21 08:56 /data/3306/mysql
设置MySQL登陆密码
[root@Mysql02 scripts]# mysqladmin -u root -S /data/3306/mysql.sock password '666666'
[root@Mysql02 scripts]# mysqladmin -u root -S /data/3307/mysql.sock password '666666'
修改密码
mysqladmin -uroot -p666666 password '123456'-S /data/3306/mysql.sock
mysqladmin -uroot -p666666 password '123456'-S /data/3306/mysql.sock
多实例数据库的登陆方法,需要参数 -s,并指定sock
mysql -S /data/3306/mysql.sock #不设置密码登陆
mysql -S /data/3307/mysql.sock
mysql -uroot -p -S /data/3306/mysql.sock #设置密码登陆
mysql -uroot -p -S /data/3307/mysql.sock
mysql -uroot -p –hlocalhost -S /data/3306/mysql.sock #远程登陆
mysql -uroot -p –hlocalhost -S /data/3307/mysql.sock
mysql -uroot -p –h 192.168.200.98 -P 3306
mysql -uroot -p –h 192.168.200.98 -P 3307
新增加一个实例:
[root@Mysql02 data]# mkdir -p /data/3308/data -p
[root@Mysql02 data]# cp /data/3306/my.cnf /data/3308/
[root@Mysql02 data]# cp /data/3306/mysql /data/3308/
[root@Mysql02 data]# chown -R mysql.mysql /data/3308/
[root@Mysql02 data]# sed -i 's#3306#3308#g' /data/3308/my.cnf
[root@Mysql02 data]# sed -i 's#3306#3308#g' /data/3308/mysql
初始化数据库:
[root@Mysql02 scripts]# ./mysql_install_db --basedir=/application/mysql/ --datadir=/data/3308/data/ --user=mysql
启动数据库,并检查端口
[root@Mysql02 scripts]# /data/3308/mysql start
[root@Mysql02 scripts]# netstat -lntup|grep 3308
tcp 0 0 0.0.0.0:3308 0.0.0.0:* LISTEN 53751/mysqld
设置密码为123456
[root@Mysql02 scripts]# mysqladmin -u root -S /data/3308/mysql.sock password '123456'
登陆mysql:
[root@Mysql02 scripts]# mysql -uroot -p -S /data/3308/mysql.sock
Enter password:
数据库重启失败
/usr/libexec/mysqld --skip-grant &
rm -fr /var/lib/mysql/*
rm /var/lock/subsys/mysqld
killall mysqld
参考文档:http://www.cnntt.com/archives/2505
完善mysql配置文件:
如果确认mysql服务正常运行,还提示文章标题的此错误,那就是/etc/my.cnf配置文件的问题了。解决办法是修改/etc/my.cnf配置文件,在配置文件中添加[client]选项和[mysql]选项,并使用这两个选项下的socket参数值,与[mysqld]选项下的socket参数值,指向的socket文件路径完全一致。如下:
[mysqld]
datadir=/storage/db/mysql
socket=/storage/db/mysql/mysql.sock
...省略n行...
[client]
default-character-set=utf8
socket=/storage/db/mysql/mysql.sock
[mysql]
default-character-set=utf8
socket=/storage/db/mysql/mysql.sock
利用mysqladmin添加mysql 的root密码
[root@test]# mysqladmin -u root password "666666" #创建密码
[root@test]# mysql -u root –p #登陆mysql
Enter password:

mysqladmin还可以创建数据库
mysqladmin -uroot -p'666666' create sbtest;
忘记密码的解决方案(4种)
如何重置mysql root密码?
【注】MySQL5.7.21版本之后password字段已从mysql.user表中删除,新的字段名是authentication_string
修改mysql的用户密码,分别可以使用grant、alter、set修改
https://blog.csdn.net/wrh_csdn/article/details/79483590
①mysql> grant all on *.* to '用户名'@'登录主机' identified by '密码';
grant all on *.* to 'test_1'@'localhost' identified by '123456';
②mysql> alter user '用户名'@'登录主机' identified by '密码';
alter user 'test_1'@'localhost' identified by '123456';
③mysql> SET PASSWORD FOR '用户名'@'登录主机' = PASSWORD('密码');
SET PASSWORD FOR 'test_1'@'localhost' = PASSWORD('123456789');
一、 在已知MYSQL数据库的ROOT用户密码的情况下,修改密码的方法:
1、 在SHELL环境下,使用mysqladmin命令设置:
mysqladmin -uroot -p password #回车后要求输入旧密码

或者

2、 在mysql>环境中,使用update命令,直接更新mysql库user表的数据:
-- 语法
update mysql.user set password=password('新密码') where user='root';
flush privileges; -- 刷新权限
注意:mysql语句要以分号;结束
-- mysql5.7语法
update mysql.user set authentication_string=password('新密码');
eg:密码为666666,修改记录是user等于root and host='localhost';
mysql> update mysql.user set password=password("666666") where user='root' and host='localhost';
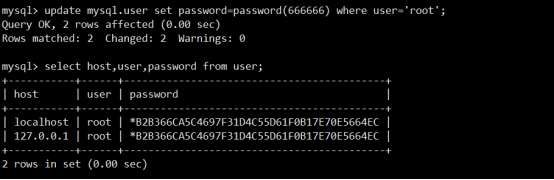
-- 5.7的语法:
mysql> update mysql.user set authentication_string=password("adminasdfghjkl123654") where user='root' and host='%';
mysql> flush privileges;

3、 在mysql>环境中,使用grant命令,修改root用户的授权权限。->需要root用户登录,进行操作
mysql> grant all [PRIVILEGES] on *.* to root@'localhost' identified by '新密码';
eg:
mysql> grant all on *.* to root@'localhost' identified by '666666' ;

4、初始化后登录数据库报错,提示修改root密码

mysql> alter user 'root'@'localhost' identified by '666666';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
二、 如忘记了mysql数据库的ROOT用户的密码,又如何做呢?方法如下:
1、 关闭当前运行的mysqld服务程序:service mysqld stop(要先将mysqld添加为系统服务)
2、 使用mysqld_safe脚本以安全模式(不加载授权表)启动mysqld 服务
/usr/local/mysql/bin/mysqld_safe --skip-grant-table &
3、 使用空密码的root用户登录数据库,重新设置ROOT用户的密码
shell> mysql -u root
Mysql> Update mysql.user set password=password('新密码') where user='root';
Mysql> flush privileges;
或者:https://www.cnblogs.com/kerrycode/p/6813497.html
检查MySQL服务是否启动,如果启动,关闭MySQL服务
找到MySQL的my.cnf配置文件,在/etc/my.cnf (有些版本是/etc/mysql/my.cnf)里面[mysqld]增加下面一段信息:
[mysqld]
skip-grant-tables
然后启动MySQL
进入MySQL后,修改root密码,操作过程中遇到ERROR 1054 (42S22): Unknown column 'password' in 'field list',查了一下user表的表结构,发现原来MySQL 5.7下,user表已经没有Password字段。加密后的用户密码存储于authentication_string字段。
具体操作过程如下所示:
update mysql.user set authentication_string=password('666666') where user='root';
在my.cnf文件中,把刚才加入的那一行skip-grant-tables注释或删除掉。 然后重启MySQL服务后需要执行命令set password=password('newpassword');后,问题搞定
MySQL命令详解
# mysql --help #(短选项不要等于号)
-u|--user=root:连接MySQL服务器的用户名;
-p''|--password='XOxz66&':连接MySQL服务器的密码(-p和密码之间不能用空格,密码用单引号囊括)。
-P:连接mysql服务器的端口(大写的p)
-e:执行mysql内部命令;
-h |--host='172.31.18.51':MySQL服务器的ip地址或主机名;
-S:指定socket文件
查看版本信息:3种方法
mysql> select version();
mysql> select @@version;
shell# mysql -V
执行mysql内部命令:
# mysql -e 'flush logs;'

拓展:在mysql命令行模式下执行shell命令(2种方法):
语法:
system (\!) Execute a system shell command.
eg:
mysql> \! ls /home
test
mysql> system ls /home
test

MySQL命令补全及查看帮助
Mysql命令对大小写不敏感,命令为大写时,可以实现命令的补全(有些版本可以补全,有些不能)
查看帮助信息:
help show #查看show的语法
help grant #查看grant的语法
MySQL [(none)]> help
General information about MariaDB can be found at
http://mariadb.org
List of all MySQL commands:
Note that all text commands must be first on line and end with ';'
? (\?) Synonym for `help'.
clear (\c) Clear the current input statement.
connect (\r) Reconnect to the server. Optional arguments are db and host.
delimiter (\d) Set statement delimiter.
edit (\e) Edit command with $EDITOR.
ego (\G) Send command to mysql server, display result vertically.
exit (\q) Exit mysql. Same as quit.
go (\g) Send command to mysql server.
help (\h) Display this help.
nopager (\n) Disable pager, print to stdout.
notee (\t) Don't write into outfile.
pager (\P) Set PAGER [to_pager]. Print the query results via PAGER.
print (\p) Print current command.
prompt (\R) Change your mysql prompt.
quit (\q) Quit mysql.
rehash (\#) Rebuild completion hash.
source (.) Execute an SQL script file. Takes a file name as an argument.
status (\s) Get status information from the server.
system (\!) Execute a system shell command.
tee (\T) Set outfile [to_outfile]. Append everything into given outfile.
use (\u) Use another database. Takes database name as argument.
charset (\C) Switch to another charset. Might be needed for processing binlog with multi-byte charsets.
warnings (\W) Show warnings after every statement.
nowarning (\w) Don't show warnings after every statement.
For server side help, type 'help contents'
eg:在mysql里执行系统命令
MySQL [(none)]> \! ls
MySQL [(none)]> \! ps aux | grep xxxx.sql
避免在脚本或命令行中明文传递 MySQL 用户名和密码
- 使用
--login-path参数
可以使用 --login-path 参数让 MySQL 客户端在登录时从配置文件中读取用户名、密码和主机名等信息,而无需在命令行中显示指定这些信息。这样做可以提高安全性和可维护性,减少敏感信息泄露的风险。
具体来说,--login-path 可以让 MySQL 客户端在登录时从配置文件中读取用户名、密码和主机名等信息,而无需在命令行中显示指定这些信息。对于需要频繁与 MySQL 服务器交互的任务,可以将 --login-path 参数添加到脚本或命令行中,简化命令行参数,提高操作效率。
使用 --login-path 参数后,我们可以通过以下步骤配置 MySQL 客户端:
-
创建
~/.mylogin.cnf配置文件,并设置文件权限为 600,只有当前用户可读写。 -
使用
mysql_config_editor工具将 MySQL 登录信息添加到配置文件中:
mysql_config_editor set --login-path=local --host=localhost --user=root --password
该命令会提示您输入 MySQL 用户口令,并将登录信息保存到 ~/.mylogin.cnf 文件中。
- 在脚本或命令行中使用
--login-path=local参数指定登录信息:
mysql --login-path=local
此时,MySQL 客户端会自动从 ~/.mylogin.cnf 文件中读取登录信息,并使用这些信息连接到 MySQL 服务器。使用 --login-path 参数可以避免在脚本或命令行中直接暴露 MySQL 用户名和密码,提高了安全性和可维护性。
- 使用环境变量
可以将 MySQL 用户名、密码等敏感信息保存到环境变量中,然后在脚本或命令行中使用这些环境变量。例如,在 Bash 脚本中可以使用以下语句:
export MYSQL_USER="root"
export MYSQL_PASSWORD="your_password"
mysql -u ${MYSQL_USER} -p ${MYSQL_PASSWORD} dbname < script.sql
- 使用
.my.cnf配置文件
可以在用户家目录下创建.my.cnf 配置文件,并在其中保存 MySQL 登录信息,然后让 MySQL 客户端自动读取该文件。例如,在 .my.cnf 文件中添加以下内容:
[client]
user=root
password=your_password
然后在脚本或命令行中不指定用户名和密码,直接连接到 MySQL 服务器:
mysql dbname < script.sql
需要注意的是,无论采用哪种方式,都需要严格控制访问敏感信息的权限,避免敏感信息被恶意程序窃取或者泄露。最好的做法是将 MySQL 用户名和密码尽量不存储在脚本或命令行中,而是通过其他安全方式进行传输和管理。
MySQL 配置安全的 SSL/TLS 加密连接
mysql_ssl_rsa_setup 是一个 MySQL 工具命令,用于生成自签名的 SSL/TLS 证书和私钥对。通过此命令,可以为 MySQL 配置安全的 SSL/TLS 加密连接。
要使用 mysql_ssl_rsa_setup 命令生成 SSL/TLS 证书和私钥对,请按照以下步骤进行:
-
打开终端或命令提示符窗口。
-
导航到 MySQL 安装目录或 bin 目录。
-
执行以下命令:
$ mysql_ssl_rsa_setup --datadir=<MySQL数据目录>
#或者
$ mysql_ssl_rsa_setup 1>/dev/null 2>&1
ll <MySQL数据目录> #额外会生产这些文件
-rw------- 1 mysql mysql 1680 May 5 01:53 ca-key.pem
-rw-r--r-- 1 mysql mysql 1112 May 5 01:53 ca.pem
-rw-r--r-- 1 mysql mysql 1112 May 5 01:53 client-cert.pem
-rw------- 1 mysql mysql 1676 May 5 01:53 client-key.pem
-rw-r--r-- 1 mysql mysql 1112 May 5 01:53 server-cert.pem
-rw------- 1 mysql mysql 1676 May 5 01:53 server-key.pem
注意将<MySQL 数据目录>替换为实际的 MySQL 数据目录路径。此命令将在指定的数据目录中生成 SSL/TLS 证书和私钥对。
#或者
$ mysql_ssl_rsa_setup 1>/dev/null 2>&1
-
在生成证书和私钥过程中,你可能需要提供一些额外的信息,例如国家代码、组织信息等。按照提示输入所需信息。
-
生成的证书和私钥对将存储在 MySQL 数据目录的中,文件名分别为
ca.pem,server-cert.pem和server-key.pem。
完成上述步骤后,你就可以将生成的 SSL/TLS 证书和私钥配置到 MySQL 服务器以启用 SSL/TLS 加密连接。以下是一个示例 MySQL 配置文件 (my.cnf) 的部分内容,用于启用 SSL/TLS:
[mysqld]
ssl-ca=<MySQL数据目录>/ca.pem
ssl-cert=<MySQL数据目录>/server-cert.pem
ssl-key=<MySQL数据目录>/server-key.pem
请注意,<MySQL 数据目录> 应该替换为实际的 MySQL 数据目录路径。
启用 SSL/TLS 后,客户端连接到 MySQL 服务器时将需要提供相应的证书和密钥来确保安全通信。
这就是使用 mysql_ssl_rsa_setup 命令生成 SSL/TLS 证书和私钥对的步骤
查看当前所在的库
mysql> status;
--------------
mysql Ver 14.14 Distrib 5.5.32, for Linux (x86_64) using readline 5.1
Connection id: 2
Current database: mysql
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.5.32 Source distribution
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /usr/local/mysql-5.5/tmp/mysql.sock
Uptime: 1 hour 22 min 31 sec
Threads: 1 Questions: 48 Slow queries: 0 Opens: 44 Flush tables: 1 Open tables: 4 Queries per second avg: 0.009
--------------
查看当前用户
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
MySQL查看连接数、最大并发数
show variables like '%max_connections%'; -- 查看最大连接数
set global max_connections=1000; -- 重新设置
mysql> show status like 'Threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 58 |
| Threads_connected | 57 | ###这个数值指的是打开的连接数
| Threads_created | 3676 |
| Threads_running | 4 | ###这个数值指的是激活的连接数,这个数值一般远低于connected数值
+-------------------+-------+
Threads_connected 跟show processlist结果相同,表示当前连接数。准确的来说,Threads_running是代表当前并发数
这是是查询数据库当前设置的最大连接数
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 1000 |
+-----------------+-------+
可以在/etc/my.cnf里面设置数据库的最大连接数
[mysqld]
max_connections = 1000
MySQL服务器的线程数需要在一个合理的范围之内,这样才能保证MySQL服务器健康平稳地运行。Threads_created表示创建过的线程数,通过查看Threads_created就可以查看MySQL服务器的进程状态。
mysql> show global status like 'Thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 46 |
| Threads_connected | 2 |
| Threads_created | 570 |
| Threads_running | 1 |
+-------------------+-------+
如果我们在MySQL服务器配置文件中设置了thread_cache_size,当客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)。
Threads_created表示创建过的线程数,如果发现Threads_created值过大的话,表明MySQL服务器一直在创建线程,这也是比较耗资源,可以适当增加配置文件中thread_cache_size值,查询服务器thread_cache_size配置:
mysql> show variables like 'thread_cache_size';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| thread_cache_size | 64 |
+-------------------+-------+
示例中的服务器还是挺健康的。
1.show status
Threads_connected 当前的连接数
Connections 试图连接到(不管是否成功)MySQL服务器的连接数。
Max_used_connections 服务器启动后已经同时使用的连接的最大数量。
2.set GLOBAL max_connections=连接数;
flush privileges
3.修改/etc/my.cnf中的max_connections
4.show processlist 显示当前正在执行的mysql连接

名词解释
-
id,线程号
-
user,操作用户
-
host,操作主机ip位置
-
db,操作数据库
-
command,执行类型(Query,Sleep......)
-
time,操作时长,秒
-
State,操作状态(starting)
-
Info,操作语句.

这个命令中最关键的就是state列,mysql列出的状态主要有以下几种:
Checking table
正在检查数据表(这是自动的)。
Closing tables
正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
Connect Out
复制从服务器正在连接主服务器。
Copying to tmp table on disk
由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
Creating tmp table
正在创建临时表以存放部分查询结果。
deleting from main table
服务器正在执行多表删除中的第一部分,刚删除第一个表。
deleting from reference tables
服务器正在执行多表删除中的第二部分,正在删除其他表的记录。
Flushing tables
正在执行FLUSH TABLES,等待其他线程关闭数据表。
Killed
发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。
Locked
被其他查询锁住了。
Sending data
正在处理SELECT查询的记录,同时正在把结果发送给客户端。
Sorting for group
正在为GROUP BY做排序。
Sorting for order
正在为ORDER BY做排序。
Opening tables
这个过程应该会很快,除非受到其他因素的干扰。例如,在执ALTER TABLE或LOCK TABLE语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。
Removing duplicates
正在执行一个SELECT DISTINCT方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。
Reopen table
获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。
Repair by sorting
修复指令正在排序以创建索引。
Repair with keycache
修复指令正在利用索引缓存一个一个地创建新索引。它会比Repair by sorting慢些。
Searching rows for update
正在讲符合条件的记录找出来以备更新。它必须在UPDATE要修改相关的记录之前就完成了。
Sleeping
正在等待客户端发送新请求.
System lock
正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加--skip-external-locking参数来禁止外部系统锁。
Upgrading lock
INSERT DELAYED正在尝试取得一个锁表以插入新记录。
Updating
正在搜索匹配的记录,并且修改它们。
User Lock
正在等待GET_LOCK()。
Waiting for tables
该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。
waiting for handler insert
INSERT DELAYED已经处理完了所有待处理的插入操作,正在等待新的请求。
大部分状态对应很快的操作,只要有一个线程保持同一个状态好几秒钟,那么可能是有问题发生了,需要检查一下。
还有其他的状态没在上面中列出来,不过它们大部分只是在查看服务器是否有存在错误是才用得着
命令: show processlist;
如果是root帐号,你能看到所有用户的当前连接。如果是其它普通帐号,只能看到自己占用的连接。
show processlist;只列出前100条,如果想全列出请使用show full processlist;
MySQL> show processlist;
5.mysqladmin -u<user> -p<pwd> -h<host> status
显示当前mysql状态
Uptime: 13131 Threads: 1 Questions: 22 Slow queries: 0 Opens: 16 Flush tables: 1 Open tables: 1 Queries per second avg: 0.1
显示mysql的其他状态
shell> mysqladmin -u<user> -p<pwd> -h<host> extended-status
+-----------------------------------+----------+
| Variable_name | Value |
+-----------------------------------+----------+
| Aborted_clients | 0 |
| Aborted_connects | 1 |
| Binlog_cache_disk_use | 0 |
| Binlog_cache_use | 0 |
| Bytes_received | 1152 |
| Bytes_sent | 10400 |
| Com_admin_commands | 0 |
| Com_assign_to_keycache | 0 |
.............................................................
| Threads_cached | 2 |
| Threads_connected | 1 |
| Threads_created | 3 |
| Threads_running | 1 |
| Uptime | 13509 |
| Uptime_since_flush_status | 13509 |
+-----------------------------------+----------+
MySQL状态情况
命令:show status;
命令:show status like '%下面变量%';
Aborted_clients 由于客户没有正确关闭连接已经死掉,已经放弃的连接数量。
Aborted_connects 尝试已经失败的MySQL服务器的连接的次数。
Connections 试图连接MySQL服务器的次数。
Created_tmp_tables 当执行语句时,已经被创造了的隐含临时表的数量。
Delayed_insert_threads 正在使用的延迟插入处理器线程的数量。
Delayed_writes 用INSERT DELAYED写入的行数。
Delayed_errors 用INSERT DELAYED写入的发生某些错误(可能重复键值)的行数。
Flush_commands 执行FLUSH命令的次数。
Handler_delete 请求从一张表中删除行的次数。
Handler_read_first 请求读入表中第一行的次数。
Handler_read_key 请求数字基于键读行。
Handler_read_next 请求读入基于一个键的一行的次数。
Handler_read_rnd 请求读入基于一个固定位置的一行的次数。
Handler_update 请求更新表中一行的次数。
Handler_write 请求向表中插入一行的次数。
Key_blocks_used 用于关键字缓存的块的数量。
Key_read_requests 请求从缓存读入一个键值的次数。
Key_reads 从磁盘物理读入一个键值的次数。
Key_write_requests 请求将一个关键字块写入缓存次数。
Key_writes 将一个键值块物理写入磁盘的次数。
Max_used_connections 同时使用的连接的最大数目。
Not_flushed_key_blocks 在键缓存中已经改变但是还没被清空到磁盘上的键块。
Not_flushed_delayed_rows 在INSERT DELAY队列中等待写入的行的数量。
Open_tables 打开表的数量。
Open_files 打开文件的数量。
Open_streams 打开流的数量(主要用于日志记载)
Opened_tables 已经打开的表的数量。
Questions 发往服务器的查询的数量。
Slow_queries 要花超过long_query_time时间的查询数量。
Threads_connected 当前打开的连接的数量。
Threads_running 不在睡眠的线程数量。
Uptime 服务器工作了多少秒。
my.ini配置 虚拟内存
innodb_buffer_pool_size=576M ->128M InnoDB引擎缓冲区
query_cache_size=100M ->32 查询缓存
tmp_table_size=102M ->32M 临时表大小
key_buffer_size=16m ->8M
MySQL 5.7之后的performance_schema
参考官方文档:
https://dev.mysql.com/doc/refman/5.7/en/performance-schema-query-profiling.html
参考:https://www.jianshu.com/p/03b5272368b7
performance_schema库,这是MySQL新增的性能优化引擎。在5.6以前是关闭的,5.6, 5.7中是默认开启的
使用profile涉及几个表,setup_actors、setup_instruments、setup_consumers。默认表setup_actors的内容如下:
SELECT * FROM performance_schema.setup_actors;

