- 正则表达式、三剑客等......
- 元字符
- 正则表达式
- gerp:强大的文本搜索工具
- sed (字符流编辑器;行编辑器)
- awk(awk外面用单引号,里面用双引号)
- awk简介:
- awk工作原理
- 使用方法及格式:
- awk命令:
- 注意
- Living Example1:-F"字符"单个字符作为分隔符(如果是以空格做分隔符,可以不写-F)
- Living Example2:和-F"[ :]"多个字符做分隔符和多个分隔符
- Living Example3、关系运算符
- Living Example4、$NF表示最后一列
- Living Example5、打印出passwd文件中UID小于10的用户名和它的登录使用的shell
- Living Example6、打印出系统中UID大于100且登录shell是/bin/bash的用户
- Living Example7、打印行号大于等于3且行号小于等于6的行 (NR)
- Living Example8、查出行号小于等于5且包括bin/bash的行
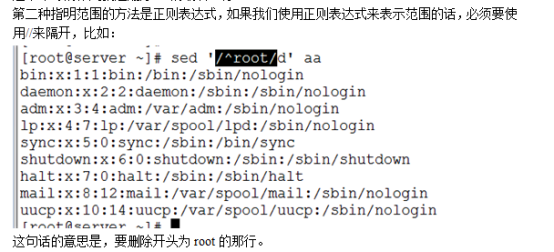
- Living Example9、打印已root开头的行
- Living Example10、使用awk查出包括root字符的行,有以下3种方法
- Living Example11、使用3种方法去除首行
- Living Example12、NR,NF,$NF,"\t",$0 (综合应用)
- Living Example13、条件表达式
- Living Example14、格式化输出
- Living Example15、awk引用变量 (很少使用)
- 综合例子
- 管道:"|"
- tee 把数据重定向到给定文件和屏幕上
- xargs是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具
- exec -->用于调用并执行指令的命令
- cut -->以某种方式按照文件的列进行分割
- paste-->将多个文件按照列队列进行合并
- split 分割文件
正则表达式、三剑客等......
元字符
元字符是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持
| 正则表达式 | 描述 | 示例 |
|---|---|---|
| \b | 单词边界 | \bcool\b匹配cool,不匹配coolant |
| \B | 非单词边界 | cool\B匹配coolant不匹配cool |
| \d | 单个数字字符 | b\db匹配b2b,不匹配bcb |
| \D | 单个非数字字符 | b\Db匹配bcb不匹配b2b |
| \w | 单个单词字符(字母,数字与_) | \w匹配1或a,不匹配& |
| \W | 单个非单词字符 | \W匹配&,不匹配1或a |
| \n | 换行符 | \n匹配一个新行 |
| \s | 单个空白字符 | x\sx匹配xx,不匹配xx |
| \S | 单个非空白字符 | x\S\x匹配xkx,不匹配xx |
| \r | 回车 | \r匹配回车 |
| \t | 横向制表符 | \t匹配一个横向制表符 |
| \v | 垂直制表符 | \v匹配一个垂直制表符 |
| \f | 换页符 | \f匹配一个换页符 |
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
一、基本正则表达式(9个)
1. 符号"."
匹配任意一个字符,除了换行符,但是需要注意的是,在sed中不能匹配换行符,但是在awk中可以匹配换行符。类似shell通配符中的"?",匹配一个任意字符。
#匹配一个非换行符的字符 如:'gr.p' 表示匹配gr后接一个任意字符,然后是p。
Notice:空白符也算一个字符
2. 符号"[]"
"[ ]"中括号中可以包含表示字符集的表达式。使用方法大概有如下几种。
[a-z]:表示a-z字符中的一个,也就是小写字母。
[0-9]:表示0-9字符中的一个,也就是表示数字。
[A-Z]:表示大写字母。
[a-zA-Z]:表示字符集为小写字母或者大写字母。
[a-zA-Z0-9]:表示普通字符,包括大小写字母和数字。
[abc]:表示字符a或者字符b或者字符c。
[^0-9] 表示非数字类型的字符,^表示取反意思,只能放在中括号的开始处才有意义。
[-cz] 表示字符-或者字符c或者字符z,Notice与[c-z]的区别,因为-符号没有放在c和z之间。
[ ]* 表示有0个或者多个空格
\s* 表示有0个或者多个空格
Notice:[.] 表示点本身,不表示任意一个字符。
1. 符号"."
