- redis缓存(6379)
- 缓存知识概况
- 分享->图片域名使用
- redis快速入门
- redis的特性
- redis的应用场景
- redis的安装(3种)
- Redis TLS支持
- redis的常用配置
- redis配置文件详解
- redis的启动(3种)
- redis停止
- systemctl管理redis
- 卸载redis
- redis配置认证密码
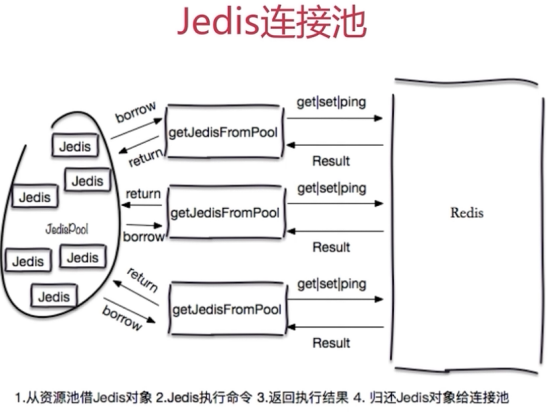
- redis的客户端使用(客户端很多,你可以自己选择)
- redis的常用命令
- 迁移redis数据
- redis的单线程
- redis数据结构
- redis事务
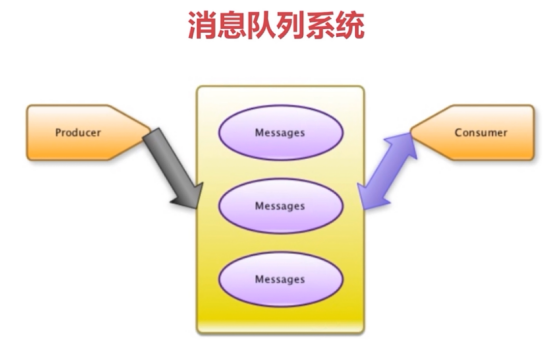
- 瑞士军刀redis
- redis 持久化
- RDB AOF混合方式进行持久化
- 持久化中开发运维问题
- redis 主从
- 主从中开发与运维中的问题
- 高可用->keepalived
- redis sentinel架构(哨兵模式->之高可用)sentinel节点数必须是三个以上(3、5、7),且最好是基数个
- sentinel架构中的开发与运维中的问题
- redis集群
- redis cluster
- redis 安全
redis缓存(6379)
缓存知识概况
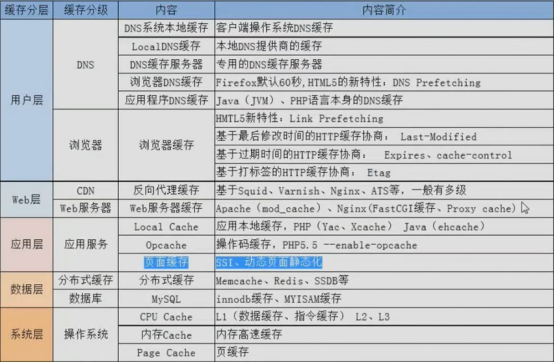

Redis和Memcached对比
| Redis/Memcached | Memcached | Redis |
|---|---|---|
| 类型 | Key-value | Key-value |
| 过期策略 | 支持 | 支持 |
| 数据类型 | 单一数据类型 | 多种数据类型 |
| 持久化 | 不支持 | 支持 |
| 主从复制 | 不支持 | 支持 |
| 虚拟化 | 不支持 | 支持(建议不使用,启用) |
分享->图片域名使用
问: 为什么要把图片放在单独的域名,这样做有什么好处?
答: 提高了速度,减少了带宽。
-
可以做组件分离(为不同资源配备不同存储和web访问,比如动静分离)。
-
如果条件运行,直接上CDN。
-
加快页面打开速度,提供浏览器并发。浏览器请求并发数是基于域名的。
-
Jd.com pic.jd.com www.jdpic.com有区别码?
1).动态请求写入的cookie,浏览器每次请求本域名下的其他资源,都会附带上Cookie.
2).如果我们使用pic.jd.com的时候,访问图片也是需要附带cookie的。
3).如果你想把静态资源单独存放,一定要使用另外的顶级域名。
如何设计一个电商购物车?
1.需求是什么? 用户把产品放入购物车,用户下次访问时,没有结算的商品还在,需要记录下来。
2.记录在哪里? 用户不登陆,购物车里的内容放在Cookie 用户登陆后,购物车里的内容放在Redis uid_xxx value内容,过期时间。
Memcached:
-
数据库读缓存
-
Session
负载均衡:sessionc处理有几种方式?
-
会话(session)保持:ip_hash
-
会话(session)复制:Tomcat Cluster复制
-
会话(session)共享:memcached(1.语言支持多,2.简单、高效,3.所有开发都会php.ini配置session存储位置)
redis快速入门
Redis命令参考:http://redisdoc.com/string/incr.html
概述:Rdis是一个开源的,使用C语言编写的,支持网络交互的,可基于内存也可持久化的key-value数据库。
redis是什么:
1、开源
2、基于键值的存储服务系统
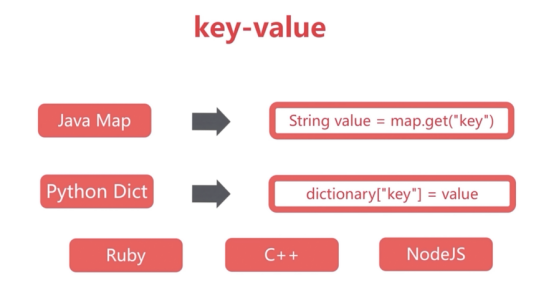
3、多种数据结构
4、高性能、功能丰富

redis的特性
1、速度快
为什么速度快?
解释:数据存储到内存中的


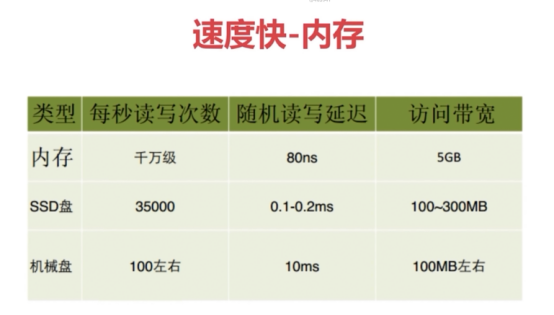
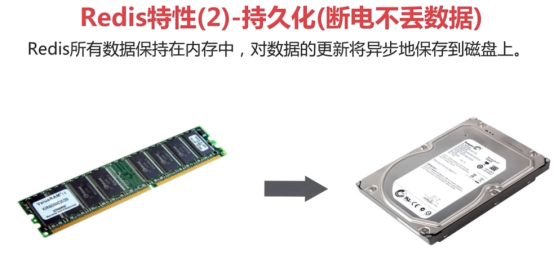
2、持久化(重点)
3、多种数据结构(重点)
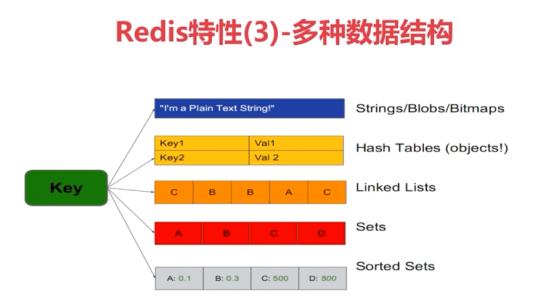

4、支持多种客户端语言

5、功能丰富

6、简单
1、源代码非常少
2、不依赖外部库(like libevent)
3、单线程
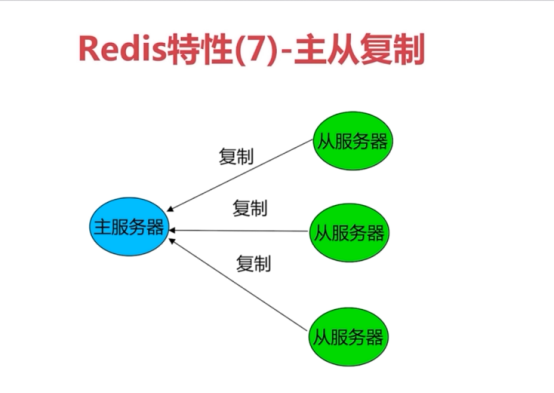
7、支持主从复制(重点)
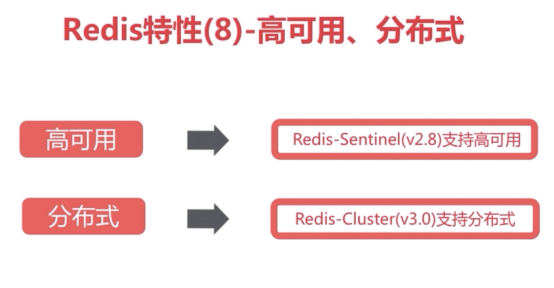
8、高可用、分布式重点)
redis的应用场景



邮件垃圾处理器、过滤器等就属于实时系统
redis的安装(3种)
源码安装
官网下载地址:
http://download.redis.io/releases/
官方安装:https://redis.io/download#installation
Windows下载地址(不在维护了):
https://github.com/MSOpenTech/redis
#源码编译所需的工具包:
yum install gcc gcc-c++ automake autoconf make libtool -y
#下载redis的源码:
Download, extract and compile Redis with:
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
tar xzf redis-5.0.7.tar.gz
ln -sv redis-5.0.7 redis
cd redis
#编译(编译后在Redis源代码目录的src文件夹中可以找到若干可执行程序,我们可以在编译后直接执行make install 命令将这些可执行程序复制到/usr/local/bin/目录中,以便以后执行时可以不用输入完整的路径。)
make
#从版本6开始,构建时添加BUILD_TLS=yes参数,开启tls.
# make BUILD_TLS=yes
#安装(make PREFIX=/usr/local/redis install #(安装到指定目录)):
make install
# 删除以前生成的构建文件
# make distclean
The binaries that are now compiled are available in the src directory. Run Redis with:
$ src/redis-server #这是前台启动的
You can interact with Redis using the built-in client:
$ src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
报错:
In file included from adlist.c:34:0:
zmalloc.h:50:31: fatal error: jemalloc/jemalloc.h: No such file or directory
#include <jemalloc/jemalloc.h>
^
compilation terminated.
make[1]: *** [adlist.o] Error 1
make[1]: Leaving directory `/usr/local/redis/src'
make: *** [all] Error 2
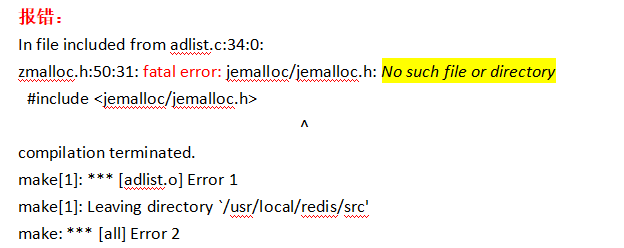
解决方案1:有些解决方法为:make MALLOC=libc,据网友说不太好,原因是make MALLOC=jemalloc就是指定内存分配器为 jemalloc ,make MALLOC=libc就是指定内存分配器为 libc ,这个是有安全隐患的,jemalloc 内存分配器在实践中处理内存碎片是要比libc 好的,而且在README.md 文档也说明到,jemalloc 内存分配器也是包含在源码包里面的,可以在 deps 目录下看到 jemalloc 目录。
# make MALLOC=libc
# cd src && make all
解决方案2:错误的本质原因是因为上次的执行make编译失败(大部分就是没有安装gcc),有残留的文件,然后我们安装好gcc在执行make就会报jemalloc/jemalloc.h: No such file or directory。因此我们需要清理下,然后重新编译就可以了。
make distclean && make
redis可执行文件说明:
redis-server->redis服务器
redis-cli->redis命令行客户端
redis-benchmark->redis性能测试工具
redis-check-aof->AOF文件检查工具
redis-check-dump->RDB文件检查工具
redis-sentinel->Sentinel服务器(2.8以后支持)
yum安装
在epel源里有redis软件包:
# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
安装redis:
yum install redis -y
查看装了什么:
rpm -ql redis
修改/etc/redis.conf:
bind=10.0.0.42 #绑定ip
启动redis:
[root@Redis yum.repos.d]# /etc/init.d/redis start
Starting redis-server: [ OK ]
[root@Redis yum.repos.d]# netstat -nutlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 10.0.0.42:6379 0.0.0.0:* LISTEN 1509/redis-server 1
登陆redis报错,因其默认登陆127.0.0.1
[root@Redis yum.repos.d]# redis-cli
Could not connect to Redis at 127.0.0.1:6379: Connection refused
Could not connect to Redis at 127.0.0.1:6379: Connection refused
使用-h参数接IP地址:
[root@Redis yum.repos.d]# redis-cli -h 10.0.0.42
10.0.0.42:6379>
rpm安装
省略
docker安装
#最简单参数的启动redis
docker run -itd \
--name redis \
--network host \
--restart always \
-v /data/redis:/data \
redis:6 \
--requirepass "123654" \
--masterauth "123654" \
--notify-keyspace-events "Ex" \
--appendonly yes \
--protected-mode no
或者使用配置文件启动,前提是准备好配置文件
cat > /opt/redis.conf << EOF
#是否是守护进程(no|yes),docker部署的时候这里改为no,非docker部署改为yes
daemonize no
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6379
#redis系统日志,这里不写入文件,可以用docker logs 查看日志
#logfile "/data/redis_6379.log"
#redis工作目录
dir "/data"
# aof持久化
appendonly yes
# rdb
dbfilename dump.rdb
protected-mode no
bind 0.0.0.0
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth 123654
#这是redis设置的密码
requirepass 123654
EOF
docker run -itd --network=host --name redis -v /opt/redis.conf:/opt/redis.conf -v /data/redis:/data redis redis-server /opt/redis.conf
docker-compose
# cat docker-compose.yml
version: "3.9"
services:
redis:
container_name: redis
image: redis:6
labels:
release: "6"
restart: always
network_mode: "host"
hostname: redis-server
privileged: true
user: root
volumes:
- /data/docker-compose-data/redis/:/data
- /etc/localtime:/etc/localtime
command: #多个命令同时执行
- /bin/bash
- -c
- |
echo 551 > /proc/sys/net/core/somaxconn #关键命令
echo 1 > /proc/sys/vm/overcommit_memory
echo never > /sys/kernel/mm/transparent_hugepage/enabled
redis-server --requirepass "123654" --notify-keyspace-events "Ex" --appendonly yes --protected-mode no
Redis TLS支持
https://zhuanlan.zhihu.com/p/637542332
从版本6开始,Redis支持SSL/TLS,这是一项需要在编译时启用的可选功能
绑定
要使用TLS支持构建,您需要OpenSSL开发库(例如Debian/Ubuntu上的libssl-dev)。
使用以下命令构建Redis:
make BUILD_TLS=yes
测试
要使用TLS运行Redis测试套件,您需要TLS支持TCL(即Debian/Ubuntu上的tcl-tls软件包)。
1.运行./utils/gen-test-certs.sh以生成根CA和服务器证书。
2.运行./runtest --tls或./runtest-cluster --tls,在TLS模式下运行Redis和Redis集群测试。
手动运行
以TLS模式手动运行Redis服务器(假设调用了gen-test-certs.sh,因此示例证书/密钥是可用的):
./src/redis-server --tls-port 6379 --port 0 \
--tls-cert-file ./tests/tls/redis.crt \
--tls-key-file ./tests/tls/redis.key \
--tls-ca-cert-file ./tests/tls/ca.crt
使用redis-cli连接到此Redis服务器:
./src/redis-cli --tls \
--cert ./tests/tls/redis.crt \
--key ./tests/tls/redis.key \
--cacert ./tests/tls/ca.crt
证书配置
为了支持TLS,Redis必须配置X.509证书和私钥。此外,在验证证书时,需要指定用作受信任根的CA证书捆绑文件或路径。为了支持基于DH的密码,还可以配置DH参数文件。例如:
tls-cert-file /path/to/redis.crt
tls-key-file /path/to/redis.key
tls-ca-cert-file /path/to/ca.crt
tls-dh-params-file /path/to/redis.dh
TLS监听端口
TLS -port配置指令允许在指定的端口上接受SSL/TLS连接。这是除监听TCP连接端口之外的端口,所以可以同时使用TLS和非TLS连接访问不同端口上的Redis。
您可以指定端口0来完全禁用非TLS端口。要在默认的Redis端口上仅启用TLS,请使用:
port 0
tls-port 6379
客户端证书认证
默认情况下,Redis使用双向TLS,并要求客户端使用有效的证书进行身份验证(针对ca-cert-file或ca-cert-dir指定的可信根CA进行身份验证)。
您可以使用tls-auth-clients no来禁用客户端身份验证。
复制
Redis主服务器以相同的方式处理连接客户端和副本服务器,因此上述tls-port和tls-auth-clients指令也适用于复制链接。
在副本服务器端,需要指定tls-replication yes才能使用TLS与主服务器的传出连接。
集群
使用Redis集群时,使用tls-cluster yes为集群总线和跨节点连接启用TLS。
哨兵
哨兵从常见的Redis配置继承了其网络配置,因此上述所有内容也适用于哨兵。
当连接到主时,哨兵将使用tls-replication指令来确定是否需要TLS或非TLS连接。
此外,相同的tls-replication指令将决定接受来自其他哨兵的连接的哨兵端口是否也支持TLS。也就是说,当且仅当启用tls-replication时,将使用tls-port配置哨兵。
附加配置
额外的TLS配置可用于控制TLS协议版本、密码和密码套件等的选择。有关更多信息,请参阅自我记录的redis.conf。
性能考虑
TLS在通信堆栈上增加了一层,由于向SSL连接写入/读取、加密/解密和完整性检查而增加了开销。因此,使用TLS会导致每个Redis实例可达到的吞吐量降低。
限制
TLS目前不支持I/O线程。
redis的常用配置
#是否是守护进程(no|yes)
daemonize no
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6379
#redis系统日志
logfile "/var/log/redis/redis_6379.log"
#redis工作目录
dir "/opt/redis/data"
# aof持久化
appendonly yes
# rdb
dbfilename dump.rdb
protected-mode no
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth 123654
#这是redis设置的密码
requirepass 123654
mkdir /var/log/redis/ -p
mkdir /opt/redis/data/ -p
ps:只需要这些都可以启动redis
redis配置文件详解
# 1k => 1000 bytes #当你需要为某个配置制定内存大小的时候,必须要带上单位,单位不区分大小写。
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
daemonize no
#默认情况下redis不是后台运行,如果要后台守护进程方式运行的话,这里改为yes
pidfile /var/run/redis.pid
#当redis作为守护进程运行的时候,pid的写入文件位置。
port 6379
#监听端口号,默认就是6379,如果你设为0,redis将不再socket上监听任何客户端链接。
bind 127.0.0.1
#默认情况下,redis是监听在0.0.0.0上面的,但是这样是危险的,漏洞已经爆出来了,所以要改为本地或者内网IP。
# unixsocket /tmp/redis.sock
# unixsocketperm 755
#如果不监听端口的话,redis还支持通过unix socket方式来接收请求。可以通过unixsocket配置项来指定unix socket文件的路径,并通过unixsocketperm来指定文件的权限。
timeout 300
#指定在一个client空闲多少秒之后关闭连接(0是不设置超时)
tcp-keepalive 0
#指定TCP连接是否为长连接,”侦探”信号由server端维护,长连接将会额外的增加server端的开支。默认为0.表示禁用,非0值表示开启”长连接” ;”侦探”信号的发送间隔将有Linux系统决定在多次”侦探”后,
如果对等端仍不回复,将会关闭连接,否则连接将会被保持开启.client端socket也可以通过配置keepalive选项,开启”长连接”.
loglevel notice
#server日志级别,合法值:debug,verbose,notice,warning 默认为notice
logfile "/usr/local/redis/conf/log/redis-6379.log"
#指定redis日志记录方式,默认值为stdout也就是输出到屏幕
databases 16
#设定redis所允许的最大db数据库的个数,默认为16个个.redis不像mysql一样可以自定义数据库,如这里只支持0-15的索引号形式的数据库,你可以将数据写入到不同的db索引号中。
#快照设置(主要涉及的是redis的RDB持久化相关的配置,让数据保存到磁盘上,即控制RDB快照功能):
save 900 1
save 300 10
save 60 10000
#用来描述在多少秒期间至少多少个变更操作触发快照。例如:save 900 1 就是在900秒期间有一个key发生了变更操作就触发快照。save ""可以关闭RDB持久化功能。
stop-writes-on-bgsave-error yes
#默认情况下,如果redis最后一次的后台保存失败,redis 将停止接受写操作,这样以一种强硬的方式让用户知道数据不能正确的持久化到磁盘,否则就会没人注意到灾难的发生。
#如果后台保存进程重新启动工作了,redis 也将自动的允许写操作。然而你要是安装了靠谱的监控,你可能不希望 redis这样做,那你就改成no好了。
rdbcompression yes
#是否启用rdb文件压缩手段,默认为yes.压缩可能需要额外的cpu开支,不过这能够有效的减小rdb文件的大小,有利于存储/备份/传输/数据恢复.
rdbchecksum yes
#是否对rdb文件使用CRC64校验和,默认为”yes”,那么每个rdb文件内容的末尾都会追加CRC校验和.对于其他第三方校验工具,可以很方便的检测文件的完整性
dbfilename dump.rdb
#指定rdb文件的名称
dir ./ #数据库镜像备份的文件放置路径
#指定rdb/AOF文件的目录位置,只能为文件夹不能为文件
#重点是 dir 的默认配置一定要改,改成确定路径,这样就不会存在每次启动服务时所在的目录不一样导致dump文件找不到的问题


主从复制设置:

#slaveof <masterip> <masterport>
#主从复制。指定master的ip和端口号。注意这个只需要在 slave 上配置。让一个redis实例成为另一个redis的副本。
#masterauth <master-password>
#如果master需要密码认证,就在这里设置
slave-serve-stale-data yes
#当一个 slave 与 master 失去联系,或者复制正在进行的时候,slave 可能会有两种表现:
1) 如果为yes,slave仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候
2)如果为 no ,在你执行除了 info he salveof 之外的其他命令时,slave 都将返回一个 "SYNC with master in progress" 的错误。
slave-read-only yes
#从redis2.6版起,默认slaves都是只读的。注意:只读的slaves没有被设计成在internet上暴露给不受信任的客户端。它仅仅是一个针对误用实例的一个保护层。
repl-ping-slave-period 10
#slaves在一个预定义的时间间隔内发送ping命令到server。你可以改变这个时间间隔。默认为10秒。
#repl-timeout 60
#设置主从复制超时时间,这个值一定要比repl-ping-slave-period大
repl-disable-tcp-nodelay no
#我们可以控制在主从同步时是否禁用TCP_NODELAY。如果开启TCP_NODELAY,那么主redis会使用更少的TCP包和更少的带宽来向从redis传输数据。
#但是这可能会增加一些同步的延迟,大概会达到40毫秒左右。如果你关闭了TCP_NODELAY,那么数据同步的延迟时间会降低,但是会消耗更多的带宽。
#repl-backlog-size 1mb
#设置主从复制容量大小。这个backlog是一个用来在slaves被断开连接时存放slave数据的buffer,所以当一个slave想要重新连接,通常不希望全部重新同步,
只是部分同步就够了,仅仅传递slave在断开连接时丢失的这部分数据。
#repl-backlog-ttl 3600
#如果主redis等了一段时间之后,还是无法连接到从redis,那么缓冲队列中的数据将被清理掉。我们可以设置主redis要等待的时间长度。如果设置为0,则表示永远不清理。默认是1个小时。
slave-priority 100
#当master不能正常工作的时候,Redis Sentinel会从slaves中选出一个新的master,这个值越小,就越会被优先选中,但是如果是0,意味着这个slave不可能被选中。默认优先级为100。
# min-slaves-to-write 3
# min-slaves-max-lag 10
#假如有大于等于3个从redis的连接延迟大于10秒,那么主redis就不再接受外部的写请求。上述两个配置中有一个被置为0,则这个特性将被关闭。默认情况下min-slaves-to-write为0,而min-slaves-max-lag为10。
安全设置:
# masterauth "redis"
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
# requirepass foobared #这是redis设置的密码
#我们可以要求redis客户端在向redis-server发送请求之前,先进行密码验证。当你的redis-server处于一个不太可信的网络环境中时,相信你会用上这个功能。
由于redis性能非常高,所以每秒钟可以完成多达15万次的密码尝试,所以你最好设置一个足够复杂的密码,否则很容易被黑客破解。
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#这里我们通过requirepass将密码设置成“芝麻开门”。redis允许我们对redis指令进行更名,比如将一些比较危险的命令改个名字,避免被误执行。
#比如可以把CONFIG命令改成一个很复杂的名字,这样可以避免外部的调用,同时还可以满足内部调用的需要
#rename-command CONFIG ""
#可以禁用掉CONFIG命令,那就是把CONFIG的名字改成一个空字符串:,但需要注意的是,如果你使用AOF方式进行数据持久化,或者需要与从redis进行通信,那么更改指令的名字可能会引起一些问题。
限制设置:
# maxclients 10000
#我们可以设置redis同时可以与多少个客户端进行连接。默认情况下为10000个客户端。当你无法设置进程文件句柄限制时,redis会设置为当前的文件句柄限制值减去32,因为redis会为自身内部处理逻辑留一些句柄出来。
如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。
# maxmemory <bytes>
#如果redis无法根据移除规则来移除内存中的数据,或者我们设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
但是对于无内存申请的指令,仍然会正常响应,比如GET等。需要注意的一点是,如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。对于内存移除规则来说,redis提供了多达8种的移除规则。他们是:volatile-lru:使用LRU算法移除过期集合中的key、allkeys-lru:使用LRU算法移除key、volatile-random:在过期集合中移除随机的key、allkeys-random:移除随机的key、volatile-ttl:移除那些TTL值最小的key,即那些最近才过期的key、noeviction:不进行移除。针对写操作,只是返回错误信息。
# maxmemory-policy volatile-lru
# 默认是volatile-lru算法,无论使用上述哪一种移除规则,如果没有合适的key可以移除的话,redis都会针对写请求返回错误信息。LRU算法和最小TTL算法都并非是精确的算法,而是估算值。所以你可以设置样本的大小。
# maxmemory-samples 3
#假如redis默认会检查三个key并选择其中LRU的那个,那么你可以改变这个key样本的数量。

追加模式设置(aof的设置):
appendonly yes
#默认情况下,redis会异步的将数据持久化到磁盘。这种模式在大部分应用程序中已被验证是很有效的,但是在一些问题发生时,比如断电,则这种机制可能会导致数分钟的写请求丢失。
#追加文件(Append Only File)是一种更好的保持数据一致性的方式。即使当服务器断电时,也仅会有1秒钟的写请求丢失,当redis进程出现问题且操作系统运行正常时,甚至只会丢失一条写请求。所以AOF机制和RDB机制可以同时使用,不会有任何冲突。
# appendfilename appendonly.aof
#设置aof文件的名称
# appendfsync always
appendfsync everysec
# appendfsync no
#fsync()调用,用来告诉操作系统立即将缓存的指令写入磁盘。一些操作系统会“立即”进行,而另外一些操作系统则会“尽快”进行。
redis支持三种不同的模式:
no:不调用fsync()。而是让操作系统自行决定sync的时间。这种模式下,redis的性能会最快。
always:在每次写请求后都调用fsync()。这种模式下,redis会相对较慢,但数据最安全。
everysec:每秒钟调用一次fsync()。这是性能和安全的折衷。
当fsync方式设置为always或everysec时,如果后台持久化进程需要执行一个很大的磁盘IO操作,那么redis可能会在fsync()调用时卡住。
#目前尚未修复这个问题,这是因为即使我们在另一个新的线程中去执行fsync(),也会阻塞住同步写调用。
no-appendfsync-on-rewrite no
#为了缓解上面提到的问题,我们可以使用上面的配置项,这样的话,当BGSAVE或BGWRITEAOF运行时,fsync()在主进程中的调用会被阻止。这意味着当另一路进程正在对AOF文件进行重构时,redis的持久化功能就失效了,就好像我们设置了“appendsync none”一样。
#如果你的redis有时延问题,那么请将下面的选项设置为yes。否则请保持no,因为这是保证数据完整性的最安全的选择。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
#允许redis自动重写aof。当aof增长到一定规模时,redis会隐式调用BGREWRITEAOF来重写log文件,以缩减文件体积。redis是这样工作的:redis会记录上次重写时的aof大小。
假如redis自启动至今还没有进行过重写,那么启动时aof文件的大小会被作为基准值。这个基准值会和当前的aof大小进行比较。如果当前aof大小超出所设置的增长比例,则会触发重写。
#另外,你还需要设置一个最小大小,是为了防止在aof很小时就触发重写。如果设置auto-aof-rewrite-percentage为0,则会关闭此重写功能。
LUA脚本设置:
lua-time-limit 5000
#Lua脚本的最大执行时间(以毫秒为单位)。 如果达到最大执行时间,Redis将记录脚本在最大允许时间后仍然执行,并且将开始回复具有错误的查询。 当长时间运行的脚本超过最大执行时间时,只有SCRIPT KILL和SHUTDOWN NOSAVE命令可用。
#第一个可以用来停止一个还没有被称为写命令的脚本。 第二个是在脚本已经发出写入命令的情况下关闭服务器的唯一方法,但用户不想等待脚本的自然终止。 将其设置为0或负值,无限制执行而不发出警告。
SHOW log设置:
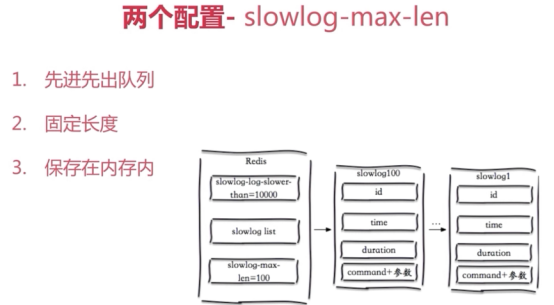
#Slow log 是 Redis 用来记录查询执行时间的日志系统。查询执行时间指的是不包括像客户端响应(talking)、发送回复等 IO 操作,而单单是执行一个查询命令所耗费的时间。另外,slow log 保存在内存里面,读写速度非常快,因此你可以放心地使用它,不必担心因为开启 slow log 而损害 Redis 的速度。
slowlog-log-slower-than 10000
#它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。这就就是记录查询大于10000微秒的记录。
slowlog-max-len 128
#slow log最多能保存多少条日志,slow log本身是一个 FIFO 队列,当队列大小超过 slowlog-max-len 时,最旧的一条日志将被删除,而最新的一条日志加入到 slow log ,以此类推。

http://doc.redisfans.com/topic/notification.html
高级配置:
#zipmap优化hash,Redis会在内部自动将zipmap替换成正常的hash实现.一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象。省内存的原因是新建一个hash对象时开始是用zipmap来存储的。
hash-max-ziplist-entries 512
#配置字段最多512个
hash-max-ziplist-value 64
#配置value最大为64字节
#ziplist优化list,如果redisObject的type成员值是REDIS_LIST类型的,则当该list的元素个数小于配置值list-max-ziplist-entries且元素值字符串的长度小于配置值list-max-ziplist-value则可以编码成 REDIS_ENCODING_ZIPLIST 类型存储,否则采用 Dict 来存储(Dict实际是Hash Table的一种实现),list采用ziplist数据结构存储数据,这样做一方面为了节省内存,另一方面这种结构式顺序存储的结构,能够更好利用cpu local和预取策略。
list-max-ziplist-entries 512
#配置元素个数最多512个
list-max-ziplist-value 64
#配置value字节最大为64个
activerehashing yes
#指定是否激活重置哈希,默认为开启。
对于Redis服务器的输出(也就是命令的返回值)来说,其大小通常是不可控制的。有可能一个简单的命令,能够产生体积庞大的返回数据。
另外也有可能因为执行了太多命令,导致产生返回数据的速率超过了往客户端发送的速率,这是也会导致服务器堆积大量消息,从而导致输出缓冲区越来越大,占用过多内存,甚至导致系统崩溃。
所幸,Redis设置了一些保护机制来避免这种情况的出现,不同类型的客户端有不同的限制参数。限制方式有如下两种:
(1)、大小限制,当某一个客户端的缓冲区超过某一个大小值时,直接关闭这个客户端的连接;
(2)、持续性限制,当某一个客户端的缓冲区持续一段时间占用过大空间时,会直接关闭客户端连接。
下面是关于客户端输出缓冲区的配置:
这些数值分别代表缓冲区软限制,硬限制和以秒为单位的超时(类似于复制缓冲区)。
client-output-buffer-limit normal 0 0 0
#对于普通客户端来说,限制为0,也就是不限制。因为普通客户端通常采用阻塞式的消息应答模式,何谓阻塞式呢?
如:发送请求,等待返回,再发送请求,再等待返回。这种模式下,通常不会导致Redis服务器输出缓冲区的堆积膨胀;
client-output-buffer-limit slave 256mb 64mb 60
#对于slave客户端来说,大小限制是256M,持续性限制是当客户端缓冲区大小持续60秒超过64M,则关闭客户端连接。
client-output-buffer-limit pubsub 32mb 8mb 60
#对于Pub/Sub客户端(也就是发布/订阅模式),大小限制是8M,当输出缓冲区超过8M时,会关闭连接。持续性限制是,当客户端缓冲区大小持续60秒超过2M,则关闭客户端连接;
hz 10
#Redis server执行后台任务的频率,默认为10,此值越大表示redis对"间歇性task"的执行次数越频繁(次数/秒)。"间歇性task"包括"过期集合"检测、关闭"空闲超时"的连接等,此值必须大于0且小于500。
#此值过小就意味着更多的cpu周期消耗,后台task被轮询的次数更频繁。此值过大意味着"内存敏感"性较差。建议采用默认值。
aof-rewrite-incremental-fsync yes
#当子进程重写AOF文件时,如果启用了以下选项,则每32MB数据生成一次文件才调用强制同步。这对于将文件更多地递增到磁盘并避免大的延迟尖峰是有用的。
tcp-backlog 511
#默认值 511 tcp-backlog:511 https://my.oschina.net/TOW/blog/684914
#此参数确定了TCP连接中已完成队列(完成三次握手之后)的长度, 当然此值必须不大于Linux系统定义的/proc/sys/net/core/somaxconn值,默认是511,而Linux的默认参数值是128。当系统并发量大并且客户端速度缓慢的时候,可以将这二个参数一起参考设定。
#建议修改为 2048
#修改somaxconn,该内核参数默认值一般是128,对于负载很大的服务程序来说大大的不够。一般会将它修改为2048或者更大。
echo 2048 > /proc/sys/net/core/somaxconn 但是这样系统重启后保存不了
#在/etc/sysctl.conf中添加如下:
net.core.somaxconn = 2048
#然后在终端中执行:
sysctl -p
vm-enabled是否开启虚拟内存支持
vm-swap-file设置虚拟内存的交换文件路径
vm-max-memory设置redis使用的最大物理内存大小
vm-page-size设置虚拟内存的页大小
vm-pages设置交换文件的总的page数量
vm-max-threads设置VMIO同时使用的线程数量
Glueoutputbuf设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
hash-max-zipmap-entries设置hash的临界值
Activerehashing重置hash,默认为开启
includes配置:
# include /path/to/local.conf
# include /path/to/other.conf
#当配置多个redis时,可能大部分配置一样,而对于不同的redis,只有少部分配置需要定制就可以配置一个公共的模板配置。 对于具体的reids,只需设置少量的配置,并用include把模板配置包含进来即可。 值得注意的是,对于同一个配置项,redis只对最后一行的有效,所以为避免模板配置覆盖当前配置,应在配置文件第一行使用include,当然,如果模板配置的优先级比较高,就在配置文件最后一行使用include
redis的启动(3种)
简单启动redis
# redis-server

这种启动,日志是打印到屏幕上的
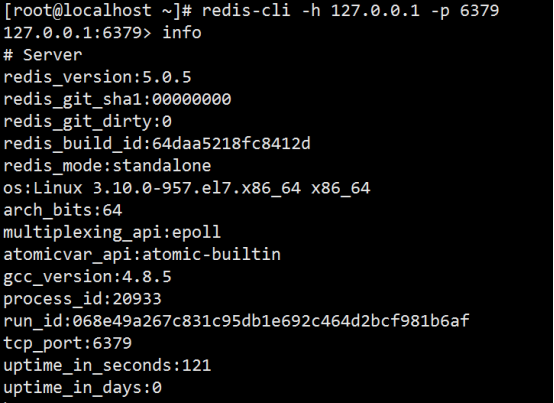
验证方式:
ps -ef | grep redis
netstat -antlp | grep redis
redis-cli -a 密码 -h ip -p port ping
停止:
redis-cli -a 密码 -h 127.0.0.1 -p 6379 shutdown
没有密码:
redis-cli -h 127.0.0.1 -p 6379 shutdown
动态参数启动redis
# redis-server --port 6380
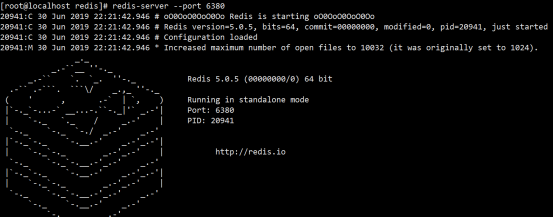
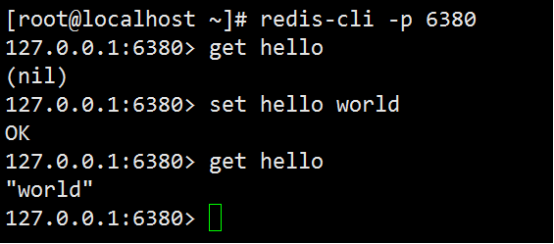
配置文件启动redis
# redis-server configPath
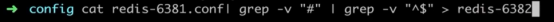
#是否是守护进程(no|yes)
daemonize yes
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6379
#redis系统日志
logfile "/var/log/redis/redis_6379.log"
#redis工作目录
dir "/opt/redis/data"
ps:只需要这些都可以启动redis
mkdir /var/log/redis/ -p
mkdir /opt/redis/data/ -p
# ps aux | grep redis
root 20998 0.0 0.2 144084 2208 ? Ssl 22:32 0:00 redis-server 127.0.0.1:6379
用初始化脚本,快速创建实例配置文件,日志目录
redis安装目录下的utils/install_server.sh执行该脚本可以快速启动一个redis实例
设置redis服务器开机自动启动:
将redis安装目录下的utils/redis_init_script复制到/etc/init.d目录下,命名为redis
[root@master utils]# cp redis_init_script /etc/init.d/redis
[root@master utils]# ll /etc/init.d/redis
继续编辑启动文件,与你配置文件中对应即可:
REDISPORT=6379
EXEC=/usr/local/bin/redis-server
CLIEXEC=/usr/local/bin/redis-cli
PIDFILE=/var/run/redis_${REDISPORT}.pid
CONF="/etc/redis/${REDISPORT}.conf"
至此为止,我们已经可以通过service redis start/stop来启动和关闭redis服务了。
最后只需要通过chkconfig redis on命令来设置开机启动即可
启动redis产生了警告消息,解决如下

vim /etc/sysctl.conf
# redis
net.core.somaxconn=65535
vm.overcommit_memory = 1
sysctl -p
echo never > /sys/kernel/mm/transparent_hugepage/enabled
或者
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo 65535 > /proc/sys/net/core/somaxconn
echo 1 > /proc/sys/vm/overcommit_memory
三种启动方式比较
1、生成环境选择配置启动比较好
2、单机多实例配置文件可以用端口区分开
redis停止
redis-cli shutdown
或者kill redis的PID
或者 pkill redis
systemctl管理redis
systemctl管理Redis启动、停止、开机启动
1、创建服务
用service来管理服务的时候,是在/etc/init.d/目录中创建一个脚本文件,来管理服务的启动和停止,
在systemctl中,也类似,文件目录有所不同,在/lib/systemd/system目录下创建一个脚本文件redis.service,里面的内容如下:
[Unit]
Description=Redis service
After=network.target
[Service]
#User=redis
#Group=redis
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/redis/redis.conf --daemonize no
#ExecStop=/usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
ExecStop=/bin/kill -SIGINT $MAINPID
Restart=on-failure
RestartPreventExitStatus=1
RestartSec=10
StartLimitInterval=300
StartLimitBurst=2
TimeoutStartSec=30
TimeoutStopSec=30
PrivateTmp=true
[Install]
WantedBy=multi-user.target
参数解释:
[Unit] 表示这是基础信息
-
Description 是描述
-
After 是在那个服务后面启动,一般是网络服务启动后启动
[Service] 表示这里是服务信息
-
ExecStart 是启动服务的命令
-
ExecStop 是停止服务的指令
[Install] 表示这是是安装相关信息
- WantedBy 是以哪种方式启动:multi-user.target表明当系统以多用户方式(默认的运行级别)启动时,这个服务需要被自动运行。
2、创建软链接
创建软链接是为了下一步系统初始化时自动启动服务
ln -s /lib/systemd/system/redis.service /etc/systemd/system/multi-user.target.wants/redis.service
创建软链接就好比Windows下的快捷方式
ln -s 是创建软链接
ln -s 原文件 目标文件(快捷方式的目标地址)
如果创建软连接的时候出现异常,不要担心,看看/etc/systemd/system/multi-user.target.wants/目录是否正常创建软链接为准,有时候报错只是提示一下,其实成功了。
$ ll /etc/systemd/system/multi-user.target.wants/
3、 刷新配置
刚刚配置的服务需要让systemctl能识别,就必须刷新配置
$ systemctl daemon-reload
如果没有权限可以使用sudo
$ sudo systemctl daemon-reload
4、启动、重启、停止
启动redis
$ systemctl start redis
重启redis
$ systemctl restart redis
停止redis
$ systemctl stop redis
5、开机自启动
redis服务加入开机启动
$ systemctl enable redis
禁止开机启动
$ systemctl disable redis
6、查看状态
$ systemctl status redis
卸载redis
如果想安装更高版本的Redis,我们可以首先卸载删除旧版本,然后按照本文介绍的方法安装新版本。 Redis源代码编译安装后的卸载,删除make的生成的以redis为前缀的文件,命令如下:
redis-cli shutdown
ll /usr/local/bin/redis-*
rm -rf /usr/local/bin/redis-*
在删除redis的源文件,查到源文件所在的目录
rm -rf redis
redis配置认证密码
redis不设置密码运行的方式安全隐患比较大,一般都会设置密码,只有通过密码验证才能登陆
# cat /data/redisdata/CMS/redis.conf
daemonize yes
port 6379
#redis工作目录
dir "/opt/redis/data"
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis系统日志
logfile "/opt/redis/redis-6379.log"
dbfilename "dump.rdb"
save 900 1
appendonly yes
appendfilename "appendonly.aof"
appendfsync always
maxmemory 8gb
maxmemory-policy volatile-lru
maxmemory-samples 3
slowlog-log-slower-than 10000
repl-backlog-size 64mb
timeout 0
repl-timeout 240
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth "redis6666s"
#这是连接redis验证的密码
requirepass "redis6666s"
# 禁止protected-mode yes/no(保护模式,是否只允许本地访问)
protected-mode no
重启redis再次尝试
pkill redis
redis-server redis.conf
#-p后面的就是端口
# ./redis-cli -p 6379
127.0.0.1:6379> get info
(error) NOAUTH Authentication required.
127.0.0.1:6379> exit
通过上面的信息提示可以看到,说是没有授权,所以查看失败
#-a后面的字符串就是验证密码
# ./redis-cli -p 6379 -a redis6666s
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> get info
(nil)
127.0.0.1:6379>
从提示可以看到虽然没东西输出,但是已经不报授权失败的错误了。
#当然除了-a指定密码外,也可以在执行操作前进行验证
# ./redis-cli -p 6379
127.0.0.1:6379> config get requirepass #直接是失败的
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth redis6666s#通过auth输入密码的形式通过验证
OK
127.0.0.1:6379> config get requirepass #现在再执行命令就没问题了
1) "requirepass"
2) "redis6666s"
当然也可以在不启动redis也就是不重新加载配置文件的形式,通过命令行设置密码
通过config set requirepass在其后面跟上密码,就可以设置新的密码,不用重启redis
127.0.0.1:6379> config set requirepass redis66sOK
127.0.0.1:20000> config get requirepass
1) "requirepass"
2) "redis66s"
redis的客户端使用(客户端很多,你可以自己选择)
redis-cli
这个是redis自带的的客户端
Usage: redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <hostname> Server hostname (default: 127.0.0.1).
-p <port> Server port (default: 6379).
-s <socket> Server socket (overrides hostname and port).
-a <password> Password to use when connecting to the server.
-u <uri> Server URI.//url格式的地址
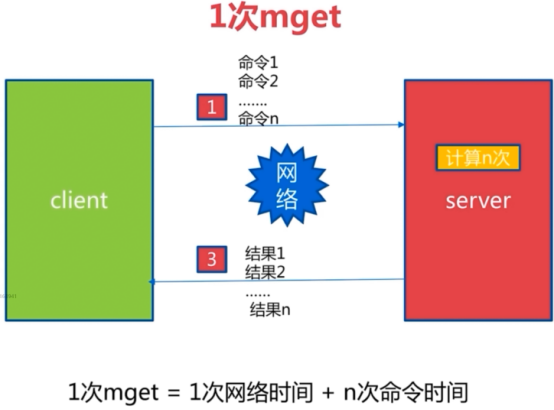
-r <repeat> Execute specified command N times. 执行指定命令N次
-c Enable cluster mode (follow -ASK and -MOVED redirections).Redis Cluster集群所独有的。(客户端命令:redis-cli -c -p port -h ip)
-n <db> Database number. //选择数据库
--eval <file> Send an EVAL command using the Lua script at <file>.//执行lua脚本
--stat Print rolling stats about server: mem, clients, ... //统计数据 连续输出
--rdb <filename> Transfer an RDB dump from remote server to local file.
--bigkeys Sample Redis keys looking for keys with many elements (complexity).
--hotkeys Sample Redis keys looking for hot keys.
--raw Use raw formatting for replies (default when STDOUT is
not a tty).1.按数据原有格式打印数据,不展示额外的类型信息 2. 显示中文
--csv 以csv格式输出