表 setup_consumers 描述各种事件
表setup_instruments 描述这个数据库下的表名以及是否开启监控
我们按照官方的建议来修改,可以看到修改的不是一行,而是相关的很多行
UPDATE performance_schema.setup_instruments
SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE '%statement/%';
SELECT * from performance_schema.setup_instruments WHERE NAME LIKE '%statement/%';
UPDATE performance_schema.setup_instruments
SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE '%stage/%';
SELECT * from performance_schema.setup_instruments WHERE NAME LIKE '%stage/%';
UPDATE performance_schema.setup_consumers
SET ENABLED = 'YES'
WHERE NAME LIKE '%events_statements_%';
SELECT * from performance_schema.setup_instruments WHERE NAME LIKE '%events_statements_%';
UPDATE performance_schema.setup_consumers
SET ENABLED = 'YES'
WHERE NAME LIKE '%events_stages_%';
SELECT * from performance_schema.setup_instruments WHERE NAME LIKE '%events_stages_%';
OK,配置完成,我们来看一下怎么用。创建一个test数据库。
create table test.test_profile as select * from information_schema.columns limit 1,5;
运行语句来得到一些详细的统计信息。
select * from test.test_profile limit 1,2 \G
根据下面的语句查询一个历史表,从表名可以看出是和事件相关的
SELECT EVENT_ID, TRUNCATE(TIMER_WAIT/1000000000000,6) as Duration, SQL_TEXT
FROM performance_schema.events_statements_history_long
WHERE SQL_TEXT like '%limit 1,2%';
通过上面的语句可以得到一个概览,对应的事件和执行时间。然后到stage相关的历史表中查看事件的详细信息,这就是我们期望的性能数据
SELECT event_name AS Stage, TRUNCATE(TIMER_WAIT/1000000000000,6) AS Duration
FROM performance_schema.events_stages_history_long
WHERE NESTING_EVENT_ID=4603;
这个方法是直接判断这个语句执行的时间(这三句应该一直执行才行)
set @d=now();
select * from test.test_profile;
select timestampdiff(second,@d,now());
历史记录数据量的配置
show variables like 'performance_schema%history%size';
查看数据库下有那些存储过程:
show procedure status
查看存储过程的语句:
show create procedure procedure_name
MySQL系统时间
参考:
https://www.jianshu.com/p/9c0c6010062c
https://www.cnblogs.com/azhqiang/p/7027821.html
MySQL [(none)]> show VARIABLES like '%time_zone%';
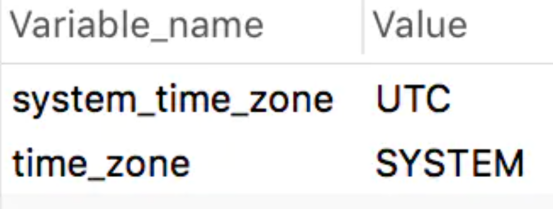
system_time_zone : 表示系统使用的时区是 UTC
time_zone: 表示 MySQL 采用的是系统的时区。也就是说,如果在连接时没有设置时区信息,就会采用这个时区配置
再通过select now()来验证时区:
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2023-10-08 13:37:37 |
+---------------------+
1 row in set (0.01 sec)
mysql查询当前系统时间
第一种方法:select current_date;
mysql> select current_date as Systemtime;
+------------+
| Systemtime |
+------------+
| 2023-10-08 |
+------------+
1 row in set (0.03 sec)
第二种方法:select now()
mysql> select now() as Systemtime;
+---------------------+
| Systemtime |
+---------------------+
| 2023-10-08 13:38:36 |
+---------------------+
1 row in set (0.03 sec)
第三种方法:select sysdate()
mysql> select sysdate() as Systemtime;
+---------------------+
| Systemtime |
+---------------------+
| 2023-10-08 13:38:50 |
+---------------------+
1 row in set (0.01 sec)
2. GMT、UTC、DST、CST时区代表的意义
2.1 GMT:Greenwich Mean Time
格林威治标准时间 ; 英国伦敦格林威治定为0°经线开始的地方,地球每15°经度 被分为一个时区,共分为24个时区,相邻时区相差一小时;例: 中国北京位于东八区,GMT时间比北京时间慢8小时。
2.2 UTC: Coordinated Universal Time
世界协调时间;经严谨计算得到的时间,精确到秒,误差在0.9s以内, 是比GMT更为精确的世界时间
2.3 DST: Daylight Saving Time
夏季节约时间,即夏令时;是为了利用夏天充足的光照而将时间调早一个小时,北美、欧洲的许多国家实行夏令时;
2.4 CST:Central Standard Time
Tips 时间戳:表示从1970年1月1日 00:00:00到现在所经历的秒数,与时区无关
-
Central Standard Time (USA) UT-6:00 美国标准时间
-
Central Standard Time (Australia) UT+9:30 澳大利亚标准时间
-
China Standard Time UT+8:00 中国标准时间
-
Cuba Standard Time UT-4:00 古巴标准时间
3. 修改时区
3.1 仅修改当前会话的时区,停止会话失效(CET)
set time_zone = '+8:00';
3.2 修改全局的时区配置
set global time_zone = '+8:00';
flush privileges;
或者在配置文件修改
default-time_zone = '+8:00'
修改时区, 修改完了记得记得重启msyql
注意一定要在[mysqld]配置块下加 ,否则会出现 unknown variable 'default-time-zone=+8:00'
了解SQL执行的状(explain)
参考:https://www.cnblogs.com/acm-bingzi/p/mysqlExplain.html
explain显示了MySQL如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。简单讲,它的作用就是分析查询性能。
mysql查看是否使用索引,简单的看type类型就可以。如果它是all,那说明这条查询语句遍历了所有的行,并没有使用到索引
使用方法:在select语句前加上explain就可以了
例如:
explain SELECT * FROM mysql.user
结果如图:
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows
https://tech.meituan.com/2014/06/30/mysql-index.html
EXPLAIN列的解释
Id
数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询
select_type
A:simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
B:primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个
C:union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
D:dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
E:union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
F:subquery:除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery
G:dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
H:derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
table
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的<derived N>就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与<derived N>类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集
type
一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL。依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
A:system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
B:const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
C:eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
D:ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
E:fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
F:ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
G:unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
H:index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
I:range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
J:index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
K:index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
L:all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录
possible_keys
显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key
实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句 中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len
使用的索引的长度。在不损失精确性的情况下,长度越短越好。用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
rows
MYSQL认为必须检查的用来返回请求数据的行数
filtered
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
Extra
关于MYSQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
#extra列返回的描述的意义
Distinct
一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
Not exists
MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
Range checked for each Record(index map:#)
没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
Using filesort
看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using index
列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候
Using temporary
看到这个的时候,查询需要优化了。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
Using where
使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题不同连接类型的解释(按照效率高低的顺序排序)
const
表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
eq_ref
在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
ref
这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
range
这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况
index
这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)
ALL
这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
MySQL数据文件介绍及存放位置
查看MySql数据库物理文件存放位置
mysql> show global variables like "%datadir%";
+---------------+----------------------------+
| Variable_name | Value |
+---------------+----------------------------+
| datadir | /usr/local/mysql-5.5/data/ |
+---------------+----------------------------+
1 row in set (0.00 sec)
MySQL数据库文件介绍
MySQL的每个数据库都对应存放在一个与数据库同名的文件夹中,MySQL数据库文件包括MySQL(server)所建数据库文件和MySQL(server)所用存储引擎创建的数据库文件。
1、MySQL(server)创建并管理的数据库文件:
.frm文件:存储数据表的框架结构,文件名与表名相同,每个表对应一个同名frm文件,与操作系统和存储引擎无关,即不管MySQL运行在何种操作系统上,使用何种存储引擎,都有这个文件。
除了必有的.frm文件,根据MySQL所使用的存储引擎的不同(MySQL常用的两个存储引擎是MyISAM和InnoDB),存储引擎会创建各自不同的数据库文件。
2、MyISAM数据库表文件:
.MYD文件:即MY Data,表数据文件
.MYI文件:即MY Index,索引文件
.log文件:日志文件
3、InnoDB采用表空间(tablespace)来管理数据,存储表数据和索引,
InnoDB数据库文件(即InnoDB文件集,ib-file set):
ibdata1、ibdata2等:系统表空间文件,存储InnoDB系统信息和用户数据库表数据和索引,所有表共用
.ibd文件:单表表空间文件,每个表使用一个表空间文件(file per table),存放用户数据库表数据和索引
日志文件: ib_logfile1、ib_logfile2
MySQL的root用户误删了或只剩下没有任何操作权限的用户?
参考:https://blog.csdn.net/weixin_30342827/article/details/101143415
root用户设置权限
update user set Host='%',select_priv='y', insert_priv='y',update_priv='y',Alter_priv='y',delete_priv='y',create_priv='y',drop_priv='y',reload_priv='y',shutdown_priv='y',Process_priv='y',file_priv='y',grant_priv='y',References_priv='y',index_priv='y',create_user_priv='y',show_db_priv='y',super_priv='y',create_tmp_table_priv='y',Lock_tables_priv='y',execute_priv='y',repl_slave_priv='y',repl_client_priv='y',create_view_priv='y',show_view_priv='y',create_routine_priv='y',alter_routine_priv='y',create_user_priv='y' where user='root';commit;
MySQL的用户管理、权限管理
mysql> help contents;
You asked for help about help category: "Contents"
For more information, type 'help <item>', where <item> is one of the following
categories:
Account Management
Administration
Compound Statements
Data Definition
Data Manipulation
Data Types
Functions
Functions and Modifiers for Use with GROUP BY
Geographic Features
Help Metadata
Language Structure
Plugins
Procedures
Storage Engines
Table Maintenance
Transactions
User-Defined Functions
Utility
mysql> help account management;
You asked for help about help category: "Account Management"
For more information, type 'help <item>', where <item> is one of the following
topics:
CREATE USER -- 创建用户
DROP USER -- 删除用户
GRANT -- 授权用户
RENAME USER -- 重命名
REVOKE -- 撤销权限
SET PASSWORD -- 设置密码
创建用户(3种方案)
syntax:
create user 'UserName'@'hostname' [ identified by 'PASSWORD' ];
eg:方案1->create user
1、创建用户tom,无密码且仅仅只能在本地登录
mysql> create user tom@'localhost';
Query OK, 0 rows affected (0.02 sec)
mysql> select host,user,password from mysql.user where user='tom';
+-----------+------+----------+
| host | user | password |
+-----------+------+----------+
| localhost | tom | |
+-----------+------+----------+
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
2、创建用户tom1,授权密码且仅仅只能在本地登录
mysql> create user tom1@'localhost' identified by '666666';
Query OK, 0 rows affected (0.01 sec)
mysql> select host,user,password from mysql.user where user='tom1';
+-----------+------+-------------------------------------------+
| host | user | password |
+-----------+------+-------------------------------------------+
| localhost | tom1 | *B2B366CA5C4697F31D4C55D61F0B17E70E5664EC |
+-----------+------+-------------------------------------------+
1 row in set (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
3、创建用户mysql tom2,仅仅只能从192.16.12.100-192.16.12.199进行登陆
mysql> create user tom2@'192.168.12.1__' identified by '666666';
Query OK, 0 rows affected (0.01 sec)
mysql> select host,user,password from mysql.user where user='tom2';
+----------------+------+-------------------------------------------+
| host | user | password |
+----------------+------+-------------------------------------------+
| 192.168.12.1__ | tom2 | *B2B366CA5C4697F31D4C55D61F0B17E70E5664EC |
+----------------+------+-------------------------------------------+
1 row in set (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
ps->若要表示:100-199,则可以使用1__,当然在登陆时,就必须跟上-h选项,指定登陆数据库的ip地址
# mysql –utom2 –p666666 -h192.16.12.111
eg:方案2->insert into
eg:方案3->grant
删除用户
Syntax:
DROP USER user [, user] ...
eg:删除用户tom
mysql> drop user tom@'localhost';
Query OK, 0 rows affected (0.01 sec)
eg:删除用户tom2
mysql> drop user tom2@'192.168.12.1__';
Query OK, 0 rows affected (0.03 sec)
注意:以上操作,均以mysql.user表中的user、host、password为准
==========================
或者使用delete删除用户:
delete from mysql.user where user='用户名称' and host='主机名称';
-- eg
DELETE FROM mysql.user WHERE user='user3' AND host='localhost';
FLUSH PRIVILEGES -- 刷新权限
使用DELETET删除用户后,必须使用FLUSH PRIVILEGES 来刷新权限,否则将无法继续创建用户名与已删用户的用户名相同的用户,即使在user表中看不到已删除的用户,如果不刷新权限,也是无法再新建的
用户重命名
Syntax:
RENAME USER old_user TO new_user
[, old_user TO new_user] ...
eg:重命名tom1用户为mimi
mysql> select user,host,password from mysql.user where user='tom1';
+------+-----------+-------------------------------------------+
| user | host | password |
+------+-----------+-------------------------------------------+
| tom1 | localhost | *B2B366CA5C4697F31D4C55D61F0B17E70E5664EC |
+------+-----------+-------------------------------------------+
1 row in set (0.00 sec)
mysql> rename user tom1@'localhost' to mimi@'localhost';
Query OK, 0 rows affected (0.03 sec)
mysql> select user,host,password from mysql.user where user='mimi';
+------+-----------+-------------------------------------------+
| user | host | password |
+------+-----------+-------------------------------------------+
| mimi | localhost | *B2B366CA5C4697F31D4C55D61F0B17E70E5664EC |
+------+-----------+-------------------------------------------+
1 row in set (0.00 sec)
修改密码
【注】MySQL 5.7.21 版本已 password 字段已从 mysql.user 表中删除,新的字段名是authentication_string
Syntax:
SET PASSWORD [FOR user] =
{
PASSWORD('cleartext password')
| OLD_PASSWORD('cleartext password')
| 'encrypted password'
}
eg:mimi用户设置新密码为666666
mysql> select user,host,password from mysql.user where user='mimi';
+------+-----------+-------------------------------------------+
| user | host | password |
+------+-----------+-------------------------------------------+
| mimi | localhost | *DA28842831B3C40F4BC1D3C76CF9AD8CBFDAE1CB |
+------+-----------+-------------------------------------------+
1 row in set (0.00 sec)
mysql> set password for mimi@'localhost' = password('666666');
Query OK, 0 rows affected (0.03 sec)
mysql> select user,host,password from mysql.user where user='mimi';
+------+-----------+-------------------------------------------+
| user | host | password |
+------+-----------+-------------------------------------------+
| mimi | localhost | *B2B366CA5C4697F31D4C55D61F0B17E70E5664EC |
+------+-----------+-------------------------------------------+
1 row in set (0.00 sec)
查询权限
syntax:
SHOW GRANTS [FOR user]
SHOW GRANTS;
SHOW GRANTS FOR CURRENT_USER;
SHOW GRANTS FOR CURRENT_USER();
1、查看Jerry的权限
mysql> show grants for jerry@'localhost';
+-------------------------------------------+
| Grants for jerry@localhost |
+-------------------------------------------+
| GRANT USAGE ON *.* TO 'jerry'@'localhost' |
+-------------------------------------------+
1 row in set (0.00 sec)
2、查看当前用户(自己)权限:
show grants;
授权用户
通常开发同事在让运维同事开通mysql权限时,他们会在自己本地mysql里生成一个密文密码,然后把这个密文密码给运维同事,运维同事在用这个密文密码进行授权,那么授权的密码就只有开发同事自己知道了,其他人都不知道!比较安全的一种做法
参考:https://zhuanlan.zhihu.com/p/55798418

注意:授权后必须FLUSH PRIVILEGES;否则无法立即生效
MySQL 赋予用户权限命令的简单格式可概括为:
grant 权限 on 数据库对象 to 用户;
Mysql的用户权限管理:
授权:grant
Mysql的授权:
权限类型:
数据库权限
表级权限
用户权限
字段级别
程序类权限
管理类权限
Syntax:
GRANT
priv_type [(column_list)]
[, priv_type [(column_list)]] ...
ON [object_type] priv_level
TO user_specification [, user_specification] ...
[REQUIRE {NONE | ssl_option [[AND] ssl_option] ...}]
[WITH with_option ...]
全局管理权限:Global Privileges
CREATE TABLESPACE:创建表的空间
CREATE USER:创建用户
FILE:允许用户读或者写某些指定的文件
PROCESS:查看用户线程状态
mysql> show processlist; //查看mysql登陆的用户及线程数
mysql> show full processlist; //查看mysql所有登陆的用户及线程数
RELOAD:重新加载,相当于flush和reset
REPLICATION CLIENT:查询主、从复制中的从客户端
REPLICATION SLAVE:查询主、从复制中,从服务器的权限
SHOW DATABASES:
SHUTDOWN:关掉
SUPER privileges:超级权限
管理类权限:数据库管理类
create temporary tables; -- 创建临时表
create user -- 创建
drop -- 删除
EVENT -- 事件
GRANT OPTION -- 添加选项
LOCK TABLES -- 锁
REFERENCES -- 性能
ALTER -- 修改
CREATE VIEW -- 创建视图
INDEX -- 索引
SHOW VIEW -- 查看视图
TRIGGER -- 触发器
EXECUTE -- 执行存储过程
数据库的操作权限:
增删改查
Insert
Delete
Update
Select
注意:以上是可以通过字段列表进行定向(column_list)
object_type:
TABLE
| FUNCTION 函数
| PROCEDURE 存储过程
priv_level:
*
| *.*
| db_name.*
| db_name.tbl_name
| tbl_name
| db_name.routine_name
user_specification:
user
[
IDENTIFIED BY [PASSWORD] 'password'
| IDENTIFIED WITH auth_plugin [AS 'auth_string']
]
ssl_option:
SSL
| X509 证书认证方式
| CIPHER 'cipher'
| ISSUER 'issuer'
| SUBJECT 'subject'
with_option:
GRANT OPTION 权限转赠
| MAX_QUERIES_PER_HOUR count 每小时允许最大访问次数
| MAX_UPDATES_PER_HOUR count 每小时允许最大更新次数
| MAX_CONNECTIONS_PER_HOUR count 每小时允许最大链接数
| MAX_USER_CONNECTIONS count 使用同一个账号可以同时连接的次数
eg:
1、给予Jerry可以创建库的权限
mysql> grant create on *.* to jerry@localhost;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
mysql> show grants for jerry@'localhost';
+--------------------------------------------+
| Grants for jerry@localhost |
+--------------------------------------------+
| GRANT CREATE ON *.* TO 'jerry'@'localhost' |
+--------------------------------------------+
1 row in set (0.00 sec)
2、在案例1的基础上,给予Jerry可以查询的mysql.user表的权限
mysql> grant select on mysql.user to jerry@'localhost';
Query OK, 0 rows affected (0.01 sec)
mysql> show grants for jerry@'localhost';
+-------------------------------------------------------+
| Grants for jerry@localhost |
+-------------------------------------------------------+
| GRANT CREATE ON *.* TO 'jerry'@'localhost' |
| GRANT SELECT ON `mysql`.`user` TO 'jerry'@'localhost' |
+-------------------------------------------------------+
2 rows in set (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.02 sec)
3、在1和2的基础上,在给予Jerry可以向student.student表中插入信息的权限
mysql> grant insert on student.student to jerry@'localhost';
Query OK, 0 rows affected (0.01 sec)
mysql> show grants for jerry@'localhost';
+------------------------------------------------------------+
| Grants for jerry@localhost |
+------------------------------------------------------------+
| GRANT CREATE ON *.* TO 'jerry'@'localhost' |
| GRANT INSERT ON `student`.`student` TO 'jerry'@'localhost' |
| GRANT SELECT ON `mysql`.`user` TO 'jerry'@'localhost' |
+------------------------------------------------------------+
3 rows in set (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
4、在1、2、3的基础上,在给予Jerry删除test1库及下面所有的表的权限
mysql> grant drop on test1.* to jerry@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
mysql> show grants for jerry@'localhost';
+------------------------------------------------------------+
| Grants for jerry@localhost |
+------------------------------------------------------------+
| GRANT CREATE ON *.* TO 'jerry'@'localhost' |
| GRANT DROP ON `test1`.* TO 'jerry'@'localhost' |
| GRANT INSERT ON `student`.`student` TO 'jerry'@'localhost' |
| GRANT SELECT ON `mysql`.`user` TO 'jerry'@'localhost' |
+------------------------------------------------------------+
4 rows in set (0.00 sec)
5、转权限(让mysql用户有root的所有权限)
mysql> grant all on *.* to mysql@'localhost' with grant option;
Query OK, 0 rows affected (0.03 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.03 sec)
注意:在添加权限时,权限是在原有的基础上进行累加
一、grant 普通数据用户,查询、插入、更新、删除 数据库中所有表数据的权利。
grant select on testdb.* to common_user@'%'
grant insert on testdb.* to common_user@'%'
grant update on testdb.* to common_user@'%'
grant delete on testdb.* to common_user@'%'
或者,用一条 MySQL 命令来替代:
grant select, insert, update, delete on testdb.* to common_user@'%'
二、grant 数据库开发人员,创建表、索引、视图、存储过程、函数。。。等权限。
grant 创建、修改、删除 MySQL 数据表结构权限。
grant create on testdb.* to developer@'192.168.0.%';
grant alter on testdb.* to developer@'192.168.0.%';
grant drop on testdb.* to developer@'192.168.0.%';
grant 操作 MySQL 外键权限。
grant references on testdb.* to developer@'192.168.0.%';
grant 操作 MySQL 临时表权限。
grant create temporary tables on testdb.* to developer@'192.168.0.%';
grant 操作 MySQL 索引权限。
grant index on testdb.* to developer@'192.168.0.%';
grant 操作 MySQL 视图、查看视图源代码 权限。
grant create view on testdb.* to developer@'192.168.0.%';
grant show view on testdb.* to developer@'192.168.0.%';
grant 操作 MySQL 存储过程、函数 权限。
grant create routine on testdb.* to developer@'192.168.0.%'; -- now, can show procedure status
grant alter routine on testdb.* to developer@'192.168.0.%'; -- now, you can drop a procedure
grant execute on testdb.* to developer@'192.168.0.%';
三、grant 普通 DBA 管理某个 MySQL 数据库的权限。
grant all privileges on testdb to dba@'localhost';
其中,关键字privileges可以省略。
四、grant 高级 DBA 管理 MySQL 中所有数据库的权限。
grant all on . to dba@'localhost';
五、MySQL grant 权限,分别可以作用在多个层次上。
- grant 作用在整个 MySQL 服务器上:
grant select on *.* to dba@localhost; -- dba 可以查询 MySQL 中所有数据库中的表。
grant all on *.* to dba@localhost; -- dba 可以管理 MySQL 中的所有数据库
2. grant 作用在单个数据库上:
grant select on testdb.* to dba@localhost; -- dba 可以查询 testdb 中的表。
3. grant 作用在单个数据表上:
grant select, insert, update, delete on testdb.orders to dba@localhost;
这里在给一个用户授权多张表时,可以多次执行以上语句。例如:
grant select(user_id,username) on smp.users to mo_user@'%' identified by '123345';
grant select on smp.mo_sms to mo_user@'%' identified by '123345';
- grant 作用在表中的列上:
grant select(id, se, rank) on testdb.apache_log to dba@localhost;
5. grant 作用在存储过程、函数上:
grant execute on procedure testdb.pr_add to 'dba'@'localhost'
grant execute on function testdb.fn_add to 'dba'@'localhost'
六、查看 MySQL 用户权限
查看当前用户(自己)权限:
show grants;
查看其他 MySQL 用户权限:
show grants for dba@localhost;
七、撤销已经赋予给 MySQL 用户权限的权限。
revoke 跟 grant 的语法差不多,只需要把关键字to换成from即可:
grant all on *.* to dba@localhost;
revoke all on *.* from dba@localhost;
八、MySQL grant、revoke 用户权限注意事项
-
grant, revoke 用户权限后,该用户只有重新连接 MySQL 数据库,权限才能生效。
-
如果想让授权的用户,也可以将这些权限 grant 给其他用户,需要选项
grant option
grant select on testdb.* to dba@localhost with grant option;
这个特性一般用不到。实际中,数据库权限最好由 DBA 来统一管理。
遇到SELECT command denied to user '用户名'@'主机名' for table '表名'这种错误,解决方法是需要把后面的表名授权,即是要你授权核心数据库也要。
我遇到的是SELECT command denied to user 'my'@'%' for table 'proc',是调用存储过程的时候出现,原以为只要把指定的数据库授权就行了,什么存储过程、函数等都不用再管了,谁知道也要把数据库mysql的proc表授权
mysql授权表共有5个表:user、db、host、tables_priv和columns_priv。
授权表的内容有如下用途:
user表
user表列出可以连接服务器的用户及其口令,并且它指定他们有哪种全局(超级用户)权限。在user表启用的任何权限均是全局权限,并适用于所有数据库。例如,如果你启用了DELETE权限,在这里列出的用户可以从任何表中删除记录,所以在你这样做之前要认真考虑。
db表
db表列出数据库,而用户有权限访问它们。在这里指定的权限适用于一个数据库中的所有表。
host表
host表与db表结合使用在一个较好层次上控制特定主机对数据库的访问权限,这可能比单独使用db好些。这个表不受GRANT和REVOKE语句的影响,所以,你可能发觉你根本不是用它。
tables_priv表
tables_priv表指定表级权限,在这里指定的一个权限适用于一个表的所有列。
columns_priv表
columns_priv表指定列级权限。这里指定的权限适用于一个表的特定列
撤销权限
revoke 跟 grant 的语法差不多,只需要把关键字to换成from即可:
撤销权限:revoke
REVOKE
priv_type [(column_list)]
[, priv_type [(column_list)]] ...
ON [object_type] priv_level
FROM user [, user] ...
REVOKE ALL PRIVILEGES, GRANT OPTION
FROM user [, user] ...
REVOKE PROXY ON user
FROM user [, user] ...
eg:
1、撤销Jerry用户对student.student表进行插入数据操作
mysql> show grants for jerry@'localhost';
+------------------------------------------------------------+
| Grants for jerry@localhost |
+------------------------------------------------------------+
| GRANT CREATE ON *.* TO 'jerry'@'localhost' |
| GRANT DROP ON `test1`.* TO 'jerry'@'localhost' |
| GRANT INSERT ON `student`.`student` TO 'jerry'@'localhost' |
| GRANT SELECT ON `mysql`.`user` TO 'jerry'@'localhost' |
+------------------------------------------------------------+
4 rows in set (0.00 sec)
mysql> revoke insert on student.student from jerry@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> show grants for jerry@'localhost';
+-------------------------------------------------------+
| Grants for jerry@localhost |
+-------------------------------------------------------+
| GRANT CREATE ON *.* TO 'jerry'@'localhost' |
| GRANT DROP ON `test1`.* TO 'jerry'@'localhost' |
| GRANT SELECT ON `mysql`.`user` TO 'jerry'@'localhost' |
+-------------------------------------------------------+
3 rows in set (0.00 sec)
2、撤销Jerry用户的所有权限
mysql> show grants for jerry@'localhost';
+-------------------------------------------------------+
| Grants for jerry@localhost |
+-------------------------------------------------------+
| GRANT USAGE ON *.* TO 'jerry'@'localhost' |
| GRANT DROP ON `test1`.* TO 'jerry'@'localhost' |
| GRANT SELECT ON `mysql`.`user` TO 'jerry'@'localhost' |
+-------------------------------------------------------+
3 rows in set (0.00 sec)
mysql> revoke all privileges ,grant option from jerry@'localhost';
Query OK, 0 rows affected (0.01 sec)
mysql> show grants for jerry@'localhost';
+-------------------------------------------+
| Grants for jerry@localhost |
+-------------------------------------------+
| GRANT USAGE ON *.* TO 'jerry'@'localhost' |
+-------------------------------------------+
1 row in set (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
MYSQL-用户权限的验证过程
参考:https://www.cnblogs.com/zuoxingyu/p/4935428.html

MySQL [(none)]> select user(), current_user();
生产环境如何授权用户权限
1)博客,CMS等产品的数据库授权:
对于web链接用户授权尽量采用最小化原则,很多开源软件都是web界面安装,因此,再安装期间除了select,insert,update,delete 4个权限外。还需要create,drop等比较危险的权限
mysql> grant select,insert,update,create,drop on blog.* to 'blog'@'10.0.0.%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
常规情况下授权,select,insert,update,delete 4个权限即可,有的开源软件例如discuz bbs还需要create,drop等比较危险的权限。
2)生成数据库表后,要收回create,drop等比较危险的权限。
3)生成环境针对主库(写为主读为辅)用户的授权:
普通环境:
本机:lnmp,lamp环境数据库授权
grant all privileges on blog.* to 'blog'@'localhost' identified by '123456';
应用服务器和数据库服务器不在一个主机上的授权:
grant all privileges on 'blog'. to 'blog'@10.0.0.% identified by '123456';
严格的授权:重视安全,忽略了方便:
grant select,insert,update,delete on 'blog'. to 'blog'@'10.0.0.%' identified by '123456';
生产环境从库(只读)用户的授权:
grant select on 'blog'. to 'blog'@10.0.0.% identified by '123456';
数据库操作(重点)

创建数据库
http://c.biancheng.net/view/2413.html
-- 格式
create database [IF NOT EXISTS] 数据库名 [库选项];
CREATE DATABASE [IF NOT EXISTS] <数据库名> [[DEFAULT] CHARACTER SET <字符集名>] [[DEFAULT] COLLATE <校对规则名>];
[ ]中的内容是可选的。语法说明如下:
- <数据库名>:创建数据库的名称。MySQL 的数据存储区将以目录方式表示 MySQL 数据库,因此数据库名称必须符合操作系统的文件夹命名规则,不能以数字开头,尽量要有实际意义。注意在 MySQL 中不区分大小写。
- IF NOT EXISTS:在创建数据库之前进行判断,只有该数据库目前尚不存在时才能执行操作。此选项可以用来避免数据库已经存在而重复创建的错误。
- [DEFAULT] CHARACTER SET:指定数据库的字符集。指定字符集的目的是为了避免在数据库中存储的数据出现乱码的情况。如果在创建数据库时不指定字符集,那么就使用系统的默认字符集。
- [DEFAULT] COLLATE:指定字符集的默认校对规则。
库选项:用来约束数据库,分为两个选项
-
字符集设定:charset、character set 具体字符集(数据存储的编码格式):常用字符集:GBK和UTF8和utf8mb4。现在一般就用utf8mb4
-
校对集设定:collate 具体校对集(数据比较规则),utf8mb4编码的默认COLLATE为
utf8mb4_general_ci
COLLATE属性用于指定列的排序和比较方式,我们在使用ORDER BY、DISTINCT、GROUP BY等命令时都会涉及到该属性。另外我们在对表建索引时,如果索引列是字符类型,那么COLLATE属性也会影响到索引的创建。
MySQL 的字符集(CHARACTER)和校对规则(COLLATION)是两个不同的概念。字符集是用来定义 MySQL 存储字符串的方式,校对规则定义了比较字符串的方式。后面我们会单独讲解 MySQL 的字符集和校对规则。
https://blog.csdn.net/wangtaoking1/article/details/107954837
MySQL 不允许在同一系统下创建两个相同名称的数据库。
没有指定字符编码格式:
create database new; -- (库名new,应该默认latin1这种格式,库名不能用特殊符号,如:-\)
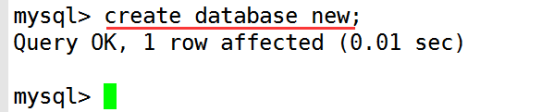
或者指定字符编码格式:
create database mimi charset utf8; -- (库名mimi,使用utf8这种格式)
Query OK, 1 row affected (0.00 sec)
create database mydb charset utf8mb4 collate utf8mb4_general_ci;
Query OK, 1 row affected (0.00 sec)
说明:在增删改查的时候不能使用关键字保留字;如果非要使用,必须用反引号把它括起来,例如:
mysql> create database `database` charset utf8;
Query OK, 1 row affected (0.00 sec)
如果需要使用中文也需要用反引号括起来
mysql> create database `中文` charset utf8;
Query OK, 1 row affected (0.00 sec)
最后,最好不要使用中文,可能会出现乱码,也尽量不要使用关键字
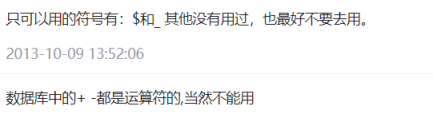
各种运算符也不能使用,最好只用下划线_
查询数据库
1)查看所有数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| 中文 |
| database |
| mimi |
| mysql |
| new |
| test |
+--------------------+
7 rows in set (0.00 sec)
2)查看指定部分数据库:模糊查询
格式:
show databases like 'pattern'; -- pattern是匹配模式
%:任意长度的任意字符
_:任意单个字符长度的任意字符
eg:
1) mysql> show databases like 'information_%'; -- (相当于information%)
+--------------------------+
| Database (information_%) |
+--------------------------+
| information_schema |
| informationtest |
+--------------------------+
2 rows in set (0.00 sec)
2)mysql> show databases like 'information_%';
+---------------------------+
| Database (information_%) |
+---------------------------+
| information_schema |
+---------------------------+
1 row in set (0.00 sec)
3)mysql> show tables like '%o%';
+-------------------------+
| Tables_in_Student (%o%) |
+-------------------------+
| Course |
| Score |
+-------------------------+
2 rows in set (0.00 sec)
说明:查看以
information_开始的数据库:_需要被转义
3)查看数据库的创建语句:
show create database 数据库名;

说明:数据库在执行SQL语句之前会优化SQL;系统保留的结果是优化的结果
进入数据库
格式:
use 数据库名[;]
eg:
use database; -- 这个分号,可以不需要(建议写上,规范操作)
更新数据库
数据库名字不可以修改,因为修改了数据库的名字后,所有关联的必须都要修改
数据库的修改仅限库选项:字符集和校对集(校对集依赖字符集)
alter database 数据库名 [库选项];
库选项:
-
charset、character set [=] 字符集
-
collate 校对集
-- 例如:修改数据库informationtest的字符集
mysql> alter database informationtest charset GBK;
Query OK, 1 row affected (0.00 sec)
删除数据库
所有的操作中:删除是最简单的(慎重)
格式:
drop database 数据库名字;
-- 例如:删除informationtest数据库
mysql> drop database informationtest;
Query OK, 0 rows affected (0.04 sec)
当删除数据库语句执行之后,发什么了什么?
1、在数据库内部看不到对应的数据库
mysql>
show databases;-- 你会发现,已经不存在这个数据库了
2、在对应的数据库存储的文件夹内,数据名字对应的文件夹也被删除了(而且是级联删除:里面的数据表全部删除了)
Notice:数据库的删除不是闹着玩的,不要随意删除,应该先进行备份后操作,(删除是不可逆的)
数据表操作(重点)
创建数据表
格式:
create table [if not exists] 表名(
字段名 数据类型,
字段名 数据类型 -- 最后一行不需要逗号
)[表选项];
解释说明:
if not exists -- 表示如果表名不存在,那么就创建,否则不执行创建代码;起一个检查功能
if exists -- 表示的意思就与if not exists相反
drop table if exists test; -- 如果存在就删除该表
表选项:控制表的表现
comment: '备注'
mysql> create table mycomm(num int) comment '测试表'; -- auto_increment = 设定当前表的自增长字段的初始值,默认是1
字符集:charset/character set 具体字符集:-- 保证表中数据存储的字符集
校对集:collate 具体校对集;
存储引擎:engine 具体的存储引擎(innodb和myisam)
Myisam不支持事务

eg:
-- 创建表
create table if not exists student(
name varchar(10),
gender varchar(10),
number varchar(10),
-- 数据类型的长度可以不指定
age int
)charset utf8;
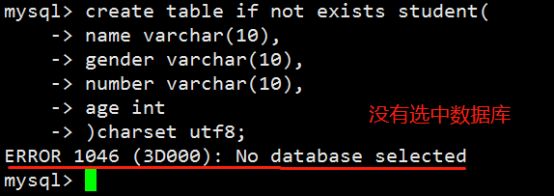
任何一个表的设计都必须指定数据库。
解决方案1:显示的制定表所属的数据库
create table 数据库名.表名(); -- 将当前的数据表创建到指定的数据库下
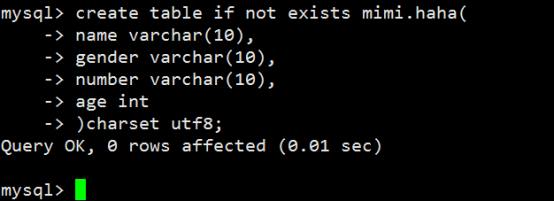
解决方案2:隐式的指定表所属数据库:先进入某个数据库环境中,然后这样创建的表自动归属到某个指定的数据库中。
-- 先进入数据库环境中:
use 数据库名;
-- 然后创建表:
当创建数据表的SQL指令执行之后,到底发生了什么?
1、指定数据库下已经存在对应的表
2、在数据库对应的文件夹下,会产生对应表的结构文件(跟存储引擎有关)
查询数据表
数据库能查看的方式,数据表都可以查看
1、查看所有表(需要先进入库):
show tables;
不需要先进入库,直接查询库下的所有表
mysql> show tables from mysql;
2、查看部分表:模糊匹配
-- show tables like 'pattern';
show tables like '%t';
建议别这样查询,效率很低,这里索引是失效的,如果要这样使用尽量匹配前面的字符
3、查询表创建语句:
show create table student\g -- \g等于分号
show create table student\G -- 将查到的结构旋转90°变成纵向
4、查看表的结构:查看表中的字段信息(3种方法)
-- 格式
desc/describe/show columns from 表名;
desc student; -- 1
describe student; -- 2
show columns from student; -- 3
Field :字段名
Type :列类型:字段类型:数据类型
Null :列属性:是否允许为UNLL(空)
Key :索引:索引类型(PRI:主键;UNI:唯一键;等等……)
Default :列属性:默认值,大部分字段默认为NULL
Extra :列属性:扩充(额外的),描述不下了,就写在这里面
修改数据表
表本身存在,还包含字段;标的修改为两个部分:修改表本身和修改字段
修改表本身:表本身可以修改:表名和表选项
-- 修改表名格式:
-- 格式:
rename table 老表名 to 新表名;
-- eg:
rename table haha to myhaha;

