MongoDB(no sql)
简介
官网:https://www.mongodb.com
下载地址:https://www.mongodb.com/download-center#community
什么是MongoDB ?
mongodb是一个基于分布式文件存储的数据。由C++语言编写。旨在为web应用提供可扩展的高性能数据存储解决方案。mongodb是一个非关系数据库,是非关系数据库当中功能丰富的
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
主要特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用
update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。 - Mongodb中的
Map/reduce主要是用来对数据进行批量处理和聚合操作。 - Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:
RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。 - MongoDB安装简单。

JSON基础语法
JSON 语法规则
JSON 语法是 JavaScript 对象表示法语法的子集。
- 数据在名称/值对中
- 数据由逗号分隔
- 花括号保存对象
- 方括号保存数组
JSON 名称/值对
JSON 数据的书写格式是:名称/值对。
名称/值对包括字段名称(在双引号中),后面写一个冒号,然后是值:
"firstName" : "John"
这很容易理解,等价于这条 JavaScript 语句:
firstName = "John"
JSON 值
JSON 值可以是:
- 数字(整数或浮点数)
- 字符串(在双引号中)
- 逻辑值(true 或 false)
- 数组(在方括号中)
- 对象(在花括号中)
- null
JSON 对象
JSON 对象在花括号中书写:
对象可以包含多个名称/值对:
{ "firstName":"John" , "lastName":"Doe" }
这一点也容易理解,与这条 JavaScript 语句等价:
firstName = "John"
lastName = "Doe"
JSON 数组
JSON 数组在方括号中书写:
数组可包含多个对象:
{
"employees": [
{ "firstName":"John" , "lastName":"Doe" },
{ "firstName":"Anna" , "lastName":"Smith" },
{ "firstName":"Peter" , "lastName":"Jones" }
]
}
在上面的例子中,对象"employees"是包含三个对象的数组。每个对象代表一条关于某人(有姓和名)的记录。
MongoDB 概念解析
不管我们学习什么数据库都应该学习其中的基础概念,在mongodb中基本的概念是文档、集合、数据库,下面我们挨个介绍。
SQL与mongodb概念的对比:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
通过下图实例,我们也可以更直观的了解Mongo中的一些概念:

数据库
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为db,该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
show dbs 命令可以显示所有数据的列表。
> show dbs
admin 0.078GB
config 0.078GB
local 0.078GB
run 0.078GB
执行db 命令可以显示当前数据库对象或集合。
> db
test
运行use命令,可以连接到一个指定的数据库。
> use local
switched to db local
> db
local
以上实例命令中,local是你要链接的数据库。
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串(
"")。 - 不得含有
' '(空格)、.、$、/、\和\0 (空字符)。 - 应全部小写。
- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin:从权限的角度来看,这是
root数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。 - local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档(Document)
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
一个简单的文档例子如下:
{"site":"www.run.com", "name":"plinux"}
下表列出了 RDBMS 与 MongoDB 对应的术语:
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
| 数据库服务和客户端 | |
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有
\0 4(空字符)。这个字符用来表示键的结尾。 .和$有特别的意义,只有在特定环境下才能使用。- 以下划线
_开头的键是保留的(不是严格要求的)。
集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"www.run.com","name":"plinux","num":5}
当第一个文档插入时,集合就会被创建。
合法的集合名
- 集合名不能是空字符串
""。 - 集合名不能含有
\0字符(空字符),这个字符表示集合名的结尾。 - 集合名不能以
system开头,这是为系统集合保留的前缀。 - 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
如下实例:
db.col.findOne()
capped collections 就是固定大小的collection。
它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和RRD概念类似。
Capped collections 是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。
Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息。
db.createCollection("mycoll", {capped:true, size:100000})
- 在 capped collection 中,你能添加新的对象。
- 能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
- 使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
- 删除之后,你必须显式的重新创建这个 collection。
- 在32bit机器中,capped collection 最大存储为 1e9( 1X10^9^)个字节。
元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:
dbname.system.*
在MongoDB数据库中名字空间<dbname>.system.*是包含多种系统信息的特殊集合(Collection),如下:
| 集合命名空间 | 描述 |
|---|---|
| dbname.system.namespaces | 列出所有名字空间。 |
| dbname.system.indexes | 列出所有索引。 |
| dbname.system.profile | 包含数据库概要(profile)信息。 |
| dbname.system.users | 列出所有可访问数据库的用户。 |
| dbname.local.sources | 包含复制对端(slave)的服务器信息和状态。 |
对于修改系统集合中的对象有如下限制。
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。 {{system.profile}}是可删除的。
MongoDB 数据类型
下表为MongoDB中常用的几种数据类型。
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
下面说明下几种重要的数据类型。
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个_id键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过getTimestamp函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2017-11-25T07:21:10Z")
ObjectId 转为字符串
> newObject.str
5a1919e63df83ce79df8b38f
字符串
BSON 字符串都是UTF-8编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date() # 格林尼治时间
> mydate1
ISODate("2018-03-04T14:58:51.233Z")
> typeof mydate1
object
安装mongodb
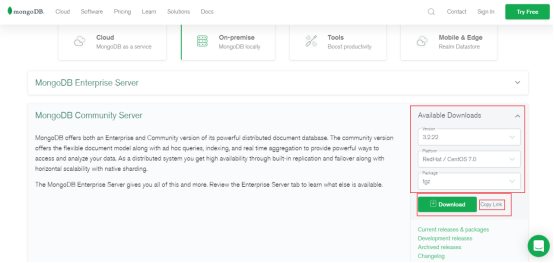
一、下载mongodb二进制包->stable版本:www.mongodb.com
https://www.mongodb.com/try/download/community
选择社区版:
二、解压二进制包
tar zxvf mongodb-linux-x86_64-rhel62-3.2.10.tgz
三、因为本身就是编译过后的二进制可执行文件,不用再编译
mv mongodb-linux-x86_64-rhel62-3.2.10 /usr/local/mongodb
bin下面的执行命令解释:
-
bsondump
->导出BSON结构 -
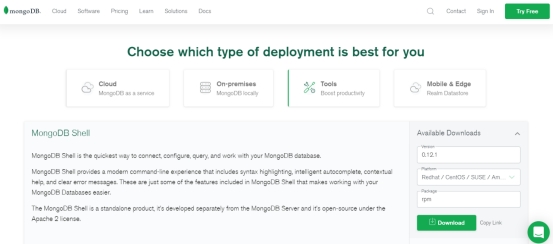
mongo
->客户端。还有专门的mongodb shell->mongosh。(下载地址: https://www.mongodb.com/try/download/shell)
-
mongod
->服务端 -
mongodump
->数据库备份 -
mongoexport
->导出易识别的json文档或csv文档 -
mongofiles
-
mongoimport
-
mongooplog
-
mongoperf
-
mongorestore
->数据库恢复 -
mongos
->路由器(分片的时候使用) -
mongosniff
->监控 -
mongosta
->监控 -
mongotop
->监控
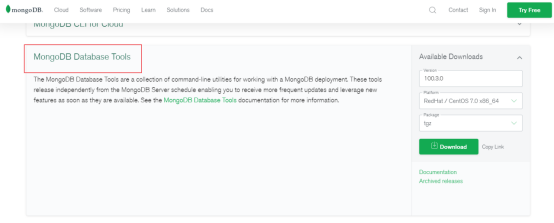
说明:新版本的MongoDB需要单独下载这些工具
原因:mongoimport mongoexport mongodump mongorestore 等工具,作为 mongodb database tools 提供了单独的下载入口 https://www.mongodb.com/try/download/database-tools?tck=docs_databasetools
Mongodb官方可视化工具
四、启动服务
1、写配置文件:vim /usr/local/mongodb/mongodb1.conf
port=27017
bind_ip=0.0.0.0
dbpath=/data/mongodb1
logpath=/data/logs/mongodb/mongodb1.log
logappend=true
fork=true
maxConns=5000
storageEngine=wiredtiger # 3.2以上的版本不能加此参数了
然后创建相关目录
#创建dbpath与logpath目录:
mkdir -pv /data/mongodb1
mkdir -pv /data/logs/mongodb/
touch /data/logs/mongodb/mongodb1.log
chmod -R 777 /data/logs/mongodb/mongodb1.log
#设置shell启动进程所占用的资源(由于频繁访问时,该值过低,会导致无法连接mongodb实例)
ulimit -n 65000
ulimit -u 65000
2、设置内核参数
echo 0 > /proc/sys/vm/zone_reclaim_mode
sysctl -w vm.zone_reclaim_mode=0 #设置永久生效
echo never > /sys/kernel/mm//transparent_hugepage/enabled
echo never > /sys/kernel/mm//transparent_hugepage/defrag
3、导入环境变量
# vim /etc/profile.d/mongodb.sh
export PATH=$PATH:/usr/local/mongodb/bin
# source /etc/profile.d/mongodb.sh
4、启动服务:
# mongod -f /usr/local/mongodb/mongodb1.conf

5、停止服务:
利用kill或者
mongod -f /usr/local/mongodb/mongodb1.conf --shutdown
参数解释:
port=27017 #默认服务器端口
dbpath=/data/mongodb1 #数据库路径(数据文件)
logpath=/data/logs/mongodb/mongodb1.log #日志文件
logappend=true #使用追加方式写入日志
fork=true #后台运行
maxConns=5000 #最大同时连接数,默认2000
storageEngine=wiredTiger #指定存储引擎为内存映射文件
存储引擎有mmapv1、wiredTiger、mongorock
#即使宕机,启动时wiredtiger会先将数据恢复到最近一次的checkpoint点,然后重放后续的journal日志来恢复。
#从MongoDB3.2 版本开始,MongoDB默认的存储引擎就已经是WiredTiger,配置文件里面配置的data目录/usr/local/mongo/data是wiredTiger引擎的数据。当引擎改成mmapv1,data目录与WiredTiger引擎还指向同一个目录,就会报“ERROR: child process failed, exited with error number 100”的错。#因为WiredTiger引擎创建的数据目录无法用mmapv1引擎去打开。#所以将配置文件的“storageEngine=mmapv1”注释掉,服务就正常启动了。
journal=true #每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。
--master 指定为主机器
--slave 指定为从机器
--source 指定主机器的IP地址
--pologSize 指定日志文件大小不超过64M.因为resync是非常操作量大且耗时,最好通过设置一个足够大的oplogSize来避免resync(默认的 oplog大小是空闲磁盘大小的5%)。
--only 指定只复制哪一个数据库
--slavedelay 指从复制检测的时间间隔
--auth 是否需要验证权限登录(用户名和密码)
关于绑定IP
bind_ip=0.0.0.0
- bind_ip = 192.168.2.136 #如果修改成本机Ip,那除了本机外的机器都可以连接(就是自己连不了、哈哈、蛋疼)
- bind_ip = 0.0.0.0 #改成0,那么大家都可以访问(共赢)
- bind_ip = 127.0.0.1 #改成127,那就只能自己练了(独吞)
所以为了方便其他服务器和自己连接,就把bind_ip改成0.0.0.0
ps:mongodb非常的占用磁盘空间,刚启动后要占3-4G左右,如果你用虚拟机练习,可能空间不够,导致无法启动->可以使用--smallfiles选项来启动,将会占用较小空间,大约为400M左右
五、配置开机自动启动
# vim /etc/rc.local
rm -rf /data/mongodb1/mongod.lock
/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb1.conf
# chmod +x /etc/rc.d/rc.local
六、为了更方便的启动和关闭MongoDB,我们可以使用Shell写脚本,当然也可以加入到service中
#!/bin/bash
#
# mongod Start up the MongoDB server daemon
#
# source function library
. /etc/rc.d/init.d/functions
#定义命令
CMD=/usr/local/mongodb/bin/mongod
#定义配置文件路径
INITFILE=/usr/local/mongodb/mongodb1.conf
start()
{
#&表示后台启动,也可以使用fork参数
$CMD -f $INITFILE &
echo "MongoDB is running background..."
