- 免费的Kubernetes在线实验平台介绍2(官网提供的在线系统)
- 安装kubernetes方法
- 通过kubeadm方式在centos7.6上安装kubernetes v1.14.2集群
- 通过kudeadm方式在centos7上安装kubernetes v1.26.3集群
- 二进制安装部署kubernetes集群-->建议首先部署docker
- 组件版本和配置策略
- 系统初始化
- 创建 CA 证书和秘钥
- 部署 kubectl 命令行工具
- 部署 etcd 集群
- 部署 flannel 网络(UDP:8472)
- 部署 master 节点
- 部署 worker 节点--->建议首先部署docker
- 验证集群功能
- 部署集群插件
- 部署 harbor 私有仓库
- 清理集群
- 二进制部署kubernetes多主多从集群
免费的Kubernetes在线实验平台介绍2(官网提供的在线系统)
现在我们已经了解了Kubernetes核心概念的基本知识,你可以进一步阅读Kubernetes 用户手册。用户手册提供了快速并且完备的学习文档。
如果迫不及待想要试试Kubernetes,可以使用Google Container Engine。Google Container Engine是托管的Kubernetes容器环境。简单注册/登录之后就可以在上面尝试示例了。
Play with Kubernetes 介绍
博客参考:
https://www.hangge.com/blog/cache/detail_2420.html
https://www.hangge.com/blog/cache/detail_2426.html
PWK 官网地址:https://labs.play-with-k8s.com/
(1)Play with Kubernetes一个提供了在浏览器中使用免费CentOS Linux虚拟机的体验平台,其内部实际上是Docker-in-Docker(DinD)技术模拟了多虚拟机/PC 的效果。
(2)Play with Kubernetes平台有如下几个特色:
-
允许我们使用 github 或 dockerhub 账号登录
-
在登录后会开始倒计时,让我们有 4 小时的时间去实践
-
K8s 环境使用 kubeadm 来部署(使用用 weave 网络)
-
平台共提供 5 台 centos7 设备供我们使用(docker 版本为 17.09.0-ce)
(1)首先访问其网站,并使用github 或dockerhub 账号进行登录。
(2)登录后点击页面上的Start 按钮,我们便拥有一个自己的实验室环境
(3)单击左侧的"Add New Instance" 来创建第一个Kubernetes 集群节点。它会自动将其命名为"node1",这个将作为我们群集的主节点
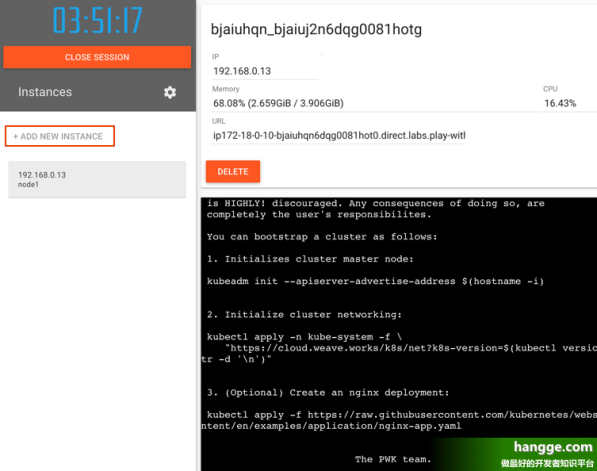
(4)由于刚创建的主节点IP 是192.168.0.13,因此我们执行如下命令进行初始化:
kubeadm init --apiserver-advertise-address 192.168.0.13 --pod-network-cidr=10.244.0.0/16
(5)初始化完毕完成之后,界面上会显示kubeadm join命令,这个用于后续node 节点加入集群使用,需要牢记
(6)接着还需要执行如下命令安装Pod 网络(这里我们使用flannel),否则Pod 之间无法通信。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
(7)最后我们执行kubectl get nodes 查看节点状态,可以看到目前只有一个Master 节点
(8)我们单击左侧的"Add New Instance"按钮继续创建4个节点作为node 节点
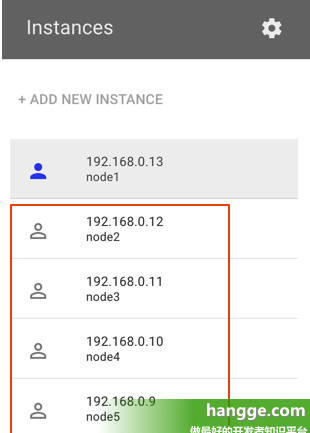
(9)这4个节点都执行类似如下的kubeadm join命令加入集群(即之前master 节点初始化完成后红框部分内容)
kubeadm join 192.168.0.13:6443 --token opip9p.rh35kkvqzwjizely --discovery-token-ca-cert-hash sha256:9252e13d2ffd3569c40b02c477f59038fac39aade9e99f282a333c0f8c5d7b22
(10)最后我们在主节点执行kubectl get nodes查看节点状态,可以看到一个包含有5 个节点集群已经部署成功了
安装kubernetes方法
方法1:使用kubeadm 安装kubernetes(本文演示的就是此方法)
-
优点:你只要安装
kubeadm即可;kubeadm会帮你自动部署安装K8S集群;如:初始化K8S集群、配置各个插件的证书认证、部署集群网络等;安装简易。 -
缺点:不是自己一步一步安装,可能对K8S的理解不会那么深;并且有那一部分有问题,自己不好修正。
方法2:二进制安装部署kubernetes(详见下篇kubernetes系列04--二进制安装部署kubernetes集群)
-
优点:K8S集群所有东西,都由自己一手安装搭建;清晰明了,更加深刻细节的掌握K8S;哪里出错便于快速查找验证。
-
缺点:安装较为繁琐麻烦,且易于出错
通过kubeadm方式在centos7.6上安装kubernetes v1.14.2集群
https://www.qikqiak.com/post/use-kubeadm-install-kubernetes-1.15.3/
kubeadm部署3节点kubernetes1.13.0集群(master节点x1,node节点x2)
集群部署博客参考:
https://www.hangge.com/blog/cache/detail_2414.html
https://blog.csdn.net/networken/article/details/84991940
https://zhuyasen.com/post/k8s.html
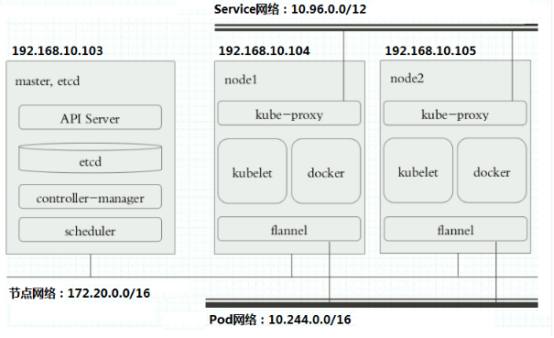
节点详细信息
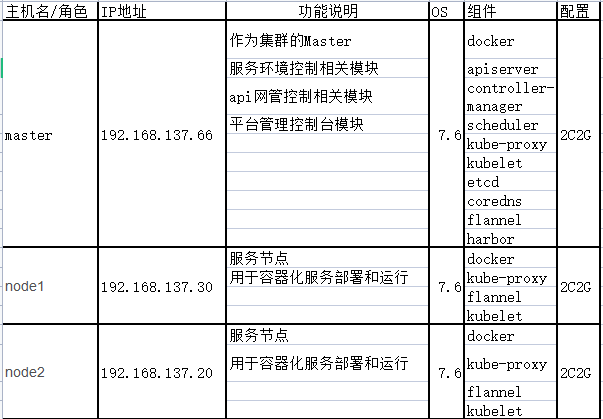
K8S搭建安装示意图
一、Docker安装
所有节点(master and node)都需要安装docker,部署的是Docker version 19.03.2
二、k8s安装准备工作
安装Centos是已经禁用了防火墙和selinux并设置了阿里源。master和node节点都执行本部分操作
1. 配置主机
1.1 修改主机名(主机名不能有下划线)
[root@centos7 ~]# hostnamectl set-hostname master
[root@centos7 ~]# cat /etc/hostname
master
退出重新登陆即可显示新设置的主机名master
1.2 修改hosts文件
[root@master ~]# cat >> /etc/hosts << EOF
192.168.137.66 master
192.168.137.30 node01
192.168.137.20 node02
EOF
2. 同步系统时间
$ yum -y install ntpdate && ntpdate time1.aliyun.com
$ crontab -e #写入定时任务
1 */2 * * * /usr/sbin/ntpdate time1.aliyun.com
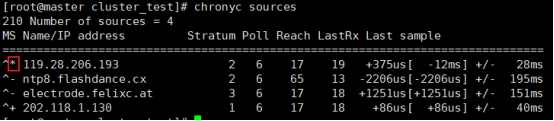
centos7默认已启用chrony服务,执行chronyc sources命令,查看存在以*开头的行,说明已经与NTP服务器时间同步
3. 验证mac地址uuid
[root@master ~]# cat /sys/class/net/ens33/address
[root@master ~]# cat /sys/class/dmi/id/product_uuid
保证各节点mac和uuid唯一
4. 禁用swap
为什么要关闭swap交换分区?
Swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定--ignore-preflight-errors=Swap来解决
解决主机重启后kubelet无法自动启动问题:https://www.hangge.com/blog/cache/detail_2419.html
由于K8s必须保持全程关闭交换内存,之前我安装是只是使用swapoff -a 命令暂时关闭swap。而机器重启后,swap 还是会自动启用,从而导致kubelet无法启动
3.1 临时禁用
[root@master ~]# swapoff -a

3.2 永久禁用
若需要重启后也生效,在禁用swap后还需修改配置文件/etc/fstab,注释swap
[root@master ~]# sed -i.bak '/swap/s/^/#/' /etc/fstab
或者修改内核参数,关闭swap
echo "vm.swappiness = 0" >> /etc/sysctl.conf
swapoff -a && swapon -a && sysctl -p
或者:Swap的问题:要么关闭swap,要么忽略swap
[root@elk-node-1 ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
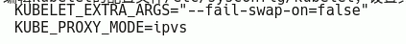
5. 关闭防火墙、SELinux
在每台机器上关闭防火墙:
① 关闭服务,并设为开机不自启
$ sudo systemctl stop firewalld
$ sudo systemctl disable firewalld
② 清空防火墙规则
$ sudo iptables -F && sudo iptables -X && sudo iptables -F -t nat && sudo iptables -X -t nat
$ sudo iptables -P FORWARD ACCEPT
-F 是清空指定某个 chains 内所有的 rule 设定
-X 是删除使用者自定 iptables 项目
1、关闭 SELinux,否则后续 K8S 挂载目录时可能报错 Permission denied :
$ sudo setenforce 0
2、修改配置文件,永久生效;
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
6. 内核参数修改
开启 bridge-nf-call-iptables,如果 Kubernetes 环境的网络链路中走了 bridge 就可能遇到上述 Service 同节点通信问题,而 Kubernetes 很多网络实现都用到了 bridge。
启用 bridge-nf-call-iptables 这个内核参数 (置为 1),表示 bridge 设备在二层转发时也去调用 iptables 配置的三层规则 (包含 conntrack),所以开启这个参数就能够解决上述 Service 同节点通信问题,这也是为什么在 Kubernetes 环境中,大多都要求开启 bridge-nf-call-iptables 的原因。
RHEL / CentOS 7上的一些用户报告了由于iptables被绕过而导致流量路由不正确的问题
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决上面的警告:打开iptables内生的桥接相关功能,已经默认开启了,没开启的自行开启(1表示开启,0表示未开启)
# cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
1
# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1

4.1 自动开启桥接功能
临时修改
[root@master ~]# sysctl net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-iptables = 1
[root@master ~]# sysctl net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-ip6tables = 1
[root@master ~]# sysctl net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
或者用echo也行:
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
echo 1 > /proc/sys/net/bridge/bridge-nf-call-ip6tables
4.2 永久修改
[root@master ~]# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
[root@master ~]# sysctl -p /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1 #Docker从1.13版本开始调整了默认的防火墙规则,禁用了iptables filter表中FOWARD链,导致pod无法通信
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
7. 加载ipvs相关模块
由于ipvs已经加入到了内核的主干,所以为kube-proxy开启ipvs的前提需要加载以下的内核模块:
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
在所有的Kubernetes节点执行以下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
执行脚本
[root@master ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4

上面脚本创建了/etc/sysconfig/modules/ipvs.modules文件,保证在节点重启后能自动加载所需模块。 使用lsmod | grep -e ip_vs -e nf_conntrack_ipv4命令查看是否已经正确加载所需的内核模块。
进行配置时会报错modprobe: FATAL: Module nf_conntrack_ipv4 not found.
这是因为使用了高内核,一般教程都是3.2的内核。在高版本内核已经把nf_conntrack_ipv4替换为nf_conntrack了
接下来还需要确保各个节点上已经安装了ipset软件包。 为了便于查看ipvs的代理规则,最好安装一下管理工具ipvsadm。
ipset是iptables的扩展,可以让你添加规则来匹配地址集合。不同于常规的iptables链是线性的存储和遍历,ipset是用索引数据结构存储,甚至对于大型集合,查询效率非常都优秀。
# yum install ipset ipvsadm -y
8. 修改Cgroup Driver
5.1 修改daemon.json
# docker info | grep -i cgroup #默认是cgroupfs
Cgroup Driver: cgroupfs
修改daemon.json,新增: "exec-opts": ["native.cgroupdriver=systemd"]
[root@master ~]# vim /etc/docker/daemon.json
{
"oom-score-adjust": -1000,
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 10,
"bip": "172.17.0.1/16",
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"],
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"live-restore": true
}
# docker info |grep -i cgroup #有可能systemd不支持,无法启动,就需要改回cgroupfs
Cgroup Driver: systemd
5.2 重新加载docker
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart docker
修改cgroupdriver是为了消除告警:
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
9. 设置kubernetes源(在阿里源)
6.1 新增kubernetes源
[root@master ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
解释:
[] 中括号中的是repository id,唯一,用来标识不同仓库
name 仓库名称,自定义
baseurl 仓库地址
enable 是否启用该仓库,默认为1表示启用
gpgcheck 是否验证从该仓库获得程序包的合法性,1为验证
repo_gpgcheck 是否验证元数据的合法性 元数据就是程序包列表,1为验证
gpgkey=URL 数字签名的公钥文件所在位置,如果gpgcheck值为1,此处就需要指定gpgkey文件的位置,如果gpgcheck值为0就不需要此项了
6.2 更新缓存
[root@master ~]# yum clean all
[root@master ~]# yum -y makecache
三、Master节点安装->对master节点也需要docker
完整的官方文档可以参考:
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
1. 版本查看
[root@master ~]# yum list kubelet --showduplicates | sort -r
[root@master ~]# yum list kubeadm --showduplicates | sort -r
[root@master ~]# yum list kubectl --showduplicates | sort -r
目前最新版是 1.16.0,该版本支持的docker版本为1.13.1, 17.03, 17.06, 17.09, 18.06, 18.09
2. 安装指定版本kubelet、kubeadm和kubectl
官方安装文档可以参考:https://kubernetes.io/docs/setup/independent/install-kubeadm/
2.1 安装三个包
[root@master ~]# yum install -y kubelet-1.14.2 kubeadm-1.14.2 kubectl-1.14.2
若不指定版本直接运行 yum install -y kubelet kubeadm kubectl 则默认安装最新版
ps:由于官网未开放同步方式, 可能会有索引gpg检查失败的情况, 这时请用 yum install -y --nogpgcheck kubelet kubeadm kubectl 安装
Kubelet的安装文件:
[root@elk-node-1 ~]# rpm -ql kubelet
/etc/kubernetes/manifests #清单目录
/etc/sysconfig/kubelet #配置文件
/usr/bin/kubelet #主程序
/usr/lib/systemd/system/kubelet.service #unit文件
2.2 安装包说明
-
kubelet 运行在集群所有节点上,用于启动Pod和containers等对象的工具,维护容器的生命周期
-
kubeadm 安装K8S工具,用于初始化集群,启动集群的命令工具
-
kubectl K8S命令行工具,用于和集群通信的命令行,通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
2.3 配置并启动kubelet
配置启动kubelet服务
(1)修改配置文件
[root@master ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
#KUBE_PROXY=MODE=ipvs
echo 'KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"' > /etc/sysconfig/kubelet
(2)启动kubelet并设置开机启动:
[root@master ~]# systemctl enable kubelet && systemctl start kubelet && systemctl enable --now kubelet
虽然启动失败,但是也得启动,否则集群初始化会卡死
此时kubelet的状态,还是启动失败,通过journalctl -xeu kubelet能看到error信息;只有当执行了kubeadm init后才会启动成功。
因为K8S集群还未初始化,所以kubelet 服务启动不成功,下面初始化完成,kubelet就会成功启动,但是还是会报错,因为没有部署flannel网络组件
搭建集群时首先保证正常kubelet运行和开机启动,只有kubelet运行才有后面的初始化集群和加入集群操作。
查找启动kubelet失败原因:查看启动状态
systemctl status kubelet
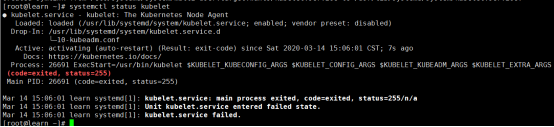
提示信息kubelet.service failed.
查看报错日志
tail /var/log/messages
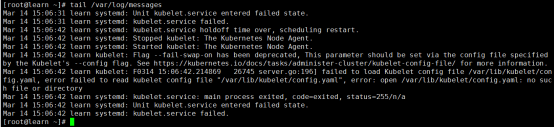
2.4 kubectl命令补全
kubectl 主要是对pod、service、replicaset、deployment、statefulset、daemonset、job、cronjob、node资源的增删改查
# 安装kubectl自动补全命令包
[root@master ~]# yum install -y bash-completion
# source /usr/share/bash-completion/bash_completion
# source <(kubectl completion bash)
# 添加的当前shell
[root@master ~]# echo "source <(kubectl completion bash)" >> ~/.bash_profile
[root@master ~]# source ~/.bash_profile
# 查看kubectl的版本:
[root@master ~]# kubectl version

3. 下载镜像(建议采取脚本方式下载必须的镜像)
3.1 镜像下载的脚本
Kubernetes几乎所有的安装组件和Docker镜像都放在goolge自己的网站上,直接访问可能会有网络问题,这里的解决办法是从阿里云镜像仓库下载镜像,拉取到本地以后改回默认的镜像tag。
可以通过如下命令导出默认的初始化配置:
$ kubeadm config print init-defaults > kubeadm.yaml
如果将来出了新版本配置文件过时,则使用以下命令转换一下:更新kubeadm文件
# kubeadm config migrate --old-config kubeadm.yaml --new-config kubeadmnew.yaml
打开该文件查看,发现配置的镜像仓库如下:
imageRepository: k8s.gcr.io
在国内该镜像仓库是连不上,可以用国内的镜像代替:
imageRepository: registry.aliyuncs.com/google_containers
采用国内镜像的方案,由于coredns的标签问题,会导致拉取coredns:v1.3.1拉取失败,这时候我们可以手动拉取,并自己打标签。
打开init-config.yaml,然后进行相应的修改,可以指定kubernetesVersion版本,pod的选址访问等。
查看初始化集群时,需要拉的镜像名
kubeadm config images list
kubernetes镜像拉取命令:
kubeadm config images pull --config=kubeadm.yaml
=======================一般采取改方式下载镜像====================
# 或者用以下方式拉取镜像到本地
[root@master ~]# vim image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.14.2
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
#采用国内镜像的方案,由于coredns的标签问题,会导致拉取coredns:v1.3.1拉取失败,这时候我们可以手动拉取,并自己打标签。
# another image
# docker pull coredns/coredns:1.3.1 && \
docker tag k8s.gcr.io/coredns:latest k8s.gcr.io/coredns/coredns:v1.3.1
docker rmi k8s.gcr.io/coredns:latest
解释:url为阿里云镜像仓库地址,version为安装的kubernetes版本
3.2 下载镜像
运行脚本image.sh,下载指定版本的镜像
[root@master ~]# bash image.sh
[root@master ~]# docker images|grep k8s

https://www.cnblogs.com/kazihuo/p/10184286.html
### k8s.gcr.io 地址替换
将k8s.gcr.io替换为
registry.cn-hangzhou.aliyuncs.com/google_containers
或者
registry.aliyuncs.com/google_containers
或者
mirrorgooglecontainers
### quay.io 地址替换
将 quay.io 替换为
quay.mirrors.ustc.edu.cn
### gcr.io 地址替换
将 gcr.io 替换为 registry.aliyuncs.com
====================也可以通过dockerhub先去搜索然后pull下来============
[root@master ~]# cat image.sh
#!/bin/bash
images=(kube-apiserver:v1.15.1 kube-controller-manager:v1.15.1 kube-scheduler:v1.15.1 kube-proxy:v1.15.1 pause:3.1 etcd:3.3.10)
for imageName in ${images[@]}
do
docker pull mirrorgooglecontainers/$imageName && \
docker tag mirrorgooglecontainers/$imageName k8s.gcr.io/$imageName &&\
docker rmi mirrorgooglecontainers/$imageName
done
#another image
docker pull coredns/coredns:1.3.1 && \
docker tag coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
将这些镜像打包推到别的机器上去:
[root@master ~]# docker save -o kubeall.gz k8s.gcr.io/kube-apiserver:v1.15.1 k8s.gcr.io/kube-controller-manager:v1.15.1 k8s.gcr.io/kube-scheduler:v1.15.1 k8s.gcr.io/kube-proxy:v1.15.1 k8s.gcr.io/pause:3.1 k8s.gcr.io/etcd:3.3.10 k8s.gcr.io/coredns:1.3.1
4. 初始化Master
kubeadm init安装失败后需要重新执行,此时要先执行kubeadm reset命令。
kubeadm --help
kubeadm init --help
集群初始化如果遇到问题,可以使用kubeadm reset命令进行清理然后重新执行初始化,然后接下来在 master 节点配置 kubeadm 初始化文件,可以通过如下命令导出默认的
4.1 初始化
获取初始化配置并利用配置文件进行初始化:
$ kubeadm config print init-defaults > kubeadm.yaml
在master节点操作
kubeadm init --config kubeadm.yaml --upload-certs
建议用下面的方式初始化:
[root@master ~]# kubeadm init \
--apiserver-advertise-address=192.168.137.50 \
--kubernetes-version=v1.14.2 \
--apiserver-bind-port 6443 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--ignore-preflight-errors=Swap
--image-repository registry.aliyuncs.com/google_containers 这里不需要更换仓库地址,因为我们第三步的时候已经拉取的相关的镜像

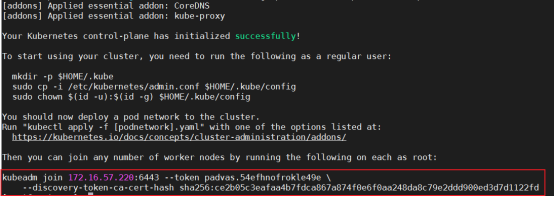
kubeadm join 192.168.137.66:6443 --token fz80zd.n9hihtiiedy38dta \
--discovery-token-ca-cert-hash sha256:837e3c07125993cd1486cddc2dbd36799efb49af9dbb9f7fd2e31bf1bdd810ae
记录kubeadm join的输出,后面需要这个命令将各个节点加入集群中
(注意记录下初始化结果中的kubeadm join命令,部署worker节点时会用到)
[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
解释:
--apiserver-advertise-address:指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface
--apiserver-bind-port 6443 :apiserver端口
--kubernetes-version:指定kubeadm版本;我这里下载的时候kubeadm最高时1.14.2版本 --kubernetes-version=v1.14.2。关闭版本探测,因为它的默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.13.1)来跳过网络请求
--pod-network-cidr:指定Pod网络的范围,这里使用flannel(10.244.0.0/16)网络方案;Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr 有自己的要求,这里设置为 10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR
--service-cidr:指定service网段
--image-repository:Kubenetes默认Registries地址是 k8s.gcr.io,在国内并不能访问gcr.io,在1.13版本中我们可以增加--image-repository参数,默认值是 k8s.gcr.io,将其指定为阿里云镜像地址:registry.aliyuncs.com/google_containers
--ignore-preflight-errors=Swap/all:忽略 swap/所有 报错
--ignore-preflight-errors=NumCPU #如果您知道自己在做什么,可以使用'--ignore-preflight-errors'进行非致命检查
--ignore-preflight-errors=Mem
--config string 通过文件来初始化k8s。 Path to a kubeadm configuration file.
初始化过程说明:
1.[init] Using Kubernetes version: v1.22.4
2.[preflight] kubeadm 执行初始化前的检查。
3.[certs] 生成相关的各种token和证书
4.[kubeconfig] 生成 KubeConfig 文件,kubelet 需要这个文件与 Master 通信
5.[kubelet-start] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
6.[control-plane] 安装 Master 组件,如果本地没有相关镜像,那么会从指定的 Registry 下载组件的 Docker 镜像。
7.[bootstraptoken] 生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
8.[addons] 安装附加组件 kube-proxy 和 coredns。
9.Kubernetes Master 初始化成功,提示如何配置常规用户使用kubectl访问集群。
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
10.提示如何安装 Pod 网络。
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
11.提示如何注册其他节点到 Cluster
开启了kube-apiserver 的6443端口:
[root@master ~]# ss -tanlp|grep 6443

各个服务的端口:master初始化过后各个服务就正常启动了
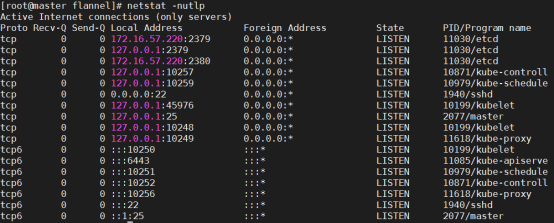
查看docker运行了那些服务了:

# systemctl status kubelet.service
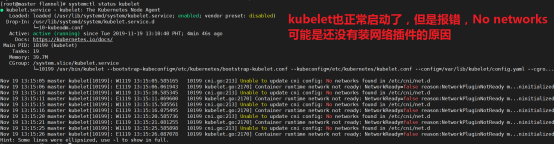
是没有装flannel的原因,装了重启kubelet就正常了:
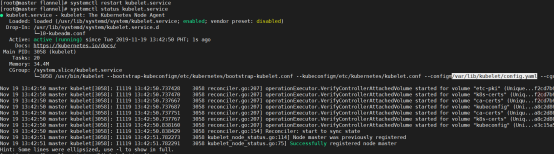
# ll /etc/kubernetes/#生成了各个组件的配置文件
total 36
-rw------- 1 root root 5453 Nov 19 13:10 admin.conf
-rw------- 1 root root 5485 Nov 19 13:10 controller-manager.conf
-rw------- 1 root root 5461 Nov 19 13:10 kubelet.conf
drwxr-xr-x 2 root root 113 Nov 19 13:10 manifests
drwxr-xr-x 3 root root 4096 Nov 19 13:10 pki
-rw------- 1 root root 5437 Nov 19 13:10 scheduler.conf
5. 配置kubectl
4.1 配置 kubectl->加载环境变量
kubectl 是管理 Kubernetes Cluster 的命令行工具, Master 初始化完成后需要做一些配置工作才能使用kubectl,这里直接配置root用户:(实际操作时只配置root用户,部署flannel会报错,最后也把node节点用户也弄上)

如果k8s服务端提示The connection to the server localhost:8080 was refused - did you specify the right host or port?出现这个问题的原因是kubectl命令需要使用kubernetes-admin来运行
[root@master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master ~]# source ~/.bash_profile
4.2 普通用户可以参考 kubeadm init 最后提示:
复制admin.conf并修改权限,否则部署flannel网络插件报下面错误
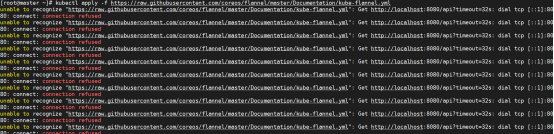
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
4.3 node节点支持kubelet:
如果不做这个操作:node操作集群也会报错如下

scp /etc/kubernetes/admin.conf node1:/etc/kubernetes/admin.conf
scp /etc/kubernetes/admin.conf node2:/etc/kubernetes/admin.conf
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
Kubernetes 集群默认需要加密方式访问,以上操作就是将刚刚部署生成的 Kubernetes 集群的安全配置文件保存到当前用户的.kube目录下,kubectl默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置
最后就可以使用kubctl命令了:
[root@master ~]# kubectl get nodes #NotReady 是因为还没有安装网络插件
NAME STATUS ROLES AGE VERSION
master NotReady control-plane,master 37m v1.22.4
[root@master ~]# kubectl get pod -A #-A查看 所以pod
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcd69978-78kn4 0/1 Pending 0 33m
kube-system coredns-78fcd69978-nkcx5 0/1 Pending 0 33m
kube-system etcd-master 1/1 Running 0 33m
kube-system kube-apiserver-master 1/1 Running 0 33m
kube-system kube-controller-manager-master 1/1 Running 1 33m
kube-system kube-proxy-bv42k 1/1 Running 0 33m
kube-system kube-scheduler-master 1/1 Running 1 33m
如果pod处于失败状态,那么不能用kubectl logs -n kube-system coredns-78fcd69978-78kn4 来查看日志。只能用 kubectl logs -n kube-system coredns-78fcd69978-78kn4 来看错误信息
这里没有coredns启动失败是因为还没有部署网络插件
[root@master ~]# kubectl get ns #查看命令空间
NAME STATUS AGE
default Active 37m
kube-node-lease Active 37m
kube-public Active 37m
kube-system Active 37m
[root@master ~]# kubectl get svc #切记不要删除这个svc,这是集群最基本的配置
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 47m
10.96.0.1 这个地址就是初始化集群时指定的--service-cidr=10.96.0.0/12 ,进行分配的地址
6. 安装pod网络->就是flannel网络插件
【注意】:正常在生产环境不能这么搞,flannel一删除,所有Pod都不能运行了,因为没有网络。系统刚装完就要去调整flannel
Deploying flannel manually
文档地址:https://github.com/coreos/flannel
要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信。
Kubernetes 支持多种网络方案,这里我们使用 flannel
Pod正确运行,并且默认会分配10.244.开头的集群IP
如果kubernetes是新版本,那么flannel也可以直接用新版。否则需要找一下对于版本
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
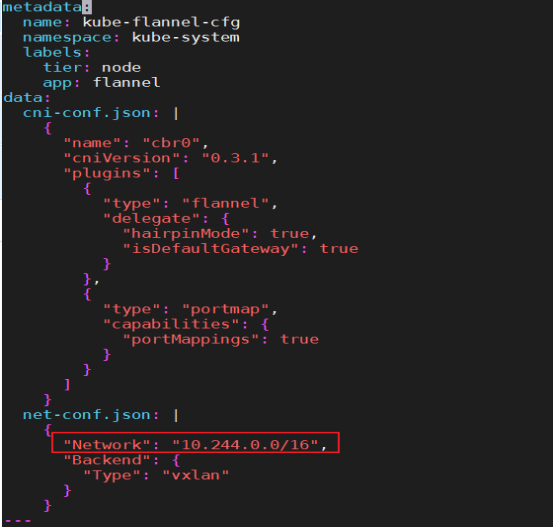
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
或者直接下载阿里云的吧(但是新版本apply报错):

https://github.com/coreos/flannel/raw/master/Documentation/kube-flannel-aliyun.yml
(2)看到下载好的flannel 的镜像
[root@master ~]# docker image ls |grep flannel

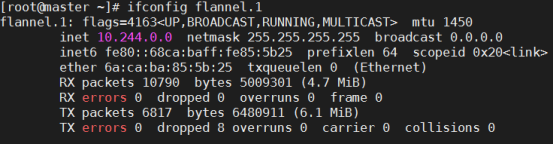
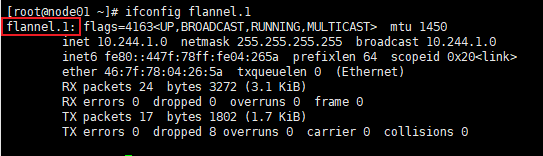
[root@master ~]# ifconfig flannel.1
# netstat -nutlp|grep 8472 #UDP端口
(3)验证
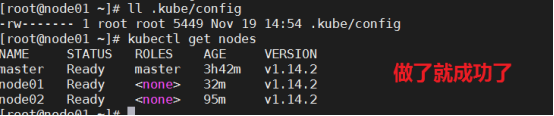
① master节点已经Ready #安装了flannel后,master就Ready
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 42m v1.14.2
发现主节点在notready状态,因为还没安装网络插件,列如:funnel
② 查询kube-system名称空间下
语法:kubectl get pods -n kube-system(指定名称空间) |grep flannel
[root@master ~]# kubectl get pods -n kube-system |grep flannel
kube-flannel-ds-amd64-jcrhm 1/1 Running 0 16m

[root@master ~]# kubectl logs -n kube-system kube-flannel-ds-amd64-jcrhm #查看日志
可以看到,所有的系统 Pod 都成功启动了,而刚刚部署的flannel网络插件则在 kube-system 下面新建了一个名叫kube-flannel-ds-amd64-jcrhm的 Pod,一般来说,这些 Pod就是容器网络插件在每个节点上的控制组件。
Kubernetes 支持容器网络插件,使用的是一个名叫 CNI 的通用接口,它也是当前容器网络的事实标准,市面上的所有容器网络开源项目都可以通过 CNI 接入 Kubernetes,比如 Flannel、Calico、Canal、Romana 等等,它们的部署方式也都是类似的"一键部署"
如果pod提示Init:ImagePullBackOff,说明这个pod的镜像在对应节点上拉取失败,我们可以通过 kubectl describe pod pod_name 查看 Pod 具体情况,以确认拉取失败的镜像
[root@master ~]# kubectl describe pod kube-flannel-ds-amd64-jcrhm --namespace=kube-system
可能无法从 quay.io/coreos/flannel:v0.10.0-amd64 下载镜像,可以从阿里云或者dockerhub镜像仓库下载,然后改回kube-flannel.yml文件里对应的tag即可:
docker pull registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.10.0-amd64
docker tag registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.10.0-amd64 quay.io/coreos/flannel:v0.10.0-amd64
docker rmi registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.10.0-amd64
7. 使用kubectl命令查询集群信息
查询组件状态信息:确认各个组件都处于healthy状态
[root@master ~]# kubectl get cs || kubectl get componentstatus #查看组件状态
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
为什么没有apiservice呢? ->你能查到信息,说明apiservice以及运行成功了
查询集群节点信息(如果还没有部署好flannel,所以节点显示为NotReady):
[root@master ~]# kubectl get nodes || kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION
master Ready master 107m v1.14.2
# kubectl get node -o wide #详细信息
# kubectl describe node master #更加详细信息,通过 kubectl describe 指令的输出,我们可以看到 Ready 的原因在于,我们已经部署了网络插件
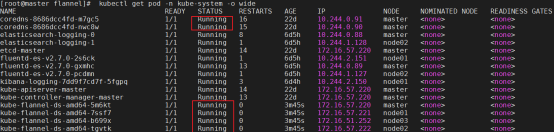
[root@master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcd69978-78kn4 1/1 Running 0 96m
kube-system coredns-78fcd69978-nkcx5 1/1 Running 0 96m
kube-system etcd-master 1/1 Running 0 96m
kube-system kube-apiserver-master 1/1 Running 0 96m
kube-system kube-controller-manager-master 1/1 Running 1 96m
kube-system kube-flannel-ds-4xz74 1/1 Running 0 13m
kube-system kube-proxy-bv42k 1/1 Running 0 96m
kube-system kube-scheduler-master 1/1 Running 1 96m
coredns已经成功启动
查询名称空间,默认:
[root@master ~]# kubectl get ns
NAME STATUS AGE
default Active 107m
kube-node-lease Active 107m
kube-public Active 107m
kube-system Active 107m
我们还可以通过 kubectl 检查这个节点上各个系统 Pod 的状态,其中,kube-system 是 Kubernetes 项目预留的系统 Pod 的工作空间(Namepsace,注意它并不是 Linux Namespace,它只是 Kubernetes 划分不同工作空间的单位)
[root@master ~]# kubectl get pod -n kube-system -o wide
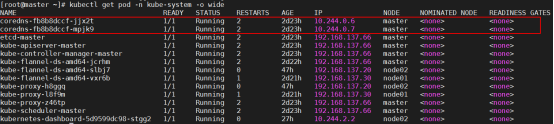
如果,CoreDNS依赖于网络的 Pod 都处于 Pending 状态,即调度失败。因为这个 Master 节点的网络尚未就绪,这里我们已经部署了网络了,所以是Running

注:
因为kubeadm需要拉取必要的镜像,这些镜像需要"科学上网";所以可以先在docker hub或其他镜像仓库拉取kube-proxy、kube-scheduler、kube-apiserver、kube-controller-manager、etcd、pause、coredns、flannel镜像;并加上 --ignore-preflight-errors=all 忽略所有报错即可
8. master节点配置(污点)
出于安全考虑,默认配置下Kubernetes不会将Pod调度到Master节点。taint:污点的意思。如果一个节点被打上了污点,那么pod是不允许运行在这个节点上面的
6.1 删除master节点默认污点
默认情况下集群不会在master上调度pod,如果偏想在master上调度Pod,可以执行如下操作:
查看污点(Taints)字段默认配置:
[root@master ~]# kubectl describe node master | grep -i taints
Taints: node-role.kubernetes.io/master:NoSchedule
删除默认污点:
[root@master ~]# kubectl taint nodes master node-role.kubernetes.io/master-
node/master untainted
6.2 污点机制
语法:
语法:
kubectl taint node [node_name] key_name=value_name[effect]
其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]
NoSchedule: 一定不能被调度
PreferNoSchedule: 尽量不要调度
NoExecute: 不仅不会调度, 还会驱逐Node上已有的Pod
打污点:
[root@master ~]# kubectl taint node master key1=value1:NoSchedule

[root@master ~]# kubectl describe node master|grep -i taints
Taints: key1=value1:NoSchedule
key为key1,value为value1(value可以为空),effect为NoSchedule表示一定不能被调度
删除污点:
[root@master ~]# kubectl taint nodes master key1-

[root@master ~]# kubectl describe node master|grep -i taints
Taints: <none>
删除指定key所有的effect,'-'表示移除所有以key1为键的污点
四、Node节点安装
Kubernetes 的 Worker 节点跟 Master 节点几乎是相同的,它们运行着的都是一个 kubelet 组件。唯一的区别在于,在 kubeadm init 的过程中,kubelet 启动后,Master 节点上还会自动运行 kube-apiserver、kube-scheduler、kube-controller-manger这三个系统 Pod
1. 安装kubelet、kubeadm和kubectl
同master节点一样操作:在node节点安装kubeadm、kubelet、kubectl
yum install -y kubelet-1.14.2 kubeadm-1.14.2 kubectl-1.14.2
systemctl enable kubelet
systemctl start kubelet
说明:其实可以不安装kubectl,因为你如果不在node上操作,就可以不用安装
2. 下载镜像
同master节点一样操作,同时node上面也需要flannel镜像
拉镜像和打tag,以下三个镜像是node节点运行起来的必要镜像(pause、kube-proxy、kube-flannel(如果本地没有镜像,在加入集群的时候自动拉取镜像然后启动))
[root@node01 ~]# docker pull mirrorgooglecontainers/pause:3.1
[root@node01 ~]# docker pull mirrorgooglecontainers/kube-proxy:v1.14.0
[root@node01 ~]# docker pull quay.io/coreos/flannel:v0.11.0-amd64
打上标签:
[root@elk-node-1 ~]# docker tag mirrorgooglecontainers/kube-proxy:v1.14.0 k8s.gcr.io/kube-proxy:v1.14.0
[root@elk-node-1 ~]# docker tag mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
[root@elk-node-1 ~]# docker tag mirrorgooglecontainers/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64
3. 加入集群
3.1-3.3在master上执行
3.1 查看令牌
[root@master ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
fz80zd.n9hihtiiedy38dta 22h 2019-10-01T16:02:44+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
如果发现之前初始化时的令牌已过期,就在生成令牌
3.2 生成新的令牌
[root@master ~]# kubeadm token create
f4e26l.xxox4o5gxuj3l6ud
或者:kubeadm token create --print-join-command
3.3 生成新的加密串,计算出token的hash值
[root@master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
837e3c07125993cd1486cddc2dbd36799efb49af9dbb9f7fd2e31bf1bdd810ae
3.4 node节点加入集群 ->加入集群就相当于初始化node节点了
在node节点上分别执行如下操作:
语法:
kubeadm join master_ip:6443 --token token_ID --discovery-token-ca-cert-hash sha256:生成的加密串
[root@node01 ~]# kubeadm join 192.168.137.66:6443 \
--token fz80zd.n9hihtiiedy38dta \
--discovery-token-ca-cert-hash sha256:837e3c07125993cd1486cddc2dbd36799efb49af9dbb9f7fd2e31bf1bdd810ae \
--ignore-preflight-errors=Swap
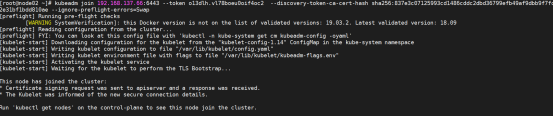
node节点加入集群启动的服务:(加入集群成功后自动成功启动了kubelet)
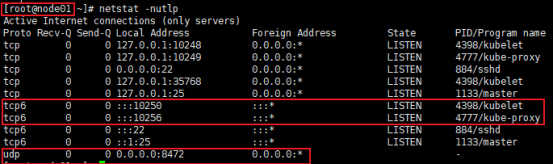
master上面查看node01已经加入集群了

这是部署了网络组件的,STATUS才为Ready;没有安装网络组件状态如下:

[root@master ~]# kubectl cluster-info
Kubernetes control plane is running at https://192.168.137.66:6443
CoreDNS is running at https://192.168.137.66:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
[root@master ~]# kubectl get nodes,cs,ns,pods -A
NAME STATUS ROLES AGE VERSION
node/master Ready control-plane,master 5h7m v1.22.4
node/node01 Ready <none> 19m v1.22.4
NAME STATUS MESSAGE ERROR
componentstatus/scheduler Healthy ok
componentstatus/controller-manager Healthy ok
componentstatus/etcd-0 Healthy {"health":"true","reason":""}
NAME STATUS AGE
namespace/default Active 5h7m
namespace/kube-node-lease Active 5h7m
namespace/kube-public Active 5h7m
namespace/kube-system Active 5h7m
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/coredns-78fcd69978-78kn4 1/1 Running 0 5h7m
kube-system pod/coredns-78fcd69978-nkcx5 1/1 Running 0 5h7m
kube-system pod/etcd-master 1/1 Running 0 5h7m
kube-system pod/kube-apiserver-master 1/1 Running 0 5h7m
kube-system pod/kube-controller-manager-master 1/1 Running 0 3h19m
kube-system pod/kube-flannel-ds-4xz74 1/1 Running 0 3h44m
kube-system pod/kube-flannel-ds-wfcpz 1/1 Running 0 19m
kube-system pod/kube-proxy-bv42k 1/1 Running 0 5h7m
kube-system pod/kube-proxy-vzlbk 1/1 Running 0 19m
kube-system pod/kube-scheduler-master 1/1 Running 0 3h19m
加入一个node节点的已完成,以上是所以启动的服务(没有部署其他服务哈)
五、Dashboard(部署dashboard v1.10.1版本)
官方文件目录:
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dashboard
https://github.com/kubernetes/dashboard
三方参考文档:
https://blog.csdn.net/networken/article/details/85607593
在 Kubernetes 社区中,有一个很受欢迎的 Dashboard 项目,它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。
用户可以用 Kubernetes Dashboard部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源
1. 下载yaml
由于yaml配置文件中指定镜像从google拉取,网络访问不通,先下载yaml文件到本地,修改配置从阿里云仓库拉取镜像
dashboard v2.4.0资源有相应的改动,部署在kubernetes-dashboard命名空间,一切参考官网
[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
2. 配置yaml
1、如果国内无法拉取镜像,那么需要修改为阿里云镜像地址
[root@master ~]# cat kubernetes-dashboard.yaml
…………
containers:
- name: kubernetes-dashboard
# image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1
image: registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.10.1
ports:
…………
3. 部署dashboard服务
部署2种命令:
[root@master ~]# kubectl create -f kubernetes-dashboard.yaml
secret/kubernetes-dashboard-certs created
serviceaccount/kubernetes-dashboard created
role.rbac.authorization.k8s.io/kubernetes-dashboard-minimal created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard-minimal created
deployment.apps/kubernetes-dashboard created
service/kubernetes-dashboard created
或者使用apply部署# kubectl apply -f kubernetes-dashboard.yaml
状态查看:
查看Pod 的状态为running说明dashboard已经部署成功
[root@master ~]# kubectl get pod --namespace=kube-system -o wide | grep dashboard

[root@master ~]# kubectl get pods -n kube-system -o wide|grep dashboard

Dashboard 会在 kube-system namespace 中创建自己的 Deployment 和 Service:
[root@master ~]# kubectl get deployment kubernetes-dashboard --namespace=kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard 1/1 1 1 2m59s
[root@master ~]# kubectl get deployment kubernetes-dashboard -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard 1/1 1 1 91m
获取dashboard的service访问端口:
[root@master ~]# kubectl get services -n kube-system
[root@master ~]# kubectl get service kubernetes-dashboard --namespace=kube-system