"*" #表示前边字符有0个或多个。".*"表示任意一个字符有0个或多个,也就是能匹配任意的字符。类似shell通配符中的"*",可以匹配任意字符。
贪婪模式:尽可能匹配长的模式
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表出现任意字符。(不是前面出现的字符,就是当前位置)
2. 符号"\"
"\"表示是转义字符,和其它语言中用到的转义字符意义基本上是一样的。其实简单理解,就是把元字符转义为普通字符,比如"\\"表示普通符号"\",把普通字符转换为特殊意义符号,比如"\n"表示把普通字符n转义为换行符。
\?:匹配其前面的字符0次或1次;即前面的字符是可有可无[区别于shell中的通配符]
\+:匹配其前面的字符1次或者多次;即前面的字符要出现至少1次
' ', '-','\', '+'等字符在正则表达式中都要转义
3. 符号"{}"
"{}"表示前边字符的数量范围,大概有三种用法,其实容易理解,看例子就知道了,但是必须Notice要加上转义字符"\",否则不生效,表示为普通字符"{"或"}"。
\{m\}:表示前边字符的重复次数是m。
\{m,n\}:匹配其前面的字符至少m次,之多n次
\{m,\}:匹配其前面的字符至少m次,也就是大于等于m
\{,n\}:匹配其前面的字符之多n次,也就是最多等于m
-----------------------------------------------------------------------------------------
x\{m\} #重复字符x,m次,如:'o\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。

1. 符号"\^"
"^"表示行首的意思,也就是每一行的开始位置。在这里并不是上边字符范围中取反的意思
#锚定行的开始 如:'^grep'匹配所有以grep开头的行。
^abc:表示以abc开头的字符串abc。
^abc.*:表示以abc开头的字符串abcxxx。
2. 符号"$"
"$"表示行尾的意思,也就是每一行的结尾位置,很好理解,和"^"正好相反。
#锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
world$:表示以world结尾的字符串world,如果该行中间有world字符串是不符合匹配条件的。
^$:表示空行。行首和行尾没有内容,可不就是空行嘛。
^[[:space:]]*$ 这个也是空白行
3. 符号"<"和">"
"\<"表示匹配条件为词首的位置,理解上可以对比 "^" 行首。
举个例子,"nihao 1hello 2hello3 hello4"有这么内容的一行内容。
"\<hello"匹配结果"nihao 1hello 2hello3 hello4";
"hello\>"匹配结果"nihao 1hello 2hello3 hello4",这种匹配方式用的不是太多,用到会用就OK。
\<keywords\>匹配keywords的所有行
#锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
#锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行
1、标签\(\) 又称分组后向引用

[root@CentOS6 ~]# grep "^\(a\|b\).*" /etc/passwd (以a或者b开头的行,分组)
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
[root@test tmp]# cat 1.txt
She loves her lover
She likes her lover
She loves her liker
She likes her liker
[root@test tmp]# grep "\(l..e\).*\1" 1.txt (分组+后向引用)
She loves her lover
She likes her liker
[root@CentOS6 ~]# grep "^\(.*\):.*/\1$" /etc/passwd (用户名与shell名相同;分组+后向引用)
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
二、扩展正则表达式(5个)
扩展正则表达式是在基本正则表达式中扩展出来的,内容不是很多,使用频率上可能没有基本正则表达式那么高,但是扩展正则依然很重要,很多情况下没有扩展正则是搞不定的。sed命令使用扩展正则需要加上Option-r。
1. 符号"?"