}
stop()
{
pkill mongod
echo "MongoDB is stopped."
}
case "$1" in
start)
start
;;
stop)
stop
;;
*)
echo $"Usage: $0 {start|stop}"
esac
七、登录MongoDB
mongo --help # 查看帮助
#常用选项
--port arg port to connect to
--host arg server to connect to
-u [ --username ] arg username for authentication
-p [ --password ] arg password for authentication
--authenticationDatabase arg user source (defaults to dbname)
1、无认证的情况
mongo # 端口默认情况下
mongo --port 31001 # 指定端口
mongo --host 117.131.199.162 --port 31001 # 指定MongoDB的地址及端口
2、认证的情况
mongo --password 'Pbu4@123' --username root # 默认端口
mongo --host 117.131.199.162 --port 31001 --password 'Pbu4@123' --username root # 指定MongoDB的地址、端口、用户名、密码
mongo --host 117.131.199.162 --port 31001 --password 'Pbu4@123' --username root --authenticationDatabase "admin" # 指定MongoDB的地址、端口、用户名、密码、认证的库
MongoDB使用认证
初始化登录账号和密码信息以及授权角色为root
# ./bin/mongo 192.168.56.101:27017
# use admin
# db.createUser({user: 'gobgm', pwd: '123456', roles: ['root']})
当然可以先创建用户,在授权
你可以按照以下步骤进行操作:
1、 使用具有管理员权限的账户连接到 MongoDB。例如:
mongo --username admin --password adminPassword --authenticationDatabase admin
2、 在 mongo shell 中,首先切换到admin数据库:
use admin
3、 然后创建一个名为gobgm的用户:
db.createUser({ user: "gobgm", pwd: "password", roles: [] })
请将password替换为你想要设置的实际密码,并根据需要为用户指定角色。
4、 最后,使用以下命令为gobgm用户授予 replSetGetStatus 角色:
db.grantRolesToUser("gobgm", [{ role: "replSetGetStatus", db: "admin" }])
MongoDB 中有多种内置角色,可以用于控制用户对数据库的访问和操作权限。以下是一些常见的 MongoDB 内置角色:
- read:允许用户读取指定数据库中的数据。
- readWrite:允许用户读取和修改指定数据库中的数据。
- dbAdmin:允许用户管理指定数据库(例如创建、删除、重命名集合)。
- userAdmin:允许用户管理指定数据库中的用户(例如创建、删除、更新用户)。
- clusterAdmin:允许用户管理整个 MongoDB 集群(例如管理复制集、分片等)。
- backup:允许用户执行数据库备份。
- restore:允许用户执行数据库还原。
- root:超级管理员角色,允许用户在所有数据库上执行任意操作。
除了这些内置角色,你还可以自定义角色来满足特定需求。自定义角色可以精确控制用户对数据库、集合和操作的访问权限。
要详细了解内置角色和自定义角色,请参考 MongoDB 官方文档中的 "Role-Based Access Control (RBAC)" 部分。
生成keyfile,副本集可以配置的安全选项
- MongoDB使用keyfile认证,如果是副本集中的每个mongod实例使用keyfile内容作为认证其他成员的共享密码。mongod实例只有拥有正确的keyfile才可以加入副本集。
- keyFile的内容必须是6到1024个字符的长度,且副本集所有成员的keyFile内容必须相同。
- 有一点要注意是的:在UNIX系统中,keyFile必须没有组权限或完全权限(也就是权限要设置成X00的形式)。Windows系统中,keyFile权限没有被检查。
- 可以使用任意方法生成keyFile。例如,如下操作使用openssl生成复杂的随机的1024个字符串。然后使用
chmod修改文件权限,只给文件拥有者提供读权限。
# 400权限是要保证安全性,否则mongod启动会报错
openssl rand -base64 756 > mongodb.key
chmod 400 mongodb.key
然后放到mongodb配置文件中的keyFile指定的目录下面,三台机器keyfile要一致。我是在一台中生成,然后传到其他的服务器中。
打开认证,三台机器都要执行
# 开启认证
auth = true
# 安全文件地址
keyFile = /data/mongodb1/mongodb.key
之后重启mongo
要查看 MongoDB 中的用户,你可以使用以下命令:
- 查看用户数量: 在 mongo shell 中运行以下命令:
bash
use admin
db.system.users.find().count()
这将返回 "admin" 数据库中存储的用户数量。
MongoDB 管理工具
有几种可用于MongoDB的管理工具。
1、监控
MongoDB提供了网络和系统监控工具Munin,它作为一个插件应用于MongoDB中。
Gangila是MongoDB高性能的系统监视的工具,它作为一个插件应用于MongoDB中。
基于图形界面的开源工具Cacti, 用于查看CPU负载, 网络带宽利用率,它也提供了一个应用于监控 MongoDB 的插件。
2、GUI
- Fang of Mongo -- 网页式,由Django和jQuery所构成。
- Futon4Mongo -- 一个CouchDB Futon web的mongodb山寨版。
- Mongo3 -- Ruby写成。
- MongoHub -- 适用于OSX的应用程序。
- Opricot -- 一个基于浏览器的MongoDB控制台, 由PHP撰写而成。
- Database Master --- Windows的mongodb管理工具
- RockMongo --- 最好的PHP语言的MongoDB管理工具,轻量级, 支持多国语言.
数据库操作
创建数据库
CURD操作
> help 不会就help
> help
> db.help();
> db.user.help(); // user为表名
注意:
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
MongoDB 创建数据库的语法格式如下:
Syntax
use DATABASE_NAME
ps:如果数据库不存在,则创建数据库,否则切换到指定数据库。
eg:创建数据库plinux
> use plinux
switched to db plinux
查询数据库
> db //查看当前数据库名
plinux
如果你想查看所有数据库并显示它们的大小,可以使用 show dbs 命令:
> show dbs
admin 0.078GB
config 0.078GB
local 0.078GB
如果你想获取数据库数量而不显示其大小,可以使用以下命令:
db.adminCommand({ listDatabases: 1 }).databases.length
3
其他参数:
show 'show databases'/'show dbs': Print a list of all available databases.
'show collections'/'show tables': Print a list of all collections for current database.
'show profile': Prints system.profile information.
'show users': Print a list of all users for current database.
'show roles': Print a list of all roles for current database.
'show log <type>': log for current connection, if type is not set uses 'global'
'show logs': Print all logs.
可以看到,我们刚创建的数据库plinux并不在数据库的列表中, 要显示它,我们需要向plinux数据库插入一些数据
> db.plinux.insert({"ID":1},{"name":"plinux"})
WriteResult({ "nInserted" : 1 })
> show dbs
admin 0.078GB
config 0.078GB
local 0.078GB
plinux 0.078GB
> db.help()
删除数据库
Syntax
db.dropDatabase()
ps:删除当前数据库,默认为 test,你可以使用db命令查看当前数据库名;如下需要删除其他数据库,必须先进入数据库,然后在删除。
eg:删除plinux数据库
首先,查看所有数据库:
> show dbs
admin 0.078GB
config 0.078GB
local 0.078GB
plinux 0.078GB
接下来我们切换到数据库plinux:
> use plinux // 切换至需要删除的数据库
switched to db plinux
> db
plinux
执行删除命令:
> db.dropDatabase() // 删除命令
{ "dropped" : "plinux", "ok" : 1 }
最后,我们再通过show dbs命令数据库是否删除成功:
> show dbs
admin 0.078GB
config 0.078GB
local 0.078GB
集合操作
查询此db里面所有collection
show collections
show tables
dbReplSet:PRIMARY> show tables
system.keys
system.users
system.version
dbReplSet:PRIMARY> db.getCollectionNames().length // 查看集合数量
3
创建集合
MongoDB 中使用createCollection()方法来创建集合。
Syntax:
db.createCollection(name, options)
参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | (可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
ps:在插入文档时,MongoDB 首先检查固定集合的size字段,然后检查max字段。
eg:在test数据库中创建test集合
> use test // 切换至test数据库
switched to db test
> db.createCollection("test") // 创建集合test
{ "ok" : 1 }
如果要查看已有集合,可以使用show collections命令:
> show collections // 查看创建的集合
test
eg:创建固定集合 test1,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection("test1", { capped : true, autoIndexId : true, size : 6142800, max : 10000 } )
{
"note" : "the autoIndexId option is deprecated and will be removed in a future release",
"ok" : 1
}
> show collections
test
test1
ps:在 MongoDB 中,不需要先创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.test2.insert({"name":"test2"})
WriteResult({ "nInserted" : 1 })
> show collections
test2
删除集合
Syntax
db.collection_name.drop()
返回值
如果成功删除选定集合,则drop()方法返回 true,否则返回 false。
eg: 在数据库 test 中,先通过show collections 命令查看已存在的集合:
> use test // 进入test库
switched to db test
> show collections // 查看test库中的集合
mycol
test
test1
test2
> db.mycol.drop() // 删除mycol集合
true
> db.test.drop() // 删除test集合
true
> show collections // 再次验证
test1
test2
文档操作
插入文档
文档的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
ps:MongoDB 使用insert()或save()方法向集合中插入文档。如果不指定_id字段save()方法类似于 insert()方法。如果指定_id字段,则会更新该_id的数据。_id字段也可以自己指定,不用系统指定。
Syntax:
db.COLLECTION_NAME.insert(document)
eg:在test库中的test3集合中,插入单条数据
> use test // 进入test库
switched to db test
> db.test3.insert({"id":1,"name":"test3","age":22}) // 插入数据
WriteResult({ "nInserted" : 1 })
ps:以上实例中test3 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档
查看已插入文档:
> db.test3.find()
{ "_id" : ObjectId("5cbd732cdcb1324473a1fbbd"), "id" : 1, "name" : "test3", "age" : 22 }
ps:_id字段的内容可以自己指定
eg:插入多条数据(数据用中括号囊括)
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd7b26dcb1324473a1fbc1"), "id" : 5 }
{ "_id" : ObjectId("5cbd811edcb1324473a1fbc2"), "id" : 5, "name" : "test" }
> db.test4.insert([{"id":5,"name":"test5"},{"id":5,"name":"test1"},{"id":6,"name":"test6"}])
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 3, // 插入了三条数据
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd7b26dcb1324473a1fbc1"), "id" : 5 }
{ "_id" : ObjectId("5cbd811edcb1324473a1fbc2"), "id" : 5, "name" : "test" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc3"), "id" : 5, "name" : "test5" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc4"), "id" : 5, "name" : "test1" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc5"), "id" : 6, "name" : "test6" }
eg:利用for循环插入多条数据(效率高)
1、先创建数组
2、将数据放在数组中
3、一次·insert·到集合中
> var arr=[];
> for(var i=1;i<=20000;i++){arr.push({num:i});}
20000
> db.numbers.insert(arr);
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 20000,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