4. 访问dashboard
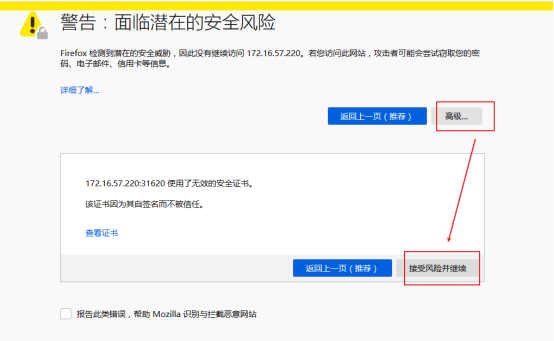
注意:要用火狐浏览器打开,其他浏览器打不开的!
官方参考文档:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/#accessing-the-dashboard-ui
有以下几种方式访问dashboard:
有以下几种方式访问dashboard:
Nodport方式访问dashboard,service类型改为NodePort
loadbalacer方式,service类型改为loadbalacer
Ingress方式访问dashboard
API server方式访问 dashboard
kubectl proxy方式访问dashboard
NodePort方式
只建议在开发环境,单节点的安装方式中使用
为了便于本地访问,修改yaml文件,将service改为NodePort 类型:
配置NodePort,外部通过https://NodeIp:NodePort 访问Dashboard,此时端口为31620
[root@master ~]# cat kubernetes-dashboard.yaml
…………
---
# ------------------- Dashboard Service ------------------- #
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort #增加type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31620 #增加nodePort: 31620
selector:
k8s-app: kubernetes-dashboard
重新应用yaml文件:
[root@master ~]# kubectl apply -f kubernetes-dashboard.yaml
secret/kubernetes-dashboard-certs unchanged
serviceaccount/kubernetes-dashboard unchanged
role.rbac.authorization.k8s.io/kubernetes-dashboard-minimal unchanged
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard-minimal unchanged
deployment.apps/kubernetes-dashboard unchanged
service/kubernetes-dashboard configured
查看service,TYPE类型已经变为NodePort,端口为31620:
#这是已经用NodePort暴露了端口,默认文件是cluster-ip方式
[root@master ~]# kubectl -n kube-system get svc kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.111.214.172 <none> 443:31620/TCP 26h
通过浏览器访问:https://192.168.137.66:31620/ 登录界面如下:
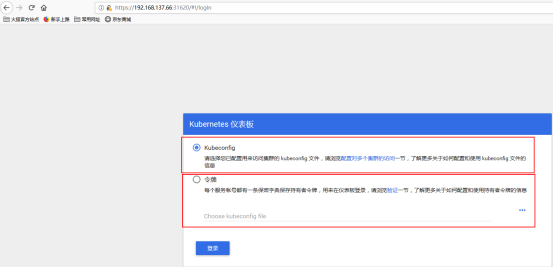
Dashboard 支持 Kubeconfig 和 Token 两种认证方式,我们这里选择Token认证方式登录:
创建登录用户: 官方参考文档:https://github.com/kubernetes/dashboard/wiki/Creating-sample-user 创建dashboard-adminuser.yaml:
[root@master ~]#vim dashboard-adminuser.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
说明:上面创建了一个叫admin-user的服务账号,并放在kube-system命名空间下,并将cluster-admin角色绑定到admin-user账户,这样admin-user账户就有了管理员的权限。默认情况下,kubeadm创建集群时已经创建了cluster-admin角色,我们直接绑定即可
执行yaml文件:
[root@master ~]# kubectl apply -f dashboard-adminuser.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
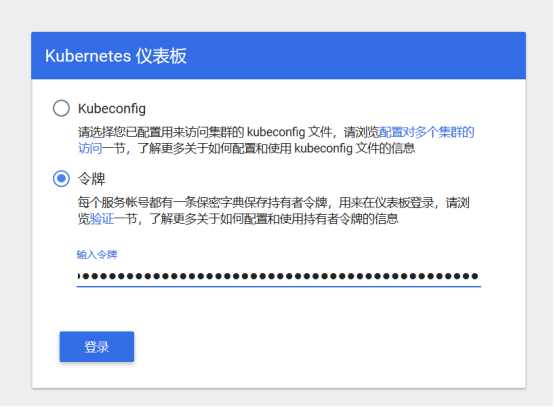
查看admin-user账户的token(令牌):
[root@master ~]# kubectl describe secrets -n kube-system admin-user
[root@master ~]# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')

把获取到的Token复制到登录界面的Token输入框中:
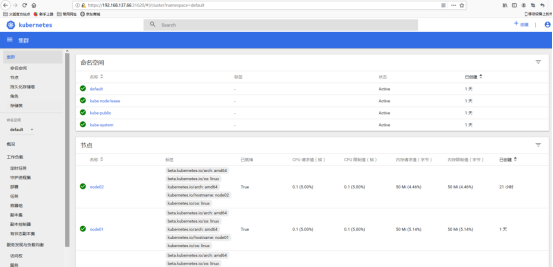
成功登陆dashboard:
--------------------------------------------------------------------------
或者直接在kubernetes-dashboard.yaml文件中追加
创建超级管理员的账号用于登录Dashboard
cat >> kubernetes-dashboard.yaml << EOF
---# ------------------- dashboard-admin ------------------- #
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
EOF
部署访问:
部署Dashboard
[root@master ~]# kubectl apply -f kubernetes-dashboard.yaml
状态查看:
[root@master ~]# kubectl get deployment kubernetes-dashboard -n kube-system
[root@master ~]# kubectl get pods -n kube-system -o wide
[root@master ~]# kubectl get services -n kube-system
令牌查看:
[root@master ~]# kubectl describe secrets -n kube-system dashboard-admin
访问
loadbalacer方式
首先需要部署metallb负载均衡器,部署参考:
https://blog.csdn.net/networken/article/details/85928369
LoadBalancer 更适合结合云提供商的 LB 来使用,但是在 LB 越来越多的情况下对成本的花费也是不可小觑
Ingress方式
详细部署参考:
https://blog.csdn.net/networken/article/details/85881558
https://www.kubernetes.org.cn/1885.html
github地址:
https://github.com/kubernetes/ingress-nginx
https://kubernetes.github.io/ingress-nginx/
基于 Nginx 的 Ingress Controller 有两种:
一种是 k8s 社区提供的: https://github.com/nginxinc/kubernetes-ingress
另一种是 Nginx 社区提供的 :
https://kubernetes.io/docs/concepts/services-networking/ingress/
关于两者的区别见:
https://github.com/nginxinc/kubernetes-ingress/blob/master/docs/nginx-ingress-controllers.md
Ingress-nginx简介
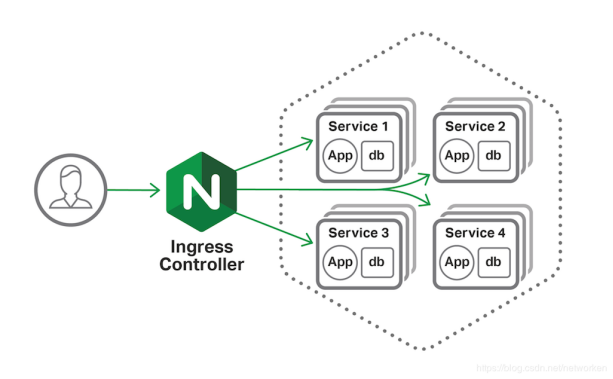
Ingress 是 k8s 官方提供的用于对外暴露服务的方式,也是在生产环境用的比较多的方式,一般在云环境下是 LB + Ingress Ctroller 方式对外提供服务,这样就可以在一个 LB 的情况下根据域名路由到对应后端的 Service,有点类似于 Nginx 反向代理,只不过在 k8s 集群中,这个反向代理是集群外部流量的统一入口
Pod的IP以及service IP只能在集群内访问,如果想在集群外访问kubernetes提供的服务,可以使用nodeport、proxy、loadbalacer以及ingress等方式,由于service的IP集群外不能访问,就是使用ingress方式再代理一次,即ingress代理service,service代理pod.
Ingress将开源的反向代理负载均衡器(如 Nginx、Apache、Haproxy等)与k8s进行集成,并可以动态的更新Nginx配置等,是比较灵活,更为推荐的暴露服务的方式,但也相对比较复杂
Ingress基本原理图如下:
部署nginx-ingress-controller:
下载nginx-ingress-controller配置文件:
[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.21.0/deploy/mandatory.yaml
修改镜像路径:
#替换镜像路径
vim mandatory.yaml
......
#image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.21.0
image: willdockerhub/nginx-ingress-controller:0.21.0
......
执行yaml文件部署
[root@master ~]# kubectl apply -f mandatory.yaml
namespace/ingress-nginx created
configmap/nginx-configuration created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k8s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created
deployment.extensions/nginx-ingress-controller created
创建Dashboard TLS证书:
[root@master ~]# mkdir -p /usr/local/src/kubernetes/certs
[root@master ~]# cd /usr/local/src/kubernetes
[root@master kubernetes]# openssl genrsa -des3 -passout pass:x -out certs/dashboard.pass.key 2048
Generating RSA private key, 2048 bit long modulus
..........+++
.................+++
e is 65537 (0x10001)
[root@master kubernetes]# openssl rsa -passin pass:x -in certs/dashboard.pass.key -out certs/dashboard.key
writing RSA key
[root@master kubernetes]# openssl req -new -key certs/dashboard.key -out certs/dashboard.csr -subj '/CN=kube-dashboard'
[root@master kubernetes]# openssl x509 -req -sha256 -days 365 -in certs/dashboard.csr -signkey certs/dashboard.key -out certs/dashboard.crt
Signature ok
subject=/CN=kube-dashboard
Getting Private key
[root@master kubernetes]# ls
certs
[root@master kubernetes]# tree certs/
certs/
├── dashboard.crt
├── dashboard.csr
├── dashboard.key
└── dashboard.pass.key
0 directories, 4 files
[root@master kubernetes]# rm certs/dashboard.pass.key
rm: remove regular file ‘certs/dashboard.pass.key’? y
[root@master kubernetes]# kubectl create secret generic kubernetes-dashboard-certs --from-file=certs -n kube-system
Error from server (AlreadyExists): secrets "kubernetes-dashboard-certs" already exists
[root@master kubernetes]# tree certs/
certs/
├── dashboard.crt
├── dashboard.csr
└── dashboard.key
0 directories, 3 files
[root@master kubernetes]# kubectl create secret generic kubernetes-dashboard-certs --from-file=certs -n kube-system
Error from server (AlreadyExists): secrets "kubernetes-dashboard-certs" already exists
[root@master kubernetes]# kubectl create secret generic kubernetes-dashboard-certs1 --from-file=certs -n kube-system
secret/kubernetes-dashboard-certs1 created
创建ingress规则:
文件末尾添加tls配置项即可:
[root@master kubernetes]# vim kubernetes-dashboard-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
labels:
k8s-app: kubernetes-dashboard
annotations:
kubernetes.io/ingress.class: "nginx"
https://github.com/kubernetes/ingress-nginx/blob/master/docs/user-guide/nginx-configuration/annotations.md
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/ssl-passthrough: "true"
name: kubernetes-dashboard
namespace: kube-system
spec:
rules:
- host: dashboard.host.com
http:
paths:
- path: /
backend:
servicePort: 443
serviceName: kubernetes-dashboard
tls:
- hosts:
- dashboard.host.com
secretName: kubernetes-dashboard-certs
访问这个域名: dashboard.host.com
API Server方式(建议采用这种方式)
->如果Kubernetes API服务器是公开的,并可以从外部访问,那我们可以直接使用API Server的方式来访问,也是比较推荐的方式
如果Kubernetes API服务器是公开的,并可以从外部访问,那我们可以直接使用API Server的方式来访问,也是比较推荐的方式。
Dashboard的访问地址为:
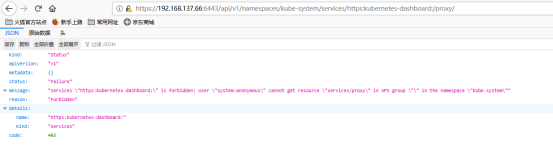
https://<master-ip>:<apiserver-port>/api/v1/namespaces/Dashboard_NameSpacesNname/services/https:kubernetes-dashboard:/proxy/
https://<master-ip>:<apiserver-port>/api/v1/namespaces/Dashboard_NameSpacesNname/services/https:Dashboard_NameSpacesNname:/proxy/
但是浏览器返回的结果可能如下:
这是因为最新版的k8s默认启用了RBAC,并为未认证用户赋予了一个默认的身份:anonymous。
对于API Server来说,它是使用证书进行认证的,我们需要先创建一个证书:
我们使用client-certificate-data和client-key-data生成一个p12文件,可使用下列命令:
mkdir /dashboard
cd /dashboard
# 生成client-certificate-data
grep 'client-certificate-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> kubecfg.crt
# 生成client-key-data
grep 'client-key-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> kubecfg.key
# 生成p12
[root@master dashboard]# openssl pkcs12 -export -clcerts -inkey kubecfg.key -in kubecfg.crt -out kubecfg.p12 -name "kubernetes-client"
Enter Export Password:
Verifying - Enter Export Password:
[root@master ~]# ll -t
-rw-r--r--. 1 root root 2464 Oct 2 15:19 kubecfg.p12
-rw-r--r--. 1 root root 1679 Oct 2 15:18 kubecfg.key
-rw-r--r--. 1 root root 1082 Oct 2 15:18 kubecfg.crt
最后导入上面生成的kubecfg.p12文件,重新打开浏览器,显示如下:(不知道怎么导入证书,自己百度)
浏览器的设置->搜索证书
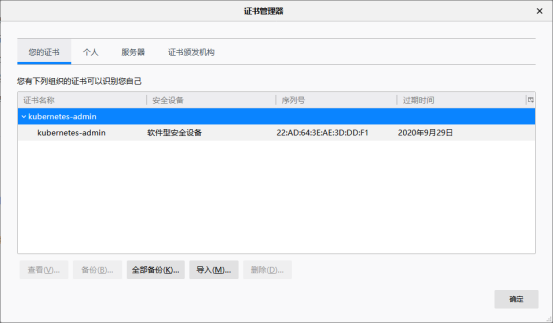
点击确定,便可以看到熟悉的登录界面了: 我们可以使用一开始创建的admin-user用户的token进行登录,一切OK
再次访问浏览器会弹出下面信息,点击确定
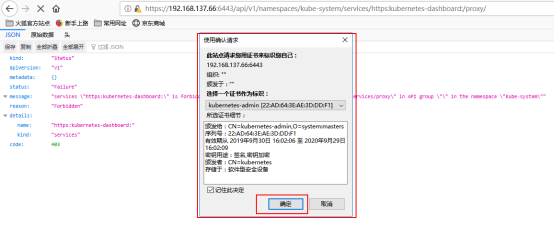
然后进入登录界面,选择令牌:
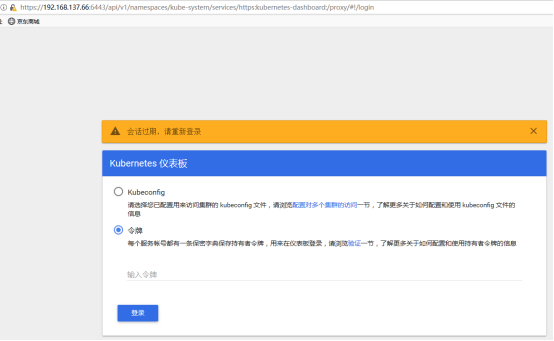
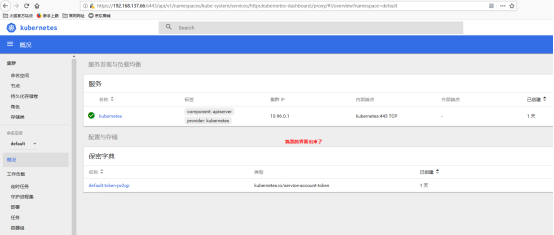
输入token,进入登录:
Porxy方式
如果要在本地访问dashboard,可运行如下命令:
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
现在就可以通过以下链接来访问Dashborad UI:
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
这种方式默认情况下,只能从本地访问(启动它的机器)。
我们也可以使用--address和--accept-hosts参数来允许外部访问:
$ kubectl proxy --address='0.0.0.0' --accept-hosts='^*$'
Starting to serve on [::]:8001
然后我们在外网访问以下链接:
http://
可以成功访问到登录界面,但是填入token也无法登录,这是因为Dashboard只允许localhost和127.0.0.1使用HTTP连接进行访问,而其它地址只允许使用HTTPS。因此,如果需要在非本机访问Dashboard的话,只能选择其他访问方式
使用Dashboard
Dashboard 界面结构分为三个大的区域。
-
顶部操作区,在这里用户可以搜索集群中的资源、创建资源或退出。
-
左边导航菜单,通过导航菜单可以查看和管理集群中的各种资源。菜单项按照资源的层级分为两类:Cluster 级别的资源 ,Namespace 级别的资源 ,默认显示的是 default Namespace,可以进行切换:
-
中间主体区,在导航菜单中点击了某类资源,中间主体区就会显示该资源所有实例,比如点击 Pods
六、集群测试
1. 部署应用
1.1 通过命令方式部署
通过命令行方式部署apache服务,--replicas=3设置副本数3(在K8S v1.18.0以后,--replicas已弃用 ,推荐用 deployment 创建 pods)
[root@master ~]# kubectl run httpd-app --image=httpd --replicas=3
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/httpd-app created
# kubectl delete pods httpd-app #删除pod
eg:应用创建
1.创建一个测试用的deployment:
[root@master ~]# kubectl run net-test --image=alpine --replicas=2 sleep 360000
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/net-test created
2.查看获取IP情况
[root@master ~]# kubectl get pod -o wide

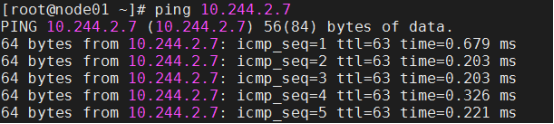
3.测试联通性(在对应的node节点去测试)


1.2 通过配置文件方式部署nginx服务
cat > nginx.yml << EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
restartPolicy: Always
containers:
- name: nginx
image: nginx:latest
EOF
说明:在K8S v1.18.0以后,Deployment对于的apiVersion已经更改
查看apiVersion: kubectl api-versions
查看Kind,并且可以得到apiVersion与Kind的对应关系: kubectl api-resources
[root@master ~]# kubectl apply -f nginx.yml
deployment.extensions/nginx created
# kubectl describe deployments nginx #查看详情
# kubectl logs nginx-55649fd747-d86js #查看日志
# kubectl get pod #查看pod
NAME READY STATUS RESTARTS AGE
nginx-55649fd747-5dlxg 1/1 Running 0 2m6s
nginx-55649fd747-d86js 1/1 Running 0 2m6s
nginx-55649fd747-dqq46 1/1 Running 0 2m6s
# kubectl get pod -w #一直watch着!
[root@master ~]# kubectl get pods -o wide //查看所有的pods更详细些
可以看到nginx的3个副本pod均匀分布在2个node节点上,为什么没有分配在master上了,因为master上打了污点
# kubectl get rs #查看副本
NAME DESIRED CURRENT READY AGE
nginx-55649fd747 3 3 3 3m3s
#通过标签查看指定的pod
语法:kubectl get pods -l Labels -o wide
如何查看Labels:# kubectl describe deployment deployment_name
或者:kubectl get pod --show-labels
[root@master ~]# kubectl get pods -l app=nginx -o wide
[root@master ~]# kubectl get pods --all-namespaces || kubectl get pods -A #查看所以pod(不同namespace下的pod)
---------------------以上只是部署了,下面就暴露端口提供外部访问----------------
[root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
[root@master ~]# kubectl get services nginx || kubectl get svc nginx #service缩写为svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx NodePort 10.109.227.43 <none> 80:30999/TCP 10s
说明:用NodePort方式把k8s集群的nginx services 的80端口通过kube-proxy映射到宿主机的30999,然后就可以在集群外部用:集群集群IP:30999访问服务了
[root@master ~]# netstat -nutlp| grep 30999
tcp 0 0 0.0.0.0:30999 0.0.0.0:* LISTEN 6334/kube-proxy
[root@node01 ~]# netstat -nutlp| grep 30999
tcp 0 0 0.0.0.0:30999 0.0.0.0:* LISTEN 6334/kube-proxy
# kubectl exec nginx-55649fd747-5dlxg -it -- nginx -v #查看版本
可以通过任意 CLUSTER-IP:Port 在集群内部访问这个服务:
[root@master ~]# curl -I 10.109.227.43:80
可以通过任意 NodeIP:Port 在集群外部访问这个服务:
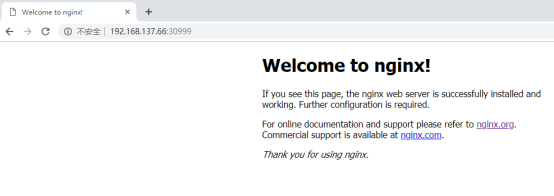
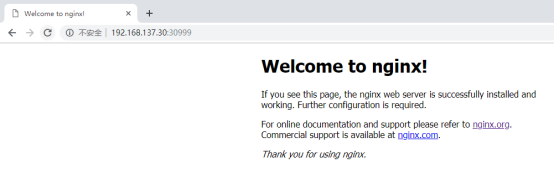
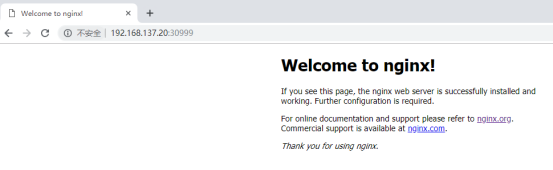
[root@master ~]# curl -I 192.168.137.66:30999
[root@master ~]# curl -I 192.168.137.30:30999
[root@master ~]# curl -I 192.168.137.20:30999
访问master_ip:30999
访问Node01_ip:30999
访问Node02_ip:30999
最后验证一下coredns(需要coredns服务正常), pod network是否正常:
运行Busybox并进入交互模式(busybox是一个很小的操作系统)
[root@master ~]# kubectl run -it curl --image=radial/busyboxplus:curl
If you don't see a command prompt, try pressing enter.
输入nslookup nginx查看是否可以正确解析出集群内的IP,以验证DNS是否正常
[ root@curl-66bdcf564-brhnk:/ ]$ nslookup nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.109.227.43 nginx.default.svc.cluster.local
说明: 10.109.227.43 :cluster_IP
通过服务名进行访问,验证kube-proxy是否正常:
[ root@curl-66bdcf564-brhnk:/ ]$ curl http://nginx/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[ root@curl-66bdcf564-brhnk:/ ]$ wget -O- -q http://nginx:80/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
分别访问一下3个Pod的内网IP,验证跨Node的网络通信是否正常
[root@master ~]# kubectl get pod -o wide
[ root@curl-66bdcf564-brhnk:/ ]$ curl -I 10.244.2.5
HTTP/1.1 200 OK
[ root@curl-66bdcf564-brhnk:/ ]$ curl -I 10.244.1.4
HTTP/1.1 200 OK
[ root@curl-66bdcf564-brhnk:/ ]$ curl -I 10.244.2.6
HTTP/1.1 200 OK
删除相关操作
# kubectl delete svc nginx #删除svc
# kubectl delete deployments nginx #删除deploy
# kubectl delete -f nginx.yml #或者利用配置文件删除
# kubectl get svc #查看是否删除
# kubectl get deployments #查看是否删除
# kubectl get pod #查看是否删除
# kubectl get rs #查看副本
七、驱逐pod & 移除节点和集群
kubernetes集群移除节点
以移除node02节点为例,在Master节点上运行:
第一步:设置节点不可调度,即不会有新的pod在该节点上创建
kubectl cordon node02
设置完成后,该节点STATUS 将会多一个SchedulingDisabled的tag,表示配置成功。
然后开始对节点上的pod进行驱逐,迁移该pod到其他节点
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 3d v1.14.2
node01 Ready <none> 2d22h v1.14.2
node02 Ready,SchedulingDisabled <none> 2d v1.14.2
第二步:pod驱逐迁移
[root@master ~]# kubectl drain node02 --delete-local-data --force --ignore-daemonsets
node/node02 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-amd64-slbj7, kube-system/kube-proxy-h8ggq
evicting pod "kubernetes-dashboard-5d9599dc98-stgg2"
evicting pod "nginx-9d4cf4f77-sj9nn"
evicting pod "net-test-59ff94d98d-dfnfp"
evicting pod "httpd-app-6df58645c6-rkkb5"
evicting pod "httpd-app-6df58645c6-sgjq2"
evicting pod "nginx-9d4cf4f77-wmvhj"
pod/kubernetes-dashboard-5d9599dc98-stgg2 evicted
pod/httpd-app-6df58645c6-sgjq2 evicted
pod/nginx-9d4cf4f77-wmvhj evicted
pod/nginx-9d4cf4f77-sj9nn evicted
pod/httpd-app-6df58645c6-rkkb5 evicted
pod/net-test-59ff94d98d-dfnfp evicted
node/node02 evicted
参数说明:k8s Pod驱逐迁移
https://blog.51cto.com/lookingdream/2539526
--delete-local-data: 即使pod使用了emptyDir也删除。(Flag --delete-local-data has been deprecated, This option is deprecated and will be deleted. Use --delete-emptydir-data.)
--ignore-daemonsets: 忽略deamonset控制器的pod,如果不忽略,deamonset控制器控制的pod被删除后可能马上又在此节点上启动起来,会成为死循环;
--force: 不加force参数只会删除该NODE上由ReplicationController, ReplicaSet, DaemonSet,StatefulSet or Job创建的Pod,加了后还会删除’裸奔的pod’(没有绑定到任何replication controller)
第三步:观察pod重建情况后,对节点进行维护操作。维护结束后对节点重新配置可以调度。
kubectl uncordon node02
维护结束
说明:如果你是kubernetes集群移除节点就不能操作第三步,如果你是驱逐pod那么就不能操作第四步及以后的操作
第四步:移除节点
[root@master ~]# kubectl delete node node02
node "node02" deleted
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 3d v1.14.2
node01 Ready <none> 2d22h v1.14.2
第五步:上面两条命令执行完成后,在node02节点执行清理命令,重置kubeadm的安装状态:
[root@node02 ~]# kubeadm reset
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W1003 16:32:34.505195 82844 reset.go:234] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of stateful directories: [/var/lib/kubelet /etc/cni/net.d /var/lib/dockershim /var/run/kubernetes]
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually.
For example:
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
在master上删除node并不会清理node02运行的容器,需要在删除节点上面手动运行清理命令
如果你想重新配置集群,使用新的参数重新运行kubeadm init或者kubeadm join即可
安装完成集群后清除yum安装aliyun的插件
# 修改插件配置文件
vim /etc/yum/pluginconf.d/fastestmirror.conf
# 把enabled=1改成0,禁用该插件
# 修改yum 配置文件
vim /etc/yum.conf
把plugins=1改为0,不使用插件
yum clean all
yum makecache
通过kudeadm方式在centos7上安装kubernetes v1.26.3集群
docker、Containerd ctr、crictl 区别
一、docker 和 containerd区别
- docker 由 docker-client ,dockerd,containerd,docker-shim,runc组成,所以containerd是docker的基础组件之一
- 从k8s的角度看,可以选择 containerd 或 docker 作为运行时组件:其中 containerd 调用链更短,组件更少,更稳定,占用节点资源更少。所以k8s后来的版本开始默认使用 containerd 。
- containerd 相比于docker , 多了 namespace 概念,每个 image 和 container 都会在各自的namespace下可见。
- 调用关系
- docker 作为 k8s 容器运行时,调用关系为:kubelet
-->dockershim (在 kubelet 进程中)-->dockerd--> containerd - containerd 作为 k8s 容器运行时,调用关系为:kubelet
-->cri plugin(在 containerd 进程中)-->containerd
| 命令 | docker | ctr(containerd) | crictl(kubernetes) |
|---|---|---|---|
| 查看运行的容器 | docker ps | ctr task ls/ctr container ls | crictl ps |
| 查看镜像 | docker images | ctr image ls | crictl images |
| 查看容器日志 | docker logs | 无 | crictl logs |
| 查看容器数据信息 | docker inspect | ctr container info | crictl inspect |
| 查看容器资源 | docker stats | 无 | crictl stats |
| 启动/关闭已有的容器 | docker start/stop | ctr task start/kill | crictl start/stop |
| 运行一个新的容器 | docker run | ctr run | 无(最小单元为pod) |
| 修改镜像标签 | docker tag | ctr image tag | 无 |
| 创建一个新的容器 | docker create | ctr container create | crictl create |
| 导入镜像 | docker load | ctr image import | 无 |
| 导出镜像 | docker save | ctr image export | 无 |
| 删除容器 | docker rm | ctr container rm | crictl rm |
| 删除镜像 | docker rmi | ctr image rm | crictl rmi |
| 拉取镜像 | docker pull | ctr image pull | ctictl pull |
| 推送镜像 | docker push | ctr image push | 无 |
| 在容器内部执行命令 | docker exec | 无 | crictl exec |
二、ctr 和 crictl 命令区分
- ctr 是 containerd 自带的CLI命令行工具。不支持 build,commit 镜像,使用ctr 看镜像列表就需要加上-n 参数指定命名空间。
ctr -n=k8s.io image ls - crictl 是 k8s中CRI(容器运行时接口) 兼容的容器运行时命令行客户端,可以使用它来检查和调试 k8s 节点上的容器运行时和应用程序,k8s使用该客户端和containerd进行交互。
ctr -v输出的是 containerd 的版本,crictl -v输出的是当前 k8s 的版本,从结果显而易见你可以认为 crictl 是用于 k8s 的。
# crictl -v
crictl version v1.26.0
# ctr -v
ctr containerd.io 1.6.19
注:一般来说你某个主机安装了 k8s 后,命令行才会有 crictl 命令。而 ctr 是跟 k8s 无关的,你主机安装了containerd 服务后就可以操作 ctr 命令。
containerd 相比于docker , 多了namespace概念,每个image和container 都会在各自的namespace下可见。
ctr 客户端 主要区分了 3 个命名空间分别是k8s.io、moby和default,目前k8s会使用k8s.io作为命名空间.我们用crictl操作的均在k8s.io命名空间,使用ctr 看镜像列表就需要加上-n参数。crictl 是只有一个k8s.io命名空间,但是没有-n参数.
一、每台机器安装containerd
docker跟containerd不冲突,docker是为了能基于dockerfile构建镜像
# 添加docker源
curl -L -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装containerd
yum install -y containerd.io
# 创建默认配置文件
containerd config default > /etc/containerd/config.toml
# 修改sandbox_image的前缀为阿里云前缀地址,不设置会连接不上。根据实际情况修改
sed -i "s#registry.k8s.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
# 设置驱动为systemd
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
# 设置containerd地址为aliyun镜像地址
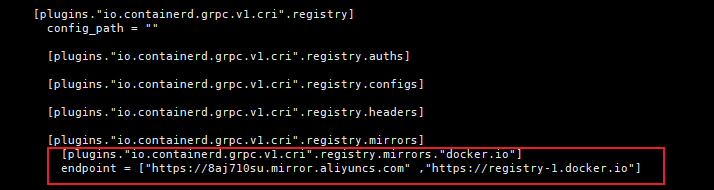
vi /etc/containerd/config.toml #注意,配置文件有格式要求。实测配置后报错
# 文件内容为
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
[plugins."io.containerd.grpc.v1.cri".registry.auths]
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.headers]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.mirrors.ustc.edu.cn","http://hub-mirror.c.163.com"]
[plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming]
tls_cert_file = ""
tls_key_file = ""
# 配置containerd镜像加速器
sed -i 's@config_path = ""@config_path = "/etc/containerd/certs.d"@g' /etc/containerd/config.toml
mkdir /etc/containerd/certs.d/docker.io/ -p
cat >/etc/containerd/certs.d/docker.io/hosts.toml <<EOF
[host."https://dbxvt5s3.mirror.aliyuncs.com",host."https://registry.docker-cn.com"]
capabilities = ["pull"]
EOF
# 重启服务
systemctl daemon-reload
systemctl enable --now containerd
systemctl restart containerd
systemctl status containerd
# 是否安装成功
# ctr -v
ctr containerd.io 1.6.19
# runc -v
runc version 1.1.4
commit: v1.1.4-0-g5fd4c4d
spec: 1.0.2-dev
go: go1.19.7
libseccomp: 2.3.1
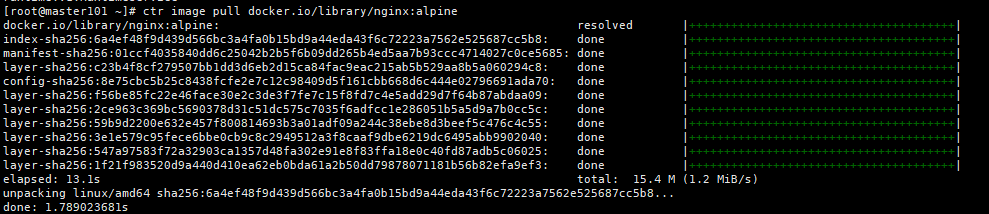
# ctr image pull docker.io/library/nginx:alpine #拉取镜像
docker.io/library/nginx:alpine: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:6a4ef48f9d439d566bc3a4fa0b15bd9a44eda43f6c72223a7562e525687cc5b8: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:01ccf4035840dd6c25042b2b5f6b09dd265b4ed5aa7b93ccc4714027c0ce5685: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:c23b4f8cf279507bb1dd3d6eb2d15ca84fac9eac215ab5b529aa8b5a060294c8: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:8e75cbc5b25c8438fcfe2e7c12c98409d5f161cbb668d6c444e02796691ada70: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:f56be85fc22e46face30e2c3de3f7fe7c15f8fd7c4e5add29d7f64b87abdaa09: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:2ce963c369bc5690378d31c51dc575c7035f6adfcc1e286051b5a5d9a7b0cc5c: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:59b9d2200e632e457f800814693b3a01adf09a244c38ebe8d3beef5c476c4c55: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:3e1e579c95fece6bbe0cb9c8c2949512a3f8caaf9dbe6219dc6495abb9902040: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:547a97583f72a32903ca1357d48fa302e91e8f83ffa18e0c40fd87adb5c06025: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:1f21f983520d9a440d410ea62eb0bda61a2b50dd79878071181b56b82efa9ef3: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 13.1s total: 15.4 M (1.2 MiB/s)
unpacking linux/amd64 sha256:6a4ef48f9d439d566bc3a4fa0b15bd9a44eda43f6c72223a7562e525687cc5b8...
done: 1.789023681s
# ctr images ls
REF TYPE DIGEST SIZE PLATFORMS LABELS
docker.io/library/nginx:alpine application/vnd.docker.distribution.manifest.list.v2+json sha256:6a4ef48f9d439d566bc3a4fa0b15bd9a44eda43f6c72223a7562e525687cc5b8 16.0 MiB linux/386,linux/amd64,linux/arm/v6,linux/arm/v7,linux/arm64/v8,linux/ppc64le,linux/s390x -
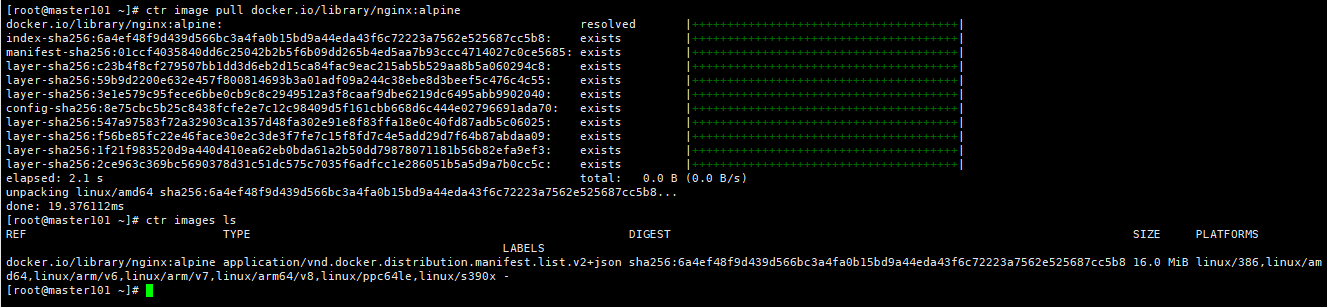
# 安装crictl工具,其实在安装kubelet、kubectl、kubeadm的时候会作为依赖安装cri-tools
yum install -y cri-tools
# 生成配置文件
crictl config runtime-endpoint
# 编辑配置文件
cat << EOF | tee /etc/crictl.yaml
runtime-endpoint: "unix:///run/containerd/containerd.sock"
image-endpoint: "unix:///run/containerd/containerd.sock"
timeout: 10
debug: false
pull-image-on-create: false
disable-pull-on-run: false
EOF
# 重启containerd
systemctl restart containerd
# crictl images
IMAGE TAG IMAGE ID SIZE
二、k8s安装准备工作
安装Centos是已经禁用了防火墙和selinux并设置了阿里源。master和node节点都执行本部分操作
1. 配置主机
1.1 修改主机名(主机名不能有下划线)
[root@centos7 ~]# hostnamectl set-hostname master
[root@centos7 ~]# cat /etc/hostname
master
退出重新登陆即可显示新设置的主机名master
1.2 修改hosts文件
[root@master ~]# cat >> /etc/hosts << EOF
192.168.137.66 master
192.168.137.30 node01
192.168.137.20 node02
EOF
2. 同步系统时间
$ yum -y install ntpdate chrony && systemctl enable chronyd && systemctl start chronyd && ntpdate time1.aliyun.com
vi /etc/chrony.conf #添加阿里云的时间服务器地址
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server ntp1.aliyun.com iburst minpoll 4 maxpoll 10
server ntp2.aliyun.com iburst minpoll 4 maxpoll 10
server ntp3.aliyun.com iburst minpoll 4 maxpoll 10
server ntp4.aliyun.com iburst minpoll 4 maxpoll 10
server ntp5.aliyun.com iburst minpoll 4 maxpoll 10
server ntp6.aliyun.com iburst minpoll 4 maxpoll 10
server ntp7.aliyun.com iburst minpoll 4 maxpoll 10
systemctl restart chronyd
# 查看时间同步源状态
chronyc sourcestats -v
chronyc sources
centos7默认已启用chrony服务,执行chronyc sources命令,查看存在以*开头的行,说明已经与NTP服务器时间同步
$ crontab -e #写入定时任务
1 */2 * * * /usr/sbin/ntpdate time1.aliyun.com
3. 验证mac地址uuid
[root@master ~]# cat /sys/class/net/ens33/address
[root@master ~]# cat /sys/class/dmi/id/product_uuid
保证各节点mac和uuid唯一
4. 禁用swap
为什么要关闭swap交换分区?
Swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定--ignore-preflight-errors=Swap来解决
解决主机重启后kubelet无法自动启动问题:https://www.hangge.com/blog/cache/detail_2419.html
由于K8s必须保持全程关闭交换内存,之前我安装是只是使用swapoff -a 命令暂时关闭swap。而机器重启后,swap 还是会自动启用,从而导致kubelet无法启动
3.1 临时禁用
[root@master ~]# swapoff -a
3.2 永久禁用
若需要重启后也生效,在禁用swap后还需修改配置文件/etc/fstab,注释swap
[root@master ~]# sed -i.bak '/swap/s/^/#/' /etc/fstab
或者修改内核参数,关闭swap
echo "vm.swappiness = 0" >> /etc/sysctl.conf
swapoff -a && swapon -a && sysctl -p
或者:Swap的问题:要么关闭swap,要么忽略swap
通过参数忽略swap报错
在kubeadm初始化时增加--ignore-preflight-errors=Swap参数,注意Swap中S要大写
kubeadm init --ignore-preflight-errors=Swap
另外还要设置/etc/sysconfig/kubelet参数
sed -i 's/KUBELET_EXTRA_ARGS=/KUBELET_EXTRA_ARGS="--fail-swap-on=false"/' /etc/sysconfig/kubelet
在以往老版本中是必须要关闭swap的,但是现在新版又多了一个选择,可以通过参数指定,忽略swap报错!
[root@elk-node-1 ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
5. 关闭防火墙、SELinux
在每台机器上关闭防火墙:
① 关闭服务,并设为开机不自启
$ sudo systemctl stop firewalld
$ sudo systemctl disable firewalld
② 清空防火墙规则
sudo iptables -F && sudo iptables -X && sudo iptables -F -t nat && sudo iptables -X -t nat
sudo iptables -P FORWARD ACCEPT
-F 是清空指定某个 chains 内所有的 rule 设定
-X 是删除使用者自定 iptables 项目
1、关闭 SELinux,否则后续 K8S 挂载目录时可能报错 Permission denied :
$ sudo setenforce 0
2、修改配置文件,永久生效;
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
6. 内核参数修改
https://zhuanlan.zhihu.com/p/374919190
开启 bridge-nf-call-iptables,如果 Kubernetes 环境的网络链路中走了 bridge 就可能遇到上述 Service 同节点通信问题,而 Kubernetes 很多网络实现都用到了 bridge。
启用 bridge-nf-call-iptables 这个内核参数 (置为 1),表示 bridge 设备在二层转发时也去调用 iptables 配置的三层规则 (包含 conntrack),所以开启这个参数就能够解决上述 Service 同节点通信问题,这也是为什么在 Kubernetes 环境中,大多都要求开启 bridge-nf-call-iptables 的原因。
RHEL / CentOS 7上的一些用户报告了由于iptables被绕过而导致流量路由不正确的问题
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决上面的警告:打开iptables内生的桥接相关功能,已经默认开启了,没开启的自行开启(1表示开启,0表示未开启)
# cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
1
# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1
4.1 自动开启桥接功能
临时修改
[root@master ~]# sysctl net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-iptables = 1
[root@master ~]# sysctl net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-ip6tables = 1
[root@master ~]# sysctl net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
或者用echo也行:
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
echo 1 > /proc/sys/net/bridge/bridge-nf-call-ip6tables
4.2 永久修改
[root@master ~]# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
[root@master ~]# sysctl -p /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1 #Docker从1.13版本开始调整了默认的防火墙规则,禁用了iptables filter表中FOWARD链,导致pod无法通信
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
7. 加载ipvs相关模块
由于ipvs已经加入到了内核的主干,所以为kube-proxy开启ipvs的前提需要加载以下的内核模块:
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
br_netfilter
在所有的Kubernetes节点执行以下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
modprobe -- br_netfilter
EOF
执行脚本
[root@master ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
上面脚本创建了/etc/sysconfig/modules/ipvs.modules文件,保证在节点重启后能自动加载所需模块。 使用lsmod | grep -e ip_vs -e nf_conntrack_ipv4命令查看是否已经正确加载所需的内核模块。
进行配置时会报错modprobe: FATAL: Module nf_conntrack_ipv4 not found.
这是因为使用了高内核,一般教程都是3.2的内核。在高版本内核已经把nf_conntrack_ipv4替换为nf_conntrack了
接下来还需要确保各个节点上已经安装了ipset软件包。 为了便于查看ipvs的代理规则,最好安装一下管理工具ipvsadm。
ipset是iptables的扩展,可以让你添加规则来匹配地址集合。不同于常规的iptables链是线性的存储和遍历,ipset是用索引数据结构存储,甚至对于大型集合,查询效率非常都优秀。
# yum install ipset ipvsadm -y
8. 设置kubernetes源(在阿里源)
6.1 新增kubernetes源
[root@master ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
解释:
[] 中括号中的是repository id,唯一,用来标识不同仓库
name 仓库名称,自定义
baseurl 仓库地址
enable 是否启用该仓库,默认为1表示启用
gpgcheck 是否验证从该仓库获得程序包的合法性,1为验证
repo_gpgcheck 是否验证元数据的合法性 元数据就是程序包列表,1为验证
gpgkey=URL 数字签名的公钥文件所在位置,如果gpgcheck值为1,此处就需要指定gpgkey文件的位置,如果gpgcheck值为0就不需要此项了
6.2 更新缓存
[root@master ~]# yum clean all
[root@master ~]# yum -y makecache
三、Master节点安装->对master节点也需要docker
完整的官方文档可以参考:
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
Master节点端口
| 端口 | 用途 |
|---|---|
| 6443 | Kubernetes API server |
| 2379-2380 | etcd server client API |
| 10250 | kubelet API |
| 10251 | Kube-scheduler |
| 10252 | Kube-controller-manager |
1. 版本查看
[root@master ~]# yum list kubelet --showduplicates | sort -r
[root@master ~]# yum list kubeadm --showduplicates | sort -r
[root@master ~]# yum list kubectl --showduplicates | sort -r
目前最新版是
kubelet.x86_64 1.26.3-0 kubernetes
kubeadm.x86_64 1.26.3-0 kubernetes
kubectl.x86_64 1.26.3-0 kubernetes
2. 安装指定版本kubelet、kubeadm和kubectl
官方安装文档可以参考:https://kubernetes.io/docs/setup/independent/install-kubeadm/
2.1 安装三个包
[root@master ~]# yum install -y kubelet-1.14.2 kubeadm-1.14.2 kubectl-1.14.2
若不指定版本直接运行
yum install -y kubelet kubeadm kubectl #默认安装最新版
ps:由于官网未开放同步方式, 可能会有索引gpg检查失败的情况, 这时请用 yum install -y --nogpgcheck kubelet kubeadm kubectl 安装
Kubelet的安装文件:
[root@elk-node-1 ~]# rpm -ql kubelet
/etc/kubernetes/manifests #清单目录
/etc/sysconfig/kubelet #配置文件
/usr/bin/kubelet #主程序
/usr/lib/systemd/system/kubelet.service #unit文件
2.2 安装包说明
-
kubelet 运行在集群所有节点上,用于启动Pod和containers等对象的工具,维护容器的生命周期
-
kubeadm 安装K8S工具,用于初始化集群,启动集群的命令工具
-
kubectl K8S命令行工具,用于和集群通信的命令行,通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
2.3 配置并启动kubelet
配置启动kubelet服务
(1)修改配置文件
[root@master ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
#KUBE_PROXY=MODE=ipvs
echo 'KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"' > /etc/sysconfig/kubelet
(2)启动kubelet并设置开机启动:
[root@master ~]# systemctl enable kubelet && systemctl start kubelet && systemctl enable --now kubelet
虽然启动失败,但是也得启动,否则集群初始化会卡死
此时kubelet的状态,还是启动失败,通过journalctl -xeu kubelet能看到error信息;只有当执行了kubeadm init后才会启动成功。
因为K8S集群还未初始化,所以kubelet 服务启动不成功,下面初始化完成,kubelet就会成功启动,但是还是会报错,因为没有部署flannel网络组件
搭建集群时首先保证正常kubelet运行和开机启动,只有kubelet运行才有后面的初始化集群和加入集群操作。
查找启动kubelet失败原因:查看启动状态
systemctl status kubelet
提示信息kubelet.service failed.
查看报错日志
tail /var/log/messages
2.4 kubectl命令补全
kubectl 主要是对pod、service、replicaset、deployment、statefulset、daemonset、job、cronjob、node资源的增删改查
# 安装kubectl自动补全命令包
[root@master ~]# yum install -y bash-completion
[root@master ~]# source /usr/share/bash-completion/bash_completion
[root@master ~]# source <(kubectl completion bash)
# 添加的当前shell
[root@master ~]# echo "source <(kubectl completion bash)" >> ~/.bash_profile
[root@master ~]# source ~/.bash_profile
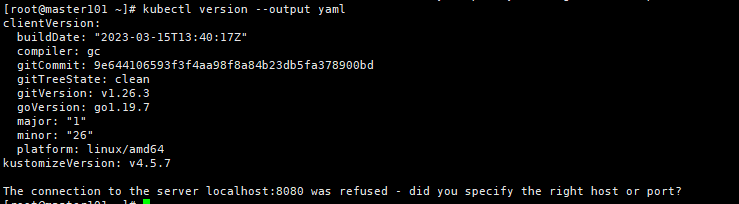
# 查看kubectl的版本:
[root@master101 ~]# kubectl version --output yaml
clientVersion:
buildDate: "2023-03-15T13:40:17Z"
compiler: gc
gitCommit: 9e644106593f3f4aa98f8a84b23db5fa378900bd
gitTreeState: clean
gitVersion: v1.26.3
goVersion: go1.19.7
major: "1"
minor: "26"
platform: linux/amd64
kustomizeVersion: v4.5.7
The connection to the server localhost:8080 was refused - did you specify the right host or port?
3. 下载镜像(建议采取脚本方式下载必须的镜像)
3.1 镜像下载的脚本
Kubernetes几乎所有的安装组件和Docker镜像都放在goolge自己的网站上,直接访问可能会有网络问题,这里的解决办法是从阿里云镜像仓库下载镜像,拉取到本地以后改回默认的镜像tag。
可以通过如下命令导出默认的初始化配置:
$ kubeadm config print init-defaults > kubeadm.yaml
如果将来出了新版本配置文件过时,则使用以下命令转换一下:更新kubeadm文件
# kubeadm config migrate --old-config kubeadm.yaml --new-config kubeadmnew.yaml
打开该文件查看,发现配置的镜像仓库如下:
imageRepository: registry.k8s.io
在国内该镜像仓库是连不上,可以用国内的镜像代替:
imageRepository: registry.aliyuncs.com/google_containers
采用国内镜像的方案,由于coredns的标签问题,会导致拉取coredns:v1.3.1拉取失败,这时候我们可以手动拉取,并自己打标签。
打开kubeadm.yaml,然后进行相应的修改,可以指定kubernetesVersion版本,pod的选址访问等。
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.11.100.101 #控制节点IP
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock #使用containerd作为容器运行时
imagePullPolicy: IfNotPresent
name: master101 #控制节点主机名
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.k8s.io #镜像仓库地址,如果提前准备好了镜像则不用修改.否则修改为可访问的地址.如aliyun的registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.26.3 #k8s版本
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 #Pod网段
serviceSubnet: 10.96.0.0/12 #Service网段
scheduler: {}
#kubelet cgroup配置为systemd
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
查看初始化集群时,需要拉的镜像名
[root@master101 ~]# kubeadm config images list
[root@master101 ~]# kubeadm config images list --kubernetes-version=v1.26.3
registry.k8s.io/kube-apiserver:v1.26.3
registry.k8s.io/kube-controller-manager:v1.26.3
registry.k8s.io/kube-scheduler:v1.26.3
registry.k8s.io/kube-proxy:v1.26.3
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.6-0
registry.k8s.io/coredns/coredns:v1.9.3
kubernetes镜像拉取命令:
[root@master101 ~]# kubeadm config images pull --config=kubeadm.yaml #拉取镜像后还需要修改tag
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.3
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.26.3
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.26.3
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.26.3
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.9
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.6-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.9.3
=======================一般采取改方式下载镜像====================
# 或者用以下方式拉取镜像到本地
[root@master ~]# vim image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.26.3
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}' | grep -v coredns`)
for imagename in ${images[@]} ; do
ctr -n k8s.io image pull $url/$imagename
ctr -n k8s.io images tag $url/$imagename registry.k8s.io/$imagename
ctr -n k8s.io images rm $url/$imagename
done
#采用国内镜像的方案,由于coredns的标签问题,会导致拉取coredns:v1.3.1拉取失败,这时候我们可以手动拉取,并自己打标签。
#another image
ctr -n k8s.io image pull $url/coredns:v1.9.3
ctr -n k8s.io images tag $url/coredns:v1.9.3 registry.k8s.io/coredns/coredns:v1.9.3
ctr -n k8s.io images rm $url/coredns:v1.9.3
解释:url为阿里云镜像仓库地址,version为安装的kubernetes版本
3.2 下载镜像
运行脚本image.sh,下载指定版本的镜像
[root@master ~]# bash image.sh
[root@master ~]# crictl images
IMAGE TAG IMAGE ID SIZE
registry.k8s.io/coredns/coredns v1.9.3 5185b96f0becf 14.8MB
registry.k8s.io/etcd 3.5.6-0 fce326961ae2d 103MB
registry.k8s.io/kube-apiserver v1.26.3 1d9b3cbae03ce 35.4MB
registry.k8s.io/kube-controller-manager v1.26.3 ce8c2293ef09c 32.2MB
registry.k8s.io/kube-proxy v1.26.3 92ed2bec97a63 21.5MB
registry.k8s.io/kube-scheduler v1.26.3 5a79047369329 17.5MB
registry.k8s.io/pause 3.9 e6f1816883972 322kB

