- vim编辑器(可以在详细的听一听)
- vim里面的命令
- 调用外部文件或命令(掌握可以提速哦)
- vim多文件功能
- 输入带颜色的文字
- 全部替换vim里面的某些内容
- linux下查看文件编码及修改编码
- iconv -->用来转换文件的编码方式的
- dos2unix -->将DOS格式的文本文件转换成UNIX格式的
- unix2dos -->将unix下的文件格式转成dos下的文件格式
- Living Example:vim /root/.vimrc:打开vim过后显示保存自己存储的格式
- Living Example:在windows中编辑好的汉字文本文档,上传到Linux下打开乱码(系统中必须先安装好中文包)
- Living Example:解决将Linux服务器上的脚本导到windows上打开串行的问题
vim编辑器(可以在详细的听一听)
参考:https://vimjc.com
vim里面的命令
命令历史
以:和/开头的命令都有历史纪录,可以首先键入:或/然后按上下箭头来选择某个历史命令。
导航命令
% 括号匹配 (全部匹配的时候可以用到)
启动vim,在命令行窗口中输入以下命令即可
vim filename # 打开vim并创建名为filename的文件
vim +/keyword /etc/passwd # 打开是直接跳转到keyword处
vim +NUM /etc/passwd # 打开是直接跳转到NUM行处
vim -b file # 二进制方式打开文件
vim -d file1 file2.... # 打开并比较多个文件,不同处并以高亮显示
vim -m file # 以只读方式打开文件
文件命令
| vim file | 打开单个文件 |
|---|---|
| :open file | 在vim窗口中打开一个新文件 |
| :split file | 在新窗口中打开文件 |
| :bn | 切换到下一个文件 |
| :bp | 切换到上一个文件 |
| :args | 查看当前打开的文件列表,当前正在编辑的文件会用[]括起来 |
| vim file1 file2 file3 ... | 同时打开多个文件 |
|---|---|
| :e ftp://192.168.10.76/abc.txt | 打开远程文件,比如ftp |
| :e \qadrive\test\1.txt | 打开远程文件,比如share folder |
vim的模式
正常模式(按
Esc或Ctrl+[进入) 左下角显示文件名或为空 插入模式(按i键进入) 左下角显示-- INSERT -- 可视模式(按v键进入) 左下角显示-- VISUAL --
插入:
| a | 在光标所在位置的后面插入 |
|---|---|
| A | 在光标所在位置的行尾插入 |
| o | 在光标所在行的下一行插入 |
| O | 在光标所在行的上面一行插入 |
| i | 在光标所在位置插入 |
| I | 在光标所在位置的行首插入 |
删除:
| 快捷键 | 用途 |
|---|---|
| dl | 删除当前字符,dl=x |
| x或者delete | 一个一个删除当前的字符 |
| 3x | 删除当前光标开始向后三个字符 |
| dh | 删除前一个字符 |
| ndd | 删除从光标所处的行起始的共n行 |
| dd | 删除当前光标所在行 |
| dj | 删除上一行 |
| dk | 删除下一行 |
| ddp | 对换光标所在行与光标下一行内容 - 手速要快哈,要不 dd 就删除当前行了,哈哈哈 |
| ci" | 先将光标定位到两个引号中间,然后依次输入 ci" ,快速删除光标所在的引号中间的全部内容(非常适用于配置文件中的参数修改,墙裂推荐,如果是删除单引号中间的内容,将 ci" 中的双引号改成单引号即可,即 ci') |
| dgg | 删除当前光标之前所有行内容 |
| dG | 删除当前光标之后所有行内容 |
| kdgg | 删除当前行之前所有行(不包括当前行) |
| jdG | 删除当前行之后所有行(不包括当前行) |
| d^ | 删除当前光标以及“之前”的所有本行内容 |
| d$或者D | 删除当前光标以及“之后”的所有本行内容 |
| dw | 删除当前光标之后的单词[能删除空白字符] |
| de | 删除当前光标之后的单词[不能删除空白字符] |
| db | 删除当前光标之前的单词 |
| :%d | 删除全文内容 |
| :1,$d | 删除全文内容 |
| :1,10d | 删除1-10行 |
| :11,$d | 删除11行及以后所有的行 |
| :1,$d | 删除所有行 |
| J(shift + j) | 删除两行之间的空行,实际上是合并两行。 |


