- 磁盘管理
- 理论概述
- df 显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB
- du 也是查看使用空间的(默认显示目录下的所有文件)
- ncdu du的升级版
- du 和 df 的定义,以及区别?
- 内存
- 查看CPU、内存、分区、交换分区信息
- lsblk 列出所有可用块设备的信息
- fdisk 观察硬盘实体使用情况,也可对硬盘分区
- mke2fs 用于创建磁盘分区上的"etc"文件系统
- mkfs 用于在设备上(通常为硬盘)创建Linux文件系统
- blkid 通俗易懂,查看分区是否格式化、以及文件系统
- 分区的两种方法
- swap(创建交换分区;开启或关闭)
- mount 挂载文件系统 (拓展)
- 实现开机自动挂载:
- umount 卸载已经加载的文件系统
- fuser 查看正在访问指定文件系统的进程
- tune2fs:更改与查看磁盘详细信息
- dumpe2fs 打印ext2/ext3文件系统的超级块和快组信息
- dstat 全能系统信息统计工具
- vmstat 显示虚拟内存状态(Virtual Memory Statistics)
- iotop 用于检查 I/O 的使用情况
- IO测试工具之fio详解
- ===RAID技术===
- ==LVM(logicalvolumemanager)==
- fsck 检查并且试图修复文件系统中的错误
- 检查磁盘是否存在坏道 badblocks
- 使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
- Living Example:一步操作删除分区表 (超级危险)
- Living Example:深入理解Linux文件系统:
磁盘管理
(查看、分区、挂载)
理论概述
硬盘接口类型:
IDE SATA SCSI SAS USB
IDE:Integated Drive Electronics (电子集成驱动器)
特点:
1、一般应用于机械硬盘
2、最大支持的速率:100MB/sec
3、接口类型:并口
SATA:Serial ATA
特点:
SATA 1.5G/s ->最大硬盘的主流
SATA 3G/s
SATA 6G/s
1、接口类型是串口
SCSI:小型计算机的系统接口
特点:
1、一般应用于服务器
2、可以实现异步传输数据
3、传输速率最大理论值可以实现1.5M[异步传输]
4、接口类型:并口
SAS:serial attached scsi [专用的小型计算机接口]
特点:
1、最大传输速率可以达到6.0G/s
2、接口类型:串口
USB:serial attached serial通用串行接口
革新:usb1.0 2.0 3.0
特点:
1、接口:串口
最大传输速率:10Gbit/s ->1.25G/s (2.0)
Linux系统平台是如何识别硬盘接口:
通过硬盘的接口不同,实现区分硬盘的设备号
IDE硬盘接口 ->以hd开头
SATA、SCSI、SAS硬盘接口 -> 以sd开头
设备号:分为主设备号与次设备号
major:主设备号;主要用于区分磁盘的类型
例如:sda、hdb、hdf
sda:sata接口的第一块硬盘
hdb:ide接口的第二块硬盘
hdf:ide接口的第第六块硬盘
minor:次设备号:主要区分同类型下不同的设备号
例如:sda4、hdb3
sda4:sata接口的第一块硬盘的第4个分区
hdb3:ide接口的第二块磁盘的第3个分区
Notice:以上的所有设备文件均存放在/dev/FileName
磁盘的分区类型:
主分区、扩展分区、逻辑分区、交换分区
Notice:一块磁盘只能划分4个主分区[why ?]
because:磁盘的制作工艺,一个扇区的单位大小为512byte
每一个字节包含了
- 446byte:用于引导磁盘启动的字符码[标识设备号]
- 64byte:用于记录磁盘的分区信息表
- 2byte:幻数[Magic Number]--- 指明当前磁盘是否被分区
Notice:一个分区的最小字节数为16byte,二分区信息表最大存储64byte,因此64/16=4,就是最大只能划分4个主分区
分区的大小配置:
/boot 200-300M
/ 根分区
/swap 内存小于8G,内存的1.5-2
SAS>SATA>SSD
Linux的文件系统:
ext2、ext3、ext4、xfs、ntfs、resiserfs、btrfs、nfs
Notice:针对ext文件系统是向下兼容的
光盘的文件系统:iso9660
网络文件系统:nfs、cifs
集群式文件系统:gfs、ocfs
分布式文件系统:moosefs
伪文件系统:proc、sysfs
df 显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB
df命令用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
Grammar
df (Option) (参数)
Option
-
-a或--all:包含全部的文件系统;
-
-h或--human-readable:以可读性较高的方式来显示信息;
-
-T或--print-type:显示文件系统的类型(xfs、ext4、iso9660等等);
-
-i或--inodes:显示inode的信息;(小文件会占用这个inode)
-
--block-size=<区块大小>:以指定的区块大小来显示区块数目;(大文件会占block)
-
-t<文件系统类型>或--type=<文件系统类型>:仅显示指定文件系统类型的磁盘信息;
-
-H或--si:与-h参数相同,但在计算时是以1000 Bytes为换算单位而非1024 Bytes;
-
-k或--kilobytes:指定区块大小为1024字节;
-
-l或--local:仅显示本地端的文件系统;
-
-m或--megabytes:指定区块大小为1048576字节;
-
--no-sync:在取得磁盘使用信息前,不要执行sync指令,此为预设值;
-
-P或--portability:使用POSIX的输出格式;
-
--sync:在取得磁盘使用信息前,先执行sync指令;
-
-x<文件系统类型>或--exclude-type=<文件系统类型>:不要显示指定文件系统类型的磁盘信息;
-
--help:显示帮助;
-
--version:显示版本信息。
参数
文件:指定文件系统上的文件。
Living Example
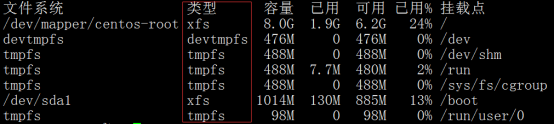
查看系统磁盘设备,默认是KB为单位:
[root@LinServ-1 ~]# df (默认是显示block) 使用-h选项以KB以上的单位来显示,可读性高:
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda2 146294492 28244432 110498708 21% /
/dev/sda1 1019208 62360 904240 7% /boot
tmpfs 1032204 0 1032204 0% /dev/shm
/dev/sdb1 2884284108 218826068 2518944764 8% /data1
[root@LinServ-1 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda2 140G 27G 106G 21% /
/dev/sda1 996M 61M 884M 7% /boot
tmpfs 1009M 0 1009M 0% /dev/shm
/dev/sdb1 2.7T 209G 2.4T 8% /data1
查看全部文件系统:
[root@LinServ-1 ~]# df -a
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda2 146294492 28244432 110498708 21% /
proc 0 0 0 - /proc
sysfs 0 0 0 - /sys
devpts 0 0 0 - /dev/pts
/dev/sda1 1019208 62360 904240 7% /boot
tmpfs 1032204 0 1032204 0% /dev/shm
/dev/sdb1 2884284108 218826068 2518944764 8% /data1
none 0 0 0 - /proc/sys/fs/binfmt_misc
显示磁盘信息及类型
[root@test ~]# df -hT
du 也是查看使用空间的(默认显示目录下的所有文件)
du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。
Grammar
du [选项]
Option
- -a或-all 显示所有文件占用的大小情况,并包含目录;最后一项是总计的大小。
-
-s或--summarize 仅显示总计,只列出最后加总的值。
-
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-
-S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
-
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-
-t 200M 列出大于200M的文件
-
-k或--kilobytes 以KB(1024bytes)为单位输出。
-
-m或--megabytes 以MB为单位输出。
-
-b或-bytes 显示目录或文件大小时,以byte为单位。
-
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-
-L<符号链接>或--dereference<符号链接> 显示Option中所指定符号链接的源文件大小。
-
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
-
--exclude=<目录或文件> 略过指定的目录或文件。
-
-D或--dereference-args 显示指定符号链接的源文件大小。
-
-l或--count-links 重复计算硬件链接的文件。
Living Example
只显示当前目录下面的子目录的目录大小和当前目录的总的大小,最下面的282M为当前目录的总大小
显示指定文件所占空间:
[root@test-6 ~]# du -h /root/
52K /root/.thumbnails/fail/gnome-thumbnail-factory
56K /root/.thumbnails/fail
552K /root/.thumbnails/normal
612K /root/.thumbnails
4.0K /root/.gnome2_private
282M /root/
查看指定目录的所占空间:
[root@test-6 ~]# du test
4 test
查看指定目录的所占空间,只显示整个目录的大小:
[root@test-6 ~]# du -sh /root/
282M /root/
查看根下面所有目录分别的大小 (很常用)
[root@test-6 ~]# du -sh /*
7.7M /bin
64M /boot
304K /dev
40M /etc
120K /home
321M /lib
28M /lib64
16K /lost+found
8.0K /media
0 /misc
4.0K /mnt
0 /net
12K /opt
du: 无法访问"/proc/2292/task/2292/fd/4": 没有那个文件或目录
du: 无法访问"/proc/2292/task/2292/fdinfo/4": 没有那个文件或目录
du: 无法访问"/proc/2292/fd/4": 没有那个文件或目录
du: 无法访问"/proc/2292/fdinfo/4": 没有那个文件或目录
0 /proc
283M /root
17M /sbin
0 /selinux
4.0K /srv
0 /sys
392K /tmp
3.3G /usr
397M /var
ncdu du的升级版
1、安装
cd /usr/local/
wget https:# dev.yorhel.nl/download/ncdu-1.9.tar.gz
tar zxvf ncdu-1.12.tar.gz
cd ncdu-1.12/
./configure --prefix=/usr
echo $? # 返回值为0说明安装成功
make && make install
echo $?
2、使用
2.1.
[root@test ~]# ncdu /root/ # 回车
2.2. 如下图所示,我想查看/root下所有一级目录和文件(/root所有)的大小
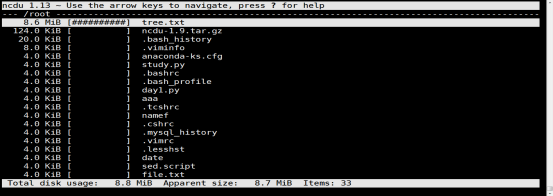
交互式界面快捷键:
然后你就可以用方向键操作了。相当方便。附上该工具的命令:
up, k — 向上移动光标
down, j – 向下移动光标
right/enter — 打开选定的目录
left, <, h — 打开父目录
n — 按文件名排序(升序/降序)
s — 按文件大小排序(升序/降序)
C – 按项目数排序(升序/降序)
d – 删除选定的文件或目录
t — 排序时将目录放在文件前面
g – 以图形方式显示百分比
I 查看文件的信息
4.最后,假如说你想退出去,但是又不想关闭终端,control+z即可
du 和 df 的定义,以及区别?
du命令可以显示目前的目录所占用的磁盘空间,df命令可以显示目前磁盘剩余空间。
df 命令获得真正的文件系统数据,而 du 命令只查看文件系统的部分情况。
如果du命令不加任何参数,那么返回的是整个磁盘的使用情况,如果后面加了目录的话,就是这个目录在磁盘上的使用情况。
du -hs 指定目录 查看指定目录的总大小
du -hs ./* 查看当前目录下的所有文件夹和文件的大小
df 显示每个<文件>所在的文件系统的信息,默认是显示所有文件系统。
(文件系统分配其中的一些磁盘块用来记录它自身的一些数据,如 i 节点,磁盘分布图,间接块,超级块等。这些数据对大多数用户级的程序来说是不可见的,通常称为 Meta Data。) du 命令是用户级的程序,它不考虑 Meta Data,而 df 命令则查看文件系统的磁盘分配图并考虑 Meta Data。
这两个命令都支持-k,-m和-h参数,-k和-m类似,都表示显示单位,一个是k字节一个是兆字节,-h则表示human-readable,即友好可读的显示方式。
内存
参考:
https:# blog.csdn.net/qq_39526250/article/details/89491565
http://www.51niux.com/?id=76
free 显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区
free命令可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
Grammar
free (Option)
Option
- -m:以MB为单位显示内存使用情况;
- -h:易读懂的格式显示
-
-b:以Byte为单位显示内存使用情况;
-
-k:以KB为单位显示内存使用情况;
-
-o:不显示缓冲区调节列;
-
-s<间隔秒数>:持续观察内存使用状况;
-
-t:显示内存总和列;
-
-V:显示版本信息。
Living Example
[root@CentOS6 ~]# free -h
total used free shared buffers cached
Mem: 980M 842M 137M 240K 29M 647M
-/+ buffers/cache: 165M 814M
Swap: 1.9G 0B 1.9G
-----------------------------------------------------------------------------------------
[root@CentOS6 ~]# free -m
total used free shared buffers cached
Mem: 2016 1973 42 0 163 1497
-/+ buffers/cache: 312 1703
Swap: 4094 0 4094
- total:总计物理内存的大小。
- used:已使用多大。
- free:可用有多少。
- Shared:多个进程共享的内存总额。
- Buffers/cached:磁盘缓存的大小。
- 所以空闲内存=free+buffers+cached=total-used
第一部分Mem行解释:
total:内存总数;
used:已经使用的内存数;
free:空闲的内存数;
shared:当前已经废弃不用;
buffers Buffer:缓冲内存数;
cached Page:缓存内存数。
Cache(缓存)位于CPU与内存之间的临时存储器,缓存容量比内存小的多但交换速度比内存要快得多。Cache通过缓存文件数据块,解决CPU运算速度与内存读写速度不匹配的矛盾,提高CPU和内存之间的数据交换速度。Cache缓存越大,CPU处理速度越快。
Buffer(缓冲)高速缓冲存储器,通过缓存磁盘(I/O设备)数据块,加快对磁盘上数据的访问,减少I/O,提高内存和硬盘(或其他I/O设备)之间的数据交换速度。Buffer是即将要被写入磁盘的,而Cache是被从磁盘中读出来的。
换算关系:total = used + free
第二部分(-/+ buffers/cache)解释:
(-buffers/cache) used内存数:第一部分Mem行中的 used - buffers - cached
(+buffers/cache) free内存数: 第一部分Mem行中的 free + buffers + cached
可见-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。
第三部分是指交换分区:
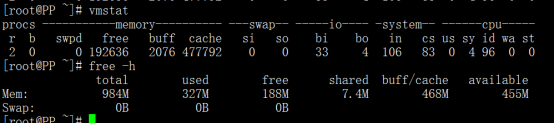
free -m 或者vmstat 或者vmstat 1 10 (这个表示1s更新一次,总共10次)
查看进程的内存占用
pidof bash
pidstat -r -p 24427 1 5
内存占用高的前20
ps aux | head -1;ps aux |grep -v PID |sort -rn -k +4 | head -20
动态查看内存占用
slabtop
问题定位及解决方法 cached 占用过高问题
参考:https:# mp.weixin.qq.com/s/1rrlq2HZdEoRub7EHSWnEA
buffer,cached的作用:
cached主要负责缓存文件使用, 日志文件过大造成cached区内存增大把内存占用完 .