### k8s.gcr.io 地址替换
将k8s.gcr.io替换为
registry.cn-hangzhou.aliyuncs.com/google_containers
或者
registry.aliyuncs.com/google_containers
或者
mirrorgooglecontainers
### quay.io 地址替换
将 quay.io 替换为
quay.mirrors.ustc.edu.cn
### gcr.io 地址替换
将 gcr.io 替换为 registry.aliyuncs.com
====================也可以通过dockerhub先去搜索然后pull下来============
[root@master ~]# cat image.sh
#!/bin/bash
images=(kube-apiserver:v1.15.1 kube-controller-manager:v1.15.1 kube-scheduler:v1.15.1 kube-proxy:v1.15.1 pause:3.1 etcd:3.3.10)
for imageName in ${images[@]}
do
docker pull mirrorgooglecontainers/$imageName && \
docker tag mirrorgooglecontainers/$imageName k8s.gcr.io/$imageName &&\
docker rmi mirrorgooglecontainers/$imageName
done
#another image
docker pull coredns/coredns:1.3.1 && \
docker tag coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
将这些镜像打包推到别的机器上去:
#以coredns为例导出
[root@master101 k8simagesv1263]# ctr -n k8s.io i export corednsv193.tar.gz registry.k8s.io/coredns/coredns:v1.9.3
[root@master101 k8simagesv1263]# ls
corednsv193.tar.gz
[root@master101 k8simagesv1263]# vim corednsv193.tar.gz
[root@master101 k8simagesv1263]# tar tf corednsv193.tar.gz
blobs/
blobs/sha256/
blobs/sha256/5185b96f0becf59032b8e3646e99f84d9655dff3ac9e2605e0dc77f9c441ae4a
blobs/sha256/8e352a029d304ca7431c6507b56800636c321cb52289686a581ab70aaa8a2e2a
blobs/sha256/bdb36ee882c13135669cfc2bb91c808a33926ad1a411fee07bd2dc344bb8f782
blobs/sha256/d92bdee797857f997be3c92988a15c196893cbbd6d5db2aadcdffd2a98475d2d
blobs/sha256/f2401d57212f95ea8e82ff8728f4f99ef02d4b39459837244d1b049c5d43de43
index.json
manifest.json
oci-layout
#以coredns为例导入
[root@master101 k8simagesv1263]# ctr -n k8s.io i import corednsv193.tar.gz
4. 初始化Master
kubeadm init安装失败后需要重新执行,此时要先执行kubeadm reset命令。
kubeadm --help
kubeadm init --help
集群初始化如果遇到问题,可以使用kubeadm reset命令进行清理然后重新执行初始化,然后接下来在 master 节点配置 kubeadm 初始化文件,可以通过如下命令导出默认的
4.1 初始化
第三步已获取初始化配置,那么利用配置文件进行初始化:
[root@master101 ~]# kubeadm config print init-defaults > kubeadm.yaml
在master节点操作
[root@master101 ~]# kubeadm init --config kubeadm.yaml --upload-certs #通过配置文件初始化
[init] Using Kubernetes version: v1.26.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master101] and IPs [10.96.0.1 10.11.100.101]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master101] and IPs [10.11.100.101 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master101] and IPs [10.11.100.101 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 7.004055 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
9ca8c2013234ecf1bebfa9e7e3dd8be1726efef6319b8d757a5097817e61056d
[mark-control-plane] Marking the node master101 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master101 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.11.100.101:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:3d9f70a7bd419b38753fc413155cd5cdedcc5763e5b3682b5c7879c1ea29561e
建议用下面的命令方式初始化:
[root@master ~]# kubeadm init \
--apiserver-advertise-address=10.11.100.101 \
--kubernetes-version=v1.26.3 \
--apiserver-bind-port 6443 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--ignore-preflight-errors=Swap \
-v=5
--image-repository registry.aliyuncs.com/google_containers 这里不需要更换仓库地址,因为我们第三步的时候已经拉取的相关的镜像
记录kubeadm join的输出,后面需要这个命令将各个节点加入集群中
(注意记录下初始化结果中的kubeadm join命令,部署worker节点时会用到)
[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
解释:
--apiserver-advertise-address#指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface
--apiserver-bind-port 6443 #apiserver端口
--kubernetes-version#指定kubeadm版本;我这里下载的时候kubeadm最高时1.14.2版本 --kubernetes-version=v1.14.2。关闭版本探测,因为它的默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.13.1)来跳过网络请求
--pod-network-cidr#指定Pod网络的范围,这里使用flannel(10.244.0.0/16)网络方案;Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr 有自己的要求,这里设置为 10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR
--service-cidr:指定service网段
--image-repository #Kubenetes默认Registries地址是 k8s.gcr.io,在国内并不能访问gcr.io,在1.13版本中我们可以增加--image-repository参数,默认值是 k8s.gcr.io,将其指定为阿里云镜像地址:registry.aliyuncs.com/google_containers
--ignore-preflight-errors=Swap/all:忽略 swap/所有 报错
--ignore-preflight-errors=NumCPU #如果您知道自己在做什么,可以使用'--ignore-preflight-errors'进行非致命检查
--ignore-preflight-errors=Mem
--config string #通过文件来初始化k8s。 Path to a kubeadm configuration file.
初始化过程说明:
1.[init] Using Kubernetes version: v1.26.3
2.[preflight] kubeadm 执行初始化前的检查。
3.[certs] 生成相关的各种token和证书
4.[kubeconfig] 生成 KubeConfig 文件,kubelet 需要这个文件与 Master 通信
5.[kubelet-start] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
6.[control-plane] 安装 Master 组件,如果本地没有相关镜像,那么会从指定的 Registry 下载组件的 Docker 镜像。
7.[bootstraptoken] 生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
8.[addons] 安装附加组件 kube-proxy 和 coredns。
9.Kubernetes Master 初始化成功,提示如何配置常规用户使用kubectl访问集群。
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
10.提示如何安装 Pod 网络。
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
11.提示如何注册其他节点到 Cluster
开启了kube-apiserver 的6443端口:
[root@master101 ~]# ss -tanlp | grep 6443
LISTEN 0 4096 [::]:6443 [::]:* users:(("kube-apiserver",pid=4449,fd=7))

各个服务的端口:master初始化过后各个服务就正常启动了
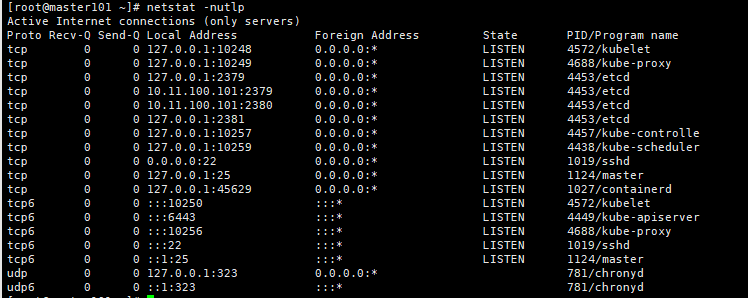
查看containerd运行了那些服务了:
[root@master101 ~]# crictl pods
POD ID CREATED STATE NAME NAMESPACE ATTEMPT RUNTIME
03acd0db80a29 10 minutes ago Ready kube-proxy-ckmr4 kube-system 0 (default)
2978636f489ec 10 minutes ago Ready kube-apiserver-master101 kube-system 0 (default)
fb27ce367404d 10 minutes ago Ready etcd-master101 kube-system 0 (default)
62b997b340e39 10 minutes ago Ready kube-scheduler-master101 kube-system 0 (default)
138c3b92a1aa8 10 minutes ago Ready kube-controller-manager-master101 kube-system 0 (default)

[root@master101 ~]# systemctl status kubelet.service
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since 五 2023-03-31 22:29:40 CST; 11min ago
Docs: https://kubernetes.io/docs/
Main PID: 4572 (kubelet)
Tasks: 12
Memory: 49.7M
CGroup: /system.slice/kubelet.service
└─4572 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --contai...
3月 31 22:40:41 master101 kubelet[4572]: E0331 22:40:41.188407 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:40:46 master101 kubelet[4572]: E0331 22:40:46.190356 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:40:51 master101 kubelet[4572]: E0331 22:40:51.191586 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:40:56 master101 kubelet[4572]: E0331 22:40:56.192946 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:41:01 master101 kubelet[4572]: E0331 22:41:01.194453 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:41:06 master101 kubelet[4572]: E0331 22:41:06.196367 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:41:11 master101 kubelet[4572]: E0331 22:41:11.198384 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:41:16 master101 kubelet[4572]: E0331 22:41:16.199761 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:41:21 master101 kubelet[4572]: E0331 22:41:21.201960 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
3月 31 22:41:26 master101 kubelet[4572]: E0331 22:41:26.204297 4572 kubelet.go:2475] "Container runtime network not ready" networkReady="NetworkReady=false reason:Networ...initialized"
Hint: Some lines were ellipsized, use -l to show in full.
是没有装网络组件(flannel)的原因,装了重启kubelet就正常了:
[root@master101 ~]# ll /etc/kubernetes/ #生成了各个组件的配置文件
总用量 32
-rw------- 1 root root 5637 3月 31 22:29 admin.conf
-rw------- 1 root root 5669 3月 31 22:29 controller-manager.conf
-rw------- 1 root root 1973 3月 31 22:29 kubelet.conf
drwx------ 2 root root 113 3月 31 22:29 manifests
drwxr-xr-x 3 root root 4096 3月 31 22:29 pki
-rw------- 1 root root 5617 3月 31 22:29 scheduler.conf
5. 配置kubectl
4.1 配置 kubectl->加载环境变量
kubectl 是管理 Kubernetes Cluster 的命令行工具, Master 初始化完成后需要做一些配置工作才能使用kubectl,这里直接配置root用户:(实际操作时只配置root用户,部署flannel会报错,最后也把node节点用户也弄上)
如果k8s服务端提示The connection to the server localhost:8080 was refused - did you specify the right host or port?出现这个问题的原因是kubectl命令需要使用kubernetes-admin来运行
[root@master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master ~]# source ~/.bash_profile
4.2 普通用户可以参考 kubeadm init 最后提示,复制admin.conf并修改权限,否则部署flannel网络插件报下面错误
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
4.3 如果node节点需要使用kubelet命令:
如果不做这个操作:node操作集群也会报错如下
scp /etc/kubernetes/admin.conf node1:/etc/kubernetes/admin.conf
scp /etc/kubernetes/admin.conf node2:/etc/kubernetes/admin.conf
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
Kubernetes 集群默认需要加密方式访问,以上操作就是将刚刚部署生成的 Kubernetes 集群的安全配置文件保存到当前用户的.kube目录下,kubectl默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置
最后就可以使用kubctl命令了:
[root@master101 ~]# kubectl get nodes master101 #NotReady 是因为还没有安装网络插件
NAME STATUS ROLES AGE VERSION
master101 NotReady control-plane 19m v1.26.3
[root@master101 ~]# kubectl get pod -A #-A查看 所以pod
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-787d4945fb-xqrcs 0/1 Pending 0 19m
kube-system coredns-787d4945fb-zmjrd 0/1 Pending 0 19m
kube-system etcd-master101 1/1 Running 0 19m
kube-system kube-apiserver-master101 1/1 Running 0 19m
kube-system kube-controller-manager-master101 1/1 Running 1 19m
kube-system kube-proxy-ckmr4 1/1 Running 0 19m
kube-system kube-scheduler-master101 1/1 Running 1 19m
如果pod处于失败状态,那么不能用kubectl logs -n kube-system coredns-787d4945fb-xqrcs 来查看日志。只能用 kubectl describe pods -n kube-system coredns-787d4945fb-xqrcs 来看错误信息
[root@master101 ~]# kubectl describe pods -n kube-system coredns-787d4945fb-xqrcs
Name: coredns-787d4945fb-xqrcs
Namespace: kube-system
Priority: 2000000000
Priority Class Name: system-cluster-critical
Service Account: coredns
Node: <none>
Labels: k8s-app=kube-dns
pod-template-hash=787d4945fb
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/coredns-787d4945fb
Containers:
coredns:
Image: registry.k8s.io/coredns/coredns:v1.9.3
Ports: 53/UDP, 53/TCP, 9153/TCP
Host Ports: 0/UDP, 0/TCP, 0/TCP
Args:
-conf
/etc/coredns/Corefile
Limits:
memory: 170Mi
Requests:
cpu: 100m
memory: 70Mi
Liveness: http-get http://:8080/health delay=60s timeout=5s period=10s #success=1 #failure=5
Readiness: http-get http://:8181/ready delay=0s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts:
/etc/coredns from config-volume (ro)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-nlv8p (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
config-volume:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: coredns
Optional: false
kube-api-access-nlv8p:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: kubernetes.io/os=linux
Tolerations: CriticalAddonsOnly op=Exists
node-role.kubernetes.io/control-plane:NoSchedule
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 95s (x5 over 22m) default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
这里没有coredns启动失败是因为还没有部署网络插件
[root@master101 ~]# kubectl get ns #查看命令空间
NAME STATUS AGE
default Active 24m
kube-node-lease Active 24m
kube-public Active 24m
kube-system Active 24m
[root@master101 ~]# kubectl get svc #切记不要删除这个svc,这是集群最基本的配置
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24m
10.96.0.1 这个地址就是初始化集群时指定的--service-cidr=10.96.0.0/12 ,进行分配的地址
6. 安装pod网络->就是flannel网络插件
【注意】:正常在生产环境不能这么搞,flannel一删除,所有Pod都不能运行了,因为没有网络。系统刚装完就要去调整flannel
Deploying flannel manually
文档地址:https://github.com/flannel-io/flannel
要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信。
Kubernetes 支持多种网络方案,这里我们使用 flannel
Pod正确运行,并且默认会分配10.244.开头的集群IP
如果kubernetes是新版本,那么flannel也可以直接用新版。否则需要找一下对于版本
[root@master101 ~]# wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
[root@master101 ~]# kubectl apply -f kube-flannel.yml
namespace/kube-flannel created
serviceaccount/flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
[root@master101 ~]# kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
(2)看到下载好的flannel 的镜像
[root@master101 ~]# crictl images | grep flannel
docker.io/flannel/flannel-cni-plugin v1.1.2 7a2dcab94698c 3.84MB
docker.io/flannel/flannel v0.21.4 11ae74319a21e 24.3MB

[root@master101 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::cc6e:5dff:fe2e:5497 prefixlen 64 scopeid 0x20<link>
ether ce:6e:5d:2e:54:97 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 10 overruns 0 carrier 0 collisions 0
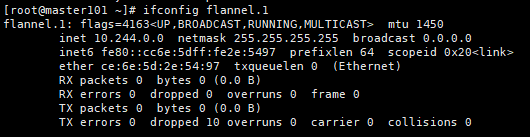
# netstat -nutlp | grep 8472 #UDP端口

(3)验证
① master节点已经Ready .安装了flannel后,master就Ready
[root@master101 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master101 Ready control-plane 6m4s v1.26.3

发现主节点在notready状态,因为还没安装网络插件,例如:flannel
② 查询kube-flannel名称空间下
语法:kubectl get pods -n kube-flannel(指定名称空间) | grep flannel
[root@master101 ~]# kubectl get pods -n kube-flannel |grep flannel
kube-flannel-ds-rz28k 1/1 Running 0 4m35s

[root@master101 ~]# kubectl logs -n kube-flannel kube-flannel-ds-rz28k #查看日志
Defaulted container "kube-flannel" out of: kube-flannel, install-cni-plugin (init), install-cni (init)
I0331 16:39:36.018299 1 main.go:211] CLI flags config: {etcdEndpoints:http://127.0.0.1:4001,http://127.0.0.1:2379 etcdPrefix:/coreos.com/network etcdKeyfile: etcdCertfile: etcdCAFile: etcdUsername: etcdPassword: version:false kubeSubnetMgr:true kubeApiUrl: kubeAnnotationPrefix:flannel.alpha.coreos.com kubeConfigFile: iface:[] ifaceRegex:[] ipMasq:true ifaceCanReach: subnetFile:/run/flannel/subnet.env publicIP: publicIPv6: subnetLeaseRenewMargin:60 healthzIP:0.0.0.0 healthzPort:0 iptablesResyncSeconds:5 iptablesForwardRules:true netConfPath:/etc/kube-flannel/net-conf.json setNodeNetworkUnavailable:true useMultiClusterCidr:false}
W0331 16:39:36.018538 1 client_config.go:617] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I0331 16:39:36.055236 1 kube.go:144] Waiting 10m0s for node controller to sync
I0331 16:39:36.055300 1 kube.go:485] Starting kube subnet manager
I0331 16:39:37.055816 1 kube.go:151] Node controller sync successful
I0331 16:39:37.055864 1 main.go:231] Created subnet manager: Kubernetes Subnet Manager - master101
I0331 16:39:37.055875 1 main.go:234] Installing signal handlers
I0331 16:39:37.056166 1 main.go:542] Found network config - Backend type: vxlan
I0331 16:39:37.056210 1 match.go:206] Determining IP address of default interface
I0331 16:39:37.057231 1 match.go:259] Using interface with name ens160 and address 10.11.100.101
I0331 16:39:37.057325 1 match.go:281] Defaulting external address to interface address (10.11.100.101)
I0331 16:39:37.057423 1 vxlan.go:140] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
W0331 16:39:37.075038 1 main.go:595] no subnet found for key: FLANNEL_SUBNET in file: /run/flannel/subnet.env
I0331 16:39:37.075072 1 main.go:481] Current network or subnet (10.244.0.0/16, 10.244.0.0/24) is not equal to previous one (0.0.0.0/0, 0.0.0.0/0), trying to recycle old iptables rules
I0331 16:39:37.075040 1 kube.go:506] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.244.0.0/24]
I0331 16:39:37.122378 1 main.go:356] Setting up masking rules
I0331 16:39:37.125753 1 main.go:407] Changing default FORWARD chain policy to ACCEPT
I0331 16:39:37.127565 1 iptables.go:290] generated 7 rules
I0331 16:39:37.129279 1 iptables.go:290] generated 3 rules
I0331 16:39:37.129404 1 main.go:435] Wrote subnet file to /run/flannel/subnet.env
I0331 16:39:37.129452 1 main.go:439] Running backend.
I0331 16:39:37.130087 1 vxlan_network.go:64] watching for new subnet leases
I0331 16:39:37.145140 1 main.go:460] Waiting for all goroutines to exit
I0331 16:39:37.156137 1 iptables.go:283] bootstrap done
I0331 16:39:37.171786 1 iptables.go:283] bootstrap done
可以看到,所有的系统 Pod 都成功启动了,而刚刚部署的flannel网络插件则在 kube-flannel下面新建了一个名叫kube-flannel-ds-rz28k的 Pod,一般来说,这些 Pod就是容器网络插件在每个节点上的控制组件。
Kubernetes 支持容器网络插件,使用的是一个名叫 CNI 的通用接口,它也是当前容器网络的事实标准,市面上的所有容器网络开源项目都可以通过 CNI 接入 Kubernetes,比如 Flannel、Calico、Canal、Romana 等等,它们的部署方式也都是类似的"一键部署"
如果pod提示Init:ImagePullBackOff,说明这个pod的镜像在对应节点上拉取失败,我们可以通过 kubectl describe pod pod_name 查看 Pod 具体情况,以确认拉取失败的镜像
[root@master101 ~]# kubectl describe pod kube-flannel-ds-rz28k --namespace=kube-flannel
Name: kube-flannel-ds-rz28k
Namespace: kube-flannel
Priority: 2000001000
Priority Class Name: system-node-critical
Service Account: flannel
Node: master101/10.11.100.101
Start Time: Sat, 01 Apr 2023 00:39:33 +0800
Labels: app=flannel
controller-revision-hash=56bb7c5f7b
k8s-app=flannel
pod-template-generation=1
tier=node
Annotations: <none>
Status: Running
IP: 10.11.100.101
IPs:
IP: 10.11.100.101
Controlled By: DaemonSet/kube-flannel-ds
Init Containers:
install-cni-plugin:
Container ID: containerd://969a5ccd882824557ecde44df914bcd712c85c114e885e45f3cca136ff6c0617
Image: docker.io/flannel/flannel-cni-plugin:v1.1.2
Image ID: docker.io/flannel/flannel-cni-plugin@sha256:bf4b62b131666d040f35a327d906ee5a3418280b68a88d9b9c7e828057210443
Port: <none>
Host Port: <none>
Command:
cp
Args:
-f
/flannel
/opt/cni/bin/flannel
State: Terminated
Reason: Completed
Exit Code: 0
Started: Sat, 01 Apr 2023 00:39:34 +0800
Finished: Sat, 01 Apr 2023 00:39:34 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/opt/cni/bin from cni-plugin (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-gv4jr (ro)
install-cni:
Container ID: containerd://8f721b33cdc954e4aa5a88f4dd99b0683cc8de503d61b0d9908ef332e8c334a5
Image: docker.io/flannel/flannel:v0.21.4
Image ID: docker.io/flannel/flannel@sha256:373a63e92c0428122a55581021eb9d3c780885fbab91c373012ec77e5c7288dc
Port: <none>
Host Port: <none>
Command:
cp
Args:
-f
/etc/kube-flannel/cni-conf.json
/etc/cni/net.d/10-flannel.conflist
State: Terminated
Reason: Completed
Exit Code: 0
Started: Sat, 01 Apr 2023 00:39:34 +0800
Finished: Sat, 01 Apr 2023 00:39:34 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/etc/cni/net.d from cni (rw)
/etc/kube-flannel/ from flannel-cfg (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-gv4jr (ro)
Containers:
kube-flannel:
Container ID: containerd://fd77ff2cee1a0d1dbd7000e79882f630545630fb15e26df2ab49a2f1f7891846
Image: docker.io/flannel/flannel:v0.21.4
Image ID: docker.io/flannel/flannel@sha256:373a63e92c0428122a55581021eb9d3c780885fbab91c373012ec77e5c7288dc
Port: <none>
Host Port: <none>
Command:
/opt/bin/flanneld
Args:
--ip-masq
--kube-subnet-mgr
State: Running
Started: Sat, 01 Apr 2023 00:39:35 +0800
Ready: True
Restart Count: 0
Requests:
cpu: 100m
memory: 50Mi
Environment:
POD_NAME: kube-flannel-ds-rz28k (v1:metadata.name)
POD_NAMESPACE: kube-flannel (v1:metadata.namespace)
EVENT_QUEUE_DEPTH: 5000
Mounts:
/etc/kube-flannel/ from flannel-cfg (rw)
/run/flannel from run (rw)
/run/xtables.lock from xtables-lock (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-gv4jr (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
run:
Type: HostPath (bare host directory volume)
Path: /run/flannel
HostPathType:
cni-plugin:
Type: HostPath (bare host directory volume)
Path: /opt/cni/bin
HostPathType:
cni:
Type: HostPath (bare host directory volume)
Path: /etc/cni/net.d
HostPathType:
flannel-cfg:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: kube-flannel-cfg
Optional: false
xtables-lock:
Type: HostPath (bare host directory volume)
Path: /run/xtables.lock
HostPathType: FileOrCreate
kube-api-access-gv4jr:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: :NoSchedule op=Exists
node.kubernetes.io/disk-pressure:NoSchedule op=Exists
node.kubernetes.io/memory-pressure:NoSchedule op=Exists
node.kubernetes.io/network-unavailable:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists
node.kubernetes.io/pid-pressure:NoSchedule op=Exists
node.kubernetes.io/unreachable:NoExecute op=Exists
node.kubernetes.io/unschedulable:NoSchedule op=Exists
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7m7s default-scheduler Successfully assigned kube-flannel/kube-flannel-ds-rz28k to master101
Normal Pulled 7m6s kubelet Container image "docker.io/flannel/flannel-cni-plugin:v1.1.2" already present on machine
Normal Created 7m6s kubelet Created container install-cni-plugin
Normal Started 7m6s kubelet Started container install-cni-plugin
Normal Pulled 7m6s kubelet Container image "docker.io/flannel/flannel:v0.21.4" already present on machine
Normal Created 7m6s kubelet Created container install-cni
Normal Started 7m6s kubelet Started container install-cni
Normal Pulled 7m5s kubelet Container image "docker.io/flannel/flannel:v0.21.4" already present on machine
Normal Created 7m5s kubelet Created container kube-flannel
Normal Started 7m5s kubelet Started container kube-flannel
可能无法从 quay.io/coreos/flannel:v0.10.0-amd64 下载镜像,可以从阿里云或者dockerhub镜像仓库下载,然后改回kube-flannel.yml文件里对应的tag即可:
docker pull registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.10.0-amd64
docker tag registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.10.0-amd64 quay.io/coreos/flannel:v0.10.0-amd64
docker rmi registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.10.0-amd64
7. 使用kubectl命令查询集群信息
查询组件状态信息:确认各个组件都处于healthy状态
[root@master101 ~]# kubectl get cs || kubectl get componentstatuses #查看组件状态
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
为什么没有apiservice呢? ->你能查到信息,说明apiservice以及运行成功了
查询集群节点信息(如果还没有部署好flannel,所以节点显示为NotReady):
[root@master101 ~]# kubectl get nodes || kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION
master101 Ready control-plane 13m v1.26.3
[root@master101 ~]# kubectl get nodes -o wide #详细信息
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master101 Ready control-plane 67m v1.26.3 10.11.100.101 <none> CentOS Linux 7 (Core) 5.4.238-1.el7.elrepo.x86_64 containerd://1.6.19
# kubectl describe node master101 #更加详细信息,通过 kubectl describe 指令的输出,我们可以看到 Ready 的原因在于,我们已经部署了网络插件
[root@master101 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-rz28k 1/1 Running 0 10m
kube-system coredns-787d4945fb-7dpvl 1/1 Running 0 13m
kube-system coredns-787d4945fb-hpxx4 1/1 Running 0 13m
kube-system etcd-master101 1/1 Running 1 14m
kube-system kube-apiserver-master101 1/1 Running 1 14m
kube-system kube-controller-manager-master101 1/1 Running 0 14m
kube-system kube-proxy-pwlbj 1/1 Running 0 13m
kube-system kube-scheduler-master101 1/1 Running 2 14m
coredns已经成功启动
查询名称空间,默认:
[root@master101 ~]# kubectl get ns
NAME STATUS AGE
default Active 14m
kube-flannel Active 11m
kube-node-lease Active 14m
kube-public Active 14m
kube-system Active 14m
我们还可以通过 kubectl 检查这个节点上各个系统 Pod 的状态,其中,kube-system 是 Kubernetes 项目预留的系统 Pod 的工作空间(Namepsace,注意它并不是 Linux Namespace,它只是 Kubernetes 划分不同工作空间的单位)
[root@master ~]# kubectl get pod -n kube-system -o wide

如果,CoreDNS依赖于网络的 Pod 都处于 Pending 状态,即调度失败。因为这个 Master 节点的网络尚未就绪,这里我们已经部署了网络了,所以是Running
注:
因为kubeadm需要拉取必要的镜像,这些镜像需要"科学上网";所以可以先在docker hub或其他镜像仓库拉取kube-proxy、kube-scheduler、kube-apiserver、kube-controller-manager、etcd、pause、coredns、flannel镜像;并加上 --ignore-preflight-errors=all 忽略所有报错即可
8. master节点配置(污点)
出于安全考虑,默认配置下Kubernetes不会将Pod调度到Master节点。taint:污点的意思。如果一个节点被打上了污点,那么pod是不允许运行在这个节点上面的
6.1 删除master节点默认污点
默认情况下集群不会在master上调度pod,如果偏想在master上调度Pod,可以执行如下操作:
查看污点(Taints)字段默认配置:
[root@master101 ~]# kubectl describe node master | grep -i taints
Taints: node-role.kubernetes.io/control-plane:NoSchedule

删除默认污点:
[root@master101 ~]# kubectl taint nodes master101 node-role.kubernetes.io/control-plane-
node/master101 untainted
6.2 污点机制
语法:
语法:
kubectl taint node [node_name] key_name=value_name[effect]
其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]
NoSchedule: 一定不能被调度
PreferNoSchedule: 尽量不要调度
NoExecute: 不仅不会调度, 还会驱逐Node上已有的Pod
打污点:
[root@master101 ~]# kubectl taint node master101 key1=value1:NoSchedule
node/master101 tainted
[root@master101 ~]# kubectl describe node master101 | grep -i taints
Taints: key1=value1:NoSchedule
key为key1,value为value1(value可以为空),effect为NoSchedule表示一定不能被调度

删除污点:
[root@master101 ~]# kubectl taint nodes master101 key1-
node/master101 untainted
[root@master101 ~]# kubectl describe node master101 | grep -i taints
Taints: <none>

删除指定key所有的effect,'-'表示移除所有以key1为键的污点
[root@master101 ~]# kubectl taint node master101 node-role.kubernetes.io/control-plane:NoSchedule
node/master101 tainted
[root@master101 ~]# kubectl describe node master101 | grep -i taints
Taints: node-role.kubernetes.io/control-plane:NoSchedule
四、Node节点安装
Kubernetes 的 Worker 节点跟 Master 节点几乎是相同的,它们运行着的都是一个 kubelet 组件。唯一的区别在于,在kubeadm init的过程中,kubelet 启动后,Master 节点上还会自动运行 kube-apiserver、kube-scheduler、kube-controller-manger这三个系统 Pod
1. 安装kubelet、kubeadm和kubectl
与master节点一样操作:在node节点安装kubeadm、kubelet、kubectl
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet
systemctl start kubelet
说明:其实可以不安装kubectl,因为你如果不在node上操作,就可以不用安装
2. 下载镜像
同master节点一样操作,同时node上面也需要flannel镜像
拉镜像和打tag,以下三个镜像是node节点运行起来的必要镜像(pause、kube-proxy、kube-flannel(如果本地没有镜像,在加入集群的时候自动拉取镜像然后启动))
[root@node01 ~]# docker pull mirrorgooglecontainers/pause:3.1
[root@node01 ~]# docker pull mirrorgooglecontainers/kube-proxy:v1.14.0
[root@node01 ~]# docker pull quay.io/coreos/flannel:v0.11.0-amd64
打上标签:
[root@node01 ~]# docker tag mirrorgooglecontainers/kube-proxy:v1.14.0 k8s.gcr.io/kube-proxy:v1.14.0
[root@node01 ~]# docker tag mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
[root@node01 ~]# docker tag mirrorgooglecontainers/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64
3. 加入集群
3.1-3.3在master上执行
3.1 查看令牌
[root@master101 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
0mt5hy.ltjw48rh5ftf448y 1h 2023-03-31T18:36:23Z <none> Proxy for managing TTL for the kubeadm-certs secret <none>
abcdef.0123456789abcdef 23h 2023-04-01T16:36:23Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
如果发现之前初始化时的令牌已过期,就在生成令牌
3.2 生成新的令牌
[root@master101 ~]# kubeadm token create
f4e26l.xxox4o5gxuj3l6ud
#或者
kubeadm token create --print-join-command
3.3 生成新的加密串,计算出token的hash值
[root@maste101r ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
837e3c07125993cd1486cddc2dbd36799efb49af9dbb9f7fd2e31bf1bdd810ae
3.4 node节点加入集群->加入集群就相当于初始化node节点了
在node节点上分别执行如下操作:
语法:
kubeadm join master_ip:6443 --token token_ID --discovery-token-ca-cert-hash sha256:生成的加密串
[root@node102 ~]# kubeadm join 10.11.100.101:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:3d9f70a7bd419b38753fc413155cd5cdedcc5763e5b3682b5c7879c1ea29561e \
--ignore-preflight-errors=Swap
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
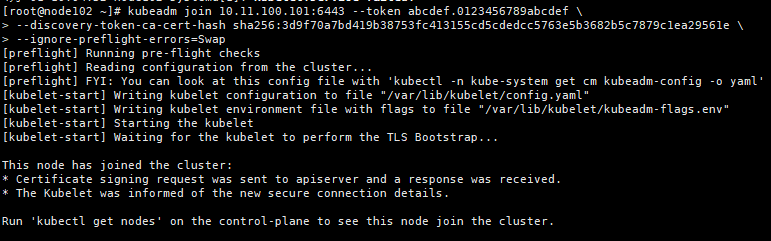
node节点加入集群启动的服务:(加入集群成功后自动成功启动了kubelet)
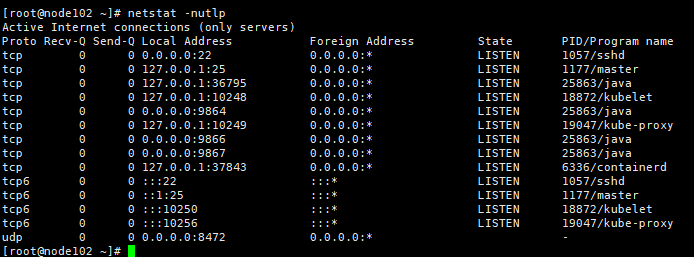
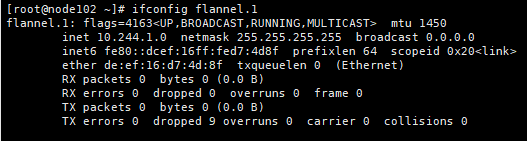
[root@node102 ~]# crictl pods
POD ID CREATED STATE NAME NAMESPACE ATTEMPT RUNTIME
3d16738357fd7 4 minutes ago Ready kube-flannel-ds-fzh47 kube-flannel 0 (default)
354397b8674d1 4 minutes ago Ready kube-proxy-2hgmj kube-system 0 (default)

master上面查看node01已经加入集群了
[root@master101 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master101 Ready control-plane 65m v1.26.3
node102 Ready <none> 5m40s v1.26.3

这是部署了网络组件的,STATUS才为Ready;没有安装网络组件状态如下:
[root@master101 ~]# kubectl cluster-info
Kubernetes control plane is running at https://10.11.100.101:6443
CoreDNS is running at https://10.11.100.101:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.

