- MySQL备份与还原操作(重点)
- Xtrabackup备份及恢复
- Xtrabackup完全备份+两次增量备份
- MySQL不停机维护主从同步
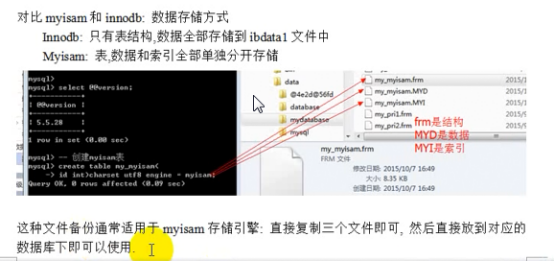
- MySql5.7从.frm和.ibd文件恢复数据
- 删库不跑路:论MySQL数据恢复
- MySQL的Gtid同步
- MySQL主从复制(重点)
- MySQL的读写分离Amoeba(已经没有维护了,建议不用)
- MySQL-MMM高可用集群(线上建议不用)
- MySQL-MHA高可用(线上建议使用)
- MySQL高可用之PXC
- Mycat中间件实现Mysql数据分片(之一)
- Mysql+haproxy+mycat+pxc+zookeeper实现高可用集群
- MySQL Router 高可用原理与实战
- MySQL监控
- 架构扩展方案
- MySQL进行压测
- MYSQL 开源SQL语句审核平台
- Archery
- MySQL 导致 CPU 消耗过大,如何优化
MySQL备份与还原操作(重点)
备份:将当前已有的数据或者记录保留
还原:将已经保留的数据恢复到对应的表中
为什么需要备份数据?

具体了解一下为什么要备份数据:在生产环境中我们数据库可能会遭遇各种各样的不测从而导致数据丢失, 大概分为以下几种.
-
硬件故障
-
软件故障
-
自然灾害
-
黑客攻击
-
误操作 (占比最大)
-
保护数据记录(利用数据,进行分析数据
->为什么销户等原因)
所以, 为了在数据丢失之后能够恢复数据, 我们就需要定期的备份数据, 备份数据的策略要根据不同的应用场景进行定制, 大致有几个参考数值, 我们可以根据这些数值从而定制符合特定环境中的数据备份策略
-
能够容忍丢失多少数据
-
恢复数据需要多长时间
-
需要恢复哪一些数据
企业应用
企业场景全量和增量的频率
1、中小公司,全量一般每天一次,业务流量低谷进行,备份时锁表
增量:定时,例如每分钟rsync推一次binlog
2、大公司,一般周备,节省备份时间,减小备份压力,缺点是binlog文件副本太多,还原比较麻烦
3、一主多从环境,主从复制本身就是实时远程备份,可以解决物理故障
4、一主多从环境,可以采取一个从库上专门进行备份,通过延时同步解决人为误操作
MySQL备份类型
根据服务器状态
Hot backup:热备
-
在数据库运行的过程中,进行备份[虽然可以实现备份]
-
数据库的读写不受影响;但是读写效率明显很低[一般都将其排程到凌晨执行]
Cold backup:冷备
-
在数据库停止运行的情况下,进行备份
-
相对安全,离线备份;读、写操作均中止;但是无法正常运行数据库
Warm backup:温备
-
备份时,同样是在数据库运行的情况下,仅可以执行读操作;但对于当前数据库的操作有一定影响。会以一个全局读锁保证备份数据的一致性
-
锁:为了保证数据的完整性和一致性,通过事务的隔离性实现的一种数据分割的过程
从对象来分
从物理与逻辑角度,可以将备份分为:
A、物理备份:->直接复制(归档)数据文件的备份方式
-
冷备份
-
热备份
B、逻辑备份:->把数据从库中提取出来保存为文本文件
将对数据库逻辑组件(如表等数据库对象)的备份->将数据导出至文本文件中
逻辑备份
逻辑备份的优点:
-
在备份速度上两种备份要取决于不同的存储引擎
-
物理备份的还原速度非常快。但是物理备份的最小力度只能做到表
-
逻辑备份保存的结构通常都是纯ASCII的,所以我们可以使用文本处理工具来处理
-
逻辑备份有非常强的兼容性,而物理备份则对版本要求非常高
-
逻辑备份也对保持数据的安全性有保证

逻辑备份的缺点:
-
逻辑备份要对RDBMS产生额外的压力,而裸备份无压力
-
逻辑备份的结果可能要比源文件更大。所以很多人都对备份的内容进行压缩
-
逻辑备份可能会丢失浮点数的精度信息

物理备份



从数据收集来分
也可以说从备份策略上讲:
A、完全备份:每次对数据库进行完整的备份[包括所有的数据文件]
B、差异备份:以完全备份作为基础,备份那些自从上次完全备份之后,又被修改过的文件
C、增量备份:仅仅只有上次完全备份或者增量备份以后被修改的文件才做备份
完全备份:[相当于'冷备份'],会对整个数据进行备份(数据库的结构和数据文件的类型以及数据文件结构的备份)
注意:完全备份可以保存上一时刻的完整数据,完全备份是差异备份的基础
优点:备份与恢复简单
缺点:
A、数据存储量比较大,且备份的内容有重复
B、占用数据备份空间
C、备份和恢复时间较长
说明,差异备份要比增量备份占用的空间大,但恢复时比较方便!但我们一般都用增量备份!
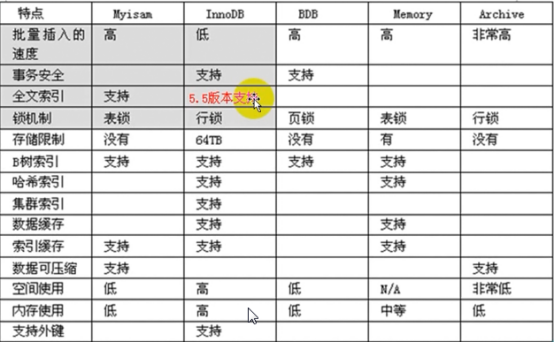
MySQL中进行不同方式的备份还要考虑存储引擎是否支持
- MyISAM
热备 ×
温备 √
冷备 √
- InnoDB
热备 √
温备 √
冷备 √
我们在考虑完数据在备份时, 数据库的运行状态之后还需要考虑对于MySQL数据库中数据的备份方式
- 物理备份
- 逻辑备份
物理备份一般就是通过
tar,cp等命令直接打包复制数据库的数据文件达到备份的效果逻辑备份一般就是通过特定工具从数据库中导出数据并另存备份(逻辑备份会丢失数据精度)
备份需要考虑的问题,定制备份策略前, 我们还需要考虑一些问题
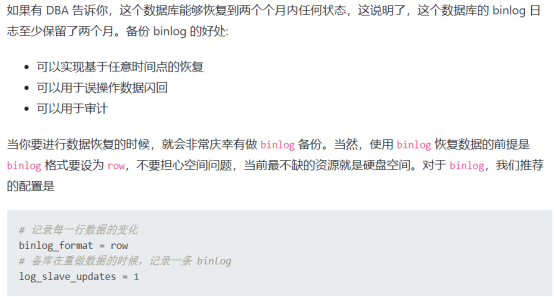
为什么要备份binlog
复制和备份

我们要备份什么?
一般情况下, 我们需要备份的数据分为以下几种
-
数据
-
二进制日志, InnoDB事务日志
-
代码(存储过程、存储函数、触发器、事件调度器)
-
服务器配置文件
MySQL备份策略
1.策略一:直接拷贝数据库文件(文件系统备份工具 cp)(适合小型数据库,是最可靠的)
当你使用直接备份方法时,必须保证表不在被使用。如果服务器在你正在拷贝一个表时改变它,拷贝就失去意义。保证你的拷贝完整性的最好方法是关闭服务器,拷贝文件,然后重启服务器。如果你不想关闭服务器,要在执行表检查的同时锁定服务器。如果服务器在运行,相同的制约也适用于拷贝文件,而且你应该使用相同的锁定协议让服务器"安静下来"。当你完成了备份时,需要重启服务器(如果关闭了它)或释放加在表上的锁定(如果你让服务器运行)。要用直接拷贝文件把一个数据库从一台机器拷贝到另一台机器上,只是将文件拷贝到另一台服务器主机的适当数据目录下即可。要确保文件是MyIASM格式或两台机器有相同的硬件结构,否则你的数据库在另一台主机上有奇怪的内容。你也应该保证在另一台机器上的服务器在你正在安装数据库表时不访问它们。
2.策略二:mysqldump备份数据库(完全备份+增加备份,速度相对较慢,适合中小型数据库)(MyISAM是温备份,InnoDB是热备份)
mysqldump 是采用SQL级别的备份机制,它将数据表导成 SQL 脚本文件,在不同的 MySQL 版本之间升级时相对比较合适,这也是最常用的备份方法。mysqldump 比直接拷贝要慢些。对于中等级别业务量的系统来说,备份策略可以这么定:第一次完全备份,每天一次增量备份,每周再做一次完全备份,如此一直重复。而对于重要的且繁忙的系统来说,则可能需要每天一次全量备份,每小时一次增量备份,甚至更频繁。为了不影响线上业务,实现在线备份,并且能增量备份,最好的办法就是采用主从复制机制(replication),在 slave 机器上做备份。
3.策略三:lvs快照从物理角度实现几乎热备的完全备份,配合二进制日志备份实现增量备份,速度快适合比较烦忙的数据库
前提:
-
数据文件要在逻辑卷上;
-
此逻辑卷所在卷组必须有足够空间使用快照卷;
-
数据文件和事务日志要在同一个逻辑卷上;
策略三步骤:
(1).打开会话,施加读锁,锁定所有表;
mysql> FLUSH TABLES WITH READ LOCK;
mysql> FLUSH LOGS;
(2).通过另一个终端,保存二进制日志文件及相关位置信息;
mysql -uroot -p -e 'SHOW MASTER STATUS\G' > /path/to/master.info
(3).创建快照卷
lvcreate -L -s -p r -n LV_NAME /path/to/source_lv
(4).释放锁
mysql> UNLOCK TABLES;
(5).挂载快照卷,备份
mount
cp
(6).删除快照卷;
或者用现成的集成命令工具mylvmbackup(可以集成上面的命令集合,自动完成备份)
mylvmbackup --user=dba --password=xxx --mycnf=/etc/my.cnf --vgname=testvg --lvname=testlv --backuptype=tar --lvsize=100M --backupdir=/var/lib/backup
4.策略四:xtrabackup备份数据库,实现完全热备份与增量热备份(MyISAM是温备份,InnoDB是热备份),由于有的数据在设计之初,数据目录没有存放在LVM上,所以不能用LVM作备份,则用xtrabackup代替来备份数据库
说明:Xtrabackup是一个对InnoDB做数据备份的工具,支持在线热备份(备份时不影响数据读写),是商业备份工具InnoDB Hotbackup或ibbackup的一个很好的替代品。
Xtrabackup有两个主要的工具:xtrabackup、innobackupex
-
xtrabackup 只能备份InnoDB和XtraDB两种数据表,而不能备份MyISAM数据表。
-
innobackupex 是参考了InnoDB Hotbackup的innoback脚本修改而来的。innobackupex是一个perl脚本封装,封装了xtrabackup。主要是为了方便的同时备份InnoDB和MyISAM引擎的表,但在处理myisam时需要加一个读锁。并且加入了一些使用的选项。如slave-info可以记录备份恢复后作为slave需要的一些信息,根据这些信息,可以很方便的利用备份来重做slave。
特点:
-
备份过程快速、可靠;
-
备份过程不会打断正在执行的事务;
-
能够基于压缩等功能节约磁盘空间和流量;
-
自动实现备份检验;
-
还原速度快;
下载地址:https://www.percona.com
举例:

5.策略五:主从复制(replication)实现数据库实时备份(集群中常用)
常用的备份工具
| 备份方法 | 备份速度 | 恢复速度 | 便捷性 | 功能 | 一般用于 |
|---|---|---|---|---|---|
| cp | 快 | 快 | 一般、灵活性低 | 很弱 | 少量数据备份 |
| mysqldump | 慢 | 慢 | 一般、可无视存储引擎的差异 | 一般 | 中小型数据量的备份 |
| lvm2快照 | 快 | 快 | 一般、支持几乎热备、速度快 | 一般 | 中小型数据量的备份 |
| xtrabackup | 较快 | 较快 | 实现innodb热备、对存储引擎有要求 | 强大 | 较大规模的备份 |
1.Mysql自带的备份工具
-
mysqldump 逻辑备份工具,支持所有引擎,MyISAM引擎是温备,InnoDB引擎是热备,备份速度中速,还原速度非常非常慢,但是在实现还原的时候,具有很大的操作余地。具有很好的弹性。
-
mysqlhotcopy 物理备份工具,但只支持MyISAM引擎,基本上属于冷备的范畴,物理备份,速度比较快。
2.文件系统备份工具
- cp 冷备份,支持所有引擎,复制命令,只能实现冷备,物理备份。使用归档工具,cp命令,对其进行备份的,备份速度快,还原速度几乎最快,但是灵活度很低,可以跨系统,但是跨平台能力很差。
lvm 几乎是热备份,支持所有引擎,基于快照(LVM,ZFS)的物理备份,速度非常快,几乎是热备。只影响数据几秒钟而已。但是创建快照的过程本身就影响到了数据库在线的使用,所以备份速度比较快,恢复速度比较快,没有什么弹性空间,而且LVM的限制:不能对多个逻辑卷同一时间进行备份,所以数据文件和事务日志等各种文件必须放在同一个LVM上。而ZFS则非常好的可以在多逻辑卷之间备份。
3.其它工具
-
ibbackup 商业工具 MyISAM是温备份,InnoDB是热备份 ,备份和还原速度都很快,这个软件它的每服务器授权版本是5000美元。
-
xtrabackup 开源工具 MyISAM是温备份,InnoDB是热备份 ,是ibbackup商业工具的替代工具。
这里我们列举出常用的几种备份工具
- mysqldump : 逻辑备份工具, 适用于所有的存储引擎, 支持温备、完全备份、部分备份、对于InnoDB存储引擎支持热备
- cp, tar 等归档复制工具: 物理备份工具, 适用于所有的存储引擎, 冷备、完全备份、部分备份
- lvm2 snapshot: 几乎热备, 借助文件系统管理工具进行备份
- mysqlhotcopy: 名不副实的的一个工具, 几乎冷备, 仅支持MyISAM存储引擎
- xtrabackup: 一款非常强大的InnoDB/XtraDB热备工具, 支持完全备份、增量备份, 由percona提供
设计合适的备份策略
针对不同的场景下, 我们应该制定不同的备份策略对数据库进行备份, 一般情况下, 备份策略一般为以下三种
-
直接cp,tar复制数据库文件
-
mysqldump+复制BIN LOGS
-
lvm2快照+复制BIN LOGS
-
xtrabackup
以上的几种解决方案分别针对于不同的场景
-
如果数据量较小, 可以使用第一种方式, 直接复制数据库文件
-
如果数据量还行, 可以使用第二种方式, 先使用mysqldump对数据库进行完全备份, 然后定期备份BINARY LOG达到增量备份的效果
-
如果数据量一般, 而又不过分影响业务运行, 可以使用第三种方式, 使用lvm2的快照对数据文件进行备份, 而后定期备份BINARY LOG达到增量备份的效果
-
如果数据量很大, 而又不过分影响业务运行, 可以使用第四种方式, 使用xtrabackup进行完全备份后, 定期使用xtrabackup进行增量备份或差异备份
完全备份及恢复(3种方法)

进行冷备->完全备份
将当前数据库停止运行,然后对数据库文件,整体进行copy操作
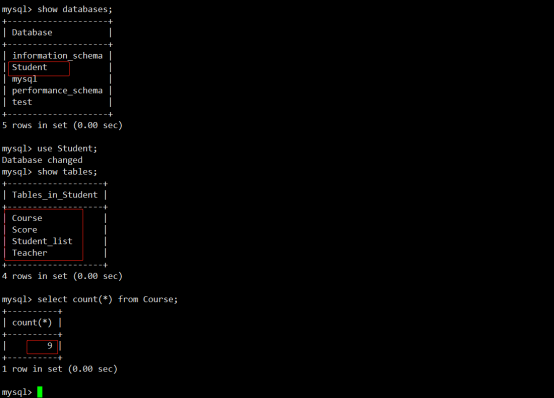
查看当前数据库的信息:

查看库下面的表信息:

查看表下面的行数:(由于时间问题,就查看Course表的行数)

Course表的总行数9条。
向所有表施加读锁:

停止运行数据库:
service mysqld stop
恢复数据库:
创建目录用于存放备份数据:

保留权限的拷贝源数据文件:

(生产环境中应把备份文件拷到另一台服务器上)
模拟数据丢失并恢复:(删除Student库)

删除Student库过后,再次查看没有Student库:

恢复数据(把删除的数据从备份区域copy至MySQL的data目录下):

重启数据库:

重新连接数据库,然后进行验证:
库已经恢复
表的行数未发生变化
完成。
通过mysqldump命令进行完全备份
官网: https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
[自带的工具],mysqldump是一个客户端的逻辑备份工具, 适用于相对不那么大的数据库,因为使用mysql协议,速度比较慢; 可以生成一个重现创建原始数据库和表的SQL语句, 可以支持所有的存储引擎, 对于InnoDB支持热备
mysqldump备份方式是采用的逻辑备份,其最大的缺陷是备份和恢复速度较慢,如果数据库大于50G,mysqldump备份就不太适合
基本语法格式:
默认不带参数的导出,导出文本内容大概如下:创建数据库判断语句-删除表-创建表-锁表-禁用索引-插入数据-启用索引-解锁表。
shell> mysqldump [options] db_name [tbl_name ...]恢复需要手动CRATE DATABASES
shell> mysqldump [options] --databases db_name ...恢复不需要手动创建数据库
shell> mysqldump [options] --all-databases 恢复不需要手动创建数据库
mysql 导出表结构和表数据 mysqldump用法,命令行下具体用法如下:
mysqldump -u用户名 -p密码 -d 数据库名 表名 > 脚本名;
常用选项:使用时请mysqldump --help查看本版本支持的参数
说明:长选项需要加等于符合,短选项除了-p(密码)直接接到后面
--user=root -padmin -B djangoblog --flush-privileges
- -u[user_name] |--user:通过指定用户名进行备份;连接MySQL服务器的用户名。
- -p[password] |--password:连接MySQL服务器的密码;提醒:数据库有密码时,就需要用这些参数
- -P[port] |--port:MySQL服务器的端口号;
-
-h|--host:指定要备份数据库的服务器;
-
-B|--databases:指定要备份的数据库1、数据库2......;如果没有该选项,mysqldump把第一个名字参数作为数据库名,后面的作为表名;如果使用该选项,mysqldum把每个名字都当作为数据库名
-
-A|--all-databases:备份MySQL服务器上的所有数据库(适用于不记得数据库名或者表名的情况下)
-
--tables Overrides option --databases (-B).
-
--master-data=2表示在备份文件中记录当前二进制日志的位置;
-
--master-data={0|1|2} 此选项会自动关闭
--lock-tables功能,自动打开--lock-all-tables功能(除非开启--single-transaction) -
0: 不记录二进制日志文件及路位置
-
1:以CHNAGE MASTER TO的方式记录位置,可用于恢复后直接启动从服务器
-
2:以CHANGE MASTER TO的方式记录位置,但默认为被注释

-
-d | --no-data 只备份表结构
-
-t |--no-create-info:只备份数据,不备份表结构(create table),只导出数据,而不添加CREATE TABLE 语句。
mysqldump -uroot -p --host=localhost --all-databases --no-create-info -
-n|--no-create-db 禁止生成创建数据库语句;只导出数据,而不添加CREATE DATABASE 语句
mysqldump -uroot -p --host=localhost --all-databases --no-create-db -
--add-drop-database每个数据库创建之前添加drop数据库语句。
mysqldump -uroot -p --all-databases --add-drop-database -
--add-drop-table:在每个创建数据库表语句前添加删除数据库表的语句;每个数据表创建之前添加drop数据表语句。(默认为打开状态,使用
--skip-add-drop-table取消选项)
mysqldump -uroot -p --all-databases (默认添加drop语句)
mysqldump -uroot -p --all-databases --skip-add-drop-table (取消drop语句)
- -E|--events表示备份数据的同时备份时间调度器代码;
-
-R|--routines表示备份数据的同时备份存储过程和存储函数;
-
--triggers:备份表相关触发器,默认启用,用--skip-triggers,不备份触发器
- -F|--flush-logs: 备份前滚动日志,锁定表完成后,执行
flush logs命令,生成新的二进制日志文件,配合-A时,会导致刷新多次数据库,在同一时刻执行转储和日志刷新,则应同时使用--flush-logs和-x,--master-data或-single-transaction,此时只刷新一次。建议:和-x,--master-data或--single-transaction一起使用 -
--log-error=name 指定此次备份的出错日志文件路径,附加警告和错误信息到给定文件。
mysqldump -uroot -p --host=localhost --all-databases --log-error=/tmp/mysqldump_error_log.err -
--add-locks:备份数据库表时锁定数据库表;在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(默认为打开状态,使用
--skip-add-locks取消选项)
mysqldump -uroot -p --all-databases (默认添加LOCK语句)
mysqldump -uroot -p --all-databases --skip-add-locks (取消LOCK语句)
- --compact Give less verbose output (useful for debugging). Disables:产生更少的输出(一般用于Debug调试);导出更少的输出信息(用于调试)。去掉注释和头尾等结构。可以使用选项:
--skip-add-drop-table --skip-add-locks --skip-comments --skip-disable-keys
mysqldump -uroot -p --all-databases --compact
-
-C, --compress Use compression in server/client protocol. 在服务器/客户端协议中使用压缩
-
--complete-insert:输出完成的插入语句;使用完整的insert语句(包含列名称)。这么做能提高插入效率,但是可能会受到max_allowed_packet参数的影响而导致插入失败。
mysqldump -uroot -p --all-databases --complete-insert
- -f |--force:在导出过程中忽略出现的SQL错误,当出现错误时仍然继续备份操作
mysqldump -uroot -p --all-databases --force
-
--quick,-q 该选项在导出大表时很有用,它强制 mysqldump 从服务器查询取得记录直接输出而不是取得所有记录后将它们缓存到内存中。默认为打开状态,使用
--skip-quick取消该选项 -
--ignore-table=dbname.tablename 不导出指定表。指定忽略多个表时,需要重复多次,每次一个表。每个表必须同时指定数据库和表名。例如:
--ignore-table=database.table1 --ignore-table=database.table2 ......
mysqldump -uroot -p --host=localhost --all-databases --ignore-table=mysql.user
- --hex-blob 该参数文档描述该工具只能对BINARY, VARBINARY, BLOB类型作十六进制转换。但是测试过程中发现,对bit类型也可以作十六进制转换. 同版本下不加此参数一般不会有什么问题,但在不同MySQL版本间最好加此参数。使用十六进制格式导出二进制字符串字段。如果有二进制数据就必须使用该选项。影响到的字段类型有BINARY、VARBINARY、BLOB。
mysqldump -uroot -p --all-databases --hex-blob
- --opt 如果有这个参数表示同时激活了mysqldump命令的quick, add-drop-table, add-locks,extended-insert, lock-tables 等参数,它可以给出很快的转储操作并产生一个可以很快装入MySQL服务器的转储文件。当备份大表时,这个参数可以防止占用过多内存。该选项默认开启, 可以用--skip-opt禁用。Same as --add-drop-table, --add-locks, --create-options,--quick, --extended-insert, --lock-tables, --set-charset,and --disable-keys. Enabled by default, disable with--skip-opt.
mysqldump -uroot -p --host=localhost --all-databases --opt
- --include-master-host-port在
--dump-slave产生的'CHANGE MASTER TO..'语句中增加MASTER_HOST=<host>,MASTER_PORT=<port>
mysqldump -uroot -p --host=localhost --all-databases --include-master-host-port
- --insert-ignore 在插入行时使用INSERT IGNORE语句.
mysqldump -uroot -p --host=localhost --all-databases --insert-ignore
- --replace 使用REPLACE INTO 取代INSERT INTO.
mysqldump -uroot -p --host=localhost --all-databases --replace
- --default-character-set 设置默认字符集,默认值为utf8
mysqldump -uroot -p --all-databases --default-character-set=utf8
mysqldump -uroot -p --all-databases --default-character-set=latin
- --comments 附加注释信息。默认为打开,可以用
--skip-comments取消
mysqldump -uroot -p --all-databases (默认记录注释)
mysqldump -uroot -p --all-databases --skip-comments (取消注释)
- -w, --where=name Dump only selected records. Quotes are mandatory. 条件导出,导出db1表a1中id=1的数据
mysqldump -uroot -proot --databases db1 --tables a1 --where='id=1' >/tmp/a1.sql
跨服务器导出导入数据
mysqldump --host=h1 -uroot -proot --databases db1 | mysql --host=h2 -uroot -proot db2
将h1服务器中的db1数据库的所有数据导入到h2中的db2数据库中,db2的数据库必须存在否则会报错
mysqldump --host=192.168.80.137 -uroot -proot -C --databases test | mysql --host=192.168.80.133 -uroot -proot test
默认mysqldump会将多条插入语句导出成一条insert语句格式,如:
insert into t values(1),(2);
那有时我想生成多条insert语句,如:
insert into t values(1);
insert into t values(2);
这时,在mysqldump时加上参数--skip-extended-insert即可。
mysqldump 会导出一条insert语句,虽说执行起来会快一些。但是遇到大表,很可能因为缓冲区过载而挂掉。 而且不容易阅读 mysqldump 的--skip-opt这个参数,就可以导出多条insert
mysqldump --skip-opt -uroot -p database tablename > script.sql
1 -A --all-databases:导出全部数据库
2 -Y --all-tablespaces:导出全部表空间
3 -y --no-tablespaces:不导出任何表空间信息
4 --add-drop-database每个数据库创建之前添加drop数据库语句。
5 --add-drop-table每个数据表创建之前添加drop数据表语句。(默认为打开状态,使用--skip-add-drop-table取消选项)
6 --add-locks在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(默认为打开状态,使用--skip-add-locks取消选项)
7 --comments附加注释信息。默认为打开,可以用--skip-comments取消
8 --compact导出更少的输出信息(用于调试)。去掉注释和头尾等结构。便会忽略:--skip-add-drop-table --skip-add-locks --skip-comments --skip-disable-keys等几个参数的功能
9 -c --complete-insert:使用完整的insert语句(包含列名称)。这么做能提高插入效率,但是可能会受到max_allowed_packet参数的影响而导致插入失败。
10 -C --compress:在客户端和服务器之间启用压缩传递所有信息
11 -B --databases:导出几个数据库。参数后面所有名字参量都被看作数据库名。
12 --debug输出debug信息,用于调试。默认值为:d:t:o,/tmp/
13 --debug-info输出调试信息并退出
14 --default-character-set设置默认字符集,默认值为utf8
15 --delayed-insert 采用延时插入方式(INSERT DELAYED)导出数据
16 -E --events:导出事件。
17 --master-data:在备份文件中写入备份时的binlog文件,在恢复进,增量数据从这个文件之后的日志开始恢复。值为1时,binlog文件名和位置没有注释,为2时,则在备份文件中将binlog的文件名和位置进行注释
18 -F, --flush-logs 开始导出之前刷新日志。请注意:假如一次导出多个数据库(使用选项--databases或者--all-databases),将会逐个数据库刷新日志。除使用--lock-all-tables或者--master-data外。在这种情况下,日志将会被刷新一次,相应的所以表同时被锁定。因此,如果打算同时导出和刷新日志应该使用--lock-all-tables 或者--master-data 和--flush-logs。 刷新binlog,如果binlog打开了,-F参数会在备份时自动刷新binlog进行切换。
19 --flush-privileges在导出mysql数据库之后,发出一条FLUSH PRIVILEGES 语句。为了正确恢复,该选项应该用于导出mysql数据库和依赖mysql数据库数据的任何时候。
20 --force在导出过程中忽略出现的SQL错误。
21 -h --host:需要导出的主机信息
22 --ignore-table不导出指定表。指定忽略多个表时,需要重复多次,每次一个表。每个表必须同时指定数据库和表名。例如:--ignore-table=database.table1 --ignore-table=database.table2 ……
23 -x --lock-all-tables:提交请求锁定所有数据库中的所有表,以保证数据的一致性。这是一个全局读锁,并且自动关闭--single-transaction 和--lock-tables 选项。
24 -l --lock-tables:开始导出前,锁定所有表。用READ LOCAL锁定表以允许MyISAM表并行插入。
对于支持事务的表例如InnoDB和BDB --single-transaction是一个更好的选择,因为它根本不需要锁定表。请注意当导出多个数据库时,--lock-tables分别为每个数据库锁定表。因此,该选项不能保证导出文件中的表在数据库之间的逻辑一致性。不同数据库表的导出状态可以完全不同。
25 --single-transaction:适合innodb事务数据库的备份。保证备份的一致性,原理是设定本次会话的隔离级别为Repeatable read,来保证本次会话(也就是dump)时,不会看到其它会话已经提交了的数据。
26 -n --no-create-db:只导出数据,而不添加CREATE DATABASE 语句。
27 -t --no-create-info:只导出数据,而不添加CREATE TABLE 语句。
28 -d --no-data:不导出任何数据,只导出数据库表结构。
29 -p --password:连接数据库密码
30 -P --port:连接数据库端口号
31 -u --user:指定连接的用户名。
MyISAM备份选项:
支持温备;不支持热备,所以必须先锁定要备份的库,而后启动备份操作
锁定方法如下:
- -x,--lock-all-tables:加全局读锁,锁定所有库的所有表,同时加
--single-transaction或--lock-tables选项会关闭此选项功能
注意:数据量大时,可能会导致长时间无法并发访问数据库
-l,--lock-tables:对于需要备份的每个数据库,在启动备份之前分别锁定其所有表,默认为on,--skip-lock-tables选项可禁用,对备份MyISAM的多个库,可能会造成数据不一致
注:以上选项对InnoDB表一样生效,实现温备,但不推荐使用
- -B:指定多个库,在备份文件中增加建库语句和use语句
-
--compact:去掉备份文件中的注释,适合调试,生产场景不用
-
-A:备份所有库
- -F:刷新binlog日志
- --master-data:在备份文件中增加binlog日志文件名及对应的位置点
-
-x --lock-all-tables:锁表
-
-l:只读锁表
-
-d:只备份表结构
-
-t:只备份数据
InnoDB备份选项:
支持热备,可用温备但不建议用
--single-transaction
此选项Innodb中推荐使用,适合innodb事务数据库的备份,不适用MyISAM,此选项会开始备份前,先执行START TRANSACTION指令,并且在备份期间,不允许对数据进行修改操作,此选项和--lock-tables(此选项隐含提交挂起的事务)选项是相互排斥;备份大型表时,建议将--single-transaction选项和--quick结合一起使用
InnoDB表在备份时,通常启用选项--single-transaction来保证备份的一致性,原理是设定本次会话的隔离级别为Repeatable read,来保证本次会话(也就是dump)时,不会看到其它会话已经提交了的数据
综合示例:
- 备份所有数据库:
shell> mysqldump -uroot -p --all-database > all.sql
- 备份数据库 test
shell> mysqldump -uroot -p test > test.sql
- 备份数据库 test 下的emp表
shell> mysqldump -uroot -p test emp > emp.sql
- 备份数据库 test 下的 emp 和 dept 表
shell> mysqldump -uroot -p test emp dept > emp_dept.sql
- 备份数据库test 下的所有表为逗号分割的文本,备份到 /tmp:
shell> mysqlddump -uroot -p -T /tmp test emp --fields-terminated-by ','
shell> more emp.txt
1,z1
2,z2
3,z3
4,z4
6、导出单个数据表结构和数据
mysqldump -h localhost -uroot -p123456 database table > dump.sql
7、导出整个数据库结构(不包含数据)
mysqldump -h localhost -uroot -p123456 -d database > dump.sql
8、导出单个数据表结构(不包含数据)
mysqldump -h localhost -uroot -p123456 -d database table > dump.sql
9、mysqldump 备份导出数据排除某张表就用--ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtables > dump.sql
注意: 为了保证数据备份的一致性,myisam 存储引擎在备份时需要加上-l参数,表示将所有表加上读锁,在备份期间,所有表将只能读而不能进行数据更新。但是对于事务存储引擎来说,可以采用更好的选项--single-transaction,此选项使得 innodb 存储引擎得到一个快照(snapshot),使得备份的数据能够保证一致性。
不同引擎备份命令参数用法(重点)
(1)Myisam引擎:
mysqldump -uroot -p123456 -A -B --master-data=1 -x | gzip > /data/all_$(date +%F).sql.gz
(2)InnoDB引擎:
mysqldump -uroot -p123456 -A -B --master-data=1 --single-transaction > /data/bak.sql
(3)生产环境DBA给出的命令
a、for MyISAM
mysqldump --user=root --all-databases --opt --flush-privileges \
--lock-all-tables \
--master-data=2 --flush-logs --triggers --routines --events \
--hex-blob > $BACKUP_DIR/full_dump_$BACKUP_TIMESTAMP.sql
b、for InnoDB
mysqldump --user=root --all-databases --opt --flush-privileges --single-transaction \
--master-data=2 --flush-logs --triggers --routines --events \
--hex-blob > $BACKUP_DIR/full_dump_$BACKUP_TIMESTAMP.sql
恢复数据库[针对mysqldump及mysql命令导出的sql备份文件进行恢复]
A、source命令:在mysql内部命令行执行。如果sql文件中没有创建库语句,必须手动创建该库且进入该库
语法:
mysql> source /backup/backup.sql
mysql> \. /backup/backup.sql
-- /backup/backup.sql -> /备份路径/备份文件名称
B、mysql命令:在Linux命令行执行。如果sql文件中没有创建库语句,必须手动创建
语法:
mysql [options] < 备份数据库文件
mysql -u root -p666666 zabbix < /root/zabbix-4.4.7/database/mysql/schema.sql
1、首先建空数据库
mysql> create database abc;
2、导入数据库
方法一:
(1)选择数据库
mysql> use abc;
(2)设置数据库编码
mysql> set names utf8;
(3)导入数据(注意sql文件的路径)
mysql> source /home/abc/abc.sql;
方法二:建议使用第二种方法导入
mysql -u用户名 -p密码 数据库名 < 数据库名.sql
mysql -uroot -p abc < abc.sql
注意:完全备份与恢复,都是在实际环境中经常使用,且必须搭配crontab进行定时任务备份
Xtrabackup
增量备份及恢复
基于binlog时间点增量备份及恢复

增量备份的特点:
-
没有重复的数据文件,且备份量不大,用时比较短
-
增量恢复的基础
->上一次完全备份,而且要对所有增量备份进行逐个反推恢复
增量备份实现方法:mysqlbinlog命令
必须依赖于二进制日志文件进行备份[binary log]
从binlog日志恢复数据,恢复语法格式:
# mysqlbinlog mysql-bin.0000xx | mysql -u用户名 -p密码 数据库名
常用选项:
-
-d 指定库的binlog
-
-r 相当于重定向到指定文件
-
--start-position=953 起始pos点
-
--stop-position=1437 结束pos点
-
--start-datetime=
2013-11-29 13:18:54起始时间点 -
--stop-datetime=
2013-11-29 13:21:53结束时间点 -
--database=zyyshop 指定只恢复zyyshop数据库(一台主机上往往有多个数据库,只限本地log日志)
不常用选项:
-
-u --user=name Connect to the remote server as username.连接到远程主机的用户名
-
-p --password[=name] Password to connect to remote server.连接到远程主机的密码
-
-h --host=name Get the binlog from server.从远程主机上获取binlog日志
-
--read-from-remote-server Read binary logs from a MySQL server.从某个MySQL服务器上读取binlog日志
小结:实际是将读出的binlog日志内容,通过管道符传递给mysql命令。这些命令、文件尽量写成绝对路径;
1、首先做一次完整备份:
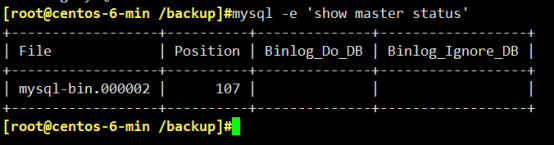
mysqldump -h10.6.208.183 -utest2 -p123 -P3310 --single-transaction --master-data=2 test > test.sql #这时候就会得到一个全备文件test.sql
在test.sql文件中我们会看到:
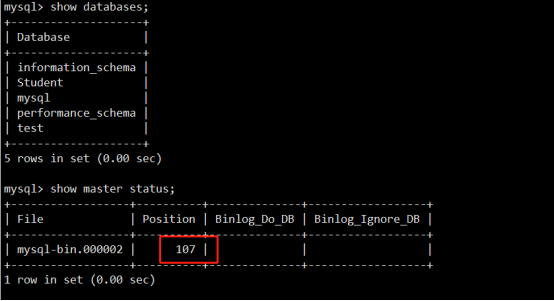
-- CHANGE MASTER TO MASTER_LOG_FILE='bin-log.000002', MASTER_LOG_POS=107; #是指备份后所有的更改将会保存到bin-log.000002二进制文件中。
2、在test库的t_student表中增加两条记录,然后执行flush logs命令。这时将会产生一个新的二进制日志文件bin-log.000003,bin-log.000002则保存了全备过后的所有更改,既增加记录的操作也保存在了bin-log.00002中。
3、再在test库中的a表中增加两条记录,然后误删除t_student表和a表。a中增加记录的操作和删除表a和t_student的操作都记录在bin-log.000003中。
三、恢复
1、首先导入全备数据
mysql -h10.6.208.183 -utest2 -p123 -P3310 < test.sql #也可以直接在mysql内部用source导入
2、恢复bin-log.000002
mysqlbinlog bin-log.000002 | mysql -h10.6.208.183 -utest2 -p123 -P3310
3、恢复部分 bin-log.000003
在general_log中找到误删除的时间点,然后更加对应的时间点到bin-log.000003中找到相应的position点,需要恢复到误删除的前面一个position点。
可以用如下参数来控制binlog的区间
- --start-position 开始点 --stop-position 结束点
- --start-date 开始时间 --stop-date 结束时间
找到恢复点后,既可以开始恢复。
mysqlbinlog mysql-bin.000003 --stop-position=208 |mysql -h10.6.208.183 -utest2 -p123 -P3310
实例:
查看当前二进制文件的状态, 并记录下position的数字:
备份数据库到/backup/backup.sql文件中:
mysqldump --all-databases --lock-tables > /backup/backup.sql