Free中的buffer和cache:(它们都是占用内存):
buffer: 作为buffer cache的内存,是块设备(磁盘)的缓冲区,包括读、写磁盘
cache: 作为page cache的内存, 文件系统的cache,包括读、写文件
如果 cache 的值很大,说明cache住的文件数很多。
linux服务器会自动释放内存,保障系统运行,但只会释放够用的内存,而不会去释放更多的内存。
解决方法:
手动释放cached方法有三种(系统默认值是0,释放之后你需要再改回0值):
释放前最好sync一下,防止丢数据
sync 在启动机器或关机之前一定要运行sync命令。记住在任何情况下,慎重地执行sync命令决不会有任何坏处,sync命令强制把磁盘缓冲的所有数据写入磁盘
To free pagecache: #echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes: #echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes: #echo 3 > /proc/sys/vm/drop_caches
#常用方法是drop_caches:
仅清除缓存页;清空 page cache:
sync
echo 1 > /proc/sys/vm/drop_caches
或者:
sync
sysctl -w vm.drop_caches=1
清除目录项和inodes;清空 dentries 和 inodes:
sync
echo 2 > /proc/sys/vm/drop_caches
或者:
sync
sysctl -w vm.drop_caches=2
清除,缓存页,目录项和inodes;清空所有缓存(pagecache、dentries 和 inodes):
sync
echo 3 > /proc/sys/vm/drop_caches
或者:
sync
sysctl -w vm.drop_caches=3
上述命令的说明:
sync将刷新文件系统缓存,命令通过";"分隔,顺序执行,shell等待终止在序列中的每一个命令执行之前。正如内核文档中提到的,写到drop_cache将清空缓存而不杀死任何应用程序/服务,echo命令做写入文件的工作。
如果你必须清除磁盘高速缓存,第一个命令在企业和生产环境中是最安全,"...echo 1> ..."只会清除页缓存。
不建议使用上面第三个选项在生产环境中"...echo 3 >" ,除非你明确自己在做什么,因为它会清除缓存页,目录项和inodes
实例演示:
[root@aliyun-8-server ~]#free -h
total used free shared buff/cache available
Mem: 1.6G 572M 269M 10M 760M 864M
Swap: 2.5G 0B 2.5G
[root@aliyun-8-server ~]#sync
[root@aliyun-8-server ~]#echo 1 > /proc/sys/vm/drop_caches
[root@aliyun-8-server ~]#echo 2 > /proc/sys/vm/drop_caches
[root@aliyun-8-server ~]#echo 3 > /proc/sys/vm/drop_caches
#清除后要还原系统默认配置:
[root@aliyun-8-server ~]#echo 0 > /proc/sys/vm/drop_caches
-bash: echo: write error: Invalid argument
说明:这里报错,好像是内核3.x不支持该参数了。
#查看设置
[root@aliyun-8-server ~]#sysctl -a | grep drop_caches
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens33.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.drop_caches = 3
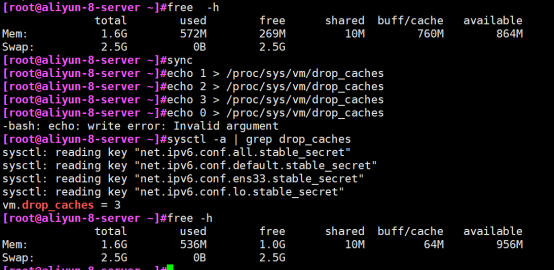
这时查看 free 可以看到 cached 降低了很多
[root@aliyun-8-server ~]#free -h
total used free shared buff/cache available
Mem: 1.6G 536M 1.0G 10M 64M 956M
Swap: 2.5G 0B 2.5G
补充: echo 字符串 > 文件 就是把字符串内容从定向到文件中
注:
swap清理:
swapoff -a && swapon -a
注意:这样清理有个前提条件,空闲的内存必须比已经使用的swap空间大。
linux vm内核参数优化设置
(1)vm.min_free_kbytes
[root@learn ~]# sysctl -a | grep min_free_kbytes #centos7.7默认44M
vm.min_free_kbytes = 45056
该文件表示强制Linux VM最低保留多少空闲内存(Kbytes)。
当可用内存低于这个参数时,系统开始回收cache内存,以释放内存,直到可用内存大于这个值。
#改为1g
命令:
[root@aliyun-6-server ~]#sysctl -w vm.min_free_kbytes=1048576
vm.min_free_kbytes = 1048576
(如果命令执行不成功,直接编辑文件进行替换即可)
#查看是否改动
[root@aliyun-6-server ~]#sysctl -a | grep min_free_kbytes
vm.min_free_kbytes = 1048576
(2)vm.overcommit_memory
执行grep -i commit /proc/meminfo
[root@learn ~]# grep -i commit /proc/meminfo
CommitLimit: 941036 kB
Committed_AS: 7018764 kB
看到CommitLimit和Committed_As参数。
-
CommitLimit是一个内存分配上限,CommitLimit = 物理内存 * overcommit_ratio(默认50,即50%) + swap大小
-
Committed_As是已经分配的内存大小。
vm.overcommit_memory文件指定了内核针对内存分配的策略,其值可以是0、1、2
-
0: (默认)表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。0 即是启发式的overcommitting handle,会尽量减少swap的使用,root可以分配比一般用户略多的内存
-
1: 表示内核允许分配所有的物理内存,而不管当前的内存状态如何,允许超过CommitLimit,直至内存用完为止。在数据库服务器上不建议设置为1,从而尽量避免使用swap.
-
2: 表示不允许超过CommitLimit值
(3)vm.overcommit_ratio
默认值为:50 (即50%)
这个参数值只有在vm.overcommit_memory=2的情况下,这个参数才会生效。
------------------------------------------------------------------------------
(4)vm.vfs_cache_pressure
该项表示内核回收用于directory和inode cache内存的倾向:
缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比
降低该值低于100,将导致内核倾向于保留directory和inode cache
增加该值超过100,将导致内核倾向于回收directory和inode cache。
网上文章建议 执行命令:
bash
sysctl -a | grep vfs_cache_pressure
sysctl -w vm.vfs_cache_pressure=200
其实一般情况下不需要调整,只有在极端场景下才建议进行调整,只有此时,才有必要进行调优,这也是调优的意义所在。
(5)vm.dirty_background_ratio 默认为10
所有全局系统进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行。
将vm.dirty_background_ratio设置为5-10,将vm.dirty_ratio设置为它的两倍左右,以确保能持续将脏数据刷新到磁盘,避免瞬间I/O写,产生严重等待(和MySQL中的innodb_max_dirty_pages_pct类似)
(6)vm.dirty_ratio 默认为20
单个进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行。
(7)vm.panic_on_oom 默认为0开启 为1时表示关闭此功能
等于0时,表示当内存耗尽时,内核会触发OOM killer杀掉最耗内存的进程。
当OOM Killer被启动时,通过观察进程自动计算得出各当前进程的得分 /proc/
而且计算分值时主要参照/proc/<PID>/oom_adj, oom_adj 取值范围从-17到15,当等于-17时表示在任何时候此进程都不会被 oom killer kill掉(适用于mysql)。
/proc/[pid]/oom_adj ,该pid进程被oom killer杀掉的权重,介于 [-17,15]之间,越高的权重,意味着更可能被oom killer选中,-17表示禁止被kill掉。
/proc/[pid]/oom_score,当前该pid进程的被kill的分数,越高的分数意味着越可能被kill,这个数值是根据oom_adj运算后的结果,是oom_killer的主要参考。
(8)sysctl 下有2个可配置选项:
vm.panic_on_oom = 0 #内存不够时内核是否直接panic
vm.oom_kill_allocating_task = 1 #oom-killer是否选择当前正在申请内存的进程进行kill
查看CPU、内存、分区、交换分区信息
Linux查看物理CPU个数、核数、逻辑CPU个数
参考: https:# www.cnblogs.com/emanlee/p/3587571.html
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo | grep "physical id" | sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo | grep "cpu cores" | uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo | grep "processor" | wc -l
# 查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
nproc命令
nproc 命令用于获取当前系统上可用的处理器核心数量。它返回一个整数,表示可用的处理器核心数。
在 Linux 系统中,您可以在终端中直接运行 nproc 命令来获取处理器核心数量。例如:
$ nproc
8
上述示例输出表示系统上有 8 个可用的处理器核心。
cat /proc/cpuinfo或者lscpu:查看CPU
# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz
stepping : 9
microcode : 18
cpu MHz : 3293.690
cache size : 3072 KB
physical id : 0
……………………………………………………………………
address sizes : 42 bits physical, 48 bits virtual
power management:
什么是cpu
CPU(Central Processing Unit)是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元,相当于系统的“大脑”。
当 CPU 过于繁忙,就像“人脑”并发处理过多的事情,会降低做事的效率,严重时甚至会导致崩溃“宕机”。因此,理解 CPU 的工作原理,合理控制负载,是保障系统稳定持续运行的重要手段。
CPU 的物理核与逻辑核
一台机器可能包含多块 CPU 芯片,多个 CPU 之间通过系统总线通信。
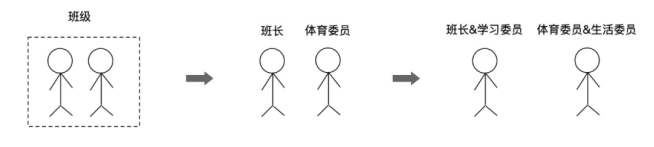
超线程(Hyper-Threading)技术可以让一个物理核在单位时间内同时处理两个线程,变成两个逻辑核。但它不会拥有传统单核 2 倍的处理能力,也不可能提供完整的并行处理能力。
举个例子,假设一个 CPU 芯片就是一个班级;它有 2 个物理核,也就是 2 个同学,老师让他们分别担任班长和体育委员;过了一段时间,校长要求每个班级还要有学习委员和生活委员,理论上还需要 2 位同学,但是这个班级只有 2 个人,最后老师只能让班长和体育委员兼任。
这样一来,对于不了解的人来说,这个班级有班长、体育委员、学习委员和生活委员 4 个职位,应该有 4 个人,每个职位就是一个逻辑核;但是,实际上这个班级只有 2 位同学,也就是只有 2 个物理核,虽然他们可以做 4 份工作,但是不能把他们当做 4 个人。
如何查询 CPU 信息?
在 Linux 系统下,可以从 /proc/cpuinfo 文件中读取 CPU 信息,如下图所示:
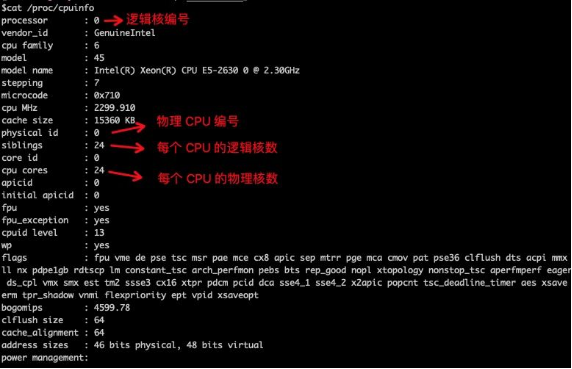
查看 CPU 个数:
cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -l
查看 CPU 物理核数:
cat /proc/cpuinfo | grep 'cpu cores' | sort | uniq
查看 CPU 逻辑核数:
cat /proc/cpuinfo | grep 'siblings' | sort | uniq
什么是 CPU 使用率?
CPU 使用率就是 CPU 非空闲态运行的时间占比,它反映了 CPU 的繁忙程度。比如,单核 CPU 1s 内非空闲态运行时间为 0.8s,那么它的 CPU 使用率就是 80%;双核 CPU 1s 内非空闲态运行时间分别为 0.4s 和 0.6s,那么,总体 CPU 使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%,其中 2 表示 CPU 核数,多核 CPU 同理。
在 Linux 系统下,使用 top 命令查看 CPU 使用情况,可以得到如下信息:
Cpu(s): 0.2%us, 0.1%sy, 0.0%ni, 77.5%id, 2.1%wa, 0.0%hi, 0.0%si, 20.0%st
us(user):表示 CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。
sy(sys):表示 CPU 在内核态运行的时间百分比(不包括中断),通常内核态 CPU 越低越好,否则表示系统存在某些瓶颈。
ni(nice):表示用 nice 修正进程优先级的用户态进程执行的 CPU 时间。nice 是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计 CPU 开销。
id(idle):表示 CPU 处于空闲态的时间占比,此时,CPU 会执行一个特定的虚拟进程,名为 System Idle Process。
wa(iowait):表示 CPU 在等待 I/O 操作完成所花费的时间,通常该指标越低越好,否则表示 I/O 存在瓶颈,可以用 iostat 等命令做进一步分析。
hi(hardirq):表示 CPU 处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。
si(softirq):表示 CPU 处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。
st(steal):表示 CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。
由于 CPU 有多种非空闲态,因此,CPU 使用率计算公式可以总结为:CPU 使用率 = (1 - 空闲态运行时间/总运行时间) * 100%。
根据经验法则, 建议生产系统的 CPU 总使用率不要超过 70%。
什么是平均负载?
平均负载(Load Average)是指单位时间内,系统处于 可运行状态(Running / Runnable) 和 不可中断态 的平均进程数,也就是 平均活跃进程数。
可运行态进程包括正在使用 CPU 或者等待 CPU 的进程;不可中断态进程是指处于内核态关键流程中的进程,并且该流程不可被打断。比如当进程向磁盘写数据时,如果被打断,就可能出现磁盘数据与进程数据不一致。不可中断态,本质上是系统对进程和硬件设备的一种保护机制。
在 Linux 系统下,使用 top 命令查看平均负载,可以得到如下信息:
load average: 1.09, 1.12, 1.52
这 3 个数字分别表示 1分钟、5分钟、15分钟内系统的平均负载。该值越小,表示系统工作量越少,负荷越低;反之负荷越高。
平均负载为多少更合理?
理想情况下,每个 CPU 应该满负荷工作,并且没有等待进程,此时,平均负载 = CPU 逻辑核数。但是,在实际生产系统中,不建议系统满负荷运行。通用的经验法则是:平均负载 = 0.7 * CPU 逻辑核数。
当平均负载持续大于 0.7 * CPU 逻辑核数,就需要开始调查原因,防止系统恶化;
当平均负载持续大于 1.0 * CPU 逻辑核数,必须寻找解决办法,降低平均负载;
当平均负载持续大于 5.0 * CPU 逻辑核数,表明系统已出现严重问题,长时间未响应,或者接近死机。
除了关注平均负载值本身,我们也应关注平均负载的变化趋势,这包含两层含义。一是 load1、load5、load15 之间的变化趋势;二是历史的变化趋势。
当 load1、load5、load15 三个值非常接近,表明短期内系统负载比较平稳。
此时,应该将其与昨天或上周同时段的历史负载进行比对,观察是否有显著上升。
当 load1 远小于 load5 或 load15 时,表明系统最近 1 分钟的负载在降低,而过去 5 分钟或 15 分钟的平均负载却很高。
当 load1 远大于 load5 或 load15 时,表明系统负载在急剧升高,如果不是临时性抖动,而是持续升高,特别是当 load5 都已超过 0.7 * CPU 逻辑核数 时,应调查原因,降低系统负载。
CPU 使用率与平均负载的关系
CPU 使用率是单位时间内 CPU 繁忙程度的统计。而平均负载不仅包括正在使用 CPU 的进程,还包括等待 CPU 或 I/O 的进程。因此,两者不能等同,有两种常见的场景如下所述:
CPU 密集型应用,大量进程在等待或使用 CPU,此时 CPU 使用率与平均负载呈正相关状态。
I/O 密集型应用,大量进程在等待 I/O,此时平均负载会升高,但 CPU 使用率不一定很高。
为了更深入的理解 CPU 使用率与平均负载的关系,我们举一个例子:假设现在有一个电话亭,有 4 个人在等待打电话,电话亭同一时刻只能容纳 1 个人打电话,只有拿起电话筒才算是真正使用。那么 CPU 使用率就是拿起电话筒的时间占比,它只取决于在电话亭里的人的行为,与平均负载没有非常直接的关系。而平均负载是指在电话亭里的人加上排队的总人数,如下图所示:
性能优化实战
无论是 CPU 使用率,还是平均负载,都只是反映系统健康状态的度量指标,而不是问题的根因。
因此,它们的价值主要体现在两个方面:一是综合反映当前系统的健康程度,结合监控告警产品,实现快速响应;二是初步定位问题方向,缩小排查范围,降低故障恢复时间。比如当 CPU iowait 高时,应优先排查磁盘 I/O;当 CPU steal 高时,就优先排查宿主机状态。
CPU 涵盖的问题场景有很多,限于篇幅限制,下面以最常见的用户态 CPU 使用率高为例,介绍下 Java 应用的排查思路,其他场景留待后续分享,推荐阅读 《如何迅速分析出系统CPU的瓶颈在哪里?》。
如何排查用户态 CPU 使用率高?
