- nginx的历史
- nginx的功能特性
- 常见功能介绍
- 特点:高效、可靠、开源
- 作用
- 技术(4个主要技术)
- 学习环境
- 安装Nginx(yum安装)
- 安装nginx(rpm安装)
- 安装Nginx(源码包安装1.14)
- 对nginx的配置文件语法高亮设置
- Nginx基本配置指令(重点)
- conf目录中内容
- A、全局块配置
- B、events块配置 ->I/O事件配置
- C、http块配置
- D、server块
- E、location指令
- 配置运行nginx服务器用户、用户组
- 配置允许生成的worker process数
- 配置nginx主进程pid存放路径
- 配置错误日志的存放路径
- 配置文件的引入
- 设置网络连接的序列化
- 设置是否允许同时接收多个网络连接
- 事件驱动模型选择
- 配置最大连接数
- 定义MIME-type
- 自定义服务日志
- 配置允许sendfile方式传输文件
- 配置连接超时时间
- 单连接请求上限
- 配置网络监听
- 配置主机名称
- http完整配置-1及详解
- http完整配置-2及详解
- nginx.conf
- nginx一键生成配置文件
- Nginx模块(面试必问)
- Nginx内置绑定变量
- 如何获取用户真实IP地址信息
- HTTP请求
- 静态资源web服务
- nginx服务器的web请求机制
- nginx服务器的事件处理机制
- nginx服务器架构
- nginx服务器的进程
- nginx服务器的高级配置
- nginx服务器的Gzip压缩
- Nginx的请求限制(高并发系统是如何做限流的?)
- If指令
- break指令
- set指令
- nginx的location作用
- try_files指令说明->按照顺序检查文件是否存在
- return的配置说明->跳转
- rewrite规则->跳转
- 跳转3种方式
- error-page
- Nginx访问状态监控
- 一个小工具帮你搞定实时监控Nginx服务器
- Nginx共享文件web页面(download)
- nginx+fancyindex漂亮目录浏览带搜索功能
- 访问控制
- nginx虚拟主机
- Nginx的alias和root的区别->虚拟目录
- Nginx优化(重点)
- 代理服务(重点)
- 代理类型
- 正向代理
- 反向代理
- 概述
- 反向代理的基本设置的21个相关指令
- proxy_pass指令
- proxy_redirect指令
- proxy_set_header指令
- proxy_send_timeout指令
- proxy_read_timeout指令
- proxy_connect_timeout指令
- proxy_intercept_errors指令
- proxy_headers_hash_max_size指令
- proxy_headers_hash_bucket_size
- proxy_next_upstream指令
- proxy_ssl_session_reuse
- proxy_pass_header指令
- proxy_hide_header指令
- proxy_pass_request_body指令
- proxy_set_body指令
- proxy_bind指令
- proxy_http_version指令
- proxy_method指令
- proxy_ignore_client_abort指令
- proxy_ignore_headers指令
- proxy buffer的配置的7个指令
- proxy Cache的配置的12个指令
- nginx 反向代理时丢失端口的解决方案
- nginx 浏览器的缓存问题(不缓存add_header Cache-Control )
- 实例
- 实例
- 实例:反向代理负载均衡的应用架构
- 正、反向代理的区别
- nginx stream模块-->基于4层(tcp)代理
- 负载均衡(重点)基于OSI的7层负载
- Nginx 基于nginx-sticky-module模块进行会话保持
- 缓存服务(重点)
- 动静分离(重点)
- https服务
- 如何在根 CA 下生成服务器和客户端证书
- 阿里云的个人博客添加免费的HTTPS证书
- HTTP状态码(HTTP Status Code)
- 陷进和常见错误
- 跨域访问
- 高级模块
- 读取地域信息模块geoip
- nginx与Lua(鲁瓦)的开发(实现代码的灰度发布)
- 基于 Nginx+lua+Memcache企业场景->实现灰度发布
- Nginx架构的安全(sql注入)
- 系统与Nginx的性能优化
- 性能优化
- Nginx静态资源服务的功能设计
- Nginx作为代理服务器的需求
- 需求设计评估
http://nginx.org/
https://github.com/dunwu/nginx-tutorial
nginx的历史
Netcraft公司,1994年在英国成立,官方网址为http://uptime.netcraft.com,该公司为互联网市场以及在线安全方面提供咨询服务,同时针对网站服务器、域名解析、主机提供商以及SSL市场进行客观严谨的分析研究。
nginx的官方网站http://www.nginx.org,同时wiki为nginx开设了专门的介绍页面,链接为http://wiki.nginx.org/Main
nginx服务器是轻量级web服务器,2002年第一个版本发布,是开源的高性能httd服务器及反向代理服务器(reverse proxy)产品,同时,它还可以提供IMAP/POP3代理服务器等功能。在实际的使用中,nginx还可以提供更多更丰富的功能。

Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日。其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名。2011年6月1日,nginx 1.0.4发布
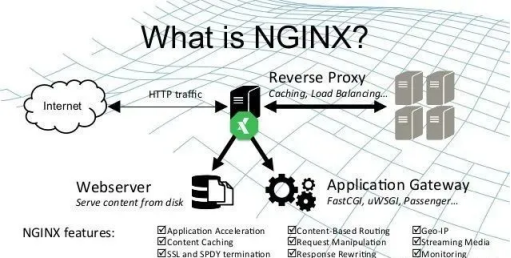
nginx的功能特性
nginx既可以作为http服务器,也可以作为方向代理服务器或者邮件服务器,能够快速响应静态页面(HTML)的请求,支持fastcgi、ssl、virtual host、URL rewrite、http basic auth、gzip等大量使用功能,并且支持更多的第三方功能模块的扩展
-
nginx提供基本http服务,可以作为http代理服务器和方向代理服务器,支持通过缓存加速访问,可以完成简单的负载均衡和容错,支持包括过滤功能,支持ssl等
-
nginx提供高级http服务,可以进行自定义配置,支持虚拟主机,支持URL重定向,支持网络监控,支持流媒体传输
-
nginx作为邮件代理服务器是最早开发这个产品的目的之一,它支持IMAP/pop3代理服务功能,支持内部smtp代理服务功能
基本http服务
-
处理静态文件(如HTML静态网页及请求),处理索引文件及支持自动索引
-
打开并自行管理文件描述符缓存
-
提供反向代理服务,并且可以使用缓存加速反向代理,同时完成简单的负载均衡及容错
-
提供远程fastcgi服务的缓存机制,加速访问,同时完成简单的负载均衡以及容错
-
使用nginx的模块化特性提供过滤器功能。nginx基本过滤包括gzip压缩、ranges支持、chunked响应、xslt、ssl以及图像缩放等。其中,针对包含多个ssi的页面,经由fastcgi或方向代理,ssi过滤可以进行处理
-
支持http下的安全套接层安全协议ssl
高级http服务
-
支持基于域名和ip及端口的虚拟主机设置
-
支持http/1.0中的keep-alive模式和管线(pipelined)模型连接
-
支持重新加载配置以及在线升级时,无须中断正在处理的请求
-
自定义访问日志格式、带缓存的日志写操作以及快速日志轮询
-
提供3xxx-5xxx错误代码重定向功能。
-
支持重写rewrite模块功能
-
支持http dav模块,从而为http webdav提供put、delet、mkcol、copy以及move方法
-
支持flv流很热MP4流传输
-
支持网络监控,包括基于客户端ip地址、http基本认证机制的访问控制、速度限制、来自同一地址的同时连接数或者请求数限制等
-
支持嵌入perl语言
邮件代理服务
-
支持使用外部http认证服务器重定向用户到IMAP/POP3后端,并支持IMAP认证方式(LOGIN、AUTH LOGIN/PLAIN/CRAM-MD5)和POP3认证方式(USER/PASS、APOP、AUTH LOGIN/PLAIN/CRAM-MD5)
-
支持使用外部http认证服务器认证用户后重定向连接到内部SMTP后端,并支持SMTP认证方式(AUTH LOGIN/PLAIN/CRAM-MD5)
-
支持邮件代理服务下的安全套接层安全协议ssl
-
支持纯文本通信协议的扩展协议starttls
常见功能介绍
http代理和方向代理
代理服务及反向代理服务是nginx服务器作为web服务器的主要功能之一,尤其是反向代理服务,是应用十分广泛的功能
在提供反向代理服务方面,nginx服务器转发前端请求性能稳定,并且后端转发与业务配置相互分离,配置相当灵活。在进行nginx服务器配置时,配置后端转发请求完全不用关心网络环境如何,可以指定任意的ip地址和端口号,或者其他类型连接、请求等
它支持判断表达式。通过使用正则表达式进行相关配置、可以实现根据不同表达式、采取不同的转发策略。它对后端返回情况进行异常判断,如果返回结果不正常,则重新请求另一台主机(即将前端请求转向另一后端ip),并且自动剔除返回异常的主机。它还支持错误页面跳转功能
负载均衡
负载均衡一般包含两方面的含义。一方面:将单一的重负载分担到多个网络节点上做并行处理,每个节点处理结束后将结果汇总返回给用户,这样可以大幅度提高网络系统的处理能力;第二个方面:将大量的前端并发访问或者数据流量分担到多个后端网络节点上分别处理,这样就可以减少前端用户等待响应的时间。 web服务器、ftp服务器、企业关键应用服务器等网络应用方面谈到的负载均衡问题,基本隶属于后一方面的含义。因此,nginx服务器的负载均衡主要是针对大量前端访问和流量进行分流,以保证前端用户访问效率。可以说,在绝大数nginx应用中,都会或多或少涉及它的负载均衡服务
nginx服务器的负载均衡策略可以分两大类:即内置策略和扩展策略。内置策略主要包含轮询、加权轮询和IP hash三种;扩展策略主要通过第三方模块实现,种类比较丰富,常见的有url hash、fair等
在默认情况下,内置策略会被编译进nginx内核,使用时只需在nginx服务器配置中设置相关参数即可。扩展策略不会编译到nginx内核,需要手动将第三方模块编译到nginx内核
几种负载策略的实现原理
- 轮询策略,比较简单,就是讲每个前端的请求顺序(时间顺序或者排列次序)逐一分配到不同的后端节点上,对于出现问题的后端节点自动排除。
- 加权轮询策略,顾名思义,就是在基本的轮询策略上考虑各后盾节点接受请求的权重,指定各个后端节点被轮询的几率。加权轮询主要是用于后端节点性能不均的情况。根据后端节点性能的实际情况,我们可以在nginx服务器的配置文件中进行权值的调整,使得整个网络对前端请求达到最佳的响应能力
-
ip hash策略,是将前端的访问ip进行hash操作,然后根据hash结果将请求分配给不同的后端节点。事实上,这种策略可以看做是一种特殊的轮询策略。通过nginx的实现,每个前端访问ip会固定访问一个后端节点。这样做的好处是避免考虑前端用户的session在后端多个节点上共享的问题
-
扩展策略中的url hash在形式上和ip hash相近,不同之在于,ip hash策略是对前端访问ip进行了hash操作,而url hash策略是对 前端请求额url进行了hash操作。url hash策略的优点在于,如果后端有缓存服务器,它能够提供缓存效率,同时也也解决session的问题,但是其缺点是,如果后端出现异常,他不能自动排除异常,不能自动排除节点。在实际使用过程中发现,后端节点出现异常会导致nginx服务器返回503错误。
-
扩展的第三方模块fair,是从另一角度来实现nginx服务器负载均衡策略的。该模块将前端请求转发到一个最近负载最小的后端节点。那么,负载最小怎么判断呢?nginx通过后端节点对请求的响应时间来判断负载情况。响应时间短的节点负载相对就轻。得出结果后,nginx就将前端请求转发到选中的负载最轻的节点
web缓存
相信不少读者对squid有所了解。它在web服务器领域中是一款相当流行的开源代理服务器和web缓存服务器。作为网页的服务器的前置缓存服务器,在很多优秀的站点中,它被用以缓存前端请求,从而提高web服务器的性能;而且,他还可以缓存万维网、域名系统或者其他网络搜索,为一个整体提供网络资源共享服务
nginx在0.7.48版本开始,也支持了和squid类型的缓存功能。
nginx服务器的web缓存服务主要由proxy_cache相关指令集和fastcgi_cache相关指令集构成。其中,proxy_cache主要用于在nginx服务器提供方向代理服务时,对后端资源服务器的返回内容进行url缓存。fgastcgi_cache主要用于对fastcgi的动态程序进行缓存。另外还有一款常用的第三方模块ngx_cache_purge也是nginx服务器web缓存功能中经常用到的,它主要用于清除nginx服务器上的指定的url缓存
到nginx08.32版本后,proxy_cache和fastcgi_cache两部分的功能已经比较完善,再配合第三方的ngx_cache_purge模块,nginx服务器已具备了squid所有拥有的web缓存加速功能和清除指定url缓存功能;同时nginx服务器对多核CPU的调度比squid更胜一筹,性能高于squid,而在反向代理、负载均衡等其他方面,nginx也 不逊于squid。这使得nginx服务器可以同时作为负载均衡服务器和web缓存服务器来使用,基本可以取代squid
特点:高效、可靠、开源
高效:支持海量的并发请求
可靠:稳定性好、运行可靠
开源:
-
支持高并发:能支持几万并发连接(特别是静态小文件业务环境)
-
资源消耗少:在3万并发连接下,开启10个Nginx线程消耗的内存不到200MB
-
可以做HTTP反向代理及加速缓存、即负载均衡功能,内置对RS节点服务器健康检查功能,这相当于专业的Haproxy软件或LVS的功能。
-
具备Squid等专业缓存软件等的缓存功能。
-
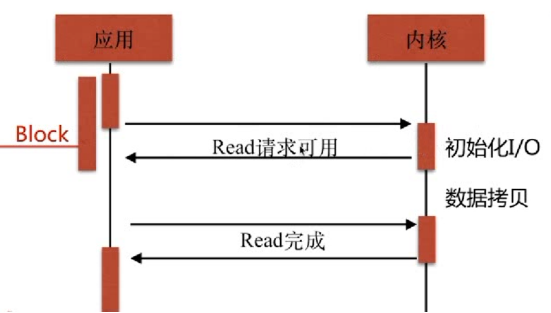
支持异步网络I/O事件模型epoll(Linux 2.6+)(绘图说明同步和异步)
大并发写操作;先写内存,再将内存数据存储到硬盘中---保证访问效率
大并发读操作;先写磁盘,再将磁盘数据存储到内存中---保证数据安全
总结:高并发-->资源消耗少-->功能多样(web服务/负载均衡/支持缓存)-->通讯模型先进(epoll)
作用
解决c10k问题->https://moonbingbing.gitbooks.io/openresty-best-practices/web/c10k.html
实现反向代理及电子邮件(IMAP/POP3)代理服务器
实现缓存功能
实现负载均衡
技术(4个主要技术)
IO多路复用:
多个描述符的I/O操作都能在一个线程内并发交替的顺序完成,这就叫I/O多路复用,这里的"复用"指的是复用同一个线程。

举例:由A学生报备自己做完的情况,然后在由老师来解答这个学校的疑惑,因为A学生比较优秀,其他的同学还没有做完,等做完了,老师也解答完了,然后在给下个做完的同学解答
epoll模型:

3、IO多路复用epoll
IO多路复用的实现方式有:select、poll、epoll
select方式缺点:
-
能够监视文件描述符的数量存在最大限制
-
线性扫描效率低下
select方式优点:
- Windows、linux都支持
epoll方式优点:
-
没有最大并发连接的限制
-
效率提升,不是轮询的方式,不会随着FD数目的增加效率下降
轻量级

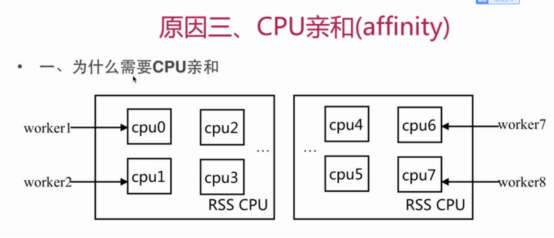
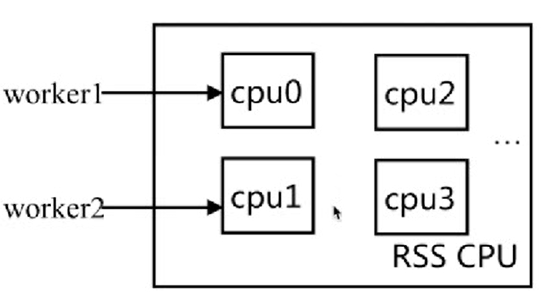
cpu亲和
CPU亲和是一种把CPU核心和Nginx工作进程绑定方式,把每个worker进程固定在一个CPU上执行,减少切换CPU的cache miss,获得更好的性能。
sendfile
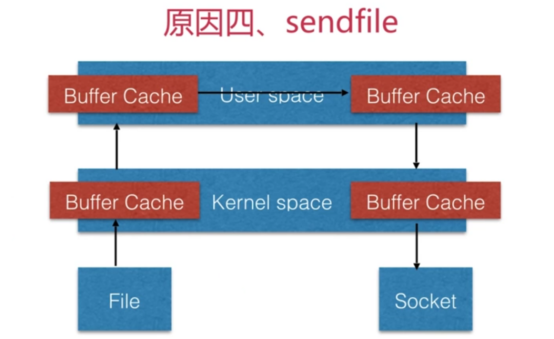
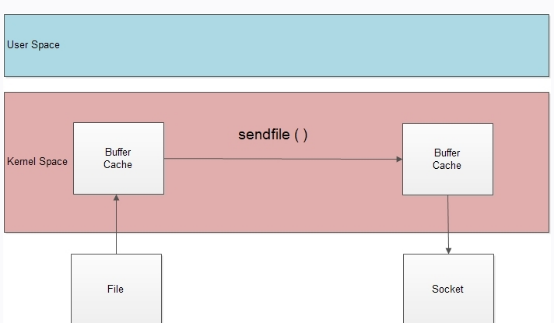
这个模式针对静态文件处理速度非常之快。
学习环境
nginx软件包总共不到20M的磁盘空间,实际情况可能因为编译设置不同会有所不同,但是至少保证有20M以上的空间吧



# yum -y install gcc gcc-c++ autoconf pcre pcre-devle make automake httpd-tools

安装Nginx(yum安装)
进入官网下载yum源:http://nginx.org/
进入稳定版本下载链接地址:
把官网的yum源复制到服务器上面,并修改一下信息
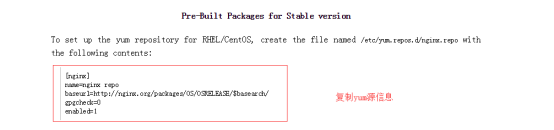
修改如下(修改原因:我们用的是centos,并且是7版本的系统)

查看yum源是否可用,如果可用-->然后进行安装Nginx
[root@test-7 ~]# yum list | grep nginx
[root@test-7 ~]# yum install nginx -y
在次查看版本信息,如果出现下面内容,说明安装成功
[root@test-7 ~]# nginx -v
nginx version: nginx/1.14.2
[root@test-7 ~]# nginx -V
nginx version: nginx/1.14.2
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC)
built with OpenSSL 1.0.2k-fips 26 Jan 2017
TLS SNI support enabled
configure arguments: --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log ……………………--with-stream_realip_module --with-stream_ssl_module --with-stream_ssl_preread_module --with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fPIC' --with-ld-opt='-Wl,-z,relro -Wl,-z,now -pie'
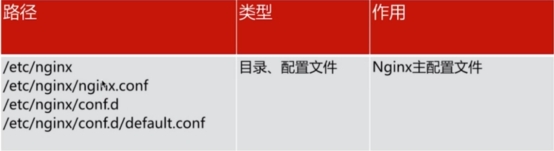
Nginx的安装目录详解
查看软件安装的位置:
[root@test-7 ~]# rpm -ql nginx
etc下面主要放置Nginx的主要配置















安装nginx(rpm安装)
下载地址:我们是centos7 x86_64系统
https://nginx.org/packages/centos/7/x86_64/RPMS/nginx-1.20.2-1.el7.ngx.x86_64.rpm
rpm -ivh --test nginx-1.20.2-1.el7.ngx.x86_64.rpm
rpm -ivh nginx-1.20.2-1.el7.ngx.x86_64.rpm
安装Nginx(源码包安装1.14)
nginx服务器版本包括Windows和linux,在官网就能找到对应的下载链接。
网页上提供了nginx服务器三种版本的下载,分别是开发版本(Development version)、稳定版本(Stable version)和过期版本(Legacy version)。其中,开发版本主要用于nginx软件项目的研发(其中,开发版本同时也是nginx全部版本中最新的版本),稳定版本即可以作为web服务器投入使用
下载链接各部分的含义:
- CHANGES-x.xx链接,记录的是对应版本的功能变更日志。包括新增功能,功能的优化和功能缺陷的修复。
- nginx-x.x.x链接,是nginx服务器linux版本下载链接,下载后的文件后缀名以.tar.gz结尾
- pgp链接,记录的是提供下载的版本使用pgp加密自由软件GunPG计算后的签。GPG可以解释为Pretty Good Privacy,是PGP公司的加密或者签名工具套件。点击链接进入相关页面,可以查看GunPG针对下载版本的签名,已经执行本次计算的GunPGP软件版本号。这些数据可以用于下载文件的校验
- nginx/Windows-x.xx.x链接,是nginx服务器的Windows版本下载链接,下载后得到的文件后缀名是以.zip结尾的
准备编译环境
在安装Nginx之前,需确保系统已经安装了gcc openssl openssl-devel pcre-devel和zlib-devel软件库。
编译nginx源代码,需要标准的GCC编译器。GCC的全称为GUNCompiler Collection,其有GUN开发,并以GPL及LGPL许可证发行,是自由的类UNIX及苹果电脑Mac OS X 操作系统的标准编译器。因为GCC原本只能处理C语言,所有原名为GUN C语言编译器,后来得到快速发展,可处理C++、Fortran、Pascal、Objective-C、java以及Ada等其他语言
除此之外,我们还需要Automake工具,已完成自动创建Makefile文件的工作
由于nginx的一些模块需要依赖其他第三方库,通常有pcre库(支持rewrite模块)、zlib库(支持gzip模块)和openssl库(支持ssl模块)等
yum groupinstall 'Development Tools' -y #组包里面基本基本包含了一下软件包,可以直接安装这个组包就行了
yum install -y gcc gcc-c++ automake make autoconf pcre pcre-devel zlib zlib-devel openssl openssl-devel
(gzip模块需要 zlib 库,rewrite模块需要 pcre 库,ssl 功能需要openssl库)
注意的是,我们可以不需要安装autoconf工具。nginx软件的自动脚本不是用autoconf工具生成的,而是作者手工编写的。
创建系统用户
[root@test]# groupadd -r nginx
[root@test]# useradd -r -g nginx -s /sbin/nologin -M -c "create-time is `date +%Y/%m/%d` ;is web service" nginx
下载源码包并了解源码包的结构
[root@test nginx]# wget http://nginx.org/download/nginx-1.14.2.tar.gz #(下载源码包)
[root@test nginx]# tar zxf nginx-1.14.2.tar.gz #(解压源码包)
[root@test nginx]# ls
nginx-1.14.2 nginx-1.14.2.tar.gz
[root@test nginx]# cd nginx-1.14.2
了解nginx软件包的结构:
# ll
total 732
drwxr-xr-x. 6 1001 1001 4096 Nov 30 22:04 auto
-rw-r--r--. 1 1001 1001 288742 Dec 4 2018 CHANGES
-rw-r--r--. 1 1001 1001 440121 Dec 4 2018 CHANGES.ru
drwxr-xr-x. 2 1001 1001 168 Nov 30 22:04 conf
-rwxr-xr-x. 1 1001 1001 2502 Dec 4 2018 configure
drwxr-xr-x. 4 1001 1001 72 Nov 30 22:04 contrib
drwxr-xr-x. 2 1001 1001 40 Nov 30 22:04 html
-rw-r--r--. 1 1001 1001 1397 Dec 4 2018 LICENSE
drwxr-xr-x. 2 1001 1001 21 Nov 30 22:04 man
-rw-r--r--. 1 1001 1001 49 Dec 4 2018 README
drwxr-xr-x. 9 1001 1001 91 Nov 30 22:04 src
-
src目录存放了nginx软件的所有源码
-
man目录存放nginx软件的帮助文档,nginx安装完成过去,可以使用
man nginx查看帮助 -
html目录存放了两个后缀名为.html的静态网页文件。这两个文件与nginx服务器的运行相关
-
log目录存放nginx服务器的运行日志文件
-
conf目录存放nginx的配置文件
-
auto目录存放了大量的脚本文件,和configure脚本程序有关
-
configure文件时nginx软件的自动脚本程序。运行configure自动脚本一般会完成两项工作:一、检查环境,根据环境检查结果生成c代码;二、生成编译代码需要的Makefie文件
-
CHANGES CHANGES.ru LICENSE README nginx服务器的文档资料
进入auto目录,我们可以看到各种资源脚本。这些脚本职能划分清晰,有的检查环境(如os目录下的脚本),有个检查模块(如modules脚本),有的处理脚本参数(options脚本),有的用来输出信息到生成文件的(如hava、nohava、make、及install等),还有的是为自动脚本本身服务(如feature脚本)的。前面已经提到,nginx软件的自动脚本是作者手工编写的,如果你在工作中需要编写自动脚本或者希望学习相关内容,这个目录具有很高的参考价值。
生成Makefile文件过程
nginx源代码的编译需要使用configure脚本自动生成Makefile文件,在介绍生成Makefile文件操作之前,我们先介绍下nginx 的configure脚本支持的常用选项:
./configure --help
--prefix=/usr/local/nginx #指定nginx软件的安装路径,此项如果未指定,默认/usr/local/nginx
--conf-path=/usr/local/nginx/conf/nginx.conf #指定默认的nginx.conf文件的路径及名字,未指定,默认<prefix>/conf/nginx.conf
--sbin-path=/usr/local/nginx/sbin/nginx #指定nginx可执行文件安装路径及名字,如果未指定,默认<prefix>/sbin/目录里
--user=nginx #指定运行nginx进程的用户,默认是nobody,表示不限制
--group=nginx #指定运行nginx进程的组,默认是nobody,表示不限制
--pid-path=/run/nginx.pid #指定pid文件,保存了nginx服务当前运行的进程号
--lock-path=/var/lock/nginx.lock #指定lock文件,nginx.lock是nginx服务器的锁文件。指向 lock 文件(nginx.lock)(安装文件锁定,防止安装文件被别人利用,或自己误操作。)进程ID文件
--http-log-path=/var/log/nginx/access.log #指定访问日志
--error-log-path=/var/log/nginx/error.log #指定错误日志
--with-http_ssl_module #启用HTTP的ssl模块,这样nginx服务器就可以支持HTTPS请求了。这个模块的正常运行需要安装openssl库(在debian上为libssl)
--with-http_realip_module #启用http的realip模块,此模块支持显示真实来源IP地址,主要用于nginx做前端负载均衡服务器使用。默认不启用
--with-http_realip_module #允许从请求标头更改客户端的IP地址值,默认关闭。此模块支持显示真实来源IP地址,主要用于nginx做前端负载均衡服务器使用
--with-http_gzip_static_module #在线实时压缩输出数据流,就是指定压缩
--with-http_stub_status_module #获取nginx自上次启动以来的状态,默认不启用
--with-pcre #此模块支持rewrite功能
--with-stream #支持4层转发,Nginx Stream 模块允许配置和管理基于 TCP 和 UDP 的流量,例如代理、负载均衡、SSL/TLS 终端等。
--with-stream=dynamic #使用动态编译选项 --with-stream=dynamic,可以在编译 Nginx 时启用 Stream 模块,并将其作为动态模块加载。通过将 Stream 模块设置为动态加载,可以灵活地根据需要加载或卸载该模块,而无需重新编译和安装整个 Nginx 服务器。编译完成后,在 Nginx 配置文件中可以使用 load_module 指令加载 Stream 模块: load_module modules/ngx_stream_module.so; 这样就完成了 Nginx 动态加载 Stream 模块的配置。
--with-stream_ssl_module #enable ngx_stream_ssl_module
--with-stream_realip_module #enable ngx_stream_realip_module
--with-stream_geoip_module #enable ngx_stream_geoip_module
--with-stream_geoip_module=dynamic #enable dynamic ngx_stream_geoip_module
--with-stream_ssl_preread_module #enable ngx_stream_ssl_preread_module
--http-client-body-temp-path=/var/lib/nginx/body #设定http客户端请求临时文件路径
--http-fastcgi-temp-path=/var/lib/nginx/fastcgi #设定http fastcgi临时文件路径
--http-proxy-temp-path=/var/lib/nginx/proxy #设定http代理临时文件路径
--http-scgi-temp-path=/var/lib/nginx/scgi #设定http scgi临时文件路径
--http-uwsgi-temp-path=/var/lib/nginx/uwsgi #设定http uwsgi临时文件路径
--with-debug #启用debug日志,默认不开启,实际建议开启
--with-pcre-jit #编译PCRE包含“just-in-time compilation”。是 Nginx 编译选项中的一个参数,用于启用 PCRE(Perl Compatible Regular Expressions)的 Just-In-Time 编译功能。PCRE 是一个用于正则表达式匹配的库,Nginx 使用 PCRE 来处理正则表达式相关的配置和规则。Just-In-Time 编译是 PCRE 的一项优化技术,它可以在运行时将部分正则表达式编译为机器码,以提高正则表达式的匹配性能。通过添加 --with-pcre-jit 编译选项进行编译,可以启用 PCRE 的 JIT 编译功能,从而获得更快的正则表达式匹配性能。
--with-ipv6 #启用ipv6支持
--with-http_auth_request_module #实现基于一个子请求的结果的客户端授权。如果该子请求返回的2xx响应代码,所述接入是允许的。如果它返回401或403中,访问被拒绝与相应的错误代码。由子请求返回的任何其他响应代码被认为是一个错误。
--with-http_addition_module #作为一个输出过滤器,支持不完全缓冲,分部分响应请求
--with-http_dav_module #增加PUT,DELETE,MKCOL:创建集合,COPY和MOVE方法 默认关闭,需编译开启
--with-http_geoip_module #使用预编译的MaxMind数据库解析客户端IP地址,得到变量值
--with-http_gunzip_module #它为不支持“gzip”编码方法的客户端解压具有“Content-Encoding: gzip”头的响应。
--with-http_image_filter_module #传输JPEG/GIF/PNG 图片的一个过滤器)(默认为不启用。gd库要用到)
--with-http_spdy_module #SPDY可以缩短网页的加载时间
--with-http_sub_module #允许用一些其他文本替换nginx响应中的一些文本
--with-http_xslt_module #过滤转换XML请求
--with-mail #启用POP3/IMAP4/SMTP代理模块支持
--with-mail_ssl_module #启用ngx_mail_ssl_module支持
--with-http_secure_link_module #高级模块之安全模块,HTTP Secure Link 模块是 Nginx 的一个内置模块,用于生成和验证安全链接。安全链接是一种带有签名的 URL,用于授权访问受限资源。通过添加 --with-http_secure_link_module 编译选项进行编译,可以启用 HTTP Secure Link 模块,在 Nginx 中使用相关指令来生成和验证安全链接。
--builddir=DIR #指定编译时的目录
--add-module=PATH #指定第三方模块的路径,用于编译到nginx服务器中
--with-poll_module #声明启用poll模块,poll模块是信号处理的一种方法,和下面提到的select模式类似,都是采用轮询方法处理信号
--without-poll_module #禁用poll模块
--with-select_module #启用select信号处理模式。若configure未找到指定信号处理模式(上面提到的SUN系统中的kqueue、linux2.6+内核的epoll、实时信号rtsig以及和select类似的/dev/poll等),则默认使用select模式
--without-select_module #禁用select模块
--with-perl_modules_path=PATH #指定perl模块的路径
--with-perl=PATH #指定perl执行文件路径
--with-zlib=DIR #指定zlib库源码的路径。这样可以在编译nginx源码的同时编译zlib库,可以不提前用yum安装zlib库。zlib支持gzip模块
--with-zlib-opt=OPT #为zlib库的building指定额外的指令
--with-zlib-asm=CPU #针对特殊的cpu声明使用汇编源代码
--with-openssl=DIR #指定openssl库源码的路径。这样可以在编译nginx源码的同时编译openssl库,而不需要提前安装openssl库
--with-openssl-opt=OPTIONS #为openssl库的building指定额外的指令
--with-cc= #指向 C 编译器路径
--with-cpp= #指向 C 预处理路径
--with-cc-opt= #设置 C 编译器参数
--with-ld-opt= #设置连接文件参数
--with-cpu-opt= #指定编译的 CPU,可用的值为:pentium, pentiumpro, pentium3, pentium4, athlon, opteron, amd64, sparc32, sparc64, ppc64
--with-threads #开始为AIO引入了线程池支持,能够使用多线程读取和发送文件,以免工人进程被阻塞.要启用多线程支持,configure时需要显式加入–with-threads选项. 具体讲解可以参考该博客 Nginx线程池性能提升9倍,http://segmentfault.com/a/1190000002924458
--with-file-aio #启用aio时会自动启用directio,小于directio定义的大小的文件则采用sendfile进行发送,超过或等于directio定义的大小的文件,将采用aio线程池进行发送,也就是说aio和directio适合大文件下载.因为大文件不适合进入操作系统的buffers/cache,这样会浪费内存,而且Linux AIO(异步磁盘IO)也要求使用directio的形式. sendfile_max_chunk可以减少阻塞调用sendfile()所花费的最长时间.因为Nginx不会尝试一次将整个文件发送出去,而是每次发送大小为256KB的块数据
--with-compat #是 Nginx 编译选项中的一个参数,用于启用与第三方动态模块兼容的能力。当使用 --with-compat 编译选项编译 Nginx 时,会生成一个特殊的“兼容性”模块。这个模块的作用是允许使用以前版本编译的动态模块在新版本的 Nginx 上继续工作,减少模块升级所需的修改和兼容性问题。通过添加 --with-compat 编译选项进行编译,可以确保新版本的 Nginx 与旧版本的第三方动态模块保持兼容。这意味着,你无需对现有的第三方模块进行重新编译,而是可以直接加载它们而不会出现兼容性问题。
--with-http_flv_module #是 Nginx 的编译选项,用于启用 http_flv_module 模块的支持。通过添加这个选项进行编译,可以使 Nginx 具备处理 FLV 文件的能力。这样,客户端发送 FLV 文件的请求时,Nginx 就能够正确地处理并传输 FLV 文件给客户端。
--with-http_mp4_module #是 Nginx 的编译选项之一,用于启用对 MP4 视频文件的支持。该选项允许 Nginx 处理和传输 MP4 文件。 MP4(MPEG-4 Part 14)是一种常见的数字多媒体容器格式,常用于存储音频和视频数据。通过启用 --with-http_mp4_module 编译选项,你可以使 Nginx 具备处理和传输 MP4 文件的能力。
--with-http_v2_module #是一个 Nginx 编译选项,用于启用 HTTP/2 模块。 HTTP/2 是一种新一代的网络传输协议,与之前的 HTTP/1.1 相比,它具有更高效的传输性能和更多的功能。启用 HTTP/2 模块后,Nginx 将能够提供对客户端使用 HTTP/2 进行通信的支持。完成编译和安装后,在 Nginx 的配置文件中,可以使用 listen 指令启用 HTTP/2 支持: listen 443 ssl http2; 使用上述配置指令将 Nginx 监听在端口 443 上,并启用 SSL 和 HTTP/2。`请注意`,这只是启用 HTTP/2 模块的基本步骤。还可以根据需要对 Nginx 进行更多的配置和定制。另外,确保你的 OpenSSL 版本支持 HTTP/2,因为 HTTP/2 需要适当的 OpenSSL 版本才能正常工作。
使用如下命令配置生成Makefile文件:
[root@test nginx-1.14.2]# #(进入编译安装的目录)
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--http-log-path=/usr/local/nginx/logs/access.log \
--error-log-path=/usr/local/nginx/logs/error.log \
--pid-path=/usr/local/nginx/logs/nginx.pid \
--lock-path=/usr/local/nginx/logs/nginx.lock \
--with-http_ssl_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-http_realip_module \
--with-http_secure_link_module \
--with-http_sub_module \
--with-pcre \
--with-stream \
--http-client-body-temp-path=/usr/local/nginx/client_body_temp \
--http-proxy-temp-path=/usr/local/nginx/proxy_temp \
--http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp \
--http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp \
--http-scgi-temp-path=/usr/local/nginx/scgi_temp
可以在屏幕上看到configure自动脚本运行的全过程。在运行过程中,configure脚本调用auto目录中的各种脚本对系统已经相关的配置和设置进行检查
报错:
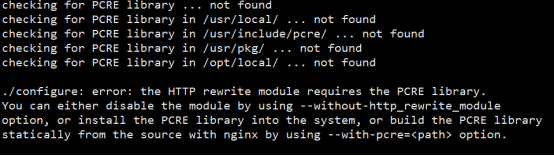
解决方案:安装pcre pcre-devel软件包,然后重新执行./configure ......
成功编译的界面:

nginx的编译、安装过程
得到了nginx软件的Makefile文件后,我们就可以使用make命令进行源码编译:
# make #把源代码文件编译成可执行的二进制文件,按照Makefile文件编译,可以使用-j 4 来指定4核心CPU编译,提升速度(根据你机器的CPU来指定哈)。如果是多核,那么可以make -j n #n代表物理机核数
同样,我们可以在屏幕上看到nginx源码的编译全过程
编译顺利完成后,使用make的install命令安装nginx软件了:
# make install #按Makefile定义的文件路径安装
或者直接合并在一起:
[root@test nginx-1.14.2]# make && make install
不报错默认已完成安装
# make clean #清除上次的make命令所产生的object和Makefile文件。使用场景:当需要重新执行./configure时,需要先执行make clean
配置环境变量或者软连接二进制文件
echo 'export PATH=/usr/local/nginx/sbin/:$PATH' /etc/profile.d/nginx.sh
# source /etc/profile.d/nginx.sh #加载环境变量
#或者软连接:
ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin
[root@nginx-1.8.1]# mkdir /var/run/nginx # 创建 nginx pid 文件目录(需要看你安装在哪里的)
#mkdir -pv /var/tmp/nginx/client #创建http客户端请求临时文件(需要看你安装在哪里的)
[root@nginx-1.8.1]# chown nginx.nginx /var/run/nginx # 配置/var/run/nginx 文件属性
初次调整nginx配置文件
有路径的必须写正确:
# vim /usr/local/nginx/conf/nginx.conf
user nginx nginx;
worker_processes auto;
error_log /usr/local/nginx/logs/error.log;
pid /usr/local/nginx/logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
access_log logs/access-main.log main;
location / {
root /usr/local/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/nginx/html;
}
}
include /usr/local/nginx/conf/vhost/*.conf;
}
# nginx -t -c /usr/local/nginx/conf/nginx.conf # 确认配置文件格式及语法是否正确
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
安装后初次检查配置文件是否报错
# cd /usr/local/nginx/ #安装后,未启动nginx是,安装目录所包含的文件

# ./sbin/nginx -t #检查配置文件是否正确

如果有报错,一步一步解决,可能提示你为创建某些目录,你跟着创建后在次检查配置文件是否正确
nginx服务启动脚本,有无都可以
# centos6
# 从其他yum 安装nginx的服务器拷贝nginx 服务启动脚本到/etc/init.d 目录中
[root@conf]# scp root@192.168.23.100:/etc/rc.d/init.d/nginx /etc/init.d/
root@192.168.23.100's password:
nginx 100% 2795 2.7KB/s 00:00
[root@conf]# vi /etc/init.d/nginx # 修改nginx服务启动脚本
...
nginx="/usr/local/nginx/bin/nginx" # 指定nginx命令路径
lockfile="/var/lock/nginx" # 指定nginx lockfile文件
pidfile="/var/run/nginx/${prog}.pid" # 指定nginx 启动pid文件路径
NGINX_CONF_FILE="/etc/nginx/nginx.conf" # 指定配置脚本nginx.conf 文件路径
[root@nginx]# chkconfig --add nginx # 设置添加到chkconfig 列表
[root@nginx]# chkconfig nginx on # 设置开机自动启动
[root@nginx]# service nginx start # nginx服务启动
[root@nginx]# ss -tunlp | grep nginx
tcp LISTEN 0 128 *:80 *:* users:(("nginx",11893,6),("nginx",11895,6))
[root@nginx]# ps aux | grep nginx # 验证nginx服务 ,root角色启动主进程 ,nginx角色启动worker proess进程
# centos7的system启动文件
cat > /usr/lib/systemd/system/nginx.service << EOF
[Unit]
Description=nginx web service
After=network.target
[Service]
# 指定程序运行的用户
User=nginx
# 指定程序运行的组
Group=nginx
#Type 属性设置为 forking,表示 Systemd 将期望从 ExecStart 指定的命令中获取一个进程ID,并将其作为主服务进程。
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf
ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
ExecStop=/usr/local/nginx/sbin/nginx -s stop -c /usr/local/nginx/conf/nginx.conf
ExecReload=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf -s reload
# on-failure,表示服务在发生故障时将自动重启
Restart=on-failure
# 状态码为1时不自动重启,1为正常关闭状态码
RestartPreventExitStatus=1
# 等多久(秒)重启
RestartSec=10
# 重启只限制在300秒内
StartLimitInterval=300
# 300秒内只能重启2次
StartLimitBurst=2
# 启动服务的超时时间
TimeoutStartSec=30
# 停止服务的超时时间
TimeoutStopSec=30
# PrivateTmp=true 属性指示 Systemd 创建一个私有的临时文件系统来运行该服务,以提高安全性并避免与其他进程冲突
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
# 确保在修改 system.service 文件后重新加载服务配置以使其生效。可以使用以下命令重新加载 Systemd 配置:
systemctl daemon-reload
# 启动服务
systemctl start nginx
nginx服务的信号控制
在nginx服务的启停办法中,有一类是通过信号机制来实现的,介绍下nginx服务器的信号控制
nginx服务在运行时,会保持一个主进程和一个或多个worker process工作进程,只需要给nginx服务的主进程发起信号就可以控制服务的启停了,那么如何给主进程发起信号呢?首先我们要知道主进程的进程号PID

获取nginx的PID有两个方法:
一、nginx在启动后,会产生文件名为nginx.pid的文件,此文件中保存的就是nginx服务主进程的PID。这个pid文件存放的路径及位置都可以在nginx主配置文件中进行设置。
# cat /usr/local/nginx/logs/nginx.pid
7595
二、用进程工具进行查看。
ps aux | grep nginx | grep nginx

nginx的主进程是以root用户运行的,所有pid为7595,和nginx.pid里的pid一致

nginx服务主进程能够接收的信号如下:
信号 作用
TERM或者INT 快速停止nginx服务
QUIT 平缓停止nginx服务
HUP 使用新的配置文件启动进程,之后平缓停止原有进程,也就是所谓的“平缓启动”
USR1 重新打开日志文件,常用于日志切割
USER2 使用新版本的nginx文件启动服务,之后平缓停止原有nginx进程,也就是所谓的“平滑升级”
WINCH 平缓停止worker process,用于nginx服务器平滑升级
向nginx服务主进程发送信号也有两种方法:一种是使用nginx二进制文件,另一种是使用kill命令发送信号,用法如下:
kill SIGNAL PID
SIGNAL,用于指定信号,即指定上面信号中的某一个
PID,指定nginx服务主进程的PID,也可以使用nginx.pid动态获取pid:
kill SIGNAL `pid_file_path`
pid_file_path,nginx的pid文件路径
nginx服务的启动
在linux平台下,启动nginx服务器直接运行安装目录下sbin目录中的二进制文件即可
1、直接在命令行键入nginx:这样默认的启动的配置文件/usr/local/nginx/conf/nginx.conf,你也可以nginx -h查看
# nginx #启动nginx服务
如果没有任何错误信息输出,就表示nginx服务正常启动了。可以用ps -ef | grep nginx命令查看nginx服务进程的状态
2、加入-c filename,通过配置文件启动nginx
再次查看安装目录下包括的文件:会生成你编译时所加入参数的目录:

接下来我们来看看nginx的安装目录包含的内容:
# ll
total 4
drwx------. 2 nginx root 6 Oct 20 17:12 client_body_temp
drwxr-xr-x. 2 root root 4096 Nov 7 21:25 conf
drwx------. 2 nginx root 6 Oct 20 17:12 fastcgi_temp
drwxr-xr-x. 3 root root 92 Oct 29 22:57 html
drwxr-xr-x. 2 root root 41 Nov 7 23:59 logs
drwx------. 12 nginx root 96 Oct 20 22:40 proxy_temp
drwxr-xr-x. 2 root root 19 Oct 20 17:09 sbin
drwx------. 2 nginx root 6 Oct 20 17:12 scgi_temp
drwx------. 2 nginx root 6 Oct 20 17:12 uwsgi_temp
nginx服务器的安装目录主要包括conf、html、logs、sbin等4个目录:
-
conf目录中存放了nginx的所有配置文件。而nginx.conf文件时nginx服务的主配置文件,其他的文件时用来配置nginx的相关功能的,比如,配置fastcgi使用的fastcgi.conf和fastc_params两个文件。在此目录下,所有的配置文件都提供了以.default结尾的默认配置文件,方便我们将配置过的.conf文件恢复到初始状态
-
html目录中存放了nginx服务器在运行过程中调用的一些html网页文件。其他index.html文件,是nginx服务器运行成功后,默认调用的网页,提示用户nginx服务器成功运行了。50x.html则是nginx出现某些问题是将会调用的这个页面
-
logs目录,顾名思义,就是存放nginx服务器的日志的,nginx的日志功能比较强大,有不同种类,并且可以自定义输出格式内容等。
-
sbin目录,目前其中只有nginx一个文件,这就nginx服务器的主程序
注意:在启动nginx服务前,应该先检查下配置文件语法是否正确
这里简单介绍下二进制文件nginx的相关用法
# nginx -h
nginx version: nginx/1.14.2
Usage: nginx [-?hvVtTq] [-s signal] [-c filename] [-p prefix] [-g directives]
Options:
-?,-h : this help
-v : show version and exit
-V : show version and configure options then exit
-t : test configuration and exit
-T : test configuration, dump it and exit
-q : suppress non-error messages during configuration testing
-s signal : send signal to a master process: stop, quit, reopen, reload
-p prefix : set prefix path (default: /usr/local/nginx/)
-c filename : set configuration file (default: /usr/local/nginx/conf/nginx.conf)
-g directives : set global directives out of configuration file
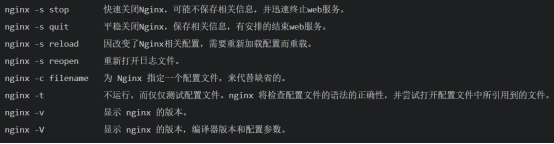
-v 显示nginx版本信息并退出
-V 显示版本号和nginx的编译情况并退出
-t 测试配置文件的语法正确性并退出
-T 测试配置文件正确性并输出到屏幕,然后退出
-q 测试配置时只显示错误
-s 向主进程发起信号
-c filename 用来指定启动nginx服务使用的配置文件
-p 指定nginx服务器路径前缀
-g directives 指定附加的配置文件路径,向nginx服务指定启动时应用全局的配置
-t可以与-c联用,是输出内容更详细,这对查找配置文件中的语法错误很有帮助,如下是正确配置的情况:
# nginx -t -c /usr/local/nginx/conf/nginx.conf
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
-q可以与-t联用,如果配置文件无错误,将不输出任何内容
# nginx -qt
nginx服务的停止
停止nginx服务用两种方法:一、快速停止;二、平缓停止
快速停止是指立即停止当前nginx服务正在处理的所有网络请求,马上丢弃连接,停止工作
平缓停止是指运行nginx服务将当前正在处理的网络请求处理完成,但不在接受新的请求,之后再关闭nginx连接,最后停止工作
停止nginx服务的操作很多:
# nginx -s stop #建议用这种方式,这种方式关闭了nginx不会留下pid文件,防止其他报错行为
# pkill nginx
# killall nginx
# kill -9 2927 #2927是nginx主进程的pid,虽然worker进程是没有杀死的,但是nginx服务是停止了,不建议用这种方式
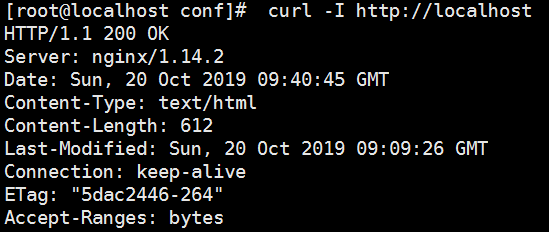
# curl -I localhost
HTTP/1.1 502 Bad Gateway
Server: nginx/1.14.2
Date: Sun, 01 Dec 2019 08:07:10 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 537
Connection: keep-alive
ETag: "5dac2446-219"
#或者:
# nginx -g TERM | INT | QUIT ->这种操作不行,,,不知道啥原因
其中,TERM | INT信号用于快速停止,QUIT用于平缓停止
nginx服务的重载
更改nginx服务器的配置和加入了新的模块,如果希望当前的nginx服务应用新的配置或者使用新的模块生效,那么就需要重启nginx服务。当然可以先关闭nginx服务,然后使用新的配置文件重启服务。
但是在实际环境中,我们是平滑启动或者是重载配置文件
平滑启动是这样的一个过程:nginx服务接收到信号后,首先读取新的配置文件,乳房配置语法正确,则启动新的nginx服务,然后平缓关闭旧的服务进程;如果新的nginx配置有问题,将显示错误,仍然使用旧的nginx进程提供服务
使用以下命令,实现nginx服务的平滑重启:
# nginx -g HUP [-c newConffile]
-
HUP信号用户发送平滑重启信号
-
newConffile可选项,用于指定新的配置文件路径
重载配置nginx服务:在实际环境中,都是用这种来重载nginx服务
nginx -s reload
查看端口是否监听着(默认是80)
# lsof -i :80