常用实例
# redis-cli -h 192.168.137.66 -p 6379
192.168.137.66:6379> ping
PONG
192.168.137.66:6379> set hello world
OK
192.168.137.66:6379> get hello
“world”
#查看中间为aa的所有key
# redis-cli -h 127.0.0.1 -a ')O123654Gc@Ht' -n 5 keys '*aa*'
#统计数据
# redis-cli --stat
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
2626398 3.65G 59 0 138547655371 (+0) 250581513
2626397 3.65G 60 0 138547660467 (+5096) 250581523
2626395 3.65G 59 0 138547666002 (+5535) 250581531
2626394 3.65G 59 0 138547671169 (+5167) 250581539
列表中选项说明:
| 选项 | 含义 |
|---|---|
| keys | server中key的数量 |
| mem | 键值对的总内存量 |
| clients | 当前连接的总clients数量 |
| blocked | 当前阻塞的客户端数量 |
| requests | 服务器请求总次数 (+1) 截止上次请求增加次数 |
| connections | 服务器连接次数 |
例子3:导入rdb文件
# redis-cli --rdb rdb.log
SYNC sent to master, writing 344 bytes to 'rdb.log'
Transfer finished with success.
该命令选项实现:
1、向server发送SYNC命令,返回需要写的总字节数
2、从server读取总字节数据写到指定文件中
例子4:该选项实现:通过使用scan命令遍历server中的键值对,针对不同数据类型进行统计
找出各种数据类型的最大键值对,命令:redis-cli --big-keys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest hash found so far 'player:last_login:18577262994' with 9 fields
-------- summary -------
Sampled 10 keys in the keyspace!
Total key length in bytes is 353 (avg len 35.30)
Biggest hash found 'player:last_login:18577262994' has 9 fields
0 strings with 0 bytes (00.00% of keys, avg size 0.00)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
10 hashs with 55 fields (100.00% of keys, avg size 5.50)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
例子5:找出server中热点key 命令:redis-cli --hotkeys
选项实现:
redis实现8种缓存淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
volatile-lfu: 从已设置过期时间的数据集驱逐使用频率最少的键
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-lfu: 从所有键中驱逐使用频率最少的键
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据 当内存不足以容纳新写入数据时,新写入操作会报错
需要设置淘汰策略为lru或者lfu
有时候会有中文乱码。要在 redis-cli 后面加上--raw,就可以避免中文乱码了
redis-cli --raw
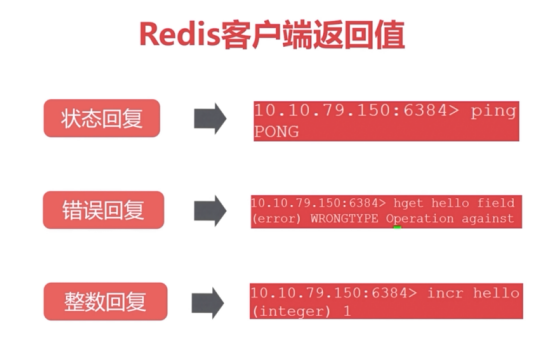
redis客户端返回值

Java客户端


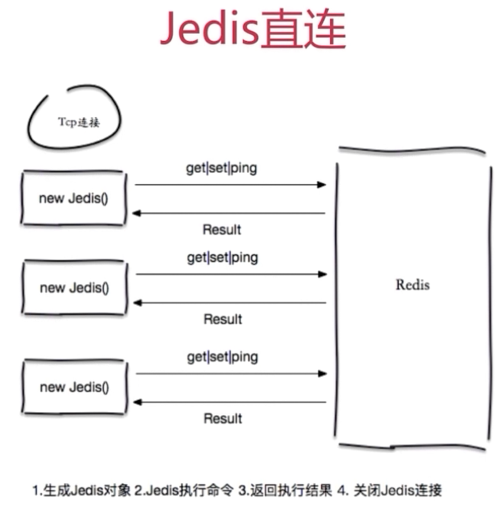
直连


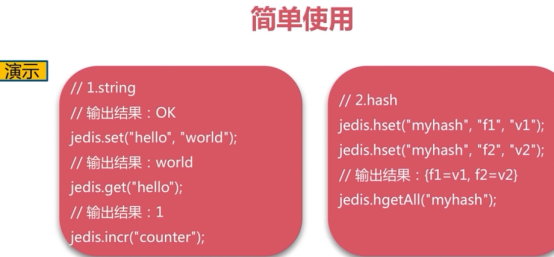

连接池



Python客户端

获取方式,去redis官网,找到Python客户端,点击进去,就可以看到怎么获取





go客户端


redis的常用命令
更多redis的常用操作命令:
http://doc.redisfans.com/server/index.html
https://haicoder.net/redis/redis-scan.html
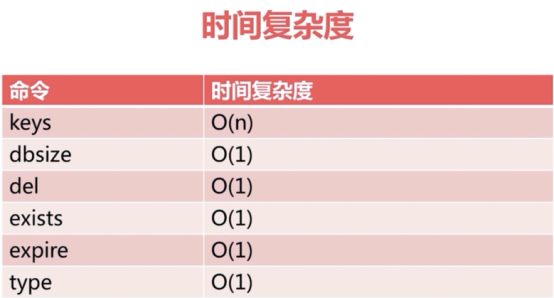
O(1)表示大部分可以在实际环境中随便使用
info
提供服务器的信息和统计
127.0.0.1:6379> info
# Server #一般Redis服务器信息,包含以下域
redis_version:3.2.9 #redis服务器版本
redis_git_sha1:00000000 #git SHA1
redis_git_dirty:0 #git dirty flag
redis_build_id:981e5dd19fd02099 #redis的build_id
redis_mode:standalone #redis的运行模式,这里是单机不是集群(cluster)
os:Linux 2.6.32-358.el6.x86_64 x86_64 #redis服务器的宿主机操作系统
arch_bits:64 #架构(32位还是64位)
multiplexing_api:epoll #Redis 所使用的事件处理机制
gcc_version:4.4.7 #gcc版本
process_id:2753 #redis服务器的进程ID
run_id:08b8effd5d82c8c99edef99259f282aa76dba5a1 #Redis 服务器的随机标识符(用于 Sentinel 和集群)
tcp_port:6379 #tcp/ip监听端口
uptime_in_seconds:15 #自redis服务器启动以来,经过的秒数
uptime_in_days:0 #自redis启动以来经过的天数
hz:10 #redis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次
lru_clock:5314336 #自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次.
executable:/root/redis-server
config_file:
# Clients #已连接客户端信息,包含以下域
connected_clients:1 #已连接客户端的数量(不包括通过从属服务器连接的客户端)
client_longest_output_list:0 #当前连接客户端当中,最长的输出列表,用client list命令观察omem字段最大值client_biggest_input_buf:0 #当前连接客户端当中,最大的输入缓存.用client list命令观察qbuf和qbuf-free两个字段最大值blocked_clients:0 #正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
# Memory #内存信息,包含以下域
used_memory:1330504 #由 Redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human:1.27M #以人类可读的格式返回 Redis 分配的内存总量
used_memory_rss:5955584 #从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)这个值和 top、ps 等命令的输出一致used_memory_rss_human:5.68M #这个就是把上面的的字节转换成MB
used_memory_peak:1330504 #Redis 的内存消耗峰值(以字节为单位)
used_memory_peak_human:1.27M #以人类可读的格式返回redis内存消耗的峰值
total_system_memory:1036849152 #操作系统本身的内存大小
total_system_memory_human:988.82M #操作系统内存大小转换成可读的方式
used_memory_lua:37888 #Lua 引擎所使用的内存大小(以字节为单位)
used_memory_lua_human:37.00K #将上面转换成可读的方式
maxmemory:0 #redis使用内存的上限,这里是没有设置。一般是要设置的。
maxmemory_human:0B #上面的字节转换成可读的形式
maxmemory_policy:noeviction #内存不足时候的清除策略。
mem_fragmentation_ratio:4.48 #used_memory_rss和used_memory之间的比率,小于1表示使用了swap,大于1表示碎片比较多mem_allocator:jemalloc-4.0.3 #在编译时指定的redis所使用的内存分配器。可以是libc、jemalloc或者tcmalloc
# Persistence #持久化的相关信息
loading:0 #服务器是否正在载入持久化文件
rdb_changes_since_last_save:0 #距离最近的一次持久化,有多少个个写入命令没有持久化
rdb_bgsave_in_progress:0 #服务器是否正在创建rdb文件
rdb_last_save_time:1498486545 #离最近一次成功创建rdb文件的时间戳。当前时间戳 - rdb_last_save_time=多少秒未成功生成rdb文件rdb_last_bgsave_status:ok #最近一次持久化是否成功
rdb_last_bgsave_time_sec:-1 #最近一次生成rdb文件的秒数
rdb_current_bgsave_time_sec:-1 #如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数
aof_enabled:0 #是否开启了aof,这里0是未开启
aof_rewrite_in_progress:0 #标识aof的rewrite操作是否在进行中
aof_rewrite_scheduled:0 #rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite 。
aof_last_rewrite_time_sec:-1 #最近一次aof rewrite耗费的时长
aof_current_rewrite_time_sec:-1 #如果rewrite操作正在进行,则记录所使用的时间,单位秒
aof_last_bgrewrite_status:ok #上次bgrewrite aof操作的状态
aof_last_write_status:ok #最近一次aof的写入状态
# Stats #一般统计信息
total_connections_received:1 #新创建的连接个数
total_commands_processed:1 #redis处理的命令个数
instantaneous_ops_per_sec:0 #redis当前的qps,redis内部较实时的每秒执行的命令数。
total_net_input_bytes:31 #redis网络入口流量字节数
total_net_output_bytes:6035691 #redis网络出口流量字节数
instantaneous_input_kbps:0.00 #redis网络入口kps
instantaneous_output_kbps:0.00 #redis网络出口kps
rejected_connections:0 #拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数
sync_full:0 #主从完全同步成功次数
sync_partial_ok:0 #主从部分同步成功次数
sync_partial_err:0 #主从部分同步失败次数
expired_keys:0 #运行以来过期的key的数量
evicted_keys:0 #运行以来剔除(超过了maxmemory后)的key的数量
keyspace_hits:0 #命中次数
keyspace_misses:0 #没命中次数
pubsub_channels:0 #当前使用中的频道数量
pubsub_patterns:0 #当前使用的模式的数量
latest_fork_usec:0 #最近一次fork操作阻塞redis进程的耗时数,单位微秒
migrate_cached_sockets:0
# Replication #主从信息,这里是master上显示的信息
role:master #实例的角色
connected_slaves:0 #连接的slave实例个数
master_repl_offset:0 #主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟
repl_backlog_active:0 #复制积压缓冲区是否开启
repl_backlog_size:1048576 #复制积压缓冲大小
repl_backlog_first_byte_offset:0 #复制缓冲区里偏移量的大小
repl_backlog_histlen:0 #此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小
# CPU #CPU计算量统计信息
used_cpu_sys:0.17 #Redis服务器耗费的系统 CPU。
used_cpu_user:0.17 #Redis服务器耗费的用户CPU 。
used_cpu_sys_children:0.00 #后台进程耗费的系统 CPU。
used_cpu_user_children:0.00 #后台进程耗费的用户 CPU。
# Cluster
cluster_enabled:0 #一个标志值,记录集群功能是否已经开启。
# Keyspace #keyspace 部分记录了数据库相关的统计信息,比如数据库的键数量、数据库已经被删除的过期键数量等
select
redis中默认会准备16个库,可以在配置文件中修改默认数量。
每个库之间的数据是隔离的
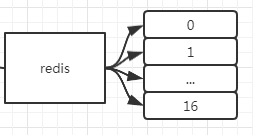
切换db。默认进入db0
实例:切换至db10
select 10
exists

0表示不存在
1表示存在
type

hash ——哈希
string ——字符串
list ——列表
set ——集合
zset zset是set的一个升级版本,他在set的基础上增加了一个`顺序`属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。 可以对指定键的值进行排序权重的设定,它应用排名模块比较多
none ——空
keys
建议生产环境屏蔽keys命令

原因:key非常多、redis是单线程,会阻塞其他命令
这个指令使用非常简单,提供一个简单的正则字符串即可,但是有很明显的两个缺点。没有 offset、limit 参数,一次性吐出所有满足条件的 key,万一实例中有几百 w 个 key 满足条件,当你看到满屏的字符串刷的没有尽头时,你就知道难受了。
keys 算法是遍历算法,复杂度是O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,
所有读写 Redis 的其它的指令都会被延后甚至会超时报错,因为 Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的keys指令执行完了才可以继续。

keys * // 遍历当前数据库中所有的key
keys *xx // 匹配以xx结尾的key
keys *xx* // 匹配字段中含有xx的字段
keys xx* // 匹配以xx开头的key


scan
Redis 为了解决这个问题,它在 2.8 版本中加入了指令scan。
Redis SCAN 命令用于增量地迭代 Redis 元素集合。
SCAN命令是一个基于游标的迭代器,SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
当 SCAN 命令的游标参数被设置为0时, 服务器将开始一次新的迭代,而当服务器向用户返回值为 0 的游标时,表示迭代已结束。
scan 相比 keys 具备有以下特点:
-
复杂度虽然也是
O(n),但是它是通过游标分步进行的,不会阻塞线程; -
提供
limit参数,可以控制每次返回结果的最大条数,limit 只是对增量式迭代命令的一种提示(hint),返回的结果可多可少; -
同 keys 一样,它也提供模式匹配功能;
-
服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
-
返回的结果可能会有重复,需要客户端去重复,这点非常重要;
-
遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
-
单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零
SCAN 命令及其相关的 SSCAN 命令、 HSCAN 命令和 ZSCAN 命令都用于增量地迭代元素集。
SCAN、 SSCAN、 HSCAN 和 ZSCAN 四个命令的工作方式都非常相似:
SSCAN 命令、 HSCAN 命令和 ZSCAN 命令的第一个参数总是一个数据库键。
而 SCAN 命令则不需要在第一个参数提供任何数据库键 ------ 因为它迭代的是当前数据库中的所有数据库键
Redis SCAN命令详解
语法
192.168.10.70:6379> SCAN CURSOR [MATCH pattern] [COUNT count]
参数
MATCH选项
和 KEYS 命令一样, 增量式迭代命令也可以通过提供一个 glob 风格的模式参数, 让命令只返回和给定模式相匹配的元素, 这一点可以通过在执行增量式迭代命令时, 通过给定MATCH <pattern>参数来实现。
COUNT选项
-
虽然增量式迭代命令不保证每次迭代所返回的元素数量, 但我们可以使用 COUNT 选项, 对命令的行为进行一定程度上的调整。
-
基本上, COUNT 选项的作用就是让用户告知迭代命令, 在每次迭代中应该从数据集里返回多少元素。
-
虽然 COUNT 选项只是对增量式迭代命令的一种提示(hint), 但是在大多数情况下, 这种提示都是有效的。
-
COUNT 参数的默认值为 10 。
-
在迭代一个足够大的、由哈希表实现的数据库、集合键、哈希键或者有序集合键时, 如果用户没有使用 MATCH 选项, 那么命令返回的元素数量通常和 COUNT 选项指定的一样, 或者比 COUNT 选项指定的数量稍多一些。
-
在迭代一个编码为整数集合(intset,一个只由整数值构成的小集合)、 或者编码为压缩列表(ziplist,由不同值构成的一个小哈希或者一个小有序集合)时, 增量式迭代命令通常会无视 COUNT 选项指定的值, 在第一次迭代就将数据集包含的所有元素都返回给用户。
返回值
SCAN、 SSCAN、 HSCAN 和 ZSCAN 命令都返回两个元素
- 第一个元素是字符串表示的无符号 64 位整数(游标)。
- 第二个元素是本次被迭代的元素。
scan指令是一系列指令,除了可以遍历所有的 key之外,还可以对指定的容器集合进行遍历。
zscan遍历 zset 集合元素,
hscan遍历 hash 字典的元素、
sscan遍历 set 集合的元素。
注意点:
SSCAN 命令、 HSCAN 命令和 ZSCAN 命令的第一个参数总是一个数据库键。而 SCAN 命令则不需要在第一个参数提供任何数据库键,因为它迭代的是当前数据库中的所有数据库键。
SCAN 命令返回的每个元素都是一个数据库键。
##迭代已online开头的元素
pre:0>scan 0 match online* count 100
SSCAN 命令返回的每个元素都是一个集合成员。
SSCAN www.gobgm.com 0 MATCH M*
HSCAN 命令返回的每个元素都是一个键值对,一个键值对由一个键和一个值组成。
HSCAN onlinePlay:2021-02-12:online:0 0
ZSCAN 命令返回的每个元素都是一个有序集合元素,一个有序集合元素由一个成员(member)和一个分值(score)组成。
ZSCAN friends_ids_100256 0
返回元素个数
增量式迭代命令并不保证每次执行都返回某个给定数量的元素。
增量式命令甚至可能会返回零个元素, 但只要命令返回的游标不是 0 , 应用程序就不应该将迭代视作结束。
不过命令返回的元素数量总是符合一定规则的, 在实际中:
- 对于一个大数据集来说, 增量式迭代命令每次最多可能会返回数十个元素;
- 而对于一个足够小的数据集来说, 如果这个数据集的底层表示为编码数据结构(encoded data structure,适用于是小集合键、小哈希键和小有序集合键), 那么增量迭代命令将在一次调用中返回数据集中的所有元素。
最后, 用户可以通过增量式迭代命令提供的 COUNT 选项来指定每次迭代返回元素的最大值。
时间复杂度
增量式迭代命令每次执行的复杂度为O(1), 对数据集进行一次完整迭代的复杂度为 O(N) , 其中 N 为数据集中的元素数量。
并发执行多个迭代
在同一时间, 可以有任意多个客户端对同一数据集进行迭代。
客户端每次执行迭代都需要传入一个游标, 并在迭代执行之后获得一个新的游标, 而这个游标就包含了迭代的所有状态, 因此, 服务器无须为迭代记录任何状态。
中途停止迭代
因为迭代的所有状态都保存在游标里面, 而服务器无须为迭代保存任何状态, 所以客户端可以在中途停止一个迭代, 而无须对服务器进行任何通知。
即使有任意数量的迭代在中途停止, 也不会产生任何问题
使用错误的游标进行增量式迭代
使用间断的(broken)、负数、超出范围或者其他非正常的游标来执行增量式迭代并不会造成服务器崩溃, 但可能会让命令产生未定义的行为。
未定义行为指的是, 增量式命令对返回值所做的保证可能会不再为真。
只有两种游标是合法的:
1、在开始一个新的迭代时, 游标必须为 0 。
2、增量式迭代命令在执行之后返回的, 用于延续(continue)迭代过程的游标。
迭代的终止
增量式迭代命令所使用的算法只保证在数据集的大小有限的情况下, 迭代才会停止, 换句话说, 如果被迭代数据集的大小不断地增长的话, 增量式迭代命令可能永远也无法完成一次完整迭代。
所以, 当一个数据集不断地变大时, 想要访问这个数据集中的所有元素就需要做越来越多的工作, 能否结束一个迭代取决于用户执行迭代的速度是否比数据集增长的速度更快
案例
基本迭代
使用 SCAN 开始迭代
# 基本迭代
192.168.10.70:6379> scan 0
1) "21"
2) 1) "key:1"
2) "key:8"
3) "key:4"
4) "key:7"
5) "key:16"
6) "key:15"
7) "key:17"
8) "key:10"
9) "key:3"
10) "key:14"
11) "key:12"
192.168.10.70:6379> scan 21
1) "0"
2) 1) "key:9"
2) "key:18"
3) "key:0"
4) "key:19"
5) "key:13"
6) "key:2"
7) "key:6"
8) "key:5"
9) "key:11"
第一次迭代使用0作为游标, 表示开始一次新的迭代。第二次迭代使用的是第一次迭代时返回的游标, 也即是命令回复第一个元素的值21。
从上面的示例可以看到,SCAN 命令的回复是一个包含两个元素的数组, 第一个数组元素是用于进行下一次迭代的新游标, 而第二个数组元素则是一个数组, 这个数组中包含了所有被迭代的元素。
在第二次调用 SCAN 命令时, 命令返回了游标 0 , 这表示迭代已经结束, 整个数据集(collection)已经被完整遍历过了。
以 0 作为游标开始一次新的迭代, 一直调用 SCAN 命令, 直到命令返回游标 0 , 我们称这个过程为一次完整迭代。
MATCH 迭代
使用 MATCH 参数开始迭代
# MATCH 参数迭代
192.168.98.77:6379> SADD www.gobgm.com Redis MongoDb Mysql Java Php GoLang HTML CSS Vue Js
(integer) 10
192.168.98.77:6379> SSCAN www.gobgm.com 0 MATCH M*
1) "0"
2) 1) "Mysql"
2) "MongoDb"
192.168.98.77:6379> DEL www.gobgm.com
(integer) 1
我们首先,使用 SADD 命令向 SET 添加多个元素。接着,使用 SSCAN 命令加上 MATCH 参数,匹配集合中以M 开头的元素 。游标返回了 0,表示迭代结束,并且返回了 以 M 开头的元素 。
需要注意的是, 对元素的模式匹配工作是在命令从数据集中取出元素之后, 向客户端返回元素之前的这段时间内进行的, 所以如果被迭代的数据集中只有少量元素和模式相匹配, 那么迭代命令或许会在多次执行中都不返回任何元素,但此时迭代并没有结束。
slowlog
上面提到不能使用keys命令,如果就有开发这么做了呢,我们如何得知?
与其他任意存储系统例如mysql,mongodb可以查看慢日志一样,redis也可以,即通过命令slowlog
用法如下
SLOWLOG subcommand [argument]
subcommand主要有:
- get,用法:slowlog get [argument],获取argument参数指定数量的慢日志。
- len,用法:slowlog len,总慢日志数量。
- reset,用法:slowlog reset,清空慢日志。
redis-cli slowlog get 5 # 获取5条
dbsize
下面的命令可以查看db的大小(key 个数),其他的以此类推。
select 0
dbsize
或者使用info keyspace同时得到所有 db 信息