用户态 CPU 使用率反映了应用程序的繁忙程度,通常与我们自己写的代码息息相关。因此,当你在做应用发布、配置变更或性能优化时,如果想定位消耗 CPU 最多的 Java 代码,可以遵循如下思路:
1、通过 top 命令找到 CPU 消耗最多的进程号;
2、通过 top -Hp 进程号 命令找到 CPU 消耗最多的线程号(列名仍然为 PID);
3、通过printf "%x\n" 线程号 命令输出该线程号对应的 16 进制数字;
4、通过 jstack 进程号 | grep 16进制线程号 -A 10 命令找到 CPU 消耗
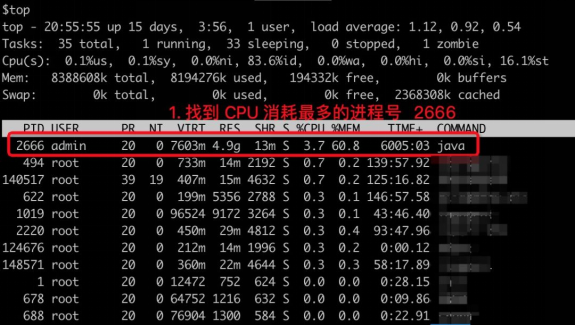
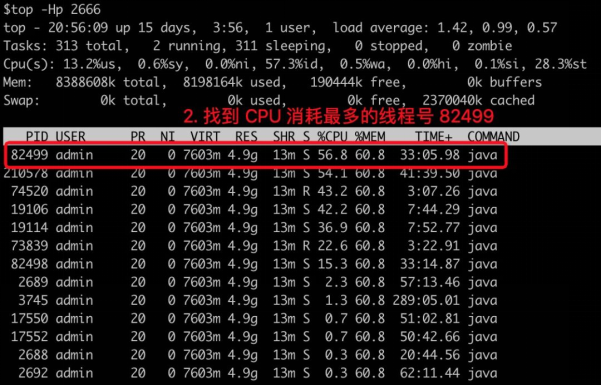
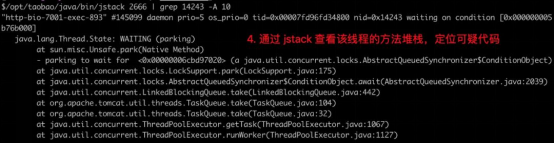
上述方法是目前业界最常用的诊断流程,如果是非 Java 应用,可以将 jstack 替换为 perf,推荐阅读 《Perf -- Linux下的系统性能调优工具》。
然而,上述方法有两个显著缺陷,一是操作流程复杂,而且往往一次 jstack 还不足以定位根因,需要执行多次;二是只能用于诊断在线问题,如果问题已经发生,无法复现的话,往往只能不了了之
cat /proc/meminfo:查看内存信息
[root@test-6 ~]# cat /proc/meminfo
MemTotal: 1002992 kB
MemFree: 143892 kB
……………………………………
Hugepagesize: 2048 kB
DirectMap4k: 14336 kB
DirectMap2M: 1034240 kB
cat /proc/partitions:查看分区信息
[root@test-6 ~]# cat /proc/partitions
major minor #blocks name
8 0 10485760 sda
8 1 512000 sda1
8 2 9972736 sda2
253 0 8921088 dm-0
253 1 1048576 dm-1
cat /proc/swaps:查看交换分区信息
[root@test-6 ~]# cat /proc/swaps
Filename Type Size Used Priority
/dev/dm-1 partition 1048572 0 -1
lsblk 列出所有可用块设备的信息
lsblk命令用于列出所有可用块设备的信息,而且还能显示他们之间的依赖关系,但是它不会列出RAM盘的信息。块设备有硬盘,闪存盘,cd-ROM等等。lsblk命令包含在util-linux-ng包中,现在该包改名为util-linux。
这个包带了几个其它工具,如dmesg。要安装lsblk,请在此处下载util-linux包。
Fedora用户可以通过命令sudo yum install util-linux-ng来安装该包。
选项
- -a, --all 显示所有设备。
-
-l, --list 使用列表格式显示。
-
-b, --bytes 以bytes方式显示设备大小。
-
-d, --nodeps 不显示 slaves 或 holders。
-
-D, --discard print discard capabilities。
-
-e, --exclude
- 排除设备 (default: RAM disks)。
-
-f, --fs 显示文件系统信息。
-
-h, --help 显示帮助信息。
-
-i, --ascii use ascii characters only。
-
-m, --perms 显示权限信息。
-
-n, --noheadings 不显示标题。
-
-o, --output
- 输出列。
-
-P, --pairs 使用key="value"格式显示。
-
-r, --raw 使用原始格式显示。
-
-t, --topology 显示拓扑结构信息。
实例
lsblk命令默认情况下将以树状列出所有块设备。打开终端,并输入以下命令:
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 80G 0 disk
├─vda1 253:1 0 200M 0 part /boot/efi
├─vda2 253:2 0 1G 0 part /boot
└─vda3 253:3 0 78.8G 0 part
├─klas-root 252:0 0 70.8G 0 lvm /
└─klas-swap 252:1 0 8G 0 lvm [SWAP]
vdb 253:16 0 2T 0 disk /data
7个栏目名称如下:
NAME:这是块设备名。
MAJ:MIN:本栏显示主要和次要设备号。
RM:本栏显示设备是否可移动设备。注意,在本例中设备sdb和sr0的RM值等于1,这说明他们是可移动设备。
SIZE:本栏列出设备的容量大小信息。例如298.1G表明该设备大小为298.1GB,而1K表明该设备大小为1KB。
RO:该项表明设备是否为只读。在本案例中,所有设备的RO值为0,表明他们不是只读的。
TYPE:本栏显示块设备是否是磁盘或磁盘上的一个分区。在本例中,sda和sdb是磁盘,而sr0是只读存储(rom)。
MOUNTPOINT:本栏指出设备挂载的挂载点。
默认选项不会列出所有空设备。要查看这些空设备,请使用以下命令:
lsblk -a
lsblk命令也可以用于列出一个特定设备的拥有关系,同时也可以列出组和模式。可以通过以下命令来获取这些信息:
lsblk -m
该命令也可以只获取指定设备的信息。这可以通过在提供给lsblk命令的选项后指定设备名来实现。例如,你可能对了解以字节显示你的磁盘驱动器大小比较感兴趣,那么你可以通过运行以下命令来实现:
lsblk -b /dev/sda
等价于
lsblk --bytes /dev/sda
你也可以组合几个选项来获取指定的输出。例如,你也许想要以列表格式列出设备,而不是默认的树状格式。你可能也对移除不同栏目名称的标题感兴趣。可以将两个不同的选项组合,以获得期望的输出,命令如下:
lsblk -nl
要获取SCSI设备的列表,你只能使用-S选项。该选项是大写字母S,不能和-s选项混淆,该选项是用来以颠倒的顺序打印依赖的。
lsblk -S
lsblk列出SCSI设备,而-s是逆序选项(将设备和分区的组织关系逆转过来显示),其将给出如下输出。输入命令:
lsblk -s
fdisk 观察硬盘实体使用情况,也可对硬盘分区
fdisk命令用于观察硬盘实体使用情况,也可对硬盘分区。它采用传统的问答式界面,而非类似DOS fdisk的cfdisk互动式操作界面,因此在使用上较为不便,但功能却丝毫不打折扣。
Notice:fdisk只能用于2T的磁盘大小,进行分区,这种就是MBR分区表
Grammar
fdisk (Option) (参数)
Option
-
-l:列出指定的外围设备的分区表状况;
-
-u:搭配"-l"参数列表,会用分区数目取代柱面数目,来表示每个分区的起始地址;
-
-c:创建文件系统之前,对文件块进行检查;
-
-s<分区编号>:将指定的分区大小输出到标准输出上,单位为区块;
-
-b<分区大小>:指定每个分区的大小,最小为512 字节,且是512的倍数;
-
-H heads:指定磁头数。(当然,不是物理数字,而是用于分区表的数字)合理值255与16
-
-v:显示版本信息。
参数
设备文件:指定要进行分区或者显示分区的硬盘设备文件。
mke2fs 用于创建磁盘分区上的"etc"文件系统
Option
-
-b<区块大小>:指定区块大小,单位为字节,必须是1024的倍数,最大4k;
-
-I<字节>:指定"字节/inode"的大小(128,256这两种);
-
-L<标签>:设置文件系统的标签名称;
-
-c;在创建文件系统之前,检查是否有损坏的区块;
-
-m<百分比值>:指定给管理员保留区块的比例,预设为5%;
-
-u:为磁盘指定UUID
mkfs 用于在设备上(通常为硬盘)创建Linux文件系统
mkfs命令用于在设备上(通常为硬盘)创建Linux文件系统。mkfs本身并不执行建立文件系统的工作,而是去调用相关的程序来执行。
Grammar
mkfs(Option)(参数)
Option
-
fs:指定建立文件系统时的参数;
-
-t<文件系统类型>:指定要建立何种文件系统;
-
-v:显示版本信息与详细的使用方法;
-
-V:显示简要的使用方法;
-
-c:在制做档案系统前,检查该partition是否有坏轨。
参数
文件系统:指定要创建的文件系统对应的设备文件名;
块数:指定文件系统的磁盘块数。
Living Example
在格式化sdb5的时候,同时指定block和iNode的大小
[root@test ~]# mkfs.ext4 -b 2048 -I 128 /dev/sdb5
blkid 通俗易懂,查看分区是否格式化、以及文件系统
在Linux下可以使用blkid命令对查询设备上所采用文件系统类型进行查询。blkid主要用来对系统的块设备(包括交换分区)所使用的文件系统类型、LABEL、UUID等信息进行查询。要使用这个命令必须安装e2fsprogs软件包。
Grammar
blkid -L | -U
blkid [-c ] [-ghlLv] [-o] [-s ][-t ] [-w ] [ ...]
blkid -p [-s ] [-O ] [-S ][-o] ...
blkid -i [-s ] [-o] ....
Option
- -L
- -U
convert UUID to device name -
-c
指定cache文件(default: /etc/blkid.tab, /dev/null = none) -
-d don't encode non-printing characters
- -h 显示帮助信息
-
-g garbage collect the blkid cache
-
-o
指定输出格式 -
-k list all known filesystems/RAIDs and exit
-
-s
显示指定信息,默认显示所有信息 -
-t
find device with a specific token (NAME=value pair) -
-l look up only first device with token specified by -t
-
-v 显示版本信息
-
-w
write cache to different file (/dev/null = no write) -
specify device(s) to probe (default: all devices) -
Low-level probing Options:
-
-p low-level superblocks probing (bypass cache)
-
-i gather information about I/O limits
-
-S
overwrite device size -
-O
probe at the given offset -
-u
- filter by "usage" (e.g. -u filesystem,raid)
-
-n
- filter by filesystem type (e.g. -n vfat,ext3)
Living Example:
[root@test6 ~]# blkid
/dev/sda1: UUID="5b4e320d-217d-4433-9782-1272e6766f09" TYPE="ext4"
/dev/sda2:UUID="2b9Gd8-Dum9-jZAJ-0UJw-UgXy-w0HS-PFjlP3" TYPE="LVM2_member"
/dev/mapper/vg_test6-lv_root:UUID="2becbe7e-1389-4495-9b5b-b4dccfae45b5" TYPE="ext4"
/dev/mapper/vg_test6-lv_swap:UUID="4f342068-f15a-4497-b014-07d01b02543f" TYPE="swap"
分区的两种方法
==Living Example==fdisk磁盘分区4大步
加硬盘、然后进行分区
第一步:新加一块硬盘
第二步:刷新地址总线,重新扫描磁盘信息(如果不刷新,重启服务器也可以,这个刷新地址总线只针对虚拟机而已,真是机是可以自动识别的)
echo "- - -" > /sys/class/scsi_host/host0/scan
echo "- - -" > /sys/class/scsi_host/host1/scan
echo "- - -" > /sys/class/scsi_host/host2/scan
第三部:首先选择要进行操作的磁盘:
[root@localhost ~]# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x120ec09d.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
警告:不支持dos兼容模式。强烈建议
关闭模式(命令“c”)并将显示单元更改为
部门(命令“u”)。
解决这个警告用这个命令进行分区:fdisk –uc /dev/sdb (这个告警不影响分区)
输入m列出可以执行的命令:
command (m for help): m (执行ctrl+backspace,删除输入的)
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition (删除分区)
l list known partition types (列出分区类型)
m print this menu (显示帮助信息)
n add a new partition (新建分区)
o create a new empty DOS partition table
p print the partition table (显示分区表)
q quit without saving changes (退出不保存分区信息)
s create a new empty Sun disklabel
t change a partition's system id (更改分区类型)
u change display/entry units
v verify the partition table (检查分区表)
w write table to disk and exit (保存退出)
x extra functionality (experts only)
输入p列出磁盘目前的分区情况:
Command (m for help): p
Disk /dev/sdb: 3221 MB, 3221225472 bytes
255 heads, 63 sectors/track, 391 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 1 8001 8e Linux LVM
/dev/sdb2 2 26 200812+ 83 Linux
输入d然后选择分区,删除现有分区:
Command (m for help): d
Partition number (1-4): 1
Command (m for help): d
Selected partition 2
查看分区情况,确认分区已经删除:
Command (m for help): p
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x90ca09c1
Device Boot Start End Blocks Id System
输入n建立新的磁盘分区,首先建立两个主磁盘分区:
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p # 建立主分区
Partition number (1-4): 1 # 分区号
First cylinder (1-391, default 1): # 分区起始位置 (默认就好,直接回车)
Using default value 1
last cylinder or +size or +sizeM or +sizeK (1-391, default 391): 100M # 分区结束位置,单位为扇区 (如果写错了就执行ctrl+backspace进行删除)
Command (m for help): n # 再建立一个分区
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2 # 分区号为2
First cylinder (101-391, default 101):
Using default value 101
Last cylinder or +size or +sizeM or +sizeK (101-391, default 391): +200M # 分区结束位置,单位为M (如果写错了就执行ctrl+backspace进行删除)
确认分区建立成功:
Command (m for help): p
Disk /dev/sdb: 3221 MB, 3221225472 bytes
255 heads, 63 sectors/track, 391 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 100 803218+ 83 Linux
/dev/sdb2 101 125 200812+ 83 Linux
再建立一个逻辑分区:
Command (m for help): n
Command action
e extended
p primary partition (1-4)
e # 选择扩展分区
Partition number (1-4): 3
First cylinder (126-391, default 126):
Using default value 126
Last cylinder or +size or +sizeM or +sizeK (126-391, default 391):
Using default value 391
确认扩展分区建立成功:
Command (m for help): p
Disk /dev/sdb: 3221 MB, 3221225472 bytes
255 heads, 63 sectors/track, 391 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 100 803218+ 83 Linux
/dev/sdb2 101 125 200812+ 83 Linux
/dev/sdb3 126 391 2136645 5 Extended
在扩展分区上建立两个逻辑分区:
Command (m for help): n
Command action
l logical (5 or over)
p primary partition (1-4)
l # 选择逻辑分区
First cylinder (126-391, default 126):
Using default value 126
Last cylinder or +size or +sizeM or +sizeK (126-391, default 391): +400M
Command (m for help): n
Command action
l logical (5 or over)
p primary partition (1-4)
l # 选择逻辑分区
First cylinder (176-391, default 176):
Using default value 176
Last cylinder or +size or +sizeM or +sizeK (176-391, default 391):
Using default value 391
确认逻辑分区建立成功:
Command (m for help): p
Disk /dev/sdb: 3221 MB, 3221225472 bytes
255 heads, 63 sectors/track, 391 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 100 803218+ 83 Linux
/dev/sdb2 101 125 200812+ 83 Linux
/dev/sdb3 126 391 2136645 5 Extended
/dev/sdb5 126 175 401593+ 83 Linux
/dev/sdb6 176 391 1734988+ 83 Linux
创建交换分区
Command (m for help): t #(修改分区类型,还有一种创建swap的方法)
Partition number (1-5): 1
Hex code (type L to list codes): 82 #(82表示swap分区,这个内存不够使,就需要swap分区大小)
Changed system type of partition 1 to 82 (Linux swap / Solaris)
Command (m for help): p
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders, total 20971520 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x90ca09c1
Device Boot Start End Blocks Id System
/dev/sdb1 2048 411647 204800 82 Linux swap / Solaris
/dev/sdb2 411648 821247 204800 5 Extended
/dev/sdb5 413696 618495 102400 83 Linux
Command (m for help):
从上面的结果我们可以看到,在硬盘sdb我们建立了2个主分区(sdb1,sdb2),1个扩展分区(sdb3),2个逻辑分区(sdb5,sdb6)
Notice:主分区和扩展分区的磁盘号位1-4,也就是说最多有4个主分区或者扩展分区,逻辑分区开始的磁盘号为5,因此在这个实验中试没有sdb4的。
最后对分区操作进行保存:
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
告知内核当前磁盘分区信息(3种,最好用后两种)
partx:告知内核当前磁盘分区信息 # 第一种
SYNOPSIS
partx [partition] disk
OPTIONS
-a add specified partitions or read disk and add all partitions
(重读分区信息表)
-d delete specified or all partitions
(删除所有分区,或者删除指定分区)
-l list partitions. Note that the all numbers are in 512-byte sectors.