# ps aux|grep nginx
nginx默认会启动一个root 的master进程、剩下就是worker进程,根据worker_processes auto;这个参数来启动的worker进程

# curl -I http://localhost # 验证nginx 运行状态
Nginx的编译配置参数
[root@test-7 ~]# nginx -V
nginx version: nginx/1.14.2
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-39) (GCC)
built with OpenSSL 1.0.2k-fips 26 Jan 2017
TLS SNI support enabled
configure arguments: --prefix=/usr/local/nginx --user=nginx --group=nginx --sbin-path=/usr/local/nginx/sbin/nginx --conf-path=/usr/local/nginx/conf/nginx.conf --http-log-path=/usr/local/nginx/logs/access.log --error-log-path=/usr/local/nginx/logs/error.log --pid-path=/usr/local/nginx/logs/nginx.pid --lock-path=/usr/local/nginx/logs/nginx.lock --with-http_ssl_module --with-http_stub_status_module --with-http_gzip_static_module --with-http_realip_module --with-http_secure_link_module --with-http_sub_module --with-pcre --with-stream --http-client-body-temp-path=/usr/local/nginx/client_body_temp --http-proxy-temp-path=/usr/local/nginx/proxy_temp --http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp --http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp --http-scgi-temp-path=/usr/local/nginx/scgi_temp
以上就是源码安装时编译用的参数
重新编译和安装nginx
另外,在没有修改nginx的源码情况下,如果需要重新编译和安装nginx,就不必再使用configure脚本自动生成Makefile文件了,直接使用以下命令删除上次安装的nginx软件:
# rm -rf /usr/local/nginx/
然后进入nginx软件包的解压目录,清除上次编译的遗留文件:
# make clean
最后在使用一下命令进行编译和安装nginx:
# make && make install
到此nginx就成功部署完成
nginx服务器的升级
如果要对当前nginx服务器进行版本升级、应用新模块,最简单的方法就是停止当前nginx服务,然后开启新的nginx服务,缺点就是,在一段时间内无法访问服务器。为了解决此问题,nginx服务器提供平滑升级的功能
按照原来的编译参数安装 nginx 的方法进行安装,只需要到make,不需要执行make install 。
以此建议用户在安装新服务器之前先备份旧服务器。
nginx服务器平滑升级
注意:为了实现nginx服务器的平滑升级,新的服务器安装路径应该和旧的保持一致。以此建议用户在安装新服务器之前先备份旧服务器。以此建议用户在安装新服务器之前先备份旧服务器。
第一步:安装新版本nginx,同时启动2个版本的nginx
第二步:关闭旧版本nginx的worker进程
第三步:优雅关闭旧版本的master进程
第一步:如果你是用systemctl或者service管理nginx服务,那么必须先停止旧版本的nginx,然后用原生的方式启动nginx。
# systemctl stop nginx
# /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf # 原生方式启动就版本nginx
# curl -I localhost # 现在的请求都是走的旧的nginx
HTTP/1.1 200 OK
Server: nginx/1.20.2
Date: Mon, 08 Apr 2024 06:27:18 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Mon, 08 Apr 2024 06:25:58 GMT
Connection: keep-alive
ETag: "66138df6-264"
Accept-Ranges: bytes
# /data/nginx/sbin/nginx -V
nginx version: nginx/1.20.2
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
configure arguments: --prefix=/data/nginx
第二步:编译安装新版本nginx
tar xf nginx-1.24.0.tar.gz
cd nginx-1.24.0 && ./configure --prefix=/data/nginx .... # --prefix=参数必须和旧版本保持一致
make && make install
在Linux服务器如果编译两个nginx的--prefix参数相同,那么sbin/目录下面会存在两个可执行文件,如下:
[root@k8s13343 nginx]# ll sbin/ # 执行make install后就会存在两个nginx可执行文件
total 7620
-rwxr-xr-x 1 root root 3913936 Apr 7 18:17 nginx # 新版本
-rwxr-xr-x 1 root root 3883616 Apr 7 18:15 nginx.old # 旧版本
# /data/nginx/sbin/nginx -V # 现在是最新版本了
nginx version: nginx/1.24.0
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
configure arguments: --prefix=/data/nginx
# curl -I localhost # 现在的请求还是走的旧版本nginx
HTTP/1.1 200 OK
Server: nginx/1.20.2
Date: Mon, 08 Apr 2024 06:33:58 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Mon, 08 Apr 2024 06:25:58 GMT
Connection: keep-alive
ETag: "66138df6-264"
Accept-Ranges: bytes
第三步:同时启动两个nginx
# ps aux | grep nginx # 查看旧版本nginx的PID
root 12595 0.0 0.0 20572 616 ? Ss 18:25 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 12596 0.0 0.0 21016 1308 ? S 18:25 0:00 nginx: worker process
root 12638 0.0 0.0 112812 976 pts/0 S+ 18:25 0:00 grep --color=auto nginx
kill -USR2 旧版本nginx的master的进程IP
# kill -USR2 12595
# ps aux | grep nginx
root 12595 0.0 0.0 20572 804 ? Ss 18:25 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 12596 0.0 0.0 21016 1308 ? S 18:25 0:00 nginx: worker process
root 20875 0.0 0.0 20580 1592 ? S 18:29 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf # 第2个nginx的master进程
nobody 20878 0.0 0.0 21024 1312 ? S 18:29 0:00 nginx: worker process # 第2个nginx的worker进程
root 20903 0.0 0.0 112812 980 pts/0 R+ 18:29 0:00 grep --color=auto nginx
# curl -I localhost # 启动新的nginx后,后续的请求都是走的新的nginx
HTTP/1.1 200 OK
Server: nginx/1.24.0
Date: Sun, 07 Apr 2024 10:31:06 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Sun, 07 Apr 2024 10:23:45 GMT
Connection: keep-alive
ETag: "66127431-264"
Accept-Ranges: bytes
第四步:把旧版本nginx的worker进程关掉
kill -WINCH 旧版本nginx的worker进程ID
[root@k8s13343 nginx-1.20.2]# ps aux| grep nginx
root 12595 0.0 0.0 20572 804 ? Ss 18:25 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 12596 0.0 0.0 21016 1308 ? S 18:25 0:00 nginx: worker process
root 20875 0.0 0.0 20580 1592 ? S 18:29 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 20878 0.0 0.0 21024 1560 ? S 18:29 0:00 nginx: worker process
root 21296 0.0 0.0 112816 980 pts/0 R+ 18:32 0:00 grep --color=auto nginx
[root@k8s13343 nginx-1.20.2]# kill -WINCH 12596
[root@k8s13343 nginx-1.20.2]# ps aux | grep nginx
root 12595 0.0 0.0 20572 804 ? Ss 18:25 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
root 20875 0.0 0.0 20580 1592 ? S 18:29 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 20878 0.0 0.0 21024 1560 ? S 18:29 0:00 nginx: worker process
nobody 21553 0.0 0.0 21016 1308 ? S 18:34 0:00 nginx: worker process
root 21570 0.0 0.0 112812 976 pts/0 S+ 18:34 0:00 grep --color=auto nginx
第四步:把旧版本nginx的master进程关掉
kill -QUIT 旧版本nginx的master进程ID
[root@k8s13343 nginx-1.20.2]# ps aux | grep nginx
root 12595 0.0 0.0 20572 804 ? Ss 18:25 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
root 20875 0.0 0.0 20580 1592 ? S 18:29 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 20878 0.0 0.0 21024 1560 ? S 18:29 0:00 nginx: worker process
nobody 21553 0.0 0.0 21016 1308 ? S 18:34 0:00 nginx: worker process
root 21570 0.0 0.0 112812 976 pts/0 S+ 18:34 0:00 grep --color=auto nginx
[root@k8s13343 nginx-1.20.2]# kill -QUIT 12595
[root@k8s13343 nginx-1.20.2]# ps aux | grep nginx # 只有一个nginx服务了
root 20875 0.0 0.0 20580 1592 ? S 18:29 0:00 nginx: master process /data/nginx/sbin/nginx -c /data/nginx/conf/nginx.conf
nobody 20878 0.0 0.0 21024 1560 ? S 18:29 0:00 nginx: worker process
root 21885 0.0 0.0 112812 980 pts/0 S+ 18:37 0:00 grep --color=auto nginx
卸载nginx
# rm -rf /usr/local/nginx
解决云主机的报错
在重启云主机(系统)之后,执行 nginx -t 是OK的,然而在执行 nginx -s reload 的时候报错
nginx: [error] invalid PID number "" in "/run/nginx.pid"
经过查找,找到http://www.cnblogs.com/yuqianwen/p/4285686.html
#需要先执行
nginx -c /etc/nginx/nginx.conf #需要配置文件的全路径
nginx.conf文件的路径可以从`nginx -t`的返回中找到。
nginx -s reload
对nginx的配置文件语法高亮设置
1.下载nginx.vim语法高亮配置到 ~/.vim/syntax,如果不存在则创建该目录
cd ~/.vim/syntax
wget http://www.vim.org/scripts/download_script.php?src_id=14376 -O nginx.vim
http://www.vim.org/scripts/script.php?script_id=1886 #这里使用的是0.3.3版本
2.增加配置~/.vim/filetype.vim 到最后一行,如果文件不存在则创建
vim ~/.vim/filetype.vim
加入如下内容:
au BufRead,BufNewFile /etc/nginx/* set ft=nginx
其中红色路径为你的nginx.conf文件路径
Nginx基本配置指令(重点)
注意:
在nginx配置中,每一条指令配置必须已分号结束,切记。
nginx.conf配置文件一共由三部分组成,分别为:全局块、events块和http块。在http块中,又包含http全局快、多个server块。每个server块,可以包含server全局块和多个location块。在用一个配置块中嵌套的配置块,各个之间不存在次序关系。
配置文件支持大量可配置的指令,绝大多数指令不是特定属于某一块的。用一个指令放在不同层级的块中,其作用域不同,一般情况下,高一级块中的指令可以作用于自身所在的块和此块包含的所有低层级块。
如果某个指令在两个不同层级的块同时出现,则采用"就近原则",即以较低层级块中的配置为准。比如,某指令同时出现在http全局块中和server块中,并且配置不同,则应该以server块中的配置为准
conf目录中内容
nginx.conf --- nginx程序的主配置文件
nginx.conf.default --- nginx配置备份文件
因为初始化的nginx配置文件内有较多注释,影响对配置文件的修改,所以进行精简化配置文件
[root@test-7 ~]# vim /etc/nginx/conf.d/default.conf #(如果主配置文件没有配置,就默认读取这个默认的配置里面的内容)
A、全局块配置
全局块是默认配置文件从开始到events块之间的配置内容,主要设置一些影响nginx服务器整体运行的配置指令,因此,这些指令的作用域是nginx服务器全局
通常包括配置运行nginx服务器的用户、用户组、运行生成的worker process数、nginx进程pid、存放路径、日志存放路径和类型以及配置文件引入等。
全局配置->nginx在运行时与具体业务功能(比如http服务或者email服务代理)无关的一些参数,比如工作进程数,运行的身份等

user nginx nginx;
worker_processes auto;
error_log /usr/local/nginx/logs/error.log info;
pid /usr/local/nginx/logs/nginx.pid;
worker_rlimit_nofile 51200;
daemon on;# daemon off 可关闭 Nginx 后台守护进程,默认开启.在docker中需要关闭,让进程在前台启动
参数解释:
#定义Nginx运行的用户和用户组
user www www; 配置为nginx运行用户及用户组,否则报403错误
#nginx进程数,建议设置为等于CPU总核心数。
worker_processes auto;
• woker_processes 2
在配置文件的顶级main部分,worker角色的工作进程的个数,master进程是接收并分配请求给worker处理。这个数值简单一点可以设置为cpu的核数grep ^processor /proc/cpuinfo | wc -l,也是 auto 值,如果开启了ssl和gzip更应该设置成与逻辑CPU数量一样甚至为2倍,可以减少I/O操作。如果nginx服务器还有其它服务,可以考虑适当减少。
#全局错误日志定义类型,[ debug | info | notice | warn | error | crit ]
error_log /var/log/nginx/error.log info;
关键字:其中关键字error_log不能改变
日志文件:可以指定任意存放日志的目录
错误日志级别:常见的错误日志级别有[debug | info | notice | warn | error | crit | alert | emerg],级别越高记录的信息越少。
生产场景一般是 warn | error | crit 这三个级别之一
#进程文件
pid /usr/local/nginx/logs/nginx.pid;
• worker_rlimit_nofile 10240
#写在main部分。默认是没有设置,可以限制为操作系统最大的限制65535
#一个nginx进程打开的最多文件描述符数目,理论值应该是最多打开文件数(系统的值ulimit -n)与nginx进程数相除,但是nginx分配请求并不均匀,所以建议与ulimit -n的值保持一致。
• worker_cpu_affinity
#也是写在main部分。在高并发情况下,通过设置cpu粘性来降低由于多CPU核切换造成的寄存器等现场重建带来的性能损耗。如worker_cpu_affinity 0001 0010 0100 1000; (四核)。
B、events块配置 ->I/O事件配置
events块涉及的指令主要影响nginx服务器与用户的网络连接。常用到的设置包括是否开启对多worker process下的网络连接进行系列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型处理连接请求,每个worker process可以同时支持的最大连接数等
该部分指令对nginx服务器的性能影响较大,在实际情况中应该根据实际情况灵活调整。
events {
use epoll; #使用epoll模型
worker_connections 65535; #每个worker进程支持的最大连接数
multi_accept on;
accept_mutex on;
}
使用"events"界定标记,用来指定nginx进行的I/O响应模型,每个进行的连接数量设置。对于2.6及以上版本内核,建议使用epoll模型以提高性能;每个进程的连接数应根据实际需求来定,一般在10000以下(默认为1024)
工作模式与连接数上限

work_connection:每个进程数的最大连接,这个是工作中必须优化的,一般是10000个,就可以达到要求
参数解释:
·use epoll #use 设置用于复用客户端线程的轮询方法
写在events部分。在Linux操作系统下,nginx默认使用epoll事件模型,得益于此,nginx在Linux操作系统下效率相当高。同时Nginx在OpenBSD或FreeBSD操作系统上采用类似于epoll的高效事件模型kqueue。在操作系统不支持这些高效模型时才使用select。
#参考事件模型,use [ kqueue | rtsig | epoll | /dev/poll | select | poll ]; epoll模型是Linux 2.6以上版本内核中的高性能网络I/O模型,如果跑在FreeBSD上面,就用kqueue模型。
• epoll是多路复用I/O中的一种方式,epoll 有两种工作模式:LT(水平触发)模式和 ET(边缘触发)模式。
默认情况下,epoll 采用 LT 模式工作,这时可以处理阻塞和非阻塞套接字。ET 模式的效率要比 LT 模式高,它只支持非阻塞字。ET 和 LT 模式的区别在于,当一个新的事件到来时,ET 模式下当然可以从 epoll_wait调用中获取这个事件,可是如果这次没有把这个事件对应的套接字缓冲区处理完,在这个套接字没有新的事件再次到来时,在 ET 模式下是无法再次从epoll_wait 调用中获取这个事件的;而 LT 模式则相反,只要一个事件对应的套接字缓冲区还有数据,就总能从 epoll_wait中获取这个事件。因此,LT 模式相对简单,而在 ET 模式下事件发生时,如果没有彻底地将缓冲区数据处理完,则会导致缓冲区中的用户请求得不到响应。默认情况下,Nginx 是通过 ET 模式使用 epoll 的。
·worker_connections 2048 #最大连接数=连接数*进程数
写在events部分。每一个worker进程能并发处理(发起)的最大连接数(包含与客户端或后端被代理服务器间等所有连接数)。nginx作为反向代理服务器,计算公式 最大连接数 = worker_processes * worker_connections/4,所以这里客户端最大连接数是1024,这个可以增到到8192都没关系,看情况而定,但不能超过后面的worker_rlimit_nofile。当nginx作为http服务器时,计算公式里面是除以2。
·multi_accept 告诉nginx收到一个新连接通知后接受尽可能多的连接
C、http块配置
http块是nginx服务器配置中的重要部分,代理、缓存和日志定义等绝大多数的功能及第三方模块配置都可以放在这个快中。
在本书中,我们使用http全局快,来表示http中自己的全局块,即http块中不包含在server块中的部分
可以在http全局中配置的指令包括文件引入、MIME-type定义、日志定义、是否使用sendfile传输文件、连接超时时间、单链接请求数上限等
作用->与提供http服务相关的一些配置参数。例如:是否使用keepalive啊,是否使用gzip进行压缩等
http {
include mime.types; #Nginx支持的媒体类型库文件
default_type application/octet-stream; #默认的媒体类型
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main; #访问日志位置
sendfile on; #支持文件发送(下载)
#tcp_nopush on; #告诉nginx在一个数据包里发送所有头文件,而不一个接一个的发送
keepalive_timeout 65; ##给客户端分配keep-alive连接超时时间
#gzip on; #开启gzip压缩
server { #web服务的监听配置
listen 80; #监听地址及端口
server_name localhost; #网站名称(FQDN)
#ssl_protocols TLSv1 TLSv1.1 TLSv1.2; #协议配置
#ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5; #加密套件配置
#charset utf-8; #网页默认字符集
location / { #根目录配置;匹配任何查询,因为所有请求都以 / 开头
root html; #网站根目录的位置;指定对应uri的资源查找路径,这里html为相对路径
index index.html index.htm; #默认首页(索引页);指定首页index文件的名称,可以配置多个,以空格分开。如有多个,按配置顺序查找
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
error_page 500 502 503 504 /50x.html; #内部错误的反馈页面
location = /50x.html {
root html; #指定对应的站点目录为html
}
}
D、server块
server块和"虚拟主机"的概念密切联系。
虚拟主机,又称虚拟服务器、主机空间或者网页空间,它是一种技术。该技术是为了节省互联网服务器硬件成本而出现的。这里的"主机"或者"空间"是由实体的服务延伸而来的,硬件系统可以基于服务器群,或者单个服务器等。
虚拟主机技术主要应用于http、ftp及EMAIL等多项服务,将一台服务器的某项或者全部服务内容逻辑划分为多个服务单位,对外表现为多个服务器,从而充分利用服务器硬件资源。
从用户的角度来看,一台虚拟主机和一台独立的硬件主机时完全一样的。
在使用nginx服务器提供web服务时,利用虚拟主机的技术就可以避免为每一个要运行的网站提供单独的nginx服务器,也无需为每个网站对应运行一组nginx进程。虚拟主机技术使得nginx服务器可以在同一台服务器上只运行一组nginx进程,就可以运行多个网站
注意:和http块相同,server块也可以包含自己的全局块,同时可以包含多个location块。在server全局块中,最常见的两个配置项是虚拟主机的监听配置和本地虚拟主机的名称或者IP配置
E、location指令
每个server块可以包含多个location块。从严格意义上来说,location其实是server块的一个指令,但是由于其在整个nginx配置文件中起着重要作用,而且nginx服务器在许多功能上的灵活性往往在location指令的配置中体现出来
location指令的主要作用,基于nginx服务器接收请求字符串(例如,server_name/uri-string)对除虚拟主机名称(也可以是IP别名)之外的字符串(/uri-string)进行匹配,对特定的请求进行匹配。地址定向、数据缓存和应答控制等功能。许多第三方模块的配置也是在location块中提供功能
配置运行nginx服务器用户、用户组
指令user,其语法格式:
user user [group];
-
user指定可以运行nginx服务器的用户
-
group可选项,指定可以运行nginx服务器的用户组
只有被设置的用户或者用户组成员才能有权限启动nginx进程。
如果希望所有用户都可以启动nginx进程,有两种方法:(但是实际环境中,不允许所有用户启动nginx进程哈!!!!)
一、将此指令注释掉
#user nginx nginx;
二、将用户和用户组设置为nobody,这也是user指令的默认配置,user指令只能在全局快配置
user nobody nobody;
配置允许生成的worker process数
worker process是nginx服务器实现并发处理服务的关键所在。从理论上来说,worker process的值越大,可以支持的并发处理量也越多,但是实际上它还是受到来自软件本身、操作系统本身资源和能力、硬件设备(如CPU和磁盘驱动器)等的制约。
指令worker_process,其语法格式:
worker_processes auto | number;
-
number指定nginx进程最多可以产生的worker process数
-
auto设置此值,nginx进程将自动检测
在默认配置文件中,number=1启动nginx服务器后,可以使用如下命令查看:
# ps aux|grep nginx |grep -v grep
root 7505 0.0 0.1 46188 2060 ? Ss 18:02 0:00 nginx: master process nginx
nginx 7998 0.0 0.1 46596 1984 ? S 18:14 0:00 nginx: worker process
配置nginx主进程pid存放路径
nginx进程作为系统的守护进程运行,如果需要在某文件中保存当前运行程序的主进程号。nginx支持对它的存放路径进行自定义配置
指令pid,其语法格式:
pid path_file-name;
path_file-name指定存放路径和文件名
配置文件默认将此文件存放在nginx安装目录logs下,名字为nginx.pid。path可以是绝对路径,也可以是以nginx安装目录为根目录的相对路径。
注意:
在指定path的时候,一定要包括文件名,如果只设置了路径,没有设置文件名,会报一下错误:
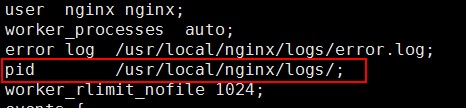
nginx: [crit] pread() "/usr/local/nginx/logs/" failed (21: Is a directory)
此指令也只能在全局快配置
配置错误日志的存放路径
在全局块、http块和server块中都可以对nginx服务器日志进行相关配置。
指令error_log,其语法格式:
error_log path_filel |stderr[debug|info|notice|warn|error|crit|alert|emerg];
从语法结构可以看到,nginx服务器的日志支持输出到某一固定的文件file或者输出到标准错误输出stderr;日志级别是可选项,有低到高分为debug(需要在编译时使用--with-debug开启debug开关)|info|notice|warn|error|crit|alert|emerg
注意:
不要配置info等级较低的级别,会带来大量的磁盘I/O消耗
设置某一级别后,比这一级别高的日志也会被记录。比如设置error级别后,级别为error以及crit、alert、emerg的日志都会被记录下来。
指定的文件对于运行nginx进程的用户具有写权限,否则在启动nginx进程的时候会出现无法打开该文件,且权限失败的字眼
日志的级别越高,那么输出的内容就越少
此指令可以在全局快、http块、server块以及location指令中配置,但是错误日志一般就在全局配置中设置就行了,除非有其他需要就才对应块进行设置
配置文件的引入
此指令可以放在配置文件的任意地方
在一些情况下,我们可能需要将其他的nginx配置或者第三方模块的配置引用到当前的主配置文件中。nginx提供了include指令来完成配置文件的引入,语法如下:
include file;
其中,file是要引入的配置文件,它支持相对路径和绝对路径,并且支持通配符
注意:新引入进来的文件同样要求运行nginx进程的用户对其具有写权限,并且符合nginx配置文件规定的相关语法和结构
设置网络连接的序列化
在\<\
为了解决此问题,nginx配置中包含了这样一条指令accept_mutex,当其设置为开启的时候,将会对多个nginx进程接收连接进行序列化,防止多个进程对其连接的争抢。语法结构如下:
accept_mutex on|off;
此指令默认为开启(on)状态,只能在events块进行配置
设置是否允许同时接收多个网络连接
此指令只能在events块进行配置
每个nginx服务器的worker process都有能力同时接收多个新到达的网络连接,但是这需要在配置文件中进行配置,其指令为multi_accept,语法格式如下:
multi_accept on|off;
此指令默认为关闭(off)状态,即每个worker process一次只能接收一个新到达的网络连接。
事件驱动模型选择
nginx服务器提供了多种事件驱动模型来处理网络消息。配置文件中为我们提供了相关的指令来强制nginx服务器选择哪种事件驱动模型进行消息处理,指令为use,语法结构如下:
use method;
其中,method可选择的内容有:select、poll、kqueeu、epoll、rtsig、/dev/poll以及eventport
注意:
可以在编译时使用--with-select_module和--without-select_module设置是否强制编译select模块到nginx内核;使用--with-poll_module和--without-poll_module设置是否强制编译poll模块到nginx内核。
此指令 只能在events块中进行配置
配置最大连接数
指令worker_connections主要用来设置允许每一个worker process同时开启的最大连接数。其语法结构为:
worker_connections number;
注意:
这里的number不仅仅包括和前端用户建立的连接数,而是包括所有可能的连接数。另外,number值不能大于操作系统支持打开的最大文件句柄数量。用ulimit -n命令查看打开的最大文件句柄数量
此指令只能在events块进行配置
定义MIME-type
在常用浏览器中,可以显示的内容有HTML、xml、GIF及flash等种类繁多的文本、媒体等资源,浏览器为了区分这些资源,需要使用MIME Type。换言之,MIME type是网络资源的媒体类型
nginx服务器作为web服务器,必须能够识别前端请求的资源类型
在默认的nginx配置文件中,我们看到在http全局块中有一下两行配置:
include mime.types;
default_type application/octet-stream;
第一行从外部引用了mime_types文件,我们来查看下它的内容片段:
# cat /usr/local/nginx/conf/mime.types
types {
text/html html htm shtml;
text/xml xml;
……………………………省略…………………………
image/gif gif;
video/quicktime mov;
}
从mime_types文件的内容片断可以看到,其中定义了一个type结构,结构中包含了浏览器能够识别的MIME类型以及对应相关类型的文件后缀名。
由于mime_types文件时主配置文件应用的第三方文件,因此,types也是nginx配置文件中的一个配置块,我们可以称为types块
其用于定义MIME类型。
第二行中使用指令default_type配置了用于处理前端请求的MIME类型,其语法结构为:
default_type mime-type;
其中,mime-type为types块中定义的MIME-type,如果不加此指令,默认值为test/plain。
此指令可以在http块、server块、location指令中进行配置
自定义服务日志
在全局块中,error_log指令,其用于配置nginx进程运行时的日志存放位置及级别,此处所指的日志与常规的不同,它是指记录nginx服务器提供服务过程应答前端请求的日志,我们将其称为服务日志来区分开
nginx服务器支持对服务日志的格式,大小,输出等进行配置,需要使用两个指令,分别是access_log和log_format指令。
assess_log指令的语法结构为:
access_log path [format [buffer=size]]
-
path配置服务日志的文件存放的路径和名称
-
format可选项,自定义服务日志的格式字符串,也可以通过"格式串的名称"使用log_format指令定义好的格式。"格式串的名称"在log_format指令中定义
-
size配置临时存放日志的内存缓存区的大小
此指令可以在http块、server块、location指令中进行设置
access_log /usr/local/nginx/logs/access.log combined;
其中,combined为log_format指令默认定义的日志格式字符串的名称
如果需要取消记录服务日志的功能,则使用:
access_log off;

和access_log联合使用的另一个指令是log_format,它专门定义服务日志的格式,并且可以为格式字符串定义一个名字,以便access_log指令可以直接调用。语法如下:
log_format name string ……; 此指令只能在http块中进行配置
-
name,格式字符串的名字,默认的名字为combined
-
string,服务日志的格式字符串。在定义过程中,可以使用nginx配置预设的一些变量获取相关内容,变量的名称使用双引号括起来,string整体使用单引号括起来。
实例:
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;


| Nginx日志变量 | 说明 |
|---|---|
| $remote_addr | 记录访问网站的客户端地址;即源 ip地址 |
| $http_x_forwarded_for | 当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器上也进行了相关的 x_forwarded_for设置可以记录用户真实的IP地址信息 |
| $remote_user | 远程客户端用户名称 |
| $request | 用户的 http请求和http协议起始行信息 |
| $status | http状态码,记录请求返回的状态,例如:200,404,301等 |
| $body_bytes_sents | 服务器发送给客户端的响应body字节数;不包括响应头的大小 |
| $http_referer | 记录此次请求是从哪个链接访问过来的,可以根据referer进行防盗链设置即表示是哪个网站介绍过来的 |
| $http_user_agent | 记录客户端访问信息,例如:浏览器、手机客户端等 |
| $bytes_sent | 发送给客户端的总字节数 |
| $connection | 连接的序列号 |
| $connection_requests | 当前通过一个连接获得的请求数量 |
| $msec | 日志写入时间。单位为秒,精度是毫秒 |
| $pipe | 如果请求是通过HTTP流水线(pipelined)发送,pipe值为"p",否则为"." |
| $request_length | 请求的长度(包括请求行,请求头和请求正文) |
| $request_time | 请求处理时间,单位为秒,精度毫秒 |
| $time_iso8601 | ISO8601标准格式下的本地时间 |
| $time_local | 记录访问时间与时区 |
| $upstream_addr | 负载均衡时,转发的真实后端地址 |
| $upstream_status | 负载均衡时,转发后端时的状态码 |
| $request_time | 服务端从接受客户端请求的第一个字节到服务端应用程序处理完发送完响应数据的时间,包括请求数据时间、程序响应时间、输出响应时间 |
| $upstream_response_time | 指nginx向后端如php,tomcat等建立连接开始到到处理完数据关闭连接为止的时间。$request_time肯定比$upstream_response_time值大,特别是使用POST方式传递参数时,因为Nginx会把request body缓存住,接受完毕后才会把数据一起发给后端。所以如果用户网络较差,或者传递数据较大时,$request_time会比$upstream_response_time大很多。参考: https://blog.51cto.com/qiangsh/1743207 |
| $upstream_cache_status | 记录缓存的命中率到日志中 |
在没有特殊要求的情况下,采用默认的配置即可,更多可以设置的记录日志信息的变量见: http://nginx.org/en/docs/http/ngx_httpJog_module.html
配置允许sendfile方式传输文件
在Apache、lighttpd服务器配置中,都有和sendfile相关配置,主要学习下配置sendfile传输方式的相关指令sendfile和sendfile_max_chunk,语法结构如下:
sendfile on|off;
用于开启或者关闭使用sendfile()传输文件,默认值off
该指令可以http块、server块、location指令中进行配置
sendfile_max_chunk size;
其中,size值如果大于0,nginx进程的每个worker process每次调用sendfile()传输的数据量最大不能超过这个值;如果设置为0,则无限制。默认值也是为0
此指令可以在http块、server块、location块中配置
配置实例:
sendfile_max_chunk 128k;
配置连接超时时间
与用户建立会话连接后,nginx服务器可以保持这些连接打开一段时间,指令keepalive_timeout就是用来设置此时间的,语法结构如下:
keepalive_timeout timeout [header_timeout];
-
timeout,服务器端对连接保持时间。默认值75s
-
header_timeout,可选项,在应答报文头部的Keep-Alive域设置超时时间:
"Keep-Alive:timeout=header_timeout"。报文在的这个指令可以被Mozilla或者konqueror识别
实例:
keepalive_timeout 120s 100s;
其含义,在服务器保持连接的时间设置120s,发给用户端的应答报文头部中Keep-Alive域的超时时间设置为100s
此指令可以出现在http块、server块和location指令中配置
单连接请求上限
nginx服务器和用户端建立会话连接后,用户端通过此连接发送请求。指令keepalive_requests用于限制用户通过某一连接向nginx服务器发送请求的次数。语法结构如下:
keepalive_requests number;
此指令还可以出现在server块和location中,默认值是100
配置网络监听
第一种:配置监听的IP地址
第二种:配置监听端口
第三种:配置UNIX Domain Socker
-
IP地址,如果是ipv6,需要使用中括号括起来,比如[dsadas::55],如果自定义了ip地址没有定义端口号,那么端口号就是80
-
端口号,如果只定义了端口号,那么ip就是0.0.0.0
-
socket文件路径,如/var/run/nginx.socket
配置主机名称
指令为server_name,语法结构如下:
server_name name……
对于name来说,可以是一个名称,也可以由多个名称并列,之间用空格隔开。每个名字就是一个域名,由2段或者3端组成,之间由.隔开
name中可以使用通配符*,但是通配符只能用在由三段字符串组成的名字的首段或者尾段,或者有2段字符串组成的名称的尾段,如下:
server_name *.test.com www.test.*;
在name中还可以使用正则表达式,并使用波浪号~作为正则表达式字符串的开始标记,如下:
server_name ~^www\d\.test\.com$;
由于server_name指令支持使用通配符和正则表达式两种配置名称的方式,因此在包含有多个虚拟主机的配置文件,可能会出现一个名称被多个虚拟主机的server_name匹配成功。那么,来自这个名称的请求到底要交给哪个虚拟主机处理呢?nginx服务器做了如下规定:
a.对于匹配方式不同,按照以下方式进行处理,排在前面的优先处理请求
1、准确匹配server_name
2、通配符在开始时匹配server_name成功
3、通配符在结尾时匹配server_name成功
4、正则表达式匹配server_name成功
b.在以上四种匹配方式中,如果server_name被处于同一优先级的匹配方式多次匹配成功,则首先匹配成功的虚拟主机处理请求
http完整配置-1及详解
http {
include mime.types;
server_tokens off;
#charset utf-8;
default_type application/octet-stream;
#default_type text/html;
large_client_header_buffers 4 32k;
client_max_body_size 1024m;
client_body_buffer_size 10m;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 120;
server_names_hash_max_size 512;
#服务器名字的hash表最大值
server_names_hash_bucket_size 128;
#如果Nginx检查语法提示需增大server_names_hash_max_size或server_names_hash_bucket_size,那么首要增大hash_max_size
client_header_timeout 10;
client_body_timeout 10;
reset_timedout_connection on;
send_timeout 10;
log_format main '"$http_x_forwarded_for" - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $remote_addr';
#fastcgi配置
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
#Gzip Compression
gzip on;
gzip_buffers 16 8k;
gzip_comp_level 6;
gzip_http_version 1.1;
gzip_min_length 256;
gzip_proxied any;
gzip_vary on;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
#gzip_disable "msie6";
gzip_types
text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xml
text/javascript application/javascript application/x-javascript
text/x-json application/json application/x-web-app-manifest+json
text/css text/plain text/x-component
font/opentype application/x-font-ttf application/vnd.ms-fontobject
image/x-icon;
#If you have a lot of static files to serve through Nginx then caching of the files' metadata (not the actual files' contents) can save some latency.
open_file_cache max=1000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
server{
listen 80 default;
location / {
return 403;
}
}
# server{
# listen 81;
# ## server_name ; #绑定域名
# index index.htm index.html; #默认文件
# root /home/www/; #网站根目录
# location ~ .*.jsp$ {
# proxy_pass http://localhost:8080;
# proxy_set_header Host $host:$server_port;
# }
# location ~ .*.php$ {
# proxy_pass http://localhost:80;
# proxy_set_header Host $host:$server_port;
# }
# location / {
# try_files $uri $uri/ /index.html;
# }
# }
access_log off;
#将服务器404错误页面重定向到静态页面/404.html
#error_page 404 /404.html;
#将服务器错误页面重定向到静态页面/50x.html
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
include vhost/*.conf;
}
参数解释:
·include
只是一个在当前文件中包含另一个文件内容的指令。这里我们使用它来加载稍后会用到的一系列的MIME类型。
·default_type
设置文件使用的默认的MIME-type。
• server_tokens
并不会让nginx执行的速度更快,但它可以关闭在错误页面中的nginx版本数字,这样对于安全性是有好处的
• charset utf-8; # charset UTF-8;
设置我们的头文件中的默认的字符集
• sendfile on
开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,减少用户空间到内核空间的上下文切换。对于普通应用设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络I/O处理速度,降低系统的负载。
• tcp_nopush
告诉nginx在一个数据包里发送所有头文件,而不一个接一个的发送
• tcp_nodelay
告诉nginx不要缓存数据,而是一段一段的发送当需要及时发送数据时,就应该给应用设置这个属性,这样发送一小块数据信息时就不能立即得到返回值
Nginx的TCP配置:
HTTP是一个应用层协议,在传输层使用TCP协议。在TCP协议中,数据是以一块一块的TCP数据包传输的。Nginx提供了多个directive,可以用来调整TCP栈。
TCP_NODELAY
TCP/IP网络有一个"小数据包"的问题,如果一条信息中只有一个字符,那么网络可能会堵塞。这样的数据包大小为41字节,其中TCP信头40字节,内容为1字节。像这种小数据包,它们的开销是4000%。大量的小数据包可以迅速让网络饱和。
John Nagle发明了Nagle算法,它在一定的时间段,将小数据包暂存,将这些小数据包集合起来,整合为一个数据包发送,在下一个时间段又是如此。这改善了网络传输的效率。时间段通常为200ms。
但值得注意的是,小数据包的问题在telnet的通信过程中仍然存在。在telnet中,每一次敲键都分别在网络发送。不过这跟web服务器没有关联。web服务器发送的文件大多是大数据包,所以它们会被立即发送,而不需要等待200ms。
TCP_NODELAY可以用来关闭Nagle的缓冲算法,将数据尽快地发送。Nginx可以在http, server, location当中定义
http {
tcp_nodelay on;
}
Nginx默认启用了tcp_nodelay。Nginx在keep-alive模式下会使用tcp_nodelay。
TCP_CORK
除了Nagle算法外,Linux内核提供了一个TCP_CORK选项,也可以解决小数据包问题。TCP_CORK告诉TCP栈将数据包附加在另外一个数据包,当数据包饱和时或程序明确地指示发送时再发送。在FreeBSD和Mac OS系统上,TCP_NOPUSH选项相当于TCP_CORK。
Nginx可以在http, server和location模块中定义tcp_nopush。
http {
tcp_nopush on;
}
Nginx默认启用了tcp_nopush
上面的两个directives负责不同的任务。tcp_nodelay可以降低网络延迟,而tcp_nopush可以优化发送的数据包。
同时启用tcp_nopush和sendfile可以确保在传输文件时,内核总是生成最大量的完整TCP数据包以供传输,而最后一个TCP数据包可以是不完整的,这个不完整的数据包
• keepalive_timeout 65 50;
长连接超时时间,单位是秒,这个参数很敏感,涉及浏览器的种类、 后端服务器的超时设置、操作系统的设置,可以另外起一片文章了。长连接请求大量小文件的时候,可以减少重建连接的开销,但假如有大文件上传,65s内没上传完成会导致失败。如果设置时间过长,用户又多,长时间保持连接会占用大量资源。
• send_timeout 60;
用于指定响应客户端的超时时间。这个超时仅限于两个连接活动之间的时间,如果超过这个时间,客户端没有任何活动,Nginx将会关闭连接。
指定客户端的响应超时时间。这个设置不会用于整个转发器,而是在两次客户端读取操作之间。如果在这段时间内,客户端没有读取任何数据,nginx就会关闭连接
• client_max_body_size 10m;
允许客户端请求的最大单文件字节数。如果有上传较大文件,请设置它的限制值
上传文件最大限制,php.ini中也要修改,最后优化时会提及
• client_body_buffer_size 128k;
缓冲区代理缓冲用户端请求的最大字节数
·client_header_timeout 和client_body_timeout
设置请求头和请求体(各自)的超时时间。我们也可以把这个设置低些
client_header_timeout 10;
client_body_timeout 10;
·reset_timeout_connection on;
告诉nginx关闭不响应的客户端连接。这将会释放那个客户端所占有的内存空间
·gzip on;
是告诉nginx采用gzip压缩的形式发送数据。这将会减少我们发送的数据量。
·gzip_disable "MSIE [1-6]\.(?!.*SV1)";
为指定的客户端禁用gzip功能。我们设置成IE6或者更低版本以使我们的方案能够广泛兼容。
·gzip_static
告诉nginx在压缩资源之前,先查找是否有预先gzip处理过的资源。这要求你预先压缩你的文件(在这个例子中被注释掉了),从而允许你使用最高压缩比,这样nginx就不用再压缩这些文件了(想要更详尽的gzip_static的信息,请点击这里)。
·gzip_proxied
允许或者禁止压缩基于请求和响应的响应流。我们设置为any,意味着将会压缩所有的请求。
·gzip_min_length
设置对数据启用压缩的最少字节数。如果一个请求小于1000字节,我们最好不要压缩它,因为压缩这些小的数据会降低处理此请求的所有进程的速度。
·gzip_comp_level
设置数据的压缩等级。这个等级可以是1-9之间的任意数值,9是最慢但是压缩比最大的。我们设置为4,这是一个比较折中的设置。
·gzip_type
设置需要压缩的数据格式。上面例子中已经有一些了,你也可以再添加更多的格式
# cache informations about file descriptors, frequently accessed files
# can boost performance, but you need to test those values
·open_file_cache
打开缓存的同时也指定了缓存最大数目,以及缓存的时间。我们可以设置一个相对高的最大时间,这样我们可以在它们不活动超过20秒后清除掉。
·open_file_cache_valid
在open_file_cache中指定检测正确信息的间隔时间。
·open_file_cache_min_uses
定义了open_file_cache中指令参数不活动时间期间里最小的文件数。
·open_file_cache_errors
指定了当搜索一个文件时是否缓存错误信息,也包括再次给配置中添加文件。我们也包括了服务器模块,这些是在不同文件中定义的。如果你的服务器模块不在这些位置,你就得修改这一行来指定正确的位置
·underscores_in_headers off;
默认off,配置在http、server中;启用或禁用客户端请求标头字段中下划线的使用。禁用下划线时,名称包含下划线的请求标头字段将标记为无效,并受到ignore_invalid_headers指令的约束
·server_names_hash_max_size 512;
服务器名字的hash表最大值
·server_names_hash_bucket_size 128;
如果Nginx检查语法提示需增大server_names_hash_max_size或server_names_hash_bucket_size,那么首要增大hash_max_size
模块http_proxy
这个模块实现的是nginx作为反向代理服务器的功能,包括缓存功能(另见文章)
• proxy_connect_timeout 60
nginx跟后端服务器连接超时时间(代理连接超时)
• proxy_read_timeout 60
连接成功后,与后端服务器两个成功的响应操作之间超时时间(代理接收超时)
• proxy_buffer_size 4k
设置代理服务器(nginx)从后端realserver读取并保存用户头信息的缓冲区大小,默认与proxy_buffers大小相同,其实可以将这个指令值设的小一点
• proxy_buffers 4 32k
proxy_buffers缓冲区,nginx针对单个连接缓存来自后端realserver的响应,网页平均在32k以下的话,这样设置
• proxy_busy_buffers_size 64k
高负荷下缓冲大小(proxy_buffers*2)
• proxy_max_temp_file_size
当proxy_buffers放不下后端服务器的响应内容时,会将一部分保存到硬盘的临时文件中,这个值用来设置最大临时文件大小,默认1024M,它与proxy_cache没有关系。大于这个值,将从upstream服务器传回。设置为0禁用。
• proxy_temp_file_write_size 64k
当缓存被代理的服务器响应到临时文件时,这个选项限制每次写临时文件的大小。proxy_temp_path(可以在编译的时候)指定写到哪那个目录。
proxy_pass,proxy_redirect见 location 部分。
-
gzip on : 开启gzip压缩输出,减少网络传输。
-
gzip_min_length 1k :设置允许压缩的页面最小字节数,页面字节数从header头得content-length中进行获取。默认值是20。建议设置成大于1k的字节数,小于1k可能会越压越大。
-
gzip_buffers 4 16k :设置系统获取几个单位的缓存用于存储gzip的压缩结果数据流。4 16k代表以16k为单位,安装原始数据大小以16k为单位的4倍申请内存。
-
gzip_http_version 1.0 :用于识别 http 协议的版本,早期的浏览器不支持 Gzip 压缩,用户就会看到乱码,所以为了支持前期版本加上了这个选项,如果你用了 Nginx 的反向代理并期望也启用 Gzip 压缩的话,由于末端通信是 http/1.0,故请设置为 1.0。
-
gzip_comp_level 6 :gzip压缩比,1压缩比最小处理速度最快,9压缩比最大但处理速度最慢(传输快但比较消耗cpu)
-
gzip_types :匹配mime类型进行压缩,无论是否指定,"text/html"类型总是会被压缩的。
-
gzip_proxied any :Nginx作为反向代理的时候启用,决定开启或者关闭后端服务器返回的结果是否压缩,匹配的前提是后端服务器必须要返回包含"Via"的 header头。
-
gzip_vary on :和http头有关系,会在响应头加个 Vary: Accept-Encoding ,可以让前端的缓存服务器缓存经过gzip压缩的页面,例如,用Squid缓存经过Nginx压缩的数据。。
server虚拟主机
http服务上支持若干虚拟主机。每个虚拟主机一个对应的server配置项,配置项里面包含该虚拟主机相关的配置。在提供mail服务的代理时,也可以建立若干server。每个server通过监听地址或端口来区分。
• listen
监听端口,默认80,小于1024的要以root启动。可以为listen *:80、listen 127.0.0.1:80等形式。
• server_name
服务器名,如localhost、www.example.com,可以通过正则匹配。
• ssl_protocols TLSv1 TLSv1.1 TLSv1.2;#协议配置
Nginx的虚拟主机配置,使多个网站可以部署在同一个服务器(同一IP地址)对外提供服务。但是在实际测试中发现,虽然两个配置都在server 块内,ssl_protocols 却属于全局配置,而 ssl_ciphers 却针对特定的虚拟主机起作用
由于 SSLv3 的 POODLE 漏洞, 建议不要在开启 SSL 的网站使用 SSLv3。 你可以简单粗暴的直接禁用 SSLv3,用 TLS 来替代
• ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5;#加密套件
模块http_stream
这个模块通过一个简单的调度算法来实现客户端IP到后端服务器的负载均衡,upstream后接负载均衡器的名字,后端realserver以 host:port options; 方式组织在 {} 中。如果后端被代理的只有一台,也可以直接写在 proxy_pass 。
location->http服务中,某些特定的URL对应的一系列配置项
• root /var/www/html
定义服务器的默认网站根目录位置。如果locationURL匹配的是子目录或文件,root没什么作用,一般放在server指令里面或/下。
• index index.jsp index.html index.htm index.php
定义路径下默认访问的文件名,一般跟着root放
• proxy_pass http:/backend
请求转向backend定义的服务器列表,即反向代理,对应upstream负载均衡器。也可以proxy_pass http://ip:port。
• proxy_redirect off;
proxy_set_header Host \$host:\$server_port;
proxy_set_header X-Real-IP \$remote_addr;
proxy_set_header X-Forwarded-For \$proxy_add_x_forwarded_for;
这四个暂且这样设,如果深究的话,每一个都涉及到很复杂的内容,也将通过另一篇文章来解读。
关于location匹配规则的写法,可以说尤为关键且基础的,参考文章 nginx配置location总结及rewrite规则写法;
http完整配置-2及详解
http {
include mime.types; #文件扩展名与文件类型映射表,#设定mime类型(邮件支持类型),类型由mime.types文件定义
default_type application/octet-stream; #默认文件类型
charset utf-8; #默认编码
server_names_hash_bucket_size 128; #服务器名字的hash表大小
client_header_buffer_size 32k; #上传文件大小限制
large_client_header_buffers 4 64k; #设定请求缓
client_max_body_size 8m; #设定请求缓
sendfile on; #开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,对于普通应用设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络I/O处理速度,降低系统的负载。注意:如果图片显示不正常把这个改成off。
autoindex on; #开启目录列表访问,合适下载服务器,默认关闭。
tcp_nopush on; #防止网络阻塞
tcp_nodelay on; #防止网络阻塞
keepalive_timeout 120; #长连接超时时间,单位是秒
#FastCGI相关参数是为了改善网站的性能:减少资源占用,提高访问速度。下面参数看字面意思都能理解。
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
#gzip模块设置
gzip on; #开启gzip压缩输出
gzip_vary on;#gzip_vary on 给响应头加上 Vary: Accept-Encoding
gzip_proxied any;#gzip_proxied any 为所有的代理的响应头启用压缩
gzip_http_version 1.1;
#gzip_http_version 1.0; #压缩版本(默认1.1,前端如果是squid2.5请使用1.0)
gzip_comp_level 2; #压缩等级,指定压缩级别[1-9],数字越小,压缩比越小,压缩速度越快
gzip_min_length 1k; #最小压缩文件大小
gzip_buffers 4 16k; #设置缓冲区的个数和大小
gzip_disable "MSIE [1-6]\.";#对于特定浏览器禁用压缩功能
gzip_disable "MSIE [1-6]\.(?!.*SV1)";#设定启用压缩的文件类型
#gzip_types text/plain application/x-javascript text/css application/xml;
#压缩类型,默认就已经包含text/html,所以下面就不用再写了,写上去也不会有问题,但是会有一个warn。
gzip_types
text/plain
text/html
text/css
text/javascript
text/xml
application/json
application/x-javascript
application/javascript
application/xml
application/xhtml+xml
application/atom+xml
application/xml+rss
image/png
image/jpeg
image/gif
image/x-icon
image/bmp
image/svg+xml
audio/mpeg
audio/ogg
video/mp4
video/quicktime
video/ogg
video/webm;
#开启限制IP连接数的时候需要使用
#limit_zone crawler $binary_remote_addr 10m;
#配置共享会话缓存大小
ssl_session_cache shared:SSL:10m;
#配置会话超时时间
ssl_session_timeout 10m;
#upstream的负载均衡,weight是权重,可以根据机器配置定义权重。weigth参数表示权值,权值越高被分配到的几率越大。
upstream www.test.com {
server 192.168.80.121:80 weight=3;
server 192.168.80.122:80 weight=2;
}
#虚拟主机的配置
server {
#监听端口
listen 80;
#域名可以有多个,用空格隔开
server_name www.test.com test.com;
#设置长连接
keepalive_timeout 70;
#HSTS策略
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always;
#证书文件
ssl_certificate www.example.com.crt;
#私钥文件
ssl_certificate_key www.example.com.key;
#优先采取服务器算法
ssl_prefer_server_ciphers on;
#使用DH文件
ssl_dhparam /etc/ssl/certs/dhparam.pem;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5;
#定义算法
ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5;
#ssl_ciphers "EECDH+ECDSA+AESGCM EECDH+aRSA+AESGCM EECDH+ECDSA+SHA384 EECDH+ECDSA+SHA256 EECDH+aRSA+SHA384 EECDH+aRSA+SHA256 EECDH+aRSA+RC4 EECDH EDH+aRSA !aNULL !eNULL !LOW !3DES !MD5 !EXP !PSK !SRP !DSS !RC4";
#减少点击劫持
add_header X-Frame-Options DENY;
#禁止服务器自动解析资源类型
add_header X-Content-Type-Options nosniff;
#防XSS攻擊
add_header X-Xss-Protection 1;
index index.html index.htm index.php;
root /data/www/test;
location ~ .*\.(php|php5)?$
{
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
}
#浏览器缓存,静态资源缓存用expire;图片缓存时间设置
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ {
expires 10d;
}
#浏览器缓存,静态资源缓存用expire;JS和CSS缓存时间设置
location ~ .*\.(js|css)?$ {
expires 1h;
}
#日志格式设定
log_format access '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $http_x_forwarded_for';
#定义本虚拟主机的访问日志
access_log /var/log/nginx/access.log access;
#对 "/" 启用反向代理
location / {
proxy_pass http://127.0.0.1:888;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
#后端的Web服务器可以通过X-Forwarded-For获取用户真实IP
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#以下是一些反向代理的配置,可选。
proxy_set_header Host $host; # 设置浏览器请求的host
client_max_body_size 10m; #允许客户端请求的最大单文件字节数
client_body_buffer_size 128k; #缓冲区代理缓冲用户端请求的最大字节数,
proxy_connect_timeout 90; #nginx跟后端服务器连接超时时间(代理连接超时)
proxy_send_timeout 90; #后端服务器数据回传时间(代理发送超时)
proxy_read_timeout 90; #连接成功后,后端服务器响应时间(代理接收超时)
proxy_buffer_size 4k; #设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffers 4 32k; #proxy_buffers缓冲区,网页平均在32k以下的设置
proxy_busy_buffers_size 64k; #高负荷下缓冲大小(proxy_buffers*2)
proxy_temp_file_write_size 64k;
#设定缓存文件夹大小,大于这个值,将从upstream服务器传
}
#设定查看Nginx状态的地址
location /NginxStatus {
stub_status on;
access_log on;
auth_basic "NginxStatus";
auth_basic_user_file conf/htpasswd;
#htpasswd文件的内容可以用apache提供的htpasswd工具来产生。
}
#---------------------------------------------------------------
#本地动静分离反向代理配置
#所有jsp的页面均交由tomcat或resin处理
location ~ .(jsp|jspx|do)?$ {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
#所有静态文件由nginx直接读取不经过tomcat或resin
location ~ .*.(htm|html|gif|jpg|jpeg|png|bmp|swf|ioc|rar|zip|txt|flv|mid|doc|ppt|pdf|xls|mp3|wma)$ {
expires 15d;
}
location ~ .*.(js|css)?$ {
expires 1h;
}
}
}
nginx.conf
[root@learn conf]# cat nginx.conf
user nginx nginx;
error_log logs/error.log;
pid logs/nginx.pid;
#可以写绝对路径或者相对路径
#pid /usr/local/nginx/logs/nginx.pid;
worker_processes auto;
worker_rlimit_nofile 51200;
worker_cpu_affinity auto;
events {
use epoll;
multi_accept on;
accept_mutex on;
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
log_format main '$remote_addr - $http_x_forwarded_for - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" ';
# server_tokens off;
sendfile on;
charset utf-8;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65 50;
keepalive_requests 100;
send_timeout 60;
client_max_body_size 100m;
client_body_buffer_size 256k;
client_header_timeout 10;
client_body_timeout 10;
reset_timedout_connection on;
client_header_buffer_size 16k;
server_names_hash_max_size 512;
server_names_hash_bucket_size 128;
#proxy_pass http://39.107.229.89:8100;
#proxy_redirect default;
#proxy_set_header X-Real-IP $remote_addr;
#proxy_set_header X-Forwaarded-For $proxy_add_x_forwarded_for;
#proxy_set_header Host $host:$server_port;
#proxy_send_timeout 180;
#proxy_read_timeout 180;
#proxy_connect_timeout 180;
#proxy_buffering on;
#proxy_buffer_size 8k;
#proxy_buffers 8 64k;
#proxy_busy_buffers_size 128k;
#proxy_max_temp_file_size 256k;
#proxy_temp_file_write_size 128k;
#proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504 http_404;
#Gzip Compression
gzip on;
gzip_buffers 16 8k;
gzip_comp_level 6;
gzip_http_version 1.0;
gzip_min_length 1024;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
gzip_proxied any;
gzip_vary on;
gzip_types
application/atom+xml
application/javascript
application/x-javascript
application/json
application/ld+json
application/manifest+json
application/rss+xml
application/vnd.geo+json
application/vnd.ms-fontobject
application/x-font-ttf
application/x-web-app-manifest+json
application/xhtml+xml
application/xml
font/opentype
image/bmp
image/svg+xml
image/x-icon
text/xml
text/x-json
text/javascript
text/cache-manifest
text/css
text/plain
text/vcard
text/vnd.rim.location.xloc
text/vtt
text/x-component
text/x-cross-domain-policy;
#If you have a lot of static files to serve through Nginx then caching of the files' metadata (not the actual files' contents) can save some latency.
open_file_cache max=1000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
#fastcgi配置
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
#proxy cache
# proxy_cache_path /usr/local/nginx/cache/a levels=1:1 keys_zone=zone_a:10m inactive=300s max_size=5g;
# proxy_cache_path /usr/local/nginx/cache/b levels=1:2 keys_zone=zone_b:100m inactive=300s max_size=5g;
# proxy_cache_path /usr/local/nginx/cache/c levels=1:1:2 keys_zone=zone_c:100m inactive=300s max_size=5g;
#limit_conn && limit_req
# limit_conn_zone $binary_remote_addr zone=one:10m;
# limit_conn_zone $server_name zone=two:10m;
# limit_req_zone $binary_remote_addr zone=three:10m rate=1r/s;
# limit_conn_log_level error;
# limit_conn_status 503;
server {
listen 80;
server_name localhost;
access_log logs/access.log main;
location / {
# try_files $uri $uri/ /index.html;
# root /usr/local/nginx/html;
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
include /usr/local/nginx/conf/vhost/*.conf;
}
nginx一键生成配置文件
Nginx模块(面试必问)
模块化设计的概念:以"功能块"为单位进行程序设计、实现其求解算法的方法
nginx涉及到的模块分为核心模块、标准HTTP模块、可选HTTP模块、邮件服务模块以及第三方模块等五大类,如下:
-
核心模块是指nginx服务器正常运行必不可少的模块,他们提供了nginx最基本核心服的服务,如进程管路、权限控制、错误日志记录等
-
标准HTTP模块是指编译nginx后包含的模块,其支持nginx服务器的标准HTTP功能
-
可选HTTP模块是指主要用于扩展标准的HTTP功能,使其能处理一些特殊的HTTP请求
-
邮件服务模块主要用于支持nginx邮件服务,默认不编译进nginx,需要自定义加入
-
第三方模块是为了扩展nginx服务器应用,完成特殊功能而由第三方机构或者个人编写的可编译到nginx中的模块

nginx的每个模块都基本符合单一职责原则,在具体环境中可以根据实际情况进行裁减和加入
nginx所有固有模块的源码放在编译目录下的src目录中。在src目录中,我们看到一共分成了core event http mail misc os stream 等7个目录。从这里看,源码包含了邮件服务的模块,但是在快速编译时默认不将其编译到nginx中。
核心模块
核心模块主要包含对两类功能的支持:
一类是主体功能,包括进行管理、权限管理、错误日志记录、配置解析等
另一类是用于响应请求时间必须的功能,包括时间驱动机制、正则表达式解析等。
标准HTTP模块
这些模块在默认情况下是被编译到nginx内核中,除非在配置是添加--without-xxx参数声明不编译
比较重要的标准HTTP模块:
-
ngx_http_core_module 配置端口、URI分析、服务器响应错误处理,别名控制以及其他HTTP核心事务
-
ngx_http_access_module 基于IP地址访问控制(运行/拒绝)
-
ngx_http_auth_basic_module 基于HTTP的身份认证
-
ngx_http_autoindex_module 处理以"/"结尾的请求并自动生成目录列表
-
ngx_http_browser_module 解析http请求头中的"User-Agent"域的值
-
ngx_http_charset_module 指定网页编码
-
ngx_http_empty_gif_module 从内存创建一个1*1的透明gif图片,可以快速调用
-
ngx_http_fastcgi_module 对fastcgi的支持
-
ngx_http_geo_module 将客户端请求中的参数转化为键值对变量
-
ngx_http_gzip_module 压缩请求响应,可以减少数据传输
-
ngx_http_index_module 处理以"/"结尾的请求,如果没有找到该目录下的index页,就将请求转发给ngx_http_autoindex_module模块处理;如果nginx开启了ngx_http_random_index_module模块,则随机选择index页ngx_http_geoip_module
-
ngx_http_limit_conn_module 限制来自客户端的连接的响应和处理速率
-
ngx_http_limit_req_module 限制来自客户端的请求的响应和处理速率
-
ngx_http_log_module 自定义access日志
-
ngx_http_map_module 创建任意键值对变量
-
ngx_http_memcached_module 对memcached的支持
-
ngx_http_proxy_module 支持代理服务
-
ngx_http_referer_module 过滤HTTP头中"Referer"域值为空的HTTP请求
-
ngx_http_rewrite_module 通过正则表达式重定向请求
-
ngx_http_scgi_module 对SCGI的支持
-
ngx_http_ssl_module 对HTTPS的支持
可选的HTTP模块
- ngx_http_f4f_module
- ngx_http_auth_jwt_module
- ngx_http_auth_request_module
- ngx_http_addition_module 在响应请求的页面开始或者结尾添加文本信息
- ngx_http_api_module
- ngx_http_dav_module 支持http协议和webDAV协议中PUT、DELETE、MKCOL、COPY很热MOVE方法
- ngx_http_flv_module 支持将Flash多媒体信息按照流文件传输,可以根据客户端指定的开始位置返回Flash
- ngx_http_grpc_module
- ngx_http_gunzip_module
- ngx_http_gzip_static_module 搜索并使用预压缩的以
.gz为后缀的文件代替一般文件响应客户端请求 - ngx_http_headers_module
- ngx_http_hls_module
- ngx_http_image_filter_module 支持改变JPEG、GIF很热PNG图片的尺寸和旋转方向
- ngx_http_js_module
- ngx_http_keyval_module
- ngx_http_mirror_module
- ngx_http_mp4_module 支持将H.264/AAC编码的多媒体信息(后缀名通常为MP4、m4v或者m4a)安装流文件传输,常与ngx_http_flv_module模块一起使用
- ngx_http_perl_module 在nginx的配置文件中可以使用perl脚本
- ngx_http_secure_link_module 支持对请求链接的有效检查
- ngx_http_random_index_module nginx接收到以
/结尾请求时,在对应目录下随机选择一个文件作为index文件 - ngx_http_realip_module
- ngx_http_session_log_module
- ngx_http_slice_module
- ngx_http_spdy_module
- ngx_http_split_clients_module
- ngx_http_ssi_module
- ngx_http_status_module
- ngx_http_stub_status_module 支持返回nginx服务器的统计信息,一般包括处理连接的数量,连接成功的数量,处理的请求、读取和返回header信息数等信息
- ngx_http_sub_module 使用指定的字符串替换响应信息中的信息
- ngx_http_upstream_module
- ngx_http_upstream_conf_module
- ngx_http_upstream_hc_module
- ngx_http_userid_module
- ngx_http_uwsgi_module
- ngx_http_v2_module
-
ngx_http_xslt_module 将xml响应信息使用xslt(扩展样式表转换语言)进行转换
-
ngx_stream_geoip_module 支持解析基于GeoIP数据库的客户端请求(关于GeoIP数据库,查看官网http://www.maxmind.com)
-
ngx_google_perftools_module 支持Google Performance Tools(Google Performance Tools是Google公司开发的一套用于C++Profile的工具集,详解查看官网:http://code.google.com/p/gperftools)
服务邮件模块
邮件服务是nginx服务器提供的主要服务之一,这些模块完成了邮件服务的主要功能,包括多pop/3、imap协议和smtp协议的支持,对身份认证、邮件代理和ssl安全服务的提供
第三方模块
参考:https://www.nginx.com/resources/wiki/modules
记录在wiki站点,如:
echo-nginx-module
memc-nginx-module
rds-json-nginx-module
lua-nginx-module
编译三方模块:echo-nginx-module 模块为例
参考:https://www.cnblogs.com/52fhy/p/10166333.html
获取echo-nginx-module
我们下载最新稳定版(截止到2018-12-23),并解压,不用安装:
$ cd /opt
$ wget https://github.com/openresty/echo-nginx-module/archive/v0.61.tar.gz
$ tar zxvf v0.61.tar.gz
编译Nginx
注意:重新编译 Nginx 二进制,Nginx 需要停止重启。而普通配置更新则 reload 即可
Nginx编译参数配置:
$ cd /opt/nginx-1.12.2/
$ ./configure
--prefix=/usr/local/nginx --user=nginx --group=nginx --sbin-path=/usr/local/nginx/sbin/nginx --conf-path=/usr/local/nginx/conf/nginx.conf --http-log-path=/usr/local/nginx/logs/access.log --error-log-path=/usr/local/nginx/logs/error.log --pid-path=/usr/local/nginx/logs/nginx.pid --lock-path=/usr/local/nginx/logs/nginx.lock --with-http_ssl_module --with-http_flv_module --with-http_stub_status_module --with-http_gzip_static_module --with-http_realip_module --with-http_secure_link_module --with-http_sub_module --with-pcre --with-stream --http-client-body-temp-path=/usr/local/nginx/client_body_temp --http-proxy-temp-path=/usr/local/nginx/proxy_temp --http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp --http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp --http-scgi-temp-path=/usr/local/nginx/scgi_temp --add-module=/opt/echo-nginx-module-0.61