-- 修改表选项:字符集,校对集和存储引擎
-- 格式:
alter table 表名 表选项 [=] 值;
-- eg:
-- 修改表Option:字符集
alter table myhaha charset = GBK;
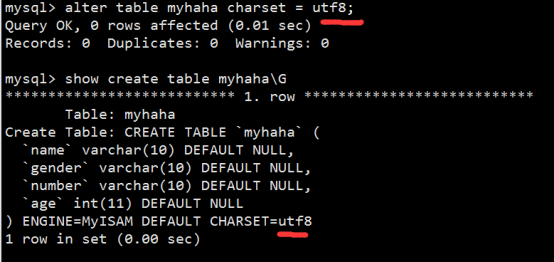
修改字段:字段操作很多(新增、修改、重名、删除)
新增字段:
-- 格式:
alter table 表名 add [column] 字段名 数据类型 [列属性] [位置];
-- 位置:字段名可以存放表中的任意位置
-- first:第一个位置
-- after:在哪个字段之后
-- 格式:after 字段名;(默认的是在最后一个字段之后)
-- eg:
-- 给student表增加ID放在第一位置
alter table student
add column ID int
first;

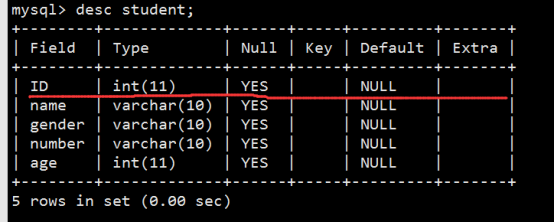
说明:mysql会自动寻找分号,分号就代表语句结束符。
修改字段:修改通常是修改属性或者数据类型
-- 格式:
alter table 表名 modify 字段名 数据类型 [属性] [位置];
-- 位置:字段名可以存放表中的任意位置
-- first:第一个位置
-- after:在哪个字段之后
-- 格式:after 字段名;(默认的是在最后一个字段之后)
-- eg:
-- 将student表中的number字段变成固定长度,且放到第二位(ID之后)
alter table student
modify number char(10)
after ID;
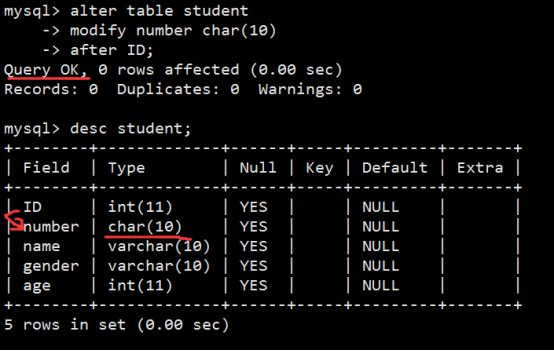
重命名字段:
-- 格式:
alter table 表名 change 旧字段名 新字段名 [属性] [位置];
-- 位置:字段名可以存放表中的任意位置
-- first:第一个位置
-- after:在哪个字段之后
-- 格式:after 字段名;(默认的是在最后一个字段之后)
-- eg:
-- 将student表中gender字段名修改为sex字段名
alter table student
change gender sex varchar(10);
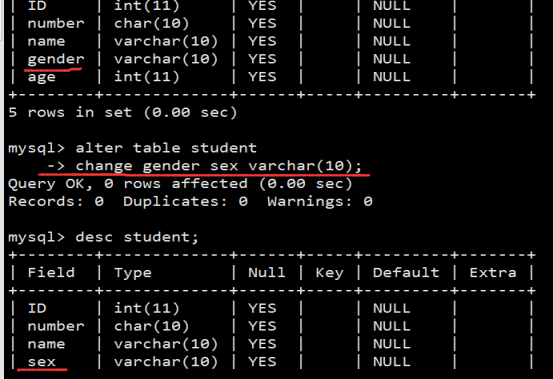
删除字段:
-- 格式:
alter table 表名 drop字段名;
-- eg:
-- 将student表中age字段删除
alter table student drop age;
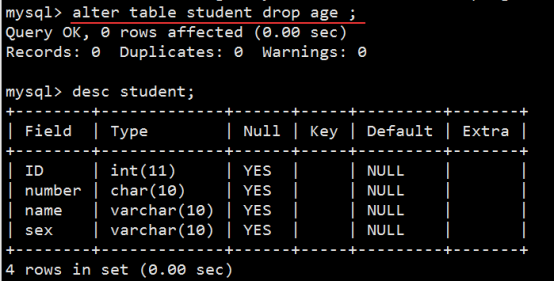
Notice:切记需小心处理;如果表中已经存在数据,那么删除字段会清空改字段的所有数据(不可逆的)
删除数据表
-- 格式:
drop table 表名1,表名2……; -- 可以一次性删除多张表

当删除数据表的指令执行之后发生了什么?
1、在表空间中,没有了指定的表(数据也没有了)
2、在数据库对应的文件夹下,表对应的文件(与存储引擎有关)也会被删除
Notice:删除有危险,操作需谨慎(不可逆)
复制表
参考:https://blog.csdn.net/cuiruidu3106/article/details/100438940
第一种:
(不能复制表结构,而且如果被复制的表数据很多,那么需要用where或者limit限制条数,否则会卡死)
create table DBName.NewTbale as select * from DBName.TablesName [where|limit];
二、逻辑导出:
1、mysqldump逻辑导出
mysqldump -h$host -P$port -u$user --add-locks=0 --no-create-info --single-transaction --set-gtid-purged=off test01 t2 --where='c1>4' --result-file=/mysql/backup/t2.sql
-- single-transaction
不需要对t2进行加锁,而是使用start transaction with consistent snapshop的方法
--add-locks=0
表示在输出的的文件结果里,不增加"lock tbales t2 write"
--no-create-info
不需要导出表结构
-set-gtid-purged=off
不导出gtid相关信息
--result-file
指定导出文件的路径
2、导出csv文件
创建t3表结构
create table t3 like t2;
导出需要导出t2的数据
select * from t2 where c1>4 into outfile '/mysql/backup/t2.csv';
将csv文件导入到t3
load data infile '/mysql/backup/t2.csv' into table test01.t3;
三、物理拷贝的方法
1、创建t3表结构 最常用(可以复制表结构)
create table t3 like t2;
2、执行alter table t3 discard tablespace;此时t3.ibd会被删除
3、执行flush table t2 for export;此时test01目录下会生成一个t2.cfg文件
4、拷贝t2.ibd,t2.cfg,注意权限
cp t2.cfg t3.cfg
cp t2.ibd t3.ibd
5、unlock tables,这时候t2.cfg会被删除
6、执行alter table t3 import tablespace;将t3.ibd作为t3新的表空间,数据和t2也是相同的
总结:
1、对于大表,物理拷贝方法最快,对于误删表的情况,比较有用,但是也存在一定的弊端:
-
必须是全表拷贝;
-
必须能连服务器;
-
源表和目标表都必须是innodb存储引擎。
2、mysqldump方法可以生成insert的语句,可以加过滤条件拷贝部分数据,但是不能使用join这种比较复杂的条件。
3、select .... into outfile的方法最灵活,但是缺点是每次只能导出一张表。
数据操作(重点)
新增数据(有4种方案)
方案一:给全表字段插入数据,不需要指定字段列表,但是要求数据的值出现的顺序必须与表中设计的字段出现的顺序一致;凡是非数值数据,都需要使用引号(建议是单引号)包囊
格式:
insert into 表名 values(值列表)[,(值列表)]; -- 可以一次性插入多条记录
-- eg:
insert into student values(1,'itcast0001','Jim','male'),
(2,'itcast0002','Haha','female');

方案二:给部分字段插入数据,需要选定字段列表:字段列表出现的顺序与字段的顺序无关;但是值列表的顺序必须与选定的字段的顺序一致
格式:
insert into 表名 字段列表 values(值列表)[,(值列表)];
-- eg:
-- 插入数据:指定字段列表
insert into student (number,sex,name,ID) values
('itcast0003','male','Tom',3),
('itcast0004','female','Lily',4);
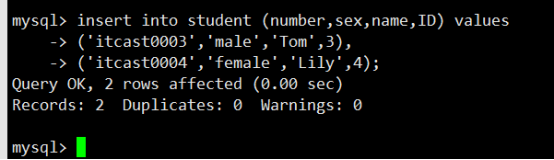
参考:https://www.cnblogs.com/stevin-john/p/4768904.html
INSERT IGNORE与INSERT INTO的区别
INSERT IGNORE会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
-- eg:
insert ignore into table(name) select name from table2
mysql中常用的三种插入数据的语句:
insert into表示插入数据,数据库会检查主键(PrimaryKey),如果出现重复会报错
replace into表示插入替换数据,需求表中有PrimaryKey,或者unique索引的话,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;REPLACE语句会返回一个数,来指示受影响的行的数目。该数是被删除和被插入的行数的和。如果对于一个单行REPLACE该数为1,则一行被插入,同时没有行被删除。如果该数大于1,则在新行被插入前,有一个或多个旧行被删除。如果表包含多个唯一索引,并且新行复制了在不同的唯一索引中的不同旧行的值,则有可能是一个单一行替换了多个旧行。
insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据;
方案三:利用set插入数据(set只能插入一行数据)
-- eg:
mysql> insert into haha set id=2,age=2;
Query OK, 1 row affected (0.04 sec)
mysql> select * from haha;
+------+------+
| id | age |
+------+------+
| 1 | NULL |
| 2 | 2 |
+------+------+
2 rows in set (0.00 sec)
说明:除数字都需要用单引号囊括。
方案4: 蠕虫复制(数据是指数幂的增长,控制好复制的次数,否则会卡死)
insert into tablesName select * from DBname.tablesName;
查看数据
格式:
select */字段列表 from 表名 [where 条件];
-- eg:查看所有数据:
select * from student;
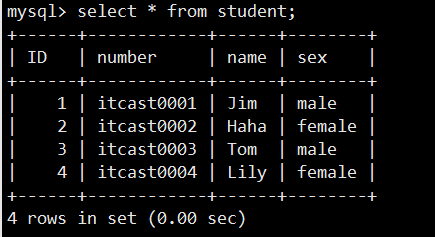
查看指定数据,指定条件数据:
-- eg:
select ID,number,name,sex from student where ID = 1; -- 查看满足ID为1的学生信息
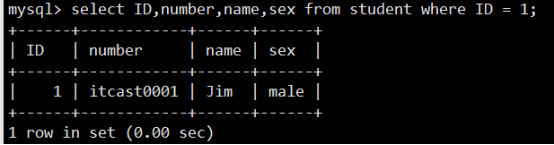
更新数据
格式:
update 表名 set 字段 = 值 [where 条件]; -- 建议都有where条件,要不然是更新全部数据
-- eg:
update student set sex = 'female' where name = 'jim';

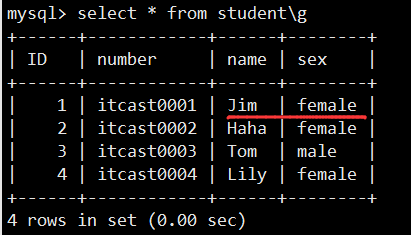
说明:更新不一定会成功,如果没有真正要更新的数据
删除数据
删除是不可逆的,谨慎操作
删除表信息的方式有两种 :
truncate table table_name;
delete * from table_name;
注 : truncate操作中的table可以省略,delete操作中的可以省略
truncate、delete 清空表数据的区别 :
1> truncate 是整体删除 (速度较快),delete是逐条删除 (速度较慢)
2> truncate 不写服务器 log,delete 写服务器 log,也就是 truncate 效率比 delete高的原因
3> truncate 不激活trigger (触发器),但是会重置Identity (标识列、自增字段),相当于自增列会被置为初始值,又重新从1开始记录,而不是接着原来的 ID数。而 delete 删除以后,identity 依旧是接着被删除的最近的那一条记录ID加1后进行记录。如果只需删除表中的部分记录,只能使用 DELETE语句配合 where条件
格式:
delete from 表名 [where 条件];
delete from 表名 limit number ;
-- eg:
delete from student where sex = 'male';
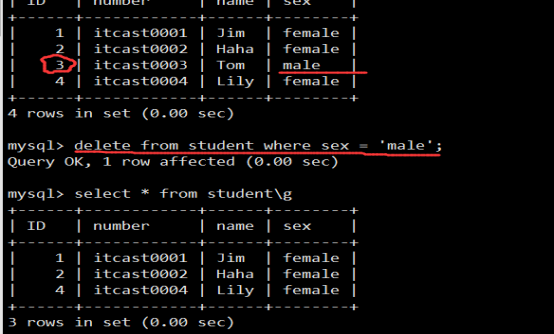
查看数据库的数据大小
-- 查看库中有多少张表
SELECT COUNT(*) TABLES, table_schema FROM information_schema.TABLES WHERE table_schema = 'testbatch';
1、查询所有数据库占用磁盘空间大小
select
TABLE_SCHEMA,
concat(truncate(sum(data_length)/1024/1024,2),' MB') as data_size,
concat(truncate(sum(index_length)/1024/1024,2),'MB') as index_size
from information_schema.tables
group by TABLE_SCHEMA
ORDER BY data_size desc;
2、查询单个库中所有表磁盘占用大小
select
TABLE_NAME,
concat(truncate(data_length/1024/1024,2),' MB') as data_size,
concat(truncate(index_length/1024/1024,2),' MB') as index_size
from information_schema.tables
where TABLE_SCHEMA = 'you DB name'
group by TABLE_NAME
order by data_length desc;

3、使用optimize命令
optimize table tb_report_inventory;
使用的时间比较长,需要耐心等待。
innodb与myisam
如何选择合适的存储引擎:
- 并发量、缓存池中的命中率
不同的存储引擎都有各自的特点,以适应不同的需求,如下表所示:
| 功 能 | MYISAM | Memory | InnoDB | Archive |
|---|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB | None |
| 支持事物 | No | No | Yes | No |
| 支持全文索引 | Yes | No | No | No |
| 支持数索引 | Yes | Yes | Yes | No |
| 支持哈希索引 | No | Yes | No | No |
| 支持数据缓存 | No | N/A | Yes | No |
| 支持外键 | No | No | Yes | No |
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择;当高并发是,缓存池中的命中率高时,就选择inodb
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
数据库中存在若干表,而表与表之间、库与库之间存在很多关系链接;而如果更加利用表的存储->存储引擎
存储引擎:合理的管理表用于存储和组织信息的数据结构
mysql的存储引擎的分类:
eg:mysql现在已提供什么存储引擎:
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| CSV | YES | CSV storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
8 rows in set (0.00 sec)
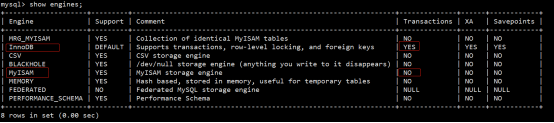
eg:mysql现在已提供什么存储引擎:
mysql> show global variables like '%engine%';
+---------------------------+--------+
| Variable_name | Value |
+---------------------------+--------+
| default_storage_engine | InnoDB |
| engine_condition_pushdown | ON |
| storage_engine | InnoDB |
+---------------------------+--------+
3 rows in set (0.00 sec)
eg:查看innodb的参数设置情况
mysql> show global variables like '%innodb%';
MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。MyISAM主要特性有:
1、大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持
2、当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成
3、每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
4、最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上
5、BLOB和TEXT列可以被索引
6、NULL被允许在索引的列中,这个值占每个键的0\~1个字节
7、所有数字键值以高字节优先被存储以允许一个更高的索引压缩
8、每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快
9、可以把数据文件和索引文件放在不同目录
10、每个字符列可以有不同的字符集
11、有VARCHAR的表可以固定或动态记录长度
12、VARCHAR和CHAR列可以多达64KB
13、使用MyISAM引擎创建数据库,将产生3个文件。
文件的名字以表名字开始,
扩展名之处文件类型:frm文件存储表定义
数据文件的扩展名为.MYD(MYData)
索引文件的扩展名时.MYI(MYIndex)
14、myisam的表支持3中存储格式
静态(固定长度)表
动态表
压缩表
15、myisam仅仅只支持表级锁
myisam不支持高并发[锁的层级化较高]
16、不支持外键、外键约束等关联
InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键, InnoDB是默认的MySQL引擎。InnoDB主要特性有:
1、InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
2、InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
3、InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上
4、InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
5、InnoDB被用在众多需要高性能的大型数据库站点上
InnoDB不创建目录,使用InnoDB时,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为ib_logfile0和ib_logfile1的5MB大小的日志文件
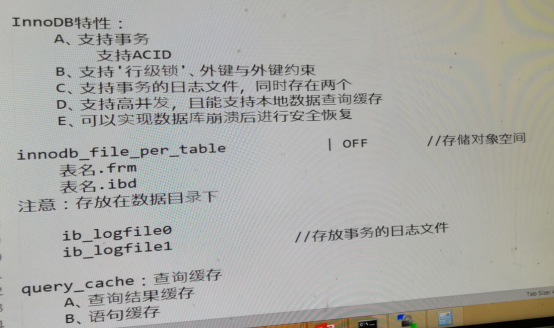
查看表使用的存储引擎,三种方法:
-- a
show table status from db_name where name='table_name';
-- eg:查看mysql.user表的存储引擎
mysql> show table status from mysql where name='user'\G
*************************** 1. row ***************************
Name: user -- 表名
Engine: MyISAM -- 存储引擎
Version: 10 -- 存储引擎版本
Row_format: Dynamic -- 行格式
Rows: 8 -- 表中的行数
Avg_row_length: 90 -- 平均每行包含的字节数
Data_length: 720 -- 数据总大小;单位:字节数
Max_data_length: 281474976710655 -- 一条数据支持的最大字节;0:表示无上限
Index_length: 2048 -- 索引大小,0:代表未设置大小
Data_free: 0 -- 表示尚未分配使用的空间
Auto_increment: NULL -- 是否设置自增值
Create_time: 2019-04-01 16:47:36 -- 创建表的时间
Update_time: 2019-04-14 05:38:05 -- 最近一次修改表数据的时间
Check_time: NULL -- 使用check table检查表
Collation: utf8_bin -- 字符编码排列规则
Checksum: NULL -- 启动表的校验
Create_options: -- 创建表时,指定的其他选项
Comment: Users and global privileges -- 表的注释信息
1 row in set (0.00 sec)
eg:检查mysql.user表
mysql> check table user;
+------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------+-------+----------+----------+
| mysql.user | check | status | OK |
+------------+-------+----------+----------+
1 row in set (0.00 sec)
b、show create table table_name;
c、进入数据库:
mysql> show table status\G
ps:如果显示的格式不好看,可以用\G代替行尾分号
有人说用第二种方法不准确,我试了下,关闭掉原先默认的Innodb引擎后根本无法执行show create table table_name指令,因为之前建的是Innodb表,关掉后默认用MyISAM引擎,导致Innodb表数据无法被正确读取。
中文数据问题->字符集1
中文数据问题本质是字符集问题;计算机只识别二进制,人类更多是识别符号,需要有个二进制与符号的对应关系(字符集)



-- 查看服务器到底识别哪些字符集:
show character set;
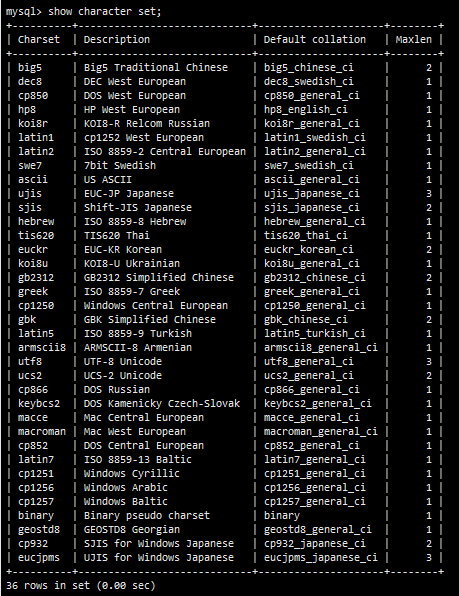
基本上:服务器是万能的,什么字符集都支持
-- 查看服务器默认的对外处理的字符集
show variables like 'character_set%';
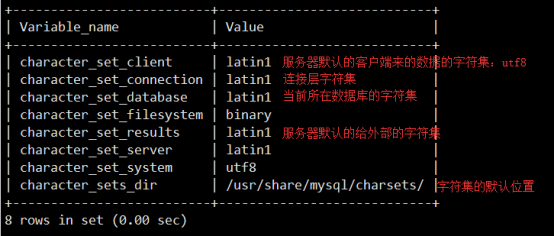
问题根源:客户端数据只能是GBK,而服务器认为是UTF8,矛盾产生
解决方案:改变服务器,默认的接受字符集为GBK;
-- 修改服务器认为的客户端数据的字符集为GBK
set character_set_client = gbk;
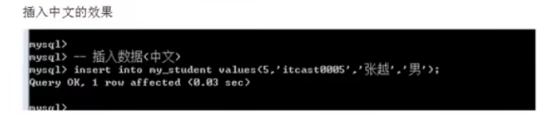
查看效果:出现乱码

原因:数据来源是服务器,解析数据是客户端(客户端只识别GBK:只会两个字节是一个汉字),但是事实服务器给的数据却是utf8:三个字节是一个汉字,结果乱码。
解决方案:修改服务器给客户端的数据字符集为gbk
set character_set_results = gbk
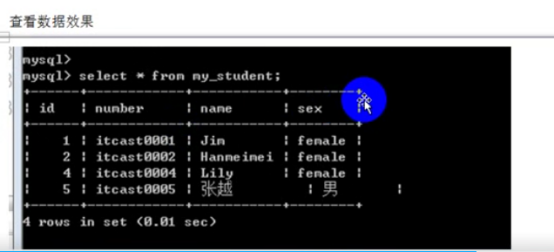
说明:set 变量 = 值; -- 修改只是会话级别(当前客户端,当次连接有效,关闭失效)
设置服务器对客户端的字符集的认识,可以使用快捷方式:
set names 字符集;
set names gbk; -- 就是等于character_set_client,character_set_results,character_set_connection
character_set_connection表示connection连接层:是字符集转变的中间者,如果统一了效率更高,不统一也没有问题
字符集2
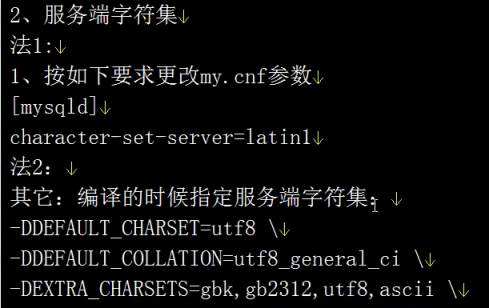
修改字符集:
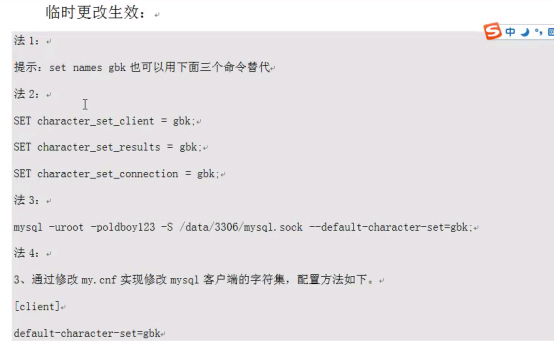
注意:多实例此步骤字符集的修改/etc/my.cnf

下面模拟将Latin1字符集的数据看修改成utf8字符集的实际过程(包括之前的数据)
1.导出表结构
mysqldump -uroot -p --default-character-set=latin1 -d dbname > alltable.sql
-- --default-character-set=utf8表示以UTF8字符集进行连接 -d 只导表结构
2.编辑表结构语句alltable.sql将所有字符串改成utf8
3.确保数据库不在更新,导出所有数据(不带表结构)
mysqldump -uroot -p --quick --no-create-info --extended-insert --default-character-set=latin1 dbname > /dalldata.sql
参数说明:
--quick:用于转储大的表,强制mysqldump从服务器一次一行的检索数据而不是检索所有行,并输出前cache到内存中。--no-create-info:不创建create table语句--extend-insert:使用包括几个values列表的多行insert语法,这样文件更小,IO也小导入数据时会非常快- --default-character-set=latin1`按照原有字符集导出数据,这样导出的文件中,所有中文都是可见的,不会保存成乱码。
4.修改my.cnf配置调整客户端集服务端字符集,重启生效
5.通过utf8建库(可选)
删除原库,然后create database dnname default charset utf8;
6.导入表结构(更改过字符集的表结构)
7.导入数据
mysql -uroot -p dbname < alldata.sql
注意:选择目标字符集时,要注意最好大于等于源字符集(字库更大),否则可能会丢失不被支持的数据。
总结:

校对集问题
校对集:数据比较的方式
校对集有三种格式:
_bin:binary,二进制比较,取出二进制位,一位一位的比较,区分大小写_cs:case sensitive,大小写敏感,区分大小写_ci:case insensitive,大小写不敏感,不区分大小写
-- 查看数据库所支持的校对集
show collation;
由于有129种,就没有截图了。
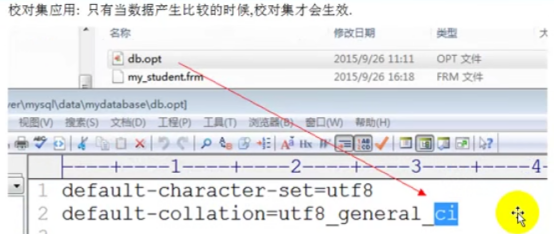
对比:使用utf8的_bin和_ci来验证不同的校对集的效果



校对集:必须在没有数据之前申明好,如果有了数据,那么在进行校对集修改,那么修改无效。
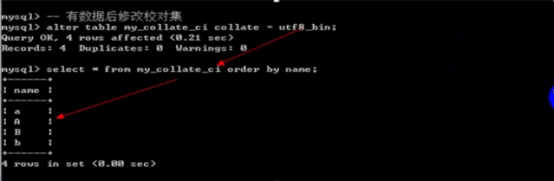
web乱码问题


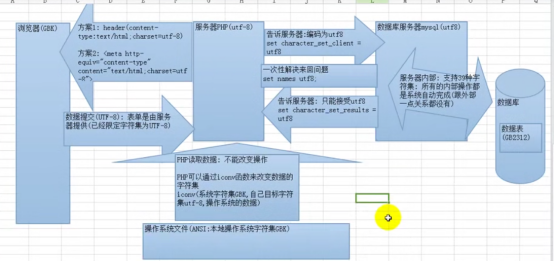
数据类型(列类型)
概述:
所谓的数据类型,对数据进行统一的分类,从系统的角度出发为了能够使用统一的方式进行管理,从而更好的利用有限的空间
SQL中将数据类型分成了3大类型:数值类型,字符串类型和时间日期类型
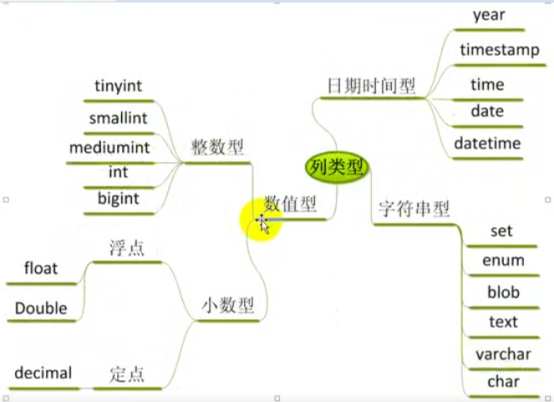
数值类型:
数值型数据:都是数值
系统将数值型分为整数型和小数型
整数类型