"?":表示前面字符可以有也可以没有。
2. 符号"+"
"+":表示前面字符至少出现1次。
3. 符号"|"
"|":表示指明两项之间的一个选择。
abc|ABC:表示可以匹配abc或者ABC。
4. 符号"()"
"()"表示分组,类似算数表达式中的()。子命令表达式中可以通过\1,\2,\3等来表示分组匹配到的内容。其实"()"也可以在基本正则表达式中使用的。
(a|b)b:表示可以匹配ab或者bb字串
([0-9])|([0][0-9])|([1][0-9]):表示匹配0-9或者00-09或者10-19范围的字符。
5. 符号"{}"
{m,n}
{m}
{m,}
这里的"{}"和基本正则表达式中的大括号意义是一样的,只不过在使用时不用加"\"转义符号。
说明:

三、正则表达式的分类和应用
字符类
[Ww]hat \.H[12345]
字符的范围
[a-z] [0-9] [Cc]hapter[1-9] [-+*/]
[0-1][0-9][-/][0-3][0-9][-/][0-9][0-9]
排除字符类
[^0-9]
重复出现的字符
[15]0* [15]00
*[15]0. [15]00
字符的跨度
*与\{n,m\}
电话号码的匹配
[0-9]\{3\}-[0-9]\{7,8\}
分组操作
compan(y|ies)
gerp:强大的文本搜索工具
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
作用:用来过滤含有特定字符的行;是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的标准输出。
Notice:扩展正则表达式较标准正则表达式更加简洁,无需"\"转义符
Grammar:
**grep [Option] pattern filename **
Notice: pattern如果是表达式或者超过两个单词的, 需要用引号引用.可以是单引号也可双引号,区别是单引号无法引用变量而双引号可以.
Option:
https://blog.csdn.net/xiaoxinyu316/article/details/46729443
提取含有关键字的一行,并且标注关键字的颜色:
grep 关键字 文件名 --color或者grep 关键字 文件名 –col
#sed -i "/alias rm='rm -i'/i\alias grep='grep --color=auto'" .bashrc
#source .bashrc
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。(可以搜索多个关键词)
-F, --fixed-strings, --fixed-regexp
-P, --perl-regexp 将模式解释为Perl正则表达式,这是高度实验性的,grep -P可能会警告未实现的特殊
----------------------------------------------------------------------------------------------------------------
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-i 忽略字符的大小写。
-v 反转查找。
-w 只显示全字符合的列。(精确匹配出keyword的这一行)
-c 计算符合范本样式的列数。(相当于符合内容的次数)
-o 只输出文件中匹配到的部分。(精确匹配出keyword的字符)
-B (before):在显示符合范本样式的那一行之外,并显示该行之前的内容。
-C<显示列数>或-<显示列数> (context): 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-A<显示列数>(after):除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-q 不显示任何信息。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。(或关系)
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。(或关系)
-G:使得扩展正则表达式支持标准正则表达式
-R/-r 此参数的效果和指定"-d recurse"参数相同。
-I : 忽略二进制文件(大写i)
-l 列出文件内容符合指定的范本样式的文件名称。(小写L)
-L 列出文件内容不符合指定的范本样式的文件名称。grep -rl "root"