del

expire、ttl、persist



-1代表key存在,并且没有过期时间
-2代表key已经不存在了
FLUSHDB
删除该db的所有key
FLUSHALL
删除redis所有db的所有key
rename-command
为了防止把问题带到生产环境,我们可以通过配置文件重命名一些危险命令,
Redis的危险命令主要有:
-
flushdb,清空数据库
-
flushall,清空所有记录,数据库
-
config,客户端连接后可配置服务器
-
keys,客户端连接后可查看所有存在的键
作为服务端的redis-server,我们常常需要禁用以上命令来使服务器更加安全
操作非常简单,只需要在conf配置文件增加如下所示配置即可:
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
rename-command KEYS ""
rename-command SHUTDOWN ""
rename-command DEL ""
rename-command EVAL ""
然后重启redis。 重命名为""代表禁用命令,如想保留命令,可以重命名为不可猜测的字符串,如:
rename-command flushdb flushdbdb
rename-command flushall flushallall
rename-command keys keysys
迁移redis数据
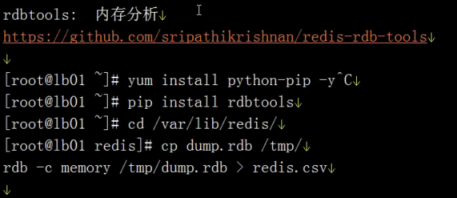
https://my.oschina.net/u/3455207/blog/1859033
https://cloud.tencent.com/developer/article/1403529
三种方案:
- 第三方工具redis-dump,redis-load
- aof机制,需要开启aof功能
- rdb存储机制
这里介绍第一种方式,通过redis-dump导出数据,再通过redis-load导入。
redis-dump这款工具需要用到Ruby,而centos环境中的yum工具可以安装的Ruby版本最高是2.0的版本,而当前Redis最新的4.0版本中需要用到的Ruby >= 2.2版本,所以我们需要先安装Ruby,而安装Ruby有一个很好的命令行工具可以帮助我们,这款工具就是RVM,RVM可以提供一个便捷的多版本 Ruby 环境的管理和切换
Ruby官网及下载地址:
地址一:https://www.ruby-lang.org/en/downloads/
地址二:https://ftp.ruby-lang.org/pub/ruby/
地址三:https://rvm.io/binaries/
第一步:安装gcc
终端执行gcc命令,如果提示没有此命令,说明需要安装。否则跳过此步
yum -y install gcc gcc-c++ glibc automake autoconf libtool make
第二步:安装rvm命令
配置Google DNS
vim /etc/resolv.conf
nameserver 8.8.8.8
我们先到tmp下,用来存放下载的安装文件
cd /tmp
mkdir -p rvm && cd rvm
# 开始安装RVM
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
curl -O https://raw.githubusercontent.com/rvm/rvm/master/binscripts/rvm-installer
curl -O https://raw.githubusercontent.com/rvm/rvm/master/binscripts/rvm-installer.asc
gpg --verify rvm-installer.asc
bash rvm-installer stable
source /etc/profile.d/rvm.sh
或者这样安装(https://ruby-china.org/wiki/rvm-guide)
sudo gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
command curl -sSL https://rvm.io/mpapis.asc | sudo gpg2 --import -
command curl -sSL https://rvm.io/pkuczynski.asc | sudo gpg2 --import -
curl -L get.rvm.io | bash -s stable
source ~/.bashrc
source ~/.bash_profile
echo "export rvm_max_time_flag=20" >> ~/.rvmrc
修改 RVM 的 Ruby 安装源到 Ruby China 的 Ruby 镜像服务器,这样能提高安装速度
$ echo "ruby_url=https://cache.ruby-china.com/pub/ruby" > ~/.rvm/user/db
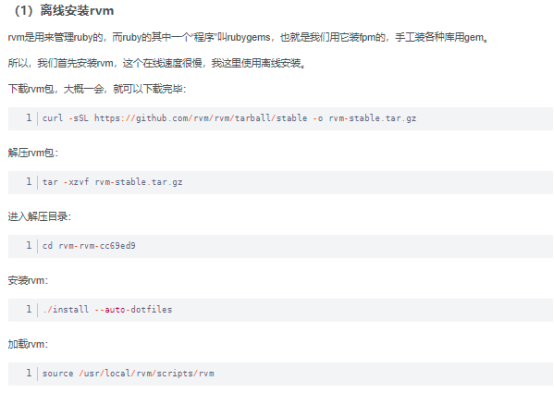
1.安装gcc环境
yum install gcc-c++
2.下载rvm文件
mkdir rvm && cd rvm
curl -sSL https://github.com/rvm/rvm/tarball/stable -o rvm-stable.tar.gz
解压:
tar --sctrip-components=1 -xzf rvm-stable.tar.gz
cd rvm-rvm-cc69ed9
安装:
./install --auto-dotfiles
使文件生效
source /home/rvm/scripts/rvm
/home替换成你们的安装目录即可,我这里是装在/home路径下
查看版本
rvm -v
第三步:安装Ruby
# 查看可以安装的Ruby版本
rvm list known
# 这里我们安装2.4.1
rvm install ruby 2.4.1
第四步:配置Ruby官网源地址
因为默认的Ruby官网源地址在国外,访问速度很慢,所以需要配置成国内的源地址
gem sources -a https://gems.ruby-china.com/ #添加国内源地址
# 或者添加淘宝源
# gem sources -a https://ruby.taobao.org/
gem source -l #查看是否添加成功
gem source --remove https://rubygems.org/ #去掉国外源地址
gem source -l #确认现在的源地址只有国内
第五步:确认Ruby版本
因为redis-dump必须要求ruby的版本不低于2.2.2
ruby -v如果输出信息是ruby 2.4.1xxx,说明现在用的版本是正确的,直接跳到下一步。否则还要执行以下操作:
# 查看
rvm list
rvm use 2.4.1 --default #将默认使用ruby的版本设置为2.4.1
rvm remove $version #删除旧版本,$version就是ruby -v查到的版本,只需要指定前面的数字版本号就行
第六步:安装redis-dump
# gem -h #查看帮助
gem search redis-dump #查看版本信息
gem dependency -r redis-dump #查看依赖
gem install -l xxx.gem #离线安装gem包
gem install redis-dump -V #安装
gem install redis-dump -v xxx #安装指定xxx版本
安装了redis-dump就有了2个命令(redis-dump、redis-load)
第七步:确认redis-dump安装成功
find / -iname redis-dump
# /usr/local/rvm/gems/ruby-2.4.1/bin/redis-dump --help
Try: /usr/local/rvm/gems/ruby-2.4.1/bin/redis-dump show-commands
Usage: /usr/local/rvm/gems/ruby-2.4.1/bin/redis-dump [global options] COMMAND [command options]
-u, --uri=S Redis URI (e.g. redis://hostname[:port])
-d, --database=S Redis database (e.g. -d 15)
-a, --password=S Redis password (e.g. -a 'my@pass/word')
-s, --sleep=S Sleep for S seconds after dumping (for debugging)
-c, --count=S Chunk size (default: 10000)
-f, --filter=S Filter selected keys (passed directly to redis' KEYS command) # 只支持与redis一样的正则表达式? 、[] 、*这三种
-b, --base64 Encode key values as base64 (useful for binary values)
-O, --without_optimizations Disable run time optimizations
-V, --version Display version
-D, --debug
--nosafe
# find / -iname redis-load
# /usr/local/rvm/gems/ruby-2.4.1/bin/redis-load --help
Try: /usr/local/rvm/gems/ruby-2.4.1/bin/redis-load show-commands
Usage: /usr/local/rvm/gems/ruby-2.4.1/bin/redis-load [global options] COMMAND [command options]
-u, --uri=S Redis URI (e.g. redis://hostname[:port])
-d, --database=S Redis database (e.g. -d 15)
-a, --password=S Redis password (e.g. -a 'my@pass/word')
-s, --sleep=S Sleep for S seconds after dumping (for debugging)
-b, --base64 Decode key values from base64 (used with redis-dump -b)
-n, --no_check_utf8
-V, --version Display version
-D, --debug
--nosafe

第八步:redis-dump导出数据
用redis-dump导出的数据格式都是json格式
# 导出命令
redis-dump –u 127.0.0.1:6379 > test.json
# 导出指定数据库数据
redis-dump -u 127.0.0.1:6379 -d 15 > test.json
# 如果redis设有密码
redis-dump –u :your_password@127.0.0.1:6379 > test.json
第九步:将导出的数据文件移动到导入的redis服务器上去
第十步:redis-load导入数据(不能跨库导入,除非修改导出数据中的db为你导入的db)
# 注意换成自己的密码,如果没有密码就去掉
cat redis-mv.json | redis-load -u :yourpassword@127.0.0.1:6379
到此数据就迁移完了。别忘了去导入的redis查看验证下
#导入命令
< test.json redis-load
# 如果redis设有密码
< test.json redis-load -u :your_password@127.0.0.1:6379
实例:(如果密码有特殊字符,建议用-a参数传递密码)
redis-dump -u :'1Ek5cCOL'@127.0.0.1:6379 -d 5 -D > 1.json #导出redis数据库中的数
redis-dump -u 127.0.0.1:6379 -a '1Ek5cCOL' -d 5 -D > 1.json
< 1.json redis-load -u 127.0.0.1 -a '1Ek5cCOL' -d 5 -n -D #把redis中的数据导入到新的redis中
# 导出player_*的key,实际这里会匹配*player_*(但是注意本地不能有匹配文件存在,如果有就无法要匹配到本地的文件。例如:这里不能存在player_id.txt的文件)
redis-dump -u :123456@127.0.0.1:6379 -d 0 -D -f player_* > ./db0_user_data.json

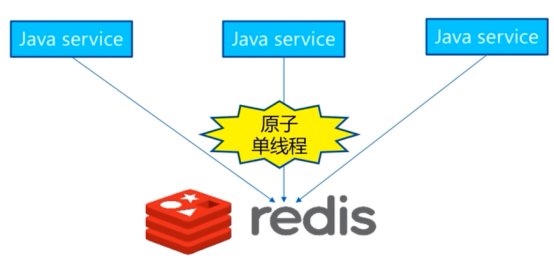
redis的单线程
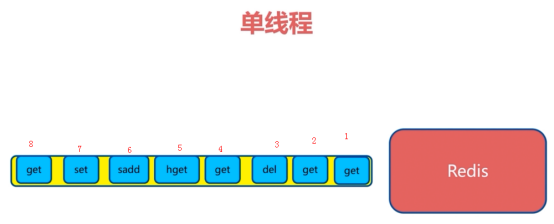
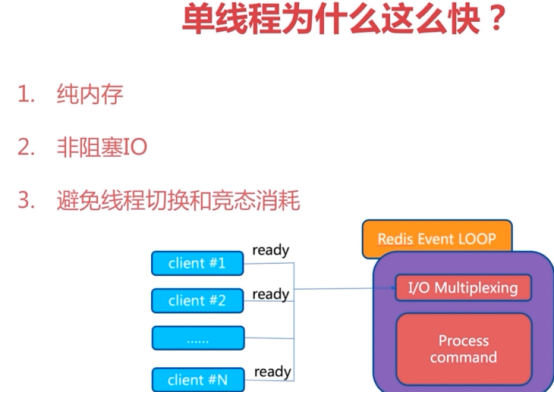
ps:最主要是第一点->纯内存

redis数据结构
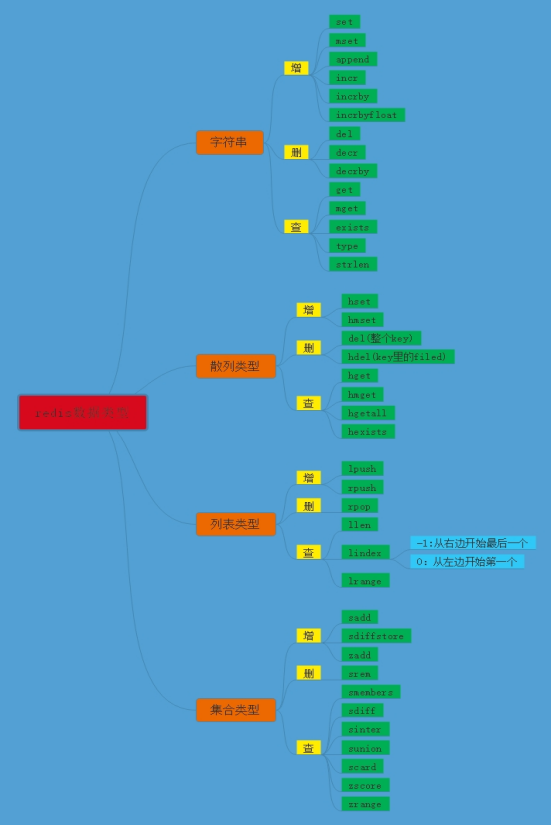
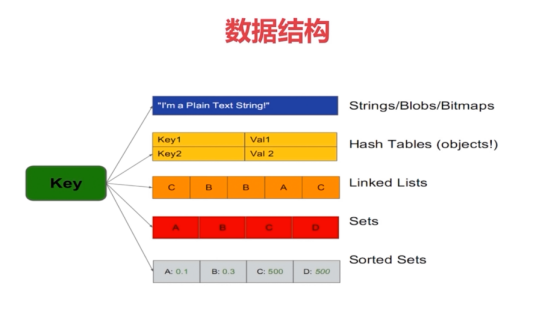
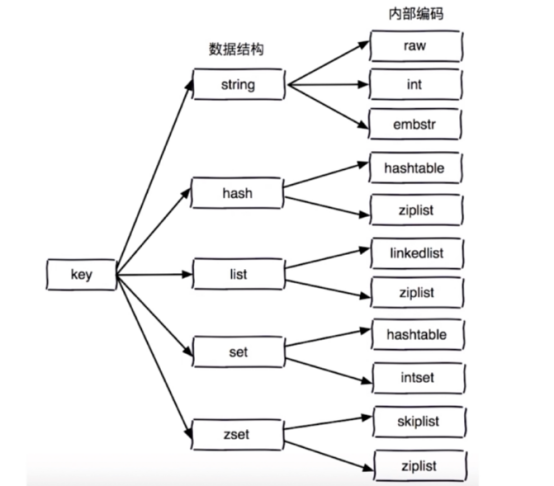
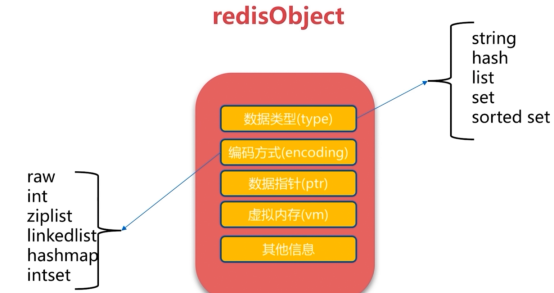
1 字符串类型(string)
字符串类型常见的命令分三种
增:set mset append incr incrby incrbyfloat
删:del decr decrby
查:get mget strlen exists type
incr key
#key自增1,如果key不存在,自增后get(key)=1
decr key
#key自减1,如果key不存在,自减后get(key)=-1
incrby key k
#key自增k,如果ket不存在,自减后get(key)=k
decr key k
#key自减k,如果key不存在,自减后get(key)=-k
set key value
#不管key是否存在,都设置
setnx key value
#key不存在,才设置
set key value xx
#key存在,才设置
mget key1 key2 key3……
#批量获取key,原子操作
mset key1 value1 key2 value2 key3 value3……
#批量设置key-value
getset key newvalue
#set key newvalue并返回旧的value
append key value
#将value追加到旧的value
strlen key
#返回字符串的长度(注意中文)
incrbyfloat key 3.5
#增加key对应的值3.5
getrange key start end
#获取字符串指定下标所有的值
setrange key index value
#设置指定下标所有对应的值
设置key
10.0.0.42:6379> set mykey hehe
OK
获取key
10.0.0.42:6379> get mykey #双引号表示字符串
"hehe"
查看有多少个key
10.0.0.42:6379> keys * #生产环境不用*,类似select *
1) "mykey"
查看key是否存在,存在为1,不存在为0
10.0.0.42:6379> EXISTS mykey
(integer) 1
10.0.0.42:6379> EXISTS mykeys
(integer) 0
删除key,不存在返回0,存在返回1
10.0.0.42:6379> EXISTS mykey
(integer) 1
10.0.0.42:6379> EXISTS mykeys
(integer) 0
查看数据结构类型
10.0.0.42:6379> TYPE mykey
String
追加数据
10.0.0.42:6379> APPEND mykey haha
(integer) 8
查看字符串的长度
10.0.0.42:6379> strlen mykey
(integer) 8
自增
10.0.0.42:6379> incr num
(integer) 1
10.0.0.42:6379> get num
"1"
指定步长的自增
10.0.0.42:6379> get num
"6"
10.0.0.42:6379> incrby num 10
(integer) 16
10.0.0.42:6379> get num
"16"
自减
10.0.0.42:6379> get num
"16"
10.0.0.42:6379> decr num
(integer) 15
10.0.0.42:6379> decr num
(integer) 14
10.0.0.42:6379> decr num
(integer) 13
10.0.0.42:6379> decr num
(integer) 12
指定步长的自减
10.0.0.42:6379> decrby num 5
(integer) 7
10.0.0.42:6379> decrby num 5
(integer) 2
10.0.0.42:6379> decrby num 5
(integer) -3
10.0.0.42:6379> decrby num 5
(integer) -8
10.0.0.42:6379> decrby num 5
(integer) -13
10.0.0.42:6379> decrby num 5
(integer) -18
10.0.0.42:6379> decrby num 5
(integer) -23
指定步长的自增并支持浮点
10.0.0.42:6379> incrbyfloat hhh 2
"2"
10.0.0.42:6379> get hhh
"2"
10.0.0.42:6379> incrbyfloat hhh 2.35354
"4.35354"
10.0.0.42:6379> get hhh
"4.35354"
同时设置多个值
10.0.0.42:6379> mset key1 v1 key2 v2 key3 v3
OK
10.0.0.42:6379> keys *
1) "key3"
2) "bun"
3) "mykey"
4) "key2"
5) "key1"
6) "num"
7) "hhh"

同时get多个值
10.0.0.42:6379> mget key1 key2 key3
1) "v1"
2) "v2"
3) "v3"





实战1:
如何实现记录网站每个用户个人主页的访问量?
思路:

实战2:
如何实现缓存视频的基本信息(数据源在MySQL中)伪代码
思路:

实战3:
如何实现分布式ID生成器
思路:
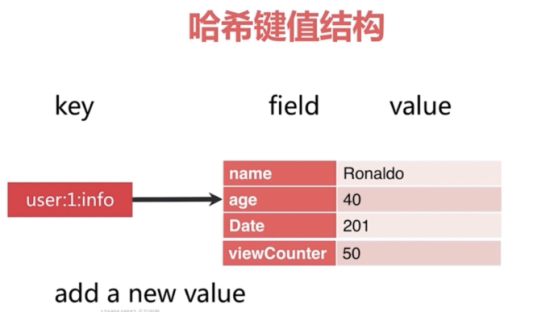
2 散列类型=哈希键值(hash)
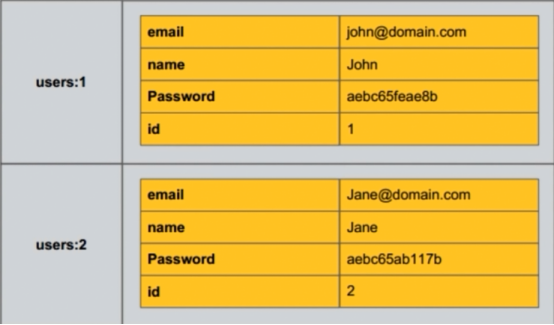

常见的散列类型有三种
增:hset,hmset
删:del,hdel
查:hget,hmget,hgetall,hexists
Hash类型的键最多2的32次方-1










设置单个key的field1
10.0.0.42:6379> hset car name BMW
(integer) 1
设置单个key的field2
10.0.0.42:6379> hset car price 500
(integer) 1
获取单个key的field1
10.0.0.42:6379> hget car name
"BMW"
获取单个key的field2
10.0.0.42:6379> hget car price
"500"
更新单个key的field2
10.0.0.42:6379> hset car price 5000
(integer) 0
10.0.0.42:6379> hget car price
"5000" #field没有就插入,有就更新
同时设置key的多个field
10.0.0.42:6379> hmset book price 10 name redis
OK
10.0.0.42:6379> hmget book name price
1) "redis"
2) "10"
10.0.0.42:6379> hget book name #也可以单个的获取
"redis"
10.0.0.42:6379> hget book price #也可以单个的获取
"10"
获取key里的所有值
10.0.0.42:6379> hgetall book
1) "price"
2) "10"
3) "name"
4) "redis"
删除key里的某个field
10.0.0.42:6379> hdel book name
(integer) 1
10.0.0.42:6379> hgetall book
1) "price"
2) "10"
删除某个key
10.0.0.42:6379> del mountain tree #没有hmdel和mdel
(integer) 2
查看key里的field的值是否存在
10.0.0.42:6379> hexists book name
(integer) 0
10.0.0.42:6379> hexists book price
(integer) 1
3 列表类型(list)


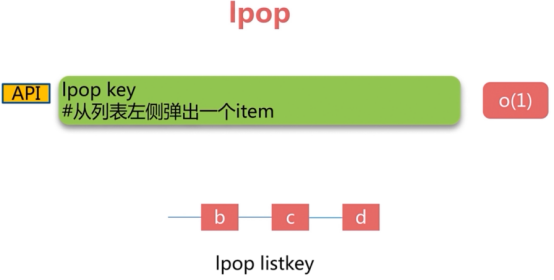
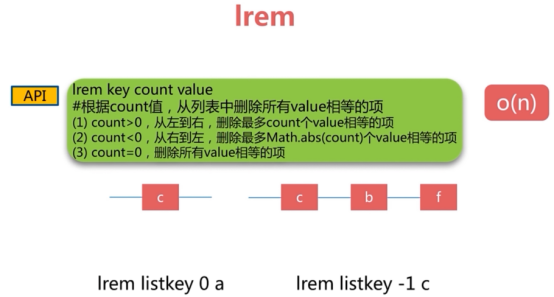
可以从两端存取
从左侧插入
10.0.0.42:6379> lpush mylist 1hehe
(integer) 1
10.0.0.42:6379> lpush mylist 2hehe
(integer) 2
查看key的长度
10.0.0.42:6379> llen mylist
(integer) 2
从右边插入
10.0.0.42:6379> rpush mylist 1hehe 2hehe
(integer) 4
查看key的长度
10.0.0.42:6379> llen mylist
(integer) 4
查看key列表里的值
10.0.0.42:6379> lindex mylist -1 #从右边开始最后一个
"2hehe"
10.0.0.42:6379> lindex mylist -2 #从右边开始倒数第二个
"1hehe"
10.0.0.42:6379> lindex mylist -3 #从右边开始倒数第三个
"1hehe
10.0.0.42:6379> lindex mylist -4 #从右边开始倒数第四个
"2hehe"
弹出key列表里的值(弹出就会被删除)
10.0.0.42:6379> rpop mylist
"2hehe"
10.0.0.42:6379> rpop mylist
"1hehe"
10.0.0.42:6379> rpop mylist
"1hehe"
10.0.0.42:6379> rpop mylist
"2hehe"
从左边插入值
10.0.0.42:6379> lpush mylist k1
(integer) 1
10.0.0.42:6379> lpush mylist k2
(integer) 2
10.0.0.42:6379> lpush mylist k3
(integer) 3
10.0.0.42:6379> lpush mylist k4
(integer) 4
10.0.0.42:6379> lpush mylist k5
(integer) 5
10.0.0.42:6379> llen mylist
(integer) 5
查看key区间里的值
10.0.0.42:6379> lrange mylist 0 -1
1) "k5"
2) "k4"
3) "k3"
4) "k2"
5) "k1"
10.0.0.42:6379> lrange mylist -5 -1
1) "k5"
2) "k4"
3) "k3"
4) "k2"
5) "k1"
这里方向只能从左到右,所以不能用lrange mylist -5 -1或lange mylist -1 -5
4 集合(set)
Set 就是一个集合,集合的概念就是一堆不重复值的组合。利用 Redis 提供的 Set 数据结构,可以存储一些集合性的数据。
比如在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。
因为 Redis 非常人性化的为集合提供了求交集、并集、差集等操作,那么就可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
1.共同好友、二度好友
2.利用唯一性,可以统计访问网站的所有独立 IP
3.好友推荐的时候,根据 tag 求交集,大于某个 threshold 就可以推荐
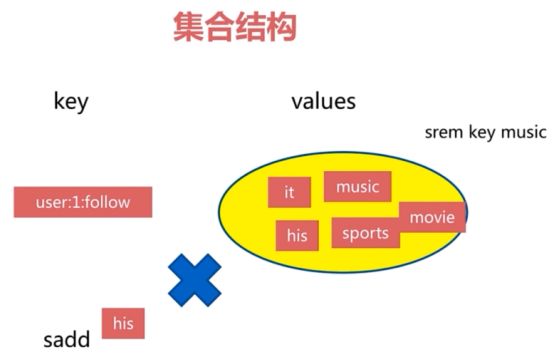

增加key集合元素
10.0.0.42:6379> sadd word1 a
(integer) 1
10.0.0.42:6379> sadd word1 a b c
(integer) 2 #一个集合里只能有一个相同的元素
10.0.0.42:6379> sadd word1 a b c c d
(integer) 1 #一个集合里只能有一个相同的元素
10.0.0.42:6379> sadd word1 a b c d e
(integer) 1 #一个集合里只能由一个相同的元素
删除key集合里的元素
10.0.0.42:6379> srem word1 e
(integer) 1
查看key集合里的所有元素
10.0.0.42:6379> smembers word1
1) "d"
2) "a"
3) "b"
4) "c"
查看集合里某个元素是否存在
10.0.0.42:6379> sismember word1 e
(integer) 0
10.0.0.42:6379> sismember word1 d
(integer) 1
10.0.0.42:6379> sadd setA 1 2 3
(integer) 3
10.0.0.42:6379> sadd setB 2 3 4
(integer) 3
差集
10.0.0.42:6379> sdiff setA setB
1) "1"
10.0.0.42:6379> sdiff setB setA
1) "4"
交集
10.0.0.42:6379> sinter setA setB
1) "2"
2) "3"
10.0.0.42:6379> sinter setB setA
1) "2"
2) "3"
并集
10.0.0.42:6379> sunion setA setB
1) "1"
2) "2"
3) "3"
4) "4"
查看集合的个数
10.0.0.42:6379> scard setA
(integer) 3
将差集定向到另外一个集合
10.0.0.42:6379> sdiffstore hehe setA setB
(integer) 1
10.0.0.42:6379> key *
(error) ERR unknown command 'key'
10.0.0.42:6379> keys *
1) "mylist"
2) "key3"
3) "setA"
4) "mykey"
5) "hehe"
6) "key1"
7) "key2"
8) "car"
9) "word1"
10) "num"
11) "setB"
10.0.0.42:6379> scard hehe
(integer) 1
10.0.0.42:6379> smembers hehe
1) "1"
添加有序集合
10.0.0.42:6379> zadd OLD1 1 zhangssan 2 zhangsi 3 zhangwu
(integer) 3