[root@master101 ~]# kubectl get nodes,cs,ns,pods -A
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS ROLES AGE VERSION
node/master101 Ready control-plane 62m v1.26.3
node/node102 Ready <none> 3m3s v1.26.3
NAME STATUS MESSAGE ERROR
componentstatus/controller-manager Healthy ok
componentstatus/etcd-0 Healthy {"health":"true","reason":""}
componentstatus/scheduler Healthy ok
NAME STATUS AGE
namespace/default Active 62m
namespace/kube-flannel Active 59m
namespace/kube-node-lease Active 62m
namespace/kube-public Active 62m
namespace/kube-system Active 62m
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel pod/kube-flannel-ds-fzh47 1/1 Running 0 3m3s
kube-flannel pod/kube-flannel-ds-rz28k 1/1 Running 0 59m
kube-system pod/coredns-787d4945fb-7dpvl 1/1 Running 0 62m
kube-system pod/coredns-787d4945fb-hpxx4 1/1 Running 0 62m
kube-system pod/etcd-master101 1/1 Running 1 62m
kube-system pod/kube-apiserver-master101 1/1 Running 1 62m
kube-system pod/kube-controller-manager-master101 1/1 Running 0 62m
kube-system pod/kube-proxy-2hgmj 1/1 Running 0 3m3s
kube-system pod/kube-proxy-pwlbj 1/1 Running 0 62m
kube-system pod/kube-scheduler-master101 1/1 Running 2 62m
加入一个node节点的已完成,以上是所以启动的服务(没有部署其他服务哈)
五、Dashboard(部署dashboard v1.10.1版本)
官方文件目录:
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dashboard
https://github.com/kubernetes/dashboard
三方参考文档:
https://blog.csdn.net/networken/article/details/85607593
在 Kubernetes 社区中,有一个很受欢迎的 Dashboard 项目,它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。
用户可以用 Kubernetes Dashboard部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源
1. 下载yaml
由于yaml配置文件中指定镜像从google拉取,网络访问不通,先下载yaml文件到本地,修改配置从阿里云仓库拉取镜像。一切参考官网
Images
Kubernetes Dashboard
kubernetesui/dashboard:v2.7.0
Metrics Scraper
kubernetesui/metrics-scraper:v1.0.8
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
2. 配置yaml
1、如果国内无法拉取镜像,那么需要修改为阿里云镜像地址
#registry.cn-hangzhou.aliyuncs.com/google_containers/dashboard:v2.7.0
[root@master101 ~]# grep image: recommended.yaml
image: kubernetesui/dashboard:v2.7.0
image: kubernetesui/metrics-scraper:v1.0.8
3. 部署dashboard服务
部署2种命令:
[root@master101 ~]# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
[root@node102 ~]# crictl images | grep dashboard
docker.io/kubernetesui/dashboard v2.7.0 07655ddf2eebe 75.8MB
[root@node103 ~]# crictl images | grep metrics-scraper
docker.io/kubernetesui/metrics-scraper v1.0.8 115053965e86b 19.7MB
#或者使用create部署
[root@master101 ~]# kubectl create -f recommended.yaml
状态查看:
查看Pod 的状态为running说明dashboard已经部署成功
[root@master101 ~]# kubectl get pods -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-7bc864c59-ngn47 1/1 Running 0 10m
kubernetes-dashboard-6c7ccbcf87-mh7r9 1/1 Running 0 10m

[root@master101 ~]# kubectl get pods -n kubernetes-dashboard -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dashboard-metrics-scraper-7bc864c59-ngn47 1/1 Running 0 11m 10.244.2.2 node103 <none> <none>
kubernetes-dashboard-6c7ccbcf87-mh7r9 1/1 Running 0 11m 10.244.1.2 node102 <none> <none>

Dashboard 会在 kubernetes-dashboard namespace 中创建自己的 Deployment 和 Service:
[root@master101 ~]# kubectl get deployments.apps --namespace=kubernetes-dashboard
NAME READY UP-TO-DATE AVAILABLE AGE
dashboard-metrics-scraper 1/1 1 1 13m
kubernetes-dashboard 1/1 1 1 13m
[root@master101 ~]# kubectl get deployments.apps -n kubernetes-dashboard
NAME READY UP-TO-DATE AVAILABLE AGE
dashboard-metrics-scraper 1/1 1 1 12m
kubernetes-dashboard 1/1 1 1 12m
获取dashboard的service访问端口:
[root@master101 ~]# kubectl get services -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.99.4.32 <none> 8000/TCP 14m
kubernetes-dashboard ClusterIP 10.99.165.18 <none> 443/TCP 14m

4. 访问dashboard
注意:要用火狐浏览器、谷歌打开,其他浏览器打不开的!
官方参考文档:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/#accessing-the-dashboard-ui
有以下几种方式访问dashboard:
有以下几种方式访问dashboard:
Nodport方式访问dashboard,service类型改为NodePort
loadbalacer方式,service类型改为loadbalacer
Ingress方式访问dashboard
API server方式访问 dashboard
kubectl proxy方式访问dashboard
NodePort方式
只建议在开发环境,单节点的安装方式中使用
为了便于本地访问,修改yaml文件,将service改为NodePort 类型:
配置NodePort,外部通过https://NodeIp:NodePort 访问Dashboard,此时端口为31620
[root@master ~]# cat recommended.yaml
…………
---
# ------------------- Dashboard Service ------------------- #
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort #增加type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31620 #增加nodePort: 31620
selector:
k8s-app: kubernetes-dashboard
---
重新应用yaml文件:
[root@master101 ~]# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard unchanged
serviceaccount/kubernetes-dashboard unchanged
service/kubernetes-dashboard configured
secret/kubernetes-dashboard-certs unchanged
secret/kubernetes-dashboard-csrf configured
Warning: resource secrets/kubernetes-dashboard-key-holder is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
secret/kubernetes-dashboard-key-holder configured
configmap/kubernetes-dashboard-settings unchanged
role.rbac.authorization.k8s.io/kubernetes-dashboard unchanged
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard unchanged
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard unchanged
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard unchanged
deployment.apps/kubernetes-dashboard unchanged
service/dashboard-metrics-scraper unchanged
deployment.apps/dashboard-metrics-scraper unchanged
查看service,TYPE类型已经变为NodePort,端口为31620:
#这是已经用NodePort暴露了端口,默认文件是cluster-ip方式
[root@master101 ~]# kubectl -n kubernetes-dashboard get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.99.4.32 <none> 8000/TCP 23h
kubernetes-dashboard NodePort 10.99.165.18 <none> 443:31620/TCP 23h
通过浏览器访问:https://10.11.100.101:31620/ 登录界面如下:


Dashboard 支持 Kubeconfig 和 Token 两种认证方式,我们这里选择Token认证方式登录:
创建登录用户:(这个版本这一步其实已经包含在recommended.yaml 文件中了)
执行yaml文件:
# 创建管理员账号,具有查看任何空间的权限,可以管理所有资源对象
[root@master101 ~]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard #不需要执行这一步,这一步对应的yaml文件
clusterrolebinding.rbac.authorization.k8s.io/dashboard-cluster-admin created
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
# 查看角色是否创建成功
[root@master101 ~]# kubectl -n kubernetes-dashboard get serviceaccounts | grep kubernetes-dashboard
kubernetes-dashboard 0 3d
查看kubernetes-dashboard账户的token(令牌):
# 创建token
# 'v1.24.0 更新之后进行创建 ServiceAccount 不会自动生成 Secret 需要对其手动创建'
# --duration 设置过期时间,也可以不加
[root@master101 ~]# kubectl -n kubernetes-dashboard create token kubernetes-dashboard --duration 604800s
eyJhbGciOiJSUzI1NiIsImtpZCI6ImJsYmRTWTBZQVVHQngya25JUGNaT2NDN3BaWXdGd3YtN3AyM1BzUzdOOE0ifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgxMzc2MDA2LCJpYXQiOjE2ODA3NzEyMDYsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInVpZCI6ImU4N2JhYjNiLTJlNDctNDA0ZS1hYTBmLTExOGUxYTk2YTg5MSJ9fSwibmJmIjoxNjgwNzcxMjA2LCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQifQ.Foxyx5qix91qOgeS_H_SFaOxDt2TkxWmHOKEWp8ua8Qvxyq80XV-l3qr-oBWfz1hf6BVp0Ev_HBEBU28E-t0XwaooUyxjh1qkgOxZgnFD1pnJmt1FLMOOHkw1lsd1qtQbt4RATSsUmSFRih_JwhtDMr1Fu0w2uuK-wljmXErY6yAiTW3l5bGnxoEQohhYAJvPcxNyL8N3L3cdTjmgr3xc8bzL4-syt17L787a-kY1sdTY6eN769ZnhfipQ-HIgt2CtGphm_a8vmBxvXpEJHtLs_Hv6GVw6rSAxfr6aNLaYmErpog6ibv2wb-WkRJ_Spu2ereCHsPZZl3OBdFWPGYIg
把获取到的Token复制到登录界面的Token输入框中:
成功登陆dashboard:


loadbalacer方式
首先需要部署metallb负载均衡器,部署参考:
https://blog.csdn.net/networken/article/details/85928369
LoadBalancer 更适合结合云提供商的 LB 来使用,但是在 LB 越来越多的情况下对成本的花费也是不可小觑
Ingress方式
详细部署参考:
https://blog.csdn.net/networken/article/details/85881558
https://www.kubernetes.org.cn/1885.html
github地址:
https://github.com/kubernetes/ingress-nginx
https://kubernetes.github.io/ingress-nginx/
基于 Nginx 的 Ingress Controller 有两种:
一种是 k8s 社区提供的: https://github.com/nginxinc/kubernetes-ingress
另一种是 Nginx 社区提供的 :
https://kubernetes.io/docs/concepts/services-networking/ingress/
关于两者的区别见:
https://github.com/nginxinc/kubernetes-ingress/blob/master/docs/nginx-ingress-controllers.md
Ingress-nginx简介
Ingress 是 k8s 官方提供的用于对外暴露服务的方式,也是在生产环境用的比较多的方式,一般在云环境下是 LB + Ingress Ctroller 方式对外提供服务,这样就可以在一个 LB 的情况下根据域名路由到对应后端的 Service,有点类似于 Nginx 反向代理,只不过在 k8s 集群中,这个反向代理是集群外部流量的统一入口
Pod的IP以及service IP只能在集群内访问,如果想在集群外访问kubernetes提供的服务,可以使用nodeport、proxy、loadbalacer以及ingress等方式,由于service的IP集群外不能访问,就是使用ingress方式再代理一次,即ingress代理service,service代理pod.
Ingress将开源的反向代理负载均衡器(如 Nginx、Apache、Haproxy等)与k8s进行集成,并可以动态的更新Nginx配置等,是比较灵活,更为推荐的暴露服务的方式,但也相对比较复杂
Ingress基本原理图如下:
部署nginx-ingress-controller:
下载nginx-ingress-controller配置文件:
[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.21.0/deploy/mandatory.yaml
修改镜像路径:
#替换镜像路径
vim mandatory.yaml
......
#image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.21.0
image: willdockerhub/nginx-ingress-controller:0.21.0
......
执行yaml文件部署
[root@master ~]# kubectl apply -f mandatory.yaml
namespace/ingress-nginx created
configmap/nginx-configuration created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k8s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created
deployment.extensions/nginx-ingress-controller created
创建Dashboard TLS证书:
[root@master ~]# mkdir -p /usr/local/src/kubernetes/certs
[root@master ~]# cd /usr/local/src/kubernetes
[root@master kubernetes]# openssl genrsa -des3 -passout pass:x -out certs/dashboard.pass.key 2048
Generating RSA private key, 2048 bit long modulus
..........+++
.................+++
e is 65537 (0x10001)
[root@master kubernetes]# openssl rsa -passin pass:x -in certs/dashboard.pass.key -out certs/dashboard.key
writing RSA key
[root@master kubernetes]# openssl req -new -key certs/dashboard.key -out certs/dashboard.csr -subj '/CN=kube-dashboard'
[root@master kubernetes]# openssl x509 -req -sha256 -days 365 -in certs/dashboard.csr -signkey certs/dashboard.key -out certs/dashboard.crt
Signature ok
subject=/CN=kube-dashboard
Getting Private key
[root@master kubernetes]# ls
certs
[root@master kubernetes]# tree certs/
certs/
├── dashboard.crt
├── dashboard.csr
├── dashboard.key
└── dashboard.pass.key
0 directories, 4 files
[root@master kubernetes]# rm certs/dashboard.pass.key
rm: remove regular file ‘certs/dashboard.pass.key’? y
[root@master kubernetes]# kubectl create secret generic kubernetes-dashboard-certs --from-file=certs -n kube-system
Error from server (AlreadyExists): secrets "kubernetes-dashboard-certs" already exists
[root@master kubernetes]# tree certs/
certs/
├── dashboard.crt
├── dashboard.csr
└── dashboard.key
0 directories, 3 files
[root@master kubernetes]# kubectl create secret generic kubernetes-dashboard-certs --from-file=certs -n kube-system
Error from server (AlreadyExists): secrets "kubernetes-dashboard-certs" already exists
[root@master kubernetes]# kubectl create secret generic kubernetes-dashboard-certs1 --from-file=certs -n kube-system
secret/kubernetes-dashboard-certs1 created
创建ingress规则:文件末尾添加tls配置项即可
[root@master kubernetes]# vim kubernetes-dashboard-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
labels:
k8s-app: kubernetes-dashboard
annotations:
kubernetes.io/ingress.class: "nginx"
https://github.com/kubernetes/ingress-nginx/blob/master/docs/user-guide/nginx-configuration/annotations.md
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/ssl-passthrough: "true"
name: kubernetes-dashboard
namespace: kube-system
spec:
rules:
- host: dashboard.host.com
http:
paths:
- path: /
backend:
servicePort: 443
serviceName: kubernetes-dashboard
tls:
- hosts:
- dashboard.host.com
secretName: kubernetes-dashboard-certs
访问这个域名: dashboard.host.com
API Server方式(建议采用这种方式)
如果Kubernetes API服务器是公开的,并可以从外部访问,那我们可以直接使用API Server的方式来访问,也是比较推荐的方式
Dashboard的访问地址为:
https://<master-ip>:<apiserver-port>/api/v1/namespaces/Dashboard_NameSpacesNname/services/https:kubernetes-dashboard:/proxy/
https://<master-ip>:<apiserver-port>/api/v1/namespaces/Dashboard_NameSpacesNname/services/https:Dashboard_NameSpacesNname:/proxy/
但是浏览器返回的结果可能如下:
这是因为最新版的k8s默认启用了RBAC,并为未认证用户赋予了一个默认的身份:anonymous。
对于API Server来说,它是使用证书进行认证的,我们需要先创建一个证书:
我们使用client-certificate-data和client-key-data生成一个p12文件,可使用下列命令:
mkdir /dashboard
cd /dashboard
# 生成client-certificate-data
grep 'client-certificate-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> kubecfg.crt
# 生成client-key-data
grep 'client-key-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> kubecfg.key
# 生成p12
[root@master dashboard]# openssl pkcs12 -export -clcerts -inkey kubecfg.key -in kubecfg.crt -out kubecfg.p12 -name "kubernetes-client"
Enter Export Password:
Verifying - Enter Export Password:
[root@master ~]# ll -t
-rw-r--r--. 1 root root 2464 Oct 2 15:19 kubecfg.p12
-rw-r--r--. 1 root root 1679 Oct 2 15:18 kubecfg.key
-rw-r--r--. 1 root root 1082 Oct 2 15:18 kubecfg.crt
最后导入上面生成的kubecfg.p12文件,重新打开浏览器,显示如下:(不知道怎么导入证书,自己百度)
浏览器的设置->搜索证书
点击确定,便可以看到熟悉的登录界面了: 我们可以使用一开始创建的admin-user用户的token进行登录,一切OK
再次访问浏览器会弹出下面信息,点击确定
然后进入登录界面,选择令牌:
输入token,进入登录:
Porxy方式
如果要在本地访问dashboard,可运行如下命令:
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
现在就可以通过以下链接来访问Dashborad UI:
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
这种方式默认情况下,只能从本地访问(启动它的机器)。
我们也可以使用--address和--accept-hosts参数来允许外部访问:
$ kubectl proxy --address='0.0.0.0' --accept-hosts='^*$'
Starting to serve on [::]:8001
然后我们在外网访问以下链接:
http://<master-ip>:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
可以成功访问到登录界面,但是填入token也无法登录,这是因为Dashboard只允许localhost和127.0.0.1使用HTTP连接进行访问,而其它地址只允许使用HTTPS。因此,如果需要在非本机访问Dashboard的话,只能选择其他访问方式
使用Dashboard
Dashboard 界面结构分为三个大的区域。
-
顶部操作区,在这里用户可以搜索集群中的资源、创建资源或退出。
-
左边导航菜单,通过导航菜单可以查看和管理集群中的各种资源。菜单项按照资源的层级分为两类:Cluster 级别的资源 ,Namespace 级别的资源 ,默认显示的是 default Namespace,可以进行切换:
-
中间主体区,在导航菜单中点击了某类资源,中间主体区就会显示该资源所有实例,比如点击 Pods
六、集群测试
1. 部署应用
1.1 通过命令方式部署
通过命令行方式部署apache服务
[root@master101 ~]# kubectl run httpd-app --image=httpd
pod/httpd-app created
[root@master101 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
httpd-app 0/1 ContainerCreating 0 15s
[root@master101 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
httpd-app 1/1 Running 0 27s
[root@master101 ~]# kubectl delete pods httpd-app #删除pod
pod "httpd-app" deleted
eg:应用创建
1.创建一个测试用的deployment:
[root@master101 ~]# kubectl create deployment net-test --image=alpine --replicas=2 -- sleep 360000
deployment.apps/net-test created
2.查看获取IP情况
[root@master101 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
net-test-596c5747d4-lqnbd 1/1 Running 0 35s 10.244.1.6 node102 <none> <none>
net-test-596c5747d4-mjqk2 1/1 Running 0 35s 10.244.2.6 node103 <none> <none>
[root@master101 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
net-test-596c5747d4-lqnbd 1/1 Running 0 5s
net-test-596c5747d4-mjqk2 1/1 Running 0 5s

3.测试联通性(在pod里面ping node节点)



1.2 通过配置文件方式部署nginx服务
cat > nginx.yml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
restartPolicy: Always
containers:
- name: nginx
image: nginx:latest
EOF
说明:在K8S v1.18.0以后,Deployment对于的apiVersion已经更改
查看apiVersion:
kubectl api-versions
查看Kind,并且可以得到apiVersion与Kind的对应关系:
kubectl api-resources
[root@master101 ~]# kubectl apply -f nginx.yml
deployment.apps/nginx created
[root@master101 ~]# kubectl describe deployments nginx #查看详情
Name: nginx
Namespace: default
CreationTimestamp: Fri, 07 Apr 2023 18:12:21 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:latest
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-654975c8cd (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 34s deployment-controller Scaled up replica set nginx-654975c8cd to 3
[root@master101 ~]# kubectl get pod | grep nginx #查看pod
nginx-654975c8cd-qw47g 1/1 Running 0 3m15s
nginx-654975c8cd-rh88w 1/1 Running 0 3m15s
nginx-654975c8cd-wgtmm 1/1 Running 0 3m15s
# kubectl get pod -w #一直watch着!
[root@master101 ~]# kubectl get pods -o wide | grep nginx #查看所有的pods更详细些
nginx-654975c8cd-qw47g 1/1 Running 0 4m38s 10.244.2.7 node103 <none> <none>
nginx-654975c8cd-rh88w 1/1 Running 0 4m38s 10.244.1.8 node102 <none> <none>
nginx-654975c8cd-wgtmm 1/1 Running 0 4m38s 10.244.1.7 node102 <none> <none>
[root@master101 ~]# kubectl exec nginx-654975c8cd-wgtmm -it -- nginx -v #查看版本
nginx version: nginx/1.23.4
[root@master101 ~]# kubectl logs nginx-654975c8cd-wgtmm #查看日志
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2023/04/07 18:48:06 [notice] 1#1: using the "epoll" event method
2023/04/07 18:48:06 [notice] 1#1: nginx/1.23.4
2023/04/07 18:48:06 [notice] 1#1: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2023/04/07 18:48:06 [notice] 1#1: OS: Linux 5.4.238-1.el7.elrepo.x86_64
2023/04/07 18:48:06 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2023/04/07 18:48:06 [notice] 1#1: start worker processes
2023/04/07 18:48:06 [notice] 1#1: start worker process 29
2023/04/07 18:48:06 [notice] 1#1: start worker process 30
2023/04/07 18:48:06 [notice] 1#1: start worker process 31
2023/04/07 18:48:06 [notice] 1#1: start worker process 32
[root@master101 ~]# kubectl logs pods/nginx-654975c8cd-qw47g
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2023/04/07 18:48:04 [notice] 1#1: using the "epoll" event method
2023/04/07 18:48:04 [notice] 1#1: nginx/1.23.4
2023/04/07 18:48:04 [notice] 1#1: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2023/04/07 18:48:04 [notice] 1#1: OS: Linux 5.4.238-1.el7.elrepo.x86_64
2023/04/07 18:48:04 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2023/04/07 18:48:04 [notice] 1#1: start worker processes
2023/04/07 18:48:04 [notice] 1#1: start worker process 29
2023/04/07 18:48:04 [notice] 1#1: start worker process 30
2023/04/07 18:48:04 [notice] 1#1: start worker process 31
2023/04/07 18:48:04 [notice] 1#1: start worker process 32
[root@master101 ~]# kubectl logs deployments/nginx
Found 3 pods, using pod/nginx-654975c8cd-qw47g #3个pod
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2023/04/07 18:48:04 [notice] 1#1: using the "epoll" event method
2023/04/07 18:48:04 [notice] 1#1: nginx/1.23.4
2023/04/07 18:48:04 [notice] 1#1: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2023/04/07 18:48:04 [notice] 1#1: OS: Linux 5.4.238-1.el7.elrepo.x86_64
2023/04/07 18:48:04 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2023/04/07 18:48:04 [notice] 1#1: start worker processes
2023/04/07 18:48:04 [notice] 1#1: start worker process 29
2023/04/07 18:48:04 [notice] 1#1: start worker process 30
2023/04/07 18:48:04 [notice] 1#1: start worker process 31
2023/04/07 18:48:04 [notice] 1#1: start worker process 32
可以看到nginx的3个副本pod均匀分布在2个node节点上,为什么没有分配在master上了,因为master上打了污点
[root@master101 ~]# kubectl get rs nginx-654975c8cd #查看副本
NAME DESIRED CURRENT READY AGE
nginx-654975c8cd 3 3 3 8m17s
#通过标签查看指定的pod
语法:kubectl get pods -l Labels -o wide
如何查看Labels:# kubectl describe deployment deployment_name
或者:
[root@master101 ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
net-test-596c5747d4-lqnbd 1/1 Running 0 24h app=net-test,pod-template-hash=596c5747d4
net-test-596c5747d4-mjqk2 1/1 Running 0 24h app=net-test,pod-template-hash=596c5747d4
nginx-654975c8cd-qw47g 1/1 Running 0 12m app=nginx,pod-template-hash=654975c8cd
nginx-654975c8cd-rh88w 1/1 Running 0 12m app=nginx,pod-template-hash=654975c8cd
nginx-654975c8cd-wgtmm 1/1 Running 0 12m app=nginx,pod-template-hash=654975c8cd
[root@master101 ~]# kubectl get pods -l app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-654975c8cd-qw47g 1/1 Running 0 12m 10.244.2.7 node103 <none> <none>
nginx-654975c8cd-rh88w 1/1 Running 0 12m 10.244.1.8 node102 <none> <none>
nginx-654975c8cd-wgtmm 1/1 Running 0 12m 10.244.1.7 node102 <none> <none>
[root@master101 ~]# kubectl get pods --all-namespaces || kubectl get pods -A #查看所以pod(不同namespace下的pod)
NAMESPACE NAME READY STATUS RESTARTS AGE
default net-test-596c5747d4-lqnbd 1/1 Running 0 24h
default net-test-596c5747d4-mjqk2 1/1 Running 0 24h
default nginx-654975c8cd-qw47g 1/1 Running 0 13m
default nginx-654975c8cd-rh88w 1/1 Running 0 13m
default nginx-654975c8cd-wgtmm 1/1 Running 0 13m
kube-flannel kube-flannel-ds-fzh47 1/1 Running 0 6d16h
kube-flannel kube-flannel-ds-rz28k 1/1 Running 0 6d17h
kube-flannel kube-flannel-ds-w6gmn 1/1 Running 0 6d16h
kube-system coredns-787d4945fb-7dpvl 1/1 Running 0 6d17h
kube-system coredns-787d4945fb-hpxx4 1/1 Running 0 6d17h
kube-system etcd-master101 1/1 Running 1 6d17h
kube-system kube-apiserver-master101 1/1 Running 1 6d17h
kube-system kube-controller-manager-master101 1/1 Running 0 6d17h
kube-system kube-proxy-2hgmj 1/1 Running 0 6d16h
kube-system kube-proxy-pwlbj 1/1 Running 0 6d17h
kube-system kube-proxy-vxf4v 1/1 Running 0 6d16h
kube-system kube-scheduler-master101 1/1 Running 2 6d17h
kubernetes-dashboard dashboard-metrics-scraper-7bc864c59-gjdqq 1/1 Running 0 25h
kubernetes-dashboard kubernetes-dashboard-6c7ccbcf87-5skjm 1/1 Running 0 25h
---------------------以上只是部署了,下面就暴露端口提供外部访问----------------
[root@master101 ~]# kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
[root@master101 ~]# kubectl get services nginx || kubectl get svc nginx #service缩写为svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx NodePort 10.107.67.123 <none> 80:32383/TCP 14s
[root@master101 ~]# kubectl delete services nginx #删除
service "nginx" deleted
说明:用NodePort方式把k8s集群的nginx services 的80端口通过kube-proxy映射到宿主机上的随机端口的32383,然后就可以在集群外部用:集群集群IP:32383访问服务了
[root@master ~]# netstat -nutlp| grep 32383
tcp 0 0 0.0.0.0:32383 0.0.0.0:* LISTEN 6334/kube-proxy
[root@node01 ~]# netstat -nutlp| grep 32383
tcp 0 0 0.0.0.0:30999 0.0.0.0:* LISTEN 6334/kube-proxy
通过对应的pod ip访问对应的服务
[root@master101 ~]# curl 10.244.2.7
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
可以通过任意CLUSTER-IP:Port在集群内部访问这个服务:
[root@master101 ~]# curl 10.105.57.107:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
可以通过任意NodeIP:Port在集群外部访问这个服务:
[root@master101 ~]# curl -I 10.11.100.101:32383
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Mon, 10 Apr 2023 11:02:14 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 15:01:54 GMT
Connection: keep-alive
ETag: "64230162-267"
Accept-Ranges: bytes
[root@master101 ~]# curl -I 10.11.100.102:32383
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Mon, 10 Apr 2023 11:02:22 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 15:01:54 GMT
Connection: keep-alive
ETag: "64230162-267"
Accept-Ranges: bytes
[root@master101 ~]# curl -I 10.11.100.103:32383
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Mon, 10 Apr 2023 11:02:21 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 15:01:54 GMT
Connection: keep-alive
ETag: "64230162-267"
Accept-Ranges: bytes
访问master_ip:32383
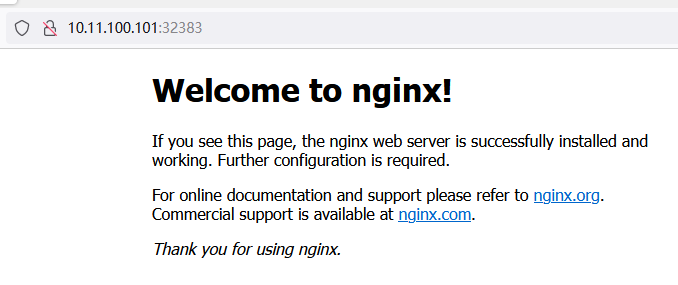
访问Node01_ip:32383
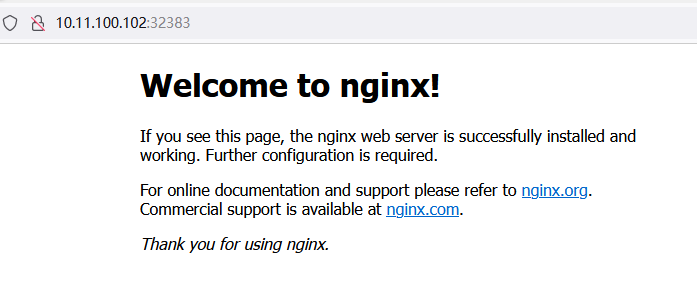
访问Node02_ip:32383
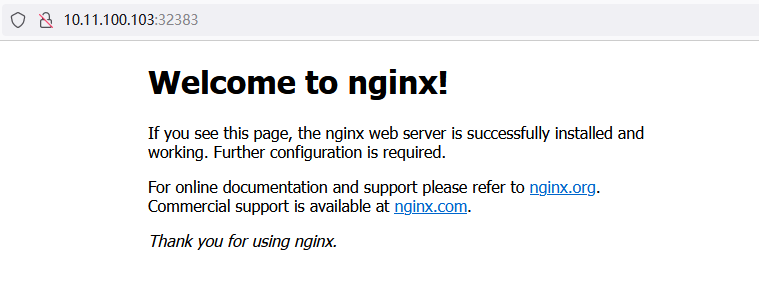
最后验证一下coredns(需要coredns服务正常), pod network是否正常:
运行Busybox并进入交互模式(busybox是一个很小的操作系统)
[root@master101 ~]# kubectl run -it curl --image=radial/busyboxplus:curl
If you don't see a command prompt, try pressing enter.
[ root@curl:/ ]$

输入nslookup nginx查看是否可以正确解析出集群内的IP,以验证DNS是否正常
[ root@curl:/ ]$ nslookup nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.107.67.123 nginx.default.svc.cluster.local
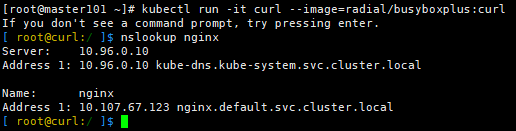
说明: 10.107.67.123 是nginx的cluster_IP
通过svc服务名进行访问,验证kube-proxy是否正常:
[ root@curl:/ ]$ curl http://nginx/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[ root@curl:/ ]$ wget -O- -q http://nginx:80/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[ root@curl:/ ]$ exit
Session ended, resume using 'kubectl attach curl -c curl -i -t' command when the pod is running
分别访问一下3个Pod的内网IP,验证跨Node的网络通信是否正常
[root@master101 ~]# kubectl get pod -l app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-654975c8cd-qw47g 1/1 Running 0 2d16h 10.244.2.7 node103 <none> <none>
nginx-654975c8cd-rh88w 1/1 Running 0 2d16h 10.244.1.8 node102 <none> <none>
nginx-654975c8cd-wgtmm 1/1 Running 0 2d16h 10.244.1.7 node102 <none> <none>
[root@master101 ~]# kubectl attach curl -c curl -i -t
If you don't see a command prompt, try pressing enter.
[ root@curl:/ ]$ curl -I 10.244.2.7
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Mon, 10 Apr 2023 11:31:09 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 15:01:54 GMT
Connection: keep-alive
ETag: "64230162-267"
Accept-Ranges: bytes
[ root@curl:/ ]$ curl -I 10.244.1.8
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Mon, 10 Apr 2023 11:31:23 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 15:01:54 GMT
Connection: keep-alive
ETag: "64230162-267"
Accept-Ranges: bytes
[ root@curl:/ ]$ curl -I 10.244.1.7
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Mon, 10 Apr 2023 11:31:31 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 15:01:54 GMT
Connection: keep-alive
ETag: "64230162-267"
Accept-Ranges: bytes
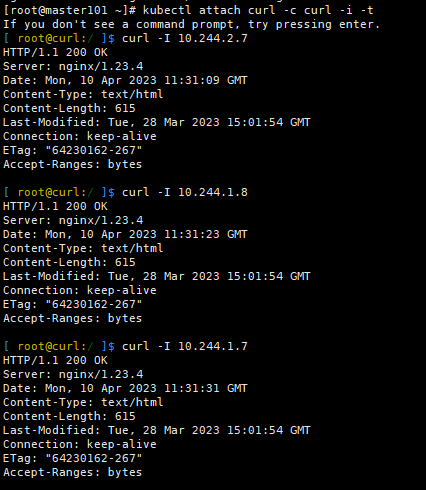
删除相关操作
#删除svc
[root@master101 ~]# kubectl delete svc nginx
service "nginx" deleted
#删除deploy
[root@master101 ~]# kubectl delete deployments nginx #删除deploy
deployment.apps "nginx" deleted
# kubectl delete -f nginx.yml #或者利用配置文件删除
# kubectl get svc #查看是否删除
# kubectl get deployments #查看是否删除
# kubectl get pod #查看是否删除
# kubectl get rs #查看副本
二进制安装部署kubernetes集群-->建议首先部署docker
GitHub参考文档:https://github.com/opsnull/follow-me-install-kubernetes-cluster
三方参考:
https://jimmysong.io/kubernetes-handbook/practice/install-kubernetes-on-centos.html
https://www.cnblogs.com/along21/p/10044931.html#auto_id_95
https://blog.csdn.net/networken/article/details/84991940
二进制安装需要4套4A证书才安全。
组件版本和配置策略
组件版本
-
Kubernetes 1.14.2
-
Docker 18.09.6-ce
-
Etcd 3.3.13
-
Flanneld 0.11.0
-
插件:
-
Coredns
-
Dashboard
-
Metrics-server
-
EFK (elasticsearch、fluentd、kibana)
-
-
镜像仓库:
-
docker registry
-
harbor
-
主要配置策略
kube-apiserver:
-
使用节点本地nginx 4 层透明代理实现高可用;
-
关闭非安全端口 8080 和匿名访问;
-
在安全端口 6443 接收 https 请求;
-
严格的认证和授权策略 (x509、token、RBAC);
-
开启 bootstrap token 认证,支持 kubelet TLS bootstrapping;
-
使用 https 访问 kubelet、etcd,加密通信;
kube-controller-manager:
-
3 节点高可用;
-
关闭非安全端口,在安全端口 10252 接收 https 请求;
-
使用 kubeconfig 访问 apiserver 的安全端口;
-
自动 approve kubelet 证书签名请求 (CSR),证书过期后自动轮转;
-
各 controller 使用自己的 ServiceAccount 访问 apiserver;
kube-scheduler:
-
3 节点高可用
-
使用 kubeconfig 访问 apiserver 的安全端口;
kubelet:
-
使用 kubeadm 动态创建 bootstrap token,而不是在 apiserver 中静态配置;
-
使用 TLS bootstrap 机制自动生成 client 和 server 证书,过期后自动轮转;
-
在 KubeletConfiguration 类型的 JSON 文件配置主要参数;
-
关闭只读端口,在安全端口 10250 接收 https 请求,对请求进行认证和授权,拒绝匿名访问和非授权访问;
-
使用 kubeconfig 访问 apiserver 的安全端口;
kube-proxy:
-
使用 kubeconfig 访问 apiserver 的安全端口;
-
在 KubeProxyConfiguration 类型的 JSON 文件配置主要参数;
-
使用 ipvs 代理模式;
集群插件:
-
DNS:使用功能、性能更好的 coredns;
-
Dashboard:支持登录认证;
-
Metric:metrics-server,使用 https 访问 kubelet 安全端口;
-
Log:Elasticsearch、Fluend、Kibana;
-
Registry 镜像库:docker-registry、harbor
系统初始化
集群机器
-
master:192.168.137.50
-
node01:192.168.137.60
-
node02:192.168.137.70
注意:
-
本文档中的 etcd 集群、master 节点、worker 节点均使用这三台机器;
-
需要在所有机器上执行本文档的初始化命令;
-
需要使用root 账号执行这些命令;
-
如果没有特殊指明,本文档的所有操作均在 master 节点上执行,然后远程分发文件和执行命令
在每个服务器上都要执行以下全部操作,如果没有特殊指明,本文档的所有操作均在master 节点上执行
主机名
1、设置永久主机名称,然后重新登录
hostnamectl set-hostname master
hostnamectl set-hostname node01
hostnamectl set-hostname node02
2、修改 /etc/hostname 文件,添加主机名和 IP 的对应关系:
$ vim /etc/hosts
192.168.137.50 master
192.168.137.60 node01
192.168.137.70 node02
添加 k8s 和 docker 账户
1、在每台机器上添加 k8s 账户并设置密码
# useradd -m k8s && sh -c 'echo 666666 | passwd k8s --stdin'
2、修改visudo权限
# visudo #去掉# %wheel ALL=(ALL) NOPASSWD: ALL这行的注释
# grep '%wheel.*NOPASSWD: ALL' /etc/sudoers
%wheel ALL=(ALL) NOPASSWD: ALL
3、将k8s用户归到wheel组
# gpasswd -a k8s wheel
Adding user k8s to group wheel
# id k8s
uid=1000(k8s) gid=1000(k8s) groups=1000(k8s),10(wheel)
4、在每台机器上添加 docker 账户,将 k8s 账户添加到 docker 组中,同时配置 dockerd 参数(注:安装完docker才有):
# useradd -m docker && gpasswd -a k8s docker
# mkdir -p /opt/docker/
# 使用国内的仓库镜像服务器以加快 pull image 的速度,同时增加下载的并发数 (需要重启 dockerd 生效):
# vim /opt/docker/daemon.json #可以后续部署docker时在操作
{
"registry-mirrors": ["https://hub-mirror.c.163.com", "https://docker.mirrors.ustc.edu.cn"],
"max-concurrent-downloads": 20
}
无密码 ssh 登录其它节点
1、生成秘钥对
[root@master ~]# ssh-keygen -t rsa #连续回车即可
2、将自己的公钥发给其他服务器
[root@master ~]# ssh-copy-id root@master
[root@master ~]# ssh-copy-id root@node01
[root@master ~]# ssh-copy-id root@node02
[root@master ~]# ssh-copy-id k8s@master
[root@master ~]# ssh-copy-id k8s@node01
[root@master ~]# ssh-copy-id k8s@node02
将可执行文件路径 /opt/k8s/bin 添加到 PATH 变量
这是为后续做准备
在每台机器上添加环境变量:
# sh -c "echo 'PATH=/opt/k8s/bin:$PATH:$HOME/bin:$JAVA_HOME/bin' >> /etc/profile.d/k8s.sh"
# source /etc/profile.d/k8s.sh
安装依赖包
在每台机器上安装依赖包:
CentOS:
yum install -y epel-release
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget net-tools
Ubuntu:
# apt-get install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp
注:
-
ipvs 依赖 ipset;
-
ntp 保证各机器系统时间同步
关闭防火墙
在每台机器上关闭防火墙:
① 关闭服务,并设为开机不自启
# systemctl stop firewalld && sudo systemctl disable firewalld
② 清空防火墙规则
# iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
# iptables -P FORWARD ACCEPT
关闭 swap 分区
1、如果开启了 swap 分区,kubelet 会启动失败(可以通过将参数 --fail-swap-on 设置为false 来忽略 swap on),故需要在每台机器上关闭 swap 分区:
# swapoff -a
2、为了防止开机自动挂载 swap 分区,可以注释 /etc/fstab 中相应的条目:
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
关闭 SELinux
1、关闭 SELinux,否则后续 K8S 挂载目录时可能报错 Permission denied :
# setenforce 0
2、修改配置文件,永久生效;
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
关闭 dnsmasq (可选)
linux 系统开启了 dnsmasq 后(如 GUI 环境),将系统 DNS Server 设置为 127.0.0.1,这会导致 docker 容器无法解析域名,需要关闭它:
# service dnsmasq stop
# systemctl disable dnsmasq
加载内核模块
# modprobe br_netfilter && modprobe ip_vs
-
系统内核相关参数参考:
-
https://docs.openshift.com/enterprise/3.2/admin_guide/overcommit.html
-
3.10.x 内核 kmem bugs 相关的讨论和解决办法:
-
https://support.mesosphere.com/s/article/Critical-Issue-KMEM-MSPH-2018-0006
-
https://pingcap.com/blog/try-to-fix-two-linux-kernel-bugs-while-testing-tidb-operator-in-k8s/
设置docker所需要的系统参数
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf && sysctl -p /etc/sysctl.d/kubernetes.conf && mount -t cgroup -o cpu,cpuacct none /sys/fs/cgroup/cpu,cpuacct
注:
tcp_tw_recycle 和 Kubernetes 的 NAT 冲突,必须关闭 ,否则会导致服务不通;
关闭不使用的 IPV6 协议栈,防止触发 docker BUG;
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
设置系统时区
1、调整系统 TimeZone
timedatectl set-timezone Asia/Shanghai
2、将当前的 UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
3、重启依赖于系统时间的服务
systemctl restart rsyslog && systemctl restart crond
更新系统时间
yum -y install ntpdate && ntpdate cn.pool.ntp.org
关闭无关的服务
systemctl stop postfix && systemctl disable postfix
创建目录
在每台机器上创建目录:
mkdir -p /opt/k8s/bin ;mkdir -p /opt/k8s/cert
mkdir -p /opt/etcd/cert;mkdir -p /opt/lib/etcd;mkdir -p /opt/k8s/script
chown -R k8s /opt/k8s && chown -R k8s /opt/lib/etcd && chown -R k8s /opt/k8s/script
设置 rsyslogd 和 systemd journald
systemd 的 journald 是 Centos 7 缺省的日志记录工具,它记录了所有系统、内核、Service Unit 的日志。
相比 systemd,journald 记录的日志有如下优势:
可以记录到内存或文件系统;(默认记录到内存,对应的位置为 /run/log/jounal);
可以限制占用的磁盘空间、保证磁盘剩余空间;
可以限制日志文件大小、保存的时间;
journald 默认将日志转发给 rsyslog,这会导致日志写了多份,/var/log/messages中包含了太多无关日志,不方便后续查看,同时也影响系统性能。
mkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
# systemctl restart systemd-journald
检查系统内核和模块是否适合运行 docker (仅适用于linux 系统)
curl https://raw.githubusercontent.com/docker/docker/master/contrib/check-config.sh > check-config.sh
chmod +x check-config.sh && bash ./check-config.sh
升级内核
CentOS 7.x 系统自带的 3.10.x 内核存在一些 Bugs,导致运行的 Docker、Kubernetes 不稳定,例如:高版本的 docker(1.13 以后) 启用了 3.10 kernel 实验支持的 kernel memory account 功能(无法关闭),当节点压力大如频繁启动和停止容器时会导致cgroup memory leak;
网络设备引用计数泄漏,会导致类似于报错:"kernel:unregister_netdevice: waiting for eth0 to become free. Usage count = 1";
3种解决方案如下:
- 升级内核到 4.4.X 以上;
- 或者,手动编译内核,disable CONFIG_MEMCG_KMEM 特性;
- 或者,安装修复了该问题的 Docker 18.09.1 及以上的版本。但由于 kubelet 也会设置 kmem(它 vendor 了 runc),所以需要重新编译 kubelet 并指定
GOFLAGS="-tags=nokmem";
git clone --branch v1.14.1 --single-branch --depth 1 https://github.com/kubernetes/kubernetes
cd kubernetes
KUBE_GIT_VERSION=v1.14.1 ./build/run.sh make kubelet GOFLAGS="-tags=nokmem"
这里采用升级内核的解决办法:
安装elrepo 载入公钥,安装eprepo源(网址:http://elrepo.org/)
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
载入elrepo-kernel元数据
yum --disablerepo="*" --enablerepo="elrepo-kernel" repolist
查看可用的内核版本
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
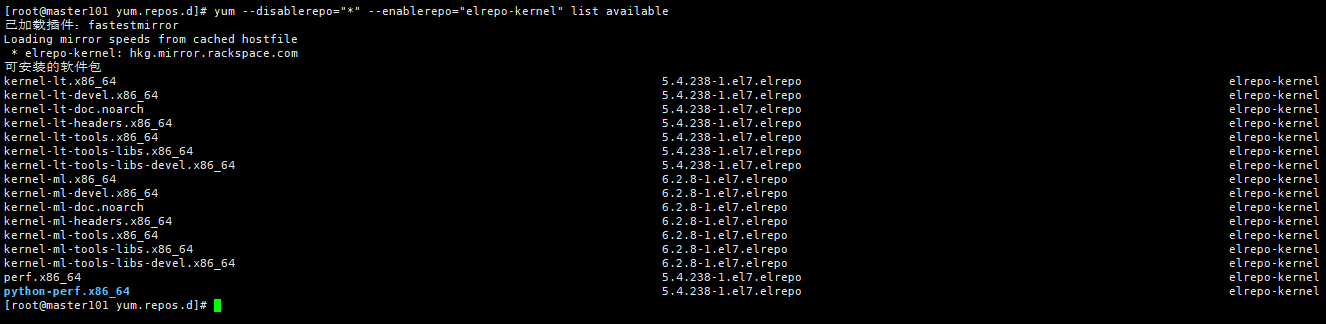
kernel-lt和kernel-ml二者的区别:
kernel-ml软件包是根据Linux Kernel Archives的主线稳定分支提供的源构建的。 内核配置基于默认的RHEL-7配置,并根据需要启用了添加的功能。 这些软件包有意命名为kernel-ml,以免与RHEL-7内核发生冲突,因此,它们可以与常规内核一起安装和更新。
kernel-lt包是从Linux Kernel Archives提供的源代码构建的,就像kernel-ml软件包一样。 不同之处在于kernel-lt基于长期支持分支,而kernel-ml基于主线稳定分支。
在 ELRepo中有两个内核选项,一个是kernel-lt(长期支持版),一个是 kernel-ml(主线最新版本),采用长期支持版本(kernel-lt),更加稳定一些。
安装长期支持版
yum --enablerepo=elrepo-kernel install -y kernel-lt
安装完成后检查/boot/grub2/grub.cfg中对应内核menuentr 中是否包含initrd16配置,如果没有,再安装一次!
检查系统上可用的内核
# awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
CentOS Linux (5.4.238-1.el7.elrepo.x86_64) 7 (Core)
CentOS Linux (3.10.0-1160.88.1.el7.x86_64) 7 (Core)
CentOS Linux (3.10.0-957.el7.x86_64) 7 (Core)
CentOS Linux (0-rescue-e9e8b6c269914c21b6e4cce4b67d5679) 7 (Core)
设置开机从新内核启动
方法1:
# grub2-set-default 0
方法2:
编辑配置文件 vim /etc/default/grub
将GRUB_DEFAULT=saved改为GRUB_0=saved,保存退出vim。
创建内核配置
运行grub2-mkconfig命令来重新创建内核配置
# cp /boot/grub2/grub.cfg{,.bak}
# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.4.238-1.el7.elrepo.x86_64
Found initrd image: /boot/initramfs-5.4.238-1.el7.elrepo.x86_64.img
Found linux image: /boot/vmlinuz-3.10.0-1160.88.1.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.88.1.el7.x86_64.img
Found linux image: /boot/vmlinuz-3.10.0-957.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-957.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-e9e8b6c269914c21b6e4cce4b67d5679
Found initrd image: /boot/initramfs-0-rescue-e9e8b6c269914c21b6e4cce4b67d5679.img
done
重启服务器并验证
# reboot
# uname -sr
安装内核源文件(可选,在升级完内核并重启机器后执行):
# yum erase kernel-headers
# yum --enablerepo=elrepo-kernel install kernel-lt-devel-$(uname -r) kernel-lt-headers-$(uname -r)
关闭 NUMA
cp /etc/default/grub{,.bak}
vim /etc/default/grub # 在 GRUB_CMDLINE_LINUX 一行添加 `numa=off` 参数,如下所示:
diff /etc/default/grub.bak /etc/default/grub
6c6
< GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rhgb quiet"
---
> GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rhgb quiet numa=off"
#重新生成 grub2 配置文件:
cp /boot/grub2/grub.cfg{,.bak}
grub2-mkconfig -o /boot/grub2/grub.cfg
创建 CA 证书和秘钥
为确保安全, kubernetes 系统各组件需要使用 x509 证书对通信进行加密和认证。
CA (Certificate Authority) 是自签名的根证书,用来签名后续创建的其它证书。
本文档使用 CloudFlare 的 PKI 工具集 cfssl 创建所有证书
cfssl项目地址:https://github.com/cloudflare/cfssl
各种 CA 证书类型:
https://github.com/kubernetes-incubator/apiserver-builder/blob/master/docs/concepts/auth.md
k8s集群所需证书参考:https://coreos.com/os/docs/latest/generate-self-signed-certificates.html
安装 cfssl 工具集
mkdir -p /opt/k8s/cert && chown -R k8s /opt/k8s && cd /opt/k8s
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
mv cfssl_linux-amd64 /opt/k8s/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
mv cfssljson_linux-amd64 /opt/k8s/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /opt/k8s/bin/cfssl-certinfo
chmod +x /opt/k8s/bin/*
source /etc/profile.d/k8s.sh
或者:安装CFSSL
curl -s -L -o /bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
curl -s -L -o /bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
curl -s -L -o /bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x /bin/cfssl*
创建根证书 (CA)
CA 证书是集群所有节点共享的,只需要创建一个 CA 证书,后续创建的所有证书都由它签名。
创建配置文件:
CA 配置文件用于配置根证书的使用场景 (profile) 和具体参数 (usage,过期时间、服务端认证、客户端认证、加密等),后续在签名其它证书时需要指定特定场景。
[root@master ~]# cd /opt/k8s/cert
[root@kube-master cert]# vim ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}
}
注:
① signing :表示该证书可用于签名其它证书,生成的 ca.pem 证书中CA=TRUE ;
② server auth :表示 client 可以用该该证书对 server 提供的证书进行验证;
③ client auth :表示 server 可以用该该证书对 client 提供的证书进行验证;
创建证书签名请求文件
[root@kube-master cert]# vim ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "4Paradigm"
}
]
}
注:
① CN: Common Name ,kube-apiserver 从证书中提取该字段作为请求的用户名(User Name),浏览器使用该字段验证网站是否合法;
② O: Organization ,kube-apiserver 从证书中提取该字段作为请求用户所属的组(Group);
③ kube-apiserver 将提取的 User、Group 作为 RBAC 授权的用户标识;
生成 CA 证书和私钥
[root@kube-master cert]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca
2019/10/07 11:15:08 [INFO] generating a new CA key and certificate from CSR
2019/10/07 11:15:08 [INFO] generate received request
2019/10/07 11:15:08 [INFO] received CSR
2019/10/07 11:15:08 [INFO] generating key: rsa-2048
2019/10/07 11:15:08 [INFO] encoded CSR
2019/10/07 11:15:08 [INFO] signed certificate with serial number 339802055410846423585552015910983013265752633145
[root@kube-master cert]# ls ca*
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
注意:生成ca.pem、ca.csr、ca-key.pem(CA私钥,需妥善保管)
分发证书文件
将生成的 CA 证书、秘钥文件、配置文件拷贝到所有节点的/opt/k8s/cert 目录下:
[root@master ~]# vim /opt/k8s/script/scp_k8scert.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/k8s/cert && chown -R k8s /opt/k8s"
scp /opt/k8s/cert/ca*.pem /opt/k8s/cert/ca-config.json k8s@${node_ip}:/opt/k8s/cert
done
[root@master ~]# chmod +x /opt/k8s/script/scp_k8scert.sh && /opt/k8s/script/scp_k8scert.sh
部署 kubectl 命令行工具
kubectl是 kubernetes 集群的命令行管理工具,本文档介绍安装和配置它的步骤。
kubectl默认从 ~/.kube/config 文件读取 kube-apiserver 地址、证书、用户名等信息,如果没有配置,执行 kubectl 命令时可能会出错:
$ kubectl get pods
The connection to the server localhost:8080 was refused - did you specify the right host or port?