-V 版本信息
-s 不显示错误信息。
-x 只显示全列符合的列。
-y 此参数效果跟"-i"相同。
-F 将范本样式视为固定字符串的列表。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-a 不要忽略二进制数据。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
grep:支持正则表达式
[root@test ~]# grep "root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@CentOS6 ~]# grep -e root -e bash /etc/passwd (包含root或者bash)
[root@test tmp]# cat 1.txt
She loves her lover
She likes her lover
She loves her liker
She likes her liker
[root@test tmp]# grep -o "loves" 1.txt
loves
loves
[root@test tmp]# grep -w "loves" 1.txt
She loves her lover
She loves her liker
[root@elk-node2 ~]# grep -n root /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
egrep:支持扩展正则表达式
[root@6 ~]# egrep "^(root|peng)" /etc/passwd (过滤以root或者peng开头的行)
root:x:0:0:root:/root:/bin/bash
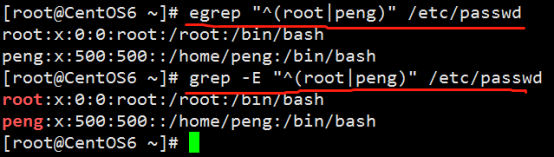
grep -E 'root.+' /etc/passwd (-E表示扩展的grep)
grep不支持+ ?这两个通配符,如果要使用的话,只能使用扩展的grep(egrep或者grep –E)

grep "^[^#]" /etc/dhcp/dhcpd.conf (显示除开头为#号外的行)
sed -n '/^[^#]/p' /etc/dhcp/dhcpd.conf(显示除开头为#号外的行)
grep -n "^$" /etc/dhcp/dhcpd.conf (除空白行的所有行)
fgrep:不支持正则表达式

grep -P:

sed (字符流编辑器;行编辑器)
sed工作流程
大概简单描述一下sed的工作流程,读取文件的一行,存入模式空间,然后进行所有子命令的处理,处理完后默认会将模式空间的内容输出打印到标准输出,也就是在屏幕上显示出来,接着清空模式空间的内存,继续读取下一行的内容到模式空间,继续处理,依次循环处理。

模式空间和保持空间
模式空间初始化为空,处理完一行后会自动输出到屏幕并清除模式空间;保持空间初始化为一个空行,也就是默认带一个\n,处理完后不会自动清除。模式空间和保持空间,从程序的角度去看,其实就是sed在工作的时候占用了一些内存空间和地址,sed工作完毕就会把内存释放并归还给操作系统。
[模式空间和保持空间的置换]
h:把模式空间内容覆盖到保持空间中 H:把模式空间内容追加到保持空间中 g:把保持空间内容覆盖到模式空间中 G:把保持空间内容追加到模式空间中 x:交换模式空间与保持空间的内容
Grammar



sed [Option] 'command' 文件名称
Option部分,常见Option包括-n,-e,-i,-f,-r
command部分包括:[地址1,地址2] [函数] [参数(标记)]
常用选项
选项-n
sed默认会把模式空间处理完毕后的内容输出到标准输出,也就是输出到屏幕上,加上-n选项后被设定为安静模式,也就是不会输出默认打印信息,除非子命令中特别指定打印选项,则只会把匹配修改的行进行打印。
例子1:
echo -e 'hello world\nnihao' | sed 's/hello/A/'
结果:
A world
nihao
例子2:
echo -e 'hello world\nnihao' | sed -n 's/hello/A/'
结果:加-n选项后什么也没有显示。
例子3:
echo -e 'hello world\nnihao' | sed -n 's/hello/A/p'
结果:A world/
说明:-n选项后,再加p标记,只会把匹配并修改的内容打印了出来。


选项-e
如果需要用sed对文本内容进行多次操作,则需要执行多条子命令来进行操作。