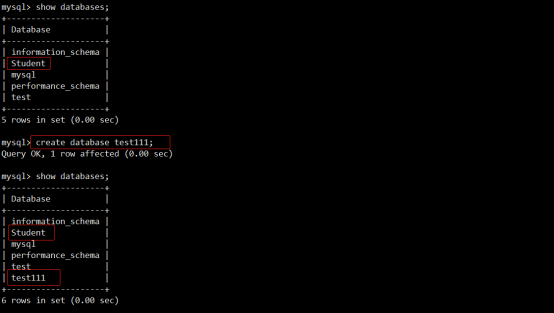
创建一个数据库test111(用于实现增量备份):
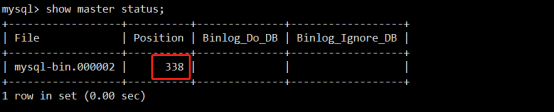
记下现在的position(用于实现增量备份):
备份二进制文件(用于实现增量备份):
cp /usr/local/mysql/data/mysql-bin.000002 /backup/
停止MySQL
service mysqld stop
模拟数据丢失(删除Student和test111数据库):
rm -rf Student/ test111/
启动MySQL, 如果是编译安装的应该不能启动(需重新初始化), 如果rpm安装则会重新初始化数据库
service mysqld start
说明:这里只删除了两个库,并没有删除数据库下面的所有内容,所有可以启动
连接数据库,查看数据库,数据已丢失:

暂时先将二进制日志关闭:
mysql> SET sql_log_bin=OFF;
Query OK, 0 rows affected (0.00 sec)
恢复数据,所需时间根据数据库时间大小而定:
mysql> create database Studnet;
mysql> create database test111;
mysql> source /backup/backup.sql
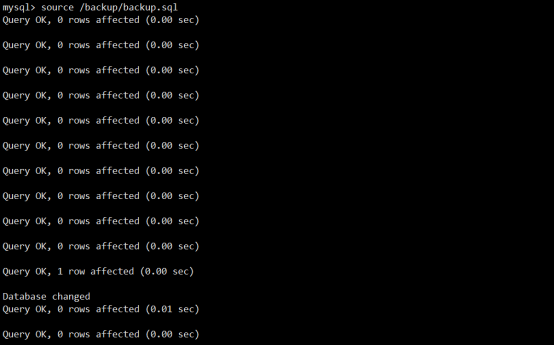
开启二进制日志:
mysql> SET sql_log_bin=ON;
Query OK, 0 rows affected (0.00 sec)
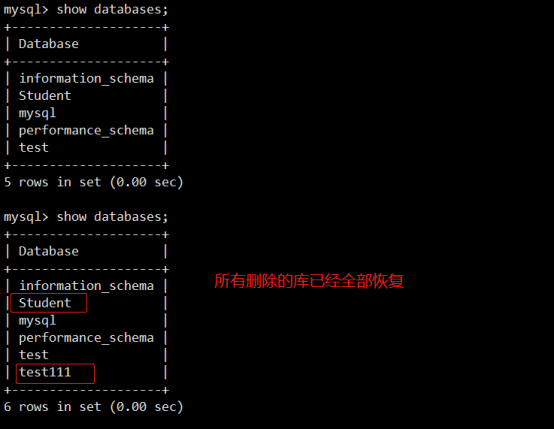
数据库恢复, 但是缺少test111:

通过二进制日志增量恢复数据:
mysqlbinlog --start-position=107 --stop-position=338 /backup/mysql-bin.000002 | mysql Student
Xtrabackup
参考下一章节
MySQL基于日志还原数据
简介
Binlog日志,即二进制日志文件,用于记录用户对数据库操作的SQL语句信息,当发生数据误删除的时候我们可以通过binlog日志来还原已经删除的数据,还原数据的方法分为传统二进制文件还原数据和基于GTID的二进制文件还原数据
传统二进制日志还原数据
1.修改配置文件
[root@localhost ~]# vi /etc/my.cnf
server-id=1
log-bin=binlog
#重启数据库服务
[root@localhost ~]# systemctl restart mysqld
2.操作数据库
mysql> create database mydb charset utf8mb4;
mysql> use mydb;
mysql> create table test(id int)engine=innodb charset=utf8mb4;
mysql> insert into test values(1);
mysql> insert into test values(2);
mysql> insert into test values(3);
mysql> insert into test values(4);
mysql> commit;
mysql> update test set id=10 where id=4;
mysql> commit;
mysql> select * from test;
+------+
| id |
+------+
| 1 |
| 2 |
| 3 |
| 10 |
+------+
4 rows in set (0.00 sec)
mysql> drop database mydb;
3.查看二进制日志信息
[14:59: -(none)] mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000071
Position: 2284
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
查找创库和删库的点,为543和2192
mysql> show binlog events in 'mysql-bin.000071';
4.另存为二进制日志信息
[root@learn ~]# mysqlbinlog --start-position=543 --stop-position=2192 /MysqlData/mysql-bin.000071 > /root/mydb_binlog.sql
5.恢复数据
#临时关闭二进制日志记录以免重复记录
mysql> set sql_log_bin=0;
#恢复数据
mysql> source /root/mydb_binlog.sql
#重启二进制日志记录
mysql> set sql_log_bin=1;
6.查看数据恢复情况
mysql> show databases;
mysql> use mydb;
mysql> select from test;
基于GTID二进制日志还原数据
参考:https://www.jianshu.com/p/ea9fdcc25378
原创地址:https://blog.51cto.com/14832653/2509121?source=drh
1.修改配置文件
[root@localhost ~]# vi /etc/my.cnf
server-id=1
log-bin=binlog
gtid_mode=ON
enforce_gtid_consistency=true
log_slave_updates=1
#重启数据库服务
[root@localhost ~]# systemctl restart mysqld
2.操作数据库
mysql> create database mydb1;
mysql> use mydb1;
mysql> create table t1(id int)engine=innodb charset=utf8mb4;
mysql> insert into t1 values(1);
mysql> insert into t1 values(2);
mysql> insert into t1 values(3);
mysql> insert into t1 values(11);
mysql> insert into t1 values(12);
mysql> commit;
mysql> select * from t1;
+------+
| id |
+------+
| 1 |
| 2 |
| 3 |
| 11 |
| 12 |
+------+
5 rows in set (0.00 sec)
mysql> drop database mydb1;
3.查看二进制日志信息
mysql> show master status\G
mysql> show binlog events in 'mysql-bin.000002';
[15:25: -(none)] mysql> show binlog events in 'mysql-bin.000002';
+------------------+------+----------------+-----------+-------------+-------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+------+----------------+-----------+-------------+-------------------------------------------------------------------+
| mysql-bin.000002 | 4 | Format_desc | 12 | 123 | Server ver: 5.7.28-log, Binlog ver: 4 |
| mysql-bin.000002 | 123 | Previous_gtids | 12 | 154 | |
| mysql-bin.000002 | 154 | Gtid | 12 | 219 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:1' |
| mysql-bin.000002 | 219 | Query | 12 | 316 | create database mydb1 |
| mysql-bin.000002 | 316 | Gtid | 12 | 381 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:2' |
| mysql-bin.000002 | 381 | Query | 12 | 509 | use `mydb1`; create table t1(id int)engine=innodb charset=utf8mb4 |
| mysql-bin.000002 | 509 | Gtid | 12 | 574 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:3' |
| mysql-bin.000002 | 574 | Query | 12 | 647 | BEGIN |
| mysql-bin.000002 | 647 | Table_map | 12 | 693 | table_id: 108 (mydb1.t1) |
| mysql-bin.000002 | 693 | Write_rows | 12 | 733 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 733 | Xid | 12 | 764 | COMMIT /* xid=7 */ |
| mysql-bin.000002 | 764 | Gtid | 12 | 829 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:4' |
| mysql-bin.000002 | 829 | Query | 12 | 902 | BEGIN |
| mysql-bin.000002 | 902 | Table_map | 12 | 948 | table_id: 108 (mydb1.t1) |
| mysql-bin.000002 | 948 | Write_rows | 12 | 988 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 988 | Xid | 12 | 1019 | COMMIT /* xid=8 */ |
| mysql-bin.000002 | 1019 | Gtid | 12 | 1084 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:5' |
| mysql-bin.000002 | 1084 | Query | 12 | 1157 | BEGIN |
| mysql-bin.000002 | 1157 | Table_map | 12 | 1203 | table_id: 108 (mydb1.t1) |
| mysql-bin.000002 | 1203 | Write_rows | 12 | 1243 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 1243 | Xid | 12 | 1274 | COMMIT /* xid=9 */ |
| mysql-bin.000002 | 1274 | Gtid | 12 | 1339 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:6' |
| mysql-bin.000002 | 1339 | Query | 12 | 1412 | BEGIN |
| mysql-bin.000002 | 1412 | Table_map | 12 | 1458 | table_id: 108 (mydb1.t1) |
| mysql-bin.000002 | 1458 | Write_rows | 12 | 1498 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 1498 | Xid | 12 | 1529 | COMMIT /* xid=10 */ |
| mysql-bin.000002 | 1529 | Gtid | 12 | 1594 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:7' |
| mysql-bin.000002 | 1594 | Query | 12 | 1667 | BEGIN |
| mysql-bin.000002 | 1667 | Table_map | 12 | 1713 | table_id: 108 (mydb1.t1) |
| mysql-bin.000002 | 1713 | Write_rows | 12 | 1753 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 1753 | Xid | 12 | 1784 | COMMIT /* xid=11 */ |
| mysql-bin.000002 | 1784 | Gtid | 12 | 1849 | SET @@SESSION.GTID_NEXT= 'ed199600-7750-11ea-a19f-00163e322fa1:8' |
| mysql-bin.000002 | 1849 | Query | 12 | 1944 | drop database mydb1 |
+------------------+------+----------------+-----------+-------------+-------------------------------------------------------------------+
33 rows in set (0.00 sec)
4.另存为二进制日志信息
#8号事务记录为删除数据库,因此只需恢复1-7号事务记录即可
mysqlbinlog --skip-gtids --include-gtids='ed199600-7750-11ea-a19f-00163e322fa1:1-7' /MysqlData/mysql-bin.000002 > /root/gtid.sql
参数说明:
- --include-gtids:包含事务
- --exclude-gtids:排除事务
- --skip-gtids:跳过事务
5.恢复数据
mysql> set sql_log_bin=0;
mysql> source /root/gtid.sql
mysql> set sql_log_bin=1;
6.查看数据恢复情况
mysql> show databases;
mysql> use mydb1;
mysql> select * from t1;
binlog相关设置
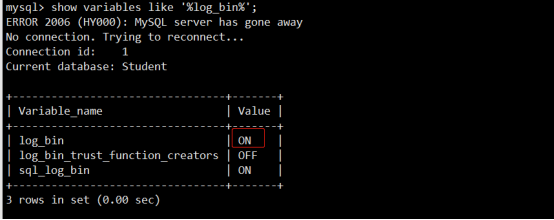
show master status; -- 输出结果为空?
原因:mysql没有开启日志。查看log_bin选项:
mysql> show variables like '%log_bin%';
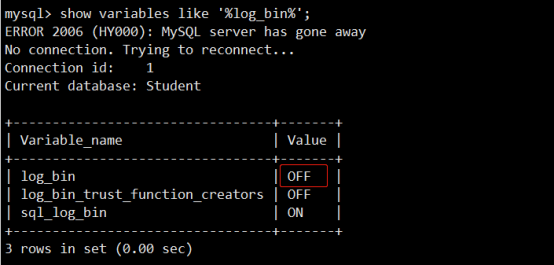
可以看到log_bin是OFF,解决方法:在mysql 配置文件/etc/my.cnf中
[mysqld]下添加:
log-bin=mysql-bin
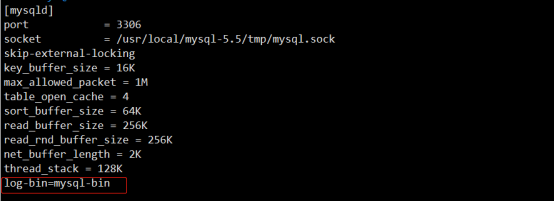
log-bin配置项表示binlog的base name,产生的日志文件名称类似,mysql-bin.00001,mysql-bin.00002,mysql-bin.00003。
然后保存,重启mysql服务,进行查看log_bin的value是on。
注意:二进制日志文件不应该与数据文件放在同一磁盘
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000002
Position: 107
Binlog_Do_DB:
Binlog_Ignore_DB:
1 row in set (0.00 sec)
show master status命令列出了日志位点信息,包括binlog file,binlog position等。如果使用了GTID(global transaction ID),Executed_Gtid_Set表示已经在这个master上执行的GTID集合,与这个server上的系统变量gtid_executed 含义相同。

如果该server是slave,则执行show slave status中是输出的对应列Executed_Gtid_Set,含义也相同。
在MySQL配置文件my.cnf文件中的mysqld节中添加下面的配置文件:
[mysqld]
#设置日志格式
binlog_format = row
#设置日志路径,注意路经需要mysql用户有权限写
log-bin = /data/mysql/logs/mysql-bin
#设置binlog清理时间
expire_logs_days = 7
#binlog每个日志文件大小
max_binlog_size = 100m
#binlog缓存大小
binlog_cache_size = 4m
#最大binlog缓存大小
max_binlog_cache_size = 512m
重启MySQL生效,如果不方便重启服务,也可以直接修改对应的变量即可。
在 MySQL 主从复制中,有多个选项用于控制对于哪些数据库和表进行数据同步或者忽略。下面是这些选项的简介:
1、 replicate_ignore_db
replicate_ignore_db 参数用于指定需要忽略的数据库名,这些数据库中的任何更改都不会被复制到从服务器。可以使用多个逗号分隔的数据库名指定多个数据库。
示例:replicate_ignore_db = mysql,test
2、 replicate_wild_ignore_table
replicate_wild_ignore_table 参数用于指定需要忽略的表名通配符,这些符合通配符模式的表中的任何更改都不会被复制到从服务器。可以使用多个逗号分隔的通配符指定多个表名。
示例:replicate_wild_ignore_table = db1.%,db2.foo,db3.bar%
3、 replicate_do_table
replicate_do_table 参数用于指定需要复制的表名,只有指定的表中的更改才会被复制到从服务器。可以使用多个逗号分隔的表名指定多个需要复制的表名。
示例:replicate_do_table = db1.table1,db2.%
4、binlog-ignore-db
binlog-ignore-db 参数用于指定需要忽略的数据库名,在主服务器上不会将这些数据库的更改写入二进制日志文件。可以使用多个逗号分隔的数据库名指定多个需要忽略的数据库。
示例:binlog-ignore-db = mysql,test
5、 replicate-do-db
replicate-do-db参数允许你指定主服务器上的数据库名称,只有在指定的数据库中发生更改时,这些更改才会被复制到从服务器上。
示例:replicate-do-db = mydatabase,test
这些选项可以通过在主服务器和从服务器的配置文件中设置来控制 MySQL 主从复制中哪些数据库和表需要同步,哪些需要忽略,使用这些选项可以帮助您更好地控制数据同步,提高 MySQL 的可用性和稳定性。
binlog的删除可以手工删除或自动删除:

a)自动删除binlog,通过binlog参数(expire_logs_days )来实现mysql自动删除binlog
mysql> show binary logs;
mysql> show variables like 'expire_logs_days'; -- 该参数表示binlog日志自动删除/过期的天数,默认值为0,表示不自动删除
mysql> set global expire_logs_days=3; -- 表示日志保留3天,3天后就自动过期。
b)手工删除binlog
mysql> reset master; -- 删除binlog,即手动删除所有的binlog日志
mysql> reset slave; -- 删除中继日志,包括还没有应用完的日志,创建一个新的relay log文件
mysql> purge master logs before '2012-03-30 17:20:00'; -- 删除指定日期以前的日志索引中binlog日志文件
mysql> purge master logs to 'binlog.000002'; -- 删除指定日志文件的日志索引中binlog日志文件
mysql> set sql_log_bin='1/0'; -- 如果用户有super权限,可以启用或禁用当前会话的binlog记录
mysql> show master logs; -- 查看master的binlog日志列表
mysql> show binary logs; -- 查看master的binlog日志文件大小
mysql> show master status; -- 用于提供master二进制日志文件的状态信息
mysql> show slave hosts; -- 显示当前注册的slave的列表。不以--report-host=slave_name选项为开头的slave不会显示在本列表中
mysql> flush logs; -- 产生一个新的binlog日志文件
mysql> SHOW RELAYLOG EVENTS; -- 将显示中继日志文件中的事件列表,包括每个事件的执行时间、事件类型、主服务器信息以及相关语句,如果你只想查看最近的几个事件,可以在命令后面加上 LIMIT 子句
mysql> SHOW RELAYLOG EVENTS LIMIT 10; -- 显示最近的 10 个中继日志事件
总结:
reset slave命令进行两个动作:
- 清除
master.info,relay-log.info文件(记录),就是清除master.info文件和relay-log.info文件,需要注意的是,新版本的mysql中,这两个文件已经不存在了,而是存储在mysql数据库的slave_master_info表和slave_relay_log_info表中 - 删除所有的relay log,包括还没有应用完的日志,创建一个新的relay log文件.
reset slave和reset slave all命令
reset slave命令和reset slave all命令会删除所有的relay log(包括还没有应用完的日志),创建一个新的relay log文件;- 使用
reset slave命令,那么所有的连接信息仍然保留在内存中,包括主库地址、端口、用户、密码等。这样可以直接运行start slave命令而不必重新输入change master to命令,而运行show slave status也仍和没有运行reset slave一样,有正常的输出。但如果使用reset slave all命令,那么这些内存中的数据也会被清除掉,运行show slave status就输出为空了。 reset slave和reset slave all命令会将系统mysql数据库的slave_master_info表和slave_relay_log_info表中对应的复制记录清除。
reset master命令
先来说说这个命令的结果:
- 清理所有的binlog文件,创建一个新的文件,起始值从1开始。并且之前的复制信息将被清除,这个命令通常在重新设置主从复制环境时使用,比如设置一个新的从服务器。
- GTID环境中,
reset master会清理掉gtid_executed的值,在搭建主从的时候可以使用,但是要慎用(如果你的二进制日志还有需要的话)
说明: show master status也就等于mysql -e 'show master status'
延迟同步
数据校验(重要)

分库分表备份脚本实现
脚本思路:
如果库较少,可以使用for in db1 db2 db3;do ;done来实例
如果库较多,则应该先用show databases取出库名,做为for循环变量的取值列表,然后再执行备份操作:
取库名:
mysql -uroot -p666666 -S /tmp/mysql.sock -e "show databases;" | egrep -vi "Database|information_schema|mysql|performance_schema|sys"
备份一个库:
mysqldump -uroot -p666666 -S /tmp/mysql.sock \
--compact -F --master-data=2 --single-transaction --events \
-B mimi | gzip >/opt/mysql_bak_db_mimi.sql.gz
说明:mimi就是数据库名
备份所有库:
mysqldump -uroot -p666666 -S /tmp/mysql.sock \
--compact -F --master-data=2 --single-transaction --events \
-A | gzip >/opt/mysql_bak_db_All.sql.gz
了解脚本思路了脚本就很好写了,下面自己编写的一个示例脚本:
#!/bin/bash
bin_Path="/usr/local/mysql/bin"
my_user="root"
my_pass="666666"
backup_Dir="/opt"
socket_file="/tmp/mysql.sock"
#取数据库名
dbList=`mysql -u${my_user} -p$my_pass -S ${socket_file} -e "show databases;" | \
egrep -vi "Database|information_schema|mysql|performance_schema|sys"`
echo "即将备份以下数据库"
sleep 6
echo "$dbList"
sleep 3
echo "----------------------"
#备份上面的库,并且刷新log_bin日志
for db in $dbList
do
${bin_Path}/mysqldump -u$my_user -p$my_pass -S ${socket_file} -B -F \
--master-data=2 --single-transaction --events --compact \
${db} | gzip >${backup_Dir}/mysql_backup_database_${db}_$(date +%Y%m%d-%H-%M-%S).sql.gz
if [ $? = 0 ];then
echo "${db}库备份成功"
sleep 6
else
echo "${db}库备份失败,即将退出备份"
exit 22
sleep 6
fi
done
分表备份实现脚本
脚本思路:大致思路是在库中再分表进行备份,那就会用到for循环嵌套,外层for循环是库,内层for循环是表,并将每个库中的表存放在各自库名命名的目录下面。
取到某库中的表名:注:没有表的库被自动过滤掉了。
mysql -uroot -p666666 -S /tmp/mysql.sock -e "show tables from mimi"|sed '1d'
示例脚本:
#!/bin/bash
Backup_Databases_tables(){
bin_Path="/usr/local/mysql/bin"
my_user="root"
my_pass='asdfghjkl@#$!123654$'
backup_Dir="/opt/backupmysql"
socket_file="/tmp/mysql.sock"
#取库名
dbList=`mysql -u$my_user -p$my_pass -S ${socket_file} -e "show databases;" \
| egrep -vi "Database|information_schema|mysql|performance_schema|sys"`
#|egrep -v "Database|information_schema|mysql|performance_schema|sys"`
echo "所需要的库"
echo "$dbList"
for db in $dbList
do
#取库中的表名
table=`mysql -u$my_user -p$my_pass -S ${socket_file} -e "show tables from $db"|sed '1d'`
echo "${db}库下的所有表"
echo "${table}"
for tb in $table
do
echo "创建以库命名的目录"
echo "创建${backup_Dir}/${db}"
[ -d ${backup_Dir}/${db} ] || mkdir -p ${backup_Dir}/${db}
echo "即将开始备份$db库下$tb表"
${bin_Path}/mysqldump -u$my_user -p$my_pass -S ${socket_file} --flush-logs --triggers --events --routines --opt \
--quick --master-data=2 --hex-blob --single-transaction $db $tb | \
gzip > $backup_Dir/${db}/$(date +%Y%m%d-%H-%M-%S)-${db}-${tb}.sql.gz
if [ $? = 0 ];then
echo "${db}库下${tb}表备份成功"
sleep 5
else
echo "${db}库下${tb}表备份失败,即将退出备份"
exit 22
sleep 5
fi
done
done
}
Backup_Databases_tables
Xtrabackup备份及恢复
官网:http://www.percona.com
官方手册:
https://www.percona.com/doc/percona-xtrabackup/2.3/index.html
更多XtraBackup相关教程见以下内容:
MySQL管理之使用XtraBackup进行热备 http://www.linuxidc.com/Linux/2014-04/99671.htm
使用Xtrabackup进行MySQL备份 http://www.linuxidc.com/Linux/2016-11/137734.htm
MySQL开源备份工具Xtrabackup备份部署 http://www.linuxidc.com/Linux/2013-06/85627.htm
MySQL Xtrabackup备份和恢复 http://www.linuxidc.com/Linux/2011-12/50275.htm
Percona Xtrabackup 安装 http://www.linuxidc.com/Linux/2016-11/137735.htm
使用XtraBackup 备份MySQL数据库 http://www.linuxidc.com/Linux/2016-12/138688.htm
使用Xtrabackup进行MySQL数据库全备和全备还原 http://www.linuxidc.com/Linux/2016-11/137736.htm
XtraBackup备份原理和实战详解 http://www.linuxidc.com/Linux/2017-04/142477.htm
Percona XtraBackup 实现全备&增量备份与恢复 http://www.linuxidc.com/Linux/2017-03/142380.htm
本文永久更新链接地址:http://www.linuxidc.com/Linux/2017-06/145040.htm
博客参考:
https://www.cnblogs.com/linuxk/p/9372990.html
https://segmentfault.com/a/1190000022293848
Xtrabackup介绍
MySQL冷备、mysqldump、MySQL热拷贝都无法实现对数据库进行增量备份。在实际生产环境中增量备份是非常实用的,如果数据大于50G或100G,存储空间足够的情况下,可以每天进行完整备份,如果每天产生的数据量较大,需要定制数据备份策略。例如每周实用完整备份,周一到周六实用增量备份。而Percona-Xtrabackup就是为了实现增量备份而出现的一款主流备份工具,xtrabakackup有2个工具,分别是xtrabakup、innobakupe。
Percona-xtrabackup是 Percona公司开发的一个用于MySQL数据库物理热备的备份工具,支持MySQL、Percona server和MariaDB,开源免费,是目前较为受欢迎的主流备份工具。xtrabackup只能备份innoDB和xtraDB两种数据引擎的表,而不能备份MyISAM数据表
Xtrabackup优点
(1)备份速度快,物理备份可靠
(2)备份过程不会打断正在执行的事务(无需锁表)
(3)能够基于压缩等功能节约磁盘空间和流量
(4)自动备份校验
(5)还原速度快
(6)可以流传将备份传输到另外一台机器上
(7)在不增加服务器负载的情况备份数据
Xtrabackup备份原理
https://www.cnblogs.com/f-ck-need-u/p/9018716.html#auto_id_2
Xtrabackup备份流程图:

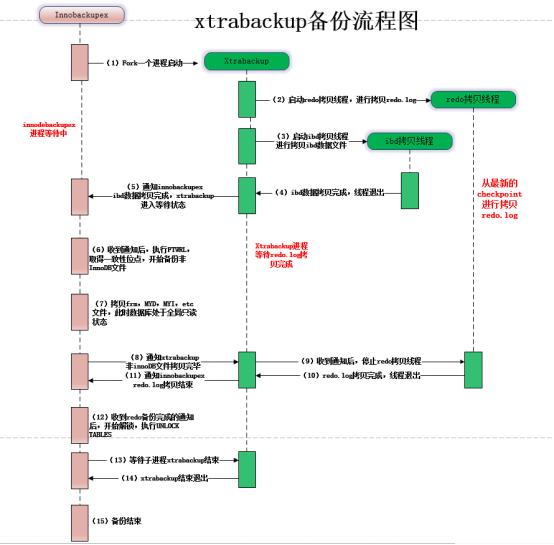
(1)innobackupex启动后,会先fork一个进程,用于启动xtrabackup,然后等待xtrabackup备份ibd数据文件;
(2)xtrabackup在备份innoDB数据是,有2种线程:redo拷贝线程和ibd数据拷贝线程。xtrabackup进程开始执行后,会启动一个redo拷贝的线程,用于从最新的checkpoint点开始顺序拷贝redo.log;再启动ibd数据拷贝线程,进行拷贝ibd数据。这里是先启动redo拷贝线程的。在此阶段,innobackupex进行处于等待状态(等待文件被创建)
(3)xtrabackup拷贝完成ibd数据文件后,会通知innobackupex(通过创建文件),同时xtrabackup进入等待状态(redo线程依旧在拷贝redo.log)
(4)innobackupex收到xtrabackup通知后哦,执行FLUSH TABLES WITH READ LOCK(FTWRL),取得一致性位点,然后开始备份非InnoDB文件(如frm、MYD、MYI、CSV、opt、par等格式的文件),在拷贝非InnoDB文件的过程当中,数据库处于全局只读状态。
(5)当innobackup拷贝完所有的非InnoDB文件后,会通知xtrabackup,通知完成后,进入等待状态;
(6)xtrabackup收到innobackupex备份完成的通知后,会停止redo拷贝线程,然后通知innobackupex,redo.log文件拷贝完成;
(7)innobackupex收到redo.log备份完成后,就进行解锁操作,执行:UNLOCK TABLES;
(8)最后innbackupex和xtrabackup进程各自释放资源,写备份元数据信息等,innobackupex等xtrabackup子进程结束后退出
xtrabackup的安装部署
恢复前的准备工作包括如下几项:
安装数据恢复工具Percona XtraBackup 2.4
-
MySQL 5.6及之前的版本需要安装 Percona XtraBackup 2.3或2.2,安装指导请参见官方文档Percona XtraBackup 2.3。
-
MySQL 5.7版本需要安装 Percona XtraBackup 2.4,安装指导请参见官方文档Percona XtraBackup 2.4。
-
MySQL 8.0版本需要安装 Percona XtraBackup 8.0,安装指导请参见官方文档Percona XtraBackup 8.0。

安装超简单(只能在linux上用,不过但这就够了)
二进制下载:
https://www.percona.com/downloads/Percona-XtraBackup-2.4/LATEST/
源码包的安装,可以参考: https://www.linuxidc.com/Linux/2016-11/137735.htm
rpm仓库(实际上是percona的仓库):http://repo.percona.com/release/
清华大学percona源:https://mirrors.tuna.tsinghua.edu.cn/percona/
因为只是一个备份工具,所以没必要编译安装,直接下载它的rpm包即可
下载地址:https://www.percona.com/downloads/Percona-XtraBackup-2.4/LATEST/
可以选择rpm包方式安装,也可以下载源码包编译安装,这里直接采用rpm包的方式进行安装
https://repo.percona.com/yum/release/7/RPMS/x86_64/
[root@master tools]# wget https://repo.percona.com/yum/release/7/RPMS/x86_64/percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
# xtrabackup 的使用需要安装相关的依赖包 否则使用过程中会报相关错误
[root@master tools]# yum install -y rsync perl perl-Digest-MD5 perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL
[root@master tools]# yum localinstall -y percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
[root@master ~]# rpm -qa | grep percona-xtrabackup
percona-xtrabackup-24-2.4.9-1.el7.x86_64
或者安装yum源,然后在安装xtrabackup:
参考文档:https://www.percona.com/doc/percona-xtrabackup/2.4/installation/yum_repo.html
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum update percona-release
yum list | grep percona
# qpress 用作压缩解压
yum install percona-xtrabackup-24 qpress
如果yum无法安装qpress
下载qpress-11-linux-x64.tar,解压即可,这个很简单
wget http://www.quicklz.com/qpress-11-linux-x64.tar
tar xvf qpress-11-linux-x64.tar
cp qpress /usr/bin
# 源码安装
wget -c https://github.com/PierreLvx/qpress/archive/refs/tags/20230507.tar.gz
tar xf 20230507
cd 20230507
make
make install
或者在该站下载rpm包:
https://pkgs.org/download/qpress
wget https://repo.percona.com/yum/release/7/RPMS/x86_64/qpress-11-1.el7.x86_64.rpm
Xtrabackup中主要包含两个工具详解
https://www.cnblogs.com/FireLL/p/13042287.html

-
xbcloud和xbcloud_osenv是xtrabackup新的高级特性:云备份;
-
xbcrypt也是新的特性,加密备份集;
-
xbstream是xtrabackup的流数据功能,通过流数据功能,可将备份内容打包并传给管道后的压缩工具进行压缩;
-
xtrabackup是主程序;
-
innobackupex在以前是一个perl脚本,会调用xtrabackup这个二进制工具,从xtrabackup 2.3开始,该工具使用C语言进行了重写,当前它是xtabackup二进制工具的一个软连接,但是实际的使用方法却不同,并且在以后的版本中会删除该工具
xtrabackup:是用于热备innodb,xtradb表中数据的工具,不能备份其他类型的表,也不能备份数据表结构;不能备份非 InnoDB 表,和 mysqld server 没有交互
innobackupex:是将xtrabackup进行封装的perl脚本,提供了备份myisam表的能力。
脚本用来备份非 InnoDB 表,同时会调用 xtrabackup 命令来备份 InnoDB 表,还会和 mysqld server 发送命令进行交互,如加读锁(FTWRL)、获取位点(SHOW SLAVE STATUS)等
在以前是一个perl脚本,会调用xtrabackup这个二进制工具,从xtrabackup 2.3开始,该工具使用C语言进行了重写,当前它是xtabackup二进制工具的一个软连接,但是实际的使用方法却不同,并且在以后的版本中会删除该工具