获取集合元素的分值
10.0.0.42:6379> zscore OLD1 zhangssan
"1"
10.0.0.42:6379> zscore OLD1 zhangsi
"2"
列出集合元素区间的值
10.0.0.42:6379> zrange OLD1 0 2
1) "zhangssan"
2) "zhangsi"
3) "zhangwu"
10.0.0.42:6379> zrange OLD1 -3 -1
1) "zhangssan"
2) "zhangsi"
3) "zhangwu"
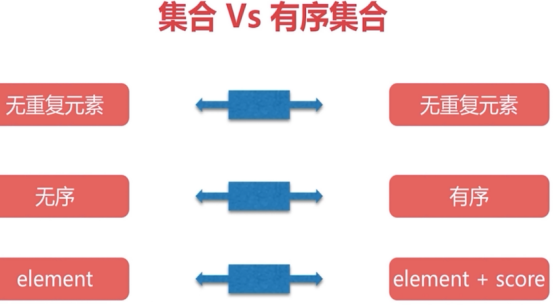
5有序集合(zset)Sorted Sets
有序集合的成员是唯一的,但分数(score)却可以重复

redis事务
要么都执行,要么都不执行(跟成功与否无关)
瑞士军刀redis

慢查询

生命周期很重要
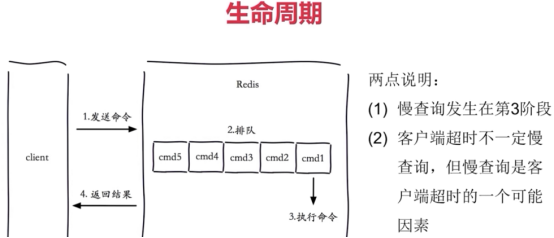
客户端超时不一定是慢查询造成的


pipeline

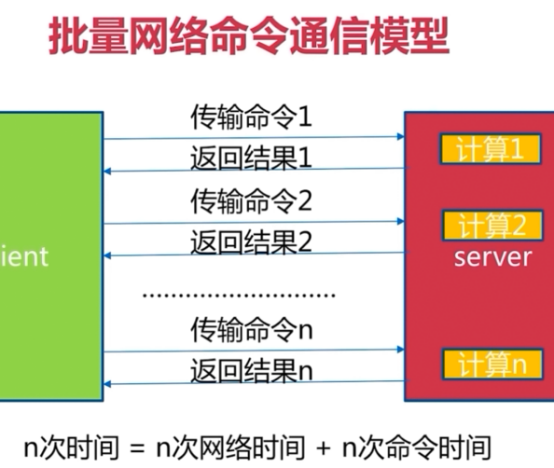
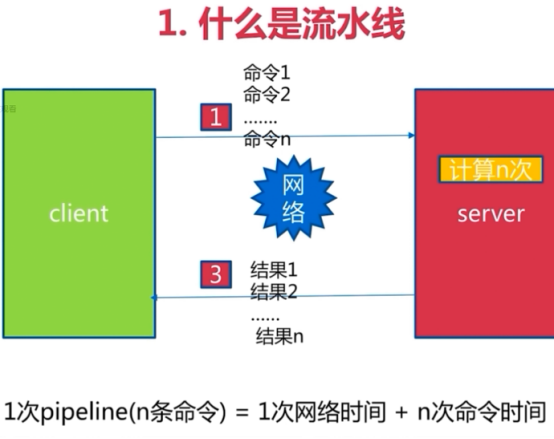

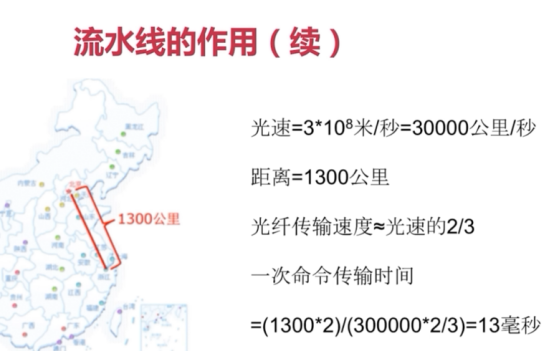


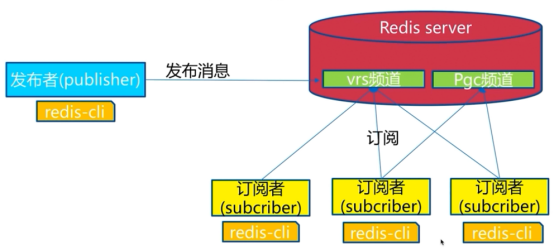
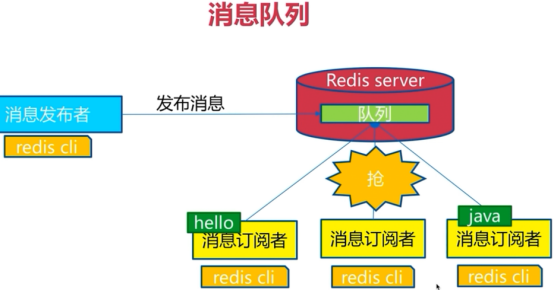
发布订阅


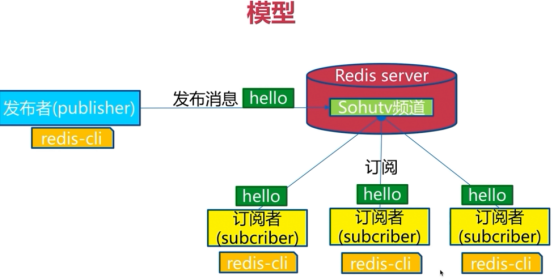
可以订阅不同的频道





Bitmap

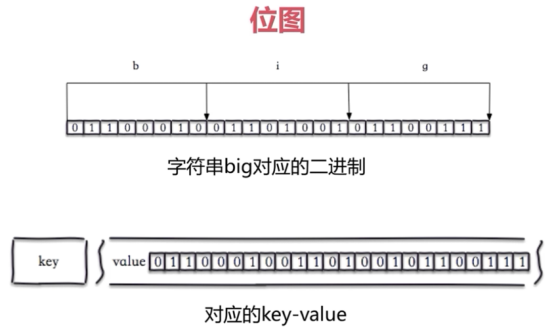
位图可以操作位
HypeLogLog
是数据结构



GEO

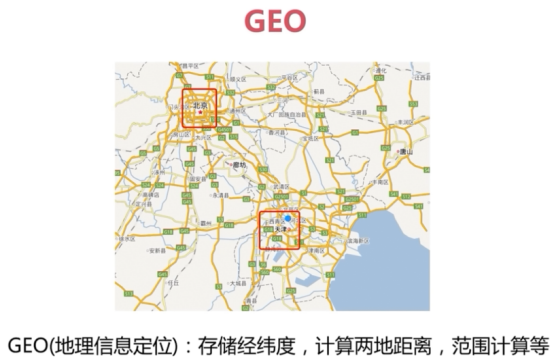




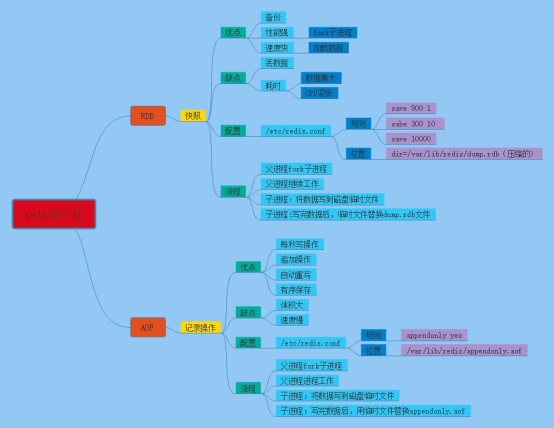
redis 持久化
Redis支持两种方式的持久化,一种是RDB方式一种是AOF方式。可以单独使用其中一种或将二者结合使用。
概述


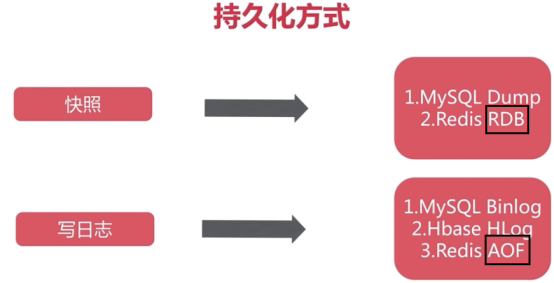
可以同时使用AOF和RDB
RDB
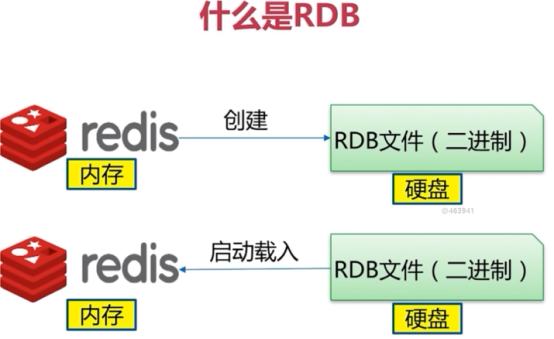
什么是RDB
在指定的时间间隔内生产数据集的时间点快照(ponit-in-time snapshot)
RDB优点:
- RDB是一个非常紧凑(compact)的文件,它保存了redis在某个时间点上的数据集,这种文件非常适合用于进行备份,比如说,你可以在最近的24小时内,每小时备份一次RDB文件,并且每个月的每一条也备份一个RDB文件。这样的话,即使遇到问题,也可以随时将数据集还原到不同版本。
- RDB非常使用于灾难恢复(disaster recovery)。它只用一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊S3中
- RDB可以最大化Redis的性能,父进程在保存RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会出路接下来的所有保存工作,父进程无须执行任何磁盘I/O操作。
- RDB在恢复大数据时的速度比AOF的恢复速度要快。
RDB缺点:
RBD的缺点:
- 如果你需要尽量避免服务器故障时丢失数据,那么RDB不适合你。虽然Redis允许你设置不同的保存点(save point)来控制保存RDB文件的频率,但是,因为RDB文件需要保存整个数据即的状态,所以它并不是一个轻松的操作。因此你可能至少5分钟才保存一次RDB文件。在这种情况下,一旦发生故障停机,你就可能丢失好几分钟的数据。
- 每次保存RDB的时候,Redis都要fork()出一个子进程,并由子进程来进行实际的持久化工作。在数据集比较庞大的时候,fork()可能会非常耗时,造成服务器在某某毫秒内停止处理客户端,如果数据集非常巨大,并且CPU时间非常紧张的话,那么这种停止时间甚至可能会长达整整1秒,虽然AOF重写也需要进行fork(),但无论AOF重写的执行间隔有多长,数据的耐久性都不会有任何损失。
1、耗时、耗性能
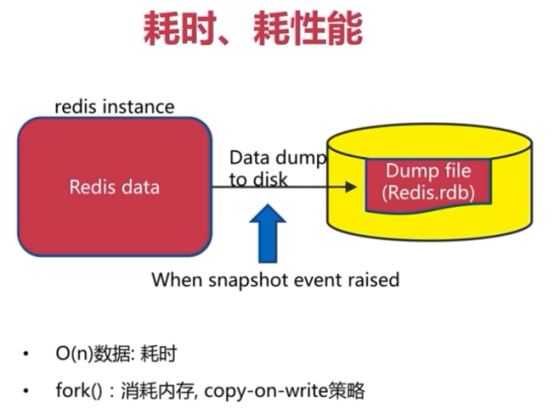
2、不可控、丢失数据
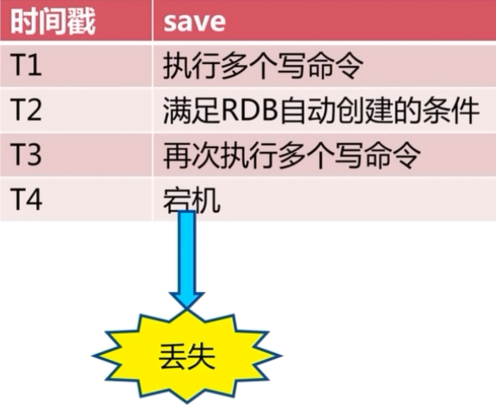
触发机制(3种):
1、save(同步)
2、bgsave(异步)
3、自动
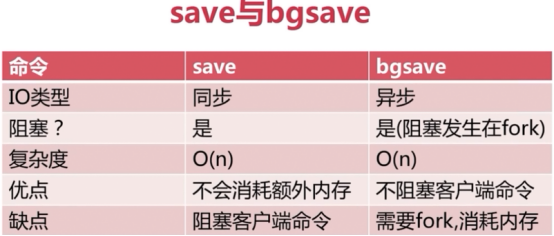
save(同步)

由于redis是单线程,当数据量大的时候会造成阻塞:(当执行save时,有其他命令执行是阻塞的,只有当save执行完过后,其他命令才会执行,这有体现了单线程)
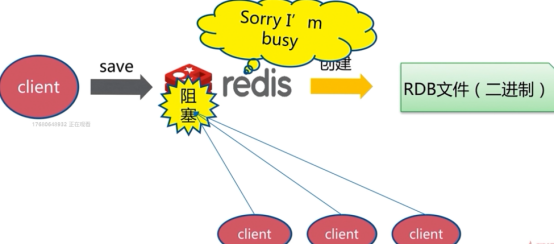
文件策略:

bgsave(异步)
异步,不会阻塞,会生成一个子进程,
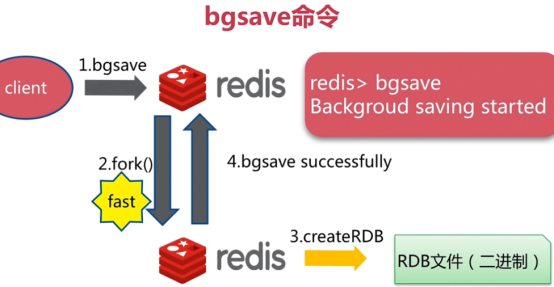
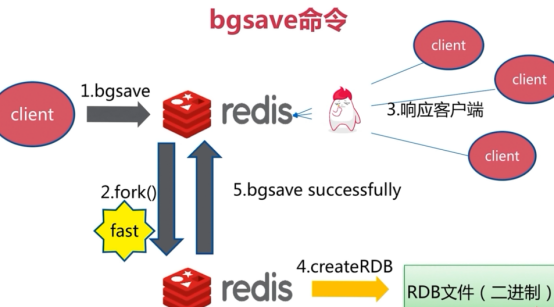
文件策略
save与bgsave的比较:
自动
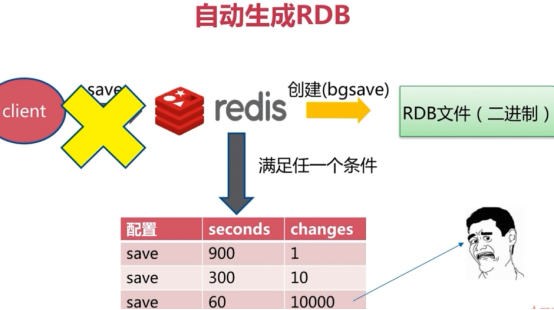

save 900 1 #在900秒内如果有一个key被改变,就做一次快照
save 300 10 #在300秒内 如果有十个key被改变,就做一次快照
save 60 10000 #在60秒内如果有一万个key被改变,就做一次快照
上面三个选项就是RDB的自动触发条件,都是或的关系,自动配置满足任一就会被执行。如果要禁用RDB持久化策略,只要不设置任何save指令或者save ""便可。
rdbcompression yes
默认是开启压缩存储的,采用LZF算法进行压缩,如果redis占用空间不大或者不想消耗CPU来进行压缩可以设置no为关闭此功能,一般不关闭。
rdbchecksum yes
在存储快照后,还可以让redis使用CRC64算法来进行数据检验,但是这样会增加大约10%的性能消耗,一般也是开启的。
dbfilename dump.rdb
指定rdb文件的名称
dir ./
指定rdb文件的目录位置,只能为文件夹不能为文件,一般我们保持到一个单独的目录中,如我们生产就是单挂的SSD盘
stop-writes-on-bgsave-error yes
当bgsave发生错入,就停止写入


这三种机制都会生成rdb文件
快照存在哪儿?(yum安装位置是在这里,源码就是dbfilename的位置)
[root@Redis ~]# ls /var/lib/redis/
dump.rdb
[root@Redis ~]# vim /var/lib/redis/dump.rdb
总结
1、RDB是redis内存到硬盘的快照,用于持久化
2、save通常会阻塞redis
3、bgsave不会阻塞redis,但是会fork新进程
4、save自动配置满足任一就会被执行
5、有些触发机制不容忽视
RDB最佳策略
1、"关掉RDB"
2、集中管理
3、做主从的时候,从开启RDB
AOF
什么是AOF
记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据。Redis还可以在后台对AOF文件进行重写(rewrite),使得AOF文件的体积不会超出保持数据集体状态所需实际大小。
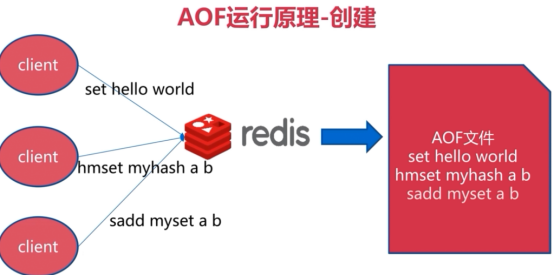
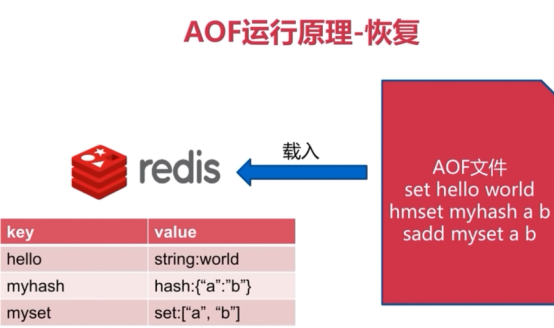
AOF策略(3种)
1、always

2、everysec

2、no

三种策略比较:

AOF重写配置
流程:
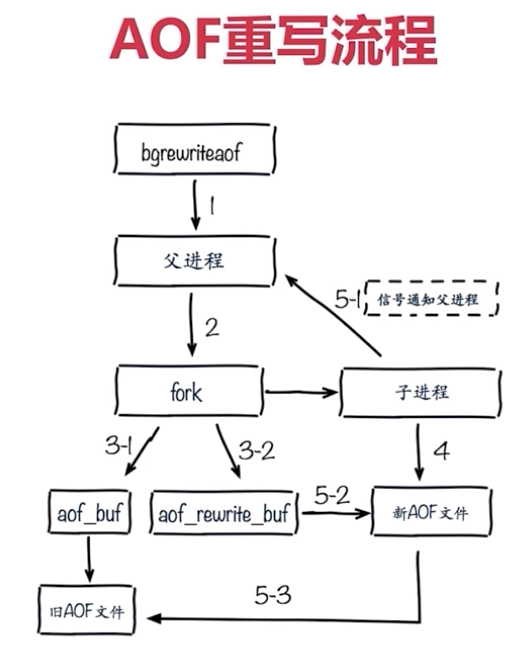

AOF重写的作用:
1、减少硬盘占用量
2、加速恢复速度
AOF重写实现方式:
1、bgrewriteaof命令
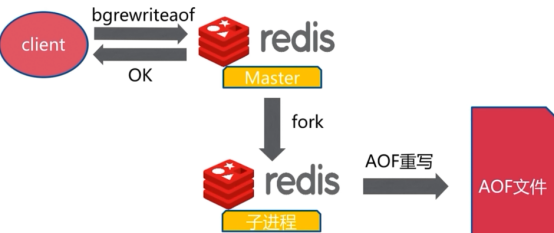
2、AOF重写配置

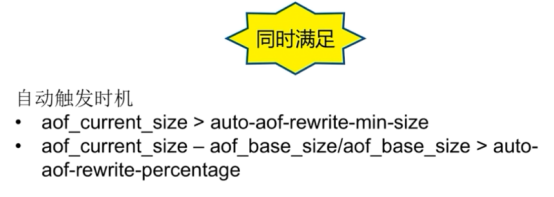
开启重写配置(开启AOF):

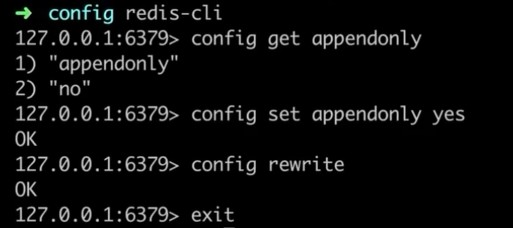
参数解释:
appendonly yes #上面是开启AOF持久化。每执行一条会更改redis中的数据的命令,redis就会将该命令写入硬盘中的AOF文件。appendonly是支持动态配置
appendfilename appendonly.aof #设置AOF文件的名称。因为我们上面已经制定了目录文件是/bigdiskpath 所以这个AOF文件也会存储在/bigdiskpath中。
auto-aof-rewrite-percentage 100 #当目前AOF文件大小超过上一次重写时的AOF文件的百分之多少时会再次进行重写,这里是百分之百也就是翻了一倍。如果之前没有重写过,则以启动时的AOF文件大小为依据。
auto-aof-rewrite-min-size 64mb #允许重写的最小AOF文件的大小,这里是当小于64MB的时候不执行重写。
appendfsync everysec #默认采用的是这种形式即每秒执行一次同步操作。# appendfsync always表示每次执行写入操作都会执行同步这是最安全的也是最慢的方式。# appendfsync no表示交给系统来执行同步操作这是最快也是最不安全的方式。一般选择默认便可。
no-appendfsync-on-rewrite yes #防止因为磁盘同步,卡掉住进程的情况出现
AOF文件里面的内容:
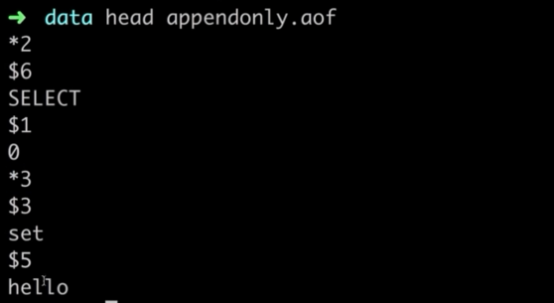
*2代表下面有两个参数
$6第一个参数,有6个字节
SELECT
$1第二个参数,有一个字节
0
以此内推
AOF的优点:
- 使用AOF持久化会让redis变得非常耐久(much more durable),你可以设置不同的fsync,每秒钟一次fsync,或者每次执行写入命令
fsync。AOF的默认策略为每秒钟fsync一次,在这种配置下,redis仍然可以保持良好的性能,并且就算发生故障停机,也最多会丢失1秒中的数据(fsync会在后台线程执行,所以主线程可以继续努力的处理命令请求) - AOF文件是一个只进行追加操作的日志文件(append only log),因此AOF文件的写入不需要进行seek,即使日志因为某些原因而包含了未写入完整命令(比如磁盘已满,写入时磁盘已满,写入中途停机,等等)redis-check-aof工具也可以轻易地修复这种问题。
- Redis可以在AOF文件体积变得过大时,自动的在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为redis在创建新的AOF文件的过程中,会继续将命令追加到现有的AOF文件里,即使重写过程发售那个停机,现有的AOF文件按也不会丢失。而一旦新AOF文件创建完毕,redis就会从旧AOF文件切换到新AOF文件,并开始对新的AOF进行追加操作。
- AOF文件有序地保存了对数据库执行的所有写入操作。这些操作以redis协议的格式保存,因此AOF文件的内容非常容易被人读懂,对文件进行分析也很轻松。导出(export)AOF文件也非常简单,举个例子,如果你不小心执行了FLUSH命令,但只要AOF文件未被重写,那么只要停止服务器,移除AOF文件末尾的FLUSH命令,并重启Redis,就可以将数据集恢复到FLUSH执行之前的状态。
AOF的缺点:
- 对于相同的数据集来说,AOF文件体积通常要大于RDB的体积。
- 根据所使用的fsync策略,AOF的速度可能会慢于RDB。在一般情况下,每秒fsync的性能依然非常高,而关闭fsync可以让AOF速度和RDB一样快,即使在高负荷之下也是如此。不过在处理储大的写入载入时,RDB可以提供更有保证的最大延迟时间(latency)6
总结
AOF最佳策略
1、开启AOF:缓存和存储
2、AOF重写集中管理
3、everysec
怎么从RDB持久化切换到AOF持久化
1.为最新的dump.rdb文件创建一个备份
2.将备份放到一个安全的地方
3.执行以下两条命令
10.0.0.42:6379> config set appendonly yes #开启AOF
10.0.0.42:6379> config set save "" #关闭RDB
4.确保命令执行之后,数据库的键的数量没有改变
5.确保写命令会被正确追加到AOF文件的末尾
AOF与RDB的比较
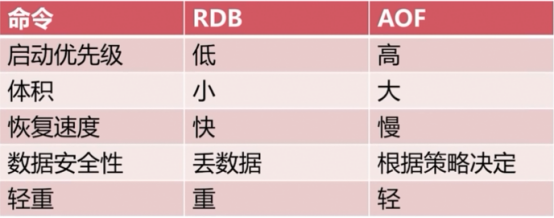
AOF与RDB的最佳策略:(两种都适合)
1、小分片
2、缓存或者存储
3、监控(硬盘、内存、负载、网络)
4、足够的内存
RDB AOF混合方式进行持久化
Redis4.0之后可以使用RDB AOF混合方式进行持久化了,说到持久化,持久化在Redis里有两种使用场景
1 服务器重启的时候可以加载持久化文件恢复数据
2 AOF由于是采用顺序写的方式,所以经过一定的时间旧的AOF就不够新了需要进行重写保证数据一致性
# When rewriting the AOF file, Redis is able to use an RDB preamble in the
# AOF file for faster rewrites and recoveries. When this option is turned
# on the rewritten AOF file is composed of two different stanzas:
#
# [RDB file][AOF tail]
#
# When loading Redis recognizes that the AOF file starts with the "REDIS"
# string and loads the prefixed RDB file, and continues loading the AOF
# tail.
#
# This is currently turned off by default in order to avoid the surprise
# of a format change, but will at some point be used as the default.
aof-use-rdb-preamble no # 默认是no,配成 yes就行了
上面的注释说了,开启了aof-use-rdb-preamble后,在对AOF进行重写的时候,AOF文件前半部分是RDB格式,后半部分是AOF格式
持久化中开发运维问题
fork
1、fork操作
-
A、同步操作
-
B、与内存量息息相关:内存越大,耗时越长(与机器类型有关)
-
C、info:latest_fork_usec 查看最后一次fork的内存
2、改善fork