这里因为已经安装了Nginx,所以这里的参数是从Nginx -V的输出里获取的,并追加了新的参数:
--add-module=/opt/echo-nginx-module-0.61
运行上面的./configure后进行编译安装:
$ make -j 2
$ make install
make install后,会覆盖之前安装的Nginx
查看是否编译成功:
nginx -V

示例




注意:这个模块不会识别是隐藏文件的网页

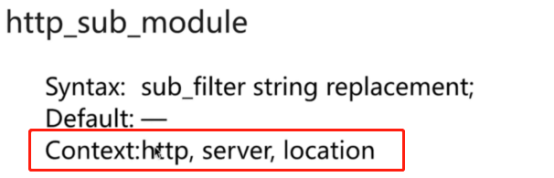
sub_filter '替换前的内容' '替换后的内容'


location / {
root /opt/app/code
index index.html index.htm;
sub_filter '<a>gobgm' '<a>GOBGM'; #只替换第一个参数
}
#test,只替换第一个gobgm
curl 127.0.0.1
welcome GOBGM gobgm.com
location / {
root /opt/app/code
index index.html index.htm;
sub_filter '<a>gobgm' '<a>GOBGM'; #全局替换
sub_filter_once off;
}
#test,替换全部的gobgm
curl 127.0.0.1
welcome GOBGM GOBGM.com
Nginx内置绑定变量
官网:http://nginx.org/en/docs/http/ngx_http_core_module.html#underscores_in_headers
参考文档:
https://moonbingbing.gitbooks.io/openresty-best-practices/openresty/inline_var.html
https://blog.51cto.com/xikder/2141820
Nginx作为一个成熟、久经考验的负载均衡软件,与其提供丰富、完整的内置变量是分不开的,它极大增加了对Nginx网络行为的控制细度。这些变量大部分都是在请求进入时解析的,并把他们缓存到请求cycle中,方便下一次获取使用。首先来看看Nginx对都开放了那些API。
参看下表:
| 名称 | 说明 |
|---|---|
| $arg_name | 请求中的name参数 |
| $args | 请求中的参数 |
| $binary_remote_addr | 远程地址的二进制表示 |
| $body_bytes_sent | 已发送的消息体字节数 |
| $content_length | HTTP请求信息里的"Content-Length" |
| $content_type | 请求信息里的"Content-Type" |
| $document_root | 针对当前请求的根路径设置值 |
| $document_uri | 与$uri相同; 比如 /test2/test.php |
| $host | 请求信息中的"Host",如果请求中没有Host行,则等于设置的服务器名 |
| $hostname | 机器名使用 gethostname系统调用的值 |
| $http_cookie | cookie 信息 |
| $http_referer | 引用地址 |
| $http_user_agent | 客户端代理信息 |
| $http_via | 最后一个访问服务器的Ip地址。 |
| $http_x_forwarded_for | 相当于网络访问路径 |
| $is_args | 如果请求行带有参数,返回“?”,否则返回空字符串 |
| $limit_rate | 对连接速率的限制 |
| $nginx_version | 当前运行的nginx版本号 |
| $pid | worker进程的PID |
| $query_string | 与$args相同 |
| $realpath_root | 按root指令或alias指令算出的当前请求的绝对路径。其中的符号链接都会解析成真是文件路径 |
| $remote_addr | 客户端IP地址 |
| $remote_port | 客户端端口号 |
| $remote_user | 客户端用户名,认证用 |
| $request | 用户请求 |
| $request_body | 这个变量(0.7.58+)包含请求的主要信息。在使用proxy_pass或fastcgi_pass指令的location中比较有意义 |
| $request_body_file | 客户端请求主体信息的临时文件名 |
| $request_completion | 如果请求成功,设为"OK";如果请求未完成或者不是一系列请求中最后一部分则设为空 |
| $request_filename | 当前请求的文件路径名,比如/opt/nginx/www/test.php |
| $request_method | 请求的方法,比如"GET"、"POST"等 |
| $request_uri | 请求的URI,带参数 |
| $scheme | 所用的协议,比如http或者是https |
| $server_addr | 服务器地址,如果没有用listen指明服务器地址,使用这个变量将发起一次系统调用以取得地址(造成资源浪费) |
| $server_name | 请求到达的服务器名 |
| $server_port | 请求到达的服务器端口号 |
| $server_protocol | 请求的协议版本,"HTTP/1.0"或"HTTP/1.1" |
| $uri | 请求的URI,可能和最初的值有不同,比如经过重定向之类的 |
如何获取用户真实IP地址信息
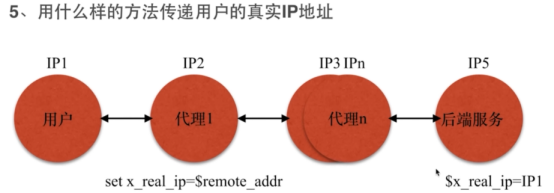
HTTP请求
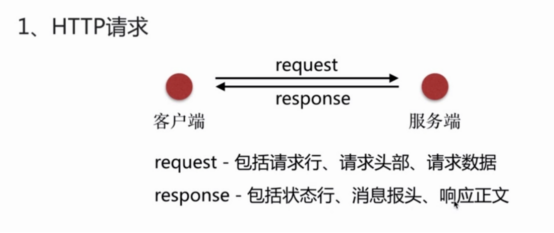
静态资源web服务
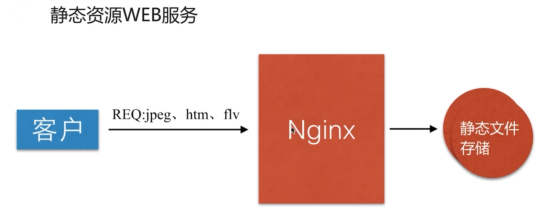
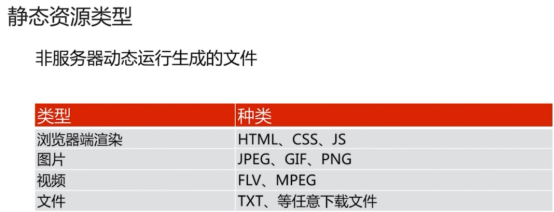
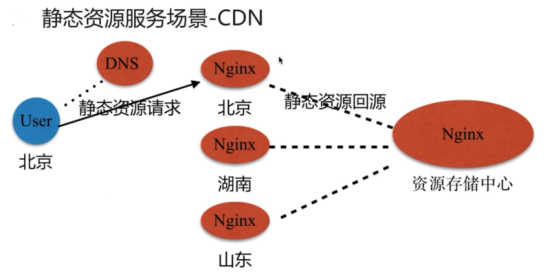




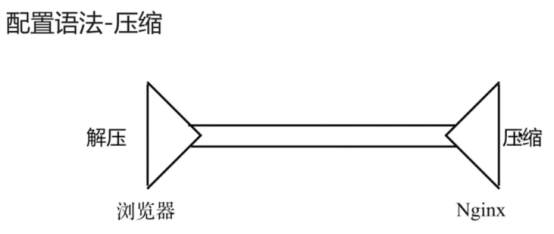



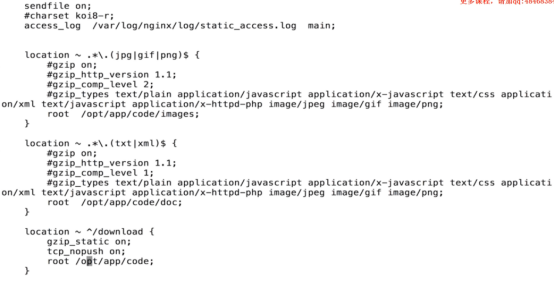
nginx服务器的web请求机制
从架构上来说,nginx服务器是与众不同的。不同之处一方面体现在它的模块化设计,另一方面,也是更重要的一方面,体现在它对客户端请求的处理机制上
web服务器和客户端是一对多的关系,web服务器必须有能力同时为多个客户端提供服务。一般来说,完成并行处理请求工作有三种方式可供选择:多进程方式、多线程方式、异步方式
多进程方式
多进程的方式是指:服务器每当接收到一个客户端的请求时,就由服务器主进程生成一个子进程出来和该客户端建立连接进行交互,直到断开连接,该子进程就结束了
多进程方式的优点:设计和实现相对简单,各个子进程之间相互独立,处理客户端请求的过程彼此不受到干扰,并且当一个子进程产生问题时,不容易将影响漫延到其他的进程中,这保证了提供服务器的稳定性。当子进程退出时,其占用资源会被操作系统回收,也不会留下任何垃圾。
缺点:操作系统中生成一个子进程需要进行内存复制等操作,在资源和时间上会产生一定的额外开销,因此,如果web服务器接收大量并发请求,就会对系统资源造成压力,导致系统性能下降
初期的Apache服务器就是采用这种方式对外提供服务的。为了大量并大请求,Apache服务器采用"预生成进程"的机制对多进程方式进行改进。
预生成进程的工作方式:它将生成子进程的时间提前,在客户端请求还没有到来之前就预先生成好,当请求到来时,主进程分配一个子进程和客户端进行交互,交互完成后,该子进程也就结束,而被主进程管理起来等待下一个客户端请求的到来。改进的多进程方式在一定程度上缓解了大量并发请求情形下web服务器对系统资源造成的压力。
但是由于Apache服务器在最初期的架构设计上采用了多进程方式,因此不能从根本上解决问题
多线程方式
多线程方式和多进程方式相似,它是指:服务器每当接收一个客户端请求时,会由服务器主进程派生一个线程出来和该客户端进行交互
由于操作系统产生一个线程的开销远远小于产生一个进程的开销,所有多线程方式在很大程度上减轻了web服务器对系统资源的要求。该方式使用线程进程任务调度,开发方面可以遵守一定的标准,这相对来说比较规范和有利于协作 但在线程管理方面,该方式有一定不足:多个线程位于同一个进程内,可以访问同样的内存空间,彼此之间相互影响;同时,在开发过程中不可避免的要由开发者自己多内存进行管理,其增加了出错的风险。服务器系统需要长时间连续不停的运转,错误的逐渐积累可能最终对整个服务器产生重大影响
IIS服务器使用了多线程方式对外提供服务,它的稳定性相对来说还不错,但是对于经验丰富的web服务器管理人员而言,他们通常还是会定期检查和重启服务器,以预防不可料的故障发生
异步方式
异步方式是和多进程方式及多线程方式完全不同的一种处理客户端请求的方式
网络通信中的同步机制和异步机制是描述通信模式的概念。
同步机制:是指发送方发送请求后,需要等待接收到接收方发回的响应,才接着发送下一个请求;在同步机制中。所有的请求在服务器端得到同步,发送方和接收方对请求的处理步调是一致的
异步机制:与同步机制正好相反,在异步机制中,发送方发出请求后,不等待接收方响应这个请求,就继续发送下个请求。在异步机制中,所有来自发送方的请求形成一个队列,接收到处理完成通知发送方
阻塞和非阻塞用来描述进程处理调用的方式,在网络通信中,主要指网络套接字socket的阻塞和非阻塞方式,而socket的实质也就是IO操作。
socket的阻塞调用方式为,调用结果返回之前,当前线程从运行状态被挂起,一直等到调用结果返回之后,才进入就绪状态,获取CPU后继续执行
socket的非阻塞调用方式,与阻塞调用方式恰好相反,在非阻塞方式中,如果调用结果不能马上返回,当前线程也不会被挂起,而是立即返回执行下一个调用
在网络通信中,经常可以看到有人讲同步和阻塞等同、异步和非阻塞等同。事实上,这两对概念有一定的区别,不能混淆。两对概念组合,就会产生四个新概念,同步阻塞、异步阻塞、同步非阻塞、异步非阻塞
-
同步阻塞方式:发送方向接收方发送请求后,一直等待响应;接收方处理请求时进行的IO操作如果不能马上得到结果,就一直等待到返回结果后,才响应发送方,期间不能进行其他工作。 比如,在超市排队付账时,客户(发送方)向收银员(接收方)付款(发送请求)后需要等待收银员找零,期间不能做其他的事情;而收银员等待收款机返回结果(IO操作)后才能把零钱取出来交给客户(响应请求),期间也只能等待,不能做其他事情。这种方式实现简单,但效率不高
-
同步非阻塞方式:发送方向接收方发送请求后,一直等待响应;接收方处理请求时进行的IO操作如果不能马上得到结果,就立即返回,去做其他事情,但由于没有请求处理结果,不响应发送方,发送方一直等待。一直到IO操作完成后,接收方获取结果响应发送方后,接收方才进入下一次请求过程。 在实际中不使用这种方式
-
异步阻塞方式:发送方向接收方发送请求后,不用等待响应,可以接着进行其他工作;接收方处理请求时进行的IO操作如果不能马上得到结果,就一直等到返回结果后,才响应发送方,期间不能进行其他工作。在实际中不使用这种方式
-
异步非阻塞方式:发送方向接收方发送请求后,不用等待响应,可以继续其他工作;接收方处理请求时进行的IO操作如果不能马上得到结果,也不等待,而是马上返回去做其他事情。当IO操作完成后,将完成状态和结果通知接收方,接收方在响应发送方。 如:客户(发送方)向收银员(接收方)付款(发送请求)后在等待收银员找零的过程中,还可以做其他事情,比如打电话、聊天等;而收银员在等待收款机处理交易(IO操作)的过程中可以帮助客户打包商品,当收款机产生结果后,收银员给客户结账(响应请求)。在这四种过程中,这种方式发送方和接收方通信效率最高的一种
nginx服务器如何处理请求多进程机制和异步非阻塞机制
nginx服务器的一个显著优势是能够同时处理大量并发请求。它结合多进程机制和异步非阻塞机制对外提供服务。
注意:
实际上,nginx服务器的进程模式有两种:single模型和master-worker模型。single模型为单进程方式,性能较差,一般在实际工作中不使用。master-worker模型实际上被更广泛的称为master-slave模型。在nginx服务器中,充当slave角色的是工作进程
每个工作进程使用了异步非阻塞方式,可以处理多个客户端请求。当某个工作进程接收到客户端的请求以后,调用IO进行处理,如果不能立即得到结果,就去处理其他的请求;而客户端在此期间也无需等待响应,可以去处理其他事情;当IO调用返回结果时,就会通知此工作进程;该进程得到通知,暂时挂起当前处理的事务,去响应客户端请求
客户端请求数量增长、网络负载繁重时,nginx服务器使用多进程机制能够保证不增长对系统资源的压力;同时使用异步非阻塞方式减少了工作进程在IO调用上的阻塞延迟,保证了不降低对请求的处理能力
nginx服务器的事件处理机制
nginx服务器的工作进程调用IO后,就去进行其他工作了;当IO调用返回后,会通知工作进程。这里有一个问题,IO调用后如何把自己的状态通知给工作进程的呢?
两种解决方案:
-
一、让工作进程在进行其他工作的过程中间隔一段时间就去检查一下IO的运行状态,如果完成,就去响应客户端,如果未完成,就继续正在进行的工作
-
二、IO调用在完成后能主动通知工作进程。
对于第一种情况,虽然工作进程在IO调用过程中没有等待,但不断的检查仍然在时间和资源上导致了不小的开销,最理想的解决是第二种
具体来说,select/poll/epoll/kqueue等这样的系统调用就是来支持第二种解决方案的。这些系统调用,也被称为事件驱动模型,它们提供了一种机制,让进程可以同时处理多个并发请求,不用关心IO调用的具体情况。IO调用完全由事件驱动模型来管理,事件准备好之后就通知工作进程事件已经就绪
事件驱动模型概述
实际上,事件驱动并不是计算机编程领域的专业词汇,它是一种比较古老的响应时间的模型,在计算机编程、公共关系、经济活动等领域均有很广泛的应用。顾名思义,时间驱动就是在持续事务管理过程中,由当前时间点上出现的事件引发的调动可用资源执行相关任务,解决不断出现的问题,房子事务堆积的一种策略。在计算机编程领域,时间驱动模型对应一种程序设计方式,Event-driven programming,即事件驱动程序设计
事件驱动模型一般是由事件收集器、事件发送器和事件处理器三部分基本单元组成
Windows操作系统,就是基于事件驱动程序设计的典型实例。windows操作系统是用C语言实现的。
nginx事件驱动模型
nginx服务器响应和处理web请求过程,就是基于事件驱动模型的,它包含事件收集器、事件发送器、事件处理器等三部分基本单元
事件驱动处理库又被称为多路IO复用方法,最常见的包括以下三种:select模型、poll模型、epoll模型。nginx服务器还支持rtsig模型、kqueue模型、dev/poll模型、和eventport模型等
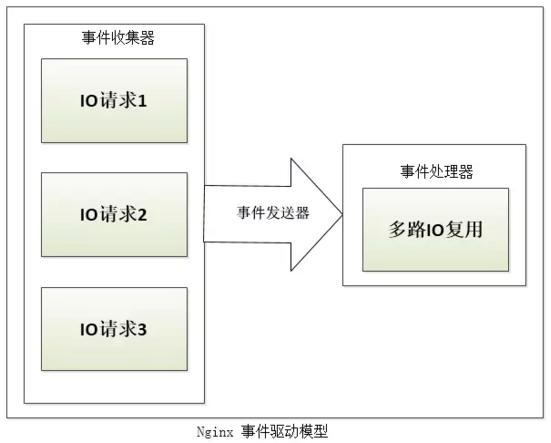
如上图所示, Nginx 的 事件驱动模型由事件发送器、事件收集器和事件处理器三部分基本单元组成:
-
事件发送器:负责将 IO 事件发送到事件处理器 ;
-
事件收集器:负责收集Worker 进程的各种 IO 请求;
-
事件处理器:负责各种事件的响应工作 。
事件发送器将每个请求放入一个 待处理事件列表 ,使用非阻塞 I/O 方式调用 事件处理器来处理该请求。其处理方式称为 "多路 IO 复用方法"
select库
select库,是各个版本的linux和Windows平台都支持的基本事件驱动模型库,并且在接口的定义也基本相同,只是部分参数的含义略有不同。
nginx服务器在编译过程中如果没有为其指定其他高性能事件驱动模型库,它将指定编译该库。我们可以使用--with-select_module和--without-select_module两个参数强制nginx是否编译该库
poll库
poll库,作为linux平台上的基本事件驱动模型,是在linux2.1.23引入的。Windows平台不支持该库
可以说poll库是select库的优化实现的
nginx服务器在编译过程中如果没有为其指定其他高性能事件驱动模型库,它将指定编译该库。我们可以使用--with-poll_module和--without-poll_module两个参数强制nginx是否编译该库
epoll库
epoll库是nginx服务器支持的高性能事件驱动库之一,它是公认的非常优秀的事件驱动模型,和poll库及select库有很大的不同。epoll属于pol库的一个变种,是在linux2.5.44中引入的,在linux2.6及以上的版本都可以使用它。
首先,epoll库通过相关调用通知内核创建一个有N个描述符的事件列表;然后,给这些描述符设置所有关注事件,并把它添加到内核的事件列表中去,在具体编码过程中也可以通过相关调用对事件列表中的描述符进行修改和删除
完成设置之后,epoll库就开始等待内核通知事件发生了。某一事件发生后,内核将发生事件的描述符列表上报给epoll库。得到事件列表的epoll库,就可以进行事件处理了
epoll库在linux平台上是高效的。它支持一个进程打开大数目的时间描述符,上限是系统可以打开的最大数目;同时,epoll库的IO效率不随描述符数目增加而线性下降,因为它只会对内核上报"活跃"的描述符进行操作
rtsig库
其他事件驱动模型
nginx服务器架构
Nginx 启动后,会生成两种类型的进程,一个是主进程(master process),或多个工作进程(worker processes)。
主进程并不处理网络请求,主要负责 调度工作进程,也就是配置文件解析、数据结构初始化、模块配置和注册、信号处理、网络监听生成、工作进程生成和管理等工作
工作进程主要进行进程初始化、模块调用和请求处理等工作,是nginx服务器提供服务的主体
在客户端请求动态站点过程中,nginx服务器还涉及和后端服务器的通信。nginx服务器将接收到的web请求通过代理转发到后端服务器,由后端服务器进行数据处理和页面组织,然后将结果返回
另外,nginx服务器为了提高对请求的响应效率,进一步降低网络压力,采用缓存机制,将历史应答数据缓存到本地。在每次nginx服务器启动后的一段时间内,会启动专门的进程对本地缓存的内容重建索引,保证对缓存文件的快速访问
nginx服务器的进程
主进程 master process
nginx服务器启动是运行的主要进程。它的主要功能是与外教通信和对内部其他进程进行管理,具体说下以下几点:
-
读取nginx配置文件并验证其有效性和正确性
-
建立、绑定和关闭socket
-
按照配置生成、管理和结束工作进程
-
接收外界指令、比如重启、升级、退出服务器等指令
-
不中断服务、实现平滑重启、应用新配置
-
不中断服务、实现平滑升级、升级失败进行回滚
-
开启日志文件、获取文件描述符
-
编译和处理perl脚本
工作进程 worker process
由主进程生成,生成数量可以通过nginx配置文件指定,正常情况下生成于主进程的整个生命周期,主要工作如下几项:
-
接收客户端信息
-
将请求依次送人各个功能模块进程过滤处理
-
IO调用,获取响应时间
-
与后端服务通信、接收后端服务器处理结果
-
数据缓存、访问缓存索引、查用和调用缓存数据
-
发送请求结果、响应客户端请求
-
接收主进程指令、比如重启、升级和退出等
工作进程完成的工作还有很多,这里是主要的几项。该进程是nginx服务器提供web服务、处理客户端请求的主要进程,完成了nginx服务器的主体工作
缓存索引重建及管理进程(Cache Loader & Cache Manager)
Cache模块,主要有由缓存索引重建(Cache Loader)和缓存索引管理(Cache Manager)两类进程完成工作。
缓存索引重建进程是在nginx服务器一段时间之内(默认一分钟)由主进程生成,在缓存元数据重建完成后就自动退出;
缓存索引管理进程一般存在于主进程的整个生命周期,负责对缓存索引进行管理
缓存索引重建进程完成的主要工作是,根据本地磁盘上的缓存文件在内存中建立索引元数据。该进程启动后,对本地磁盘上存放缓存文件的目录结构进行扫描,检查内存中已有的缓存数据是否正确,并更新索引元数据库
缓存索引管理进程主要负责在索引元数据更新完成后,对元数据是否过期做出判断
这两个进程维护的内存索引元数据库,为工作进程对缓存数据的快速查询提供了便利
进程交互
nginx服务器在使用Master-Worker模型时,会涉及主进程与工作进程(Master-worker)之间的交互和工作进程(Worker-Worker)之间的交互。这两类交互依赖管道(channel)机制,交互的准备工作都是在工作进程生成是完成的
Master-worker
工作进程是有主进程生成的(使用了fork函数)。nginx服务器启动以后,主进程根据配置文件决定生成的工作进程的数量,然后建立一张全局的工作进程表用于存放当前未退出的所有工作进程
在主进程生成工作进程后,将新生成的工作进程加入到工作进程表中,并建立一个单向管道将其传递给该工作进程
Worker-Worker
实现原理和Master-worker交互基本是一样的
Run Loops事件处理循环模型
Run Loops,指的是进程内部用来不停的调配工作,对事件进行循环处理的一种模型。它属于进程或者线程的基础架构部分。该模型对事件的处理不是自动的,需要在设计代码过程中,在适当的时候启动Run-loop机制对输入的事件作出响应
该模型是一个集合,集合中的每一个元素称为一个Run-Loop。每个Run-Loop可运行在不同的模式下,其中可以包含它所监听的输入事件源、定时器以及在事件发生时需要通知的Run-Loop监听器(Run-Loop Observers)。为了监听特定的事件,可以在Run-Loops中添加相应的Run-Loop监听器。当监听器的事件发生时,Run-Loop会产生一个消息,被Run-Loop监听器捕获,从而执行预定的动作
nginx服务器在工作进程中实现了Run-Loop事件处理循环模型的使用,用来处理客户端发来的请求事件,该部分的实现可以说是nginx服务器程序实现中最为复杂的部分,包含了对输入事件繁杂的响应和处理过程,并且这些处理过程都是基于异步任务处理的。这里就不在深入了解了,有兴趣的自己查阅相关资料
nginx服务器的高级配置
针对IPv4的内核7个参数的配置优化
这里提及的参数是和ipv4网络有关的linux内核参数。我们可以将这些内核参数的值追加到linux系统的/etc/sysctl.conf文件中,然后使用如下命令使其修改生效:
# /sbin/sysctl -p
常用参数如下:
net.core.netdev_max_backlog参数
该参数表示:当每个网络接口接收数据包的速率比内核处理这些包的速率快时,运行发送到队列的数据包的最大数目。一般默认值为128(不同的linux发行版本可能不同)。nginx服务器中定义的NGX_LISTEN_BACKLOG默认是511。我们可以将其调整如下:
net.core.netdev_max_backlog = 262144
net.core.somaxconn参数
该参数作用:用于调节系统同时发起的TCP连接数,一般默认值为128。在客户端存在高并发请求的情况下,该默认值较小,可能导致连接超时或者重传问题,我们可以根据实际需要结合并发请求数来调节此参数。如下:
net.core.somaxconn = 40000
net.ipv4.tcp_max_orphans参数
作用:用于设定系统中最多允许存在多少TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个值,没有与用户句柄关联的TCP套接字将立即被复位,同时给出告警信息。这个限制只是为了防止简单的Dos(Denial of service,拒绝服务)攻击。一般在系统内存比较充足的情况下,可以增大这个参数的值。如下:
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog参数
作用:用于记录尚未收到客户端确认信息的连接请求的最大值。对于拥有128MB内存的系统而言,此参数的默认值是1024,对于内存小的系统则是128.一般在系统内存比较充足的情况下,可以增加该参数的值。如下:
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps参数
该参数用于设置时间戳,这可以避免序列号的卷绕。在一个1Gb/s的链路上,遇到以前用过的序列号的概率很大。当此参数的值为0时,禁止对于TCP时间戳的支持。在默认情况下,TCP协议会让内核接受这种'异常'的数据包。针对nginx服务器来说。建议将其关闭
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries参数
该参数用于设置:内核放弃TCP连接之间向客户端发送SYN+ACK包的值。为了建立对端的连接服务,服务器和客户端需要进行三次握手,第二次握手期间,内核需要发送SYN并附带一个回应前一个SYN的ACK,这个参数主要影响这个过程,一般赋值为1,即内核放弃连接之前发送一次SYN+ACK包,可以设置为如下:
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries参数
该参数的作用与上一个参数类似,设置内核放弃建立连接之前发送SYN包的数量,它的赋值和上一个参数即可,如下:
net.ipv4.tcp_syn_retries = 1
针对CPU的nginx配置优化的2个指令
处理器已经进入了多核时代,多内核是指在一枚处理器中集成两个或者多个完整的计算引擎,多核处理器是单枚芯片。一枚多核处理器上可以承载多枚内核,但只需要单一的处理器插槽就可以工作,同时,目前流行的操作系统都已经可以利用这样的资源,将每个执行内核作为分立的逻辑处理器,通过在多个执行内核之间划分任务,在特定的时钟周期内执行更多任务,提高并行处理任务的能力
在nginx配置中,有两个指令:worker_processes和worker_cpu_affinity,它们可以针对多核CPU进行配置优化
worker_processes指令
worker_processes指令:用来设置nginx服务器的进程数。官方文档建议此指令一般设置为1即可,赋值太多会影响系统的IO效率,降低nginx服务器的性能。但是,为了让多核CPU能够很好地并行处理任务,我们可以将worker_processes指令的赋值适当的增大一些,最好是赋值为机器CPU的倍数。当然,这个值并不是越大越好,nginx进程太多可能增加主进程调度负担,也可能影响系统的IO效率。针对双核CPU,建议设置为2或者4。本次实验是4核cpu,设置如下:
worker_processes 4;
当然,语法为:
worker_processes number|auto;
解释:
-
auto表示自动设置,一般就用auto
-
number表示自己设置cpu个数
设置好了该参数那么就有必要设置worker_cpu_affinity指令
worker_cpu_affinity指令
官网参考:http://nginx.org/en/docs/ngx_core_module.html#worker_cpu_affinity
该指令用来为每个进程分配CPU的工作内核。这个指令的设置方法有些麻烦。该指令的值是由几组二进制值表示的。其中,每一组代表一个进程,每组中的每一位表示该进程使用CPU的情况,1代表使用,0代表不使用。
注意:二进制位排列顺序和CPU的顺序是相反的。建议将不同的进程平均分配到不同的CPU运行内核上。
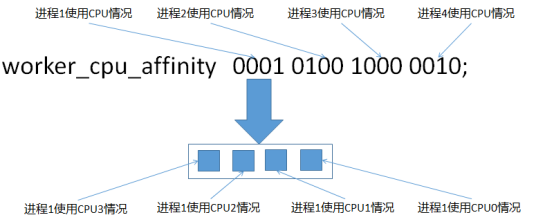
当然,语法为:
worker_cpu_affinity number |auto;
本次nginx服务器的进程数为4,CPU是四核,因此会有4组值,并且每组有四位,所有,此指令设置为:
worker_cpu_affinity 0001 0100 1000 0010;
四组二进制数值分别对应4进程,第一个进程对应0001,表示使用第一个CPU内核;第二个进程对应0010,表示使用第二个CPU内核
如果将worker_processes指令的值设置为8,即赋值为CPU内核个数的两倍,则worker_cpu_affinity指令的设置可以是:
worker_cpu_affinity 0001 0010 0100 1000 0001 00100100 1000;
如果一台机器的CPU是八核CPU,并且worker_processes指令的赋值为8,那么worker_cpu_affinity指令的设置可以是:
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
与网络连接相关的配置的4个指令
keepalive_timeout指令
该指令用于设置nginx服务器与客户端保持连接的超时时间
这个指令支持两个选项,中间用空格隔开。
-
第一个选项:指定客户端连接保持活动的超时时间,在这个时间之后,服务器会关闭此连接
-
第二个选项可选:其指定了使用keep-alive消息头以保持与客户端某些浏览器(如Mozilla、konqueror等)的连接,超过设置的时间后,客户端就可以关闭连接,而不需要服务器关闭了。
可以根据自己实际情况设置此值,建议从服务器的访问数量、处理速度以及网络状况方面考虑。设置示例:
keepalive_timeout 60 50;
该设置表示nginx服务器与客户端连接保持活动的时间是60s,60s后服务器与客户端断开连接;使用keep-alive消息头保持与客户端某些浏览器(如Mozilla,konqueror)的连接时间为50s,50s后浏览器主动与服务器断开连接
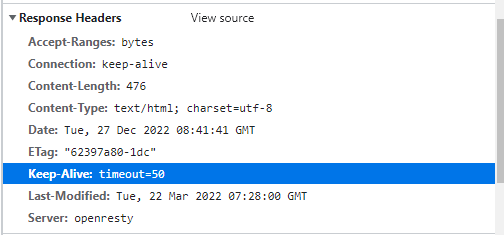
send_timeout指令
该指令用于设置nginx服务器响应客户端的超时时间,这个超时时间仅针对两个客户端和服务器之间建立连接后,某次活动之间的时间。如果这个活动时间后的客户端没有任何活动,nginx服务器将会关闭连接。此指令的设置需要考虑服务器访问数量和网络状况等方面。示例如下:
send_timeout 10;
该设置表示nginx服务器与客户端建立连接后,某次会话中服务器等待客户端响应超过10s,就会自动关闭连接
client_header_buffer_size指令
该指令用于设置nginx服务器允许的客户端请求头部的缓冲区大小,默认为kb。此指令的赋值可以根据系统分页大小来设置。分页大小可以用以下命令获取:
[root@localhost ~]# getconf PAGESIZE
4096
有过nginx服务器工作经验的朋友可能遇到过nginx服务器返回400错误的情况。查找nginx服务器的400错误原因比较困难,因为此错误并不是每次都会出现,出现错误的时候,通常在浏览器和日志里也看不到任何有关的提示信息。根据实际的经验来看,有很大一部分情况是客户端的请求头部过大造成的。请求头部过大,通常是客户端cookie中写入了较大的值引起的。于是适当增大此指令的赋值,允许nginx服务器接收较大的请求头部,可以改善服务器对客户端的支持能力。建议设置如下:
client_header_buffer_size 16k;
multi_accept指令
该指令用于配置nginx服务器是否尽可能多地接收客户端的网络连接请求,默认值是off
此指令只能在events块进行配置
与事件驱动模型相关的配置的指令
use指令
use指令用于指定nginx服务器使用的时间驱动模型
worker_connections指令
该指令用于设置nginx服务器的每个工作进程允许同时连接客户端的最大数量,语法为:
worker_connections number;
其中,number为设置的最大数量。结合worker_processes指令,我们可以计算出nginx服务器允许同时连接的客户端最大数量Client=worker_processes * woeker_connections / 2
此指令设置的就是nginx服务器能接受的最大访问量,其中包括前端用户连接也包括其他连接,这个值在理论上等于此指令的值与它允许开启的工作进程最大数的乘积。此指令一般设置为65535:
worker_connections 1024;
此指令的赋值与linux操作系统中进程可以打开的文件句柄数量有关系。linux系统中有一个系统指令open file resource limit,它设置了进程可以打开的文件句柄数量。worker_connections指令的赋值当然不能超过open file resource limit的赋值。可以使用如下命令查看在你的linux系统中open file resource limit指令的值:
[root@localhost nginx]# cat /proc/sys/fs/file-max
171185
通过以下命令将open file resource limit指令的值设置为:2390251
echo "2390251" > /proc/sys/fs/file-max ;sysctl -p
nginx服务器的Gzip压缩
在nginx配置文件中,可以配置gzip的使用,相关指令可以在配置文件中的http块、server块或者location块中设置,nginx服务器通过ngx_http_gzip_module模型、ngx_http_gzip_static_module模块、ngx_http_gunzip_module模块对这些指令进行解析和处理
ngx_http_gzip_module模块处理的9个指令
ngx_http_gzip_module模块主要负责gzip功能的开启和设置,对响应数据进行在线实时压缩。该模块包含以下主要指令:
- gzip指令
该指令用于开启或关闭gzip功能,语法结构如下:
gzip on|off;
默认情况下,该指令设置为off,即不启用gzip功能。只有将该指令设置为on时,下列各指令才生效
实例:
gzip on; #开启gzip压缩输出,减少网络传输。

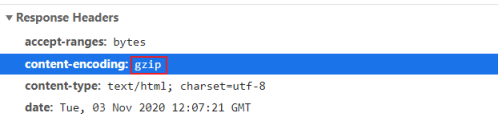
- gzip_buffers指令
该指令用于设置gzip压缩文件使用缓存空间的大小,即设置系统获取几个单位的缓存用于存储gzip的压缩结果数据流,语法结构如下:
gzip_buffers number size;
-
number指定nginx服务器需要向系统申请缓存空间的个数
-
size指定每个缓存空间的大小
根据该配置项,nginx服务器在对响应输出数据进行gzip压缩时需要向系统申请number * size大小的空间用于存储压缩数据。默认情况下number * size的值为,其中size的值取系统内存一页的大小,为4KB或者8KB,即:
gzip_buffers 32 4k |16 8k;
实例:
gzip_buffers 16 8k;
- gzip_comp_level指令
该指令用于设定gzip压缩程度,包括级别1到级别9。gzip压缩比级别:1表示压缩程度最低,压缩效率最高,处理速度最快;级别9压缩比最大但处理速度最慢(传输快但比较消耗cpu)。语法结构如下:
gzip_comp_level level;
实例:
gzip_comp_level 6;
默认值设置为级别1
- gzip_disable指令
针对不同种类客户端发起的请求,可以选择性地开启和关闭gzip功能。nginx服务器在响应这些种类的客户端请求时,不使用gzip功能缓存响应输出数据。语法格式如下:
gzip_disable regex ……;
其中,regex根据客户端的浏览器标志(User-Agent,UA)进行设置,支持使用正则表达式。
实例:
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
#或者:
gzip_disable MSIE [4-6]\.;
gzip_disable MSIE [4-6]\.; 改设置使用了正则表达式,其可以匹配UC字符串中包含MSIE4、MSIE5和MSIE6的所有流量器。响应这些浏览器发出的请求时,nginx服务器不进行gzip压缩
注意:由于浏览器的UA可以人为更改,因此对于实际情况还需要进行具体分析。
- gzip_http_version指令
该指令用于设置gzip功能的最低http协议版本。早起的一些浏览器或者http客户端,可能不支持gzip自解压,因此用户有时会看到乱码,所有针对不同的http协议版本,需要选择性德开启或者关闭gzip功能。语法结构如下:
gzip_http_version 1.0|1.1;
默认设置为1.1版本,即只有客户端使用1.1以以上版本的http协议时,才使用gzip功能对响应输出数据进行压缩。从目前来看,绝大多数的浏览器都支持gzip自解压,一般采用默认值即可
实例:
gzip_http_version 1.0;
用于识别 http 协议的版本,早期的浏览器不支持 Gzip 压缩,用户就会看到乱码,所以为了支持前期版本加上了这个选项,如果你用了 Nginx 的反向代理并期望也启用 Gzip 压缩的话,由于末端通信是 http/1.0,故请设置为 1.0。
- gzip_min_length指令
gzip压缩功能对大数据的压缩效果明显;但是如果压缩很小的数据,可能出现越压缩数据量越大(许多压缩算法都有这样的情况发生),因此应该根据响应页面的大小,选择性地开启或者关闭gzip功能。该指令设置页面的字节数,当响应页面的大小大于该值时,才启用gzip功能。响应页面的大小通过HTTP响应头部中的Content-Length指令获取,但是如果使用了Chunk编码动态压缩,Content-Length或不存在或被忽略,该指令不起作用。语法结构如下:
gzip_min_length length;
length设置允许压缩的页面最小字节数,页面字节数从header头得content-length中进行获取。默认值是20。建议设置成大于1k的字节数,小于1k可能会越压越大;设置为0时表示不管响应页面大小如何通通压缩。
实例:
gzip_min_length 1024;
- gzip_proxied指令
官方参考:http://nginx.org/en/docs/http/ngx_http_gzip_module.html#gzip_proxied
Nginx作为反向代理的时候启用时有效,决定开启或者关闭后端服务器返回的结果是否压缩,匹配的前提是后端服务器必须要返回包含的响应页面头部中,requests部分包含用于通知代理服务器的"Via"头域。
它主要用于设置nginx服务器是否对后端服务器返回的结果进行gzip压缩。语法如下:
gzip_proxied off|expired|no-cache|no-store|private|no_last_modified|no_etag|auth|any……;
- off
禁用nginx服务器对后端服务器返回结果的gzip压缩;这是默认设置
- expired
当后端服务器响应头部包含用于指示响应数据过期时间的expired头域时,则启用压缩;
- no-cache
当后端服务器响应头部包含用于通知所有缓存机制是否缓存的 " Cache-Control"字段、且其指令值为no-cache时,则启用压缩;
- no-store
如果响应头包含带有" no-store"参数的" Cache-Control"字段,则启用压缩;
- private
如果响应头包含带有" private"参数的" Cache-Control"字段,则启用压缩;
- no_last_modified
如果响应头不包含" Last-Modified"字段,则启用压缩;
- no_etag
如果响应头不包含" ETag"字段,则启用压缩;
- auth
如果请求标头包含"authorization"字段,则启用压缩;
- any
为所有代理请求启用压缩
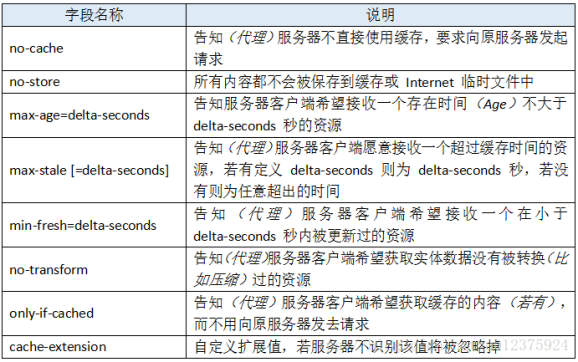
实例:
gzip_proxied any;
- gzip_types指令
nginx服务器可以根据响应页的MIME类型选择性的开启Gzip压缩功能,匹配mime类型进行压缩,无论是否指定,"text/html"类型总是会被压缩的
实例:
gzip_types
text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xml
text/javascript application/javascript application/x-javascript
text/x-json application/json application/x-web-app-manifest+json
text/css text/plain text/x-component
font/opentype application/x-font-ttf application/vnd.ms-fontobject
- gzip_vary指令
该指令用于设置在使用gzip功能是是否发送带有"Vary: Accept-Encoding"头域的响应头部。和http头有关系,会在响应头加个 Vary: Accept-Encoding ,可以让前端的缓存服务器缓存经过gzip压缩的页面,例如,用Squid缓存经过Nginx压缩的数据。语法如下:
gzip_vary on|off;
默认设置off。事实上,我们可以通过nginx配置的add_header指令强制nginx服务器在响应头部添加"Vary: Accept-Encoding"头域,以达到相关效果:
add_header Vary Accept-Encoding gzip;
实例:
gzip_vary on;
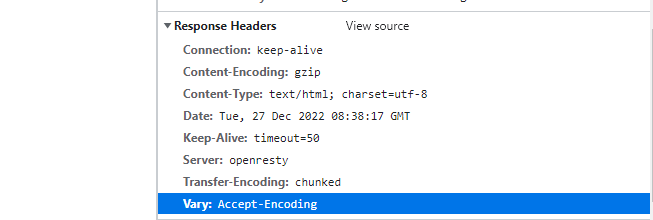
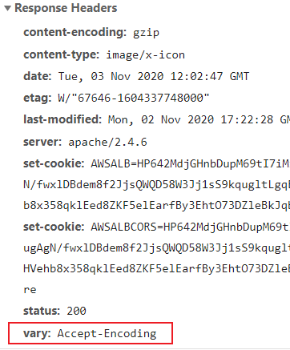
注意:该指令在使用过程中存在bug,会导致IE4及以上浏览器的数据缓存功能失效
ngx_http_gzip_static_module模块处理的指令
ngx_http_gzip_static_module模块主要负责搜索和发送经过gzip功能预压缩的数据。这些数据已.gz作为后缀名存储在服务器上。如果客户端请求的数据在之前被压缩过,并且客户端浏览器支持gzip压缩,就直接返回压缩后的数据
该模块与ngx_http_gzip_module模块的不同之处主要在于,该模块使用的是静态压缩,在http响应头部包含Content-Length头域来指明报文体的长度,用于服务器可确定响应数据长度的情况;而后者默认使用chunked编码的动态压缩,其主要适用于服务器无法确定响应数据长度的情况,比如大文件下载的情形,这是需要实时生成数据长度。
与该模块有关的指令主要有一下几个:gzip_static、gzip_http_version、gzip_proxied、gzip_disable和gzip_vary等
- gzip_static指令
用于开启和关闭该模块的功能,语法如下:
gzip_static on|off|always;
-
·on开启该模块的功能
-
·off关闭该模块的功能
-
·always一直发送gzip预压缩文件,而不检查客户端浏览器是否支持gzip压缩
其中指令与ngx_http_gzip_module模块下的使用方式相同。需要注意的是,gzip_proxied指令只接收一下设置:
gzip_proxied expired no-cache no-store private auth;
另外,对于该模块 下的gzip_vary指令,开启以后只给未压缩的内容添加Vary:Accept-Encoding头域,而不是多所以内容都添加。如果需要给所以的响应头添加该头域,可以通过nginx配置的add_header指令实现。
注意:该模块是nginx服务器的可选http模块,如果要使用,必须在nginx程序配置时添加--with--http_gzip_static_module指令
ngx_http_gunzip_module模块处理的指令
nginx服务器支持对响应输出数据流进行gzip压缩,这对客户端浏览器来说,需要有能力解压和处理gzip压缩数据,但如果客户端本身不支持该功能,就需要nginx服务器在其发送数据之前先将该数据解压。这些压缩数据可能来自于后端服务器压缩产生或者nginx服务器预压缩产生。该模块便是用来针对不支持gzip压缩数据处理的客户端浏览器,对压缩数据进行解压处理,与它有关的主要指令有以下几个:gunzip、gunzip_buffers、gzip_http_version、gzip_proxied、gzip_disable和gzip_vary等
- gunzip指令
该指令用于开启或者关闭该模块的功能,语法如下:
gunzip_static on|off;
-
·on开启该模块功能
-
·off关闭该模块功能
该指令默认设置为关闭功能。当功能开启时,如果客户端浏览器不支持gzip处理,nginx服务器将返回解压后的数据;如果客户端浏览器支持gzip处理,nginx服务器忽略该指令的设置,仍然返回压缩数据。
当客户端浏览器不支持gzip数据处理时,使用该模块可以解决数据解析的问题,同时保证nginx服务器与后端服务器交互数据或本身存储数据时仍然使用压缩数据,从而减少了服务器之间的数据传输量,降低了本地存储空间和缓存的使用率
- gunzip_buffers指令
该指令与ngx_http_gzip_module模块中的gzip_buffers指令非常类似,都是用于设置nginx服务器解压gzip文件使用缓存空间的大小的,语法如下:
gunzip_buffers number size;
-
·number指定nginx服务器需要向系统申请缓存空间的个数
-
·size指定每个缓存空间的大小
根据该配置项,nginx服务器在对gzip数据进行减压是需向系统申请number * size大小的空间。默认情况下number * size的值为128,其中size的值也取系统内存一页的大小,为4kb或者8kb,即:
gunzip_buffers 32 4k|16 8k;
注意:该模块是nginx服务器的可选http模块,如果要使用,必须在nginx程序配置时添加--with-http_gunzip_module指令
gzip压缩功能使用
为了使用nginx服务器能够在全局范围内应用gzip,一般都将其放在http全局块中。如果要对各个虚拟主机差别性对待,我们可以在对应的server块中添加各自的gzip配置指令。
nginx与其他服务器交互时产生的gzip压缩功能相关问题
该类问题产生原因又可以分为两类:
- 一、多层服务器同时开启gzip压缩功能导致;
- 二、多层服务器之间对gzip压缩功能支持能力不同导致
gzip压缩功能在各种服务器中应用广泛,包括IIS、tomcat、Apache等多种服务器都支持该功能。nginx服务器作为前端服务器接收后端服务器返回的数据时,如果nginx服务器和后端服务器同时开启gzip压缩功能,会产生怎么样的问题呢?
如果nginx服务器与后端服务器(如tomcat)同时开启gzip压缩功能对JavaScript脚本进行压缩,在大多数浏览器中刷新页面会导致脚本运行发送异常,唯一可以运行的浏览器是谷歌的chrome浏览器。分析发现,在客户端首次加载页面时,JavaScript脚本传输和运行正常,但刷新页面时传输的JavaScript脚本发送了缺失的现象,返回状态为304,即请求的网页与上次比没有更新。然后将其中一台服务器的gzip压缩功能关闭,这样客户端页面显示和脚本运行都正常了
Nginx的请求限制(高并发系统是如何做限流的?)
参考:
https://mp.weixin.qq.com/s/BKzEidW62gvsFOnSkMF-yQ
https://mp.weixin.qq.com/s/oRyFvICowKgrshWxB6PBIA
http://www.eryajf.net/3133.html
作用:限流
理论
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流
缓存
缓存比较好理解,在大型高并发系统中,如果没有缓存数据库将分分钟被爆,系统也会瞬间瘫痪。使用缓存不单单能够提升系统访问速度、提高并发访问量,也是保护数据库、保护系统的有效方式。
大型网站一般主要是"读",缓存的使用很容易被想到。在大型"写"系统中,缓存也常常扮演者非常重要的角色。比如累积一些数据批量写入,内存里面的缓存队列(生产消费),以及HBase写数据的机制等等也都是通过缓存提升系统的吞吐量或者实现系统的保护措施。甚至消息中间件,你也可以认为是一种分布式的数据缓存。
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
降级往往会指定不同的级别,面临不同的异常等级执行不同的处理:
根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。
根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
限流的算法
常见的限流算法有:计数器、漏桶和令牌桶算法
计数器
计数器是最简单粗暴的算法。比如:某个服务最多只能每秒钟处理100个请求。我们可以设置一个1秒钟的滑动窗口,窗口中有10个格子,每个格子100毫秒,每100毫秒移动一次,每次移动都需要记录当前服务请求的次数。内存中需要保存10次的次数。可以用数据结构LinkedList来实现。格子每次移动的时候判断一次,当前访问次数和LinkedList中最后一个相差是否超过100,如果超过就需要限流了
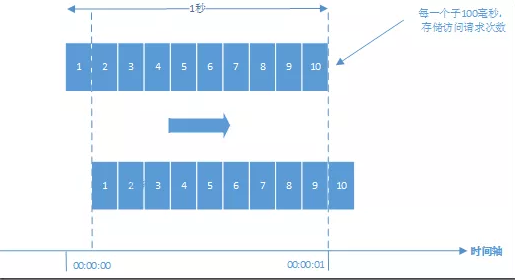
很明显,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
示例代码如下:
//服务访问次数,可以放在Redis中,实现分布式系统的访问计数
Long counter = 0L;
//使用LinkedList来记录滑动窗口的10个格子。
LinkedList<Long> ll = new LinkedList<Long>();
public static void main(String[] args)
{
Counter counter = new Counter();
counter.doCheck();
}
private void doCheck()
{
while (true)
{
ll.addLast(counter);
if (ll.size() > 10)
{
ll.removeFirst();
}
//比较最后一个和第一个,两者相差一秒
if ((ll.peekLast() - ll.peekFirst()) > 100)
{
//To limit rate
}
Thread.sleep(100);
}
}
漏桶算法
漏桶算法即leaky bucket是一种非常常用的限流算法,可以用来实现流量整形(Traffic Shaping)和流量控制(Traffic Policing)。贴了一张维基百科上示意图帮助大家理解:
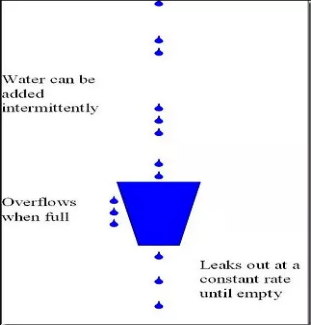
漏桶算法的主要概念如下:
-
一个固定容量的漏桶,按照常量固定速率流出水滴
-
如果桶是空的,则不需流出水滴
-
可以以任意速率流入水滴到漏桶
-
如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的
漏桶算法比较好实现,在单机系统中可以使用队列来实现(.Net中TPL DataFlow可以较好的处理类似的问题,你可以在这里找到相关的介绍),在分布式环境中消息中间件或者Redis都是可选的方案
算法思想是:
-
水(请求)从上方倒入水桶,从水桶下方流出(被处理);
-
来不及流出的水存在水桶中(缓冲),以固定速率流出;
-
水桶满后水溢出(丢弃)。
-
这个算法的核心是:缓存请求、匀速处理、多余的请求直接丢弃。
-
相比漏桶算法,令牌桶算法不同之处在于它不但有一只"桶",还有个队列,这个桶是用来存放令牌的,队列才是用来存放请求的
从作用上来说,漏桶和令牌桶算法最明显的区别就是是否允许突发流量(burst)的处理,漏桶算法能够强行限制数据的实时传输(处理)速率,对突发流量不做额外处理;而令牌桶算法能够在限制数据的平均传输速率的同时允许某种程度的突发传输。
Nginx按请求速率限速模块使用的是漏桶算法,即能够强行保证请求的实时处理速度不会超过设置的阈值。
Nginx官方版本限制IP的连接和并发分别有两个模块:
-
limit_req_zone 用来限制单位时间内的请求数,即速率限制,采用的漏桶算法 "leaky bucket"。
-
limit_req_conn 用来限制同一时间连接数,即并发限制
令牌桶算法
令牌桶算法是一个存放固定容量令牌(token)的桶,按照固定速率往桶里添加令牌。令牌桶算法基本可以用下面的几个概念来描述:
-
令牌将按照固定的速率被放入令牌桶中。比如每秒放10个。
-
桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝。
-
当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上。
-
如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)
如下图:
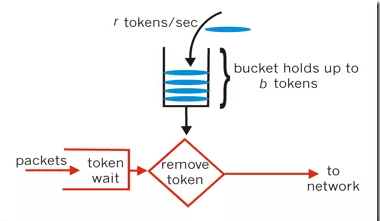
令牌算法是根据放令牌的速率去控制输出的速率,也就是上图的to network的速率。to network我们可以理解为消息的处理程序,执行某段业务或者调用某个RPC。
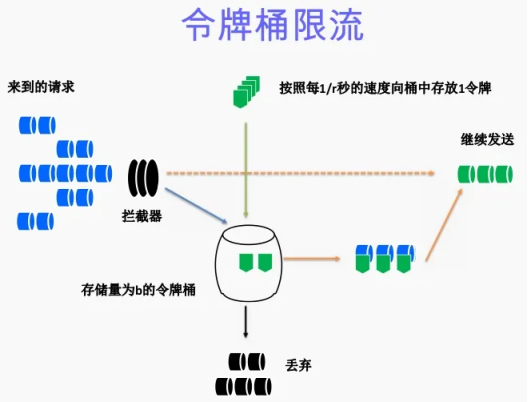
算法思想是:
- 令牌以固定速率产生,并缓存到令牌桶中;
- 令牌桶放满时,多余的令牌被丢弃;
- 请求要消耗等比例的令牌才能被处理;
- 令牌不够时,请求被缓存
漏桶和令牌桶的比较
令牌桶可以在运行时控制和调整数据处理的速率,处理某时的突发流量。放令牌的频率增加可以提升整体数据处理的速度,而通过每次获取令牌的个数增加或者放慢令牌的发放速度和降低整体数据处理速度。而漏桶不行,因为它的流出速率是固定的,程序处理速度也是固定的。
整体而言,令牌桶算法更优,但是实现更为复杂一些。
从作用上来说,漏桶和令牌桶算法最明显的区别就是是否允许突发流量(burst)的处理,漏桶算法能够强行限制数据的实时传输(处理)速率,对突发流量不做额外处理;而令牌桶算法能够在限制数据的平均传输速率的同时允许某种程度的突发传输。
限流算法实现
Guava
Guava是一个Google开源项目,包含了若干被Google的Java项目广泛依赖的核心库,其中的RateLimiter提供了令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
1. 常规速率:
创建一个限流器,设置每秒放置的令牌数:2个。返回的RateLimiter对象可以保证1秒内不会给超过2个令牌,并且是固定速率的放置。达到平滑输出的效果
public void test()
{
/**
* 创建一个限流器,设置每秒放置的令牌数:2个。速率是每秒可以2个的消息。
* 返回的RateLimiter对象可以保证1秒内不会给超过2个令牌,并且是固定速率的放置。达到平滑输出的效果
*/
RateLimiter r = RateLimiter.create(2);
while (true)
{
/**
* acquire()获取一个令牌,并且返回这个获取这个令牌所需要的时间。如果桶里没有令牌则等待,直到有令牌。
* acquire(N)可以获取多个令牌。
*/
System.out.println(r.acquire());
}
}
上面代码执行的结果如下图,基本是0.5秒一个数据。拿到令牌后才能处理数据,达到输出数据或者调用接口的平滑效果。acquire()的返回值是等待令牌的时间,如果需要对某些突发的流量进行处理的话,可以对这个返回值设置一个阈值,根据不同的情况进行处理,比如过期丢弃。
2. 突发流量:
突发流量可以是突发的多,也可以是突发的少。首先来看个突发多的例子。还是上面例子的流量,每秒2个数据令牌。如下代码使用acquire方法,指定参数。
System.out.println(r.acquire(2));
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
得到如下类似的输出:
如果要一次新处理更多的数据,则需要更多的令牌。代码首先获取2个令牌,那么下一个令牌就不是0.5秒之后获得了,还是1秒以后,之后又恢复常规速度。这是一个突发多的例子,如果是突发没有流量,如下代码:
System.out.println(r.acquire(1));
Thread.sleep(2000);
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
得到如下类似的结果:
等了两秒钟之后,令牌桶里面就积累了3个令牌,可以连续不花时间的获取出来。处理突发其实也就是在单位时间内输出恒定。这两种方式都是使用的RateLimiter的子类SmoothBursty。另一个子类是SmoothWarmingUp,它提供的有一定缓冲的流量输出方案。
/**
* 创建一个限流器,设置每秒放置的令牌数:2个。速率是每秒可以210的消息。
* 返回的RateLimiter对象可以保证1秒内不会给超过2个令牌,并且是固定速率的放置。达到平滑输出的效果
* 设置缓冲时间为3秒
*/
RateLimiter r = RateLimiter.create(2,3,TimeUnit.SECONDS);
while (true) {
/**
* acquire()获取一个令牌,并且返回这个获取这个令牌所需要的时间。如果桶里没有令牌则等待,直到有令牌。
* acquire(N)可以获取多个令牌。
*/
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
System.out.println(r.acquire(1));
}
输出结果如下图,由于设置了缓冲的时间是3秒,令牌桶一开始并不会0.5秒给一个消息,而是形成一个平滑线性下降的坡度,频率越来越高,在3秒钟之内达到原本设置的频率,以后就以固定的频率输出。图中红线圈出来的3次累加起来正好是3秒左右。这种功能适合系统刚启动需要一点时间来"热身"的场景。