例子1:
echo -e 'hello world' | sed -e 's/hello/A/' -e 's/world/B/'
结果:A B
例子2:
echo -e 'hello world' | sed 's/hello/A/;s/world/B/'
结果:A B
说明:例子1和例子2的写法的作用完全等同,可以根据喜好来选择,如果需要的子命令操作比较多的时候,无论是选择-e选项方式,还是选择分号的方式,都会使命令显得臃肿不堪,此时使用-f选项来指定脚本文件来执行各种操作会比较清晰明了。
选项-i
sed默认会把输入行读取到模式空间,简单理解就是一个内存缓冲区,sed子命令处理的内容是模式空间中的内容,而非直接处理文件内容。因此在sed修改模式空间内容之后,并非直接写入修改输入文件,而是打印输出到标准输出。如果需要修改输入文件,那么就可以指定-i 选项
例子1:
cat file.txt
hello world
[root@localhost]# sed 's/hello/A/' file.txt
A world
[root@localhost]# cat file.txt
hello world
例子2:
[root@localhost]# sed -i 's/hello/A/' file.txt
[root@localhost]# cat file.txt
A world
例子3:
[root@localhost]# sed -i.bak 's/hello/A/' file.txt
说明:最后一个例子会把修改内容保存到file.txt,同时会以file.txt.bak文件备份原来未修改文件内容,以确保原始文件内容安全性,防止错误操作而无法恢复原来内容。
选项-f
还记得 -e选项可以来执行多个子命令操作,用分号分隔多个命令操作也是可以的,如果命令操作比较多的时候就会比较麻烦,这时候把多个子命令操作写入脚本文件,**然后使用 -f 选项来指定该脚本。
例子1:
echo "hello world" | sed -f sed.script
结果:A B
sed.script脚本内容:
s/hello/A/
s/world/B/
说明:在脚本文件中的子命令串就不需要输入单引号了。
选项-r
sed命令的匹配模式支持正则表达式的,默认只能支持基本正则表达式,如果需要支持扩展正则表达式,那么需要添加-r选择。
例子1:
echo "hello world" | sed -r 's/(hello)|(world)/A/g'
A A
例子2:
service_addr=8.8.8.8 && service_port=3369 && echo 'DB_URL="jdbc:dm://6.6.6.6:6?schema=NACOS&characterEncoding=utf-8"' | sed -r "s/(jdbc:[^:]+:\/\/)[^:]+:[0-9]+/\1${service_addr}:${service_port}/g"
数字定址和正则定址
1、关于定址的概念
默认情况下sed会对每一行内容进行匹配、处理、输出,某些情况不需要对处理的文本全部编辑,只需要其中的一部分,比如1-10行,偶数行,或者是包含"hello"字符串的行,这种情况下就需要我们去定位特定的行来处理,而不是全部内容,这里把这个定位指定的行叫做"定址"。
2、数字定址
数字定址其实就是通过数字去指定具体要操作编辑的行,数字定址有几种方式,每种方式都有不同的应用场景,下边以举例的方式来描述每种数字定址的用法。
例子1:
sed -n '1s/hello/A/' messge
说明:将第1行中hello字符串替换为A,其它行如果有hello也不会被替换。
例子2:
sed -n '2,4s/hello/B/' messge
说明:将第2-4行中hello字符串替换为B,其它行如果有hello也不会被替换。
例子3:
sed -n '2,+4s/hello/A/' messge
说明:从第2行开始,再接着往下数4行,也就是2-6行,这些行会把hello字符替换为A。
例子4:
sed –n ‘4,~3s/hello/A/’ message (没有做出来)
说明:第4行开始,到第6行。解释6的由来,"4,~3"表示从4行开始到下一个3的倍数,这里从4开始算,那就是6了,当然9就不是了,因为是要求3的第一个超过前边数字4的倍数,感觉这种适用场景不会太多。
例子5:
sed –n ‘4~3s/hello/A/’ message (也没有做出来)
说明:从第4行开始,每隔3行就把hello替换为A。比如从4行开始,7行,10行等依次+3行。这个比较常用,比如3替换为2的时候,也就是每隔2行的步调,可以实现奇数和偶数行的操作。