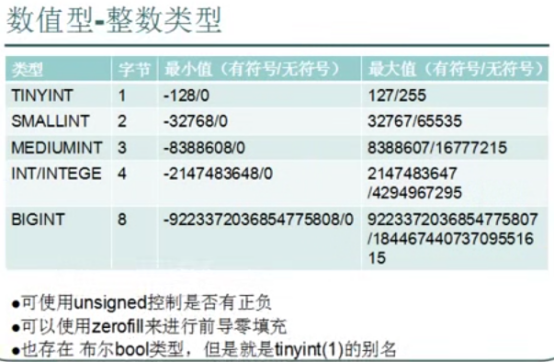
MYSQL保存BOOLEAN值时用1代表TRUE,0代表FALSE,boolean在MySQL里的类型为tinyint(1)
创建整型表
create table my_int(
int_1 tinyint,
int_2 smallint,
int_3 int,
int_4 bigint
)charset utf8;

插入数据:只能插入整型,只能插入范围内的整型
-- 插入数据
insert into my_int values (100,100,100,100); -- 有效数据
insert into my_int values ('a','b','199','f'); -- 无效数据,类型限定
insert into my_int values (255,10000,100000,1000000); -- 错误,超出范围
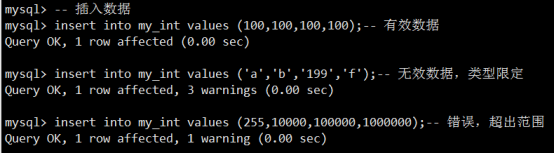

SQL中的数值类型全部都是默认有符号:分正负
有时候需要使用无符号数据,需要给数据类型限定:
int unsigned; -- 无符号,是从0开始

给表增加一个无符号类型
alter table my_int add int_5 tinyint unsigned; -- 无符号类型
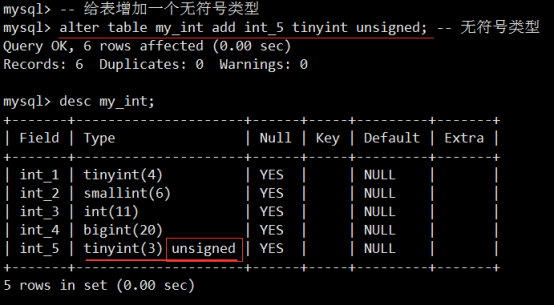
查看表结构的时候,发现每个字段的数据类型之后都会自带一个括号,里面有指定的数字
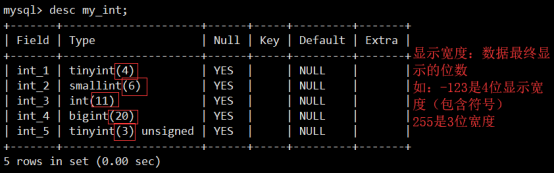
指定显示宽度为1
alter table my_int add int_6 tinyint(1) unsigned;
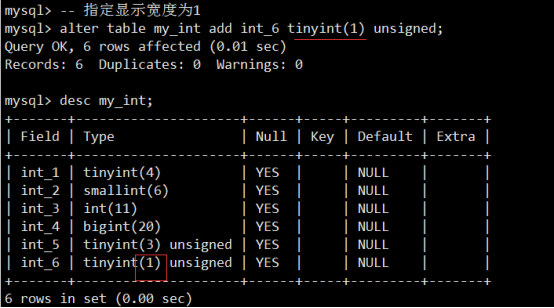
说明:显示宽度,没有特别的含义,只是默认的告诉用户可以显示的形式而已;实际上用户是可以自己控制的,这种控制不会改变数据本身的大小
显示宽度的意思:在于当数据不够显示宽度的时候,会自动让数据变成对应的显示宽度,通常需要搭配一个前导0来增加宽度,不改变大小,zerofill(零填充)
-- 显示宽度为2,0填充
alter table my_int add int_7 tinyint(2) zerofill;
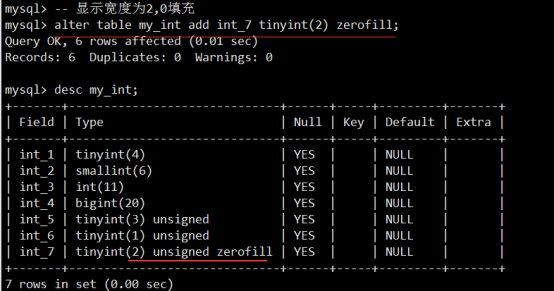
零填充+显示宽度的效果

零填充的意义(显示宽度):保证数据格式
例如:在登陆界面时,我们选择日期时,年月日下拉菜单的长度都是一致的。
小数类型

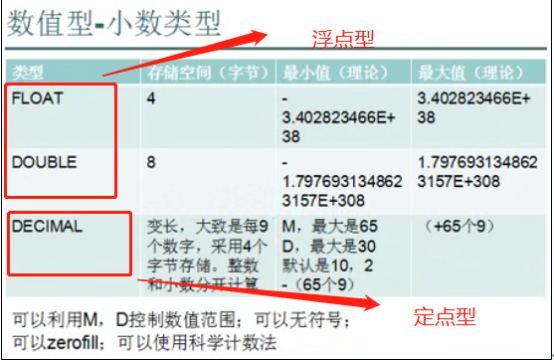

decimal(18,4)同decimal(19,1)之间的区别:
精度不同,一个是小数点后面精确4位,一个是精确1位
注意的是:decimal(18,4)总长18位,包括1位小数点和4为小数,也就是说18-1-4=13整数位只有13位,decimal(19,1)总长19位,17位整数,1位小数
创建浮点数表:浮点的使用方式,直接float表示没有小数部分;float(M,D):M代表总长度,D代表小数部分长度,整数部分长度为M-D
创建浮点数表
-- 创建浮点数表
create table my_float(
f1 float,
f2 float(10,2), -- 10位在精度范围之外
f3 float(6,2) -- 6位在精度范围之内
)charset utf8;
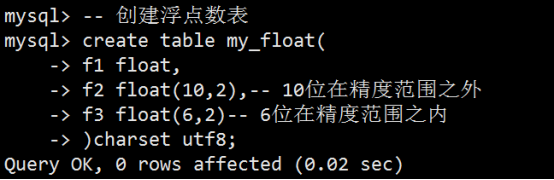
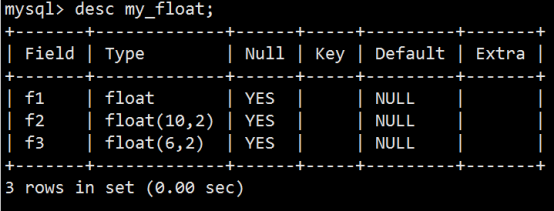
插入数据:可以直接是小数,也可以是科学计数法
-- 插入数据
insert into my_float values(1000.10,1000.10,1000.10); -- 符合条件
insert into my_float values(1234567890,12345678.90,1234.56); -- 符合条件
insert into my_float values(3e38,3.01e7,1234.56);
insert into my_float values(9999999999,99999999.99,9999.99); -- 最大值
浮点型整数的插入:整型部分是不能超出长度的,但是小数部分可以超出长度(系统会自动四舍五入的)
超出长度插入数据
-- 超出长度插入数据
insert into my_float values(123456,1234.12345678,123.9876543);-- 小数部分符合
insert into my_float values(123456,1234.12,12345678.56);-- 整数部分超出
结果:浮点数一定会进行四舍五入(超出精度范围),浮点数如果是因为系统进位导致整数部分超出指定的长度,那么系统也允许成立。
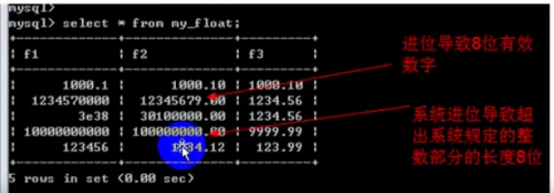
定点型:
定点型:绝对的保证整数部分不会被四舍五入(不会丢失精度),小数部分有可以丢失(理论小数部分也不会丢失精度)
创建定点型数据表:(以浮点数作为对比)
-- 创建定点型数据表:(以浮点数作为对比)
create table my_decimal(
f1 float(10,2),
f2 decimal(10,2)
)charset utf8;
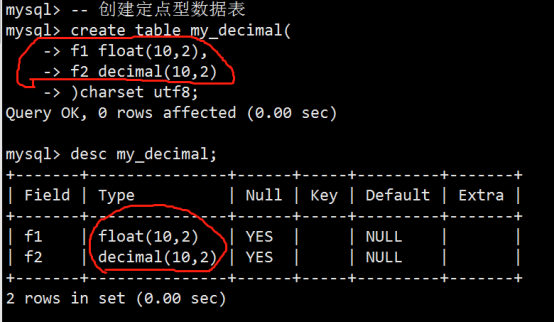
插入数据:定点数的整数部分一定不能超出长度(进位不可以),小数部分的长度可以随意超出(系统自动四舍五入)
-- 插入数据
insert into my_decimal values(12345678.90,12345678.90);-- 有效数据
insert into my_decimal values(1234.123456,1234.1234356);-- 小数部分超出范围
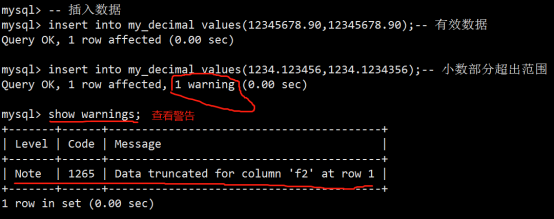
浮点数如果进位导致长度溢出没有问题,但是定点数不行
insert into my_decimal values(99999999.99,99999999.99);-- 没有问题
insert into my_decimal values(99999999.99,99999999.999);-- 进位超出范围

查看数据效果:
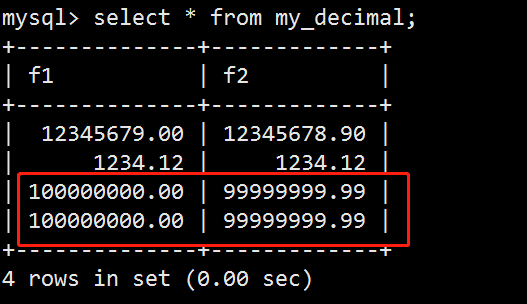
字符串类型:

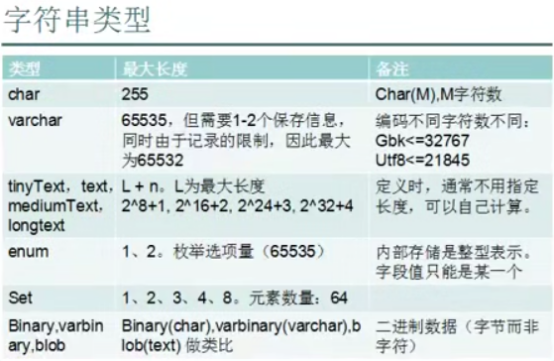
定长字符串

变长字符串
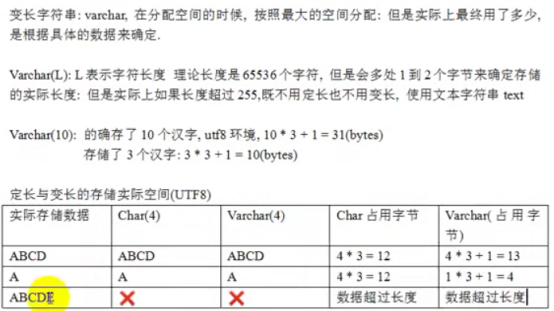

文件字符串

枚举字符串

创建枚举表:
-- 创建枚举表
create table my_enum(
gender enum('男','女','保密')
)charset utf8;
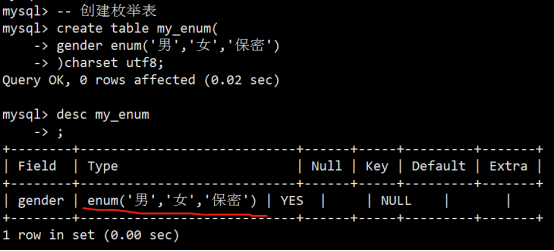
加入数据:作用之一;规范数据格式,数据只能是规定的数据中的其中一个
-- 插入数据
insert into my_enum values('男'),('保密');-- 有效数据
insert into my_enum values('male');-- 错误数据,没有该元素
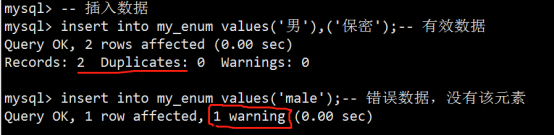

-- 将字段结果取出来进行+0运算
select gender + 0, gender from my_enum;


枚举的原理:

因为枚举实际存储的是数值,所以可以直接插入数值
-- 数值插入枚举元素
insert into my_enum values(1),(2);
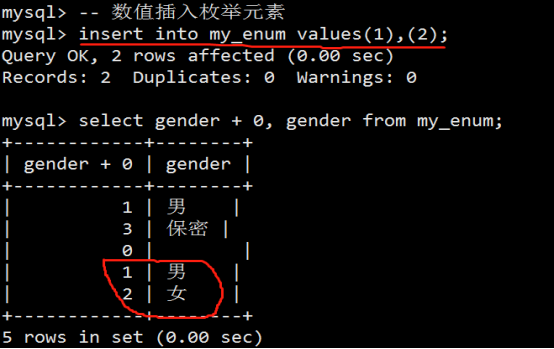
集合字符串



创建集合表:
-- 创建几何表
create table my_set(
hoboy set ('篮球','足球','乒乓球','羽毛球','排球','台球','网球','棒球')
)charset utf8;


插入数据并查看:
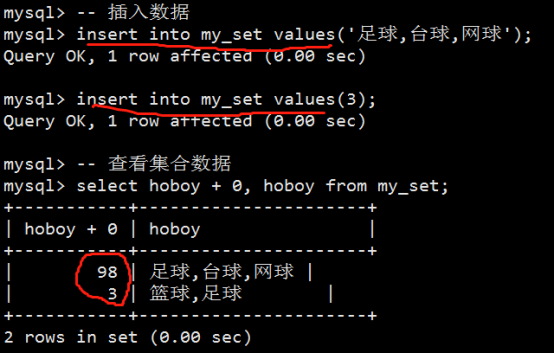
集合中每一个元素都是对应一个对应的二进制位
-- 创建几何表
create table my_set(
hoboy set ('篮球','足球','乒乓球','羽毛球','排球','台球','网球','棒球')
-- 足球 台球 网球
-- 集合中:每一个元素都是对应一个二进制位,被选中为1,没有则为0,最后反过来
-- 0 1 0 0 0 1 1 0
-- 反过来:01100010 = 98
)charset utf8;
-- 插入数据
insert into my_set values('足球,台球,网球');
insert into my_set values(3);
-- 查看集合数据
select hoboy + 0, hoboy from my_set;
-- 98转成二进制 = 64 + 32 + 2 = 01100010

集合中元素的顺序没有关系,最后系统都会去匹配顺序


时间日期类型


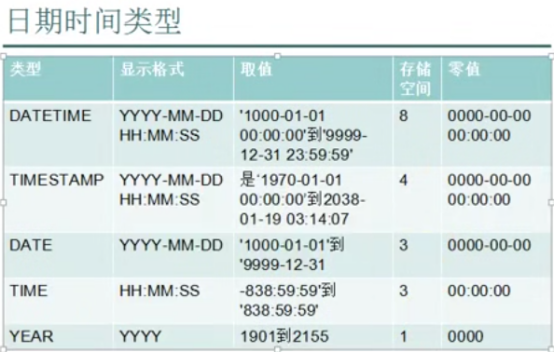
-- 创建时间日期表
create table my_date(
d1 datetime,
d2 date,
d3 time,
d4 timestamp,
d5 year
)charset utf8;
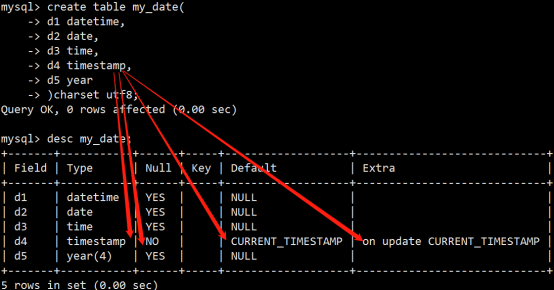
插入数据:时间time可以是负数,而且可以是很大的负数,year可以使用2位数插入,也可以使用4位数数
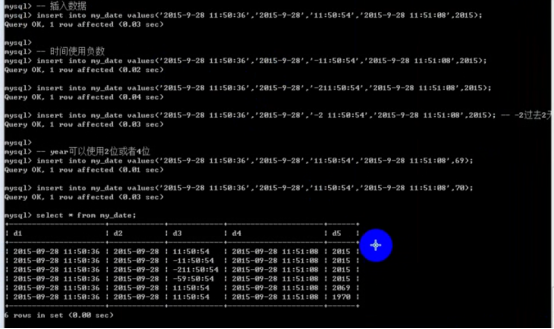
timestamp字段:只要当前所在的记录被更新,该字段一定会自动更新成当前时间
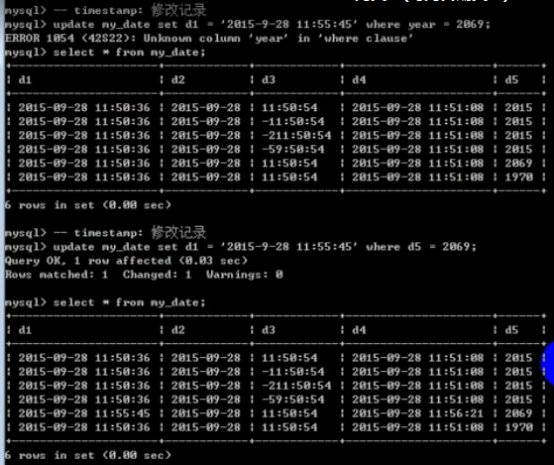
网站是以PHP为实现的主要操作对象:PHP中有非常强大的时间日期处理函数:date,只需要一个时间戳就可以转换成任意类型的时间;以PHP为主的时候,都是在数据库使用时间戳(整型)来存储时间
MySQL记录长度
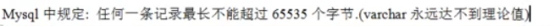
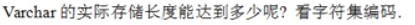

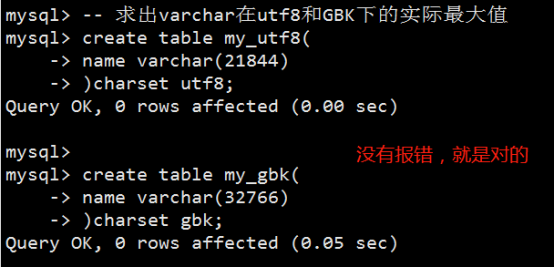




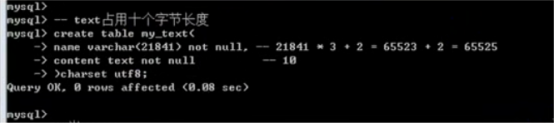
索引



PRI主键约束;
UNI唯一约束;
MUL可以重复
https://www.cnblogs.com/luyucheng/p/6289714.html
MySQL目前主要有以下几种索引类型:
-
普通索引
-
唯一索引
-
主键索引
-
组合索引
-
全文索引
语句
CREATE TABLE table_name[col_name data type][unique|fulltext][index|key][index_name](col_name[length])[asc|desc]
unique|fulltext为可选参数,分别表示唯一索引、全文索引index和key为同义词,两者作用相同,用来指定创建索引col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择index_name指定索引的名称,为可选参数,如果不指定,默认col_name为索引值length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度asc或desc指定升序或降序的索引值存储
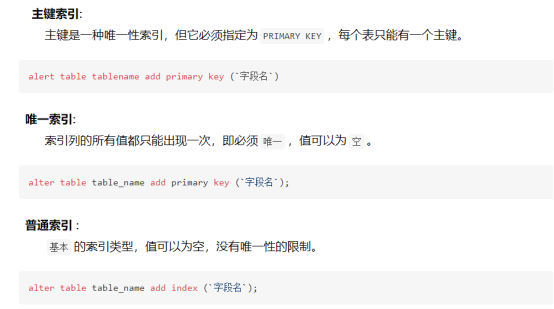
alter table table_name add index index_name (column_list) ;
alter table table_name add unique (column_list) ;
alter table table_name add primary key (column_list) ;
其中包括普通索引、UNIQUE索引和PRIMARY KEY索引3种创建索引的格式,table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以同时创建多个索引。
何时使用聚集索引或非聚集索引?
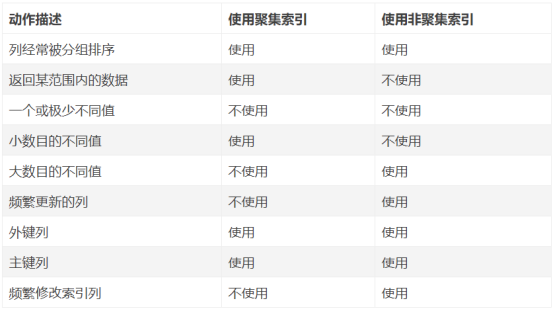
列属性
https://dev.mysql.com/doc/refman/5.7/en/show-columns.html
列属性:真正的约束字段的是数据类型,但是数据类型的约束很单一,需要有一些额外的约束,来更加保证数据的合法性。
列属性有很多:null/not null、default、primary key、unique key、auto_increment、comment
空/非空属性null/not null
两个值:null(默认的)和not null(不为空)
虽然默认的,数据库基本都是字段为空,但是实际上在真实开发的时候,尽可能的要保证所有的数据都不应该为空->空数据没有意义;空数据没有办法参与运算

创建一个实际案列表:班级表(名字:教师)
-- 创建班级表
create table my_class(
name varchar(20) not null,
room varchar(20) null -- 代表允许为空:不写默认就是允许为空
)charset utf8;
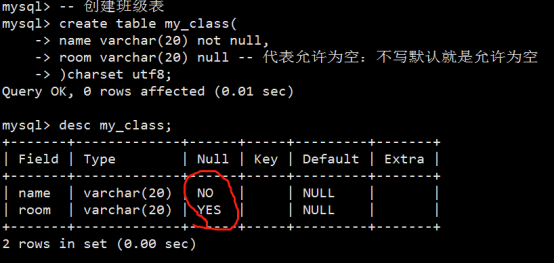
列描述comment
列描述:comment,描述,没有实际含义:是专门用来描述字段,会根据表创建语句保存->用来给程序猿(数据管理员)来进行了解的。
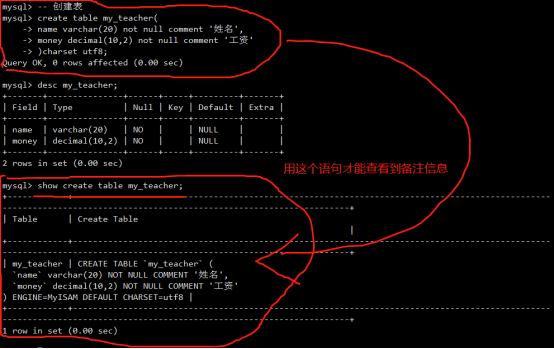
默认值default
默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候,用户可以选择性的使用默认值。
-- 默认值
create table my_default(
name varchar(20) not null,
age tinyint unsigned default 0,
gender enum('男','女','保密') default '男'
)charset utf8;
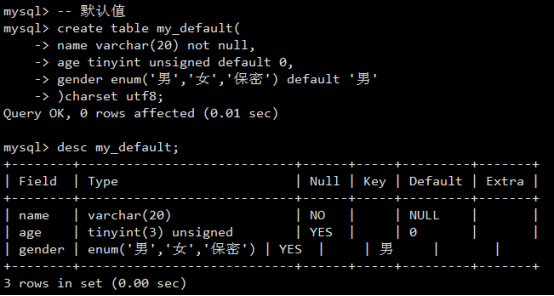
默认值得生效:使用在数据进行插入的时候,不给该字段赋值
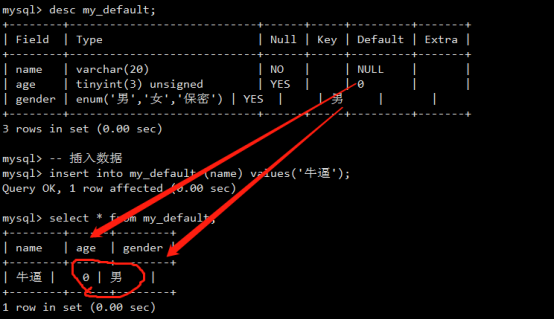
想要使用默认值,可以不一定去指定列表,故意不使用字段列表:可以使用default关键字代替值
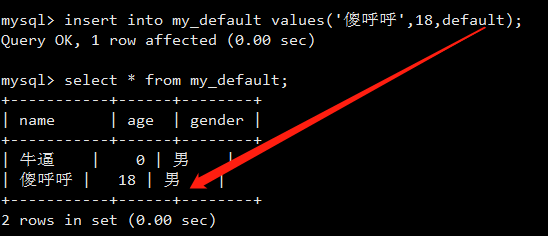
字段属性之主键
增加主键primary key
主键:primary key,主要的键,一张表只能有一个字段可以使用对应的键,用来唯一的约束该字段里面的数据,不能重复;这种称之为主键
一张表只能有最多一个主键
增加主键
SQL操作中有多种方式可以给表增加主键:大体分为3种
方案1:
-- 增加主键
create table my_pri1(
name varchar(20) not null comment '姓名',
number char(10) primary key comment '学号: itcast + 0000, 不能重复'
)charset utf8;
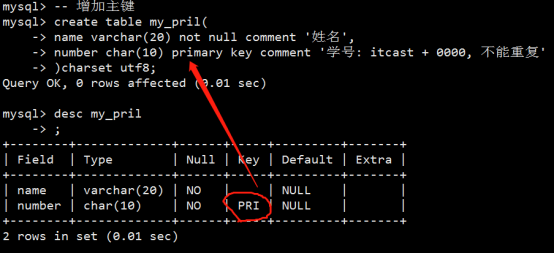
优点:非常直接;确定:只能使用一个字段作为主键
说明:comment->描述、注释
方案2:
在创建表的时候,在所有的字段之后,使用primary key(主键字段列表)来创建主键(如果有多个字段作为主键,可以是复合主键)
-- 复合主键
create table my_pri2(
number char(10) comment '学号:itcast + 0000',
course char(10) comment '课程代码:1807 + 0000',
score tinyint unsigned default 60 comment '成绩',
-- 增加主键限制:学号和课程号应该是个对应的,具有唯一性
primary key(number,course)
)charset utf8;
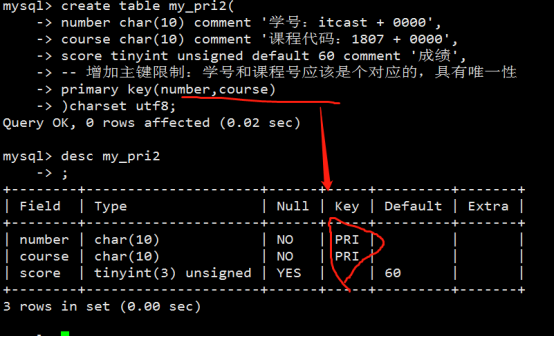
方案3:
当表已经创建好之后,额外追加主键:可以通过修改表字段属性,也可以直接追加
格式:
alter table 表名 add primary key(字段列表);
-- 先创建表
create table my_pri3(
course char(10) not null comment '课程编号:1807 + 0000',
name varchar(10) not null comment '课程名称'
)charset utf8;
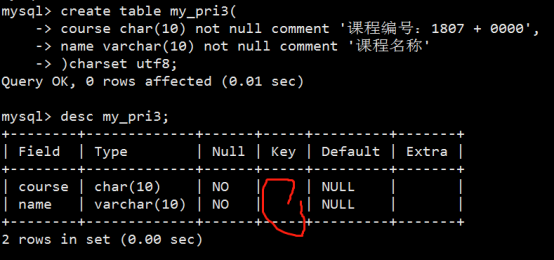
alter table my_pri3 add primary key(course);

前提:表中字段对应的数据本身是独立的(不重复)
主键约束
主键对应的字段中的数据不允许重复:一旦重复,数据操作失败(增和改)
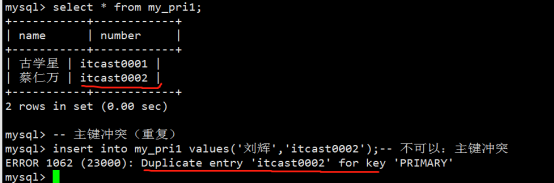
更新主键 & 删除主键
没有办法更新主键;主键必须先删除,才能增加。
格式:
alter table 表名 drop primary key;
-- eg:
-- 删除主键
alter table my_pri1 drop primary key;
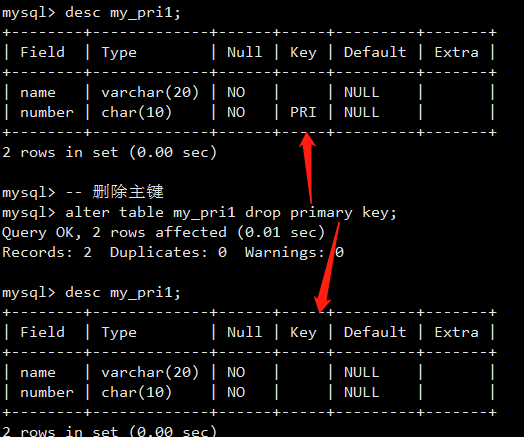
主键分类
在实际创建表的过程中,很少使用真实业务数据作为主键字段(业务主键,如学号、课程号);大部分的时候是使用逻辑性的字段(字段没有业务含义,值是什么都没有关系),将这种字段主键称之为逻辑主键

字段属性之自动增长
自增长:当对应的字段,不给值,或者说给默认值。或者给null的时候,会自动的被系统触发,系统会从当前字段中已有的最大值在进行+1操作,得到一个新的在不同的字段
自增长通常是跟主键搭配
新增自增长auto_increment
1、任何一个字段要做自增长必须前提是本身是一个索引(key一栏有值)

2、自增长字段必须是数字(而且是整型)