> for (var i=0;i<=10;i++){ db.test6.insert({number:i})} // 效率不高
> for (var i=0;i<=10;i++){ db.test7.insert({"number":i,"name":"test"+i})} // 多域插入
eg:也可以将数据定义为一个变量,如下所示:
> document=({"id":2,"name":"test2","age":33}) // 定义变量,并写入数据
{ "id" : 2, "name" : "test2", "age" : 33 }
> db.test4.insert(document) // 执行插入命令
WriteResult({ "nInserted" : 1 })
> show collections;
test4
> db.test4.find() // 查看插入结果
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 2, "name" : "test2", "age" : 33 }
更新文档
MongoDB 使用update()和save()方法来更新集合中的文档
方法1、update()方法用于更新已存在的文档
Syntax
db.collection_name.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的

- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
eg:修改test4集合中的文档内容的某个字段
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 2, "name" : "test2", "age" : 33 }
> db.test4.update({"name":"test2"},{$set:{"name":"test4"}}) // 修改为test4
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.test4.find() // 再次查看
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 2, "name" : "test4", "age" : 33 }
可以看到name由原来的"test2"更新为了"test4"
ps:以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置multi参数为true。
> db.test4.update({"name":"test2"},{$set:{"name":"test4"}},{multi:true})
eg:赋值表达式的综合应用
> db.student.insert({name:"wukong",jingu:"true",sex:"man",age:500})
WriteResult({ "nInserted" : 1 })
> db.student.find()
{ "_id" : ObjectId("5cbdedc00f7f41d4fe1a3304"), "name" : "wukong", "jingu" : "true", "sex" : "man", "age" : 500 }
>db.student.update({name:"wukong"},{$set:{name:"dzsf"},$unset:{jingu:1},$rename:{sex:"gender"},$inc:{age:20}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.student.find()
{ "_id" : ObjectId("5cbdedc00f7f41d4fe1a3304"), "name" : "dzsf", "age" : 520, "gender" : "man" }
方法2、save()方法通过传入的文档来替换已有文档
Syntax
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
参数说明:
- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
eg:根据_id来修改test4集合中文档的内容
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 4, "name" : "test", "age" : 24 }
> db.test4.save({"_id" : ObjectId("5cbd752ddcb1324473a1fbbe"),"id":8,"name":"test8","age":28})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
ps:更新文档内容时,如果不用$set,那么就是全部更新,否则数据只会写入你当前更新域的东西
删除文档
MongoDB的remove()函数是用来移除集合中的数据。
MongoDB数据更新可以使用update()函数。在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
Syntax
db.collection.remove(
<query>,
<justOne>
)
如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
- writeConcern :(可选)抛出异常的级别。
eg:删除所有匹配的数据
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd7a6fdcb1324473a1fbbf"), "id" : 4 }
{ "_id" : ObjectId("5cbd7b12dcb1324473a1fbc0"), "id" : 4 }
{ "_id" : ObjectId("5cbd7b26dcb1324473a1fbc1"), "id" : 5 }
> db.test4.remove({"id":4}) // 删除id等于4的所有数据
WriteResult({ "nRemoved" : 2 })
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd7b26dcb1324473a1fbc1"), "id" : 5 }
eg:只删除第一条找到的记录可以设置justOne为1,如下所示:
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd7b26dcb1324473a1fbc1"), "id" : 5 }
{ "_id" : ObjectId("5cbd811edcb1324473a1fbc2"), "id" : 5, "name" : "test" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc3"), "id" : 5, "name" : "test5" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc4"), "id" : 5, "name" : "test1" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc5"), "id" : 6, "name" : "test6" }
> db.test4.remove({"id":5},1)
WriteResult({ "nRemoved" : 1 })
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd811edcb1324473a1fbc2"), "id" : 5, "name" : "test" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc3"), "id" : 5, "name" : "test5" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc4"), "id" : 5, "name" : "test1" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc5"), "id" : 6, "name" : "test6" }
eg:想删除所有数据(类似常规 SQL 的 truncate 命令)
> db.test4.find()
{ "_id" : ObjectId("5cbd752ddcb1324473a1fbbe"), "id" : 8, "name" : "test8", "age" : 28 }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc3"), "id" : 5, "name" : "test5" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc4"), "id" : 5, "name" : "test1" }
{ "_id" : ObjectId("5cbd8186dcb1324473a1fbc5"), "id" : 6, "name" : "test6" }
> db.test4.remove({}) // 删除所有数据
WriteResult({ "nRemoved" : 4 })
> db.test4.find()
扩展:remove()方法已经过时了,现在官方推荐使用deleteOne()和deleteMany()方法。
ps:remove()方法并不会真正释放空间。需要继续执行db.repairDatabase()来回收磁盘空间。
> db.repairDatabase()
或者
> db.runCommand({ repairDatabase: 1 })
eg:删除 numbers集合中num 等于 22 的全部文档:
> db.numbers.deleteMany({num:22})
{ "acknowledged" : true, "deletedCount" : 5 }
eg:删除 numbers集合中num 等于 1的一个文档:
> db.numbers.find()
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc6"), "num" : 1 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc7"), "num" : 1 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc8"), "num" : 3 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc9"), "num" : 4 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbca"), "num" : 5 }
> db.numbers.deleteOne({num:1}) // 只删除匹配中的第一个
{ "acknowledged" : true, "deletedCount" : 1 }
> db.numbers.find()
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc7"), "num" : 1 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc8"), "num" : 3 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc9"), "num" : 4 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbca"), "num" : 5 }
eg:删除集合下全部文档:
> db.numbers.find()
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc7"), "num" : 1 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc8"), "num" : 3 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbc9"), "num" : 4 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbca"), "num" : 5 }
{ "_id" : ObjectId("5cbd836fdcb1324473a1fbcb"), "num" : 6 }
Type "it" for more
> db.numbers.deleteMany({})
{ "acknowledged" : true, "deletedCount" : 20004 }
查询文档
MongoDB 查询文档使用find()方法。find()方法以非结构化的方式来显示所有文档
Syntax
db.Collection_Name.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用pretty()方法,语法格式如下:
> db.col.find().pretty()
ps: 除了find()方法之外,还有一个findOne() 方法,它只返回一个文档。
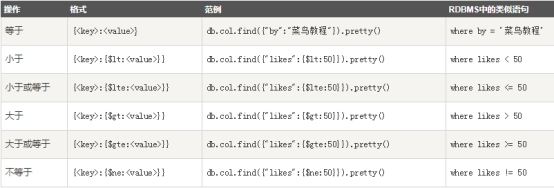
条件操作符
http://cw.hubwiz.com/card/c/543b2f3cf86387171814c026/1/1/1/
MongoDB 与 RDBMS Where 语句比较,如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
$exists:判断字段是否存在
查询所有存在age 字段的记录
db.users.find({age: {$exists: true}});
查询所有不存在name 字段的记录
db.users.find({name: {$exists: false}});
$in:在范围之内
与sql 标准语法的用途是一样的,即要查询的是一系列枚举值的范围内,查询x 的值在2,4,6 范围内的数据:
db.things.find({x:{$in: [2,4,6]}});
举例如下:
C1 表的数据如下:
> db.c1.find()
{ "_id" : ObjectId("4fb4af85afa87dc1bed94330"), "age" : 7, "length_1" : 30 }
{ "_id" : ObjectId("4fb4af89afa87dc1bed94331"), "age" : 8, "length_1" : 30 }
{ "_id" : ObjectId("4fb4af8cafa87dc1bed94332"), "age" : 6, "length_1" : 30 }
查询age 的值在7,8 范围内的数据
> db.c1.find({age:{$in: [7,8]}});
{ "_id" : ObjectId("4fb4af85afa87dc1bed94330"), "age" : 7, "length_1" : 30 }
{ "_id" : ObjectId("4fb4af89afa87dc1bed94331"), "age" : 8, "length_1" : 30 }
可以看出只显示出了age 等于7 或8 的数据,其它不符合规则的数据并没有显示出来,$in非常灵活,可以指定不同类型的条件和值
$nin不包含
与sql 标准语法的用途是一样的,即要查询的数据在一系列枚举值的范围外,查询x 的值在2,4,6 范围外的数据:
db.things.find({x:{$nin: [2,4,6]}});
Null空值处理
Null空值的处理稍微有一点奇怪,具体看下面的样例数据:
> db.c2.find()
{ "_id" : ObjectId("4fc34bb81d8a39f01cc17ef4"), "name" : "Lily", "age" : null }
{ "_id" : ObjectId("4fc34be01d8a39f01cc17ef5"), "name" : "Jacky", "age" : 23 }
{ "_id" : ObjectId("4fc34c1e1d8a39f01cc17ef6"), "name" : "Tom", "addr" : 23 }
其中"Lily"的age 字段为空,Tom 没有age 字段,我们想找到age 为空的行,具体如下:
> db.c2.find({age:null})
{ "_id" : ObjectId("4fc34bb81d8a39f01cc17ef4"), "name" : "Lily", "age" : null }
{ "_id" : ObjectId("4fc34c1e1d8a39f01cc17ef6"), "name" : "Tom", "addr" : 23 }
奇怪的是我们以为只能找到"Lily",但"Tom"也被找出来了,因为"null"不仅会匹配某个键的值为null的文档, 而且还会匹配不包含这个键的文档 。那么怎么样才能只找到"Lily"呢?我们用exists来限制一下即可.