简单来说,innobackupex 在 xtrabackup 之上做了一层封装。
一般情况下,我们是希望能备份 MyISAM 表的,虽然我们可能自己不用 MyISAM 表,但是 mysql 库下的系统表是 MyISAM 的,因此备份基本都通过 innobackupex 命令进行
参数详解
https://www.cnblogs.com/zhoujinyi/p/5893333.html
备份阶段参数
-
--compress:该选项表示压缩innodb数据文件的备份。
-
--compress-threads:该选项表示并行压缩worker线程的数量。
-
--compress-chunk-size:该选项表示每个压缩线程worker buffer的大小,单位是字节,默认是64K。
-
--encrypt:该选项表示通过ENCRYPTION_ALGORITHM的算法加密innodb数据文件的备份,目前支持的算法有ASE128,AES192,AES256。
-
--encrypt-threads:该选项表示并行加密的worker线程数量。
-
--encrypt-chunk-size:该选项表示每个加密线程worker buffer的大小,单位是字节,默认是64K。
-
--encrypt-key:该选项使用合适长度加密key,因为会记录到命令行,所以不推荐使用。
-
--encryption-key-file:该选项表示文件必须是一个简单二进制或者文本文件,加密key可通过以下命令行命令生成:
openssl rand -base64 24。 -
--include:该选项表示使用正则表达式匹配表的名字[db.tb],要求为其指定匹配要备份的表的完整名称,即databasename.tablename。
-
--user:该选项表示备份账号。
-
--password:该选项表示备份的密码。
-
--port:该选项表示备份数据库的端口。
-
--host:该选项表示备份数据库的地址。
-
--databases:该选项接受的参数为数据名,如果要指定多个数据库,彼此间需要以空格隔开;如:
"xtra_test dba_test",同时,在指定某数据库时,也可以只指定其中的某张表。如:mydatabase.mytable。该选项对innodb引擎表无效,还是会备份所有innodb表。此外,此选项也可以接受一个文件为参数,文件中每一行为一个要备份的对象。 -
--tables-file:该选项表示指定含有表列表的文件,格式为database.table,该选项直接传给--tables-file。
-
--socket:该选项表示mysql.sock所在位置,以便备份进程登录mysql。
-
--no-timestamp:该选项可以表示不要创建一个时间戳目录来存储备份,指定到自己想要的备份文件夹。
-
--ibbackup:该选项指定了使用哪个xtrabackup二进制程序。IBBACKUP-BINARY是运行percona xtrabackup的命令。这个选项适用于xtrbackup二进制不在你是搜索和工作目录,如果指定了该选项,innoabackupex自动决定用的二进制程序。
-
--slave-info:该选项表示对slave进行备份的时候使用,打印出master的名字和binlog pos,同样将这些信息以change master的命令写入xtrabackup_slave_info文件。可以通过基于这份备份启动一个从库。
-
--safe-slave-backup:该选项表示为保证一致性复制状态,这个选项停止SQL线程并且等到show status中的slave_open_temp_tables为0的时候开始备份,如果没有打开临时表,bakcup会立刻开始,否则SQL线程启动或者关闭知道没有打开的临时表。如果slave_open_temp_tables在--safe-slave-backup-timeount(默认300秒)秒之后不为0,从库sql线程会在备份完成的时候重启。
-
--rsync:该选项表示通过rsync工具优化本地传输,当指定这个选项,innobackupex使用rsync拷贝非Innodb文件而替换cp,当有很多DB和表的时候会快很多,不能--stream一起使用。
-
--kill-long-queries-timeout:该选项表示从开始执行FLUSH TABLES WITH READ LOCK到kill掉阻塞它的这些查询之间等待的秒数。默认值为0,不会kill任何查询,使用这个选项xtrabackup需要有Process和super权限。
-
--kill-long-query-type:该选项表示kill的类型,默认是all,可选select。
-
--ftwrl-wait-threshold:该选项表示检测到长查询,单位是秒,表示长查询的阈值。
-
--ftwrl-wait-query-type:该选项表示获得全局锁之前允许那种查询完成,默认是ALL,可选update。
-
--galera-info:该选项表示生成了包含创建备份时候本地节点状态的文件xtrabackup_galera_info文件,该选项只适用于备份PXC。
-
--stream:该选项表示流式备份的格式,backup完成之后以指定格式到STDOUT,目前只支持tar和xbstream。
-
--defaults-file:该选项指定了从哪个文件读取MySQL配置,必须放在命令行第一个选项的位置。
-
--defaults-extra-file:该选项指定了在标准defaults-file之前从哪个额外的文件读取MySQL配置,必须在命令行的第一个选项的位置。一般用于存备份用户的用户名和密码的配置文件。
-
----defaults-group:该选项表示从配置文件读取的组,innobakcupex多个实例部署时使用。
-
--no-lock:该选项表示关闭FTWRL的表锁,只有在所有表都是Innodb表并且不关心backup的binlog pos点,如果有任何DDL语句正在执行或者非InnoDB正在更新时(包括mysql库下的表),都不应该使用这个选项,后果是导致备份数据不一致,如果考虑备份因为获得锁失败,可以考虑--safe-slave-backup立刻停止复制线程。
-
--tmpdir:该选项表示指定--stream的时候,指定临时文件存在哪里,在streaming和拷贝到远程server之前,事务日志首先存在临时文件里。在 使用参数stream=tar备份的时候,你的xtrabackup_logfile可能会临时放在/tmp目录下,如果你备份的时候并发写入较大的话 xtrabackup_logfile可能会很大(5G+),很可能会撑满你的/tmp目录,可以通过参数--tmpdir指定目录来解决这个问题。
-
--history:该选项表示percona server 的备份历史记录在percona_schema.xtrabackup_history表。
-
--incremental:该选项表示创建一个增量备份,需要指定--incremental-basedir。
-
--incremental-basedir:该选项表示接受了一个字符串参数指定含有full backup的目录为增量备份的base目录,与--incremental同时使用。
-
--incremental-dir:该选项表示增量备份的目录。
-
--incremental-force-scan:该选项表示创建一份增量备份时,强制扫描所有增量备份中的数据页。
-
--incremental-lsn:该选项表示指定增量备份的LSN,与--incremental选项一起使用。
-
--incremental-history-name:该选项表示存储在PERCONA_SCHEMA.xtrabackup_history基于增量备份的历史记录的名字。Percona Xtrabackup搜索历史表查找最近(innodb_to_lsn)成功备份并且将to_lsn值作为增量备份启动出事lsn.与innobackupex--incremental-history-uuid互斥。如果没有检测到有效的lsn,xtrabackup会返回error。
-
--incremental-history-uuid:该选项表示存储在percona_schema.xtrabackup_history基于增量备份的特定历史记录的UUID。
-
--close-files:该选项表示关闭不再访问的文件句柄,当xtrabackup打开表空间通常并不关闭文件句柄目的是正确的处理DDL操作。如果表空间数量巨大,这是一种可以关闭不再访问的文件句柄的方法。使用该选项有风险,会有产生不一致备份的可能。
-
--compact:该选项表示创建一份没有辅助索引的紧凑的备份。
-
--throttle:该选项表示每秒IO操作的次数,只作用于bakcup阶段有效。apply-log和--copy-back不生效不要一起用。
prepare阶段参数
- --apply-log:该选项表示同xtrabackup的--prepare参数,一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数据中可能会包含尚未提交的事务或已经提交但尚未同步至数据文件中的事务。因此,此时数据 文件仍处理不一致状态。--apply-log的作用是通过回滚未提交的事务及同步已经提交的事务至数据文件使数据文件处于一致性状态。
-
--use-memory:该选项表示和--apply-log选项一起使用,prepare 备份的时候,xtrabackup做crash recovery分配的内存大小,单位字节。也可(1MB,1M,1G,1GB),推荐1G。
-
--defaults-file:该选项指定了从哪个文件读取MySQL配置,必须放在命令行第一个选项的位置。
-
--export:这个选项表示开启可导出单独的表之后再导入其他Mysql中。
-
--redo-only:这个选项在prepare base full backup,往其中merge增量备份(但不包括最后一个)时候使用
解压解密:
-
--decompress:该选项表示解压--compress选项压缩的文件。
-
--parallel:该选项表示允许多个文件同时解压。为了解压,qpress工具必须有安装并且访问这个文件的权限。这个进程将在同一个位置移除原来的压缩/加密文件。
-
--decrypt:该选项表示解密通过--encrypt选项加密的.xbcrypt文件
还原:
-
--copy-back:做数据恢复时将备份数据文件拷贝到MySQL服务器的datadir。
-
--move-back:这个选项与--copy-back相似,唯一的区别是它不拷贝文件,而是移动文件到目的地。这个选项移除backup文件,用时候必须小心。使用场景:没有足够的磁盘空间同事保留数据文件和Backup副本
注意:
1.datadir目录必须为空。除非指定innobackupex --force-non-empty-directorires选项指定,否则--copy-backup选项不会覆盖
2.在restore之前,必须shutdown MySQL实例,你不能将一个运行中的实例restore到datadir目录中
3.由于文件属性会被保留,大部分情况下你需要在启动实例之前将文件的属主改为mysql,这些文件将属于创建备份的用户
chown -R my5711:mysql /data1/dbrestore
以上需要在用户调用Innobackupex之前完成
- --force-non-empty-directories:指定该参数时候,使得innobackupex
--copy-back或--move-back选项转移文件到非空目录,已存在的文件不会被覆盖。如果--copy-back和--move-back文件需要从备份目录拷贝一个在datadir已经存在的文件,会报错失败。即原data目录下可以有其他文件,但是不能有与恢复文件中同名的文件,否则恢复失败
常用选项:
-
--host 指定主机
-
--user 指定用户名
-
--password 指定密码
-
--port 指定端口
-
--socket= #指定socket文件路径
-
--databases 备份指定数据库,多个空格隔开,如--databases=
"dbname1 dbname2",不加该参数是备份所有库,注意 --databases参数值要用引号括起来 -
--tables-file 将要备份的表名或库名都写在一个文本文件中
-
--defaults-file 从MySQL的选项文件中读取参数,使用选项--defaluts-file指定连接时的参数配置文件,但如果指定该选项,该选项只能放在第一个选项位置(这个参数默认就本机的my.cnf配置文件,就是你在那台服务器上备份就是这台服务器上的my.cnf文件)
-
--incremental 创建增量备份,后跟增量备份路径
-
--incremental-basedir 指定包含完全备份的目录
增备时使用--incremental选项表示增量备份,增量备份时需要通过--incremental-basedir=fullback_PATH指定基于哪个备份集备份,因为是第一次增备,所以要基于完全备份增量集
-
--incremental-dir 指定包含增量备份的目录
-
--apply-log 对备份进行预处理操作
一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数据中可能会包含尚未提交的事务或已经提交但尚未同步至数据文件中的事务。因此,此时数据文件仍处理不一致状态。"准备"的主要作用正是通过回滚未提交的事务及同步已经提交的事务至数据文件也使得数据文件处于一致性状态。
-
--redo-only #合并全备和增量备份数据文件,不回滚未提交事务
-
--copy-back 恢复备份目录,数据库目录要为空
-
--no-timestamp #生成备份文件不以时间戳为目录名
-
--stream= #指定流的格式做备份,--stream=tar,将备份文件归档
-
--compress #压缩功能,配合-stream=xbstream
-
--compress-threads=4 #用于并行数据压缩的线程数。此选项的默认值为1。配合-stream=xbstream
-
--parallel= #指定线程数
-
--no-timestamp #生成备份文件不以时间戳为目录名
-
--remote-host=user@ip DST_DIR #备份到远程主机
-
--user-memory选项来指定其可以使用的内存的大小,默认为100M
-
--no-timestamp 在使用innobackupex进行备份时,还可以使用--no-timestamp选项来阻止命令自动创建一个以时间命名的目录:如此一来,innobackupex命令将会创建一个BACKUP-DIR目录来存储备份数据
-
--throttle=NUMBER #限制innobackupex读写InnoDB数据的速率
-
--slave-info, 备 份从库, 加上--slave-info备份目录下会多生成一个xtrabackup_slave_info 文件, 这里会保存主日志文件以及偏移, 文件内容类似于:CHANGE MASTER TO MASTER_LOG_FILE='', MASTER_LOG_POS=0
-
--rsync 加快本地文件传输,适用于non-InnoDB数据库引擎。不与--stream共用
备份时生成的文件详解
使用innobackupex备份时,其会调用xtrabackup备份所有的InnoDB表,复制所有关于表结构定义的相关文件(.frm)、以及MyISAM、MERGE、CSV和ARCHIVE表的相关文件,同时还会备份触发器和数据库配置信息相关的文件,这些文件会被保存到一个以时间命名的目录当中。在备份的同时,innobackupex还会在备份目录中创建如下文件:
- xtrabackup_checkpoints -- backup_type(备份类型(如完全(full-backuped)或增量))、备份状态(如是否已经为prepared状态)和LSN(备份的起始、终止LSN号,日志序列号)范围信息:
每个InnoDB页(通常为16k大小)都会包含一个日志序列号,即LSN,LSN是整个数据库系统的系统版本号,每个页面相关的LSN能够表明此页面最近是如何发生改变的。
-
xtrabackup_binlog_info -- mysql服务器当前正在使用的二进制日志文件及备份这一刻位置二进制日志时间的位置。
-
xtrabackup_binlog_pos_innodb -- 二进制日志文件及用于InnoDB或XtraDB表的二进制日志文件的当前position。
-
xtrabackup_binary -- 备份中用到的xtrabackup的可执行文件;
-
backup-my.cnf -- 备份命令用到的配置选项信息。backup-my.cnf是拷贝过来的配置文件。里面只包含[mysqld]配置片段和备份有关的选项
-
xtrabackup_info -- 备份用到命令及相关配置选项信息。备份过程中的一些信息
-
xtrabackup_logfile -- 是复制和监控后写的redo日志。该日志是备份后下一个操作
准备的关键。只有通过它才能实现数据一致性
使用一个最小权限的用户进行备份
如果要使用一个最小权限的用户进行备份,则可基于如下命令创建此类用户:如果要使用一个最小权限的用户进行备份,则可基于如下命令创建此类用户:
mysql> CREATE USER 'bkpuser'@'localhost' IDENTIFIED BY '123456'; #创建用户
mysql> REVOKE ALL PRIVILEGES,GRANT OPTION FROM 'bkpuser'; #回收此用户所有权限
mysql> GRANT PROCESS,RELOAD,LOCK TABLES,RELICATION CLIENT ON *.* TO 'bkpuser'@'localhost'; #授权查看所有用户线程/连接的权限、刷新、锁定表、用户查看服务器状态
mysql> FLUSH PRIVILEGES; #刷新授权表
注意:备份时需启动MySQL,恢复时需关闭MySQL,清空mysql数据目录且不能重新初始化,恢复数据后应该立即进行一次完全备份
xtrabackup全量备份与恢复详解
备份:
不压缩:
innobackupex --defaults-file=/etc/my.cnf --user=DBUSER --password=DBUSERPASS --parallel=4 /path/to/BACKUP-DIR/
压缩:
innobackupex --defaults-file=/etc/my.cnf --user=DBUSER --password=DBUSERPASS --compress --compress-threads=4 --parallel=4 /path/to/BACKUP-DIR/
不使用当前时间创建目录:
- --no-timestamp
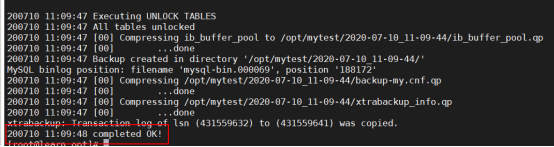
如果使用了压缩功能,某些备份的文件是以qp结尾的文件且是加密的。恢复时需要解压(解压需要安装qpress工具),否则备份的数据无法导入
恢复:(全备恢复数据时,数据库目录必须为空目录才能进行恢复成功)
恢复的阶段就是向MySQL的datadir拷贝。全备份的恢复要求MySQL必须处于stop状态,并且datadir必须为空哪怕是和MySQL无关的文件也不能存在,它不会去覆盖datadir中已存在的内容。否则会提示如下错误:
innobackupex version 2.4.6 based on MySQL server 5.7.13 Linux (x86_64) (revision id: 8ec05b7)
Original data directory /mydata/data is not empty!
innobackupex --decompress ./2020-07-10_11-14-39/ --parallel=4
innobackupex --apply-log /backups/2018-07-30_11-04-55/
innobackupex --defaults-file=/etc/my.cnf --datadir=/MysqlData/ --copy-back /backups/2018-07-30_11-04-55/

(1)准备(prepare)一个完全备份
一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数据中可能会包含尚未提交的事务或者已经提交但尚未同步至数据文件中的事务。因此,此时数据文件仍处于不一致状态。准备的主要作用正是通过回滚未提交的事务及同步已经提交的事务至数据文件也使用得数据文件处于一致性状态。
innobackupex命令的--apply-log选项可用于实现上述功能,如下面的命令:
innobackupex --apply-log /path/to/BACKUP-DIR # 如果执行正确,其最后输出的几行信息通常如下:
120407 09:01:04 innobackupex: completed OK!
在实现准备的过程中,innobackupex通常还可以使用--user-memory选项来指定其可以使用的内存的大小,默认为100M.如果有足够的内存空间可用,可以多划分一些内存给prepare的过程,以提高其完成备份的速度。
(2)从一个完全备份中恢复数据
注意:恢复不用启动MySQL
innobackupex命令的--copy-back选项用于恢复操作,其通过复制所有数据相关的文件至mysql服务器DATADIR目录中来执行恢复过程。innobackupex通过backup-my.cnf来获取DATADIR目录的相关信息。
# innobackupex --copy-back /path/to/BACKUP-DIR
当数据恢复至DATADIR目录以后,还需要确保所有的数据文件的属主和属组均为正确的用户,如mysql,否则,在启动mysqld之前还需要事先修改数据文件的属主和属组。如:
# chown -R mysql.mysql /mydata/data/
xtrabackup全量备份及恢复
(1)全量备份
[root@learn ~]# innobackupex --user=root --password=666666 --host=127.0.0.1 /backups/
#在master上进行全库备份#语法解释说明:
#--user=root 指定备份用户
#--password=666666 指定备份用户密码
#--host 指定主机
#/backups 指定备份目录,没有该目录,会自动创建
[root@learn ~]# tree /backups/ -L 2 #查看备份数据
/backups/
└── 2020-04-05_21-10-38
├── backup
├── backup-my.cnf #备份用到的配置选项信息文件
├── ib_buffer_pool
├── ibdata1 #数据文件
├── mimi
├── mysql
├── performance_schema
├── sys
├── xtrabackup_binlog_info #mysql服务器当前正在使用的二进制日志文件和此时二进制日志时间的位置信息文件
├── xtrabackup_checkpoints #备份的类型、状态和LSN状态信息文件
├── xtrabackup_info
└── xtrabackup_logfile #备份的日志文件
6 directories, 7 files
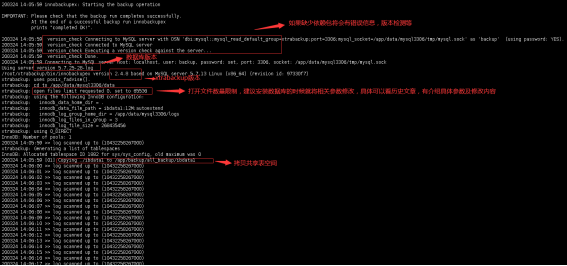
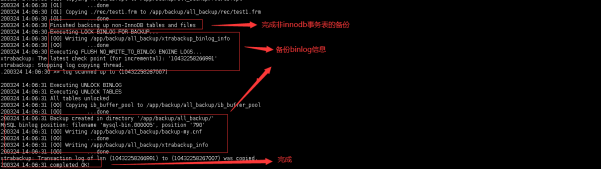
备份的结果存放在指定的目录里,内容如下:

注: 如果没有添加阻塞DDL操作的参数,备份过程中如有DDL操作,备份将终止。因此建议日常备份放在从库中进行
(2)基于全量备份的恢复
恢复的阶段就是向MySQL的datadir拷贝。全备份的恢复要求MySQL必须处于stop状态,并且datadir必须为空哪怕是和MySQL无关的文件也不能存在,它不会去覆盖datadir中已存在的内容。否则会提示如下错误:
innobackupex version 2.4.6 based on MySQL server 5.7.13 Linux (x86_64) (revision id: 8ec05b7)
Original data directory /mydata/data is not empty!
[root@learn ~]# /etc/init.d/mysql stop #停止slave上的mysql
Shutting down MySQL.. [ OK ]
#安装xtrabackup
[root@master tools]# wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.9/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
[root@master tools]# yum install -y percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
[root@master ~]# rpm -qa |grep xtrabackup
percona-xtrabackup-24-2.4.9-1.el7.x86_64
#从master上拷贝备份数据
[root@learn ~]# cd /backups/
[root@learn backups]# ls
2020-04-05_21-10-38
[root@learn backups]# scp -r 2020-04-05_21-10-38/ root@172.17.135.42:/opt/
#合并数据,使数据文件处于一致性的状态
[root@learn backups]# innobackupex --apply-log --redo-only /opt/2020-04-05_21-10-38/
#在这个准备阶段,有一个内存使用量选项"--use-memory",该选项默认值为100M,值越大准备的过程越快。当然,将该值加大的前提是服务器内存够用
#在slave上删除原有的数据
[root@learn ~]# rm -rf /MysqlData/*
#配置my.cnf的数据目录路径,否则会报错,要和master一致
[root@learn ~]# grep "datadir" /etc/my.cnf
datadir=/MysqlData
#在slave上数据恢复
[root@learn ~]# innobackupex --copy-back /opt/2020-04-05_21-10-38/
…………
200405 21:33:39 completed OK! #看到completed OK就是恢复正常了
#slave上查看数据目录,可以看到数据已经恢复,但是属主会有问题,需要进行修改,所以一般使用mysql的运行用户进行恢复,否则需要进行修改属主和属组信息
[root@learn ~]# ll /MysqlData
total 122920
drwxr-x--- 2 root root 4096 Apr 5 21:33 backup
-rw-r----- 1 root root 422 Apr 5 21:33 ib_buffer_pool
-rw-r----- 1 root root 12582912 Apr 5 21:33 ibdata1
-rw-r----- 1 root root 50331648 Apr 5 21:33 ib_logfile0
-rw-r----- 1 root root 50331648 Apr 5 21:33 ib_logfile1
-rw-r----- 1 root root 12582912 Apr 5 21:33 ibtmp1
drwxr-x--- 2 root root 4096 Apr 5 21:33 mimi
drwxr-x--- 2 root root 4096 Apr 5 21:33 mysql
drwxr-x--- 2 root root 4096 Apr 5 21:33 performance_schema
drwxr-x--- 2 root root 12288 Apr 5 21:33 sys
-rw-r----- 1 root root 484 Apr 5 21:33 xtrabackup_info
-rw-r----- 1 root root 1 Apr 5 21:33 xtrabackup_master_key_id
#修改属主属组
[root@learn ~]# chown -R mysql.mysql /MysqlData
#启动mysql
[root@learn ~]# /etc/init.d/mysql start
Starting MySQL.Logging to '/MysqlData/mysql-error.log'.
. [ OK ]
#查看数据,是否恢复
[root@learn ~]# mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| backup |
| mimi |
| mysql |
| performance_schema |
| sys |
+--------------------+
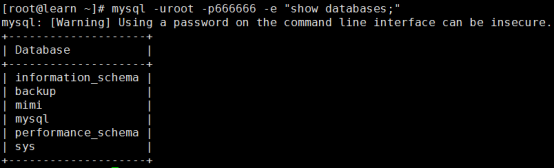
总结全库备份与恢复三步曲:
a. innobackupex全量备份,并指定备份目录路径;
b. 在恢复前,需要使用--apply-log参数先进行合并数据文件,确保数据的一致性要求;
c. 恢复时,直接使用--copy-back参数进行恢复,需要注意的是,在my.cnf中要指定数据文件目录的路径
xtrabackup基于第一次全备后再增量备份与恢复
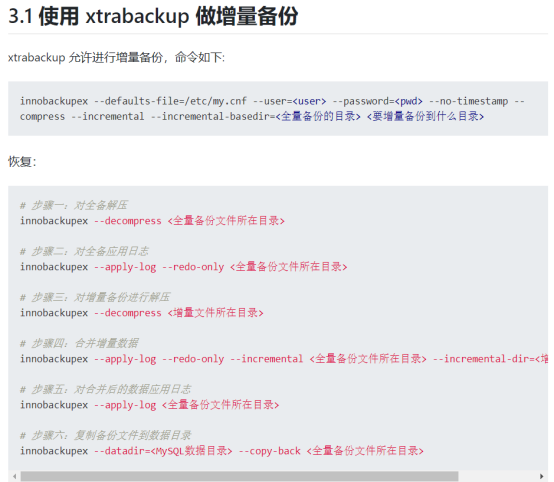
步骤四:

增量备份:
innobackupex --defaults-file=/etc/my.cnf --user=<user> --password=<pwd> --no-timestamp -compress --incremental --incremental-basedir=<全量备份的目录> <要增量备份到什么目录>
#步骤一:对全备解压
innobackupex --decompress <全量备份文件所在目录>
#步骤二:对全备应用日志
innobackupex --apply-log --redo-only <全量备份文件所在目录>
#步骤三:对增量备的进行解压
innobackupex --decompress <增量文件所在目录>
#步骤四:合并增量数据
innobackupex --apply-log --redo-only --incremental <全量备份文件所在目录> --incremental-dir=<增量文件所在目录>
#步骤五:对合并后的数据应用日志
innobackupex --apply-log <全量备份文件所在目录>
#步骤六:复制备份文件到数据目录
innobackupex --datadir=<MysQL数据目录> --copy-back <全量备份文件所在目录>
使用innobackupex进行增量备份,每个InnoDB的页面都会包含一个LSN信息,每当相关的数据发生改变,相关的页面的LSN就会自动增长。这正是InnoDB表可以进行增量备份的基础,即innobackupex通过备份上次完全备份之后发生改变的页面来实现。在进行增量备份时,首先要进行一次全量备份,第一次增量备份是基于全备的,之后的增量备份都是基于上一次的增量备份的,以此类推
要实现第一次增量备份,可以使用下面的命令进行:
基于全量备份的增量备份与恢复
做一次增量备份(基于当前最新的全量备份)
innobackupex --user=root --password=root --defaults-file=/etc/my.cnf --incremental /backups/ --incremental-basedir=/backups/2018-07-30_11-01-37
- 准备基于全量
innobackupex --user=root --password=root --defaults-file=/etc/my.cnf --apply-log --redo-only /backups/2018-07-30_11-01-37
- 准备基于增量
innobackupex --user=root --password=root --defaults-file=/etc/my.cnf --apply-log --redo-only /backups/2018-07-30_11-01-37 --incremental-dir=/backups/2018-07-30_13-51-47/
- 恢复
innobackupex --copy-back --defaults-file=/etc/my.cnf /opt/2017-01-05_11-04-55/
解释:
- 2018-07-30_11-01-37指的是完全备份所在的目录。
- 2018-07-30_13-51-47指定是第一次基于2018-07-30_11-01-37增量备份的目录,其他时有多次增量备份。每一次都要执行如上操作
需要注意的是:增量备份仅能应用于InnoDB或XtraDB表,对于MyISAM表而言,执行增量备份时其实进行的是完全备份。
"准备"(prepare)增量备份与整理完全备份有着一些不同,尤其要注意的是:
①需要在每个备份 (包括完全和各个增量备份)上,将已经提交的事务进行"重放"。"重放"之后,所有的备份数据将合并到完全备份上。
②基于所有的备份将未提交的事务进行回滚
(1)增量备份演示-->增量备份依赖于全备份
增量备份依赖于全备份。xtrabackup实现增量备份的原理是通过比较全备份的终点LSN和当前的LSN,增备时将从终点LSN开始一直备份到当前的LSN。在备份时也有redo log的监控线程,对于增备过程中导致LSN增长的操作也会写入到日志中。
增备的实现依赖于LSN,所以只对innodb有效,对myisam表使用增备时,背后进行的是全备
#全备数据
[root@learn ~]# innobackupex --user=root --password=666666 --host=127.0.0.1 /backups/
[root@learn ~]# tree /backups/ -L 2
/backups/
└── 2020-04-05_22-01-43
├── backup
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1
├── mimi
├── mysql
├── performance_schema
├── sys
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
6 directories, 7 files
查看xtrabackup_checkpoints可以得知相关的LSN
注意:要实现增备,这一次的全备一定不能进行"准备"操作(--apply-log操作),原因稍后给出。
#在master上创建student库并创建testtb表插入若干数据
[root@learn ~]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.7.28-log MySQL Community Server (GPL)
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| backup |
| mimi |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> create database student;
Query OK, 1 row affected (0.01 sec)
mysql> use student;
Database changed
mysql> create table testtb(id int);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into testtb values(1),(10),(99);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from testtb;
+------+
| id |
+------+
| 1 |
| 10 |
| 99 |
+------+
3 rows in set (0.00 sec)
mysql> quit;
Bye
#使用innobackupex进行增量备份
[root@learn ~]# innobackupex --user=root --password=666666 --host=127.0.0.1 --incremental /backups/ --incremental-basedir=/backups/2020-04-05_22-01-43/
……………………
200405 22:09:25 Executing UNLOCK TABLES
200405 22:09:25 All tables unlocked
200405 22:09:25 [00] Copying ib_buffer_pool to /backups/2020-04-05_22-09-21/ib_buffer_pool
200405 22:09:25 [00] ...done
200405 22:09:25 Backup created in directory '/backups/2020-04-05_22-09-21/'
MySQL binlog position: filename 'mysql-bin.000001', position '767'
200405 22:09:25 [00] Writing /backups/2020-04-05_22-09-21/backup-my.cnf
200405 22:09:25 [00] ...done
200405 22:09:25 [00] Writing /backups/2020-04-05_22-09-21/xtrabackup_info
200405 22:09:25 [00] ...done
xtrabackup: Transaction log of lsn (2642063) to (2642072) was copied.
200405 22:09:25 completed OK!
[root@learn ~]# tree /backups/ -L 1
/backups/
├── 2020-04-05_22-01-43 #全备数据
└── 2020-04-05_22-09-21 #基于全备的第一次增量备份数据
2 directories, 0 files
#查看全量备份的xtrabackup_checkpoints
[root@learn ~]# cat /backups/2020-04-05_22-01-43/xtrabackup_checkpoints
backup_type = full-backuped #备份类型为全量备份
from_lsn = 0 #lsn从0开始
to_lsn = 2634299 #lsn到2634299结束
last_lsn = 2634308
compact = 0
recover_binlog_info = 0
flushed_lsn = 2634308
#查看增量备份的xtrabackup_checkpoints
[root@learn ~]# cat /backups/2020-04-05_22-09-21/xtrabackup_checkpoints
backup_type = incremental #备份类型为增量备份
from_lsn = 2634299 #lsn从2634299开始(与全备的结束位置一致的)
to_lsn = 2642069 #lsn到2642069结束
last_lsn = 2642072
compact = 0
recover_binlog_info = 0
flushed_lsn = 2642072
默认情况下,增备的起始LSN是自动获取的,但是在某些情况下无法获取,还有些情况下无法获取到将要增备的basedir。xtrabackup提供的选项--incremental-lsn=N可以显式指定增备的起始LSN,显式指定LSN时,可以无需提供增备的basedir。
例如,如果获取到了上次全备的终止LSN为7533367093,可以如下方式增备:
innobackupex --user=root --password=123456 --incremental /bakdir/ --incremental-lsn=7533367093
(2)增量备份后数据恢复演示
(1)模拟mysql故障,删除数据目录所有数据
#模拟mysql故障,停止mysql
[root@learn ~]# /etc/init.d/mysql stop
Shutting down MySQL.. [ OK ]
#模拟数据错误,删除数据目录中的所有数据
[root@learn ~]# rm -rf /MysqlData/*
(2)合并全备数据目录,确保数据的一致性
[root@learn ~]# innobackupex --apply-log --redo-only /backups/2020-04-05_22-01-43/
(3)将增量备份数据合并到全备数据目录当中
[root@learn ~]# innobackupex --apply-log --redo-only /backups/2020-04-05_22-01-43/ --incremental-dir=/backups/2020-04-05_22-09-21/
[root@learn ~]# cat /backups/2020-04-05_22-01-43/xtrabackup_checkpoints
backup_type = log-applied #查看到数据备份类型是增加
from_lsn = 0 #lsn从0开始
to_lsn = 2642063 #lsn结束号为最新的lsn
last_lsn = 2642072
compact = 0
recover_binlog_info = 0
flushed_lsn = 2642072
(4)对整合完成的全备集进行一次整体的准备
innobackupex --apply-log --redo-only /backups/2020-04-05_22-01-43/
(5)恢复数据
[root@learn ~]# innobackupex --copy-back /backups/2020-04-05_22-01-43/
再次查看数据目录就有数据了,但是权限未更改。
[root@learn ~]# ll /MysqlData
total 12336
drwxr-x--- 2 root root 4096 Apr 5 22:29 backup
-rw-r----- 1 root root 422 Apr 5 22:29 ib_buffer_pool
-rw-r----- 1 root root 12582912 Apr 5 22:29 ibdata1
drwxr-x--- 2 root root 4096 Apr 5 22:29 mimi
drwxr-x--- 2 root root 4096 Apr 5 22:29 mysql
drwxr-x--- 2 root root 4096 Apr 5 22:29 performance_schema
drwxr-x--- 2 root root 4096 Apr 5 22:29 student
drwxr-x--- 2 root root 12288 Apr 5 22:29 sys
-rw-r----- 1 root root 21 Apr 5 22:29 xtrabackup_binlog_pos_innodb
-rw-r----- 1 root root 556 Apr 5 22:29 xtrabackup_info
-rw-r----- 1 root root 1 Apr 5 22:29 xtrabackup_master_key_id
#更改数据的属主属组
[root@learn ~]# chown -R mysql.mysql /MysqlData
#启动mysql
[root@learn ~]# /etc/init.d/mysql start
Starting MySQL.Logging to '/MysqlData/mysql-error.log'.
.. [ OK ]
#查看数据是否恢复
[root@learn ~]# mysql -uroot -p -e "show databases;"
Enter password:
+--------------------+
| Database |
+--------------------+
| information_schema |
| backup |
| mimi |
| mysql |
| performance_schema |
| student |
| sys |
+--------------------+
从xtrabackup备份文件中恢复单表
https://www.cnblogs.com/f-ck-need-u/p/9018716.html#auto_id_10
https://www.cnblogs.com/xuanzhi201111/p/6609867.html
目前对MySQL比较流行的备份方式有两种,一种上是使用自带的mysqldump,另一种是xtrabackup,对于数据时大的环境,普遍使用了xtrabackup+binlog进行全量或者增量备份, 那么如何快速的从xtrabackup备份中恢复单张表呢?从mysql 5.6版本开始,支持可移动表空间(Transportable Tablespace),利用这个功能也可以实现单表的恢复,下面进行从备份中恢复单张innodb表进行演练
默认情况下,InnoDB表不能通过直接复制表文件的方式在mysql服务器之间进行移植,即便使用了innodb_file_per_table选项。而使用Xtrabackup工具可以实现此种功能,不过只能"导出"具有.ibd文件的表,也就是说导出表的mysql服务器启用了innodb_file_per_table选项,而且要导出的表还是在启用该选项之后才创建的。
导入表的是,要求导入表的服务器版本是MySQL 5.6+,且启用了innodb_file_per_table选项
安装工具
-
针对InnoDB表恢复
-
开启了参数:
innodb_file_per_table -
安装工具:mysql-utilities,其中mysqlfrm可以读取表结构
进行mysql-utilities安装:使用mysqlfrm从备份中读取表结构(或者在未丢失的情况下备份表结构,而且建议用这种方式。而不是用mysqlfrm 工具查看):
yum install mysql-utilities -y
# mysqlfrm --server=root:'Oez@L*K1&'@172.31.18.51:3306 ./local_full/2021-01-09_19-07-26/test/test.frm --diagnostic
# mysqlfrm --diagnostic local_full/2021-01-09_19-07-26/test/test.frm
2、mysqlfrm相关参数介绍
- --server : 远程连接到mysql,如--server=user:password@192.168.1.10:3306
- --diagnostic : 开启按字节模式来恢复frm结构
-
--user :启动MySQL用户,通常为mysql
-
--port :启动MySQL端口,通常为3306
- --basedir :如 --basedir=/usr/local/mysql
注意: 使用--basedir恢复出来的varchar竟然是--server模式的3倍;这应该是mysqlfrm在使用basedir模式时,无法进行字符编码校验所致引起的。
再次看了下--server的文件:(重点看标红加粗的文字),建议:能用--server模式时,尽量使用--server同时保证提供mysqld环境与原生产环境的一致。
--server=server
Connection information for a server. Use this option or --basedir for the default mode. If provided with the diagnostic mode, the storage engine and character set information are validated against this server.
(1). 导出表
导出表是在准备的过程中进行的,不是在备份的时候导出。对于一个已经备份好的备份集,使用"--apply-log"和"--export"选项即可导出备份集中的表。
假如以全备份集local_full/2021-01-09_19-07-26/为例,要导出其中的表。
在导出其中的表之前需要预处理
# innobackupex --apply-log --redo-only local_full/2021-01-09_19-07-26/
然后在导出
# innobackupex --apply-log --export local_full/2021-01-09_19-07-26/
在导出过程中,会看到如下关键信息:
xtrabackup: export metadata of table 'test/test' to file `./test/test.exp` (1 indexes)
xtrabackup: name=GEN_CLUST_INDEX, id.low=11782, page=3
它说明了创建了一个.exp文件。
查看备份集目录下的local_full/2021-01-09_19-07-26/test/目录,会发现多出了2个文件:.cfg和.exp,再加上.ibd文件,这3个文件是后续导入表时所需的文件
# ll local_full/2021-01-09_19-07-26/test/
total 132
-rw-r----- 1 root root 60 Jan 9 20:19 db.opt
-rw-r--r-- 1 root root 2755 Jan 9 20:22 test.cfg
-rw-r----- 1 root root 16384 Jan 9 20:22 test.exp
-rw-r----- 1 root root 11088 Jan 9 20:19 test.frm
-rw-r----- 1 root root 98304 Jan 9 20:19 test.ibd
(2). 导入表
要在mysql服务器上导入来自于其它服务器的某innodb表,需要先在当前服务器上创建一个跟原表表结构一致的表,而后才能实现将表导入:
利用 mysqlfrm工具查看表结构,或者在之前就备份表结构
# mysqlfrm --server=root:'Oez@L*K1&'@172.31.18.51:3306 ./local_full/2021-01-09_19-07-26/test/test.frm --diagnostic
根据上面的结构创建表结构
mysql> CREATE TABLE `test`.`test` ( `id` bigint(20) NOT NULL,……) ENGINE=InnoDB;
然后将此表的表空间删除(删除了就无法查看这个表的内容了,表空间就是这个特征):
mysql> ALTER TABLE `test`.`test` DISCARD TABLESPACE;
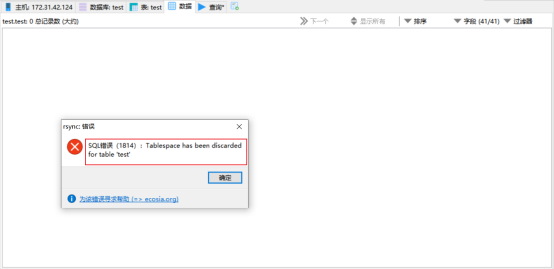
接下来,将来自于"导出"表的的.ibd和.exp文件复制到当前服务器的数据目录(新数据库的数据目录这里是/MysqlData/test/),然后修改文件的权限。
cp local_full/2021-01-09_19-07-26/test/test.exp /MysqlData/test/
cp local_full/2021-01-09_19-07-26/test/test.ibd /MysqlData/test/
chown mysql.mysql /MysqlData/test/test.exp
chown mysql.mysql /MysqlData/test/test.ibd
如果导入目标服务器是MySQL 5.6+,也可以复制.cfg文件。然后使用如下命令将其"导":
mysql> ALTER TABLE test.test IMPORT TABLESPACE;
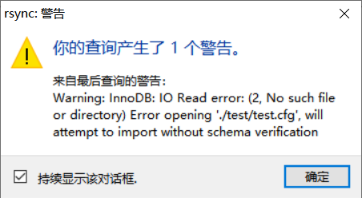
有报一个warning,但不影响恢复,详情可以看:https://yq.aliyun.com/articles/59271,我们查一下数据:
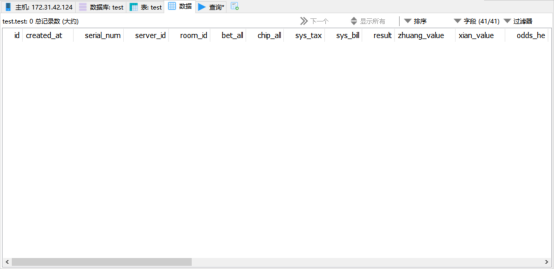
test表已经成功恢复
innobackupex实现部分备份和恢复的过程(Creating Partial Backups)
https://www.cnblogs.com/f-ck-need-u/p/9018716.html#auto_id_11
https://blog.csdn.net/zhu19774279/article/details/49681767
https://www.cnblogs.com/allenhu320/p/11311056.html
注意:部分备份(--include、--tables-file、--database)需要开启 innodb_file_per_table
xtrabackup支持部分备份,意味着可以指定备份哪个数据库或者哪个表。
部分备份只有一点需要注意:在恢复的时候不要通过"--copy-back"的方式拷贝回datadir,而是应该使用导入表的方式。尽管使用拷贝的方式有时候是可行的,但是很多情况下会出现数据库不一致的状态。
(1). 备份
部分备份共有三种方式,分别是:
- 用正则表达式表示要备份的库名及表名(参数为--include),这种方式要使用完整对象引用格式,即db_name.tab_name的方式
- 将要备份的表分行枚举到一个文件中,通过"--tables-file"指定该文件(参数为--tables-file)
- 或者使用"--databases"指定要备份的数据库或表,指定备份的表时要使用完整对象引用格式,多个元素使用空格分开(参数为:--databases)。
使用前两种部分备份方式,只能备份innodb表,不会备份任何myisam,即使指定了也不会备份。而且要备份的表必须有独立的表空间文件,也就是说必须开启了innodb_file_per_table,更精确的说,要备份的表是在开启了innodb_file_per_table选项之后才创建的。第三种备份方式可以备份myisam表
(译者注:不管你备份哪个库或是哪张表,强烈推荐把mysql库也一起备份,恢复的时候要用。)
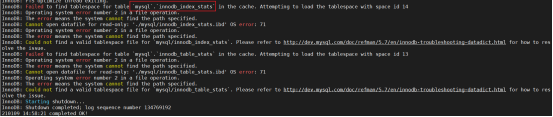
这就是没有备份mysql库,会报错找不到该库
方式一:使用--include参数
使用正则模式匹配备份部分库表,需要使用参数--include
innobackupex --include='^back.*[.]num_*' /backupdir --user=root --password=msds007
将备份back字母开头的数据库中num开头的表,其中[.]的中括号不能少,因为正则中.有特殊意义,所以使用中括号来枚举以实现对象的完整引用。
方式二:使用表列表备份部分表,需要使用参数--tables-file,语句类似如下:
cat /tmp/tables.txt
test.t
test.testflashback2
innobackupex --tables-file=/tmp/tables.txt /backup --user=root --password=msds007
使用--include和--tables-file备份后,会生成一个时间戳目录,目录中只有和要备份的表有关的文件
如果使用的是--databases选项,则会生成一个时间戳目录,里面有备份的数据库代表的目录,如果只备份了某个表,则该数据库目录中只有该表相关的文件
方式三:使用--databases参数
innobackupex --user=root --password='123654$' --databases='mysql.user test' ./bakdir
上面只备份mysql.user表和test数据库,在生成的时间戳目录中将有两个mysql目录和test目录
# tree bakdir/
bakdir/
└── 2021-01-11_14-24-48
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1
├── mysql
│ ├── user.frm
│ ├── user.MYD
│ └── user.MYI
├── test
│ ├── db.opt
│ ├── test.frm
│ └── test.ibd
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
3 directories, 13 files
(2). 部分备份的准备和恢复过程
部分备份的准备和恢复过程分别是导出表和导入表的过程。见上文
准备部分备份(Preparing Partial Backups)
执行preparing partial backups,与恢复独立的表(Restoring Individual Tables)很类似:使用--apply-log和--export参数,并包含上一步生成的时间戳文件夹
innobackupex --apply-log --export bakdir/2021-01-11_14-24-48/
流备份和备份到远程
https://www.cnblogs.com/f-ck-need-u/p/9018716.html#auto_id_13
xtrabackup支持备份流,当前可用的流类型只有tar和xtrabackup自带的xbstream,通过流可以将它们传递给其他程序进行相关的操作,如压缩。但是不建议在备份的同时进行压缩,因为压缩会占用极大的cpu资源,使得备份时间延长很多,温备的过程也就延长了。
另外,MySQL的数据文件压缩比非常大,所以建议备份后在空闲的时候进行压缩。
xtrabackup还支持备份到远程,只需使用--remote-host指定远程的主机名即可,指定方式和ssh指定的方式一样。如--remote-host=root@192.168.100.18
使用流备份的方法如下:
#使用tar流
innobackupex --user=root --password=123456 --stream=tar /bakdir/ >/tmp/a.tar
# 使用tar流的同时交给gzip压缩
innobackupex --user=root --password=123456 --stream=tar /bakdir/ | gzip >/tmp/a.tar.gz
# 使用tar流备份到远程主机中并归档
innobackupex --user=root --password=123456 --stream=tar /bakdir/ | ssh root@192.168.100.10 "cat - > /tmp/`date +%F_%H-%M-%S`.tar"
# 使用tar流备份到原远程主机中并解包
innobackupex --user=root --password=123456 --stream=tar /bakdir/ | ssh root@192.168.100.10 "cat - | tar -x -C /tmp/"
# 使用xtrabackup自带的xbstream流
innobackupex --user=root --password=123456 --stream=xbstream /bakdir/ >/tmp/b.xbs
# 解压xbstream流
innobackupex --user=root --password=123456 --stream=xbstream /bakdir/ | ssh root@192.168.100.10 "cat - | xbstream -x -C /tmp/"
# 使用xbstream流的同时进行压缩,使用"--compress"选项
innobackupex --user=root --password=123456 --stream=xbstream --compress /bakdir/ > /bakdir/backup.xbs
注意:如果在解压备份的.tar.gz时出错,可能在解压的时候需要使用-i选项。如
tar -xif /tmp/b.tar/gz
加速备份
https://www.cnblogs.com/f-ck-need-u/p/9018716.html#auto_id_14
当备份到本地的时候,可以使用--rsync选项,该选项用于在flush tables with read lock后调用rsync替代cp进程复制非Innodb数据和.frm文件,加快复制速度。
但要注意,因为支持备份锁的版本在获取到backup locks的时候会自动复制非Innodb数据和.frm文件,所以--rsync选项是无效的。
另外,该选项不能和--stream选项和--remote-host选项同时使用
脚本
https://www.cnblogs.com/FireLL/p/13042287.html
总结:
(1)增量备份需要使用参数--incremental指定需要备份到哪个目录,使用incremental-basedir指定全备目录;
(2)进行数据备份时,需要使用参数--apply-log redo-only先合并全备数据目录数据,确保全备数据目录数据的一致性;
(3)再将增量备份数据使用参数--incremental-dir合并到全备数据当中;
(4)最后通过最后的全备数据进行恢复数据,注意,如果有多个增量备份,需要逐一合并到全备数据当中,再进行恢复
#1. --user=root 指定备份的用户
#2. --password=root指定备份用户的密码
#3. --defaults-file=/etc/my.cnf 指定的备份数据的配置文件
#4. /opt/ 指定备份后的数据保存路径
关于阿里云RDS物理备份数据使用xtrabackup工具恢复到本地mysql当中,请参考阿里云文档:https://help.aliyun.com/knowledge_detail/41817.html?spm=5176.11065259.1996646101.searchclickresult.53d420cclqekK3
Xtrabackup完全备份+两次增量备份
博客参考:https://blog.51cto.com/bigboss/2095153
https://blog.csdn.net/qq_36183569/article/details/83024114
环境:
CentOS Linux release 7.7.1908 (Core)
mysql Ver 14.14 Distrib 5.7.28, for linux-glibc2.12 (x86_64) using EditLine wrapper
EPEL源
Xtrabackup-24工具包
一、两台主机分别安装Xtrabackup
wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.9/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
yum install percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm -y
# Xtrabackup包依赖于epel源一些工具包,所以使用yum安装。
二、完全备份数据库
当前数据库状态:
[root@learn ~]# mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| backup |
| mimi |
| mysql |
| performance_schema |
| student |
| sys |
+--------------------+
完全备份数据库:
[root@learn ~]# innobackupex --defaults-file=/etc/my.cnf --user=root --password=666666 /backup/
出现completed OK!表示备份完成
备份的数据:
[root@learn ~]# tree /backup -L 2
/backup
└── 2020-04-05_22-57-56
├── backup
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1
├── mimi
├── mysql
├── performance_schema
├── student
├── sys
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
7 directories, 7 files
三、修改数据,并执行第一次增量备份
mysql> create database 1st;
[root@learn ~]# mysql -uroot -p666666 -e "create database 1st"
mysql: [Warning] Using a password on the command line interface can be insecure.
修改后的数据:
[root@learn ~]# mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| 1st |
| backup |
| mimi |
| mysql |
| performance_schema |
| student |
| sys |
+--------------------+
进行增量备份:
[root@learn ~]# mkdir /backup/up1
[root@learn ~]# innobackupex --defaults-file=/etc/my.cnf --user=root --password=666666 --incremental /backup/up1 --incremental-basedir=/backup/2020-04-05_22-57-56/
第一次增量备份的数据:
[root@learn ~]# tree /backup/up1/ -L 2
/backup/up1/
└── 2020-04-05_23-02-41
├── 1st
├── backup
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1.delta
├── ibdata1.meta
├── mimi
├── mysql
├── performance_schema
├── student
├── sys
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
8 directories, 8 files
四、再次修改数据,进行第二次增量备份
[root@learn ~]# mysql -uroot -p666666 -e "create database 2st;"
[root@learn ~]# mysql -uroot -p666666 -e "create database Xtrabackup_test;"
修改后的数据:
[root@learn ~]# mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| 1st |
| 2st |
| Xtrabackup_test |
| backup |
| mimi |
| mysql |
| performance_schema |
| student |
| sys |
+--------------------+
进行第二次增量备份:
[root@learn ~]# innobackupex --defaults-file=/etc/my.cnf --user=root --password=666666 --incremental --incremental-basedir=/backup/up1/2020-04-05_23-02-41/ /backup/up2/
三次备份后的数据:
[root@learn ~]# tree /backup -L 2
/backup
├── 2020-04-05_22-57-56
│ ├── backup
│ ├── backup-my.cnf
│ ├── ib_buffer_pool
│ ├── ibdata1
│ ├── mimi
│ ├── mysql
│ ├── performance_schema
│ ├── student
│ ├── sys
│ ├── xtrabackup_binlog_info
│ ├── xtrabackup_checkpoints
│ ├── xtrabackup_info
│ └── xtrabackup_logfile
├── up1
│ └── 2020-04-05_23-02-41
└── up2
└── 2020-04-05_23-08-09
11 directories, 7 files
五、恢复前准备
1.将备份数据和/etc/my.cnf文件拷贝到另一台主机
scp -r /backup/ 172.17.135.42:/root
scp /etc/my.cnf 172.17.135.42:/etc/
2.停止数据库,开始恢复前的准备工作;
[root@learn ~]# /etc/init.d/mysql stop
Shutting down MySQL.. [ OK ]
#回滚未提交的事务及同步已经提交的事务至数据文件使数据文件处于一致性状态:
[root@learn ~]# innobackupex --apply-log --redo-only /root/backup/2020-04-05_22-57-56/
3.将第一次增量备份整合进全备份中:
[root@learn ~]# innobackupex --apply-log --redo-only /root/backup/2020-04-05_22-57-56/ --incremental-dir=/root/backup/up1/2020-04-05_23-02-41/
4.将第二次增量备份整合进全备份中:
[root@learn ~]# innobackupex --apply-log --redo-only /root/backup/2020-04-05_22-57-56/ --incremental-dir=/root/backup/up2/2020-04-05_23-08-09/
六、开始恢复
1.确保数据目录为空,这里模拟删除mysql数据目录
[root@learn ~]# rm -rf /MysqlData/*
2.拷贝文件到数据目录
[root@learn ~]# innobackupex --copy-back --datadir=/MysqlData /root/backup/2020-04-05_22-57-56/
七、启动数据库
修改数据库目录权限:
[root@learn ~]# chown -R mysql.mysql /MysqlData
启动数据库:
[root@learn ~]# /etc/init.d/mysql start
Starting MySQL.Logging to '/MysqlData/mysql-error.log'.
.. [ OK ]
查看数据:
[root@learn ~]# mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| 1st |
| 2st |
| Xtrabackup_test |
| backup |
| mimi |
| mysql |
| performance_schema |
| student |
| sys |
+--------------------+
MySQL不停机维护主从同步
参考:https://mp.weixin.qq.com/s/CQFmFhtRMFsESofDpTOvUA
实战环境:
-
Mysql-5.7
-
Xtrabackup-2.4
-
若MySQL版本为5.7.x,建议使用xtrabackup 2.4.x
Xtrabackup 介绍:
官网:http://www.percona.com
Percona XtraBackup是一款基于MySQL的服务器的开源热备份实用程序,在备份过程中不会锁定数据库。它可以备份来自MySQL5.1,5.5,5.6和5.7服务器上的InnoDB,XtraDB和MyISAM表的数据,以及带有XtraDB的Percona服务器。
XtraBackup 有两个工具:xtrabackup 和innobackupex
-
Xtrabackup 本身只能备份InnoDB和XtraDB,不能备份MyISAM;
-
innobackupex 它是封装了xtrabackup的perl脚本,覆盖了xtrabackup的功能。
它不但可以备份Innodb和xtradb两种引擎的表,还可以备份myisam引擎的表(在备份myisam表时需要加一个读锁)
Xtrabackup特点:
-
备份过程快速、可靠;
-
备份过程不会打断正在执行的事务;
-
能够基于压缩等功能节约磁盘空间和流量;
-
自动实现备份检验;
-
还原速度快
Xtrabackup备份实现原理:
innobackupex开启xtrabackup_log监控线程,实时监测redolog文件的变化,将新备份过程中新写入到事务日志中的日志拷贝至innobackup_log中;同时开启xtrabackup拷贝线程,开始拷贝innodb文件,拷贝数据数据结构,记录当前binlog及position完成备份
全备恢复原理:
将全备文件进行xtrabackup_log日志回放,并对提交的事务进行重做,同时rollback未提交的事务。并将全备文件复制到mysql 下的data目录下
备份恢复操作实例
主数据库
1、安装xtrabackup工具
[root@learn ~]# yum install -y http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
[root@learn ~]# rpm -qa percona-release
percona-release-0.1-4.noarch
[root@learn ~]# ll /etc/yum.repos.d/percona-release.repo
-rw-r--r-- 1 root root 2501 Sep 20 2016 /etc/yum.repos.d/percona-release.repo
[root@learn ~]# yum update percona-release
Updated:
percona-release.noarch 0:1.0-15
Complete!
[root@learn ~]# ll /etc/yum.repos.d/percona-original-release.repo
-rw-r--r-- 1 root root 780 Apr 5 12:29 /etc/yum.repos.d/percona-original-release.repo
[root@learn ~]# rpm -qa percona-release
percona-release-1.0-15.noarch
[root@learn ~]# yum list percona-xtrabackup*
[root@learn ~]# yum install percona-xtrabackup-24 -y
[root@learn ~]# rpm -ql percona-xtrabackup-24
2、主数据库全量备份
全量备份
[root@learn ~]# innobackupex --defaults-file=/etc/my.cnf --user=root --password=666666 /data/backup