eg:
ra 将当前字符替换为a,当前字符即光标所在字符

移动:
k、j、h、l:光标上下左右移动一个字符
以上四个命令可以配合数字使用,比如20j就是向下移动20行,5h就是向左移动5个字符,在Vim中,很多命令都可以配合数字使用,比如删除10个字符10x,在当前位置后插入3个!,3a!<Esc>,这里的Esc是必须的,否则命令不生效。
w 向前移动一个单词(光标停在单词首部),如果已到行尾,则转至下一行行首。此命令快,可以代替l命令。
e 同w,只不过是光标停在单词尾部
b 向后移动一个单词 2b 向后移动2个单词
ge 同b,光标停在单词尾部。
ctrl+左右方向键也可以
^ 移动到本行第一个非空白字符上
$ 移动到行尾 3$ 移动到下面3行的行尾
0或者home(数字0) 移动到本行第一个字符上,
home/end 针对本行的首末位置
H/L 针对本屏跳转到行首
nG 可跳转到文件的第n行
ngg 光标移动到文件内容的的n行
G 光标移动到文件内容的末行
冒号+行号 回车跳到指定行,比如跳到240行就是 :240回车。另一个方法是行号+G,比如230G跳到230行。
行之间的跳转:
-向上一个行进行跳转到该行的行首
+向下一个句子进行跳转到该行的行首
句子之间的跳转:
)向上一个句子进行跳转
(向下一个句子进行跳转
段间跳转:
}向上一个段进行跳转
{向下一个段进行跳转
翻屏查看:
Ctrl + e 向下滚动一行
Ctrl + y 向上滚动一行
Ctrl + d 向下滚动半屏
Ctrl + u 向上滚动半屏
Ctrl + f 向下滚动一屏
Ctrl + b 向上滚动一屏
复制粘贴
p 在当前光标后粘贴,如果之前使用了yy命令来复制一行,那么就在当前行的下一行粘贴。
shift+p 在当前行前粘贴
nyy:在光标处的行开始复制n行的内容
:1,10 co 20 将1-10行插入到第20行之后。
:1,$ co $ 将整个文件复制一份并添加到文件尾部。
正常模式下按v(逐字)或V(逐行)进入可视模式,然后用jklh命令移动即可选择某些行或字符,再按y即可复制
ddp交换当前行和其下一行
xp交换当前字符和其后一个字符

剪切命令
:1,10d 将1-10行剪切。利用p命令可将剪切后的内容进行粘贴。
:1, 10 m 20 将第1-10行移动到第20行之后。
ndd 剪切或者删除n行
正常模式下按v(逐字)或V(逐行)进入可视模式,然后用jklh命令移动即可选择某些行或字符,再按d即可剪切
Vim自带自动补齐功能
https://vimjc.com/vim-auto-complement.html
一、单词补全
Ctrl + n:当输入完第一个字母后,再按Ctrl + n,Vim会自动出现下拉菜单,且默认选中第一个单词,继续按 Ctrl + n 可以上下选择,但如果缓冲区没有可选单词,那么下拉列表不会有任何选项
Ctrl + p:功能同上,只是默认选中的是列表最后一个单词
二、行补全
在Vim插入模式下输入已经存在行的第一个单词,再按Ctrl + x、Ctrl + l命令,就会列出该整行出来实现Vim行自动补全
三、字典补全
地址定界[在末行模式下进行编辑]
:start_position[,end_pos]
num:特定的第num行,例如:5即第5行
.:当前行
%:全文
$:最后一行 ($-NUM:倒数的NUM $-2:倒数的2行)
NUM1,NUM2:指定范围,左侧为起始行,右侧为结束行(.,$-5)
NUM1,NUM2:指定范围,左侧为起始行绝对编号,右侧为相对左侧行号的偏移量;例如:3,+7
撤销:
NUM+u 撤销此前的NUM步
U 撤销对整行的操作
ctrl+r 撤销之前的撤销命令
ctrl +s 删除本行内容,并进入插入模式
查找与替换:
/ keywords 正向
?keywords 反向查找
n,N:跳到下一个匹配的内容,跳到上一个匹配的内容
-----------------------------------------------------------
s:末行模式的命令
Grammar:
s/要查找的内容/替换为的内容/修饰符
s@要查找的内容@替换为的内容@修饰符
s#要查找的内容#替换为的内容#修饰符
要查找的内容:模式的匹配[使用正则表达式]
替换的内容,不能使用正则表达式,但是可以引用
如果“要查找的内容”部分在模式中使用分组符号:在“替换为的内容”中使用后向引用;直接引用查找模式匹配全部文本,要使用%s符号;
修饰符:
i:忽略大小写
g:全局替换,意味着一行中如果配置到多次,则均替换
c:询问是否做替换
Living Example:
:s/root/hello/ 用root替换hello,替换当前行的第一个匹配
:s/root/hello/g 用root替换hello,替换当前行的所有匹配
:s/root/hello/ig 用root替换hello,替换当前行的所有匹配,且忽略大小写
:%s/root/hello/g 用root替换hello,替换整个文件的所有匹配
:6,11 s/^/#/g 在第6行至第11行前面每行加一个”#”,用于注释 添加注释换可以下“v“模式下操作
:%s@^/etc@#&@ 为/etc开头的行添加注释
:10,20 s/^/ /g 在第10行知第20行每行前面加四个空格,用于缩进。
:g/^\s*$/d 删除全文的空白行
:%s/xyz/&er/g xyz替换成xyzer