本文档只需要部署一次,生成的 kubeconfig 文件与机器无关
注意:
-
如果没有特殊指明,本文档的所有操作均在master节点上执行,然后远程分发文件和执行命令;
-
本文档只需要部署一次,生成的 kubeconfig 文件是通用的,可以拷贝到需要执行 kubectl 命令的机器,重命名为
~/.kube/config;
下载kubectl 二进制文件
官方网址:https://kubernetes.io/docs/tasks/tools/install-kubectl/
官方提供的安装,但是由于该命令有些文件,在国内无法下载,导致安装命令一直卡在不动,安装失败
解决办法:
到github上找到指定版本的kubectl的下载路径,下载到本地,进行安装
1、到这个页面选择当前的版本,点击进去
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG.md#client-binaries-1
2、找到client binaries(也就是kubectl),选择对应操作系统的客户端(我这里是centos的系统),然后复制连接地址
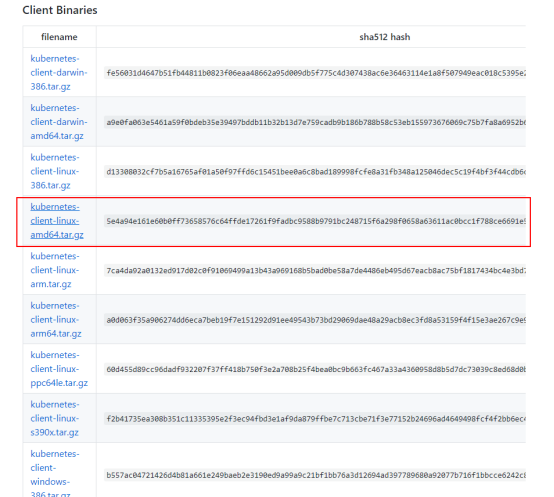
3、下载kubectl包,解压后,将kubectl命令赋予权限和拷贝到用户命令目录下
cd
wget https://dl.k8s.io/v1.15.4/kubernetes-client-linux-amd64.tar.gz
tar xf kubernetes-client-linux-amd64.tar.gz
cd kubernetes/client/bin
chmod +x ./kubectl
cp ./kubectl /opt/k8s/bin/
cp ./kubectl /usr/local/bin/kubectl
4、运行 ./kubectl version,返回版本信息,说明安装成功

创建 admin 证书和私钥
-
kubectl 与 apiserver https 安全端口通信,apiserver 对提供的证书进行认证和授权。
-
kubectl 作为集群的管理工具,需要被授予最高权限。这里创建具有最高权限的admin 证书
创建证书签名请求:
[root@master ~]# cd /opt/k8s/cert/
[root@master cert]# cat > admin-csr.json <<EOF
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:masters",
"OU": "4Paradigm"
}
]
}
EOF
注:
① O 为 system:masters ,kube-apiserver 收到该证书后将请求的 Group 设置为system:masters;
② 预定义的 ClusterRoleBinding cluster-admin 将 Group system:masters 与Role cluster-admin 绑定,该 Role 授予所有 API的权限;
③ 该证书只会被 kubectl 当做 client 证书使用,所以 hosts 字段为空;
生成证书和私钥:
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes admin-csr.json | cfssljson -bare admin
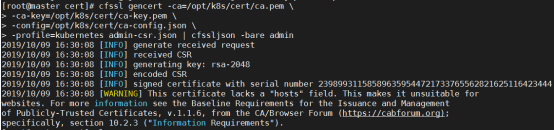
[root@master cert]# ls admin*
admin.csr admin-csr.json admin-key.pem admin.pem
创建kubeconfig 文件:
创建kubeconfig文件
kubeconfig 为 kubectl 的配置文件,包含访问 apiserver 的所有信息,如 apiserver 地址、CA 证书和自身使用的证书;
① 设置集群参数,(--server=${KUBE_APISERVER} ,指定IP和端口;我使用的是haproxy的VIP和端口;如果没有haproxy代理,就用实际服务的IP和端口;如:https://192.168.137.50:6443)
[root@master cert]# cd
[root@master ~]# kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/cert/ca.pem \
--embed-certs=true \
--server=https://192.168.137.50:6443 \
--kubeconfig=/root/.kube/kubectl.kubeconfig #其实标准的文件名是config,否则后面用kubectl命令是必须指定配置文件,如果不知道就会报错

② 设置客户端认证参数
[root@master ~]# kubectl config set-credentials kube-admin \
--client-certificate=/opt/k8s/cert/admin.pem \
--client-key=/opt/k8s/cert/admin-key.pem \
--embed-certs=true \
--kubeconfig=/root/.kube/kubectl.kubeconfig

③ 设置上下文参数
[root@master ~]# kubectl config set-context kube-admin@kubernetes \
--cluster=kubernetes \
--user=kube-admin \
--kubeconfig=/root/.kube/kubectl.kubeconfig

④ 设置默认上下文
[root@master ~]# kubectl config use-context kube-admin@kubernetes --kubeconfig=/root/.kube/kubectl.kubeconfig

注:在后续kubernetes认证,文章中会详细讲解
-
--certificate-authority:验证 kube-apiserver 证书的根证书; -
--client-certificate 、 --client-key:刚生成的 admin 证书和私钥,连接 kube-apiserver 时使用; -
--embed-certs=true:将 ca.pem 和 admin.pem 证书内容嵌入到生成的kubectl.kubeconfig 文件中(不加时,写入的是证书文件路径);
验证kubeconfig文件:
[root@master ~]# ll /root/.kube/kubectl.kubeconfig
-rw-------. 1 root root 6314 Oct 21 13:33 /root/.kube/kubectl.kubeconfig
[root@kube-master ~]# kubectl config view --kubeconfig=/root/.kube/kubectl.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.137.50:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kube-admin
name: kube-admin@kubernetes
current-context: kube-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kube-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
分发到所有使用kubectl 命令的节点和config 文件
[root@master ~]# vim /opt/k8s/script/scp_kubectl.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
#创建bin目录
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh k8s@${node_ip} "mkdir -p /opt/k8s/bin/ && chown -R k8s /opt/k8s"
#分发 kubectl 二进制文件
scp /root/kubernetes/client/bin/kubectl root@${node_ip}:/opt/k8s/bin/
ssh root@${node_ip} "chmod +x /opt/k8s/bin/*"
#分发 kubeconfig 文件
scp ~/.kube/kubectl.kubeconfig root@${node_ip}:~/.kube/config
done
[root@master ~]# chmod +x /opt/k8s/script/scp_kubectl.sh && /opt/k8s/script/scp_kubectl.sh
- 保存的文件名为
~/.kube/config,如果这里没有更改,后面运行命令会指定该配置文件才行
部署 etcd 集群
etcd 是基于Raft 的分布式 key-value 存储系统,由 CoreOS 开发,常用于服务发现、共享配置以及并发控制(如 leader 选举、分布式锁等)。kubernetes 使用 etcd 存储所有运行数据。
本文档介绍部署一个三节点高可用 etcd 集群的步骤:
① 下载和分发 etcd 二进制文件
② 创建 etcd 集群各节点的 x509 证书,用于加密客户端(如 etcdctl) 与 etcd 集群、etcd 集群之间的数据流;
③ 创建 etcd 的 systemd unit 文件,配置服务参数;
④ 检查集群工作状态;
etcd 集群各节点的名称和 IP 如下:
-
master:192.168.137.50
-
node01:192.168.137.60
-
node02:192.168.137.70
注意:如果没有特殊指明,本文档的所有操作master 节点上执行,然后远程分发文件和执行命令
下载etcd 二进制文件
到 https://github.com/coreos/etcd/releases页面下载最新版本的发布包:
[root@master ~]# wget https://github.com/coreos/etcd/releases/download/v3.3.7/etcd-v3.3.7-linux-amd64.tar.gz
[root@master ~]# tar -xvf etcd-v3.3.7-linux-amd64.tar.gz
创建 etcd 证书和私钥
创建证书签名请求:
[root@master ~]# cd /opt/etcd/cert
[root@master cert]# cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.137.50",
"192.168.137.60",
"192.168.137.70"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "4Paradigm"
}
]
}
EOF
注:hosts 字段指定授权使用该证书的 etcd 节点 IP 或域名列表,这里将 etcd 集群的三个节点 IP 都列在其中;
生成证书和私钥:
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
[root@master cert]# ls etcd*
etcd.csr etcd-csr.json etcd-key.pem etcd.pem
分发生成的证书和私钥、二进制文件到各 etcd 节点:
[root@master ~]# vim /opt/k8s/script/scp_etcd.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
scp /root/etcd-v3.3.7-linux-amd64/etcd* k8s@${node_ip}:/opt/k8s/bin
ssh root@${node_ip} "chmod +x /opt/k8s/bin/*"
ssh root@${node_ip} "mkdir -p /opt/etcd/cert && chown -R k8s /opt/etcd/cert"
scp /opt/etcd/cert/etcd*.pem k8s@${node_ip}:/opt/etcd/cert/
done
[root@master ~]# chmod +x /opt/k8s/script/scp_etcd.sh && /opt/k8s/script/scp_etcd.sh
创建etcd的systemd unit 模板及etcd 配置文件
完整 unit 文件见:etcd.service
创建etcd 的systemd unit 模板:
[root@master ~]# cat > /opt/etcd/etcd.service.template <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
User=k8s
Type=notify
WorkingDirectory=/opt/lib/etcd/
ExecStart=/opt/k8s/bin/etcd \
--data-dir=/opt/lib/etcd \
--name ##NODE_NAME## \
--cert-file=/opt/etcd/cert/etcd.pem \
--key-file=/opt/etcd/cert/etcd-key.pem \
--trusted-ca-file=/opt/k8s/cert/ca.pem \
--peer-cert-file=/opt/etcd/cert/etcd.pem \
--peer-key-file=/opt/etcd/cert/etcd-key.pem \
--peer-trusted-ca-file=/opt/k8s/cert/ca.pem \
--peer-client-cert-auth \
--client-cert-auth \
--listen-peer-urls=https://##NODE_IP##:2380 \
--initial-advertise-peer-urls=https://##NODE_IP##:2380 \
--listen-client-urls=https://##NODE_IP##:2379,http://127.0.0.1:2379\
--advertise-client-urls=https://##NODE_IP##:2379 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=etcd0=https://192.168.137.50:2380,etcd1=https://192.168.137.60:2380,etcd2=https://192.168.137.70:2380 \
--initial-cluster-state=new
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
注:
-
User :指定以 k8s 账户运行;
-
WorkingDirectory 、 --data-dir :指定工作目录和数据目录为/opt/lib/etcd ,需在启动服务前创建这个目录;
-
--name :指定节点名称,当 --initial-cluster-state 值为 new 时, --name 的参数值必须位于 --initial-cluster 列表中;
-
--cert-file 、 --key-file :etcd server 与 client 通信时使用的证书和私钥;
-
--trusted-ca-file :签名 client 证书的 CA 证书,用于验证 client 证书;
-
--peer-cert-file 、 --peer-key-file :etcd 与 peer 通信使用的证书和私钥;
-
--peer-trusted-ca-file :签名 peer 证书的 CA 证书,用于验证 peer 证书;
-
--data-dir:etcd数据目录
-
--wal-dir:etcd WAL 目录,建议是 SSD 磁盘分区,或者和 ETCD_DATA_DIR 不同的磁盘分区---->脚本中未使用该参数
-
--name:集群各 IP 对应的主机名数组
-
NODE_IP:集群各机器 IP 数组,需要加端口
-
--initial-cluster:etcd 集群间通信的 IP 和端口
为各节点创建和分发 etcd systemd unit 文件:
[root@master ~]# cd /opt/k8s/script
[root@master script]# vim /opt/k8s/script/etcd_service.sh
NODE_NAMES=("etcd0" "etcd1" "etcd2")
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
#替换模板文件中的变量
for (( i=0; i < 3; i++ ));do
sed -e "s/##NODE_NAME##/${NODE_NAMES[i]}/g" -e "s/##NODE_IP##/${NODE_IPS[i]}/g" /opt/etcd/etcd.service.template > /opt/etcd/etcd-${NODE_IPS[i]}.service
done
#分发生成的 systemd unit文件并且文件重命名为 etcd.service;
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/lib/etcd && chown -R k8s /opt/lib/etcd"
scp /opt/etcd/etcd-${node_ip}.service root@${node_ip}:/etc/systemd/system/etcd.service
done
[root@master script]# chmod +x /opt/k8s/script/etcd_service.sh && /opt/k8s/script/etcd_service.sh
[root@master script]# ls /opt/etcd/*.service
/opt/etcd/etcd-192.168.137.50.service /opt/etcd/etcd-192.168.137.60.service /opt/etcd/etcd-192.168.137.70.service
[root@master script]# cat /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
User=k8s
Type=notify
WorkingDirectory=/opt/lib/etcd/
ExecStart=/opt/k8s/bin/etcd --data-dir=/opt/lib/etcd --name etcd0 --cert-file=/opt/etcd/cert/etcd.pem --key-file=/opt/etcd/cert/etcd-key.pem --trusted-ca-file=/opt/k8s/cert/ca.pem --peer-cert-file=/opt/etcd/cert/etcd.pem --peer-key-file=/opt/etcd/cert/etcd-key.pem --peer-trusted-ca-file=/opt/k8s/cert/ca.pem --peer-client-cert-auth --client-cert-auth --listen-peer-urls=https://192.168.137.50:2380 --initial-advertise-peer-urls=https://192.168.137.50:2380 --listen-client-urls=https://192.168.137.50:2379,http://127.0.0.1:2379 --advertise-client-urls=https://192.168.137.50:2379 --initial-cluster-token=etcd-cluster-0 --initial-cluster=etcd0=https://192.168.137.50:2380,etcd1=https://192.168.137.60:2380,etcd2=https://192.168.137.70:2380 --initial-cluster-state=new
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
启动、验证etcd 服务
-
必须创建 etcd 数据目录和工作目录;
-
etcd 进程首次启动时会等待其它节点的 etcd 加入集群,命令 systemctl start etcd 会卡住一段时间,为正常现象
[root@master script]# vim /opt/k8s/script/start_etcd.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
#启动 etcd 服务
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable etcd && systemctl start etcd"
done
#检查启动结果,确保状态为 active (running)
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh k8s@${node_ip} "systemctl status etcd|grep Active"
done
#验证服务状态,输出均为healthy 时表示集群服务正常
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ETCDCTL_API=3 /opt/k8s/bin/etcdctl \
--endpoints=https://${node_ip}:2379 \
--cacert=/opt/k8s/cert/ca.pem \
--cert=/opt/etcd/cert/etcd.pem \
--key=/opt/etcd/cert/etcd-key.pem endpoint health
done
[root@master script]# chmod +x /opt/k8s/script/start_etcd.sh && /opt/k8s/script/start_etcd.sh
>>> 192.168.137.50
Created symlink from /etc/systemd/system/multi-user.target.wants/etcd.service to /etc/systemd/system/etcd.service.
Job for etcd.service failed because a timeout was exceeded. See "systemctl status etcd.service" and "journalctl -xe" for details.
>>> 192.168.137.60
Created symlink from /etc/systemd/system/multi-user.target.wants/etcd.service to /etc/systemd/system/etcd.service.
>>> 192.168.137.70
Created symlink from /etc/systemd/system/multi-user.target.wants/etcd.service to /etc/systemd/system/etcd.service.
#确保状态为 active (running),否则查看日志,确认原因:$ journalctl -u etcd 50的机器出现超时,我们直接去重启,服务正常
>>> 192.168.137.50
Active: active (running) since Thu 2019-10-10 09:44:09 CST; 2s ago
>>> 192.168.137.60
Active: active (running) since Thu 2019-10-10 09:44:09 CST; 3s ago
>>> 192.168.137.70
Active: active (running) since Thu 2019-10-10 09:44:11 CST; 1s ago
>>> 192.168.137.50
#输出均为healthy 时表示集群服务正常
>>> 192.168.137.50
https://192.168.137.50:2379 is healthy: successfully committed proposal: took = 20.184458ms
>>> 192.168.137.60
https://192.168.137.60:2379 is healthy: successfully committed proposal: took = 1.736975ms
>>> 192.168.137.70
https://192.168.137.70:2379 is healthy: successfully committed proposal: took = 38.290374ms
确保状态为 active (running),否则查看日志,确认原因:
$ journalctl -u etcd
端口是:2379 is healthy
查看当前的 leader
# cd /opt/k8s/script/
# vim checketcd_leader.sh
ETCD_ENDPOINTS="https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379"
ETCDCTL_API=3 /opt/k8s/bin/etcdctl \
-w table --cacert=/opt/k8s/cert/ca.pem \
--cert=/opt/etcd/cert/etcd.pem \
--key=/opt/etcd/cert/etcd-key.pem \
--endpoints=${ETCD_ENDPOINTS} endpoint status
# chmod +x /opt/k8s/script/checketcd_leader.sh && /opt/k8s/script/checketcd_leader.sh
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.137.50:2379 | b723365123b8196b | 3.3.7 | 1.1 MB | true | 69711 | 817583 |
| https://192.168.137.60:2379 | 3928deba4cbeb093 | 3.3.7 | 1.1 MB | false | 69711 | 817583 |
| https://192.168.137.70:2379 | 88c485bb271b9d45 | 3.3.7 | 1.2 MB | false | 69711 | 817583 |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+

可见,当前的 leader 为 192.168.137.50
部署 flannel 网络(UDP:8472)
- kubernetes要求集群内各节点(包括 master 节点)能通过 Pod 网段互联互通。flannel 使用 vxlan 技术为各节点创建一个可以互通的 Pod 网络,使用的端口为 UDP 8472,需要开放该端口(如公有云 AWS 等)。
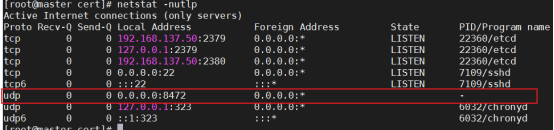
- flannel 第一次启动时,从 etcd 获取 Pod 网段信息,为本节点分配一个未使用的 /24段地址,然后创建 flannel.1 (也可能是其它名称,如 flannel1 等) 接口
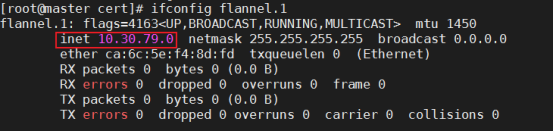
- flannel 将分配的 Pod 网段信息写入 /run/flannel/docker 文件,docker 后续使用这个文件中的环境变量设置 docker0 网桥。
注意:如果没有特殊指明,本文档的所有操作均在 master 节点上执行,然后远程分发文件和执行命令
下载flanneld二进制文件
从flannel 的 release 页面(https://github.com/coreos/flannel/releases)页面下载最新版本的发布包:
[root@master ~]# cd
[root@master ~]# mkdir flannel
[root@master ~]# wget https://github.com/coreos/flannel/releases/download/v0.10.0/flannel-v0.10.0-linux-amd64.tar.gz
[root@master ~]# tar -xzvf flannel-v0.10.0-linux-amd64.tar.gz -C ./flannel
创建 flannel 证书和私钥
flannel 从 etcd 集群存取网段分配信息,而 etcd 集群启用了双向 x509 证书认证,所以需要为 flanneld 生成证书和私钥
创建证书签名请求:
[root@master ~]# mkdir -p /opt/flannel/cert
[root@master ~]# cd /opt/flannel/cert
[root@master cert]# cat > flanneld-csr.json <<EOF
{
"CN": "flanneld",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "4Paradigm"
}
]
}
EOF
- 该证书只会被 kubectl 当做 client 证书使用,所以 hosts 字段为空
生成证书和私钥:
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes flanneld-csr.json | cfssljson -bare flanneld
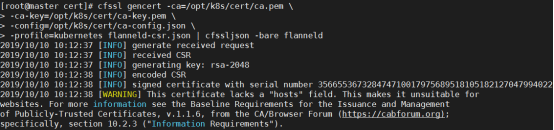
[root@master cert]# ls
flanneld.csr flanneld-csr.json flanneld-key.pem flanneld.pem
将flanneld 二进制文件和生成的证书和私钥分发到所有节点
[root@master cert]# vim /opt/k8s/script/scp_flannel.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#复制flanneld二进制
scp /root/flannel/{flanneld,mk-docker-opts.sh} k8s@${node_ip}:/opt/k8s/bin/
ssh k8s@${node_ip} "chmod +x /opt/k8s/bin/*"
#证书和私钥分发到所有节点
ssh root@${node_ip} "mkdir -p /opt/flannel/cert && chown -R k8s /opt/flannel"
scp /opt/flannel/cert/flanneld*.pem k8s@${node_ip}:/opt/flannel/cert
done
[root@master cert]# chmod +x /opt/k8s/script/scp_flannel.sh && /opt/k8s/script/scp_flannel.sh
向etcd 写入集群Pod 网段信息
注意:本步骤只需执行一次。
[root@master ~]# etcdctl \
--endpoints="https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379" \
--ca-file=/opt/k8s/cert/ca.pem \
--cert-file=/opt/flannel/cert/flanneld.pem \
--key-file=/opt/flannel/cert/flanneld-key.pem \
set /atomic.io/network/config '{"Network":"10.30.0.0/16","SubnetLen": 24, "Backend": {"Type": "vxlan"}}'

注:
-
flanneld 当前版本 (v0.10.0) 不支持 etcd v3,故使用 etcd v2 API 写入配置 key 和网段数据;
-
Pod 网段,我们这里用10.30.0.0/16;部署前路由不可达,部署后集群内路由可达(flanneld 保证),写入的 Pod 网段
"Network":"'${CLUSTER_CIDR}'"-----> "Network":"10.30.0.0/16"必须是/16 段地址,~~必须与kube-controller-manager 的 --cluster-cidr 参数值一致;~~-->后面部署coredns,需要用到pod网段 -
--endpoints:etcd 集群服务地址列表
创建 flanneld 的 systemd unit 文件
完整 unit 见 flanneld.service
[root@master cert]# cat > /opt/flannel/flanneld.service << EOF
[Unit]
Description=Flanneld overlay address etcd agent
After=network.target
After=network-online.target
Wants=network-online.target
After=etcd.service
Before=docker.service
[Service]
Type=notify
ExecStart=/opt/k8s/bin/flanneld \
-etcd-cafile=/opt/k8s/cert/ca.pem \
-etcd-certfile=/opt/flannel/cert/flanneld.pem \
-etcd-keyfile=/opt/flannel/cert/flanneld-key.pem \
-etcd-endpoints=https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379 \
-etcd-prefix=/atomic.io/network \
-iface=ens33 \
-ip-masq #真实环境中没有使用这三个参数
ExecStartPost=/opt/k8s/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
Restart=on-failure
Restart=always #真实环境中没有使用这三个参数
RestartSec=5
StartLimitInterval=0
[Install]
WantedBy=multi-user.target
RequiredBy=docker.service
EOF
注:
A. mk-docker-opts.sh 脚本将分配给 flanneld 的 Pod 子网网段信息写入/run/flannel/docker 文件,后续 docker 启动时使用这个文件中的环境变量配置docker0 网桥;
B. -iface:节点间互联网络接口名称;flanneld 使用系统缺省路由所在的接口与其它节点通信,对于有多个网络接口(如内网和公网)的节点,可以用 -iface 参数指定通信接口,如上面的 ens33 接口;
C. flanneld 运行时需要 root 权限
D. -ip-masq: flanneld 为访问 Pod 网络外的流量设置 SNAT 规则,同时将传递给 Docker 的变量 --ip-masq(/run/flannel/docker 文件中)设置为 false,这样 Docker 将不再创建 SNAT 规则; Docker 的 --ip-masq 为 true 时,创建的 SNAT 规则比较"暴力":将所有本节点 Pod 发起的、访问非 docker0 接口的请求做 SNAT,这样访问其他节点 Pod 的请求来源 IP 会被设置为 flannel.1 接口的 IP,导致目的 Pod 看不到真实的来源 Pod IP。 flanneld 创建的 SNAT 规则比较温和,只对访问非 Pod 网段的请求做 SNAT真实环境中没有使用这个参数
E. -etcd-endpoints:etcd 集群服务地址列表
F. -etcd-prefix:flanneld 网络配置前缀
说明:具体的差别我也不知道,如下图:
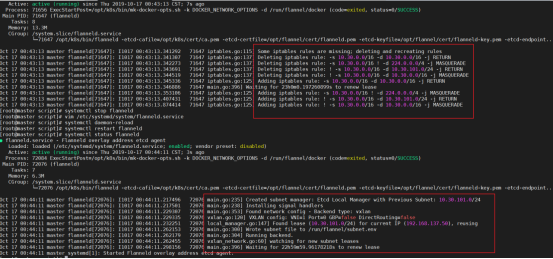
分发flanneld systemd unit 文件到所有节点,启动并检查flanneld 服务:
[root@master cert]# cd
[root@kube-master ~]# vim /opt/k8s/script/flanneld_service.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#分发 flanneld systemd unit 文件到所有节点
scp /opt/flannel/flanneld.service root@${node_ip}:/etc/systemd/system/
#启动 flanneld 服务
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable flanneld && systemctl restart flanneld"
#检查启动结果
ssh k8s@${node_ip} "systemctl status flanneld|grep Active"
done
[root@master ~]# chmod +x /opt/k8s/script/flanneld_service.sh && /opt/k8s/script/flanneld_service.sh

注:确保状态为 active (running) ,否则查看日志,确认原因:
$ journalctl -u flanneld
启动服务服务后就会有网卡信息了:
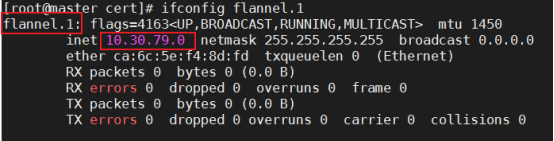
我们写入pod网段是:10.30.0.0/16。所有给我们分配的ip是:10.30.79.0。这只是在master上面查看的
检查分配给各 flanneld 的 Pod 网段信息:
查看集群 Pod 网段(/16):
[root@master ~]# etcdctl \
--endpoints="https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379" \
--ca-file=/opt/k8s/cert/ca.pem \
--cert-file=/opt/flannel/cert/flanneld.pem \
--key-file=/opt/flannel/cert/flanneld-key.pem \
get /atomic.io/network/config
输出:
{"Network":"10.30.0.0/16","SubnetLen": 24, "Backend": {"Type": "vxlan"}}

查看已分配的 Pod 子网段列表(/24):
[root@master ~]# etcdctl \
--endpoints="https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379" \
--ca-file=/opt/k8s/cert/ca.pem \
--cert-file=/opt/flannel/cert/flanneld.pem \
--key-file=/opt/flannel/cert/flanneld-key.pem \
ls /atomic.io/network/subnets
输出:
/atomic.io/network/subnets/10.30.60.0-24
/atomic.io/network/subnets/10.30.79.0-24
/atomic.io/network/subnets/10.30.65.0-24

查看某一 Pod 网段对应的节点 IP 和 flannel 接口地址:
[root@master ~]# etcdctl \
--endpoints="https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379" \
--ca-file=/opt/k8s/cert/ca.pem \
--cert-file=/opt/flannel/cert/flanneld.pem \
--key-file=/opt/flannel/cert/flanneld-key.pem \
get /atomic.io/network/subnets/10.30.79.0-24
输出:
{"PublicIP":"192.168.137.50","BackendType":"vxlan","BackendData":{"VtepMAC":"ca:6c:5e:f4:8d:fd"}}
-
10.30.79.0-24 被分配给节点 master(192.168.137.50);
-
VtepMAC 为master节点的 flannel.1 网卡 MAC 地址
[root@master ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.30.79.0 netmask 255.255.255.255 broadcast 0.0.0.0
ether ca:6c:5e:f4:8d:fd txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- flannel.1 网卡的地址为分配的 Pod 子网段的第一个 IP(.0),且是 /32 的地址;
[root@master script]# ip route show |grep flannel.1
10.30.60.0/24 via 10.30.60.0 dev flannel.1 onlink
10.30.65.0/24 via 10.30.65.0 dev flannel.1 onlink
-
到其它节点 Pod 网段请求都被转发到 flannel.1 网卡;
-
flanneld 根据 etcd 中子网段的信息,如 /atomic.io/network/subnets/10.30.79.0-24 ,来决定进请求发送给哪个节点的互联 IP
验证各节点能通过 Pod 网段互通:
[root@master ~]# vim /opt/k8s/script/ping_flanneld.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#在各节点上部署 flannel 后,检查是否创建了 flannel 接口(名称可能为 flannel0、flannel.0、flannel.1 等)
ssh ${node_ip} "/usr/sbin/ip addr show flannel.1|grep -w inet"
#在各节点上 ping 所有 flannel 接口 IP,确保能通
ssh ${node_ip} "ping -c 4 10.30.79.0"
ssh ${node_ip} "ping -c 4 10.30.65.0"
ssh ${node_ip} "ping -c 4 10.30.60.0"
done
[root@kube-master ~]# chmod +x /opt/k8s/script/ping_flanneld.sh && /opt/k8s/script/ping_flanneld.sh
部署 master 节点
① kubernetes master 节点运行如下组件:
kube-apiserver
kube-scheduler
kube-controller-manager
kube-apiserver、kube-scheduler 和 kube-controller-manager 均以多实例模式运行:
② kube-scheduler 和 kube-controller-manager可以以集群模式运行,通过 leader 选举产生一个工作进程,其它进程处于阻塞模式。
③ 对于 kube-apiserver,是无状态的;可以运行多个实例(本文档是 3 实例),但对其它组件需要提供统一的访问地址,该地址需要高可用。可以使用 keepalived 和 haproxy 实现 kube-apiserver VIP 高可用和负载均衡。
④ 因为对master做了keepalived高可用,所以3台服务器都有可能会升成master服务器(主master宕机,会有从升级为主);因此所有的master操作,在3个服务器上都要进行。
下载最新版kubernetes-server-linux-amd64.tar.gz
1、下载最新版本的二进制文件
从 CHANGELOG 页面 下载二进制 tar 文件并解压
(https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.15.md)
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.8.md#v1813
Server:
Node:
[root@master ~]# wget https://dl.k8s.io/v1.15.4/kubernetes-server-linux-amd64.tar.gz
[root@master ~]# tar xf kubernetes-server-linux-amd64.tar.gz
[root@master ~]# cd kubernetes
[root@master kubernetes]# tar xf kubernetes-src.tar.gz
2、将二进制文件拷贝到所有 master 节点
[root@master kubernetes]# cd
[root@master ~]# vim /opt/k8s/script/scp_master.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
scp /root/kubernetes/server/bin/* k8s@${node_ip}:/opt/k8s/bin/
ssh k8s@${node_ip} "chmod +x /opt/k8s/bin/*"
done
[root@master ~]# chmod +x /opt/k8s/script/scp_master.sh && /opt/k8s/script/scp_master.sh
kube-apiserver 高可用之haproxy部署组件
① 本文档讲解使用 keepalived 和 haproxy 实现 kube-apiserver 高可用的步骤:
keepalived 提供 kube-apiserver 对外服务的 VIP;
haproxy 监听 VIP,后端连接所有 kube-apiserver 实例,提供健康检查和负载均衡功能;
② 运行 keepalived 和 haproxy 的节点称为 LB 节点。由于 keepalived 是一主多备运行模式,故至少两个 LB 节点。
③ 本文档复用 master 节点的三台机器,haproxy 监听的端口(8443) 需要与 kube-apiserver的端口 6443 不同,避免冲突。
④ keepalived 在运行过程中周期检查本机的 haproxy 进程状态,如果检测到 haproxy 进程异常,则触发重新选主的过程,VIP 将飘移到新选出来的主节点,从而实现 VIP 的高可用。
⑤ 所有组件(如 kubeclt、apiserver、controller-manager、scheduler 等)都通过 VIP 和haproxy 监听的 8443 端口访问 kube-apiserver 服务
安装软件包,配置haproxy 配置文件
[root@master ~]# yum install -y keepalived haproxy
[root@master ~]# mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
[root@master ~]# cat /etc/haproxy/haproxy.cfg
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /var/run/haproxy-admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
nbproc 1
defaults
log global
timeout connect 5000
timeout client 10m
timeout server 10m
listen admin_stats
bind 0.0.0.0:10080
mode http
log 127.0.0.1 local0 err
stats refresh 30s
stats uri /status
stats realm welcome login\ Haproxy
stats auth k8s:666666
stats hide-version
stats admin if TRUE
listen kube-master
bind 0.0.0.0:8443
mode tcp
option tcplog
balance source
server 192.168.137.50 192.168.137.50:6443 check inter 2000 fall 2 rise 2 weight 1
server 192.168.137.60 192.168.137.60:6443 check inter 2000 fall 2 rise 2 weight 1
server 192.168.137.70 192.168.137.70:6443 check inter 2000 fall 2 rise 2 weight 1
注:
-
haproxy 在 10080 端口输出 status 信息;
-
haproxy 监听所有接口的 8443 端口,该端口与环境变量 \${KUBE_APISERVER} 指定的端口必须一致;
-
server 字段列出所有kube-apiserver监听的 IP 和端口
在其他服务器安装、下发haproxy 配置文件;并启动检查haproxy服务:
[root@master ~]# vim /opt/k8s/script/haproxy.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#安装haproxy
ssh root@${node_ip} "yum install -y -q keepalived haproxy net-tools"
#下发配置文件
scp /etc/haproxy/haproxy.cfg root@${node_ip}:/etc/haproxy
#启动检查haproxy服务
ssh root@${node_ip} "systemctl restart haproxy"
ssh root@${node_ip} "systemctl enable haproxy.service"
ssh root@${node_ip} "systemctl status haproxy|grep Active"
#检查 haproxy 是否监听8443 端口
ssh root@${node_ip} "netstat -lnpt|grep haproxy"
done
[root@master ~]# chmod +x /opt/k8s/script/haproxy.sh && /opt/k8s/script/haproxy.sh
确保输出类似于:
tcp 0 0 0.0.0.0:8443 0.0.0.0:* LISTEN 31860/haproxy
tcp 0 0 0.0.0.0:10080 0.0.0.0:* LISTEN 31860/haproxy
说明,这里haproxy启动不了,需要用这个命令haproxy -f /etc/haproxy/haproxy.cfg
配置和启动 keepalived 服务
keepalived 是一主(master)多备(backup)运行模式,故有两种类型的配置文件。
master 配置文件只有一份,backup 配置文件视节点数目而定,对于本文档而言,规划如下:
master: 192.168.137.50
backup:192.168.137.60、192.168.137.70
(1)在192.168.137.50 master服务;配置文件:
[root@master ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
[root@master ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id keepalived_hap
}
vrrp_script check-haproxy {
script "killall -0 haproxy"
interval 5
weight -30
}
vrrp_instance VI-kube-master {
state MASTER
priority 120
dont_track_primary
interface ens33
virtual_router_id 68
advert_int 3
track_script {
check-haproxy
}
virtual_ipaddress {
192.168.137.10
}
}
注:
我的VIP 所在的接口Interface 为 ens33;根据自己的情况改变
使用 killall -0 haproxy 命令检查所在节点的 haproxy 进程是否正常。如果异常则将权重减少(-30),从而触发重新选主过程;
router_id、virtual_router_id 用于标识属于该 HA 的 keepalived 实例,如果有多套keepalived HA,则必须各不相同;
(2)在两台backup 服务;配置文件:
[root@node01 ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
[root@node01 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id keepalived_hap
}
vrrp_script check-haproxy {
script "killall -0 haproxy"
interval 5
weight -30
}
vrrp_instance VI-kube-master {
state BACKUP
priority 110 #第2台从为100
dont_track_primary
interface ens33
virtual_router_id 68
advert_int 3
track_script {
check-haproxy
}
virtual_ipaddress {
192.168.137.10
}
}
注:
我的VIP 所在的接口Interface 为 ens33;根据自己的情况改变
使用 killall -0 haproxy 命令检查所在节点的 haproxy 进程是否正常。如果异常则将权重减少(-30),从而触发重新选主过程;
router_id、virtual_router_id 用于标识属于该 HA 的 keepalived 实例,如果有多套keepalived HA,则必须各不相同;
priority 的值必须小于 master 的值;两个从的值也需要不一样;
(3)开启keepalived 服务
[root@master ~]# vim /opt/k8s/script/keepalived.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
VIP="192.168.137.10"
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "systemctl restart keepalived && systemctl enable keepalived"
ssh root@${node_ip} "systemctl status keepalived|grep Active"
ssh ${node_ip} "ping -c 1 ${VIP}"
done
[root@master ~]# chmod +x /opt/k8s/script/keepalived.sh && /opt/k8s/script/keepalived.sh
(4)在master服务器上能看到ens33网卡上已经有192.168.137.10 VIP了
[root@master ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:b4:03:15 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.50/24 brd 192.168.137.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.137.10/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::f187:774c:e299:a81/64 scope link noprefixroute
valid_lft forever preferred_lft forever
查看 haproxy 状态页面
浏览器访问192.168.137.10:10080/status 地址 (192.168.137.10是虚拟ip)
① 输入用户名、密码;在配置文件中自己定义的
② 查看 haproxy 状态页面
解决no destination available
启动keepalived,/etc/init.d/keepalived start,用命令查看后台日志:tail -fn 100 /var/log/messages
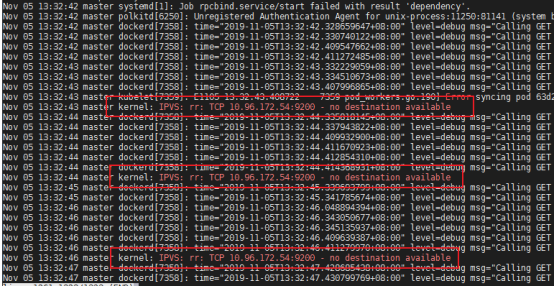
出现这个问题,一般有两种原因: 1、IPVS WRR模块没有添加,你需要使用modprobe手动加载。
modprobe ip_vs
modprobe ip_vs_wrr
2、还有一种情况就是keepalived所在的服务器,均衡的端口服务没启动,或者是mysql、nginx等
kube-apiserver 高可用之 nginx 代理
本文档讲解使用 nginx 4 层透明代理功能实现 K8S 节点( master 节点和 worker 节点)高可用访问 kube-apiserver 的步骤。
注意:如果没有特殊指明,本文档的所有操作均在 master 节点上执行,然后远程分发文件和执行命令。
基于 nginx 代理的 kube-apiserver 高可用方案
-
控制节点的 kube-controller-manager、kube-scheduler 是多实例部署,所以只要有一个实例正常,就可以保证高可用;
-
集群内的 Pod 使用 K8S 服务域名 kubernetes 访问 kube-apiserver, kube-dns 会自动解析出多个 kube-apiserver 节点的 IP,所以也是高可用的;
-
在每个节点起一个 nginx 进程,后端对接多个 apiserver 实例,nginx 对它们做健康检查和负载均衡;
-
kubelet、kube-proxy、controller-manager、scheduler 通过本地的 nginx(监听 127.0.0.1)访问 kube-apiserver,从而实现 kube-apiserver 的高可用;
安装依赖包
yum -y groupinstall 'Development Tools'
yum groupinstall "Server Platform Development" -y
yum -y install gcc gcc-c++ autoconf pcre pcre-devel openssl openssl-devel zlib zlib-devel make automake (安装了两个组包个,里面基本都已安装这些包)
下载和编译 nginx
下载源码:
mkdir /opt/k8s/work
cd /opt/k8s/work
wget http://nginx.org/download/nginx-1.15.3.tar.gz
tar -xzvf nginx-1.15.3.tar.gz
配置编译参数:
cd /opt/k8s/work/nginx-1.15.3
mkdir nginx-prefix
./configure --with-stream --without-http --prefix=$(pwd)/nginx-prefix --without-http_uwsgi_module --without-http_scgi_module --without-http_fastcgi_module
-
--with-stream:开启 4 层透明转发(TCP Proxy)功能;
-
--without-xxx:关闭所有其他功能,这样生成的动态链接二进制程序依赖最小;
输出:
Configuration summary
+ PCRE library is not used
+ OpenSSL library is not used
+ zlib library is not used
nginx path prefix: "/opt/k8s/work/nginx-1.15.3/nginx-prefix"
nginx binary file: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/sbin/nginx"
nginx modules path: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/modules"
nginx configuration prefix: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/conf"
nginx configuration file: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/conf/nginx.conf"
nginx pid file: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/logs/nginx.pid"
nginx error log file: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/logs/error.log"
nginx http access log file: "/opt/k8s/work/nginx-1.15.3/nginx-prefix/logs/access.log"
nginx http client request body temporary files: "client_body_temp"
nginx http proxy temporary files: "proxy_temp"
编译和安装:
cd /opt/k8s/work/nginx-1.15.3
make && make install
验证编译的 nginx
cd /opt/k8s/work/nginx-1.15.3
./nginx-prefix/sbin/nginx -v
输出:
nginx version: nginx/1.15.3
查看 nginx 动态链接的库:
$ ldd ./nginx-prefix/sbin/nginx
输出:
linux-vdso.so.1 => (0x00007ffebe310000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007ff7d52ea000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007ff7d50ce000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff7d4d00000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff7d54ee000)
- 由于只开启了 4 层透明转发功能,所以除了依赖 libc 等操作系统核心 lib 库外,没有对其它 lib 的依赖(如 libz、libssl 等),这样可以方便部署到各版本操作系统中
安装和部署 nginx
创建目录结构:
cd /opt/k8s/work
# vim /opt/k8s/script/create_directory.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/k8s/kube-nginx/{conf,logs,sbin}"
done
# chmod +x /opt/k8s/script/create_directory.sh && /opt/k8s/script/create_directory.sh
拷贝二进制程序:
cd /opt/k8s/work
# vim /opt/k8s/script/scp_sbin.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/k8s/kube-nginx/{conf,logs,sbin}"
#把二进制文件重命名为kube-nginx
scp /opt/k8s/work/nginx-1.15.3/nginx-prefix/sbin/nginx root@${node_ip}:/opt/k8s/kube-nginx/sbin/kube-nginx
ssh root@${node_ip} "chmod a+x /opt/k8s/kube-nginx/sbin/*"
done
# chmod +x /opt/k8s/script/scp_sbin.sh && /opt/k8s/script/scp_sbin.sh
- 重命名二进制文件为 kube-nginx;
配置 nginx,开启 4 层透明转发功能:
cd /opt/k8s/work
cat > kube-nginx.conf << \EOF
worker_processes 1;
events {
worker_connections 1024;
}
stream {
upstream backend {
hash $remote_addr consistent;
server 192.168.137.50:6443 max_fails=3 fail_timeout=30s;
server 192.168.137.60:6443 max_fails=3 fail_timeout=30s;
server 192.168.137.70:6443 max_fails=3 fail_timeout=30s;
}
server {
listen 127.0.0.1:8443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
EOF
- 需要根据集群 kube-apiserver 的实际情况,替换 backend 中 server 列表;
分发配置文件:
cd /opt/k8s/work
vim /opt/k8s/script/scp_kube-nginx_conf.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
scp /opt/k8s/work/kube-nginx.conf root@${node_ip}:/opt/k8s/kube-nginx/conf/kube-nginx.conf
done
# chmod +x /opt/k8s/script/scp_kube-nginx_conf.sh && /opt/k8s/script/scp_kube-nginx_conf.sh
配置 systemd unit 文件,启动服务
配置 kube-nginx systemd unit 文件:
cd /opt/k8s/work
cat > kube-nginx.service <<EOF
[Unit]
Description=kube-apiserver nginx proxy
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=forking
ExecStartPre=/opt/k8s/kube-nginx/sbin/kube-nginx -c /opt/k8s/kube-nginx/conf/kube-nginx.conf -p /opt/k8s/kube-nginx -t
ExecStart=/opt/k8s/kube-nginx/sbin/kube-nginx -c /opt/k8s/kube-nginx/conf/kube-nginx.conf -p /opt/k8s/kube-nginx
ExecReload=/opt/k8s/kube-nginx/sbin/kube-nginx -c /opt/k8s/kube-nginx/conf/kube-nginx.conf -p /opt/k8s/kube-nginx -s reload
PrivateTmp=true
Restart=always
RestartSec=5
StartLimitInterval=0
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
分发 systemd unit 文件:
cd /opt/k8s/work
vim /opt/k8s/script/scp_kube-nginx_service.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
scp /opt/k8s/work/kube-nginx.service root@${node_ip}:/etc/systemd/system/
done
# chmod +x /opt/k8s/script/scp_kube-nginx_service.sh && /opt/k8s/script/scp_kube-nginx_service.sh
启动 kube-nginx 服务:
cd /opt/k8s/work
vim /opt/k8s/script/scp_start_nginx.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-nginx && systemctl restart kube-nginx"
done
# chmod +x /opt/k8s/script/scp_start_nginx.sh && /opt/k8s/script/scp_start_nginx.sh
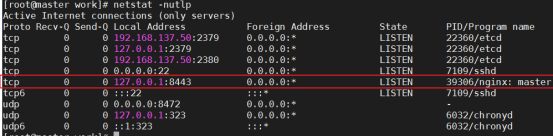
配置文件些的监听本地8443端口
检查 kube-nginx 服务运行状态
cd /opt/k8s/work
vim /opt/k8s/script/scp_check_nginx.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "systemctl status kube-nginx |grep 'Active:'"
done
# chmod +x /opt/k8s/script/scp_check_nginx.sh && /opt/k8s/script/scp_check_nginx.sh
确保状态为 active (running),否则查看日志,确认原因:
journalctl -u kube-nginx
部署 kube-apiserver 组件集群(默认6443端口)
本文档讲解使用 keepalived 和 haproxy 部署一个 3 节点高可用 master 集群的步骤,对应的 LB VIP 为环境变量 ${MASTER_VIP}
准备工作:下载最新版本的二进制文件、安装和配置 flanneld
创建 kubernetes 证书和私钥
(1)创建证书签名请求:
[root@master ~]# cd /opt/k8s/cert/
[root@master cert]# cat > kubernetes-csr.json <<EOF
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"192.168.137.10",
"192.168.137.50",
"192.168.137.60",
"192.168.137.70",
"10.96.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "4Paradigm"
}
]
}
EOF
"192.168.137.10", "127.0.0.1":都是虚拟IP,看你监控的本地还是服务器ip,只需要一个就行
"10.96.0.1":kubernetes 服务 IP (一般是 SERVICE_CIDR网段 中第一个IP),# 服务网段,部署前路由不可达,部署后集群内路由可达(kube-proxy 保证)
SERVICE_CIDR="10.96.0.0/16"
apiserver节点 IP -> "192.168.137.50", "192.168.137.60","192.168.137.70",
kubernetes 服务 IP -> "10.96.0.1",
域名 ->kubernetes.default.svc.cluster.local
注:
-
hosts 字段指定授权使用该证书的 IP 或域名列表,这里列出了 VIP 、apiserver节点 IP、kubernetes 服务 IP 和域名;
-
域名最后字符不能是
.(如不能为kubernetes.default.svc.cluster.local.),否则解析时失败,提示:x509:cannot parse dnsName "kubernetes.default.svc.cluster.local.";如果使用非 cluster.local 域名,如 opsnull.com ,则需要修改域名列表中的最后两个域名为: kubernetes.default.svc.opsnull 、 kubernetes.default.svc.opsnull.com -
kubernetes 服务 IP 是 apiserver 自动创建的,一般是
--service-cluster-ip-range参数指定的网段的第一个IP,后续可以通过如下命令获取:
[root@master cert]# kubectl get svc kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d