子进程开销和优化


AOF追加阻塞
AOF追加阻塞
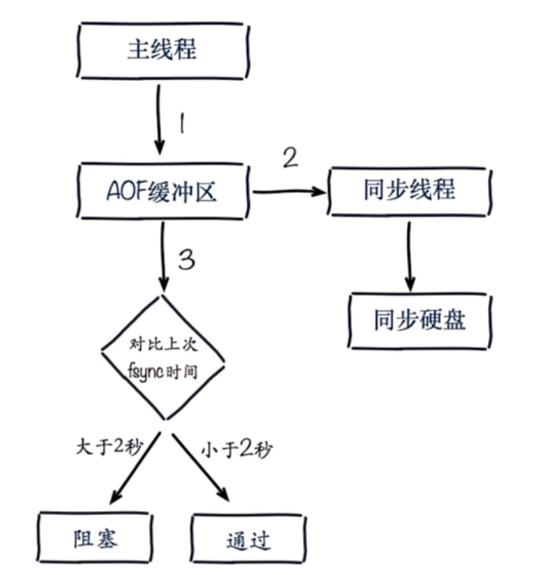
AOF阻塞定位
1、redis日志

2、info Persistence命令
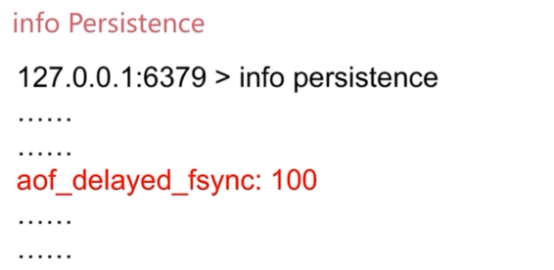
3、top命令

redis 主从
单机问题
1、机器故障
2、容量瓶颈
3、QPS瓶颈
概述
Redis支持简单且易用的主从复制(master-slave replication)功能,该功能可以让从服务器(slave server)成为主服务器(master server)的精确复制品。
以下是关于redis复制功能的各个重要方面:
- Redis使用异步复制。从redis 2.8开始,从服务器会以每秒一次的频率向主服务器报告复制流(replication stream)的处理进度。
- 一个服务器可以有多个从服务器。
- 不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个图装结构。
- 复制功能不会阻塞主服务器,即使有一个或多个服务器正在进行初次同步,主服务器也可以继续处理命令请求。
- 复制功能也不会阻塞从服务器:只要在redis.conf文件中进行了相应的设置,即使从服务器正在进行初次同步,服务器已也可使用旧版本的数据集来处理命令查询。
- 复制功能可以单纯地用于数据冗余,也可以通过让多个从服务器处理只读命令请求来提升扩展性,比如说,反正的sort命令可以交给附属节点去允许。
- 可以通过复制功能来让主服务器免于执行持久化操作,只要关闭主服务器的持久化功能,然后由从服务器去执行持久化操作即可。
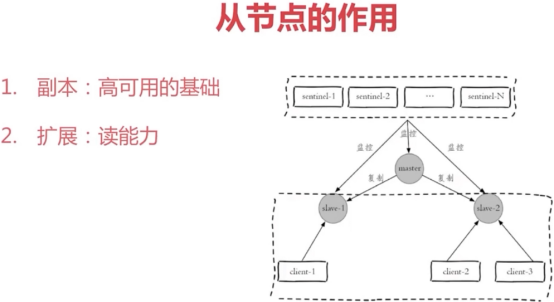
主从复制的作用
1、数据副本
2、扩展读性能
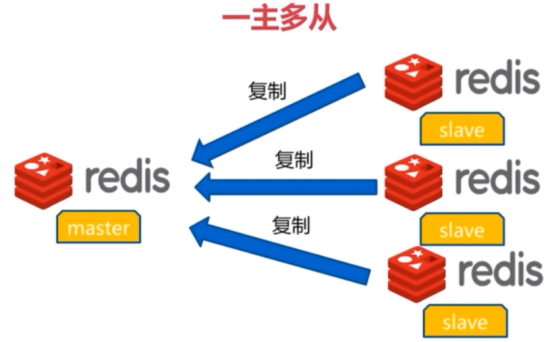
总结:
1、一个master可以有多个slave
2、一个slave只能有一个master
3、数据流向是单向的,master到slave
实现主从复制(2种方式):
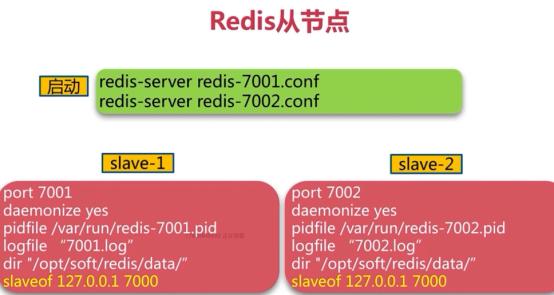
slaveof命令
cp /etc/redis.conf /etc/redis6380.conf
vim /etc/redis6380.conf
port 6380
启动从节点并配置主从关系:
redis-server /etc/redis2.conf &
10.0.0.42:6380> slaveof 10.0.0.42 6379 #5.x版本是replicaof 主IP 主端口。如果设置了密码,关联后动态设置密码使用 config set masterauth 密码
OK
info Replication查看主从关系,主、从上执行都可以
测试主从:
10.0.0.42:6379> set masterkey1 1
OK
10.0.0.42:6380> get masterkey1
"1"
注意事项:
1.默认情况下,redis从库是只读的。slave-read-only yes
2.slaveof no one将从库提升为主数据库,相当于关闭主从了

3.从redis持久化
4.复制功能运作原理
- 无论是初次链接还是重新链接,当建立一个从服务器时,从服务器将向主服务器发送一个SYNC命令。
-
直到sync命令的主服务器开始执行BGSAVE,并在保存操作执行期间,减所有新执行的写入命令都保存一个缓冲区里面。
-
当BGSAVE执行完毕后,主服务器将执行保存操作所得的
.rdb文件发送给从服务器,从服务器接收这个.rdb文件,并将文件中的数据载入到内存中。之后主服务器会以redis命令协议的格式,将写命令缓冲区中积累的所有内容都发送给从服务器。
配置文件
cp /etc/redis6379.conf /etc/redis638.conf
vim /etc/redis6380.conf #从redis配置
daemonize yes
pidfile /var/run/redis-6379.pid
port 6380
logfile "6380.log"
dbfilename dump-6380.rdb
appendonly yes
slave-read-only yes # redis主从默认从库是只读的
slaveof 172.0.0.1 6379 #5.x及以上版本是replicaof 主IP 主端口
masterauth <master-paasword> #如果主节点有密码,那么从节点需要在这里指定这个密码。或者动态配置使用命令 SLAVEOF 动态指定主从关系 ,如果设置了密码,关联后动态设置密码使用 config set masterauth 密码
#启动从redis
redis-server /etc/redis6380.conf &
> info Replication #查看主从相关信息
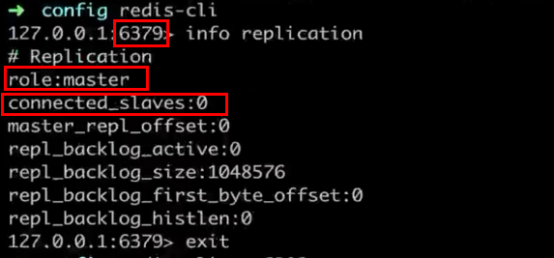
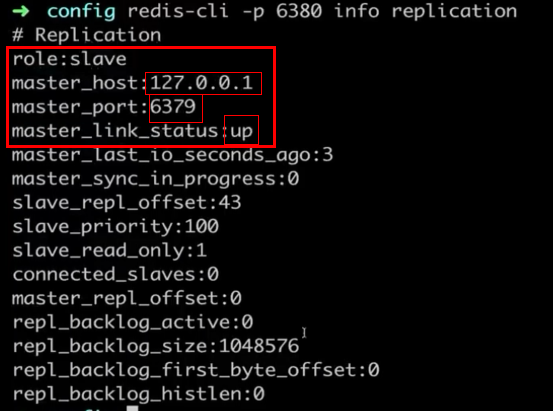
验证:
在主上进行写操作:
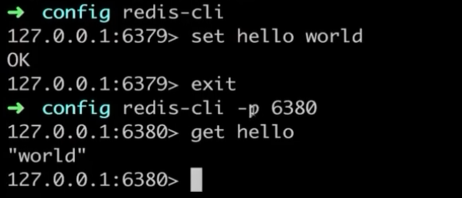
在从上面进行写操作(验证从节点上面默认只能读,不能写):

从节点是否只读;默认yes只读,为了保持数据一致性,应保持默认。如果要写操作yes改为no
slave-read-only yes
2种方式比较

全量复制
过程:
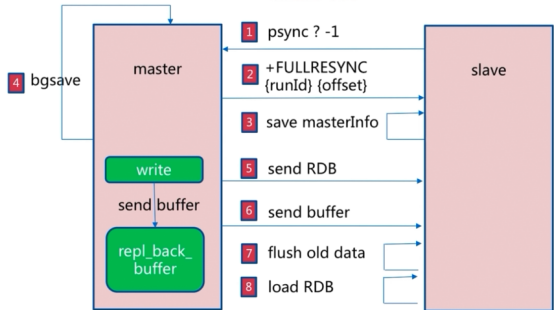
开销:
1、bgsave时间
2、RDB文件网络传输时间
3、从节点清空数据时间
4、从节点加载RDB的时间
5、可能的AOF重写时间
部分复制
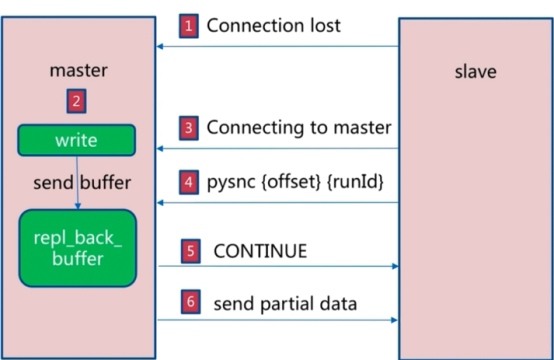
利用docker单机部署1主1从
cat > redis1.conf << EOF
#是否是守护进程(no|yes)
daemonize no
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6379
#redis系统日志
#logfile "/data/redis_6379.log"
#redis工作目录
dir "/data"
# aof持久化
appendonly yes
# rdb
dbfilename dump.rdb
protected-mode no
bind 0.0.0.0
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth 123654
#这是redis设置的密码
requirepass 123654
EOF
cat > redis2.conf << EOF
#是否是守护进程(no|yes)
daemonize no
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6380
#redis系统日志
#logfile "/data/redis_6379.log"
#redis工作目录
dir "/data"
# aof持久化
appendonly yes
# rdb
dbfilename dump.rdb
protected-mode no
bind 0.0.0.0
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth 123654
#这是redis设置的密码
requirepass 123654
EOF
cat > redis1m1s.sh << EOF
#!/bin/bash
start_redis1() {
echo "Starting the redis1..."
test -d /data/redis1 || mkdir -p /data/redis1
#如果在配置文件指定了requirepass、masterauth参数,那么就不需要在启动参数指定了
docker run -itd --name redis1 --restart=always --network=host -d -v ./redis1.conf:/opt/redis.conf -v /data/redis1:/data redis redis-server /opt/redis.conf --requirepass "123654" --masterauth 123654
}
start_redis2() {
echo "Starting the redis2..."
test -d /data/redis2 || mkdir -p /data/redis2
#如果在配置文件指定了requirepass、masterauth参数,那么就不需要在启动参数指定了
docker run -itd --name redis2 --restart=always --network=host -d -v ./redis2.conf:/opt/redis.conf -v /data/redis2:/data redis redis-server /opt/redis.conf --requirepass "123654" --replicaof 10.11.100.103 6379 --masterauth 123654
}
Usage() {
echo "Usage: \$0 {start|stop|rm|(redis1/redis2/all)}"
}
case \$1 in
"start")
case \$2 in
"redis1")
start_redis1
;;
"redis2")
start_redis2
;;
"all")
start_redis1
start_redis2
;;
*)
Usage
exit 1
;;
esac
;;
"stop")
case \$2 in
"redis1")
docker stop redis1
;;
"redis2")
docker stop redis2
;;
"all")
docker stop redis1
docker stop redis2
;;
*)
Usage
exit 1
;;
esac
;;
"rm")
case \$2 in
"redis1")
docker rm -f redis1
;;
"redis2")
docker rm -f redis2
;;
"all")
docker rm -f redis1
docker rm -f redis2
;;
*)
Usage
exit 1
;;
esac
;;
*)
Usage
exit 1
;;
esac
EOF
bash ./redis1m1s.sh start all
主从故障处理
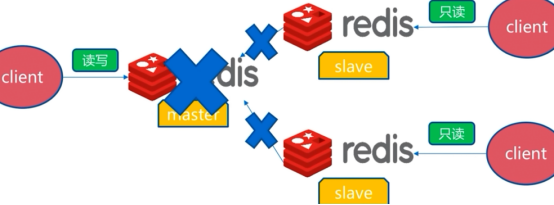
slave故障:
master故障:
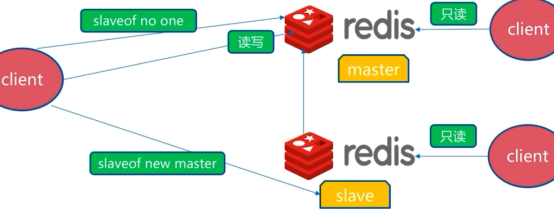
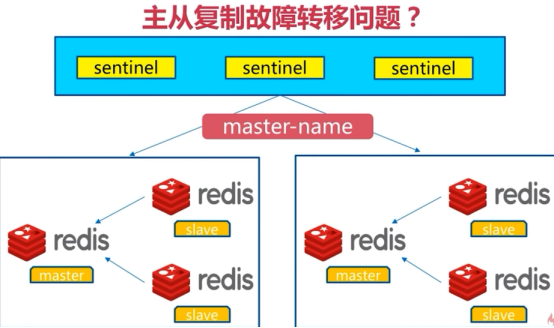
主从复制问题
1、手动故障转移
2、写能力和存储能力受限
注意(配置前确认redis版本)
1.replicaof和slaveof
在redis5.x的主从配置中,从机配置要配置replicaof参数。而早期版本,要配置的是slaveof参数。
2.已有redis容器
得先删除该容器,待配置好外部redis.conf后,重新创建。
3.daemonize参数
在docker中,redis.conf文件中的daemonize参数要设置为no(默认是no)。
daemonize yes的意思为后台运行redis,但这会导致容器跑不起来。
4.protected-mode
设置为yes时,只允许本地服务端连接,导致不同机子(或虚拟机)的主从机无法连接。
主从中开发与运维中的问题
读写分离
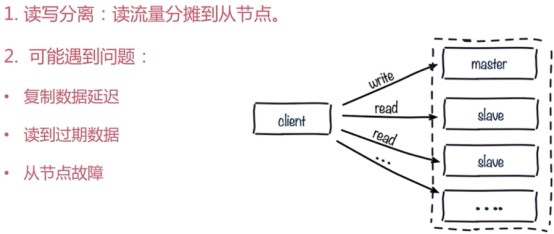
主从配置不一致

避免全量复制

避免复制风暴

高可用->keepalived
主从+keepalived
Php环境的redis主从
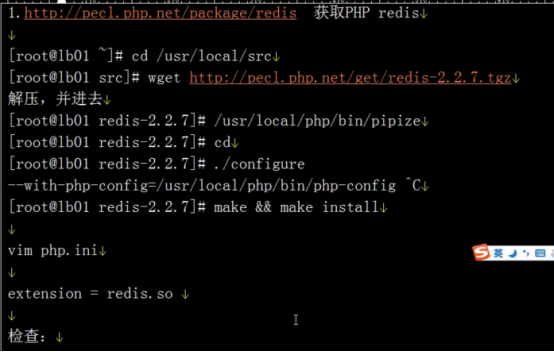
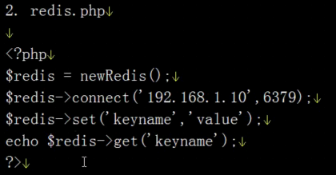
[root@Redis redis-2.2.7]# yum install httpd php php-pdo php-cli php-gd php-mbstring -y #gd画图,pdo扩展
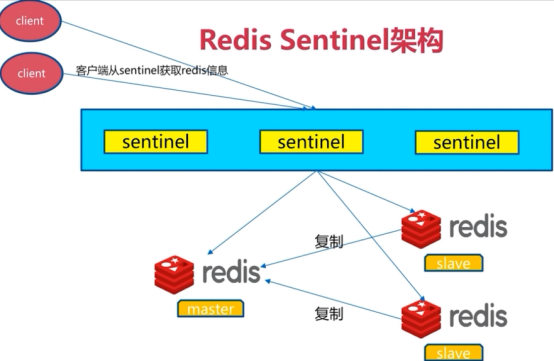
redis sentinel架构(哨兵模式->之高可用)sentinel节点数必须是三个以上(3、5、7),且最好是基数个
在线文档:http://doc.redisfans.com/topic/sentinel.html
这个是从开发的角度讲的很详细:http://blog.csdn.net/gqtcgq/article/details/51531328
部署参考文档:https://www.cnblogs.com/kevingrace/p/9004460.html
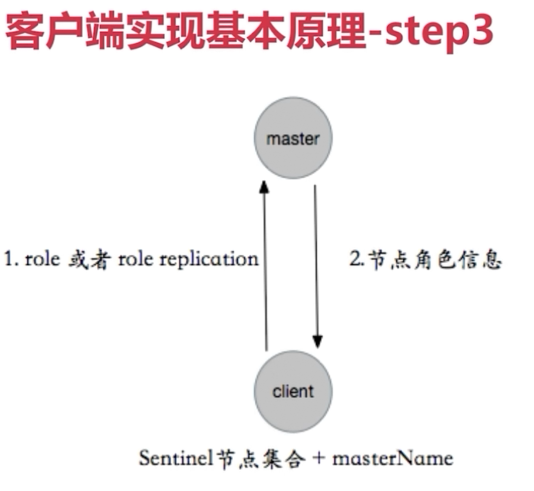
Sentinel介绍
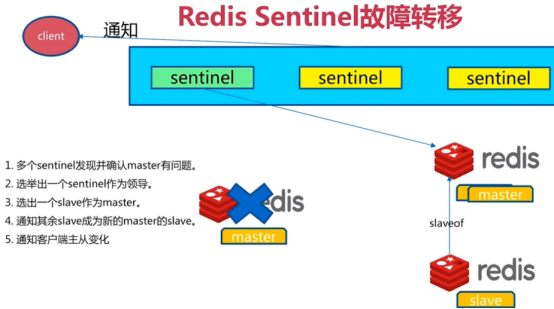
Sentinel是一个管理多个redis实例的工具,它可以实现对redis的监控、通知、自动故障转移。sentinel不断的检测redis实例是否可以正常工作,通过API向其他程序报告redis的状态,如果redis master不能工作,则会自动启动故障转移进程,将其中的一个slave提升为master,其他的slave重新设置新的master实例。也就是说,它提供了:
-
监控(Monitoring): Sentinel 会不断地检查你的主实例和从实例是否正常。
-
通知(Notification): 当被监控的某个 Redis 实例出现问题时, Sentinel 进程可以通过 API 向管理员或者其他应用程序发送通知。
-
自动故障迁移(Automatic failover): 当一个主redis实例失效时, Sentinel 会开始记性一次failover, 它会将失效主实例的其中一个从实例升级为新的主实例, 并让失效主实例的其他从实例改为复制新的主实例; 而当客户端试图连接失效的主实例时, 集群也会向客户端返回新主实例的地址, 使得集群可以使用新主实例代替失效实例。
Redis Sentinel自身也是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程, 这些进程使用流言协议(gossip protocols)来接收关于主Redis实例是否失效的信息, 然后使用投票协议来决定是否执行自动failover,以及评选出从Redis实例作为新的主Redis实例。
架构图及原理



安装与配置
1、配置开启主从节点
2、配置开启sentinel监控主节点。(sentinel是特殊的redis,不存数据的)
3、实际应该是多机器
4、详细配置节点
sentinel默认端口是26379