Nginx
对于Nginx接入层限流可以使用Nginx自带了两个模块:
-
连接数限流模块: ngx_http_limit_conn_module
-
漏桶算法实现的请求限流模块: ngx_http_limit_req_module
Nginx的请求限流模块,是基于漏桶算法实现的,在高并发的场景下非常实用
Nginx请求限制相关语法



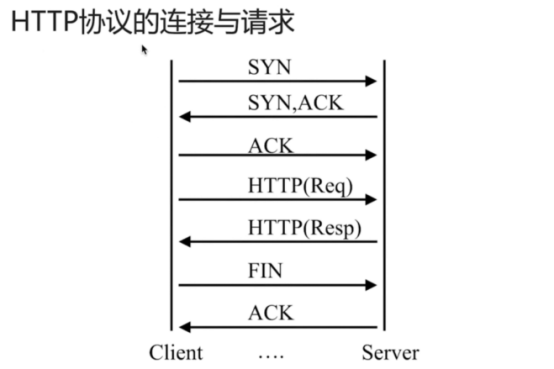
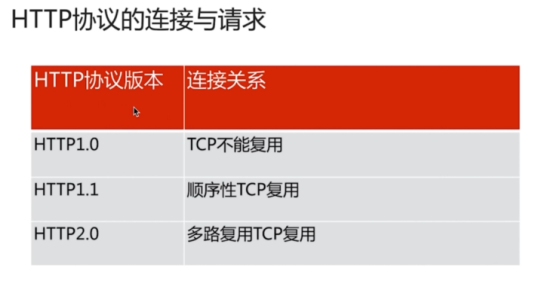

ngx_http_limit_conn_module
我们经常会遇到这种情况:服务器流量异常,负载过大等等。对于大流量恶意的攻击访问,会带来带宽的浪费,服务器压力,影响业务,往往考虑对同一个ip的连接数,并发数进行限制。ngx_http_limit_conn_module 模块来实现该需求。 该模块可以根据定义的键来限制每个键值的连接数,如同一个IP来源的连接数。并不是所有的连接都会被该模块计数,只有那些正在被处理的请求(这些请求的头信息已被完全读入)所在的连接才会被计数
1、同一个IP来源:$binary_remote_addr
我们可以在nginx_conf的http{}中加上如下配置实现限制:
#限制每个用户的并发连接数,取名one
limit_conn_zone $binary_remote_addr zone=one:10m;
#配置记录被限流后的日志级别,默认error级别
limit_conn_log_level error;
#配置被限流后返回的状态码,默认返回503
limit_conn_status 503;
#自定义状态码的区间: nginx: [emerg] value must be between 400 and 599
然后在server{}里加上如下代码:
#限制用户并发连接数为1
limit_conn one 1;

**然后我们是使用ab测试来模拟并发请求: **
# yum install httpd-tools -y
-n代表请求数,-c代表并发数
ab -n 5 -c 5 http://localhost/index.html
得到下面的结果,很明显并发被限制住了,超过阈值的都显示503,limit_conn_status的值就是503:

测试的时候访问小文件不适合验证并发,上一条请求很快就处理完了,limit_conn实际上是在ngx_http_pre_access阶段是检查当前同一个key的连接数,请求结束的时候连接数会减1。测试的时候改成一个大文件就可以看出来效果。本地测试 10M的文件的并发传输可以看出来生效了。这里我是用的三方模块echo来做的实验
参考:http://cn.voidcc.com/question/p-pzgretie-tt.html
我觉得你的设置工作。之所以我认为你有时会得到200,有时会得到403,是因为有时当你的第二个请求运行时,第一个请求已经完成,让nginx服务器再次没有连接。
我想出的一件事就是通过睡觉让请求变成一个长时间的请求。在nginx的情况下,你可以使用echo_sleep来睡一定秒。echo_sleep指令需要第三方模块
limit_conn_zone $binary_remote_addr zone=one:10m;
limit_conn_log_level error;
limit_conn_status 503;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.php index.htm;
echo_sleep 2; #sleep 2s
limit_conn one 1;
}
}
另外刚才是配置针对单个IP的并发限制,还是可以针对域名进行并发限制,配置和客户端IP类似:
2、同一个域名来源:$server_name
我们可以在nginx_conf的http{}中加上如下配置实现限制:
#http{}段配置
limit_conn_zone $server_name zone=perserver:10m;
#server{}段配置
limit_conn perserver 1;
说明:
-
limit_conn_zone \$binary_remote_addr zone=addr:5m;
-
limit_conn addr 100;
limit_conn_zone设置用于保存各种key(比如当前连接数)的共享内存的参数。5m就是5兆字节,这个值应该被设置的足够大以存储(32K * 5)32byte状态或者(16K * 5)64byte状态。
limit_conn为给定的key设置最大连接数。这里key是addr,我们设置的值是100,也就是说我们允许每一个IP地址最多同时打开有100个连接
这个模块用来限制单个IP的请求数。并非所有的连接都被计数。只有在服务器处理了请求并且已经读取了整个请求头时,连接才被计数。
Syntax: limit_conn zone number;
Default: —
Context: http, server, location
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /download/ {
limit_conn addr 1;
}
}
一次只允许每个IP地址一个连接
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
...
limit_conn perip 10;
limit_conn perserver 100;
}
可以配置多个limit_conn指令。例如,以上配置将限制每个客户端IP连接到服务器的数量,同时限制连接到虚拟服务器的总数。
Syntax: limit_conn_zone key zone=name:size;
Default: —
Context: http
limit_conn_zone $binary_remote_addr zone=addr:10m;
在这里,客户端IP地址作为关键。请注意,不是 $remote_addr ,而是使用 $binary_remote_addr 变量。$remote_addr变量的大小可以从7到15个字节不等。存储的状态在32位平台上占用32或64字节的内存,在64位平台上总是占用64字节。对于IPv4地址, $binary_remote_addr变量的大小始终为4个字节,对于IPv6地址则为16个字节。存储状态在32位平台上始终占用32或64个字节,在64位平台上占用64个字节。一个兆字节的区域可以保持大约32000个32字节的状态或大约16000个64字节的状态。如果区域存储耗尽,服务器会将错误返回给所有其他请求。
Syntax: limit_conn_log_level info | notice | warn | error;
Default:
limit_conn_log_level error;
Context: http, server, location
当服务器限制连接数时,设置所需的日志记录级别。
Syntax: limit_conn_status code;
Default:
limit_conn_status 503;
Context: http, server, location
设置拒绝请求的返回值
ngx_http_limit_req_module
上面我们使用到了ngx_http_limit_conn_module 模块,来限制连接数。那么请求数的限制该怎么做呢?
这就需要通过ngx_http_limit_req_module 模块来实现,该模块可以通过定义的键值来限制请求处理的频率。特别的是可以限制来自单个IP地址的请求处理频率。
限制的方法是使用了漏斗算法,每秒固定处理请求数,推迟过多请求。如果请求的频率超过了限制域配置的值,请求处理会被延迟或被丢弃,所以所有的请求都是以定义的频率被处理的
只能在http{}中配置这个参数:
#区域名称为two,大小为10m,平均处理的请求频率不能超过每秒一次
limit_req_zone $binary_remote_addr zone=two:10m rate=1r/s;
在server{}中配置:
#设置每个IP桶的数量为5
limit_req zone=two burst=5;
上面设置定义了:每个IP的请求处理只能限制在每秒1个。并且服务端可以为每个IP缓存5个请求,如果操作了5个请求,请求就会被丢弃
使用ab测试模拟客户端连续访问10次:
ab -n 10 -c 10 http://localhost/index.html
如下图,设置了桶的个数为5个。一共10个请求,第一个请求马上被处理。第2-6个被存放在桶中。由于桶满了,没有设置nodelay因此,余下的4个请求被丢弃。
但是这里测试是2-5个被存放在桶中
location /download {
limit_rate_after 10m;
limit_rate 128k;
}
-
limit_rate:这是ngx_http_core_module提供的功能,用于限制Nginx的下载速率。如果是对代理限速,也可以使用X-Accel-Limit-Rate响应头。
-
limit_rate_after:通常与limit_rate一起使用。在上例中,10m以前不限速,10m以后才限制下载速率
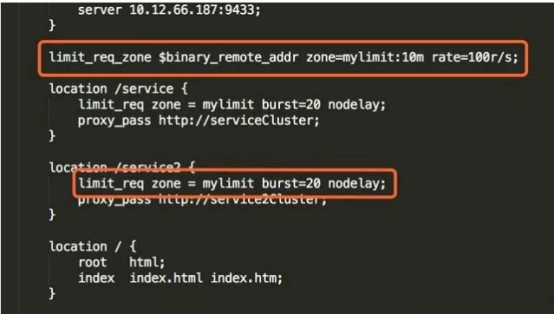
1、配置参数详解:
- limit_req_zone定义在http块中,\$binary_remote_addr 表示保存客户端IP地址的二进制形式。
- zone定义IP状态及URL访问频率的共享内存区域。zone=keyword标识区域的名字,以及冒号后面跟区域大小。16000个IP地址的状态信息约1MB,所以示例中区域可以存储160000个IP地址
- rate定义最大请求速率。示例中速率不能超过每秒100个请求。
2、设置限流
-
burst排队大小(漏桶的最大容量,默认为0),即溢出(Nginx将拒绝该请求);
-
nodelay不限制单个请求间的时间
Syntax: limit_req zone=name [burst=number] [nodelay];
Default: —
Context: http, server, location
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
-
第一个参数:
$binary_remote_addr表示通过remote_addr这个标识来做限制,"binary_"的目的是缩写内存占用量,是限制同一客户端ip地址。 -
第二个参数:zone=one:10m表示生成一个大小为10M,名字为one的内存区域,用来存储访问的频次信息。
-
第三个参数:rate=1r/s表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,还可以有比如30r/m的。
limit_req zone=one burst=5 nodelay;
-
第一个参数:zone=one 设置使用哪个配置区域来做限制,与上面limit_req_zone 里的name对应。
-
第二个参数:burst=5,重点说明一下这个配置,burst爆发的意思,这个配置的意思是设置一个大小为5的缓冲区当有大量请求(爆发)过来时,超过了访问频次限制的请求可以先放到这个缓冲区内。
-
第三个参数:nodelay,如果设置,超过访问频次而且缓冲区也满了的时候就会直接返回503,如果没有设置,则所有请求会等待排队。
例子:
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=5 nodelay;
}
}
下面配置可以限制特定UA(比如搜索引擎)的访问:
limit_req_zone $anti_spider zone=one:10m rate=10r/s;
limit_req zone=one burst=100 nodelay;
if ($http_user_agent ~* "googlebot|bingbot|Feedfetcher-Google") {
set $anti_spider $http_user_agent;
}
其他参数
Syntax: limit_req_log_level info | notice | warn | error;
Default:
limit_req_log_level error;
Context: http, server, location
当服务器由于limit被限速或缓存时,配置写入日志。延迟的记录比拒绝的记录低一个级别。例子:limit_req_log_level notice;延迟的的基本是info。
Syntax: limit_req_status code;
Default:
limit_req_status 503;
Context: http, server, location
设置拒绝请求的返回值。值只能设置 400 到 599 之间
实例一 限制访问速率
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit;
}
}
上述规则限制了每个IP访问的速度为2r/s,并将该规则作用于根目录。如果单个IP在非常短的时间内并发发送多个请求,结果会怎样呢?

单个IP 10ms内发送6个请求
我们使用单个IP在10ms内发并发送了6个请求,只有1个成功,剩下的5个都被拒绝。我们设置的速度是2r/s,为什么只有1个成功呢,是不是Nginx限制错了?当然不是,是因为Nginx的限流统计是基于毫秒的,我们设置的速度是2r/s,转换一下就是500ms内单个IP只允许通过1个请求,从501ms开始才允许通过第二个请求
实例二 burst缓存处理
我们看到,我们短时间内发送了大量请求,Nginx按照毫秒级精度统计,超出限制的请求直接拒绝。这在实际场景中未免过于苛刻,真实网络环境中请求到来不是匀速的,很可能有请求"突发"的情况,也就是"一股子一股子"的。Nginx考虑到了这种情况,可以通过burst关键字开启对突发请求的缓存处理,而不是直接拒绝。 来看我们的配置:
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4;
}
}
我们加入了burst=4,意思是每个key(此处是每个IP)最多允许4个突发请求的到来。如果单个IP在10ms内发送6个请求,结果会怎样呢?

设置burst
相比实例一成功数增加了4个,这个我们设置的burst数目是一致的。具体处理流程是:1个请求被立即处理,4个请求被放到burst队列里,另外一个请求被拒绝。通过burst参数,我们使得Nginx限流具备了缓存处理突发流量的能力。
但是请注意:burst的作用是让多余的请求可以先放到队列里,慢慢处理。如果不加nodelay参数,队列里的请求不会立即处理,而是按照rate设置的速度,以毫秒级精确的速度慢慢处理
实例三 nodelay降低排队时间
实例二中我们看到,通过设置burst参数,我们可以允许Nginx缓存处理一定程度的突发,多余的请求可以先放到队列里,慢慢处理,这起到了平滑流量的作用。但是如果队列设置的比较大,请求排队的时间就会比较长,用户角度看来就是RT变长了,这对用户很不友好。有什么解决办法呢?nodelay参数允许请求在排队的时候就立即被处理,也就是说只要请求能够进入burst队列,就会立即被后台worker处理,请注意,这意味着burst设置了nodelay时,系统瞬间的QPS可能会超过rate设置的阈值。nodelay参数要跟burst一起使用才有作用。
延续实例二的配置,我们加入nodelay选项:
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4 nodelay;
}
}
单个IP 10ms内并发发送6个请求,结果如下:
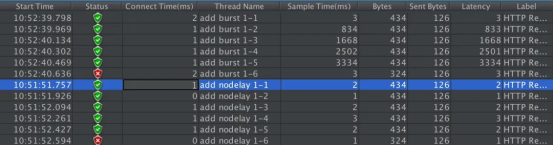
设置burst和nodela
跟实例二相比,请求成功率没变化,但是总体耗时变短了。这怎么解释呢?实例二中,有4个请求被放到burst队列当中,工作进程每隔500ms(rate=2r/s)取一个请求进行处理,最后一个请求要排队2s才会被处理;实例三中,请求放入队列跟实例二是一样的,但不同的是,队列中的请求同时具有了被处理的资格,所以实例三中的5个请求可以说是同时开始被处理的,花费时间自然变短了。
但是请注意,虽然设置burst和nodelay能够降低突发请求的处理时间,但是长期来看并不会提高吞吐量的上限,长期吞吐量的上限是由rate决定的,因为nodelay只能保证burst的请求被立即处理,但Nginx会限制队列元素释放的速度,就像是限制了令牌桶中令牌产生的速度。
看到这里你可能会问,加入了nodelay参数之后的限速算法,到底算是哪一个"桶",是漏桶算法还是令牌桶算法?当然还算是漏桶算法。考虑一种情况,令牌桶算法的token为耗尽时会怎么做呢?由于它有一个请求队列,所以会把接下来的请求缓存下来,缓存多少受限于队列大小。但此时缓存这些请求还有意义吗?如果server已经过载,缓存队列越来越长,RT越来越高,即使过了很久请求被处理了,对用户来说也没什么价值了。所以当token不够用时,最明智的做法就是直接拒绝用户的请求,这就成了漏桶算法
示例四 自定义返回值
自定义状态码的区间: nginx: [emerg] value must be between 400 and 599
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4 nodelay;
limit_req_status 598;
limit_req_log_level info;
}
}
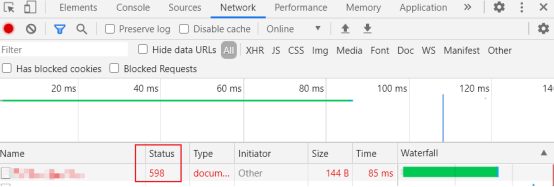
默认情况下 没有配置 status 返回值的状态:

没有配置 status
自定义 status 返回值的状态:
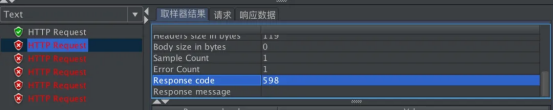
自定义返回值
综合示例
limit_conn_zone $binary_remote_addr zone=one:10m;
limit_conn_zone $server_name zone=two:10m;
limit_req_zone $binary_remote_addr zone=three:10m rate=1r/s;
limit_conn_log_level error;
limit_conn_status 503;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.php index.htm;
echo_sleep 2;
limit_conn one 1;
limit_conn two 1;
limit_req zone=three burst=5 nodelay;
# limit_req zone=three burst=5;
# limit_req zone=three;
}
}
ab -n 5 -c 5 http://192.168.137.6/index.html

ab -n 10 -c 10 http://localhost/index.html
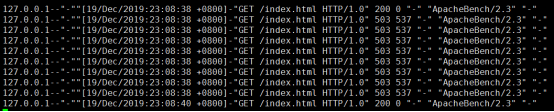
If指令
官网:http://nginx.org/en/docs/http/ngx_http_rewrite_module.html#if
| Syntax: | if (condition) |
|---|---|
| Default: | — |
| Context: | server, location |
if 的可用上下文有:server、location。if 的条件可能是以下任何一种情况:
可以参考 Nginx 模块 -> Nginx 模块 - ngx_http_rewrite_module
变量名;
如果变量值是空字符串或"0"则为 FALSE。注意,在 1.0.1 版本之前,任何以"0"开头的字符串都会被当做 FALSE。
使用"="和"!="的变量跟字符串的比较
使用"~"(区分大小写匹配)和"~\*"(不区分大小写匹配)运算符将变量与正则表达式匹配。正则表达式可以包含捕获,之后可以通过 \$1 到 \$9 这几个变量名重复使用。"!~"和"!~\*"用作不匹配运算符。如果正则表达式包含"}"或";"字符,则整个表达式应该用单引号或双引号括起来。
用"-f"和"!-f"运算符检查文件是否存在
用"-d"和"!-d"运算符检查目录是否存在
用"-e"和"!-e"运算符检查文件、目录或符号链接的存在性
用"-x"和"!-x"运算符检查可执行文件
示例:
# 如果用户代理 User-Agent 包含"MSIE",rewrite 请求到 /msie/ 目录下。通过正则匹配的捕获可以用 $1 $2 等使用
if ($http_user_agent ~ MSIE) {
rewrite ^(.*)$ /msie/$1 break;
}
# 如果 cookie 匹配正则,设置变量 $id 等于匹配到的正则部分
if ($http_cookie ~* "id=([^;]+)(?:;|$)") {
set $id $1;
}
# 如果请求方法为 POST,则返回状态 405(Method not allowed)
if ($request_method = POST) {
return 405;
}
# 如果通过 set 指令设置了 $slow,限速
if ($slow) {
limit_rate 10k;
}
# 如果请求的文件存在,则开启缓存,并通过 break 停止后面的检查
if (-f $request_filename) {
expires max;
break;
}
# 如果请求的文件、目录或符号链接都不存在,则用 rewrite 在 URI 头部添加 /index.php
if (!-e $request_filename) {
rewrite ^/(.*)$ /index.php/$1 break;
}
####
server {
listen *:80;
server_name example.com;
# Static directory
location /data/ {
autoindex on;
alias /data/;
expires 30d;
if ($request_filename ~ "^.*/(.+\.zip|tgz|iso|gz)$"){
set $fname $1;
add_header Content-Disposition 'attachment; filename="$fname"';
}
}
break指令
官网:http://nginx.org/en/docs/http/ngx_http_rewrite_module.html#break
| Syntax: | break; |
|---|---|
| Default: | — |
| Context: | server, location, if |
该指令用于中断当前相同作用域中的其他nginx配置。与该指令处于同一作用域的nginx配置中,位于它前面的指令生效,位于后面的指令配置无效。
break 的可用上下文有:server、location、if。用于停止处理当前的 ngx_http_rewrite_module 指令集合。
if ($slow) {
limit_rate 10k;
break;
}
set指令
语法:set variable value ; 默认值:none ; 使用环境:server,location,if;
-
variable为变量的名称。注意要用符号
$作为变量的第一个字符,且变量不能与nginx服务器预设的全局变量相同 -
value为变量的值,可以是字符串、其他变量或变量的组合等
该指令用于定义一个变量,并给变量赋值。变量的值可以为文本、变量以及文本变量的联合。
示例:
set $varname "hello world!!!!!!";
nginx的location作用
三方参考:https://mp.weixin.qq.com/s/WWaut-JWPOx8zYeiGLUUqg
https://www.cnblogs.com/lidabo/p/4169396.html
location表示位置的概念,类似于if,即满足什么条件,就做什么
控制访问网段,设置访问网段白名单和黑名单
格式:
| Syntax: | location [ = | ~ | ~ | ^~ ] uri { ... } location @name* |
|---|---|
| Default: | — |
| Context: | server, location |
在 Nginx 的配置文件中,通过 location 匹配用户请求中的 URI。格式如下:
location 前缀字符串 URL {
[ 配置 ]
}
前缀字符串及优先级
优先级为:
= > 完整路径 > ^~ > ~、~* > 部分起始路径 > /
其中,前缀字符串部分支持 5 种
=:精确匹配,优先级最高。如果找到了这个精确匹配,则停止查找。
^~:URI以某个常规字符串开头,不支持正则匹配
~:区分大小写的正则匹配
~*:不区分大小写的正则匹配
/:通用匹配, 优先级最低;符合最长匹配原则,名字最长的优先匹配。任何请求都会匹配到这个规则


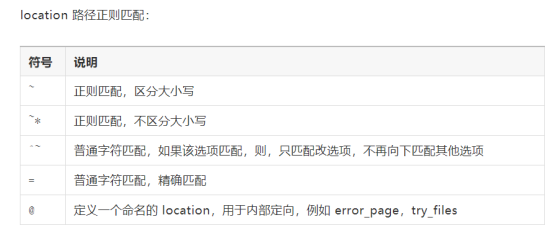
| 不用URI及特殊字符组合匹配 | 匹配说明 |
|---|---|
| location = / { | 精确匹配 / 只有完全匹配上才能生效 |
| location ^~ /images { | 匹配常规字符串,不做正则匹配检查;并且在正则之前 |
| location ~* . ( gif|jpg|jpeg ) $ { | 表示不区分大小写的正则匹配,匹配后缀为gif|jpg|jpeg的 |
| location ~ pattern | 开头表示区分大小写的正则匹配 |
| location /documents/ { | 匹配常规字符串,如果有正则,优先匹配正则 |
| location / { | 所有location都不能匹配后的默认匹配 |
| @ | 定义一个命名的location,用于内部定向,例如error_page,try_files |

location 匹配原则
可以 参考这篇译文
每个请求的处理逻辑顺序如下:
1、用所有的前缀字符串测试 URI。
2、等号 = 定义了前缀字符串和 URI 的精确匹配关系。如果找到了这个精确匹配,则停止查找。
3、如果 ^~ 修饰符预先匹配到最长的前缀字符串,则不检查正则表达式。
4、存储最长的匹配前缀字符串。
5、用正则表达式测试 URI。
6、匹配到第一个正则表达式后停止查找,使用对应的 location。
7、如果没有匹配到正则表达式,则使用之前存储的前缀字符串对应的 location
示例
# 精确匹配 / ,域名后面不能带任何字符串。匹配到后,停止继续匹配
location = / {
}
# 匹配到所有请求
location / {
if (-f $request_filename) {
expires max;
break;
}
if (!-e $request_filename) {
rewrite ^/(.*)$ /index.php/$1 break;
}
index index.php;
autoindex off;
}
# 匹配任何以 /documents/ 开头的 URI。优先级低于正则表达式,匹配到后还会继续往下匹配,当后面没有正则匹配或正则匹配失败时,使用这里代码
location /documents/ {
}
# 最长字符匹配到 /images/abc,继续往下,会发现 ^~ 存在
location /images/abc {
}
# 匹配任何以 /images/ 开头的 URI。优先级高于正则表达式,匹配成功后,停止往下搜索正则。
location ^~ /images/ {
}
# 正则匹配,区分大小写。匹配任何以 /documents/Abc 开头的地址,匹配符合以后,还要继续往下搜索
location ~ /documents/Abc {
}
# 正则匹配,忽略大小写。匹配所有以 gif、jpg 或 jpeg 结尾的请求
location ~* \.(gif|jpg|jpeg)$ {
}
try_files指令说明->按照顺序检查文件是否存在
参考文档:
https://blog.51cto.com/13930997/2311716
https://www.hi-linux.com/posts/53878.html#try_files%E6%8C%87%E4%BB%A4%E8%AF%B4%E6%98%8E


try_files语法
nginx 里边 try_files的用法
语法: try_files [$ur] [$uri/] 参数
核心作用:可以替代rewrite
作用域: server 、location
没有默认值
如:
try_files $uri $uri/ /index.php$is_args$args
-
\$uri 是请求文件的路径
-
\$uri/ 是请求目录的路径
参数:$is_args 解释: 表示请求中的URL是否带参数,如果带参数,$is_args值为?。如果不带参数,则是空字符串
访问: curl http://test.wanglei.com/192.168.1.200?a=10 -I 返回: "?"
访问: curl http://test.wanglei.com/192.168.1.200 -I 返回: ""
参数: $args只接收参数,解释: HTTP请求中的完整参数。
访问: curl http://test.wanglei.com/192.168.1.200?a=10 -I
返回: "a=10"
有参数的话 就变成了 /index.php?a=10 //这样就能访问了
作用:
按顺序检查文件是否存在,返回第一个找到的文件或文件夹(结尾加斜线表示为文件夹),如果所有的文件或文件夹都找不到,会进行一个内部重定向到最后一个参数。
需要注意的是,只有最后一个参数可以引起一个内部重定向,之前的参数只设置内部URI的指向。最后一个参数是回退URI且必须存在,否则会出现内部500错误;如下:

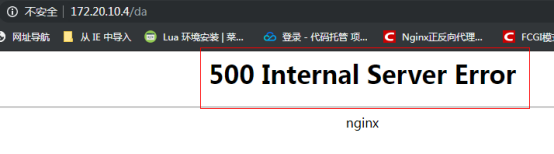
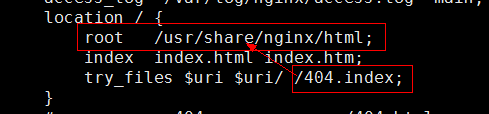
查找文件:404.index,的确不存在

命名的location也可以使用在最后一个参数中。与rewrite指令不同,如果回退URI不是命名的location那么$args不会自动保留,如果你想保留$args,则必须明确声明
try_files $uri $uri/ /index.php?q=$uri&$args;
示例一
try_files 将尝试你列出的文件并设置内部文件指向。
例如:
try_files /app/cache/ $uri @fallback;
index index.php index.html;
它将检测$document_root/app/cache/index.php,$document_root/app/cache/index.html和 $document_root$uri是否存在,如果不存在着内部重定向到@fallback(@表示配置文件中预定义标记点) 。
你也可以使用一个文件或者状态码(=404)作为最后一个参数,如果是最后一个参数是文件,那么这个文件必须存在。
示例二
例如nginx不解析PHP文件,以文本代码返回
try_files $uri /cache.php @fallback;
因为这个指令设置内部文件指向到$document_root/cache.php 并返回,但没有发生内部重定向,因而没有进行location段处理而返回文本 。
(如果加上index指令可以解析PHP是因为index会触发一个内部重定向)
示例三
结合rewrite跳转到变量
server {
listen 8000;
server_name 192.168.119.100;
root html;
index index.html index.php;
location /abc {
try_files /4.html /5.html @qwe; #检测文件$document_root/abc/4.html和$document_root/abc/5.html,如果存在正常显示,不存在就去查找@qwe值
}
location @qwe {
rewrite ^/(.*)$ http://www.baidu.com; #跳转到百度页面
}
示例四
跳转指定文件
server {
listen 8000;
server_name 192.168.119.100;
root html;
index index.php index.html;
location /abc {
try_files /4.html /5.html /6.html;
}
示例五
将请求跳转到后端
upstream srv {
server 127.0.0.1:8001;
}
server {
server_name gobgm.com;
return 301 $scheme://www.example.com$request_uri;
}
server {
listen 80;
server_name www.gobgm.com;
root html;
index index.html index.htm;
try_files $uri @gobgm;
location @gobgm {
proxy_pass_header Server;
proxy_set_header Host $http_host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://srv;
}
}
示例六
现在解释自己的配置:如下
server{
listen 80;
server_name www.gobgm.com;
index index.html index.htm index.php;
root html;
location / {
root html;
index index.html index.php index.htm;
try_files $uri $uri/ /index.php$is_args$args;
}
location ~ .php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
定义到了html。web里边有index.php,
当我访问 www.gobgm.com/index 的时候,try_files 会在web下找是否有index文件和目录(因为配置了 $uri 和$uri/ ), 很显然web目录里边没有,所以就把index当成了参数,所以呢原来的 www.gobgm.com/index 就变成了 www.gobgm.com/index.php?index 就这样
常见错误一
try_files 按顺序检查文件是否存在,返回第一个找到的文件,至少需要两个参数,但最后一个是内部重定向也就是说和rewrite效果一致,前面的值是相对$document_root的文件路径。也就是说参数的意义不同,甚至可以用一个状态码 (404)作为最后一个参数。如果不注意会有死循环造成500错误。
location ~.*\.(gif|jpg|jpeg|png)$ {
root html;
try_files /static/$uri $uri;
}
原意图是访问http://example.com/test.jpg时先去检查/web/wwwroot/static/test.jpg是否存在,不存在就取/web/wwwroot/test.jpg
但由于最后一个参数是一个内部重定向,所以并不会检查$document_root是否存在,只要第一个路径不存在就会重定向然后再进入这个location造成死循环。结果出现500 Internal Server Error
location ~.*\.(gif|jpg|jpeg|png)$ {
root html;
try_files /static/$uri $uri 404;
}
这样才会先检查$document_root/static/test.jpg是否存在,不存在就取$document_root/test.jpg再不存在则返回404 not found
常见错误二
Nginx try_files $query_string为空的解决办法
server {
listen 80;
server_name localhost.dev;
index index.php index.html index.htm;
set $root_path '/data/www';
root $root_path;
location / {
try_files $uri $uri/ /index.php;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
location ~* ^/(css|img|js|flv|swf|download)/(.+)$ {
root $root_path;
}
location ~ /\.ht {
deny all;
}
}
发现PHP无法获取$_GET信息
try_files $uri $uri/ /index.php;
改为
try_files $uri $uri/ /index.php?$query_string;
即可解决
return的配置说明->跳转
官方文档:http://nginx.org/en/docs/http/ngx_http_rewrite_module.html#return
该指令一般用于对请求的客户端直接返回响应状态码。在该作用域内return后面的所有nginx配置都是无效的。 可以使用在server、location以及if配置中。 除了支持跟状态码,还可以跟字符串或者url链接。
语法:return http状态码
| Syntax: | return code [text]; return code URL; return URL; |
|---|---|
| Default: | — |
| Context: | server, location, if |
该指令将结束执行直接返回http状态码到客户端.
支持的http状态码:200, 204, 400, 402-406, 408, 410, 411, 413, 416 , 500-504,还有非标准的444状态码.
直接返回状态码:
示例1:
server{
listen 80;
server_name www.aming.com;
return 403;
rewrite /(.*) /abc/$1; #该行配置不会被执行
}
示例2:
server {
.....
if ($request_uri ~ "\.htpasswd|\.bak")
{
return 404;
rewrite /(.*) /aaa.txt; #该行配置不会被执行。
}
#如果下面还有其他配置,会被执行。
.....
}
直接文本信息:
示例2:
server{
listen 80;
server_name www.aming.com;
return 200 "hello";
}
说明:如果要想返回字符串,必须要加上状态码,否则会报错。
还可以支持json数据
示例3:
location ^~ /gobgm {
default_type application/json ;
return 200 '{"name":"gobgm","id":"18"}';
}
也支持写一个变量
示例4:
location /test {
return 200 "$host $request_uri";
}
直接跳转功能
示例5:
server{
listen 80;
server_name www.test.com;
return http://www.test.com/123.html;
rewrite /(.*) /abc/$1; #该行配置不会被执行。
}
注意:return后面的url必须是以http://或者https://开头的。
示例6:
将流量重定向到一个新域名的示例:
server {
listen 80;
listen 443 ssl;
server_name www.old-name.com;
return 301 $scheme://www.new-name.com$request_uri;
}
上面代码中,listen 指令表明 server 块同时用于 HTTP 和 HTTPS 流量。server_name 指令匹配包含域名 www.old-name.com 的请求。return 指令告诉 Nginx 停止处理请求,直接返回 301 (Moved Permanently) 代码和指定的重写过的 URL 到客户端。$scheme 是协议(HTTP 或 HTTPS),$request_uri 是包含参数的完整的 URI。
对于 3xx 系列响应码,url 参数定义了新的(重写过的)URL:
return (301 | 302 | 303 | 307) url;
对于其他响应码,可以选择定义一个出现在响应正文中的文本字符串(HTTP 代码的标准文本,例如 404 的 Not Found,仍包含在标题中)。文本可以包含 NGINX 变量。
return (1xx | 2xx | 4xx | 5xx) ["text"];
例如,在拒绝没有有效身份验证令牌的请求时,此指令可能适用:
return 401 "Access denied because token is expired or invalid";
也可以通过 error_page 指令,可以为每个 HTTP 代码返回一个完整的自定义 HTML 页面,也可以更改响应代码或执行重定向
背景:网站被黑了,凡是在百度点击到本网站的请求,全部都跳转到了一个其他网站
通过nginx解决:
if ($http_referer ~ 'baidu.com')
{
return 200 "<html><script>window.location.href='//$host$request_uri';</script></html>";
}
如果写成下面的:在浏览器中会提示重定向的次数过多,因为会被反复跳转。
return http://$host$request_uri;
rewrite规则->跳转
nginx的rewrite规则:
实现url重写以及重定向。nginx服务器的rewrite功能是比较完善的,并且在配置上灵活自由,定制性非常高

地址重写与地址转发:
-
地址重写与转发在计算机网络领域是两个重要概念。
-
地址重写,实际上是为了实现地址标准化。那么,什么是地址标准化呢?例子:比如我们在访问Google首页时,我们在地址栏可以输入www.google.com,也可以输入google.cn,他们都能准确的指向Google首页,从客户端来看,Google首页同时对应了两个地址,实际上,Google服务器是在不同的地址中选择了确定的一个,即www.google.com,进而返回服务器响应的。这个过程就是地址标准化的过程。Google这个地址在服务器中被改变为www.google.com的过程就是地址重定向的过程
-
转发的概念最初和网页的访问并没有太大关系,它是指在网络数据传输过程中数据分组到达路由器或者桥接后该设备通过检查分组地址并将数据转到相邻局域网上的过程。后来改概念被用在网页访问中,出现了"地址转发"的说法。"地址转发",是指将一个域名指到另一个已有站点的过程。
语法配置:
Syntax: rewrite regex replacement [flag];
Default: ---
Context: server, location, if

^是开头,$是结尾,(.*)指的是任意内容,这句话意思是把任意内容都跳转到/pages/目录下的maintain.html文件,且不再往下匹配
正则表达式

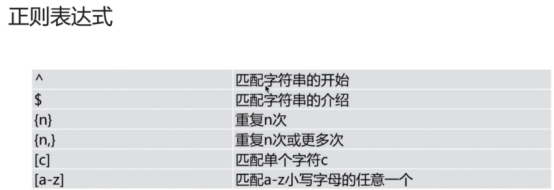

$1、$2的用法:

正则表达式测试模拟软件:
yum install -y pcre-tools

Flag标记符号
| Flag标记符号 | 说明 |
|---|---|
| last | 本条规则匹配完成后,继续向下匹配新的locationURL规则 |
| break | 本条规则匹配完成即终止。不在匹配后面的任何规则。 |
| redirect | 返回302临时重定向,浏览器地址会显示跳转后的URL地址 |
| permanent | 返回301永久重定向,浏览器地址会显示跳转后的URL地址 |
last 和 break 的区别及共同处:
1、last 重写 url 后,会再从 server 走一遍匹配流程,而 break 终止重写后的匹配
2、break 和 last 都能阻止后面的 rewrite 指令再次执行
ps:last还会继续匹配下面的location;而break匹配了当前级的location后,不会再往下匹配
rewrite规则优先级

eg:
server {
listen 80;
server_name www.gobgm.com;
root html;
location ~^/break {
rewrite ^/break /test/ break;
}
location ~^/last {
rewrite ^/last /test/ last;
}
location /test/ {
default_type application/json;
return 200 '{"status": "success"}';
}
}
访问:会返回200,
rewrite 指令只能返回代码 301 或 302。要返回其他代码,需要在 rewrite 指令后面包含 return 指令
eg:
下面是使用 rewrite 指令的 NGINX 重写规则的示例。它匹配以字符串/download开头的 URL,然后用/mp3/ 替换在路径稍后的某个位置包含的/media/或/audio/目录,并添加适当的文件扩展名.mp3或.ra。$1和$2变量捕获不变的路径元素。例如,/download/cdn-west/media/file1变为/download/cdn-west/mp3/file1.mp3。如果文件名上有扩展名(例如.flv),表达式会将其剥离并用.mp3替换。
server {
# ...
rewrite ^(/download/.*)/media/(\w+)\.?.*$ $1/mp3/$2.mp3 last;
rewrite ^(/download/.*)/audio/(\w+)\.?.*$ $1/mp3/$2.ra last;
return 403;
# ...
}
可以将flag添加到重写指令来控制处理流程。示例中的 last 告诉 NGINX 跳过当前服务器或位置块中的任何后续 ngx_http_rewrite_module 重写模块的指令,并开始搜索与重写的 URL 匹配的新位置。
这个例子中的最后一个 return 指令意味着如果 URL 不匹配任何一个 rewrite 指令,将返回给客户端 403 代码。
书写规范


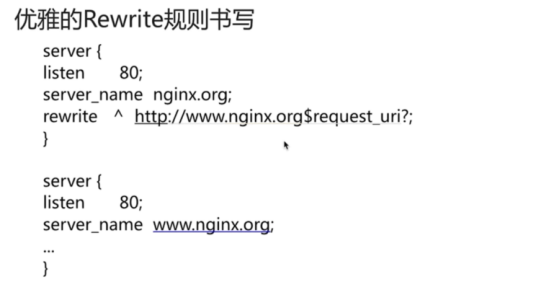
跳转3种方式
第一种:使用rewrite指令,通过正则匹配所有的URI后再去掉开头第一个/(反斜线)。
rewrite ^/(.*)$ https://www.gobgm.com/$1;
或者:
rewrite ^(.*)$ https://$server_name$1 permanent;
^是开头,$是结尾,(.*)指的是任意内容,这句话的意思是把任意内容都跳转到$server_name的第一个变量,这里的第一个变量其实就是用户输入的那个地址
第二种:同样使用rewrite指令,不同的是通过$request_uri变量匹配所有的URI。
rewrite ^ https://www.gobgm.com$request_uri? permanent;
这样写的好处是省去了去掉开头第一个反斜线的过程,正则匹配上性能更优
或者:$server_name$request_uri
rewrite ^ https://$server_name$request_uri? permanent;
第三种:见return篇的直接跳转功能
error-page
官网:http://nginx.org/en/docs/http/ngx_http_core_module.html#error_page
error_page语法
| Syntax: | error_page code ... [=[response]] uri; |
|---|---|
| Default: | — |
| Context: | http, server, location, if in location |
-
code,要处理的http错误代码
-
response,可选项,将code指定的错误代码转化为新的错误代码response
-
uri,错误页面的路径或者网站地址。如果设置为路径,则是以nginx服务器安装路径下的html目录为根路径的相对路径;如果设置为网址,那么nginx服务器会直接访问改网址获取错误页面,并返回给用户端
nginx指令error_page的作用是当发生错误的时候能够显示一个预定义的uri
nginx proxy 启用自定义错误页面:
1、要添加:fastcgi_intercept_errors on 或者 proxy_intercept_errors
-
默认:
fastcgi_intercept_errors off -
添加位置: http, server, location
-
默认情况下,nginx不支持自定义404错误页面,只有这个指令被设置为on,nginx才支持将404错误重定向
这个指令指定是否传递4xx和5xx错误信息到客户端,或者允许nginx使用error_page处理错误信息。你必须明确的在error_page中指定处理方法使这个参数有效
同时error_page在一次请求中只能响应一次,对应的nginx有另外一个配置可以控制这个选项:recursive_error_pages,该配置默认为false,作用是控制error_page能否在一次请求中触发多次
2.不要出于省事或者提高首页权重的目的将首页指定为404错误页面,也不要用其它方法跳转到首页
3.自定义的404页面必须大于512字节,否则可能会出现IE默认的404页面。例如,假设自定义了404.html,大小只有11个字节(内容为:404错误)
两个参数解释:
语法:proxy_intercept_errors on | off;
默认值:proxy_intercept_errors off;
上下文:http, server, location
当被代理的后端服务器的响应状态码大于等于300时,决定是否直接将响应发送给客户端,亦或将响应转发给nginx由error_page指令来处理。
http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_intercept_errors
proxy_intercept_errors 为on 表示 nginx按照原response code 输出,后端是404,就是404.这个变量开启后,我们才能自定义错误页面。
语法:fastcgi_intercept_errors on | off;
默认值:fastcgi_intercept_errors off;
上下文:http, server, location
当FastCGI后端服务器响应状态码大于等于300时,决定是否直接将响应发送给后端客户端,或者将响应转发给nginx由 error_page指令来处理。
http://nginx.org/en/docs/http/ngx_http_fastcgi_module.html#fastcgi_intercept_errors
fastcgi_intercept_errors on表示接收fastcgi输出的http 1.0 response code,后端php可以输出header指示nginx输出什么错误页面。开启这个之后,我们才能在php里面自定义错误代码和页面。
必须明确的在error_page中指定处理方法使这个参数有效,如果没有适当的处理方法,nginx不会拦截一个错误,这个错误不会显示自己的默认页面,这里允许通过某些方法拦截错误
404页面
参考:https://www.cnblogs.com/chenpingzhao/p/4813078.html
如果碰巧网站出了问题,或者用户试图访问一个并不存在的页面时,此时服务器会返回代码为404的错误信息,此时对应页面就是404页面。404页面的默认内容和具体的服务器有关。如果后台用的是NGINX服务器,那么404页面的内容则为:404 Not Found
NGINX下如何自定义404页面:
1、更改nginx.conf在http定义区域加入: proxy_intercept_errors或者fastcgi_intercept_errors
2、更改nginx.conf,在server 区域加入:
error_page 404 /404.html;
或者
error_page 404 http://www.gobgm.com/404.html;
error_page 404 http://www.gobgm.com/;
看日志发现,相当于做了一个302的临时跳转

3、更改后重启nginx,,测试nginx.conf正确性
50x页面
error_page 502 503 /50x.html;
这样实际上产生了一个内部跳转(internal redirect),当访问出现502、503的时候就能返回50x.html中的内容。
同时我们也可以自己定义这种情况下的返回状态码,比如:返回状态码为200的情况谨慎使用,不利于排查问题
error_page 502 503 =200 /50x.html;
这样用户访问产生502 、503的时候给用户的返回状态是200,内容是50x.html。