(列出分区信息)
--type TYPE
Specify the partition type -- dos, bsd, solaris, unixware or gpt.
(指定分区类型)
[root@AAAA7 ~]# partx -af /dev/sdb
BLKPG: Device or resource busy (这里是虚拟机做的实验,真机是不会报错的)
error adding partition 1
BLKPG: Device or resource busy
error adding partition 2
BLKPG: Device or resource busy
error adding partition 4
BLKPG: Device or resource busy
error adding partition 5
-----------------------------------------------------------------------------------------
kpartx:从分区表创建设备映射 # 第二种
SYNOPSIS
kpartx [-a | -d | -l] [-v] wholedisk
OPTIONS
-a Add partition mappings
(增加一个分区表映射)
-f force creation of mappings; overrides 'no_partitions' feature
(强制执行)
[root@AAAA7 ~]# kpartx -af /dev/sdb
-----------------------------------------------------------------------------------------
partprobe:通知内核分区表的变更 # 第三种
NAME
partprobe - inform the OS of partition table changes
SYNOPSIS
partprobe [-d] [-s] [devices...]
OPTIONS
This program uses short UNIX style Options.
-s Show a summary of devices and their partitions.
(显示设备及其分区摘要)
[root@AAAA7 ~]# partprobe -s /dev/sdb
建立好分区之后我们还需对分区进行格式化才能在系统中使用磁盘。
例如:在sdb1上建立ext4分区:
[root@localhost ~]# mkfs.ext4 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
文件系统标签=
操作系统:Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
328656 inodes, 1313305 blocks
65665 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=1346371584
41 block groups
32768 blocks per group, 32768 fragments per group
8016 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
This filesystem will be automatically checked every 32 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
在sdb6上建立ext3分区:
[root@localhost ~]# mkfs.ext4 /dev/sdb6
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
217280 inodes, 433747 blocks
21687 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=444596224
14 block groups
32768 blocks per group, 32768 fragments per group
15520 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 32 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
这个文件系统将每32个或更多的挂载被自动检查一次
180天,以先到为准。使用tune2fs -c或-i重写。
[root@test6 ~]# tune2fs -c -1 /dev/sdb5 (不检查磁盘)
tune2fs 1.41.12 (17-May-2010)
Setting maximal mount count to -1
查看分区的格式化情况 (blkid)
[root@test6 ~]# blkid
/dev/sda1: UUID="5b4e320d-217d-4433-9782-1272e6766f09" TYPE="ext4"
/dev/sda2: UUID="2b9Gd8-Dum9-jZAJ-0UJw-UgXy-w0HS-PFjlP3" TYPE="LVM2_member"
/dev/sdb1: UUID="2857d4c7-516b-4d63-95e2-94004e7240e3" TYPE="ext4"
/dev/sdb5: UUID="0fff4c14-e4be-4e2b-95d4-bdce2d7ed19b" TYPE="swap"
/dev/mapper/vg_test6-lv_root: UUID="2becbe7e-1389-4495-9b5b-b4dccfae45b5" TYPE="ext4"
/dev/mapper/vg_test6-lv_swap: UUID="4f342068-f15a-4497-b014-07d01b02543f" TYPE="swap"
解释说明:红色的表示分区已经格式化了
建立两个目录/oracle和/web,将新建好的两个分区挂载到系统:
[root@localhost ~]# mkdir /oracle /web
[root@localhost ~]# mount /dev/sdb1 /oracle
[root@localhost ~]# mount /dev/sdb6 /web
查看分区挂载情况:
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/VolGroup00-LogVol00
6.7G 2.8G 3.6G 44% /
/dev/sda1 99M 12M 82M 13% /boot
tmpfs 125M 0 125M 0% /dev/shm
/dev/sdb1 773M 808K 733M 1% /oracle
/dev/sdb6 1.7G 35M 1.6G 3% /web
如果需要每次开机自动挂载则需要修改/etc/fstab文件,加入两行配置:
[root@localhost ~]# vim /etc/fstab
/dev/VolGroup00/LogVol00 / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
/dev/VolGroup00/LogVol01 swap swap defaults 0 0
/dev/sdb1 /oracle ext4 defaults 0 0
/dev/sdb6 /web ext4 defaults 0 0
==Living Example==parted磁盘分区
parted 是一个用于对磁盘进行分区的工具。它提供了一种在命令行界面下管理磁盘分区的方式。
使用 parted 可以执行以下操作:
- 创建分区表:使用 parted,您可以创建不同类型的分区表,如 MBR(主引导记录)或 GPT(GUID 分区表)。分区表是用于存储磁盘分区信息的数据结构。
- 创建分区:通过指定分区的起始位置和大小,使用 parted 可以在磁盘上创建新的分区。您可以选择不同的分区类型(如主分区、扩展分区、逻辑分区)以及文件系统类型。
- 调整分区大小:如果需要调整分区的大小,parted 可以帮助您重新分配分区的空间,使其更大或更小。这对于扩展已有分区或回收未使用空间非常有用。
- 移动分区:当需要更改分区的位置时,parted 允许您移动现有的分区到新的位置。
- 删除分区:使用 parted,您可以删除不再需要的分区,以释放空间或重组分区表。
- 检查对齐性:parted 提供了对分区对齐方式的检查和优化功能。良好的分区对齐可以提高磁盘性能,并减少数据损坏的风险。
- 显示分区表信息:您可以使用 parted 查看磁盘上的分区表及其相关信息,如分区号、起始位置、大小、文件系统类型等。
当使用 parted 工具时,以下是一些常用的命令和参数:
print:显示设备的分区表信息。mkpart [part-type fs-type start end]:创建一个新分区。其中,part-type是分区类型(如 primary、logical、extended 等),fs-type是文件系统类型(如 ext4、ntfs、fat32 等),start和end是分区的起始和结束位置,可以使用扇区或百分比表示。resizepart partition end:调整分区的大小,将分区的结束位置设置为指定的位置。move partition start end:移动分区到指定的位置。rm partition:删除指定的分区。unit unit-name:设置单位为扇区、GB、MB 等。align-check [alignment [partition]]:检查分区的对齐方式是否符合最佳实践。align-check optimal partition [min] [optimal] [max]:检查分区的对齐方式,并给出建议的最佳对齐位置。select device:选择要操作的设备。quit:退出 parted。
交互式
[root@test6 ~]# parted /dev/sdb #选择需要分区的磁盘
GNU Parted 2.1
使用 /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted)mklabel #这里类型只有两种-> msdos|gpt
mkfs mklabel mkpart mkpartfs mktable
(parted) mklabel gpt #分区表类型设为gpt
警告: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do
you want to continue?
是/Yes/否/No? y #忽略警告,直接y
(parted) p #p:打印分区表信息
Model: ATA VMware Virtual S (scsi)
Disk /dev/sdb: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
(parted) mkpart primary ext4 0 1G #创建主分区 格式为ext4 1G
警告: The resulting partition is not properly aligned for best performance.
忽略/Ignore/放弃/Cancel? i #忽略
(parted)
(parted) rm 1 #删除分区
(parted) p #p:打印分区表信息
Model: ATA VMware Virtual S (scsi)
Disk /dev/sdb: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
(parted)
(parted) mkpart
mkpart mkpartfs
(parted) mkpart primary 1000 1500M #创建主分区,500M
警告: The resulting partition is not properly aligned for best performance.
忽略/Ignore/放弃/Cancel? i #忽略
(parted) p
Model: ATA VMware Virtual S (scsi)
Disk /dev/sdb: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
1 17.4kB 500MB 500MB primary
2 1000MB 1500MB 500MB primary
(parted) mkpart primary 1501 2000M #创建分区
(parted) p #p显示分区信息
Model: ATA VMware Virtual S (scsi)
Disk /dev/sdb: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name 标志
1 17.4kB 500MB 500MB primary
2 1000MB 1500MB 500MB primary
3 1501MB 2000MB 499MB primary
(parted) q #退出
信息: You may need to update /etc/fstab.
[root@test6 ~]# partprobe -s /dev/sdb #告知内核分区表变更
/dev/sdb: gpt partitions 1 2 3
[root@test6 ~]# mkfs.ext4 /dev/sdb1 #格式化分区sdb1
mke2fs 1.41.12 (17-May-2010)
文件系统标签=
操作系统:Linux
块大小=1024 (log=0)
分块大小=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
122400 inodes, 488264 blocks
24413 blocks (5.00%) reserved for the super user
第一个数据块=1
Maximum filesystem blocks=67633152
60 block groups
8192 blocks per group, 8192 fragments per group
2040 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409
正在写入inode表: 完成
Creating journal (8192 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
This filesystem will be automatically checked every 25 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@test6 ~]# blkid /dev/sdb1 #查看分区是否格式化成功
/dev/sdb1: UUID="83df88be-d5f8-44bb-967d-b135f06790c5" TYPE="ext4"
#解释说明:能显示分区,uuid,type的才能说明是格式化成功的
[root@test6 ~]# mount /dev/sdb1 /media/ #挂载sdb1
sdb1
[root@test6 ~]# mount /dev/sdb1 /media/
[root@test6 ~]# df -hT #查看挂载是否成功
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_test6-lv_root
ext4 18G 1.4G 15G 9% /
tmpfs tmpfs 491M 0 491M 0% /dev/shm
/dev/sda1 ext4 477M 33M 419M 8% /boot
/dev/sdb1 ext4 454M 2.3M 428M 1% /media
非交互式
下面是一些非交互式常用的 parted 命令参数的详细解释:
-s:以非交互模式运行 parted,并且在执行操作后立即退出。-a optimal:设置分区对齐方式为optimal。这将根据设备的特性自动选择最佳的对齐方式。/dev/nvme0n1:指定要进行分区操作的设备路径。mklabel gpt:创建一个 GPT(GUID 分区表)标签,该标签适用于大多数现代系统。--:用于分隔 parted 命令和选项部分。mkpart primary ext4 1 -1:创建一个主分区,使用 ext4 文件系统格式化,从第一个扇区(1)到最后一个扇区(-1)。
参考: https://docs.pingcap.com/zh/tidb/v6.5/check-before-deployment#%E5%9C%A8-tikv-%E9%83%A8%E7%BD%B2%E7%9B%AE%E6%A0%87%E6%9C%BA%E5%99%A8%E4%B8%8A%E6%B7%BB%E5%8A%A0%E6%95%B0%E6%8D%AE%E7%9B%98-ext4-%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F%E6%8C%82%E8%BD%BD%E5%8F%82%E6%95%B0
如果你的数据盘已经格式化成 ext4 并挂载了磁盘,可先执行 umount /dev/nvme0n1p1 命令卸载,从编辑 /etc/fstab 文件步骤开始执行,添加挂载参数重新挂载即可。
以 /dev/nvme0n1 数据盘为例,具体操作步骤如下:
1、 查看数据盘。
fdisk -l
Disk /dev/nvme0n1: 1000 GB
2、 创建分区。
使用 parted 工具在 /dev/nvme0n1 设备上进行磁盘分区和标签操作。该命令将创建一个 GPT 分区表,并在该设备上创建一个以 ext4 文件系统格式化的主分区,从第一个扇区(1)到最后一个扇区(-1)。
这个命令会以非交互方式执行,并且会立即应用更改,因此请确保在使用之前已经确认了目标设备和分区范围,以防止意外的数据丢失。
parted -s -a optimal /dev/nvme0n1 mklabel gpt -- mkpart primary ext4 1 -1
总体而言,上述命令的作用是在 /dev/nvme0n1 设备上创建一个 GPT 标签,并在该设备上创建一个大小跨越整个设备的主分区,使用 ext4 文件系统进行格式化。
注意
使用 lsblk 命令查看分区的设备号:对于 nvme 磁盘,生成的分区设备号一般为 nvme0n1p1;对于普通磁盘(例如 /dev/sdb),生成的分区设备号一般为 sdb1。
3、 格式化文件系统。
mkfs.ext4 /dev/nvme0n1p1
4、 查看数据盘分区 UUID。
本例中 nvme0n1p1 的 UUID 为 c51eb23b-195c-4061-92a9-3fad812cc12f。
lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 ext4 237b634b-a565-477b-8371-6dff0c41f5ab /boot
├─sda2 swap f414c5c0-f823-4bb1-8fdf-e531173a72ed
└─sda3 ext4 547909c1-398d-4696-94c6-03e43e317b60 /
sr0
nvme0n1
└─nvme0n1p1 ext4 c51eb23b-195c-4061-92a9-3fad812cc12f
5、 编辑 /etc/fstab 文件,添加 nodelalloc 挂载参数。
vi /etc/fstab
UUID=c51eb23b-195c-4061-92a9-3fad812cc12f /data1 ext4 defaults,nodelalloc,noatime 0 2
6、 挂载数据盘。
mkdir /data1 && \
mount -a
7、 执行以下命令,如果文件系统为 ext4,并且挂载参数中包含 nodelalloc,则表示已生效。
mount -t ext4
/dev/nvme0n1p1 on /data1 type ext4 (rw,noatime,nodelalloc,data=ordered)
swap(创建交换分区;开启或关闭)
说明:swap分区格式化后设置启用或关闭 ,不需要挂载;其他的就必须格式化后挂载
swap分区作用:当内存不足时,就用swap分区
Swap分区,即交换区,系统在物理内存不够时,与Swap进行交换。即当系统的物理内存不够用时,把硬盘中一部分空间释放出来,以供当前运行的程序使用。当那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。那些被释放内存空间的程序一般是很长时间没有什么操作的程序。
Swap空间一般应大于或等于物理内存的大小,同时最小不应小于64M,最大应该是物理内存的两倍。

[root@test6 ~]# mkswap /dev/sdb5 #格式化swap分区
Setting up swapspace version 1, size = 1060252 KiB
no label, UUID=0fff4c14-e4be-4e2b-95d4-bdce2d7ed19b
[root@test6 ~]# swapon /dev/sdb #开启swap分区
[root@test6 ~]# swapon /dev/sdb5 #关闭swap分区)
[root@test6 ~]# grep "SwapTotal" /proc/meminfo --col #查看swap分区
SwapTotal: 3091864 kB
mount 挂载文件系统 (拓展)
linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。这里所说的“按一定方式”就是指的挂载。 将一个文件系统的顶层目录挂到另一个文件系统的子目录上,使它们成为一个整体,称为挂载。把该子目录称为挂载点.