[root@learn ~]# tree /data/backup/ -L 2
/data/backup/
└── 2020-04-05_12-48-10
├── backup
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1
├── mimi
├── mysql
├── performance_schema
├── sys
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
6 directories, 7 files
保持事务一致性 apply-log的作用是通过回滚未提交的事务及同步已经提交的事务至数据文件处于一致性状态,把已提交的事务合并到ibdata文件
[root@learn ~]# innobackupex --apply-log /data/backup/2020-04-05_12-48-10
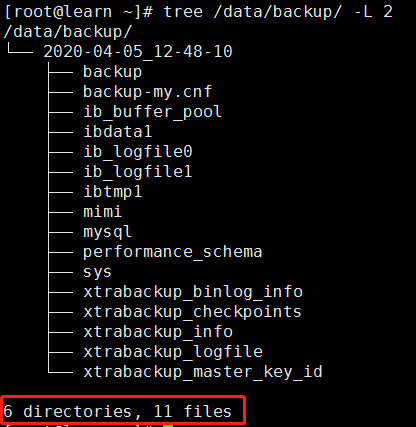
3、 将主数据库备份文件压缩并拷贝到从数据库
[root@learn ~]# cd /data/backup/
[root@learn backup]# tar czf backup.tar.gz 2020-04-05_12-48-10/
[root@learn backup]# ls
2020-04-05_12-48-10 backup.tar.gz
[root@learn ~]# scp -r /data/backup/backup.tar.gz 172.17.135.42:/opt/
4、 主库授权同步帐号
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slave_passport';
mysql> FLUSH PRIVILEGES;
5、查看主库备份到位置,从库从备份位置开始同步
[root@learn ~]# cat /data/backup/2020-04-05_12-48-10/xtrabackup_binlog_info
mysql-bin.000269 154
从数据库操作
1、从数据全量恢复
[root@learn ~]# cd /opt/ && tar xf backup.tar.gz
[root@learn opt]# ls backup.tar.gz 2020-04-05_12-48-10/
backup.tar.gz
2020-04-05_12-48-10/:
backup ibdata1 ibtmp1 performance_schema xtrabackup_checkpoints xtrabackup_master_key_id
backup-my.cnf ib_logfile0 mimi sys xtrabackup_info
ib_buffer_pool ib_logfile1 mysql xtrabackup_binlog_info xtrabackup_logfile
[root@learn opt]# innobackupex --defaults-file=/etc/my.cnf --user=root --copy-back /opt/2020-04-05_12-48-10

恢复成功的前提是数据库数据目录必须为空才行
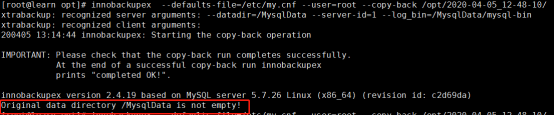
2、修改数据文件权限
[root@learn ~]# chown -R mysql:mysql /MysqlData
如果不修改数据库目录的权限,操作数据库就没有权限:
mysql> use mimi
Database changed
mysql> show tables;
ERROR 1018 (HY000): Can't read dir of './mimi/' (errno: 13 - Permission denied)
3、 启动从数据库
# /etc/init.d/mysql restart
4、查看主数据库第五步主库备份的位置,开始同步
mysql> CHANGE MASTER TO MASTER_HOST='172.21.0.9', \
MASTER_USER='slave', \
MASTER_PASSWORD='slave_passport', \
MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000269', \
MASTER_LOG_POS= 154;
5、开启主从同步
mysql> start slave;
mysql> show slave status\G
……
Slave_IO_Running=Yes
Slave_SQL_Running=Yes
……
MySql5.7从.frm和.ibd文件恢复数据
第一步:下载工具
# mysqlfrm,只支持python2
wget -c https://cdn.mysql.com/archives/mysql-utilities/mysql-utilities-1.6.5.tar.gz
cd python ./setup.py build
python ./setup.py install
python ./setup.py build
# mysqlfrm --diagnostic /data/mysql/gobgm/gobgm_users.frm # 解析出表结构
# dbsake
curl -s get.dbsake.net > /opt/dbsake
chmod +x /opt/dbsake
第二步:创建数据库
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `gobgm` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
第三步:从.frm文件中提取表结构,需要借助工具dbsake或者官方工具mysqlfrm
cat gobgm.sh
#!/bin/bash
#!/bin/bash
# Modify 1
dbName="gobgm"
# Modify 2
mysqlDataDir="/data/mysql"
dbDataDir="${mysqlDataDir}/${dbName}"
# Modify 3
dbsakeBin="/opt/dbsake"
# Modify 4
rdir="/opt/${dbName}"
test -d $rdir || mkdir $rdir
> $rdir/discard.sql
> $rdir/import.sql
# 检查目录是否存在
if [ -d "$dbDataDir" ]; then
# 遍历目录下的文件
for file in "$dbDataDir"/*.frm
do
if [ -f "$file" ]; then
echo "$file"
tName=`echo "$file" | awk -F'/' '{print $NF}' | awk -F'.' '{print $1}'`
# /data/mysql/gobgm/gobgm_users.frm
${dbsakeBin} frmdump $file > $rdir/${dbName}_$tName.sql
if [ $? -ne 0 ];then
echo "$file" >> $rdir/skiptname.txt
else
echo "ALTER TABLE ${dbName}.${tName} DISCARD TABLESPACE;" | awk '{printf "%-4s %-5s %-50s %-7s %-11s\n", $1, $2, $3, $4, $5}' >> $rdir/discard.sql
echo "ALTER TABLE ${dbName}.${tName} IMPORT TABLESPACE;" | awk '{printf "%-5s %-5s %-50s %-6s %-11s\n", $1, $2, $3, $4, $5}' >> $rdir/import.sql
fi
fi
done
else
echo "目录不存在: $dbDataDir"
exit 6
fi
cat $rdir/${dbName}_*.sql > /opt/${dbName}.sql
第四步:创建表
mysql --binary-mode=1 -u root -p gobgm < /opt/gobgm.sql # gobgm是导入到的目标库
第五步:清除表空间
# 只演示一个表的操作,其他表一样的操作,只修改表名即可
ALTER TABLE `gobgm`.`gobgm_users` DISCARD TABLESPACE; # 这一步会删除数据库下面的.ibd文件
第六步:复制.ibd文件到目标数据库的数据目录下面
cp -rp /data/mysql/gobgm/*.ibd path/gobgm/ # path/gobgm/表示新的数据库数据目录
第七步:将所有表导入表空间
# 只演示一个表的操作,其他表一样的操作,只修改表名即可
ALTER TABLE `gobgm`.`gobgm_users` IMPORT TABLESPACE;
第八步:验证数据完整性
一键自动恢复脚本
cat db_gobgm_auto.sh
#!/bin/bash
# Modify 1
dbName="gobgm"
# Modify 2
mysqlDataDir="/data/mysql"
dbDataDir="${mysqlDataDir}/${dbName}"
# Modify 3
dbsakeBin="/opt/dbsake"
# Modify 4
rdir="/opt/${dbName}"
test -d $rdir || mkdir $rdir
# Modify 5
newdbName="gobgm"
newMysqlDataDir="/data/testmysql"
newDbDataDir="${newMysqlDataDir}/${newdbName}"
newMysqlUser="root"
newMysqlPass="xxxxxx"
newMysqlHost="10.10.10.10"
newMysqlContainerName="testmysql"
##############################################
# 检查目录是否存在
if [ -d "$dbDataDir" ]; then
# 遍历目录下的文件
for file in "$dbDataDir"/*.frm
do
if [ -f "$file" ]; then
echo "$file"
tName=`echo "$file" | awk -F'/' '{print $NF}' | awk -F'.' '{print $1}'`
# /data/mysql/gobgm/gobgm_users.frm
${dbsakeBin} frmdump $file > $rdir/${dbName}_$tName.sql
if [ $? -ne 0 ];then
echo "$file" >> $rdir/skiptname.txt
else
# 本地没有mysql客户端命令
# 复制表结构sql到mysql容器里
docker cp $rdir/${dbName}_$tName.sql ${newMysqlContainerName}:/
# 先删除表,防止执行多次出错
docker exec -i ${newMysqlContainerName} bash -c "mysql -u ${newMysqlUser} -p${newMysqlPass} -D ${newdbName} -e \"DROP TABLE IF EXISTS ${newdbName}.${tName};\""
# 导入表结构
docker exec -i ${newMysqlContainerName} bash -c "mysql --binary-mode=1 -u ${newMysqlUser} -p${newMysqlPass} ${newdbName} < /${dbName}_$tName.sql"
# 删除表空间
docker exec -i ${newMysqlContainerName} bash -c "mysql -u ${newMysqlUser} -p${newMysqlPass} -D ${newdbName} -e \"ALTER TABLE ${newdbName}.${tName} DISCARD TABLESPACE;\""
# 复制ibd文件到新数据库
\cp -rp ${dbDataDir}/${tName}.ibd ${newDbDataDir}
# 导入表空间
docker exec -i ${newMysqlContainerName} bash -c "mysql -u ${newMysqlUser} -p${newMysqlPass} -D ${newdbName} -e \"ALTER TABLE ${newdbName}.${tName} IMPORT TABLESPACE;\""
# 本地有客户端命令
#mysql --no-defaults --binary-mode=1 -h ${newMysqlHost} -u ${newMysqlUser} -p${newMysqlPass} ${newdbName} < $rdir/${dbName}_$tName.sql
#mysql --no-defaults -h ${newMysqlHost} -u ${newMysqlUser} -p${newMysqlPass} -D ${newdbName} -e \"ALTER TABLE ${newdbName}.${tName} DISCARD TABLESPACE;\""
#\cp -rp ${dbDataDir}/${tName}.ibd ${newDbDataDir}
#mysql --no-defaults -h ${newMysqlHost} -u ${newMysqlUser} -p${newMysqlPass} -D ${newdbName} -e \"ALTER TABLE ${newdbName}.${tName} IMPORT TABLESPACE;\""
fi
fi
sleep 3
done
else
echo "目录不存在: $dbDataDir"
exit 6
fi
删库不跑路:论MySQL数据恢复
参考: https://mp.weixin.qq.com/s/RBWt2DOSRwRCjD1gi-JvGg
MySQL备份策略:
https://segmentfault.com/a/1190000019955399
MySQL数据恢复:
https://segmentfault.com/a/1190000020116271
1.前言
数据恢复的前提的做好备份,且开启 binlog, 格式为 row。如果没有备份文件,那么删掉库表后就真的删掉了,lsof中还有记录的话,有可能恢复一部分文件,但若刚好数据库没有打开这个表文件,那就只能跑路了。
如果没有开启 binlog,那么恢复数据后,从备份时间点开始的数据都没得了。如果 binlog 格式不为 row,那么在误操作数据后就没有办法做闪回操作,只能老老实实地走备份恢复流程
2.直接恢复
直接恢复是使用备份文件做全量恢复,这是最常见的场景
# gzip -d backup.sql.gz | mysql -u<user> -h<host> -P<port> -p
2.2.xtrabackup备份全量恢复
恢复过程
# 步骤一:解压(如果没有压缩可以忽略这一步)
innobackupex --decompress <备份文件所在目录>
# 步骤二:应用日志
innobackupex --apply-log <备份文件所在目录>
# 步骤三:复制备份文件到数据目录
innobackupex --datadir=<MySQL数据目录> --copy-back <备份文件所在目录>
2.3.基于时间点恢复
基于时间点的恢复依赖的是binlog日志,需要从 binlog 中找过从备份点到恢复点的所有日志,然后应用,我们测试一下
先创建数据库
mysql> create database mytest charset utf8;
新建测试表
CREATE TABLE mytest.mytest (
`id` int(11) NOT NULL AUTO_INCREMENT,
`ctime` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> show create table mytest.mytest \G
*************************** 1. row ***************************
Table: mytest
Create Table: CREATE TABLE `mytest` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`ctime` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
每秒插入一条数据
[root@learn ~]# while true; do mysql -uroot -p666666 -S /tmp/mysql.sock -e 'insert into mytest.mytest(ctime)values(now())';date;sleep 1;done
备份
mysqldump -uroot -p666666 --flush-logs --opt --single-transaction --master-data=2 --default-character-set=utf8 -S /tmp/mysql.sock -B mytest > /root/mytest_backup.sql
找出备份时的日志位置
[root@learn ~]# head -n 25 /root/mytest_backup.sql | grep 'CHANGE MASTER TO MASTER_LOG_FILE'
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000068', MASTER_LOG_POS=383955;
[root@learn ~]# tail -10 /root/mytest_backup.sql
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2020-07-09 15:30:11
假设要恢复到2020-07-09 15:40:11这个时间点,我们从 binlog 中查找从383955到2020-07-09 15:40:11的日志
[root@learn ~]# mysqlbinlog -uroot -padminasdfghjkl123654 --start-position=383955 --stop-datetime='2020-07-09 15:40:11' /MysqlData/mysql-bin.000068 > /root/backup_inc.sql
[root@learn ~]# tail -n 20 backup_inc.sql
SET TIMESTAMP=1594280410/*!*/;
BEGIN
/*!*/;
# at 543666
#200709 15:40:10 server id 12 end_log_pos 543719 CRC32 0xc9b44d16 Table_map: `mytest`.`mytest` mapped to number 122
# at 543719
#200709 15:40:10 server id 12 end_log_pos 543764 CRC32 0x93795b6a Write_rows: table id 122 flags: STMT_END_F
BINLOG '
2skGXxMMAAAANQAAAOdLCAAAAHoAAAAAAAEABm15dGVzdAAGbXl0ZXN0AAIDEgEAAhZNtMk=
2skGXx4MAAAALQAAABRMCAAAAHoAAAAAAAEAAgAC//zaBwAAmabS+gpqW3mT
'/*!*/;
# at 543764
#200709 15:40:10 server id 12 end_log_pos 543795 CRC32 0x4c0ee3d8 Xid = 6238
COMMIT/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
当前数据条数
-- 2020-07-09 15:40:11之前的数据条数
[16:12: -(none)] mysql> select count(*) from mytest.mytest where ctime < '2020-07-09 15:40:11';
+----------+
| count(*) |
+----------+
| 2010 |
+----------+
1 row in set (0.00 sec)
-- 所有数据条数
[16:12: -(none)] mysql> select count(*) from mytest.mytest;
+----------+
| count(*) |
+----------+
| 3198 |
+----------+
1 row in set (0.00 sec)
然后执行恢复
模拟删除mytest库
[16:23: -(none)] mysql> drop database mytest;
Query OK, 1 row affected (0.02 sec)
# 全量恢复
[root@learn ~]# mysql -uroot -padminasdfghjkl123654 -S /tmp/mysql.sock < /root/mytest_backup.sql
# 应用增量日志
mysql -uroot -padminasdfghjkl123654 -S /tmp/mysql.sock < /root/backup_inc.sql
检查数据
[16:30: -(none)] mysql> select count(*) from mytest.mytest;
+----------+
| count(*) |
+----------+
| 2010 |
+----------+
1 row in set (0.00 sec)
[16:30: -(none)] mysql> select * from mytest.mytest order by id desc limit 5;
+------+---------------------+
| id | ctime |
+------+---------------------+
| 2010 | 2020-07-09 15:40:10 |
| 2009 | 2020-07-09 15:40:09 |
| 2008 | 2020-07-09 15:40:08 |
| 2007 | 2020-07-09 15:40:07 |
| 2006 | 2020-07-09 15:40:06 |
+------+---------------------+
5 rows in set (0.00 sec)
已经恢复到2020-07-09 15:40:11这个时间点
3.恢复一个表
3.1.从mysqldump备份恢复一个表
假设要恢复的表是mytest.mytest
# 提取某个库的所有数据
sed -n '/^-- Current Database: `mytest`/,/^-- Current Database:/p' mytest_backup.sql > backup_mytest.sql
# 从库备份文件中提取建表语句
sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `mytest`/!d;q' backup_mytest.sql > mytest_table_create.sql
# 从库备份文件中提取插入数据语句
grep -i 'INSERT INTO `mytest`' backup_mytest.sql > mytest_table_insert.sql
# 从库备份文件中提取创建库语句
grep -i "CREATE DATABASE.*\`mytest\`.*" mytest_backup.sql > mytest_database_create.sql
#恢复mytest库
mysql -u<user> -p < mytest_database_create.sql
# 恢复表结构到 mytest 库
mysql -u<user> -p mytest < mytest_table_create.sql
# 恢复表数据到 mytest.mytest 表
mysql -u<user> -p mytest < mytest_table_insert.sql
3.2.从xtrabackup备份恢复一个表
假设./backup_xtra_full目录为解压后应用过日志的备份文件
3.2.1 MyISAM 表
假设从备份文件中恢复表mytest.t_myisam,从备份文件中找到t_myisam.frm t_myisam.MYD t_myisam.MYI这 3 个文件,复制到对应的数据目录中,并授权。
进入 MySQL,检查表情况
chengqm-3306>>show tables;
+------------------+
| Tables_in_mytest |
+------------------+
| mytest |
| t_myisam |
+------------------+
2 rows in set (0.00 sec)
chengqm-3306>>check table t_myisam;
+-----------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------------+-------+----------+----------+
| mytest.t_myisam | check | status | OK |
+-----------------+-------+----------+----------+
1 row in set (0.00 sec)
3.2.2.Innodb 表
假设从备份文件中恢复表mytest.t_innodb,恢复前提是设置了innodb_file_per_table = on
-
起一个新实例
-
在实例上建一个和原来一模一样的表
-
执行
alter table t_innodb discard tablespace;,删除表空间,这个操作会把t_innodb.ibd删除 -
从备份文件中找到
t_innodb.ibd这个文件,复制到对应的数据目录,并授权 -
执行
alter table t_innodb IMPORT tablespace;加载表空间 -
执行
flush table t_innodb;check table t_innodb;检查表 -
使用 mysqldump 导出数据,然后再导入到要恢复的数据库
注意:
在新实例上恢复再dump出来是为了避免风险,如果是测试,可以直接在原库上操作步骤 2-6
只在 8.0 以前的版本有效
4.跳过误操作SQL
跳过误操作 SQL 一般用于执行了无法闪回的操作比如 drop table\database
5.闪回
闪回操作就是反向操作,比如执行了 delete from a where id=1,闪回就会执行对应的插入操作 insert into a (id,...) values(1,...),用于误操作数据,只对 DML 语句有效,且要求 binlog 格式设为 ROW。本章介绍两个比较好用的开源工具
5.1.binlog2sql
官网:https://github.com/danfengcao/binlog2sql
博客:http://www.cnblogs.com/xuanzhi201111/p/6602489.html
binlog2sql 是大众点评开源的一款用于解析 binlog 的工具,可以用于生成闪回语句,项目地址 binlog2sql
5.1.1 安装
wget https://github.com/danfengcao/binlog2sql/archive/master.zip -O binlog2sql.zip
unzip binlog2sql.zip
cd binlog2sql-master/
# 安装依赖
pip install -r requirements.txt
5.1.2 数据库配置
MySQL server必须设置以下参数:
[mysqld]
server_id = 1
log_bin = /var/log/mysql/mysql-bin.log
max_binlog_size = 1G
binlog_format = row
binlog_row_image = full
5.1.3 user需要的最小权限集合:
select, super/replication client, replication slave
建议授权
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO flashback@'127.0.0.1' identified by 'adminasdfghjkl123654';
mysql> show grants for flashback@'127.0.0.1';
权限说明
-
select:需要读取server端
information_schema.COLUMNS表,获取表结构的元信息,拼接成可视化的sql语句 -
super/replication client:两个权限都可以,需要执行
SHOW MASTER STATUS, 获取server端的binlog列表 -
replication slave:通过BINLOG_DUMP协议获取binlog内容的权限
选项详解
mysql连接配置
- -h host
- -P port
- -u user
- -p password
解析模式
- --stop-never 持续解析binlog。可选。默认False,同步至执行命令时最新的binlog位置。
- -K, --no-primary-key 对INSERT语句去除主键。可选。默认False
-
-B, --flashback 生成回滚SQL,可解析大文件,不受内存限制。可选。默认False。与stop-never或no-primary-key不能同时添加。
-
--back-interval -B模式下,每打印一千行回滚SQL,加一句SLEEP多少秒,如不想加SLEEP,请设为0。可选。默认1.0。
解析范围控制
- --start-file 起始解析文件,只需文件名,无需全路径 。必须。
-
--start-position/--start-pos 起始解析位置。可选。默认为start-file的起始位置。
-
--stop-file/--end-file 终止解析文件。可选。默认为start-file同一个文件。若解析模式为stop-never,此选项失效。
-
--stop-position/--end-pos 终止解析位置。可选。默认为stop-file的最末位置;若解析模式为stop-never,此选项失效。
-
--start-datetime 起始解析时间,格式'%Y-%m-%d %H:%M:%S'。可选。默认不过滤。
-
--stop-datetime 终止解析时间,格式'%Y-%m-%d %H:%M:%S'。可选。默认不过滤。
对象过滤
-
-d, --databases 只解析目标db的sql,多个库用空格隔开,如-d db1 db2。可选。默认为空。
-
-t, --tables 只解析目标table的sql,多张表用空格隔开,如-t tbl1 tbl2。可选。默认为空。
-
--only-dml 只解析dml,忽略ddl。可选。默认False。
-
--sql-type 只解析指定类型,支持INSERT, UPDATE, DELETE。多个类型用空格隔开,如--sql-type INSERT DELETE。可选。默认为增删改都解析。用了此参数但没填任何类型,则三者都不解析
基本用法
解析出标准SQL
# python ./binlog2sql/binlog2sql.py -h127.0.0.1 -P3306 -uflashback -p'adminasdfghjkl123654' -dmytest -t mytest --start-file='mysql-bin.000071'
输出:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flashback'@'127.0.0.1' IDENTIFIED WITH 'mysql_native_password' AS '*5A92F7B7DBDE14EC2F221E30354F694B76A654E3';
解析出回滚SQL
# python ./binlog2sql/binlog2sql.py --flashback -h127.0.0.1 -P3306 -uflashback -p'adminasdfghjkl123654' -dmytest -t mytest --start-file='mysql-bin.000068'
5.2 MyFlash
MyFlash 是由美团点评公司技术工程部开发维护的一个回滚 DML 操作的工具。
项目链接 https://github.com/Meituan-Dianping/MyFlash/
限制:
binlog格式必须为row,且binlog_row_image=full
仅支持5.6与5.7
只能回滚DML(增、删、改)
5.2.1 安装
# 依赖(centos)
yum install gcc* pkg-config glib2 libgnomeui-devel -y
# 下载文件
wget https://github.com/Meituan-Dianping/MyFlash/archive/master.zip -O MyFlash.zip
unzip MyFlash.zip
cd MyFlash-master
# 编译安装
gcc -w `pkg-config --cflags --libs glib-2.0` source/binlogParseGlib.c -o binary/flashback
mv binary /usr/local/MyFlash
ln -s /usr/local/MyFlash/flashback /usr/bin/flashback
5.2.2 使用
生成回滚语句
flashback --databaseNames=<dbname>
--binlogFileNames=<binlog_file>
--start-position=<start_pos>
--stop-position=<stop_pos>
执行后会生成binlog_output_base.flashback文件,需要用 mysqlbinlog 解析出来再使用
mysqlbinlog -vv binlog_output_base.flashback | mysql -u<user> -p
MySQL的Gtid同步
1)什么是GTID
GTID(Global Transaction ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。
GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识,保存在mysql数据目录下的auto.cnf文件里。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。下面是一个GTID的具体形式:ed199600-7750-11ea-a19f-00163e322fa1:1
2)GTID的作用
根据GTID可以知道事务最初是在哪个实例上提交的,GTID的存在方便了Replication的Failover
3)GTID比传统复制的优势
-
更简单的实现failover,不用以前那样在需要找log_file和log_Pos。
-
更简单的搭建主从复制。
-
比传统复制更加安全。
-
GTID是连续没有空洞的,因此主从库出现数据冲突时,可以用添加空事物的方式进行跳过。
4)GTID的工作原理
master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
slave端的i/o线程将变更的binlog,写入到本地的relay log中。
sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
如果有记录,说明该GTID的事务已经执行,slave会忽略。
如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描
5)GTID常用参数注释
GTID的参数注释:
master> show global variables like '%gtid%';
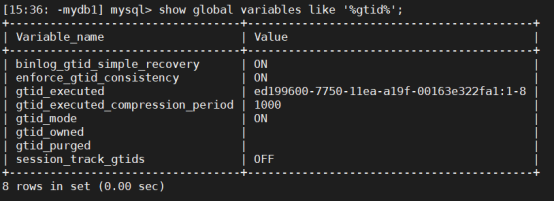
-
gtid_mode:是否开启GTID功能。
-
enforce_gtid_consistency:开启gtid的一些安全限制(建议开启)。
-
gtid_executed:全局和seeeion级别都可以用,用来保存已经执行过的GTIDs。
注:show master status\G;输出结果中的Executed_Gtid_Set和gitd_executed一致。`reset
master`时,此值会被清空。
-
gtid_purged:全局参数,设置在binlog中,已经purged的GTIDs,并且purged掉的GTIDs会包含到gtid_executed中。从而导致slave不会再去master请求这些GTIDs,并且Executed_Gtid_Set为空时,才可以设置此值。
-
binlog_gtid_simple_recovery:GTID 处理模式,用于处理主从复制中出现的 GTID 不一致问题。需要注意的是,
binlog_gtid_simple_recovery处理模式只适用于简单的 GTID 不一致问题,对于其他情况(例如 master 服务器上的数据已经被清除等),可能需要使用更复杂的 GTID 处理方式。 -
gtid_next:这个是session级别的参数
-
gtid_owned:全局和session级别都可用,全局表示所有服务器拥有GTIDs,session级别表示当前client拥有所有GTIDs。(此功能用的少)
6)使用GTID配置主从复制
实际工作主要会在两种情况下配置:
-
一是新搭建的服务器,直接配置启动就可以
-
二是已经在运行的服务器,这时候需要关闭master的写,保证所有slave端都已经和master端数据保持同步。然后即可按如下方法配置
主服务器配置:停止mysql服务,修改/etc/my.cnf配置文件,主要配置以下几项:
[client]
port = 3306
socket = /tmp/mysql.sock
[mysql]
no-auto-rehash
[mysqld]
user = mysql
port = 3306
socket = /tmp/mysql.sock
basedir = /usr/local/mysql
datadir = /data/mysql/data
back_log = 2000
open_files_limit = 4095
max_connections = 800
max_connect_errors = 3000
max_allowed_packet = 33554432
external-locking = FALSE
character_set_server = utf8mb4
lower_case_table_names=1
#binlog
log_bin =mysql-bin
log_bin_index =mysql-bin.index
expire_logs_days = 30
binlog_format = ROW
log_slave_updates = true
#log_slave_updates=1
sync_binlog = 1
binlog_cache_size = 1M
max_binlog_cache_size = 1M
max_binlog_size = 2M
#replicate-ignore-db=mysql #忽略需要同步的库
skip-name-resolve
slave-skip-errors = 1032,1062
skip_slave_start=1
#relay log
relay-log = /data/mysql/logs/relay-log/relay-bin
relay-log-info-file = /data/mysql/relay-log.info
#slow_log
slow_query_log = 1
slow-query-log-file = /data/mysql/logs/mysql-slow.log
#error_log
log-error = /data/mysql/logs/error.log
#gtid复制需要加上的必须项
server_id = 1
gtid_mode = on
enforce_gtid_consistency = true
[mysqldump]
quick
max_allowed_packet = 64M
启动数据库服务,查看相关信息,使用如下命令查看GTID的相关参数:
show global variables like '%gtid%';
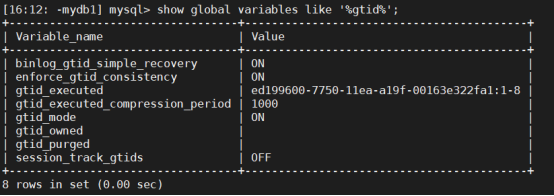
下图显示GTID是否正常使用:

2.主库授权主从复制用户(在主库上面操作)
replication slave一个特殊的权限,专门用于主从复制
mysql> grant replication slave on *.* to repl_user@'192.168.10.%' identified by '123456';
mysql> flush privileges;
在 MySQL 5.7.6 及以后的版本中,官方已经不再推荐使用这种方式,而是建议将创建用户和授权拆分为两个独立的命令进行处理,例如:
CREATE USER 'repl_user'@'192.168.10.%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO 'repl_user'@'192.168.10.%';
这样,可以更加清晰地了解和控制每个步骤的操作和效果,并提高代码的可读性和可维护性。
为了解决这个问题,可以按照以上方法将创建用户和授权拆分为两个独立的命令进行处理。具体步骤如下:
- 创建用户并设置密码:
CREATE USER 'repl_user'@'192.168.10.%' IDENTIFIED BY '123456';
- 授权用户访问数据库:
GRANT ALL PRIVILEGES ON *.* TO 'repl_user'@'192.168.10.%';
如果需要对用户进行更细粒度的授权或者撤销某些权限,可以使用其他授权命令进行设置和调整,例如:
- REVOKE 命令:用于撤销用户的权限;
- GRANT SELECT、INSERT、UPDATE 等命令:用于授权用户进行指定操作;
- GRANT OPTION 命令:用于授权用户将授权转移给其他用户。
配置从服务器:停止mysql服务,修改/etc/my.cnf配置文件,主要配置以下几项:
# 必须项
gtid_mode = on
enforce_gtid_consistency=true
server-id = 2
relay-log = relay-log
# 建议项
log_bin = mysql-bin
log_bin_index =mysql-bin.index
expire_logs_days = 7
binlog_format = row
sync_binlog = 1
relay_log_index = relay-log.index
log_slave_updates=1
master-info-repository = table
relay-log-info-repository = table
slave-parallel-workers = 1
relay_log_purge = 1
relay_log_recovery = 1
report-port = 3306
report-host = 192.168.10.72
skip-slave-start
mysql的slave从库的配置文件/etc/my.cnf中参数只是sever_id和主库的不一样,其他的参数都保持一致
启动数据库服务
1.在从库操作,连接master:
CHANGE MASTER TO MASTER_HOST='192.168.10.71',MASTER_PORT=3306,MASTER_USER='repl_user',MASTER_PASSWORD='123456', MASTER_AUTO_POSITION=1 for channel 'channel_gobgm';
for channel 'channel_gobgm'通道名,在同一台MySQL服务器上可以运行多个复制通道,每个通道可以配置不同的主服务器(master),从服务器(slave),和其他复制参数。
MASTER_AUTO_POSITION=1 是 MySQL 中的一个配置选项,用于启用自动位点记录(automatic position-based replication)功能。此选项允许从库使用 GTID 技术来跟踪主库和从库之间的复制进程,并确保每个事务在主库和从库之间的唯一性。
启用自动位点记录后,从库会自动获取主库的 GTID 位点并将其记录到 relay-log.info 文件中。这些信息可以帮助管理员了解在从库上发生了哪些事,而无需手动查看二进制日志文件。
要启用自动位点记录功能,请在从库上执行以下命令:
CHANGE MASTER TO MASTER_AUTO_POSITION = 1;
这将触发从库连接到主库并开始自动位点记录模式。请注意,在启用自动位点记录功能后,从库不再需要使用 MASTER_LOG_FILE 和 MASTER_LOG_POS 指定位置信息,因为它们将由 GTID 自动管理。
2.启动复制线程:
start slave;
3.相看相关状态:
-- 在slave上执行:
mysql> show slave status;
-- 在master上执行
mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 2 | | 3306 | 1 | 587abb65-6f9d-11ec-a6fe-fa163eb4b73f |
+-----------+------+------+-----------+--------------------------------------+
1 row in set, 1 warning (0.00 sec)
7)修复GTID复制错误
在基于GTID的复制拓扑中,要想修复Slave的SQL线程错误,过去的SQL_SLAVE_SKIP_COUNTER方式不再适用。需要通过设置gtid_next或gtid_purged完成,当然前提是已经确保主从数据一致,仅仅需要跳过复制错误让复制继续下去。
其中gtid_next就是跳过某个执行事务,设置gtid_next的方法一次只能跳过一个事务,要批量的跳过事务可以通过设置gtid_purged完成
设置 gtid_next 变量的方法只能跳过一个事务。gtid_next 变量是包含要跳过的下一个 GTID 的UUID:NUMBER 对,用于让 MySQL 跳过当前 GTID,然后继续进行复制。以下是一些使用 gtid_next 变量来跳过单个事务的示例命令:
# 查看当前的 gtid_executed 值
SELECT @@GLOBAL.gtid_executed;
# 将 "cb1d77eb-f3f1-11e9-8e9a-0242ac110002:21" 设置为 gtid_next 变量
SET @@GLOBAL.gtid_next = "cb1d77eb-f3f1-11e9-8e9a-0242ac110002:21";
# 执行一个查询语句,并跳过前面设置的 GTID(也就是 21)
SELECT * FROM mytable;
# 将 gtid_next 变量重置为下一个未应用的 GTID
SET @@GLOBAL.gtid_next = AUTOMATIC;
需要注意的是,使用 gtid_next 变量跳过事务可能会导致主从不一致或数据丢失。因此,在使用此方法时,请确保您已经备份了数据并了解了可能出现的问题及解决方案。同时,请谨慎操作,以免意外删除或修改数据。
您可以通过设置 gtid_purged 变量来批量跳过多个事务。gtid_purged 是一个包含所有已经执行的 GTID 的UUID:NUMBER对列表。通过将要跳过的 GTID 添加到 gtid_purged 变量中,您可以告诉 MySQL 跳过从主库传输的数据并从新的位置开始重启复制。以下是一些示例性的命令来操作 gtid_purged 变量:
# 查看当前的 gtid_purged 值
SELECT @@GLOBAL.gtid_purged;
# 将 "cb1d77eb-f3f1-11e9-8e9a-0242ac110002:1-20" 添加到 gtid_purged 中
SET @@GLOBAL.gtid_purged = "cb1d77eb-f3f1-11e9-8e9a-0242ac110002:1-20";
# 将 "cb1d77eb-f3f1-11e9-8e9a-0242ac110002:21" 添加到 gtid_purged 中
SET @@GLOBAL.gtid_purged = CONCAT(@@GLOBAL.gtid_purged, ",cb1d77eb-f3f1-11e9-8e9a-0242ac110002:21");
# 删除 gtid_purged 中的特定 GTID
SET @@GLOBAL.gtid_purged = REPLACE(@@GLOBAL.gtid_purged, "cb1d77eb-f3f1-11e9-8e9a-0242ac110002:1-20", "");
需要注意的是,设置 gtid_purged 变量将删除指定 GTID 后的所有事务记录。因此,在使用该方法时,请确保您了解这些操作的影响,并采取其他恢复措施以确保数据的完整性和一致性
8)主从同步异常处理
处理思路1:把slave上的gtid_purged设置为master还没有被purge掉的值,然后借助第三方一致性同步工具来做数据的一致性同步。
mysql> reset master;
mysql> set global GTID_PURGED="326fe663-cdab-11e9-8ef6-080027364db6:1-616463";
mysql> start slave;
mysql> show slave status \G
当然执行完这个之后数据是不一致的,那么此时就需要通过使用percona-toolkit工具进行数据修复,PT工具包中包含pt-table-checksum和pt-table-sync两个工具,主要用于检测主从是否一致以及修复数据不一致情况。
前提条件,MySQL 机器上需要安装 percona-toolkit 工具
工具优点
- 修复速度快,不需要停止从库
工具缺点
- 操作复杂,操作前最后先备份数据库
- 待修复的表需要具有 unique constraint
处理思路2:重建slave
第一步:停止主库的写入操作,然后导出需要同步的数据(一般要导出带有GTIDs的,因为后面配置主从需要使用到GTIDs参数),最后传输到从服务器上(在主库操作)
# 需要锁表备份数据,应用空闲时间处理。
FLUSH TABLES WITH READ LOCK;
# 导出带有GTIDs的sql。
mysqldump --routines --triggers --events --master-data=2 --single-transaction --databases gobgm > ./gobgm_$(date +"%Y%m%d").sql
# 回到主库解锁表
UNLOCK TABLES
第二步:在从服务器执行如下操作
mysql> stop slave;
mysql> reset slave all;
mysql> reset master;
mysql> source gobgm_$(date +"%Y%m%d").sql;
mysql> CHANGE MASTER TO MASTER_HOST ='192.168.9.71',MASTER_PORT = 3306,MASTER_USER = 'repl',MASTER_PASSWORD = '123456',MASTER_AUTO_POSITION = 1;
mysql> start slave;
mysql> show slave status\G;
如果以上还是无法同步,就找到备份文件中的GLOBAL.GTID_PURGED
--
-- GTID state at the beginning of the backup
--
SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '587abb65-6f9d-11ec-a6fe-fa163eb4b73f:1-681,
8c02945e-6f9a-11ec-9ba5-fa163efcfc4a:1-896216311';
--
操作如下:
mysql> reset master;
mysql> SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '587abb65-6f9d-11ec-a6fe-fa163eb4b73f:1-681,8c02945e-6f9a-11ec-9ba5-fa163efcfc4a:1-896216311';
mysql> CHANGE MASTER TO MASTER_HOST ='192.168.9.71',MASTER_PORT = 3306,MASTER_USER = 'repl',MASTER_PASSWORD = '123456',MASTER_AUTO_POSITION = 1;
mysql> start slave;
mysql> show slave status\G;
错误示例:可以参照处理思路2解决
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Slave has more GTIDs than the master has, using the master's SERVER_UUID. This may indicate that the end of the binary log was truncated or that the last binary log file was lost, e.g., after a power or disk failure when sync_binlog != 1. The master may or may not have rolled back transactions that were already replica'
我们可以发现,复制的结果出错了,找找原因,Slave has more GTIDs than the master has,using the master's SERVER_UUID. 提示我们slave包含太多UUID了,需要指定master的UUID,这个时候我们应该怎么办呢?
既然已经说了slave的GTID太多了,我们直接使用reset master命令给它清理掉就行了。说干就干,查看下当前slave的GTID,然后进行处理:
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000005
Position:
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: db33b36-0e51-409f-a61d-c99756e90155:1-14,
bd0d-8691-11e8-afd6-4c3e51db5828:1-9,
bb874065-c485-11e8-8b52-000c2934472e:
row in set (0.00 sec)
mysql> stop slave;
Query OK, rows affected (0.00 sec)
mysql> reset slave all;
Query OK, rows affected (0.01 sec)
mysql> change master to master_host='192.168.197.6',
-> master_user='repluser',
-> master_password='123456',
-> master_port=,
-> master_auto_position=;
Query OK, rows affected, warnings (0.03 sec)
搭建完毕之后,我们看看结果:
mysql> start slave;
Query OK, rows affected (0.01 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.197.128
Master_User: repluser
Master_Port:
Connect_Retry:
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos:
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos:
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
可以看到,reset master操作会将GTID都清空。
9)导出数据
当前GTID_EXECUTED参数已经有值,而从master主库倒出来的dump文件中包含了SET @@GLOBAL.GTID_PURGED的操作
解决方法:
方法一:reset mater
这个操作要在slave机器上操作,可以将当前slave库的GTID_EXECUTED值置空
方法二:--set-gtid-purged=off
在dump导出master数据时,添加--set-gtid-purged=OFF参数,避免将master上的gtid信息导出,然后再导入到slave库
# 导出不带GTIDs的sql
mysqldump --routines --triggers --events --master-data=2 --single-transaction --set-gtid-purged=OFF --databases gobgm > ./gobgm_$(date +"%Y%m%d").sql
10)GTID模式跳过错误GTID事务的正确方法
-- 要跳过失败事务的GTID可以通过sql直接查询到
mysql> select * from performance_schema.replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: NULL
SERVICE_STATE: OFF
LAST_ERROR_NUMBER: 1813
LAST_ERROR_MESSAGE: #失败事务的错误信息
LAST_APPLIED_TRANSACTION:
LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_APPLIED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_APPLIED_TRANSACTION_START_APPLY_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP: 0000-00-00 00:00:00.000000
APPLYING_TRANSACTION: 4efcbd9f-c1e2-11eb-b710-0050569e2112:1441877108 #要跳过的事务
APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 2023-06-07 14:42:22.913515
APPLYING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 2023-06-07 14:42:22.913515
APPLYING_TRANSACTION_START_APPLY_TIMESTAMP: 2023-06-07 16:11:59.392908
LAST_APPLIED_TRANSACTION_RETRIES_COUNT: 0
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_NUMBER: 0
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_MESSAGE:
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
APPLYING_TRANSACTION_RETRIES_COUNT: 0
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_NUMBER: 0
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_MESSAGE:
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
1 row in set (0.00 sec)
-- 假设要忽略的GTID是'4efcbd9f-c1e2-11eb-b710-0050569e2112:1441877108',设置GTID_NEXT
SET GTID_NEXT = '4efcbd9f-c1e2-11eb-b710-0050569e2112:1441877108';
-- 查询gtid_next值
select @@gtid_next;
+-------------------------------------------------+
| @@gtid_next |
+-------------------------------------------------+
| 4efcbd9f-c1e2-11eb-b710-0050569e2112:1441877108 |
+-------------------------------------------------+
1 row in set (0.00 sec)
-- 执行一个空事务来忽略错误的GTID
BEGIN;
COMMIT;
-- 重置GTID_NEXT以自动继续复制
SET GTID_NEXT = 'AUTOMATIC';
-- 查询gtid_next值
select @@gtid_next;
+-------------+
| @@gtid_next |
+-------------+
| AUTOMATIC |
+-------------+
1 row in set (0.00 sec)
-- 开启slave
start slave;
-- 然后再次查看同步状态,如果异常则重复这些操作
show slave status\G
MySQL主从复制(重点)
MySQL主从复制简介
Mysql的主从复制方案,都是数据传输的,只不过MySQL无需借助第三方工具,而是自带的同步复制功能,MySQL的主从复制并不是磁盘上文件直接同步,而是将binlog日志发送给从库,由从库将binlog文件里的内容写入本地数据库。
在生产环境中,MySQL主从复制都是异步方式同步,即不是实时同步数据。
MySQL主从复制原理:
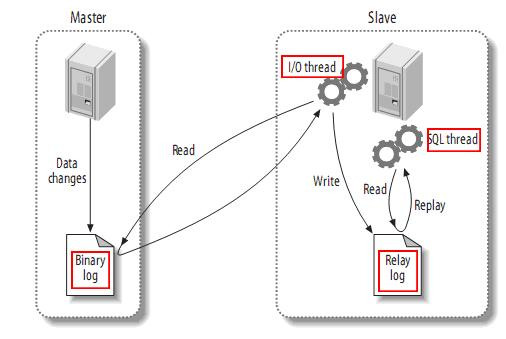
- i/o线程去请求主库的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
- 主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
- sql线程从中继日志读取事件,并重放其中事件而更新slave的数据。
整体上来说,复制有3个步骤:
1)master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
2)slave将master的binary log events拷贝到它的中继日志(relay log);
3)slave重做中继日志中的事件,将改变反映它自己的数据。
第一步: 就是master记录二进制日志。
在每个事务更新数据完成之前,master在二进制日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
第二步: 就是slave将master的binary log拷贝到它自己的中继日志。
1)slave开始一个工作线程->I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。
2)I/O线程将这些事件写入中继日志。
第三步: SQL slave thread(SQL从线程)处理该过程的最后一步。
SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
注:此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制------复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
MySQL主从复制部署
MySQL主从复制条件:
-
两台以上mysql实例(多台物理机或多个mysql实例)
-
开启binlog功能,确保所有实例
server-id唯一 -
主库建立同步账号(
replication slave特殊的权限) -
将全备文件恢复到从库上(需人为操作)
-
从库配置master.info(change master),复制的binlog位置点(需人为操作)
-
start slave 复制开关
1.环境规划
所有机器统一centos6.8系统环境,并且都已经安装好了mysql 5.1.73(yum安装的)
| 主机名 | IP地址 | 服务 |
|---|---|---|
| db主 | 172.20.10.13 | mysql 主库 |
| db从 | 172.20.10.3 | mysql 从库 |
2.所有mysql都开启binlog功能,确保所有mysql的server-id不同
需要添加的配置如下:
#主库 /etc/my.cnf
[mysqld]
server_id=1 #server-id
log-bin=mysql-bin #开启binlog功能
binlog_format = row #binlog日志模式
sync_binlog = 1 #控制数据库的binlog刷到磁盘上去
log-slave-updates=true #参数用来控制是否把所有的操作写入到binary log,默认的情况下mysql是关闭的
skip-name-resolve #关闭域名解析
binlog-ignore-db=mysql,information_schema #参数用于指定需要忽略的数据库名,在主服务器上不会将这些数据库的更改写入二进制日志文件。可以使用多个逗号分隔的数据库名指定多个需要忽略的数据库。
#binlog_checksum =none #不校验bin-log(有这个选项好像无法启动mysql)
参数解释:
Mysql配置参数sync_binlog说明,MySQL提供一个sync_binlog参数来控制数据库的binlog刷到磁盘上去。
默认,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
如果sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。最安全的就是sync_binlog=1了,表示每次事务提交,MySQL都会把binlog刷下去,是最安全但是性能损耗最大的设置。这样的话,在数据库所在的主机操作系统损坏或者突然掉电的情况下,系统才有可能丢失1个事务的数据。但是binlog虽然是顺序IO,但是设置sync_binlog=1,多个事务同时提交,同样很大的影响MySQL和IO性能。虽然可以通过group commit的补丁缓解,但是刷新的频率过高对IO的影响也非常大。对于高并发事务的系统来说,sync_binlog设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
所以很多MySQL DBA设置的sync_binlog并不是最安全的1,而是100或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。
#从库 /etc/my.cnf
[mysqld]
server_id=2
relay-bin=relay-bin
sync_binlog = 1
binlog_format = row
skip-name-resolve
提示:从库的relay-log路径可自定义,默认在data目录下以主机为前缀保存
server-id用于全网唯一标识一台mysql机器
2.主库授权主从复制用户(在主库上面操作)
replication slave一个特殊的权限,专门用于主从复制
mysql> grant replication slave on *.* to rep@'172.20.10.%' identified by '666666';
mysql> flush privileges;
解释:
-
replication slave表示只有复制的权限
-
rep表示授权的用户名
-
172.20.10.%表示这个网段都可以连接mysql - 666666表示授权用户的登录密码
在 MySQL 5.7.6 及以后的版本中,官方已经不再推荐使用这种方式,而是建议将创建用户和授权拆分为两个独立的命令进行处理,例如:
CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON *.* TO 'user'@'localhost';
这样,可以更加清晰地了解和控制每个步骤的操作和效果,并提高代码的可读性和可维护性。
为了解决这个问题,可以按照以上方法将创建用户和授权拆分为两个独立的命令进行处理。具体步骤如下:
- 创建用户并设置密码:
CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
- 授权用户访问数据库:
GRANT ALL PRIVILEGES ON *.* TO 'user'@'localhost';
如果需要对用户进行更细粒度的授权或者撤销某些权限,可以使用其他授权命令进行设置和调整,例如:
- REVOKE 命令:用于撤销用户的权限;
- GRANT SELECT、INSERT、UPDATE 等命令:用于授权用户进行指定操作;
- GRANT OPTION 命令:用于授权用户将授权转移给其他用户。
3.主库将数据库数据做全备,然后将备份文件推送至从库
-
主和从同时搭建新的环境,就不需要备份主库数据,恢复从库了,直接从第一个binlog(mysql-bin.000001)开头位置(默认120)
-
如果主库已经工作了很长时间了,那么需要备份主库数据,恢复到从库,然后从库从备份的时间点起,自动进行复制
1.将数据库的数据全备到/opt目录下(建议不要用mysqldump、用xtrabackup)**
[root@db主 ~]# mysqldump -uroot -p666666 -A -B -R --master-data=2 --single-transaction | gzip > /opt/full_$(date +%F).sql.gz
2.将全备通过scp推送到从库的/backup目录下
[root@db主 ~]# scp /opt/ full_2019-04-10.sql.gz root@172.20.10.3:/opt
提示:完全备份的目录可以随意指定,但是必须该目录是存在的,若不存在,需要创建
4.关闭从库,从库将备份文件恢复至数据库
1.解压备份文件
[root@db从 ~]# gunzip /opt/full_2019-04-10.sql.gz
如果使用xtrabackup备份的,那么要进行预处理:

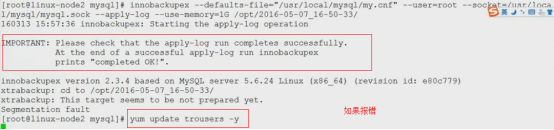
2.进入数据库,将备份文件导入到本地数据库
mysql> source /opt/full_2019-04-10.sql
如果使用xtrabackup备份的,有专门的命令进入导入数据:
1、进入mysql存放数据的目录(可选)
2、进行导入数据

注意,因为--move-back它会删除备份文件。我们可以选择使用--copy-back
3.检查数据是否恢复成功
mysql> show databases;
5.从库上都找到binlog位置点,然后启动从库
虽然全备文件已经恢复到了从库,但是全备之后的数据的变化是没有进行备份的,所以从库还需要指定binlog位置点,这样从库才知道该从哪里开始同步数据,直接在从库的全备文件中找到binlog位置点
[root@db从 /]# sed -n '22p' /opt/full_2019-04-10.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=660;
如果使用xtrabackup备份的,怎么查看binlog位置点:
1、进入mysql存放数据的目录
2、查看节点位置,然后修改数据存放目录的权限
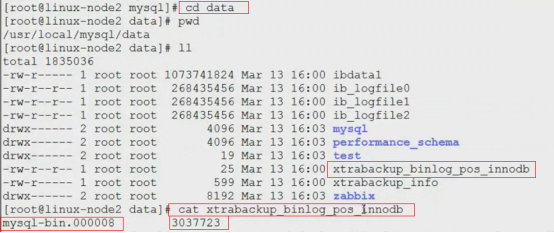

6.从库配置master info
master info就是指配置一系列主从复制参数,该参数为change master to,来实现主从复制
提示:mysql> help change master to 可获取配置案例
1.进入数据库配置 change master to
change master to
master_host='172.20.10.13',
master_port=3306,
master_user='rep',
master_password='666666',
master_log_file='mysql-bin.000004',
master_log_pos=660;
说明:如果到这里报错,就停掉stop slave;然后reset slave;最后在执行从库配置master info
参数解释:
-
change master to
-
master_host='172.20.10.13', 主库的IP地址
-
master_port=3306, 主库的端口
-
master_user='rep', 主库上创建的用于复制的用户rep
-
master_password='666666', rep用户的密码
-
master_log_file='mysql-bin.000004', 二进制日志文件的名称
-
master_log_pos=660; 二进制日志偏移量
2.开启主从同步功能(开启IO和SQL线程),
mysql> start slave;
3.查看主从复制的状态(截取部分)
当在slave状态中可以看到如下参数,都为yes才表明成功,(从库有一个IO和一个SQL)
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
slave的操作命令:
mysql> stop slave; #停止slave
mysql> start slave; #启动slave
mysql> reset slave; #清空slave的配置参数(change master to)
mysql> stop slave io_thread; #停止io线程
mysql> STOP SLAVE SQL_THREAD; #停止SQL线程
从库的master.info和relay-log.info文件
执行完change master to命令后,会自动生成master.info文件,保存change master to的参数和最后一次获取binlog日志文件名和对应的位置点
ls /var/lib/mysql/master.info
slave_master_info 是一个 MySQL 系统表,用于存储从库连接到主库的信息。它包含一个记录,其中列出了从库连接到的主库的名称、主库的位置和主库的 UUID。每个从库只有一行记录。
这些信息是由从库在第一次连接到主库时收集的,通常是通过执行 CHANGE MASTER TO 命令来指定的。在执行该命令时,从库会将主库名称、主库位置和主库 UUID 存储在 slave_master_info 表中。如果从库需要重新连接到主库,则可以使用 CHANGE MASTER TO 命令中的存储的信息自动进行重新连接。以下是 slave_master_info 表的示例输出:
mysql> SELECT * FROM mysql.slave_master_info;
执行完start slave命令后,会自动生成relay-log.info文件,保存已执行过的relaylog的位置点
ls /var/lib/mysql/relay-log.info
7.主库创建数据库,在到从库验证数据是否同步
1.主库创建数据库:test_sample
mysql> create database test_sample;
2.从库查看数据是否同步
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mimi |
| mysql |
| student |
| test |
| test_sample |
+--------------------+
6 rows in set (0.00 sec)
从库去向主库请求的binlog日志会保存在从库本地的relaylog日志中
[root@db从 /]# ls -1 /var/lib/mysql/mysqld-relay-bin.*
/var/lib/mysql/mysqld-relay-bin.000001
/var/lib/mysql/mysqld-relay-bin.000002
/var/lib/mysql/mysqld-relay-bin.index
扩展:从库开启记录binlog功能
从库需要记录binlog的应用场景为:当前的从库还需要作为其它从库的主库,例如:级联复制和双主互为主从场景的情况下
从库的my.cnf中加入如下参数,然后重启服务生效即可
log-slave-updates #开启从库记录binlog功能
log-bin = mysql-bin
expire_logs_days = 7 #bin-log保留时间(只保留7天)
MySQL主从复制故障
主从复制状态信息介绍
mysql> show slave status\G
Slave_IO_Running: Yes #指示从服务器的 IO 线程是否正在运行。
Slave_SQL_Running: Yes #指示从服务器的 SQL 线程是否正在运行。
Last_IO_Errno: 0 #记录最后一次IO的错误代码
Last_IO_Error: #显示导致IO的错误原因
Last_SQL_Errno: 0 #记录最后一次SQL的错误代码
Last_SQL_Error: #显示导致SQL的错误原因
Seconds_Behind_Master:0 #落后主库多少秒,0表示不落后,正常。但是需要注意的是,Seconds_Behind_Master 的值为 NULL 并不一定表示从服务器与主服务器之间的复制出现了问题。可能是由于从服务器正在应用日志文件(relay log)中的最后一条事件,此时尚未发现新的事件,因此 Seconds_Behind_Master 的值被设置为 NULL。或者,从服务器最近才加入到主服务器的复制拓扑中,因此当前还没有同步到主服务器最新的更新事件。
Master_Log_File: mysql-bin.000016 #表示从服务器当前读取到的主服务器二进制日志文件
Read_Master_Log_Pos: #表示从服务器当前读取到的主服务器二进制日志位置。
Relay_Log_File: #表示从服务器当前正在应用的中继日志文件
Relay_Log_Pos: #表示从服务器当前正在应用的中继日志文件的位置。
设置延迟复制

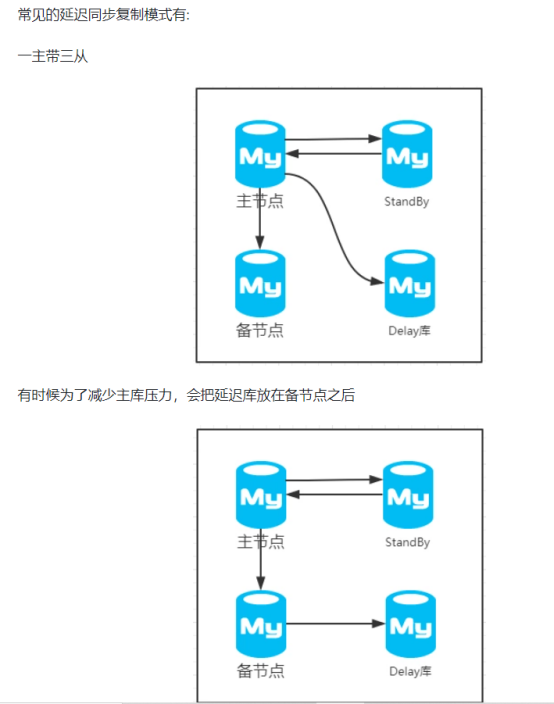

作用:
1、误删除恢复
2、延迟测试
3、历史查询(这个实际应用较少)
单位是秒
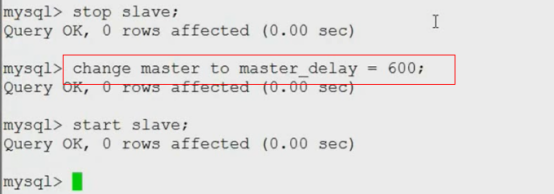
mysql> show slave status\G