(2)生成证书和私钥
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes
[root@master cert]# ls kubernetes*
kubernetes.csr kubernetes-csr.json kubernetes-key.pem kubernetes.pem
创建加密配置文件
① 产生一个用来加密etcd 的 Key:
[root@kube-master ~]# head -c 32 /dev/urandom | base64
oWpCCosw+euoo85DbsixOS6wCYySIMS8Q90vuTNdM2M=
注意:每台master节点需要用一样的 Key
② 使用这个加密的key,创建加密配置文件
[root@master cert]# vim encryption-config.yaml
kind: EncryptionConfig
apiVersion: v1
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: oWpCCosw+euoo85DbsixOS6wCYySIMS8Q90vuTNdM2M=
- identity: {}
参数解释:
secret:生成 EncryptionConfig 所需的加密 key
将生成的证书和私钥文件、加密配置文件拷贝到master 节点的/opt/k8s目录下:
[root@master cert]# vim /opt/k8s/script/scp_apiserver.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/k8s/cert/ && chown -R k8s /opt/k8s/cert/"
scp /opt/k8s/cert/kubernetes*.pem k8s@${node_ip}:/opt/k8s/cert/
scp /opt/k8s/cert/encryption-config.yaml root@${node_ip}:/opt/k8s/
done
[root@master cert]# chmod +x /opt/k8s/script/scp_apiserver.sh && /opt/k8s/script/scp_apiserver.sh
创建 kube-apiserver systemd unit 模板文件:
[root@master cert]# mkdir -p /opt/apiserver
[root@master cert]# cat > /opt/apiserver/kube-apiserver.service.template <<EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
WorkingDirectory=/opt/apiserver/kube-apiserver
#--enable-admission-plugins=Initializers,NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \
ExecStart=/opt/k8s/bin/kube-apiserver \
--anonymous-auth=false \
--experimental-encryption-provider-config=/opt/k8s/encryption-config.yaml \
--advertise-address=##NODE_IP## \
--bind-address=##NODE_IP## \
--insecure-port=0 \
--authorization-mode=Node,RBAC \
--runtime-config=api/all \
--enable-bootstrap-token-auth \
--service-cluster-ip-range=10.96.0.0/16 \
--service-node-port-range=30000-32767 \
--tls-cert-file=/opt/k8s/cert/kubernetes.pem \
--tls-private-key-file=/opt/k8s/cert/kubernetes-key.pem \
--client-ca-file=/opt/k8s/cert/ca.pem \
--kubelet-client-certificate=/opt/k8s/cert/kubernetes.pem \
--kubelet-client-key=/opt/k8s/cert/kubernetes-key.pem \
--service-account-key-file=/opt/k8s/cert/ca-key.pem \
--etcd-cafile=/opt/k8s/cert/ca.pem \
--etcd-certfile=/opt/k8s/cert/kubernetes.pem \
--etcd-keyfile=/opt/k8s/cert/kubernetes-key.pem \
--etcd-servers=https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379 \
--enable-swagger-ui=true \
--allow-privileged=true \
--apiserver-count=3 \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/var/log/kube-apiserver-audit.log \
--event-ttl=1h \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/opt/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
Type=notify
User=k8s
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
注:
WorkingDirectory:该服务的工作目录,启动前必须先创建
--advertise-address:集群各机器 IP数组(NODE_IP)
--bind-address :不能为 127.0.0.1 ,否则外界不能访问它的安全端口6443;
--experimental-encryption-provider-config :启用加密特性;
--authorization-mode=Node,RBAC : 开启 Node 和 RBAC 授权模式,拒绝未授权的请求;
~~--enable-admission-plugins :启用 ServiceAccount 和NodeRestriction ;~~
--service-account-key-file :签名 ServiceAccount Token 的公钥文件,kube-controller-manager 的 --service-account-private-key-file 指定私钥文件,两者配对使用;
--tls-*-file :指定 apiserver 使用的证书、私钥和 CA 文件。 --client-ca-file 用于验证 client (kue-controller-manager、kube-scheduler、kubelet、kube-proxy 等)请求所带的证书;
--kubelet-client-certificate 、 --kubelet-client-key :如果指定,则使用 https 访问 kubelet APIs;需要为证书对应的用户(上面 kubernetes*.pem 证书的用户为 kubernetes) 用户定义 RBAC 规则,否则访问 kubelet API 时提示未授权;
--insecure-port=0 :关闭监听非安全端口(8080);
--service-cluster-ip-range : 指定 Service Cluster IP 地址段;# 服务网段,部署前路由不可达,部署后集群内路由可达(kube-proxy 保证)
--service-node-port-range : 指定 NodePort 的端口范围;服务端口范围 (NodePort Range)
--runtime-config=api/all=true : 启用所有版本的 APIs,如autoscaling/v2alpha1;
--enable-bootstrap-token-auth :启用 kubelet bootstrap 的 token 认证;
--apiserver-count=3 :指定集群运行模式,多台 kube-apiserver 会通过 leader选举产生一个工作节点,其它节点处于阻塞状态
--etcd-servers:etcd 集群服务地址列表
User=k8s :使用 k8s 账户运行;
注意:--enable-admission-plugins该参数不能使用,会报如下错误:

--------------------第二份-----------------------------------
cat > kube-apiserver.service.template <<EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
WorkingDirectory=${K8S_DIR}/kube-apiserver
ExecStart=/opt/k8s/bin/kube-apiserver \\
--advertise-address=##NODE_IP## \\
--default-not-ready-toleration-seconds=360 \\
--default-unreachable-toleration-seconds=360 \\
--feature-gates=DynamicAuditing=true \\
--max-mutating-requests-inflight=2000 \\
--max-requests-inflight=4000 \\
--default-watch-cache-size=200 \\
--delete-collection-workers=2 \\
--encryption-provider-config=/etc/kubernetes/encryption-config.yaml \\
--etcd-cafile=/etc/kubernetes/cert/ca.pem \\
--etcd-certfile=/etc/kubernetes/cert/kubernetes.pem \\
--etcd-keyfile=/etc/kubernetes/cert/kubernetes-key.pem \\
--etcd-servers=${ETCD_ENDPOINTS} \\
--bind-address=##NODE_IP## \\
--secure-port=6443 \\
--tls-cert-file=/etc/kubernetes/cert/kubernetes.pem \\
--tls-private-key-file=/etc/kubernetes/cert/kubernetes-key.pem \\
--insecure-port=0 \\
--audit-dynamic-configuration \\
--audit-log-maxage=15 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-truncate-enabled \\
--audit-log-path=${K8S_DIR}/kube-apiserver/audit.log \\
--audit-policy-file=/etc/kubernetes/audit-policy.yaml \\
--profiling \\
--anonymous-auth=false \\
--client-ca-file=/etc/kubernetes/cert/ca.pem \\
--enable-bootstrap-token-auth \\
--requestheader-allowed-names="aggregator" \\
--requestheader-client-ca-file=/etc/kubernetes/cert/ca.pem \\
--requestheader-extra-headers-prefix="X-Remote-Extra-" \\
--requestheader-group-headers=X-Remote-Group \\
--requestheader-username-headers=X-Remote-User \\
--service-account-key-file=/etc/kubernetes/cert/ca.pem \\
--authorization-mode=Node,RBAC \\
--runtime-config=api/all=true \\
--enable-admission-plugins=NodeRestriction \\
--allow-privileged=true \\
--apiserver-count=3 \\
--event-ttl=168h \\
--kubelet-certificate-authority=/etc/kubernetes/cert/ca.pem \\
--kubelet-client-certificate=/etc/kubernetes/cert/kubernetes.pem \\
--kubelet-client-key=/etc/kubernetes/cert/kubernetes-key.pem \\
--kubelet-https=true \\
--kubelet-timeout=10s \\
--proxy-client-cert-file=/etc/kubernetes/cert/proxy-client.pem \\
--proxy-client-key-file=/etc/kubernetes/cert/proxy-client-key.pem \\
--service-cluster-ip-range=${SERVICE_CIDR} \\
--service-node-port-range=${NODE_PORT_RANGE} \\
--logtostderr=true \\
--v=2
Restart=on-failure
RestartSec=10
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
-
--advertise-address:apiserver 对外通告的 IP(kubernetes 服务后端节点 IP);
-
--default-*-toleration-seconds:设置节点异常相关的阈值;
-
--max-*-requests-inflight:请求相关的最大阈值;
-
--etcd-*:访问 etcd 的证书和 etcd 服务器地址;
-
--experimental-encryption-provider-config:指定用于加密 etcd 中 secret 的配置;
-
--bind-address: https 监听的 IP,不能为 127.0.0.1,否则外界不能访问它的安全端口 6443;
-
--secret-port:https 监听端口;
-
--insecure-port=0:关闭监听 http 非安全端口(8080);
-
--tls-*-file:指定 apiserver 使用的证书、私钥和 CA 文件;
-
--audit-*:配置审计策略和审计日志文件相关的参数;
-
--client-ca-file:验证 client (kue-controller-manager、kube-scheduler、kubelet、kube-proxy 等)请求所带的证书;
-
--enable-bootstrap-token-auth:启用 kubelet bootstrap 的 token 认证;
-
--requestheader-*:kube-apiserver 的 aggregator layer 相关的配置参数,proxy-client & HPA 需要使用;
-
--requestheader-client-ca-file:用于签名 --proxy-client-cert-file 和 --proxy-client-key-file 指定的证书;在启用了 metric aggregator 时使用;
-
--requestheader-allowed-names:不能为空,值为逗号分割的 --proxy-client-cert-file 证书的 CN 名称,这里设置为 "aggregator";
-
--service-account-key-file:签名 ServiceAccount Token 的公钥文件,kube-controller-manager 的 --service-account-private-key-file 指定私钥文件,两者配对使用;
-
--runtime-config=api/all=true: 启用所有版本的 APIs,如 autoscaling/v2alpha1;
-
--authorization-mode=Node,RBAC、--anonymous-auth=false: 开启 Node 和 RBAC 授权模式,拒绝未授权的请求;
-
--enable-admission-plugins:启用一些默认关闭的 plugins;
-
--allow-privileged:运行执行 privileged 权限的容器;
-
--apiserver-count=3:指定 apiserver 实例的数量;
-
--event-ttl:指定 events 的保存时间;
-
--kubelet-*:如果指定,则使用 https 访问 kubelet APIs;需要为证书对应的用户(上面 kubernetes*.pem 证书的用户为 kubernetes) 用户定义 RBAC 规则,否则访问 kubelet API 时提示未授权;
-
--proxy-client-*:apiserver 访问 metrics-server 使用的证书;
-
--service-cluster-ip-range: 指定 Service Cluster IP 地址段;
-
--service-node-port-range: 指定 NodePort 的端口范围;
如果 kube-apiserver 机器没有运行 kube-proxy,则还需要添加 --enable-aggregator-routing=true 参数;
关于 --requestheader-XXX 相关参数,参考:
-
https://github.com/kubernetes-incubator/apiserver-builder/blob/master/docs/concepts/auth.md
-
https://docs.bitnami.com/kubernetes/how-to/configure-autoscaling-custom-metrics/
注意:
-
requestheader-client-ca-file 指定的 CA 证书,必须具有 client auth and server auth;
-
如果 --requestheader-allowed-names 为空,或者 --proxy-client-cert-file 证书的 CN 名称不在 allowed-names 中,则后续查看 node 或 pods 的 metrics 失败,提示:
[root@zhangjun-k8s01 1.8+]# kubectl top nodes
Error from server (Forbidden): nodes.metrics.k8s.io is forbidden: User "aggregator" cannot list resource "nodes" in API group "metrics.k8s.io" at the cluster scope
为各节点分发 kube-apiserver systemd unit文件;启动检查 kube-apiserver 服务:
[root@master ~]# vim /opt/k8s/script/apiserver_service.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
#替换模板文件中的变量,为各节点创建 systemd unit 文件
for (( i=0; i < 3; i++ ));do
sed "s/##NODE_IP##/${NODE_IPS[i]}/g" /opt/apiserver/kube-apiserver.service.template > /opt/apiserver/kube-apiserver-${NODE_IPS[i]}.service
done
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#启动服务前必须先创建工作目录、日志目录
ssh root@${node_ip} "mkdir -p /opt/apiserver/kube-apiserver && chown -R k8s /opt/apiserver/kube-apiserver"
ssh root@${node_ip} "mkdir -p /opt/log/kubernetes && chown -R k8s /opt/log/kubernetes"
#分发生成的 systemd unit 文件,文件重命名为 kube-apiserver.service
scp /opt/apiserver/kube-apiserver-${node_ip}.service root@${node_ip}:/etc/systemd/system/kube-apiserver.service
#启动并检查 kube-apiserver 服务
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-apiserver && systemctl restart kube-apiserver"
ssh root@${node_ip} "systemctl status kube-apiserver |grep 'Active:'"
done
[root@master apiserver]# chmod +x /opt/k8s/script/apiserver_service.sh && /opt/k8s/script/apiserver_service.sh
确保状态为 active (running) ,否则到 master 节点查看日志,确认原因:
journalctl -u kube-apiserver
打印 kube-apiserver 写入 etcd 的数据
[root@master ~]# ETCDCTL_API=3 etcdctl \
--endpoints="https://192.168.137.50:2379,https://192.168.137.60:2379,https://192.168.137.70:2379" \
--cacert=/opt/k8s/cert/ca.pem \
--cert=/opt/etcd/cert/etcd.pem \
--key=/opt/etcd/cert/etcd-key.pem \
get /registry/ --prefix --keys-only
说明:
--endpoints:etcd 集群服务地址列表
检查集群信息
如果报错如下:(这里必须指定配置文件,否则会报错,因为改变了默认的名字)

解决办法:
-
指定配置文件
-
修改配置文件名字
[root@master ~]# cd ~/.kube/
[root@master .kube]# ls
cache http-cache kubectl.kubeconfig
[root@master .kube]# cp kubectl.kubeconfig config
[root@master .kube]# ls
cache config http-cache kubectl.kubeconfig
[root@master .kube]# kubectl cluster-info
Kubernetes master is running at https://192.168.137.50:6443
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.

[root@master ~]# kubectl cluster-info --kubeconfig=/root/.kube/kubectl.kubeconfig
Kubernetes master is running at https://192.168.137.50:6443
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.

[root@master ~]# kubectl get all --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d17h

[root@master ~]# kubectl get componentstatuses --kubeconfig=/root/.kube/kubectl.kubeconfig
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}

注意:
① 如果执行 kubectl 命令式时输出如下错误信息,则说明使用的 ~/.kube/config文件不对,请切换到正确的账户后再执行该命令、或者检查是否存在config文件:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
② 执行 kubectl get componentstatuses 命令时,apiserver 默认向 127.0.0.1 发送请求。当controller-manager、scheduler 以集群模式运行时,有可能和 kube-apiserver 不在一台机器上,这时 controller-manager 或 scheduler 的状态为Unhealthy,但实际上它们工作正常。
检查 kube-apiserver 监听的端口
[root@master ~]# ss -nutlp | grep apiserver
tcp LISTEN 0 128 192.168.137.50:6443 *:* users:(("kube-apiserver",pid=44971,fd=5))

说明:
-
6443: 接收 https 请求的安全端口,对所有请求做认证和授权
-
由于关闭了非安全端口,故没有监听 8080
授予 kubernetes 证书访问 kubelet API 的权限
在执行 kubectl exec、run、logs 等命令时,apiserver 会转发到 kubelet。这里定义RBAC 规则,授权 apiserver 调用 kubelet API
这里需要特别注意,为了方便管理集群,因此需要通过 kubectl logs 来查看,但由于 API 权限问题,故需要建立一个 RBAC Role 来获取访问权限,否则,这个不授权,kubectl 会无权访问pod 的log内容 报错:
# kubectl logs coredns-6fcd79879-q425r -n kube-system
Error from server (Forbidden): Forbidden (user=kubernetes, verb=get, resource=nodes, subresource=proxy) ( pods/log coredns-6fcd79879-q425r)
[root@master ~]# kubectl create clusterrolebinding kube-apiserver:kubelet-apis --clusterrole=system:kubelet-api-admin --user kubernetes --kubeconfig=/root/.kube/config

部署高可用kube-controller-manager 集群(默认端口10252)
本文档介绍部署高可用 kube-controller-manager 集群的步骤。
该集群包含 3 个节点,启动后将通过竞争选举机制产生一个 leader 节点,其它节点为阻塞状态。当 leader 节点不可用后,剩余节点将再次进行选举产生新的 leader 节点,从而保证服务的可用性。
为保证通信安全,本文档先生成 x509 证书和私钥,kube-controller-manager 在如下两种情况下使用该证书:
① 与 kube-apiserver 的安全端口通信时;
② 在安全端口(https,10252) 输出 prometheus 格式的 metrics;
准备工作:下载最新版本的二进制文件、安装和配置 flanneld
创建 kube-controller-manager 证书和私钥
创建证书签名请求:
[root@master ~]# cd /opt/k8s/cert/
[root@master cert]# cat > kube-controller-manager-csr.json <<EOF
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.137.50",
"192.168.137.60",
"192.168.137.70"
],
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-controller-manager",
"OU": "4Paradigm"
}
]
}
EOF
注:
-
hosts 列表包含所有 kube-controller-manager 节点 IP;
-
CN 为 system:kube-controller-manager、O 为 system:kube-controller-manager,kubernetes 内置的 ClusterRoleBindings system:kube-controller-manager 赋予kube-controller-manager 工作所需的权限
生成证书和私钥
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager
[root@master cert]# ls *controller-manager*
kube-controller-manager.csr kube-controller-manager-csr.json kube-controller-manager-key.pem kube-controller-manager.pem
创建kubeconfig 文件
kubeconfig 文件包含访问 apiserver 的所有信息,如 apiserver 地址、CA 证书和自身使用的证书;
① 执行命令,生产kube-controller-manager.kubeconfig文件
[root@master ~]# kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/cert/ca.pem \
--embed-certs=true \
--server=https://192.168.137.10:8443 \
--kubeconfig=/root/.kube/kube-controller-manager.kubeconfig
输出:
Cluster "kubernetes" set.
说明:
--server=https://192.168.137.10:8443这里是指定的虚拟ip
[root@master ~]# kubectl config set-credentials system:kube-controller-manager \
--client-certificate=/opt/k8s/cert/kube-controller-manager.pem \
--client-key=/opt/k8s/cert/kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=/root/.kube/kube-controller-manager.kubeconfig
输出:
User "system:kube-controller-manager" set.
[root@master ~]# kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=/root/.kube/kube-controller-manager.kubeconfig
输出:
Context "system:kube-controller-manager@kubernetes" created.
[root@master ~]# kubectl config use-context system:kube-controller-manager@kubernetes --kubeconfig=/root/.kube/kube-controller-manager.kubeconfig
输出:
Switched to context "system:kube-controller-manager@kubernetes".
② 验证kube-controller-manager.kubeconfig文件
[root@master cert]# ls /root/.kube/kube-controller-manager.kubeconfig
/root/.kube/kube-controller-manager.kubeconfig
[root@master ~]# kubectl config view --kubeconfig=/root/.kube/kube-controller-manager.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.137.10:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: system:kube-controller-manager
name: system:kube-controller-manager@kubernetes
current-context: system:kube-controller-manager@kubernetes
kind: Config
preferences: {}
users:
- name: system:kube-controller-manager
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
分发生成的证书和私钥、kubeconfig 到所有 master 节点
[root@master ~]# vim /opt/k8s/script/scp_controller_manager.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "chown k8s /opt/k8s/cert/*"
scp /opt/k8s/cert/kube-controller-manager*.pem k8s@${node_ip}:/opt/k8s/cert/
scp /root/.kube/kube-controller-manager.kubeconfig k8s@${node_ip}:/opt/k8s/
done
[root@master ~]# chmod +x /opt/k8s/script/scp_controller_manager.sh && /opt/k8s/script/scp_controller_manager.sh
创建kube-controller-manager systemd unit 文件
[root@master ~]# mkdir /opt/controller-manager
[root@master ~]# cd /opt/controller_manager
[root@master controller_manager]# cat > kube-controller-manager.service <<EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
WorkingDirectory=/opt/controller-manager/kube-controller-manager
ExecStart=/opt/k8s/bin/kube-controller-manager \
--port=0 \
--secure-port=10252 \
--bind-address=127.0.0.1 \
--kubeconfig=/opt/k8s/kube-controller-manager.kubeconfig \
--service-cluster-ip-range=10.96.0.0/16 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/opt/k8s/cert/ca.pem \
--cluster-signing-key-file=/opt/k8s/cert/ca-key.pem \
--experimental-cluster-signing-duration=8760h \
--root-ca-file=/opt/k8s/cert/ca.pem \
--service-account-private-key-file=/opt/k8s/cert/ca-key.pem \
--leader-elect=true \
--feature-gates=RotateKubeletServerCertificate=true \
--controllers=*,bootstrapsigner,tokencleaner \
--horizontal-pod-autoscaler-use-rest-clients=true \
--horizontal-pod-autoscaler-sync-period=10s \
--tls-cert-file=/opt/k8s/cert/kube-controller-manager.pem \
--tls-private-key-file=/opt/k8s/cert/kube-controller-manager-key.pem \
--use-service-account-credentials=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/opt/controller-manager/kube-controller-manager \
--v=2
Restart=on
Restart=on-failure
RestartSec=5
User=k8s
[Install]
WantedBy=multi-user.target
EOF
注:
-
WorkingDirectory:服务的工作目录,启动前必须先创建
-
--port=0:关闭监听 http /metrics 的请求,同时 --address 参数无效,--bind-address 参数有效;
-
--secure-port=10252、--bind-address=0.0.0.0: 在所有网络接口监听 10252 端口的 https /metrics 请求;
-
--kubeconfig:指定 kubeconfig 文件路径,kube-controller-manager 使用它连接和验证 kube-apiserver;
-
--cluster-signing-*-file:签名 TLS Bootstrap 创建的证书;
-
--experimental-cluster-signing-duration:指定 TLS Bootstrap 证书的有效期;
-
--root-ca-file:放置到容器 ServiceAccount 中的 CA 证书,用来对 kube-apiserver 的证书进行校验;
-
--service-account-private-key-file:签名 ServiceAccount 中 Token 的私钥文件,必须和 kube-apiserver 的 --service-account-key-file 指定的公钥文件配对使用;
-
--service-cluster-ip-range :指定 Service Cluster IP 网段,必须和 kube-apiserver 中的同名参数一致;
-
--leader-elect=true:集群运行模式,启用选举功能;被选为 leader 的节点负责处理工作,其它节点为阻塞状态;
-
--feature-gates=RotateKubeletServerCertificate=true:开启 kublet server 证书的自动更新特性;
-
--controllers=*,bootstrapsigner,tokencleaner:启用的控制器列表,tokencleaner 用于自动清理过期的 Bootstrap token;
-
--horizontal-pod-autoscaler-*:custom metrics 相关参数,支持 autoscaling/v2alpha1;
-
--tls-cert-file、--tls-private-key-file:使用 https 输出 metrics 时使用的 Server 证书和秘钥;
-
--use-service-account-credentials=true:
-
User=k8s:使用 k8s 账户运行
-
--service-cluster-ip-range:SERVICE_CIDR->服务网段,部署前路由不可达,部署后集群内路由可达(kube-proxy 保证)
kube-controller-manager 不对请求 https metrics 的 Client 证书进行校验,故不需要指定 --tls-ca-file 参数,而且该参数已被淘汰
------------或者--------------------
cat > kube-controller-manager.service.template <<EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
WorkingDirectory=${K8S_DIR}/kube-controller-manager
ExecStart=/opt/k8s/bin/kube-controller-manager \\
--profiling \\
--cluster-name=kubernetes \\
--controllers=*,bootstrapsigner,tokencleaner \\
--kube-api-qps=1000 \\
--kube-api-burst=2000 \\
--leader-elect \\
--use-service-account-credentials\\
--concurrent-service-syncs=2 \\
--bind-address=##NODE_IP## \\
--secure-port=10252 \\
--tls-cert-file=/etc/kubernetes/cert/kube-controller-manager.pem \\
--tls-private-key-file=/etc/kubernetes/cert/kube-controller-manager-key.pem \\
--port=0 \\
--authentication-kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\
--client-ca-file=/etc/kubernetes/cert/ca.pem \\
--requestheader-allowed-names="" \\
--requestheader-client-ca-file=/etc/kubernetes/cert/ca.pem \\
--requestheader-extra-headers-prefix="X-Remote-Extra-" \\
--requestheader-group-headers=X-Remote-Group \\
--requestheader-username-headers=X-Remote-User \\
--authorization-kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\
--cluster-signing-cert-file=/etc/kubernetes/cert/ca.pem \\
--cluster-signing-key-file=/etc/kubernetes/cert/ca-key.pem \\
--experimental-cluster-signing-duration=876000h \\
--horizontal-pod-autoscaler-sync-period=10s \\
--concurrent-deployment-syncs=10 \\
--concurrent-gc-syncs=30 \\
--node-cidr-mask-size=24 \\
--service-cluster-ip-range=${SERVICE_CIDR} \\
--pod-eviction-timeout=6m \\
--terminated-pod-gc-threshold=10000 \\
--root-ca-file=/etc/kubernetes/cert/ca.pem \\
--service-account-private-key-file=/etc/kubernetes/cert/ca-key.pem \\
--kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\
--logtostderr=true \\
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
----需要替换模板文件中的变量,为各节点创建 systemd unit 文件:
cd /opt/k8s/work
source /opt/k8s/bin/environment.sh
for (( i=0; i < 3; i++ ))
do
sed -e "s/##NODE_NAME##/${NODE_NAMES[i]}/" -e "s/##NODE_IP##/${NODE_IPS[i]}/" kube-controller-manager.service.template > kube-controller-manager-${NODE_IPS[i]}.service
done
ls kube-controller-manager*.service
kube-controller-manager 的权限
参考:https://github.com/kubernetes/kubeadm/issues/1285
关于 controller 权限和 use-service-account-credentials 参数:https://github.com/kubernetes/kubernetes/issues/48208
kubelet 认证和授权:https://kubernetes.io/docs/admin/kubelet-authentication-authorization/#kubelet-authorization
ClusteRole: system:kube-controller-manager的权限很小,只能创建 secret、serviceaccount 等资源对象,各 controller 的权限分散到 ClusterRole system:controller:XXX 中。
需要在 kube-controller-manager 的启动参数中添加 --use-service-account-credentials=true 参数,这样 main controller 会为各 controller 创建对应的 ServiceAccount XXX-controller。
内置的 ClusterRoleBinding system:controller:XXX 将赋予各 XXX-controller ServiceAccount 对应的 ClusterRole system:controller:XXX 权限
# curl --cacert /opt/k8s/cert/ca.pem --cert /opt/k8s/cert/admin.pem --key /opt/k8s/cert/admin-key.pem https://127.0.0.1:10252/metrics
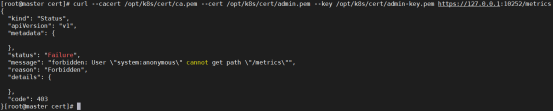
解决办法是创建一个 ClusterRoleBinding,赋予相应的权限:
[root@master ~]# kubectl create clusterrolebinding controller-manager:system:auth-delegator --user system:kube-controller-manager --clusterrole system:auth-delegator
[root@master ~]# kubectl describe clusterrole system:kube-controller-manager
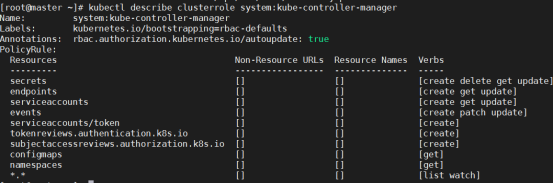
[root@master ~]# kubectl get clusterrole|grep controller
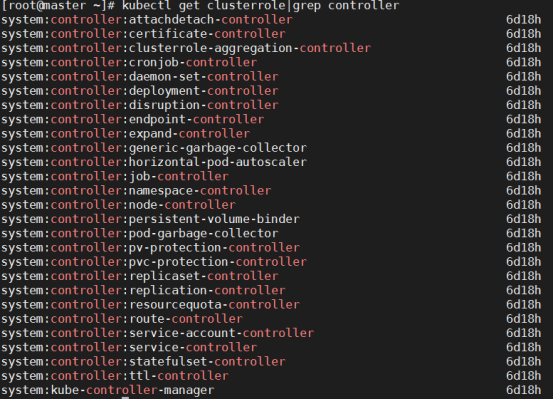
以 deployment controller 为例:
[root@master ~]# kubectl describe clusterrole system:controller:deployment-controller
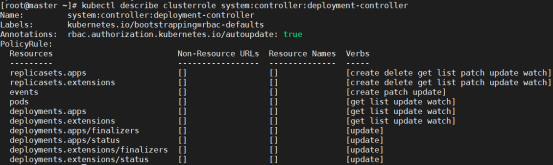
分发systemd unit 文件到所有master 节点;启动检查 kube-controller-manager 服务
[root@master controller_manager]# cd
[root@master ~]# vim /opt/k8s/script/controller_manager.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#分发启动脚本
scp /opt/controller_manager/kube-controller-manager.service root@${node_ip}:/etc/systemd/system/
#创建工作目录、日志目录
ssh root@${node_ip} "mkdir -p /opt/log/kubernetes && chown -R k8s /opt/log/kubernetes"
ssh root@${node_ip} "mkdir -p /opt/controller-manager/kube-controller-manager && chown -R k8s /opt/controller-manager/kube-controller-manager"
#启动服务器
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-controller-manager && systemctl start kube-controller-manager"
done
#验证是否启动成功
for node_ip2 in ${NODE_IPS[@]};do
echo ">>> ${node_ip2}"
ssh k8s@${node_ip2} "systemctl status kube-controller-manager|grep Active"
done
[root@master ~]# chmod +x /opt/k8s/script/controller_manager.sh && /opt/k8s/script/controller_manager.sh
确保状态为 active (running),否则查看日志,确认原因:
journalctl -u kube-controller-manager
kube-controller-manager 监听 10252 端口,接收 https 请求:
[root@master ~]# netstat -lnpt | grep kube-cont
tcp 0 0 127.0.0.1:10252 0.0.0.0:* LISTEN 103931/kube-control
查看输出的 metric
注意:以下命令在 kube-controller-manager 节点上执行
[root@master ~]# curl -s --cacert /opt/k8s/cert/ca.pem --cert /opt/k8s/cert/admin.pem --key /opt/k8s/cert/admin-key.pem https://127.0.0.1:10252/metrics | head
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/metrics\"",
"reason": "Forbidden",
"details": {
},
"code": 403
}
将 kube-controller-manager 的日志级别设置为 4 后,可以看到原因是:
$ journalctl -u kube-controller-manager -f | grep /metrics
2月 22 19:07:28 m7-inf-prod01 kube-controller-manager[1416748]: I0222 19:07:28.003325 1416748 authorization.go:73] Forbidden: "/metrics", Reason: "no RBAC policy matched"
2月 22 19:07:28 m7-inf-prod01 kube-controller-manager[1416748]: I0222 19:07:28.003472 1416748 wrap.go:42] GET /metrics: (2.600519ms) 403 [curl/7.29.0 127.0.0.1:36324]
这是由于没有部署 metrics-server 的缘故。后续在https://github.com/opsnull/follow-me-install-kubernetes-cluster/blob/v1.12.x/09-4.metrics-server%E6%8F%92%E4%BB%B6.md将介绍部署 metrics-server 的步骤。
参考:https://github.com/kubernetes-incubator/metrics-server/issues/85
注:curl --cacert CA 证书用来验证 kube-controller-manager https server 证书;
查看当前的 leader
[root@master ~]# kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml

当前leader是master
测试 kube-controller-manager 集群的高可用
1、停掉一个或两个节点的 kube-controller-manager 服务,观察其它节点的日志,看是否获取了 leader 权限。
2、没有停止服务前,查看当前的 leader
[root@master ~]# kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master_c02bf19e-5d17-4814-bc0c-df58c38ca8ba","leaseDurationSeconds":15,"acquireTime":"2019-10-10T09:47:06Z","renewTime":"2019-10-10T09:52:42Z","leaderTransitions":0}'
creationTimestamp: "2019-10-10T09:47:07Z"
name: kube-controller-manager
namespace: kube-system
resourceVersion: "1775"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-controller-manager
uid: f5c8d90c-5430-4492-9625-a2b9dad2eea8
停止服务后查看:
[root@master ~]# kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"node02_93ee234c-3fb6-454f-b542-c0eedd0aa3c3","leaseDurationSeconds":15,"acquireTime":"2019-10-10T09:57:47Z","renewTime":"2019-10-10T09:58:13Z","leaderTransitions":1}'
creationTimestamp: "2019-10-10T09:47:07Z"
name: kube-controller-manager
namespace: kube-system
resourceVersion: "2034"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-controller-manager
uid: f5c8d90c-5430-4492-9625-a2b9dad2eea8
可见,当前的 leader 为 node02 节点。(本来是在master节点)
部署高可用 kube-scheduler 集群
本文档介绍部署高可用 kube-scheduler 集群的步骤。
该集群包含 3 个节点,启动后将通过竞争选举机制产生一个 leader 节点,其它节点为阻塞状态。当 leader 节点不可用后,剩余节点将再次进行选举产生新的 leader 节点,从而保证服务的可用性。
为保证通信安全,本文档先生成 x509 证书和私钥,kube-scheduler 在如下两种情况下使用该证书:
① 与 kube-apiserver 的安全端口通信;
② 在安全端口(https,10251) 输出 prometheus 格式的 metrics;
准备工作:下载最新版本的二进制文件、安装和配置 flanneld
创建 kube-scheduler 证书
创建证书签名请求:
[root@master ~]# cd /opt/k8s/cert/
[root@master cert]# cat > kube-scheduler-csr.json <<EOF
{
"CN": "system:kube-scheduler",
"hosts": [
"127.0.0.1",
"192.168.137.50",
"192.168.137.60",
"192.168.137.70"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-scheduler",
"OU": "4Paradigm"
}
]
}
EOF
注:
-
hosts 列表包含所有 kube-scheduler 节点 IP;
-
CN 为 system:kube-scheduler、O 为 system:kube-scheduler,kubernetes 内置的 ClusterRoleBindings system:kube-scheduler 将赋予 kube-scheduler 工作所需的权限
生成证书和私钥
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler
[root@master cert]# ls *scheduler*
kube-scheduler.csr kube-scheduler-csr.json kube-scheduler-key.pem kube-scheduler.pem
创建kubeconfig 文件
kubeconfig 文件包含访问 apiserver 的所有信息,如 apiserver 地址、CA 证书和自身使用的证书;
① 执行命令,生产kube-scheduler.kubeconfig文件
[root@master cert]# kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/cert/ca.pem \
--embed-certs=true \
--server=https://192.168.137.10:8443 \
--kubeconfig=/root/.kube/kube-scheduler.kubeconfig
输出:
Cluster "kubernetes" set.
说明:192.168.137.10:8443这里是虚拟ip
[root@master cert]# kubectl config set-credentials system:kube-scheduler \
--client-certificate=/opt/k8s/cert/kube-scheduler.pem \
--client-key=/opt/k8s/cert/kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=/root/.kube/kube-scheduler.kubeconfig
输出:
User "system:kube-scheduler" set.
[root@master cert]# kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=/root/.kube/kube-scheduler.kubeconfig
输出:
Context "system:kube-scheduler@kubernetes" created.
[root@master cert]# kubectl config use-context system:kube-scheduler@kubernetes --kubeconfig=/root/.kube/kube-scheduler.kubeconfig
输出:
Switched to context "system:kube-scheduler@kubernetes".
② 验证kube-controller-manager.kubeconfig文件
[root@master cert]# ls /root/.kube/kube-scheduler.kubeconfig
/root/.kube/kube-scheduler.kubeconfig
- 上一步创建的证书、私钥以及 kube-apiserver 地址被写入到 kubeconfig 文件中
[root@master cert]# kubectl config view --kubeconfig=/root/.kube/kube-scheduler.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.137.10:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: system:kube-scheduler
name: system:kube-scheduler@kubernetes
current-context: system:kube-scheduler@kubernetes
kind: Config
preferences: {}
users:
- name: system:kube-scheduler
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
分发生成的证书和私钥、kubeconfig 到所有 master 节点
[root@master cert]# cd
[root@master ~]# vim /opt/k8s/script/scp_scheduler.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "chown k8s /opt/k8s/cert/*"
scp /opt/k8s/cert/kube-scheduler*.pem k8s@${node_ip}:/opt/k8s/cert/
scp /root/.kube/kube-scheduler.kubeconfig k8s@${node_ip}:/opt/k8s/
done
[root@master ~]# chmod +x /opt/k8s/script/scp_scheduler.sh && /opt/k8s/script/scp_scheduler.sh
创建kube-scheduler 配置文件
# mkdir -p /opt/scheduler && cd /opt/scheduler
# vim /opt/scheduler/kube-scheduler.yaml.template
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
bindTimeoutSeconds: 600
clientConnection:
burst: 200
kubeconfig: "/opt/k8s/kube-scheduler.kubeconfig"
qps: 100
enableContentionProfiling: false
enableProfiling: true
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: ##NODE_IP##:10251
leaderElection:
leaderElect: true
metricsBindAddress: ##NODE_IP##:10251
--------------或者用骚气-----------
cat <<EOF | sudo tee kube-scheduler.yaml
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: "/etc/kubernetes/kube-scheduler.kubeconfig"
leaderElection:
leaderElect: true
EOF
说明:
-
--kubeconfig:指定 kubeconfig 文件路径,kube-scheduler 使用它连接和验证 kube-apiserver;
-
--leader-elect=true:集群运行模式,启用选举功能;被选为 leader 的节点负责处理工作,其它节点为阻塞状态
分发kube-scheduler 配置文件
# vim /opt/k8s/script/scp_scheduler_yaml.sh
#!/bin/bash
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
#替换模板文件中的变量:
for (( i=0; i < 3; i++ ))
do
sed "s/##NODE_IP##/${NODE_IPS[i]}/" /opt/scheduler/kube-scheduler.yaml.template > /opt/scheduler/kube-scheduler-${NODE_IPS[i]}.yaml
done
#分发 kube-scheduler 配置文件并重命名为 kube-scheduler.yaml到所有 master 节点:
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/scheduler/ && chown -R k8s /opt/scheduler/"
scp /opt/scheduler/kube-scheduler-${node_ip}.yaml root@${node_ip}:/opt/scheduler/kube-scheduler.yaml
done
# chmod +x /opt/k8s/script/scp_scheduler_yaml.sh && /opt/k8s/script/scp_scheduler_yaml.sh
# ls kube-scheduler*.yaml
kube-scheduler-192.168.137.50.yaml kube-scheduler-192.168.137.60.yaml kube-scheduler-192.168.137.70.yaml kube-scheduler.yaml
创建kube-scheduler systemd unit 文件
[root@master ~]# mkdir /opt/scheduler
[root@master ~]# cd /opt/scheduler
[root@master scheduler]# cat > kube-scheduler.service <<EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
WorkingDirectory=/opt/scheduler/kube-scheduler
ExecStart=/opt/k8s/bin/kube-scheduler \
--address=127.0.0.1 \
--config=/opt/scheduler/kube-scheduler.yaml \
--kubeconfig=/opt/k8s/kube-scheduler.kubeconfig \
--leader-elect=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/opt/scheduler/kube-scheduler \
--v=2
Restart=on-failure
RestartSec=5
User=k8s
[Install]
WantedBy=multi-user.target
EOF
注:
- --address:在 127.0.0.1:10251 端口接收 http /metrics 请求;kube-scheduler 目前还不支持接收 https 请求;
- --kubeconfig:指定kubeconfig 文件路径,kube-scheduler 使用它连接和验证 kube-apiserver;
- --config:指定kube-scheduler配置文件路径
- --leader-elect=true:集群运行模式,启用选举功能;被选为 leader 的节点负责处理工作,其它节点为阻塞状态;
- User=k8s:使用 k8s 账户运行;
--------下面这个脚本没有成功请检查--------------
cat > kube-scheduler.service <<EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
WorkingDirectory=/opt/scheduler/
ExecStart=/opt/k8s/bin/kube-scheduler \
--address=127.0.0.1 \
--kubeconfig=/opt/k8s/kube-scheduler.kubeconfig \
--config=/opt/scheduler/kube-scheduler.yaml \
--secure-port=10259 \
--port=0 \
--tls-cert-file=/opt/k8s/certkube-scheduler.pem \
--tls-private-key-file=/opt/k8s/cert/kube-scheduler-key.pem \
--authentication-kubeconfig=/opt/k8s/kube-scheduler.kubeconfig \
--client-ca-file=/opt/k8s/cert/ca.pem \
--requestheader-allowed-names="" \
--requestheader-client-ca-file=/opt/k8s/cert/ca.pem \
--requestheader-extra-headers-prefix="X-Remote-Extra-" \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--leader-elect=true \
--alsologtostderr=true \
--logtostderr=true \
--log-dir=/opt/log/kubernetes \
--v=2
User=k8s
Restart=always
RestartSec=5
StartLimitInterval=0
[Install]
WantedBy=multi-user.target
EOF
分发systemd unit 文件到所有master 节点;启动检查kube-scheduler 服务
[root@master scheduler]# vim /opt/k8s/script/scheduler.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#分发启动脚本
scp /opt/scheduler/kube-scheduler.service root@${node_ip}:/etc/systemd/system/
#创建工作目录
ssh root@${node_ip} "mkdir -p /opt/log/kubernetes && chown -R k8s /opt/log/kubernetes"
ssh root@${node_ip} "mkdir -p /opt/scheduler/kube-scheduler && chown -R k8s /opt/scheduler/kube-scheduler"
#启动服务
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-scheduler && systemctl start kube-scheduler"
done
#验证服务
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh k8s@${node_ip} "systemctl status kube-scheduler|grep Active"
done
[root@master scheduler]# chmod +x /opt/k8s/script/scheduler.sh && /opt/k8s/script/scheduler.sh
确保状态为 active (running),否则查看日志,确认原因:
journalctl -u kube-scheduler