3、一张表最多只能有一个自增长
-- eg:
-- 自动增长
create table my_auto(
id int primary key auto_increment comment '自动增长',
name varchar(10) not null
)charset utf8;
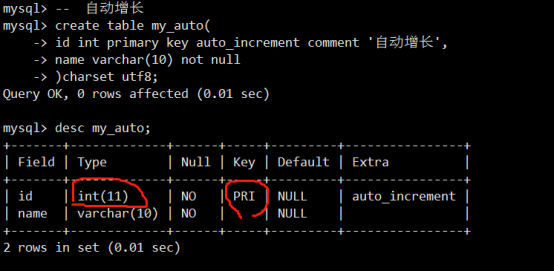
自增长的使用
当自增长被给定的值为null或者默认值的时候会触发自动增长
eg:
-- 触发自增长
insert into my_auto(name) values('哈哈');
insert into my_auto values(null,'嘎嘎');
insert into my_auto values(default,'嘻嘻');
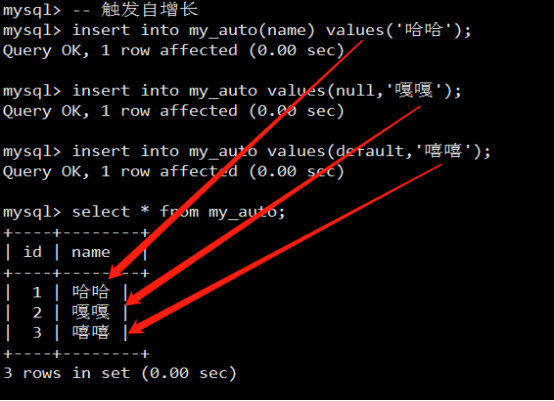
总结:
1、自增长的第一个元素默认是1
2、自增长每次都是自增1

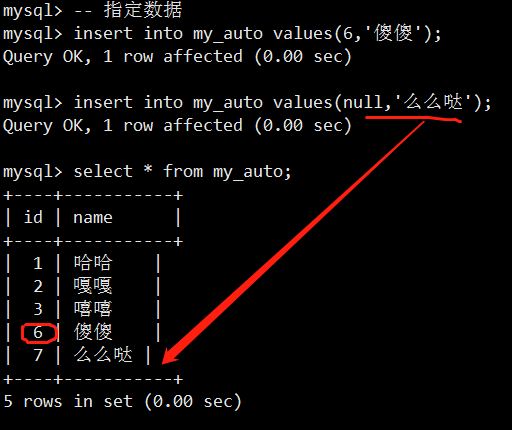
如何确定下一次是什么自增长呢?可以通过查看表创建语句看到
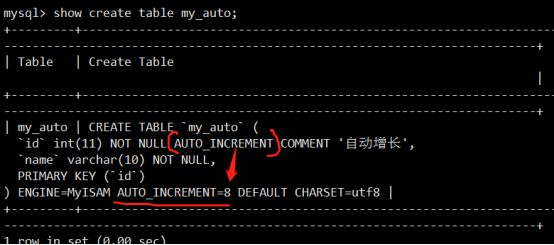
修改自增长
1自增长如果是涉及到字段改变:必须先删除自增长,后增加(一张表只能有一个自增长)
2、修改当前自增长已经存在的值:修改只能比当前已有的自增长的最大值大,不能小(小不会生效的)
格式:
alter table 表名 auto_increment = 值;
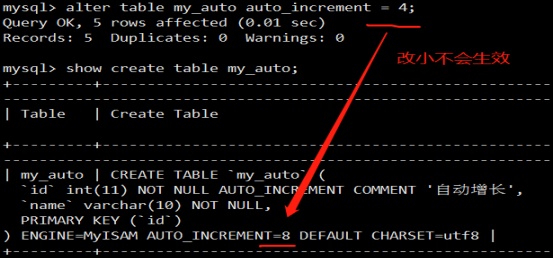
改大才能生效:
mysql> alter table my_auto auto_increment = 10;
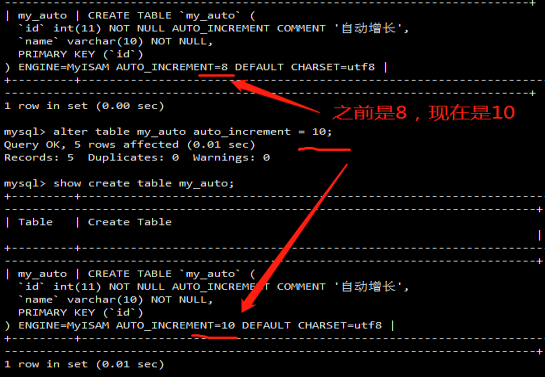
思考:为什么自增长是从1开始?为什么每次都是自增1呢?
所有系统的变现(如字符集、校对集)都是由系统内部的变量进行控制的
-- 查看自增长变量
show variables like 'auto_increment%';
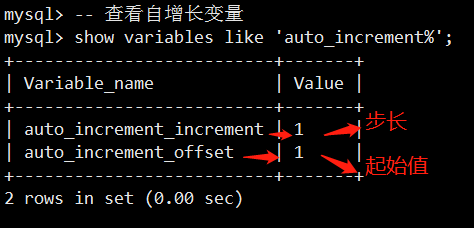
可以修改变量实现不同的效果:修改是对整个数据修改,而不是单张表:(修改是会话级)
格式:
-- 一次自增5
set auoto_increment_ increment = 5;
说明:这个变量没有必要修改。
删除自增长
自增长是字段的一个属性:可以通过modify来进行修改(保证字段没有auto_increment即可)
格式:
alter table 表名 modify 字段 类型;
eg:
-- 删除自增长(有主键的时候,千万不要再加主键)
alter table my_auto modify id int;
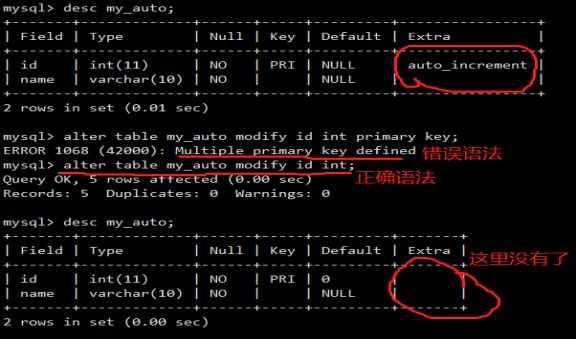
字段属性之唯一键


增加唯一键unique/unique key
方案1:在创建表的时候,字段之后直接跟unique/unique key
方案2:在所有的字段之后增加unique key(字段列表); -- 复合唯一键
方案3:在创建完表后,在添加唯一键
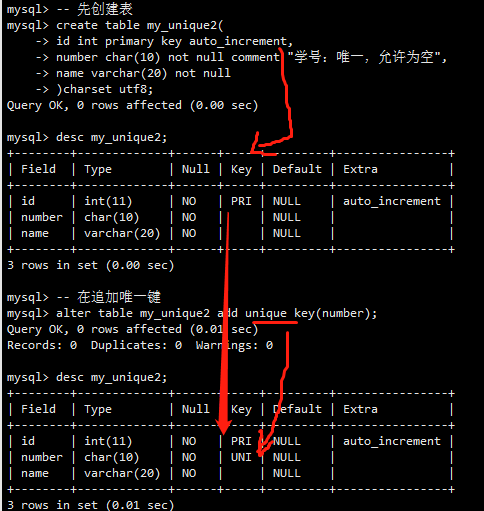
唯一键约束
唯一键与主键本质相同:唯一的区别就是唯一键默认允许为空,而且是多个为空
如果唯一键也不允许为空:与主键的约束作用是一致的。
更新唯一键 & 删除唯一键
更新唯一键:先删除后新增(唯一键可以有多个,可以不用删除)
删除唯一键:
alter table 表名 drop index 索引名;
唯一键默认的使用字段名作为索引名字。
eg:
-- 删除唯一键
alter table my_unique2 drop index number;
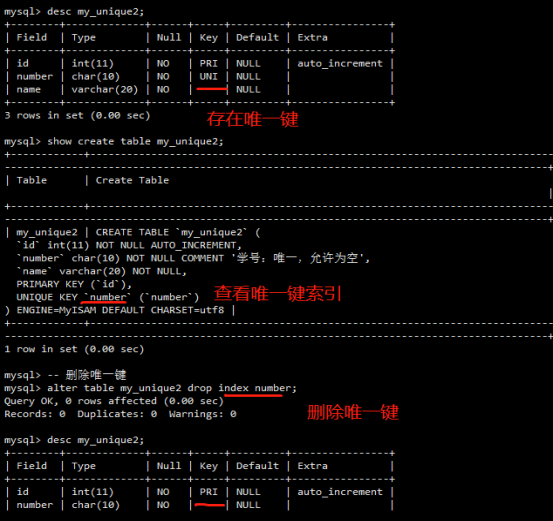
关系

一对一

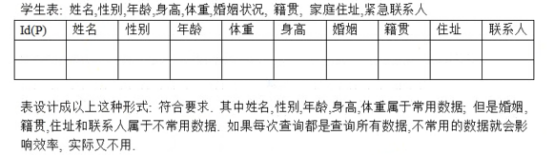
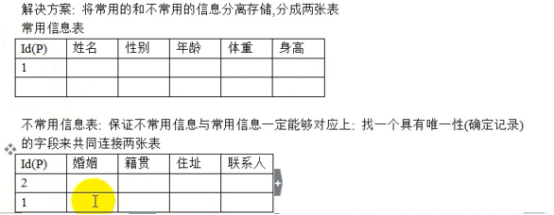

一对多

多对多

范式

1NF
第一范式要求字段的数据具有原子性(原子性就是不可再分)


2NF



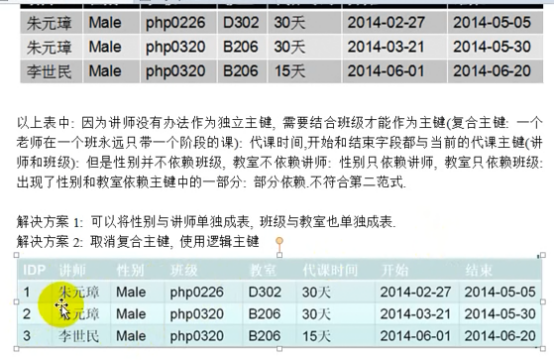
总结:只要永远不存在复合主键,就不存在部分依赖,就永远满足第二范式
3NF
要满足第三范式,必须满足第二范式,同时也必须满足第一范式
第三范式:理论上讲,应该一张表中的所有字段都应该直接依赖主键(逻辑主键除外,逻辑主键,代表的是业务主键),如果表设计中存在一个字段,并不直接依赖主键,而是通过某个非主键字段依赖,最终实现依赖主键:把这种不是直接依赖主键,而是依赖非主键字段的依赖关系称之为传递依赖。第三范式就是要解决传递依赖问题
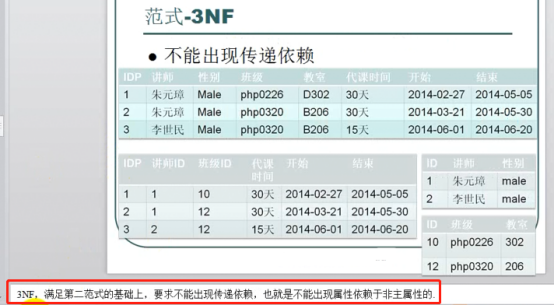

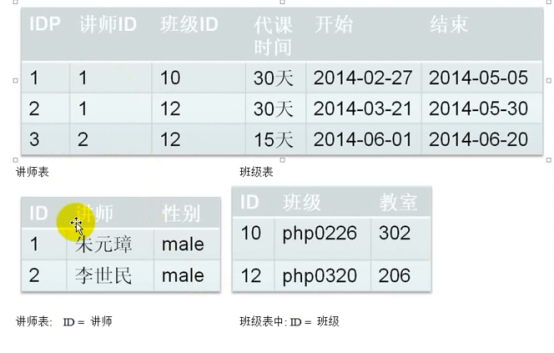
逆规范化
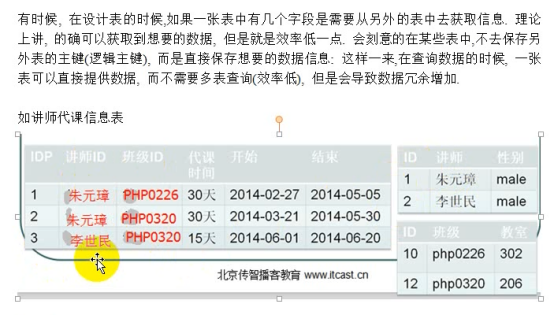
逆规范化:磁盘利用率与效率的对抗
注意:一般设计数据库时,就在第三范式这里;因此第三范式就要影响效率了。
数据高级操作
数据操作:增删改查
查询数据

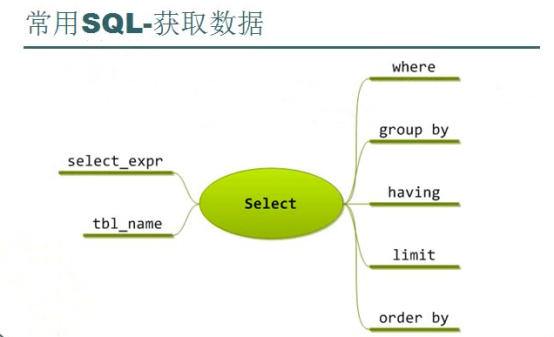
select选项
select 选项:select对查出来的结果的处理方式
all:默认的,保留所有的结果
distinct:去重,查出来的结果,将重复给去除(所有字段都相同才能去重)
SQL提供了一系列统计函数
count():统计分组后的记录数,每一组有多个记录
max():统计每组中最大的值
min():统计最小值
avg():统计平均值
sum():统计和
distinct:去重,查出来的结果,将重复给去除(所有字段都相同)

-- Eg:
-- select选项
-- 不去重
select * from Course;
select all * from Course;
-- 去重
select distinct * from Course;
-- 不去重
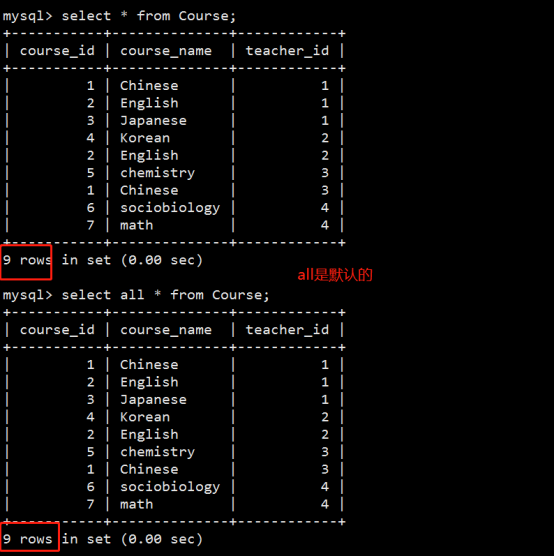
-- 去重
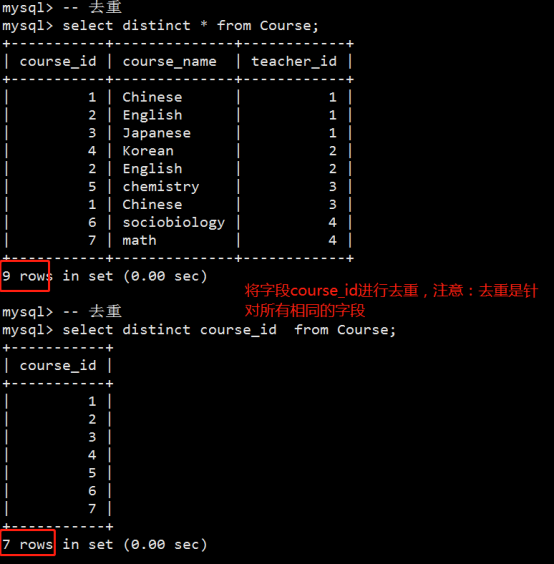
字段/表 别名(别名尽量还是用英文,提高查询速度)
- 字段别名:
当数据进行查询出来的时候,有时候名字并不一定满足需求(多表查询的是时候,会有同名字段,需要对字段名进行重命名->别名)
- 表别名:
查询数据时,如果表名很长,使用起来不方便,此时,就可以为表取一个别名,用这个别名来代替表的名称
-- 语法:
SELECT FROM 表名 [AS] 表别名;
注意,为表指定别名,AS关键字可以省略不写。
eg:


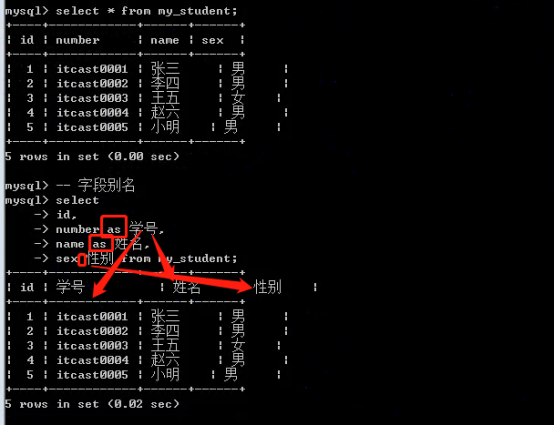
列别名(别名尽量还是用英文,提高查询速度)
在查询数据时,为了使显示的查询结果更加直观,可以为字段取一个别名
-- 语法:
SELECT 字段名 [AS] 别名 [,字段名 [AS] 别名,……] FROM 表名;
注意,为字段指定别名,AS关键字可以省略不写。
eg:
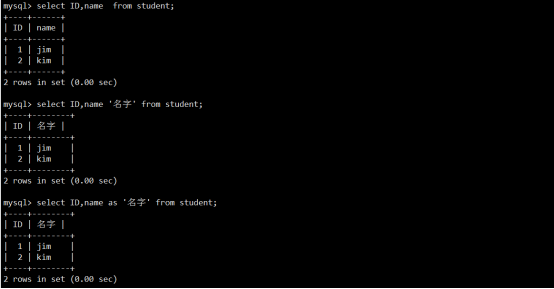
数据源
数据源:数据的来源,关系型数据库的来源都是数据表,本质上只要保证数据类似二维表,最终都可以作为数据源
数据源分为多种:单表数据源,多表数据源,查询语句
单表数据源:select from 表名;

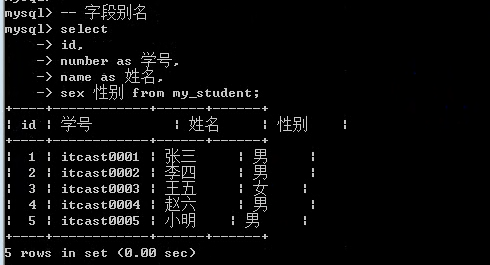
多表数据源:select from 表明1,表明2......;

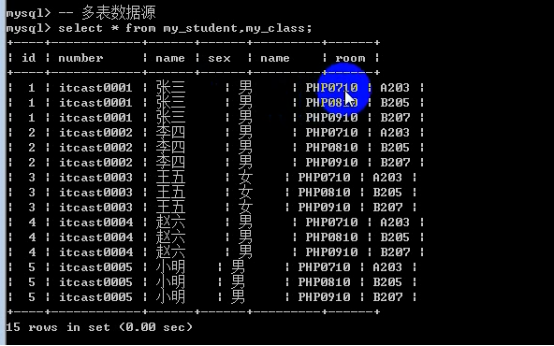
从一张表中取出一条记录,去另外一张表中匹配所有记录,而且全部保留(记录数和字段数),将这种结果成为:迪卡尓积(交叉连接),迪卡尔积没有什么卵用,所有尽量避免
子查询:数据的来源是一条查询语句(查询语句的结果是二维表)
-- 语法:
select * from (select 语句) as 表名; -- 必须接as 表名

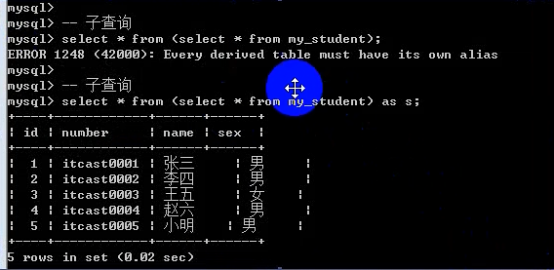
where子句
where子句:用来判断数据,筛选数据
where原理:where是唯一一个直接从磁盘获取数据的时候就开始判断条件,从磁盘取出一条记录,开始进行where判断->判断的结果如果成立则保存到内存;如果失败则直接放弃
where子句返回结果:0或者1
0代表false
1代表true
判断条件:
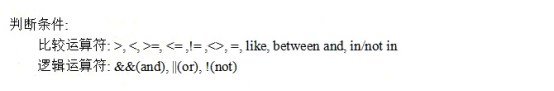
!=表示不等于
<>也表示不等于
like表示模糊匹配使用
Between……and……表示在什么之间
in/not in (……) 表示判断多个数据时使用
eg:

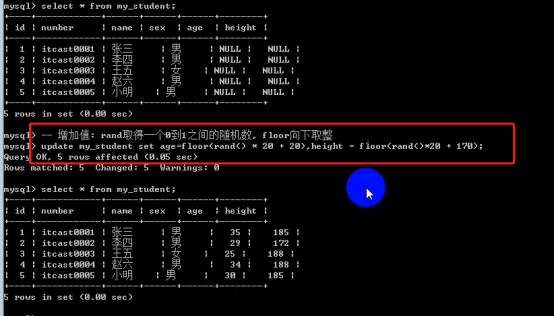
条件查询1、要求找出学生id为1或者3或者5的学生

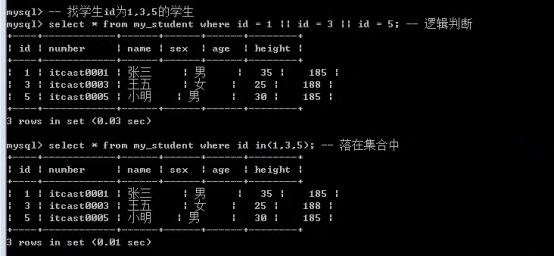
条件查询2、查出区间落在身高为180-190之间的学生

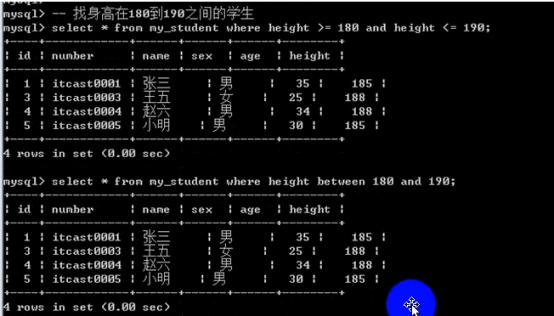
注意:


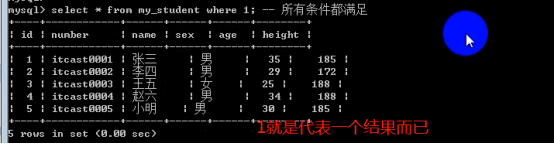
group by子句
group by:分组的意思,根据某个字段进行分组(相同的放一组,不同的分到另一组)
-- 基本语法:
group by 字段名;
eg:
-- 根据性别分组
select * from Student_list group by sex;
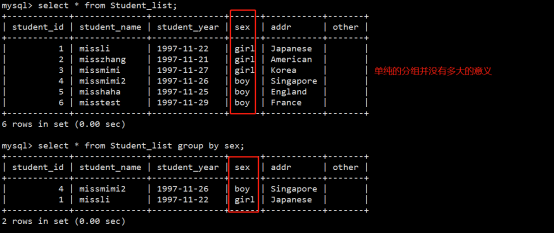
分组的意义:是为了统计数据(按组统计:按分组字段进行数据统计)
SQL提供了一系列统计函数
count():统计分组后的记录数,每一组有多个记录
max():统计每组中最大的值
min():统计最小值
avg():统计平均值
sum():统计和
distinct:去重,查出来的结果,将重复给去除(所有字段都相同)
eg:分组+统计
-- 分组+统计
select sex,count(*),max(student_id),sum(student_id),min(student_id),avg(student_id) from Student_list group by sex;
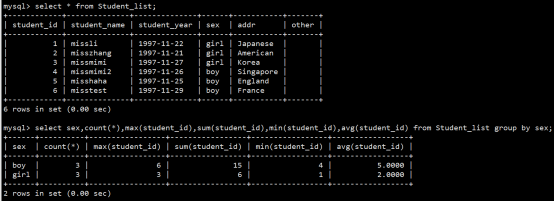

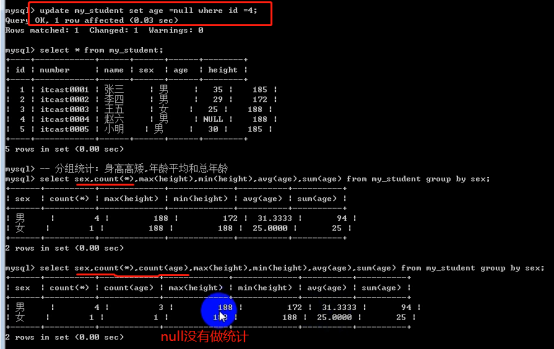
分组会自动排序->根据分组字段;默认升序
group by 字段 [asc|desc]; -- 对分组的结果然后合并之后的整个结果进行排序
asc -- 升序
desc -- 降序

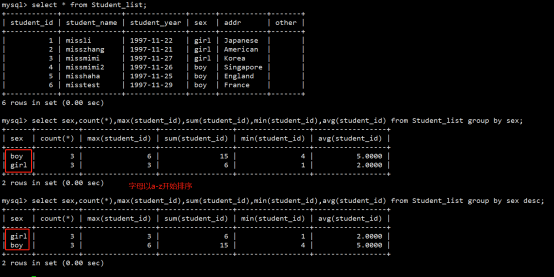

eg:



eg:
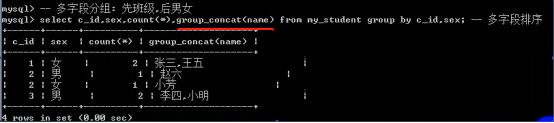

eg:


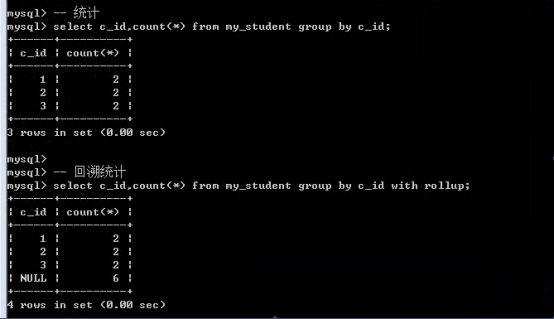
多字段回溯:

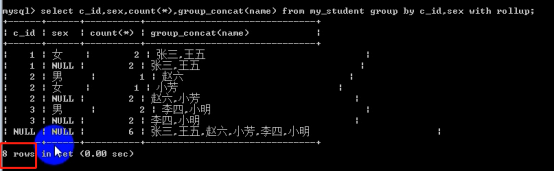
having子句
having子句:与where子句一样,进行条件判断的。
where是针对磁盘数据进行判断的->进行到内存之后,会进行分组操作->分组结果就需要having来处理
having能做where能做的几乎所有事情,但是where却不能做having能做的很多事情
1、分组统计的结果或者说统计函数都只有having能够使用
eg:

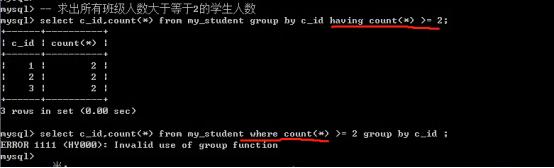
2、having能够使用字段别名->where不能,where是从磁盘取数据,而名字只可能是字段名;别名是在字段进入到内存后才会产生
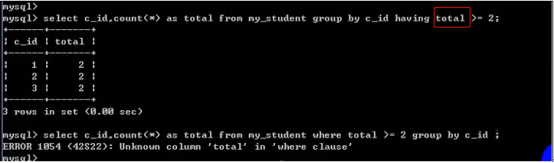
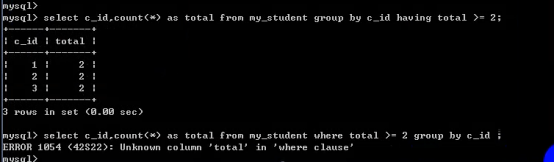
order by子句
order by:排序,根据某个字段进行升序或者降序排序,依赖校对集
-- 使用的基本语法:
order by 字段名 [asc|desc]; --asc是升序(默认的);desc是降序
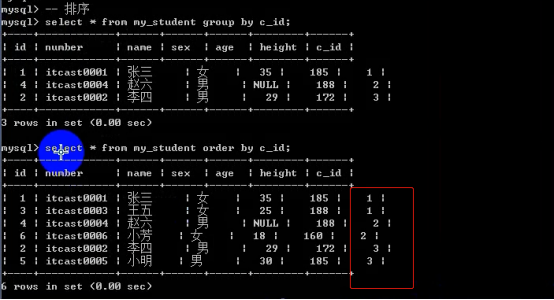
排序可以进行多字段排序:先根据某个字段进行排序,然后排序好的内部,在按照另外的某个数据进行再次排序
eg:
-- 多字段排序:先班级排序,后性别排序
select * from Student_list order by sex,addr;
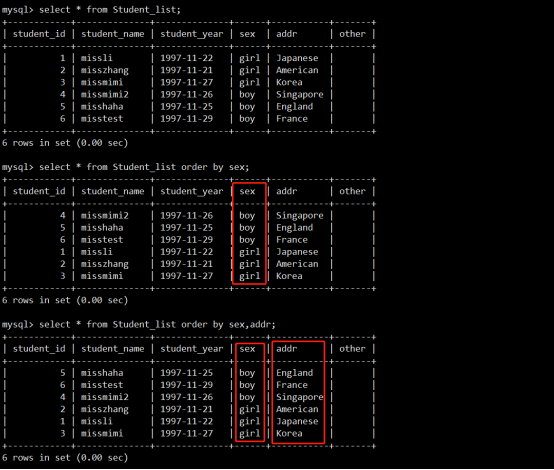
limit子句
limit子句是一种限制结果的语句->限制数量
limit有两种使用方式:
方案1、只用来限制长度(数据量)->limit数据量
eg:
-- 前两个数据
select * from Student_list limit 2;
方案2、限制起始位置,限制数量->起始位置,长度;
-- 前两个数据,记录数例如从1开始编号
select * from Student_list limit 1,2;
-- 前两个数据,记录数例如从2开始编号
select * from Student_list limit 2,2;