v模式:
v:选择需要的内容,然后y复制,然后p粘贴
NUM+V(shift+v):选择NUM整行内容,然后y复制,然后p粘贴
shift+v:选择整行,如果按上下键,可以连续选择整行的内容,然后进行操作(复制、粘贴、剪切等)

如何批量注释多行, 我找到一个很好的解决方法,学会此方法,效率提高不只一点点啊.
1、ctrl+v使用方向键上下选择范围;
2、shift+i进入编辑模式,添加"#"。随后按两次esc退出(也可理解为运行批量添加);此时批注已加好
批量删除添加的注释行.
ctrl+v使用方向键上下选择去除批注的范围,按"x";
注释命令
perl程序中#开始的行为注释,所以要注释某些行,只需在行首加入#
| 3,5 s/^/#/g | 注释第3-5行 |
|---|---|
| 3,5 s/^#//g | 解除3-5行的注释 |
| 1,$ s/^/#/g | 注释整个文档。 |
| :%s/^/#/g | 注释整个文档,此法更快 |
保存与退出:
| :wq | 保存并退出 |
|---|---|
| :w /path/Newfilename | 另存为文件 |
| :x | 保存退出 |
| ZQ | 不保存退出 |
| Shift+zz | 保存并退出(不用到末行模式也可以保存退出) |
| q、q! | (退出、强制退出) |
| qa | 退出全部 |
| :e! | 放弃所有修改,并打开原来文件。 |

调用外部文件或命令(掌握可以提速哦)
假如:我想要写入我的网卡MAC地址,我想查看一下,当前在vim编辑文档,照着写,这样超级麻烦
在命令行模式下操作:
:!command
:!ifconfig 调用系统命令
读取其他文件。(把其他文件中的内容追加到当前文档中)
:r /etc/passwd
读取其内容并写入到改文件中
:r!command
vim多文件功能
:sp (进行分屏)
Ctrl+w:快速在多个窗口进行切换
:q退出一个文件
:wqall保存所有文件并退出
:wall 写入全部文档
:first回到第一个
:last最后一个
:next切换到下一个
:prev上一个

vim的多窗口模式:
-o:水平分割窗口对文档进行查看
-O:垂直分割窗口对文档进行查看
Notice:
单个文件也可以分割为多个窗口进行查看:
ctrl+w, s:水平分割窗口
ctrl+w, v垂直分割窗口

帮助命令
:help or F1 显示整个帮助
:help xxx 显示xxx的帮助,比如 :help i, :help CTRL-[(即Ctrl+[的帮助)。
:help 'number' VimOption的帮助用单引号括起
:help <Esc> 特殊键的帮助用<>扩起
:help -t Vim启动参数的帮助用-
:help i_<Esc> 插入模式下Esc的帮助,某个模式下的帮助用模式_主题的模式
帮助文件中位于||之间的内容是超链接,可以用Ctrl+]进入链接,Ctrl+o(Ctrl + t)返回