当error_page后面跟的不是一个静态的内容的话,比如是由proxyed server或者FastCGI/uwsgi/SCGI server处理的话,server返回的状态(200, 302, 401 或者 404)也能返回给用户,如:
error_page 404 = /404.php;
50x页面
502等错误同样可以用一个named location方法来配置:
error_page 500 501 502 503 504 @errpage;
location @errpage {
access_log logs/access.log maintry;
proxy_pass url;
}
-------或者----------
server {
listen 80;
server_name localhost;
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
同时也能够通过使客户端进行302、301等重定向的方式处理错误页面,默认状态码为302。
返回状态码的情况谨慎使用,不利于排查问题
error_page 403 http://example.com/forbidden.html;
error_page 404 =301 http://example.com/notfound.html;

error_page进行web站点降级服务
下面介绍一种我们这边经常使用的利用error_page来进行降级的一个方案:
对于基于nginx的web站点来说,如果用户访问量过大可能会导致nginx返回50x错误,这样用户就会看到错误页面,非常不友好,如果是一个偏静态的站点,当出现这种错误的时候如果将静态化的页面返回给用户也是一种在极端情况下比较合适的降级方案。
我们定期的去curl我们的页面,生成静态化的html页面,然后当发生错误的时候使用nginx lua去获取静态页面返回给用户
示例配置如下:
server {
...
location @jump_to_error {
lua_code_cache on;
content_by_lua_file /project_home/lua/error.lua;
}
error_page 500 502 503 504 @jump_to_error;
}
使用error_page时候的gzip问题
我们观察到当经过error_page处理之后,返回给用户的状态码是对应的5xx,这时页面是不会被gzip的,而将对应配置改成:
error_page 500 502 503 504 =200 @jump_to_error;
这样页面就会被gzip,但是由于这样在access log中会看到对应返回码是200而不是本来的5xx,不利于我们查找错误,在这样错误的情况下定位问题更加重要,而没有gzip不是有非常大的影响,所以最后我们衡量没有采用这种方式,保持原来方式不变。
最后去调研了下为什么nginx会这样处理,看到nginx的源码中有相应的处理,代码如下:
nginx/src/http/modules/ngx_http_gzip_filter_module.c
static ngx_int_t
ngx_http_gzip_header_filter(ngx_http_request_t *r)
{
...
conf = ngx_http_get_module_loc_conf(r, ngx_http_gzip_filter_module);
if (!conf->enable
|| (r->headers_out.status != NGX_HTTP_OK
&& r->headers_out.status != NGX_HTTP_FORBIDDEN
&& r->headers_out.status != NGX_HTTP_NOT_FOUND)
|| (r->headers_out.content_encoding
&& r->headers_out.content_encoding->value.len)
|| (r->headers_out.content_length_n != -1
&& r->headers_out.content_length_n < conf->min_length)
|| ngx_http_test_content_type(r, &conf->types) == NULL
|| r->header_only)
{
return ngx_http_next_header_filter(r);
}
...
}
可以看到代码里面直接判断了一下返回的header里面的status是不是200、403或者404,如果不是的话就跳过gzip filter这个模块。
为什么nginx要这么处理呢,去挖了一下,在nginx的mailing list看到有人提问,nginx开发组给出了一些解答,举了一些栗子:比如当由于服务器原因导致内存分配异常导致返回给用户500的时候再分配内存进行gzip显然不合适,感兴趣同学可以去详细看下,链接:nginx开发组对于error_page不做gzip的解答
Nginx访问状态监控


location ~ /status { #访问状态为/status
stub_status on; #打开状态统计功能
access_log off; #关闭此位置的日志记录
}
###########################
server {
listen 80;
server_name 192.168.2.171;
location /status {
stub_status on;
access_log off;
#allow 127.0.0.1;
allow all;
#deny all;
}
}
访问查看结果(红色框里面每刷新都会更新):
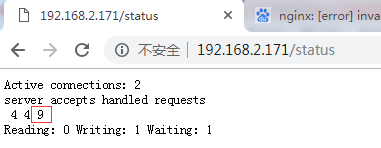
-
Active connections 客户端连接数
-
accepts 接收数值
-
handled 处理数值(通常跟接收值是一样的,但是限制值达到上限就例外了)
-
requests 客户端请求值
-
Reading 请求报文的连接数
-
Writing 响应
-
Waiting 等待请求的数量
说明:一般以上页面内容信息主要会被test-6监控服务调取,形成图像信息;根据图像信息,从而判断nginx网站服务用户访问量情况
一个小工具帮你搞定实时监控Nginx服务器
官网:
https://github.com/lebinh/ngxtop
参考:https://mp.weixin.qq.com/s/5zKkMsmhwyp_tVaqPmJHBQ
Linux运维工程师的首要职责就是保证业务7 x 24小时稳定的运行,监控Web服务器对于查看网站上发生的情况至关重要。关注最多的便是日志变动,查看实时日志文件变动大家第一反应应该是tail -f /path/to/log命令吧,但是如果每个网站的访问日志都是使用这种方式查看也是相当崩溃的,今天小编就跟大家分享一个强大的Nginx日志监控工具。
ngxtop是一个基于python的程序,可以在Python上安装。ngxtop通过实时解析nginx访问日志,并将结果(nginx服务器的有用指标)输出到终端。
主要的功能
-
当前有效请求
-
总请求计数摘要
-
按状态代码提供的总请求数(2xx,3xx,4xx,5xx)
-
发送平均字节
-
顶级远程地址
不仅能实时监控Nginx日志的访问还可以对以前的日志进行排查整理
在Linux上安装ngxtop
以下操作是在CentOS 7-64bit上测试
首先,你需要安装pip(Python包管理系统)
-
使用root凭据登录你的服务器
-
通过安装以下包启用EPEL存储库
wget http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-6.noarch.rpm
rpm -ivh epel-release-7-6.noarch.rpm
然后执行以下命令安装pip
yum install python-pip
最后使用下面安装ngxtop
pip install ngxtop
ngxtop使用详解
[root@localhost local]# ngxtop -h
ngxtop - ad-hoc query for nginx access log.
Usage:
ngxtop [options]
ngxtop [options] (print|top|avg|sum) <var> ...
ngxtop info
ngxtop [options] query <query> ...
Options:
-l <file>, --access-log <file> access log file to parse.
-f <format>, --log-format <format> log format as specify in log_format directive. [default: combined]
--no-follow ngxtop default behavior is to ignore current lines in log
and only watch for new lines as they are written to the access log.
Use this flag to tell ngxtop to process the current content of the access log instead.
-t <seconds>, --interval <seconds> report interval when running in follow mode [default: 2.0]
-g <var>, --group-by <var> group by variable [default: request_path]
-w <var>, --having <expr> having clause [default: 1]
-o <var>, --order-by <var> order of output for default query [default: count]
-n <number>, --limit <number> limit the number of records included in report for top command [default: 10]
-a <exp> ..., --a <exp> ... add exp (must be aggregation exp: sum, avg, min, max, etc.) into output
-v, --verbose more verbose output
-d, --debug print every line and parsed record
-h, --help print this help message.
--version print version information.
Advanced / experimental options:
-c <file>, --config <file> allow ngxtop to parse nginx config file for log format and location.
-i <filter-expression>, --filter <filter-expression> filter in, records satisfied given expression are processed.
-p <filter-expression>, --pre-filter <filter-expression> in-filter expression to check in pre-parsing phase.
Examples:
All examples read nginx config file for access log location and format.
If you want to specify the access log file and / or log format, use the -f and -a options.
"top" like view of nginx requests
$ ngxtop
Top 10 requested path with status 404:
$ ngxtop top request_path --filter 'status == 404'
Top 10 requests with highest total bytes sent
$ ngxtop --order-by 'avg(bytes_sent) * count'
Top 10 remote address, e.g., who's hitting you the most
$ ngxtop --group-by remote_addr
Print requests with 4xx or 5xx status, together with status and http referer
$ ngxtop -i 'status >= 400' print request status http_referer
Average body bytes sent of 200 responses of requested path begin with 'foo':
$ ngxtop avg bytes_sent --filter 'status == 200 and request_path.startswith("foo")'
Analyze apache access log from remote machine using 'common' log format
$ ssh remote tail -f /var/log/apache2/access.log | ngxtop -f common

ngxtop实践
1.使用ngxtop命令查看请求计数摘要,请求的URI,状态码请求的数量。
$ ngxtop
2.检查顶级客户端的IP
查看谁向你的Nginx服务器发出大量请求。
ngxtop top remote_addr
3.仅显示出404的HTTP请求
ngxtop -i'status> = 404'
4.分析access.log
ngxtop -l /path/access.log
5.解析Apache的offline access.log
ngxtop -f common -l /path/access.log
另外你可以可以使用多种组合来过滤access.log以获取有用的数据
Nginx共享文件web页面(download)
参考:http://www.eryajf.net/1086.html
Nginx默认是不允许列出整个目录的。如需此功能,打开nginx.conf文件,在location,server 或 http段中加入autoindex on;,另外两个参数最好也加上去:
autoindex_exact_size off;默认为on,显示出文件的确切大小,单位是bytes。改为off后,显示出文件的大概大小,单位是kB或者MB或者GBautoindex_localtime on;默认为off,显示的文件时间为GMT时间。改为on后,显示的文件时间为文件的服务器时间
当配置autoindex on参数以后,会显示站点目录文件列表信息:
1. 对于nginx服务可以识别解析资源,进行点击,会显示相应内容
2. 对于nginx服务不可以识别解析资源,进行点击,会直接下载
server {
listen 192.168.2.171:80;
server_name 192.168.2.171; #设置访问你的IP或域名
charset utf-8;
location /haha/ {
autoindex on; # 索引
autoindex_exact_size on; # 显示文件大小
root /usr/local/nginx/; #定义你的共享目录路径 其他路径注意安全上下文
autoindex_localtime on; # 显示文件时间
index index.html index.htm; #这里要在站点目录中把主页文件删除,否则会直接显示主页
}
}
访问:192.168.2.171/haha/ (必须访问这个目录,否则报404错误)
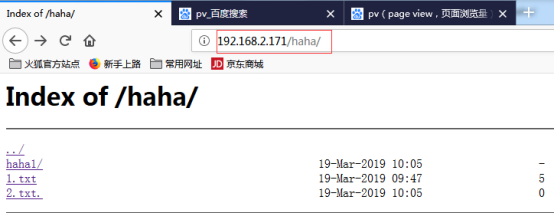
由于我一台服务器,而且只有一个外网一个内网ip,没有域名,操作如下:
[root@learn conf]# tail -16 /usr/local/nginx/conf/nginx.conf
server {
listen 80;
server_name 172.17.135.42;#内网ip
access_log logs/access.log main;
location / {
# try_files $uri $uri/ /index.html;
root /usr/local/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/nginx/html;
}
}
[root@learn ~]# tail -15 /usr/local/nginx/conf/vhost/download.conf
server {
listen 80;
server_name 39.107.229.89; #外网ip
charset utf-8;
location /download {
autoindex on; # 索引
autoindex_exact_size on; # 显示文件大小
root /usr/local/nginx/html/; #定义你的共享目录路径 其他路径注意安全上下文
autoindex_localtime on; # 显示文件时间
# index index.html index.htm; #这里要在站点目录中把主页文件删除,否则会直接显示主页
}
}
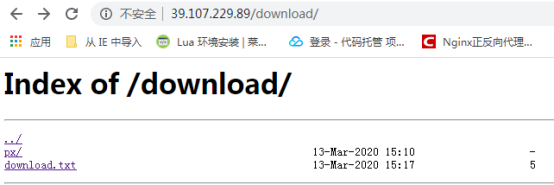
这样保证了我的主页可以访问,又保证了可以下载文件。
nginx+fancyindex漂亮目录浏览带搜索功能
https://github.com/aperezdc/ngx-fancyindex
https://blog.csdn.net/cp_zhong/article/details/84066892
https://www.jianshu.com/p/5b2914c19253
https://www.cnblogs.com/djoker/p/6396510.html
http://www.ttlsa.com/nginx/nginx-module-ngx-fancyindex/
更换原因
nginx自带目录索引,功能简单、样式也不好看,现在使用fancyindex插件来做索引,配上一个漂亮的主题还有搜索的功能
系统环境
-
系统:CentOS Linux release 7.5.1804
-
web:Nginx 1.18.0
-
ngx-fancyindex: fancyindex V0.4.4
-
fancy-theme: fancy v1.1
安装所需包并下载nginx1.18.0和fancy插件
wget https://github.com/aperezdc/ngx-fancyindex/releases/download/v0.4.4/ngx-fancyindex-0.4.4.tar.xz
wget -O fancytheme.zip https://github.com/Naereen/Nginx-Fancyindex-Theme/archive/master.zip
unzip fancytheme.zip
tar xf ngx-fancyindex-0.4.4.tar.xz
# /usr/local/nginx-1.18.0
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--http-log-path=/usr/local/nginx/logs/access.log \
--error-log-path=/usr/local/nginx/logs/error.log \
--pid-path=/usr/local/nginx/logs/nginx.pid \
--lock-path=/usr/local/nginx/logs/nginx.lock \
--with-http_ssl_module \
--with-http_flv_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-http_realip_module \
--with-http_secure_link_module \
--with-http_sub_module \
--with-pcre \
--with-stream \
--http-client-body-temp-path=/usr/local/nginx/client_body_temp \
--http-proxy-temp-path=/usr/local/nginx/proxy_temp \
--http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp \
--http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp \
--http-scgi-temp-path=/usr/local/nginx/scgi_temp \
--add-module=/usr/local/ngx-fancyindex-0.4.4 #编译此模块
确定没有错误后,在执行
$ make && make install
$ ln -s /usr/local/nginx/sbin/nginx /usr/sbin/
复制fancyindex.conf 配置到nginx配置文件中
# cp /usr/local/Nginx-Fancyindex-Theme-master/fancyindex.conf /usr/local/nginx/conf/vhost/
复制fancy根目录
# cp -rf /usr/local/Nginx-Fancyindex-Theme-master/Nginx-Fancyindex-Theme-light/ /usr/local/nginx/html/download/
配置nginx
location /file {
# 防止浏览器预览打开
# if ($request_filename ~* ^.*?\.(txt|doc|pdf|rar|gz|zip|docx|exe|xlsx|ppt|pptx)$){
# add_header Content-Disposition attachment;
# }
# 这里是代理的路径,文件都要放在这里,Nginx-Fancyindex-Theme主题也要放在这个路径下
alias /usr/data;
fancyindex on;
fancyindex_exact_size off;
fancyindex_localtime on;
# 由于我配置了访问路径是http://ip:port/file,主题的路径前需要加上/file,
# 如果配置的是location /,则路径为/Nginx-Fancyindex-Theme-light/header.html
fancyindex_header "/file/Nginx-Fancyindex-Theme-light/header.html";
# 由于我配置了访问路径是http://ip:port/file,主题的路径前需要加上/file
# 如果配置的是location /,则路径为/Nginx-Fancyindex-Theme-light/footer.html
fancyindex_footer "/file/Nginx-Fancyindex-Theme-light/footer.html";
#忽略要显示的文件
fancyindex_ignore "examplefile.html";
fancyindex_ignore "Nginx-Fancyindex-Theme-light";
fancyindex_name_length 255;
# 配置用户访问权限,见3.2用户访问权限配置
# auth_basic "Restricted";
# auth_basic_user_file "/usr/local/nginx/htpasswd";
}
访问控制
基于授权的访问控制



说明:这里的密码文件支持明文或者密码加密后的文件
明文的格式如下:
name1:password1
name1:password1:comment
加密密码可以使用crypt()函数进行密码加密的格式,在linux平台可以使用htpasswd命令生成,在php和perl等语言中,也提供crypt()函数。
我们这里使用htpasswd:
第一步:使用htpasswd生成用户认证文件,如果没有该命令,可以使用yum安装httpd-tools软件包。

[root@haha ~ 15:38]# htpasswd -c -m /etc/nginx/.htpasswd admin (admin登陆时的用户名)
New password: #输入密码
Re-type new password: #再次输入密码
Adding password for user admin
[root@haha ~ 16:05]# cat /etc/nginx/.htpasswd
admin:$apr1$KicP4PS4$gaIe/C5ShY8xIsso9OuKs.
在/etc/nginx目录下生成.htpasswd文件,用户名是admin,密码输入2次,在.htpasswd中生成用户名和密码的密文。
第二步:修改密码文件的权限为400,将所有者改为nginx,设置nginx的运行用户能够读取。

[root@haha ~ 15:44]# chmod 400 /etc/nginx/.htpasswd
[root@haha ~ 15:49]# chown nginx /etc/nginx/.htpasswd
[root@haha ~ 15:49]# ll -d /etc/nginx/.htpasswd
-r--------. 1 nginx root 44 3月 18 15:44 /etc/nginx/.htpasswd
第三步:修改主配置文件nginx.conf,添加相应认证配置项
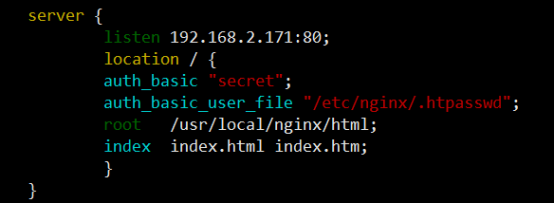
server {
listen 192.168.2.171:80;
location / {
auth_basic "secret";
auth_basic_user_file "/etc/nginx/.htpasswd";
root /usr/local/nginx/html;
index index.html index.htm;
}
}
第四步:检查语法,重载配置文件。

[root@haha ~ 15:55]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
如果报如下错误:
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx:[warn]4096 work_connection exceed open file resource limit:1024
nginx: configuration file /etc/nginx/nginx.conf test is successful
解决方案:
[root@haha ~ 15:56]# ulimit -n 65530
重载服务:
[root@haha ~ 16:00]#nginx -s reload
第五步:用浏览器访问网址,检验控制效果
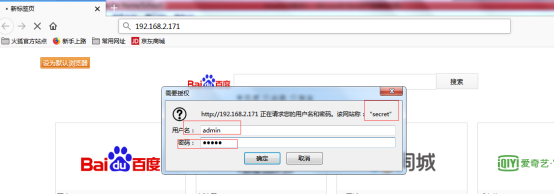
基于IP的访问控制
模块:

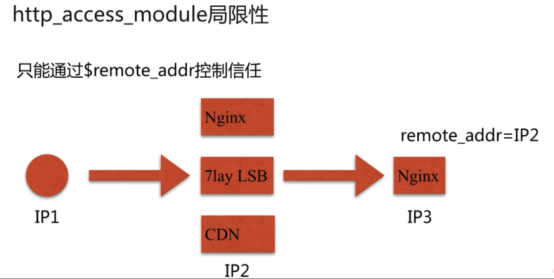
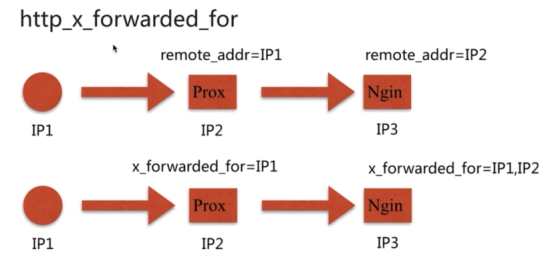


指令:
allow指令,用于设置允许访问nginx的客户端IP,语法如下:
allow address |CIDR|all;
-
address允许访问客户端的IP,不支持同时设置多个。如果有多个IP需要设置,需要重复使用allow指令
-
CIDR允许访问的客户端的CIDR地址,例如
202.80.18.33/25,前面是32位IP地址,后面/25代表该IP地址中前25位是网络部分,其余位代表主机部分。 -
all代表允许所有客户端访问
deny指令,用于设置禁止访问nginx的客户端IP,语法如下:
deny address |CIDR|all;
-
deny禁止访问客户端的IP,不支持同时设置多个。如果有多个IP需要设置,需要重复使用deny指令
-
CIDR禁止访问的客户端的CIDR地址,例如202.80.18.33/25,前面是32位IP地址,后面"/25"代表该IP地址中前25位是网络部分,其余位代表主机部分。
-
all代表禁止所有客户端访问
基于IP的访问控制:
-
deny IP/IP段 : 拒绝某个IP或IP段的客户端访问。
-
allow IP/IP段 : 允许某个IP或IP段的客户端访问。
-
规则从上往下执行,如匹配停止,不再往下匹配
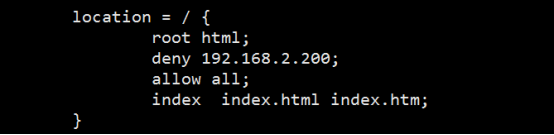
location = / {
root html;
deny 192.168.2.200; #拒绝访问的IP地址
allow all;
index index.html index.htm;
}
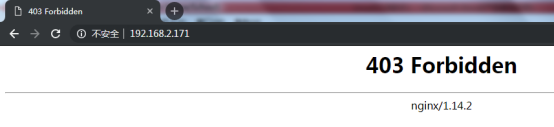
注意:这是在原网页测试的,如果是其他网页,需要写在serve中。
nginx虚拟主机
虚拟主机通常有三种情况:
一、多ip地址 二、单ip多端口实现 三、单ip一个端口多主机头(或者是多域名实现)
在这里只是实现后两种虚拟主机的配置方法: 方法一: 1.修改配置文件
vi /usr/local/nginx/conf/nginx.conf
#注释原有server内容,加入以下内容,相关内容省略,如日志出错提示等。
server {
listen 99;
server_name localhost;
location / {
index index.html;
root /usr/local/www1/htdocs;
}
}
server {
listen 88;
server_name localhost;
location / {
index index.html;
root /usr/local/www2/htdocs;
}
}
2.其它准备工作
mkdir -p /usr/local/www1/htdocs
cd /usr/local/www1/htdocs
echo "web server 1" >index.html
mkdir -p /usr/local/www2/htdocs
cd /usr/local/www2/htdocs
echo "web server 2">index.html
3.重启nginx服务
(1) kill -HUP `cat /usr/local/nginx/logs/nginx.pid`
(2) 如果不行的话,先杀,再启动
4.测试
http://192.168.129.21:88
http://192.168.129.21:99
方法二:
方法二采用的是比较常用的虚拟主机配置,如单IP,80端口,通过域名来实现区分不同的网站主页。在方法一的基础上修改为以下配置
注:需要有dns的支持,有域名,在下面的配置中,只是实现了静态页面实现,如果要实现动态的功能,参考相头内容。
server {
listen 80;
server_name www.gobgm.com;
access_log logs/gobgm.access.log main;
location / {
index index.html;
root /var/www/gobgm.com/htdocs;
}
}
server {
listen 80;
server_name www.gobgm2.com;
access_log logs/gobgm2.access.log main;
location / {
index index.html;
root /var/www/gobgm2/htdocs;
}
}
基于域名的虚拟主机
1、修改Windows客户机的hosts文件(C:\Windows\System32\drivers\etc),加入www.haha.com和www.test.com这两个域名,它们指向同一服务器IP地址,用于实现不同的域名访问不同的虚拟主机。

2、准备两个网站的目录和测试首页

[root@haha ~ 17:04]# mkdir -pv /var/www/html/haha /var/www/html/test
[root@haha ~ 17:07]# echo "This is www.haha.com ,welcome to you" > /var/www/html/haha/index.html
[root@haha ~ 17:08]# echo "This is www.test.com ,welcome to you" > /var/www/html/test/index.html

3、修改配置文件,把下面的内容添加到http模块中。
# vim /etc/nginx/nginx.conf
server {
listen 80;
server_name www.haha.com;
charset utf-8;
access_log /var/www/html/www.haha.com.access.log ;
location / {
root /var/www/html/haha;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = 50x.html {
root html;
}
}
server {
listen 80;
server_name www.test.com;
charset utf-8;
access_log /var/www/html/www.test.com.access.log ;
location / {
root /var/www/html/test;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = 50x.html {
root html;
}
}
4、重启服务,然后分别访问两个域名,结果如下
基于IP地址的虚拟主机
1、一台主机如果有多个IP地址,可以设置每一个IP对应一个站点。主机安装多个网卡可以有多个IP地址,这里采用虚拟IP地址。
[root@haha ~]# ifconfig eth0:1 192.168.2.222
[root@haha ~]# ifconfig eth0:2 192.168.2.221


[root@haha ~]#ifconfig eth0:1 ;ifconfig eth0:2
2、以/var/www/html{haha,test}为两个站点的根目录,修改nginx的配置文件,使基于IP地址的虚拟主机生效。这里省略了和基于域名的虚拟主机的相同配置代码。
vim /etc/nginx/nginx.conf
server {
listen 192.168.2.221:80;
server_name 192.168.2.221:80;
……………………………
}
server {
listen 192.168.2.222:80;
server_name 192.168.2.222:80;
……………………………
}
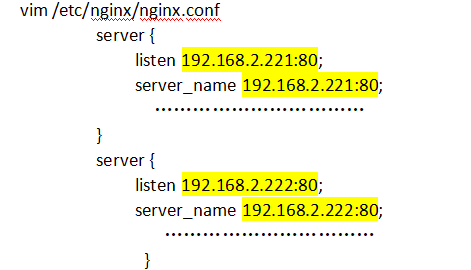
3、重启服务,然后分别访问两个IP地址
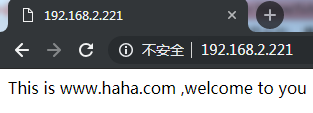
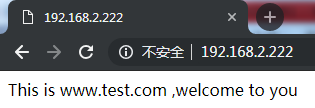
基于端口的虚拟主机
1、选择系统中不使用的端口,将多个端口映射到同一IP地址。
vim /etc/nginx/nginx.conf
server {
listen 192.168.2.222:8888;
server_name 192.168.2.222:8888;
………………
}
server {
listen 192.168.2.222:7777;
server_name 192.168.2.222:7777;
………………
}
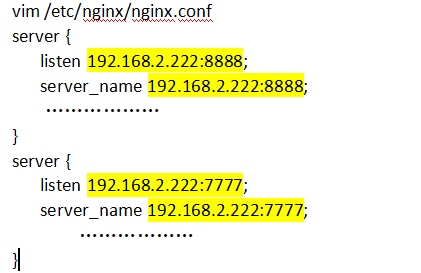
2、重启服务、查看端口是否启用、然后进行验证


验证结果:
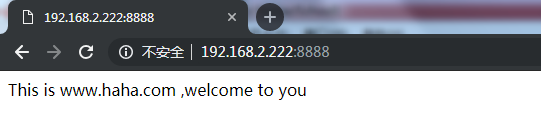
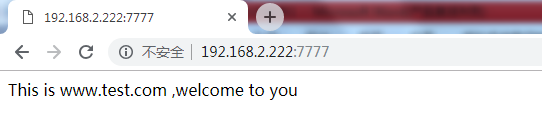
实现一个域名配置多个站点
https://www.jb51.net/article/154631.htm
相同sever_name多个虚拟主机优先级

Nginx的alias和root的区别->虚拟目录
最基本的区别:alias指定的目录是准确的,root是指定目录的上级目录,并且该上级目录要含有location指定名称的同名目录。另外,根据前文所述,使用alias标签的目录块中不能使用rewrite的break。
示例1:
location /abc/ {
alias /home/html/abc/;
}
在这段配置下,http://test/abc/a.html就指定的是/home/html/abc/a.html
示例2: 这段配置亦可改成
location /abc/ {
root /home/html/; #是abc的上级目录
}
示例3: 把alias的配置改成:
location /abc/ {
alias /home/html/def/;
}
那么nginx将会从/home/html/def/取数据,这段配置还不能直接使用root配置,如果非要配置,只有在/home/html/下建立一个 def->abc的软link(快捷方式)了。
说明:
- 使用alias时目录名后面一定要加
/ - nginx、resin当虚拟目录名与真实目录同名时,虚拟目录比真实目录优先级要高
Nginx优化(重点)
1.隐藏版本号;
2.修改用户和用户组;
3.设置网页缓存时间;
4.日志切割;
5.设置连接超时时间;
6.工作进程数;每个工作进程的连接数(与CPU个数保持一致,或者CPU个数减1)
7.配置网页压缩;
8.防盗链,rewrite模块;
9.FPM的参数优化。
10.CPU的亲和
11、性能优化,进行压力测试
隐藏版本信息
方法一:
在http模块下面添加server_tokens off;
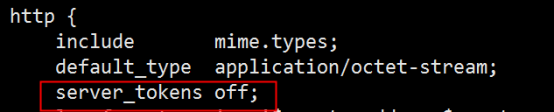
修改后的结果(已成功更改):
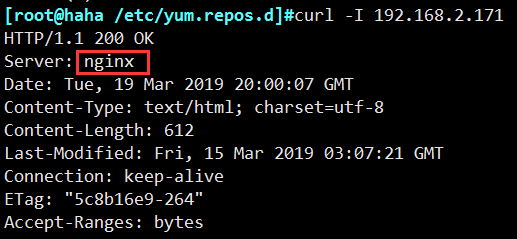
方法二:
Nginx源码文件包含的版本信息,修改下面两项内容,可以随意修改内容,然后在进行编译安装。
vim nginx-1.14.2/src/core/nginx.h
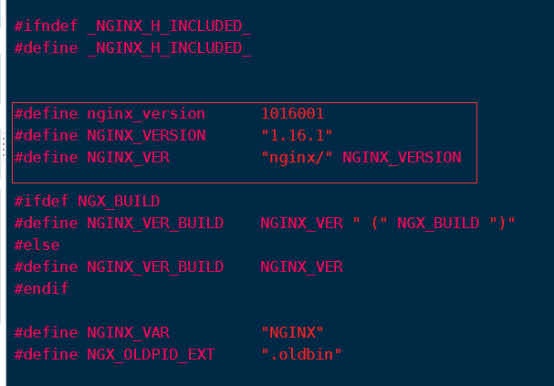
以上是源代码
#define NGINX_VERSION "2.2.2"
#define NGINX_VER "apache/" NGINX_VERSION

注意,修改不能把前面的#号去掉哦
然后在进行编译nginx,完成后重启nginx服务,最后在访问才能看到效果
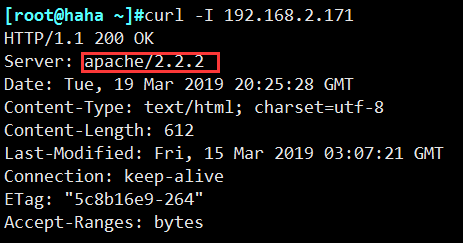
修改用户与组
方法一:在编译之前,就指定用户和组,然后进行安装
方法二:在配置文件中进行修改(用户与组之间用空格隔开)
 ->修改用户与组
->修改用户与组
网页缓存时间
当Nginx将网页数据返回给客户端后,可设置缓存的时间,以方便日后进行相同内容的请求时直接返回,避免重复请求,加快访问速度,一般只针对静态资源进行设置,对动态网页不用设置缓存时间。

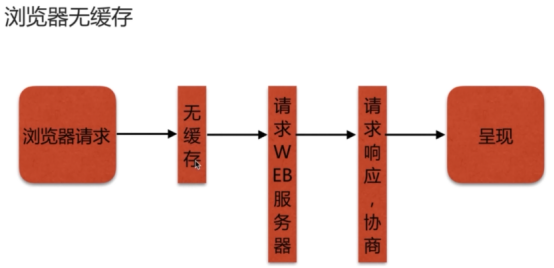
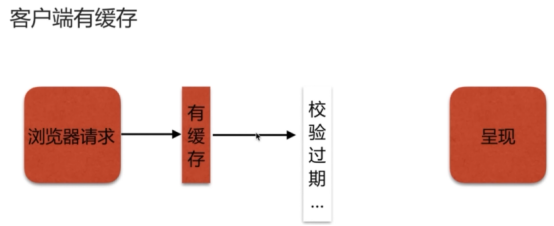
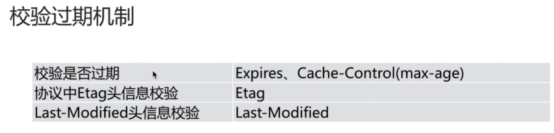
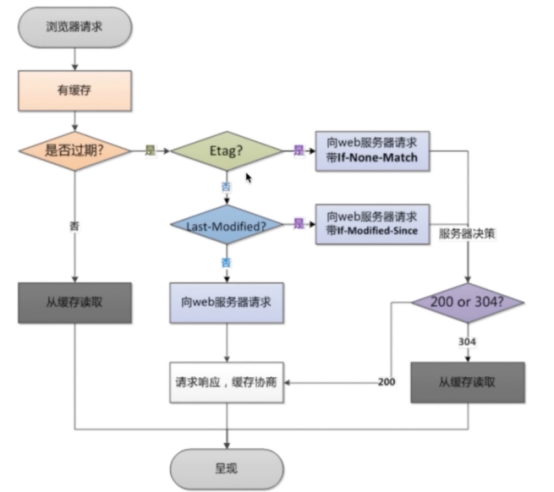

eg:以图片作为缓存对象,用fiddler工具抓包。
未设置前:
location / {
root html;
index index.html index.htm index.php;
}
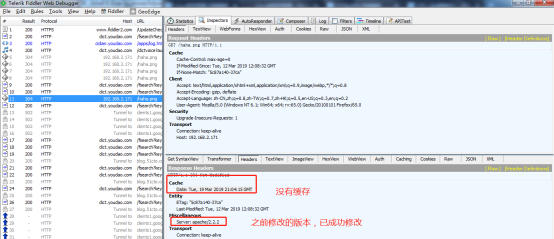
设置后:
location / {
root html;
index index.html index.htm index.php;
}
#加入缓存配置
location ~ \.(gif|jpg|jepg|png|bmp|ico)$ {
root html;
expires 1d;
}
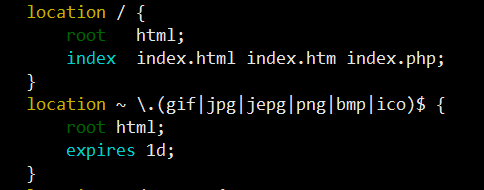
重启服务进行查看:
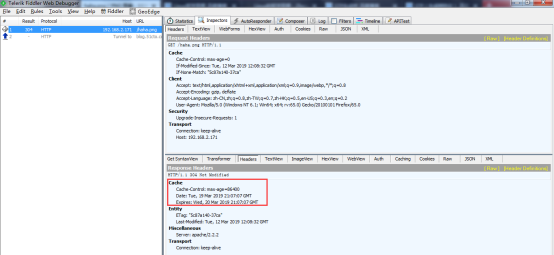
其中Cache-Control: max-age=86400表示缓存时间是86400秒,也就是缓存一天的时间,一天之内浏览访问这个页面,都使用缓存中的数据,而不需要向nginx服务器重新发出请求,减少了服务器的使用频度。
日志切割
参考:https://www.cnblogs.com/kevingrace/p/6307298.html
方法1:logrotate
参考:https://www.cnblogs.com/clsn/p/8428257.html
1、安装软件:
[root@learn ~]# yum install logrotate -y
[root@learn ~]# rpm -qc logrotate
/etc/cron.daily/logrotate
/etc/logrotate.conf # 主配置文件
/etc/rwtab.d/logrotate
logrotate的配置文件是/etc/logrotate.conf,通常不需要对它进行修改。日志文件的轮循设置在独立的配置文件中,它(们)放在/etc/logrotate.d/目录下
Logrotate是基于CRON来运行的,其脚本是/etc/cron.daily/logrotate,实际运行时,Logrotate会调用配置文件/etc/logrotate.conf
Logrotate是基于CRON运行的,所以这个时间是由CRON控制的,具体可以查询CRON的配置文件/etc/anacrontab
[root@test ~]# cat /etc/anacrontab
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45 #这个是随机的延迟时间,表示最大45分钟
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22 #这个是开始时间
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
#第一个是Recurrence period
#第二个是延迟时间
所以cron.daily会在3:22+(5,45)这个时间段执行,/etc/cron.daily是个文件夹
通过默认/etc/anacrontab文件配置,会发现logrotate自动切割日志文件的默认时间是凌晨3点多
logrotate可以在任何时候从命令行手动调用。要调用为/etc/lograte.d/下配置的所有日志调用logrotate:
# logrotate /etc/logrotate.conf
2、编辑配置文件vim /etc/logrotate.d/nginx:(可以参照/etc/logrotate.d目录下的其他文件进行编写)
#/usr/local/nginx/logs/*.log {#这是多个日志进行分隔
/usr/local/nginx/logs/access.log {#这表示单个日志进行分隔
daily
missingok
rotate 7
dateext
dateformat -%Y-%m-%d-%s
compress
delaycompress
notifempty
create 640 root root
sharedscripts
postrotate
[ -f /usr/local/nginx/logs/nginx.pid ] && kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`
endscript
}
----------------------------------------每项详解-----------------------------------------------------------------------
/var/log/nginx/*.log { #/var/log/nginx/日志的存储目录,可以根据实际情况进行修改
daily ##日志文件将按天轮循
weekly ##日志文件将按周轮循
monthly ##日志文件将按月轮循
missingok ##在日志轮循期间,任何错误将被忽略,例如“文件无法找到”之类的错误
rotate 7 #一次存储7个日志文件。对于第8个日志文件,时间最久的那个日志文件将被删除
dateext #定义日志文件后缀是当前日期格式,也就是切割后文件是:xxx.log-2020-03-12-1584015799这样的格式。如果该参数被注释掉,切割出来是按数字递增,即前面说的 xxx.log-1这种格式
dateformat -%Y-%m-%d-%s 配合dateext使用,紧跟在下一行出现,定义文件切割后的文件名,必须配合dateext使用,只支持 %Y %m %d %s 这四个参数
# compress ##在轮循任务完成后,已轮循的归档将使用gzip进行压缩
delaycompress ##总是与compress选项一起用,delaycompress选项指示logrotate不要将最近的归档压缩,压缩将在下一次轮循周期进行。这在你或任何软件仍然需要读取最新归档时很有用
notifempty ##如果是空文件的话,不进行转储
create 640 root root ##以指定的权限创建全新的日志文件,同时logrotate也会重命名原始日志文件
sharedscripts ##表示postrotate脚本在压缩了日志之后只执行一次
postrotate
[ -f /var/run/nginx.pid ] && kill -USR1 `cat /var/run/nginx.pid`
endscript
}
## postrotate/endscript:在所有其它指令完成后,postrotate和endscript里面指定的命令将被执行。在这种情况下,rsyslogd进程将立即再次读取其配置并继续运行。注意:这两个关键字必须单独成行
size(或minsize) log-size ##当日志文件到达指定的大小时才转储,log-size能指定bytes(缺省)及KB (sizek)或MB(sizem).
当日志文件 >= log-size 的时候就转储。 以下为合法格式:(其他格式的单位大小写没有试过)
size = 5 或 size 5 (>= 5 个字节就转储)
size = 100k 或 size 100k
size = 100M 或 size 100M
olddir directory ##转储后的日志文件放入指定的目录,必须和当前日志文件在同一个文件系统
noolddir ##转储后的日志文件和当前日志文件放在同一个目录下(默认这个参数,所有可以不用写)
3、设置什么时候切割日志:vim /etc/anacrontab
START_HOURS_RANGE=04-39 #表示04:39切割日志
4、logrotate -vf /etc/logrotate.d/nginx立即验证,执行这个命令就去查看日志目录下的变化情况。
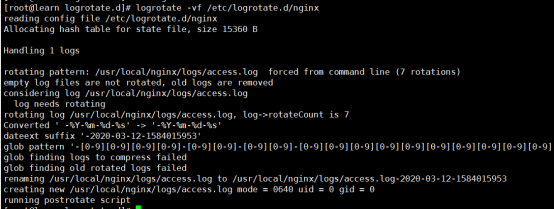
方法二:shell脚本
# cat segmentation.sh #写一个脚本
#!/bin/bash
#version:1.1
#系统日志文件的位置
LOGPATH=/usr/local/nginx/logs/error.log
#备份的路径
BASEPATH=/opt
#备份日志
bak=$BASEPATH/$(date -d "1 day ago" +"%Y-%m-%d").error.log
#echo $bak
#移动日志文件并改名
mv $LOGPATH $bak
touch $LOGPATH
kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`
# crontab -l #做成计划任务
30 05 * * * /bin/sh /opt/segmentation.sh
方法3:python脚本
实例1:对jumpserver日志进行切割
[root@test-vm01 mnt]# vim log_rotate.py
#!/usr/bin/env python
import datetime,os,sys,shutil
log_path = '/opt/jumpserver/logs/'
log_file = 'jumpserver.log'
yesterday = (datetime.datetime.now() - datetime.timedelta(days = 1))
try:
os.makedirs(log_path + yesterday.strftime('%Y') + os.sep + \
yesterday.strftime('%m'))
except OSError,e:
print
print e
sys.exit()
shutil.move(log_path + log_file,log_path \
+ yesterday.strftime('%Y') + os.sep \
+ yesterday.strftime('%m') + os.sep \
+ log_file + '_' + yesterday.strftime('%Y%m%d') + '.log')
os.popen("sudo /opt/jumpserver/service.sh restart")
手动执行这个脚本:
[root@test-vm01 mnt]# chmod 755 log_rotate.py
[root@test-vm01 mnt]# python log_rotate.py
查看日志切割后的效果:
[root@test-vm01 mnt]# ls /opt/jumpserver/logs/
2017 jumpserver.log
[root@test-vm01 mnt]# ls /opt/jumpserver/logs/2017/
09
[root@test-vm01 mnt]# ls /opt/jumpserver/logs/2017/09/
jumpserver.log_20170916.log
然后做每日的定时切割任务:
[root@test-vm01 mnt]# crontab -e
30 1 * * * /usr/bin/python /mnt/log_rotate.py > /dev/null 2>&1
实例2:对nginx日志进行切割
[root@test-vm01 mnt]# vim log_rotate.py
[root@learn logs]# cat log_rotate.py
#!/usr/bin/env python
import datetime,os,sys,shutil
log_path = '/usr/local/nginx/logs/'
log_file = 'access.log'
yesterday = (datetime.datetime.now() - datetime.timedelta(days = 1))
try:
os.makedirs(log_path + yesterday.strftime('%Y') + os.sep + \
yesterday.strftime('%m'))
except OSError,e:
print
print e
sys.exit()
shutil.move(log_path + log_file,log_path \
+ yesterday.strftime('%Y') + os.sep \
+ yesterday.strftime('%m') + os.sep \
+ log_file + '_' + yesterday.strftime('%Y%m%d') + '.log')
os.popen("sudo kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`")
连接超时
keepalive_timeout 65 #设置保持连接的超时时间,作用:
keepalive_timeout 0 #如果为0表示关闭这个功能
keepalive_timeout 65 180 #默认65s,最大180s
防盗链


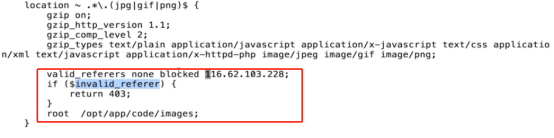
~* .*\.(jpg|gif|png)$:这段正则表达式表示匹配不区分大小写,以.jpg | .gif | .png结尾的文件valid_referers:设置信任的网站,可以正常使用图片none:浏览器中referer为空的情况下,就是直接在浏览器访问图片blocked:浏览器中referer不为空的情况,但是值被代理或防火墙删除了,这些值不以http://或https://开头。-
后面的网址或者域名:referer中包含相关字符串的网址。
-
if语句:如果连接的来源域名不在valid_referers所列出的列表中,
$invalid_referer为1,则执行后面的操作,即进行重写或返回403页面。 - 把重写的图片放在源主机的工作目录下。
还支持这种匹配的 写法:



location ~* .(gif|jpg|png|swf|flv)$ {
valid_referers none blocked *.gobgm.com www.gobgm.com;
if ($invalid_referer) {
rewrite ^/ http://www.gobgm.com/403.html;
#return 404;
}
}
CPU的亲和


3种方式:
worker_cpu_affinity 把每个CPU位置都写出来;
worker_cpu_affinity 写在哪些位置占用;
worker_cpu_affinity auto; #(建议用这个)
查看设置的内容:
[root@VM-16-16-centos ~ 08:59:39]# ps -eo pid,args,psr | grep [n]ginx
6177 nginx: master process /usr/ 0
8998 nginx: worker process 0
8999 nginx: worker process 1
代理服务(重点)
代理类型
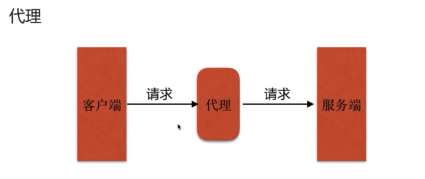
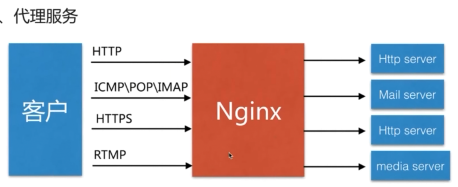
正向代理
概述
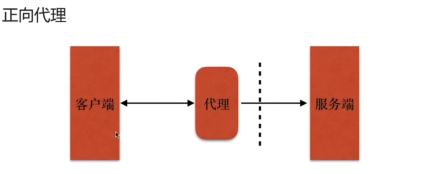
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。当你需要把你的服务器作为代理服务器的时候,可以用Nginx来实现正向代理,但是目前Nginx有一个问题,那么就是不支持HTTPS,虽然我百度到过配置HTTPS的正向代理,但是到最后发现还是代理不了,
代理(proxy)服务,通常也称正向代理服务,其中箭头的方向指向访问的方向。如果把局域网外Internet想象成一个巨大的资源,那么资源就分布在Internet的各个站点上,局域网的客户端要访问这个库里的资源必须统一通过代理服务器才能对各个站点进行访问。
局域网内的机器借助代理服务访问局域网外的网站,这主要是为了增强局域网内部网络的安全性,使得网外的威胁因素不容易影响到网内,这里代理服务器起到了一部分防火墙的功能。同时利用代理服务器也可以对局域网对外网的访问进行必要的监控和管理。正向代理服务器不支持外部对内部网络的访问请求
正向代理服务器的3个指令:
- resolver
该指令用于DNS服务器的ip地址。DNS服务器的主要工作是进行域名解析,将域名映射为对应的IP地址。语法结构如下:
resolver address …… [valia=time];
address表示dns服务器的IP地址。如果不指定端口号,默认使用53端口。支持设置多个ip地址
time设置数据包在网络中的有效时间。出现该指令的主要原因是,在访问站点时,有很多情况使得数据包在一定时间内不能被传递到目的地,但是又不能让数据包无期限的存在,于是就需要设定一段时间,当数据包在这段时间内没有到达目的地,就会被丢弃,然后发送者会接收到一个消息,并决定是否重发该数据包
- resolver_timeout
该指令用于设置DNS服务器域名解析超时时间,语法如下:
resolver_timeout time;
- proxy_pass
该指令用于设置代理服务器的协议和地址,语法如下:
proxy_pass URL;
其中URL即为设置的代理服务器协议和地址
注意
Nginx正向代理不支持https,因为https走的是443端口,是安全传输协议,服务器需要同客户端建立连接,才可以通讯,所以无法中转的,证书问题。
也可以源码编译时加载第三方模块,从而进行https正向代理
示例
1.1 环境介绍
系统环境:
-
VirtualBox Manager
-
Centos6.4
-
nginx1.10.0
IP对应的机器名:
IP 机器名 角色名
10.0.0.139 [elk] client
10.0.0.136 [lvs-master] nginx server
10.0.0.137 [kvm] web server 1
10.0.0.111 [lvs-backup] web server 2
一、正向代理
概念这里不在介绍,可以参考此文http://my.oschina.net/yoyoko/blog/147414。
1.2 配置介绍
Nginx server:(内网地址:10.0.0.136,外网地址:172.16.27.64)
使用VirtualBox Manager虚拟出双网卡。
[root@lvs-master conf.d]# ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:30:56:99
inet addr:10.0.0.136 Bcast:10.255.255.255 Mask:255.0.0.0
inet6 addr: fe80::a00:27ff:fe30:5699/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:891978 errors:0 dropped:0 overruns:0 frame:0
TX packets:9509 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:81841095 (78.0 MiB) TX bytes:13339058 (12.7 MiB)
eth1 Link encap:Ethernet HWaddr 08:00:27:55:4C:72
inet addr:172.16.27.64 Bcast:172.16.27.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe55:4c72/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:913671 errors:0 dropped:0 overruns:0 frame:0
TX packets:22712 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:109369858 (104.3 MiB) TX bytes:1903855 (1.8 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:36222 errors:0 dropped:0 overruns:0 frame:0
TX packets:36222 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:3899937 (3.7 MiB) TX bytes:3899937 (3.7 MiB)
[root@lvs-master conf.d]# cat zxproxy.conf
server {
listen 80; #监听的端口
server_name 10.0.0.136; #server的内网地址,与client需要网络互通
resolver 114.114.114.114 8.8.8.8; #DNS,这个是DNS,访问外网
resolver_timeout 5s;
access_log logs/access.log main;
location / {
proxy_pass http://$http_host$request_uri; #$http_host和$request_uri是nginx系统变量,不需要替换,保持原样
}
}
Nginx client:
只有一个内网网卡,通过访问Nginx server去访问internet,其实翻墙、肉鸡、之类的俗称就是这个原理。
[root@kvm ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:72:8C:3B
inet addr:10.0.0.137 Bcast:10.255.255.255 Mask:255.0.0.0
inet6 addr: fe80::a00:27ff:fe72:8c3b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1462448 errors:0 dropped:0 overruns:0 frame:0
TX packets:21130 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:145119904 (138.3 MiB) TX bytes:2814635 (2.6 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:60800 errors:0 dropped:0 overruns:0 frame:0
TX packets:60800 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:4831102 (4.6 MiB) TX bytes:4831102 (4.6 MiB)
测试
[root@kvm ~]# wget www.baidu.com
--2016-06-08 13:02:08-- http://www.baidu.com/
正在解析主机 www.baidu.com... 失败:域名解析暂时失败。 #无法访问百度
wget: 无法解析主机地址 “www.baidu.com”
[root@kvm ~]# export http_proxy=http://10.0.0.136:80 #设定环境变量,指定代理服务器的ip及端口
[root@kvm ~]# wget www.baidu.com #可以成功访问百度了
--2016-06-08 13:08:15-- http://www.baidu.com/
正在连接 10.0.0.136:80... 已连接。
已发出 Proxy 请求,正在等待回应... 200 OK
长度:未指定 [text/html]
正在保存至: “index.html.1”
[ <=> ] 99,762 --.-K/s in 0.07s
2016-06-08 13:08:16 (1.36 MB/s) - “index.html.1” 已保存 [99762]
resolver是配置正向代理的DNS服务器,listen 是正向代理的端口,配置好了就可以在ie上面或者其他代理插件上面使用服务器ip+端口号进行代理了。
反向代理
概述
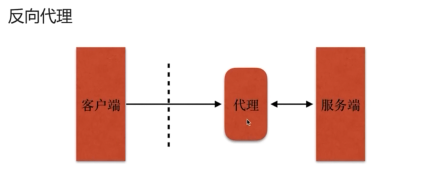
方向代理(Reverse Proxy)方式是指代理服务器来接收Internet上的连接请求,然后将请求转发给内部网路上的服务器,并将从服务器上的到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器
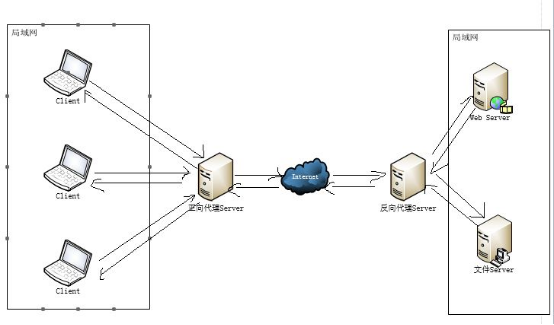
反向代理的基本设置的21个相关指令




#proxy_http_version 1.1;
#proxy_set_header Upgrade $http_upgrade;
#proxy_set_header Connection "upgrade";
其中:proxy_http_version、proxy_set_header Upgrade、proxy_set_header Connection部分为websocket部分配置。
proxy_pass指令