查看输出的 metric
注意:以下命令在 kube-scheduler 节点上执行。
kube-scheduler 监听 10251 端口,接收 http 请求:
[root@master scheduler]# ss -nutlp |grep kube-scheduler
tcp LISTEN 0 128 127.0.0.1:10251 *:* users:(("kube-scheduler",pid=8835,fd=5))
tcp LISTEN 0 128 [::]:10259 [::]:* users:(("kube-scheduler",pid=8835,fd=6))
kube-scheduler 监听 10251 和 10259 端口:
-
10251:接收 http 请求,非安全端口,不需要认证授权;
-
10259:接收 https 请求,安全端口,需要认证授权;
两个接口都对外提供 /metrics 和 /healthz 的访问
[root@master scheduler]# curl -s http://127.0.0.1:10251/metrics | head

[root@master ~]# curl -s http://192.168.137.50:10251/metrics |head #这里监听的是服务器的ip,不是本地,所有需要ip

# curl -s --cacert /opt/k8s/cert/ca.pem --cert /opt/k8s/cert/admin.pem --key /opt/k8s/cert/admin-key.pem https://127.0.0.1:10259/metrics #这个无法访问
测试 kube-scheduler 集群的高可用
1、随便找一个或两个 master 节点,停掉 kube-scheduler 服务,看其它节点是否获取了 leader 权限(systemd 日志)。
[root@master scheduler]# kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master_c837f3a6-be1e-4e40-84e9-28ce3bfab147","leaseDurationSeconds":15,"acquireTime":"2019-10-10T21:43:26Z","renewTime":"2019-10-10T21:44:16Z","leaderTransitions":1}'
creationTimestamp: "2019-10-10T21:34:50Z"
name: kube-scheduler
namespace: kube-system
resourceVersion: "34039"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler
uid: 29c28f8a-9f61-4f27-aea0-2070787b5271
2、查看当前的 leader
[root@node02 ~]# systemctl stop kube-scheduler
[root@master scheduler]# kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"node02_db027d35-ffbc-4ae9-861c-eb74c0dd02d8","leaseDurationSeconds":15,"acquireTime":"2019-10-11T06:20:15Z","renewTime":"2019-10-11T06:26:44Z","leaderTransitions":0}'
creationTimestamp: "2019-10-10T21:34:50Z"
name: kube-scheduler
namespace: kube-system
resourceVersion: "33811"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler
uid: 29c28f8a-9f61-4f27-aea0-2070787b5271
可见,当前的 leader 为 node2 节点。(本来是在master节点)
部署 worker 节点--->建议首先部署docker
kubernetes work 节点运行如下组件:
-
docker
-
kubelet
-
kube-proxy
-
flanneld
1、安装和配置 flanneld
部署 flannel 网络
2、安装依赖包
CentOS:
$ yum install -y epel-release
$ yum install -y conntrack ipvsadm ipset jq iptables curl sysstat libseccomp && /usr/sbin/modprobe ip_vs
# vim /opt/k8s/script/Depend_packages.sh
NODE_IPS=(192.168.137.50 192.168.137.60 192.168.137.70)
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "yum install -y epel-release"
ssh root@${node_ip} "yum install -y conntrack ipvsadm ntp ntpdate ipset jq iptables curl sysstat libseccomp && modprobe ip_vs "
done
# chmod +x /opt/k8s/script/Depend_packages.sh && /opt/k8s/script/Depend_packages.sh
Ubuntu:
$ apt-get install -y conntrack ipvsadm ipset jq iptables curl sysstat libseccomp && /usr/sbin/modprobe ip_vs
部署 docker 组件
docker 是容器的运行环境,管理它的生命周期。kubelet 通过 Container Runtime Interface (CRI) 与 docker 进行交互
下载docker 二进制文件
到 https://download.docker.com/linux/static/stable/x86_64/ 页面下载最新发布包:
[root@master ~]# wget https://download.docker.com/linux/static/stable/x86_64/docker-18.03.1-ce.tgz && tar -xvf docker-18.03.1-ce.tgz
创建systemd unit 文件
[root@master ~]# mkdir /opt/docker
[root@master ~]# cd /opt/
[root@master docker]# cat > /opt/docker.service << "EOF"
[Unit]
Description=Docker Application Container Engine
Documentation=http://docs.docker.io
[Service]
WorkingDirectory=/data/k8s/docker
Environment="PATH=/opt/k8s/bin:/bin:/sbin:/usr/bin:/usr/sbin"
EnvironmentFile=-/run/flannel/docker
ExecStart=/opt/k8s/bin/dockerd --log-level=error $DOCKER_NETWORK_OPTIONS
ExecReload=/bin/kill -s HUP $MAINPID
Restart=on-failure
RestartSec=5
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
注意:
-
EOF 前后有双引号,这样 bash 不会替换文档中的变量,如 \$DOCKER_NETWORK_OPTIONS;
-
dockerd 运行时会调用其它 docker 命令,如 docker-proxy,所以需要将 docker 命令所在的目录加到 PATH 环境变量中;
-
flanneld 启动时将网络配置写入 /run/flannel/docker 文件中,dockerd 启动前读取该文件中的环境变量 DOCKER_NETWORK_OPTIONS ,然后设置 docker0 网桥网段;
-
如果指定了多个 EnvironmentFile 选项,则必须将 /run/flannel/docker 放在最后(确保 docker0 使用 flanneld 生成的 bip 参数);
-
docker 需要以 root 用于运行;
-
docker 从 1.13 版本开始,可能将 iptables FORWARD chain的默认策略设置为DROP,从而导致 ping 其它 Node 上的 Pod IP 失败,遇到这种情况时,需要手动设置策略为 ACCEPT:
$ sudo iptables -P FORWARD ACCEPT;并且把以下命令写入/etc/rc.local 文件中,防止节点重启iptables FORWARD chain的默认策略又还原为DROP:$ /sbin/iptables -P FORWARD ACCEPT -
WorkingDirectory:服务的数据目录
配置docker 配置文件
使用国内的仓库镜像服务器以加快 pull image 的速度,同时增加下载的并发数 (需要重启 dockerd 生效):
docker安装后默认没有/etc/docker/daemon.json 文件,需要进行手动创建。--config-file命令参数可用于指定非默认位置。但请注意:配置文件中设置的选项不得与启动参数设置的选项冲突。 如果文件和启动参数之间的选项重复,则docker守护程序无法启动,无论其值如何。 例如,如果在daemon.json配置文件中设置了守护程序标签并且还通过--label命令参数设置守护程序标签,则守护程序无法启动。 守护程序启动时将忽略文件中不存在的选项
[root@master docker]# cat > docker-daemon.json <<EOF
{
"registry-mirrors": ["https://hub-mirror.c.163.com", "https://docker.mirrors.ustc.edu.cn"],
"insecure-registries": ["192.168.137.50"],
"max-concurrent-downloads": 20,
"live-restore": true,
"max-concurrent-uploads": 10,
"debug": true,
"data-root": "/data/k8s/docker/data",
"exec-root": "/data/k8s/docker/exec",
"log-opts": {
"max-size": "100m",
"max-file": "5"
}
}
EOF
分发docker 二进制文件、systemd unit 文件、docker 配置文件到所有 worker 机器
[root@master opt]# cd
[root@master ~]# vim /opt/k8s/script/scp_docker.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#分发二进制文件到所有 worker 节点
scp /root/docker/docker* k8s@${node_ip}:/opt/k8s/bin/
ssh k8s@${node_ip} "chmod +x /opt/k8s/bin/*"
#分发 systemd unit 文件到所有 worker 机器
scp /opt/docker.service root@${node_ip}:/etc/systemd/system/
#创建docker数据目录
ssh root@${node_ip} "mkdir -p /data/k8s/docker/{data,exec} /etc/docker/"
#分发 docker 配置文件到所有 worker 节点,并重命名为daemon.json
scp /opt/docker-daemon.json root@${node_ip}:/etc/docker/daemon.json
done
[root@master ~]# chmod +x /opt/k8s/script/scp_docker.sh && /opt/k8s/script/scp_docker.sh
启动并检查 docker 服务(docker必须启动,不然节点也是NotReady)
[root@master ~]# vim /opt/k8s/script/start_docker.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#关闭防火墙
ssh root@${node_ip} "systemctl stop firewalld && systemctl disable firewalld"
#这里不要关闭防火墙了,因为有防火墙规则了,我建议先安装docker。在安装k8s组件
# ssh root@${node_ip} "/usr/sbin/iptables -F && /usr/sbin/iptables -X && /usr/sbin/iptables -F -t nat && /usr/sbin/iptables -X -t nat"
# ssh root@${node_ip} "/usr/sbin/iptables -P FORWARD ACCEPT"
#启动docker
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable docker && systemctl restart docker"
# ssh root@${node_ip} 'for intf in /sys/devices/virtual/net/docker0/brif/*; do echo 1 > $intf/hairpin_mode; done'
#加载内核参数
ssh root@${node_ip} "sudo sysctl -p /etc/sysctl.d/kubernetes.conf"
#检查服务运行状态
ssh k8s@${node_ip} "systemctl status docker|grep Active"
#检查 docker0 网桥
ssh k8s@${node_ip} "/usr/sbin/ip addr show flannel.1 && /usr/sbin/ip addr show docker0"
done
[root@master ~]# chmod +x /opt/k8s/script/start_docker.sh && /opt/k8s/script/start_docker.sh
注:
-
关闭 firewalld(centos7)/ufw(ubuntu16.04),否则可能会重复创建 iptables 规则;
-
清理旧的 iptables rules 和 chains 规则;
-
开启 docker0 网桥下虚拟网卡的 hairpin 模式;
① 确保状态为 active (running),否则查看日志,确认原因:
$ journalctl -u docker
②确认各 work 节点的 docker0 网桥和 flannel.1 接口的 IP 处于同一个网段中(如下10.30.45.0和10.30.45.1):
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.30.45.0 netmask 255.255.255.255 broadcast 0.0.0.0
ether ee:db:f2:60:cb:81 txqueuelen 0 (Ethernet)
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 10.30.45.1 netmask 255.255.255.0 broadcast 10.30.45.255
ether 02:42:fe:c8:83:4a txqueuelen 0 (Ethernet)
解决:docker0 网桥和 flannel.1 接口的 IP 不在同一个网段中
* 修改文件 /etc/docker/daemon.json 添加内容 "bip": "ip/netmask" [切勿与宿主机同网段]
# vim /etc/docker/daemon.json
{
"bip": "10.30.79.1/24",
}
* 重启 docker 服务
* 查看修改后的 docker0 网桥信息
部署 kubelet 组件(https,10250)
kublet 运行在每个 worker 节点上,接收 kube-apiserver 发送的请求,管理 Pod 容器,执行交互式命令,如 exec、run、logs 等。
kublet 启动时自动向 kube-apiserver 注册节点信息,内置的 cadvisor 统计和监控节点的资源使用情况。
为确保安全,本文档只开启接收 https 请求的安全端口,对请求进行认证和授权,拒绝未授权的访问(如 apiserver、heapster)。
1、下载和分发 kubelet 二进制文件
参考部署master节点.md
2、安装依赖包
参考部署worker节点.md
创建 kubelet bootstrap kubeconfig 文件
[root@master ~]# vim /opt/k8s/script/bootstrap_kubeconfig.sh
NODE_NAMES=("master" "node01" "node02")
for node_name in ${NODE_NAMES[@]};do
echo ">>> ${node_name}"
# 创建 token
export BOOTSTRAP_TOKEN=$(kubeadm token create \
--description kubelet-bootstrap-token \
--groups system:bootstrappers:${node_name} \
--kubeconfig ~/.kube/config)
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/cert/ca.pem \
--embed-certs=true \
--server=https://192.168.137.10:8443 \
--kubeconfig=/root/.kube/kubelet-bootstrap-${node_name}.kubeconfig
#192.168.137.10是虚拟IP地址
# 设置客户端认证参数
kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=/root/.kube/kubelet-bootstrap-${node_name}.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=/root/.kube/kubelet-bootstrap-${node_name}.kubeconfig
# 设置默认上下文
kubectl config use-context default --kubeconfig=/root/.kube/kubelet-bootstrap-${node_name}.kubeconfig
done
[root@master ~]# chmod +x /opt/k8s/script/bootstrap_kubeconfig.sh && /opt/k8s/script/bootstrap_kubeconfig.sh
输出结果:
>>> master
Cluster "kubernetes" set.
User "kubelet-bootstrap" set.
Context "default" created.
Switched to context "default".
>>> node01
Cluster "kubernetes" set.
User "kubelet-bootstrap" set.
Context "default" created.
Switched to context "default".
>>> node02
Cluster "kubernetes" set.
User "kubelet-bootstrap" set.
Context "default" created.
Switched to context "default".
注:
① 证书中写入 Token 而非证书,证书后续由 controller-manager 创建。
查看 kubeadm 为各节点创建的 token:
[root@master ~]# kubeadm token list --kubeconfig ~/.kube/config
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
4nxevc.ddlwfxjjhn3qi4oc 23h 2019-10-12T07:47:46+08:00 authentication,signing kubelet-bootstrap-token system:bootstrappers:node02
qj4o1x.izdtidmyb00gku4r 23h 2019-10-12T07:47:43+08:00 authentication,signing kubelet-bootstrap-token system:bootstrappers:master
z52pgf.ehdm8wofcwx8egop 23h 2019-10-12T07:47:44+08:00 authentication,signing kubelet-bootstrap-token system:bootstrappers:node01
② 创建的 token 有效期为 1 天,超期后将不能再被使用,且会被 kube-controller-manager 的 tokencleaner 清理(如果启用该 controller 的话);
③ kube-apiserver 接收 kubelet 的 bootstrap token 后,将请求的 user 设置为 system:bootstrap:,group 设置为 system:bootstrappers;
各 token 关联的 Secret:
[root@master ~]# kubectl get secrets -n kube-system
NAME TYPE DATA AGE
attachdetach-controller-token-gm4zj kubernetes.io/service-account-token 3 14h
bootstrap-signer-token-2llt6 kubernetes.io/service-account-token 3 14h
bootstrap-token-4nxevc bootstrap.kubernetes.io/token 7 65s
bootstrap-token-qj4o1x bootstrap.kubernetes.io/token 7 68s
bootstrap-token-z52pgf bootstrap.kubernetes.io/token 7 67s
certificate-controller-token-m7bw7 kubernetes.io/service-account-token 3 14h
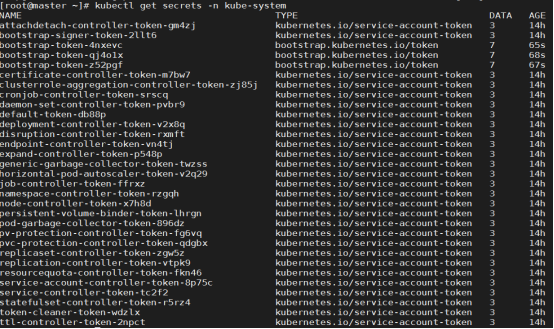
创建kubelet 参数配置文件
从 v1.10 开始,kubelet 部分参数需在配置文件中配置,kubelet --help 会提示:
DEPRECATED: This parameter should be set via the config file specified by the Kubelet\'s --config flag
创建 kubelet 参数配置文件模板(可配置项参考代码中注释 ):
https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/config/types.go
[root@master ~]# mkdir /opt/kubelet
[root@master ~]# cd /opt/kubelet
[root@master kubelet]# vim kubelet.config.json.template
{
"kind": "KubeletConfiguration",
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"authentication": {
"x509": {
"clientCAFile": "/opt/k8s/cert/ca.pem"
},
"webhook": {
"enabled": true,
"cacheTTL": "2m0s"
},
"anonymous": {
"enabled": false
}
},
"authorization": {
"mode": "Webhook",
"webhook": {
"cacheAuthorizedTTL": "5m0s",
"cacheUnauthorizedTTL": "30s"
}
},
"address": "##NODE_IP##",
"port": 10250,
"readOnlyPort": 0,
"cgroupDriver": "cgroupfs",
"hairpinMode": "promiscuous-bridge",
"serializeImagePulls": false,
"featureGates": {
"RotateKubeletClientCertificate": true,
"RotateKubeletServerCertificate": true
},
"clusterDomain": "cluster.local",
"clusterDNS": ["10.96.0.2"]
}
参考:
https://github.com/opsnull/follow-me-install-kubernetes-cluster/blob/master/07-2.kubelet.md
- address:kubelet 安全端口(https,10250)监听的地址,不能为 127.0.0.1,否则 kube-apiserver、heapster 等不能调用 kubelet 的 API;
- readOnlyPort=0:关闭只读端口(默认 10255),等效为未指定;
- authentication.anonymous.enabled:设置为 false,不允许匿名�访问 10250 端口;
- authentication.x509.clientCAFile:指定签名客户端证书的 CA 证书,开启 HTTP 证书认证;
- authentication.webhook.enabled=true:开启 HTTPs bearer token 认证;
- 对于未通过 x509 证书和 webhook 认证的请求(kube-apiserver 或其他客户端),将被拒绝,提示 Unauthorized;
- authroization.mode=Webhook:kubelet 使用 SubjectAccessReview API 查询 kube-apiserver 某 user、group 是否具有操作资源的权限(RBAC);
- featureGates.RotateKubeletClientCertificate、featureGates.RotateKubeletServerCertificate:自动 rotate 证书,证书的有效期取决于 kube-controller-manager 的 --experimental-cluster-signing-duration 参数;
- 需要 root 账户运行;
- clusterDNS:集群 DNS 服务 IP (从 SERVICE_CIDR 中预分配)->SERVICE_CIDR:服务网段,部署前路由不可达,部署后集群内路由可达(kube-proxy 保证)
- clusterDomain:# 集群 DNS 域名(末尾不带点号)
分发 bootstrap kubeconfig 、kubelet 配置文件到所有 worker 节点
[root@master kubelet]# cd
[root@master ~]# vim /opt/k8s/script/scp_kubelet.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
NODE_NAMES=("master" "node01" "node02")
#分发 bootstrap kubeconfig 文件到所有 worker 节点
for node_name in ${NODE_NAMES[@]};do
echo ">>> ${node_name}"
scp ~/.kube/kubelet-bootstrap-${node_name}.kubeconfig k8s@${node_name}:/opt/k8s/kubelet-bootstrap.kubeconfig
done
#替换kubelet 配置文件中的变量
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
sed -e "s/##NODE_IP##/${node_ip}/" /opt/kubelet/kubelet.config.json.template > /opt/kubelet/kubelet.config-${node_ip}.json
#分发kubelet 配置文件
scp /opt/kubelet/kubelet.config-${node_ip}.json root@${node_ip}:/opt/k8s/kubelet.config.json
done
[root@master ~]# chmod +x /opt/k8s/script/scp_kubelet.sh && /opt/k8s/script/scp_kubelet.sh
创建kubelet systemd unit 文件->一定要把这两个参数写正确,否则无法解析
[root@kube-master ~]# vim /opt/kubelet/kubelet.service.template
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/opt/lib/kubelet
ExecStart=/opt/k8s/bin/kubelet \
#--allow-privileged=true \
--bootstrap-kubeconfig=/opt/k8s/kubelet-bootstrap.kubeconfig \
--cert-dir=/opt/k8s/cert \
--kubeconfig=/root/.kube/kubectl.kubeconfig \
--config=/opt/k8s/kubelet.config.json \
--hostname-override=##NODE_NAME## \
--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/opt/log/kubernetes \
--v=2 \
#添加内容如下,,,后面部署coredns会用到。
--cluster-dns=10.96.0.2 \
--cluster-domain=cluster.local.
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
注意:--allow-privileged=true 加了这个参数服务起来不的
-
如果设置了 --hostname-override 选项,则 kube-proxy 也需要设置该选项,否则会出现找不到 Node 的情况;
-
--bootstrap-kubeconfig:指向 bootstrap kubeconfig 文件,kubelet 使用该文件中的用户名和 token 向 kube-apiserver 发送 TLS Bootstrapping 请求;
-
K8S approve kubelet 的 csr 请求后,在 --cert-dir 目录创建证书和私钥文件,然后写入 --kubeconfig 文件;
-
--pod-infra-container-image 不使用 redhat 的 pod-infrastructure:latest 镜像,它不能回收容器的僵尸
Bootstrap Token Auth 和授予权限
1、kublet 启动时查找配置的 --kubeletconfig 文件是否存在,如果不存在则使用 --bootstrap-kubeconfig 向 kube-apiserver 发送证书签名请求 (CSR)。
2、kube-apiserver 收到 CSR 请求后,对其中的 Token 进行认证(事先使用 kubeadm 创建的 token),认证通过后将请求的 user 设置为 system:bootstrap:,group 设置为 system:bootstrappers,这一过程称为 Bootstrap Token Auth。
3、默认情况下,这个 user 和 group 没有创建 CSR 的权限,kubelet 启动失败,错误日志如下:
$ sudo journalctl -u kubelet -a |grep -A 2 'certificatesigningrequests'
May 06 06:42:36 kube-node1 kubelet[26986]: F0506 06:42:36.314378 26986 server.go:233] failed to run Kubelet: cannot create certificate signing request: certificatesigningrequests.certificates.k8s.io is forbidden: User "system:bootstrap:lemy40" cannot create certificatesigningrequests.certificates.k8s.io at the cluster scope May 06 06:42:36 kube-node1 systemd[1]: kubelet.service: Main process exited, code=exited, status=255/n/a May 06 06:42:36 kube-node1 systemd[1]: kubelet.service: Failed with result 'exit-code'.
4、解决办法是:创建一个 clusterrolebinding,将 group system:bootstrappers 和 clusterrole system:node-bootstrapper 绑定:
[root@master ~]# kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --group=system:bootstrappers
输出结果:
clusterrolebinding.rbac.authorization.k8s.io/kubelet-bootstrap created
分发并启动 kubelet 服务
[root@master ~]# vim /opt/k8s/script/kubelet.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
NODE_NAMES=("master" "node01" "node02")
#分发kubelet systemd unit 文件
for node_name in ${NODE_NAMES[@]};do
echo ">>> ${node_name}"
sed -e "s/##NODE_NAME##/${node_name}/" /opt/kubelet/kubelet.service.template > /opt/kubelet/kubelet-${node_name}.service
scp /opt/kubelet/kubelet-${node_name}.service root@${node_name}:/etc/systemd/system/kubelet.service
done
#启动且查看kubelet 服务
for node_ip in ${NODE_IPS[@]};do
ssh root@${node_ip} "mkdir -p /opt/lib/kubelet"
ssh root@${node_ip} "/usr/sbin/swapoff -a"
ssh root@${node_ip} "mkdir -p /opt/log/kubernetes && chown -R k8s /opt/log/kubernetes"
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kubelet && systemctl restart kubelet"
ssh root@${node_ip} "systemctl status kubelet |grep active"
done
[root@master ~]# chmod +x /opt/k8s/script/kubelet.sh && /opt/k8s/script/kubelet.sh
-
必须创建工作目录;
-
关闭 swap 分区,否则 kubelet 会启动失败
# journalctl -u kubelet |tail
注:
-
关闭 swap 分区,注意/etc/fstab 要设为开机不启动swap分区,否则 kubelet 会启动失败;
-
必须先创建工作和日志目录;
-
kubelet 启动后使用 --bootstrap-kubeconfig 向 kube-apiserver 发送 CSR 请求,当这个 CSR 被 approve 后,kube-controller-manager 为 kubelet 创建 TLS 客户端证书、私钥和 --kubeletconfig 文件。
-
kube-controller-manager 需要配置 --cluster-signing-cert-file 和 --cluster-signing-key-file 参数,才会为 TLS Bootstrap 创建证书和私钥
kubelet 启动后使用 --bootstrap-kubeconfig 向 kube-apiserver 发送 CSR 请求,当这个 CSR 被 approve 后,kube-controller-manager 为 kubelet 创建 TLS 客户端证书、私钥和 --kubeletconfig 文件。
注意:kube-controller-manager 需要配置 --cluster-signing-cert-file 和 --cluster-signing-key-file 参数,才会为 TLS Bootstrap 创建证书和私钥
$ kubectl get csr
NAME AGE REQUESTOR CONDITION
csr-5f4vh 31s system:bootstrap:82jfrm Pending
csr-5rw7s 29s system:bootstrap:b1f7np Pending
csr-m29fm 31s system:bootstrap:3gzd53 Pending
- 三个 worker 节点的 csr 均处于 pending 状态
$ kubectl get nodes ->等待时间比较长
NAME STATUS ROLES AGE VERSION
master Ready <none> 22m v1.15.4
node01 Ready <none> 8m47s v1.15.4
node02 Ready <none> 8m40s v1.15.4
approve kubelet CSR 请求
可以手动或自动 approve CSR 请求。推荐使用自动的方式,因为从 v1.8 版本开始,可以自动轮转approve csr 后生成的证书。
1、手动 approve CSR 请求
(1)查看 CSR 列表:
[root@kube-master ~]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-SdkiSnAdFByBTIJDyFWTBSTIDMJKxwxQt9gEExFX5HU 4m system:bootstrap:8hpvxm Pending
node-csr-atMwF8GpKbDEcGjzCTXF1NYo9Jc1AzE2yQoxaU8NAkw 7m system:bootstrap:ttbgfq Pending
node-csr-qxa30a9GRg35iNEl3PYZOIICMo_82qPrqNu6PizEZXw 4m system:bootstrap:gktdpg Pending
三个 work 节点的 csr 均处于 pending 状态;
(2)approve CSR:
[root@kube-master ~]# kubectl certificate approve node-csr-SdkiSnAdFByBTIJDyFWTBSTIDMJKxwxQt9gEExFX5HU
certificatesigningrequest.certificates.k8s.io "node-csr-SdkiSnAdFByBTIJDyFWTBSTIDMJKxwxQt9gEExFX5HU" approved
(3)查看 Approve 结果:
[root@kube-master ~]# kubectl describe csr node-csr-SdkiSnAdFByBTIJDyFWTBSTIDMJKxwxQt9gEExFX5HU
Name: node-csr-SdkiSnAdFByBTIJDyFWTBSTIDMJKxwxQt9gEExFX5HU
Labels: <none>
Annotations: <none>
CreationTimestamp: Thu, 29 Nov 2018 17:51:43 +0800
Requesting User: system:bootstrap:8hpvxm
Status: Approved,Issued
Subject:
Common Name: system:node:kube-node1
Serial Number:
Organization: system:nodes
Events: <none>
2、自动 approve CSR 请求
(1)创建三个 ClusterRoleBinding,分别用于自动 approve client、renew client、renew server 证书:
[root@master ~]# cat > /opt/kubelet/csr-crb.yaml <<EOF
# Approve all CSRs for the group "system:bootstrappers" kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: auto-approve-csrs-for-group subjects: - kind: Group name:
# Approve all CSRs for the group "system:bootstrappers"
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: auto-approve-csrs-for-group
subjects:
- kind: Group
name: system:bootstrappers
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:nodeclient
apiGroup: rbac.authorization.k8s.io
---
# To let a node of the group "system:nodes" renew its own credentials
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: node-client-cert-renewal
subjects:
- kind: Group
name: system:nodes
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
apiGroup: rbac.authorization.k8s.io
---
# A ClusterRole which instructs the CSR approver to approve a node requesting a
# serving cert matching its client cert.
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: approve-node-server-renewal-csr
rules:
- apiGroups: ["certificates.k8s.io"]
resources: ["certificatesigningrequests/selfnodeserver"]
verbs: ["create"]
---
# To let a node of the group "system:nodes" renew its own server credentials
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: node-server-cert-renewal
subjects:
- kind: Group
name: system:nodes
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: approve-node-server-renewal-csr
apiGroup: rbac.authorization.k8s.io
EOF
注:
-
auto-approve-csrs-for-group:自动 approve node 的第一次 CSR; 注意第一次 CSR 时,请求的 Group 为 system:bootstrappers;
-
node-client-cert-renewal:自动 approve node 后续过期的 client 证书,自动生成的证书 Group 为 system:nodes;
-
node-server-cert-renewal:自动 approve node 后续过期的 server 证书,自动生成的证书 Group 为 system:nodes;
(2)生效配置:
[root@master ~]# kubectl apply -f /opt/kubelet/csr-crb.yaml
clusterrolebinding.rbac.authorization.k8s.io/auto-approve-csrs-for-group unchanged
clusterrolebinding.rbac.authorization.k8s.io/node-client-cert-renewal unchanged
clusterrole.rbac.authorization.k8s.io/approve-node-server-renewal-csr unchanged
clusterrolebinding.rbac.authorization.k8s.io/node-server-cert-renewal unchanged
查看 kublet 的情况
1、等待一段时间(1-10 分钟),三个节点的 CSR 都被自动 approve:
[root@master ~]# kubectl get csr
NAME AGE REQUESTOR CONDITION
csr-kvbtt 15h system:node:kube-node1 Approved,Issued
csr-p9b9s 15h system:node:kube-node2 Approved,Issued
csr-rjpr9 15h system:node:kube-master Approved,Issued
node-csr-8Sr42M0z_LzZeHU-RCbgOynJm3Z2TsSXHuAlohfJiIM 15h system:bootstrap:ttbgfq Approved,Issued
node-csr-SdkiSnAdFByBTIJDyFWTBSTIDMJKxwxQt9gEExFX5HU 15h system:bootstrap:8hpvxm Approved,Issued
node-csr-atMwF8GpKbDEcGjzCTXF1NYo9Jc1AzE2yQoxaU8NAkw 15h system:bootstrap:ttbgfq Approved,Issued
node-csr-elVB0jp36nOHuOYlITWDZx8LoO2Ly4aW0VqgYxw_Te0 15h system:bootstrap:gktdpg Approved,Issued
node-csr-muNcDteZINLZnSv8FkhOMaP2ob5uw82PGwIAynNNrco 15h system:bootstrap:ttbgfq Approved,Issued
node-csr-qxa30a9GRg35iNEl3PYZOIICMo_82qPrqNu6PizEZXw 15h system:bootstrap:gktdpg Approved,Issued
2、所有节点均 ready:
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready <none> 26h v1.15.4
node01 Ready <none> 26h v1.15.4
node02 Ready <none> 26h v1.15.4
3、kube-controller-manager 为各 node 生成了 kubeconfig 文件和公私钥:
[root@kube-master ~]# ll /opt/k8s/kubelet.kubeconfig
-rw------- 1 root root 2280 Nov 29 18:05 /opt/k8s/kubelet.kubeconfig
[root@kube-master ~]# ll /opt/k8s/cert/ |grep kubelet
-rw-r--r-- 1 root root 1050 Nov 29 18:05 kubelet-client.crt
-rw------- 1 root root 227 Nov 29 18:01 kubelet-client.key
-rw------- 1 root root 1338 Nov 29 18:05 kubelet-server-2018-11-29-18-05-11.pem
lrwxrwxrwx 1 root root 52 Nov 29 18:05 kubelet-server-current.pem -> /opt/k8s/cert/kubelet-server-2018-11-29-18-05-11.pem
注:kubelet-server 证书会周期轮转;
kubelet 提供的 API 接口
1、kublet 启动后监听多个端口,用于接收 kube-apiserver 或其它组件发送的请求:
[root@master ~]# ss -nutlp |grep kubelet
tcp LISTEN 0 128 127.0.0.1:10248 *:* users:(("kubelet",pid=104050,fd=26))
tcp LISTEN 0 128 192.168.137.50:10250 *:* users:(("kubelet",pid=104050,fd=25))
tcp LISTEN 0 128 127.0.0.1:44449 *:* users:(("kubelet",pid=104050,fd=12))
注:
-
44449: cadvisor http 服务;
-
10248: healthz http 服务;
-
10250: https API 服务;注意:未开启只读端口 10255;
~~2、例如执行 kubectl ec -it nginx-ds-5rmws -- sh 命令时,kube-apiserver 会向 kubelet 发送如下请求:~~
~~POST /exec/default/nginx-ds-5rmws/my-nginx?command=sh&input=1&output=1&tty=1~~
3、kubelet 接收 10250 端口的 https 请求:
/pods、/runningpods
/metrics、/metrics/cadvisor、/metrics/probes
/spec
/stats、/stats/container
/logs
/run/、"/exec/", "/attach/", "/portForward/", "/containerLogs/" 等管理;
详情参考:https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/server/server.go#L434:3
4、由于关闭了匿名认证,同时开启了 webhook 授权,所有访问 10250 端口 https API 的请求都需要被认证和授权。
预定义的 ClusterRole system:kubelet-api-admin 授予访问 kubelet 所有 API 的权限:
[root@master ~]# kubectl describe clusterrole system:kubelet-api-admin
Name: system:kubelet-api-admin
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
nodes/log [] [] [*]
nodes/metrics [] [] [*]
nodes/proxy [] [] [*]
nodes/spec [] [] [*]
nodes/stats [] [] [*]
nodes [] [] [get list watch proxy]
kublet api 认证和授权
参考:kubelet 认证和授权:https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet-authentication-authorization/
1、kublet 配置了如下认证参数:
-
authentication.anonymous.enabled:设置为 false,不允许匿名访问 10250 端口;
-
authentication.x509.clientCAFile:指定签名客户端证书的 CA 证书,开启 HTTPs 证书认证;
-
authentication.webhook.enabled=true:开启 HTTPs bearer token 认证;
同时配置了如下授权参数:
- authroization.mode=Webhook:开启 RBAC 授权;
2、kubelet 收到请求后,使用 clientCAFile 对证书签名进行认证,或者查询 bearer token 是否有效。如果两者都没通过,则拒绝请求,提示 Unauthorized:
[root@kube-master ~]# curl -s --cacert /opt/k8s/cert/ca.pem https://192.168.137.60:10250/metrics
Unauthorized
[root@kube-master ~]# curl -s --cacert /opt/k8s/cert/ca.pem -H "Authorization: Bearer 123456" https://192.168.137.60:10250/metrics
Unauthorized
3、通过认证后,kubelet 使用 SubjectAccessReview API 向 kube-apiserver 发送请求,查询证书或 token 对应的 user、group 是否有操作资源的权限(RBAC);
证书认证和授权:
$ 权限不足的证书;
[root@kube-master ~]# curl -s --cacert /opt/k8s/cert/ca.pem --cert /opt/k8s/cert/kube-controller-manager.pem --key /opt/k8s/cert/kube-controller-manager-key.pem https://192.168.10.109:10250/metrics
Forbidden (user=system:kube-controller-manager, verb=get, resource=nodes, subresource=metrics)
--cacert、--cert、--key 的参数值必须是文件路径,如上面的 ./admin.pem 不能省略 ./,否则返回 401 Unauthorized
$ 使用部署 kubectl 命令行工具时创建的、具有最高权限的 admin 证书;
[root@kube-master cert]# curl -s --cacert /opt/k8s/cert/ca.pem --cert /opt/k8s/cert/admin.pem --key /opt/k8s/cert/admin-key.pem https://192.168.137.60:10250/metrics|head
# HELP apiserver_client_certificate_expiration_seconds Distribution of the remaining lifetime on the certificate used to authenticate a request.
# TYPE apiserver_client_certificate_expiration_seconds histogram
apiserver_client_certificate_expiration_seconds_bucket{le="0"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="21600"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="43200"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="86400"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="172800"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="345600"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="604800"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="2.592e+06"} 0
--cacert、--cert、--key 的参数值必须是文件路径,如上面的/opt/k8s/cert/admin.pem 不能省略 ./,否则返回 401 Unauthorized;
4、bear token 认证和授权:
创建一个 ServiceAccount,将它和 ClusterRole system:kubelet-api-admin 绑定,从而具有调用 kubelet API 的权限:
[root@master ~]# kubectl create sa kubelet-api-test
serviceaccount/kubelet-api-test created
[root@master ~]# kubectl create clusterrolebinding kubelet-api-test --clusterrole=system:kubelet-api-admin --serviceaccount=default:kubelet-api-test
[root@master ~]# SECRET=$(kubectl get secrets | grep kubelet-api-test | awk '{print $1}')
[root@master ~]# echo $?
0
[root@kube-master ~]# TOKEN=$(kubectl describe secret ${SECRET} | grep -E '^token' | awk '{print $2}')
[root@kube-master ~]# echo ${TOKEN}
[root@kube-master ~]# curl -s --cacert /opt/k8s/cert/ca.pem -H "Authorization: Bearer ${TOKEN}" https://192.168.137.60:10250/metrics|head
# HELP apiserver_client_certificate_expiration_seconds Distribution of the remaining lifetime on the certificate used to authenticate a request.
# TYPE apiserver_client_certificate_expiration_seconds histogram
apiserver_client_certificate_expiration_seconds_bucket{le="0"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="21600"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="43200"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="86400"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="172800"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="345600"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="604800"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="2.592e+06"} 0
cadvisor 和 metrics
cadvisor 统计所在节点各容器的资源(CPU、内存、磁盘、网卡)使用情况,分别在自己的 http web 页面(4194 端口)和 10250 以 promehteus metrics 的形式输出。
浏览器访问
https://192.168.137.60:4194/containers/ 和
https://92.168.137.60:10250/metrics/cadvisor 分别返回 kubelet 和 cadvisor 的 metrics:

注意:
-
kubelet.config.json 设置 authentication.anonymous.enabled 为 false,不允许匿名证书访问 10250 的 https 服务;
-
参考A.浏览器访问kube-apiserver安全端口.md(https://github.com/opsnull/follow-me-install-kubernetes-cluster/blob/master/A.%E6%B5%8F%E8%A7%88%E5%99%A8%E8%AE%BF%E9%97%AEkube-apiserver%E5%AE%89%E5%85%A8%E7%AB%AF%E5%8F%A3.md),创建和导入相关证书,然后访问上面的 10250 端口
获取 kublet 的配置
从 kube-apiserver 获取各 node 的配置:
使用部署 kubectl 命令行工具时创建的、具有最高权限的 admin 证书;
[root@master ~]# curl -sSL --cacert /opt/k8s/cert/ca.pem --cert /opt/k8s/cert/admin.pem --key /opt/k8s/cert/admin-key.pem https://192.168.137.10:8443/api/v1/nodes/kube-node1/proxy/configz | jq \
'.kubeletconfig|.kind="KubeletConfiguration"|.apiVersion="kubelet.config.k8s.io/v1beta1"'