其他非编辑命令
. 重复前一次命令
:set ruler? 查看是否设置了ruler,在.vimrc中,使用set命令设制的Option都可以通过这个命令查看
:scriptnames 查看vim脚本文件的位置,比如.vimrc文件,Grammar文件及plugin等。
:set list 显示非打印字符,如tab,空格,行尾等。如果tab无法显示,请确定用set lcs=tab:>-命令设置了.vimrc文件,并确保你的文件中的确有tab,如果开启了expendtab,那么tab将被扩展为空格。
vim中有一些特殊字符在查找时需要转义 .*[]^%/?~$
:set ignorecase 忽略大小写的查找
:set noignorecase 不忽略大小写的查找
查找很长的词,如果一个词很长,键入麻烦,可以将光标移动到该词上,按*或#键即可以该单词进行搜索,相当于/搜索。而#命令相当于?搜索。
:set hlsearch 高亮搜索结果,所有结果都高亮显示,而不是只显示一个匹配。
:set nohlsearch 关闭高亮搜索显示
:nohlsearch 关闭当前的高亮显示,如果再次搜索或者按下n或N键,则会再次高亮。
:set incsearch 逐步搜索模式,对当前键入的字符进行搜索而不必等待键入完成。
:set wrapscan 重新搜索,在搜索到文件头或尾时,返回继续搜索,默认开启。



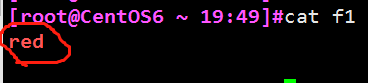
输入带颜色的文字
在插入模式下按这三个组合键:ctrl + v + [[1;31mred ctrl + v + [0m
组合键内容组合键内容