在users文档找出"sex"值为"null"并且字段存在的记录。
> db.users.find({sex:{"$in":[null], "$exists":true}});
逻辑运算符
$or逻辑或$and逻辑与$not逻辑非$nor逻辑or的取反$exists存在逻辑$type查询键的数据类型
MongoDB AND 条件
MongoDB 的find()方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
> db.col_name.find({ key1:value1, key2:value2 }).pretty()
或者
> db.col_name.find({ $and: [{key1:value1,{key2:value2}] }).pretty()
MongoDB OR 条件
MongoDB的OR条件语句使用了关键字$or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1},
{key2:value2}
]
}
).pretty()
AND 和 OR 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')'
>db.col.find({
"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]
}).pretty()
eg:查询number小于5
> db.test6.find()
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f0"), "number" : 0 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f1"), "number" : 1 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f2"), "number" : 2 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f3"), "number" : 3 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f4"), "number" : 4 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f5"), "number" : 5 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f6"), "number" : 6 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f7"), "number" : 7 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f8"), "number" : 8 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f9"), "number" : 9 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249fa"), "number" : 10 }
> db.test6.find({"number":{$lt:5}})
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f0"), "number" : 0 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f1"), "number" : 1 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f2"), "number" : 2 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f3"), "number" : 3 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f4"), "number" : 4 }
eg:查询number大于等于5且小于等于7
> db.test6.find({"number":{$gte:5,$lte:7}})
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f5"), "number" : 5 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f6"), "number" : 6 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f7"), "number" : 7 }
eg:查询number小于等于2或大于等于8
> db.test6.find({$or:[{"number":{$lte:2}},{"number":{$gte:8}}]})
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f0"), "number" : 0 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f1"), "number" : 1 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f2"), "number" : 2 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f8"), "number" : 8 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249f9"), "number" : 9 }
{ "_id" : ObjectId("5cbd8f47dcb1324473a249fa"), "number" : 10 }
MongoDB的$type操作符
描述
在本章节中,我们将继续讨论MongoDB中条件操作符$type。$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
我们使用的数据库名称为"runoob" 我们的集合名称为"col",以下为我们插入的数据。
简单的集合"col":
> db.col.insert({
title: 'PHP 教程',
description: 'PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['php'],
likes: 200})
> db.col.insert({title: 'Java 教程',
description: 'Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['java'],
likes: 150})
> db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb'],
likes: 100})
使用find()命令查看数据:
> db.col.find()
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB 操作符-$type实例
如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令:
db.col.find({"title" : {$type : 2}})
或
db.col.find({"title" : {$type : 'string'}})
输出结果为:
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb" ], "likes" : 100 }
Limit与Skip方法->可用来做小数据量分页
MongoDB的Limit()方法,如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,·limit()·方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
Syntax
limit()方法基本语法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER)
eg:查询指定数量的数据记录
> db.test3.find()
{ "_id" : ObjectId("5cbd732cdcb1324473a1fbbd"), "id" : 1, "name" : "test3", "age" : 22 }
{ "_id" : ObjectId("5cbd9821dcb1324473a24a3d"), "id" : 5, "name" : "test5" }
{ "_id" : ObjectId("5cbd9821dcb1324473a24a3e"), "id" : 5, "name" : "test1" }
{ "_id" : ObjectId("5cbd9821dcb1324473a24a3f"), "id" : 6, "name" : "test6" }
> db.test3.find().limit(1) // 前面第一条记录
{ "_id" : ObjectId("5cbd732cdcb1324473a1fbbd"), "id" : 1, "name" : "test3", "age" : 22 }
> db.test3.find().limit(2) // 前面2条记录
{ "_id" : ObjectId("5cbd732cdcb1324473a1fbbd"), "id" : 1, "name" : "test3", "age" : 22 }
{ "_id" : ObjectId("5cbd9821dcb1324473a24a3d"), "id" : 5, "name" : "test5" }
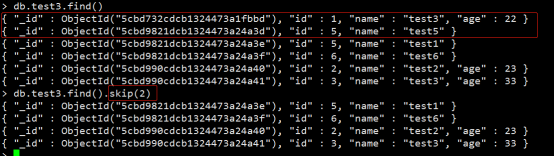
MongoDB的Skip()方法,我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
skip() 方法脚本语法格式如下:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
eg:跳过了前2条数据
排序
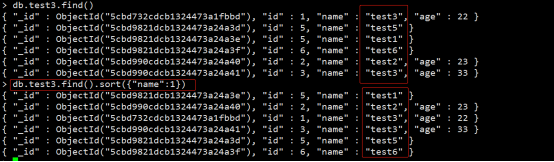
MongoDB的sort()方法
在 MongoDB 中使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1为升序排列,而-1是用于降序排列。
Syntax
sort()方法基本语法如下所示:
db.COLLECTION_NAME.find().sort({KEY:1})
eg:根据name字段排序
ps:skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先sort(), 然后是skip(),最后是显示的limit()
索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
createIndex()方法:
MongoDB使用createIndex()方法来创建索引
注意在 3.0.0 版本前创建索引方法为db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex()方法,ensureIndex()还能用,但只是createIndex()的别名。
Syntax
createIndex()方法基本语法格式如下所示:
db.collection.createIndex(keys, options)
ps:语法中 Key 值为你要创建的索引字段
options参数取1或者-1;1为指定按升序创建索引,按降序来创建索引指定为-1即可。
eg:为id字段添加索引
> db.test3.createIndex({"id":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
eg:createIndex()方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)
> db.col.createIndex({"title":1,"description":-1})
createIndex()接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language |
实例
在后台创建索引:
db.values.createIndex({open: 1, close: 1}, {background: true})
通过在创建索引时加background:true的选项,让创建工作在后台执行
1、查看集合索引
db.col_name.getIndexes()
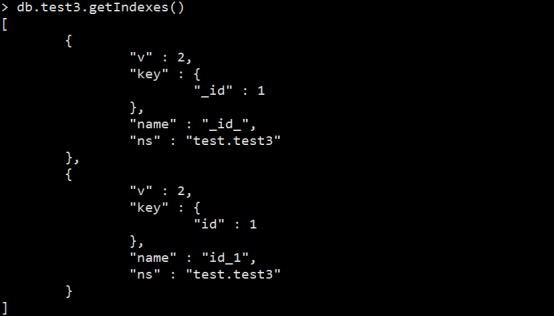
表示有两个索引
2、查看集合索引大小
db.col_name.totalIndexSize()

3、删除集合所有索引
db.col_name.dropIndexes()
4、删除集合指定索引
db.col_name.dropIndex("索引名称")
5、为了验证我们使用使用了索引,可以使用explain命令:
db.users.find({tags:"cricket"}).explain()
以上命令执行结果中会显示"cursor" : "BtreeCursor tags_1",则表示已经使用了索引
聚合
https://docs.mongodb.com/manual/core/aggregation-pipeline/
聚合概念
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的count(*)。
aggregate() 方法
MongoDB中聚合的方法使用aggregate()。
Syntax
aggregate() 方法的基本语法格式如下所示:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
| SQL 术语、函数和概念 | MongoDB 聚合操作符 |
|---|---|
| WHERE | $match |
| GROUP BY | $group |
| HAVING | $match |
| SELECT | $project |
| ORDER BY | $sort |
| LIMIT | $limit |
| SUM() | $sum |
| COUNT() | $sum $sortByCount |
| join | $lookup |
| SELECT INTO NEW_TABLE | $out |
| MERGE INTO TABLE | $merge MongoDB 4.2 可用 |
有关所有聚合管道和表达式操作符的列表,请参见:
https://docs.mongodb.com/manual/meta/aggregation-quick-reference/
https://docs.mongodb.com/manual/reference/sql-comparison/
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域、创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
聚合运算符
运算符 说明
-
$add 计算数值的总和
-
$divide 给定两个数值,用第一个数除以第二个数
-
$mod 取模。
-
$multiply 计算数值数组的乘积
-
$subtract 给定两个数值,用第一个数减去第二个数
-
$concat 连接两个字符串
-
$strcasecmp 比较两个字符串并返回一个整数来反应比较结果
-
$substr 返回字符串的一部分
-
$toLower 将字符串转化为小写
-
$toUpper 将字符串转化为大写
https://www.docs4dev.com/docs/zh/mongodb/v3.6/reference/reference-operator-aggregation-divide.html