重点:limit方案2主要用于来实现数据的分页->为用户节省时间,提交服务器的响应效率,减少资源的浪费
对于用户来讲:可以点击的分页按钮:1,2,3,4......
对于服务器来讲:根据用户选择的页码来获取不同的数据,limit offset,length;
-
length:每页显示的数据量
->基本不变 -
offset:
offset = (页码-1)*每页显示量
新增数据
-- 基本语法:
insert into 表名 values(值列表)[,(值列表)];
在数据插入的时候,假设主键对应的值已经存在,插入数据一定会失败,怎么解决?
主键冲突
当主键存在冲突时(Duplicate key),可以选择性的进行处理->更新和替换
主键冲突:更新操作
insert into 表名[字段列表:必须包含主键] values(值列表) on duplicate key update 字段 = 新值;
eg:


主键冲突:替换操作
replace into 表名[字段列表:必须包含主键] values(值列表);
eg:

蠕虫复制

eg:(这种复制只是把结构复制了也叫物理拷贝,不会复制表里面的内容)
mysql> create table my_copy like mimi.student;
Query OK, 0 rows affected (0.01 sec)
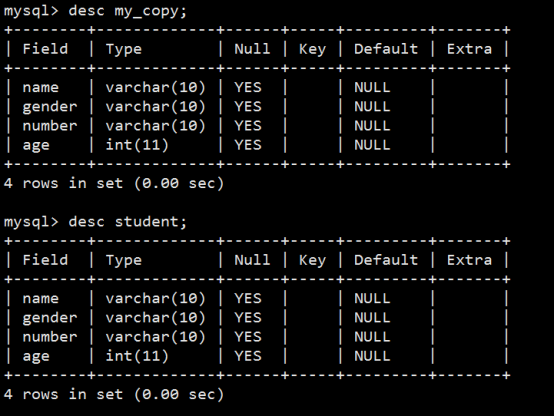

-- 蠕虫复制(复制student表里面的内容到my_copy;复制其他表里面的内容)
mysql> insert into my_copy select * from student;
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0

-- 蠕虫复制(复制my_copy表里面的内容到my_copy;复制表本身里面的内容)
mysql> insert into my_copy select * from my_copy;
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> insert into my_copy select * from my_copy;
Query OK, 12 rows affected (0.00 sec)
Records: 12 Duplicates: 0 Warnings: 0
mysql> insert into my_copy select * from my_copy;
Query OK, 24 rows affected (0.00 sec)
Records: 24 Duplicates: 0 Warnings: 0
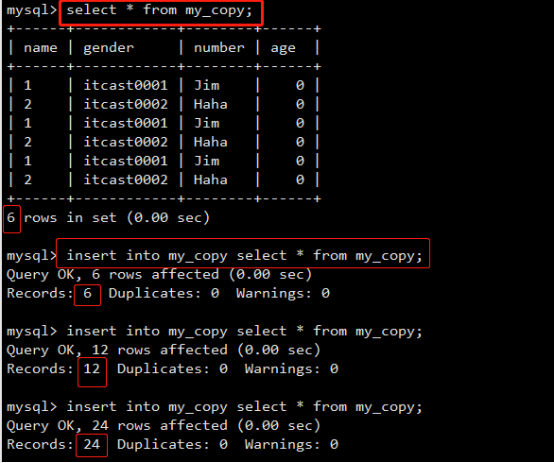

如果存在主键的字段,那么就排除该字段,不用select from 数据表名;
insert into log01 (created_at, server_id, game_bet) SELECT created_at, server_id, game_bet FROM log.log21 limit 10;
更新数据


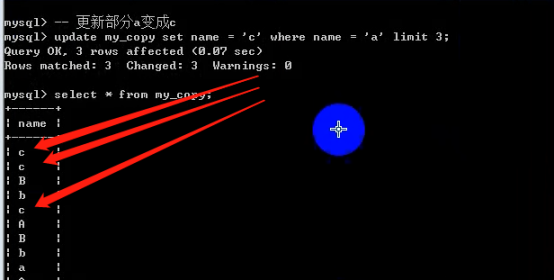
删除数据

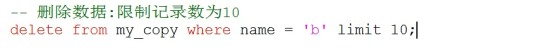

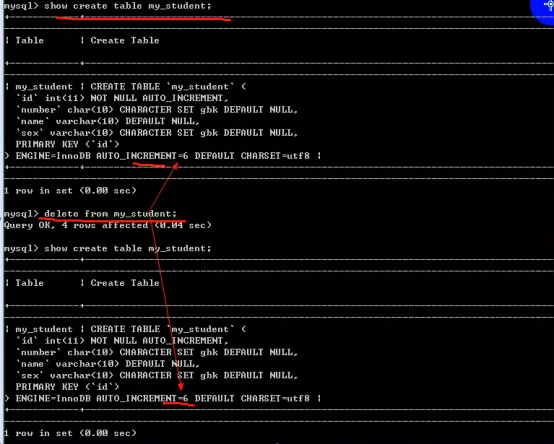

表名:先删除该表,然后创建该表。
eg:
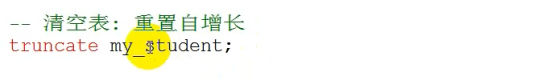
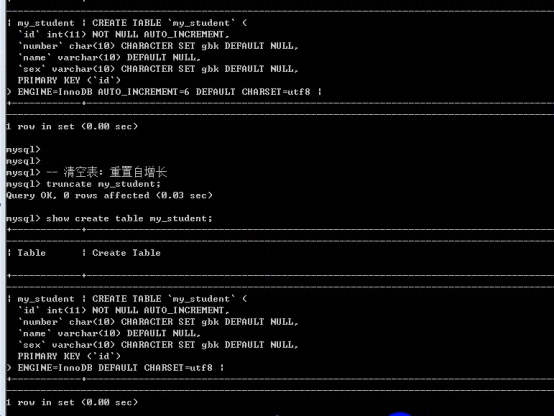
MySql的Delete、Truncate、Drop区别
相同点:
truncate和不带 where 子句的delete,以及drop都会删除表内的数据
不同点:
1. `truncate`和`delete`**只删除数据不删除表的结构**(定义)
drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index);依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。
2. delete 语句是数据库操作语言(dml),这操作会放到rollback segement中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。
truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
3. delete 语句不影响表所占用的 extent,高水线(high watermark)保持原位置不动
显然 drop 语句将表所占用的空间全部释放。
truncate 语句缺省情况下见空间释放到 minextents个 extent,除非使用reuse storage;truncate 会将高水线复位(回到最开始)。
4. 速度,一般来说:`drop> truncate > delete`
5. 安全性:小心使用 drop 和 truncate,尤其没有备份的时候.否则哭都来不及
- 使用上,**想删除部分数据行用`delete`,注意带上`where子句`. 回滚段要足够大**.
- **想删除表,当然用 drop**
- 想保留表而将所有数据删除,如果和事务无关,用`truncate`即可。如果和事务有关,或者想触发trigger,还是用`delete`。
- 如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
回顾


连接查询

概述:

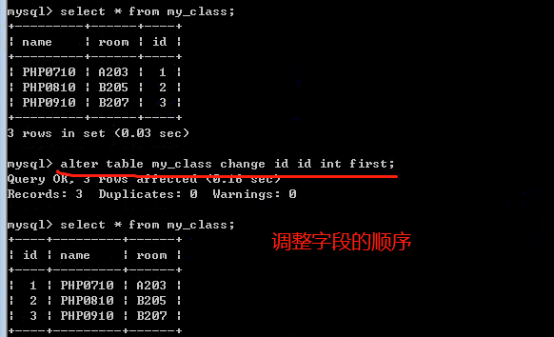
连接查询:将多张表(可以大于2张)进行记录的连接(按照某个指定的条件进行数据拼接);最终结果是,记录数有可能变化,字段一定会增加(至少两张表的合并)
连接查询的意义:在用户查看数据的时候,需要显示的数据来自多张表
连接查询:join,使用方式:左表 join 右边
左表:在join关键字左边的表
右表:在join关键字右边的表
连接查询的分类
SQL中连接查询分成四类:内连接,外链接,自然连接和交叉连接
交叉连接
交叉连接:cross join,从一张表中循环取出每一条记录,每条记录都去另外一张表进行匹配;匹配一定保留(这里是没有条件的匹配),而连接本身字段就会增加(保留),最终形成的结果叫做->笛卡尔积
-- 基本语法:
select 字段名 from 左表 cross join 右表;
eg:
-- 交叉连接
-- class cross join student是数据源
select * from class cross join student;
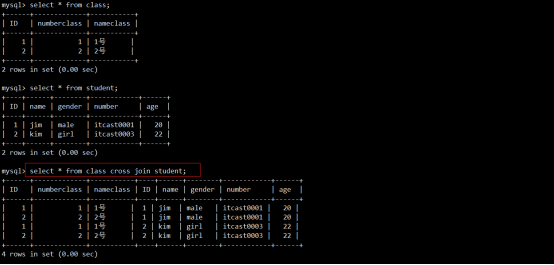
ps:迪卡尔积没有意义,应该尽量避免(交叉连接没用)
交叉连接存在的价值:保证连接这种结构的完整性
内连接(常用)
内连接:[inner] join,从左表取出每一条记录,去右表中所有的记录进行匹配,匹配必须是某个条件在左表中与右表中相同,最终才会保留合并两张表的结果,否则不保留
-- 基本语法:
select 字段名 from 左表名 [inner] join 右表名 on 左表.字段 = 右表.字段;
-
inner这个关键字可以省略
-
on表示连接条件,条件字段就是代表相同的业务含义(如
class.ID和student.ID)
eg:(1、2条语句是相等的)
-- 1
select * from class inner join student on class.ID = student.ID;
-- 2
select * from class join student on class.ID = student.ID;
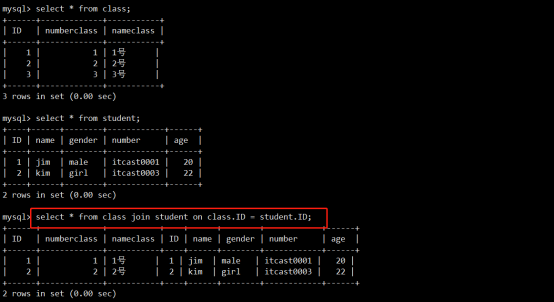

eg:

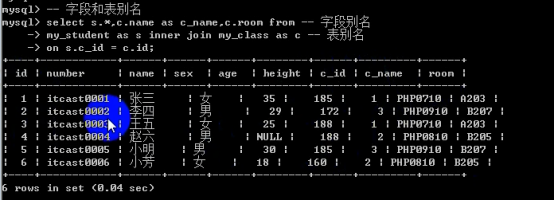

eg:
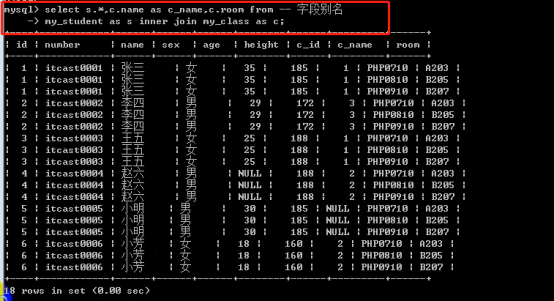


eg:
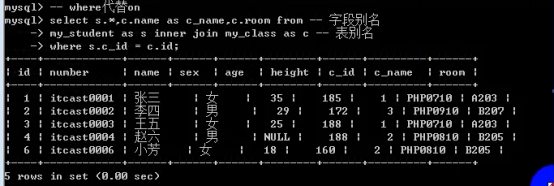
外连接(常用)
外连接:outer join,以某张表为主,取出里面的所有记录,然后每条记录与另外一张表进行连接;不管能不能匹配上,最终都会保留->能匹配,正确保留,不能匹配,其他表的字段都置空(null)
外连接分为两种:是以某张表为主,有主表
left join:左外连接(左连接),以左表为主表right join:右外连接(右连接),以右表为主表
-- 基本语法:
select 字段名 from 左表 left/right join 右表 on 左表.字段 = 右表.字段;
eg:
-- 左连接
select * from class left join student on class.numberclass = student.ID;
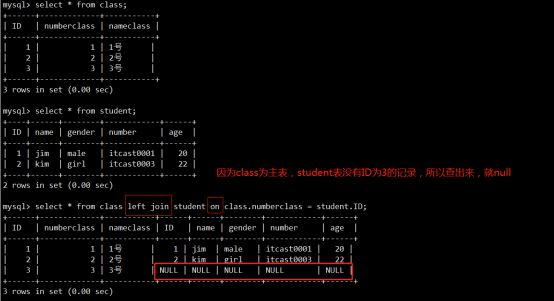


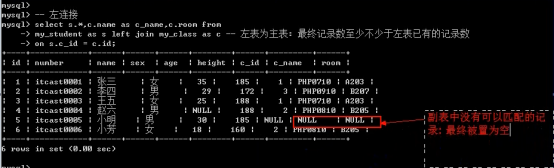
-- 右连接
select * from class right join student on student.ID = class.ID;
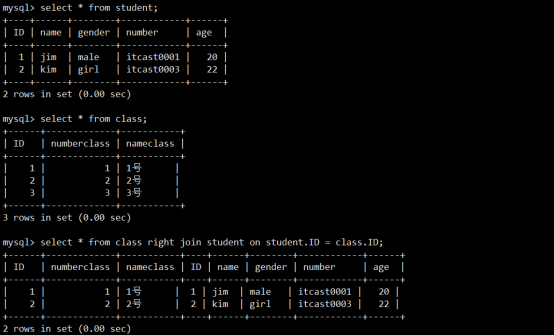

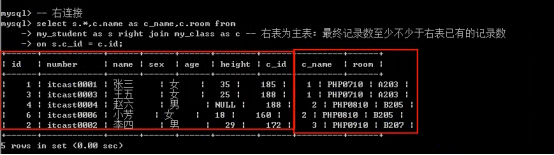
虽然左连接和右连接有主表差异,但是显示的结果:左表的数据在左边,右表数据在右边
左连接和右连接可以互相转化
自然连接(natural join)
自然连接:natural join,自然连接,就是自动匹配连接条件:系统以字段名字作为匹配模式
(同名字段就作为条件,多个同名字段作为条件)
-- 基本语法:
select 字段名 from 左表 natural join 右表;
eg:
-- 自然内连接
select * from class natural join student;
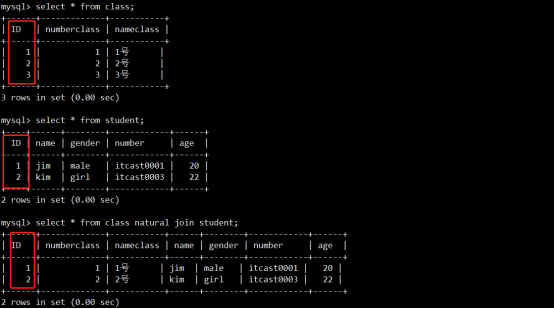
ps:自然连接自动使用同名字段作为连接条件->连接之后会合并同名字段

eg:

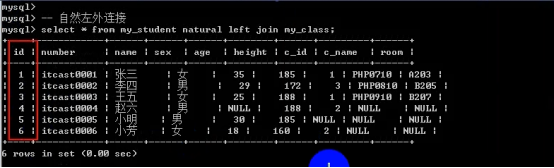

eg:

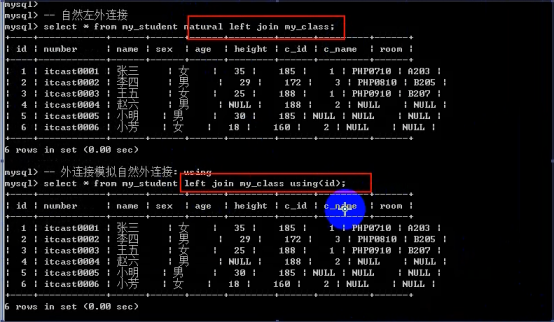

INNER JOIN、LEFT JOIN、CROSS JOIN、natural join、UNION几种方式区别与联系
inner join:
左右两张表连接字段完全一致
SELECT XXX FROM XXX INNER JOIN XXX ON XXX; -- 这里 INNER 可以省略
left join:
以左表为全部,去连接右表
cross join:
交叉连接,得到的结果是两个表的乘积,即笛卡尔积.
笛卡尔(Descartes)乘积又叫直积。假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以扩展到多个集合的情况。类似的例子有,如果A表示某学校学生的集合,B表示该学校所有课程的集合,则A与B的笛卡尔积表示所有可能的选课情况。
笛卡尔积算法针对的是表之间数据行的匹配次数,跟内连接还是外连接无关,至于查询结果与你的查询条件有关系。
natural join:
自连接是连接的一种用法,但并不是连接的一种类型,因为他的本质是把一张表当成两张表来使用。
mysql有时在信息查询时需要进行对自身连接(自连接),所以我们需要为表定义别名。
union语句:用于将不同表中相同列中查询的数据展示出来;(不包括重复数据)
union all语句:用于将不同表中相同列中查询的数据展示出来;(包括重复数据)
联合查询
基本语法


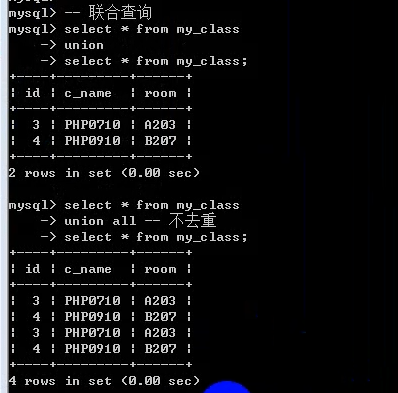

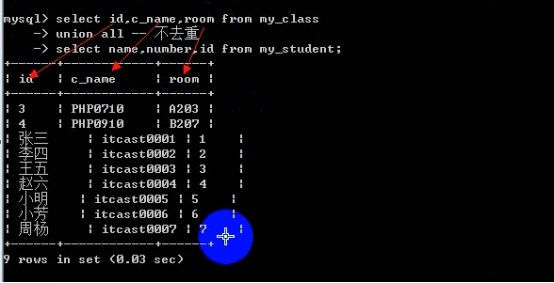
意义

order by使用(2点)

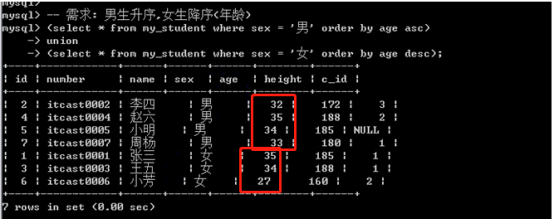


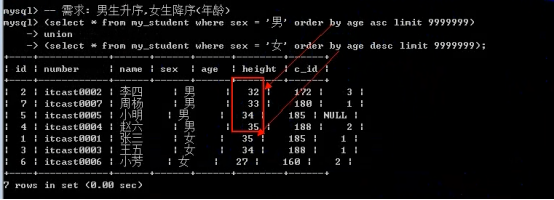
子查询
子查询:sub query,查询是在某个查询结果之上进行的(一条select语句内部包含了另一条select语句)
子查询的分类

标量子查询


列子查询


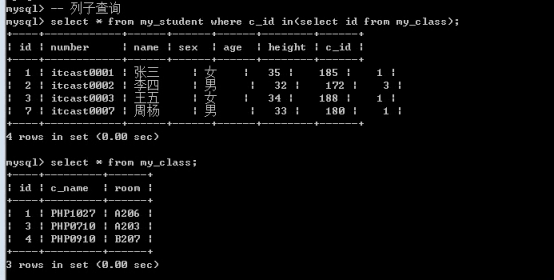

any不能直接用,需要在前面加感叹号或者等于号;例如:!any或者=any这个两个也等价于in
any在肯定句里面又等于some
eg:
肯定结果

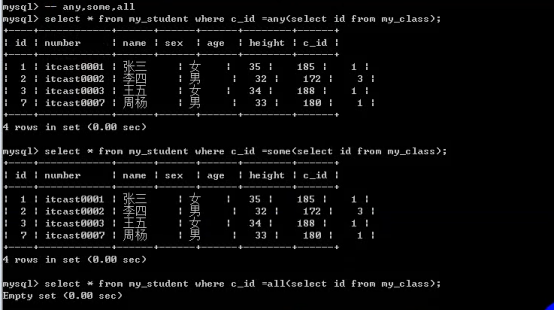
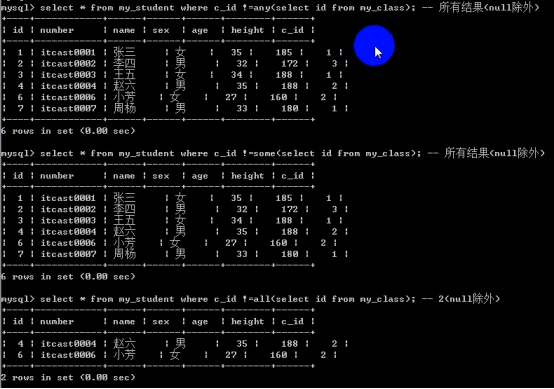
行子查询

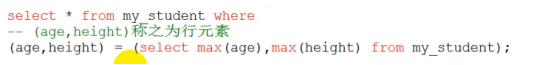
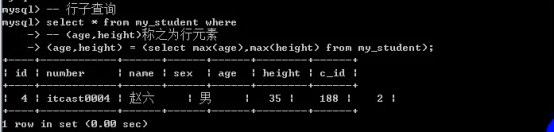
这种可以查出来,但是不好,为什么,如果数据几百万或者以上的数据,limit是不是不能确定是多少勒

表子查询


exists子查询

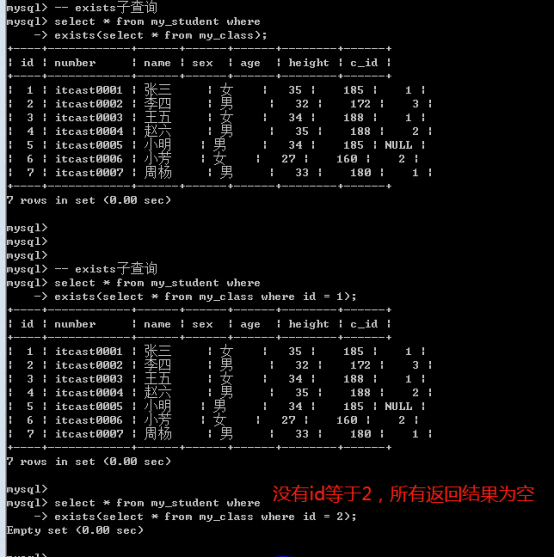
外键 foreign key
外键:foreign key,外面的键(键不在自己表中),如果一张表中有一个字段(非主键)指向另外一张表的主键,那么将该字段称为外键
外键的条件
-
外键要存在:首先必须保证表的存储引擎是innodb(默认的存储引擎)。如果不是innodb存储引擎,那么外键可以创建成功,但是没有约束效果
-
外键字段的字段类型(列类型)必须与父表的主键类型完全一致
-
一张表中的外键名字不能重复
-
增加外键的字段(数据已存在),必须保证数据与父表主键要求对应
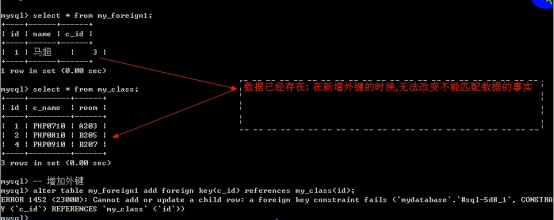
增加外键

注意:一张表可以有多个

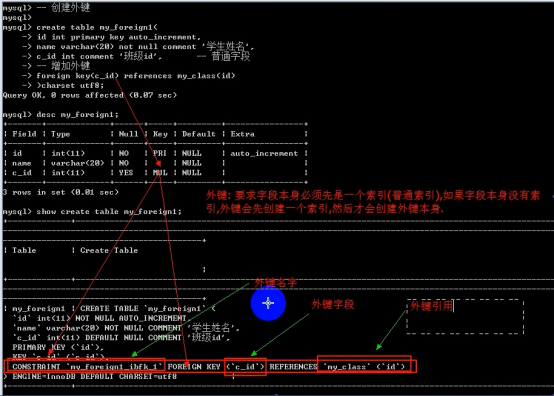


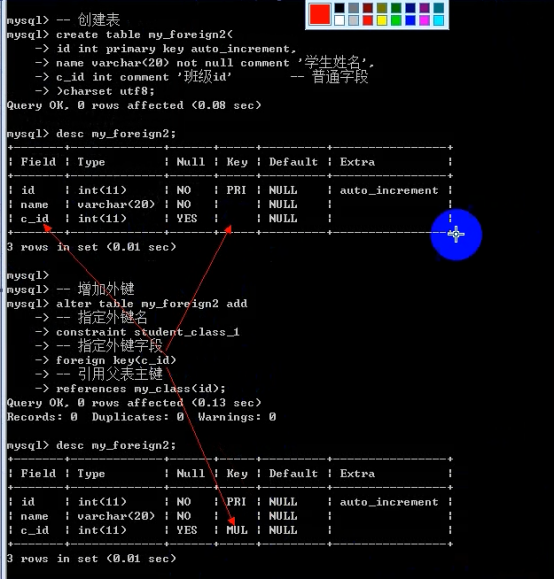
修改外键&删除外键

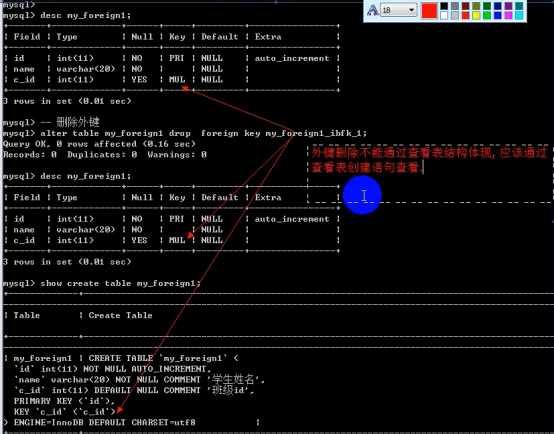
外键默认的作用


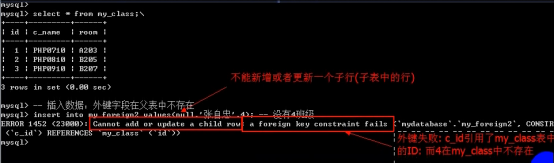



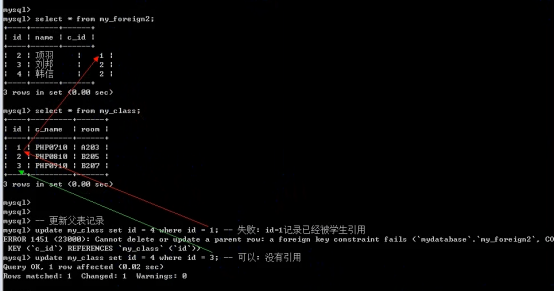
外键的约束

eg:
-- 创建外键:指定模式:删除置空,更新级联
create table my_foreign3(
id int primary key auto_increment,
name varchar(20) not null,
c_id int,
-- 增加外键
foreign key(c_id)
-- 引用表
references my_class(id)
-- 指定删除模式
no delete set null
-- 指定更新默认
on update cascade
)charset utf8;
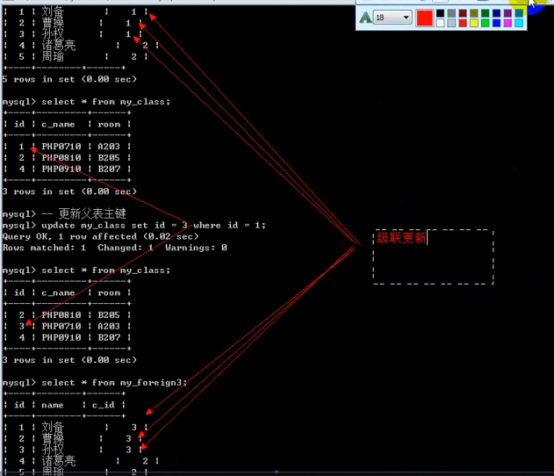
删除置空:
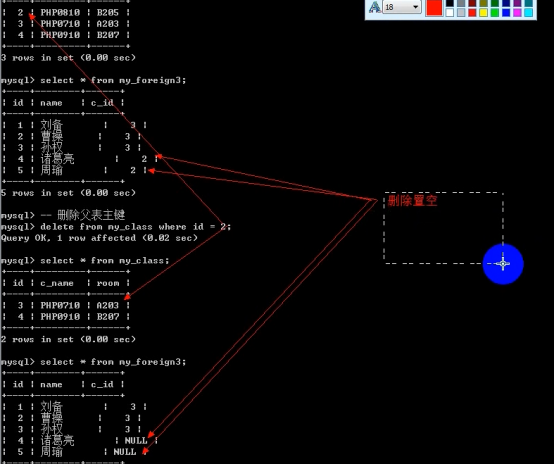