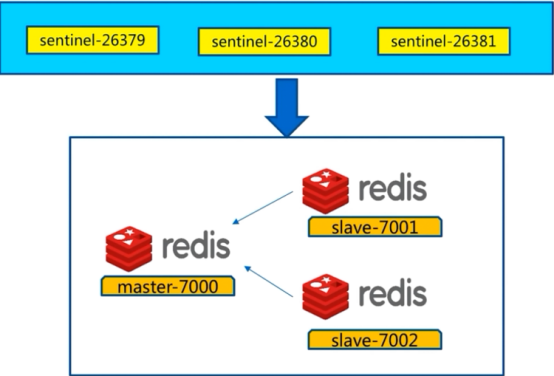
ps:sentinel节点数必须是三个以上(3、5、7),且最好是基数个


#第一步:相当于发现故障
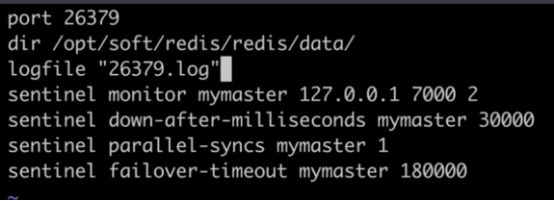
sentinel monitor mymaster 127.0.0.1 7000 2
sentinel monitor 主节点名称 主节点IP地址 主节点端口 几个sentinel发现主节点有问题,然后进行故障转移
这句话的意思是 Sentinel 去监视一个名为 mymaster 的主redis实例,这个主实例的 IP 地址为本机地址127.0.0.1 , 端口号为 6379 , 而将这个主实例判断为失效至少需要 2 个 Sentinel 进程的同意,只要同意 Sentinel 的数量不达标,自动failover就不会执行。同时,一个Sentinel都需要获得系统中大多数Sentinel进程的支持, 才能发起一次自动failover, 并预留一个新主实例配置的编号。而当超过半数Redis不能正常工作时,自动故障转移是无效的
#第二步:sentinel对master的发现,一直ping master
sentinel down-after-milliseconds mymaster 30000
主节点名称 ping30000毫秒
指定了 Sentinel 认为Redis实例已经失效所需的毫秒数。这里是30秒。当实例超过该时间没有返回PING,或者直接返回错误, 那么 Sentinel 将这个实例标记为主观下线(subjectively down,简称 SDOWN )。只有一个 Sentinel进程将实例标记为主观下线并不一定会引起实例的自动故障迁移: 只有在足够数量的 Sentinel 都将一个实例标记为主观下线之后,实例才会被标记为客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。
#第三步:复制的配置,选择新master,然后老的slave对新的master进行复制
sentinel parallel-syncs mymaster 1
复制是并发还是串行的 主节点名称 代表每次只能复制一个,减轻master的负载
指定了在执行故障转移时, 最多可以有多少个从Redis实例在同步新的主实例, 在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长。尽管复制过程的绝大部分步骤都不会阻塞从实例, 但从redis实例在载入主实例发来的 RDB 文件时, 仍然会造成从实例在一段时间内不能处理命令请求: 如果全部从实例一起对新的主实例进行同步, 那么就可能会造成所有从Redis实例在短时间内全部不可用的情况出现。所以从实例被设置为允许使用过期数据集(参见对 redis.conf 文件中对 slave-serve-stale-data 选项),可以缓解所有从实例都在同一时间向新的主实例发送同步请求的负担。你可以通过将这个值设为 1 来保证每次只有一个从Redis实例处于不能处理命令请求的同步状态
#第四步:转移时间
sentinel failover-timeout mymaster 180000
如果在该时间(ms)内未能完成failover操作,则认为该failover失败。
#第五步: 如果主redis设置了密码,那么就需要指定主的密码。
#需要注意的是,为了使这个密码生效,您还需要在 Redis 主服务器配置文件 redis.conf 中设置相应的密码参数。具体来说,您需要在配置文件中添加以下内容:requirepass 12345 这样才能确保使用密码成功连接 Redis 服务器。
sentinel auth-pass mymaster 12345
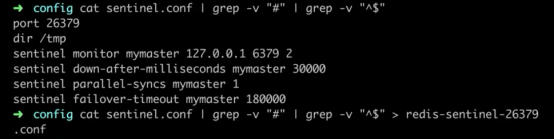
加一个守护进程启动:daemonize yes
运行Sentinel的两种方式:
第一种:# redis-sentinel /usr/redis/sentinel.conf
第二种:# redis-server /usr/redis/sentinel.conf --sentinel
Ps:以上两种方式,都必须指定一个sentinel的配置文件sentinel.conf,如果不指定,将无法启动sentinel。sentinel默认监听26379端口,所以运行前必须确定该端口没有被别的进程占用。
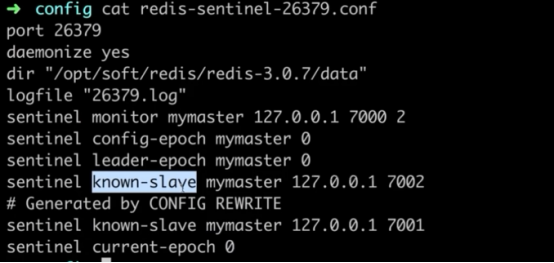
启动sentinel过后,查看配置文件过后,发现配置文件发生了改变,他把从节点也进行了自动发现,且进行监控
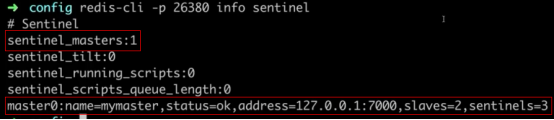
登录到sentinel,查看sentinel的info
redis-cli -p 26380 info sentinel
info Sentinel 命令用于获取 Redis Sentinel 的详细信息。执行该命令后,Sentinel 会返回有关当前 Sentinel 实例和监控的 Redis 主/从服务器的各种统计数据和配置参数。
以下是对 info Sentinel 返回结果中常见参数的详细解释:
sentinel_masters: 当前 Sentinel 监控的主服务器列表。它会列出每个主服务器的名称、状态、地址、端口和相关的故障转移信息。sentinel_tilt: 如果 Sentinel 进入 "TILT" 状态,则代表出现了主观下降(Subjective Down)或客观下降(Objective Down)。sentinel_running_scripts: Sentinel 正在运行的脚本数量。sentinel_scripts_queue_length: 待处理的脚本队列长度。sentinel_simulate_failure_flags: 指示 Sentinel 是否处于模拟失败状态的标志位。
这些参数只是 info Sentinel 命令返回结果中的一部分,而且根据 Redis 版本和配置的不同,可能会有额外的参数。
修改主从节点进行配置,并做主从后进行启动
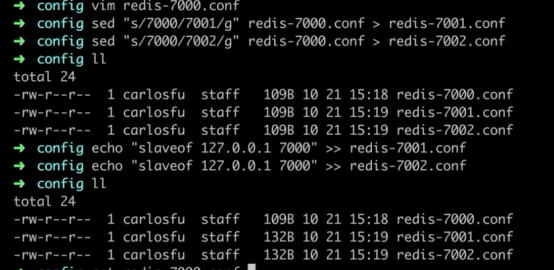
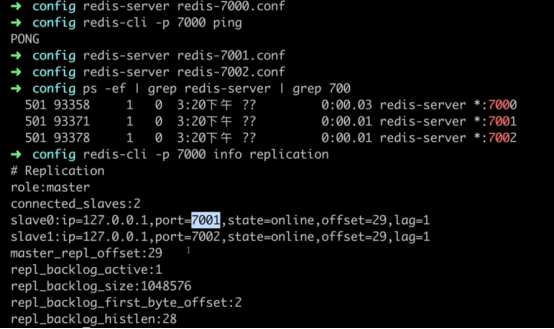
利用docker单机部署哨兵模式(3s+1m+1s)
cat > redis1.conf << EOF
#是否是守护进程(no|yes)
daemonize no
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6379
#redis系统日志
#logfile "/data/redis_6379.log"
#redis工作目录
dir "/data"
# aof持久化
appendonly yes
# rdb
dbfilename dump.rdb
protected-mode no
bind 0.0.0.0
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth 123654
#这是redis设置的密码
requirepass 123654
EOF
cat > redis2.conf << EOF
#是否是守护进程(no|yes)
daemonize no
#pid文件,一般用端口区分开
pidfile /var/run/redis-6379.pid
#redis对外端口号
port 6380
#redis系统日志
#logfile "/data/redis_6379.log"
#redis工作目录
dir "/data"
# aof持久化
appendonly yes
# rdb
dbfilename dump.rdb
protected-mode no
bind 0.0.0.0
#这是redis的slave连接master同步数据所需要的密码,若master配置了密码。
masterauth 123654
#这是redis设置的密码
requirepass 123654
EOF
cat > redis1m1s.sh << EOF
#!/bin/bash
start_redis1() {
echo "Starting the redis1..."
test -d /data/redis1 || mkdir -p /data/redis1
#如果在配置文件指定了requirepass、masterauth参数,那么就不需要在启动参数指定了
docker run -itd --name redis1 --restart=always --network=host -d -v ./redis1.conf:/opt/redis.conf -v /data/redis1:/data redis redis-server /opt/redis.conf --requirepass "123654" --masterauth 123654
}
start_redis2() {
echo "Starting the redis2..."
test -d /data/redis2 || mkdir -p /data/redis2
#如果在配置文件指定了requirepass、masterauth参数,那么就不需要在启动参数指定了
docker run -itd --name redis2 --restart=always --network=host -d -v ./redis2.conf:/opt/redis.conf -v /data/redis2:/data redis redis-server /opt/redis.conf --requirepass "123654" --replicaof 10.11.100.103 6379 --masterauth 123654
}
Usage() {
echo "Usage: \$0 {start|stop|rm|(redis1/redis2/all)}"
}
case \$1 in
"start")
case \$2 in
"redis1")
start_redis1
;;
"redis2")
start_redis2
;;
"all")
start_redis1
start_redis2
;;
*)
Usage
exit 1
;;
esac
;;
"stop")
case \$2 in
"redis1")
docker stop redis1
;;
"redis2")
docker stop redis2
;;
"all")
docker stop redis1
docker stop redis2
;;
*)
Usage
exit 1
;;
esac
;;
"rm")
case \$2 in
"redis1")
docker rm -f redis1
;;
"redis2")
docker rm -f redis2
;;
"all")
docker rm -f redis1
docker rm -f redis2
;;
*)
Usage
exit 1
;;
esac
;;
*)
Usage
exit 1
;;
esac
EOF
bash ./redis1m1s.sh start all
echo "redis 1 main 1 slave ,Deployment completion"
sleep 3
echo "Next deployment sentinel mode"
cat > sentinel1.conf << EOF
bind 0.0.0.0
port 26379
daemonize no
protected-mode no
# 这里定义主库的IP和端口,还有最后的2表示要达到2台sentinel认同才认为主库已经挂掉(即客观失效)
sentinel monitor mymaster 10.11.100.103 6379 2
# 主库在30000毫秒(即30秒)内没有反应就认为主库挂掉(即主观失效)
sentinel down-after-milliseconds mymaster 30000
# 若新主库当选后,允许最大可以同时从新主库同步数据的从库数
sentinel parallel-syncs mymaster 1
# 若在指定时间(即180000毫秒,即180秒)内没有实现故障转移,则会自动再发起一次
sentinel failover-timeout mymaster 180000
# 如果主redis设置了密码,那么就需要指定主的密码
sentinel auth-pass mymaster 123654
EOF
cat > sentinel2.conf << EOF
bind 0.0.0.0
port 36379
daemonize no
protected-mode no
# 这里定义主库的IP和端口,还有最后的2表示要达到2台sentinel认同才认为主库已经挂掉(即客观失效)
sentinel monitor mymaster 10.11.100.103 6379 2
# 主库在30000毫秒(即30秒)内没有反应就认为主库挂掉(即主观失效)
sentinel down-after-milliseconds mymaster 30000
# 若新主库当选后,允许最大可以同时从新主库同步数据的从库数
sentinel parallel-syncs mymaster 1
# 若在指定时间(即180000毫秒,即180秒)内没有实现故障转移,则会自动再发起一次
sentinel failover-timeout mymaster 180000
# 如果主redis设置了密码,那么就需要指定主的密码
sentinel auth-pass mymaster 123654
EOF
cat > sentinel3.conf << EOF
bind 0.0.0.0
port 46379
daemonize no
protected-mode no
# 这里定义主库的IP和端口,还有最后的2表示要达到2台sentinel认同才认为主库已经挂掉(即客观失效)
sentinel monitor mymaster 10.11.100.103 6379 2
# 主库在30000毫秒(即30秒)内没有反应就认为主库挂掉(即主观失效)
sentinel down-after-milliseconds mymaster 30000
# 若新主库当选后,允许最大可以同时从新主库同步数据的从库数
sentinel parallel-syncs mymaster 1
# 若在指定时间(即180000毫秒,即180秒)内没有实现故障转移,则会自动再发起一次
sentinel failover-timeout mymaster 180000
# 如果主redis设置了密码,那么就需要指定主的密码
sentinel auth-pass mymaster 123654
EOF
cat > sentinelall.sh << EOF
docker run -itd --name sentinel1 --restart=always -v ./sentinel1.conf:/opt/sentinel.conf --net=host redis redis-sentinel /opt/sentinel.conf
docker run -itd --name sentinel2 --restart=always -v ./sentinel2.conf:/opt/sentinel.conf --net=host redis redis-sentinel /opt/sentinel.conf
docker run -itd --name sentinel3 --restart=always -v ./sentinel3.conf:/opt/sentinel.conf --net=host redis redis-sentinel /opt/sentinel.conf
EOF
bash sentinelall.sh
客户端连接redis sentinel
Java客户端
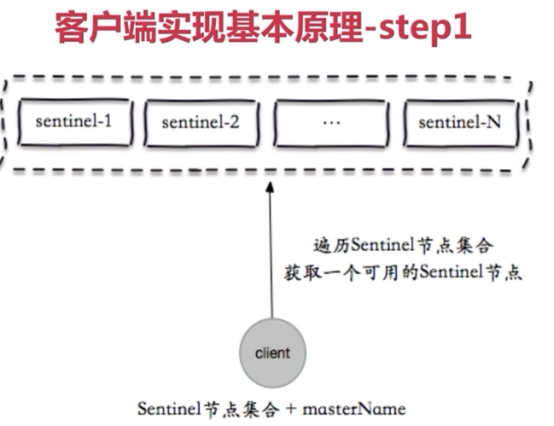
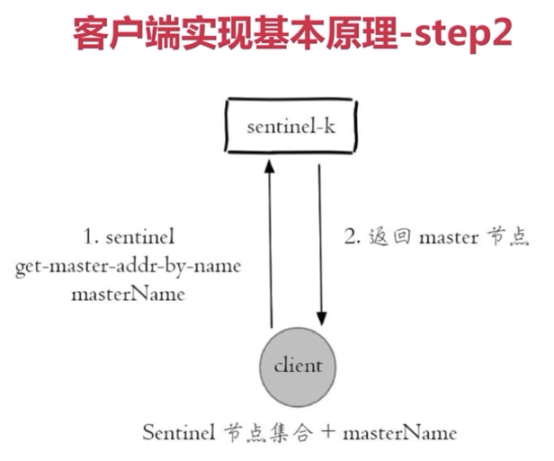
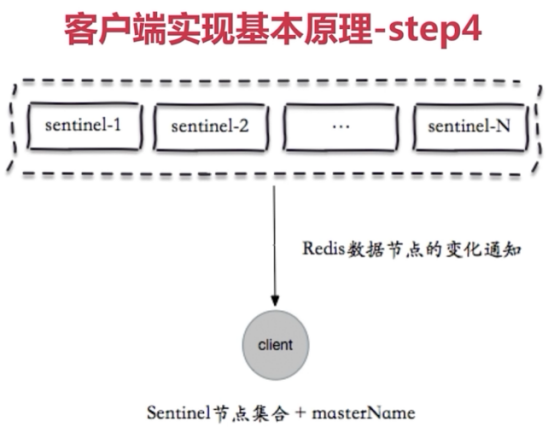


Python客户端

故障转移
杀掉redis主节点
连接redis,查看pid(info replication),然后进行kill -9,最后验证并查看各个节点的日志情况等


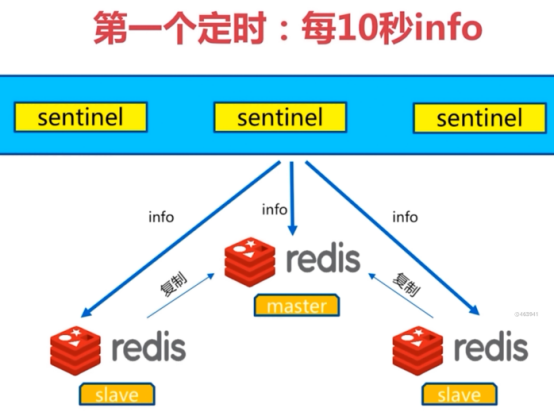
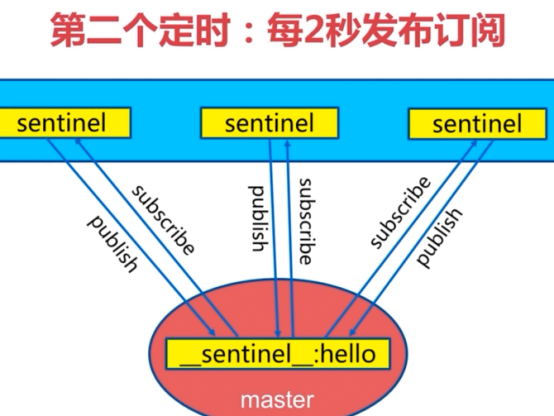
三个定时任务

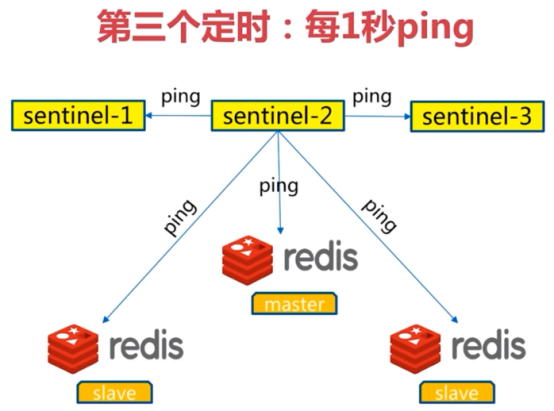
领导者选举
原因:只有一个sentinel节点完成故障转移
选举:通过sentinel is-master-down-by-addr命令都希望成为领导者
- 每个做主观下线的sentinel节点向其他sentinel节点发送命令,要求将它设置为领导者
-
收到命令的sentinel节点如果没有同意通过其他sentinel节点发送的命令,那么将同意该请求,否则拒绝
-
如果该sentinel节点发现自己的票数已经超过sentinel集合半数且超过quorum,那么它将成为领导者
-
如果此过程有多个sentinel节点成为了领导者,那么将等待一段时间重新进行选举
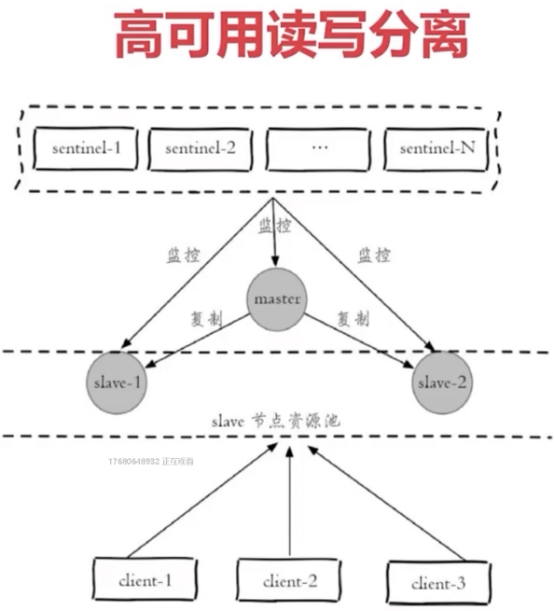
高可用读写分离


sentinel架构中的开发与运维中的问题
节点运维


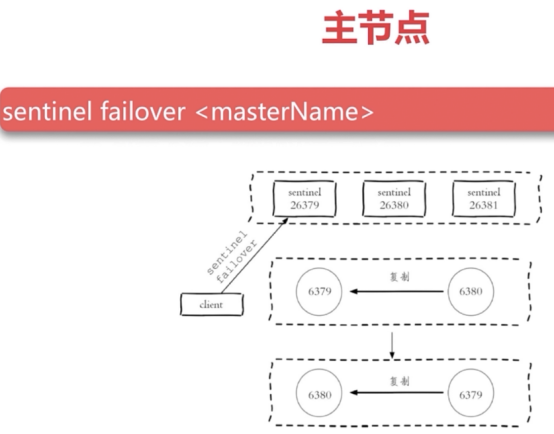


redis集群
Redis集群式一个可以在多个redis节点之间进心数据共享的设施(installation)
Redis集群不支持那些需要同时处理多个键的redis命令,因为执行这些命令需要在多个redis节点之间移动数据,并且在高负载的情况下,这些命令将降低redis集权的性能,并导致不可预测的行为。
Redis集群通过分区(partition)来提供一定程度的可用性(availability),即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
Redis好处
1.将数据自动切分(split)到多个节点的能力
2.当集群中的一部分节点失效或者无法进行通讯时,仍然可以继续处理命令请求的能力。
Redis分片方式
1.客户端分片:将redis分片的工作放在业务程序端。
-
优点:实现方法和代码全部自己掌控。随时进心调整。
-
缺点:手动迁移数据。
2.redis代理分片:Twemproxy(a fast,light-weight proxy for Memcached and redis),类似MySQL proxy。
- 缺点:对用户透明又不透明(存哪自己都不知道)
3.codis
- 不支持部分命令
4.redis cluster
redis cluster
https://www.cnblogs.com/mrhelloworld/p/docker12.html 参考本文档docker部署redis的cluster集群
https://www.modb.pro/db/107688
https://ld246.com/article/1583672691221
https://www.cnblogs.com/kevingrace/p/7910692.html
理论
哨兵模式中,单个节点的写能力,存储能力受到单机的限制,动态扩容困难复杂。于是,Redis 3.0 版本正式推出 Redis Cluster 集群模式,有效地解决了 Redis 分布式方面的需求。Redis Cluster 集群模式具有高可用、可扩展性、分布式、容错等特性。
要让集群正常运作至少需要三个主节点,为了实现主节点的高可用, 强烈建议使用六个节点:其中三个为主节点, 而其余三个则是各个主节点的从节点。
Redis Cluster 采用无中心结构,每个节点都可以保存数据和整个集群状态,每个节点都和其他所有节点连接。Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。

关于 Redis Cluster 集群更多的内容请阅读《最通俗易懂的 Redis 架构模式详解》。
按照 Redis 官网:https://redis.io/topics/cluster-tutorial 的提示,为了使 Docker 与 Redis Cluster 兼容,您需要使用 Docker 的 host 网络模式。
host 网络模式需要在创建容器时通过参数--net host 或者--network host 指定,host 网络模式可以让容器共享宿主机网络栈,容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。
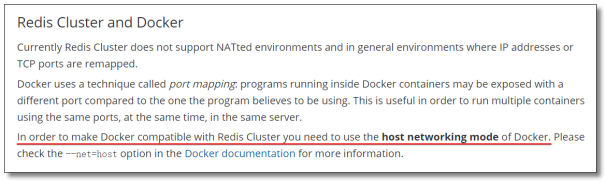
环境
为了让环境更加真实,本文使用多机环境:(每台部署2个redis实例)
- 192.168.137.7
- 192.168.137.6
- 192.168.137.5
每台机器所使用的基础设施环境如下:
- CentOS 7.8.2003
- Docker version 19.03.12