该指令用来设置被代理服务器的地址,可以是主机名称、IP地址加端口的形式,语法如下:
proxy_pass URL;
其中,URL为要设置的被代理服务器的地址,包含传输协议、主机名或者IP地址加端口、URL等。传输协议通常是http或者https。指令同时还接受以Unix开始的UNIX-domain套接字路径。如下:
proxy_pass http://www.test1.com/uri;
proxy_pass https://www.test2.com/uri;
proxy_pass http://unix:/tmp/backend.socket:/uri;
这个指令还可以结合upstream指令配置后端服务器组,从而实现反向代理的高可用,示例如下:
upstream backend {
server http://192.168.137.66;
}
server {
listen 80;
server_name test.com;
location / {
proxy_pass backend;
}
}
说明:proxy_pass指令在使用服务器组名称是应该注意的一个细节,在上例中组内的服务器中指明了传输协议http://而在proxy_pass指令中就不需要申明了,反之则需要带上协议。如果现在将upstream指令配置改为:
upstream backend {
server 192.168.137.66;
}
server {
listen 80;
server_name test.com;
location / {
proxy_pass http://backend;
}
}
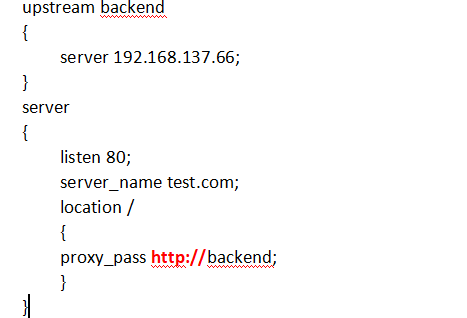
这时,我们就需要在proxy_pass指令中明确指明传输协议
在使用proxy_pass指令时,如果不想改变原地址中的URI,就不要在URL变量中配置URI
在nginx中配置proxy_pass反向代理时,当在后面的url加上了/,相当于是绝对根路径,则nginx不会把location中匹配的路径部分代理走;如果没有/,则会把匹配的路径部分也给代理走。
location /api/ { #注意,这里是/api/而不是/api,否则请求的时候路径是//login
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 后台接口地址
proxy_pass http://127.0.0.1:8080/; #路径后面带根'/'
proxy_redirect default;
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
}
如果用以上配置,访问/api/login的时候,会代理到http://127.0.0.1:8080/login
location /api/ {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 后台接口地址
proxy_pass http://127.0.0.1:8080; #路径后面不带根'/'
proxy_redirect default;
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
}
如果用以上配置,访问/api/login的时候,会代理到http://127.0.0.1:8080/api/login
proxy_redirect指令
必须放在中的proxy_pass指令之后
该指令用于修改被代理服务器返回的响应头中的location头域和refresh头域,与proxy_pass指令配置使用。比如:nginx服务器通过proxy_pass指令将客户端的请求地址重写为被代理服务器的地址,那么nginx服务器返回客户端的响应中location头域显示的地址就应该和客户端发起请求的地址相对应,而不是代理服务器直接返回的地址信息,否则就会出现问题。该指令解决了这个问题,可以把代理服务器返回的地址信息更改为需要的地址信息。语法如下:
1、proxy_redirect redirect replacement;
2、proxy_redirect default;
3、proxy_redirect off;
-
redirect表示匹配location头域值的字符串,支持变量的使用和正则表达式
-
replacement表示用于替换redirect变量内容的字符串,支持变量的使用
实例配置:
对于第1个结构,假设被代理服务器返回的响应头中location头域为:
location:http://localhost:8081/proxy/some/uri/
该指令设置为:
proxy_redirect http://localhost:8081/proxy http://mywed/frontend/;
nginx服务器会将localhost头域信息改为:
location:http://mywed/frontend/ /some/uri;
这样客户端收到的响应信息头部中location头域也被更改了
结构2使用default,代表使用location块的uri变量作为replacement,并使用proxy_pass变量作为redirect。请看下面两段配置,他们的配置效果是等同的:
###配置1
location /server/ {
proxy_pass http://proxyserver/source/;
proxy_redirect default;
}
###配置2
location /server/ {
proxy_pass http://proxyserver/source/;
proxy_redirect http://proxyserver/source/ /server/;
}
结构3 可以将当前作用域下所有的proxy_redirect指令配置全部设置为无效。
proxy_set_header指令
该指令可以更改nginx服务器接收到的客户端请求的请求头信息,然后将新的请求头发送给被代理的服务器。语法如下:
proxy_set_header field value;
-
field表示要更改的信息所在的头域
-
value表示要更改的值,支持使用文本、变量或者变量的组合
默认情况下,该指令的设置为:
proxy_set_header Host $proxy_host:$server_port;
proxy_set_header Connection close;
企业实例:
proxy_set_header Host $http_host;
将目前Host头域的值填充成客户端的地址
proxy_set_header Host $host;
将当前location块的server_name指令值填充到Host头域
proxy_set_header Host $host:$server_port; #这里是重点,这样配置才不会丢失端口

proxy_set_header Host $host:$proxy_port;
将当前location指令中的server_name指令值和listen指令值一起填充到Host头域
proxy_set_header Host $proxy_host;
当Host设置为$http_host时,则不改变请求头的值,所以当要aaa.example.com转发到bbb.example.com的时候,请求头还是aaa.example.com的Host信息,就会有问题
proxy_set_header X-Real-IP $remote_addr;
访问时,后端日志显示为客户端IP,而不是nginx代理服务器的ip地址
proxy_set_header X-Forwarded-For $remote_addr $proxy_add_x_forwarded_for;
后端的Web服务器可以通过X-Forwarded-For获取用户真实IP
注意:
如果当前级别的配置中已经定义了 proxy_set_header 指令,在上级中定义的 proxy_set_header 指令在当前级别都会失效
proxy_send_timeout指令
后端服务器回传时间,就是在规定时间内后端服务器必须传完所有数据
该指令配置nginx服务器向后端被代理服务器(组)发出write请求后,等待响应的超时时间,语法如下:
proxy_send_timeout time;
其中time为设置的超时时间,默认是60s
proxy_read_timeout指令
跟后端服务器连接超时时间,发起握手等候响应时间
该指令配置nginx服务器向后端被代理服务器(组)发出read请求后,等待响应的超时时间,语法如下:
proxy_read_timeout time;
其中time为设置的超时时间,默认是60s。我们可以设置为240s,或者300s。来应对上游服务器处理请求慢的问题
proxy_connect_timeout指令
该指令配置nginx服务器与后端被代理服务器尝试建立连接的超时时间,语法如下:
proxy_connect_timeout time;
其中time为设置的超时时间,默认是60s
proxy_intercept_errors指令
该指令用于设置一个状态是开启还是关闭。在开启该状态时,如果被代理的服务器返回的HTTP状态代码为大于等于400,则nginx服务器使用自己定义的错误页面(使用error_page指令);如果是关闭该状态,nginx服务器直接将被代理服务器返回的HTTP状态返回给客户端。语法如下:
proxy_intercept_errors on|off;
proxy_headers_hash_max_size指令
该指令用于配置存放http报文头的哈希表的内容,语法如下:
proxy_headers_hash_max_size size;
其中size为HTTP报文头哈希表的容量上限,默认为512个字符,即:
proxy_headers_hash_max_size 512;
nginx服务器为了能够快速检索HTTP报文头中的各项信息,比如服务器名称,MIME类型、请求头名称等,使用哈希表存储这些信息。nginx服务器在申请存放HTTP报文头的空间时,通常以固定大小为单位申请,该大小由proxy_headers_hash_bucket_size指令配置。
在nginx配置中,不仅能够配置整个哈希表的大小上限,对大部分的内容项也可以配置其大小上限,比如server_names_hash_max_size指令server_names_hash_bucket_size指令用来设置服务器名称的字符数长度
proxy_headers_hash_bucket_size
该指令用于设置nginx服务器申请存放http报文头的哈希表容量的单位大小。该指令的具体作用在上面proxy_headers_hash_max_size指令的使用中已经说明了。语法如下:
proxy_headers_hash_bucket_size size;
其中,size为设置的容量,默认为64个字符
proxy_next_upstream指令
参考:https://www.cnblogs.com/kevingrace/p/6685698.html
正常情况下,nginx做反向代理,如果后端节点服务器宕掉的话,nginx默认是不能把这台realserver踢出upstream负载集群的,所以还会有请求转发到后端的这台realserver上面,这样势必造成网站访问故障。虽然nginx可以在localtion中启用proxy_next_upstream来解决返回给用户的错误页面
使用nginx的一个功能,就是当后端的服务器返回给nginx502、504、404、执行超时等错误状态的时候,nginx会自动再把这个请求转发到upstream里面别的服务器上面,从而给网站用户提供更稳定的服务。
在配置nginx服务器反向代理功能时,如果使用upstream指令配置了一组服务器作为被代理服务器,服务器组中服务器的访问规则遵循upstream指令配置的轮询规则,同时可以使用该指令配置在发生哪些异常情况时,将请求顺序交由下一个组内服务器处理(健康检测的作用)。语法如下:
proxy_next_upstream status ......;
其中status为设置的服务器返回状态,可以是一个或者多个。这些状态包括:
-
error表示在建立连接、向被代理的服务器发送请求或者读取响应头时服务器发生连接错误。
-
timeout表示在建立连接、向被代理的服务器发送请求或者读取响应头时服务器发送连接超时。
-
invalid_header表示被代理的服务器返回的响应头为空或者无效
-
http_500|http_502|http_503|http_504|http_404表示被代理服务器返回500、502、503、504、或者404状态码
-
invalid_header 后端服务器返回空响应或者非法响应头
-
off 停止将请求发送给下一台后端服务器(因为nginx会直接请求后端,如果后端报错,就不会继续把请求发送给下一个后端的实例。这样就会导致服务不正常。但是某些程序可能不需要再进行请求下一个后端实例。如果后端没有启动,你开启了这个off参数,那么用户访问就会出现错误。这个参数需要看需求慎用)
需要理解一点的是,只有在没有向客户端发送任何数据以前,将请求转给下一台后端服务器才是可行的。也就是说,如果在传输响应到客户端时出现错误或者超时,这类错误是不可能恢复的。
# 示例:
# proxy_next_upstream off;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504 http_404;
但这个还是会把请求转发给这台服务器的,然后再转发给别的服务器,这样以来就浪费了一次转发,对于网站性能来说也不是最佳理想的方案。为了避免上面说顾虑的情况,可以对nginx后方realserver的健康状态进行检查,如果发现后端服务器不可用,则请求不转发到这台服务器。
目前主要有二种方式可以实现对nginx负载均衡的后端节点服务器进行健康检查: 1)ngx_http_proxy_module模块和ngx_http_upstream_module模块(这是nginx自带模块) 参考地址:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_next_upstream
2)nginx_upstream_check_module模块(淘宝技术团队开发) 参考地址:https://github.com/yaoweibin/nginx_upstream_check_module
说明:
这里说下曾经碰到过的一个反常情况:
按照上面第一种nginx upstream的健康检查配置后,发现将upstream中的后端两台机器中的一台关闭,访问请求还是会打到这台关闭的后端机器上
查看方法:
直接浏览器里访问,发现访问结果一会儿好,一会儿坏,这是因为请求不仅打到了后端好的机器上,也打到了关闭的机器上了;
原因分析:
这是因为后端两台机器+端口的访问结果被包含在了 proxy_next_upstream中定义的状态码。
解决办法:
将
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504 http_404;
改成
proxy_next_upstream error timeout invalid_header http_502 http_503 http_504;
重启nginx服务后,在浏览器里输入域名访问,发现访问结果是正常的了!
该域名的访问请求都打到了后端好着的那台服务器上了,那台关闭的服务器已经从upstream负载中踢出去了。这个通过查看对应域名的access.log日志能发现:
访问请求会同时到达后端两台机器上,只不过请求到达关闭的那台机器上时就会通过健康检查发现它是坏的,就会将它自动提出,这样在浏览器里的访问结果显示的就只是正常的那台后端机器处理后的结果了。
查看error.log错误日志,发现里面的信息都是:访问请求upstream到后端关闭的机器上时,全是"connect() failed (111: Connection refused)",这是正常的,因为upstream配置里每个几秒就会去健康后端机器,当连接失败时,错误信息就输出到error.log日志里。
注意:
与被代理的服务器进行数据传输的过程中发送错误的请求,不包含在该指令支持的状态之内。
因为proxy_next_upstream 默认值: proxy_next_upstream error timeout;
场景:当访问A时,A返回error timeout时,访问会继续分配到下一台服务器处理,就等于一个请求分发到多台服务器,就可能出现多次处理的情况,如果涉及到充值,就有可能充值多次的情况,这种情况下就要把proxy_next_upstream关掉
proxy_next_upstream off;
最后,如果还想要更好的完善后端的检测机制,需要通过第三方模块来做了,ngx_http_upstream_check_module
proxy_ssl_session_reuse
该指令用于设置是否使用基于ssl安全协议的会话连接(即使用https://)被代理的服务器,语法如下:
proxy_ssl_session_reuse on|off;
默认设置为开启(on)状态。如果我们在错误日志中发现"SSL3_GET_FINISHED:digest check failed"的情况下,可以将该指令配置为关闭(off)状态
proxy_pass_header指令
默认情况下,nginx服务器在发送响应报文时,报文头中不包含"Date"、"Server"、"X-Accel"等来自被代理服务器的头域信息。该指令可以设置头域信息已被发送,语法结构如下:
proxy_pass_header field;
其中,field为需要发送的头域。该指令可以在http块、server块、或者location中进行配置
实例:
proxy_pass_header Server;
proxy_hide_header指令
该指令用于设置nginx服务器在发送HTTP响应时,隐藏一些头域信息。语法如下:
proxy_hide_header field;
其中,field为需要隐藏的头域。该指令可以在http块,server块或者location中进行配置
proxy_pass_request_body指令
该指令用于配置是否将客户端请求的请求体发送给代理服务器,语法如下:
proxy_pass_request_body on|off;
默认设置为on,开启、关闭可以在http块、server块、location进行配置
proxy_set_body指令
该指令可以更改nginx服务器接收到的客户端请求的请求体信息,然后将新的请求体发送给被代理的服务器。语法如下:
proxy_set_body value;
其中,value为更改的信息,支持使用文本、变量或者变量的组合
proxy_bind指令
官方文档中对该指令的解释是,强制将与代理主机的连接绑定到指定的IP地址。通俗来讲就是,在配置了多个基于名称或者基于IP的主机的情况下,如果我们希望代理连接由指定的主机处理,就可以使用该指令进行配置,语法如下:
proxy_bind address;
其中address为指定主机的IP地址
proxy_http_version指令
该指令用于设置nginx服务器提供代理服务器的HTTP协议版本,语法如下:
proxy_http_version 1.0|1.1;
默认是1.0版本。1.1版本支持upstream服务器组设置中的keepalive指令
proxy_method指令
该指令用于设置nginx服务器请求被代理服务器时使用的请求方法,一般为post或者get。设置了该指令,客户端请求方法将被忽略。语法如下:
proxy_method method;
其中method的值可以设置为post或者ge,注意不加引号
proxy_ignore_client_abort指令
该指令用于设置在客户端终端网络请求时,nginx服务器是否中断对被代理服务器的请求,语法如下:
proxy_ignore_client_abort on|off;
默认设置off,当客户端中断网络请求时,nginx服务器中断对被代理服务器的请求
proxy_ignore_headers指令
该指令用于设置一些http响应头中的头域,nginx服务器接收到被代理服务器的响应数据后,不会处理被设置的头域。语法如下:
proxy_ignore_headers field ......;
其中field为要设置的HTTP响应的头域,例如:"X-Accel-Redirect"、"X-Accel-Expires"、"Expires"、"Cache-Control"或"Set-Cookie"等
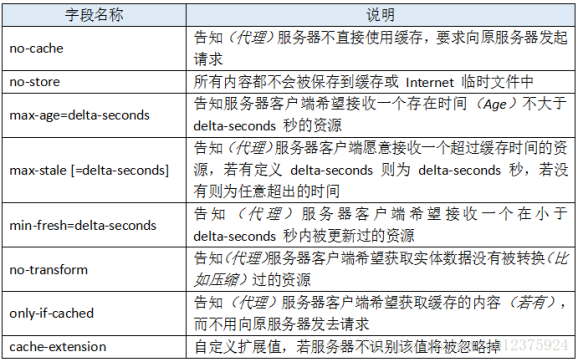
proxy buffer的配置的7个指令
proxy buffer的原理:
proxy buffer相关的指令proxy_buffer_size、proxy_buffers、proxy_busy_buffers_size等,它们的配置都是针对每一个请求起作用的,而不是全局概念,即每个请求都会按照这些指令的配置来配置各自的buffer,nginx服务器不会生成一个公共的proxy buffer供代理请求使用
proxy buffer启用以后,nginx服务器会异步的将被代理服务器的响应数据传递给客户端
nginx服务器首先尽可能地从被代理服务器哪里接收响应数据,放置在proxy buffer中,buffer的大小由proxy_buffer_size指令和proxy_buffers指令决定。如果在接收过程中,发现buffer没有足够大小来接收一次响应的数据,nginx服务器会将部分接收到的数据临时存放在磁盘的临时文件中,磁盘上的临时文件路径可以通过proxy_temp_path指令进行设置,临时文件的大小由proxy_max_temp_file_size指令和proxy_max_temp_write_size指令决定。一次响应数据被接收完成或者buffer已经装满后,nginx服务器开始向客户端传输数据。
每个proxy buffer装满数据后,在从开始向客户端发送一直到proxy buffer中的数据全部传输给客户端的整个过程中,它都处于busy状态,期间对它进行的其他操作都会失败。同时处于busy状态的proxy buffer总大小由proxy_busy_buffers_size指令限制不能超过该指令设置的大小。
当proxy buffer关闭时,nginx服务器只要接收到响应数据就会同步地传递客户端,它本身不会读取完整的响应数据
proxy_buffering指令
该指令用于配置是否启用或者关闭proxy buffer,语法如下:
proxy_buffering on|off;
默认设置为开启状态
开启和关闭proxy buffer还可以通过在http响应同步的"X-Accel-Buffering"头域设置"yes"或者"no"来实现,但nginx配置中proxy_ignore_headers指令的设置可能导致该头域设置失效
proxy_buffers指令
告诉nginx保存单个用几个buffer最大用多少空间
该指令用于配置接收一次被代理服务器响应数据的proxy buffer个数和每个buffer的大小,语法如下:
proxy_buffers number size;
-
number表示proxy buffer的个数
-
size表示每个buffer的大小,一般设置为内存页的大小。根据平台的不同,可能为4kb或者8kb
由这个指令可以得到接收一次被代理服务器响应数据的proxy buffer总大小为number * size。该指令的默认设置为:
proxy_buffers 8 4k|8k;
proxy_buffer_size指令
代理请求缓冲区,会保存用户的头信息以供nginx进行处理
该指令用于配置从被代理服务器获取的第一部分响应数据的大小,该数据中一般包含了http响应头,nginx服务器通过它来获取响应数据被代理服务器的一些必要信息。语法结构如下:
proxy_buffer_size size;
其中,size为设置的缓存大小,默认设置为4kb或者8kb,保持与proxy_buffers指令中的size变量相同,当然也可以设置得更小。
注意:该指令不要和proxy_buffers指令混淆
proxy_busy_buffers_size指令
如果系统很忙时候可以申请最大的proxy_buffers
该指令用于限制同时处于BUSY状态的proxy buffer的总大小,通过上面对proxy buffer机制的阐述,相信大家很容易理解该指令的功能。语法如下:
proxy_busy_buffers_size size;
其中,size为设置的处于busy状态的缓存区总大小。默认设置为8kb或者16kb
proxy_temp_path指令
该指令用于配置磁盘上的一个文件路径,该文件用于临时存放代理服务器的大体积响应数据。如果proxy buffer被装满后,响应数据仍然没有被nginx服务器完全接收,响应数据就会被临时存放在该文件。语法如下:
proxy_temp_path path [level1 [level2 [level3]]];
-
path表示设置磁盘上存放临时文件的路径
-
level表示设置在path变量设置的路径下第几级hash目录存放临时文件
示例:
proxy_temp_path /usr/local/nginx/proxy_temp 1 2;
在该例子中,配置临时文件存放在/usr/local/nginx/proxy_temp路径下的第二级目录中。基于该配置的一个临时文件的路径可以是:/usr/local/nginx/proxy_temp/1/10/00000100101
proxy_max_temp_file_size指令
该指令用于配置所有临时文件的总体积大小,存放在磁盘上的临时文件大小不能超过该配置值,这避免了响应数据过大造成磁盘空间不足的问题,语法如下:
proxy_max_temp_file_size size;
其中size为设置的临时文件总体积上限值,默认设置为1024M
proxy_temp_file_write_size
该指令用于配置同时写入临时文件的数据量的总大小,合理的设置可以避免磁盘IO负载过重导致系统性能下降的问题,语法如下:
proxy_temp_file_write_size size;
其中,size为设置的数据量总大小上限值,默认设置根据平台的不同,可以为8KB或者16KB,一般与平台内存页相同
proxy Cache的配置的12个指令
proxy cache机制与缓存数据的产生和使用有很大关系。proxy cache机制实际上是nginx服务器提供的web缓存机制的一部分。
buffer和cache虽然都是用于提供IO吞吐率的,但是它们是一对不同的概念,翻译成中文分别是缓冲和缓存两个词。
-
buffer,主要用于传输效率不同步或者优先级不同的设备之间传输数据,一般通过对一方数据进行临时存放,在统一发送的方式传递给另一方,以降低进程之间的等待时间,保证速度较快的进程不发生间断,临时存放的数据一旦传送给另一方,这些数据本身也就没有用处了
-
cache,主要用于将硬盘上已有的数据在内存中建立缓存数据,提高数据的访问效率,对于过期不用的缓存可以随时销毁,但不会销毁硬盘上的数据。
在nginx服务器中,proxy buffer和proxy cache都与代理服务器相关,主要用于提供客户端与被代理服务器之间的交互率。proxy buffer实现了被代理服务器响应数据的异步传输,proxy cache则主要实现nginx服务器对客户端数据请求的快速响应。nginx服务器在接收到被代理服务器的响应数据之后,一方面通过proxy buffer机制将数据传递给客户端,另一方面根据proxy cache的配置将这些数据缓存到本地硬盘上。当客户端下次要访问相同的数据时,nginx服务器直接从硬盘检索到相应的数据返回给用户,从而减少与被代理服务器之间的时间
特别需要说明的是:proxy cache机制依赖于proxy buffer机制,只有在proxy buffer机制开启的情况下proxy cache的配置才发挥作用
在nginx服务器中还提供了另一种将被代理服务器数据缓存到本地的方法proxy Store,与proxy Cache的区别是,它对来自被代理服务器的响应数据,尤其是静态数据只进行简单的缓存,不支持缓存过期更新,内存索引建立等功能,但支持设置用户或用户组对缓存数据的访问权限
proxy_cache
该指令用于配置一块公用的内存区域的名称,该区域可以存放缓存的索引数据。这些数据在nginx服务器启动时由缓存索引重建进程负责建立,在nginx服务器的整个运行过程中由缓存管理进程负责定时检查过期数据,索引等管理工作。语法如下:
proxy_cache zone | off;
-
zone表示设置的用于存放缓存索引的内存区域的名称。对应 http 段的 key_zon值
-
off表示关闭proxy_cache功能,是默认的设置
从nginx0.7.66开始,proxy cache机制开启后会检查被代理服务器响应数据HTTP头中的"Cache-Control"头域,"Expires"头域。当"Cache-Control"头域中的值为"no-cache"、"no-store"、"private"或者"max-age"赋值为0或无意义时,当"Expires"头域包含一个过期的时间时,该响应数据不被nginx服务器缓存。这样做的主要目的是为了避免私有的数据被其他客户端得到。
proxy_cache_valid
该指令可以针对不同的http响应状态设置不同的缓存时间,语法如下:
proxy_cache_valid [code......] time;
-
code设置http响应的状态代码。该指令可选,如果不设置,nginx服务器只为http状态代码为200、301、302的响应数据做缓存。可以使用"any"表示缓存所有该指令中未设置的其他响应数据
-
time设置缓存时间
实例:
proxy_cache_valid 200 302 10m;
proxy_cache_valid 200 301 1h;
proxy_cache_valid any 1m;
该例子中,对返回状态为200和302的响应数据缓存10分钟,对返回状态为301的响应数据缓存1小时,对返回非200、301、302的响应数据缓存1分钟
proxy_cache_bypass指令
该指令用于配置nginx服务器向客户端发送响应数据时,不从缓存中获取的条件。这些条件支持使用nginx配置的常用变量。语法如下:
proxy_cache_bypass string......;
其中,string为条件变量,支持设置多个,当至少有一个字符串指令不为空或者不等于0时,响应数据不从缓存中获取
配置实例:
proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment $http_pragma $http_authorization;
其中,$cookie_nocache $arg_nocache $arg_comment $http_pragma $http_authorization都是nginx配置文件的变量
proxy_cache_key指令
该指令用于设置nginx服务器在内存中为缓存数据建立索引时使用的关键字,语法如下:
proxy_cache_key string;
其中,string为设置的关键字,支持变量
如果我们希望缓存数据包含服务器主机名等关键字,则可以将该指令设置为:
proxy_cache_key $scheme $host $request_uri;
在nginx0.7.48之后的版本中,通常使用以下配置:
proxy_cache_key $scheme$proxy_host$uri$is_args$args;
proxy_cache_lock
该指令用于设置开启缓存的锁功能。在缓存中,某些数据项可以同时被多个请求返回的响应数据填充。开启功能后,nginx服务器同时只能有一个请求填充缓存中的某一数据项,这相当于给该数据项上锁,不允许其他请求操作。其他的请求如果也想填充该项,必须等待该数据项的锁被释放。这个等待时间由proxy_cache_lock_timeout指令配置。该指令语法如下:
proxy_cache_lock on|off;
该指令在nginx1.1.2及之后的版本中可以使用,默认是关闭状态
如果有大量请求进来,且没有找到对应的缓存,则只允许第一个请求去访问后端集群,然后生成缓存之后,再返回缓存给其他请求proxy_cache_lock on;
当资源被客户端请求了多少次之后才开始缓存,这有助于节省缓存空间,只缓存一些访问较为频繁的资源
proxy_cache_min_uses 1;
向客户端返回一个是否击中缓存的头信息
add_header Nginx-Cache "$upstream_cache_status";
proxy_cache_lock_timeout
该指令用于设置缓存的锁功能开启以后锁的超时时间。语法如下:
proxy_cache_lock_timeout time;
其中,time为设置的时间,默认5s
proxy_cache_min_uses
该指令用于设置客户端请求发送的次数,当客户端向被代理服务器发送相同请求到达该指令设定的次数后,nginx服务器才对该请求的响应数据做缓存。合理设置该值可以有效地较低硬盘上缓存数据的数据,并提高缓存的命中率。语法如下:
proxy_cache_min_uses number;
其中,number为设置的次数。默认是1
proxy_cache_path指令
注意:该指令只能放在http块中
该指令用于设置nginx服务器存储数据的路径以及和缓存索引相关相关的内容,语法如下 :
proxy_cache_path path [levels=levels] keys_zone=name:size [inactive=time] [max_size=size] [loader_files=number] [loader_sleep=time] [loader_threshold=time]
-
path设置缓存数据存放的根路径;该路径应该是预先存在磁盘上的
-
levels设置在相对与path指定目录的第几级hash目录中缓存数据。如:levels=1表示一级hash目录;levels=1:2,表示有两级子目录,第一个目录名取md5值的倒数第一个值,第二个目录名取md5值的第2和3个值。所有目录的名称是基于请求URL通过hash算法获取到的
-
keys_zone设置内存zone的名字和大小,如keys_zone=my_zone:10m
-
inactive设置缓存多长时间就失效,当硬盘上的缓存数据在该时间段内没有被访问过,就会失效了,该数据就会被删除,默认为10s。如果源站更新频率不怎么低,就需要根据你的需求减少这些值
-
max_size 设置硬盘中缓存数据的大小限制,我们指定,硬盘中的缓存源数据有nginx服务器的缓存管理进程进行管理,当缓存的大小到达该数值时,缓存管理进程将根据最近最少被访问的策略删除缓存
-
loader_files设置缓存索引重建进程每次加载的数据元素的数量上限。在重建缓存索引的过程中,进程通过一系列的递归遍历读取硬盘上的缓存数据目录及缓存数据文件,对每个数据文件中的缓存数据在内存中建立对应的索引,我们陈每建立一个索引为加载一个数据元素。进程正在每次遍历过程中可以同时加载多个数据元素,该值限制了每次遍历中同时加载的数据元素的数量。默认值为100
-
loader_sleep设置缓存索引重建进程在一次遍历结束、下次遍历开始之间的暂停时长。默认值为50ms
-
loader_threshold设置遍历一次磁盘存源数据的时间上限。默认设置为200ms
该指令设置比较复杂,一般需要设置前面三个指令的情形比较多,后面的几个变量与nginx服务器缓存索引重建进程及管理进程的性能相关,一般保持默认设置救你可以了。配置实例:
proxy_cache_path /usr/local/nginx/cache/a levels=1:1 keys_zone=zone_a:10m inactive=300s max_size=5g;
proxy_cache_path /usr/local/nginx/cache/b levels=1:2 keys_zone=zone_b:100m inactive=300s max_size=5g;
proxy_cache_path /usr/local/nginx/cache/c levels=1:1:2 keys_zone=zone_c:100m inactive=300s max_size=5g;
proxy_cache_use_stale
如果nginx在访问被代理服务器过程中出现被代理的服务器无法访问或者访问错误等现象时,nginx服务器可以使用历史缓存响应客户端的请求,这些数据不一定和被代理服务器上最新的数据一致,但对于更新频率不高的后端服务器来说,nginx服务器的该功能在一定程度上能够为客户端提供不间断的访问。该指令用来设置一些状态,当后端被代理的服务器处于这些状态时,nginx服务器启用该功能。语法如下:
proxy_cache_use_stale error |timeout|invalid_header|updating|http_500|http_502|http_503|http_504|http_404|off;
该指令可以支持的状态如语法结构所示。需要注意其中的updating状态的含义。该状态并不是指被代理服务器在updating状态,而是指客户端请求的数据在nginx服务器中正好处于更新状态。
该指令默认是off
proxy_no_cache
该指令用于配置在什么情况下不使用cache功能,语法如下:
proxy_no_cache string……;
其实string可以是一个或者多个变量。当string的值不为空或者不为0时,不启用cache功能
作用:不缓存url
该参数和proxy_cache_bypass类似,用来设定什么情况下不缓存
示例:
proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;
表示,如果$cookie_nocache $arg_nocache $arg_comment的值只要有一项不为0或者不为空时,不缓存数据
这若干个变量中只要有一个值不为 0,就不会触发缓存
proxy_store
官网: https://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_store
该指令配置是否在本地磁盘缓存来自被代理服务器的响应数据。这是nginx服务器提供的另一种缓存数据的方法,但是该功能相对proxy cache简单一些,它不提供缓存过期更新、内存索引建议等功能,不占用内存空间,对静态数据的效果比较好,如果如下:
proxy_store on|off|string;
-
on|off设置是否开启proxy store功能。如果使用变量on功能开启,那么缓存文件会存放到alias指令或root指令设置的本地路径下。默认设置off
-
string自定义缓存文件的存放路径。如果使用变量string,proxy store功能开启,缓存文件会存放到指定的本地路径下
实例:
proxy_store /data/www$original_uri;
proxy store方法多使用在被代理服务器端发送错误的情况下,用来缓存被代理服务器的响应数据
proxy_store_access
该指令用于设置用户或者用户组对proxy store 缓存的数据的访问权限,语法如下:
proxy_store_access users:permissions ……;
-
users可以设置为user、group、all
-
permissions设置权限
location /images/ {
root /data/www;
error_page 404 = /fetch$uri; #定义了错误页面
}
location /fetch/ { #匹配404错误时的请求
internal;
proxy_pass http://backend/;
proxy_store on; #开启proxy store 方法
proxy_store_access user:rw group:rw all:r;
proxy_temp_path /data/temp;
alias /data/www/; #缓存数据的路径
}
#or like this:
location /images/ {
root /data/www;
error_page 404 = @fetch;
}
location @fetch {
internal;
proxy_pass http://backend;
proxy_store on;
proxy_store_access user:rw group:rw all:r;
proxy_temp_path /data/temp;
root /data/www;
}
nginx 反向代理时丢失端口的解决方案
https://www.cnblogs.com/mica/p/10849871.html
https://blog.csdn.net/duilan3356/article/details/81362059
https://blog.csdn.net/weixin_30325071/article/details/94932051
配置nginx反向代理时遇到一个问题,当设置nginx监听80端口时转发请求没有问题。但一旦设置为监听其他端口,就一直跳转不正常;如,访问欢迎页面时应该是重定向到登录页面,在这个重定向的过程中端口丢失了
这里给出三个简短的解决方案,修改nginx的配置文件。
1、 proxy_set_header Host $host:$server_port; (跟版本有关系,我的失效)
2、 proxy_set_header Host $http_host;(跟版本有关系,我的失效)
3、 proxy_set_header Host $host:8080;(直接强制注入端口号,亲测有效)
nginx 浏览器的缓存问题(不缓存add_header Cache-Control )
https://www.cnblogs.com/tugenhua0707/p/10841267.html
https://www.cnblogs.com/daheiylx/p/12705090.html
location @client {
#expires -1;
#现在改为,不缓存
add_header Cache-Control "no-store, no-cache, must-revalidate, proxy-revalidate";
#add_header Cache-Control "no-cache no-store max-age=no-cache";
add_header Pragma "no-cache";
add_header Expires 0;
proxy_pass http://client;
proxy_ignore_headers X-Accel-Expires Expires Cache-Control Set-Cookie;
proxy_cache off;
}
配置后浏览器都会去服务器上拉去最新的,访问时间会变慢(自己都能发现)
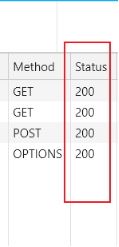 除非报错,状态都会200
除非报错,状态都会200
通过查看nginx日志也会发现,每一个请求是到了nginx这里的
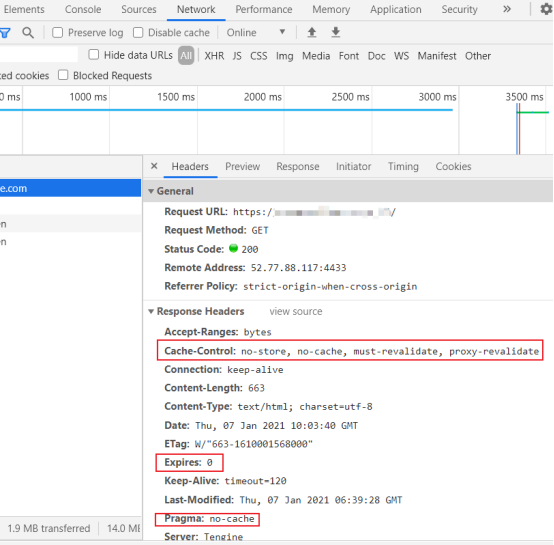
no-cache
设置了缓存,页面大多数会看到:
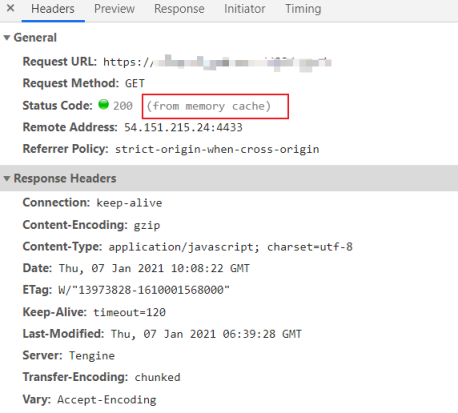
实例
1.安装httpd服务作为后端服务器:
#10.0.0.137服务器
[root@kvm ~]# yum install httpd
[root@kvm ~]# echo "<html>10.0.0.137</html>" > /var/www/html/index.html
#10.0.0.111服务器
[root@lvs-backup ~]# yum install httpd
[root@lvs-backup~]# echo "<html>10.0.0.111</html>" > /var/www/html/index.html
2.访问后端服务器,确定是否正常提供服务:
[root@lvs-backup html]# curl 10.0.0.111
<html>
10.0.0.111
</html>
[root@lvs-backup html]# curl 10.0.0.137
<html>
10.0.0.137
</html>
都成功了,我们进行下一步。
3.配置nginx反向代理服务器
#nginx-server 10.0.0.136
[root@lvs-master conf.d]# ls #nginx目录下的配置文件
zxproxy.conf
[root@lvs-master conf.d]# cp zxproxy.conf fxproxy.conf #复制一份,之前是正向代理,现在是反向代理
[root@lvs-master conf.d]# mv zxproxy.conf zxproxy.conf.bak
[root@lvs-master conf.d]# cat fxproxy.conf
server {
listen 80;
server_name 10.0.0.136; #根据环境介绍,nginx server ip
location / {
proxy_pass http://10.0.0.137; #被代理的服务器ip
}
}
[root@lvs-master conf.d]# service nginx restart #重启加载配置
4.验证
#看下结果:先登录到实验环境中的clinet机上,ip如下:
[root@elk ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:3D:40:40
inet addr:10.0.0.139 Bcast:10.255.255.255 Mask:255.0.0.0
inet6 addr: fe80::a00:27ff:fe3d:4040/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:2618345 errors:0 dropped:0 overruns:0 frame:0
TX packets:247926 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:336182790 (320.6 MiB) TX bytes:35145157 (33.5 MiB)
[root@elk ~]# curl 10.0.0.136 #访问反向代理服务器,我们看到访问代理服务器,结果被转发到了10.0.0.137上
<html>
10.0.0.137
</html>
#接下来我们分别看下nginx-server和10.0.0.137的日志:
nginx-server:
[root@lvs-master ~]# tail /var/log/nginx/access.log
10.0.0.139- - [08/Jun/2016:15:35:43 +0800] "GET / HTTP/1.1" 200 26 "-" "curl/7.19.7
(x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-"
10.0.0.137:
[root@kvm httpd]# tail /var/log/httpd/access_log
10.0.0.136 - - [08/Jun/2016:15:21:12 +0800] "GET / HTTP/1.0" 200 26 "-" "curl/7.19.7
(x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
##我们看到nginx-server上的nginx的日志,显示访问的用户是10.0.0.139也就是我们环境的clinet,
#而10.0.0.137上显示的ip是10.0.0.136,也就是nginx-server。
#说白了反向代理,对客户来说nginx-server就是真正的服务器,实际上,当用户访问nginx-server的时候,会将请求转发到10.0.0.137上,然后10.0.0.137将请求的结果发给nginx-server,然后由nginx-server将请求的结果转交给用户。
#在10.0.0.137上看到的都是nginx-server的ip,能不能也看到真实用户的ip呢?
[root@lvs-master conf.d]# cat fxproxy.conf
server {
listen 80;
server_name 10.0.0.136; #根据环境介绍,nginx server ip
location / {
proxy_pass http://10.0.0.137; #被代理的服务器ip
proxy_set_header X-Real-IP $remote_addr; #多了这行
}
}
[root@lvs-master conf.d]# service nginx restart
[root@kvm ~]# tail /var/log/httpd/access_log
10.0.0.136 - - [08/Jun/2016:16:10:53 +0800] "GET / HTTP/1.0" 200 26 "-" "curl/7.19.7
(x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
#改了之后还是显示的是代理服务器的ip,我们去10.0.0.137上修改下配置
[root@kvm ~]# vim /etc/httpd/conf/httpd.conf
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
LogFormat "%h %l %u %t \"%r\" %>s %b" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
#修改为:(%h指的的访问的主机,现在改为访问的真实主机ip)
LogFormat "%{X-Real-IP}i</span> %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
LogFormat "%h %l %u %t \"%r\" %>s %b" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent</span>
[root@kvm ~]# service httpd restart
停止 httpd: [确定]
正在启动 httpd: [确定]
[root@kvm ~]# tail /var/log/httpd/access_log #已经变成了真实的访问地址
10.0.0.139 - - [08/Jun/2016:16:10:53 +0800] "GET / HTTP/1.0" 200 26 "-" "curl/7.19.7
(x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
<span style="color:#FF0000;">10.0.0.139</span> - - [08/Jun/2016:16:16:01 +0800] "GET / HTTP/1.0" 200 26 "-" "curl/7.19.7
(x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
代理多个web服务器:
[root@lvs-master conf.d]# cat fxproxy.conf
server {
listen 80;
server_name 10.0.0.136;
location / {
proxy_pass http://10.0.0.137;
proxy_set_header X-Real-IP $remote_addr;
}
location /web2 { #多加个location
proxy_pass http://10.0.0.111;
proxy_set_header X-Real-IP $remote_addr;
}
}
#最后我们去client上访问试试:
[root@elk ~]# curl 10.0.0.136/web2/
<html>
10.0.0.111
</html>
#访问成功
实例
反向代理的后端是web服务器,fastcgi是实现php的解析程序。它们的配置代码如下:
server {
listen 80;
server_name haha.com www.haha.com;
access_log logs/access.log main;
#静态文件,nginx自己处理
location ~ ^/(images|javascript|js|css|flash|media|static)/ {
root html;
index index.html index.htm;
expires 30d;
}
#把请求转发给后台web服务器
location / {
#这里也可以由内网段其它主机提供,也可以由本地服务提供
proxy_pass http://127.0.0.1:8080;
include /usr/local/nginx/conf/proxy.conf; #需要包含的配置
}
}
实例:反向代理负载均衡的应用架构
http {
upstream backend {
server www.haha.com;
server www.test.com;
}
server {
location / {
proxy_pass http://backend;
proxy_redirect default;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwaarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $host:$server_port;
proxy_send_timeout 180;
proxy_read_timeout 180;
proxy_connect_timeout 180;
}
}
}
上面的写法实际企业中,是比较麻烦的,大多数情况如果这些代理模块是公用的那么就可以这样写:改为这样:
http {
include mime.types;
default_type application/octet-stream;
upstream test {
server 192.168.2.166;
server 192.168.2.171:8080;
server 192.168.2.185;
}
location / {
root html;
proxy_pass http://test;
include proxy_params; #引入其他公用配置
index index.html index.htm index.php;
}
}
再把这些选择写在一个文件中:(在nginx的conf目录同一级创建该文件)
# vim /etc/nginx/conf/proxy_params
proxy_redirect default;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwaarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $host:$server_port;
proxy_send_timeout 180;
proxy_read_timeout 180;
proxy_connect_timeout 180;
proxy_buffering on;
proxy_buffer_size 8k;
proxy_buffers 8 64k;
proxy_busy_buffers_size 128k;
proxy_max_temp_file_size 256k;
proxy_temp_file_write_size 128k;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
client_max_body_size 10m;
client_body_buffer_size 128k;
正、反向代理的区别

nginx stream模块-->基于4层(tcp)代理
前言
官网:http://nginx.org/en/docs/stream/ngx_stream_core_module.html
nginx从1.9.0开始,新增加了一个stream模块,用来实现四层协议的转发、代理或者负载均衡等。这完全就是抢HAproxy份额的节奏,鉴于nginx在7层负载均衡和web service上的成功,和nginx良好的框架,stream模块前景一片光明
stream 模块编译
stream模块默认没有编译到nginx, 编译nginx时候./configure --with-stream 即可
用法
stream模块用法和http模块差不多,关键的是语法几乎一致。熟悉http模块配置语法的上手更快
只能配置在http之前
实例1:
以下是一个配置了tcp负载均衡和udp(dns)负载均衡的例子, 有 server,upstream块,而且还有server,hash, listen, proxy_pass等指令,如果不看最外层的stream关键字,还以为是http模块呢
worker_processes auto;
error_log logs/error.log info;
events {
worker_connections 1024;
}
stream {
upstream backend {
hash $remote_addr consistent;
server 127.0.0.1:12346 weight=5;
server 127.0.0.1:12347 max_fails=3 fail_timeout=30s;
server 127.0.0.1:12348 max_fails=3 fail_timeout=30s;
}
upstream dns {
server 17.61.29.79:53;
server 17.61.29.80:53;
server 17.61.29.81:53;
server 17.61.29.82:53;
}
server {
listen 12345;
proxy_connect_timeout 1s;
proxy_timeout 3s;
proxy_pass backend;
}
server {
listen 127.0.0.1:53 udp;
proxy_responses 1;
proxy_timeout 20s;
proxy_pass dns;
}
}
实例2:
比如在内网有一个mysql服务,想暴露到公网上去使用,就可以通过nginx代理的方式通过nginx来进行内网mysql的访问。
实验环境
-
nginx1.12.1 : 192.168.1.19
-
mysql : 192.168.1.22:3306
1:编译或者升级nginx至版本1.9.0以上,编译过程中需带上--with-stream
# ./configure --prefix=/opt/apps/nginx --with-stream
# make && make install
2:配置stream,定义代理192.168.1.22的3306端口映射为端口2333
# vi /opt/apps/nginx/conf/nginx.conf
……
events {
use epoll;
worker_connections 65535;
}
#stream配置
stream {
server {
listen 2333; #监听的端口
proxy_connect_timeout 1s;
proxy_timeout 3s;
proxy_pass 192.168.1.22:3306; #后端的的地址
}
}
http {
……
}
3:开启nginx,验证代理是否生效。
可以看到我们现在可以通过nginx代理的端口访问到内网的mysql服务了。这也直接避免了mysql直接暴露到公网,增加些许的安全。当然,利用stream也可以实现后端服务的负载均衡
实例3:
https://www.jianshu.com/p/45cb044ba99d
stream core 一些变量
注意:变量支持是从 nginx 1.11.2版本开始的
$binary_remote_addr
二进制格式的客户端地址
$bytes_received
从客户端接收到的字节数
$bytes_sent
发往客户端的字节数
$hostname
连接域名
$msec
毫秒精度的当前时间
$nginx_version
nginx 版本
$pid
worker进程号
$protocol
通信协议(UDP or TCP)
$remote_addr
客户端ip
$remote_port
客户端端口
$server_addr
接受连接的服务器ip,计算此变量需要一次系统调用。所以避免系统调用,在listen指令里必须指定具体的服务器地址并且使用参数bind。
$server_port
接受连接的服务器端口
$session_time
毫秒精度的会话时间(版本1.11.4开始)
$status
会话状态(版本1.11.4开始), 可以是一下几个值:
200
成功
400
不能正常解析客户端数据
403
禁止访问
500
服务器内部错误
502
网关错误,比如上游服务器无法连接
503
服务不可用,比如由于限制连接等措施导致
$time_iso8601
ISO 8601时间格式
$time_local
普通日志格式的时间戳
stream 模块
目前官网上列出的第三方模块、简直就是http模块的镜像、比如access模块访问控制ip和ip段,map模块实现映射、 geo模块实现地理位置映射、等等。使用这些模块的时候一定要看是哪个版本才支持的、比如log模块,只有在nginx-1.11.4才支持。
ngx_stream_core_module
ngx_stream_access_module
ngx_stream_geo_module
ngx_stream_geoip_module
ngx_stream_js_module
ngx_stream_limit_conn_module
ngx_stream_log_module
ngx_stream_map_module
ngx_stream_proxy_module
ngx_stream_realip_module
ngx_stream_return_module
ngx_stream_split_clients_module
ngx_stream_ssl_module
ngx_stream_ssl_preread_module
ngx_stream_upstream_module
ngx_stream_upstream_hc_module
负载均衡(重点)基于OSI的7层负载
概述
负载均衡也是Nginx常用的一个功能,负载均衡其意思就是分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。简单而言就是当有2台或以上服务器时,根据规则随机的将请求分发到指定的服务器上处理,负载均衡配置一般都需要同时配置反向代理,通过反向代理跳转到负载均衡
负载均衡实现的方式有很多,常用的lvs四层(基于IP+端口的负载均衡)负载均衡,nginx是四/七层(7层是基于虚拟的URL或主机IP的负载均衡)负载均衡,可以网上查询相关资料。
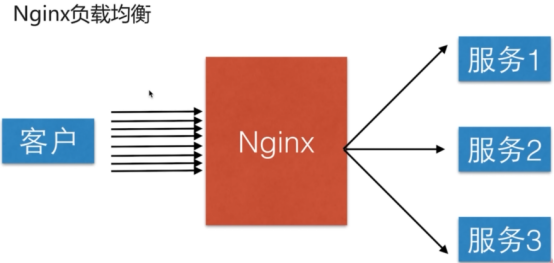
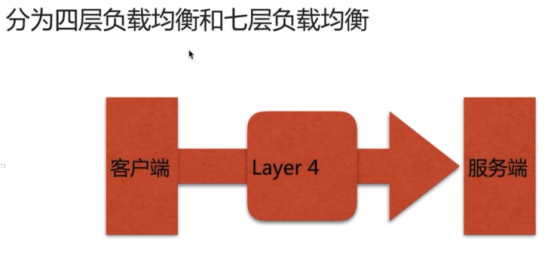
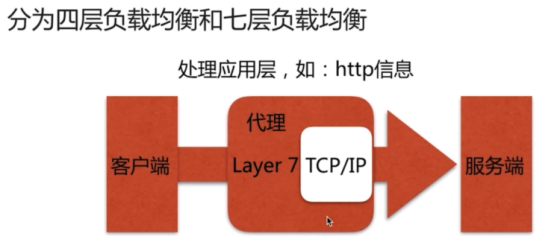
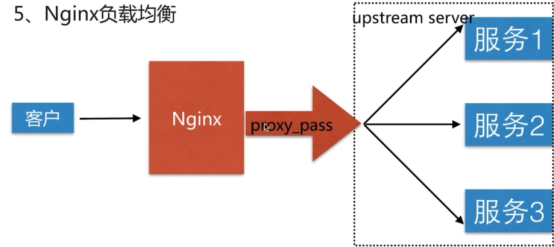
配置语法

注,upstream是定义在server{ }之外的,不能定义在server{ }内部;意思就是只能再http里面配置。定义好upstream之后,用proxy_pass引用一下即可
后端服务器在负载均衡调度中的状态(5种)
upstream 支持的状态参数:
- down:当前server暂时不参与负载均衡
- weight:权重,值越大分配的几率越大
- backup:预留的备份机器又称备份节点。当其他所有的非backup机器出现故障或者忙的时候,才会请求backup机器,因此这台机器的压力最轻。(当其他的服务器宕掉过后,就会启用)
- max_fails:允许请求失败的次数。设定Nginx与服务器通信的尝试失败的次数。在fail_timeout参数定义的时间段内,如果失败的次数达到此值,Nginx就认为后端服务器不可用。在下一个fail_timeout时间段,服务器不会再被尝试。失败的尝试次数默认是1。设为0就会停止统计尝试次数,即不对后端节点进行健康检查。认为服务器是一直可用的。
- fail_timeout:经过max_fails失败后,服务暂停的时间。设定服务器被认为不可用的时间段以及统计失败尝试次数的时间段。在这段时间中,服务器失败次数达到指定的尝试次数,服务器就被认为不可用。默认情况下,该超时时间是10秒。ps:max_fails可以和fail_timeout一起使用,进行健康状态检查。
- max_conns:限制最大的接收的连接数
一般健康检查都需要搞个keepalived,但nginx也有相应的参数可以设置。
-
max_fails,允许请求失败的次数,默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误。
-
fail_timeout,在经历了max_fails次失败后,暂停服务的时间。max_fails可以和fail_timeout一起使用,进行健康状态检查。
调度算法(6种)
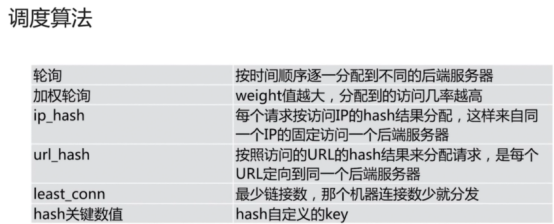
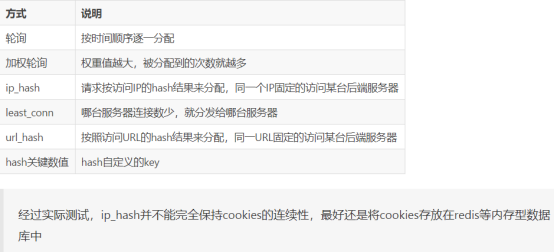
- 轮询(RR默认):每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,就能自动剔除
-
加权轮询(weight):指定轮询几率,weight和访问率成正比,用于后端服务器不均的情况
-
ip_hash:上面的2种方式都有一个问题,那就是下一个请求来的时候可能分发到另一个服务器,当我们的程序不是无状态的时间(采用了session保存数据),这时候就有一个很大的问题了,比如把登陆信息保存到session中,那么跳转到另一个服务器的时候就需要重新登陆了,所有很多时候我们需要一个客户只访问一个服务器,那么就需要用ip_hash了,ip_hash的每一个请求按访问ip_hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题,但ip_hash是有弊端的(具体百度)
-
url_hash(第三方):按访问URL的hash结果来分配请求,使每个URL定向到同一后端服务器,后端服务器为缓存时比较有效。在upstream中加入hash语句,server语句中不能写入weight等其他参数,hash_method是使用的hash算法
-
least_conn指令实际的含义就是,选取活跃连接数与权重weight的比值最小者为下一个处理请求的server。当然,上一次已选的server和已达到最大连接数的server照例不在选择的范围
-
fail(第三方):按后端服务器的响应时间来分配请求,响应时间短的优先分配
-
hash关键数值:hash自定义的key
基于轮询(RR默认)
准备4台服务器:其中三台定义在upstream里面,剩下的一台作为负载均衡用,其负载均衡的服务器,配置参数如下:
upstream gobgm {
server 192.168.137.6:8001;
server 192.168.137.6:8002;
server 192.168.137.6:8003;
}
server {
listen 80;
server_name localhost www.gobgm.com;
charset utf-8;
#access_log logs/host.access.log main;
location / {
proxy_pass http://gobgm;
include proxy_params;
}
}
然后:访问本机
如果一台宕机了,它还是会轮询
这里用防火墙模拟来做:

基于ip_hash:
ip_hash:每个请求按访问 IP 的 hash 结果分配,这样来自同一个 IP 的访客固定访问一个后端服务器,有效解决了动态网页存在的 session 共享问题,电子商务网站用的比较多
upstream gobgm {
ip_hash; #添加此配置
server 192.168.137.6:8001;
server 192.168.137.6:8002;
server 192.168.137.6:8003;
}
server {
listen 80;
server_name localhost www.gobgm.com;
location / {
proxy_pass http://gobgm;
include proxy_params;
}
}
注,当负载调度算法为 ip_hash 时,后端服务器在负载均衡调度中的状态不能有 backup。有人可能会问,为什么呢?大家想啊,如果负载均衡把你分配到 backup 服务器上,你能访问到页面吗?不能,所以了不能配置 backup 服务器
注意:
-
当负载调度算法为ip_hash时,后端服务器在负载均衡调度中的状态
不能是weight和backup。 -
导致负载不均衡。
基于url_hash

upstream gobgm {
hash $request_uri;
server 192.168.137.6:8001;
server 192.168.137.6:8002;
server 192.168.137.6:8003;
}
server {
listen 80;
server_name localhost www.gobgm.com;
charset utf-8;
#access_log logs/host.access.log main;
location / {
proxy_pass http://gobgm;
include proxy_params;
}
}
http {
include mime.types;
default_type application/octet-stream;
upstream test {
server 192.168.2.167 weight=6;
server 192.168.2.166 down;
server 192.168.2.171:8080 backup;
server 192.168.2.185 max_fails=1 fail_timeout=10s;
}
server {
listen 80;
server_name 192.168.2.171;
charset utf-8;
#access_log logs/host.access.log main;
}
location / {
root html;
proxy_pass http://test;
include proxy_params;
index index.html index.htm index.php;
}
}
基于least_conn
upstream backend {
zone backends 64k;
least_conn;
server 10.10.10.2 weight=2;
server 10.10.10.4 weight=1;
server 10.10.10.6 weight=1;
}
说明
参考:https://www.cnblogs.com/kevingrace/p/6685698.html
Nginx默认是不会提出后端异常的节点。需要配置proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504 http_404;
这是一种解决方案,另外可以用第三方模块(淘宝开发的,检测后端异常节点并剔除该节点)
1)ngx_http_proxy_module模块和ngx_http_upstream_module模块(这是nginx自带模块)
参考地址:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_next_upstream
2)nginx_upstream_check_module模块(淘宝技术团队开发)
参考地址:https://github.com/yaoweibin/nginx_upstream_check_module
在淘宝自己的tengine上是自带了该模块的,大家可以访问淘宝tengine的官网http://tengine.taobao.org来获取该版本的nginx,如果没有使用淘宝的tengine的话,可以通过补丁的方式来添加该模块到我们自己的nginx中。部署流程如下:
在实际应用当中:
1)如果后端应用是能够快速重启的应用,比如nginx的话,自带的模块是可以满足需求的。
但是需要注意,如果后端有不健康节点,负载均衡器依然会先把该请求转发给该不健康节点,然后再转发给别的节点,这样就会浪费一次转发。
2)如果当后端应用重启时,重启操作需要很久才能完成的时候就会有可能拖死整个负载均衡器。
此时,由于无法准确判断节点健康状态,导致请求handle住,出现假死状态,最终整个负载均衡器上的所有节点都无法正常响应请求。
比如公司的业务程序是java开发的,因此后端主要是nginx集群和tomcat集群。由于tomcat重启应部署上面的业务不同,有些业务启动初始化时间过长,就会导致上述现象的发生,因此不是很建议使用该模式。
并且ngx_http_upstream_module模块中的server指令中的max_fails参数设置值,也会和ngx_http_proxy_module模块中的的proxy_next_upstream指令设置起冲突。
如果将max_fails设置为0,则代表不对后端服务器进行健康检查,这样还会使fail_timeout参数失效(即不起作用)。
此时判断后端服务器情况的唯一依据便是ngx_http_proxy_module模块中的proxy_connect_timeout指令和proxy_read_timeout指令,通过将它们的值调低来发现不健康节点,进而将请求往健康节点转移。
如果这两个参数设置得过小,但后端程序的执行或多或少会超过这个时间的话,这种情况nginx的效率是非常低的。
Nginx 基于nginx-sticky-module模块进行会话保持
参考:https://mp.weixin.qq.com/s/qp0O4I_K1OrUwCnVs1B8oA
官方地址:https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/src
下载地址:https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/get/master.tar.gz
sticky介绍
sticky模块ip_hash都是与负载均衡算法相关,但又有差别,差别是
-
ip hash,根据客户端的IP,将请求分配到不同的服务器上。nginx基于访问ip的hash策略,即当前用户的请求都集中定位到一台服务器中,这样单台服务器保存了用户的session登录信息,如果宕机,则等同于单点部署,会丢失,会话不复制
-
sticky,根据服务器给客户端的cookie,客户端再次请求时会带上此cookie,nginx会把有此cookie的请求转发到颁发cookie的服务器上
sticky原理
Sticky是基于cookie的一种负载均衡解决方案,通过分发和识别cookie,使来自同一个客户端的请求落在同一台服务器上,默认cookie标识名为route :
1.客户端首次发起访问请求,nginx接收后,发现请求头没有cookie,则以轮询方式将请求分发给后端服务器。
2.后端服务器处理完请求,将响应数据返回给nginx。
3.此时nginx生成带route的cookie,返回给客户端。route的值与后端服务器对应,可能是明文,也可能是md5、sha1等Hash值。
4.客户端接收请求,并保存带route的cookie。
5.当客户端下一次发送请求时,会带上route,nginx根据接收到的cookie中的route值,转发给对应的后端服务器
注意点
1.同一客户端,如果启动时同时发起多个请求,有可能落在不同的后端服务器上。
2.由于cookie最初由服务器端下发,如果客户端禁用cookie,则cookie不会生效。
3.客户端可能不带cookie,Android客户端发送请求时,一般不会带上所有的cookie,需要明确指定哪些cookie会带上。如果希望用sticky做负载均衡,请对Android开发说加上cookie。
4.cookie名称不要和业务使用的cookie重名。Sticky默认的cookie名称是route,可以改成任何值
5.客户端发的第一个请求是不带cookie的。服务器下发的cookie,在客户端下一次请求时才能生效。
6.Nginx sticky模块不能与ip_hash同时使用
Nginx安装Sticky模块
如果你还没有部署Nginx,那么就在部署Nginx的时候进行--add-module添加上此模块就行了,我这里是Nginx已经安装过了,需要再把此模块加载进NGINX
1.下载sticky
wget https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/get/master.tar.gz
tar xf master.tar.gz
#把此模块放进nginx/module目录下,名称太长,重命名一下
mkdir /usr/local/nginx/module
mv nginx-goodies-nginx-sticky-module-ng-08a395c66e42 /usr/local/nginx/module/nginx-sticky-module
2.重新编译NGINX
下载一个NGINX后重新解压,然后看之前NGINX编译了那些模块,这里都给加上,在最后加上--add-module载入sticky模块
# cd /usr/local/nginx-1.18.0
./configure --prefix=/usr/local/nginx \
--user=nginx --group=nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--http-log-path=/usr/local/nginx/logs/access.log \
--error-log-path=/usr/local/nginx/logs/error.log \
--pid-path=/usr/local/nginx/logs/nginx.pid \
--lock-path=/usr/local/nginx/logs/nginx.lock \
--with-http_ssl_module --with-http_flv_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-http_realip_module \
--with-http_secure_link_module \
--with-http_sub_module \
--with-pcre \
--with-stream \
--http-client-body-temp-path=/usr/local/nginx/client_body_temp \
--http-proxy-temp-path=/usr/local/nginx/proxy_temp \
--http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp \
--http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp \
--http-scgi-temp-path=/usr/local/nginx/scgi_temp \
--add-module=/usr/local/ngx-fancyindex-0.4.4 \
--add-module=/usr/local/module/nginx-sticky-module #在此载入sticky模块
#./configure完后进行编译,然后更换 nginx 程序(可以不要mv 和 cp这两步骤)
make
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old
cp -rf objs/nginx /usr/local/nginx/sbin/
然后在安装
[root@learn nginx-1.18.0]# make install
最后再 make upgrade 进行更新检测
[root@learn nginx-1.18.0]# make upgrade
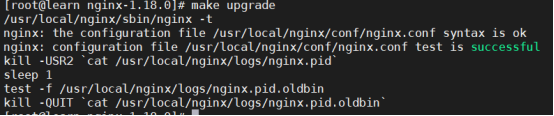
以上就完成了Nginx载入第三方模块,使用nginx -V来查看是否载入成功

3.修改NGINX配置文件 修改NGINX配置文件来启用sticky
upstream backend {
sticky name=ngx_cookie expires=6h; #开启
server 192.168.31.240:8080 weight=3 max_fails=3 fail_timeout=10s;
server 192.168.31.241:8080 weight=3 max_fails=3 fail_timeout=10s;
server 192.168.31.242:8080 weight=6 max_fails=3 fail_timeout=10s;
server 192.168.31.243:8080;
server 192.168.31.244:8080 down;
}
4.sticky语法解析
| 指令 | 描述 |
|---|---|
| name | 设置记录cookie的名称(可自定义),默认为route |
| domain | 设置cookie要使用的域名 |
| path | 设置cookie作用的URL路径,默认根目录 |
| expires | 设置cookie的生存期 |
| hash | 值为 index、md5、sha1,对应明文、md5、和sha1,默认md5,测试sha1后端服务器会变 |
| no_fallback | 当sticky的后端机器挂了以后,nginx返回502,而不转发到其他服务器,不建议设置 |
| secure | 设置启用安全的cookie,需要HTTPS支持 |
| httponly | 允许cookie不通过JS泄漏 |
5.重启NGINX
[root@learn vhost]# nginx -t
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
[root@learn vhost]# nginx -s reload
测试访问NGINX
第一次访问的时候是没有Cookie的,访问完成后NGINX才会把Cookie包含在返回的数据中,在下次请求数据的时候就会出现Cookie。所以刷新一下后才能看到Cookie
缓存服务(重点)
概述及语法
缓存分为两种:
1、浏览器缓存、静态资源缓存用expire
2、代理层缓存
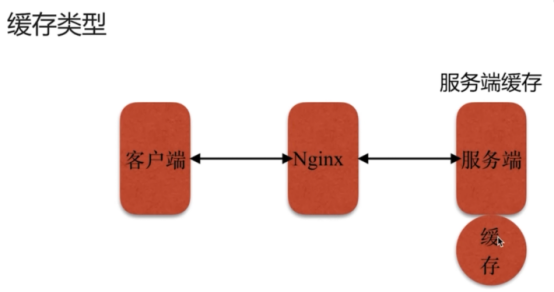
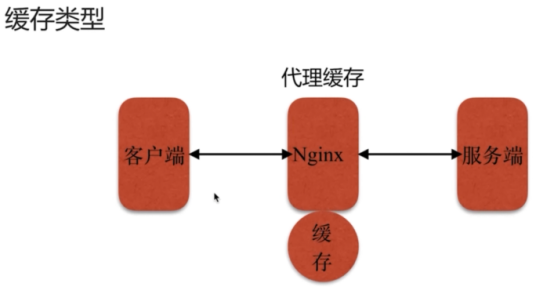
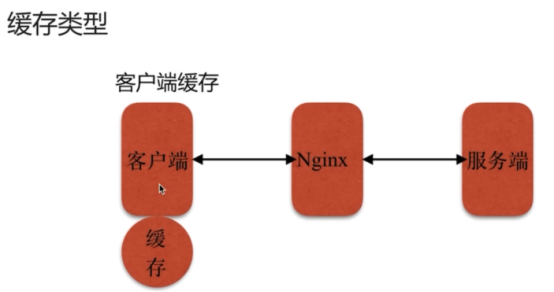
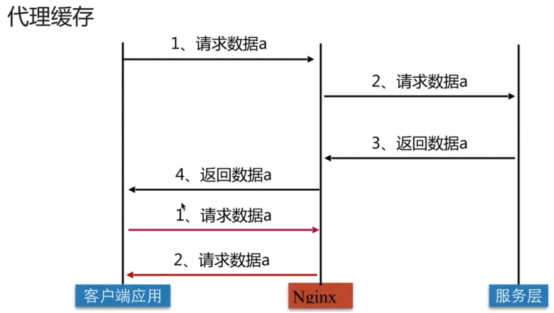




eg:浏览器缓存,静态资源缓存用expire
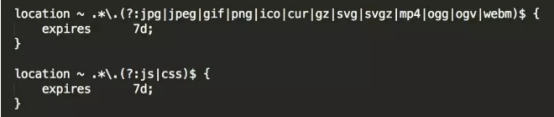
eg:代理层缓存
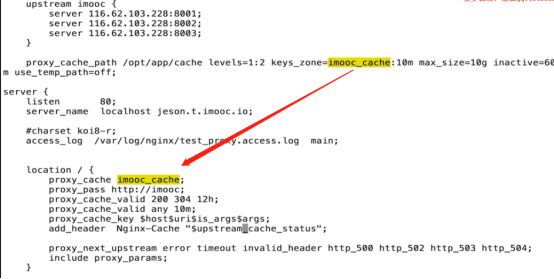
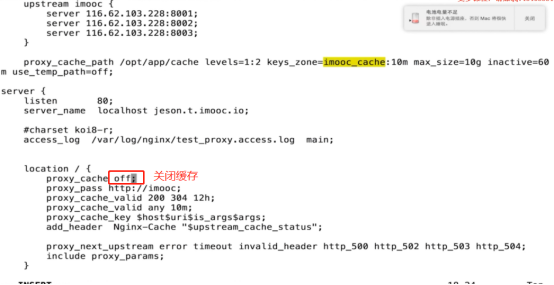


eg: 代理层缓存
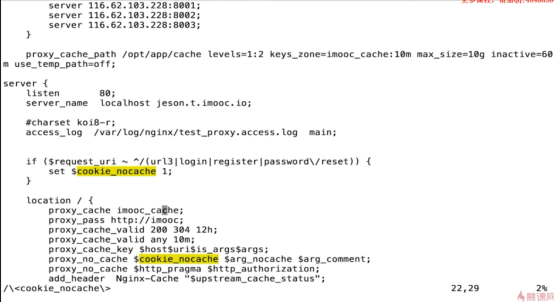

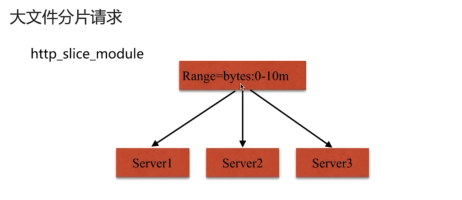

eg:代理层缓存
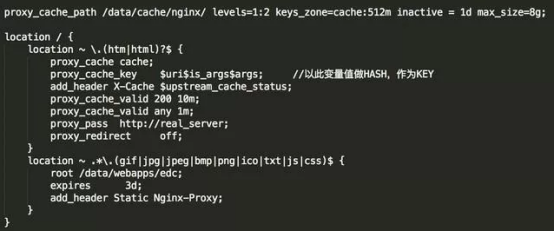
proxy_cache_path /data/nginx/cache_item levels=1:1:2 keys_zone=cache_item:10m max_size=10g inactive=60m;
server {
location ~ \.(gif|jpg|jpeg|png|bmp|ico)$ {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_cache cache_item;
proxy_cache_key $host$uri$is_args$args;#以全路径md5值做做为Key
proxy_cache_valid 200 304 12h; #对不同的HTTP状态码设置不同的缓存时间
expires 7d; #总体缓存时间
}
}
配置在http
-
proxy_cache_path 指定缓存区的根路径
-
levels 缓存目录级最高三层,每层1-2个字符表示。如
1:1:2三层。 -
keys_zone 缓存块名称及内存块大小。如
cache_item:500m表示声明一个名为cache_item大小为500m。超出大小 后最早的数据将被清除。 -
max_size 缓存区硬盘的 最大值。超出闲置数据将被清除
-
inactive 最长闲置时间 如10d 如果一个 数据被闲置10天则将被清除
配置在location
-
proxy_cache 指定缓存区,对应keys_zone中设定的值
-
proxy_cache_key 通过参数拼装参数key如:
$host$uri$is_args$args则会以全部领md5值做为key -
proxy_cache_valid 对不同的状态码设置缓存有效期
Nginx缓存实现原理
基于Proxy Store的缓存机制
01:404错误驱动
当Nginx服务器发现,用户请求数据在服务器本地不存在时,会产生404错误,服务器能够捕捉该错误,进一步转向后端服务器请求相关数据,最后将后端请求到的数据传回客户端,并在服务器本地缓存。

02:资源不存在驱动
原理上基本等同于404错误驱动,不同之处在于该方法是通过location块的location if条件判断直接驱动Nginx服务器和后端服务器的通信和Web缓存,而不对资源不存在产生404错误。
配置文件片段:

这两种缓存机制只能缓存200状态下的响应数据,同时不支持动态链接请求。比如:getsource?id=1和getsource?id=2这两个请求,返回的是相同的资源。所以实际上,一般是采用Nginx搭配Squid服务器架构实现方案。
基于memcached的缓存机制
memcached在内存中开辟一块空间,然后建立一个Hash表,将缓存数据通过键/值存储在Hash表中进行管理。memcached由服务端和客户端两个核心模块组成,服务端通过计算"键"的Hash值来确定键/值对在服务端所处的位置。当位置确定后,客户端就会向对应的服务端发送一个查询请求,让服务端查找并返回所需数据。
动静分离(重点)
参考:https://my.oschina.net/u/2347860/blog/3215029

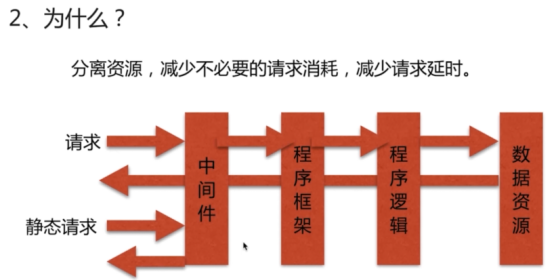
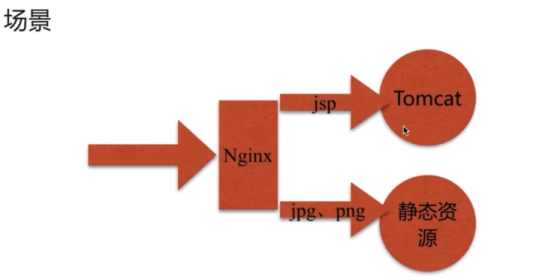
一般来说,静态资源是指JavaScript、CSS、Img等文件,动态资源则是通过PHP、Java等后端语言运行一系列的代码逻辑来获取的。
如果是静态资源的请求,就直接让nginx在静态资源目录下面读取,然后返回给客户端
如果是动态资源的请求,则nginx利用反向代理把请求转发给后端应用去处理,然后后端应用将结果返回给nginx,nginx再返回给客户端
在使用前后端分离之后,可以很大程度的提升静态资源的访问速度,同时减轻后端应用的处理压力。拿PHP之Laravel框架来说,简单的获取一个静态文件,就需要初始化框架代码,这个过程也比较耗时,性价比是很低的
# 动态内容
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params;
}
# 静态内容
location ~ \.(png|jpeg|jpg|js|css|woff|ttf)$ {
expires 1h;
}
当然,如果有条件的话,还是建议将静态资源存放到七牛或阿里云OSS中,利用CDN可以获取更快的静态资源加载速度
https服务
三方参考:https://aotu.io/notes/2016/08/16/nginx-https/index.html



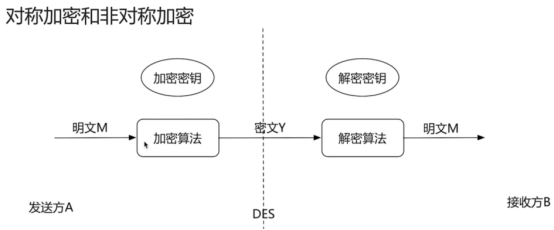
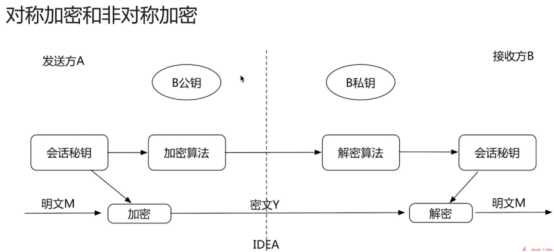
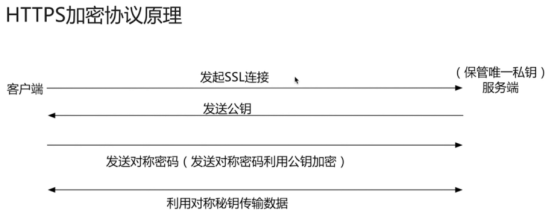
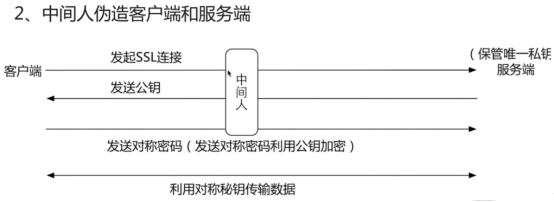
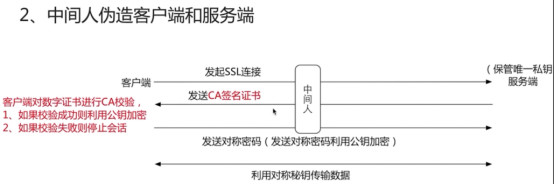

查看:


步骤一:
[root@CentOS6 /etc/nginx]# mkdir ssl_key
[root@CentOS6 /etc/nginx]# cd ssl_key/
[root@CentOS6 /etc/nginx/ssl_key]# ls
[root@CentOS6 /etc/nginx/ssl_key]# openssl genrsa -idea -out test_ssl.key 1024
#-idea 选项用于指定使用 IDEA(国际数据加密算法)来生成 RSA 密钥对
#key文件 : test_ssl.key
#加密的位数(位数越高,精度就越高),一般都需要2048,下次记得修改

查看生产的文件:

步骤二(如果是生产环境中,那么就根据要求填写一下信息):
key文件 请求文件
[root@CentOS6 /etc/nginx/ssl_key]# openssl req -new -key test_ssl.key -out test_ssl.csr
Enter pass phrase for test_ssl.key: #输入之前生成key的文件
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:beijing
Locality Name (eg, city) [Default City]:beijing
Organization Name (eg, company) [Default Company Ltd]:CN
Organizational Unit Name (eg, section) []:test_ssl
Common Name (eg, your name or your server's hostname) []:test_ssl.com
Email Address []:test_ssl@admin.com
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []: #这里密码写成空,就ok了
An optional company name []:test_ssl

[root@CentOS6 /etc/nginx/ssl_key 18:32]# ls
test_ssl.csr test_ssl.key #生产环境中,就需要把这两个文件,发给权威机构进行`签名请求`
而这里对于个人,就自己来做这个签名请求的工作,步骤如下:
[root@CentOS6 /etc/nginx/ssl_key ]# openssl x509 -req -days 3650 -in test_ssl.csr -signkey test_ssl.key -out test_ssl.crt
Signature ok
subject=/C=CN/ST=beijing/L=beijing/O=CN/OU=test_ssl/CN=test_ssl.com/emailAddress=test_ssl@admin.com
Getting Private key
Enter pass phrase for test_ssl.key: #输入密码
[root@CentOS6 /etc/nginx/ssl_key]# ls #查看生成的文件
test_ssl.crt test_ssl.csr test_ssl.key

解释:
-days 3650:表示过期时间,3650就是10年-out test_ssl.crt:表示通过这两文件来生产test_ssl.crt文件
Nginx的https配置语法:

修改配置文件:
server {
listen 443 ssl; #监听端口443
server_name 172.20.10.11; #服务名
keepalive_timeout 100 #保持连接
#ssl on; #开启ssl,到1.15.0版本就不支持这个参数
ssl_certificate /etc/nginx/ssl_key/test_ssl.crt; #指定crt文件路径
ssl_certificate_key /etc/nginx/ssl_key/test_ssl.key; #指定key文件路径
ssl_session_cache shared:SSL:10m; #ssl会话缓存,这里10m可以存8千-1万个
ssl_session_timeout 10m; #ssl会话过期时间10分钟
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_prefer_server_ciphers on;
location / { #网页根路径
root html;
index index.html index.htm;
}
}
然后关闭、重启服务,都会叫输入之前设置的密码:
[root@CentOS6 /usr/share/nginx/html]# nginx -s stop -c /etc/nginx/nginx.conf #停服务
Enter PEM pass phrase: #输入密码
[root@CentOS6 /usr/share/nginx/html]# nginx -c /etc/nginx/nginx.conf #启服务
Enter PEM pass phrase: #输入密码
[root@CentOS6 /usr/share/nginx/html]# netstat -nutlp | grep 443 #查看443端口是否已启动
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 8855/nginx
那么怎么取消每次启动时都需要输入保护码:
[root@CentOS6 /etc/nginx/ssl_key]# openssl rsa -in test_ssl.key -out test_ssl_nopas.key
Enter pass phrase for test_ssl.key:
writing RSA key
最后把key路径换成nopas.key文件,就不会输入密码了
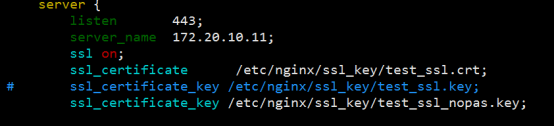

然后进行验证:https://172.20.10.11

升级openssl:
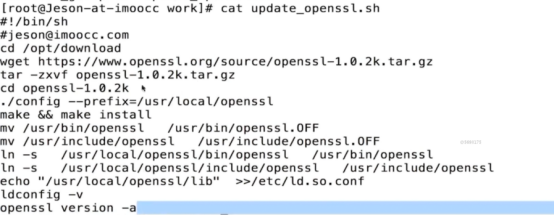


证书的版本通常由 X.509 标准定义,常见的版本包括 v1、v2 和 v3。
要生成一个使用 SHA256 哈希算法且版本为 3 的自签名 Nginx 证书,您可以按照以下步骤进行操作:
1、安装 OpenSSL: 首先,请确保您的系统中已经安装了 OpenSSL。您可以通过运行以下命令来检查是否已安装:
openssl version
如果未安装 OpenSSL,请根据您的操作系统类型和版本进行安装。
2、生成私钥(key):
使用以下命令生成一个 RSA 私钥文件(2048 位长度):
openssl genpkey -algorithm RSA -out gobgm.key -pkeyopt rsa_keygen_bits:2048
# 如果您希望在生成 RSA 密钥对时为私钥设置密码保护,您可以使用 OpenSSL 中的 -aes256 选项。这将使用 AES-256(一种对称加密算法)来加密私钥,并需要您提供一个密码以保护私钥。
# openssl genpkey -algorithm RSA -out gobgm.key -aes256
3、生成证书签名请求(CSR):
使用以下命令生成一个 CSR 文件:在此过程中,您将需要提供一些证书请求信息,如国家、组织、域名等。请根据提示填写相关信息。
# 非交互式
openssl req -new -key gobgm.key -out gobgm.csr -subj "/C=CN/ST=Beijing/L=Beijing/O=gobgm Company/CN=gobgm.com"
# 需要交互式输入-subj相关的信息
# openssl req -new -key gobgm.key -out gobgm.csr
4、创建 extensions.cnf 文件:
创建一个名为 extensions.cnf 的文本文件,并在其中添加以下内容:
cat > extensions.cnf << EOF
[req]
default_bits = 2048
distinguished_name = req_distinguished_name
req_extensions = v3_req
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = gobgm.com
DNS.2 = www.gobgm.com
IP.1 = 127.0.0.1
EOF
5、生成自签名证书:
使用以下命令生成自签名证书:
openssl x509 -req -sha256 -days 365 -in gobgm.csr -signkey gobgm.key -out gobgm.crt -extfile extensions.cnf -extensions v3_req
脚本
keyname="gobgm.key"
csrname="gobgm.csr"
crtname="gobgm.crt"
DNS="gobgm"
#公用名 (CN)
CN="gobgm"
#组织 (O)
O="ghca"
#组织单位 (OU)
OU="gobgm"
EmailAddress="gobgm@admin.com"
#有效期
ExpiryDate=3650
cat > extensions.cnf << EOF
[req]
default_bits = 2048
distinguished_name = req_distinguished_name
req_extensions = v3_req
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = ${DNS}.com
DNS.2 = www.${DNS}.com
IP.1 = 127.0.0.1
EOF
#1
openssl genpkey -algorithm RSA -out ${keyname} -pkeyopt rsa_keygen_bits:2048
#2
openssl req -new -key ${keyname} -out ${csrname} -subj "/C=CN/ST=Beijing/L=Beijing/O=${O} Company/CN=${CN}/OU=${OU}/emailAddress=${EmailAddress}"
#3
openssl x509 -req -sha256 -days ${ExpiryDate} -in ${csrname} -signkey ${keyname} -out ${crtname} -extfile extensions.cnf -extensions v3_req
如何在根 CA 下生成服务器和客户端证书
参考:https://qa.1r1g.com/sf/ask/3814433101/
因此,我一直在尝试在 python 客户端和 python 服务器之间建立 SSL 连接,其中两者都有单独的证书来相互验证,并且两个证书都由一个 CA(它也恰好是根 CA)签名. 这应该使它们对彼此都有效,对吗?
到目前为止,我的方法是创建一个 bash 脚本来完成这一切:
- 它为根 CA 生成私钥
- 它使用根 CA 私钥生成根 CA 证书
- 它为服务器生成私钥
- 它为服务器生成 CSR
- 它使用服务器 CSR 和根 CA 证书生成服务器证书
- 它为客户端生成私钥
- 它为客户端生成 CSR
- 它使用客户端 CSR 和根 CA 证书生成客户端证书
run.sh
#!/bin/bash
BOLD=$(tput bold)
CLEAR=$(tput sgr0)
echo -e "${BOLD}Generating RSA AES-256 Private Key for Root Certificate Authority${CLEAR}"
openssl genrsa -aes256 -passout pass:123654 -out Root.CA.example.llc.key 2048
echo -e "${BOLD}Generating Certificate for Root Certificate Authority${CLEAR}"
openssl req -x509 -new -nodes -key Root.CA.example.llc.key -sha256 -days 10950 -passin pass:123654 -out Root.CA.example.llc.pem -subj "/C=CN/ST=Beijing/L=Beijing/O=gobgm Company/CN=gobgm.com"
echo -e "${BOLD}Generating RSA Private Key for Server Certificate${CLEAR}"
test -d server || mkdir -p server
openssl genrsa -aes256 -passout pass:123654 -out server/example.llc.server.key 2048
echo -e "${BOLD}Generating Certificate Signing Request for Server Certificate${CLEAR}"
openssl req -new -key server/example.llc.server.key -passin pass:123654 -out server/example.llc.server.csr -subj "/C=CN/ST=Beijing/L=Beijing/O=gobgm Company/CN=gobgm.com"
echo -e "${BOLD}Generating Certificate for Server Certificate${CLEAR}"
test -f extensions.cnf || cat > extensions.cnf << EOF
[req]
default_bits = 2048
distinguished_name = req_distinguished_name
req_extensions = v3_req
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = gobgm.com
DNS.2 = www.gobgm.com
IP.1 = 127.0.0.1
EOF
openssl x509 -req -in server/example.llc.server.csr -CA Root.CA.example.llc.pem -CAkey Root.CA.example.llc.key -CAcreateserial -passin pass:123654 -out server/example.llc.server.crt -days 10950 -sha256 -extfile extensions.cnf -extensions v3_req
echo -e "${BOLD}Generating RSA Private Key for Client Certificate${CLEAR}"
test -d client || mkdir -p client
openssl genrsa -aes256 -passout pass:123654 -out client/example.llc.client.key 2048
echo -e "${BOLD}Generating Certificate Signing Request for Client Certificate${CLEAR}"
openssl req -new -key client/example.llc.client.key -passin pass:123654 -out client/example.llc.client.csr -subj "/C=CN/ST=Beijing/L=Beijing/O=gobgm Company/CN=gobgm.com"
echo -e "${BOLD}Generating Certificate for Client Certificate${CLEAR}"
openssl x509 -req -in client/example.llc.client.csr -CA Root.CA.example.llc.pem -CAkey Root.CA.example.llc.key -CAcreateserial -passin pass:123654 -out client/example.llc.client.crt -days 10950 -sha256 -extfile extensions.cnf -extensions v3_req
echo "Done!"
阿里云的个人博客添加免费的HTTPS证书
参考: https://pengrl.com/p/20060/
server {
listen 80;
server_name download.gobgm.com; #设置访问你的IP或域名
rewrite ^(.*)$ https://${server_name}$1 permanent;
location /file {
alias /usr/local/nginx/html/download/;
}
}
server {
listen 443 ssl;
ssl_certificate /root/.acme.sh/gobgm.com/fullchain.cer;
ssl_certificate_key /root/.acme.sh/gobgm.com/gobgm.com.key;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 10m;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_prefer_server_ciphers on;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
server_name download.gobgm.com; #设置访问你的IP或域名
charset utf-8;
access_log logs/access.log main;
location / {
return 404;
}
}
HTTP状态码(HTTP Status Code)
参考:https://www.shuzhiduo.com/A/mo5k8l9ndw/
https://www.cnblogs.com/sharesdk/p/9310004.html
https://www.cnblogs.com/saneri/p/7657576.html
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/status

HTTP2xx代表请求正常完成
HTTP3xx代表网站重定向
HTTP4xx代表客户端出现错误
HTTP5xx代表服务器端出现错误
200:ok
状态码 200 OK 表明请求已经成功. 默认情况下状态码为200的响应可以被缓存。
不同请求方式对于请求成功的意义如下:
-
GET: 已经取得资源,并将资源添加到响应的消息体中。
-
HEAD: 响应的消息体为头部信息。
-
POST: 响应的消息体中包含此次请求的结果。
-
TRACE: 响应的消息体中包含服务器接收到的请求信息。
PUT 和 DELETE 的请求成功通常并不是响应200 OK的状态码而是 204 No Content 表示无内容(或者 201 Created表示一个资源首次被创建成功)
还有一种情况:在error-page指令中配置了错误页面返回的状态码是200
查看nginx日志,发现状态码是200,但是服务是50x页面。
304:自上次访问,请求未改变
如果客户端发送了一个带条件的GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个304状态码。简单的表达就是:服务端已经执行了GET,但文件未变化

301:跳转(永久重定向)
302:跳转(临时重定向)
403:访问被拒绝forbidden(有可能是权限问题)
403错误,是一种在网站访问过程中,常见的错误提示,表示资源不可用。服务器理解客户的请求,但拒绝处理它,通常由于服务器上文件或目录的权限设置导致的WEB访问错误
1,如果在/data/www/(网站根目录)下面没有index.php,index.html的时候,直接访问,会报403 forbidden。->根目录下没有html文件或者目标位置没有找到html文件
2,权限问题,如果nginx没有web目录的操作权限,也会出现403错误。
chmod -R 777 /data/www/
3,权限问题,nginx.conf配置文件的user参数与nginx运行用户不一致,导致403错误。(直接修改user参数为nginx运行用户)
4,SELinux设置为开启状态(enabled)的原因。
# 查看当前selinux的状态
/usr/sbin/sestatus # or getenforce
#将SELINUX=enforcing 修改为 SELINUX=disabled 状态。
(临时)setenforce 0
(永久)
vi /etc/selinux/config
#SELINUX=enforcing
SELINUX=disabled
重启生效。reboot。
4,存在跨域请求(解决->2种情况二选一)
1、找开发解决
2、配置nginx(https://blog.csdn.net/msllws/article/details/105084281)
404:请求的资源(网页、文件、目录等)不存在
404,是一种HTTP状态码,指网页或文件未找到。
HTTP 404或Not Found错误信息是HTTP的其中一种"标准回应信息"(HTTP状态码),此信息代表客户端在浏览网页时,服务器无法正常提供信息,或是服务器无法回应且不知原因
报错:
排查1:nginx作为web容器
首先访问nginx查看是否有日志进来:
access.log的日志:

1、如果有,查看error.log日志报错的文件是否真的不存在,如果文件存在,就不是nginx web容器的问题,就是代码问题
error.log的日志:首先查找是否存在该文件

验证结果:确实不存在

2、如果没有,就是代码问题,缺少相应文件问题
排查2:nginx作为代理(在前端页面中配置了一个域名代理带后端的一个web服务,但是这个web服务配置的POST请求,而不是get请求,所有导致访问的时候出现404错误)
程序发出的是post请求,但是你是用浏览器访问的,浏览器访问是get请求。所有你要用post请求去访问
排查3:nginx作为代理服务器配置错误导致
该location配置了error_page,但是根下面又没有50x.html页面。并且后端也没有启动,这时候访问就会报404,而nginx的错误日志里面会发现找不到这个50x.html文件,所有报404错误。
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}

但是这其实是后端的问题,因为后端都没有启动。应该报502错误。这时候只需要把50.html创建出来后再访问就是报错502.这就知道是后端的问题

排查4:nginx根目录没有权限(根目录必须是nginx启动用户的属主、组)
chown -R nginx.nginx /data/www/
400:请求参数错误
HTTP 400 Bad Request 响应状态码表示由于语法无效,服务器无法理解该请求。 客户端不应该在未经修改的情况下重复此请求
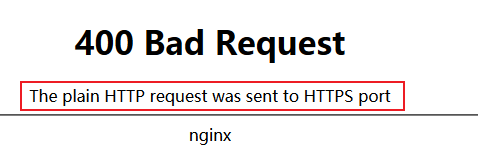
第一种情况:网站是https的,但是访问是http的。
暂时解决方案就是用https访问呢
第二种情况:网站是https的,但是访问时跳转该网站的其他页面时,自动变成了http协议,这种情况就是nginx配置错误导致的。解决如下:
解决第二种情况的方案1:https://www.cnblogs.com/52py/p/12374067.html
修改nginx配置文件:
proxy_redirect http:// <https://;
第三种情况:网站是http的,访问是http的。
程序是docker启动的,由于Docker Root Dir磁盘空间满了,导致程序读取不到相关信息,最后出现400错误。
解决方案: 清理磁盘空间
500:内部服务器错误
http 500内部服务器(HTTP-Internal Server Error)错误说明IIS服务器无法解析ASP代码,访问一个静态页面试试是否也出现这个问题,如果访问静态页面没问题,那就要分以下几种 情况来分析了: ① 你是否改变过计算机名称。 ② 站点所在的文件目录是否自定义了安全属性。 ③ 安装了域控制器后是否调整了域策略。如果是其中的一种情况,请一一将 改变的参数设置回来看是否解决问题。 如果静态空间也无法访问,则说明解析还没生效
1、请求的URL不正确(就是没有你请求的路径)
2、可能是try_files指令的内部重定向参数不存在(相当于请求的URL不正确)
报错:
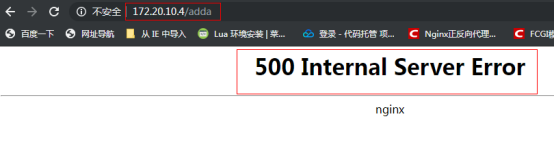
access.log日志:

error.log日志:

排查:
nginx的try_files指令配置:
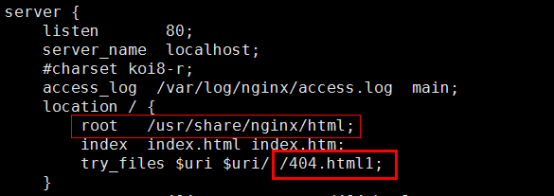
内部重定向文件确实不存在:

3、可能软件是不能解析后端代码,软件版本过低造成的
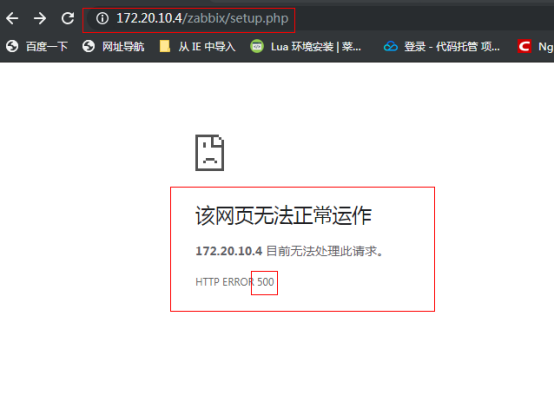
access.log日志:

error.log日志:

三方参考资料:https://www.cnblogs.com/chai-/p/9460903.html
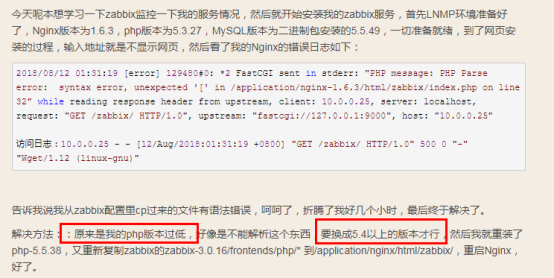
502:nginx代理的后端服务器出现问题
502 Bad Gateway 是一种HTTP协议的服务器端错误状态代码,它表示作为网关或代理角色的服务器,从上游服务器(如tomcat、php-fpm)中接收到的响应是无效的。
Gateway (网关)在计算机网络体系中可以指代不同的设备,502 错误通常不是客户端能够修复的,而是需要由途径的Web服务器或者代理服务器对其进行修复


1、不知道啥奇怪的现象:解决->重启服务
2、服务没有启动,查看是否后端服务正常启动

3、后端端口冲突:修改了后端端口,重启服务,解决
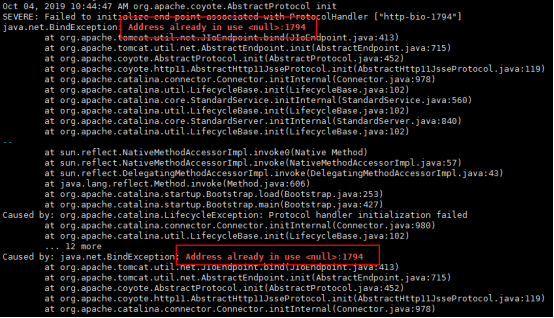
4、还有可能就是nginx没有生效。reload一下nginx
5、没有配置https,然后是用https访问的
6、配置了http和https,但是郁闷的是本地hosts文件绑定的是http访问,所有报错502
503 Service Unavailable
1、站点配置了https,但是访问时不是用的https
2、重启服务
3、nginx代理的后端,但是后端没有启动成功
504:网络或者CDN或者某服务器挂了(静态资源服务器)
1、如果在本地(服务器)端IP+port能访问,那么就检查外网网络:网络原因、域名解析到外网ip,外网出现问题,504错误


2、这就是外网崩溃导致的504,导致cdn那边解析不到外网ip

3、nginx+php访问出现504、499等情况,nginx错误日志(30993#0: *752 upstream timed out (110: Connection timed out) while reading response header from upstream)
-
检查nginx配置是否正确
-
检查php连接数是否设置合理(如果之前访问都是正常的,那一般就是php连接数设置小了)
用户访问量过大可能会导致nginx返回50x错误
一些常见的状态码为:
200 - 服务器成功返回网页
403-(禁止)服务器拒绝请求
404 - 请求的网页不存在
503 - 服务不可用
所有状态解释:
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态代码。
代码 说明
100 (继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101 (切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)
| 代码 | 说明 |
|---|---|
| 200 | (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。 |
| 201 | (已创建) 请求成功并且服务器创建了新的资源。 |
| 202 | (已接受) 服务器已接受请求,但尚未处理。 |
| 203 | (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。 |
| 204 | (无内容) 服务器成功处理了请求,但没有返回任何内容。 |
| 205 | (重置内容) 服务器成功处理了请求,但没有返回任何内容。 |
| 206 | (部分内容) 服务器成功处理了部分 GET 请求。 |
3xx (重定向)
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
| 代码 | 说明 |
|---|---|
| 300 | (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。 |
| 301 | (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 |
| 302 | (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 |
| 303 | (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。 |
| 304 | (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。 |
| 305 | (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。 |
| 306 | 未使用) 不在使用,但保留此代码以便将来使用 |
| 307 | (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 |
4xx(请求错误)
这些状态代码表示请求可能出错,妨碍了服务器的处理。
| 代码 | 说明 |
|---|---|
| 400 | (错误请求) 服务器不理解请求的语法。 |
| 400 | (无法找到网页)可以连接到web服务器,但是由于web地址的问题,无法找到网页 |
| 401 | (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。 |
| 403 | (禁止) 服务器拒绝请求。 |
| 403 | 网站拒绝显示此页面)可以连接到网站,但没有显示网页的权限 |
| 404 | (未找到) 服务器找不到请求的网页。 |
| 405 | (方法禁用) 禁用请求中指定的方法。 |
| 406 | (不接受) 无法使用请求的内容特性响应请求的网页。 |
| 407 | (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。 |
| 408 | (请求超时) 服务器等候请求时发生超时。 |
| 409 | (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。 |
| 410 | (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。 |
| 411 | (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。 |
| 412 | (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。 |
| 413 | (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。 |
| 414 | (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。 |
| 415 | (不支持的媒体类型) 请求的格式不受请求页面的支持。 |
| 416 | (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。 |
| 417 | (未满足期望值) 服务器未满足"期望"请求标头字段的要求。 |
| 499 | (反向代理的问题)日志记录中HTTP状态码出现499错误有多种情况,比如nginx反代到一个永远打不开的后端,日志状态记录就会是499、发送字节数是0。nginx 源码中,499 对应的是 client has closed connection很有可能是因为服务器端处理的时间过长,客户端关闭了连接 |

参考:https://blog.csdn.net/wuhuagu_wuhuaguo/article/details/78671813

- 如果 nginx 日志里面的状态码是 499,则为客户端主动断开连接。可能客户端ajax请求设置了超时时间。
5xx(服务器错误)
这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
| 代码 | 说明 |
|---|---|
| 500 | (服务器内部错误) 服务器遇到错误,无法完成请求。 |
| 501 | (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。 |
| 502 | (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。 |
| 503 | (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。 |
| 504 | (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。 |
| 505 | (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本 |
陷进和常见错误
三方参考:
https://moonbingbing.gitbooks.io/openresty-best-practices/ngx/pitfalls_and_common_mistakes.html
chmod 777
永远不要 使用 777,这可能是一个漂亮的数字,有时候可以懒惰的解决权限问题, 但是它同样也表示你没有线索去解决权限问题,你只是在碰运气。 你应该检查整个路径的权限,并思考发生了什么事情。
要轻松的显示一个路径的所有权限,你可以使用:
namei -om /path/to/check
把 root 放在 location 区块内
糟糕的配置:
server {
server_name www.example.com;
location / {
root /var/www/Nginx-default/;
# [...]
}
location /foo {
root /var/www/Nginx-default/;
# [...]
}
}
这个是能工作的。把 root 放在 location 区块里面会工作,但并不是完全有效的。 错就错在只要你开始增加其他的 location 区块,就需要给每一个 location 区块增加一个 root。 如果没有添加,就会没有 root。让我们看下正确的配置。
推荐的配置:
server {
server_name www.example.com;
root /var/www/Nginx-default/;
location / {
# [...]
}
location /foo {
# [...]
}
}
重复的 index 指令
糟糕的配置:
http {
index index.php index.htm index.html;
server {
server_name www.example.com;
location / {
index index.php index.htm index.html;
# [...]
}
}
server {
server_name example.com;
location / {
index index.php index.htm index.html;
# [...]
}
location /foo {
index index.php;
# [...]
}
}
}
为什么重复了这么多行不需要的配置呢?简单的使用index指令一次就够了。只需要把它放到 http {} 区块里面,下面的就会继承这个配置。
推荐的配置:
http {
index index.php index.htm index.html;
server {
server_name www.example.com;
location / {
# [...]
}
}
server {
server_name example.com;
location / {
# [...]
}
location /foo {
# [...]
}
}
}
使用 if
这里篇幅有限,只介绍一部分使用 if 指令的陷阱。更多陷阱你应该点击看看邪恶的 if 指令。 我们看下 if 指令的几个邪恶的用法。
注意看这里:邪恶的 if 指令 Sign in to comment
用 if 判断 Server Name
糟糕的配置:
server {
server_name example.com *.example.com;
if ($host ~* ^www\.(.+)) {
set $raw_domain $1;
rewrite ^/(.*)$ $raw_domain/$1 permanent;
}
# [...]
}
}
这个配置有三个问题。首先是 if 的使用, 为啥它这么糟糕呢? 你有阅读邪恶的 if 指令吗? 当 Nginx 收到无论来自哪个子域名的何种请求, 不管域名是 www.example.com 还是 example.com,这个 if 指令 总是 会被执行。 因此 Nginx 会检查 每个请求 的 Host header,这是十分低效的。 你应该避免这种情况,而是使用下面配置里面的两个 server 指令。
推荐的配置:
server {
server_name www.example.com;
return 301 $scheme://example.com$request_uri;
}
server {
server_name example.com;
# [...]
}
除了增强了配置的可读性,这种方法还降低了 Nginx 的处理要求;我们摆脱了不必要的 if 指令; 我们用了 $scheme 来表示 URI 中是 http 还是 https 协议,避免了硬编码。
用 if 检查文件是否存在
使用 if 指令来判断文件是否存在是很可怕的,如果你在使用新版本的 Nginx, 你应该看看 try_files,这会让你的生活变得更轻松。
糟糕的配置:
server {
root /var/www/example.com;
location / {
if (!-f $request_filename) {
break;
}
}
}
推荐的配置:
server {
root /var/www/example.com;
location / {
try_files $uri $uri/ /index.html;
}
}
我们不再尝试使用 if 来判断 $uri是否存在,用try_files意味着你可以测试一个序列。 如果$uri不存在,就会尝试$uri/,还不存在的话,在尝试一个回调 location。
在上面配置的例子里面,如果$uri 这个文件存在,就正常服务; 如果不存在就检测 $uri/ 这个目录是否存在;如果不存在就按照 index.html 来处理,你需要保证 index.html 是存在的。 try_files 的加载是如此简单。这是另外一个你可以完全的消除 if 指令的实例
把不可控制的请求发给 PHP
很多网络上面推荐的和 PHP 相关的 Nginx 配置,都是把每一个.php 结尾的 URI 传递给 PHP 解释器。 请注意,大部分这样的 PHP 设置都有严重的安全问题,因为它可能允许执行任意第三方代码。
有问题的配置通常如下:
location ~* \.php$ {
fastcgi_pass backend;
# [...]
}
在这里,每一个.php结尾的请求,都会传递给 FastCGI 的后台处理程序。 这样做的问题是,当完整的路径未能指向文件系统里面一个确切的文件时, 默认的 PHP 配置试图是猜测你想执行的是哪个文件。
举个例子,如果一个请求中的/forum/avatar/1232.jpg/file.php文件不存在, 但是 /forum/avatar/1232.jpg存在,那么 PHP 解释器就会取而代之, 使用/forum/avatar/1232.jpg来解释。如果这里面嵌入了 PHP 代码, 这段代码就会被执行起来。
有几个避免这种情况的选择:
在php.ini中设置cgi.fix_pathinfo=0。 这会让 PHP 解释器只尝试给定的文件路径,如果没有找到这个文件就停止处理。
确保 Nginx 只传递指定的 PHP 文件去执行
location ~* (file_a|file_b|file_c)\.php$ {
fastcgi_pass backend;
# [...]
}
对于任何用户可以上传的目录,特别的关闭 PHP 文件的执行权限
location /uploaddir {
location ~ \.php$ {return 403;}
# [...]
}
使用 try_files 指令过滤出文件不存在的情况
location ~* \.php$ {
try_files $uri =404;
fastcgi_pass backend;
# [...]
}
使用嵌套的 location 过滤出文件不存在的情况
location ~* \.php$ {
location ~ \..*/.*\.php$ {return 404;}
fastcgi_pass backend;
# [...]
}
脚本文件名里面的 FastCGI 路径:
很多外部指南喜欢依赖绝对路径来获取你的信息。这在 PHP 的配置块里面很常见。 当你从仓库安装 Nginx,通常都是以在配置里面折腾好include fastcgi_params;来收尾。 这个配置文件位于你的 Nginx 根目录下,通常在/etc/Nginx/里面。
推荐的配置:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
糟糕的配置:
fastcgi_param SCRIPT_FILENAME /var/www/yoursite.com/$fastcgi_script_name;
$document_root在哪里设置呢?它是 server 块里面的 root 指令来设置的。 你的 root 指令不在 server 块内?请看前面关于 root 指令的陷阱
费力的 rewrites:
不要知难而退,rewrite 很容易和正则表达式混为一谈。 实际上,rewrite 是很容易的,我们应该努力去保持它们的整洁。 很简单,不添加冗余代码就行了。
糟糕的配置:
rewrite ^/(.*)$ http://example.com/$1 permanent;
好点儿的配置:
rewrite ^ http://example.com$request_uri? permanent;
更好的配置:
return 301 http://example.com$request_uri;
反复对比下这几个配置。 第一个 rewrite 捕获不包含第一个斜杠的完整 URI。 使用内置的变量 $request_uri,我们可以有效的完全避免任何捕获和匹配。
忽略http://的 rewrite:
这个非常简单,rewrites 是用相对路径的,除非你告诉 Nginx 不是相对路径。 生成绝对路径的 rewrite 也很简单,加上 scheme 就行了。
糟糕的配置:
rewrite ^ example.com permanent;
推荐的配置:
rewrite ^ http://example.com permanent;
你可以看到我们做的只是在 rewrite 里面增加了http://。这个很简单而且有效
代理所有东西
糟糕的配置:
server {
server_name _;
root /var/www/site;
location / {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_pass unix:/tmp/phpcgi.socket;
}
}
这个是令人讨厌的配置,你把 所有东西 都丢给了 PHP。 为什么呢?Apache 可能要这样做,但在 Nginx 里你不必这样。 换个思路,try_files 有一个神奇之处,它是按照特定顺序去尝试文件的。 这意味着 Nginx 可以先尝试下静态文件,如果没有才继续往后走。 这样 PHP 就不用参与到这个处理中,会快很多。 特别是如果你提供一个 1MB 图片数千次请求的服务,通过 PHP 处理还是直接返回静态文件呢? 让我们看下怎么做到吧。
推荐的配置:
server {
server_name _;
root /var/www/site;
location / {
try_files $uri $uri/ @proxy;
}
location @proxy {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_pass unix:/tmp/phpcgi.socket;
}
}
另外一个推荐的配置:
server {
server_name _;
root /var/www/site;
location / {
try_files $uri $uri/ /index.php;
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_pass unix:/tmp/phpcgi.socket;
}
}
这个很容易,不是吗?你看,如果请求的 URI 存在,Nginx 会处理掉; 如果不存在,检查下目录是不是存在,是的话也可以被 Nginx 处理; 只有在 Nginx 不能直接处理请求的 URI 的时候,才会进入 proxy 这个 location 来处理。
现在,考虑下你的请求中有多少静态内容,比如图片、css、javascript 等。这可能会帮你节省很多开销
配置的修改没有起效:
浏览器缓存。你的配置可能是对的,但怎么尝试结果总是不对,百思不得其解。 罪魁祸首是你的浏览器缓存。当你下载东西的时候,浏览器做了缓存。
怎么修复:
在 Firefox/google 里面Ctrl + Shift + Delete,检查缓存,点击立即清理。可以用你喜欢的搜索引擎找到其他浏览器清理缓存的方法。 每次更改配置后,都需要清理下缓存(除非你知道这个不必要),这会省很多事儿。
使用curl
丢失(消失)的 HTTP 头
如果你没有明确的设置underscores_in_headers on; , Nginx 将会自动丢弃带有下划线的 HTTP 头(根据 HTTP 标准,这样做是完全正当的). 这样做是为了防止头信息映射到 CGI 变量时产生歧义,因为破折号和下划线都会被映射为下划线
没有使用标准的 Document Root Location
在所有的文件系统中,一些目录永远也不应该被用做数据的托管。这些目录包括 / 和 /root。 你永远不应该使用这些目录作为你的document root。
使用这些目录的话,等于打开了潘多拉魔盒,请求会超出你的预期获取到隐私的数据。
永远也不要这样做!!! ( 对,我们还是要看下飞蛾扑火的配置长什么样子)
server {
root /;
location / {
try_files /web/$uri $uri @php;
}
location @php {
[...]
}
}
当一个对/foo 的请求,会传递给 PHP 处理,因为文件没有找到。 这可能没有问题,直到遇到/etc/passwd这个请求。没错,你刚才给了我们这台服务器的所有用户列表。 在某些情况下,Nginx 的 workers 甚至是 root 用户运行的。那么,我们现在有你的用户列表, 以及密码哈希值,我们也知道哈希的方法。这台服务器已经变成我们的肉鸡了。
Filesystem Hierarchy Standard (FHS) 定义了数据应该如何存在。你一定要去阅读下。 简单点儿说,你应该把 web 的内容 放在 /var/www/ , /srv 或者 /usr/share/www 里面。
使用默认的 Document Root
在 Ubuntu、Debian 等操作系统中,Nginx 会被封装成一个易于安装的包, 里面通常会提供一个"默认"的配置文件作为范例,也通常包含一个 document root 来保存基础的 HTML 文件。
大部分这些打包系统,并没有检查默认的 document root 里面的文件是否修改或者存在。 在包升级的时候,可能会导致代码失效。有经验的系统管理员都知道,不要假设默认的 document root 里面的数据在升级的时候会原封不动。
你不应该使用默认的 document root 做网站的任何关键文件的目录。 并没有默认的 document root 目录会保持不变这样的约定,你网站的关键数据, 很可能在更新和升级系统提供的 Nginx 包时丢失。
使用主机名来解析地址
糟糕的配置:
upstream {
server http://someserver;
}
server {
listen myhostname:80;
# [...]
}
你不应该在 listen 指令里面使用主机名。 虽然这样可能是有效的,但它会带来层出不穷的问题。 其中一个问题是,这个主机名在启动时或者服务重启中不能解析。 这会导致 Nginx 不能绑定所需的 TCP socket 而启动失败。
一个更安全的做法是使用主机名对应 IP 地址,而不是主机名。 这可以防止 Nginx 去查找 IP 地址,也去掉了去内部、外部解析程序的依赖。
例子中的 upstream location 也有同样的问题,虽然有时候在 upstream 里面不可避免要使用到主机名, 但这是一个不好的实践,需要仔细考虑以防出现问题。
推荐的配置:
upstream {
server http://10.48.41.12;
}
server {
listen 127.0.0.16:80;
# [...]
}
在 HTTPS 中使用 SSLv3
由于 SSLv3 的 POODLE 漏洞, 建议不要在开启 SSL 的网站使用 SSLv3。 你可以简单粗暴的直接禁用 SSLv3,用 TLS 来替代:
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;#协议配置
ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5;#加密套件
跨域访问
web 领域开发中,经常采用前后端分离模式。这种模式下,前端和后端分别是独立的 web 应用程序,例如:后端是 Java 程序,前端是 React 或 Vue 应用。
各自独立的 web app 在互相访问时,势必存在跨域问题。解决跨域问题一般有两种思路:
1、CORS
在后端服务器设置 HTTP 响应头,把你需要运行访问的域名加入Access-Control-Allow-Origin中。
2、jsonp
把后端根据请求,构造 json 数据,并返回,前端用 jsonp 跨域
官网:http://nginx.org/en/docs/http/ngx_http_headers_module.html
跨域是前端开发中经常会遇到的问题,前端调用后台服务时,通常会遇到No 'Access-Control-Allow-Origin' header is present on the requested resource的错误,这是因为浏览器的同源策略拒绝了我们的请求。
所谓同源是指,域名,协议,端口相同,浏览器执行一个脚本时同源的脚本才会被执行。 如果非同源,那么在请求数据时,浏览器会在控制台中报一个异常,提示拒绝访问。
这个问题我们通常会使用CORS(跨源资源共享)或者JSONP去解决,这两种方法也是使用较多的方法
定义
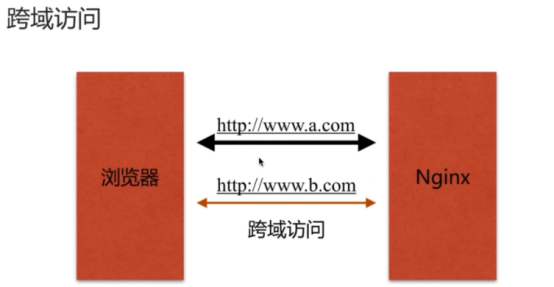
跨域是指a页面想获取b页面资源,如果a、b页面的协议、域名、端口、子域名不同,所进行的访问行动都是跨域的,而浏览器为了安全问题一般都限制了跨域访问,也就是不允许跨域请求资源。注意:跨域限制访问,其实是浏览器的限制。理解这一点很重要!!!
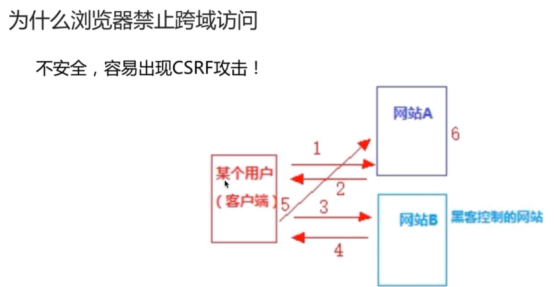
解决方案:
跨域解决方案:https://blog.51cto.com/ixdba/1928719
有多种,大多是利用JS Hack就是代码解决,还有nginx有跨越模板配置实现、nginx代理实现
1、document.domain+iframe的设置
2、动态创建script
3、利用iframe和location.hash
4、window.name实现的跨域数据传输
5、使用HTML5 postMessage
6、利用flash 以上方案见http://www.cnblogs.com/rainman/archive/2011/02/20/1959325.html#m5
7、nginx反向代理 这个方法一般很少有人提及,但是它可以不用目标服务器配合,不过需要你搭建一个中转nginx服务器,用于转发请求。
8、Jquery JSONP(本质上就是动态创建script)http://www.cnblogs.com/chopper/archive/2012/03/24/2403945.html
9、跨域资源共享(CORS) 这就是我们要介绍的跨域解决方案,也是未来的跨域问题的标准解决方案
以上都是通过代码解决