例如要读取硬盘中的一个格式化好的分区、光盘或软件等设备时,必须先把这些设备对应到某个目录上,而这个目录就称为“挂载点(mount point)”,这样才可以读取这些设备。 挂载后将物理分区细节屏蔽掉,用户只有统一的逻辑概念。所有的东西都是文件。
Notice:
1、挂载点必须是一个目录。
2、一个分区挂载在一个已存在的目录上,这个目录可以不为空,但挂载后这个目录下以前的内容将不可用。 对于其他操作系统建立的文件系统的挂载也是这样。但是需要理解的是:光盘、软盘、其他操作系统使用的文件系统的格式与linux使用的文件系统格式是不一样的。光盘是ISO9660;软盘是fat16或ext2;windows NT是fat16、NTFS;windows98是fat16、fat32;windows2000和windowsXP是fat16、fat32、 NTFS。挂载前要了解linux是否支持所要挂载的文件系统格式。
挂载时使用mount命令:
Grammar:
其格式:mount [-参数] [设备名称] [挂载点]
其中常用的参数有:
- -l, --show-labels 显示文件系统标签
-
-a 挂载fstab文件中的所有的文件系统
-
-v 挂载详情
-
-t 指定要挂载设备的文件系统类型(上面提到的文件类型)
-
-B :--bind:将文件访问入口绑定到指定目录上
-
-r 只读挂载
-
-w 只写挂载
-
-L 'LABEL': 以卷标指定挂载设备
-
-U 挂载方式以UUID的形式指明
-
-n: 不更新
/etc/mtab - -o 指定挂载文件系统时的特殊选项。有些也可用在
/etc/fstab中。常用的有
-o 选项:(挂载文件系统的选项)
async:异步模式;
sync:同步模式;
atime/noatime:包含目录和文件;
nodelalloc: 禁用延迟分配,使得数据立即写入磁盘;
diratime/nodiratime:目录的访问时间戳
auto/noauto:是否支持自动挂载
exec/noexec:是否支持将文件系统上应用程序运行为进程
dev/nodev:是否支持在此文件系统上使用设备文件;
suid/nosuid:是否支持在此文件系统上使用特殊权限
remount:重新挂载
ro:只读
rw:读写
user/nouser:是否允许普通用户挂载此设备
acl:启用此文件系统上的acl功能
在 Linux 系统中,通过在挂载磁盘时添加特定的参数可以改善磁盘的性能。对于 ext4 文件系统,两个常用的参数是 noatime 和 nodelalloc。
noatime:默认情况下,ext4 文件系统会在每次文件访问时更新文件的访问时间戳(atime)。然而,这个操作会引入额外的磁盘写入操作,对磁盘性能有一定的影响。通过添加noatime参数,可以禁止更新文件的访问时间戳,从而减少不必要的磁盘写入。这对于大量读取操作较多的应用场景(如数据库、日志等)可以提升磁盘性能。nodelalloc:默认情况下,ext4 文件系统使用延迟分配(delayed allocation)的方式进行磁盘写入。这意味着文件系统并不立即将数据写入磁盘,而是先将数据保留在内存中,然后在适当的时候一次性写入磁盘。这种方式可以提高磁盘写入的效率,但也可能导致一些问题,如写入延迟增加或数据未及时刷新到磁盘。通过添加nodelalloc参数,可以禁用延迟分配,使得数据立即写入磁盘,从而提高一些特定情况下的写入性能和数据一致性。
需要注意的是,设置这些参数可能会影响到文件系统的行为和数据的一致性。在设置之前,请确保你了解这些参数的意义和潜在风险,并在测试和验证后再在生产环境中使用。此外,推荐在修改挂载参数之前对数据进行备份,以防意外情况发生。
可以通过修改 /etc/fstab 文件来永久修改挂载参数,或者使用命令行参数在挂载时指定。例如:
/dev/sdb1 /mnt/data ext4 noatime,nodelalloc 0 0
以上示例假设 /dev/sdb1 是你要挂载的磁盘,/mnt/data 是挂载点,以 ext4 文件系统格式进行挂载,并添加了 noatime 和 nodelalloc 参数。请根据实际情况进行相应的修改。
注意:上述选项可多个同时使用,彼此使用逗号分隔;
默认挂载选项:defaults:rw, suid, dev, exec, auto, nouser, and async
上述信息可以通过查看超级块信息看到,这里不再对其进行演示
注意:查看内核追踪到的已挂载的所有设备:cat /proc/mounts
例如:
挂载/dev/sdb1到/mnt
[root@test6 ~]# mount /dev/sdb1 /mnt/
说明:
- 1)没有指定文件系统,块设备也可以正常挂载;
-
2)指定与块设备不一致的文件系统类型则命令报错;
-
3)挂载点有内容的文件夹,在挂载后内容消失,卸载后内容重现,也就是说挂载后会将原文件内容掩盖,但并不对其进行其他操作
bind绑定
查看一个目录是否已经 mount --bind
执行 mountpoint -q /test/mount
echo $? 如果是0表示已经mount
mountpoint -q /test/mount || mount -o bind /some/directory/here /test/mount
为什么需要映射一个目录?
- 原目录所在的磁盘空间不足,需要给目录分配更大的磁盘空间
- 但是不支持磁盘分区扩容
- 但是不能或者不想改变程序的配置
为什么使用bind?为什么不使用软链接?
- 文件目录不支持硬连接,支持软连接,但是有些应用程序不支持软连接
- bind是linux内核支持,使用bind后的目录, 对应用程序无感知
为什么不使用分区挂载?
- 磁盘分区通常只能挂载为1个目录,使用bind可以在同一个分区上,对多个目录进行映射
bind操作步骤
- 1. 停止所有可能对目录进行读写的程序
- 例如:cd /var/gobgm && docker-compose stop
- 检查是否有进程在读写: lsof -n +D /var/gobgm
- 2. 移动目录内的内容到新目录
- 例如:mkdir /var/new_dir && mv /var/log/gobgm/* /var/new_dir
- 3. 临时bind新目录到原目录位置
- 例如: mount -B /var/new_dir /var/log/gobgm
- 4. 启动程序,检查程序是否正常运行
- 例如:cd /var/gobgm && docker-compose start
- 5. 持久bind新目录到原目录位置
- 例如: echo "/var/new_dir /var/log/gobgm none rw,bind 0 0" >> /etc/fstab
- 6. 校验持久配置是否正常工作(不正常的时候可能会导致系统启动失败)
- 例如: mount -av
- 7. 重启设备,确认重启后服务依旧能正常工作
1.挂载光盘:# mkdir /mnt/cdrom
# mount -t iso9660 /dev/cdrom /mnt/cdrom (光盘的名字一般都是cdrom,这条命令一般都通用;光盘的文件系统是iso9660)
2. 挂载windows的文件系统:
1)首先我们使用sudo fdisk -l查看挂载的设备,例如最下面有:/dev/hda5
2)mkdir创建一个目录,这里的目录是作为挂在目录,就是你要把E盘挂到这个目录下:mkdir /mnt/winc
3)windows和linux使用的不是一个文件系统,一般情况下linux不挂载windows文件系统,所以要你手动mount:
# mount -t vfat /dev/hda5 /mnt/winc ( -t vfat指出这里的文件系统fat32)
现在就可以进入/mnt/winc等目录读写这些文件了。
3.虚拟机共享文件夹:
例如在VirtualBox下,主机是Windows,Ubuntu是Guest。共分三步:
1). 首先要安装虚拟电脑工具包:在VirtualBox的菜单里选择"设备"->"安装虚拟电脑工具包",你会发现在Ubuntu桌面上多出一个光盘图标,这张光盘默认被自动加载到了文件夹/media/cdom0,而且/cdrom自动指向这个文件夹。默认设置下文件管理器会自动打开这张光盘,可以看到里面有个"VBoxLinuxAdditions.run"文件。打开一个命令行终端,依次输入"cd /cdrom"和"sudo sh ./VBoxLinuxAdditions.run",不含双引号,开始安装工具包。安装完毕,会用英文提示要重启Ubuntu,建议立刻重启。重启后,比较明显的变化是鼠标是共享模式,并且剪贴板也和Windows共享了。如果有这些变化,说明虚拟电脑工具包已经装成功。
2). 下一步设置共享文件夹。
在共享文件夹设置窗口中,单击右侧的"添加一个共享文件夹",路径选择你想要共享的Windows文件夹,共享名任取一个自己喜欢的,比如"myshare",选项ead-only是指是否只允许ubuntu读这个文件夹,请根据需要选择这个选项。
3). 在ubuntu下挂载这个共享文件夹:sudo mount -t vboxsf myshare /media/share 其中"myshare"是之前取的共享文件夹的名字,"/media/share"是要挂载到的目标文件.
4、 自动挂载windows分区
每次开机访问windows分区都要运行mount命令显然太烦琐,为什么访问其他的linux分区不用使用mount命令呢?
其实,每次开机时,linux自动将需要挂载的linux分区挂载上了。那么我们是不是可以设定让linux在启动的时候也挂载我们希望挂载的分区,如windows分区,以实现文件系统的自动挂载呢?
这是完全可以的。在/etc目录下有个fstab文件,它里面列出了linux开机时自动挂载的文件系统的列表。我的/etc/fstab文件如下:
/dev/hda2 / ext3 defaults 1 1
/dev/hda1 /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
………………………………
在/etc/fstab文件里,第一列是挂载的文件系统的设备名,第二列是挂载点,第三列是挂载的文件系统类型,第四列是挂载的Option,Option间用逗号分隔。第五六列不知道是什么意思,还望高手指点。
在最后两行是我手工添加的windows下的C;D盘,加了codepage=936和iocharset=cp936参数以支持中文文件名。参数defaults实际上包含了一组默认参数:
rw 以可读写模式挂载
suid 开启用户ID和群组ID设置位
dev 可解读文件系统上的字符或区块设备
exec 可执行二进制文件
auto 自动挂载
nouser 使一般用户无法挂载
async 以非同步方式执行文件系统的输入输出操作
大家可以看到在这个列表里,光驱和软驱是不自动挂载的,参数设置为noauto。(如果你非要设成自动挂载,你要确保每次开机时你的光驱和软驱里都要有盘,呵呵。)
5、把光盘的东西刻录到磁盘里:
cp /dev cdrom xxx.iso
ls
mount -o loop xxx.iso /mnt/
ls /mnt
实现开机自动挂载:
参考:https:# blog.csdn.net/daydayup654/article/details/78788310
开机自动挂载
如果我们想实现开机自动挂载某设备,只要修改/etc/fstab文件即可。
文件挂载的配置文件:/etc/fstab
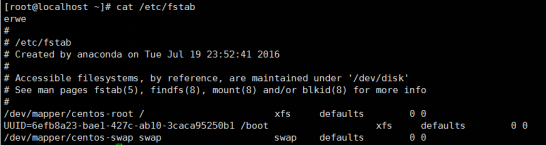
查看此文件可知.每行定义一个要挂载的文件系统;其每行的格式如下:
要挂载的设备或伪文件系统 挂载点 文件系统类型 挂载选项 转储频率 自检次序
要挂载的设备或伪文件系统 挂载点 文件系统类型 挂载选项 转储频率 自检次序
UUID=6efb8a23-bae1-427c-ab10-3caca95250b1 /boot xfs defaults 0 0
要挂载的设备或伪文件系统:设备文件、LABEL(LABEL="")、UUID(UUID="")、伪文件系统名称(proc, sysfs)
挂载点:指定的文件夹
挂载选项:defaults,uquota,pquota
转储频率:
0:不做备份
1:每天转储
2:每隔一天转储
自检次序:
0:不自检
1:首先自检;一般只有rootfs才用1;
/etc/fstab和/etc/mtab的区别
/etc/fstab文件的作用:
记录了计算机上硬盘分区的相关信息,启动 Linux 的时候,检查分区的 fsck 命令,和挂载分区的 mount 命令,都需要 fstab 中的信息,来正确的检查和挂载硬盘。
/etc/mtab文件的作用:
先看它的英文是:
This changes continuously as the file /proc/mount changes. In other words, when filesystems are mounted and unmounted, the change is immediately reflected in this file.
记载的是现在系统已经装载的文件系统,包括操作系统建立的虚拟文件等;而/etc/fstab是系统准备装载的。 每当 mount 挂载分区、umount 卸载分区,都会动态更新 mtab,mtab 总是保持着当前系统中已挂载的分区信息,fdisk、df 这类程序,必须要读取 mtab 文件,才能获得当前系统中的分区挂载情况。当然我们自己还可以通过读取/proc/mount也可以来获取当前挂载信息
例如:
[root@px ~]# vim /etc/fstab #光盘实现开机自动挂载
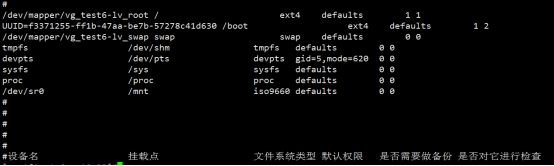
umount 卸载已经加载的文件系统
umount命令用于卸载已经加载的文件系统。利用设备名或挂载点都能umount文件系统,不过最好还是通过挂载点卸载,以免使用绑定挂载(一个设备,多个挂载点)时产生混乱。
Grammar
umount(Option)(参数)
Option
- -t<文件系统类型>:仅卸除选项中所指定的文件系统;
- -a:卸除
/etc/mtab中记录的所有文件系统; - -h:显示帮助;
-
-n:卸除时不要将信息存入/etc/mtab文件中;
-
-r:若无法成功卸除,则尝试以只读的方式重新挂入文件系统;
-
-v:执行时显示详细的信息;
-
-V:显示版本信息。
参数
文件系统:指定要卸载的文件系统或者其对应的设备文件名。
Living Example
下面两条命令分别通过设备名和挂载点卸载文件系统,同时输出详细信息:
通过设备名卸载
umount -v /dev/sda1
/dev/sda1 umounted
通过挂载点卸载
umount -v /mnt/mymount/
/tmp/diskboot.img umounted
Notice:
卸载可以有两种方式:通过设备名卸载、通过挂载点卸载
建议通过卸载设备名进行卸载,因为有可能挂载点挂载了多个设备
fuser 查看正在访问指定文件系统的进程
可以用该命令查看挂载的磁盘是否成功卸载?
fuser命令用于报告进程使用的文件和网络套接字。fuser命令列出了本地进程的进程号,那些本地进程使用file,参数指定的本地或远程文件。对于阻塞特别设备,此命令列出了使用该设备上任何文件的进程。
每个进程号后面都跟随一个字母,该字母指示进程如何使用文件。
-
c:指示进程的工作目录。
-
e:指示该文件为进程的可执行文件(即进程由该文件拉起)。
-
f:指示该文件被进程打开,默认情况下f字符不显示。
-
F:指示该文件被进程打开进行写入,默认情况下F字符不显示。
-
r:指示该目录为进程的根目录。
-
m:指示进程使用该文件进行内存映射,抑或该文件为共享库文件,被进程映射进内存。
Grammar
fuser(Option)(参数)
Option
- -m:指定一个被加载的文件系统或一个被加载的块设备;
-
-v:显示详细过程
-
-l:列出所有已知信号名;
-
-n SPACE :search in this name space (file, udp, or tcp);
-
-a:显示命令行中指定的所有文件;
-
-k:杀死访问指定文件的所有进程;
-
-i:杀死进程前需要用户进行确认;
-
-u:在每个进程后显示所属的用户名。
参数
文件:可以是文件名或者TCP、UDP端口号。
Living Example
查看端口状态:
# fuser -n tcp 80
80/tcp: 28270 28276
挂载的磁盘未能成功卸载?