Examples
考虑包含以下文档的planning集合:
{ "_id" : 1, "name" : "A", "hours" : 80, "resources" : 7 },
{ "_id" : 2, "name" : "B", "hours" : 40, "resources" : 4 }
以下汇总使用$divide表达式将hours字段除以 Literals8以计算工作日数:
db.planning.aggregate(
[
{ $project: { name: 1, workdays: { $divide: [ "$hours", 8 ] } } }
]
)
该操作返回以下结果:
{ "_id" : 1, "name" : "A", "workdays" : 10 }
{ "_id" : 2, "name" : "B", "workdays" : 5 }
管道操作符实例
https://aotu.io/notes/2020/06/07/sql-to-mongo-2/index.html
1、$project实例
- 修改输入文档的结构
- 重命名、增加或删除域
- 创建计算结果以及嵌套文档
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
这样的话结果中就只还有id,tilte和author三个字段了,默认情况下id字段是被包含的,如果要想不包含_id话可以这样:
db.article.aggregate(
{ $project : {
_id : 0 ,
title : 1 ,
author : 1
}});
说明: 1表示显示结果,0表示不显示(但是0只针对_id这个字段)
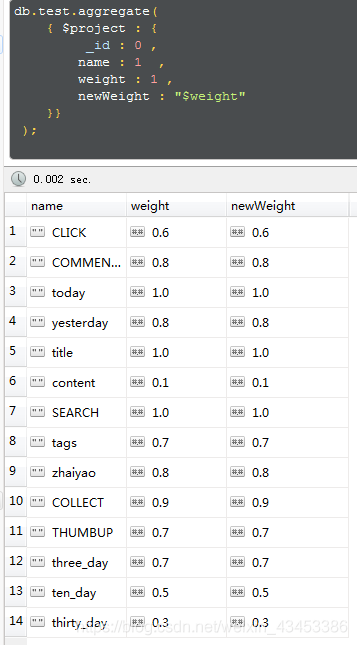
获取test集合的weight字段及name字段(_id显示)
db.test.aggregate([
{ $project : {
weight: 1 ,
name : 1
}}
]);
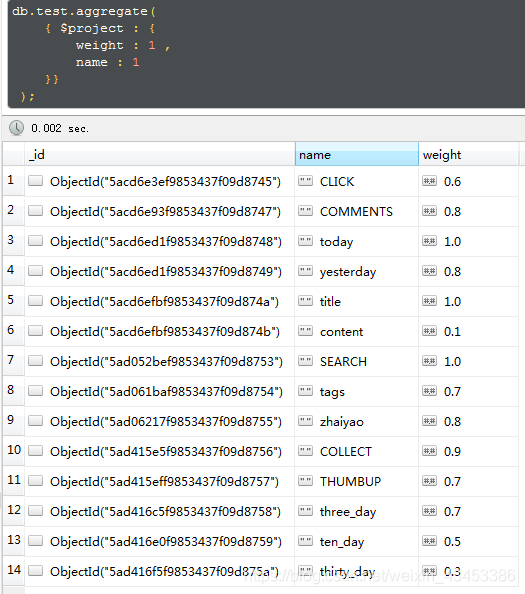
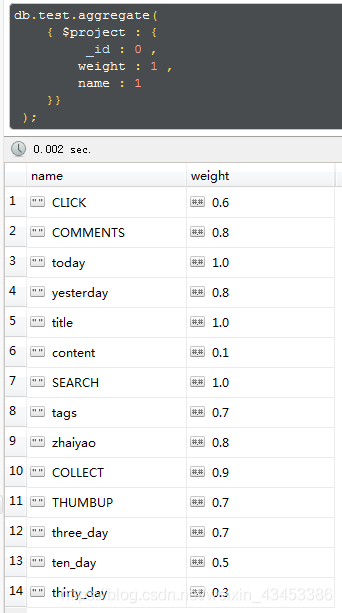
获取test集合的weight字段及name字段(_id不显示)
db.test.aggregate(
{ $project : {
_id : 0 ,
weight: 1 ,
name : 1
}}
);
使用$add给weight字段的值加10,然后将结果赋值给一个新的字段:newWeight
db.test.aggregate(
{ $project : {
_id : 0 ,
name : 1 ,
weight : 1 ,
newWeight : { $add:["$weight", 10] }
}}
);
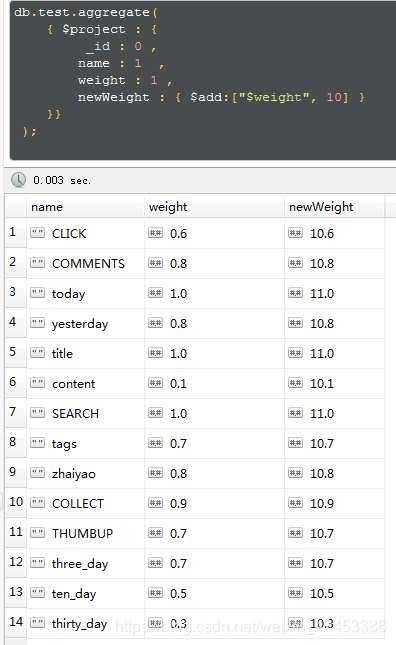
把weight重命名为newWeight
db.test.aggregate(
{ $project : {
_id : 0 ,
name : 1 ,
weight : 1 ,
newWeight : "$weight"
}}
);
2、$skip实例
$skip接受一个数字n,丢弃结果集中的前n个文档- 限定可以传递到聚合操作的下一个管道中的文档数量
db.article.aggregate(
{ $skip : 5 }
);
经过$skip管道操作符处理后,前五个文档被"过滤"掉。
3、$limit
$limit会接受一个数字n,返回结果集中的前n个文档
例:查询5条文档记录
db.test.aggregate({ $limit : 5 });
4、COUNTvscount
- SQL 示例
sql
SELECT COUNT(*) AS count FROM test4
- MongoDB 示例 (这里的null是关键字)
db.test4.aggregate([
{
$group: {
_id :null,
count: {$sum: 1}
}
}
])
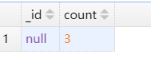
注意:这里的$sum: 1就是计数的意思,相当于count
但是一般用count()方法进行查询
使用count()方法查询表中的记录条数,例如,下面的命令查询表users的记录数量:
db.users.find().count();
当使用limit()方法限制返回的记录数时,默认情况下count()方法仍然返回全部记录条数。 例如,下面的示例中返回的不是5,而是user表中所有的记录数量:
db.users.find().skip(10).limit(5).count();
如果希望返回限制之后的记录数量,要使用count(true)或者count(非0):
db.users.find().skip(10).limit(5).count(true);
db.logs_202102.find({'game_type': {$gte: 10000},'created_at':{$gte: 1614265200,$lte:1614268800}})
.projection({})
.sort({_id:-1})
.limit(100)
.count()
=================分组计数========================
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
以上实例类似sql语句(对by_user进行分组计算):
select by_user as _id, count(*) as num_tutorial from mycol group by by_user
=================分组计数=======================

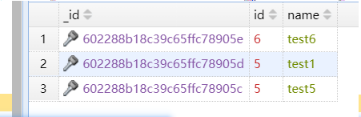
db.test4.aggregate([
{
$group: {
_id : "$id",
count: {$sum: 1}
}
}
])
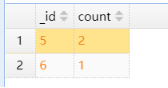
以上实例类似sql语句:
select id as _id, count(*) as count from test4 group by id
5、SUM vs $sum
- SQL 示例
SELECT SUM(id) AS total FROM orders
- MongoDB 示例(这里的null是关键字)
db.test4.aggregate([
{
$group:{
_id: null,
total: {$sum: "$id"}
}
}
])
=======分组求和========
db.test4.aggregate([
{
$group:{
_id: "$id",
total: {$sum: "$id"}
}
}
])

以上实例类似sql语句(这里的id不是MySQL的自增id得出来的效果就明显了):
select id as _id, sum(id) as total from test4 group by id
6、GROUP BY vs $group
对于每一个独特的 cust_id,计算 price 字段总和:
SQL 示例:
SELECT cust_id,SUM(price) AS total
FROM orders
GROUP BY cust_id
MongoDB 示例:
db.orders.aggregate( [
{
$group: {
_id: "$cust_id",
total: { $sum: "$price" }
}
}
] )
7、ORDER BY vs $sort
对于每一个独特的 cust_id,计算 price 字段总和,且结果按总和降序排列:
SQL 示例
SELECT cust_id,SUM(price) AS total
FROM orders
GROUP BY cust_id
ORDER BY total
MongoDB 示例
db.orders.aggregate( [
{
$group: {
_id: "$cust_id",
total: { $sum: "$price" }
}
},
{ $sort: { total: -1 } }
] )
8、WHERE vs $match
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
==============$match中的或与关系:
首先通过$match查出created_at大于等于1620387600并且小于等于1620393300,且game_type等于12或者17
然后通过$group对player_id进行分组计数,当然也可以不计数就只是分组。这一步就是相当于对player_id去重
最后通过$project只显示player_id字段信息
db.game_logs_05.aggregate([
{ $match: {
created_at: {
$gte:1620387600,
$lte:1620393300
},
$or: [
{game_type: 11},
{game_type: 15}
],
}},
{ $group: {
_id: "$player_id",
// count: {$sum:1} //对player_id进行分组计数
}},
{ $project: {
_id: 0, //不显示$_id字段
player_id: '$_id', //最后通过$project对$_id字段进行重命名为player_id字段
// count: '$count'
}}
])
=====================
对于每一个独特的 cust_id,且 status = 'A',计算 price 字段总和,只有在总和大于 250 的情况下,才可以返回。
SQL 示例
SELECT cust_id,SUM(price) as total FROM orders
WHERE status = 'A'
GROUP BY cust_id
HAVING total > 250
MongoDB 示例
db.orders.aggregate([
{
$match: { status: 'A' }
},
{
$group: {
_id: "$cust_id",
total: { $sum: "$price" }
}
},
{
$match: { total: { $gt: 250 } }
}
])
9、HAVING vs $match
对于 cust_id 如果有多个记录,就返回 cust_id 以及相应的记录数量:
SQL 示例
SELECT cust_id,count(*)
FROM orders
GROUP BY cust_id
HAVING count(*) > 1
MongoDB 示例
db.orders.aggregate( [
{
$group: {
_id: "$cust_id",
count: { $sum: 1 }
}
},
{
$match: { count: { $gt: 1 } }
}
] )
10、$match、$group、$project
先匹配,然后在求和
db.logs_02.aggregate([
{
$match: {
'created_at': {
$gte: 1614182400,
$lte:1614268800
},
'game_type': {
$gte: 1000
}
}
},
{
$group:{
_id: null,
total1: {$sum: "$cash_out"},
total2: {$sum: "$money"}
}
},
{
$project: {
_id: 0
}
}
])

数据库的备份(mongodump)与恢复(mongorestore)
数据备份
Syntax
mongodump -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 -c 表 -o 文件存放路径
参数说明:
- -h 指明数据库宿主机的IP
-
--port 指明数据库的端口
-
-u 指明数据库的用户名
-
-p 指明数据库的密码
-
-d|--db 指明数据库的名字
-
-c|--collection 指明collection的名字
-
-o|--out 指明到要导出的文件名
-
-q 指明导出数据的过滤条件
eg:备份所有数据库
# mongodump -o /tmp/data_mongodb
数据恢复
Syntax
mongorestore -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 --drop 文件存在路径
参数解释
-
--host <:port>, -h <:port>:MongoDB所在服务器地址,默认为: localhost:27017
-
--db|-d :需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
-
--drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
-
<path>:mongorestore 最后的一个参数,设置备份数据所在位置,例如:/tmp/backup
你不能同时指定<path>和--dir选项,--dir也可以设置备份目录。
- --dir:指定备份的目录
ps:不能同时指定<path>和--dir选项。
eg:恢复之前备份的所有数据库
# mongorestore --dir /tmp/data_mongodb/
数据的导出与导入
mongoexport导出(表或者表中部分字段)
mongoDB中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。
Syntax
mongoexport -d dbname -c collectionname -o file --type json/csv -f field
常用参数说明:
-
-h :主机名
-
--port :端口
-
-u, --username=
<username>username for authentication -
-p, --password=
<password>password for authentication -
-d :数据库名
-
-c :collection名
-
-o :输出的文件名
-
--type : 输出的格式,默认为json/csv
ps:csv 表示导出的文件格式为csv的。这个比较有用,因为大部分的关系型数据库都是支持csv,在这里有共同点
- -f 导出指定字段,如果--type为csv,则需要加上-f "字段名;以逗号分割,
eg:-f uid,name,age导出uid,name,age这三个字段
- -q 可以根据查询条件导出,-q '{ "uid" : "10" }' 导出uid为10的数据
eg:
[root@test /usr/local/mongodb]# mongoexport -d test -c test7 -o /tmp/test_test7 --type csv -f "_id,name,number"
2019-04-23T09:35:03.011+0800 connected to: localhost
2019-04-23T09:35:03.012+0800 exported 22 records
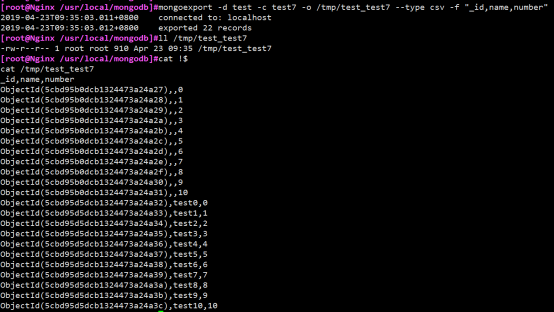
mongoimport导入(表或者表中部分字段)
Syntax
mongoimport -d dbname -c collectionname --file filename --headerline --type json/csv -f field
参数说明:
- -d :数据库名
- -c :collection名
- --type :导入的格式默认json
- -f :导入的字段名
- --headerline :如果导入的格式是csv,必须使用第一行的标题作为导入的字段
- --file :要导入的文件
eg:
[root@test /data/mongodb1]# mongoimport -d test -c test7 --file /tmp/test_test7 --type csv --headerline

MongoDB副本集
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
复制还允许您从硬件故障和服务中断中恢复数据。
什么是复制?