部署 kube-proxy 组件
kube-proxy 运行在所有 worker 节点上,它监听 apiserver 中 service 和 Endpoint 的变化情况,创建路由规则来进行服务负载均衡。
本文档讲解部署 kube-proxy 的部署,使用 ipvs 模式。
1、下载和分发 kube-proxy 二进制文件
部署master节点.md
2、安装依赖包
各节点需要安装 ipvsadm 和 ipset 命令,加载 ip_vs 内核模块。
部署worker节点.md
创建 kube-proxy 证书
创建证书签名请求:
[root@master ~]# cd /opt/k8s/cert/
[root@master cert]# cat > kube-proxy-csr.json << EOF
{
"CN": "system:kube-proxy",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "4Paradigm"
}
]
}
EOF
注:
-
CN:指定该证书的 User 为 system:kube-proxy;
-
预定义的 RoleBinding system:node-proxier 将User system:kube-proxy 与 Role system:node-proxier 绑定,该 Role 授予了调用 kube-apiserver Proxy 相关 API 的权限;
-
该证书只会被 kube-proxy 当做 client 证书使用,所以 hosts 字段为空
生成证书和私钥
[root@master cert]# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
[root@master cert]# ls *kube-proxy*
kube-proxy.csr kube-proxy-csr.json kube-proxy-key.pem kube-proxy.pem
创建kubeconfig 文件
[root@master cert]# cd
[root@master ~]# kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/cert/ca.pem \
--embed-certs=true \
--server=https://192.168.137.10:8443 \
--kubeconfig=/root/.kube/kube-proxy.kubeconfig
说明:这个是虚拟IPhttps://192.168.137.10
[root@master ~]# kubectl config set-credentials kube-proxy \
--client-certificate=/opt/k8s/cert/kube-proxy.pem \
--client-key=/opt/k8s/cert/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=/root/.kube/kube-proxy.kubeconfig
[root@master ~]# kubectl config set-context kube-proxy@kubernetes \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=/root/.kube/kube-proxy.kubeconfig
[root@master ~]# kubectl config use-context kube-proxy@kubernetes --kubeconfig=/root/.kube/kube-proxy.kubeconfig
注:
- --embed-certs=true:将 ca.pem 和 admin.pem 证书内容嵌入到生成的 kubectl-proxy.kubeconfig 文件中(不加时,写入的是证书文件路径);
[root@master ~]# kubectl config view --kubeconfig=/root/.kube/kube-proxy.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.137.10:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kube-proxy
name: kube-proxy@kubernetes
current-context: kube-proxy@kubernetes
kind: Config
preferences: {}
users:
- name: kube-proxy
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
创建 kube-proxy 配置文件
从 v1.10 开始,kube-proxy 部分参数可以配置文件中配置。可以使用 --write-config-to 选项生成该配置文件,
创建 kube-proxy config 文件模板
[root@master ~]# mkdir -p /opt/kube-proxy
[root@master ~]# cd /opt/kube-proxy
[root@master kube-proxy]# cat >kube-proxy.config.yaml.template <<EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: ##NODE_IP##
clientConnection:
burst: 200
kubeconfig: /opt/k8s/kube-proxy.kubeconfig
qps: 100
clusterCIDR: 10.30.0.0/16
healthzBindAddress: ##NODE_IP##:10256
hostnameOverride: ##NODE_NAME##
kind: KubeProxyConfiguration
metricsBindAddress: ##NODE_IP##:10249
mode: "ipvs"
portRange: ""
kubeProxyIPTablesConfiguration:
masqueradeAll: false
kubeProxyIPVSConfiguration:
scheduler: rr
excludeCIDRs: []
EOF
注:
-
bindAddress: 监听地址;
-
clientConnection.kubeconfig: 连接 apiserver 的 kubeconfig 文件;
-
clusterCIDR: kube-proxy 根据 --cluster-cidr 判断集群内部和外部流量,指定 --cluster-cidr 或 --masquerade-all选项后 kube-proxy 才会对访问 Service IP 的请求做 SNAT;
-
hostnameOverride: 参数值必须与 kubelet 的值一致,否则 kube-proxy 启动后会找不到该 Node,从而不会创建任何 ipvs 规则;
-
mode: 使用 ipvs 模式
-
clusterCIDR: 10.96.0.0/16-->是CLUSTER_CIDR->是Pod 网段,建议 /16 段地址,部署前路由不可达,部署后集群内路由可达(flanneld 保证)
创建kube-proxy systemd unit 文件
[root@master ~]# cd /opt/kube-proxy
[root@master kube-proxy]# cat > kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
WorkingDirectory=/opt/kube-proxy/proxy/
ExecStart=/opt/k8s/bin/kube-proxy \
--config=/opt/k8s/kube-proxy.config.yaml \
--logtostderr=true \
--v=2
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
分发证书、私钥 kubeconfig、kube-proxy systemd unit 文件;启动并检查kube-proxy 服务
[root@master kube-proxy]# cd
[root@master ~]# vim /opt/k8s/script/kube_proxy.sh
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
NODE_NAMES=("master" "node01" "node02")
#分发证书
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /opt/k8s/cert/ && sudo chown -R k8s /opt/k8s/cert/"
scp /opt/k8s/cert/kube-proxy*.pem k8s@${node_ip}:/opt/k8s/cert/
done
#为各节点创建和分发 kube-proxy 配置文件
for (( i=0; i < 3; i++ ));do
echo ">>> ${NODE_NAMES[i]}"
sed -e "s/##NODE_NAME##/${NODE_NAMES[i]}/" -e "s/##NODE_IP##/${NODE_IPS[i]}/" /opt/kube-proxy/kube-proxy.config.yaml.template > /opt/kube-proxy/kube-proxy-${NODE_NAMES[i]}.config.yaml
scp /opt/kube-proxy/kube-proxy-${NODE_NAMES[i]}.config.yaml root@${NODE_NAMES[i]}:/opt/k8s/kube-proxy.config.yaml
done
for node_ip in ${NODE_IPS[@]};do
echo ">>> ${node_ip}"
#分发 kubeconfig 文件
scp /root/.kube/kube-proxy.kubeconfig k8s@${node_ip}:/opt/k8s/
#分发启动脚本
scp /opt/kube-proxy/kube-proxy.service root@${node_ip}:/etc/systemd/system/
#启动服务
ssh root@${node_ip} "mkdir -p /opt/kube-proxy/proxy"
ssh root@${node_ip} "mkdir -p /opt/log/kubernetes && chown -R k8s /opt/log/kubernetes"
ssh root@${node_ip} "modprobe ip_vs_rr"
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-proxy && systemctl start kube-proxy"
#查看服务是否正常
ssh k8s@${node_ip} "systemctl status kube-proxy|grep Active"
done
[root@master ~]# chmod +x /opt/k8s/script/kube_proxy.sh && /opt/k8s/script/kube_proxy.sh
确保状态为 active (running),否则查看日志,确认原因:
journalctl -u kube-proxy
查看监听端口和 metrics
```bash\ [root@master ~]# ss -nutlp |grep kube-prox tcp LISTEN 0 128 192.168.137.50:10249 : users:(("kube-proxy",pid=55467,fd=12)) tcp LISTEN 0 128 192.168.137.50:10256 : users:(("kube-proxy",pid=55467,fd=11))
- 10249:http prometheus metrics port;
- 10256:http healthz port
##### 查看 ipvs 路由规则
```bash
NODE_IPS=("192.168.137.50" "192.168.137.60" "192.168.137.70")
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "/usr/sbin/ipvsadm -ln"
done
[root@master ~]# /usr/sbin/ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.137.50:6443 Masq 1 0 0
-> 192.168.137.60:6443 Masq 1 0 0
-> 192.168.137.70:6443 Masq 1 0 0
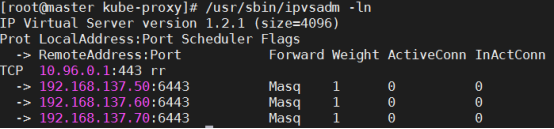
-
可见将所有到 kubernetes cluster ip 443 端口的请求都转发到 kube-apiserver 的 6443 端口
-
所有通过 https 访问 K8S SVC kubernetes 的请求都转发到 kube-apiserver 节点的 6443 端口
验证集群功能
使用 daemonset 验证 master 和 worker 节点是否工作正常
检查节点状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready <none> 7d1h v1.15.4
node01 Ready <none> 7d1h v1.15.4
node02 Ready <none> 7d1h v1.15.4
都为 Ready 时正常
创建测试文件
[root@master ~]# mkdir -p /opt/k8s/damo
[root@master ~]# cd /opt/k8s/damo/
[root@master damo]# cat > nginx-ds.yml <<EOF
apiVersion: v1
kind: Service
metadata:
name: nginx-ds
labels:
app: nginx-ds
spec:
type: NodePort
selector:
app: nginx-ds
ports:
- name: http
port: 80
targetPort: 80
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nginx-ds
labels:
addonmanager.kubernetes.io/mode: Reconcile
spec:
template:
metadata:
labels:
app: nginx-ds
spec:
containers:
- name: my-nginx
image: nginx:1.7.9
ports:
- containerPort: 80
EOF
执行测试
# kubectl create -f /opt/k8s/damo/nginx-ds.yml
service/nginx-ds created
daemonset.extensions/nginx-ds created
检查各节点的 Pod IP 连通性
注意第一个时间会比较长,因为它需要去拉取进行等操作
可以用docker ps -a 命令查看是否启动了nginx
[root@master ~]# kubectl get pods -o wide|grep nginx-ds
nginx-ds-d9ds4 1/1 Running 0 5m49s 10.30.96.2 node01 <none> <none>
nginx-ds-dpwgh 1/1 Running 0 5m49s 10.30.101.2 master <none> <none>
nginx-ds-nnc54 1/1 Running 0 5m49s 10.30.48.2 node02 <none> <none>
可见,nginx-ds 的 Pod IP 分别是 10.30.96.2、10.30.101.2、10.30.48.2,在所有 Node 上分别 ping 这三个 IP,看是否连通:
# vim /opt/k8s/script/check_pod.sh
NODE_IPS=(192.168.137.50 192.168.137.60 192.168.137.70)
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh ${node_ip} "ping -c 3 10.30.96.2"
ssh ${node_ip} "ping -c 3 10.30.101.2"
ssh ${node_ip} "ping -c 3 10.30.48.2"
done
# chmod +x /opt/k8s/script/check_pod.sh && /opt/k8s/script/check_pod.sh
检查服务IP和端口可达性
[root@master ~]# kubectl get svc |grep nginx-ds
nginx-ds NodePort 10.96.204.182 <none> 80:715/TCP 18m
可见:
-
Service Cluster IP:10.96.204.182
-
服务端口:80
-
NodePort 端口:715
在所有 Node 上 curl Service IP:->这里不能用脚本,直接在node上面执行
# vim /opt/k8s/script/node_curl_ServiceIP.sh
NODE_IPS=(192.168.137.50 192.168.137.60 192.168.137.70)
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh ${node_ip} "curl -s 10.96.204.182"
done
# chmod +x /opt/k8s/script/node_curl_ServiceIP.sh && /opt/k8s/script/node_curl_ServiceIP.sh
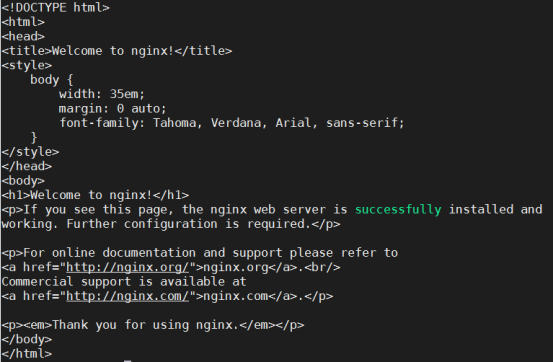
预期输出 nginx 欢迎页面内容。
检查服务的 NodePort 可达性
在所有 Node 上执行:->这里不能用脚本,直接在node上面执行
NODE_IPS=(192.168.137.50 192.168.137.60 192.168.137.70)
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh ${node_ip} "curl -s ${node_ip}:715"
done
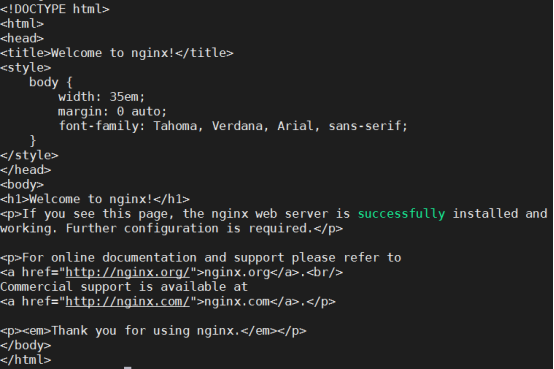
预期输出 nginx 欢迎页面内容
部署集群插件
插件是集群的附件组件,丰富和完善了集群的功能。
注意:
- kuberntes 自带插件的 manifests yaml 文件使用 gcr.io 的 docker registry,国内被墙,需要手动替换为其它 registry 地址(本文档未替换)
部署coredns 插件
CoreDNS的github地址:https://github.com/coredns/
下载地址1:
wget https://github.com/coredns/deployment/archive/master.zip
unzip master.zip
下载地址2:
git clone https://github.com/coredns/deployment.git
三方参考:
https://www.jianshu.com/p/e7ea9e0e690b
https://jimmysong.io/posts/configuring-kubernetes-kube-dns/
https://blog.51cto.com/ylw6006/2108426
https://blog.51cto.com/michaelkang/2367800
参考
-
https://community.infoblox.com/t5/Community-Blog/CoreDNS-for-Kubernetes-Service-Discovery/ba-p/8187
-
https://coredns.io/2017/03/01/coredns-for-kubernetes-service-discovery-take-2/
-
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns
-
https://github.com/opsnull/follow-me-install-kubernetes-cluster/blob/master/09-1.dns%E6%8F%92%E4%BB%B6.md
CoreDNS简介
CoreDNS 其实就是一个 DNS 服务,而 DNS 作为一种常见的服务发现手段,所以很多开源项目以及工程师都会使用 CoreDNS 为集群提供服务发现的功能,Kubernetes 就在集群中使用 CoreDNS 解决服务发现的问题。
如果想要在分布式系统实现服务发现的功能,CoreDNS 其实是一个非常好的选择,CoreDNS作为一个已经进入CNCF并且在Kubernetes中作为DNS服务使用的应用,其本身的稳定性和可用性已经得到了证明,同时它基于插件实现的方式非常轻量并且易于使用,插件链的使用也使得第三方插件的定义变得非常的方便
Coredns 架构
整个 CoreDNS 服务都建立在一个使用 Go 编写的 HTTP/2 Web 服务器 Caddy
注意:
-
如果没有特殊指明,本文档的所有操作均在master 节点上执行
-
kuberntes 自带插件的 manifests yaml 文件使用 gcr.io 的 docker registry,国内被墙,需要手动替换为其它 registry 地址(本文档未替换);
-
可以从微软中国提供的 gcr.io (http://mirror.azure.cn/help/gcr-proxy-cache.html)免费代理下载被墙的镜像
解压源码包
将下载的 kubernetes-server-linux-amd64.tar.gz 解压后,再解压其中的 kubernetes-src.tar.gz 文件
[root@master ~]# tar xf /root/kubernetes-server-linux-amd64.tar.gz
[root@master ~]# cd kubernetes
[root@master kubernetes]# tar xf kubernetes-src.tar.gz
修改coredns配置文件
coredns 目录是 cluster/addons/dns/coredns/:
[root@master kubernetes]# cd /root/kubernetes/cluster/addons/dns/coredns/
[root@master coredns]# cp coredns.yaml.base coredns.yaml
修改集群 DNS 域名和DNS服务IP:
tail /opt/k8s/kubelet.config.json #查看DNS域名及ip,在生成kubelet配置文件时会填写
"cgroupDriver": "cgroupfs",
"hairpinMode": "promiscuous-bridge",
"serializeImagePulls": false,
"featureGates": {
"RotateKubeletClientCertificate": true,
"RotateKubeletServerCertificate": true
},
"clusterDomain": "cluster.local",
"clusterDNS": ["10.90.0.2"]
}
#服务网段,部署前路由不可达,部署后集群内路由可达(kube-proxy 保证)
SERVICE_CIDR="10.96.0.0/16"
# 集群 DNS 服务 IP (从 SERVICE_CIDR 中预分配)
export CLUSTER_DNS_SVC_IP="10.96.0.2"
# 集群 DNS 域名(末尾不带点号)
export CLUSTER_DNS_DOMAIN="cluster.local"
[root@master coredns]# sed -i -e "s/__PILLAR__DNS__DOMAIN__/cluster.local/" -e "s/__PILLAR__DNS__SERVER__/10.96.0.2/" -e "s/__PILLAR__DNS__MEMORY__LIMIT__/70Mi/" coredns.yaml
注:
对应的参数:
image: k8s.gcr.io/coredns:1.3.1 #这里已经是最新版本,没有做替换
kubernetes __PILLAR__DNS__DOMAIN__ in-addr.arpa ip6.arpa {
clusterIP: __PILLAR__DNS__SERVER__
limits:
memory: __PILLAR__DNS__MEMORY__LIMIT__ #替换为70Mi
创建coredns
[root@master coredns]# kubectl create -f coredns.yaml
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
service/kube-dns created
验证服务
# kubectl get svc -o wide -n=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kube-dns ClusterIP 10.96.0.2 <none> 53/UDP,53/TCP,9153/TCP 59m k8s-app=kube-dns
# 查看的时候需要等一下,在部署,可以用docker ps 查看是否有容器运行了。镜像名称:k8s.gcr.io/coredns


查看 coredns 详细信息
# kubectl get pods -o wide -n=kube-system

修改 kubelet 启动配置文件-->一定要把这两个参数写正确,否则无法解析
# cat /opt/kubelet/kubelet.service.template
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/opt/lib/kubelet
ExecStart=/opt/k8s/bin/kubelet \
--bootstrap-kubeconfig=/opt/k8s/kubelet-bootstrap.kubeconfig \
--cert-dir=/opt/k8s/cert \
--kubeconfig=/root/.kube/kubectl.kubeconfig \
--config=/opt/k8s/kubelet.config.json \
--hostname-override=##NODE_NAME## \
--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/opt/log/kubernetes \
--v=2 \
#添加内容如下
--cluster-dns=10.96.0.2 \
--cluster-domain=cluster.local.
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
或者直接添加配置到 /etc/systemd/system/kubelet.service
--cluster-dns=10.96.0.2 \
--cluster-domain=cluster.local.
重启 kubelet 服务
#重启 kubelet 服务
systemctl daemon-reload
systemctl enable kubelet
systemctl restart kubelet
systemctl status kubelet -l
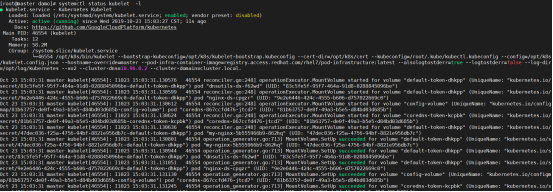
检查 coredns 功能--1
$ kubectl get all -n kube-system
NAME READY STATUS RESTARTS AGE
pod/coredns-867ccfd476-jtcd7 1/1 Running 0 47s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-dns ClusterIP 10.96.0.2 <none> 53/UDP,53/TCP,9153/TCP 37m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/coredns 1/1 1 1 47s
NAME DESIRED CURRENT READY AGE
replicaset.apps/coredns-867ccfd476 1 1 1 47s
新建一个 Deployment
[root@master ~]# cd /opt/k8s/damo/
cat > my-nginx.yaml <<EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx:1.7.9
ports:
- containerPort: 80
EOF
创建应用
kubectl create -f my-nginx.yaml
export 该 Deployment, 生成 my-nginx 服务:
$ kubectl expose deploy my-nginx
service "my-nginx" exposed
# kubectl get services --all-namespaces |grep my-nginx
default my-nginx ClusterIP 10.96.0.195 <none> 80/TCP 2m39s
创建另一个 Pod,查看 /etc/resolv.conf 是否包含 kubelet 配置的 --cluster-dns 和 --cluster-domain,是否能够将服务 my-nginx 解析到上面显示的 Cluster IP 10.96.0.2
[root@master ~]# cd /opt/k8s/damo/
cat > dnsutils-ds.yml <<EOF
apiVersion: v1
kind: Service
metadata:
name: dnsutils-ds
labels:
app: dnsutils-ds
spec:
type: NodePort
selector:
app: dnsutils-ds
ports:
- name: http
port: 80
targetPort: 80
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: dnsutils-ds
labels:
addonmanager.kubernetes.io/mode: Reconcile
spec:
template:
metadata:
labels:
app: dnsutils-ds
spec:
containers:
- name: my-dnsutils
image: tutum/dnsutils:latest
command:
- sleep
- "3600"
ports:
- containerPort: 80
EOF
创建应用
# kubectl create -f dnsutils-ds.yml
service/dnsutils-ds created
daemonset.extensions/dnsutils-ds created
验证服务启动成功
[root@master damo]# kubectl get pods -lapp=dnsutils-ds
NAME READY STATUS RESTARTS AGE
dnsutils-ds-f62wd 0/1 ContainerCreating 0 85s
dnsutils-ds-h6d5s 0/1 ContainerCreating 0 85s
dnsutils-ds-k64hx 0/1 ContainerCreating 0 85s
[root@master damo]# kubectl get pods -lapp=dnsutils-ds #过一会查看从ContainerCreating变成Running
NAME READY STATUS RESTARTS AGE
dnsutils-ds-f62wd 1/1 Running 0 3m50s
dnsutils-ds-h6d5s 1/1 Running 0 3m50s
dnsutils-ds-k64hx 1/1 Running 0 3m50s
[root@master damo]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
dnsutils-ds NodePort 10.96.135.182 <none> 80:30809/TCP 13m app=dnsutils-ds
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 27h <none>
my-nginx ClusterIP 10.96.0.195 <none> 80/TCP 20m run=my-nginx
nginx-ds NodePort 10.96.1.61 <none> 80:30096/TCP 21h app=nginx-ds
[root@master damo]# kubectl -it exec dnsutils-ds-f62wd bash
root@dnsutils-ds-f62wd:/# cat /etc/resolv.conf
nameserver 10.96.0.2
search default.svc.cluster.local. svc.cluster.local. cluster.local.
options ndots:5
root@dnsutils-ds-f62wd:/#
$ kubectl exec dnsutils-ds-f62wd nslookup kubernetes
Server: 10.96.0.2
Address: 10.96.0.2#53
Name: kubernetes.default.svc.cluster.local
Address: 10.96.0.1
$ kubectl exec dnsutils-ds-f62wd nslookup www.baidu.com
Server: 10.96.0.2
Address: 10.96.0.2#53
Non-authoritative answer:
www.baidu.com canonical name = www.a.shifen.com.
www.a.shifen.com canonical name = www.wshifen.com.
Name: www.wshifen.com
Address: 103.235.46.39
$ kubectl exec dnsutils-ds-f62wd nslookup my-nginx
Server: 10.96.0.2
Address: 10.96.0.2#53
Name: my-nginx.default.svc.cluster.local
Address: 10.96.0.195
$ kubectl exec dnsutils-ds-f62wd nslookup kube-dns.kube-system.svc.cluster
Server: 10.96.0.2
Address: 10.96.0.2#53
**server can't find kube-dns.kube-system.svc.cluster: NXDOMAIN
command terminated with exit code 1
$ kubectl exec dnsutils-ds-f62wd nslookup kube-dns.kube-system.svc
Server: 10.96.0.2
Address: 10.96.0.2#53
Name: kube-dns.kube-system.svc.cluster.local
Address: 10.96.0.2
# kubectl exec dnsutils-ds-f62wd nslookup kube-dns.kube-system.svc.cluster.local
Server: 10.96.0.2
Address: 10.96.0.2#53
Name: kube-dns.kube-system.svc.cluster.local
Address: 10.96.0.2
$ kubectl exec dnsutils-ds-f62wd nslookup kube-dns.kube-system.svc.cluster.local.
Server: 10.96.0.2
Address: 10.96.0.2#53
Name: kube-dns.kube-system.svc.cluster.local
Address: 10.96.0.2
登陆curl镜像 (node节点执行)
验证外网解析
[root@master ~]# kubectl exec -it dnsutils-ds-f62wd sh
# ping qq.com

测试DNS解析--2
启动 nginx 测试服务
kubectl run nginx --replicas=2 --image=nginx:alpine --port=80
kubectl expose deployment nginx --type=NodePort --name=example-service-nodeport
kubectl expose deployment nginx --name=example-service
启动一个工具镜像
kubectl run curl --image=radial/busyboxplus:curl
验证服务启动成功
# kubectl get pods -o wide|egrep "(curl|^nginx)"
curl-6d46987fdc-7mwnh 0/1 Completed 4 119s 10.30.65.5 node01 <none> <none>
nginx-765597756c-ddw55 1/1 Running 0 3m16s 10.30.57.6 master <none> <none>
nginx-765597756c-phkzx 1/1 Running 0 3m16s 10.30.65.4 node01 <none> <none>

登陆curl镜像 (node节点执行)
验证外网解析
# docker exec -it a331fd0310fb sh
/ # ping qq.com
验证内部解析:
/ # nslookup kubernetes
清理服务
# kubectl get svc
# kubectl delete svc example-service example-service-nodeport
service "example-service" deleted
service "example-service-nodeport" deleted
删除部署空间
# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
curl 0/1 1 0 13m
my-nginx 2/2 2 2 83m
nginx 2/2 2 2 14m
# kubectl delete deploy nginx curl
deployment.extensions "nginx" deleted
deployment.extensions "curl" deleted
删除 coredns执行如下操作
# kubectl get svc
# kubectl delete svc kube-dns -n=kube-system
部署 dashboard 插件
注意:要用火狐浏览器打开,其他浏览器打不开的!
参考
-
https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/
-
https://github.com/kubernetes/dashboard/wiki/Accessing-Dashboard---1.7.X-and-above
注意:
-
如果没有特殊指明,本文档的所有操作均在master 节点上执行;
-
kuberntes 自带插件的 manifests yaml 文件使用 gcr.io 的 docker registry,国内被墙,需要手动替换为其它 registry 地址(本文档未替换);
-
可以从微软中国提供的 gcr.io 免费代理(http://mirror.azure.cn/help/gcr-proxy-cache.html)下载被墙的镜像
解压源码包
将下载的 kubernetes-server-linux-amd64.tar.gz 解压后,再解压其中的 kubernetes-src.tar.gz 文件
[root@master ~]# tar xf /root/kubernetes-server-linux-amd64.tar.gz
[root@master ~]# cd kubernetes
[root@master kubernetes]# tar xf kubernetes-src.tar.gz
修改dashboard 配置文件
dashboard 对应的目录是:cluster/addons/dashboard:
[root@master kubernetes]# cd /root/kubernetes/cluster/addons/dashboard/
[root@master dashboard]# cp dashboard-service.yaml dashboard-service.yaml.bak
修改 service 定义,指定端口类型为 NodePort,这样外界可以通过地址 NodeIP:NodePort 访问 dashboard:
[root@master dashboard]# vim dashboard-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort # 增加这一行
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 443
targetPort: 8443
执行所有定义文件
[root@master dashboard]# kubectl apply -f .
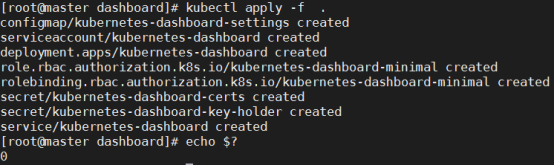
查看分配的 NodePort
[root@master dashboard]# kubectl get deployment kubernetes-dashboard -n kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard 1 1 1 1 2m
# kubectl --namespace kube-system get pods -o wide

[root@master dashboard]# kubectl get services kubernetes-dashboard -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.96.243.236 <none> 443:31077/TCP 4m22s
- NodePort 31077映射到 dashboard pod 443 端口
查看 dashboard 支持的命令行参数
# kubectl exec --namespace kube-system -it kubernetes-dashboard-66b96fb8d7-xttrf -- /dashboard --help #kubernetes-dashboard-66b96fb8d7-xttrf 为 pod 名称
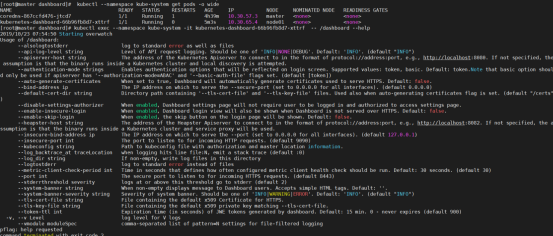
说明:dashboard 的 --authentication-mode 支持 token、basic,默认为 token。如果使用 basic,则 kube-apiserver 必须配置 --authorization-mode=ABAC 和 --basic-auth-file 参数
访问 dashboard
从 1.7 开始,dashboard 只允许通过 https 访问,如果使用 kube proxy 则必须监听 localhost 或 127.0.0.1。对于 NodePort 没有这个限制,但是仅建议在开发环境中使用。
对于不满足这些条件的登录访问,在登录成功后浏览器不跳转,始终停在登录界面。
-
kubernetes-dashboard 服务暴露了 NodePort,可以使用 https://NodeIP:NodePort 地址访问 dashboard;
-
通过 kube-apiserver 访问 dashboard;
-
通过 kubectl proxy 访问 dashboard
通过 kubectl proxy 访问 dashboard
启动代理:
# kubectl proxy --address='localhost' --port=8086 --accept-hosts='^*$'
Starting to serve on 127.0.0.1:8086

-
--address 必须为 localhost 或 127.0.0.1;
-
需要指定 --accept-hosts 选项,否则浏览器访问 dashboard 页面时提示 "Unauthorized"
访问 URL:
http://127.0.0.1:8086/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy

通过NodePort访问dashboard
获取集群服务地址列表:
[root@master ~]# kubectl cluster-info
Kubernetes master is running at https://127.0.0.1:8443
CoreDNS is running at https://127.0.0.1:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubernetes-dashboard is running at https://127.0.0.1:8443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'
Kubernetes master is running at https://192.168.137.50:6443
CoreDNS is running at https://192.168.137.50:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubernetes-dashboard is running at https://192.168.137.50:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
-
由于 apiserver 通过本地的 kube-nginx 做了代理,所以上面显示的 127.0.0.1:8443 为本地的 kube-nginx 的 IP 和 Port,浏览器访问时需要替换为 kube-apiserver 实际监听的 IP 和端口,如 172.27.137.240:6443;
-
必须通过 kube-apiserver 的安全端口(https)访问 dashbaord,访问时浏览器需要使用自定义证书,否则会被 kube-apiserver 拒绝访问。
浏览器访问 URL:https://192.168.137.50:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
但是我们没有做映射,所有是无法访问的,以此,我们查看dashboard的外网访问端口
获取dashboard的外网访问端口:
[root@master ~]# kubectl -n kube-system get svc kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.96.243.236 <none> 443:31077/TCP 29m
外网IP地址:31077
访问外网ip+端口:
创建登录 Dashboard 的 token 和 kubeconfig 配置文件
dashboard 默认只支持 token 认证(不支持 client 证书认证),所以如果使用 Kubeconfig 文件,需要将 token 写入到该文件
创建登录 token
[root@master ~]# kubectl create sa dashboard-admin -n kube-system
serviceaccount/dashboard-admin created
[root@master ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created
[root@master ~]# ADMIN_SECRET=$(kubectl get secrets -n kube-system | grep dashboard-admin | awk '{print $1}')
[root@master ~]# DASHBOARD_LOGIN_TOKEN=$(kubectl describe secret -n kube-system ${ADMIN_SECRET} | grep -E '^token' | awk '{print $2}')
[root@master ~]# echo ${DASHBOARD_LOGIN_TOKEN}

使用输出的 token 登录 Dashboard
创建使用 token 的 KubeConfig 文件
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/cert/ca.pem \
--embed-certs=true \
--server=https://192.168.137.10:8443 \
--kubeconfig=/root/.kube/dashboard.kubeconfig
说明:KUBE_APISERVER
# kube-apiserver 的反向代理(kube-nginx)地址端口
export KUBE_APISERVER="https://127.0.0.1:8443"
# 设置客户端认证参数,使用上面创建的 Token
kubectl config set-credentials dashboard_user \
--token=${DASHBOARD_LOGIN_TOKEN} \
--kubeconfig=/root/.kube/dashboard.kubeconfig
说明:${DASHBOARD_LOGIN_TOKEN}->表示生成的token
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=dashboard_user \
--kubeconfig=/root/.kube/dashboard.kubeconfig
# 设置默认上下文
kubectl config use-context default --kubeconfig=/root/.kube/dashboard.kubeconfig
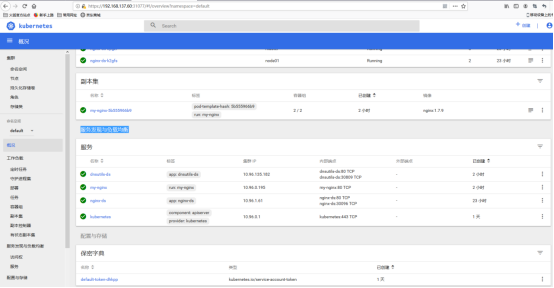
由于缺少 Heapster 插件,当前 dashboard 不能展示 Pod、Nodes 的 CPU、内存等统计数据和图表
部署heapster插件
https://jimmysong.io/kubernetes-handbook/practice/heapster-addon-installation.html
从 Kubernetes 1.12 开始,kubernetes 的安装脚本移除了 Heapster,从1.13 开始完全移除了对 Heapster 的支持,Heapster 不再被维护。
部署 metrics-server 插件
GitHub地址:https://github.com/kubernetes-incubator/metrics-server
GitHub地址:https://github.com/kubernetes-sigs/metrics-server
注意:
-
如果没有特殊指明,本文档的所有操作均在master节点上执行;
-
kuberntes 自带插件的 manifests yaml 文件使用 gcr.io 的 docker registry,国内被墙,需要手动替换为其它 registry 地址(本文档未替换);
-
可以从微软中国提供的 gcr.io 免费代理下载被墙的镜像;
metrics-server 通过 kube-apiserver 发现所有节点,然后调用 kubelet APIs(通过 https 接口)获得各节点(Node)和 Pod 的 CPU、Memory 等资源使用情况。
从 Kubernetes 1.12 开始,kubernetes 的安装脚本移除了 Heapster,从1.13 开始完全移除了对 Heapster 的支持,Heapster 不再被维护。
替代方案如下:
-
用于支持自动扩缩容的 CPU/memory HPA metrics:metrics-server;
-
通用的监控方案:使用第三方可以获取 Prometheus 格式监控指标的监控系统,如 Prometheus Operator;
-
事件传输:使用第三方工具来传输、归档 kubernetes events;
Kubernetes Dashboard 还不支持 metrics-server(PR:#3504),如果使用 metrics-server 替代 Heapster,将无法在 dashboard 中以图形展示 Pod 的内存和 CPU 情况,需要通过 Prometheus、Grafana 等监控方案来弥补
监控架构
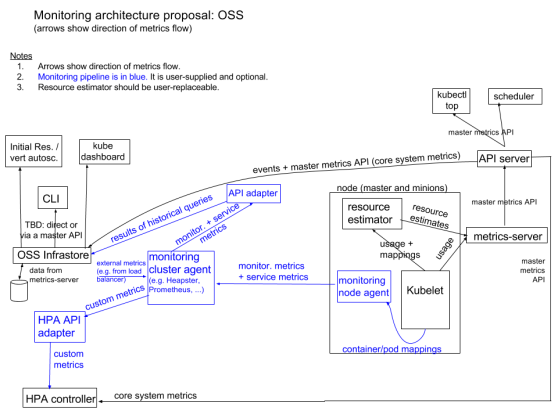
安装 metrics-server
从 github clone 源码:
[root@master ~]# mkdir /opt/metrics-server
[root@master ~]# cd /opt/metrics-server/
[root@master metrics-server]# git clone https://github.com/kubernetes-incubator/metrics-server.git
[root@master metrics-server]# cd metrics-server/deploy/1.8+/
[root@master 1.8+]# ls
aggregated-metrics-reader.yaml auth-delegator.yaml auth-reader.yaml metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml
修改 metrics-server-deployment.yaml 文件,为 metrics-server 添加三个命令行参数
# vim metrics-server-deployment.yaml
containers:
- name: metrics-server
image: k8s.gcr.io/metrics-server-amd64:v0.3.6
# image: mirrorgooglecontainers/metrics-server-amd64:v0.3.6
# imagePullPolicy: Always
imagePullPolicy: IfNotPresent
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls #必须加此选项才能启动
- --metric-resolution=30s
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
ports:
- name: main-port
containerPort: 4443
protocol: TCP
volumeMounts:
- name: tmp-dir
mountPath: /tmp
参数解释:
image: k8s.gcr.io/metrics-server-amd64:v0.3.6 #是被墙的镜像,所有需要换源
imagePullPolicy: IfNotPresent #镜像拉取策略,三个选择Always、Never、IfNotPresent,每次启动时检查和更新(registery)images的策略
command:
- /metrics-server
- --kubelet-insecure-tls #添加命令和相关参数
- --metric-resolution=30s
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
--metric-resolution=30s:从 kubelet 采集数据的周期;
--kubelet-preferred-address-types:优先使用 InternalIP 来访问 kubelet,这样可以避免节点名称没有 DNS 解析记录时,通过节点名称调用节点 kubelet API 失败的情况(未配置时默认的情况)
官网修改的两个地方:
部署 metrics-server:
cd /opt/metrics-server/metrics-server/deploy/1.8+
[root@master 1.8+]# kubectl create -f .
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
查看运行情况
[root@master 1.8+]# kubectl -n kube-system get pods -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-6b4d758d5b-b2rsf 1/1 Running 0 17m
[root@master 1.8+]# kubectl get svc -n kube-system metrics-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP 10.96.64.233 <none> 443/TCP 17m
metrics-server 的命令行参数
$ docker run -it --rm k8s.gcr.io/metrics-server-amd64:v0.3.3 --help
使用 kubectl top 命令查看集群节点资源、pod使用情况
kubectl top 命令从 metrics-server 获取集群节点基本的指标信息:
# kubectl top
Display Resource (CPU/Memory/Storage) usage.
The top command allows you to see the resource consumption for nodes or pods.
This command requires Heapster to be correctly configured and working on the server.
Available Commands:
node Display Resource (CPU/Memory/Storage) usage of nodes
pod Display Resource (CPU/Memory/Storage) usage of pods
Usage:
kubectl top [flags] [options]
Use "kubectl <command> --help" for more information about a given command.
Use "kubectl options" for a list of global command-line options (applies to all commands)
# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 305m 7% 3808Mi 24%
node01 271m 6% 6101Mi 91%
node02 451m 11% 5784Mi 76%
# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
k8s-nginx-6d4fd7cb76-dwfhc 0m 88Mi
部署EFK插件
解压源码包
将下载的 kubernetes-server-linux-amd64.tar.gz 解压后,再解压其中的 kubernetes-src.tar.gz 文件
[root@master ~]# tar xf /root/kubernetes-server-linux-amd64.tar.gz
[root@master ~]# cd kubernetes
[root@master kubernetes]# tar xf kubernetes-src.tar.gz
修改配置文件
EFK 目录是 kubernetes/cluster/addons/fluentd-elasticsearch
[root@master kubernetes]# cd /root/kubernetes/cluster/addons/fluentd-elasticsearch/
[root@master fluentd-elasticsearch]# cp fluentd-es-ds.yaml fluentd-es-ds.yaml.orig
[root@master fluentd-elasticsearch]# vim fluentd-es-ds.yaml #修改为你部署docker的数据目录
- name: varlibdockercontainers
hostPath:
path: /data/k8s/docker/data/containers
执行定义文件
[root@master fluentd-elasticsearch]# kubectl apply -f .
service/elasticsearch-logging created
serviceaccount/elasticsearch-logging created
clusterrole.rbac.authorization.k8s.io/elasticsearch-logging created
clusterrolebinding.rbac.authorization.k8s.io/elasticsearch-logging created
statefulset.apps/elasticsearch-logging created
configmap/fluentd-es-config-v0.2.0 created
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
daemonset.apps/fluentd-es-v2.5.2 created
deployment.apps/kibana-logging created
service/kibana-logging created
检查执行结果
[root@master fluentd-elasticsearch]# kubectl get pods -n kube-system -o wide|grep -E 'elasticsearch|fluentd|kibana'
elasticsearch-logging-0 0/1 Init:0/1 0 51s <none> node02 <none> <none>
fluentd-es-v2.5.2-ffcdv 0/1 ImagePullBackOff 0 51s 10.30.56.8 node02 <none> <none>
fluentd-es-v2.5.2-hdffr 0/1 ImagePullBackOff 0 51s 10.30.65.7 node01 <none> <none>
kibana-logging-889fccc88-jj7ff 0/1 ContainerCreating 0 51s <none> node02 <none> <none>

[root@master fluentd-elasticsearch]# kubectl get service -n kube-system|grep -E 'elasticsearch|kibana'
elasticsearch-logging ClusterIP 10.96.172.54 <none> 9200/TCP 110s
kibana-logging ClusterIP 10.96.210.10 <none> 5601/TCP 110s
kibana Pod 第一次启动时会用**较长时间(0-20分钟)**来优化和 Cache 状态页面,可以 tailf 该 Pod 的日志观察进度:
[root@master fluentd-elasticsearch]# kubectl logs kibana-logging-889fccc88-jj7ff -n kube-system -f
注意:只有当 Kibana pod 启动完成后,浏览器才能查看 kibana dashboard,否则会被拒绝
访问 kibana
1、通过 kube-apiserver 访问:
[root@master ~]# kubectl cluster-info|grep -E 'Elasticsearch|Kibana'
Elasticsearch is running at https://192.168.137.50:6443/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
Kibana is running at https://192.168.137.50:6443/api/v1/namespaces/kube-system/services/kibana-logging/proxy
浏览器访问 URL: https://192.168.137.50:6443/api/v1/namespaces/kube-system/services/kibana-logging/proxy

2、通过 kubectl proxy 访问:
创建代理
# kubectl proxy --address='192.168.137.50' --port=8086 --accept-hosts='^*$'
Starting to serve on 192.168.137.50:8086
浏览器访问 URL:http://192.168.137.50:8086/api/v1/namespaces/kube-system/services/kibana-logging/proxy
部署 harbor 私有仓库
使用 docker-compose 部署 harbor 私有仓库的步骤,你也可以使用 docker 官方的 registry 镜像部署私有仓库
使用的变量
# 当前部署 harbor 的节点 IP
export NODE_IP=192.168.137.50
下载文件
从 docker compose 发布页面 下载最新的 docker-compose 二进制文件
发布页面地址:https://github.com/docker/compose/releases
# wget https://github.com/docker/compose/releases/download/1.21.2/docker-compose-Linux-x86_64
# mv ./docker-compose-Linux-x86_64 /opt/k8s/bin/docker-compose
# chmod a+x /opt/k8s/bin/docker-compose
# export PATH=/opt/k8s/bin:$PATH
从 harbor 发布页面下载最新的 harbor 离线安装包
发布页面地址:https://github.com/goharbor/harbor/releases
# wget --continue https://storage.googleapis.com/harbor-releases/release-1.5.0/harbor-offline-installer-v1.5.1.tgz
# tar -xzvf harbor-offline-installer-v1.5.1.tgz
导入 docker images
# cd harbor
[root@master harbor]# ls
common docker-compose.clair.yml docker-compose.notary.yml docker-compose.yml ha harbor.cfg harbor.v1.5.1.tar.gz install.sh LICENSE NOTICE prepare
# docker load -i harbor.v1.5.1.tar.gz #或者执行install.sh脚本
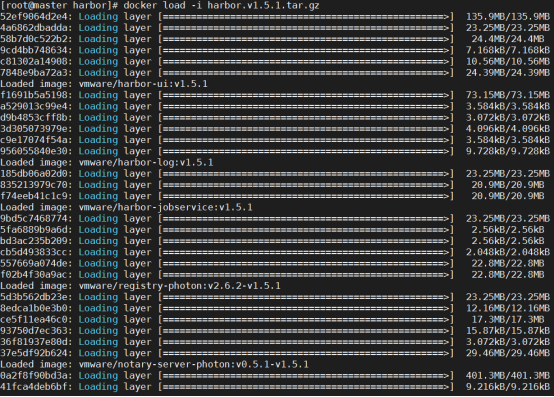
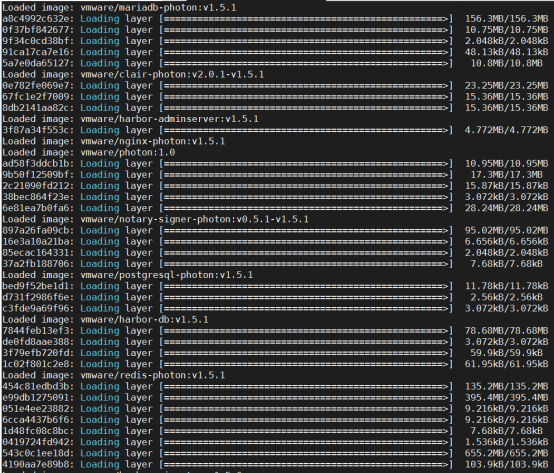
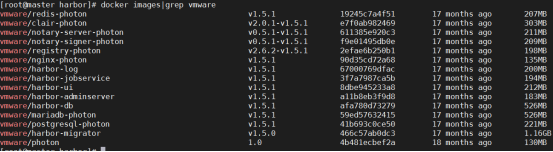
创建 harbor nginx 服务器使用的 x509 证书
创建 harbor 证书签名请求:
# cd /opt/k8s/cert/
cat > harbor-csr.json <<EOF
{
"CN": "harbor",
"hosts": [
"127.0.0.1",
"${NODE_IP}"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "4Paradigm"
}
]
}
EOF
- hosts 字段指定授权使用该证书的当前部署节点 IP,如果后续使用域名访问 harbor 则还需要添加域名
生成 harbor 证书和私钥:
# cfssl gencert -ca=/opt/k8s/cert/ca.pem \
-ca-key=/opt/k8s/cert/ca-key.pem \
-config=/opt/k8s/cert/ca-config.json \
-profile=kubernetes harbor-csr.json | cfssljson -bare harbor
# ls harbor*
harbor.csr harbor-csr.json harbor-key.pem harbor.pem
# mkdir -p /etc/harbor/ssl
# mv harbor*.pem /etc/harbor/ssl
# rm harbor.csr harbor-csr.json #可删可不删
修改 harbor.cfg 文件
# cd /root/harbor
# cp harbor.cfg{,.bak}
# diff harbor.cfg{,.bak} #修改如下
7c7
< hostname = 192.168.137.50
---
> hostname = reg.mydomain.com
11c11
< ui_url_protocol = https
---
> ui_url_protocol = http
23,24c23,24
< ssl_cert = /etc/harbor/ssl/harbor.pem
< ssl_cert_key = /etc/harbor/ssl/harbor-key.pem
---
> ssl_cert = /data/cert/server.crt
> ssl_cert_key = /data/cert/server.key
27c27
< secretkey_path = /harbor_data
---
> secretkey_path = /data
# vim prepare
root@master harbor]# diff prepare{,.bak}
490c490
< empty_subj = "/"
---
> empty_subj = "/C=/ST=/L=/O=/CN=/"
- 需要修改 prepare 脚本的 empyt_subj 参数,否则后续 install 时出错退出:
Fail to generate key file: ./common/config/ui/private_key.pem, cert file: ./common/config/registry/root.crt
参考:https://github.com/vmware/harbor/issues/2920
加载和启动 harbor 镜像
# cd /root/harbor
# mkdir /harbor_data/
# chmod 777 /run/docker.sock /harbor_data/
# yum install python
# ./install.sh #总共有四步
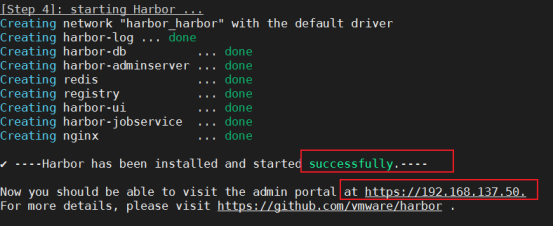
访问管理界面
确认所有组件都工作正常:8个组件

浏览器访问 https://${NODE_IP}
用账号 admin 和 harbor.cfg 配置文件中的默认密码 Harbor12345 登陆系统
harbor 运行时产生的文件、目录
harbor 将日志打印到 /var/log/harbor 的相关目录下,使用 docker logs XXX 或 docker-compose logs XXX 将看不到容器的日志
$ # 日志目录
$ ls /var/log/harbor
adminserver.log jobservice.log mysql.log proxy.log registry.log ui.log
# 数据目录,包括数据库、镜像仓库
# ls /harbor_data
ca_download config database job_logs registry secretkey
Harbor的默认镜像存储路径在/data/registry目录下,映射到docker容器里面的/storage目录下。
这个参数是在docker-compose.yml中指定的,在docker-compose up -d运行之前修改。
如果希望将Docker镜像存储到其他的磁盘路径,可以修改这个参数
docker 客户端登陆
将签署 harbor 证书的 CA 证书拷贝到 /etc/docker/certs.d/172.27.129.81 目录下
# mkdir -p /etc/docker/certs.d/192.168.137.50
# cp /opt/k8s/cert/ca.pem /etc/docker/certs.d/192.168.137.50/ca.crt
登陆 harbor:
# docker login 192.168.167.50
Username: admin
Password:
认证信息自动保存到 ~/.docker/config.json 文件
其它操作
下列操作的工作目录均为 解压离线安装文件后 生成的 harbor 目录
# cd /root/harbor #必须进入这个工作目录
# docker-compose down -v
# 更修改的配置更新到 docker-compose.yml 文件
# vim harbor.cfg
# 更修改的配置更新到 docker-compose.yml 文件
# ./prepare
# chmod -R 666 common ## 防止容器进程没有权限读取生成的配置,不行在修改
# 启动 harbor
# docker-compose up -d
清理集群
清理 Node 节点
停相关进程:
$ sudo systemctl stop kubelet kube-proxy flanneld docker kube-proxy kube-nginx
清理文件:
$ source /opt/k8s/bin/environment.sh
$ # umount kubelet 和 docker 挂载的目录
$ mount | grep "${K8S_DIR}" | awk '{print $3}'|xargs sudo umount
$ # 删除 kubelet 工作目录
$ sudo rm -rf ${K8S_DIR}/kubelet
$ # 删除 docker 工作目录
$ sudo rm -rf ${DOCKER_DIR}
$ # 删除 flanneld 写入的网络配置文件
$ sudo rm -rf /var/run/flannel/
$ # 删除 docker 的一些运行文件
$ sudo rm -rf /var/run/docker/
$ # 删除 systemd unit 文件
$ sudo rm -rf /etc/systemd/system/{kubelet,docker,flanneld,kube-nginx}.service
$ # 删除程序文件
$ sudo rm -rf /opt/k8s/bin/*
$ # 删除证书文件
$ sudo rm -rf /etc/flanneld/cert /etc/kubernetes/cert
清理 kube-proxy 和 docker 创建的 iptables:
$ sudo iptables -F && sudo iptables -X && sudo iptables -F -t nat && sudo iptables -X -t nat
删除 flanneld 和 docker 创建的网桥:
$ ip link del flannel.1
$ ip link del docker0
清理 Master 节点
停相关进程:
$ sudo systemctl stop kube-apiserver kube-controller-manager kube-scheduler kube-nginx
清理文件:
$ # 删除 systemd unit 文件
$ sudo rm -rf /etc/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler,kube-nginx}.service
$ # 删除程序文件
$ sudo rm -rf /opt/k8s/bin/{kube-apiserver,kube-controller-manager,kube-scheduler}
$ # 删除证书文件
$ sudo rm -rf /etc/flanneld/cert /etc/kubernetes/cert
清理 etcd 集群
停相关进程:
$ sudo systemctl stop etcd
清理文件:
$ source /opt/k8s/bin/environment.sh
$ # 删除 etcd 的工作目录和数据目录
$ sudo rm -rf ${ETCD_DATA_DIR} ${ETCD_WAL_DIR}
$ # 删除 systemd unit 文件
$ sudo rm -rf /etc/systemd/system/etcd.service
$ # 删除程序文件
$ sudo rm -rf /opt/k8s/bin/etcd
$ # 删除 x509 证书文件
$ sudo rm -rf /etc/etcd/cert/*
二进制部署kubernetes多主多从集群
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。