停止延迟同步:
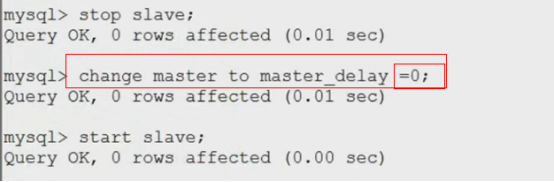
设置半同步复制
https://www.cnblogs.com/itbsl/p/13507401.html
异步复制:在主节点写入日志即返回成功,默认情况下MySQL5.5/5.6/5.7和mariaDB10.0/10.1的复制功能是异步的。异步复制可以实现最佳的性能,主库把binlog日志发送给从库,这一动作就结束了,并不验证从库,会造成主从库数据不一致。
半同步复制:一主多从模式下,有一个从节点返回成功,即成功,不必等待多个节点全部返回。
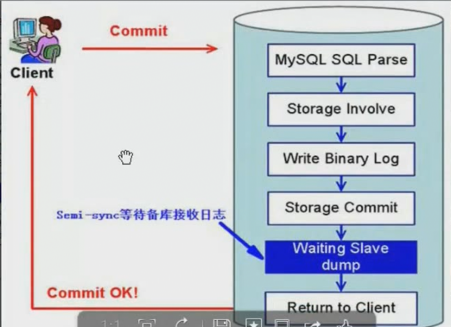
半同步复制的特点:
- 从库在连接主库时需要表明它是否支持半同步复制。
- 如果主库启用了半同步复制,且有一个支持半同步复制的从库,则主库上事务提交将等待至少一个从库确认已收到事务,或者直到发生超时。
- 默认只有在将事务写入其中继日志并刷新到磁盘后,主库才会提交事务(也可以配置成提交后等待确认)
- 如果没有任何从库确认事务的情况下发生超时,则主库将退化为异步复制。当至少有一个半同步从库赶上时,主库恢复半同步复制。退化与恢复过程都是自动的。
-
必须在主库和从库上都启用半同步复制,否则使用异步复制。
-
数据可靠性:半同步复制提供更高的数据可靠性。在传统的异步复制中,数据只会在主服务器发送成功后被异步地复制到从服务器。而在半同步复制中,主服务器会等待至少一个从服务器确认已成功接收数据才认为事务提交成功,因此可以减少数据丢失的风险。
- 较低的延迟:由于主服务器需要等待至少一个从服务器的确认,半同步复制可以提供较低的延迟。与异步复制相比,从服务器接收数据的速度更快,因此可以更及时地进行读取操作。
- 高可用性:半同步复制可以提高系统的可用性。当主服务器发生故障时,可以立即将从服务器提升为新的主服务器。由于从服务器已经接收并处理了大部分的数据,所以切换时间较短,可以快速恢复数据库的正常运行。
- 配置灵活:半同步复制可以根据需求进行灵活的配置。你可以选择启用半同步复制的方式(主服务器、从服务器或两者都启用),也可以选择等待从服务器确认的数量。这样可以根据系统的负载和性能需求进行调整。
插件位置:
mysql> show variables like '%basedir%';
+---------------+--------------+
| Variable_name | Value |
+---------------+--------------+
| basedir | /data/mysql/ |
+---------------+--------------+
1 row in set (0.00 sec)
mysql> \! ls -l /data/mysql/lib/plugin/ -- 下面全是插件
total 61828
-rwxr-xr-x 1 mysql mysql 100088 Mar 16 23:42 adt_null.so
-rwxr-xr-x 1 mysql mysql 355704 Mar 16 23:42 authentication_ldap_sasl_client.so
-rwxr-xr-x 1 mysql mysql 43176 Mar 16 23:42 auth_socket.so
-rwxr-xr-x 1 mysql mysql 938696 Mar 16 23:42 connection_control.so
drwxr-xr-x 2 mysql mysql 4096 Jul 12 15:27 debug
-rwxr-xr-x 1 mysql mysql 22062536 Mar 16 23:43 group_replication.so
-rwxr-xr-x 1 mysql mysql 485088 Mar 16 23:42 ha_example.so
-rwxr-xr-x 1 mysql mysql 902552 Mar 16 23:42 innodb_engine.so
-rwxr-xr-x 1 mysql mysql 941304 Mar 16 23:42 keyring_file.so
-rwxr-xr-x 1 mysql mysql 458952 Mar 16 23:42 keyring_udf.so
-rwxr-xr-x 1 mysql mysql 1175480 Mar 16 23:42 libmemcached.so
-rwxr-xr-x 1 mysql mysql 8972488 Mar 16 23:42 libpluginmecab.so
-rwxr-xr-x 1 mysql mysql 53784 Mar 16 23:42 libtest_framework.so
-rwxr-xr-x 1 mysql mysql 54392 Mar 16 23:42 libtest_services.so
-rwxr-xr-x 1 mysql mysql 67208 Mar 16 23:42 libtest_services_threaded.so
-rwxr-xr-x 1 mysql mysql 94496 Mar 16 23:42 libtest_session_detach.so
-rwxr-xr-x 1 mysql mysql 130808 Mar 16 23:42 libtest_session_info.so
-rwxr-xr-x 1 mysql mysql 67536 Mar 16 23:42 libtest_session_in_thd.so
-rwxr-xr-x 1 mysql mysql 112808 Mar 16 23:42 libtest_sql_2_sessions.so
-rwxr-xr-x 1 mysql mysql 115416 Mar 16 23:42 libtest_sql_all_col_types.so
-rwxr-xr-x 1 mysql mysql 212976 Mar 16 23:42 libtest_sql_cmds_1.so
-rwxr-xr-x 1 mysql mysql 116824 Mar 16 23:42 libtest_sql_commit.so
-rwxr-xr-x 1 mysql mysql 145888 Mar 16 23:42 libtest_sql_complex.so
-rwxr-xr-x 1 mysql mysql 114664 Mar 16 23:42 libtest_sql_errors.so
-rwxr-xr-x 1 mysql mysql 124080 Mar 16 23:42 libtest_sql_lock.so
-rwxr-xr-x 1 mysql mysql 103704 Mar 16 23:42 libtest_sql_processlist.so
-rwxr-xr-x 1 mysql mysql 138040 Mar 16 23:42 libtest_sql_replication.so
-rwxr-xr-x 1 mysql mysql 108504 Mar 16 23:42 libtest_sql_shutdown.so
-rwxr-xr-x 1 mysql mysql 141960 Mar 16 23:42 libtest_sql_sqlmode.so
-rwxr-xr-x 1 mysql mysql 142016 Mar 16 23:42 libtest_sql_stored_procedures_functions.so
-rwxr-xr-x 1 mysql mysql 141968 Mar 16 23:42 libtest_sql_views_triggers.so
-rwxr-xr-x 1 mysql mysql 61800 Mar 16 23:42 libtest_x_sessions_deinit.so
-rwxr-xr-x 1 mysql mysql 79336 Mar 16 23:42 libtest_x_sessions_init.so
-rwxr-xr-x 1 mysql mysql 20328 Mar 16 23:42 locking_service.so
-rwxr-xr-x 1 mysql mysql 53864 Mar 16 23:42 mypluglib.so
-rwxr-xr-x 1 mysql mysql 41312 Mar 16 23:42 mysql_no_login.so
-rwxr-xr-x 1 mysql mysql 21795952 Mar 16 23:43 mysqlx.so
-rwxr-xr-x 1 mysql mysql 49304 Mar 16 23:42 rewrite_example.so
-rwxr-xr-x 1 mysql mysql 590320 Mar 16 23:42 rewriter.so
-rwxr-xr-x 1 mysql mysql 925928 Mar 16 23:42 semisync_master.so
-rwxr-xr-x 1 mysql mysql 159488 Mar 16 23:42 semisync_slave.so
-rwxr-xr-x 1 mysql mysql 50344 Mar 16 23:42 test_security_context.so
-rwxr-xr-x 1 mysql mysql 46360 Mar 16 23:42 test_udf_services.so
-rwxr-xr-x 1 mysql mysql 209856 Mar 16 23:42 validate_password.so
-rwxr-xr-x 1 mysql mysql 502456 Mar 16 23:42 version_token.so
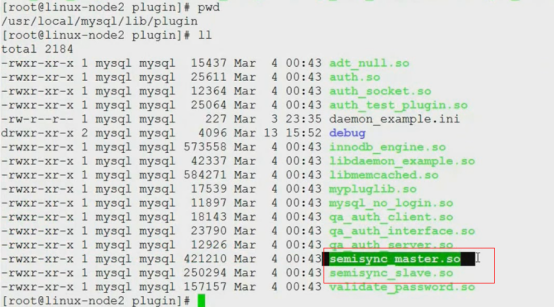
mysql> show plugins; -- 查看安装的插件,Status为ACTIVE表示该插件安装成功的
+----------------------------+----------+--------------------+---------+---------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+---------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| mysql_native_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| sha256_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MEMORY | ACTIVE | STORAGE ENGINE | NULL | GPL |
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
| INNODB_TRX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCKS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCK_WAITS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_PER_INDEX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_PER_INDEX_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_PAGE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_PAGE_LRU | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_POOL_STATS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_TEMP_TABLE_INFO | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_METRICS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_DEFAULT_STOPWORD | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_DELETED | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_BEING_DELETED | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_CONFIG | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_INDEX_CACHE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_INDEX_TABLE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLESTATS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_INDEXES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_COLUMNS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FIELDS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FOREIGN | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FOREIGN_COLS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLESPACES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_DATAFILES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_VIRTUAL | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| MyISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MRG_MYISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| PERFORMANCE_SCHEMA | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ARCHIVE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| BLACKHOLE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| FEDERATED | DISABLED | STORAGE ENGINE | NULL | GPL |
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ngram | ACTIVE | FTPARSER | NULL | GPL |
+----------------------------+----------+--------------------+---------+---------+
44 rows in set (0.04 sec)
mysql> SHOW GLOBAL STATUS LIKE 'Rpl_semi_sync%'; -- 检查主服务器的半同步复制状态,Rpl_semi_sync_master_status为ON,表示主服务器的半同步复制已经启用.Rpl_semi_sync_slave_status为ON,表示从服务器的半同步复制已经启用。
Empty set (0.00 sec) -- 为空就是没有设置半同步复制
两种方法安装插件:(1、通过命令行 2、通过配置文件)
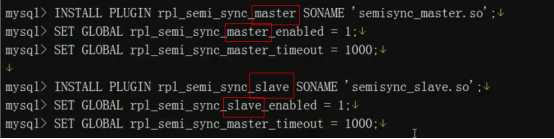
1、通过命令行 安装插件,重启数据后配置会失效(主从库插件不一样,都需要设置):
A、master端操作:
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (1.72 sec)
-- 或MySQL 8.0.26以上版本执行下面命令:
install plugin rpl_semi_sync_source soname 'semisync_source.so';
mysql> show plugins; -- 可以看到rpl_semi_sync_master插件Status为ACTIVE表示该插件安装成功的
+----------------------------+----------+--------------------+--------------------+---------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+--------------------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| mysql_native_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| sha256_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MEMORY | ACTIVE | STORAGE ENGINE | NULL | GPL |
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
| INNODB_TRX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCKS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCK_WAITS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_PER_INDEX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_PER_INDEX_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_PAGE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_PAGE_LRU | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_POOL_STATS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_TEMP_TABLE_INFO | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_METRICS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_DEFAULT_STOPWORD | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_DELETED | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_BEING_DELETED | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_CONFIG | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_INDEX_CACHE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_INDEX_TABLE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLESTATS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_INDEXES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_COLUMNS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FIELDS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FOREIGN | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FOREIGN_COLS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLESPACES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_DATAFILES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_VIRTUAL | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| MyISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MRG_MYISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| PERFORMANCE_SCHEMA | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ARCHIVE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| BLACKHOLE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| FEDERATED | DISABLED | STORAGE ENGINE | NULL | GPL |
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ngram | ACTIVE | FTPARSER | NULL | GPL |
| rpl_semi_sync_master | ACTIVE | REPLICATION | semisync_master.so | GPL |
+----------------------------+----------+--------------------+--------------------+---------+
45 rows in set (0.00 sec)
mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1; -- 主服务器上执行以下语句开启半同步复制
Query OK, 0 rows affected (0.00 sec)
-- 如果网络延迟较高或从服务器响应较慢,可能需要增加超时时间,以确保主服务器足够长的等待从服务器的确认。相反,如果需要较低的延迟,并且从服务器的响应速度较快,则可以考虑减小超时时间。
mysql> set global rpl_semi_sync_master_timeout = 1000; -- 1000毫秒,参数用于控制主服务器等待从服务器确认的超时时间,以便在半同步复制中保持一定的数据可靠性和性能平衡。
Query OK, 0 rows affected (0.01 sec)
mysql> SHOW GLOBAL STATUS LIKE 'Rpl_semi_sync%'; -- Rpl_semi_sync_master_status为ON,表示主服务器的半同步复制已经启用
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 0 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
+--------------------------------------------+-------+
14 rows in set (0.00 sec)
mysql> show variables like '%semi_sync%'; -- 查看半同步复制的相关参数
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 1000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
+-------------------------------------------+------------+
6 rows in set (0.00 sec)
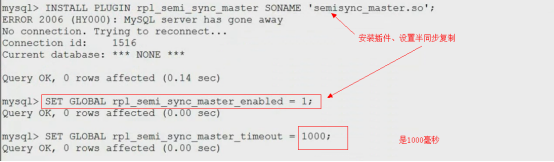
B、salve端操作:
#在备库安装插件:
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (1.72 sec)
#或MySQL 8.0.26以上版本执行下面命令:
install plugin rpl_semi_sync_replica soname 'semisync_replica.so';
mysql> show plugins; -- 可以看到rpl_semi_sync_slave插件Status为ACTIVE表示该插件安装成功的
+----------------------------+----------+--------------------+-------------------+---------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+-------------------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| mysql_native_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| sha256_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MEMORY | ACTIVE | STORAGE ENGINE | NULL | GPL |
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
| INNODB_TRX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCKS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCK_WAITS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_PER_INDEX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_PER_INDEX_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_PAGE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_PAGE_LRU | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_BUFFER_POOL_STATS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_TEMP_TABLE_INFO | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_METRICS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_DEFAULT_STOPWORD | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_DELETED | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_BEING_DELETED | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_CONFIG | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_INDEX_CACHE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_FT_INDEX_TABLE | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLESTATS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_INDEXES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_COLUMNS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FIELDS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FOREIGN | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_FOREIGN_COLS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_TABLESPACES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_DATAFILES | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_SYS_VIRTUAL | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| MyISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MRG_MYISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| PERFORMANCE_SCHEMA | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ARCHIVE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| BLACKHOLE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| FEDERATED | DISABLED | STORAGE ENGINE | NULL | GPL |
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ngram | ACTIVE | FTPARSER | NULL | GPL |
| rpl_semi_sync_slave | ACTIVE | REPLICATION | semisync_slave.so | GPL |
+----------------------------+----------+--------------------+-------------------+---------+
45 rows in set (0.00 sec)
#备库执行:
mysql> set global rpl_semi_sync_slave_enabled=1; -- 从服务器上执行以下语句开启半同步复制
#或MySQL 8.0.26以后版本执行:
set global rpl_semi_sync_replica_enabled = 1;
mysql> SHOW GLOBAL STATUS LIKE 'Rpl_semi_sync%'; -- Rpl_semi_sync_slave_status为ON,表示从服务器的半同步复制已经启用
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
1 row in set (0.01 sec)
mysql> show variables like '%semi_sync%'; -- 查看半同步复制的相关参数
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| rpl_semi_sync_slave_enabled | ON |
| rpl_semi_sync_slave_trace_level | 32 |
+---------------------------------+-------+
2 rows in set (0.00 sec)
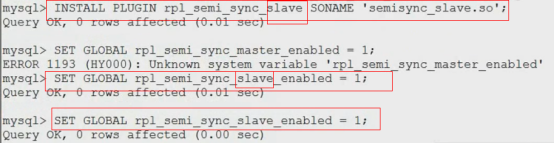
C、从库重启io线程:
-- 如果在完成上面配置时异步复制正在运行,则需要重启从库的IO线程来切换到半同步复制:
mysql> show global status like 'rpl_semi_sync_slave_status'; -- 查看备库半同步复制状态
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
1 row in set (0.00 sec)
mysql> stop slave io_thread;
Query OK, 0 rows affected (0.00 sec)
mysql> start slave io_thread;
Query OK, 0 rows affected (0.00 sec)
mysql> show global status like 'rpl_semi_sync_slave_status'; -- 再次查看备库半同步复制状态
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
1 row in set (0.00 sec)
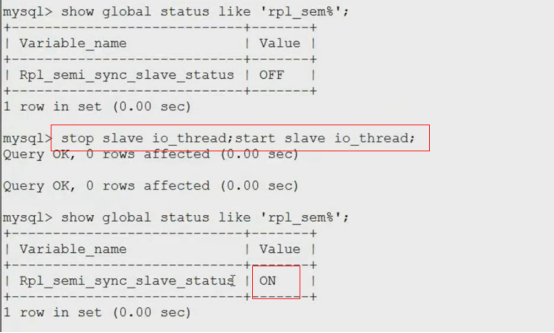
验证:创建数据库、写入删除数据等操作
1、通过配置文件 安装插件(主从库插件不一样,都需要设置):
#主库配置文件添加:
[mysqld]
plugin_dir = /data/mysql/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so"
rpl_semi_sync_master_enabled=1
# 或8.026版本添加
# гpl_semi_sync_source_enabled=1
#从库配置文件添加:
[mysqld]
plugin_dir = /data/mysql/lib/plugin
plugin_load = "rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_slave_enabled=1
# 或8.026版本添加:
# rpl_semi_sync_replica_enabled=1
在从库查看,查看步骤与命令行模式一样的。这里就省略了
-- 如果在完成上面配置时异步复制正在运行,则需要重启从库的IO线程来切换到半同步复制:
stop slave io_thread;
start slave io_thread;
show status like 'rpl_semi_sync_slave_status'; --查看备库半同步复制状态
注意,如果是双主,配置如下:
#主库配置文件添加:
[mysqld]
plugin_dir = /data/mysql/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_master_enabled=1
# 或8.026版本添加
# гpl_semi_sync_source_enabled=1
rpl_semi_sync_slave_enabled=1
rpl_semi_sync_master_timeout = 1000
#从库配置文件添加:
[mysqld]
plugin_dir = /data/mysql/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_master_enabled=1
rpl_semi_sync_slave_enabled=1
# 或8.026版本添加:
# rpl_semi_sync_replica_enabled=1
######## semi sync replication settings ########
plugin_dir = /data/mysql/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_master_timeout = 5000
loose_rpl_semi_sync_slave_enabled = 1
rpl_semi_sync_master_enabled、loose_rpl_semi_sync_master_enabled两个参数是一样的吗?
rpl_semi_sync_master_enabled 和 loose_rpl_semi_sync_master_enabled 这两个参数实际上是相同的,在不同的MySQL版本中可能有所差异。在早期的MySQL版本中,rpl_semi_sync_master_enabled 是用于配置是否启用半同步复制的主服务器的参数。而在较新的MySQL版本中,采用了更通用的参数命名规范,将参数名前面添加了 loose_ 前缀,因此变成了 loose_rpl_semi_sync_master_enabled。
无论使用哪个参数名,它们都具有相同的功能:用于控制是否启用半同步复制的主服务器。
主从复制排错步骤:
1、网络是否能ping通
2、master的密码是否正确
3、master的log-bin名字及Position是否正确
同步延迟解决策略
1、保证网络问题(至少千兆网卡)
2、从节点更换ssd硬盘
3、日志压缩(减少服务器之间通信、但是能一定能解决延迟问题、压缩会占CPU->自己衡量)
4、从架构方面考虑
监控主从脚本
local]# cat checkms.sh
#!/bin/bash
# 设置 日志存储目录,且删除7天前的日志文件
LogsDir="/data/checkmslog"
# 查询 SHOW SLAVE STATUS 的输出
slave_status=$(mysql --login-path=local -e "show slave status \G")
# 获取从服务器的复制状态
io_running=$(echo "${slave_status}" | awk '/Slave_IO_Running:/ { print $2 }')
sql_running=$(echo "${slave_status}" | awk '/Slave_SQL_Running:/ { print $2 }')
seconds_behind_master=$(echo "${slave_status}" | awk '/Seconds_Behind_Master:/ { print $2 }')
# 创建日志存储目录
test -d ${LogsDir} || mkdir -p ${LogsDir}
# 判断从服务器的复制状态是否正常
if [[ "${io_running}" == "Yes" && "${sql_running}" == "Yes" && "${seconds_behind_master}" != "NULL" ]]; then
# 判断 Seconds_Behind_Master 是否小于等于指定值,如果是,就说明同步正常
MAX_SECONDS_BEHIND=60
if [ ${seconds_behind_master} -le ${MAX_SECONDS_BEHIND} ]; then
echo "`date +"%Y-%m-%d %H:%M:%S"`: MySQL replication is normal, seconds_behind_master current value: ${seconds_behind_master}" >> ${LogsDir}/checkmslog_`date +%F`.log
find ${LogsDir} -mtime +7 -name "*.log" -exec rm -f {} +
exit 0
fi
# 否则,就说明同步出现了问题
echo "`date +"%Y-%m-%d %H:%M:%S"`: MySQL replication is normal, But MySQL replication is ${seconds_behind_master} seconds behind master!" >> ${LogsDir}/checkmslog_`date +%F`.log
find ${LogsDir} -mtime +7 -name "*.log" -exec rm -f {} +
exit 1
else
# 发送警报或进行相应的处理
echo "`date +"%Y-%m-%d %H:%M:%S"`: MySQL replication is abnormal." >> ${LogsDir}/checkmslog_`date +%F`.log
echo "`date +"%Y-%m-%d %H:%M:%S"`: IO-> ${io_running}" >> ${LogsDir}/checkmslog_`date +%F`.log
echo "`date +"%Y-%m-%d %H:%M:%S"`: SQL-> ${io_running}" >> ${LogsDir}/checkmslog_`date +%F`.log
find ${LogsDir} -mtime +7 -name "*.log" -exec rm -f {} +
# TODO: 发送邮件或短信通知管理员等
fi
总结
(1)异步方式同步
(2) 逻辑同步模式(binlog 有三种模式: SQL、混合、 rowlevel),默认是通过 SQL 语句执行
(3)主库通过记录 binlog 实现对从库的同步
(4)主库 1 个线程(IO 线程),从库 2 个线程(IO 和 SQL)来完成
(5)从库的关键文件: master.info、 relay-log、 relay-info
(6)如果从库还想级联从库,需打开 log-bin 和 log-slave-updates 参数
生产场景快速配置 MySQL 主从复制的方案
(1)安装好要配置从库的数据库,配置好log-bin和server-id参数。
(2)无需配置主库的 my.cnf 文件,主库的log-bin和server-id参数默认就是配置好的。
(3)登陆主库增加用于从库连接的帐户,并授replication slave的权限。
(4)半夜使用 mysqldump 带--master-data=1参数全备主库,并在从库进行恢复。
(5)在从库执行change master to语句,无需 binlog 文件及对应位置点。
(6)在从库开启同步开关start slave。
(7)从库show slave status\G,检查同步状态,并在主库进行更新测试。
tips:
(1)主从库服务器的配置差距不要太大。
(2)撰写方案文档和实施步骤。如可能需要停机维护,需要事先申请停机维护时间
常见错误:
Slave_IO_Running 和 Slave_SQL_Running 是用于检查 MySQL 主从复制状态的两个系统变量。
Slave_IO_Running 变量表示当前的 I/O 线程是否正在运行,该线程负责从主库读取二进制日志并写入到从库的中继日志中。如果 Slave_IO_Running 的值为 Yes,则表示 I/O 线程正在运行;如果值为 No,则表示 I/O 线程停止运行或者还未启动。
Slave_SQL_Running 变量表示当前的 SQL 线程是否正在运行,该线程负责读取中继日志中的事务,并在从库上执行这些事务。如果 Slave_SQL_Running 的值为 Yes,则表示 SQL 线程正在运行;如果值为 No,则表示 SQL 线程停止运行或者还未启动。
通常情况下,当 Slave_IO_Running 和 Slave_SQL_Running 变量的值都为 Yes 时,表示主从同步正常。如果其中任意一个变量的值为 No,则表示出现了主从同步的异常情况,需要对异常进行排查和处理。
(1)当在执行start slave条命令时,系统提示 ERROR 1200 (HY000): The server is not configured as slave; fix in config file or with CHANGE MASTER TO, 执行show slave status;又提示Empty set (0.00 sec)
原因:slave已经默认开启,要先关闭再开启,执行stop slave;再执行change master to master_host='192.168.56.11',master_user='rep',master_password='123456', master_log_file='mysql-bin.000005' ,master_log_pos=120;
(2)出现错误提示 :Slave_IO_Running:NO ,mysql的error日志中信息: Slave I/O: error connecting to master 'replication@172.16.0.100:3306' - retry-time: 60 retries: 86400, Error_code: 1045
解决方法
1.在主mysql中创建slave远程连接访问时候的登录密码一定要设置对。
2.停止slave上的mysqld服务,从服务器上删除掉所有的二进制日志文件,包括一个数据目录下的master.info文件和hostname-relay-bin开头的文件,然后启动slave上的mysqld服务。
master.info:记录了Mysql主服务器上的日志文件和记录位置、连接的密码。
(3)slave上Slave_SQL_Running: No ,提示某个表定义不正确
解决方法:清空drop掉master和slave上的已经存在所有表,然后从master库上导入新的数据即可
sql无法正常运行,不能同步:
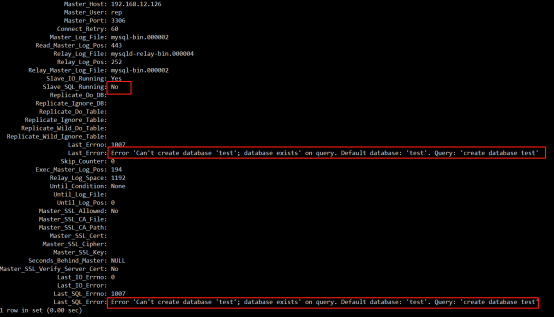
解决方案:(跳过此错误)
mysql> stop slave
mysql> set GLOBAL sql_slave_skip_counter=1;
mysql> start slave;
需要注意的是,当您使用跳过错误的方法时,可能会导致主从数据不同步,因此请务必在正确理解风险的情况下使用该方法,并在复制故障排除后及时恢复正常复制进程。
参数解释:
sql_slave_skip_counter=N跳过N个事务
1、set global sql_slave_skip_counter=N中的N是指跳过N个event
2、最好记的是N被设置为1时,效果跳过下一个事务。
3、跳过第N个event后,位置若刚好落在一个事务内部,则会跳过这整个事务
4、一个insert/update/delete不一定只对应一个event,由引擎和日志格式决定
(4)Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; 在搭建Mysql主从架构过程中,由于从服务器是直接复制的主库的data数据库,导致主从Mysql server_uuid相同, Slave_IO无法启动
mysql> show variables like '%server_uuid%';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| server_uuid | c9def4f6-1a72-11ee-8f15-fa163e95897a |
+---------------+--------------------------------------+
1 row in set (0.00 sec)
解决方案:直接删除mysql数据目录下面的auto.cnf文件,最后重启mysql服务即可解决
MySQL的读写分离Amoeba(已经没有维护了,建议不用)
资料:https://blog.51cto.com/467754239/1581954
1、Amoeba简介
Amoeba(变形虫)项目,该开源框架于2008年开始发布一款 Amoeba for Mysql软件。这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的 时候充当SQL路由功能,专注于分布式数据库代理层(Database Proxy)开发。座落与 Client、DB Server(s)之间,对客户端透明。具有负载均衡、高可用性、SQL 过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。 通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能,目前Amoeba已在很多企业的生产线上面使用
Amoeba(阿米巴原虫):Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy。它集中地响应应用的请求,依据用户事先设置的规则,将SQL请求发送到特定的数据库上执行。基于此可以实现负载均衡、读写分离、高可用性等需求。与MySQL官方的MySQL Proxy相比,作者强调的是amoeba配置的方便(基于XML的配置文件,用SQLJEP语法书写规则,比基于lua脚本的MySQL Proxy简单)。
Amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。用户需要结合使用MySQL的 Replication等机制来实现副本同步等功能。amoeba对底层数据库连接管理和路由实现也采用了可插拨的机制,第三方可以开发更高级的策略类来替代作者的实现。这个程序总体上比较符合KISS原则的思想。
代理不需要安装MySQL,只需要MySQL代理工具amoeba,而MySQL主从服务器必须安装MySQL
2、Amoeba的优缺点
优点:
(1)降低费用,简单易用
(2)提高系统整体可用性
(3)易于扩展处理能力与系统规模
(4)可以直接实现读写分离及负载均衡效果,而不用修改代码
缺点:
(1)不支持事务与存储过程
(2)暂不支持分库分表,amoeba目前只做到分数据库实例
(3)不适合从amoeba导数据的场景或者对大数据量查询的query并不合适(比如一次请求返回10w以上甚至更多数据的场合)
3、什么是读写分离
读写分离(Read/Write Splitting),基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。
数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
4、实现读写分离的方法
(1)程序修改mysql操作类
可以参考PHP实现的Mysql读写分离,阿权开始的本项目,以php程序解决此需求。
优点:直接和数据库通信,简单快捷的读写分离和随机的方式实现的负载均衡,权限独立分配
缺点:自己维护更新,增减服务器在代码处理
(2)Mysql-Proxy
MySQL的官方开源项目,但是MySQL官方并不推荐将其应用到生产环境下。
优点:直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号
缺点:字符集问题,lua语言编程,还只是alpha版本,时间消耗有点高
(3)Amoeba
阿里巴巴的开源产品,充分证明它的稳定性不容置疑。
参考官网:http://amoeba.meidusa.com/
优点:直接实现读写分离和负载均衡,不用修改代码,有很灵活的数据解决方案
缺点:自己分配账户,和后端数据库权限管理独立,权限处理不够灵活
2、拓扑图
主机地址分配:
Master主机地址:192.168.12.126
Slave1主机地址:192.168.12.57
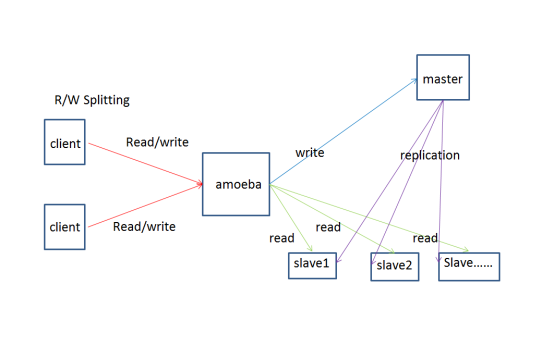
3、搭建mysql的主从复制
详见MySQL主从复制
4、安装amoeba实现读写分离
准备软件:
https://sourceforge.net/projects/amoeba/files/Amoeba%20for%20mysql/2.2.x/
amoeba-mysql-binary-2.2.0.tar.gz
jdk-6u45-linux-x64.bin
因为Amoeba是Java程序开发的,所以要安装JDK
如果是amoeba-2.X的版本的话,官方推荐的jdk是jdk1.5,jdk1.6版本不能太高
下载并安装jdk-1.6,并导出环境变量
[root@ns1 ~]# chmod +x jdk-6u45-linux-x64.bin #添加执行权限
[root@ns1 ~]# ./jdk-6u45-linux-x64.bin #运行安装脚本
[root@ns1 ~]# mv jdk1.6.0_45 /usr/local/jdk1.6 #移动并改名
[root@ns1 ~]# vim /etc/profile.d/jdk.sh
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/bin
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
[root@ns1 ~]# source /etc/profile.d/jdk.sh #生效
#必须先创建存放amoeba目录,因为这个软件解压出来没有放在一个目录里
[root@ns1~]# mkdir /usr/local/amoeba
#把代理软件(amoeba-mysql-binary-2.2.0.tar.gz)解压到/usr/local/amoeba
[root@ns1~]# tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba
[root@ns1 ~]# vim /etc/profile.d/amoeba.sh
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
[root@ns1 ~]# source /etc/profile.d/amoeba.sh #生效
[root@ ns1 /usr/local]# tree -d amoeba
amoeba
├── benchmark
├── bin
├── conf
├── lib
│ └── classes
└── logs
6 directories
然后安装运行amoeba
[root@ns1 ~]# amoeba -h
#提示错误信息
The stack size specified is too small, Specify at least 160k
Could not create the Java virtual machine.
[root@ns1 amoeba]# vim bin/amoeba #修改脚本中的58行
58 DEFAULT_OPTS="-server -Xms256m -Xmx256m -Xss256k" #将原来的Xss128改为Xss256即可
再次运行:
[root@ns1 amoeba]# amoeba –h
amoeba server not running with port=0
[root@ns1 amoeba]# amoeba start
成功!
接着配置amoeba读写分离,两个从库的负载均衡:
# cd /usr/local/amoeba/conf/
amoeba.xml #定义数据库读写分离及节点管理信息等
dbServers.xml #定义连接后端Mysql服务器信息
- 在主库和两个从库上分别授权amoeba的访问权限
理论上只需要在主库上执行,因为从库会自动同步!
mysql> grant all on *.* to test@'192.168.133.%' identified by '666666';
Query OK, 0 rows affected (0.11 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
编辑amoeba配置文件amoeba.xml:
[root@ns1 amoeba]# vim conf/amoeba.xml
#定义amoeba连接用户名和密码,客户端或程序只需要使用此用户名和密码连接即可
30 <property name="user">amoeba</property>
31
32 <property name="password">666666</property>
#定义默认池,一些sql语句默认会在此定义的服务器上执行
115 <property name="defaultPool">master</property>
#定义只写数据库
116 <property name="writePool">master</property>
#定义只读数据库,此处定义的是在"dbServer.xml"文件中定义的后端服务器名称,也可以定义数据库池的名称,实现负载均衡
117 <property name="readPool">slaves</property>
继续添加MySQL的池子中的数据库地址和登录名:
[root@ns1 amoeba]# vim conf/dbServers.xml
19 <!-- mysql port -->
#定义连接后端集群mysql的端口
20 <property name="port">3306</property>
21
22 <!-- mysql schema -->
#连接的默认数据库(填写主库里已经存在的库,建议用test库)
23 <property name="schema">test</property>
24
25 <!-- mysql user -->
#连接后端数据库的用户名和密码,需要后端数据库授权
26 <property name="user">test</property>
#授权用户的密码
27 <property name="password">666666</property>
#定义"master"数据库节点,"name"名称可以自定义,建议写master
45 <dbServer name="master" parent="abstractServer">
46 <factoryConfig>
47 <!-- mysql ip -->
#主库的IP地址
48 <property name="ipAddress">192.168.12.126</property>
49 </factoryConfig>
50 </dbServer>
51 #定义"slave1"数据库节点
52 <dbServer name="slave1" parent="abstractServer">
53 <factoryConfig>
54 <!-- mysql ip -->
#slave1库的IP地址
55 <property name="ipAddress">192.168.12.57</property>
56 </factoryConfig>
57 </dbServer>
58
定义只读数据库,与amoeba.xml配置文件中的名字必须相同
59 <dbServer name="slaves" virtual="true">
60<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
61 <!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
#定义选择哪一种算法进行负载均衡调度
62 <property name="loadbalance">1</property>
63
64 <!-- Separated by commas,such as: server1,server2,server1 -->
#定义数据库池,用于实现负载均衡."slave"为上面定义的从数据库节点,可以写多个用","分隔;
65 <property name="poolNames">slave1</property>
66 </poolConfig>
67 </dbServer>
ps:当有多个丛库时,需要在dbServers.xml配置文件中,定义多个slave节点;如下:
51 #定义"slave1"数据库节点
52 <dbServer name="slave2" parent="abstractServer">
53 <factoryConfig>
54 <!-- mysql ip -->
#slave1库的IP地址
55 <property name="ipAddress">192.168.12.58</property>
56 </factoryConfig>
57 </dbServer>
65 <property name="poolNames">slave1,slave2</property>
开启amoeba:
[root@ns1 ~]# amoeba start
log4j:WARN log4j config load completed from file:/usr/local/amoeba/conf/log4j.xml
2019-04-12 12:19:19,320 INFO context.MysqlRuntimeContext - Amoeba for Mysql current versoin=5.1.45-mysql-amoeba-proxy-2.2.0
log4j:WARN ip access config load completed from file:/usr/local/amoeba/conf/access_list.conf
2019-04-12 12:19:19,501 INFO net.ServerableConnectionManager - Amoeba for Mysql listening on 0.0.0.0/0.0.0.0:8066.
2019-04-12 12:19:19,504 INFO net.ServerableConnectionManager - Amoeba Monitor Server listening on /127.0.0.1:13242.
使用一台机器来作为客户端,连接到MySQL代理上去:
远程登录到MySQL代理上:
[root@lnmp01 ~]# mysql -u amoeba -p666666 -h 192.168.12.81 -P 8066
参数解释:
-
amoeba:在amoeba.xml配置文件,定义的用于客户端连接到mysql的代理服务器的用户
-
666666:在amoeba.xml配置文件,定义的用于客户端连接到mysql的代理服务器的用户的登录密码
-
192.168.12.81:amoeba代理服务器的IP地址
-
8066:开启amoeba时,Amoeba for Mysql listening的监听端口
测试:
在丛库1上停止主从复制,并在客户端接着插入第二条数据:
mysql> insert into acl values(12,'limama','dalian');
Query OK, 1 row affected (0.16 sec)
结果发现主库上都有这两条数据,而丛库只有第一条:而在丛库上查询的话也只查到第一条数据,这说明我们的读写分离正确配置,在主库上写,在丛库上读!
MySQL-MMM高可用集群(线上建议不用)
MMM不适用于对数据一致性要求很高的环境。但是高可用完全做到了。
简介:
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM使用Perl语言开发,主要用来监控和管理MySQL Master-Master(双主)复制,虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热,可以说MMM这套脚本程序一方面实现了故障切换的功能,另一方面其内部附加的工具脚本也可以实现多个slave的read负载均衡。
MMM提供了自动和手动两种方式移除一组服务器中复制延迟较高的服务器的虚拟ip,同时它还可以备份数据,实现两节点之间的数据同步等。由于MMM无法完全的保证数据一致性,所以MMM适用于对数据的一致性要求不是很高,但是又想最大程度的保证业务可用性的场景。对于那些对数据的一致性要求很高的业务,非常不建议采用MMM这种高可用架构。
优缺点:
优点:
高可用性,扩展性好,出现故障自动切换,对于主主同步,在同一时间只提供一台数据库写操作,保证的数据的一致性。
缺点:
Monitor节点是单点,可以结合Keepalived实现高可用,对主机的数量有要求,需要实现读写分离,对程序来说是个挑战。
mmm对数据的一致性要求不高,由于是基于网络,数据可能会缺失
由于架构里只有一个写入点,所以扩展性是有限的,但是对一般中型企业够用了。
解决方案:对于大应用可以采取垂直拆分到多个mmm架构的方式,使用mmm cluster来管理。
MySQL-MMM工作原理:
MMM(Master-Master replication managerfor Mysql,Mysql主主复制管理器)是一套灵活的脚本程序,基于perl实现,用来对mysql replication进行监控和故障迁移,并能管理mysql Master-Master复制的配置(同一时间只有一个节点是可写的)。
-
mmm_mond:监控进程,负责所有的监控工作,决定和处理所有节点角色活动。此脚本需要在监管机上运行。
-
mmm_agentd:运行在每个mysql服务器上(Master和Slave)的代理进程,完成监控的探针工作和执行简单的远端服务设置。此脚本需要在被监管机上运行。
-
mmm_control:一个简单的脚本,提供管理mmm_mond进程的命令。
mysql-mmm的监管端会提供多个虚拟IP(VIP),包括一个可写VIP,多个可读VIP,通过监管的管理,这些IP会绑定在可用mysql之上,当某一台mysql宕机时,监管会将VIP迁移至其他mysql。在整个监管过程中,需要在mysql中添加相关授权用户,以便让mysql可以支持监理机的维护。授权的用户包括一个mmm_monitor用户和一个mmm_agent用户,如果想使用mmm的备份工具则还要添加一个mmm_tools用户。
实验拓扑图:
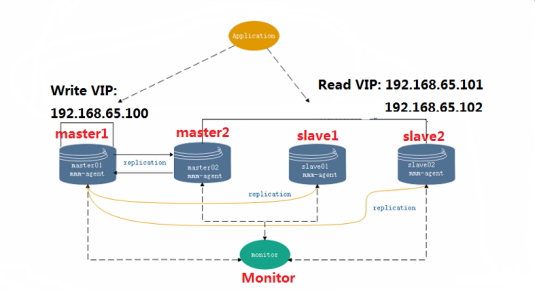
实验目的:
搭建mysql高可用群集
实验环境:
在5台服务器上关闭防火墙,selinux、同步时间
[root@centos-6-min ~]# setenforce 0
[root@centos-6-min ~]# service iptables stop
| 主机名 | 操作系统 | IP地址 | 软件包 |
|---|---|---|---|
| Master1 | Centos6.8 | 192.168.12.126 | epel-release、mysql-mmm、mysql |
| Master2 | Centos6.8 | 192.168.12.57 | epel-release、mysql-mmm、mysql |
| mysql-monitor | Centos6.8 | 192.168.12.235 | epel-release、mysql-mmm、mysql |
| slave1 | Centos6.8 | 192.168.12.201 | epel-release、mysql-mmm、mysql |
| slave2 | Centos6.8 | 192.168.12.121 | epel-release、mysql-mmm、mysql |
实验步骤:
一、Master1、Master2、mysql-monitor、slave1、slave2 5台mysql服务器配置
1.配置阿里云的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
2.配置epel源(最新版本)
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
3.加载元数据缓存
yum clean all && yum makecache
4.安装mysql数据库和mysql-mmm软件包
yum install mysql-server -y
yum install mysql -y
yum install mysql-mmm* -y
5.修改mysql数据库主配置文件(server_id必须不一样)
vim /etc/my.cnf # 在master1服务器上面修改
#在[mysqld]下面添加如下内容:
server_id=1
binlog-ignore-db=mysql,information_schema
character_set_server=utf8
binlog_format=row
log-bin=mysql-bin
log_slave_updates=true
sync_binlog=1
auto_increment_increment=2
auto_increment_offset=1
vim /etc/my.cnf # 在master2服务器上面修改
#在[mysqld]下面添加如下内容:
server_id=2
binlog-ignore-db=mysql,information_schema
character_set_server=utf8
binlog_format=row
log-bin=mysql-bin
log_slave_updates=true
sync_binlog=1
auto_increment_increment=2
auto_increment_offset=2
vim /etc/my.cnf # 在slave1服务器上面修改
#在[mysqld]下面添加如下内容:
server_id=3
binlog-ignore-db=mysql,information_schema
character_set_server=utf8
binlog_format=row
log-bin=mysql-bin
log_slave_updates=true
sync_binlog=1
vim /etc/my.cnf # 在slave2服务器上面修改
#在[mysqld]下面添加如下内容:
server_id=4
binlog-ignore-db=mysql,information_schema
character_set_server=utf8
binlog_format=row
log-bin=mysql-bin
log_slave_updates=true
sync_binlog=1
备注:分别修改master02、slave01、slave02的配置文件server_id参数
参数解释:
[mysqld]
log_error=/var/lib/mysql/mysql.err #错误日志
log=/var/lib/mysql/mysql_log.log #访问日志
log_slow_queries=/var/lib/mysql_slow_queris.log #慢日志
binlog-ignore-db=mysql,information_schema #不生成二进制日志文件
binlog_format={mixed|row|statement} #记录二进制日志的格式(这三种针对innodb存储引擎)
character_set_server=utf8 #字符集
log-bin=mysql-bin #开启二进制文件
server_id=1 #id号是唯一的
log_slave_updates=true #同步开启
sync_binlog=1 #同步二进制日志,1设为安全值
auto_increment_increment=2 #自增列,起点为1,增量为2
auto_increment_offset=1
6.启动mysqld服务
chkconfig --add mysqld #开机自启动mysqld
chkconfig mysqld on #启动mysqld服务
二、主、主复制(主服务器之间相互复制)
master1上进行操作:
1.登录mysql,在主服务器master1上授权
grant replication slave on *.* to 'replication'@'192.168.12.%' identified by '666666';
flush privileges; -- 刷新生效
192.168.12.57表示master2的IP地址
2.在master1上指定master2的日志和位置参数
change master to master_host='192.168.12.57',master_user='replication',master_password
='666666',master_log_file='mysql-bin.000001',master_log_pos=106;
3.开启同步
start slave;
master2上进行操作:
1.登录mysql,在主服务器master2上授权
grant replication slave on *.* to 'replication'@'192.168.12.%' identified by '666666';
flush privileges; #刷新生效
192.168.12.126表示master1的IP地址
2.在master2上指定master1的日志和位置参数
change master to master_host='192.168.12.126',master_user='replication',master_password
='666666',master_log_file='mysql-bin.000001',master_log_pos=107;
3.开启同步
start slave;
在slave1、slave2进行主从相同操作:
从服务器同步主(必须两台从服务器都指向同一台主服务器);两台从服务器同样操作:
-- 注意主服务器位置参数变化
change master to master_host='192.168.12.126',master_user='replication',master_password='666666',master_log_file='mysql-bin.000005',master_log_pos=195;
-- 开启同步
start slave;
测试:四台全部同步
到此处四台可以同步,就说明主主及主从就ok了
三、配置mysql-MMM服务器(5台服务器都配置)
1.编辑mysql-mmm的配置文件
vim mmm_common.conf #所有主机都要配置,复制
<host default>
cluster_interface eth0 #群集的网络接口eth0
pid_path /var/run/mysql-mmm/mmm_agentd.pid #pid文件
bin_path /usr/libexec/mysql-mmm/ #可执行文件路径
replication_user replication #修改mysql给予权限的用户
replication_password 666666 #修改mysql给予权限的用户密码
agent_user mmm_agent #修改agent客户端代理用户
agent_password 666666 #修改agent客户端代理用户密码
</host>
<host db1> #指定第一个主数据库
ip 192.168.12.126 #指定IP地址
mode master #模式为主服务器
peer db2 #与db2互为切换
</host>
<host db2> #指定第二个主数据库
ip 192.168.12.57 #指定IP地址
mode master #模式为主服务器
peer db1 #与db1互为切换
</host>
<host db3> #指定第一个从数据库
ip 192.168.12.201 #指定IP地址
mode slave #模式为从服务器
</host>
<host db4> #指定第二个从数据库
ip 192.168.12.121 #指定IP地址
mode slave #模式为从服务器
</host>
<role writer> #指定写入服务器
hosts db1, db2 #指定db1,db2为写入服务器
ips 192.168.12.250 #指定写入虚拟ip地址
mode exclusive #模式为单独的(只能有一个)
</role>
<role reader> #指定读取服务器
hosts db3, db4 #指定db3,db4为写入服务器
ips 192.168.12.251, 192.168.12.252 #指定读取虚拟ip地址
mode balanced #模式为负载均衡,读取操作会从db3、db4主机进行
</role>
备注:一定要去其它4台服务器上确认已修改!
2、将配置文件传输到其它4台数据库服务器上
scp /etc/mysql-mmm/mmm_common.conf 192.168.12.57:/etc/mysql-mmm/mmm_common.conf
scp /etc/mysql-mmm/mmm_common.conf 192.168.12.201:/etc/mysql-mmm/mmm_common.conf
scp /etc/mysql-mmm/mmm_common.conf 192.168.12.121:/etc/mysql-mmm/mmm_common.conf
scp /etc/mysql-mmm/mmm_common.conf 192.168.12.235:/etc/mysql-mmm/mmm_common.conf
3.monitor配置
vim mmm_mon.conf
include mmm_common.conf
<monitor>
ip 127.0.0.1 #monitor监控的IP地址
pid_path /var/run/mysql-mmm/mmm_mond.pid
bin_path /usr/libexec/mysql-mmm
status_path /var/lib/mysql-mmm/mmm_mond.status
ping_ips 192.168.12.126,192.168.12.57,192.168.12.201,192.168.12.121 #监控的IP(一定要写被监控务器的真实IP地址,不能写虚拟IP地址)
auto_set_online 10 #切换浮动IP的时间(默认为60秒)
# The kill_host_bin does not exist by default, though the monitor will
# throw a warning about it missing. See the section 5.10 "Kill Host
# Functionality" in the PDF documentation.
#
# kill_host_bin /usr/libexec/mysql-mmm/monitor/kill_host
#
</monitor>
<host default>
monitor_user mmm_monitor #mmm_monitor 用户
monitor_password 666666 #mmm_monitor 密码
</host>
debug 0
4.在所有数据库上为mmm_agent、mmm_monitor授权
-- 为mmm_agent授权
grant super,replication client,process on *.* to 'mmm_agent'@'192.168.12.%' identified by '666666';
-- 为mmm_monitor授权
grant replication client on *.* to 'mmm_monitor'@'192.168.12.%' identified by '666666';
-- 刷新生效
flush privileges;
5.在4台数据库上分别修改mmm_agent.conf
vim mmm_agent.conf #在db1上面修改
this db1
vim mmm_agent.conf #在db2上面修改
this db2
vim mmm_agent.conf #在db3上面修改
this db3
vim mmm_agent.conf #在db4上面修改
this db4