[root@px ~]# fuser -mv /mnt/ #(查看是哪个进程在占用)然后杀死这个进程就ok了
用户 进程号 权限 命令
/mnt/: root 1 .rce. init
root 2 .rc.. kthreadd
root 3 .rc.. migration/0
root 4 .rc.. ksoftirqd/0
root 5 .rc.. stopper/0
root 6 .rc.. watchdog/0
………………
root 1568 .rc.. scsi_eh_31
root 1569 .rc.. scsi_eh_32
root 1664 .rce. udevd
root 1715 .rce. udevd
root 1755 .rc.. flush-8:16
[root@px ~]# fuser -kmv /mnt/ #这是终止相关进程
tune2fs:更改与查看磁盘详细信息
tune2fs命令允许系统管理员调整"ext2/ext3"文件系统中的可该参数。Windows下面如果出现意外断电死机情况,下次开机一般都会出现系统自检。Linux系统下面也有文件系统自检,而且是可以通过tune2fs命令,自行定义自检周期及方式。
Grammar
tune2fs(Option)(参数)
Option
-
-c:调整最大加载次数;
-
-L:设置文件系统卷标;
-
-f:强制执行修改,即使发生错误;
-
-m:显示文件保留块的百分比;
-
-j:为"ext2"文件系统添加日志功能,将其转换为"ext3"文件系统;
-
-U:设置文件系统的UUID。
-
-C:设置文件系统已经被加载的次数;
-
-e:设置内核代码检测到错误时的行为;
-
-i:设置相邻两次文件系统检查的相隔时间;
-
-l:显示文件超级块内容;
-
-M:设置文件系统最后被加载到的目录;
-
-o:设置或清除文件系统加载的特性或Option;
-
-O:设置或清除文件系统的特性或Option;
-
-r:设置文件系统保留块的大小;
-
-T:设置文件系统上次被检查的时间;
-
-u:设置可以使用文件系统保留块的用户;
参数
文件系统:指定调整的文件系统或者其对应的设备文件名。
Living Example
tune2fs -c -l /dev/hda1 关闭强制检查挂载次数限制。
tune2fs -l /dev/sda1 显示sda1信息
tune2fs -c 30 /dev/hda1 设置强制检查前文件系统可以挂载的次数
tune2fs -i 10 /dev/hda1 10天后检查
tune2fs -i 1d /dev/hda1 1天后检查
tune2fs -i 3w /dev/hda1 3周后检查
tune2fs -i 6m /dev/hda1 半年后检查
tune2fs -i 0 /dev/hda1 禁用时间检查
tune2fs -j /dev/hda1 添加日志功能,将ext2转换成ext3文件系统
tune2fs -r 40000 /dev/hda1 调整/dev/hda1分区的保留空间为40000个磁盘块
tune2fs -o acl,user_xattr /dev/hda1 设置/dev/hda1挂载Option,启用Posix Access Control Lists和用户指定的扩展属性
dumpe2fs 打印ext2/ext3文件系统的超级块和快组信息
dumpe2fs命令用于打印"ext2/ext3"文件系统的超级块和快组信息。
Grammar
dumpe2fs(Option)(参数)
Option
-
-h:仅显示超级块信息;
-
-b:打印文件系统中预留的块信息;
-
-ob<超级块>:指定检查文件系统时使用的超级块;
-
-OB<块大小>:检查文件系统时使用的指定的块大小;
-
-i:从指定的文件系统映像文件中读取文件系统信息;
-
-x:以16进制格式打印信息块成员。
参数
文件系统:指定要查看信息的文件系统。
Living Example:
[root@test ~]# dumpe2fs -h /dev/sda1
dumpe2fs 1.41.12 (17-May-2010)
Filesystem volume name: <none>
Last mounted on: /boot
Filesystem UUID: 71174849-8c16-42fc-a0f2-b3440ecd9e94
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount Options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 128016
Block count: 512000
Reserved block count: 25600
Free blocks: 420368
Free inodes: 127972
First block: 1
Block size: 1024
Fragment size: 1024
Reserved GDT blocks: 256
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2032
Inode blocks per group: 254
Flex block group size: 16
Filesystem created: Tue Nov 27 00:20:35 2018
Last mount time: Wed Jan 16 14:37:04 2019
Last write time: Wed Jan 16 14:37:04 2019
Mount count: 57
Maximum mount count: -1
Last checked: Tue Nov 27 00:20:35 2018
Check interval: 0 (<none>)
Lifetime writes: 253 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 2a1d24c1-51d4-48b0-89d9-69a57ed43a45
Journal backup: inode blocks
Journal features: (none)
日志大小: 8M
Journal length: 8192
Journal sequence: 0x000000a0
Journal start: 1
dstat 全能系统信息统计工具
dstat命令是一个用来替换vmstat、iostat、netstat、nfsstat和ifstat这些命令的工具,是一个全能系统信息统计工具。与sysstat相比,dstat拥有一个彩色的界面,在手动观察性能状况时,数据比较显眼容易观察;而且dstat支持即时刷新,譬如输入dstat 3即每三秒收集一次,但最新的数据都会每秒刷新显示。和sysstat相同的是,dstat也可以收集指定的性能资源,譬如dstat -c即显示CPU的使用情况。
下载安装
方法一
yum install -y dstat
方法二
官网下载地址:http://dag.wieers.com/rpm/packages/dstat
wget http://dag.wieers.com/rpm/packages/dstat/dstat-0.6.7-1.rh7.rf.noarch.rpm
rpm -ivh dstat-0.6.7-1.rh7.rf.noarch.rpm
使用说明
安装完后就可以使用了,dstat非常强大,可以实时的监控cpu、磁盘、网络、IO、内存等使用情况。
直接使用dstat,默认使用的是-cdngy参数,分别显示cpu、disk、net、page、system信息,默认是1s显示一条信息。
可以在最后指定显示一条信息的时间间隔,如dstat 5是每5s显示一条,dstat 5 10表示没5s显示一条,一共显示10条。
[root@iZ23uulau1tZ ~]# dstat
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
0 0 99 0 0 0|7706B 164k| 0 0 | 0 0 | 189 225
0 0 100 0 0 0| 0 0 |4436B 826B| 0 0 | 195 248
1 0 99 0 0 0| 0 0 |4744B 346B| 0 0 | 203 242
0 0 100 0 0 0| 0 0 |5080B 346B| 0 0 | 206 242
0 1 99 0 0 0| 0 0 |5458B 444B| 0 0 | 214 244
1 0 99 0 0 0| 0 0 |5080B 346B| 0 0 | 208 242
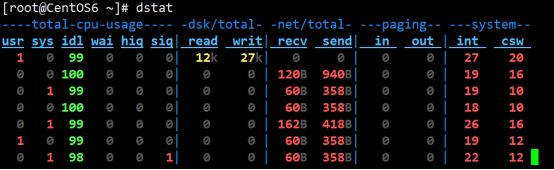
| 针对默认输出字段解释如下 | |
|---|---|
| 分组 | 分组含义及子项字段含义 |
| CPU状态 | CPU的使用率。显示了用户占比,系统占比、空闲占比、等待占比、硬中断和软中断情况 |
| 磁盘统计 | 磁盘的读写,分别显示磁盘的读、写总数。 |
| 网络统计 | 网络设备发送和接受的数据,分别显示的网络收、发数据总数。 |
| 分页统计 | 系统的分页活动。分别显示换入(in)和换出(out)。 |
| 系统统计 | 统计中断(int)和上下文切换(csw)。 |
CPU状态:CPU的使用率。这项报告更有趣的部分是显示了用户,系统和空闲部分,这更好地分析了CPU当前的使用状况。如果你看到"wait"一栏中,CPU的状态是一个高使用率值,那说明系统存在一些其它问题。当CPU的状态处在"waits"时,那是因为它正在等待I/O设备(例如内存,磁盘或者网络)的响应而且还没有收到。await:IO 操作的平均等待时间,单位是毫秒。这是应用程序在和磁盘交互时,需要消耗的时间,包括 IO 等待和实际操作的耗时。如果这个数值过大,可能是硬件设备遇到了瓶颈或者出现故障
磁盘统计:磁盘的读写操作,这一栏显示磁盘的读、写总数。
网络统计:网络设备发送和接受的数据,这一栏显示的网络收、发数据总数。
分页统计:系统的分页活动。分页指的是一种内存管理技术用于查找系统场景,一个较大的分页表明系统正在使用大量的交换空间,或者说内存非常分散,大多数情况下你都希望看到page in(换入)和page out(换出)的值是0 0。
系统统计:这一项显示的是中断(int)和上下文切换(csw)。这项统计仅在有比较基线时才有意义。这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。你的服务器一般情况下都会运行运行一些程序,所以这项总是显示一些数值。
Grammar
dstat [-afv] [Options..] [delay [count]]
常用Option
-
-n:显示网络状态。
-
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-
-d:显示磁盘读写数据大小。
-
-l:显示系统负载情况。
-
-m:显示内存使用情况。
-
-p:显示进程状态。
-
-r:I/O请求情况。
-
-y:系统状态。
-
--socket:用来显示tcp udp端口状态。
-
--output 文件:此Option也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。例:dstat --output /root/dstat.csv & 此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。
-
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C 0,1 是显示cpu0和cpu1的信息。
-
-D hda,total:include hda and total。
-
-N eth1,total:有多块网卡时,指定要显示的网卡。
-
-g:显示页面使用情况。
-
-s:显示交换分区使用情况。
-
-S:类似D/N。
-
--ipc:显示ipc消息队列,信号等信息。
-
-a:此为默认Option,等同于-cdngy。
-
-v:等同于 -pmgdsc -D total。
当然dstat还有很多更高级的用法,常用的基本这些Option,更高级的用法可以结合man文档。
命令插件
虽然anyone可以自由的为dstat编写插件,但dstat附带大量的插件已经大大扩展其功能,下面是dstat附带插件的一个概述:
插件名称 插件描述
- -battery 电池电池百分比(需要ACPI)
- -battery-remain 电池剩余小时、分钟(需要ACPI)
- -cpufreq CPU频率百分比(需要ACPI)
- -dbus dbus连接的数量(需要python-dbus)
- -disk-util 显示某一时间磁盘的忙碌状况
- -fan 风扇转速(需要ACPI)
- -freespace 每个文件系统的磁盘使用情况
- -gpfs gpfs读/写 I / O(需要mmpmon)
- -gpfs-ops GPFS文件系统操作(需要mmpmon)
- -helloworld dstat插件Hello world示例
- -innodb-buffer 显示innodb缓冲区统计
- -innodb-io 显示innodb I / O统计数据
- -innodb-ops 显示innodb操作计数器
- -lustre 显示lustreI / O吞吐量
- -memcache-hits 显示memcache 的命中和未命中的数量
- -mysql5-cmds 显示MySQL5命令统计
- -mysql5-conn 显示MySQL5连接统计
- -mysql5-io MySQL5 I / O统计数据
- -mysql5-keys 显示MySQL5关键字统计
- -mysql-io 显示MySQL I / O统计数据
- -mysql-keys 显示MySQL关键字统计
- -net-packets 显示接收和发送的数据包的数量
- -nfs3 显示NFS v3客户端操作
- -nfs3-ops 显示扩展NFS v3客户端操作
- -nfsd3 显示NFS v3服务器操作
- -nfsd3-ops 显示扩展NFS v3服务器操作
- -ntp 显示NTP服务器的ntp时间
- -postfix 显示后缀队列大小(需要后缀)
- -power 显示电源使用量
- -proc-count 显示处理器的总数
- -rpc 显示rpc客户端调用统计
- -rpcd 显示RPC服务器调用统计
- -sendmail 显示sendmail队列大小(需要sendmail)
- -snooze 显示每秒运算次数
- -test 显示插件输出
- -thermal 热系统的温度传感器
- -top-bio 显示消耗块I/O最大的进程
- -top-cpu 显示消耗CPU最大的进程
- -top-cputime 显示使用CPU时间最大的进程(单位ms)
- -top-cputime-avg 显示使用CPU时间平均最大的进程(单位ms)
- -top-io 显示消耗I/O最大进程
- -top-latency 显示总延迟最大的进程(单位ms)
- -top-latency-avg 显示平均延时最大的进程(单位ms)
- -top-mem 显示使用内存最大的进程
- -top-oom 显示第一个被OOM结束的进程
- -utmp 显示utmp连接的数量(需要python-utmp)
- -vmk-hba 显示VMware ESX内核vmhba统计数
- -vmk-int 显示VMware ESX内核中断数据
- -vmk-nic 显示VMware ESX内核端口统计
- -vz-io 显示每个OpenVZ请求CPU使用率
- -vz-ubc 显示OpenVZ用户统计
- -wifi 无线连接质量和信号噪声比
---------------------------------------------------------------------------------------------------------
常用插件
插件名称 插件描述
- -disk-util 显示某一时间磁盘的忙碌状况
- -freespace 显示当前磁盘空间使用率
- -proc-count 显示正在运行的程序数量
- -top-bio 显示块I/O最大的进程
- -top-cpu 显示CPU占用最大的进程
- -top-io 显示正常I/O最大的进程
- -top-mem 显示占用最多内存的进程
---------------------------------------------------------------------------------------------------------
Living Example
高级用法:找出占用资源最高的进程和用户
[root@CentOS6 ~]# dstat --top-mem --top-io --top-cpu
[root@CentOS6 ~]# dstat --top-mem --top-io --top-cpu
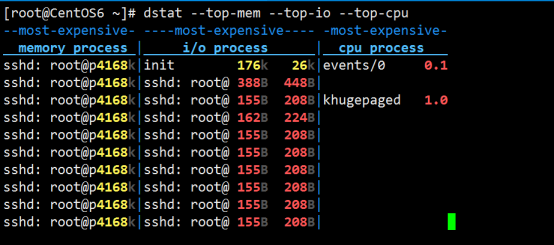
[root@CentOS6 ~]# dstat 2 5 (每两秒显示一个,共显示5条)
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
1 0 99 0 0 0| 12k 27k| 0 0 | 0 0 | 27 20
0 1 100 0 0 0| 0 0 | 120B 598B| 0 0 | 21 11
1 1 99 0 0 1| 0 0 | 120B 350B| 0 0 | 23 15
0 1 99 0 0 0| 0 0 | 120B 350B| 0 0 | 17 11
0 1 99 0 0 0| 0 0 | 171B 380B| 0 0 | 23 13
1 1 99 0 0 0| 0 0 | 90B 350B| 0 0 | 24 14
如想监控swap,process,sockets,filesystem并显示监控的时间:
[root@iZ23uulau1tZ ~]# dstat -tsp --socket --fs
----system---- ----swap--- ---procs--- ------sockets------ --filesystem-
date/time | used free|run blk new|tot tcp udp raw frg|files inodes
26-07 09:23:48| 0 0 | 0 0 0.0|104 8 5 0 0| 704 6488
26-07 09:23:49| 0 0 | 0 0 0|104 8 5 0 0| 704 6488
26-07 09:23:50| 0 0 | 0 0 0|104 8 5 0 0| 704 6489
26-07 09:23:51| 0 0 | 0 0 0|104 8 5 0 0| 704 6489
26-07 09:23:52| 0 0 | 0 0 0|104 8 5 0 0| 704 6489
26-07 09:23:53| 0 0 | 0 0 0|104 8 5 0 0| 704 6489
若要将结果输出到文件可以加--output filename:
[root@iZ23uulau1tZ ~]# dstat -tsp --socket --fs --output /tmp/ds.csv
----system---- ----swap--- ---procs--- ------sockets------ --filesystem-
date/time | used free|run blk new|tot tcp udp raw frg|files inodes
26-07 09:25:31| 0 0 | 0 0 0.0|104 8 5 0 0| 736 6493
26-07 09:25:32| 0 0 | 0 0 0|104 8 5 0 0| 736 6493
26-07 09:25:33| 0 0 | 0 0 0|104 8 5 0 0| 736 6493
26-07 09:25:34| 0 0 | 0 0 0|104 8 5 0 0| 736 6493
26-07 09:25:35| 0 0 | 0 0 0|104 8 5 0 0| 736 6494
26-07 09:25:36| 0 0 | 0 0 0|104 8 5 0 0| 736 6494
这样生成的csv文件可以用excel打开,然后生成图表。
通过dstat --list可以查看dstat能使用的所有参数,其中上面internal是dstat本身自带的一些监控参数,下面/usr/share/dstat中是dstat的插件,这些插件可以扩展dstat的功能,如可以监控电源(battery)、mysql等。
下面这些插件并不是都可以直接使用的,有的还依赖其他包,如想监控mysql,必须要装python连接mysql的一些包。
[root@iZ23uulau1tZ ~]# dstat --list
internal:
aio, cpu, cpu24, disk, disk24, disk24old, epoch, fs, int, int24, io, ipc, load, lock, mem, net, page, page24, proc, raw, socket, swap, swapold, sys, tcp, time, udp, unix, vm
/usr/share/dstat:
battery, battery-remain, cpufreq, dbus, disk-util, fan, freespace, gpfs, gpfs-ops, helloworld, innodb-buffer, innodb-io, innodb-ops, lustre, memcache-hits, mysql-io, mysql-keys, mysql5-cmds, mysql5-conn, mysql5-io, mysql5-keys,
net-packets, nfs3, nfs3-ops, nfsd3, nfsd3-ops, ntp, postfix, power, proc-count, rpc, rpcd, sendmail, snooze, thermal, top-bio, top-cpu, top-cputime, top-cputime-avg, top-io, top-latency, top-latency-avg, top-mem, top-oom, utmp,
vm-memctl, vmk-hba, vmk-int, vmk-nic, vz-cpu, vz-io, vz-ubc, wifi
vmstat 显示虚拟内存状态(Virtual Memory Statistics)
vmstat命令的含义为显示虚拟内存状态("Virtual Memory Statistics"),但是它可以报告关于进程、内存、I/O等系统整体运行状态。
Grammar
vmstat [options] [delay [count]]
Option
-
-a:显示活动内页;
-
-f:显示启动后创建的进程总数;
-
-m:显示slab信息;
-
-n:头信息仅显示一次;
-
-s:以表格方式显示事件计数器和内存状态;
-
-d:报告磁盘状态;
-
-p:显示指定的硬盘分区状态;
-
-S:输出信息的单位。
-
delay:刷新时间间隔。如果不指定,只显示一条结果。
-
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
参数
- 事件间隔:状态信息刷新的时间间隔;
- 次数:显示报告的次数。
Living Example
vmstat 3 (每三秒输出一条)
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 320 42188 167332 1534368 0 0 4 7 1 0 0 0 99 0 0
0 0 320 42188 167332 1534392 0 0 0 0 1002 39 0 0 100 0 0
vmstat第一次输出表示从开机到vmstat运行时的平均值;剩余输出的都是在指定的时间间隔内的平均值,上述例子中delay的值设置为1,除第一次以外,剩余的都是1秒统计一次,count未设置,将会一直循环打印
字段说明:
Procs(进程)
- r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于cpu数目就会出现瓶颈)
- b: 等待IO的进程数量。
Memory(内存)
- swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
- free: 空闲物理内存大小。
- buff: 用作缓冲的内存大小。
- cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap
- si: 每秒从交换区写到内存的大小,由磁盘调入内存。
- so: 每秒写入交换区的内存大小,由内存调入磁盘。
Notice:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(现在的Linux版本块的大小为1kb)
- bi: 每秒读取的块数
- bo: 每秒写入的块数
Notice:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
- in: 每秒中断数,包括时钟中断。
- cs: 每秒上下文切换数。
Notice:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示)
- us: 用户进程执行时间百分比(user time)
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
- sy: 内核系统进程执行时间百分比(system time)
sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
- wa: IO等待时间百分比
wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
- id: 空闲时间百分比
[root@CentOS6 ~]# vmstat 3 5 # 每三秒输出一条信息,共输出5条
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 139820 32096 663120 0 0 11 26 26 20 1 1 99 0 0
0 0 0 139772 32096 663120 0 0 0 0 14 12 0 0 100 0 0
0 0 0 139772 32096 663120 0 0 0 0 11 10 0 0 100 0 0
0 0 0 139772 32096 663120 0 0 0 0 12 13 0 0 100 0 0
0 0 0 139772 32096 663120 0 0 0 0 15 13 0 0 100 0 0
实际分析
1. r:运行队列的等待进程数
r(run:运行队列正在执行进程数)和 b(block等待CPU资源的进程个数)。当r超过了CPU数目,就会出现CPU瓶颈了。
查看CPU的核的数量:cat /proc/cpuinfo|grep processor|wc -l
在评估cpu的性能优劣时完全照搬网上说的几倍几倍是不准确的,不能只看top里的参数,还得你自己动手看看vmstat显示的run值和blocked值,当出现明显较多的blocked的时候,就说明cpu产生了瓶颈。而top命令和uptime命令显示的负载均值,只能作为判断系统过去某个时间段的状态的参照,与cpu的性能关系不大。
当r值超过了CPU个数,就会出现CPU瓶颈,解决办法大体几种:
1. 最简单的就是增加CPU个数和核数
2. 通过调整任务执行时间,如大任务放到系统不繁忙的情况下进行执行,进尔平衡系统任务
3. 调整已有任务的优先级
(tips:
vmstat中CPU的度量是百分比的。当us+sy的值接近100的时候,表示CPU正在接近满负荷工作。
但要注意的是,CPU 满负荷工作并不能说明什么,Linux总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化。
唯一能够确定CPU瓶颈的还是r(运行队列)的值。)
2.cpu使用率
如果CPU的id(空闲率)长期低于10%,那么表示CPU的资源已经非常紧张,应该考虑进程优化或添加更多地CPU。
wa(等待IO)表示CPU因等待IO资源而被迫处于空闲状态,这时候的CPU并没有处于运算状态,而是被白白浪费了,所以“等待IO应该越小越好。”
【top命令和uptime命令显示的负载均值,只能作为判断系统过去某个时间段的状态的参照,与cpu的性能关系不大。】
------------------------------------------------------------------------------------------------------------------------------
iotop 用于检查 I/O 的使用情况
官方网站: http://guichaz.free.fr/iotop/
三方参考:https:# www.cnblogs.com/legendbaby/p/5056967.html
iotop 用于检查 I/O 的使用情况,并为你提供了一个类似 top 的界面来显示。它按列显示读和写的速率,每行代表一个进程。当发生交换或 I/O 等待时,它会显示进程消耗时间的百分比。
安装
Ubuntu
apt-get install iotop
CentOS
yum install iotop
编译安装
wget http://guichaz.free.fr/iotop/files/iotop-0.4.4.tar.gz
tar zxf iotop-0.4.4.tar.gz
python setup.py build
python setup.py install
语法
iotop(选项)
选项
-
--version #显示版本号
-
-o:只显示有io操作的进程
-
-b:批量显示,无交互,主要用作记录到文件。
-
-n NUM:显示NUM次,主要用于非交互式模式。
-
-d SEC:间隔SEC秒显示一次。
-
-h, --help #显示帮助信息
-
-o, --only #显示进程或者线程实际上正在做的I/O,而不是全部的,可以随时切换按o
-
-n NUM, --iter=NUM #在非交互式模式下,设置显示的次数,
-
-d SEC, --delay=SEC #设置显示的间隔秒数,支持非整数值
-
-p PID, --pid=PID #只显示指定PID的信息
-
-u USER, --user=USER #显示指定的用户的进程的信息
-
-P, --processes #只显示进程,一般为显示所有的线程
-
-a, --accumulated #显示从iotop启动后每个线程完成了的IO总数
-
-k, --kilobytes #以千字节显示
-
-t, --time #在每一行前添加一个当前的时间
-
-q, --quiet #suppress some lines of header (implies --batch). This option can be specified up to three times to remove header lines.