- 保障数据的安全性
- 数据高可用性 (
24 * 7) - 灾难恢复
- 无需停机维护(如备份,重建索引,压缩)
- 分布式读取数据
复制集的目的
保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险。
换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载。
MongoDB复制原理
mongodb的复制至少需要三个节点。其中一个是主节点,负责处理客户端请求;其中一个是仲裁节点,用于选举,不作数据处理;其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
副本集(Replica Set)成员
1,Primary 主节点
接收所有的读写操作
2,Secondaries 副节点
主要从Primar(主节点) 复制数据,不接收写操作
3,Arbiter 仲裁者
只负责选举不报错数据 ,不接收客户端的读写操作
MongoDB复制结构图如下所示:
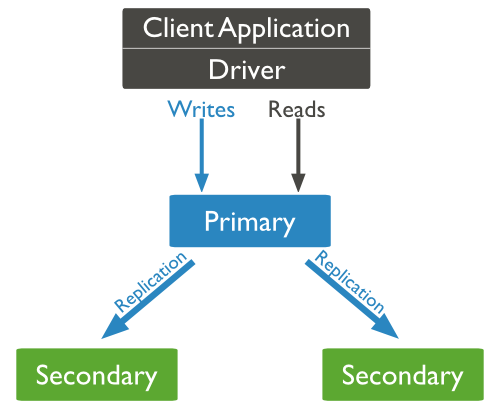
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
当主节点挂掉后,副节点会有10秒的时间选举出副节点升级为主节点,有很强的容错能力
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
环境搭建及操作:
1)机器环境
192.168.12.65 ->primary
192.168.12.162 ->secondary_1
192.168.12.192 ->secondary_2
关闭防火墙与selinux
2)primary配置文件
port=27017
dbpath=/data/mongodb1
logpath=/data/logs/mongodb/mongodb1.log
logappend=true
fork=true
maxConns=5000
storageEngine=wiredTiger
bind_ip=192.168.12.65 #不同的机器绑定本机ip不同
replSet =haha #副本集名称
3)secondary_1配置文件
port=27017
dbpath=/data/mongodb1
logpath=/data/logs/mongodb/mongodb1.log
logappend=true
fork=true
maxConns=5000
storageEngine=wiredTiger
bind_ip = 192.168.12.162,127.0.0.1
replSet=haha
4)secondary_2配置文件
port=27017
dbpath=/data/mongodb1
logpath=/data/logs/mongodb/mongodb1.log
logappend=true
fork=true
maxConns=5000
storageEngine=wiredTiger
bind_ip = 192.168.12.192
replSet =haha
5)在primary主机上操作,加入新节点(2种方法)
第一种:通过变量,来进行初始化
#副本集也可以通过定义主机集合的方式:
config_rs1={
_id:"haha", // 复制集的名称,需要和配置文件里replSet相同
protocolVersion:1, // 指明版本
members:[
{_id:0,host:"192.168.12.192:27017"},
{_id:1,host:"192.168.12.162:27017"},
{_id:2,host:"192.168.12.65:27017"},]
}
#初始化配置
rs.initiate(config_rs1)
第二种:先初始化,在加入新节点
rs.initiate()
rs.add( { host: "192.168.12.162:27017" } )
rs.add( { host: "192.168.12.192:27017" } )
rs.add( { host: "192.168.12.65:27017" } )
6)到这一步就可以实现副本集
可以在primary主机上进行读写操作,然后在secondary主机上可以查看到对应的数据。如果在secondary主机上操作是报如下错误:
haha:SECONDARY> show collections
2019-04-23T17:44:23.811+0800 E QUERY [js] Error: listCollections failed: {
"operationTime" : Timestamp(1556012651, 1),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotMasterNoSlaveOk",
"$clusterTime" : {
"clusterTime" : Timestamp(1556012651, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
DB.prototype._getCollectionInfosCommand@src/mongo/shell/db.js:943:1
DB.prototype.getCollectionInfos@src/mongo/shell/db.js:993:20
DB.prototype.getCollectionNames@src/mongo/shell/db.js:1031:16
shellHelper.show@src/mongo/shell/utils.js:869:9
shellHelper@src/mongo/shell/utils.js:766:15
@(shellhelp2):1:1
需要在secondary主机上执行这条命令后,才能进行查询操作了:
haha:SECONDARY> rs.slaveOk() // 允许副节点查询东西
haha:SECONDARY> show collections // 可以正常操作了,并同步数据了
test1
ps:primary与secondary终端提示符是不一样的
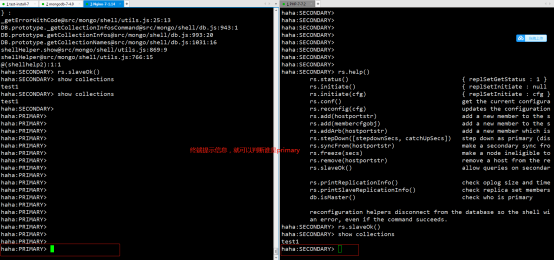
7)查看副本集(Replica Set)状态
rs是辅助函数,其中包含了与复制相关的辅助函数,可以通过rs.help()查看。
rs.help()
| 函数 | 描述 |
|---|---|
| rs.status() | 查看副本集状态 |
| rs.initiate(cfg) | 副本集进行初始化 |
| rs.conf() | local.system.replset 中获取配置信息 |
| rs.reconfig(cfg) | 更新副本集配置 |
| rs.add(hostportstr) | 添加一个成员 |
| rs.addArb(hostportstr) | 添加一个选举者 arbiterOnly:true |
| rs.stepDown([stepdownSecs, catchUpSecs]) | 主服务器变为备份服务器 |
| rs.syncFrom(hostportstr) | 备份服务器指定hostportstr中同步数据 |
| rs.freeze(secs) | 使不能成为主节点的节点可以成为主节点 |
| rs.remove(hostportstr) | 从副本集删除一个节点 |
| rs.slaveOk() | 允许副节点查询数据 |
| rs.printReplicationInfo() | 查看oplog 的大小时间 |
| rs.printSlaveReplicationInfo() | 查看副本集成员同步情况 |
| db.isMaster() | 查看是否为主节点 |
haha:PRIMARY> rs.status()
{
"set" : "haha",
"date" : ISODate("2019-04-23T09:52:04.667Z"),
"myState" : 1,
"term" : NumberLong(1),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
},
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
}
},
"members" : [
{
"_id" : 0,
"name" : "192.168.12.65:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 23109,
"optime" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2019-04-23T09:51:55Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1555990071, 1),
"electionDate" : ISODate("2019-04-23T03:27:51Z"),
"configVersion" : 5,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "192.168.12.162:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 977,
"optime" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1556013115, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2019-04-23T09:51:55Z"),
"optimeDurableDate" : ISODate("2019-04-23T09:51:55Z"),
"lastHeartbeat" : ISODate("2019-04-23T09:52:04.432Z"),
"lastHeartbeatRecv" : ISODate("2019-04-23T09:52:03.493Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "192.168.12.65:27017",
"syncSourceHost" : "192.168.12.65:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 5
},
],
"ok" : 1,
"operationTime" : Timestamp(1556013115, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1556013115, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
详细解释:
-
1, self:这个字段只会出现在运行
rs.status函数的成员信息中。 -
2, stateStr: 服务器状态
PRIMARY,SECONDARY,ARBITER。 -
3, uptime: 从成员可达一直到现在所经历的时间,单位是秒。
-
4,optimeDate: 每个成员的oplog中最后一个操作发生的时间。
注意:这里的状态是每个成员通过心跳报告上来的状态,所以optime跟实际时间可能会有 几秒钟的偏差。
-
5,lastHeartbeat:当前服务器最后一次收到其他成员心跳的时间,如果网络故障,或者是当前服务器比较繁忙,这个时间可能会是2秒钟之前。
-
6,pingMs:心跳从当前服务器到达某个成员所花费的平均时间。
-
7,errmsg:成员在心跳请求中返回的状态信息,通常是一些状态信息,而不是错误信息。
-
8,state:也表示服务器的状态,state是内部表示,而stateStr是适合阅读的表示。
1表明是Primary;2表明是Secondary; -
9,optime:和optimeDate也是一样的,只是optimeDate更适合阅读。
-
10,syncingTo:表示当前成员正在从哪个成员处进行复制。
-
11,"health" : 1, 1 表明正常; 0 表明异常
副本集中主节点的确认
是通过选举机制,要大多数节点同意的节点才能成为主节点。
成员配置选项--选举仲裁者
所谓仲裁者,就是不保存数据,专门用来投票选举主节点的副本,以解决副本个数为偶数的情况
1,启动仲裁者和普通的副本方式一样。
2, 只是配置该节点的时候,设置:arbiterOnly:true,如果用rs来加入的话应该是:rs.addArb("ip:port")
rs.initiate({_id:"haha",members:[
{_id:0,host:'127.0.0.1:20001'},
{_id:1,host:'127.0.0.1:20002'},
{_id:2,host:'127.0.0.1:20003,arbiterOnly:true }
]
})
3,最多只能有一个仲裁者。
4,尽量使用奇数个成员,而不是采用仲裁者
成员配置选项priority--优先级
优先级用来表示一个成员渴望成为主节点的程度,可以在0-100之间,默认是1.
查看priority,可以用该命令:
rs.config()
ps:
1:如果优先级为0的话,表示这个成员永远不能够成为主节点。
2:拥有最高优先级的成员会优先选举为主节点,只要它能得到"大多数"的票,并且数据是最新的,就可以了。
3:如果一个高优先级的成员,数据又是最新的,通常会使得当前的主节点自动退位,让这个优先级高的做主节点。
把主节点变为备份节点
可以使用stepDown函数,可以自己指定退化的持续时间,
rs.stepDown();
#或者
rs.stepDown(60); #秒为单位
MongoDB分片(Sharding)技术
分片(sharding)是MongoDB用来将大型集合分割到不同服务器(或者说一个集群)上所采用的方法。尽管分片起源于关系型数据库分区,但MongoDB分片完全又是另一回事。
和MySQL分区方案相比,MongoDB的最大区别在于它几乎能自动完成所有事情,只要告诉MongoDB要分配数据,它就能自动维护数据在不同服务器之间的均衡。
分片的目的
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。
为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。
水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
分片设计思想
分片为应对高吞吐量与大数据量提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高自己的存储容量和吞吐量。举例来说,当插入一条数据时,应用只需要访问存储这条数据的分片.