Docker部署
整体搭建步骤主要分为以下几步:
- 下载 Redis 镜像(其实这步可以省略,因为创建容器时,如果本地镜像不存在,就会去远程拉取);
- 编写 Redis 配置文件;
- 创建 Redis 容器;
- 创建 Redis Cluster 集群。
下载镜像
docker pull redis:5.0
设置Redis参数:
echo "vm.overcommit_memory = 1" >> etc/sysctl.conf
echo "net.core.somaxconn = 512" >> etc/sysctl.conf
echo never > sys/kernel/mm/transparent_hugepage/enabled
sysctl -p
创建目录及文件
分别在 192.168.137.7 、192.168.137.6和 192.168.137.5 三台台机器上执行以下操作。
# 创建目录
mkdir -p /usr/local/docker-redis/redis-cluster
# 切换至指定目录
cd /usr/local/docker-redis/redis-cluster/
# 编写 redis-cluster.tmpl 文件
vi redis-cluster.tmpl
编写配置文件
192.168.137.7 机器的redis-cluster.tmpl 文件内容如下:重点redis设置了密码后requirepass 、masterauth 这两个参数必须有,否则连接集群的时候从节点无法认证导致获取不到key
port ${PORT}
requirepass 1234
masterauth 1234
protected-mode no
daemonize no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
cluster-announce-ip 192.168.137.7
cluster-announce-port ${PORT}
cluster-announce-bus-port 1${PORT}
cluster-require-full-coverage no
192.168.137.6 机器的 redis-cluster.tmpl 文件内容如下:
port ${PORT}
requirepass 1234
masterauth 1234
protected-mode no
daemonize no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
cluster-announce-ip 192.168.137.6
cluster-announce-port ${PORT}
cluster-announce-bus-port 1${PORT}
cluster-require-full-coverage no
192.168.137.5 机器的 redis-cluster.tmpl 文件内容如下:
port ${PORT}
requirepass 1234
masterauth 1234
protected-mode no
daemonize no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
cluster-announce-ip 192.168.137.5
cluster-announce-port ${PORT}
cluster-announce-bus-port 1${PORT}
cluster-require-full-coverage no
- port:节点端口;
- requirepass:添加访问认证;
- masterauth:如果主节点开启了访问认证,从节点访问主节点需要认证;
- protected-mode:保护模式,默认值 yes,即开启。开启保护模式以后,需配置 bind ip 或者设置访问密码;关闭保护模式,外部网络可以直接访问;
- daemonize:是否以守护线程的方式启动(后台启动),默认 no;
- appendonly:是否开启 AOF 持久化模式,默认 no;
- cluster-enabled:是否开启集群模式,默认 no;
- cluster-config-file:集群节点信息文件;
- cluster-node-timeout:集群节点连接超时时间;
- cluster-announce-ip:集群节点 IP,填写宿主机的 IP;
- cluster-announce-port:集群节点映射端口;
- cluster-announce-bus-port:集群节点总线端口。
每个 Redis 集群节点都需要打开两个 TCP 连接。一个用于为客户端提供服务的正常 Redis TCP 端口,例如 6379。还有一个基于 6379 端口加 10000 的端口,比如 16379。
第二个端口用于集群总线,这是一个使用二进制协议的节点到节点通信通道。节点使用集群总线进行故障检测、配置更新、故障转移授权等等。客户端永远不要尝试与集群总线端口通信,与正常的 Redis 命令端口通信即可,但是请确保防火墙中的这两个端口都已经打开,否则 Redis 集群节点将无法通信。
在 192.168.137.7 机器的 redis-cluster 目录下执行以下命令:
for port in `seq 6379 6380`; do \
mkdir -p ${port}/conf \
&& PORT=${port} envsubst < redis-cluster.tmpl > ${port}/conf/redis.conf \
&& mkdir -p ${port}/data;\
done
在 192.168.1376 机器的 redis-cluster 目录下执行以下命令:
for port in `seq 6379 6380`; do \
mkdir -p ${port}/conf \
&& PORT=${port} envsubst < redis-cluster.tmpl > ${port}/conf/redis.conf \
&& mkdir -p ${port}/data;\
done
在 192.168.137.5 机器的 redis-cluster 目录下执行以下命令:
for port in `seq 6379 6380`; do \
mkdir -p ${port}/conf \
&& PORT=${port} envsubst < redis-cluster.tmpl > ${port}/conf/redis.conf \
&& mkdir -p ${port}/data;\
done
创建容器
启动redis容器,并将宿主机的目录与容器内的目录进行映射(目录挂载)。记得指定网络模式,使用 host 网络模式。
在 192.168.137.7、192.168.137.6、192.168.137.5 机器执行以下命令:
for port in $(seq 6379 6380); do \
docker run -dti --restart always --name redis-${port} --net host \
-v /usr/local/docker-redis/redis-cluster/${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \
-v /usr/local/docker-redis/redis-cluster/${port}/data:/data \
redis:5.0 redis-server /usr/local/etc/redis/redis.conf; \
done
在 192.168.137.7、 192.168.137.6、192.168.137.5机器执行docker ps -n 1查看容器是否创建成功。
[root@master redis-cluster]# docker ps -n 2
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
aed25c4cc819 redis:5.0 "docker-entrypoint.s…" 15 seconds ago Up 14 seconds redis-6380
e9c8ac834e55 redis:5.0 "docker-entrypoint.s…" 16 seconds ago Up 15 seconds redis-6379
[root@master redis-cluster]# ps aux| grep redis
polkitd 7119 0.5 0.1 43568 3336 ? Ssl 16:24 0:00 redis-server *:6379 [cluster]
polkitd 7199 0.2 0.3 40496 10092 ? Ssl 16:24 0:00 redis-server *:6380 [cluster]
root 8663 0.0 0.0 112812 980 pts/0 R+ 16:27 0:00 grep --color=auto redis
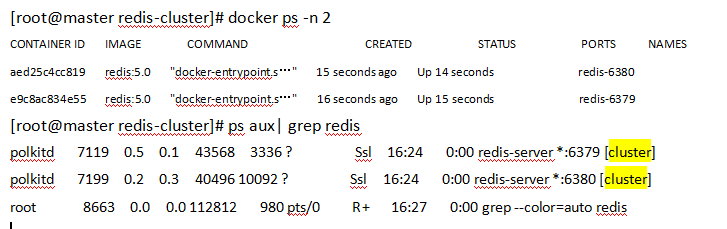
创建redis-cluster集群
随便进入一个容器节点,并进入/usr/local/bin/ 目录:
# 进入容器
docker exec -it redis-6379 bash
# 切换至指定目录
cd /usr/local/bin/
接下来我们就可以通过以下命令实现 Redis Cluster 集群的创建。
redis-cli -a 1234 --cluster create 192.168.137.7:6379 192.168.137.6:6379 192.168.137.5:6379 192.168.137.5:6380 192.168.137.7:6380 192.168.137.6:6380 --cluster-replicas 1 #一主一从模式,前面的三个地址是master,后面的三个地址是salve。

root@master:/data# redis-cli -a 1234 --cluster create 192.168.137.7:6379 192.168.137.6:6379 192.168.137.5:6379 192.168.137.5:6380 192.168.137.7:6380 192.168.137.6:6380 --cluster-replicas 1
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.137.6:6380 to 192.168.137.7:6379
Adding replica 192.168.137.5:6380 to 192.168.137.6:6379
Adding replica 192.168.137.7:6380 to 192.168.137.5:6379
M: 7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379
slots:[0-5460] (5461 slots) master
M: 9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379
slots:[5461-10922] (5462 slots) master
M: 053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379
slots:[10923-16383] (5461 slots) master
S: 10175e199f5588179c58cefe2b964eae7bcf0d23 192.168.137.5:6380
replicates 9e99c27be83a7781c119f5bd5ab6d536068fe78a
S: fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
S: 14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380
replicates 7e8d7649cee872617839dd2d623cb2ef8cababa9
Can I set the above configuration? (type 'yes' to accept): yes #出现选择提示信息,输入 yes,结果如下所示:
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
注意:在redis5.0后 创建集群统一使用redis-cli,之前的版本使用redis-trib.rb,但是需要安装ruby软件相对复杂,相比之前的版本5.0不需要安装额外的软件,方便。具体的可以参照redis官方网站查看 https://redis.io/topics/cluster-tutorial
创建集群命令:其中cluster-replicas 1代表 一个master后有几个slave,1代表为1个slave节点
--cluster-replicas 1表示为集群中的每个主节点创建一个从节点。
查看集群状态
我们先进入容器,然后通过一些集群常用的命令查看一下集群的状态。
# 进入容器
docker exec -it redis-6379 bash
# 切换至指定目录
cd /usr/local/bin/
root@master:/usr/local/bin# redis-cli -a 1234 --cluster check 192.168.137.7:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.137.7:6379 (7e8d7649...) -> 0 keys | 5461 slots | 1 slaves.
192.168.137.6:6379 (9e99c27b...) -> 0 keys | 5462 slots | 1 slaves.
192.168.137.5:6379 (053ddca8...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.137.7:6379)
M: 7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
M: 053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 10175e199f5588179c58cefe2b964eae7bcf0d23 192.168.137.5:6380
slots: (0 slots) slave
replicates 9e99c27be83a7781c119f5bd5ab6d536068fe78a
S: 14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380
slots: (0 slots) slave
replicates 7e8d7649cee872617839dd2d623cb2ef8cababa9
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
查看集群信息和节点信息
# 连接至集群某个节点
root@master:/usr/local/bin# redis-cli -c -a 1234 -h 192.168.137.7 -p 6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# 查看集群信息
192.168.137.7:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:252
cluster_stats_messages_pong_sent:232
cluster_stats_messages_sent:484
cluster_stats_messages_ping_received:227
cluster_stats_messages_pong_received:252
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:484
# 查看集群结点信息
192.168.137.7:6379> CLUSTER NODES
9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379@16379 master - 0 1650857347894 2 connected 5461-10922
fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380@16380 slave 053ddca80d98733b95c9659cbf992b89c33e5af7 0 1650857346881 5 connected
053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379@16379 master - 0 1650857348914 3 connected 10923-16383
10175e199f5588179c58cefe2b964eae7bcf0d23 192.168.137.5:6380@16380 slave 9e99c27be83a7781c119f5bd5ab6d536068fe78a 0 1650857348000 4 connected
7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379@16379 myself,master - 0 1650857347000 1 connected 0-5460
14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380@16380 slave 7e8d7649cee872617839dd2d623cb2ef8cababa9 0 1650857345849 6 connected
192.168.137.7:6379> exit
root@master:/usr/local/bin# exit
exit
写入与读取数据
在 6379 节点中执行写入和读取,命令如下:
# 进入容器并连接至集群某个节点
[root@master redis-cluster]# docker exec -it redis-6379 /usr/local/bin/redis-cli -c -a 1234 -h 192.168.137.7 -p 6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.137.7:6379> set name mrhelloworld # 写入数据
-> Redirected to slot [5798] located at 192.168.137.6:6379
OK
192.168.137.6:6379> set aaa 111 # 写入数据
OK
192.168.137.6:6379> set bbb 222 # 写入数据
-> Redirected to slot [5287] located at 192.168.137.7:6379
OK
192.168.137.7:6379> get name # 读取数据
-> Redirected to slot [5798] located at 192.168.137.6:6379
"mrhelloworld"
192.168.137.6:6379> get aaa # 读取数据
"111"
192.168.137.6:6379> get bbb # 读取数据
-> Redirected to slot [5287] located at 192.168.137.7:6379
"222"
删除节点
删除节点一定要注意,删除节点之前一定要先将数据移到其它节点,不能直接删除,不过也不用担心,即使有数据,不小心执行了删除节点指令,也会报有数据存在,不可以删除的错误。
1、先对节点进行分片工作,防止数据丢失。通过重新分片,将散列槽移到其它节点:
192.168.137.7:6379> CLUSTER NODES
3eef51c5d65138889d949be5ddf03a969a0c07b6 192.168.137.6:6380@16380 slave 94245f006d59445c7b19cc8c51df27f0212b5a73 0 1650790475000 6 connected
2a24542d4581101e79ecc7a3cddbfa0b69c62c84 192.168.137.7:6380@16380 slave 9ad449631309a09c7d0cd315cf6e23bff4e2c20c 0 1650790475000 3 connected
9ad449631309a09c7d0cd315cf6e23bff4e2c20c 192.168.137.5:6379@16379 master - 0 1650790475653 3 connected 10923-16383
94245f006d59445c7b19cc8c51df27f0212b5a73 192.168.137.7:6379@16379 myself,master - 0 1650790470000 1 connected 0-5460
24d4f9d40385fc156eb9647d34c38a63c57f0915 192.168.137.6:6379@16379 master - 0 1650790476000 2 connected 5461-10922
bab5650eb1580d06745e81dcca81bb84b93950fc 192.168.137.5:6380@16380 slave 24d4f9d40385fc156eb9647d34c38a63c57f0915 0 1650790476666 4 connected
192.168.137.7:6379> exit
例如删除 192.168.137.5:6380节点,redis-cli -a 1234 --cluster reshard 欲删除节点ip:port
root@master:/data# redis-cli -a 1234 --cluster reshard 192.168.137.5:6380
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 192.168.137.5:6380)
S: 10175e199f5588179c58cefe2b964eae7bcf0d23 192.168.137.5:6380
slots: (0 slots) slave
replicates 9e99c27be83a7781c119f5bd5ab6d536068fe78a
M: 7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
M: 053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380
slots: (0 slots) slave
replicates 7e8d7649cee872617839dd2d623cb2ef8cababa9
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 16384
What is the receiving node ID? 053ddca80d98733b95c9659cbf992b89c33e5af7 #用来接受散列槽的节点,可以任意指定节点:
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: done
2、移除节点
# 查看状态:
root@master:/data# redis-cli --cluster check 192.168.137.7:6379 -a 1234
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.137.7:6379 (7e8d7649...) -> 0 keys | 0 slots | 0 slaves.
192.168.137.6:6379 (9e99c27b...) -> 0 keys | 0 slots | 0 slaves.
192.168.137.5:6379 (053ddca8...) -> 3 keys | 16384 slots | 3 slaves.
[OK] 3 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.137.7:6379)
M: 7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379
slots: (0 slots) master
M: 9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379
slots: (0 slots) master
S: fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
M: 053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379
slots:[0-16383] (16384 slots) master
3 additional replica(s)
S: 10175e199f5588179c58cefe2b964eae7bcf0d23 192.168.137.5:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
S: 14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
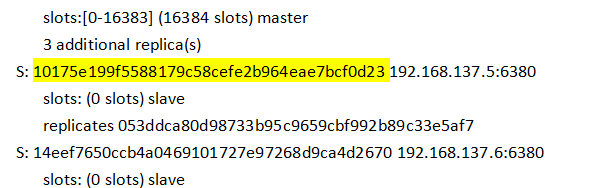
确定没问题了,执行下面命令,可以实现删除节点:redis-cli --cluster del-node 节点ip:port 节点id
root@master:/data# redis-cli -a 1234 --cluster del-node 192.168.137.5:6380 10175e199f5588179c58cefe2b964eae7bcf0d23
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node 10175e199f5588179c58cefe2b964eae7bcf0d23 from cluster 192.168.137.5:6380
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
root@master:/data# redis-cli -a 1234 CLUSTER INFO
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
cluster_state:ok #集群状态ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:5 #只有5个节点了
cluster_size:1
cluster_current_epoch:7
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1339
cluster_stats_messages_pong_sent:1199
cluster_stats_messages_update_sent:80
cluster_stats_messages_sent:2618
cluster_stats_messages_ping_received:1194
cluster_stats_messages_pong_received:1339
cluster_stats_messages_meet_received:5
cluster_stats_messages_update_received:7
cluster_stats_messages_received:2545
root@master:/data# redis-cli -a 1234 CLUSTER NODES
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379@16379 master - 0 1650858705086 2 connected
fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380@16380 slave 053ddca80d98733b95c9659cbf992b89c33e5af7 0 1650858706096 7 connected
053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379@16379 master - 0 1650858703053 7 connected 0-16383
7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379@16379 myself,master - 0 1650858706000 1 connected
14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380@16380 slave 053ddca80d98733b95c9659cbf992b89c33e5af7 0 1650858704061 7 connected
强制删除 master 节点,不做 slot 转移
1、查看 redis.conf 文件中 dir 的配置路径
2、在路径下删除关于该节点的nodes-port(对应端口号).conf、.aof 和.rdb文件
3、最后再执行移除节点的命令
如果要彻底移除集群,且不保存数据也可以使用该方式
对于执行集群相关操作的时候出现错误,可以使用redis-cli --cluster check ip:port检查集群是否有错误,使用redis-cli --cluster fix ip:port修复相关错误
添加新的节点
https://blog.csdn.net/weixin_42440345/article/details/95048739
添加节点前,一定要初始化好此节点:
(1)查看每个集群节点的node ID和身份
进入任意集群master节点:
redis-cli -a 1234
查看节点ID:cluster nodes
127.0.0.1:6379> cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379@16379 master - 0 1650858929377 2 connected
fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380@16380 slave 053ddca80d98733b95c9659cbf992b89c33e5af7 0 1650858929000 7 connected
053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379@16379 master - 0 1650858930627 7 connected 0-16383
7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379@16379 myself,master - 0 1650858928000 1 connected
14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380@16380 slave 053ddca80d98733b95c9659cbf992b89c33e5af7 0 1650858929000 7 connected
(2)添加master节点,(add-node: 后面的分别跟着新加入的slave和slave对应的master)
redis-cli --cluster add-node 127.0.0.1:6385 127.0.0.1:6379
这里是将节点加入了集群中,但是并没有分配slot,所以这个节点并没有真正的开始分担集群工作。
(3)分配slot
redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from 2846540d8284538096f111a8ce7cf01c50199237,e0a9c3e60eeb951a154d003b9b28bbdc0be67d5b,692dec0ccd6bdf68ef5d97f145ecfa6d6bca6132 --cluster-to 46f0b68b3f605b3369d3843a89a2b4a164ed21e8 --cluster-slots 1024
--cluster-from:表示slot目前所在的节点的node ID,多个ID用逗号分隔
--cluster-to:表示需要新分配节点的node ID(貌似每次只能分配一个)
--cluster-slots:分配的slot数量
(4)添加slave节点
root@master:/data# redis-cli -a 1234 --cluster add-node 192.168.137.5:6380 192.168.137.6:6379 --cluster-slave --cluster-master-id 9e99c27be83a7781c119f5bd5ab6d536068fe78a
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 192.168.137.5:6380 to cluster 192.168.137.6:6379
>>> Performing Cluster Check (using node 192.168.137.6:6379)
M: 9e99c27be83a7781c119f5bd5ab6d536068fe78a 192.168.137.6:6379
slots: (0 slots) master
M: 7e8d7649cee872617839dd2d623cb2ef8cababa9 192.168.137.7:6379
slots: (0 slots) master
M: 053ddca80d98733b95c9659cbf992b89c33e5af7 192.168.137.5:6379
slots:[0-16383] (16384 slots) master
2 additional replica(s)
S: 14eef7650ccb4a0469101727e97268d9ca4d2670 192.168.137.6:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
S: fa955758a3f350d598c61f4b5039b433f556931b 192.168.137.7:6380
slots: (0 slots) slave
replicates 053ddca80d98733b95c9659cbf992b89c33e5af7
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.137.5:6380 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 192.168.137.6:6379.
[OK] New node added correctly.
说明:
add-node: 后面的分别跟着新加入的slave和slave对应的master
cluster-slave:表示加入的是slave节点
--cluster-master-id:表示slave对应的master的node ID
收缩集群
原文链接:https://blog.csdn.net/weixin_42440345/article/details/95048739
下线节点127.0.0.1:6385(master)、127.0.0.1:6386(slave)
(1)首先删除master对应的slave
redis-cli --cluster del-node 127.0.0.1:6386 530cf27337c1141ed12268f55ba06c15ca8494fc
del-node后面跟着slave节点的 ip:port 和node ID
(2)清空master的slot
redis-cli --cluster reshard 127.0.0.1:6385 --cluster-from 46f0b68b3f605b3369d3843a89a2b4a164ed21e8 --cluster-to 2846540d8284538096f111a8ce7cf01c50199237 --cluster-slots 1024 --cluster-yes
reshard子命令前面已经介绍过了,这里需要注意的一点是,由于我们的集群一共有四个主节点,而每次reshard只能写一个目的节点,因此以上命令需要执行三次(--cluster-to对应不同的目的节点)。
--cluster-yes:不回显需要迁移的slot,直接迁移。
(3)下线(删除)节点
redis-cli --cluster del-node 127.0.0.1:6385 46f0b68b3f605b3369d3843a89a2b4a164ed21e8
至此就是redis cluster 简单的操作过程
Redis Cluster集群相关操作
关闭集群的某个节点
比如关闭端口号为7000的实例
# redis-cli -a <password> -c -h 127.0.0.1 -p 7000 shutdown
关闭之后,可以将实例重新启动,启动完成之后,自动加入到集群当中;
集群的关闭
逐个关闭Redis实例即可
Redis cluster命令手动管理Redis集群
0、重置集群
CLUSTER RESET [SOFT | HARD]
这个命令接受SOFT 和 HARD 两个可选参数,用于指定重置操作的具体行为(软重置和应重置)。默认为 SOFT 选项。
CLUSTER RESET 命令在执行时,将对节点执行以下操作:
- 遗忘该节点的所有槽,并清空节点内部的槽-节点映射表;
- 如果执行该命令的节点是一个从节点,那么将它转换成一个主节点;
- 如果执行的是硬重置,那么为节点创建一个新的运行ID;
- 如果执行的是硬重置,那么将节点的纪元和配置纪元都设置为 0;
- 通过集群节点配置文件的方式,将新的配置持久化到配置文件中;
1、打印集群的信息
CLUSTER INFO
2、列出集群当前已知的所有节点(node),以及这些节点的相关信息
CLUSTER NODES
3、将ip和port所指定的节点添加到集群中
CLUSTER MEET <ip> <port>
4、从集群中移除node_id指定的节点
CLUSTER FORGET <node_id>
5、将当前节点设置为node_id指定的节点的从节点
CLUSTER REPLICATE <node_id>
6、将节点的配置文件保存到硬盘里面
CLUSTER SAVECONFIG
7、将一个或多个槽(slot)指派(assign)给当前节点
CLUSTER ADDSLOTS <slot> [slot ...]
8、移除一个或多个槽对当前节点的指派
CLUSTER DELSLOTS <slot> [slot ...]
9、移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点
CLUSTER FLUSHSLOTS
10、将槽slot指派给node_id指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派
CLUSTER SETSLOT <slot> NODE <node_id>
11、将本节点的槽slot迁移到node_id指定的节点中
CLUSTER SETSLOT <slot> MIGRATING <node_id>
12、从node_id指定的节点中导入槽 slot 到本节点
CLUSTER SETSLOT <slot> IMPORTING <node_id>
13、取消对槽slot的导入(import)或者迁移(migrate)
CLUSTER SETSLOT <slot> STABLE
14、计算键key应该被放置在哪个槽上
CLUSTER KEYSLOT <key>
15、返回槽slot目前包含的键值对数量
CLUSTER COUNTKEYSINSLOT <slot>
16、返回count个slot槽中的键
CLUSTER GETKEYSINSLOT <slot> <count>
Redis Cluster集群性能调优
https://www.modb.pro/db/107688
4.1 关闭RDB防止fork进程的内存溢出问题
save ""
appendonly=yes
4.2 防止某个节点挂掉,整个cluster挂掉的问题
cluster-require-full-coverage no
当cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用
4.3 设置最大内存
maxmemory 11453246122
4.4 日志
logfile "./redis.log"
4.5 防止因为磁盘同步,卡掉住进程的情况出现
no-appendfsync-on-rewrite yes
4.6 内核修改,如果没开防火墙可以不设置这个
net.nf_conntrack_max = 1648576
4.7 这个用来防止内存申请不到发生卡死的情况,很重要
vm.overcommit_memory = 1
有三种方式修改内核参数,但要有root权限:
编辑/etc/sysctl.conf ,改vm.overcommit_memory = 1,然后sysctl -p使配置文件生效
sysctl vm.overcommit_memory = 1
echo 1 > /proc/sys/vm/overcommit_memory
建议使用方法1。
4.8 thp redis warning要求关掉
echo never > /sys/kernel/mm/transparent_hugepage/enabled
同时写入rc.local,保证下次重启生效
4.9 最大连接数要改一下,redis的warning会要求修改
net.core.somaxconn = 1024
编辑/etc/sysctl.conf ,增加net.core.somaxconn= 1024,然后sysctl -p使配置文件生效
4.10 设置内存超出策略
默认没有设置allkeys-lru
BGREWRITEAOF这个命令可以重写aof,因为aof长时间增量更新,导致越来越大,但是内存可能没这么大,所以可以用这个命令重写进行复制备份,恢复等
192.168.137.7:6379> BGREWRITEAOF
Background append only file rewriting started
内存吃紧的时候可以尝试手动去掉内存碎片
192.168.137.7:6379> config set activedefrag yes
OK
192.168.137.7:6379> memory purge
OK
redis 安全
1.设置密码
[root@Redis sbin]# vim /etc/redis.conf
requirepass boy6666boy #设置密码
[root@Redis sbin]# /etc/init.d/redis restart
2.给危险命令重命名
3.不使用root用户登陆到服务器
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。