-
-q column names are only printed on the first iteration,
-
-qq column names are never printed,
-
-qqq the I/O summary is never printed.
iotop常用快捷键:
-
左右箭头:改变排序方式,默认是按IO排序。
-
r:改变排序顺序。
-
o:只显示有IO输出的进程;切换至选项--only。
-
p:进程/线程的显示方式的切换;切换至--processes选项。
-
a:显示累积使用量;切换至--accumulated选项。
-
q:退出。
-
i:改变线程的优先级
实例
直接执行iotop就可以看到效果了:
IO测试工具之fio详解

===RAID技术===
磁盘阵列(Redundant Arrays of independent Disks,RAID),廉价冗余(独立)磁盘阵列。
RAID是一种把多块独立的物理硬盘按不同的方式组合起来形成一个硬盘组(逻辑硬盘),提供比单个硬盘更高的存储性能和数据备份技术。RAID技术,可以实现把多个磁盘组合在一起作为一个逻辑卷提供磁盘跨越功能;可以把数据分成多个数据块(Block)并行写入/读出多个磁盘以提高访问磁盘的速度;可以通过镜像或校验操作提供容错能力。具体的功能以不同的RAID组合实现。
在用户看来,RAID组成的磁盘组就像是一个硬盘,可以对它进行分区、格式化等操作。RAID的存储速度比单个硬盘高很多,并且可以提供自动数据备份,提供良好的容错能力。
RAID级别,不同的RAID组合方式分为不同的RAID级别:
- RAID 0:称为Stripping条带存储技术,所有磁盘完全地并行读,并行写,是组建磁盘阵列最简单的一种形式,只需要2块以上的硬盘即可,成本低,可以提供整个磁盘的性能和吞吐量,但RAID 0没有提供数据冗余和错误修复功能,因此单块硬盘的损坏会导致所有的数据丢失。(RAID 0只是单纯地提高磁盘容量和性能,没有为数据提供可靠性保证,适用于对数据安全性要求不高的环境)
- RAID 1:镜像存储,通过把两块磁盘中的一块磁盘的数据镜像到另一块磁盘上, 实现数据冗余,在两块磁盘上产生互为备份的数据,其容量仅等于一块磁盘的容量。当数据在写入一块磁盘时,会在另一块闲置的磁盘上生产镜像,在不影响性能情况下最大限度的保证系统的可靠性和可修复性;当原始数据繁忙时,可直接从镜像拷贝中读取数据(从两块硬盘中较快的一块中读出),提高读取性能。相反的,RAID 1的写入速度较缓慢。RAID 1一般支持"热交换",即阵列中硬盘的移除或替换可以在系统运行状态下进行,无须中断退出系统。RAID 1是磁盘阵列中硬盘单位成本最高的,但它提供了很高的数据安全性、可靠性和可用性,当一块硬盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。
- RAID 0+1:也被称为RAID 10,实际是将RAID 0和RAID 1结合的形式,在连续地以位或字节为单位分割数据并且并行读/写多个磁盘的同时,为每一块磁盘做镜像进行冗余。通过RAID 0+1的组合形式,数据除分布在多个盘上外,每个盘都有其物理镜像盘,提供冗余能力,允许一个以下磁盘故障,而不影响数据可用性,并且有快速读/写能力。RAID 0+1至少需要4个硬盘在磁盘镜像中建立带区集。RAID 0+1技术在保证数据高可靠性的同时,也保证了数据读/写的高效性。
- RAID 5:是一种存储性能、数据安全和存储成本兼顾的存储解决方案。RAID 5可以理解为是RAID 0和RAID 1的折衷方案,RAID 5至少需要三块硬盘。RAID 5可以为系统提供数据安全保障,但保障程度要比镜像低而磁盘空间利用率要比镜像高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低,是目前运用较多的一种解决方案。
==LVM(logicalvolumemanager)==
概述
LVM应用背景:
1、搭建后端存储器是,无法做到精确估算和分配各个磁盘空间容量导致,业务数据无法正常存储
2、在实现raid的机制上并提供整体性
LVM作用:管理针对磁盘分区进行管理。
-----------------------------------------------------------------------------------------
组成:
dm:device mapper[设备映射]
将一个或多个底层设备组织成一个逻辑设备的模块
PE:physical extents [物理扩展卷]
可以有管理员自定义,但是一般默认存储大小为:4M
pv:physical volume [物理卷]
有多个PE构成
vg:volumn group [卷组]
有多个pv构成
lv:logical volumn[逻辑卷]
只能由1个vg构成一个lv
拓扑图
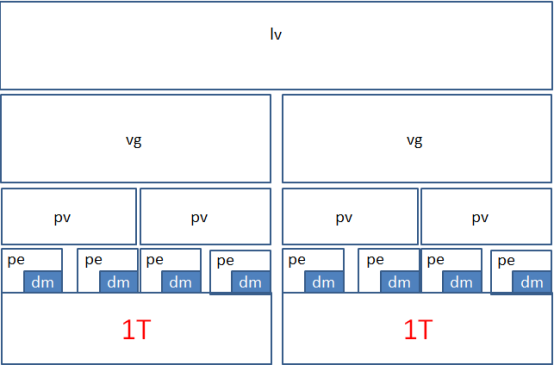
-
/boot 分区用于存放引导文件,不能基于 LVM 创建
-
lv动态扩展磁盘容量
第一步:新加一块硬盘,然后进行分区为LVM类型,最后告知内核。
[root@CentOS6 ~]# fdisk /dev/sdb #(选择需要分区的磁盘)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): p #(查看分区信息)
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00018b8c
Device Boot Start End Blocks Id System
Command (m for help): n #(新建主分区)
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-1305, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-1305, default 1305): +4G
Command (m for help): n #(新建主分区)
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (524-1305, default 524):
Using default value 524
Last cylinder, +cylinders or +size{K,M,G} (524-1305, default 1305): +4G
Command (m for help): p #(查看分区信息)
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00018b8c
Device Boot Start End Blocks Id System
/dev/sdb1 1 523 4200966 83 Linux
/dev/sdb2 524 1046 4200997+ 83 Linux
Command (m for help): t #更改分区类型)
Partition number (1-4): 1
Hex code (type L to list codes): 8e
Changed system type of partition 1 to 8e (Linux LVM)
Command (m for help): t #(更改分区类型)
Partition number (1-4): 2
Hex code (type L to list codes): 8e
Changed system type of partition 2 to 8e (Linux LVM)
Command (m for help): p #(查看分区信息)
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00018b8c
Device Boot Start End Blocks Id System
/dev/sdb1 1 523 4200966 8e Linux LVM
/dev/sdb2 524 1046 4200997+ 8e Linux LVM
Command (m for help): w #保存
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
You have new mail in /var/spool/mail/root
[root@CentOS6 yum.repos.d]# partprobe -s /dev/sdb(告知内核当前磁盘分区信息)
/dev/sdb: msdos partitions 1 2
第二部:创建物理卷,并查看pv信息(它的大小,是在vg创建时给定它的大小,或者默认)
[root@CentOS6 ~]# pvcreate –h #(查看帮助信息)
pvcreate: Initialize physical volume(s) for use by LVM
[root@CentOS6 ~]# pvcreate /dev/sdb{1,2} # (创建pv)
Physical volume "/dev/sdb1" successfully created
Physical volume "/dev/sdb2" successfully created
[root@CentOS6 ~]# pvs #(查看pv信息)
PV VG Fmt Attr PSize PFree
/dev/sda2 vg_centos6 lvm2 a--u 19.51g 0
/dev/sdb1 lvm2 ---- 4.01g 4.01g
/dev/sdb2 lvm2 ---- 4.01g 4.01g
说明:下面三个命令都可以查看pv信息
pvscan 查看当前所有物理卷
pvs 查看当前当前所有物理卷
pvdisplay 查看当前所有物理卷的详情
第三步:创建卷组,移除卷组,并查看vg信息
Notice:在实际环境中,操作vg时,必须先将单个磁盘上的数据进行拷贝,然后在进行移除或者添加
格式:vgcreate 卷组名称 物理卷1,物理卷2......
[root@CentOS6 ~]# vgcreate myvg /dev/sdb1 #(创建vg)
Volume group "myvg" successfully created
[root@CentOS6 ~]# vgremove myvg #(移除vg)
Volume group "myvg" successfully removed
[root@CentOS6 ~]# vgs #(查看vg信息)
VG #PV #LV #SN Attr VSize VFree
vg_centos6 1 2 0 wz--n- 19.51g 0
说明:下面三个命令都可以查看vg信息
vgscan查看当前所有物理卷
vgs查看当前当前所有物理卷
vgdisplay查看当前所有物理卷的详情
- -s 指定PE的大小
重新创建一个vg,使得新vg包含新建的两个pv,并且指定PE的大小为6M(测试需要用)
[root@CentOS6 ~]# vgcreate -s 6M myvg /dev/sdb{1,2} (创建vg)
Volume group "myvg" successfully created
[root@CentOS6 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 2 0 0 wz--n- 8.00g 8.00g
vg_centos6 1 2 0 wz--n- 19.51g 0
[root@CentOS6 ~]# vgdisplay
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 8.00 GiB
PE Size 6.00 MiB #(系统PE默认大小为4M,PE是可以更改)
Total PE 1366
Alloc PE / Size 0 / 0
Free PE / Size 1366 / 8.00 GiB
VG UUID 1TLlT1-KZ9f-iarQ-wqfS-UILe-KMVY-XXf1lK
--- Volume group ---
VG Name vg_centos6
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 2
Max PV 0
Cur PV 1
Act PV 1
VG Size 19.51 GiB
PE Size 4.00 MiB
Total PE 4994
Alloc PE / Size 4994 / 19.51 GiB
Free PE / Size 0 / 0
VG UUID Qs5UsI-x5he-IAGp-iVGV-E1Q6-rgRs-qepOXm
扩展/缩减巻组:就是把新加入的磁盘加入到卷组中,然后就可以真正的扩容磁盘了
[root@CentOS6 ~]# vgextend myvg /dev/sdb3 # 把sdb3添加到myvg里面
Physical volume "/dev/sdb3" successfully created
Volume group "myvg" successfully extended
[root@CentOS6 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 3 0 0 wz--n- 9.01g 9.01g
vg_centos6 1 2 0 wz--n- 19.51g 0
[root@CentOS6 ~]# vgdisplay
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 2
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 3
Act PV 3
VG Size 9.01 GiB
PE Size 6.00 MiB
Total PE 1538
Alloc PE / Size 0 / 0
Free PE / Size 1538 / 9.01 GiB
VG UUID 1TLlT1-KZ9f-iarQ-wqfS-UILe-KMVY-XXf1lK
--- Volume group ---
VG Name vg_centos6
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 2
Max PV 0
Cur PV 1
Act PV 1
VG Size 19.51 GiB
PE Size 4.00 MiB
Total PE 4994
Alloc PE / Size 4994 / 19.51 GiB
Free PE / Size 0 / 0
VG UUID Qs5UsI-x5he-IAGp-iVGV-E1Q6-rgRs-qepOXm
缩减:vgreduce: Remove physical volume(s) from a volume group
[root@CentOS6 ~]# vgreduce myvg /dev/sdb # 把sdb3从myvg里面移除
sdb sdb1 sdb2 sdb3
[root@CentOS6 ~]# vgreduce myvg /dev/sdb3
Removed "/dev/sdb3" from volume group "myvg"
[root@CentOS6 ~]# vgs # 查看下vg的信息
VG #PV #LV #SN Attr VSize VFree
myvg 2 0 0 wz--n- 8.00g 8.00g
vg_centos6 1 2 0 wz--n- 19.51g 0
第四步:创建lv,并查看lv信息
[root@CentOS6 ~]# lvcreate -L 6G -n mylv myvg
Logical volume "mylv" created.