使用分片减少了每个分片存储的数据。
例如,如果数据库1tb的数据集,并有4个分片,然后每个分片可能仅持有256 GB的数据。如果有40个分片,那么每个切分可能只有25GB的数据。
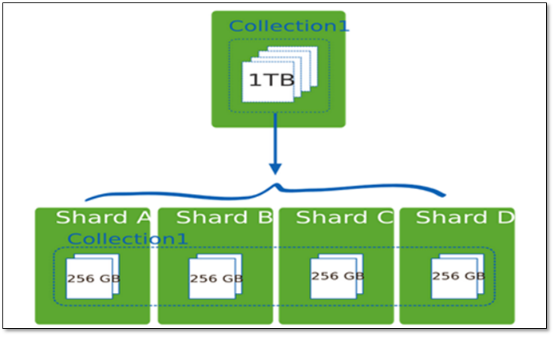
分片机制提供了如下三种优势
1.对集群进行抽象,让集群"不可见"
MongoDB自带了一个叫做mongos的专有路由进程。mongos就是掌握统一路口的路由器,其会将客户端发来的请求准确无误的路由到集群中的一个或者一组服务器上,同时会把接收到的响应拼装起来发回到客户端。
2.保证集群总是可读写
MongoDB通过多种途径来确保集群的可用性和可靠性。将MongoDB的分片和复制功能结合使用,在确保数据分片到多台服务器的同时,也确保了每分数据都有相应的备份,这样就可以确保有服务器换掉时,其他的从库可以立即接替坏掉的部分继续工作。
3.使集群易于扩展
当系统需要更多的空间和资源的时候,MongoDB使我们可以按需方便的扩充系统容量。
分片集群架构
| 组件 | 说明 |
|---|---|
| Config Server | 存储集群所有节点、分片数据路由信息。默认需要配置3个Config Server节点。 |
| Mongos | 提供对外应用访问,所有操作均通过mongos执行。一般有多个mongos节点。数据迁移和数据自动平衡。 |
| Mongod | 存储应用数据记录。一般有多个Mongod节点,达到数据分片目的。 |
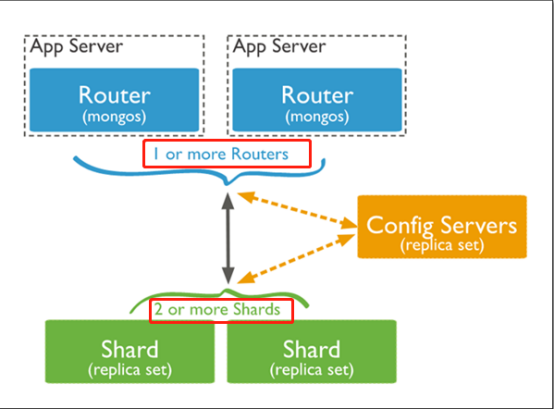
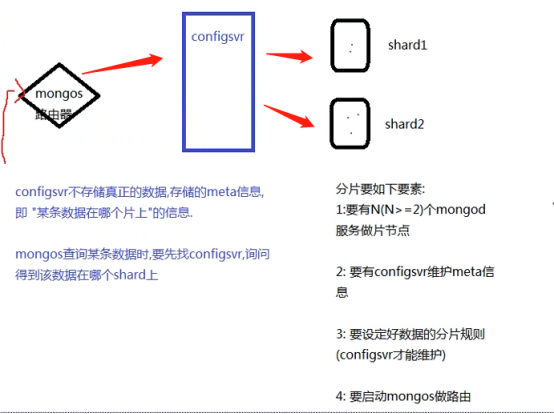
分片集群的构造
-
(1)mongos :数据路由,和客户端打交道的模块。mongos本身没有任何数据,他也不知道该怎么处理这数据,去找config server
-
(2)config server:所有存、取数据的方式,所有shard节点的信息,分片功能的一些配置信息。可以理解为真实数据的元数据。
-
(3)shard:真正的数据存储位置,以chunk为单位存数据。
Mongos本身并不持久化数据,Sharded cluster所有的元数据都会存储到Config Server,而用户的数据会议分散存储到各个shard。Mongos启动后,会从配置服务器加载元数据,开始提供服务,将用户的请求正确路由到对应的碎片。
Mongos的路由功能
当数据写入时,MongoDB Cluster根据分片键设计写入数据。
当外部语句发起数据查询时,MongoDB根据数据分布自动路由至指定节点返回数据。
集群中数据分布(chunk)
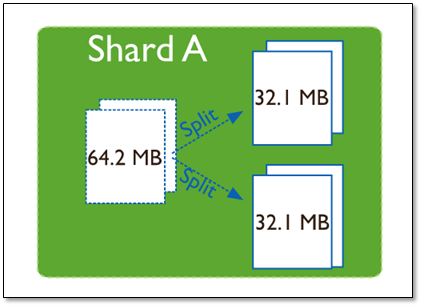
Chunk是什么
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部分数据。chunk的产生,会有以下两个用途:
Splitting:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况
Balancing:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。ongoDB会自动拆分和迁移chunks。
分片集群的数据分布(shard节点)
(1)使用chunk来存储数据
(2)进群搭建完成之后,默认开启一个chunk,大小是64M,
(3)存储需求超过64M,chunk会进行分裂,如果单位时间存储需求很大,设置更大的chunk
(4)chunk会被自动均衡迁移。
chunksize的选择
适合业务的chunksize是最好的。
chunk的分裂和迁移非常消耗IO资源;chunk分裂的时机:在插入和更新,读数据不会分裂。
chunksize的选择:小的chunksize:数据均衡是迁移速度快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。大的chunksize:数据分裂少。数据块移动集中消耗IO资源。通常100-200M
chunk分裂及迁移
随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。
这时候,各个shard 上的chunk数量就会不平衡。这时候,mongos中的一个组件balancer 就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点。
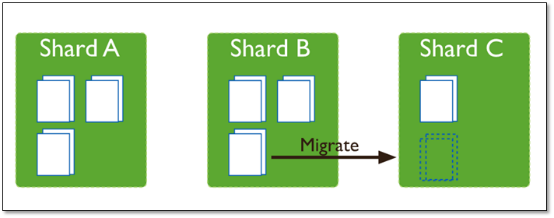
chunkSize 对分裂及迁移的影响
MongoDB 默认的 chunkSize 为64MB,如无特殊需求,建议保持默认值;chunkSize 会直接影响到 chunk 分裂、迁移的行为。
chunkSize 越小,chunk 分裂及迁移越多,数据分布越均衡;反之,chunkSize 越大,chunk 分裂及迁移会更少,但可能导致数据分布不均。
chunkSize 太小,容易出现 jumbo chunk(即shardKey 的某个取值出现频率很高,这些文档只能放到一个 chunk 里,无法再分裂)而无法迁移;chunkSize 越大,则可能出现 chunk 内文档数太多(chunk 内文档数不能超过 250000 )而无法迁移。
chunk 自动分裂只会在数据写入时触发,所以如果将 chunkSize 改小,系统需要一定的时间来将 chunk 分裂到指定的大小。
chunk 只会分裂,不会合并,所以即使将 chunkSize 改大,现有的 chunk 数量不会减少,但 chunk 大小会随着写入不断增长,直到达到目标大小。
分片键shard key
MongoDB中数据的分片是、以集合为基本单位的,集合中的数据通过片键(Shard key)被分成多部分。其实片键就是在集合中选一个键,用该键的值作为数据拆分的依据。
所以一个好的片键对分片至关重要。片键必须是一个索引,通过sh.shardCollection加会自动创建索引(前提是此集合不存在的情况下)。一个自增的片键对写入和数据均匀分布就不是很好,因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。
随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos会对结果进行归并排序。
对集合进行分片时,你需要选择一个片键,片键是每条记录都必须包含的,且建立了索引的单个字段或复合字段,MongoDB按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。
为了按照片键划分数据块,MongoDB使用基于范围的分片方式或者 基于哈希的分片方式。
注意:
分片键是不可变。
分片键必须有索引。
分片键大小限制512bytes。
分片键用于路由查询。
MongoDB不接受已进行collection级分片的collection上插入无分片
键的文档(也不支持空值插入)
部署分片集群
shard分片主机:(shard主机可以有多台,我这里就用了2台shard1、shard2)
shard1: IP:192.168.12.162
shard2: IP:192.168.12.170
shard2: IP:192.168.1.5
#三台主机分别启动三个mongod实例:
mongod1: 端口: 27017
mongod2: 端口: 27018
mongod2: 端口: 27019
configsrv主机:
IP:192.168.12.65
mongod1: 端口: 27019
mongod2: 端口: 37018
mongod2: 端口: 47019
Route主机:
192.168.12.192
mongods: 端口: 27017
在所有节点安装mongodb-4并创建相关文件夹
cat << EOF > /etc/yum.repos.d/mongodb.repo
[mongodb-org-4.0]
name=MongoDB 4.0 Repository
baseurl=https://mirrors.aliyun.com/mongodb/yum/redhat/\$releasever/mongodb-org/4.0/\$basearch/
gpgcheck=0
enabled=1
EOF
yum install -y mongodb-org #安装MongoDB
mkdir -p /var/log/mongodb/ #如果是yum安装,就不需要创建该目录
mkdir -p /var/run/mongodb
mkdir -p /data/mongod{1..3}
mkdir -p /etc/mongo
mkdir -p /tmp/mongod{1..3}
groupadd -r mongod #如果是yum安装,就不需要创建该目录
useradd -g mongod -r -M -s /sbin/nologin mongod #如果是yum安装,就不需要创建该目录
chown -R mongod.mongod /data
chown -R mongod.mongod /var/run/mongodb
chown -R mongod.mongod /tmp/mongod{1..3}
生成key并复制至所有主机
#在192.168.12.65主机执行
openssl rand -base64 756 > /etc/mongo/mongo.key
chown -R mongod.mongod /etc/mongo
chmod -R 600 /etc/mongo
scp -r /etc/mongo 192.168.12.162:/etc/mongo.key
scp -r /etc/mongo 192.168.12.192:/etc/mongo.key
scp -r /etc/mongo 192.168.12.170:/etc/mongo.key
scp -r /etc/mongo 192.168.1.5:/etc/
配置configsvr
在configsvr主机(IP:192.168.12.65)操作
生成三个configsvr的配置文件:
#configsvr1的配置文件
cat << EOF > /etc/mongo/configsvc1.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod1.log
storage:
dbPath: /data/mongod1
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod1.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27019
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod1
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: BigBoss
sharding:
clusterRole: configsvr
EOF
#configsvr2的配置文件
cat << EOF > /etc/mongo/configsvc2.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod2.log
storage:
dbPath: /data/mongod2
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod2.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 37019
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod2
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: BigBoss
sharding:
clusterRole: configsvr
EOF
#configsvr3的配置文件
cat << EOF > /etc/mongo/configsvc3.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod3.log
storage:
dbPath: /data/mongod3
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod3.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 47019
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod3
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: BigBoss
sharding:
clusterRole: configsvr
EOF
启动mongod:
mongod -f /etc/mongo/configsvc1.conf
mongod -f /etc/mongo/configsvc2.conf
mongod -f /etc/mongo/configsvc3.conf
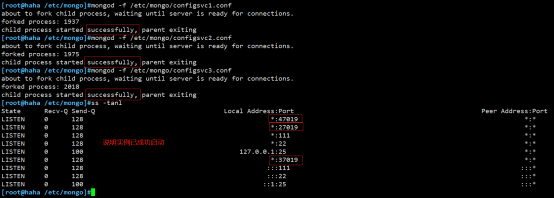
初始化configsrv副本集群:
#登录MongoDB
mongo --port 27019
#进行初始化操作
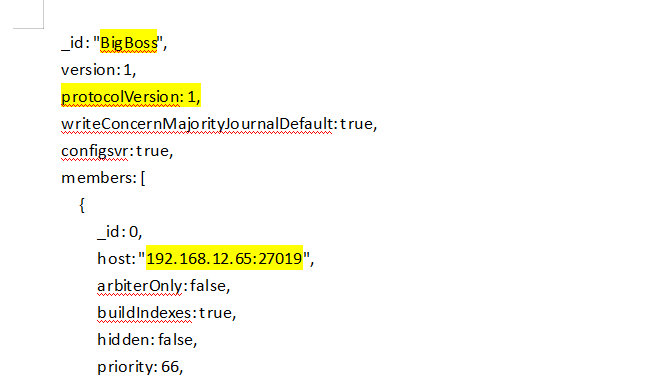
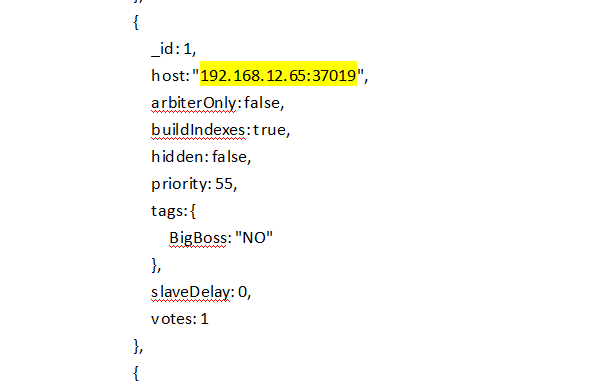
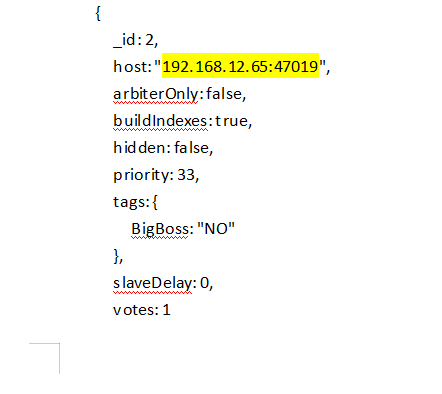
rs.initiate(
{
_id: "BigBoss",
version: 1,
protocolVersion: 1,
writeConcernMajorityJournalDefault: true,
configsvr: true,
members: [
{
_id: 0,
host: "192.168.12.65:27019",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 66,
tags: {
BigBoss: "YES"
},
slaveDelay: 0,
votes: 1
},
{
_id: 1,
host: "192.168.12.65:37019",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 55,
tags: {
BigBoss: "NO"
},
slaveDelay: 0,
votes: 1
},
{
_id: 2,