视图
视图:view,是一种有结构(有行有列),但是没有结果(结构中不真实存放数据)的虚拟表,虚拟表的结构来源不是自己定义,而是从对应基表中产生(视图的数据来源)
视图优点:
- 方便操作,特别是查询操作,减少复杂的SQL语句,增强可读性;
- 更加安全,数据库授权命令不能限定到特定行和特定列,但是通过合理创建视图,可以把权限限定到行列级别;
使用场景:
-
权限控制的时候,不希望用户访问表中某些含敏感信息的列,比如
password、salary... -
关键信息来源于多个复杂关联表,可以创建视图提取我们需要的信息,简化操作;
创建视图
基本语法:
create view 视图名字 as select语句;
说明:select语句可以是普通查询;可以是连接查询;可以是联合查询;可以是子查询
视图分为:单表视图与多表视图
eg:-- 创建单表视图
create view my_v2 as select from my_student;

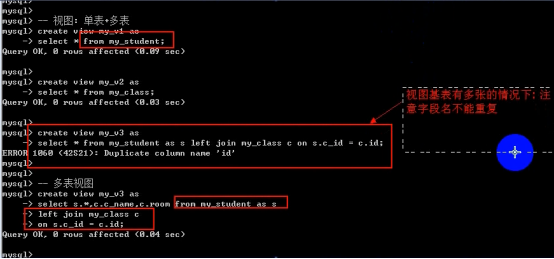
查看视图
查看视图->查看视图的结构
视图是一张虚拟表:那么表的所有查看方式都适用于视图
show tables [like] 视图名字;
desc 视图名字;
show create table 视图名;
-- 查看视图结构
mysql> desc my_v1;
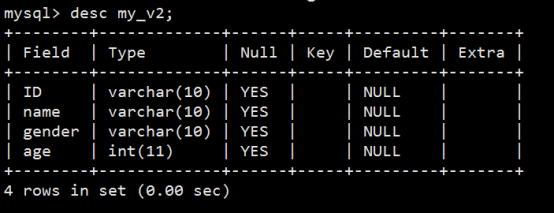
视图比表还是有一个关键字的区别:view。查看表(视图)的创建语句的时候可以使用view关键字
查看视图->视图创建语句
mysql> show create view my_v2\G
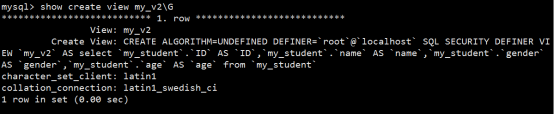
视图一旦创建->系统会在视图对应的数据库文件下创建一个对应的结构文件.frm文件

使用视图
使用视图主要是为了查询:将视图当做表一样查询即可。
-- 使用视图
select * from my_v2;
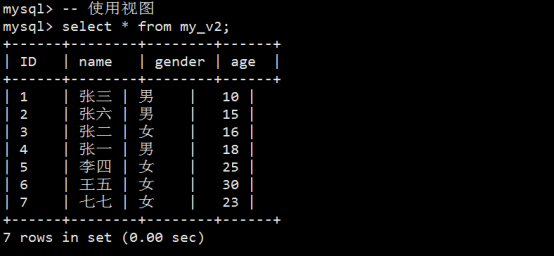
视图的执行:其实本质就是执行封装的selcet语句
修改视图
视图本身不可以修改,但是视图的来源是可以修改的。
修改视图:就是修改视图本身的来源语句(select语句)
语法:
alter view 视图名字 as 新的select语句;
-- 修改视图
alter view my_v2 as
select ID,name,age from my_student;
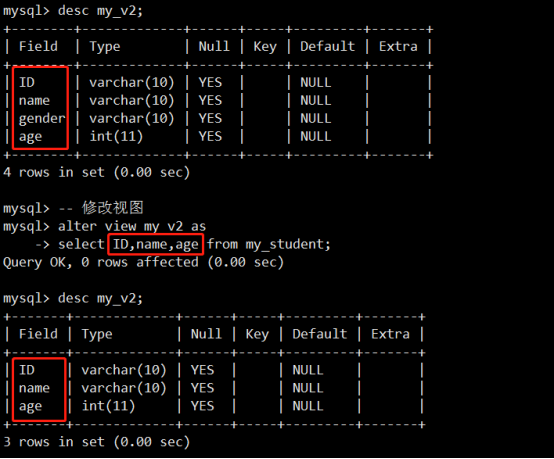
删除视图
语法:
drop view 视图名字;
-- 删除视图
drop view my_v1;
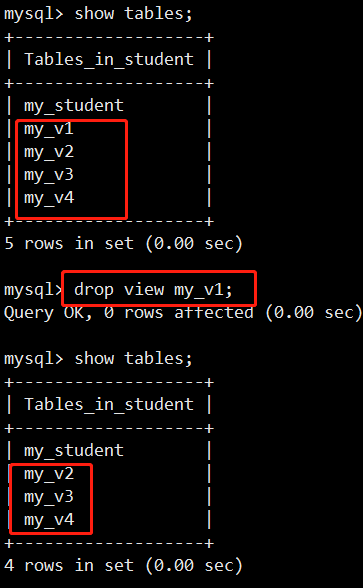
删除多个视图:
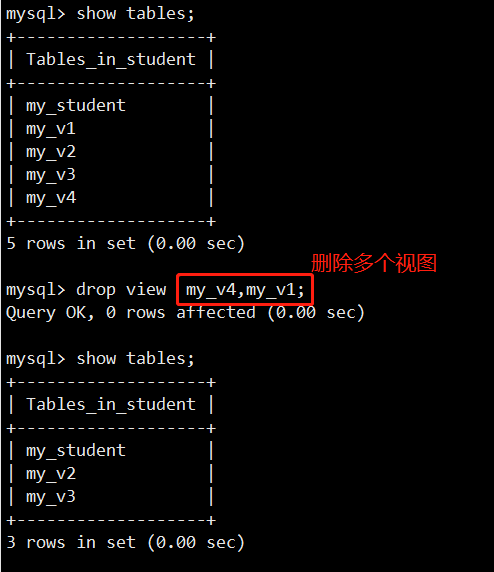
视图的意义
1、视图可以节省SQL语句->将一条复杂的查询语句使用视图进行保存->以后可以直接对视图进行操作
2、数据安全->视图操作是主要针对查询的,如果对视图结构进行处理(删除),不会影响基表数据(相对安全)
3、视图往往是在大项目中使用,而且是多系统使用->可以对外提供有用的数据,但是隐藏关键(无用)的数据->数据安全
4、视图可以对外提供友好型->不同的视图提供不同的数据,对外可以专门设计
5、视图可以更好(容易)的进行权限控制


视图数据的操作
视图是的确可以进行数据写操作,但是有很多限制
将数据直接在视图上进行操作
新增数据
数据新增就是直接对视图进行数据新增
1、多表视图不能新增数据


2、可以向单表视图插入数据,但是视图中包含的字段必须有基表中所有且不能为空(或者没有默认值)字段


3、视图是可以向基表插入数据的

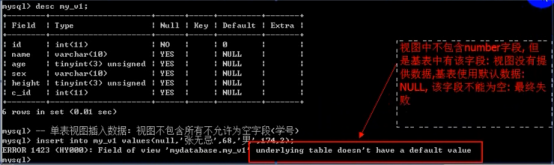

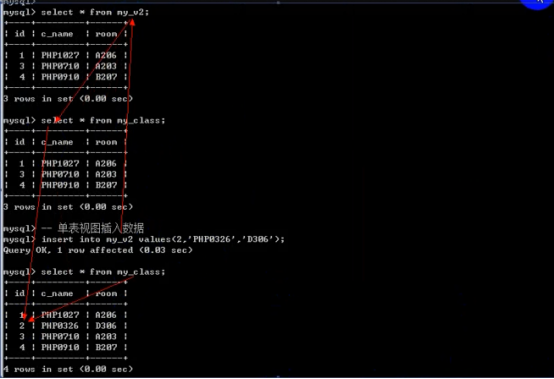
删除数据
多表视图不能删除数据

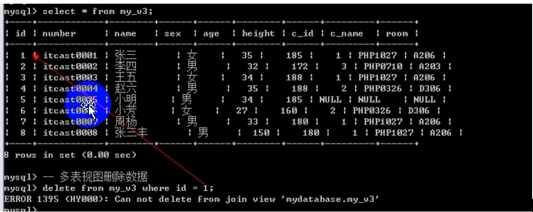
单表视图可以删除数据
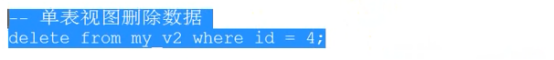
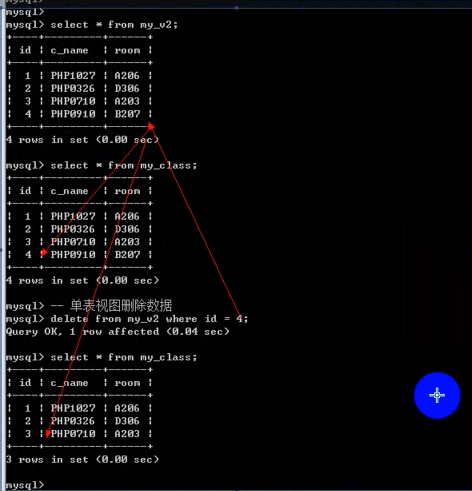
更新数据
理论上不管单表视图还是多表视图都可以更新数据


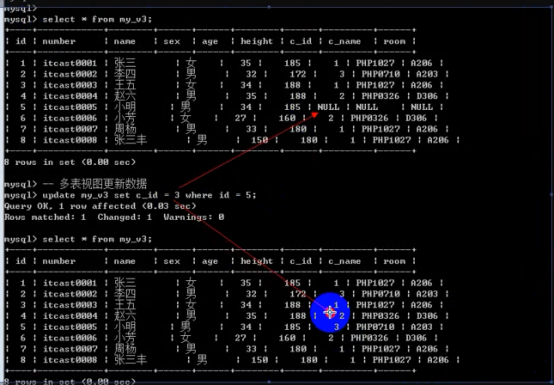


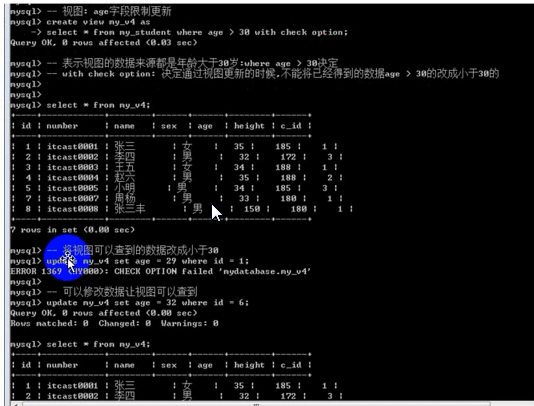
视图算法


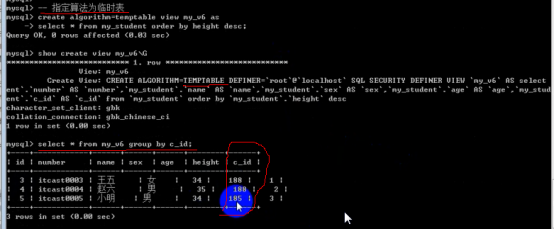
锁的分类:
https://mp.weixin.qq.com/s/QMGpOsNdg01X4_nNBHXiGg
https://blog.csdn.net/weixin_36634753/article/details/90815755
施加锁的方式:
读锁:->[共享锁]
用户在指定的表中施加读锁,其他用户可以任意读取,但不能修改[共享锁]
写锁:->[排他锁]
独享锁、只要施加了写锁,则其他用户不可以修改或者读取
按照锁的层级划分:
表级别锁:
table lock
行级锁:(行级锁,必须是InnoDB)
row lock
注意:表级锁,锁定整张表,而行级锁,锁定表中指定行;层级越小,开销越大但是并发性越好;层级越大,开销越小,并发性越差;

语法:
LOCK TABLES
tbl_name [[AS] alias] lock_type
[, tbl_name [[AS] alias] lock_type] ...
lock_type:
READ [LOCAL]
| [LOW_PRIORITY] WRITE
UNLOCK TABLES
eg:写锁
mysql> lock table student write;
注意:锁的关联和数据库的存储引擎有关,一般都是用InnoDB存储引擎
eg:解锁
mysql> UNLOCK TABLES;
InnoDB引擎,一般使用的锁都是显式锁[手动设置],若存储引擎自己设置的锁
一般称为隐式锁[一般是在备份过程中,通过存储引擎自行加载的]
InnoDB的另外一种显式锁:行级锁,必须是InnoDB
mysql> show table status like 'student'\G;
mysql> alter table student engine 'InnoDB';
mysql> select * from student where id <=2 lock in share mode;
形如:student数据库中的student表,若张三将1行2列的元素进行修改,同时李四也在对其进行修改

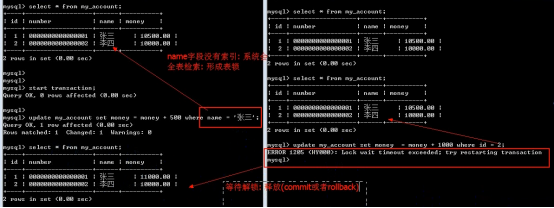
共享锁(S锁): 又称为读锁,可以查看但无法修改和删除的一种数据锁。如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排它锁。获准共享锁的事务只能读数据,不能修改数据。 共享锁下其它用户可以并发读取,查询数据。但不能修改,增加,删除数据。资源共享.
排它锁(X锁): 又称为写锁、独占锁,若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A
互斥锁: 在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为\" 互斥锁\" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
悲观锁、乐观锁:
悲观锁: 总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
悲观锁和乐观锁推荐:面试难点:你了解乐观锁和悲观锁吗?
乐观锁: 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的
行级锁: 行级锁是 MySQL 中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突,其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
表级锁: 表级锁是 MySQL 中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分 MySQL 引擎支持。最常使用的 MyISAM 与 InnoDB 都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
页级锁: 页级锁是 MySQL 中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。因此,采取了折衷的页级锁,一次锁定相邻的一组记录。BDB 支持页级锁。开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
丢失修改: 指事务1和事务2同时读入相同的数据并进行修改,事务2提交的结果破坏了事务1提交的结果,导致事务1进行的修改丢失
不可重复读: 一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!
不可重复读推荐:面试官:MySQL的可重复读级别能解决幻读问题吗?
读脏数据: 事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤消,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为\"脏\"数据,即不正确的数据。
死锁: 两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程
死锁推荐阅读:MySQL死锁产生原因和解决方法
死锁四个产生条件:预防死锁打破上述之一的条件
1)互斥条件: 指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
2)请求和保持条件: 指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
3)不剥夺条件: 指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
4)环路等待条件: 指在发生死锁时,必然存在一个进程------资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,......,Pn正在等待已被P0占用的资源。
数据库的事务(重要)
事务原理
事务操作原理:事务开启之后,所有的操作都会临时保存到事务日志,事务日志只有在得到commit命令才会同步到数据表,其他任何情况都会清空(rollback、断电、断开连接)
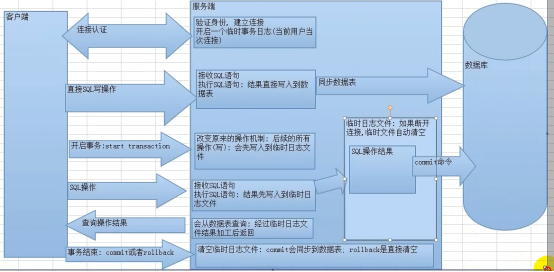
事务安全

事务(ransaction):一系列要发生的连续的操作
事务安全:一种保护连续操作同时满足(实现)的一种机制
事务安全的意义:保证数据操作的完整性
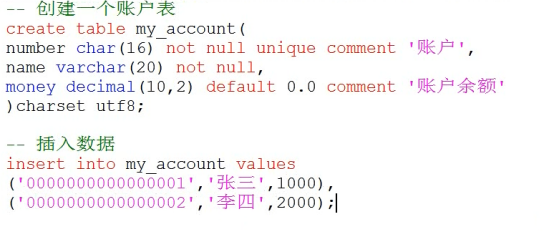

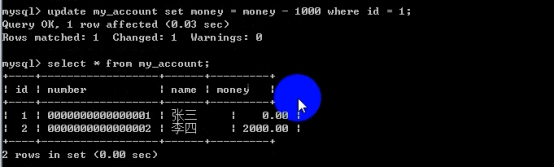
手动事务操作

事务日志(无法用记事本打开,是编译后的结果了):




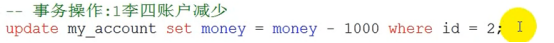
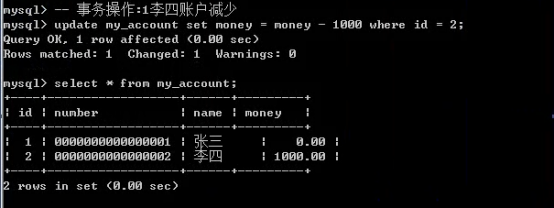

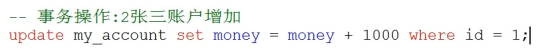
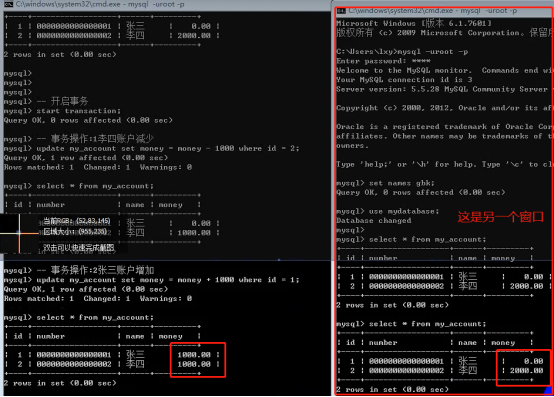
解释:另一个窗口的目的就是查看数据库是否更新了(没有发生变化则为正确,因为还没有提交事务)


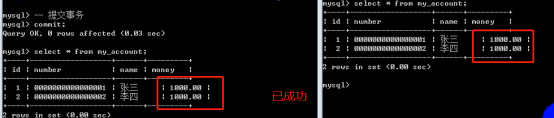

回滚点



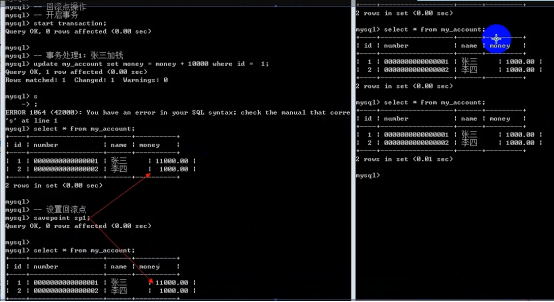

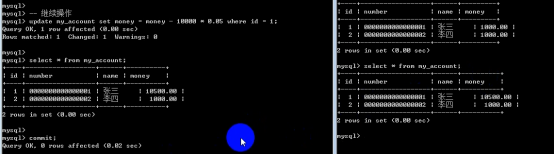
自动事务操作

mysql> show variables like 'autocommit';
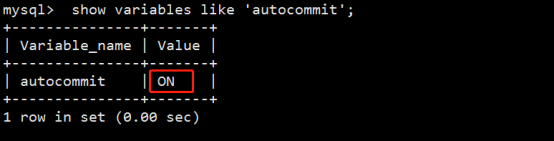
关闭自动提交:set autocommit = off;或者set autocommit = 0;
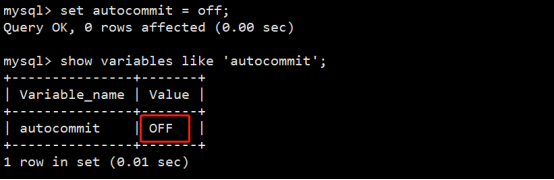
再次直接写操作:
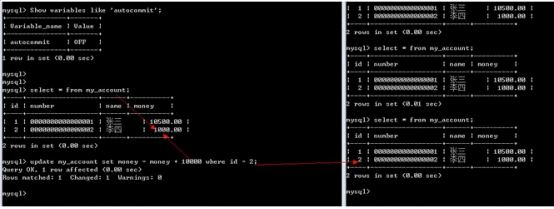

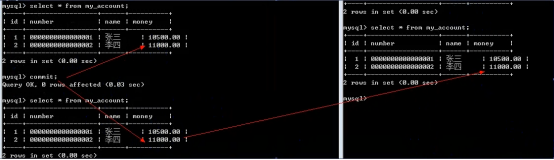
开启自动提交:set autocommit = on;或者set autocommit = 1;
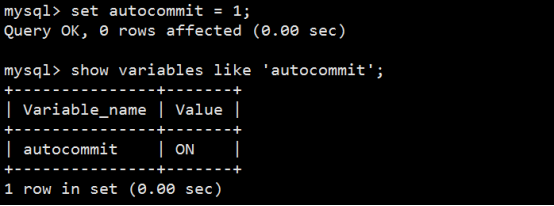
注意:通常都会使用自动事务
事务操作:
A、执行语句:
mysql> START TRANSACTION; -- 开始事务
.... -- SQL语句
....
mysql> coommit -- 提交事务

注意:在以上过程中,若没有提交但是又修改了SQL语句,就必须实现回滚
mysql> rollback //回滚事务
B、回滚到指定的某个点:
语法:
SAVEPOINT identifier
ROLLBACK [WORK] TO [SAVEPOINT] identifier
RELEASE SAVEPOINT identifier
eg:
mysql> start transaction;
mysql> update student set id=2 where name='李四';
mysql> savepoint a;
mysql> update student set id=7 where name='李四';
mysql> select * from student;
mysql> savepoint b;
mysql> rollback to a;
mysql> select * from student;
注意:以上所有的mysql的事务的操作,都必须是存储引擎为InnoDB,以上均只针对DML语句生效[数据操作语句]->select、insert、update、delete
遵循4个特性: ACID
-
A:atomicity原子性:每个事务在执行过程中,要么成功,要么失败,都是相对独立的
-
C:Consistency 一致性:执行事务后,数据必须达到一致性存储
-
I:Isolation隔离性:多个事务之间不存在依存关系
-
D:Durability持续性:可以将执行事务的结果进行持续存储
事务的隔离级别:
-
Read uncommitted:可读,但不提交
-
read committed:可读可提交
-
repeatabble read:可重复读
-
serializable:可串行化
如何修改事务的隔离级别:
SHOW [GLOBAL | SESSION] STATUS [like_or_where]
SHOW [GLOBAL | SESSION] VARIABLES [like_or_where]
eg:
-- 查看隔离级别
mysql> show global variables like "%iso%";
# 设置隔离级别
mysql> set global tx_isolation='READ-COMMITTED';
触发器
需求:有两张表,一张订单表、一张商品表,每生产一个订单,意味着商品的库存要减少
触发器
触发器:trigger,事先为某张表绑定好一段代码,当表中的某些内容发生改变(增删改)的时候,系统会自动触发代码,然后执行
触发器包含:事件类型、触发时间、触发对象
-
事件类型:增删改;三种类型insert、delete、update
-
触发时间:前后;before和after
-
触发对象:表中的每一条记录(行)
一张表中只能拥有一种触发时间的一种类型的触发器->最多一张表能有6个触发器
创建触发器
在SQL高级结构中,没有大括号,都是用对应的字符符号代替
触发器基本语法
-- 临时修改语句结束符
delimiter 自定义符号:后续代码中只有碰到自定义符号才算结束
create trigger 触发器名字 触发器时间 事件类型 on 表名 from each row
begin -- 代表左括号->开始
-- 里面就是触发器的内容->每行内容都必须使用语句结束符;分号
end -- 代表右大括号->结束
-- 语句结束符
自定义符号
-- 将临时修改修正过来
delimiter ;
eg:
-- 创建表
create table my_goods(
id int primary key auto_increment,
name varchar(20) not null,
price decimal(10,2) default 1,
inv int comment '库存数量'
)charset utf8;
insert into my_goods values(null,'iPhone6s',5288,100),(null,'s6','6088',100);
create table my_order(
id int primary key auto_increment,
g_id int not null comment '商品ID',
g_number int comment '商品数量'
)charset utf8;
-- 触发器:订单生成一个,商品库存减少一个
-- 临时修改语句结束符
delimiter $$
create trigger after_order after insert on my_order for each row
begin
-- 触发器内容开始
update my_goods set inv = inv - 1 where id = 2;
end
-- 结束触发器
$$
-- 修改临时语句结束符
-- delimiter 空格; -- 这里必须有空格哈
delimiter ;
ps:如果触发器内部只有一条要执行的SQL指令,可以省略大括号(begin和end)create trigger 触发器名字 触发时间 事件类型 on 表名 for each row一条SQL指令;触发器:可以很好的协调表内部的数据处理顺序和关系,但是从PHP角度出发,触发器会增加数据库维护的难度,所有较少使用触发器
说明:该触发器设计的设计的不合理,商品减少是固定死的;后面有优化后的触发器
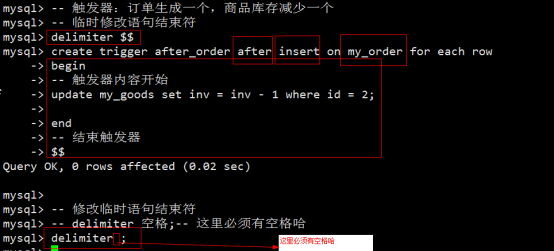
查看触发器
查看所有触发器或者模糊查询
语法:
show triggers [like 'pattern'];
eg:
-- 查看所有触发器
show triggers\G
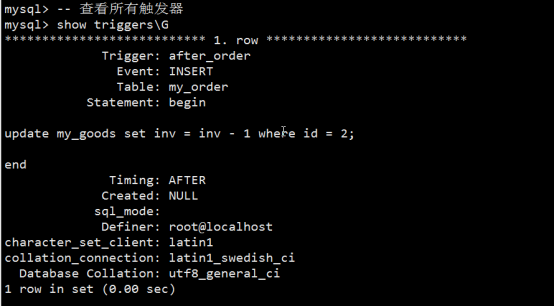
可以查看触发器创建语句
语法:
show create trigger 触发器名字\G
eg:
-- 查看触发器创建语句
show create trigger after_order\G
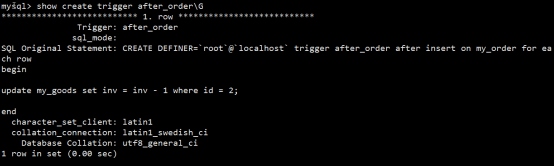
所有触发器都会保存到一张表中:information_schema.triggers
查看
select * from information_schema.triggers\G
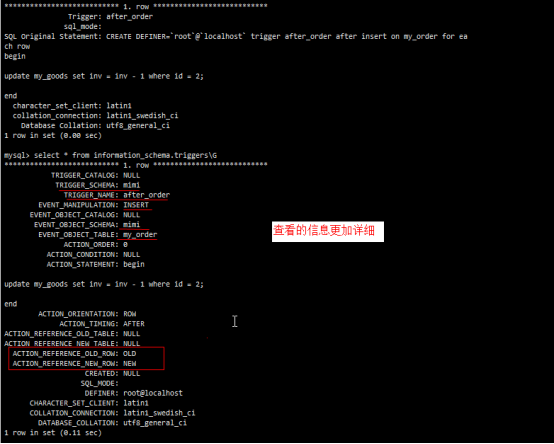
使用触发器
触发器:不需要手动调用,而是当某种情况发生时会自动触发(订单里面插入记录之后)
eg:
-- 插入订单
insert into my_order values(null,1,2);
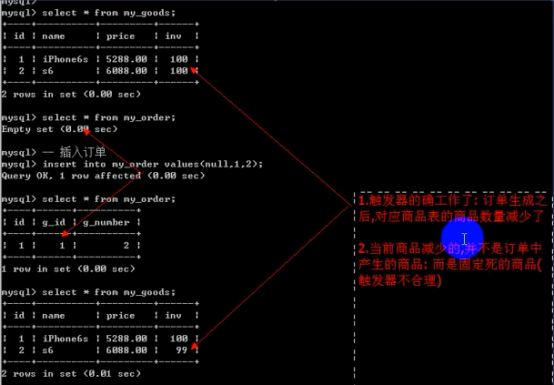
修改触发器&删除触发器
触发器不能修改,只能先删除,后新增
语法:
drop trigger 触发器名字;
eg:
-- 删除触发器
drop trigger after_order;
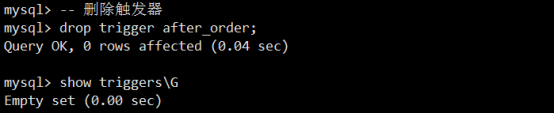
触发器记录
触发器记录:不管触发器是否触发了,只有当某种操作准备执行,系统就会将当前操作的记录的当前状态和即将执行之后新的状态分别保留下来,供触发器使用:其中,要操作的当前状态保存到old中,操作之后的可能形态保存给new
old代表的是旧记录;new代表的是新记录
删除的时候是没有new的;插入的时候是没有old
old和new都是代表记录本身:任何一条记录除了有数据,还有字段名字
使用方式:old .字段名 /new.字段名(new代表的是假设发生之后的结果)
eg:
-- 触发器:订单生成一个,商品库存减少一个
-- 临时修改语句结束符
delimiter $$
create trigger after_order after insert on my_order for each row
begin
-- 触发器内容开始:新增一条订单:old没有,new代表新的订单记录
update my_goods set inv = inv - new.g_number where id = new.g_id;
end
-- 结束触发器
$$
-- 修改临时语句结束符
-- delimiter 空格; -- 这里必须有空格哈
delimiter ;
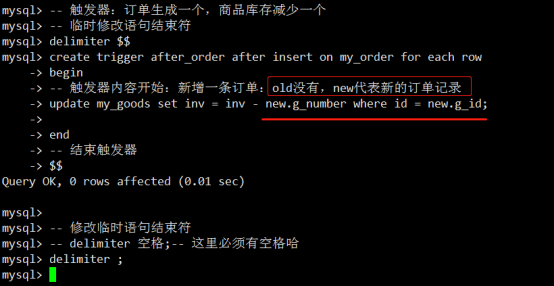
再次插入订单,然后查看触发器的效果:
eg:
-- 再次插入订单
insert into my_order values(null,1,2);
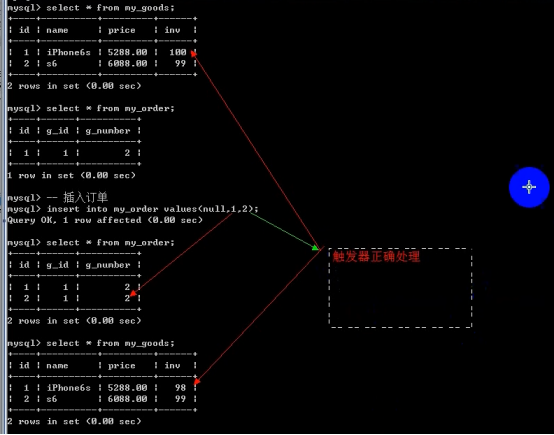
MySQL中的变量
变量分为2种:系统变量和自定义变量
系统变量
系统定义好的变量:大部分的时候用户根本不需要使用系统变量,系统变量是用来控制服务器的表现的->如:autocommit等
查看系统变量
语法:
show variables; -- 查看所有变量
查看具体变量值
任何一个有数据返回的内容都是有select查看
语法:
select @@变量名;
eg:
mysql> select @@version();
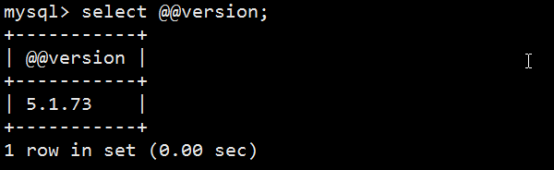
查看模糊变量
mysql> select @@version(); -- 用%%把你需要搜索的变量囊括起来
修改系统变量
修改系统变量分为两种方式:会话级别和全局级别
会话级别
临时修改,当前客户端当次连接有效
语法:
set 变量名 = 值;
或者
set @@变量名 = 值;
或者:
set session sort_buffer_size = 524288; -- 有些配置参数只允许修改全局GLOBAL
eg:
-- 修改会话级别变量
set autocommit = 0;
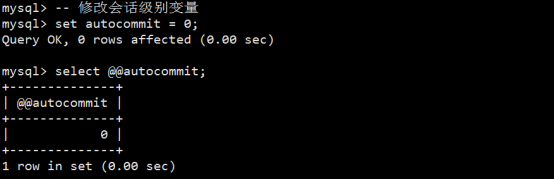
重启MySQL后参数失效
全局级别
一次修改,永久生效(对所有客户端都生效),但是重启MySQL服务器失效
语法:
set global 变量名 = 值;
说明:如果对方(其他)客户端当前已经连接上服务器,那么当次修改无效,必须退出后重新登录才会生效
总结
如果在配置文件修改相关参数值,需要重启MySQL才能生效
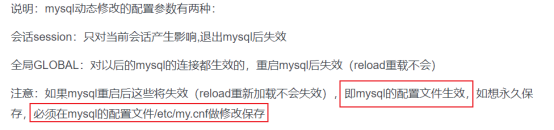
自定义变量
系统为了区分系统变量,规定用户自定义变量必须使用一个@符号
语法:
set @变量 = 值;
eg:
-- 定义自定义变量
set @name = '李四';
-- 查看变量
select @name;
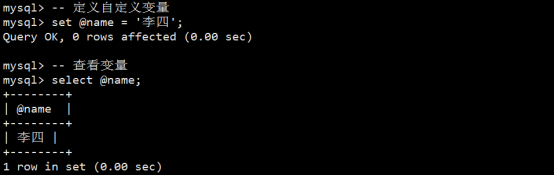
在mysql中,=会默认的当做比较符号处理(很多地方),mysql为了区分比较和赋值的概念->重新定义了一个新的赋值符号为:=
语法:
set @变量名 := 值;
eg:
-- 定义变量
set @age := 18;
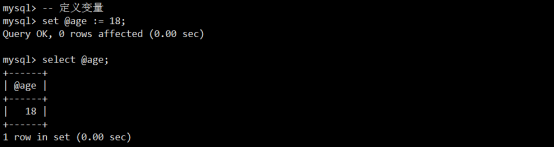
mysql允许从数据表中获取数据,然后赋值给变量:两种方式
方案1:边赋值,边查看结果
语法:
select @变量名 := 字段名 from 数据源; -- 从字段中取值并赋值给变量;如果使用=会变成
eg:
-- 从表中获取数据并赋值给变量
select @name := name,name from student;
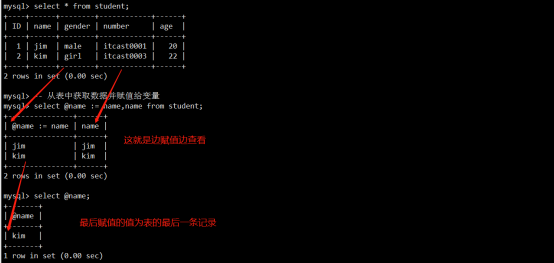
ps:方案1,在实际中,用的比较少,因为实际中,大多只需要看赋值后的最终的值