You have new mail in /var/spool/mail/root
[root@CentOS6 ~]# lvs # 查看lv信息
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mylv myvg -wi-a----- 6.00g lv_root vg_centos6 -wi-ao---- 17.57g lv_swap vg_centos6 -wi-ao---- 1.94g
解释说明:
- -L 指明lv绝对大小 如1G 或1M
- -l 指明相对大小 如+100%FREE 是把卷组175907未使用的卷全部占满
- -n 指明lv的名字
lvscan查看当前所有物理卷
lvs查看当前当前所有物理卷
lvdisplay查看当前所有物理卷的详情
逻辑卷的扩容和缩减 -> 这里是没有挂载前进行的扩容与缩减,实际情况下的是挂载后的扩容与缩减
[root@CentOS6 ~]# lvextend -l +100%FREE /dev/myvg/mylv # 将全部可用的空间添加到一个逻辑卷
[root@CentOS6 ~]# lvextend -L +1G /dev/myvg/mylv # 还可以扩容
[root@CentOS6 ~]# lvextend -L 7G /dev/myvg/mylv # 还可以这样写
Rounding size to boundary between physical extents: 1.00 GiB.
Size of logical volume myvg/mylv changed from 6.00 GiB (1024 extents) to 7.00 GiB (1195 extents).
Logical volume mylv successfully resized.
[root@CentOS6 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mylv myvg -wi-a----- 7.00g (这前是6g,扩容了1g)
lv_root vg_centos6 -wi-ao---- 17.57g
lv_swap vg_centos6 -wi-ao---- 1.94g
[root@CentOS6 ~]# lvreduce -L -1G /dev/myvg/mylv #缩减
Rounding size to boundary between physical extents: 1020.00 MiB.
WARNING: Reducing active logical volume to 6.01 GiB.
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce myvg/mylv? [y/n]: y
Size of logical volume myvg/mylv changed from 7.00 GiB (1195 extents) to 6.01 GiB (1025 extents).
Logical volume mylv successfully resized.
[root@CentOS6 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mylv myvg -wi-a----- 6.01g #扩容后是7g,缩减后是6.1g,多了0.1g,是正常的,这个是磁盘的机制)
lv_root vg_centos6 -wi-ao---- 17.57g
lv_swap vg_centos6 -wi-ao---- 1.94g
第五步:格式化逻辑分区:
[root@CentOS6 ~]# mkfs.ext4 /dev/myvg/mylv
mke2fs 1.41.12 (17-May-2010)
文件系统标签=
操作系统:Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
394352 inodes, 1574400 blocks
78720 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=1614807040
49 block groups
32768 blocks per group, 32768 fragments per group
8048 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
This filesystem will be automatically checked every 26 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
第六步:挂载lv
[root@CentOS6 opt]# mkdir /opt/lvm # 创建一个挂载点
[root@CentOS6 opt]# cd
[root@CentOS6 ~]# mount /dev/myvg/mylv /opt/lvm/ # 挂载
[root@CentOS6 ~]# df –hT # 查看挂载的情况
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_centos6-lv_root
ext4 18G 3.6G 13G 23% /
tmpfs tmpfs 490M 0 490M 0% /dev/shm
/dev/sda1 ext4 477M 64M 388M 15% /boot
/dev/mapper/myvg-mylv
ext4 5.8G 13M 5.5G 1% /opt/lvm
[root@CentOS6 ~]# ls /opt/lvm/ # 挂载后它会写入一点东西,所有5.8g是正常的,挂载成功
lost+found
# 实现开机自动挂载
[root@CentOS6 ~]# vim /etc/fstab # 在最下面新增,注意是新增哈
/dev/mapper/myvg-mylv /opt/lvm ext4 defaults 0 0
[root@CentOS6 ~]# mount -a # 测试是否挂载成功
第七步:挂载后的扩容与缩减(非常重要,实际情况下,就是挂载后在操作)
扩容:
[root@CentOS6 ~]# lvextend -L +1G /dev/myvg/mylv # 扩容1G
Rounding size to boundary between physical extents: 1.00 GiB.
Size of logical volume myvg/mylv changed from 6.01 GiB (1025 extents) to 7.01 GiB (1196 extents).
Logical volume mylv successfully resized.
[root@CentOS6 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Conver
mylv myvg -wi-ao---- 7.01g # 之前是6G,扩容成功
lv_root vg_centos6 -wi-ao---- 17.57g
lv_swap vg_centos6 -wi-ao---- 1.94g
重新识别文件系统的大小 resize2fs
[root@CentOS6 ~]# resize2fs /dev/myvg/mylv # ext4文件系统使用resize2fs
resize2fs 1.41.12 (17-May-2010)
Filesystem at /dev/myvg/mylv is mounted on /opt/lvm; on-line resizing required
old desc_blocks = 1, new_desc_blocks = 1
Performing an on-line resize of /dev/myvg/mylv to 1837056 (4k) blocks.
The filesystem on /dev/myvg/mylv is now 1837056 blocks long.
[root@CentOS6 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_centos6-lv_root
ext4 18G 3.6G 13G 23% /
tmpfs tmpfs 490M 0 490M 0% /dev/shm
/dev/sda1 ext4 477M 64M 388M 15% /boot
/dev/mapper/myvg-mylv
ext4 6.8G 14M 6.5G 1% /opt/lvm
对于 XFS 文件系统,可以使用 xfs_growfs 命令来调整文件系统的大小。该命令允许你扩展已经挂载的 XFS 文件系统以利用可用的空间。
[root@CentOS6 ~]# xfs_growfs /dev/myvg/mylv
执行命令后,xfs_growfs 将会自动识别并扩展文件系统以使用新的可用空间
为缩减做准备,创建一些文件,看缩减后,然后进行挂载,查看文件是否丢失
[root@CentOS6 lvm]# mkdir aa
[root@CentOS6 lvm]# mkdir aaa
[root@CentOS6 lvm]# echo "wqeasdasdasdada dasdasdasdaa " > test.txt
[root@CentOS6 lvm]# ls
aa aaa lost+found test.txt
[root@CentOS6 lvm]# du /opt/lvm/
4 /opt/lvm/aa
16 /opt/lvm/lost+found
4 /opt/lvm/aaa
32 /opt/lvm/
[root@CentOS6 lvm]# du -sh /opt/lvm/
32K /opt/lvm/
缩减:
Notice:缩减操作需要离线处理,即需要卸载
先要卸载
[root@CentOS6 ~]# umount /opt/lvm/
[root@CentOS6 ~]# cd /opt/lvm/
[root@CentOS6 lvm]# ls
先缩减文件系统的大小,防止数据丢失
[root@CentOS6 ~]# resize2fs /dev/myvg/mylv # 重新识别文件系统大小
resize2fs 1.41.12 (17-May-2010)
请先运行 'e2fsck -f /dev/myvg/mylv'.
[root@CentOS6 ~]# e2fsck -f /dev/myvg/mylv # 叫先运行这条命令,听它的,运行就是了
e2fsck 1.41.12 (17-May-2010)
第一步: 检查inode,块,和大小
第二步: 检查目录结构
第三步: 检查目录连接性
Pass 4: Checking reference counts
第5步: 检查簇概要信息
/dev/myvg/mylv: 14/458736 files (0.0% non-contiguous), 65036/1837056 blocks
[root@CentOS6 ~]# resize2fs /dev/myvg/mylv 3G
resize2fs 1.41.12 (17-May-2010)
Resizing the filesystem on /dev/myvg/mylv to 786432 (4k) blocks.
The filesystem on /dev/myvg/mylv is now 786432 blocks long.
[root@CentOS6 ~]# lvreduce /dev/myvg/mylv -L -2G # 缩减2G
Rounding size to boundary between physical extents: 2.00 GiB.
WARNING: Reducing active logical volume to 5.01 GiB.
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce myvg/mylv? [y/n]: y # 确定缩减
Size of logical volume myvg/mylv changed from 7.01 GiB (1196 extents) to 5.01 GiB (855 extents).
Logical volume mylv successfully resized.
[root@CentOS6 ~]# lvs # 查看缩减后的lv
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mylv myvg -wi-a----- 5.01g #这前是7g,现在是5g
lv_root vg_centos6 -wi-ao---- 17.57g
lv_swap vg_centos6 -wi-ao---- 1.94g
[root@CentOS6 ~]# lvreduce /dev/myvg/mylv -L -1G # 在次缩减一次,看看效果
Rounding size to boundary between physical extents: 1020.00 MiB.
WARNING: Reducing active logical volume to 4.01 GiB.
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce myvg/mylv? [y/n]: y
Size of logical volume myvg/mylv changed from 5.01 GiB (855 extents) to 4.01 GiB (685 extents).
Logical volume mylv successfully resized.
[root@CentOS6 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mylv myvg -wi-a----- 4.01g (这前是5g,现在是4g)成功)
lv_root vg_centos6 -wi-ao---- 17.57g
lv_swap vg_centos6 -wi-ao---- 1.94g
[root@CentOS6 lvm]# df –h # 在查看系统信息
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_centos6-lv_root
18G 3.6G 13G 23% /
tmpfs 490M 0 490M 0% /dev/shm
/dev/sda1 477M 64M 388M 15% /boot
/dev/mapper/myvg-mylv
3.9G 13M 3.7G 1% /opt/lvm (成功)
进行缩减后的挂载,验证之前的文件是否丢失?
[root@CentOS6 ~]# mount /dev/myvg/mylv /opt/lvm/ # 挂载
[root@CentOS6 ~]# cd /opt/lvm/ # 进入挂载点,查看数据是否丢失
[root@CentOS6 lvm]# ls
aa aaa lost+found test.txt
[root@CentOS6 lvm]# du /opt/lvm/ # 验证成功,数据无丢失
4 /opt/lvm/aa
16 /opt/lvm/lost+found
4 /opt/lvm/aaa
32 /opt/lvm/
[root@CentOS6 lvm]# du -sh /opt/lvm/
32K /opt/lvm/
第八步:删除lvm
先卸载挂载的文件系统,然后才能删除lvm
[root@CentOS6 ~]# lvremove /dev/myvg/mylv # 移除mylv
Logical volume myvg/mylv contains a filesystem in use.
(逻辑卷正在使用)
[root@CentOS6 ~]# umount /dev/myvg/mylv # 卸载
[root@CentOS6 ~]# lvremove /dev/myvg/mylv # 删除lvm
Do you really want to remove active logical volume mylv? [y/n]: y
Logical volume "mylv" successfully removed # 成功删除
然后移除vg
[root@CentOS6 ~]# vgremove myvg
Volume group "myvg" successfully removed # 成功移除
移除pv
[root@CentOS6 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 vg_centos6 lvm2 a--u 19.51g 0
/dev/sdb1 lvm2 ---- 4.01g 4.01g
/dev/sdb2 lvm2 ---- 4.01g 4.01g
/dev/sdb3 lvm2 ---- 1.01g 1.01g
[root@CentOS6 ~]# pvremove /dev/sdb{1..3}
Labels on physical volume "/dev/sdb1" successfully wiped
Labels on physical volume "/dev/sdb2" successfully wiped # 成功移除
Labels on physical volume "/dev/sdb3" successfully wiped
快照: (只是虚拟机上面有这个功能,实际环境中并没有)
# 创建快照
# lvcreate --size 100M --snapshot --name snap01 /dev/vg0/lv
# 从快照恢复
# lvconvert --merge /dev/vg0/snap01
fsck 检查并且试图修复文件系统中的错误
fsck命令被用于检查并且试图修复文件系统中的错误。当文件系统发生错误四化,可用fsck指令尝试加以修复。
Grammar
fsck(Option)(参数)
Option
- -a:自动修复文件系统,不询问任何问题;
-
-A:依照
/etc/fstab配置文件的内容,检查文件内所列的全部文件系统; -
-N:不执行指令,仅列出实际执行会进行的动作;
-
-P:当搭配"-A"参数使用时,则会同时检查所有的文件系统;
-
-r:采用互动模式,在执行修复时询问问题,让用户得以确认并决定处理方式;
-
-R:当搭配"-A"参数使用时,则会略过/目录的文件系统不予检查;
-
-s:依序执行检查作业,而非同时执行;
-
-t<文件系统类型>:指定要检查的文件系统类型;
-
-T:执行fsck指令时,不显示标题信息;
-
-V:显示指令执行过程。
参数
文件系统:指定要查看信息的文件系统。
Living Example
linux的文件系统损坏会导致linux不正常关机,出错的时候如果系统告诉你是哪一块硬盘的分区有问题,比如是/dev/hda2,接着用如下的命令去对付它:
fsck -y /dev/hda2
结束后使用reboot命令重启系统这样就好了!
如果不知道时哪个地方出了问题,可以直接:
fsck
在随后的多个确认对话框中输入:y
结束后同样使用reboot命令重启系统这样就好了!
检查磁盘是否存在坏道 badblocks
badblock命令用于查找磁盘中损坏的区块。 硬盘是一个损耗设备,当使用一段时间后可能会出现坏道等物理故障。电脑硬盘出现坏道后,如果不及时更换或进行技术处理,坏道就会越来越多,并会造成频繁死机和数据丢失。最好的处理方式是更换磁盘,但在临时的情况下,应及时屏蔽坏道部分的扇区,不要触动它们。badblocks就是一个很好的检查坏道位置的工具。
Grammar
badblock(Option)(参数)
Option
- -b<区块大小>:指定磁盘的区块大小,单位为字节;
-
-o<输出文件>:将检查的结果写入指定的输出文件;
-
-s:在检查时显示进度;
-
-v:执行时显示详细的信息;
-
-w:在检查时,执行写入测试。
参数
磁盘装置:指定要检查的磁盘装置;
磁盘区块数:指定磁盘装置的区块总数;
启始区块:指定要从哪个区块开始检查。
Living Example:
# badblocks -sv /dev/sda1
正在检查从 0 到 511999的块
Checking for bad blocks (read-only test): 完成
Pass completed, 0 bad blocks found.
使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
使用命令repquota 能够显示出一个文件系统的配额信息
repquota命令以报表的格式输出指定分区,或者文件系统的磁盘配额信息。
Grammar
repquota(Option)(参数)
Option
-
-a:列出在/etc/fstab文件里,有加入quota设置的分区的使用状况,包括用户和群组;
-
-g:列出所有群组的磁盘空间限制;
-
-u:列出所有用户的磁盘空间限制;
-
-v:显示该用户或群组的所有空间限制。
参数
文件系统:要打印报表的文件系统或者对应的设备文件名。
Living Example
# 显示所有文件系统的磁盘使用情况
repquota -a
Living Example:一步操作删除分区表 (超级危险)
# dd if=/dev/zero of=/dev/sdb bs=512 count=1
Living Example:深入理解Linux文件系统:
分区:创建分区
格式化:创建文件系统
# dumpe2fs -h /dev/sda1 #查看超级块中的内容
Filesystem OS type: Linux
Inode count: 128016
Block count: 512000
Block size: 1024(1k) #10m
Inode size: 128
磁盘没有空间的2种原因:
1、inode被占满 (小文件多)
2、block被占满 (大文件多)
# df -hT #查看block的使用量
# df -iT ##查看inode的使用量
--inode(index node索引节点) 数据(文件)在盘中的唯一标识,记录着文件存储位置的编号,但是不会记录文件名(文件名不是文件属性)!
读写文件的过程:
首先inode要验证权限,过了才能继续往下读取block块!
一个文件可能有多个inode 肯定不止1个block ,block之间是相互指向,建立联系的。
查看inode:
# ls -il
total 28
406402 -rw-r--r-- 1 root root 89 Jan 26 09:18 ip.log
392008 -rw-r--r--. 1 root root 512 Jan 6 22:45 mbb
# mkfs -t ext4 -b 2048 -I 256 /dev/sdd3
#格式化的时候可以指定block(1024,2048,4096)的大小和inode(128,256)的大小(单位都是字节)
创建软连接:
# ln -sv /tmp/tang/ip.log /tmp/tang/ip
`/tmp/tang/ip' -> `/tmp/tang/ip.log'
创建硬链接
# ln -v /tmp/tang/ip.log /tmp/tang/ip-hard
`/tmp/tang/ip-hard' => `/tmp/tang/ip.log'
文件的删除:
只是删除了文件入口,文件所在inode和block中的内容并没有被立刻删除点。
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。