6.mysql-mmm 启动
master-1,master-2,slave启动代理:
所有数据库主机启动mmm-agent:
/etc/init.d/mysql-mmm-agent start
7.monitor主机启动mmm-monitor
/etc/init.d/mysql-mmm-monitor start
8.在monitor主机上,检查所有选项
mmm_control命令介绍
valid commands are:
help - show this message
#查看帮助信息
ping - ping monitor
#ping监控
show - show status
#查看状态信息
checks [<host>|all [<check>|all]] - show checks status
#显示检查状态,包括(ping、mysql、rep_threads、rep_backlog)
set_online <host> - set host <host> online
#设置某host为online状态
set_offline <host> - set host <host> offline
#设置某host为offline状态
mode - print current mode.
#打印当前的模式,是ACTIVE、MANUAL、PASSIVE?
#默认ACTIVE模式
set_active - switch into active mode.
#更改为active模式
set_manual - switch into manual mode.
#更改为manual模式
set_passive - switch into passive mode.
#更改为passive模式
move_role [--force] <role> <host> - move exclusive role <role> to host <host>
#更改host的模式,比如更改处于slave的mysql数据库角色为write
(Only use --force if you know what you are doing!)
set_ip <ip> <host> - set role with ip <ip> to host <host>
#为host设置ip,只有passive模式的时候才允许更改!
mmm_control show #查看监控

mmm_control checks all
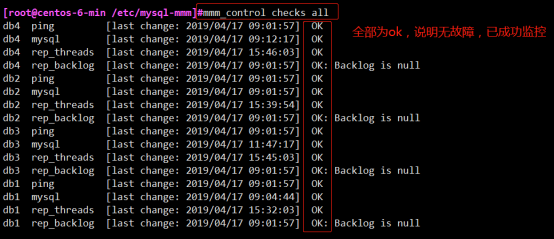
9.可以手动切换主服务器
mmm_control move_role writer db2
四、模拟故障
1.可以先停止db1,db3,再查看mysql-mmm服务器状态
ps:当db1服务器恢复后,并不会抢占vip地址,而是作为备用机在等待着
MySQL-MHA高可用(线上建议使用)
日本人写的:https://github.com/yoshinorim/mha4mysql-manager
参考文档:
-
故障切换方案,保证数据库系统的高可用。可以避免主从一致性问题,节约购买新服务器的费用,不影响服务器性能,易安装,不改变现有部署。
-
MySQL故障应对的课题:
-
2.1 MySQL的主从辅助是异步或半同步的
-
2.2 Master发生故障的时候,有可能一部分(或者全部)的SLAVE未能获取到最新的binlog
-
2.3 造成slave之间的binlog转发发生偏差
如下图所示,master宕机之后,id=102的binlog未能被发送到任何一个slave上,id=101的binlog只有slave2有,salve3上未能收到id=100和id=101的binlog
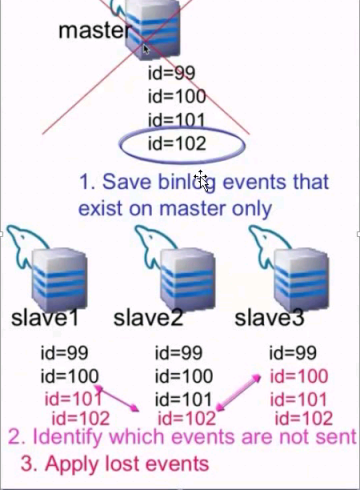
如果想要正确恢复:
- Master必须发送出id=102的binlog
-
还有消除各个slave之间的差异性
-
主要特征:
-
从master的监控到故障转移全部都能自动完成,故障转移也可手动执行
-
可在秒级单位内实现故障转移
-
将任意slave提升至master
-
具备在多个点上调用外部脚本的扩展技能,可以用在电源off或者IP地址的故障转以上
-
安装和卸载不用停止当前的MySQL进程
-
MHA自身不会增加服务器负担,不会降低性能,不用最佳服务器
-
不依赖storage engine
-
不依赖二进制文件的格式(不论是statement模式还是row模式)
-
针对OS挂掉的故障转移,检测系统是否挂掉需要10秒,故障转移仅需4秒
1、简介:
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0\~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。
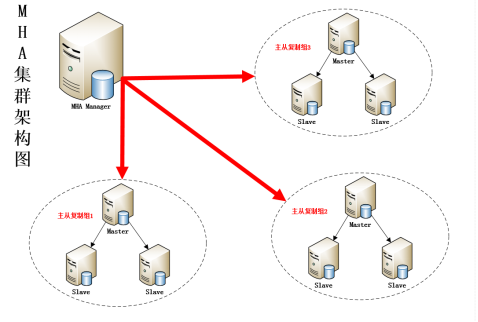
MySQL高可用之PXC
官网:https://www.percona.com/doc/percona-xtradb-cluster/5.5/howtos/centos_howto.html
博客参考:
https://blog.csdn.net/zisefeizhu/article/details/81873466
https://blog.csdn.net/liaomin416100569/article/details/79257501
https://www.cnblogs.com/markLogZhu/p/11463125.html
https://www.cnblogs.com/liushen/p/5715546.html
https://www.cnblogs.com/xyabk/p/10906952.html
https://www.jianshu.com/p/e3c66cd7c3e4
http://www.mamicode.com/info-detail-2389110.html
基于Galere协议的高可用方案:pxc
Galera是Codership提供的多主数据同步复制机制,可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据一致性。
基于Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster(简称PXC),目前PXC用的会比较多一些。
mariadb的集群原理跟PXC一样,maridb-cluster其实就是PXC,两者原理是一样的
PXC简介
Percona XtraDB Cluster简称PXC。是一套开源mysql高可用解决方案(XtraDb是mysql被oracle收购之前 开源一个分支 其他分支还有mariadb),Percona Xtradb Cluster的实现是在原mysql代码上通过Galera包将不同的mysql实例(新名称 Percona Server)连接起来,实现了multi-master(多个主都可以同时写入)的集群架构。pxc包含 Percona XtraBackup 组件用于提供Percone Server所有版本 在线备份解决方案
一个集群包含多个节点,每个节点互相同步包含相同的数据集 ,至少应该包含3个节点,每个节点都可以拥有读写的能力
-
集群是有节点组成的,推荐配置至少3个节点,但是也可以运行在2个节点上。
-
每个节点都是普通的
mysql/percona服务器,可以将现有的数据库服务器组成集群,反之,也可以将集群拆分成单独的服务器。 -
每个节点都包含完整的数据副本。
PXC集群主要由两部分组成:Percona Server with XtraDB和Write Set Replication patches(使用了Galera library,一个通用的用于事务型应用的同步、多主复制插件)
Percona XtraDB Cluster特性和优点
-
完全兼容 MySQL。
-
同步复制,事务要么在所有节点提交或不提交。
-
多主复制,可以在任意节点进行写操作。
-
多个可同时读写节点,可实现写扩展,不过最好事先进行分库分表,让各个节点分别写不同的表或者库,避免让galera解决数据冲突;
-
在从服务器上并行应用事件,真正意义上的
并行复制。 -
新节点可以自动部署,部署操作简单;数据一致性,不再是异步复制。尤其适合电商类应用
-
故障切换:因为支持多点写入,所以在出现数据库故障时可以很容易的进行故障切换。
-
自动节点克隆:在新增节点或停机维护时,增量数据或基础数据不需要人工手动备份提供,galera cluster会自动拉取在线节点数据,集群最终会变为一致;
PXC最大的优势:强一致性、无同步延迟
PXC的局限和劣势
1)只支持InnoDB引擎;当前版本(5.6.20)的复制只支持InnoDB引擎,其他存储引擎的更改不复制。然而,DDL(Data Definition Language) 语句在statement级别被复制,并且对mysql.*表的更改会基于此被复制。例如CREATE USER...语句会被复制,但是INSERT INTO mysql.user...语句则不会。
(也可以通过wsrep_replicate_myisam参数开启myisam引擎的复制,但这是一个实验性的参数)。
2)PXC集群一致性控制机制,是有可能被终止,原因如下:集群允许在两个节点上同时执行操作同一行的两个事务,但是只有一个能执行成功,另一个会被终止,集群会给被终止的
客户端返回死锁错误(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)).
3)写入效率取决于节点中最弱的一台,因为PXC集群采用的是强一致性原则,一个更改操作在所有节点都成功才算执行成功。
4)所有表都要有主键;
5)不支持LOCK TABLE等显式锁操作;
6)锁冲突、死锁问题相对更多;
7)不支持XA;
8)集群吞吐量/性能取决于短板;
9)新加入节点采用SST时代价高;
10)存在写扩大问题;
11)如果并发事务量很大的话,建议采用InfiniBand网络,降低网络延迟;
事实上,采用PXC的主要目的是解决数据的一致性问题,高可用是顺带实现的。因为PXC存在写扩大以及短板效应,并发效率会有较大损失,类似semi sync replication机制
PXC的缺点非常明显是操作表数据库会锁定整个集群的所有数据库等待写入资源竞争压力大
PXC 常用端口
-
3306:数据库对外服务的端口号。
-
4444:请求SST的端口,在新节点加入时起作用。SST: 指数据一个镜象传输 xtrabackup , rsync ,mysqldump
-
4567:组成员之间进行沟通的一个端口号
-
4568:用于传输IST,节点下线,重启加入时起作用。相对于SST来说的一个增量
mysql实例端口
1)Regular MySQL port, default 3306.
pxc cluster相互通讯的端口
2)Port for group communication, default 4567. It can be changed by the option:
wsrep_provider_options ="gmcast.listen_addr=tcp://0.0.0.0:4010;"
用于SST传送的端口,在新节点加入时起作用
3)Port for State Transfer, default 4444. It can be changed by the option:
wsrep_sst_receive_address=10.11.12.205:5555
用于IST传送的端口,节点下线,重启加入时起作用
4)Port for Incremental State Transfer, default port for group communication + 1 (4568). It can be changed by the option:
wsrep_provider_options = "ist.recv_addr=10.11.12.206:7777;"
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.10.215;ist.recv_addr=192.168.10.215;"
名词解释:
- SST(State Snapshot Transfer): 全量传输
- IST(Incremental state Transfer): 增量传输
- WS:write set 写数据集
PXC与Replication的区别
| Replication | PXC |
|---|---|
| 数据同步是单向的,master负责写,然后异步复制给slave;如果slave写入数据,不会复制给master。 | 数据同步时双向的,任何一个mysql节点写入数据,都会同步到集群中其它的节点。 |
| 异步复制,从和主无法保证数据的一致性 | 同步复制,事务在所有集群节点要么同时提交,要么同时不提交 |
Percona XtraDB Cluster与MySQL Replication区别在于:
分布式系统的CAP理论:任何一个分布式系统,需要满足这三个中的两个
C->一致性,所有节点的数据一致;
A->可用性,一个或多个节点失效,不影响服务请求;
P->分区容忍性,节点间的连接失效,仍然可以处理请求;
MySQLReplication: 可用性和分区容忍性;
Percona XtraDBCluster: 一致性和可用性。
因此MySQL Replication并不保证数据的一致性,而Percona XtraDB Cluster提供数据一致性。
官方文档参考 (https://www.percona.com/doc/percona-xtradb-cluster/LATEST/index.html)
PXC原理图
从上图可以看出:当client端执行dml操作时,将操作发给server,server的native进程处理请求,client端执行commit,server将复制写数据集发给group(cluster),cluster中每个动作对应一个GTID,其它server接收到并通过验证(合并数据)后,执行appyl_cb动作和commit_cb动作,若验证没通过,则会退出处理;当前server节点验证通过后,执行commit_cb,并返回,若没通过,执行rollback_cb。只要当前节点执行了commit_cb和其它节点验证通过后就可返回。
问题:如果主节点写入过大,apply_cb时间跟不上,怎么处理?
Wsrep_slave_threads参数配置成cpu的个数相等或是1.5倍。
用户发起Commit,在收到Ok之前,集群每次发起一个动作,都会有一个唯一的编号 ,也就是PXC独有的Global Trx Id。
动作发起者是commit_cb,其它节点多了一个动作: apply_cb上面的这些动作,是通过那个端号交互的?
4567,4568端口,IST只是在节点下线,重启加入那一个时间有用4444端口,只会在新节点加入进来时起作用
PXC结构里面,如果主节点写入过大,apply_cb 时间会不会跟不上,那么wsrep_slave_threads参数 解决apply_cb跟不上问题 配置成和CPU的个数相等或是1.5倍
当前节点commit_cb 后就可以返回了,推过去之后,验证通过就行了可以返回客户端了,cb也就是commit block 提交数据块.
PXC启动和关闭过程
State Snapshot Transfer(SST),每个节点都有一份独立的数据,当用mysql bootstrap-pxc启动第一个节点,在第一个节点上把帐号初始化,其它节点启动后加入进来。集群中有哪些节点是由wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx参数决定。第一个节点把自己备份一下(snapshot)传给加入的新节点,第三个节点的死活是由前两个节点投票决定。
状态机变化阶段:
1)OPEN: 节点启动成功,尝试连接到集群,如果失败则根据配置退出或创建新的集群
2)PRIMARY: 节点处于集群PC中,尝试从集群中选取donor进行数据同步
3)JOINER: 节点处于等待接收/接收数据文件状态,数据传输完成后在本地加载数据
4)JOINED: 节点完成数据同步工作,尝试保持和集群进度一致
5)SYNCED:节点正常提供服务:数据的读写,集群数据的同步,新加入节点的sst请求
6)DONOR(贡献数据者):节点处于为新节点准备或传输集群全量数据状态,对客户端不可用。
状态机变化因素:
1)新节点加入集群
2)节点故障恢复
3)节点同步失效
传输SST有几种方法:
1)mysqldump
2)xtrabackup
3)rsync
比如有三个节点:node1、node2、node3
当node3停机重启后,通过IST来同步增量数据,来完成保证与node1和node2的数据一致,IST的实现是由wsrep_provider_options="gcache.size=1G"参数决定,一般设置为1G大,参数大小是由什么决定的,根据停机时间,若停机一小时,需要确认1小时内产生多大的binlog来算出参数大小。
假设这三个节点都关闭了,会发生什么呢?
全部传SST,因为gcache数据没了
全部关闭需要采用滚动关闭方式:
- 关闭node1,修复完后,启动加回来;
-
关闭node2,修复完后,启动加回来;
-
......,直到最后一个节点
- 原则要保持Group里最少一个成员活着, 数据库关闭之后,最后保存一个last Txid,所以启动时,先要启动最后一个关闭的节点,启动顺序和关闭顺序刚好相反。
wsrep_recover=on参数在启动时加入,用于从log中分析gtid。
怎样避免关闭和启动时数据丢失?
1)所有的节点中最少有一个在线,进行滚动重启;
2)利用主从的概念,把一个从节点转化成PXC里的节点
PXC的架构示意图及传统架构比较
数据读写示意图
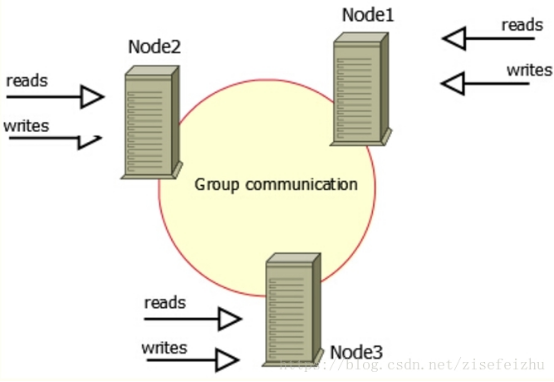
下面看传统复制流程
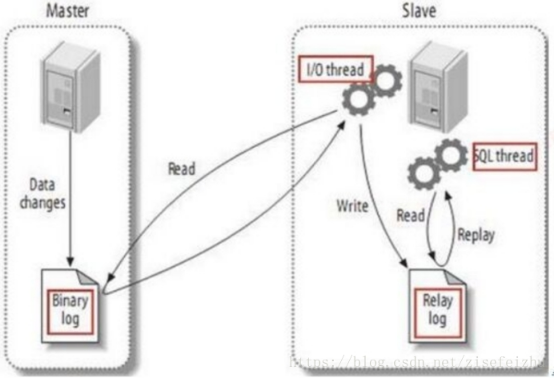
异步复制
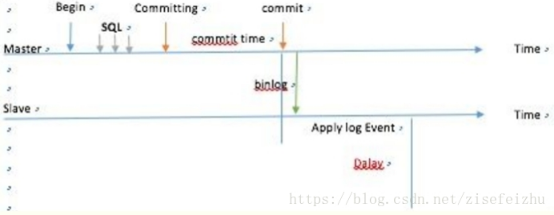
半同步 超过10秒的阀值会退化为异步
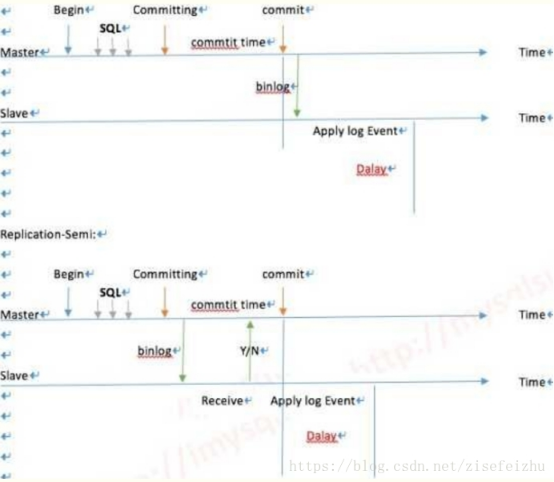
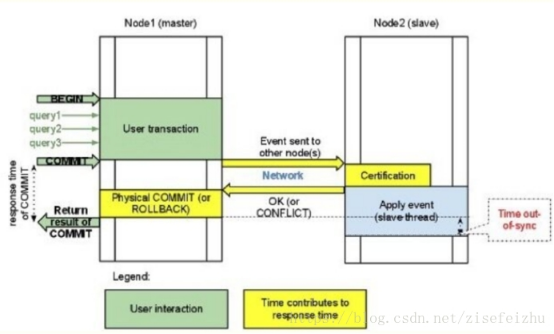
PXC要注意的问题
1)脑裂:任何命令执行出现unkown command,表示出现脑裂,集群两节点间4567端口连不通,无法提供对外服务。
SET GLOBAL wsrep_provider_options="pc.ignore_sb=true";
2)并发写:三个节点的自增起始值为1、2、3,步长都为3,解决了insert问题,但update同时对一行操作就会有问题,出现:
Error: 1213 SQLSTATE: 40001,所以更新和写入在一个节点上操作。
3)DDL:引起全局锁,采用:pt-online-schema-change
4)MyISAM引擎不能被复制,只支持innodb
5)pxc结构里面必须有主键,如果没有主建,有可能会造成集中每个节点的Data page里的数据不一样
6)不支持表级锁,不支持lock /unlock tables
7)pxc里只能把slow log ,query log 放到File里
8)不支持XA事务
9)性能由集群中性能最差的节点决定
特别说明
在实际使用时,我们知道服务的部署时根据需要后来增加的,所以相信在需要用到PXC做高可用时,已经在服务器上安装了Mysql,并跑了业务。这时候我们会发现存在错误,大致如下
大致意思是PID问题。其实percona自身就是mysql,你要原来的mysql干嘛,所以这时候应该杀死原来的Mysql,可能你又要问了那原来跑在Mysql的服务怎么办?备份还原就可以了。特此说明,以供道友参考,本人在此就出现了很大的困惑,最后才相通问题的解决方案,所以特别加冰了
PXC高可用集群方案
参考:https://www.cnblogs.com/xyabk/p/10906952.html
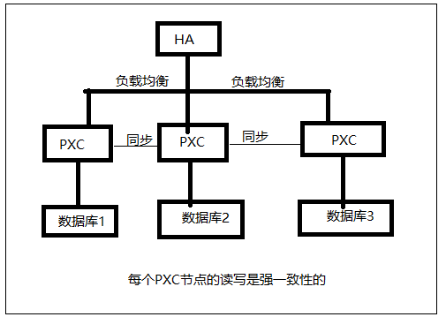
这样一个最基本的PXC集群,它保证了每个节点的的数据都是一致的,不会出现数据写入了数据库1而没有写入数据库2的情况,这种的集群在遇到单表数据量超过2000万的时候,mysql性能会受损,所以一个集群还不够,我们需要把数据分到另一个集群,这个称为切片,就是把大量的数据拆分到不同的集群中,每个集群的数据都是不一样的,看下面的截图:
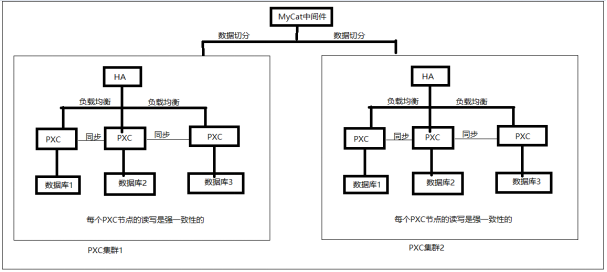
这样一来,PXC集群1存前面1000万条数据,PXC集群2存后面1000万条数据,当一个sql语句请求的时候,通过MyCat这个阿里巴巴的开源中间件,可以把sql分到不同的集群里面去。这种的分片按照数量就是2个分片。
这个切分算法也比较多,比如按照日期、月份、年份、某一列的固定值,或者最简单的按照主键值切分,主键对2求模,余0的存分片1,余1的存分片2,这样MyCat就会把2000万条数据均匀地分配到2个集群上。
PXC虽然保证了数据的强一致性,但是这是以牺牲性能为代价的,所以适合保存重要的数据,比如订单。
七、Replication集群方案

这种集群,在第一个节点插入以后,就马上返回给客户端执行成功了,然后再做每个节点之间的同步,如果某一个同步操作失败了,那用户请求的时候拿到的数据就不同步了,但是它的优势是速度快,不会牺牲任何地性能,适合保存不那么重要的数据,比如日志。
八、PXC与Replication集群结合
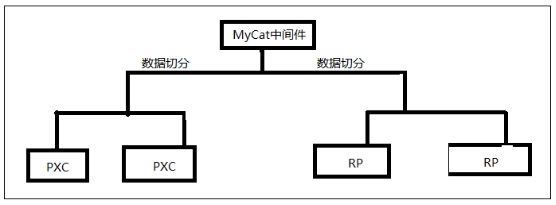
九、系统架构方案
更加清晰和详细架构请看下面的截图
十、APP的架构设计
客户端包括web浏览器端,移动手机端,用户通过客户端发送一个请求后,Nginx接收到请求后,会做负载均衡,定向到当前最适合(相对没那么繁忙)处理这个请求的服务器端,服务端接收到请求后,再访问数据库,一些热点数据需要做缓存,比如淘宝首页的商品。从上面的图中看,服务器端的某一个出现故障后,nginx会将请求定向到剩下的能正常运行的服务器上面,而数据库端也是采用的集群,这样就达到了高可用,就是任意一台机器出现故障,对整个网站的运行不会产生太大的影响,这里可能有人会问如果nginx这台服务器出现问题了怎么办?可以做虚拟ip(vip),配置主从入口,就是nginx1和nginx2的虚拟ip是一样的,其中有一个是主入口,在主入口没有出现问题的时候,从机是不会工作的,当主入口机出现问题了,从入口机就会顶替,如果主从都出现问题了,那网站将无法访问。
服务器端的spring与spring之间的调用又是如何的?现在都是分布式调用,比较经典的是dubbo+zookeeper。这里有同步调用和异步调用
同步调用:提出问题的一方直接调用处理问题的一方
异步调用:提出问题的一方将问题交个消息中间件,由消息中间件去将问题发放给处理问题的一方,在这里,提出问题的一方称为"生产者",处理问题的一方称为"消费者",他们彼此是不知道对方是谁,达到业务解耦的效果,这样做的好处是以后在部署项目、程序的升级、接口的变更的时候,它的影响面就很小。比如说生产者项目开发地有问题,然后用其他语言再做了一个项目,对消费者不会产生任何影响,只要生产生能正常往消息队列里面发送消息就好;再比如用户注册一个淘宝账号,我们连带着把支付宝账号也给你开通,然后其他的投资的项目也给用户一些优惠(给你2张淘票票的电影票,免费一个月的虾米音乐会员等等),对应淘宝这一端,它发起一个消息传达给消息队列,至于接收端是支付宝还是淘票票还是虾米音乐,淘宝这一端不知道也不需要关心,等以后阿里再有什么投资项目需要给新用户优惠的时候,只需要从消息队列里接收消息就可以,对生产者而言,没有任何影响。如果是同步调用(dubbo或者webservice调用),其中一端有修改,另一端必然也要改,这种强耦合是不好的。
以下是异步调用方案图:
Docker部署pxc
https://www.cnblogs.com/markLogZhu/p/11463125.html
PXC安装
注:可以选择源码或者yum,在此使用yum安装。
源码包地址:https://www.percona.com/downloads/Percona-XtraDB-Cluster-56/
rpm包:http://repo.percona.com/percona/yum/release/7/RPMS/x86_64/
三台机器同时安装 PXC,安装参考:
https://www.percona.com/doc/percona-xtradb-cluster/LATEST/overview.html
centos安装参考:
https://www.percona.com/doc/percona-xtradb-cluster/LATEST/install/yum.html#yum
配置yum的peronna仓库:
https://www.percona.com/doc/percona-repo-config/yum-repo.html
| Node | 主机名 | IP地址 |
|---|---|---|
| Node 1 | aliyun-6-server | 192.168.137.6 |
| Node 2 | aliyun-7-server | 192.168.137.7 |
| Node 3 | aliyun-8-server | 192.168.137.8 |
集群所需要的软件包:
rpm -ivh Percona-Server-server-57-5.7.12-5.1.el7.x86_64.rpm
rpm -ivh Percona-Server-shared-compat-57-5.7.12-5.1.el7.x86_64.rpm
rpm -ivh Percona-Server-shared-57-5.7.12-5.1.el7.x86_64.rpm
rpm -ivh Percona-Server-client-57-5.7.12-5.1.el7.x86_64.rpm
rpm -ivh percona-xtrabackup-24.x86_64.rpm
三个节点都要执行一下操作
~~yum -y groupinstall Base Compatibility libraries Debugging Tools Dial-up Networking suppport Hardware monitoring utilities Performance Tools Development tools~~
建议不安装这些组包,需要用什么包,就安装什么包。
yum install -y cmake gcc gcc-c++ libaio libaio-devel automake autoconf bzr bison libtool ncurses5-devel perl-IO-Socket-SSL perl-DBD-MySQL perl-Time-HiRes socat nc libaio perl-Digest-MD5
yum install -y https://www.percona.com/redir/downloads/percona-release/redhat/1.0-14/percona-release-1.0-14.noarch.rpm
yum update percona-release
yum list percona*
yum list Percona-XtraDB-Cluster*
yum install Percona-XtraDB-Cluster-57 -y
# rpm -qa Percona-XtraDB-Cluster-57
Percona-XtraDB-Cluster-57-5.7.28-31.41.1.el7.x86_64
# rpm -qi Percona-XtraDB-Cluster-57
如果是Percona-XtraDB-Cluster-server无法下载,那么就下载rpm进行安装,或者重启下服务器在用yum安装(本人亲测,重启下服务器能用yum安装了)

wget http://repo.percona.com/percona/yum/release/7/RPMS/x86_64/Percona-XtraDB-Cluster-server-57-5.7.28-31.41.1.el7.x86_64.rpm