host: "192.168.12.65:47019",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 33,
tags: {
BigBoss: "NO"
},
slaveDelay: 0,
votes: 1
}
],
settings: {
chainingAllowed : true,
}
}
)
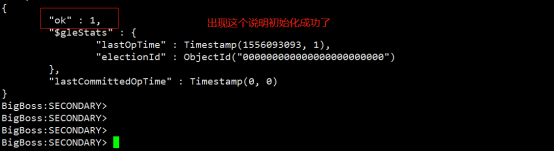
#在查看副本集状态
rs.status()
配置shard1副本集:
在shard1主机(IP:192.168.12.162)操作
生成三个mongod的配置文件:
#mongod1.conf配置文件:
cat << EOF > /etc/mongo/mongod1.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod1.log
storage:
dbPath: /data/mongod1
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod1.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27017
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod1
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: shard1
sharding:
clusterRole: shardsvr
EOF
#mongod2.conf配置文件:
cat << EOF > /etc/mongo/mongod2.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod2.log
storage:
dbPath: /data/mongod2
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod2.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27018
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod2
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: shard1
sharding:
clusterRole: shardsvr
EOF
#mongod3.conf配置文件:
cat << EOF > /etc/mongo/mongod3.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod3.log
storage:
dbPath: /data/mongod3
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod3.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27019
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod3
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: shard1
sharding:
clusterRole: shardsvr
EOF
启动mongod:
mongod -f /etc/mongo/mongod1.conf
mongod -f /etc/mongo/mongod2.conf
mongod -f /etc/mongo/mongod3.conf
初始化shard1副本集
rs.initiate(
{
_id: "shard1",
version: 1,
protocolVersion: 1,
writeConcernMajorityJournalDefault: true,
members: [
{
_id: 0,
host: "192.168.12.162:27017",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 66,
tags: {
BigBoss: "YES"
},
slaveDelay: 0,
votes: 1
},
{
_id: 1,
host: "192.168.12.162:27018",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 55,
tags: {
BigBoss: "NO"
},
slaveDelay: 0,
votes: 1
},
{
_id: 2,
host: "192.168.12.162:27019",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 33,
tags: {
BigBoss: "NO"
},
slaveDelay: 0,
votes: 1
}
],
settings: {
chainingAllowed : true,
}
}
)
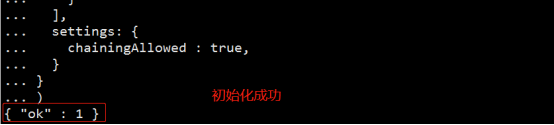
#查看副本集状态
rs.status()
配置shard2副本集
在shard2主机(IP:192.168.12.170)操作
生成三个mongod的配置文件:
#mongod1.conf配置文件:
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod1.log
storage:
dbPath: /data/mongod1
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod1.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27017
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod1
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: shard2
sharding:
clusterRole: shardsvr
EOF
cat << EOF > /etc/mongo/mongod2.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod2.log
storage:
dbPath: /data/mongod2
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod2.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27018
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod2
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: shard2
sharding:
clusterRole: shardsvr
EOF
#mongod3.conf配置文件:
cat << EOF > /etc/mongo/mongod3.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod3.log
storage:
dbPath: /data/mongod3
journal:
enabled: true
wiredTiger:
engineConfig:
directoryForIndexes: true
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod3.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27019
#bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp/mongod3
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
authorization: enabled
replication:
replSetName: shard2
sharding:
clusterRole: shardsvr
EOF
启动mongod:
mongod -f /etc/mongo/mongod1.conf
mongod -f /etc/mongo/mongod2.conf
mongod -f /etc/mongo/mongod3.conf
初始化shard2副本集
rs.initiate(
{
_id: "shard2",
version: 1,
protocolVersion: 1,
writeConcernMajorityJournalDefault: true,
members: [
{
_id: 0,
host: "192.168.12.170:27017",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 66,
tags: {
BigBoss: "YES"
},
slaveDelay: 0,
votes: 1
},
{
_id: 1,
host: "192.168.12.170:27018",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 55,
tags: {
BigBoss: "NO"
},
slaveDelay: 0,
votes: 1
},
{
_id: 2,
host: "192.168.12.170:27019",
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 33,
tags: {
BigBoss: "NO"
},
slaveDelay: 0,
votes: 1
}
],
settings: {
chainingAllowed : true,
}
}
)
#查看shard2副本集状态
rs.status()
配置Route
创建mongos配置文件:
#route是无状态的,在任何一台主机启动都行,只要能够连接至configsrv即可
cat << EOF > /etc/mongo/route.conf
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod.log
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
bindIpAll: true
maxIncomingConnections: 500
unixDomainSocket:
enabled: true
pathPrefix: /tmp
filePermissions: 0700
security:
keyFile: /etc/mongo/mongo.key
# authorization: enabled
#replication:
sharding:
configDB: BigBoss/192.168.12.65:27019,192.168.12.65:37019,192.168.12.65:47019
EOF

启动mongos并设置一个连接的账号密码
#启动
mongos -f /etc/mongo/route.conf
#连接
mongo
#设置管理员账号密码
use admin
db.createUser(
{
user: "root",
pwd: "666666",
roles: [ { role: "__system", db: "admin" } ]
}
)
exit
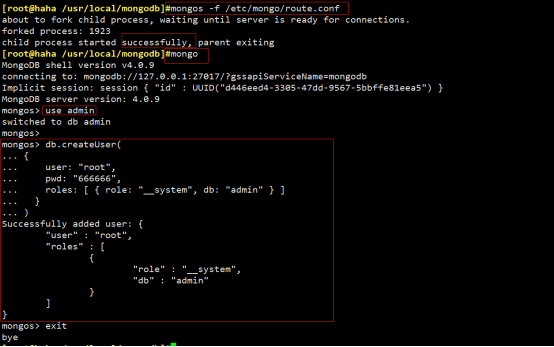
重连至mongodb
mongo -uroot -p666666 --authenticationDatabase admin

添加分片主机至集群中
sh.addShard("shard1/192.168.12.162:27017,192.168.12.162:27018,192.168.12.162:27019")

sh.addShard("shard2/192.168.12.170:27017,192.168.12.170:27018,192.168.12.170:27019")
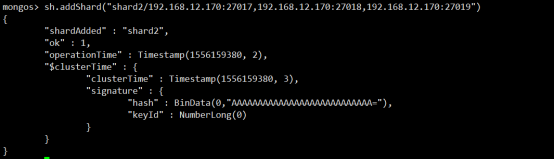
#查看状态
sh.status()
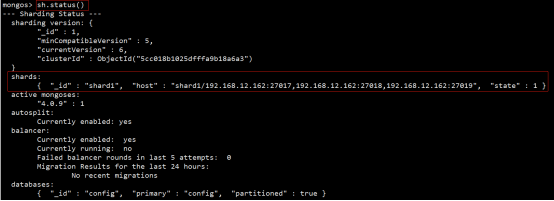
##为了展示出效果,修改一下默认的chunksize大小,这里修改为1M
#默认的chunksize大小为64M,示例修改命令如下:
#use config
#db.settings.save( { _id:"chunksize", value: <sizeInMB> } )
use config
db.settings.save( { _id:"chunksize", value: 1 } )
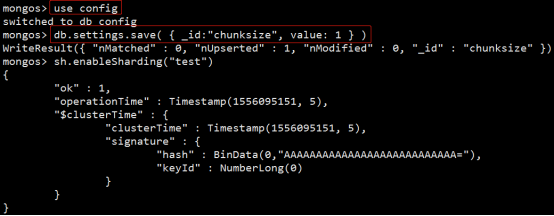
#为test数据库开启分片
#选择一个片键”age”并指定一个集合mycoll对其进行分片
mongs>sh.enableSharding("test")
mongs>sh.shardCollection("test.mycoll", {"age": 1})
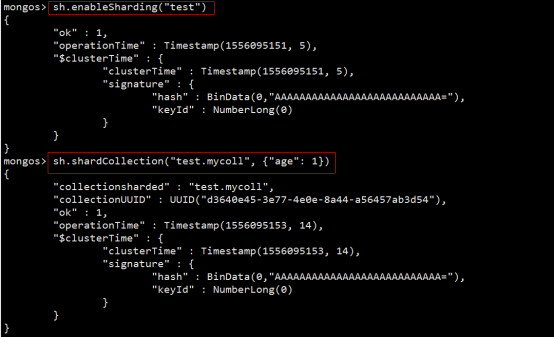
#测试分片,写入数据到数据库中
use test
for (i = 1; i <= 10000; i++) db.mycoll.insert({age:(i%100), name:"bigboss_user"+i, address:i+", Some Road, Zhengzhou, Henan", country:"China", course:"cousre"+"(i%12)"})

#写入完成之后就可以查看分片信息了
sh.status()
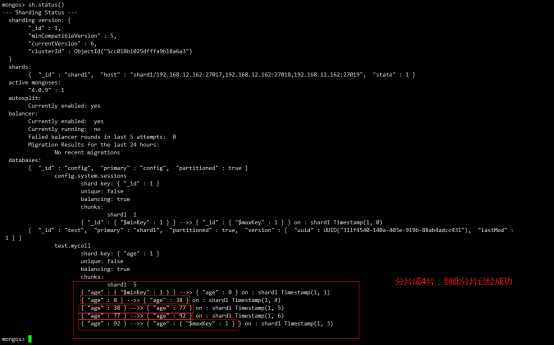

增加了两个shard后,查看状态:
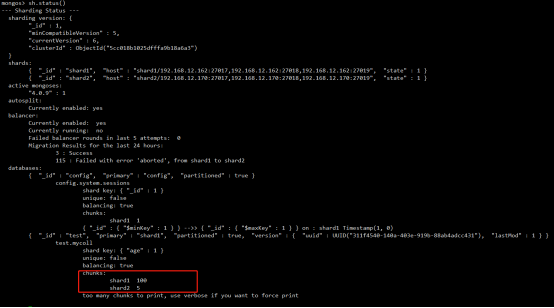
# 查看balancer的状态
sh.getBalancerState()
# 停止分片
sh.stopBalancer()
# 开始分片
sh.startBalancer()
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。