方案2:只有赋值不看结果->要求很严格,数据记录最多只允许获取一条;mysql不支持数组(无数组的概念)
语法:
select 字段列表 from 表名 into 变量列表;

ps:所有自定义的变量都是会话级别,当前客户端当次连接有效
所有自定义变量不区分数据库(用户级别)
MySQL的日志管理
参考资料:https://blog.csdn.net/chenrui310/article/details/80011774
这篇文章主要介绍了MySQL日志管理详解,本文讲解了日志种类、日志功能、MySQL中日志相关常用的服务器变量说明等内容,需要的朋友可以参考下日志文件对于一个服务器来说是非常重要的,它记录着服务器的运行信息,许多操作都会写日到日志文件,通过日志文件可以监视服务器的运行状态及查看服务器的性能,还能对服务器进行排错与故障处理,MySQl中有六种不同类型的日志。
日志的分类
- 一般查询日志:记录建立的客户端连接和执行的语句
log、general_log、log_output
- 慢查询日志:记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询,可以帮我们定位服务器性能问题。
slow_log
- 二进制日志:任何引起或可能引起数据库变化的操作,主要用于复制和即时点恢复
binlog
- 错误日志:记录启动、运行或停止时出现的问题,一般也会记录警告信息
err_log
- 中继日志:从主服务器的二进制日志文件中复制而来的事件,并保存为的日志文件。
relay_log
- 事务表日志:记录InnoDB等支持事务的存储引擎执行事务时产生的日志
MySQL中对于日志文件的环境比变量非常多,可以使用以下命令来查看:
mysql> show global variables like '%log%';
+-----------------------------------------+---------------------------------+
| Variable_name | Value |
+-----------------------------------------+---------------------------------+
| back_log | 50 |
| binlog_cache_size | 32768 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_format | ROW |
| expire_logs_days | 0 |
| general_log | OFF |
| general_log_file | /var/run/mysqld/mysqld.log |
| innodb_flush_log_at_trx_commit | 1 |
| innodb_locks_unsafe_for_binlog | OFF |
| innodb_log_buffer_size | 1048576 |
| innodb_log_file_size | 5242880 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_mirrored_log_groups | 1 |
| log | OFF |
| log_bin | ON |
| log_bin_trust_function_creators | OFF |
| log_bin_trust_routine_creators | OFF |
| log_error | /var/log/mysqld.log |
| log_output | FILE |
| log_queries_not_using_indexes | OFF |
| log_slave_updates | ON |
| log_slow_queries | OFF |
| log_warnings | 1 |
| max_binlog_cache_size | 18446744073709547520 |
| max_binlog_size | 1073741824 |
| max_relay_log_size | 0 |
| relay_log | |
| relay_log_index | |
| relay_log_info_file | relay-log.info |
| relay_log_purge | ON |
| relay_log_space_limit | 0 |
| slow_query_log | OFF |
| slow_query_log_file | /var/run/mysqld/mysqld-slow.log |
| sql_log_bin | ON |
| sql_log_off | OFF |
| sql_log_update | ON |
| sync_binlog | 1 |
+-----------------------------------------+---------------------------------+
38 rows in set (0.00 sec)
日志的功能
错误日志
错误日志主要记录如下几种日志:
- 服务器启动和关闭过程中的信息
- 服务器运行过程中的错误信息
- 事件调度器运行一个事件时产生的信息
- 在从服务器上启动从服务器进程时产生的信息
错误日志定义:
可以用--log-error [ = file_name ]选项来指定mysqld保存错误日志文件的位置。如果没有给定file_name值,mysqld使用错误日志名host_name.err并在数据目录中写入日志文件。如果你执行FLUSH LOGS,错误日志用-old重新命名后缀并且mysqld创建一个新的空日志文件。(如果未给出--log-error选项,则不会重新命名)
错误日志一般有以上两个变量可以定义:
错误日志文件:log_error
启用警告信息:log_warnings (默认启用)
mysql> show global variables like "log_error";
+---------------+---------------------+
| Variable_name | Value |
+---------------+---------------------+
| log_error | /var/log/mysqld.log |
+---------------+---------------------+
1 row in set (0.00 sec)
mysql> show global variables like 'log_warnings';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_warnings | 1 |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show global variables like 'sql_warnings'; -- 8.x版本
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sql_warnings | OFF |
+---------------+-------+
1 row in set (0.00 sec)
ps:log_warnings表示是否把告警信息写入错误日志中->1表示写入,0表示不写入
一般查询日志
启动开关:general_log={ON|OFF}
日志文件变量:general_log_file [ =/PATH/TO/file]
全局日志开关:log={ON|OFF}该开关打开后,所有日志都会被启用,默认是关闭的
记录类型:log_output={TABLE|FILE|NONE}
log_output定义了日志的输出格式,可以是表、文件、NONE,若设置为NONE,则不启用日志,因此,要启用通用查询日志,需要至少配置general_log=ON,log_output={TABLE|FILE}。而general_log_file如果没有指定,默认名是host_name.log。由于一般查询使用量比较大,启用写入日志文件,服务器的I/O操作较多,会大大降低服务器的性能,所以默认为关闭的。
mysql> show global variables like "general_log";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| general_log | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show global variables like "general_log_file";
+------------------+----------------------------+
| Variable_name | Value |
+------------------+----------------------------+
| general_log_file | /var/run/mysqld/mysqld.log |
+------------------+----------------------------+
1 row in set (0.00 sec)
可以使用以下命令开启general_log:
mysql> set global general_log=1;
Query OK, 0 rows affected (0.00 sec)
mysql> show global variables like "general_log";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| general_log | ON |
+---------------+-------+
1 row in set (0.00 sec)
慢查询日志(默认关闭,实际环境建议开启)
查询超时时间:long_query_time
启动慢查日志:log_slow_queries={YES|NO}
启动慢查日志 : slow_query_log
日志记录文件:slow_query_log_file [= file_name ]
MySQL如果启用了slow_query_log=ON选项,就会记录执行时间超过long_query_time的查询(初始表锁定的时间不算作执行时间)。日志记录文件如果没有给出file_name值, 默认为主机名,后缀为·-slow.log·。如果给出了文件名,但不是绝对路径名,文件则写入数据目录。
mysql> show global variables like '%slow_query_log%';
+---------------------+---------------------------------+
| Variable_name | Value |
+---------------------+---------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/run/mysqld/mysqld-slow.log |
+---------------------+---------------------------------+
2 rows in set (0.00 sec)
mysql > set global slow_query_log='ON'
注:打开日志记录,一旦slow_query_log变量被设置为ON,mysql会立即开始记录。/etc/my.cnf里面可以设置上面MYSQL全局变量的初始值。
默认没有启用慢查询,为了服务器调优,建议开启。
mysql> show global variables like 'long_query_time'; -- 慢日志超出时间参数
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
ps:超长时间默认为10秒,超过了即为慢查询。

二进制日志(bin_log日志)
ps:
MySQL的很多默认设置并不适合生成环境,我们需要调整很多东西。给出两点提示:
- 切勿将二进制日志与数据文件放在同一设备;
- 可以临时通过sql_log_bin来控制二进制的写入;
二进制日志启动开关:log-bin [= file_name]
在5.6及以上版本一定要手动指定。5.6以下版本默认file_name为$datadir/mysqld-binlog,二进制日志用于记录所有更改数据的语句,主要用于复制和即时点恢复。二进制日志的主要目的是在数据库存在故障时,恢复时能够最大可能地更新数据库(即时点恢复),因为二进制日志包含备份后进行的所有更新,二进制日志还用于在主复制服务器上记录所有将发送给从服务器的语句。
mysql> SHOW GLOBAL VARIABLES LIKE '%log_bin%';
+---------------------------------+-----------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/binlog |
| log_bin_index | /var/lib/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+-----------------------------+
5 rows in set (0.00 sec)
使用命令mysqlbinlog查看二进制日志内容:
基本语法:
mysqlbinlog [options] log-files
常用选项(类似字节偏移数):
--start-position:开始位置--stop-position:结束位置--start-datetime 'yyyy-mm-dd hh:mm:ss':开始时间--stop-datetime 'yyyy-mm-dd hh:mm:ss':结束时间
二进制日志文件内容格式:
-
事件发生的日期和时间(会在关键字"at")
-
服务器ID(server-id)
-
事件结束位置(end_log_pos)
-
事件的类型(如:Query,Stop等等)
-
原服务器生成此事件时的线程ID号(thead_id,可以通过"show processlist;"进行查询)
-
语句时间戳和写入二进制文件的时间差,单位为秒(exec_time,表示记录日志所用的时间戳,当他等于0时表示没有用到1秒钟。)
-
错误代码,0表示正常执行(error_code,排查方法就得查看官方文档。)
-
事件内容(修改的SQL语句)
-
事件位置(相当于下一事件的开始位置,还是用"at"关键字标志)
二进制日志的格式:
-
基于语句: statement
-
基于行: row
-
混合方式: mixed
由于基于语句和基于行的日志格式都有自己的好处,MySQL使用的二进制日志文件是混合方式的二进制日志,内置策略会自动选择最佳的格式。
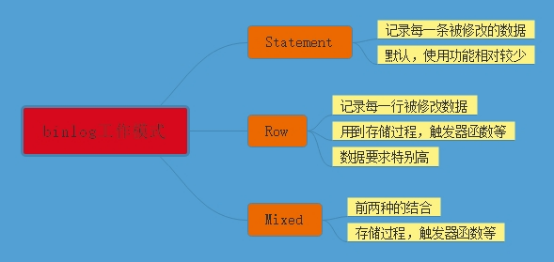
二进制日志事件:
-
产生的时间:starttime
-
相对位置:position
二进制日志文件:
-
索引文件
-
二进制日志文件
在数据目录下有一个mysql-bin.index便是索引文件,以mysql-bin开头并以数字结尾的文件为二进制日志文件。
日志的滚动:
MySQL的滚动方式与其他日志不太一样,滚动时会创建一个新的编号大于1的日志用于记录最新的日志,而原日志名字不会被改变。每次重启MySQL服务,日志都会自动滚动一次。
另外如果需要手动滚动,则使用命令:
mysql> flush logs; -- 刷新日志
Query OK, 0 rows affected (0.02 sec)
mysql> show master status; -- 查看当前正在使用的二进制文件
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000033 | 107 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
ps:其默认的position是从107开始的
mysql> show binary logs; -- 查看所有的二进制文件
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 125 |
| mysql-bin.000002 | 125 |
| mysql-bin.000003 | 125 |
| mysql-bin.000004 | 901 |
| mysql-bin.000005 | 1048 |
| mysql-bin.000006 | 1165 |
| mysql-bin.000007 | 125 |
| mysql-bin.000008 | 106 |
| mysql-bin.000009 | 149 |
| mysql-bin.000010 | 149 |
| mysql-bin.000011 | 106 |
+------------------+-----------+
11 rows in set (0.00 sec)
mysql> use test;
Database changed
mysql> insert into my_auto values (8,'咪咪');
Query OK, 1 row affected (0.00 sec)
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000011 | 341 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
ps:插入数据后,position已经发生改变了。
mysql> insert into my_auto values (9,'美眉'); #再插入一条数据
Query OK, 1 row affected (0.00 sec)
mysql> show binlog events in 'mysql-bin.000011'; #查看二进制文件中记录的内容
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
| mysql-bin.000011 | 4 | Format_desc | 1 | 106 | Server ver: 5.1.73-log, Binlog ver: 4 |
| mysql-bin.000011 | 106 | Query | 1 | 174 | BEGIN |
| mysql-bin.000011 | 174 | Table_map | 1 | 223 | table_id: 16 (test.my_auto) |
| mysql-bin.000011 | 223 | Write_rows | 1 | 272 | table_id: 16 flags: STMT_END_F |
| mysql-bin.000011 | 272 | Query | 1 | 341 | COMMIT |
| mysql-bin.000011 | 341 | Query | 1 | 409 | BEGIN |
| mysql-bin.000011 | 409 | Table_map | 1 | 458 | table_id: 16 (test.my_auto) |
| mysql-bin.000011 | 458 | Write_rows | 1 | 506 | table_id: 16 flags: STMT_END_F |
| mysql-bin.000011 | 506 | Query | 1 | 575 | COMMIT |
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
9 rows in set (0.00 sec)
mysql> show binlog events in 'mysql-bin.000033' from 407; #也可以从某个位置查看二进制文件
+------------------+-----+------------+-----------+-------------+--------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+------------+-----------+-------------+--------------------------------+
| mysql-bin.000011 | 409 | Table_map | 1 | 458 | table_id: 16 (test.my_auto) |
| mysql-bin.000011 | 458 | Write_rows | 1 | 506 | table_id: 16 flags: STMT_END_F |
| mysql-bin.000011 | 506 | Query | 1 | 575 | COMMIT |
+------------------+-----+------------+-----------+-------------+--------------------------------+
3 rows in set (0.00 sec)
mysql> purge binary logs to 'mysql-bin.000006'; #删除某个序号之前的日志文件
Query OK, 0 rows affected (0.04 sec)
mysql> show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000006 | 1165 |
| mysql-bin.000007 | 125 |
| mysql-bin.000008 | 106 |
| mysql-bin.000009 | 149 |
| mysql-bin.000010 | 149 |
| mysql-bin.000011 | 575 |
+------------------+-----------+
6 rows in set (0.00 sec)
mysql> show global variables like 'sql_log_bin'; -- 当前会话是否将二进制文件写入进二进制文件,默认为ON;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sql_log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show global variables like 'sql_log_off'; -- 是否将一般查询日志记入查询日志
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sql_log_off | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show global variables like 'sync_binlog'; -- 同步缓冲中的二进制到硬盘的时间,0不基于时间同步,只在事件提交时同步
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sync_binlog | 1 |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show global variables like 'binlog_format'; -- 指定记录二进制日志的格式,有三种格式:基于语句(statement)、基于行(row)、混合模式(mixed)
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show global variables like 'max_binlog_cache_size'; -- mysql二进制日志的缓冲区大小,仅用于缓存事务类的语句
+-----------------------+----------------------+
| Variable_name | Value |
+-----------------------+----------------------+
| max_binlog_cache_size | 18446744073709547520 |
+-----------------------+----------------------+
1 row in set (0.00 sec)
中继日志
从服务器上的二进制日志。简单的说中继日志其实就是从主服务器上的二进制日志中取数据,然后写入中继日志里面,在从服务器上,执行中继日志的sql信息,这样从服务器就会得到和主服务器一样的内容,与此同时每次执行之后从服务器的二进制日志也会记录,聪明的你可能也会想到,这个从服务器的二进制日志内容应该是和主服务器是一致的,所以我们通常采取的操作就是将从服务器的二进制日志关闭掉。
relay_log[= file_name]
对于非从服务器的中继日志并没有启用,可能会用到以下两个参数:
relay_log_purge = {ON|OFF} 是否自动清理不在需要的中继日志
relay_log_space_limit 中继(空间)大小是否限制
mysql> show global variables like 'relay_log%';
+---------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------+------------------------------------------+
| relay_log | percona-0-relay-bin |
| relay_log_basename | /var/lib/mysql/percona-0-relay-bin |
| relay_log_index | /var/lib/mysql/percona-0-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | TABLE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
+---------------------------+------------------------------------------+
8 rows in set (0.00 sec)
事务日志
事务性存储引擎用于保证(ACID)原子性、一致性、隔离性和持久性;其不会立即写到数据文件中,而是写到事务日志中。
innodb_flush_log_at_trx_commit
-
0: 每秒同步,并执行磁盘flush操作;
-
1: 每事务同步,并执行磁盘flush操作;
- 2: 每事务同步,但不执行磁盘flush操作;
mysql> show global variables like 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
1 row in set (0.00 sec)
MySQL中日志相关常用的服务器变量说明
log={YES|NO}
是否启用记录所有语句的日志信息于一般查询日志(general query log)中,默认通常为OFF。MySQL 5.6已经弃用此选项。
general_log={ON|OFF}
设定是否启用查询日志,默认值为取决于在启动mysqld时是否使用了--general_log选项。如若启用此项,其输出位置则由--log_output选项进行定义,如果log_output的值设定为NONE,即使用启用查询日志,其也不会记录任何日志信息。作用范围为全局,可用于配置文件,属动态变量。
general_log_file=FILE_NAME
查询日志的日志文件名称,默认为hostname.log。作用范围为全局,可用于配置文件,属动态变量。
log_output={TABLE|FILE|NONE}
定义一般查询日志和慢查询日志的保存方式,可以是TABLE、FILE、NONE,也可以是TABLE及FILE的组合(用逗号隔开),默认为TABLE。如果组合中出现了NONE,那么其它设定都将失效,同时,无论是否启用日志功能,也不会记录任何相关的日志信息。作用范围为全局级别,可用于配置文件,属动态变量。
log-bin={YES|NO}
是否启用二进制日志,如果为mysqld设定了--log-bin选项,则其值为ON,否则则为OFF。其仅用于显示是否启用了二进制日志,并不反应log-bin的设定值。作用范围为全局级别,属非动态变量。
log_bin_trust_function_creators={TRUE|FALSE}
此参数仅在启用二进制日志时有效,用于控制创建存储函数时如果会导致不安全的事件记录二进制日志条件下是否禁止创建存储函数。默认值为0,表示除非用户除了CREATE ROUTING或ALTER ROUTINE权限外还有SUPER权限,否则将禁止创建或修改存储函数,同时,还要求在创建函数时必需为之使用DETERMINISTIC属性,再不然就是附带READS SQL DATA或NO SQL属性。设置其值为1时则不启用这些限制。作用范围为全局级别,可用于配置文件,属动态变量。
binlog-format={ROW|STATEMENT|MIXED}
指定二进制日志的类型,默认为STATEMENT,建议更改为MIXED。如果设定了二进制日志的格式,却没有启用二进制日志,则MySQL启动时会产生警告日志信息并记录于错误日志中。作用范围为全局或会话,可用于配置文件,且属于动态变量。
expire_logs_days={0..99}
设定二进制日志的过期天数,超出此天数的二进制日志文件将被自动删除。默认为0,表示不启用过期自动删除功能。如果启用此功能,自动删除工作通常发生在MySQL启动时或FLUSH日志时。作用范围为全局,可用于配置文件,属动态变量。
log_error=/PATH/TO/ERROR_LOG_FILENAME
定义错误日志文件。作用范围为全局或会话级别,可用于配置文件,属非动态变量。
log_query_not_using_indexes={ON|OFF}
设定是否将没有使用索引的查询操作记录到慢查询日志。作用范围为全局级别,可用于配置文件,属动态变量。
log_slave_updates
用于设定复制场景中的从服务器是否将从主服务器收到的更新操作记录进本机的二进制日志中。本参数设定的生效需要在从服务器上启用二进制日志功能。
slow_query_log={YES|NO}
是否记录慢查询日志。慢查询是指查询的执行时间超出long_query_time参数所设定时长的事件。作用范围为全局级别,可用于配置文件,属动态变量。
long_query_time=
设定区别慢查询与一般查询的语句执行时间长度。这里的语句执行时长为实际的执行时间,而非在CPU上的执行时长,因此,负载较重的服务器上更容易产生慢查询。其最小值为0,默认值为10,单位是秒钟。它也支持毫秒级的解析度。作用范围为全局或会话级别,可用于配置文件,属动态变量。
sql_warnings=
设定是否将警告信息记录进错误日志。默认设定为1,表示启用;可以将其设置为0以禁用;而其值为大于1的数值时表示将新发起连接时产生的"失败的连接"和"拒绝访问"类的错误信息也记录进错误日志。
max_binlog_cache_size{4096 .. 18446744073709547520}
二进制日志缓存空间大小,5.5.9及以后的版本仅应用于事务缓存,其上限由max_binlog_stmt_cache_size决定。作用范围为全局级别,可用于配置文件,属动态变量。
max_binlog_size={4096 .. 1073741824}
设定二进制日志文件上限,单位为字节,最小值为4K,最大值为1G,默认为1G。某事务所产生的日志信息只能写入一个二进制日志文件,因此,实际上的二进制日志文件可能大于这个指定的上限。作用范围为全局级别,可用于配置文件,属动态变量。
max_relay_log_size={4096..1073741824}
设定从服务器上中继日志的体积上限,到达此限度时其会自动进行中继日志滚动。此参数值为0时,mysqld将使用max_binlog_size参数同时为二进制日志和中继日志设定日志文件体积上限。作用范围为全局级别,可用于配置文件,属动态变量。
innodb_log_buffer_size={262144 .. 4294967295}
设定InnoDB用于辅助完成日志文件写操作的日志缓冲区大小,单位是字节,默认为8MB。较大的事务可以借助于更大的日志缓冲区来避免在事务完成之前将日志缓冲区的数据写入日志文件,以减少I/O操作进而提升系统性能。因此,在有着较大事务的应用场景中,建议为此变量设定一个更大的值。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_log_file_size={108576 .. 4294967295}
设定日志组中每个日志文件的大小,单位是字节,默认值是5MB。较为明智的取值范围是从1MB到缓存池体积的1/n,其中n表示日志组中日志文件的个数。日志文件越大,在缓存池中需要执行的检查点刷写操作就越少,这意味着所需的I/O操作也就越少,然而这也会导致较慢的故障恢复速度。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_log_files_in_group={2 .. 100}
设定日志组中日志文件的个数。InnoDB以循环的方式使用这些日志文件。默认值为2。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_log_group_home_dir=/PATH/TO/DIR
设定InnoDB重做日志文件的存储目录。在缺省使用InnoDB日志相关的所有变量时,其默认会在数据目录中创建两个大小为5MB的名为ib_logfile0和ib_logfile1的日志文件。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_support_xa={TRUE|FLASE}
存储引擎事务在存储引擎内部被赋予了ACID属性,分布式(XA)事务是一种高层次的事务,它利用"准备"然后"提交"(prepare-then-commit)两段式的方式将ACID属性扩展到存储引擎外部,甚至是数据库外部。然而,"准备"阶段会导致额外的磁盘刷写操作。XA需要事务协调员,它会通知所有的参与者准备提交事务(阶段1)。当协调员从所有参与者那里收到"就绪"信息时,它会指示所有参与者进行真正的"提交"操作。
此变量正是用于定义InnoDB是否支持两段式提交的分布式事务,默认为启用。事实上,所有启用了二进制日志的并支持多个线程同时向二进制日志写入数据的MySQL服务器都需要启用分布式事务,否则,多个线程对二进制日志的写入操作可能会以与原始次序不同的方式完成,这将会在基于二进制日志的恢复操作中或者是从服务器上创建出不同原始数据的结果。因此,除了仅有一个线程可以改变数据以外的其它应用场景都不应该禁用此功能。而在仅有一个线程可以修改数据的应用中,禁用此功能是安全的并可以提升InnoDB表的性能。作用范围为全局和会话级别,可用于选项文件,属动态变量。
relay_log=file_name
设定中继日志的文件名称,默认为host_name-relay-bin。也可以使用绝对路径,以指定非数据目录来存储中继日志。作用范围为全局级别,可用于选项文件,属非动态变量。
relay_log_index=file_name
设定中继日志的索引文件名,默认为为数据目录中的host_name-relay-bin.index。作用范围为全局级别,可用于选项文件,属非动态变量。
relay-log-info-file=file_name
设定中继服务用于记录中继信息的文件,默认为数据目录中的relay-log.info。作用范围为全局级别,可用于选项文件,属非动态变量。
relay_log_purge={ON|OFF}
设定对不再需要的中继日志是否自动进行清理。默认值为ON。作用范围为全局级别,可用于选项文件,属动态变量。
relay_log_space_limit=
设定用于存储所有中继日志文件的可用空间大小。默认为0,表示不限定。最大值取决于系统平台位数。作用范围为全局级别,可用于选项文件,属非动态变量。
slow_query_log={ON|OFF}
设定是否启用慢查询日志。0或OFF表示禁用,1或ON表示启用。日志信息的输出位置取决于log_output变量的定义,如果其值为NONE,则即便slow_query_log为ON,也不会记录任何慢查询信息。作用范围为全局级别,可用于选项文件,属动态变量。
slow_query_log_file=/PATH/TO/SOMEFILE
设定慢查询日志文件的名称。默认为hostname-slow.log,但可以通过--slow_query_log_file选项修改。作用范围为全局级别,可用于选项文件,属动态变量。
sql_log_off={ON|OFF}
用于控制是否禁止将一般查询日志类信息记录进查询日志文件。默认为OFF,表示不禁止记录功能。用户可以在会话级别修改此变量的值,但其必须具有SUPER权限。作用范围为全局和会话级别,属动态变量。
sync_binlog=
设定多久同步一次二进制日志至磁盘文件中,0表示不同步,任何正数值都表示对二进制每多少次写操作之后同步一次。当autocommit的值为1时,每条语句的执行都会引起二进制日志同步,否则,每个事务的提交会引起二进制日志同步。 建议设置为1,但是也是最慢的。
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。