yum install Percona-XtraDB-Cluster-client-57 -y
yum install percona-xtrabackup-24 Percona-XtraDB-Cluster-shared-57 -y
yum install qpress -y
#在进行安装
yum install Percona-XtraDB-Cluster-server-57-5.7.28-31.41.1.el7.x86_64.rpm
启动xtradb
systemctl status mysql.service
systemctl start mysql.service
查看临时密码
重置xtradb默认密码, root默认密码是个临时密码 ,需要在启动后读取/var/log/mysqld.log获取得到后修改即可:
grep 'temporary password' /var/log/mysqld.log
[root@aliyun-7-server ~]#grep 'temporary password' /var/log/mysqld.log
2020-04-09T02:14:10.871502Z 1 [Note] A temporary password is generated for root@localhost: gIkwyne7Zw=9
如果之前安装过mysql 卸载过,就会发现没有查看到。后来用root作为密码登录测试能成功 默认临时密码就是root
[root@aliyun-7-server ~]# mysql -uroot -pgIkwyne7Zw=9
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 12
Server version: 5.7.28-31-57-log
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases; -- 必须重置密码才能操作数据库
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement
#重置密码,然后刷新权限,最后重新登录
#第一种:
mysql> set password=password('666666');
mysql> flush privileges;
#如果不小心删了日志或者查找不到临时密码 可以修改/etc/my.cnf最上面加入
[mysqld]
skip-grant-tables
#重启mysql服务 直接使用 mysql -uroot -p 不输入密码直接回车进入
#修改密码语法:
update mysql.user set authentication_string=password('666666');
#重启mysql,如果有提示叫更新密码,那么继续更新密码,然后
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
mysql> alter user 'root'@'localhost' identified by '666666';
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> help contents
You asked for help about help category: "Contents"
For more information, type 'help <item>', where <item> is one of the following
categories:
Account Management
Administration
Compound Statements
Contents
Data Definition
Data Manipulation
Data Types
Functions
Geographic Features
Help Metadata
Language Structure
Plugins
Procedures
Storage Engines
Table Maintenance
Transactions
User-Defined Functions
Utility
以上说明pxc集群中的数据库没有问题了,那么接下来配置pxc,然后启动pxc
启动pxc必须用该命令启动,否则会报错:
[root@aliyun-7-server ~]# systemctl start mysql@bootstrap.service
[root@aliyun-7-server ~]# systemctl status mysql@bootstrap.service
pxc配置文件详解
配置pxc(参考https://www.percona.com/doc/percona-xtradb-cluster/LATEST/configure.html)
默认配置文件位于 /etc/my.cnf
[root@aliyun-7-server ~]# cat /etc/my.cnf
#
# The Percona XtraDB Cluster 5.7 configuration file.
#
#
# * IMPORTANT: Additional settings that can override those from this file!
# The files must end with '.cnf', otherwise they'll be ignored.
# Please make any edits and changes to the appropriate sectional files
# included below.
#
!includedir /etc/my.cnf.d/
!includedir /etc/percona-xtradb-cluster.conf.d/
[root@aliyun-7-server ~]# cat /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
[mysqld]
# Path to Galera library
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
# Cluster connection URL contains IPs of nodes
#If no IP is found, this implies that a new cluster needs to be created,
#in order to do that you need to bootstrap this node
wsrep_cluster_address=gcomm://192.168.137.6,192.168.137.7,192.168.137.8
# In order for Galera to work correctly binlog format should be ROW
binlog_format=ROW
# MyISAM storage engine has only experimental support
default_storage_engine=InnoDB
# Slave thread to use
wsrep_slave_threads= 8
wsrep_log_conflicts
# This changes how InnoDB autoincrement locks are managed and is a requirement for Galera
innodb_autoinc_lock_mode=2
# Node IP address
wsrep_node_address=192.168.137.7
# Cluster name
wsrep_cluster_name=pxc-cluster
#If wsrep_node_name is not specified, then system hostname will be used
wsrep_node_name=pxc-cluster-node-2
#pxc_strict_mode allowed values: DISABLED,PERMISSIVE,ENFORCING,MASTER
pxc_strict_mode=ENFORCING
# SST method
wsrep_sst_method=xtrabackup-v2
#Authentication for SST method
wsrep_sst_auth="sstuser:s3cretPass"
6所有配置和7基本相同,除了
-
wsrep_node_name=node1
-
wsrep_node_address=192.168.137.6
8所有配置和7基本相同,除了
- wsrep_node_name=node3
- wsrep_node_address=192.168.137.8
配置文件各项配置意义
- wsrep_provider:指定Galera库的路径
- wsrep_cluster_name:Galera集群的名称
- wsrep_cluster_address=
gcomm://:Galera集群中各节点地址。地址使用组通信协议gcomm://(group communication) - wsrep_node_name:本节点在Galera集群中的名称
- wsrep_node_address:本节点在Galera集群中的通信地址
- wsrep_sst_auth:在SST传输时需要用到的认证凭据,格式为:
用户:密码 - wsrep_sst_method:state_snapshot_transfer(SST)使用的传输方法,可用方法有mysqldump、rsync和xtrabackup-v2,前两者在传输时都需要对Donor加全局只读锁(
FLUSH TABLES WITH READ LOCK),xtrabackup-v2则不需要(它使用percona自己提供的backup lock)。强烈建议采用xtrabackup - pxc_strict_mode:是否限制PXC启用正在试用阶段的功能,ENFORCING是默认值,表示不启用。
- binlog_format:二进制日志的格式。Galera只支持row格式的二进制日志
- default_storage_engine:指定默认存储引擎。Galera的复制功能只支持InnoDB,当然可以支持myisam,需要另外参数打开
- innodb_autoinc_lock_mode:将主键自增模式修改为交叉模式;自增锁的优化,只能设置为2,设置为0或1时会无法正确处理死锁问题
- wsrep_slave_threads=2 开启的复制线程数,cpu核数2
- wsrep_sst_donor=192.168.137.7 从哪个节点恢复数据
- wsrep_on=ON 开启全同步复制模式
- wsrep_provider_options="gcache.size=4G" 类似于缓存的大小,增量恢复都靠这个,默认128M
然后启动pxc:
启动第一个节点7 (确保该节点上拥有所有的数据,数据会被同步到其他节点)参考https://www.percona.com/doc/percona-xtradb-cluster/LATEST/bootstrap.html#bootstrap
执行启动单台节点初始化
[root@aliyun-7-server ~]# systemctl start mysql@bootstrap.service
[root@aliyun-7-server ~]# systemctl status mysql@bootstrap.service
登录确实是否成功
[root@aliyun-7-server ~]# mysql -uroot -p666666
mysql> show status like 'wsrep%';
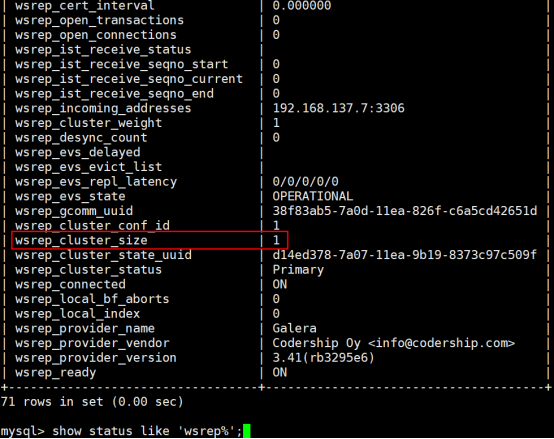
wsrep_cluster_size | 1 表示集群中有1个元素了
wsrep_incoming_addresses | 192.168.137.7:3306 实例的IP地址
wsrep_cluster_status | Primary 集群状态
首先要规范集群中节点的数量,整个集群中节点数控制在最少3个、最多8个范围内。最少3个节点是为了防止出现脑裂现象,因为只有在两个节点下才会出现此现象。脑裂现象的标志就是输入任何命令、返回结果都是unkown command,节点在集群中,会因为新节点的加入或者故障,同步失效等而发生状态的切换。
-- 节点状态变化阶段:
open:节点启动成功,尝试连接到集群。
primary:节点已处于集群中,在新节点加入时,选取donor进行数据同步时会产生的状态。
joiner:节点处于等待接收同步文件时的状态。
joined:节点完成数据同步的工作,尝试保持和集群进度一致。
synced:节点正常提供服务的状态,表示已经同步完成并和集群进度保持一致。
doner:节点处于为新加入的节点提供全量数据时的状态
注意:doner节点就是数据的贡献者,如果一个新节点加入集群,此时又需要大量数据的SST传输,就有可能因此而拖垮整个集群的性能。所以在生产环境中,如果数据量小,还可以使用SST全量传输,但如果数据量很大就不建议使用这种方式了。可以考虑先建立主从关系,在加入集群
集群完整性检查:
| 属性 | 含义 |
|---|---|
| wsrep_cluster_state_uuid | 在集群所有节点的值应该是相同的,有不同值的节点,说明其没有连接入集群. |
| wsrep_cluster_conf_id | 正常情况下所有节点上该值是一样的.如果值不同,说明该节点被临时”分区”了.当节点之间网络连接恢复 的时候应该会恢复一样的值. |
| wsrep_cluster_size | 如果这个值跟预期的节点数一致,则所有的集群节点已经连接. |
| wsrep_cluster_status | 集群组成的状态.如果不为”Primary”,说明出现”分区”或是”split-brain”脑裂状况. |
节点状态检查:
| 属性 | 含义 |
|---|---|
| wsrep_ready | 该值为 ON,则说明可以接受 SQL 负载.如果为 Off,则需要检查 wsrep_connected |
| wsrep_connected | 如果该值为 Off,且 wsrep_ready 的值也为 Off,则说明该节点没有连接到集群.(可能是 wsrep_cluster_address 或 wsrep_cluster_name 等配置错造成的.具体错误需要查看错误日志) |
| wsrep_local_state_comment | 如果 wsrep_connected 为 On,但 wsrep_ready 为 OFF,则可以从该项查看原因 |
复制健康检查:
| 属性 | 含义 |
|---|---|
| wsrep_flow_control_paused | 表示复制停止了多长时间.即表明集群因为 Slave 延迟而慢的程度.值为 0~1,越靠近 0 越好,值为 1 表示 复制完全停止.可优化 wsrep_slave_threads 的值来改善 |
| wsrep_cert_deps_distance | 有多少事务可以并行应用处理.wsrep_slave_threads 设置的值不应该高出该值太多 |
| wsrep_flow_control_sent | 表示该节点已经停止复制了多少次 |
| wsrep_local_recv_queue_avg | 表示 slave 事务队列的平均长度.slave 瓶颈的预兆. 最慢的节点的 wsrep_flow_control_sent 和 wsrep_local_recv_queue_avg 这两个值最高.这两个值较低的话,相对更好 |
检测慢网络问题:
| 属性 | 含义 |
|---|---|
| wsrep_local_send_queue_avg | 网络瓶颈的预兆.如果这个值比较高的话,可能存在网络瓶颈 |
冲突或死锁的数目:
| 属性 | 含义 |
|---|---|
| wsrep_last_committed | 最后提交的事务数目 |
| wsrep_local_cert_failures 和 wsrep_local_bf_aborts | 回滚,检测到的冲突数目 |
添加其他节点到集群
节点加入到Galera集群的两种情况
1.新节点加入Galera集群
新节点加入集群时,需要从当前集群中选择一个Donor节点来同步数据,也就是所谓的state_snapshot_tranfer(SST)过程。SST同步数据的方式由选项wsrep_sst_method决定,一般选择的是xtrabackup。
必须注意:新节点加入Galera时,会删除新节点上所有已有数据,再通过xtrabackup(假设使用的是该方式)从Donor处完整备份所有数据进行恢复。所以,如果数据量很大,新节点加入过程会很慢。而且,在一个新节点成为Synced状态之前,不要同时加入其它新节点,否则很容易将集群压垮。
如果是这种情况,可以考虑使用wsrep_sst_method=rsync来做增量同步,既然是增量同步,最好保证新节点上已经有一部分数据基础,否则和全量同步没什么区别,且这样会对Donor节点加上全局read only锁。
2.旧节点加入Galera集群
如果旧节点加入Galera集群,说明这个节点在之前已经在Galera集群中呆过,有一部分数据基础,缺少的只是它离开集群时的数据。这时加入集群时,会采用IST(incremental snapshot transfer)传输机制,即使用增量传输。
但注意,这部分增量传输的数据源是Donor上缓存在GCache文件中的,这个文件有大小限制,如果缺失的数据范围超过已缓存的内容,则自动转为SST传输。如果旧节点上的数据和Donor上的数据不匹配(例如这个节点离组后人为修改了一点数据),则自动转为SST传输。
关于GCache以及Galera是如何判断数据状态的,本文不展开描述,可参见https://severalnines.com/blog/understanding-gcache-galera
实例-新节点加入集群
再加入其他两个节点之前,需要在定义的master(这里就是7这台服务器)创建一个SST( State Snapshot Transfer)账号,用于集群间通信,必须和主机/etc/percona-xtradb-cluster.conf.d/wsrep.cnf配置的参数一致
#Authentication for SST method
wsrep_sst_auth="sstuser:s3cretPass"
[root@aliyun-7-server ~]# mysql -uroot -p666666
mysql> CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 's3cretPass';
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'sstuser'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.01 sec)
然后其他机器启动mysql服务即可
[root@aliyun-6-server ~]# systemctl start mysql
[root@aliyun-6-server ~]# systemctl status mysql
[root@aliyun-8-server ~]# systemctl start mysql
[root@aliyun-8-server ~]# systemctl status mysql
再次到7登录显示状态(表示集群中有三个元素了)
[root@aliyun-7-server ~]# mysql -uroot -p666666
mysql> show global status like '%wsrep%';
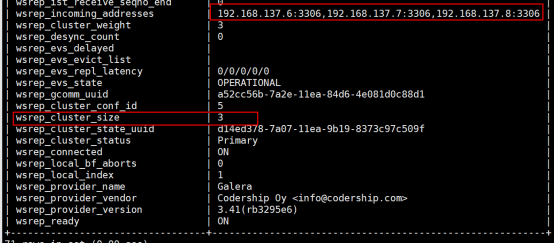
注意
-
除了名义上的master之外,其它的node节点只需要启动mysql即可。
-
节点的数据库的登陆和master节点的用户名密码一致,自动同步。所以其它的节点数据库用户名密码无须重新设置。也就是说,如上设置,只需要在名义上的master节点(如上的7)上设置权限,其它的节点配置好/etc/my.cnf后,只需要启动mysql就行,权限会自动同步过来。
如上的6,8节点,登陆mysql的权限是和7一样的(即是用7设置的权限登陆)
如果上面的node2、node3启动mysql失败,比如/var/lib/mysql下的err日志报错如下:
[ERROR]WSREP: gcs/src/gcs_group.cpp:long int gcs_group_handle_join_msg(gcs_
解决办法:
- -> 查看节点上的iptables防火墙是否关闭;检查到名义上的master节点上的4567端口是否连通(telnet)
- -> selinux是否关闭
- -> 删除名义上的master节点上的grastate.dat后,重启名义上的master节点的数据库;当然当前节点上的grastate.dat也删除并重启数据库
测试
在任意一个node上,进行添加,删除,修改操作,都会同步到其他的服务器,是现在主主的模式,当然前提是表引擎必须是innodb,因为galera目前只支持innodb的表。
mysql> show status like 'wsrep%';
在db7上创建一个库:
[root@aliyun-7-server ~]# mysql -uroot -p666666 -e "create database niubi;"
然在在db6和db8上查看,会发现自动同步过来:
[root@aliyun-6-server ~]#mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| niubi |
| performance_schema |
| sys |
+--------------------+
在db6上的niubi库下创建表,插入数据
[root@aliyun-6-server ~]# mysql -uroot -p666666
mysql> use niubi
Database changed
mysql> create table test(id int(5));
Query OK, 0 rows affected (0.01 sec)
mysql> create table aa(id int auto_increment primary key,uname varchar(20));
Query OK, 0 rows affected (0.00 sec)
同样,在其它的节点上查看,也是能自动同步过来:
mysql> show tables;
+-----------------+
| Tables_in_niubi |
+-----------------+
| aa |
| test |
+-----------------+
2 rows in set (0.00 sec)
[root@aliyun-8-server ~]# mysql -uroot -p666666 -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| niubi |
| performance_schema |
| sys |
+--------------------+
使用ProxySql负载均衡
ProxySql是一款高性能 Sql代理 ProxySql作为后台服务运行,会被后台进程监控 后台进程在Proxy当掉后 短时间内快速重启,接受来自mysql客户端的请求 将请求转发后实际的后台mysql服务器
ProxySql同时支持PXC的状态检查
1》安装ProxySql(https://www.percona.com/doc/percona-xtradb-cluster/LATEST/howtos/proxysql.html#load-balancing-with-proxysql)
centos使用yum安装(先安装之前的pxc的yum源) 机器ip 192.168.58.151
yum -y install proxysql
proxysql提供了proxysql-admin工具配置 pxc 查看该工具命令选项
[root@node4 ~]# proxysql-admin
Usage: [ options ]
Options:
--config-file Read login credentials from a configuration file (overrides any login credentials specified on the command line)
--quick-demo Setup a quick demo with no authentication
--proxysql-username=user_name Username for connecting to the ProxySQL service
--proxysql-password[=password] Password for connecting to the ProxySQL service
--proxysql-port=port_num Port Nr. for connecting to the ProxySQL service
--proxysql-hostname=host_name Hostname for connecting to the ProxySQL service
--cluster-username=user_name Username for connecting to the Percona XtraDB Cluster node
--cluster-password[=password] Password for connecting to the Percona XtraDB Cluster node
--cluster-port=port_num Port Nr. for connecting to the Percona XtraDB Cluster node
--cluster-hostname=host_name Hostname for connecting to the Percona XtraDB Cluster node
--cluster-app-username=user_name Application username for connecting to the Percona XtraDB Cluster node
--cluster-app-password[=password] Application password for connecting to the Percona XtraDB Cluster node
--without-cluster-app-user Configure Percona XtraDB Cluster without application user
--monitor-username=user_name Username for monitoring Percona XtraDB Cluster nodes through ProxySQL
--monitor-password[=password] Password for monitoring Percona XtraDB Cluster nodes through ProxySQL
--enable, -e Auto-configure Percona XtraDB Cluster nodes into ProxySQL
--disable, -d Remove any Percona XtraDB Cluster configurations from ProxySQL
--node-check-interval=3000 Interval for monitoring node checker script (in milliseconds)
--mode=[loadbal|singlewrite] ProxySQL read/write configuration mode, currently supporting: 'loadbal' and 'singlewrite' (the default) modes
--write-node=host_name:port Writer node to accept write statments. This option is supported only when using --mode=singlewrite
Can accept comma delimited list with the first listed being the highest priority.
--include-slaves=host_name:port Add specified slave node(s) to ProxySQL, these nodes will go into the reader hostgroup and will only be put into
the writer hostgroup if all cluster nodes are down. Slaves must be read only. Can accept comma delimited list.
If this is used make sure 'read_only=1' is in the slave's my.cnf
--adduser Adds the Percona XtraDB Cluster application user to the ProxySQL database
--syncusers Sync user accounts currently configured in MySQL to ProxySQL (deletes ProxySQL users not in MySQL)
--version, -v Print version info
我这里使用手动的方式配置 当前命令行的方式更好 无需重启
启动proxysql
service proxysql start
必须在151主机上 安装pxc客户端 其他机器有客户端的是无法连接的
yum install Percona-XtraDB-Cluster-client-57
登录管理接口
[root@node4 ~]# mysql -u admin -padmin -h 127.0.0.1 -P 6032
查看所有数据库
mysql> show databases;
+-----+---------------+-------------------------------------+
| seq | name | file |
+-----+---------------+-------------------------------------+
| 0 | main | |
| 2 | disk | /var/lib/proxysql/proxysql.db |
| 3 | stats | |
| 4 | monitor | |
| 5 | stats_history | /var/lib/proxysql/proxysql_stats.db |
+-----+---------------+-------------------------------------+
5 rows in set (0.00 sec)
2》添加集群到ProxySql
只需要插入对应的pxc后端数据库服务器的信息到main数据库下的mysql_servers表即可
INSERT INTO mysql_servers(hostgroup_id, hostname, port) VALUES (0,'192.168.58.147',3306);
INSERT INTO mysql_servers(hostgroup_id, hostname, port) VALUES (0,'192.168.58.149',3306);
INSERT INTO mysql_servers(hostgroup_id, hostname, port) VALUES (0,'192.168.58.150',3306);
加载服务器到实时内存中
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
配置访问后端数据库服务器的用户名和密码
INSERT INTO mysql_users (username,password) VALUES ('root','root');
加载用户名和密码到实时内存 并写入磁盘
LOAD MYSQL USERS TO RUNTIME;
SAVE MYSQL USERS TO DISK;
确保 proxysql安装机器(151)有访问集群的root用户权限 登录147插入root账号
CREATE USER root@'%' IDENTIFIED BY 'root';
grant all on *.* to root@'%';
注意管理接口是6032 代理后端mysql是 6033 测试登录
[root@node4 ~]# mysql -u root -proot -h 127.0.0.1 -P 6033
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 7
Server version: 5.5.30 (ProxySQL)
Copyright (c) 2009-2017 Percona LLC and/or its affiliates
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
测试之前集群中创建的表是否创建 其他关于监控相关的 参考(https://www.percona.com/doc/percona-xtradb-cluster/LATEST/howtos/proxysql.html#load-balancing-with-proxysql)
Mycat中间件实现Mysql数据分片(之一)
ITPUB博客:http://blog.itpub.net/25854343/viewspace-2665474/
https://mp.weixin.qq.com/s/m2xP-BSIZaFInG4eEtWD6g
Mysql+haproxy+mycat+pxc+zookeeper实现高可用集群
https://developer.aliyun.com/article/776634?spm=a2c6h.12873581.0.0.29dc767dOcNvJG&groupCode=othertech
https://blog.csdn.net/weixin_44574738/article/details/98385417
https://www.cnblogs.com/so-cool/p/9051276.html
MySQL Router 高可用原理与实战
https://mp.weixin.qq.com/s/WCx_ok-ajUgL4ICETXgVAA
MySQL监控
http://www.lepus.cc/->这个也是开源的,各种数据库都可以监控,很专业

https://www.percona.com/

https://www.percona.com/downloads/percona-monitoring-plugins/
# rpm -ivh percona-zabbix-templates-1.1.7-1.noarch.rpm
warning: percona-zabbix-templates-1.1.7-1.noarch.rpm: Header V4 DSA/SHA1 Signature, key ID cd2efd2a: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:percona-zabbix-templates-1.1.7-1 ################################# [100%]
Scripts are installed to /var/lib/zabbix/percona/scripts
Templates are installed to /var/lib/zabbix/percona/templates
# tree /var/lib/zabbix/percona
/var/lib/zabbix/percona
├── scripts
│ ├── get_mysql_stats_wrapper.sh
│ └── ss_get_mysql_stats.php
└── templates
├── userparameter_percona_mysql.conf
└── zabbix_agent_template_percona_mysql_server_ht_2.0.9-sver1.1.7.xml
2 directories, 4 files
# cd /var/lib/zabbix/percona/scripts
[root@saltstack_node2 scripts]# ls
get_mysql_stats_wrapper.sh ss_get_mysql_stats.php
# vim get_mysql_stats_wrapper.sh
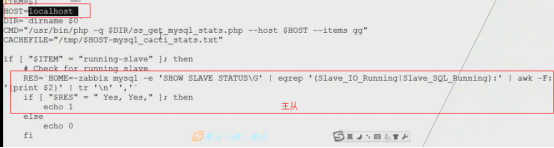
修改脚本中的主从监控:
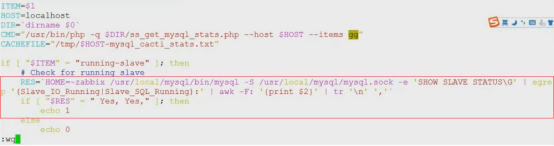
# cd /var/lib/zabbix/percona/templates
[root@saltstack_node2 templates]# ls
userparameter_percona_mysql.conf zabbix_agent_template_percona_mysql_server_ht_2.0.9-sver1.1.7.xml #zabbix模板
把模板导入zabbix中,并且必须选择Screens:

架构扩展方案
双主:
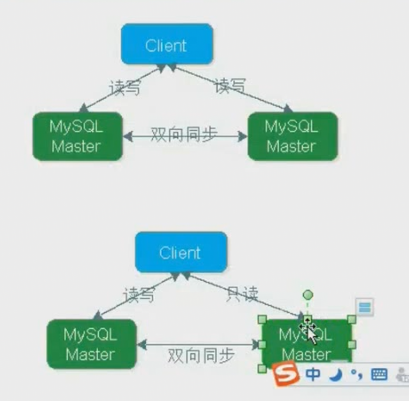
双写不建议,网络故障时,会导致无法同步
双主双从:
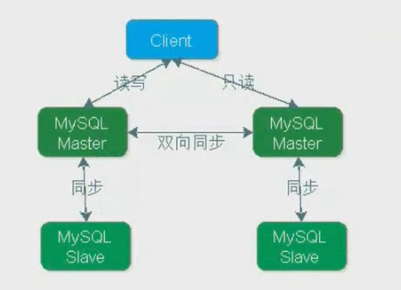
一主一从:
读写分离(一主一从):
读写分离(一主多从,从库建议不要超过3个):
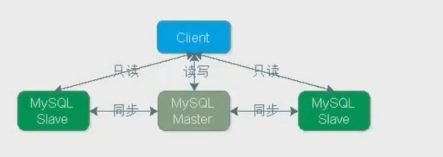
集群(一主多从[从库必须只读]+高可用):写库上不建索引,从库建索引,不会造成不同步
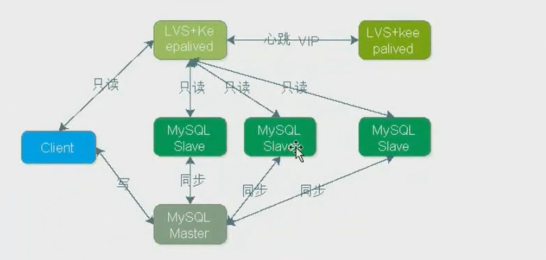
MySQL进行压测
mysqlslap
mysqlslap是mysql自带的基准测试工具,该工具查询数据,语法简单,灵活容易使用.该工具可以模拟多个客户端同时并发的向服务器发出查询更新,给出了性能测试数据而且提供了多种引擎的性能比较。mysqlslap为mysql性能优化前后提供了直观的验证依据,系统运维和DBA人员应该掌握一些常见的压力测试工具,才能准确的掌握线上数据库支撑的用户流量上限及其抗压性等问题
更改其默认的最大连接数
在对MySQL进行压力测试之前,需要更改其默认的最大连接数,如下:
# vim /etc/my.cnf
................
[mysqld]
max_connections = 1024
# /etc/init.d/mysql restart
登录MySQL查看最大连接数是否生效
# mysql -uroot -p
# 查看最大连接数
[11:52: -(none)] mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 1024 |
+-----------------+-------+
1 row in set (0.01 sec)
进行压力测试:
mysqlslap --defaults-file=/etc/my.cnf \
-uroot -padmijkl12654 \
--concurrency=100,200 \
--iterations=1 \
--number-int-cols=20 \
--number-char-cols=30 \
--auto-generate-sql \
--auto-generate-sql-add-autoincrement \
--auto-generate-sql-load-type=mixed \
--engine=myisam,innodb \
--number-of-queries=2000 \
--verbose
上述命令测试说明:
模拟测试两次读写并发,第一次100个并发,第二次200并发,自动生成SQL脚本,测试表包含20个init字段,30 个char字段,每次执行2000查询请求。测试引擎分别是myisam,innodb。(上述选项中有很多都是默认值,可以省略,如果想要了解各个选项的解释,可以使用
mysqlslap --help进行查询)
上述命令返回结果如下:
测试结果说明:
Myisam第一次100客户端同时发起增查用0.206/s,第二次200客户端同时发起增查用0.180/s
Innodb第一次100客户端同时发起增查用0.322/s,第二次200客户端同时发起增查用0.294/s
可以根据实际需求,一点点的加大并发数量进行压力测试
第三方sysbench工具进行压力测试
安装sysbench工具
[root@mysql ~]# yum -y install epel-release #安装第三方epel源
[root@mysql ~]# yum -y install sysbench #安装sysbench工具
[root@mysql ~]# sysbench --version #确定工具已安装
sysbench 可以进行以下测试:
-
CPU 运算性能测试
-
磁盘 IO 性能测试
-
调度程序性能测试
-
内存分配及传输速度测试
-
POSIX 线程性能测试
-
数据库性能测试(OLTP 基准测试,需要通过
/usr/share/sysbench/目录中的 Lua 脚本执行,例如oltp_read_only.lua脚本执行只读测试) -
sysbench 还可以通过运行命令时指定自己的 Lua 脚本来自定义测试
查看sysbench工具的帮助选项
[root@mysql ~]# sysbench --help
Usage:
sysbench [options]... [testname] [command]
Commands implemented by most tests: prepare run cleanup help # 可用的命令,四个
General options: # 通用选项
--threads=N 要使用的线程数,默认 1 个 [1]
--events=N 最大允许的事件个数 [0]
--time=N 最大的总执行时间,以秒为单位 [10]
--forced-shutdown=STRING 在 --time 时间限制到达后,强制关闭之前等待的秒数,默认“off”禁用(number of seconds to wait after the --time limit before forcing shutdown, or 'off' to disable) [off]
--thread-stack-size=SIZE 每个线程的堆栈大小 [64K]
--rate=N 平均传输速率。0 则无限制 [0]
--report-interval=N 以秒为单位定期报告具有指定间隔的中间统计信息 0 禁用中间报告 [0]
--report-checkpoints=[LIST,...] 转储完整的统计信息并在指定的时间点重置所有计数器。参数是一个逗号分隔的值列表,表示从测试开始经过这个时间量时必须执行报告检查点(以秒为单位)。报告检查点默认关闭。 []
--debug[=on|off] 打印更多 debug 信息 [off]
--validate[=on|off] 尽可能执行验证检查 [off]
--help[=on|off] 显示帮助信息并退出 [off]
--version[=on|off] 显示版本信息并退出 [off]
--config-file=FILENAME 包含命令行选项的文件
--tx-rate=N 废弃,改用 --rate [0]
--max-requests=N 废弃,改用 --events [0]
--max-time=N 废弃,改用 --time [0]
--num-threads=N 废弃,改用 --threads [1]
Pseudo-Random Numbers Generator options: # 伪随机数发生器选项
--rand-type=STRING random numbers distribution {uniform,gaussian,special,pareto} [special]
--rand-spec-iter=N number of iterations used for numbers generation [12]
--rand-spec-pct=N percentage of values to be treated as 'special' (for special distribution) [1]
--rand-spec-res=N percentage of 'special' values to use (for special distribution) [75]
--rand-seed=N seed for random number generator. When 0, the current time is used as a RNG seed. [0]
--rand-pareto-h=N parameter h for pareto distribution [0.2]
Log options: # 日志选项
--verbosity=N verbosity level {5 - debug, 0 - only critical messages} [3]
--percentile=N percentile to calculate in latency statistics (1-100). Use the special value of 0 to disable percentile calculations [95]
--histogram[=on|off] print latency histogram in report [off]
General database options: # 通用的数据库选项
--db-driver=STRING 指定要使用的数据库驱动程序 ('help' to get list of available drivers)
--db-ps-mode=STRING prepared statements usage mode {auto, disable} [auto]
--db-debug[=on|off] print database-specific debug information [off]
Compiled-in database drivers: # 內建的数据库驱动程序,默认支持 MySQL 和 PostgreSQL
mysql - MySQL driver
pgsql - PostgreSQL driver
mysql options: # MySQL 数据库专用选项
--mysql-host=[LIST,...] MySQL server host [localhost]
--mysql-port=[LIST,...] MySQL server port [3306]
--mysql-socket=[LIST,...] MySQL socket
--mysql-user=STRING MySQL user [sbtest]
--mysql-password=STRING MySQL password []
--mysql-db=STRING MySQL database name [sbtest]
--mysql-ssl[=on|off] use SSL connections, if available in the client library [off]
--mysql-ssl-cipher=STRING use specific cipher for SSL connections []
--mysql-compression[=on|off] use compression, if available in the client library [off]
--mysql-debug[=on|off] trace all client library calls [off]
--mysql-ignore-errors=[LIST,...] list of errors to ignore, or "all" [1213,1020,1205]
--mysql-dry-run[=on|off] Dry run, pretend that all MySQL client API calls are successful without executing them [off]
pgsql options: # PostgreSQL 数据库专用选项
--pgsql-host=STRING PostgreSQL server host [localhost]
--pgsql-port=N PostgreSQL server port [5432]
--pgsql-user=STRING PostgreSQL user [sbtest]
--pgsql-password=STRING PostgreSQL password []
--pgsql-db=STRING PostgreSQL database name [sbtest]
Compiled-in tests: # 內建测试类型
fileio - File I/O test
cpu - CPU performance test
memory - Memory functions speed test
threads - Threads subsystem performance test
mutex - Mutex performance test
See 'sysbench <testname> help' for a list of options for each test.
sysbench测试MySQL数据库性能
1.准备测试数据
#查看sysbench自带的lua脚本使用方法
[root@mysql ~]# sysbench /usr/share/sysbench/oltp_common.lua help
#必须创建sbtest库,sbtest是sysbench默认使用的库名
[root@mysql ~]# mysqladmin -uroot -p123 create sbtest;
#然后,准备测试所用的表,这些测试表放在测试库sbtest中。这里使用的lua脚本为/usr/share/sysbench/oltp_common.lua
[root@mysql ~]# sysbench --mysql-host=127.0.0.1 \
--mysql-port=3306 \
--mysql-user=root \
--mysql-password=123 \
/usr/share/sysbench/oltp_common.lua \
--tables=10 \
--table_size=100000 \
prepare
#其中--tables=10表示创建10个测试表,
#--table_size=100000表示每个表中插入10W行数据,
#prepare表示这是准备数据的过程
2.确认测试数据以存在
[root@mysql ~]# mysql -uroot -p123 sbtest; #登录到sbtest库
mysql> show tables; #查看相应的表
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest2 |
| sbtest3 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
10 rows in set (0.00 sec)
mysql> select count(*) from sbtest1; #随机选择一个表,确认其有100000条数据
+----------+
| count(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.01 sec)
3.数据库测试和结果分析
稍微修改下之前准备数据的语句,就可以拿来测试了。需要注意的是,之前使用的lua脚本为oltp_common.lua,它是一个通用脚本,是被其它lua脚本调用的,它不能直接拿来测试。所以,我这里用oltp_read_write.lua脚本来做读、写测试。还有很多其它类型的测试,比如只读测试、只写测试、删除测试、大批量插入测试等等。可找到对应的lua脚本进行调用即可
执行测试命令如下:
[root@mysql ~]# sysbench --threads=4 \
--time=20 \
--report-interval=5 \
--mysql-host=127.0.0.1 \
--mysql-port=3306 \
--mysql-user=root \
--mysql-password=666666 \
/usr/share/sysbench/oltp_read_write.lua \
--tables=10 \
--table_size=100000 \
run
上述命令返回的结果如下:
sysbench 1.0.17 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 4
Report intermediate results every 5 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
#以下是每5秒返回一次的结果,统计的指标包括:
# 线程数、tps(每秒事务数)、qps(每秒查询数)、
# 每秒的读/写/其它次数、延迟、每秒错误数、每秒重连次数
[ 5s ] thds: 4 tps: 158.83 qps: 3183.66 (r/w/o: 2229.26/636.13/318.27) lat (ms,95%): 41.85 err/s: 0.00 reconn/s: 0.00
[ 10s ] thds: 4 tps: 188.12 qps: 3763.20 (r/w/o: 2633.68/753.28/376.24) lat (ms,95%): 32.53 err/s: 0.00 reconn/s: 0.00
[ 15s ] thds: 4 tps: 191.60 qps: 3838.16 (r/w/o: 2687.57/767.19/383.40) lat (ms,95%): 30.81 err/s: 0.00 reconn/s: 0.00
[ 20s ] thds: 4 tps: 195.00 qps: 3900.88 (r/w/o: 2730.46/780.42/390.01) lat (ms,95%): 30.26 err/s: 0.00 reconn/s: 0.00
SQL statistics:
queries performed:
read: 51408 # 执行的读操作数量
write: 14688 # 执行的写操作数量
other: 7344 # 执行的其它操作数量
total: 73440
transactions: 3672 (182.57 per sec.) # 执行事务的平均速率
queries: 73440 (3651.43 per sec.) # 平均每秒能执行多少次查询
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 20.1111s # 总消耗时间
total number of events: 3672 # 总请求数量(读、写、其它)
Latency (ms):
min: 5.58
avg: 21.79
max: 163.94
95th percentile: 33.72 # 采样计算的平均延迟
sum: 80030.61
Threads fairness:
events (avg/stddev): 918.0000/2.74
execution time (avg/stddev): 20.0077/0.01
4.cpu/io/内存等测试 sysbench内置的几个测试指标如下:
[root@mysql ~]# sysbench --help
.......... # 省略部分内容
Compiled-in tests:
fileio - File I/O test
cpu - CPU performance test
memory - Memory functions speed test
threads - Threads subsystem performance test
mutex - Mutex performance test
#可以直接help输出测试方法,例如,fileio测试:
[root@mysql ~]# sysbench fileio help
sysbench 1.0.17 (using system LuaJIT 2.0.4)
fileio options:
--file-num=N number of files to create [128]
--file-block-size=N block size to use in all IO operations [16384]
--file-total-size=SIZE total size of files to create [2G]
--file-test-mode=STRING test mode {seqwr, seqrewr, seqrd, rndrd, rndwr, rndrw}
--file-io-mode=STRING file operations mode {sync,async,mmap} [sync]
--file-async-backlog=N number of asynchronous operatons to queue per thread [128]
--file-extra-flags=[LIST,...] list of additional flags to use to open files {sync,dsync,direct} []
--file-fsync-freq=N do fsync() after this number of requests (0 - don't use fsync()) [100]
--file-fsync-all[=on|off] do fsync() after each write operation [off]
--file-fsync-end[=on|off] do fsync() at the end of test [on]
--file-fsync-mode=STRING which method to use for synchronization {fsync, fdatasync} [fsync]
--file-merged-requests=N merge at most this number of IO requests if possible (0 - don't merge) [0]
--file-rw-ratio=N reads/writes ratio for combined test [1.5]
5.测试io性能 例如,创建5个文件,总共2G,每个文件大概400M
[root@mysql ~]# sysbench fileio --file-num=5 --file-total-size=2G prepare
[root@mysql ~]# ll -lh test*
-rw------- 1 root root 410M May 26 16:05 test_file.0
-rw------- 1 root root 410M May 26 16:05 test_file.1
-rw------- 1 root root 410M May 26 16:05 test_file.2
-rw------- 1 root root 410M May 26 16:05 test_file.3
-rw------- 1 root root 410M May 26 16:05 test_file.4
然后运行测试:
[root@mysql ~]# sysbench --events=5000 \
--threads=16 \
fileio \
--file-num=5 \
--file-total-size=2G \
--file-test-mode=rndrw \
--file-fsync-freq=0 \
--file-block-size=16384 \
run
返回的结果如下:
sysbench 1.0.17 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 16
Initializing random number generator from current time
Extra file open flags: (none)
5 files, 409.6MiB each
2GiB total file size
Block size 16KiB
Number of IO requests: 5000
Read/Write ratio for combined random IO test: 1.50
Calling fsync() at the end of test, Enabled.
Using synchronous I/O mode
Doing random r/w test
Initializing worker threads...
Threads started!
File operations:
reads/s: 903.74
writes/s: 604.50
fsyncs/s: 24.13
Throughput: # 吞吐量
read, MiB/s: 14.12 #表示读带宽
written, MiB/s: 9.45 #表示写的带宽
General statistics:
total time: 3.3135s
total number of events: 5000
Latency (ms):
min: 0.00
avg: 9.26
max: 301.61
95th percentile: 77.19
sum: 46308.38
Threads fairness:
events (avg/stddev): 312.5000/18.69
execution time (avg/stddev): 2.8943/0.08
6.测试cpu性能
[root@mysql ~]# sysbench cpu --threads=40 --events=10000 --cpu-max-prime=20000 run
然后对返回结果进行分析
MYSQL 开源SQL语句审核平台
官网:https://yearning.io/
创建yearning数据库,在自己的数据库实例中创建yearning所需的数据库
create database Yearning DEFAULT CHARACTER SET utf8mb4;
grant all on Yearning.* to root@'127.0.0.1' identified by 'adminasdfghjkl123654' ;
关于SecretKey
SecretKey是token/数据库密码加密/解密的salt。
建议所有用户在初次安装Yearning之前将SecretKey更改(不更改将存在安全风险)
格式: 大小写字母均可, 长度必须为16位。且只能为16位
特别注意:
此key仅可在初次安装时更改!之后不可再次更改!如再次更改会导致之前已存放的数据源密码无法解密,最终导致无法获取相关数据源信息
初始化成功!
用户名: admin
密码:Yearning_admin
nginx方向代理:
server {
listen 80;
server_name yearning.gobgm.com;
rewrite ^(.*)$ https://${server_name}$1 permanent;
}
server {
listen 443 ssl;
server_name yearning.gobgm.com;
access_log logs/access.log main;
location / {
proxy_pass http://127.0.0.1:8000;
include proxy_params;
}
}
Archery
https://archerydms.com/
MySQL 导致 CPU 消耗过大,如何优化
https://mp.weixin.qq.com/s/1kC_cr7h84l2gf9950L1ag
谁在消耗cpu?
用户+系统+IO等待+软硬中断+空闲
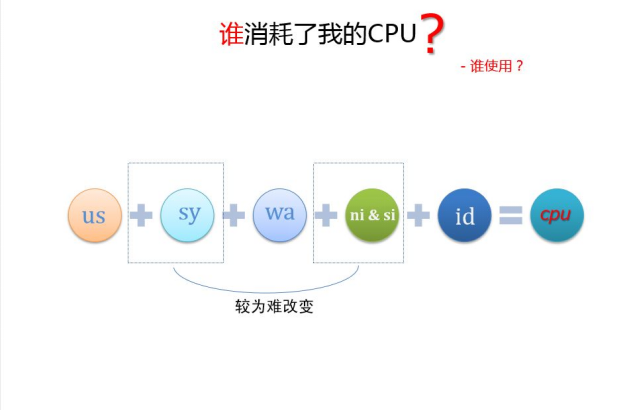
祸首是谁?
用户
-
用户空间CPU消耗,各种逻辑运算
-
正在进行大量tps
- 函数/排序/类型转化/逻辑IO访问...
IO等待
等待IO请求的完成
此时CPU实际上空闲
如vmstat中的wa 很高。但IO等待增加,wa也不一定会上升(请求I/O后等待响应,但进程从核上移开了)
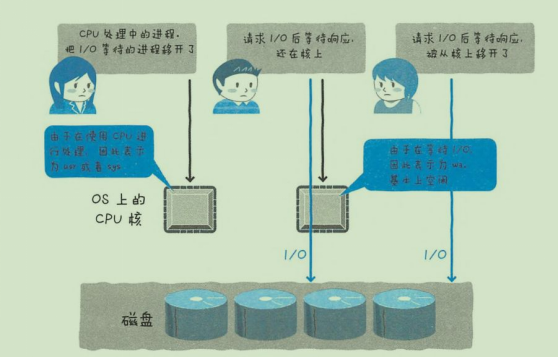
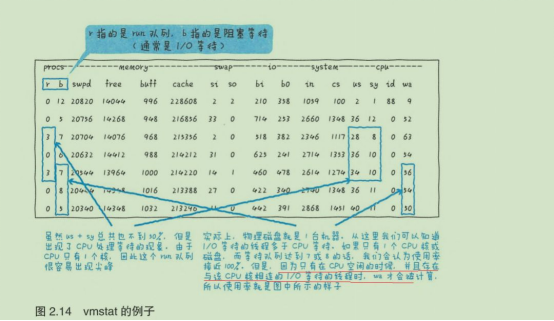
产生影响
用户和IO等待消耗了大部分cpu
-
吞吐量下降(tps)
-
查询响应时间增加
-
慢查询数增加
-
对mysql的并发陡增,也会产生上述影响
如何减少CPU消耗?
减少等待
减少IO量
SQL/index,使用合适的索引减少扫描的行数(需平衡索引的正收益和维护开销,空间换时间)
提升IO处理能力
加cache/加磁盘/SSD
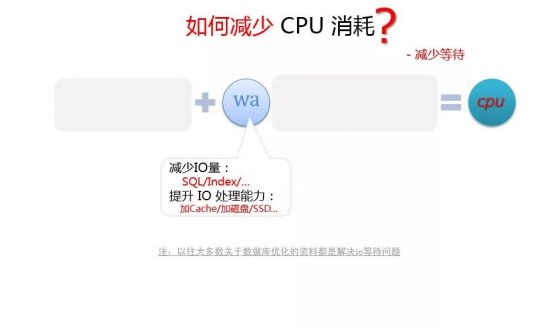
减少计算
减少逻辑运算量
- 避免使用函数,将运算转移至易扩展的应用服务器中 如substr等字符运算,dateadd/datesub等日期运算,abs等数学函数
- 减少排序,利用索引取得有序数据或避免不必要排序 如union all代替 union,order by 索引字段等
- 禁止类型转换,使用合适类型并保证传入参数类型与数据库字段类型绝对一致 如数字用tiny/int/bigint等,必需转换的在传入数据库之前在应用中转好
- 简单类型,尽量避免复杂类型,降低由于复杂类型带来的附加运算。更小的数据类型占用更少的磁盘、内存、cpu缓存和cpu周期
- ....
减少逻辑IO量
-
index,优化索引,减少不必要的表扫描 如增加索引,调整组合索引字段顺序,去除选择性很差的索引字段等等
-
table,合理拆分,适度冗余 如将很少使用的大字段拆分到独立表,非常频繁的小字段冗余到"引用表"
-
SQL,调整SQL写法,充分利用现有索引,避免不必要的扫描,排序及其他操作 如减少复杂join,减少order by,尽量union all,避免子查询等
-
数据类型,够用就好,减少不必要使用大字段 如tinyint够用就别总是int,int够用也别老bigint,date够用也别总是timestamp
-
....

减少query请求量(非数据库本身)
-
适当缓存,降低缓存数据粒度,对静态并被频繁请求的数据进行适当的缓存 如用户信息,商品信息等
-
优化实现,尽量去除不必要的重复请求 如禁止同一页面多次重复请求相同数据的问题,通过跨页面参数传递减少访问等
-
合理需求,评估需求产出比,对产出比极端底下的需求合理去除
-
....
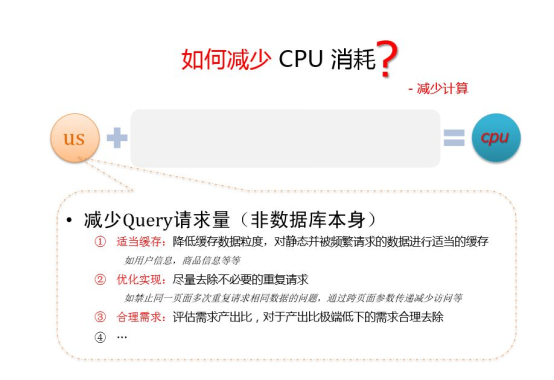
升级cpu
-
若经过减少计算和减少等待后还不能满足需求,cpu利用率还高T_T
-
是时候拿出最后的杀手锏了,升级cpu,是选择更快的cpu还是更多的cpu了?
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。