最终效果如下:
全部替换vim里面的某些内容
几个常用的方法如下:
:%s/foo/bar/g
把全部foo替换为bar,全局替换
:s/foo/bar/g
当前行替换foo为bar
:%s/foo/bar/gc
替换每个foo为bar,但需要确认.
:%s/\<foo\>/bar/gc
单词匹配替换, 需确认
:%s/foo/bar/gci
忽略foo大小写,替换为bar, 需确认
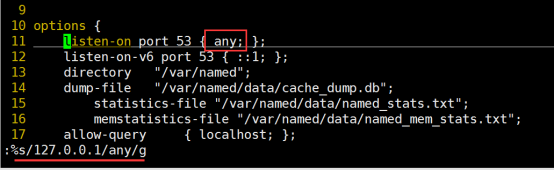
Living Example:把所有的127.0.0.1换成any
linux下查看文件编码及修改编码
查看文件编码
在Linux中查看文件编码可以通过以下几种方式:
1.在Vim中可以直接查看文件编码
:set fileencoding
即可显示文件编码格式。
如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,那么你可以在
~/.vimrc 文件中添加以下内容:
set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936
这样,就可以让vim自动识别文件编码(可以自动识别UTF-8或者GBK编码的文件),其实就是依照 fileencodings提供的编码列表尝试,如果没有找到合适的编码,就用latin-1(ASCII)编码打开。
2. enca (如果你的系统中没有安装这个命令,可以用sudo yum install -y enca 安装 )查看文件编码
$ enca filename
filename: Universal transformation format 8 bits; UTF-8
CRLF line terminators
需要说明一点的是,enca对某些GBK编码的文件识别的不是很好,识别时会出现:
Unrecognized encoding
查看文件编码file命令
file ip.txt
ip.txt: UTF-8 Unicode text, with escape sequences
文件编码转换
1.在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式
:set fileencoding=utf-8
2. enconv 转换文件编码,比如要将一个GBK编码的文件转换成UTF-8编码,操作如下
enconv -L zh_CN -x UTF-8 filename
3. iconv 转换,iconv的命令格式如下:
iconv -f encoding -t encoding inputfile
比如将一个UTF-8 编码的文件转换成GBK编码
iconv -f UTF-8 -t GBK file1 -o file2
一、利用iconv命令进行编码转换文件内容编码转换
iconv命令用于转换指定文件的编码,默认输出到标准输出设备,亦可指定输出文件。
用法: iconv [Option...] [文件...]
有如下选项可用:
输入/输出格式规范:
-f, --from-code=名称 原始文本编码 -t, --to-code=名称 输出编码 信息:
-l, --list 列举所有已知的字符集 输出控制:
-c 从输出中忽略无效的字符
-o, --output=FILE 输出文件 -s, --silent 关闭警告
--verbose 打印进度信息
-?, --help 给出该系统求助列表
--usage 给出简要的用法信息
-V, --version 打印程序版本号
例子: iconv -f utf-8 -t gb2312 aaa.txt >bbb.txt
这个命令读取aaa.txt文件,从utf-8编码转换为gb2312编码,其输出定向到bbb.txt文件
二、文件名编码转换
因为现在用linux,原来在windows里的文件都是用GBK编码的。所以copy到linux下是乱码,文件内容可以用iconv来转换可是好多中文的文件名还是乱码,找到个可以转换文件名编码的命令,就是convmv。
convmv命令详细参数 例如
convmv -f GBK -t UTF-8 *.mp3
不过这个命令不会直正的转换,你可以看到转换前后的对比。如果要直正的转换要加上参数--notest
convmv -f GBK -t UTF-8 --notest *.mp3
-f 参数是指出转换前的编码,
-t 是转换后的编码。这个千万不要弄错了。不然可能还是乱码哦。还有一个参数很有用。就是 -r 这个表示递归转换当前目录下的所有子目录。
需要安装 convmv-1.10-1.el5.noarch.rpm
三、更好的傻瓜型命令行工具enca,它不但能智能的识别文件的编码,而且还支持成批转换。
1.安装 $sudo apt-get install enca
2.查看当前文件编码 enca -L zh_CN ip.txt
Simplified Chinese National Standard; GB2312 Surrounded by/intermixed with non-text data
pasting
3.转换 命令格式如下
$enca -L 当前语言 -x 目标编码 文件名
例如要把当前目录下的所有文件都转成utf-8
enca -L zh_CN -x utf-8 *
检查文件的编码 enca -L zh_CN file
将文件编码转换为"UTF-8"编码 enca -L zh_CN -x UTF-8 file
如果不想覆盖原文件可以这样 enca -L zh_CN -x UTF-8 < file1 > file2
iconv -->用来转换文件的编码方式的
iconv命令是用来转换文件的编码方式的,比如它可以将UTF8编码的转换成GB18030的编码,反过来也行。JDK中也提供了类似的工具native2ascii。Linux下的iconv开发库包括iconv_open,iconv_close,iconv等C函数,可以用来在C/C++程序中很方便的转换字符编码,这在抓取网页的程序中很有用处,而iconv命令在调试此类程序时用得着。
Grammar
iconv [-f encoding] [-t encoding] [inputfile ...]
Option
-l :列出已知的编码字符集合
-f encoding :=名称 原始文本编码。
-t encoding :=输出编码。
-o file :指定输出文件
-c :忽略输出的非法字符
-s :禁止警告信息,但不是错误信息
--verbose :显示进度信息
-f和-t所能指定的合法字符在-lOption的命令里面都列出来了。
Living Example
列出当前支持的字符编码:
iconv -l
将文件file1转码,转后文件输出到fil2中:
iconv file1 -f EUC-JP-MS -t UTF-8 -o file2
这里,没-o那么会输出到标准输出。
Living Example:[root@test-6 test]# iconv -f gb2312 -t utf8 aaa.txt -o xx.txt
将aaa.txt文件的编码gb2312转成utf8,并输出到xx.txt
dos2unix -->将DOS格式的文本文件转换成UNIX格式的
dos2unix命令用来将DOS格式的文本文件转换成UNIX格式的(DOS/MAC to UNIX text file format converter)。DOS下的文本文件是以\r\n作为断行标志的,表示成十六进制就是0D0A。而Unix下的文本文件是以\n作为断行标志的,表示成十六进制就是0A。DOS格式的文本文件在Linux底下,用较低版本的vi打开时行尾会显示\^M,而且很多命令都无法很好的处理这种格式的文件,如果是个shell脚本。而Unix格式的文本文件在Windows下用Notepad打开时会拼在一起显示。因此产生了两种格式文件相互转换的需求,对应的将UNIX格式文本文件转成成DOS格式的是unix2dos命令。
Grammar
dos2unix [-hkqV] [-c convmode] [-o file ...] [-n infile outfile...]
Option
-k:保持输出文件的日期不变
-q:安静模式,不提示任何警告信息。
-V:查看版本
-c:转换模式,模式有:ASCII, 7bit, ISO, Mac, 默认是:ASCII。
-o:写入到源文件
-n:写入到新文件
参数
参数:需要转换到文件。
Living Example
最简单的用法就是dos2unix直接跟上文件名:
dos2unix file
如果一次转换多个文件,把这些文件名直接跟在dos2unix之后。(注:也可以加上-o参数,也可以不加,效果一样)
dos2unix file1 file2 file3
dos2unix -o file1 file2 file3
上面在转换时,都会直接在原来的文件上修改,如果想把转换的结果保存在别的文件,而源文件不变,则可以使用-n参数。
dos2unix oldfile newfile
如果要保持文件时间戳不变,加上-k参数。所以上面几条命令都是可以加上-k参数来保持文件时间戳的。
dos2unix -k file
dos2unix -k file1 file2 file3
dos2unix -k -o file1 file2 file3
dos2unix -k -n oldfile newfile
unix2dos -->将unix下的文件格式转成dos下的文件格式
Grammar:
unix2dos FileName
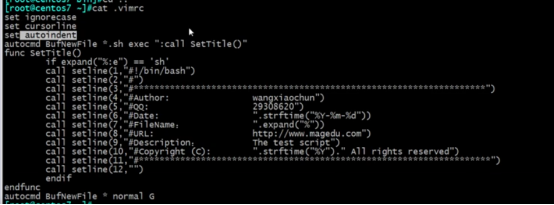
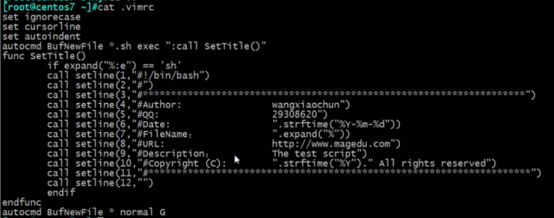
Living Example:vim /root/.vimrc:打开vim过后显示保存自己存储的格式
:syntax on 高亮显示
:set cursorline 水平线
:set tabstop=4 tab为4个空格
:set nu 显示行号
:set nonu
:noh (取消查询的高亮显示)
如果卸载配置文件/root/.vimrc时,这时不需要前面的冒号