location / {
add_header Access-Control-Allow-Origin *;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header Access-Control-Allow-Methods 'GET, POST, OPTIONS';
add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization';
if ($request_method = 'OPTIONS') {
return 204;
}
}
解释
- Access-Control-Allow-Origin
服务器默认是不被允许跨域的。给Nginx服务器配置Access-Control-Allow-Origin *后,表示服务器可以接受所有的请求源(Origin),即接受所有跨域的请求。
- Access-Control-Allow-Headers 是为了防止出现以下错误:
Request header field Content-Type is not allowed by Access-Control-Allow-Headers in preflight response.
这个错误表示当前请求Content-Type的值不被支持。其实是我们发起了"application/json"的类型请求导致的。这里涉及到一个概念:预检请求(preflight request),请看下面预检请求的介绍。
- Access-Control-Allow-Methods 是为了防止出现以下错误:
Content-Type is not allowed by Access-Control-Allow-Headers in preflight response.
- 给OPTIONS 添加 204的返回,是为了处理在发送POST请求时Nginx依然拒绝访问的错误;发送
预检请求时,需要用到方法 OPTIONS ,所以服务器需要允许该方法
1.问题描述:参考https://blog.csdn.net/xiojing825/article/details/83383524 前端域名A 在POST请求后端域名为B 的一个接口时候请求成功时不存在跨域问题,请求失败时浏览器提示跨域。
解决:
当请求成功时,HTTP CODE 为200。而请求失败时HTTP CODE 为400, 此时add_header Access-Control-Allow-Origin '*'配置无效!设置无论HTTP CODE 为何值时都生效需要加 always 。nginx版本>1.7.5时候无须加always。
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*' always;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, PATCH, DELETE, PUT, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type, Access-Control-Expose-Headers, Token, Authorization';
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain charset=UTF-8';
add_header 'Content-Length' 0;
return 204;
}
add_header 'Access-Control-Allow-Origin' '*' always;
或者:nginx反向代理解决跨域
nginx反向代理 这个方法一般很少有人提及,但是他可以不用目标服务器配合,不过需要你搭建一个中转nginx服务器,用于转发请求。
禁止跨域问题其实是浏览器的一种安全行为,而现在的大多数解决方案都是用标签可以跨域访问的这个漏洞或者是技巧去完成,但都少不了目标服务器做相应的改变,如果目标服务器无法改变的时候,就需要本地服务器实现,本地实现的话,需要搭建一个nginx并把相应代码部署在它的下面,由页面请求本域名的一个地址,转由nginx代理到目标服务器处理后返回结果给页面,而且这一切都是同步的。
假如代理服务器地址是 www.c.com/proxy/html/api/msg?method=1=2; www.c.com是nginx主机地址
远端服务器地址:http://www.b.com/api/msg?method=1=2
在nginx服务器上做如下配置,在location下面再添加一个location:
location ^~/proxy/html/{
rewrite ^/proxy/html/(.*)$ /$1 break;
proxy_pass http://www.b.com/;
}
以下做一个解释:
1.^~ /proxy/html/
就像上面说的一样是一个匹配规则,用于拦截请求,匹配任何以/proxy/html/开头的地址,匹配符合以后,停止往下搜索正则。
2.rewrite ^/proxy/html/(.*)$ /$1 break;
代表重写拦截进来的请求,并且只能对域名后边的除去传递的参数外的字符串起作用,例如: www.c.com/proxy/html/api/msg?method=1=2重写。只对/proxy/html/api/msg重写。
rewrite后面的参数是一个简单的正则^/proxy/html/(.*)$ ,$1代表正则中的第一个(),$2代表第二个()的值,以此类推。
break代表匹配一个之后停止匹配
高级模块
http_secure_link_module



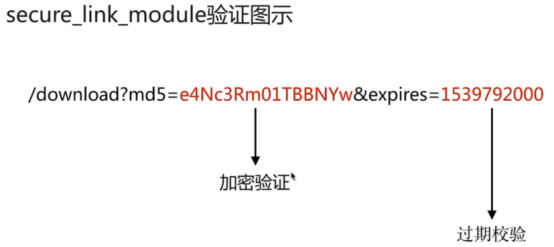
查看编译时,是否加载了模块:

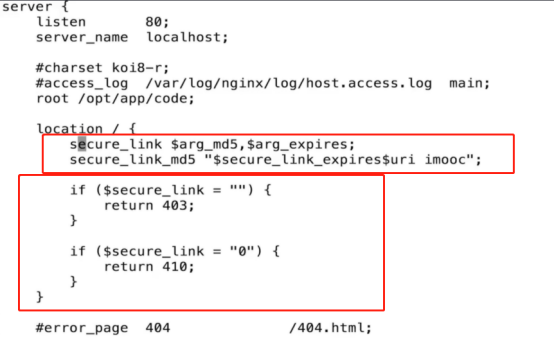
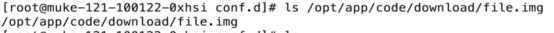

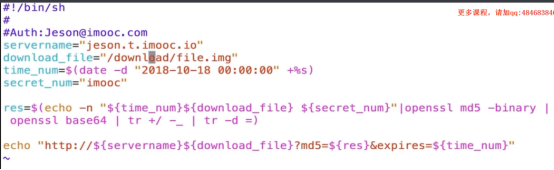

就可以用这个下载文件。
读取地域信息模块geoip
官网:http://nginx.org/en/docs/stream/ngx_stream_geoip_module.html
参考:https://wxnacy.com/2018/04/01/nginx-geoip/
https://blog.csdn.net/u012600104/article/details/80887422
https://www.jianshu.com/p/de4749970469


检查 GeoIP 是否安装
首先需要确认当前安装的 Nginx 是否安装了 GeoIP 模块,如果版本信息中包含--with-http_geoip_module,则说明已经支持该模块,如果不支持请往下看
查看是否加载了此模块
nginx -V
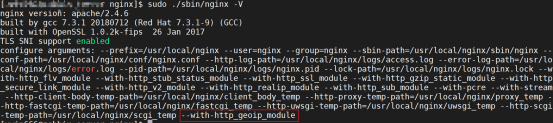
安装 GeoIP模块
Yum安装的groip模块
相关rpm包的下载地址:http://nginx.org/packages/mainline/rhel/7/x86_64/RPMS/
注意:如果nginx不是yum安装的而是源码编译安装的需要从新安装编译一次nginx加上此模块,然后就不用手动加入此模块了
yum安装模块、然后在加载到配置文件中:
yum install nginx-module-geoip

源码安装的geoip模块
首先安装依赖:
yum -y install zlib zlib-devel
编译安装 GeoIP
链接: https://pan.baidu.com/s/1dFl1zZN 密码: x37s
$ wget http://geolite.maxmind.com/download/geoip/api/c/GeoIP.tar.gz
$ tar -zxvf GeoIP.tar.gz
$ cd GeoIP-1.4.8
$ ./configure
$ make
$ make install
刚才安装的库自动安装到/usr/local/lib下,所以这个目录需要加到动态链接配置里面以便运行相关程序的时候能自动绑定到这个 GeoIP 库:
使用ldconfig将库索引到系统中:
$ echo '/usr/local/lib' > /etc/ld.so.conf.d/geoip.conf
$ ldconfig
检查库是否加载成功
$ ldconfig -v | grep GeoIP
libGeoIPUpdate.so.0 -> libGeoIPUpdate.so.0.0.0
libGeoIP.so.1 -> libGeoIP.so.1.4.8
libGeoIPUpdate.so.0 -> libGeoIPUpdate.so.0.0.0
libGeoIP.so.1 -> libGeoIP.so.1.5.0
yum安装GeoIP数据库
CentOS下安装比较简单,使用yum即可,
yum -y install gperftools
yum -y install GeoIP GeoIP-devel GeoIP-data
安装完成之后,GeoIP数据库会被安装在/usr/share/GeoIP/GeoIP.dat
使用ls命令查看
ls /usr/share/GeoIP/GeoIP.dat
将 GeoIP 模块编译到 Nginx 中
根据你当前Nginx 的安装参数带上--with-stream_geoip_module --with-http_geoip_module重新编译:
./configure \
--prefix=/usr/local/tengine232 \
--sbin-path=/usr/local/tengine232/sbin/nginx \
--conf-path=/usr/local/tengine232/conf/nginx.conf \
--http-log-path=/usr/local/tengine232/logs/access.log \
--error-log-path=/usr/local/tengine232/logs/error.log \
--pid-path=/usr/local/tengine232/run/nginx.pid \
--lock-path=/usr/local/tengine232/run/nginx.lock \
--user=nginx \
--group=nginx \
--with-http_ssl_module \
--with-http_secure_link_module \
--with-http_flv_module \
--with-http_gzip_static_module \
--with-http_mp4_module \
--with-http_gunzip_module \
--with-http_sub_module \
--with-http_stub_status_module \
--with-http_realip_module \
--with-pcre \
--with-stream \
--with-stream=dynamic \
--with-stream_ssl_module \
--with-stream_sni \
--with-stream_realip_module \
--with-stream_ssl_preread_module \
--with-threads \
--with-file-aio \
--with-http_addition_module \
--with-http_dav_module \
--with-http_random_index_module \
--http-client-body-temp-path=/usr/local/tengine232/client_body_temp \
--http-proxy-temp-path=/usr/local/tengine232/proxy_temp \
--http-fastcgi-temp-path=/usr/local/tengine232/fastcgi_temp \
--http-uwsgi-temp-path=/usr/local/tengine232/uwsgi_temp \
--http-scgi-temp-path=/usr/local/tengine232/scgi_temp \
--with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fPIC' \
--with-ld-opt='-Wl,-z,relro -Wl,-z,now -pie' \
--with-ld-opt="-Wl,-rpath,/usr/local/LuaJIT/lib/" \
--add-module=../nginx_upstream_check_module-master/ \
--add-module=/usr/local/src/ngx_devel_kit-0.3.0 \
--add-module=/usr/local/src/lua-nginx-module-0.10.15 \
--add-module=/usr/local/src/echo-nginx-module-0.62 \
--add-module=/usr/local/src/redis2-nginx-module-0.15 \
--with-http_geoip_module \ #添加下面两个参数
--with-stream_geoip_module #
$ make && make install
如果reload nginx报错:
2020/12/16 21:24:36 [emerg] 20001#20001: unknown directive "geoip_country" in /usr/local/tengine232/conf/nginx.conf:97
那么在编译nginx的时候把动态模块加上:
--with-http_geoip_module=dynamic --with-stream_geoip_module=dynamic
最后在nginx的配置文件nginx.conf中动态加载geoip模块
# head conf/nginx.conf
# load 模块
load_module "/usr/local/tengine232/modules/ngx_http_geoip_module.so";
user nginx;
error_log logs/error.log;
pid run/nginx.pid;
………………
使用 GeoIP
因为GeoIP是基于MaxMind 提供了数据库文件来读取地域信息的所以需要下载ip的地域文件。 这个数据库是二进制的,不能用文本编辑器打开,需要上面的 GeoIP 库来读取
首先查看本地是否已有 GeoIP 数据库(yum安装过就是在这个位置)
ll /usr/share/GeoIP/
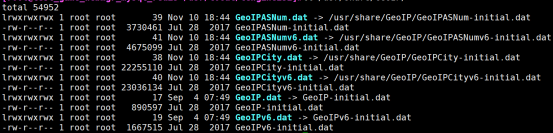
如果yum没有这两个库,则手动下载下载文件并解压:
#国家的地域IP
wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCountry/GeoIP.dat.gz
gzip -d /usr/local/share/GeoIP/GeoIP.dat.gz
http://web.archive.org/web/20181229152721/http://geolite.maxmind.com/download/geoip/database/GeoLiteCountry/GeoIP.dat.gz
#城市的地域IP
wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
gzip -d /usr/local/share/GeoIP/GeoLiteCity.dat.gz
https://2heng.xin/2019/05/11/blocking-country-and-continent-with-nginx-geoip/
DAT 版数据库官方已不再提供下载,下面的链接是祖传备份
详见:https://dev.maxmind.com/geoip/legacy/downloadable/
wget https://cloud.moezx.cc/mirrors/geoip/database/GeoIPv6.dat.gz
gzip -d -k GeoIPv6.dat.gz
# GeoIPv6.dat 覆盖了 IPv4 和 IPv6 的数据,如果仅需 IPv4,使用下面这个文件
wget https://cloud.moezx.cc/mirrors/geoip/database/GeoIP.dat.gz
将库地址配置到 nginx.conf 中这个位置:
http{
...
geoip_country /usr/share/GeoIP/GeoIP.dat;
geoip_city /usr/share/GeoIP/GeoIPCity.dat;
server {
location / {
root /www;
#判断如果是中国的就返回到/root /www/zh下面;
if( $geoip_country_code = CN ){
root /www/zh;
}
}
location / {
#判断如果不是中国的就返回403;
if ($geoip_country_code != CN) {
return 403;
}
}
#返回国家城市信息
location /myip {
default_type text/plain;
return 200 "$remote_addr $geoip_country_name $geoip_country_code $geoip_city";
}
}
}

这个if语句表示:如果这个IP是中国的,那么就返回正确网页,否则还回403
其他参数
$geoip_country_code; - 两个字母的国家代码,如:”RU”, “US”,“CN”。
$geoip_country_code3; - 三个字母的国家代码,如:”RUS”, “USA”。
$geoip_country_name; - 国家的完整名称,如:”Russian Federation”, “United States”。
$geoip_region - 地区的名称(类似于省,地区,州,行政区,联邦土地等),如:”30”。 30代码就是广州的意思
$geoip_city - 城市名称,如”Guangzhou”, “ShangHai”(如果可用)。
$geoip_postal_code - 邮政编码。
$geoip_city_continent_code。
$geoip_latitude - 所在维度。
$geoip_longitude - 所在经度
查询IP信息
geoiplookup x.x.x.x
查询IP所在经纬度
geoiplookup -f GeoLiteCity.dat x.x.x.x
nginx与Lua(鲁瓦)的开发(实现代码的灰度发布)
LUA参考文档:https://moonbingbing.gitbooks.io/openresty-best-practices/lua/main.html
参考:
http://www.dczou.com/viemall/873.html
https://i4t.com/4070.html
https://www.cnblogs.com/Eivll0m/p/6774622.html
https://www.jianshu.com/p/5167325edb09
https://www.hi-linux.com/posts/34319.html
https://blog.csdn.net/cgj296645438/article/details/88560461
http://blog.ouronghui.com/2018/08/05/Nginx-Lua-%E5%AE%9E%E7%8E%B0%E7%81%B0%E5%BA%A6%E5%8F%91%E5%B8%83/
https://vther.github.io/nginx-dark-launch/
lua语言


nginx+lua的使用场景与优势


lua的安装及基础语法

第一种方式:直接用yum安装

第二种方式:源码安装 (见nginx编译安装lua模块)
运行lua:
第一种:直接在命令输入lua

第二种:写lua的脚本,然后运行脚本


如果是局部变量,前面加一个local

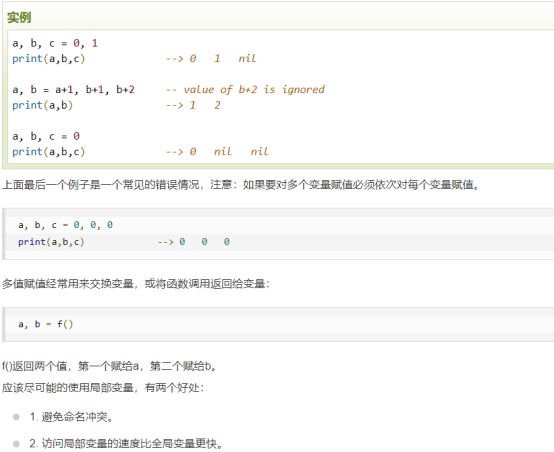

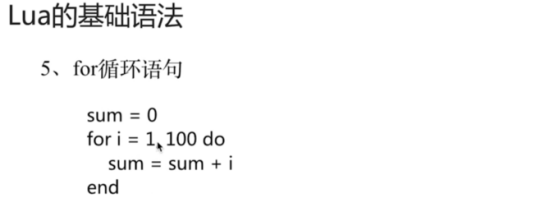




nginx调用lua模块指令
参考:https://github.com/openresty/lua-nginx-module#nginx-api-for-lua

content_by_lua_block这个指令块,它的主要作用是在HTTP的内容处理阶段生成数据
access_by_lua access_by_lua是nginx权限访问控制的一个模块,通过配置相关参数可以达到访问应用权限控制的目的
content_by_lua内容处理器,接受请求处理并输出响应
ngx.header.content_type = "application/json;charset=utf8" 控制返回数据的类型
nginx lua API
官网: https://github.com/openresty/lua-nginx-module#nginx-api-for-lua
参考:https://openresty-reference.readthedocs.io/en/latest/
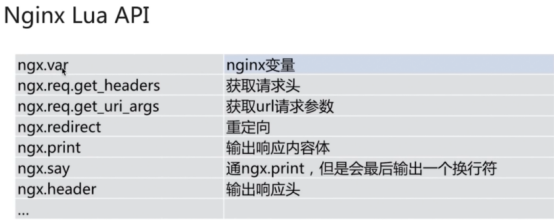
ngx.say用来返回数据
ngx.exit退出并返回状态码; ngx.exit(401)
ngx.var: nginx变量,如果要赋值如ngx.var.b = 2,此变量必须提前声明;另外对于nginx location中使用正则捕获的捕获组可以使用ngx.var[捕获组数字]获取;
ngx.req.get_headers:获取请求头,默认只获取前100,如果想要获取所以可以调用
ngx.req.get_headers(0):获取带中划线的请求头时请使用如headers.user_agent这种方式;如果一个请求头有多个值,则返回的是table;
ngx.req.get_uri_args:获取url请求参数,其用法和get_headers类似;
ngx.req.get_post_args:获取post请求内容体,其用法和get_headers类似,但是必须提前调用ngx.req.read_body()来读取body体(也可以选择在nginx配置文件使用)lua_need_request_body on;开启读取body体,但是官方不推荐);
ngx.req.raw_header:未解析的请求头字符串;
ngx.req.get_body_data:为解析的请求body体内容字符串
ngx.exec主要实现的是内部的重定向,等价于下面的rewrite指令 rewrite regrex replacement last;
使用uri、args参数来完成内部重定向,类似于echo-nginx-module 的echo_exec指令
参考:
https://www.cnblogs.com/tinywan/p/7001124.html
https://developer.aliyun.com/article/311833
语法:
syntax: ngx.exec(uri, args?)
context: rewrite_by_lua*, access_by_lua*, content_by_lua*

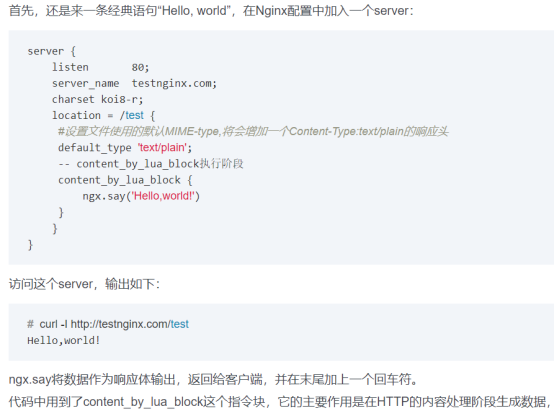
ngx.say将数据作为响应体输出,返回给客户端,并在末尾加上一个回车符。
content_by_lua_block这个指令块,它的主要作用是在HTTP的内容处理阶段生成数据
编译安装Lua的环境及模块
参考博客:
https://segmentfault.com/a/1190000014621318
http://blog.ouronghui.com/2018/08/05/Nginx-Lua-%E5%AE%9E%E7%8E%B0%E7%81%B0%E5%BA%A6%E5%8F%91%E5%B8%83/

官方网站: https://github.com/openresty/lua-nginx-module
1、安装LUA环境->LuaJIT(源码安装)
注意:让nginx支持lua,有两种方法:一是使用luajit即时编译器,二是使用lua编译器。推荐使用luajit,因为效率高
# 安装
cd /usr/local/
wget http://luajit.org/download/LuaJIT-2.0.2.tar.gz
tar -zxvf LuaJIT-2.0.2.tar.gz
cd LuaJIT-2.0.2
make install PREFIX=/usr/local/LuaJIT
# 加入环境变量:
vim /etc/profile
export LUAJIT_LIB=/usr/local/LuaJIT/lib
export LUAJIT_INC=/usr/local/LuaJIT/include/luajit-2.0
source /etc/profile
# 加载lua库
echo "/usr/local/LuaJIT/lib" >> /etc/ld.so.conf
ldconfig
2、下载并解压模块 ngx_devel_kit和lua-nginx-module
cd /usr/local
wget https://github.com/simpl/ngx_devel_kit/archive/v0.3.0.tar.gz
wget https://github.com/openresty/lua-nginx-module/archive/v0.10.9rc7.tar.gz
lua-nginx-module这里是重点啊!!!很多坑都是这个家伙带来的 一定要用v0.10.9rc7版本,我试了其他几个版本,比如说v0.10.8、v0.10.15等,都是不行的,都会遇到下面说的那些坑,只有v0.10.9rc7不会
cd /usr/local
wget https://github.com/simpl/ngx_devel_kit/archive/v0.3.0.tar.gz
wget https://github.com/openresty/lua-nginx-module/archive/v0.10.9rc7.tar.gz
3、重新编译编译Nginx
先停止nginx:
nginx -s stop
在重新编译nginx:
# wget http://nginx.org/download/nginx-1.14.2.tar.gz
# tar -zxvf nginx-1.14.2.tar.gz
cd /usr/local/nginx-1.14.2
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--http-log-path=/usr/local/nginx/logs/access.log \
--error-log-path=/usr/local/nginx/logs/error.log \
--pid-path=/usr/local/nginx/logs/nginx.pid \
--lock-path=/usr/local/nginx/logs/nginx.lock \
--with-http_ssl_module \
--with-http_flv_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-http_realip_module \
--with-http_secure_link_module \
--with-http_sub_module \
--with-pcre \
--with-stream \
--http-client-body-temp-path=/usr/local/nginx/client_body_temp \
--http-proxy-temp-path=/usr/local/nginx/proxy_temp \
--http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp \
--http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp \
--http-scgi-temp-path=/usr/local/nginx/scgi_temp \
--add-module=/usr/local/ngx_devel_kit-0.3.0 \
--add-module=/usr/local/lua-nginx-module-0.10.9rc7 #加上上面两个参数
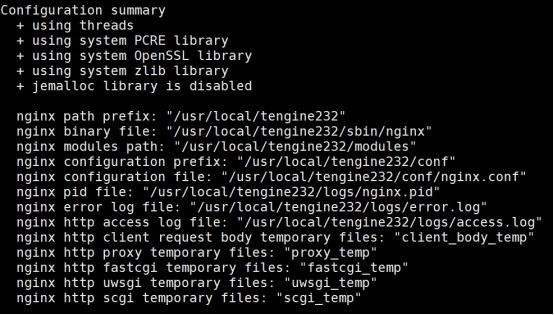
# 如若出现: 安装下面包一下即可
# error: the HTTP gzip module requires the zlib library.
# yum install zlib zlib-devel
make -j 4 && make install
4、加载lua库,加入到ld.so.conf文件
echo "/usr/local/LuaJIT/lib" >> /etc/ld.so.conf
# 然后执行如下命令
ldconfig
5、查看是否已加载模块
nginx -V
6、安装lua-resty-memcached
这里使用 memcache 来存储哪些ip要访问新的,哪些ip访问稳定的老的。
# 安装 memcach
yum install memcached
memcached -p11211 -u nobody -d
# 设置 灰度ip
telnet 127.0.0.1 11211
set 192.168.56.1 0 0 1
1
get 192.168.56.1
# 安装lua-resty-memcached
wget https://github.com/openresty/lua-resty-memcached/archive/v0.14.tar.gz
tar -zxvf v0.14.tar.gz -C /usr/local/src/
cp -r /usr/local/src/lua-resty-memcached-0.14/lib/resty /usr/local/LuaJIT/share/luajit-2.0.2/
lua来提供status服务
小例子而已,前面已经说过了,我们要针对storage做监控,根据fdfs_monitor的输出信息来监控storage节点是否处于active状态:
user nginx nginx;
worker_processes auto;
error_log /usr/local/nginx/logs/error.log;
#pid /usr/local/nginx/logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
sendfile on;
keepalive_timeout 65;
server {
listen 9092;
server_name 192.168.137.50;
location /nginx_status {
set $stat "OK";
content_by_lua '
ngx.header.content_type = "text/plain";
ngx.say(ngx.var.stat);
';
access_log logs/status.access.log main;
}
}
server {
listen 9090;
server_name 192.168.137.50;
location ~ /group1/ {
access_log logs/fast.access.log main;
ngx_fastdfs_module;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/nginx/html;
}
}
include /usr/local/nginx/conf/vhost/*.conf;
}
需要编译lua模块
返回OK说明9092端口,也就是我们的storage的web服务是正常提供的,你除了对端口做监控以外也可以根据URL做监控,显然URL做监控更好一点,端口就算在进程就算在,但是可能网页访问不了
基于 Nginx+lua+Memcache企业场景->实现灰度发布
参考:https://mp.weixin.qq.com/s/TN8iB6zZpk9eepAbiBSVRA
https://www.cnblogs.com/zy108830/p/12600387.html


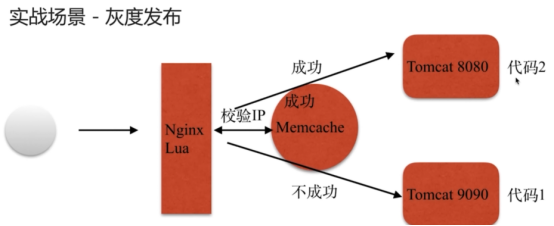
一、灰度发布原理说明
灰度发布在百度百科中解释:
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面 来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
这里的用于WEB系统新代码的测试发布,让一部分(IP)用户访问新版本,一部分用户仍然访问正常版本,其原理如图:
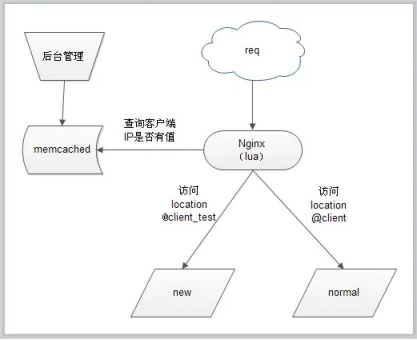
执行过程:
-
当用户请求到达前端代理服务Nginx,内嵌的lua模块解析Nginx配置文件中的lua脚本代码;
-
Lua变量获得客户端IP地址,去查询memcached缓存内是否有该键值,如果有返回值执行
@client_test,否则执行@client。 -
location @client_test把请求转发给部署了new版代码的服务器,location @client把请求转发给部署了normal版代码的服务器,服务器返回结果。整个过程完成。
二、安装配置过程详解
1、安装依赖包
yum -y install gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5 krb5-devel libidn libidn-devel openssl openssl-devel openldap openldap-devel nss_ldap openldap-clients openldap-servers make pcre-devel
yum -y install gd gd2 gd-devel gd2-devel lua lua-devel
2、安装memcached
yum -y install memcached
3、下载lua模块、lua-memcache操作库文件和nginx包
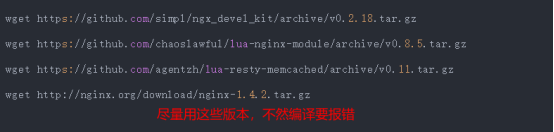
nginx建议用 nginx/1.14.2;模块版本需要与nginx版本对应
wget -c https://github.com/vision5/ngx_devel_kit/archive/v0.3.0.tar.gz
wget -c https://github.com/openresty/lua-nginx-module/archive/v0.10.15.zip #(make是报错)
wget -c https://github.com/openresty/lua-resty-memcached/archive/v0.15.zip
wget http://nginx.org/download/nginx-1.14.2.tar.gz
~~http://download.gobgm.com:8000/download/pack/nginx-1.18.0.tar.gz(不能用1.18.1)~~
4、解压编译安装
tar xvf nginx-1.14.2.tar.gz
cd nginx-1.14.2/
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--http-log-path=/usr/local/nginx/logs/access.log \
--error-log-path=/usr/local/nginx/logs/error.log \
--pid-path=/usr/local/nginx/logs/nginx.pid \
--lock-path=/usr/local/nginx/logs/nginx.lock \
--with-http_ssl_module \
--with-http_flv_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-http_realip_module \
--with-http_secure_link_module \
--with-http_sub_module \
--with-pcre \
--with-stream \
--http-client-body-temp-path=/usr/local/nginx/client_body_temp \
--http-proxy-temp-path=/usr/local/nginx/proxy_temp \
--http-fastcgi-temp-path=/usr/local/nginx/fastcgi_temp \
--http-uwsgi-temp-path=/usr/local/nginx/uwsgi_temp \
--http-scgi-temp-path=/usr/local/nginx/scgi_temp \
--add-module=/usr/local/lua/ngx_devel_kit-0.3.0 \ #加入下面模块
--add-module=/usr/local/lua/lua-nginx-module-0.10.15
5、拷贝lua的memcached操作库文件 (这里是用lua编译器结合nginx,没有用LuaJIT,但是nginx1.17.3就需要结合LuaJIT编译器)

unzip v0.15.zip
cp -r lua-resty-memcached-0.15/lib/resty/ /usr/lib64/lua/5.1/
6、配置nginx
# vim /usr/local/nginx/conf/nginx.conf
user nginx nginx;
error_log logs/error.log;
pid logs/nginx.pid;
#可以写绝对路径或者相对路径
#pid /usr/local/nginx/logs/nginx.pid;
worker_processes auto;
worker_rlimit_nofile 51200;
worker_cpu_affinity auto;
events {
use epoll;
multi_accept on;
accept_mutex on;
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
log_format main '$http_x_forwarded_for - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" ';
# server_tokens off;
sendfile on;
charset utf-8;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65 50;
keepalive_requests 100;
send_timeout 60;
client_max_body_size 100m;
client_body_buffer_size 256k;
client_header_timeout 10;
client_body_timeout 10;
reset_timedout_connection on;
client_header_buffer_size 16k;
server_names_hash_max_size 512;
server_names_hash_bucket_size 128;
proxy_connect_timeout 180;
proxy_send_timeout 180;
proxy_read_timeout 180;
proxy_buffer_size 8k;
proxy_buffers 8 64k;
proxy_busy_buffers_size 128k;
proxy_temp_file_write_size 128k;
#Gzip Compression
gzip on;
gzip_buffers 16 8k;
gzip_comp_level 6;
gzip_http_version 1.0;
gzip_min_length 1024;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
gzip_proxied any;
gzip_vary on;
gzip_types
text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xml
text/javascript application/javascript application/x-javascript
text/x-json application/json application/x-web-app-manifest+json
text/css text/plain text/x-component
font/opentype application/x-font-ttf application/vnd.ms-fontobject
image/x-icon;
#If you have a lot of static files to serve through Nginx then caching of the files' metadata (not the actual files' contents) can save some latency.
open_file_cache max=1000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
#fastcgi配置
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
#proxy cache
# proxy_cache_path /usr/local/nginx/cache/a levels=1:1 keys_zone=zone_a:10m inactive=300s max_size=5g;
# proxy_cache_path /usr/local/nginx/cache/b levels=1:2 keys_zone=zone_b:100m inactive=300s max_size=5g;
# proxy_cache_path /usr/local/nginx/cache/c levels=1:1:2 keys_zone=zone_c:100m inactive=300s max_size=5g;
#limit_conn && limit_req
# limit_conn_zone $binary_remote_addr zone=one:10m;
# limit_conn_zone $server_name zone=two:10m;
# limit_req_zone $binary_remote_addr zone=three:10m rate=1r/s;
# limit_conn_log_level error;
# limit_conn_status 503;
lua_package_path "/usr/lib64/lua/5.1/?.lua;;";
upstream client {
server 192.168.200.29:80;
}
upstream client_test {
server 192.168.200.29:81;
}
server {
listen 80;
server_name localhost;
location / {
content_by_lua '
clientIP = ngx.req.get_headers()["X-Real-IP"]
if clientIP == nil then
clientIP = ngx.req.get_headers()["x_forwarded_for"]
end
if clientIP == nil then
clientIP = ngx.var.remote_addr
end
local memcached = require "resty.memcached"
local memc, err = memcached:new()
if not memc then
ngx.say("failed to instantiate memc: ", err)
return
end
local ok, err = memc:connect("127.0.0.1", 11211)
if not ok then
ngx.say("failed to connect: ", err)
return
end
local res, flags, err = memc:get(clientIP)
if err then
ngx.say("failed to get clientIP ", err)
return
end
if res == "1" then
ngx.exec("@client_test")
return
end
ngx.exec("@client")
';
}
location @client{
proxy_pass http://client;
}
location @client_test{
proxy_pass http://client_test;
}
location /hello {
default_type 'text/plain';
content_by_lua 'ngx.say("hello, lua")';
}
# location /hello {
# set $stat "OK";
# content_by_lua '
# ngx.header.content_type = "text/plain";
# ngx.say(ngx.var.stat);
# ';
# access_log logs/status.access.log main;
# }
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/nginx/html;
#root /usr/local/nginx/html/Boundless-UI/templates;
}
}
include /usr/local/nginx/conf/vhost/*.conf;
}
7、检测配置文件
nginx -t
8、启动nginx
nginx
netstat -nutlp |grep nginx
9、启动memcached服务
memcached -u nobody -m 1024 -c 2048 -p 11211 -d
三、测试验证
测试lua模块是否运行正常
访问http://测试服务器ip地址/hello。如果显示:hello,lua表示安装成功
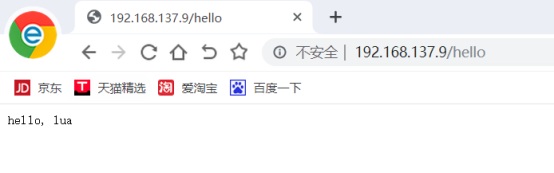
在另一台测试机(这里是192.168.200.29)设置两个虚拟主机,一个用80端口是执行正常代码,一个是81端口执行灰度测试代码
在memcached中以你的客户机IP地址为key,value值为1。这里我的IP是192.168.68.211.
telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
set 192.168.68.211 0 3600 1
1
STORED
get 192.168.68.211
VALUE 192.168.68.211 9 1
1
END
quit
注意:
-
set后第一个值为key值。
-
192.168.68.211这是key值是需要灰度测试的IP地址(就是客户端的IP地址);
-
0 表示一个跟该key有关的自定义数据;
-
3600 表示该key值的有效时间;
-
1 表示key所对应的value值的字节数
下面访问Nginx,效果符合预期,我的IP已经在memcached中存储值,所以请求转发给执行灰度测试代码的主机
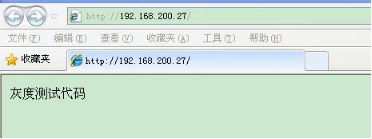
从memcached删除我的主机IP值
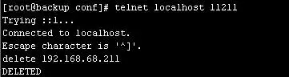
delete 192.168.68.211
再次请求Nginx,请求转发给执行正常代码内容的主机
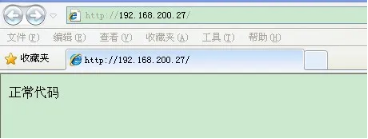
整个配置并不复杂,整个判断过程对服务的影响非常小。如果需要使用这个系统最好自己看看lua脚本
Nginx架构的安全(sql注入)
sql注入文档:
https://moonbingbing.gitbooks.io/openresty-best-practices/postgres/sql_inject.html
防sql注入:
https://moonbingbing.gitbooks.io/openresty-best-practices/openresty/safe_sql.html
nginx与lua实现防火墙






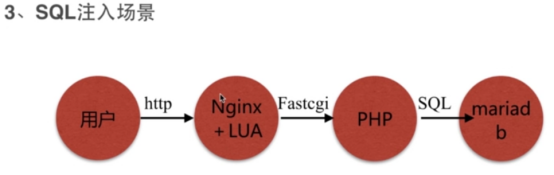

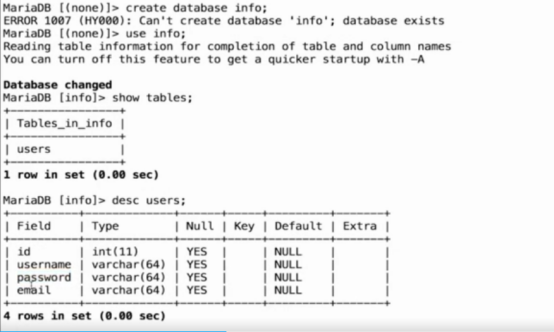
<html>
<head>
<title>welcome login</title>
<meta http-equiv=”content-type” content=”text/html;charset=utf-8”>
</head>
<body>
<from action="validate.php" method="post">
<table>
<tr>
<td>用户名:</td>
<td><input type="text" name="username"></td>
</tr>
<tr>
<td>密码:</td>
<td><input type="text" name="password"></td>
</tr>
<tr>
<td><input type="submit" value="提交"></td>
<td><input type="reset" name="重置"></td>
</tr>
</table>
</from>
</body>
</html>
<?php
$conn = mysql_connect("localhost",'root','') or die("Failed to connect to database!");
mysql_select_db("info",$conn) or die("The database you want to select does not exist");
$name=$_POST['username'];
$pwd=$_POST['password'];
$sql="select * from users where username='$name' and password='$pwd'";
echo $sql."<br /><br />";
$query=mysql_query($sql);
$arr=mysql_fetch_arry($query);
if($arr){
echo "login success!\n";
echo $arr[1];
echo $arr[3]."<br /><br />";
}else{
echo "login failed!";
}
# if(is_array($arr)){
# header("Location:manager.php");
# }else{
# echo "您 的用户名或密码有误,<a herf="Longin.php">请重新登陆! </a>";
# }
?>
访问两个页面:
用户名:' or 1=1#
密码:随意输入
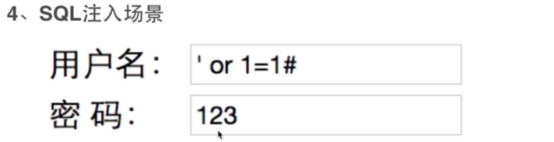
发现依然能够登陆,这表示一个SQL语句
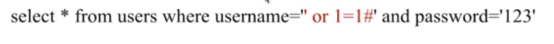

1) CC攻击的原理 一般cc攻击可以查看nginx日志来分析
CC攻击的原理就是攻击者控制某些主机不停地发大量数据包给对方服务器造成服务器资源耗尽,一直到宕机崩溃。CC主要是用来消耗服务器资源的,每个人都有这样的体验:当一个网页访问的人数特别多的时候,打开网页就慢了,CC就是模拟多个用户(多少线程就是多少用户)不停地进行访问那些需要大量数据操作(就是需要大量CPU时间)的页面,造成服务器资源的浪费,CPU长时间处于100%,永远都有处理不完的连接直至就网络拥塞,正常的访问被中止。
CC攻击的种类:
CC攻击的种类有三种,直接攻击,代理攻击,僵尸网络攻击,直接攻击主要针对有重要缺陷的 WEB 应用程序,一般说来是程序写的有问题的时候才会出现这种情况,比较少见。僵尸网络攻击有点类似于 DDOS 攻击了,从 WEB 应用程序层面上已经无法防御,所以代理攻击是CC 攻击者一般会操作一批代理服务器,比方说 100 个代理,然后每个代理同时发出 10 个请求,这样 WEB 服务器同时收到 1000 个并发请求的,并且在发出请求后,立刻断掉与代理的连接,避免代理返回的数据将本身的带宽堵死,而不能发动再次请求,这时 WEB 服务器会将响应这些请求的进程进行队列,数据库服务器也同样如此,这样一来,正常请求将会被排在很后被处理,就象本来你去食堂吃饭时,一般只有不到十个人在排队,今天前面却插了一千个人,那么轮到你的机会就很小很小了,这时就出现页面打开极其缓慢或者白屏
2) 什么是DDoS攻击? 基本无法通过日志来分析
分布式拒绝服务(Distributed Denial of Service,简称DDoS)
DDoS攻击就是分布式的拒绝服务攻击,DDoS攻击手段是在传统的DoS攻击基础之上产生的一类攻击方式。单一的DoS攻击一般是采用一对一方式的,随着计算机与网络技术的发展,DoS攻击的困难程度加大了。于是就产生了DDoS攻击,它的原理就很简单:计算机与网络的处理能力加大了10倍,用一台攻击机来攻击不再能起作用,那么DDoS就是利用更多的傀儡机来发起进攻,以比从前更大的规模来进攻受害者。常用的DDoS软件有:LOIC。
在这里补充两点:
第一就是DDOS攻击不仅能攻击计算机,还能攻击路由器,因为路由器是一台特殊类型的计算机;
第二是网速决定攻击的好和快,比如说,如果你一个被限制网速的环境下,它们的攻击效果不是很明显,但是快的网速相比之下更加具有攻击效果。
3) 两者区别
DDoS是针对IP的攻击,而CC攻击的是服务器资源。
https://github.com/loveshell/ngx_lua_waf
[root@CentOS6 /opt/download]#pwd
/opt/download
[root@CentOS6 /opt/download]#git clone https://github.com/loveshell/ngx_lua_waf.git
Initialized empty Git repository in /opt/download/ngx_lua_waf/.git/
remote: Enumerating objects: 538, done.
remote: Total 538 (delta 0), reused 0 (delta 0), pack-reused 538
Receiving objects: 100% (538/538), 82.47 KiB | 1 KiB/s, done.
Resolving deltas: 100% (298/298), done.
[root@CentOS6 /opt/download]#ls
ngx_lua_waf
[root@CentOS6 /opt/download]#cd /etc/nginx/
[root@CentOS6 /etc/nginx]#mv /opt/download/ngx_lua_waf/ ./waf/
[root@CentOS6 /etc/nginx]#cd waf/
[root@CentOS6 /etc/nginx/waf]#ls
config.lua init.lua install.sh README.md wafconf waf.lua
[root@CentOS6 /etc/nginx/waf]#vim config.lua #修改RUlePath路径,然后保存并退出
RulePath = "/etc/nginx/waf/wafconf/"
[root@CentOS6 /etc/nginx/waf]#ls wafconf/ #这就是所有规则
args cookie post url user-agent whiteurl
这些规则里面,都是一些正则表达式,实际企业中,就可以把你需要过滤掉的写入到这些规则里面。
RulePath = "/etc/nginx/waf/wafconf/" #规则的位置
attacklog = "on" #启用日志
logdir = "/usr/local/nginx/logs/hack/" #日志的位置
UrlDeny="on" #开启URL规则
Redirect="on" #一些跳转信息
CookieMatch="on" #cookie的匹配
postMatch="on" #post的请求的匹配
whiteModule="on" #白名单(可以把内部的IP添加到名单里面,以免误杀)
black_fileExt={"php","jsp"} #在上传时,禁止上传php以及jsp文件
ipWhitelist={"127.0.0.1"} #这就是白名单列表
ipBlocklist={"1.0.0.1"}
CCDeny="off" #如果是on,就开启防止cc攻击(爬虫、恶意的IP、)
CCrate="100/60" #100个/60表示每一分钟有100个就屏蔽了
html=[[ #这个html,如果发现有触犯规则的行为,它就跳转到这个页面
<html xmlns="http://www.w3.org/1999/xhtml"><head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>网站防火墙</title>
<style>
p {
line-height:20px;
}
ul{ list-style-type:none;}
li{ list-style-type:none;}
</style>
有了这些规则过后了,我们就可以在nginx集成luawaf脚本了,只需要在nginx配置文件里,http加入如下几行内容:

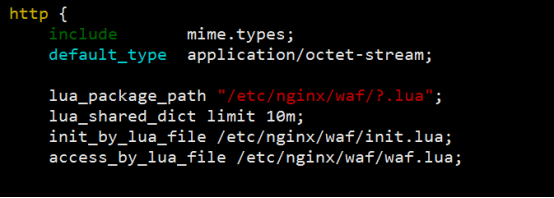
lua_package_path "/etc/nginx/waf/?.lua";
lua_shared_dict limit 10m;
init_by_lua_file /etc/nginx/waf/init.lua;
access_by_lua_file /etc/nginx/waf/waf.lua;
然后在post规则里面加入如下规则:
\sor\s+
然后进行登录,你会发现就无法用SQL注入的方式登录了。
注意:
lua_package_path "/usr/local/nginx/lua/?.lua;;"; #lua 模块
说明:#lua模块路径,多个之间;分隔,其中;;表示默认搜索路径,默认到/usr/local/nginx下找
防止cc方式攻击网站:(还有一种方案就是直接配置nginx配置文件,不需要结合lua)
这里只需要开启ccdeny,并调整次数,就可以防攻击了

登录官方网站,对应去查看:
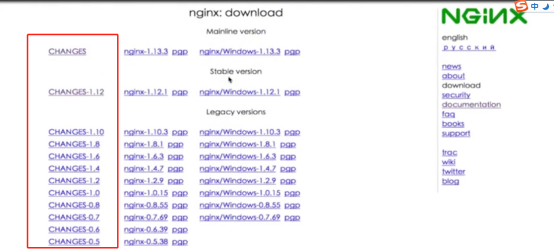
系统与Nginx的性能优化


针对全局或用户:
# vim /etc/security/limits.conf
root soft nofile 10000
root hard nofile 15535
* soft nofile 5535
* hard nofile 5535
#用户 发这个提醒 文件数 最大的大小
针对进程:vim /etc/nginx/nginx.conf(建议调到1万以上)
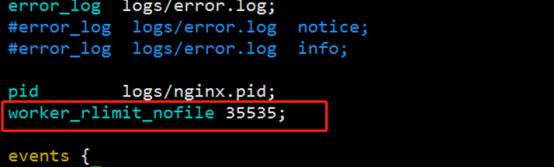
性能优化



Nginx静态资源服务的功能设计

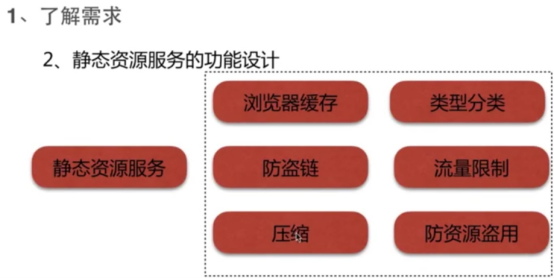
Nginx作为代理服务器的需求
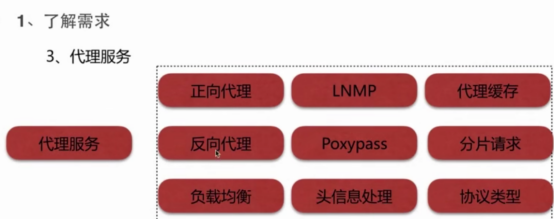
需求设计评估
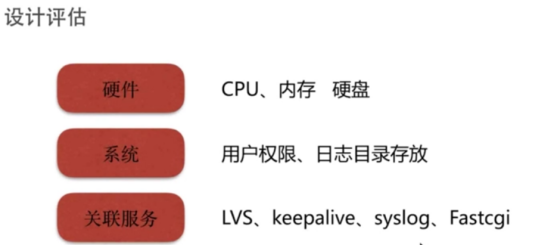
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。