如果是在vim里面就需要这么些 :syntax on,前面需要加冒号。
Notice:
[root@test-6 ~]# vim /root/.vimrc # 针对root用户
[root@test-6 ~]# vim /etc/vimrc # 针对所有用户
Living Example:在windows中编辑好的汉字文本文档,上传到Linux下打开乱码(系统中必须先安装好中文包)
[root@test-6 tmp]# cat aaa.txt
#/bin/bash
NAME=$1
LINE=$(cat $NAME | wc -l)
echo "˽ؖ¸뻺$LINE"
LINE1=$(echo "$LINE*0.08"|bc|awk '{print sprintf("%d",$0);}')
echo "˽ؖ¸뽵¶%:$LINE1"
sort -nr $1 | tail -n $LINE1 > ./${NAME}_bak
SUM=$(cat ./${NAME}_bak | awk '{sum+=$1} END {print sum}')
SUM1=$(echo "$SUM $LINE1" | awk '{print sprintf("%f",$1/$2);}')
echo "خС˽ֵº˺$SUM"
echo "ƽ¾㸤SUM1"
原因:编码问题
[root@test-6 test]# iconv -f gb2312 -t utf8 aaa.txt
#/bin/bash
NAME=$1
LINE=$(cat $NAME | wc -l)
echo "数字总个数:$LINE"
LINE1=$(echo "$LINE*0.08"|bc|awk '{print sprintf("%d",$0);}')
echo "数字总个数的6%:$LINE1"
sort -nr $1 | tail -n $LINE1 > ./${NAME}_bak
SUM=$(cat ./${NAME}_bak | awk '{sum+=$1} END {print sum}')
SUM1=$(echo "$SUM $LINE1" | awk '{print sprintf("%f",$1/$2);}')
echo "最小数值总和:$SUM"
echo "平均值:$SUM1"
Living Example:解决将Linux服务器上的脚本导到windows上打开串行的问题
安装dos2nuix:
[root@test-6 tmp]# yum install unix2dos
[root@test-6 tmp]# unix2dos www (unix2dos filename)
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。