例子6:
sed -i '$s/hello/A/' messge
说明:$符号表示最后一行,和正则中的$符号类似,但是第1行不用^表示,直接1就行了。
例子7:
sed -i '1!s/word/A/' messge
说明:!符号表示取反,该命令是将除了第1行,其它行hello替换为A,上述定址方式也可以使用!符号。
3、正则定址
正则定址使用目的和数字定址完全一样,使用方式上有所不同,是通过正则表达式的匹配来确定需要处理编辑哪些行,其它行就不需要额外处理。
例子1:
sed -n '/hello/d' messge
说明:将匹配到hello的行执行删除操作。
例子2:
sed -n '/^$/d' messge
说明:删除空行
例子3:
sed -n ‘/^TS/,/^TE/d’ message
说明:匹配以TS开头的行到TE开头的行之间的行,并且包含以TS开头和TE开头的行,把匹配到的这些行删除。
4、数字定址和正则定址混用
其实数字定址和正则定址可以配合使用,参考下边的例子。
例子1:
sed -n ‘1,/^TS/d’ message
说明:匹配从第1行到TS开头的行,把匹配的行删除。
5、关于定址的分组命令
例子1:
/^TS/,/^TE/{
s/CN/China/
s/Beijing/BJ/
}
说明:该命令表示将从TS开头的行到TE开头的行之间范围的行内容中CN替换为China,并且把Beijing替换为BJ,类似于多命令之间用分号的那种方式,不过这样定址代码只写了一遍,相当于执行了一条子命令。
例子2:
sed -n ‘2,3s{/cn/china/;/a/b/}’ message
说明:效果类似例子1,有点数学上的乘法分配率的意思。

6、使用sed操作两个模式行之间的内容
基于sed定位两个模式匹配行之间内容的方法
'/[section1]/,/[section2]/{/[section1]/!{/[section2]/!d}}'
将d命令修改为相应的命令集合即可,例如
'/[section1]/,/[section2]/{/[section1]/!{/[section2]/!{s/string1/string2/g;…;}}}'
————————————————
说明:
1、中括号需要用转义运算符。
\[section1\]
2、/string1/!,其中的!表示行中没有匹配到string1。
3、/[section1]/,/[section2]/为行定位,选择在小节[section1]到[section2]之间的行,包含[section1]和[section2]这两行。
4、{/[section1]/!{/[section2]/!d}}为之前定位后的操作,需要排除掉[section1]和[section2]这两行,使用/[section1]/!来排除掉[section1]这一行,使用{/[section2]/!d}}继续排除掉[section2]这一行,然后执行删除操作。
原文链接:https://blog.csdn.net/weixin_43516626/article/details/93712151
7、sed定址的总结
sed 默认的命令执行范围是全局编辑的,如果不明确指定行的话,命令会在所有输入行上执行,如果想仅对其中部分行执行命令,可以使用地址限制。如果给了 2 个地址,即地址对(地址范围),则命令匹配的这个地址范围内执行,但是需要Notice的是:对于像 "addr1,addr2" 这种形式的地址匹配,如果addr1 匹配,则匹配成功,"开关"打开,在该行上执行命令,此时不管 addr2 是否匹配,即使 addr2 在 addr1 这一行之前;接下来读入下一行,如果addr2 匹配,则执行命令,同样开关"关闭";如果 addr2 在 addr1 之后,则一直处理到匹配为止,换句话说,如果 addr2 一直不匹配,则开关一直不关闭,因此会持续执行命令到最后一行。
基本子命令
1、子命令a
子命令a表示在指定行下边插入指定行的内容。
例子1:
sed 'a A' messge
说明:将message文件中每一行下边都插入添加一行内容是A。
例子2:
sed '1,2a A' messge
说明:将message文件中1-2行的下边插入添加一行内容是A
例子3:
sed '1,2a A\nB\nC' messge
说明:将message文件中1-2行的下边分别添加3行,3行内容分别是A、B、C,这里使用了\n,插入多行内容都可以按照这种方式来实现。
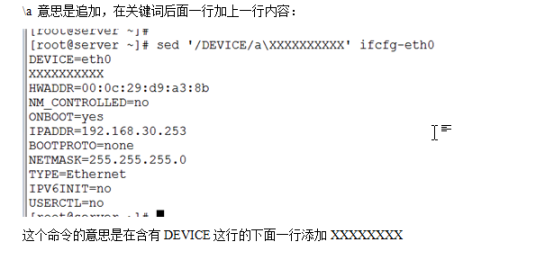
例子4:
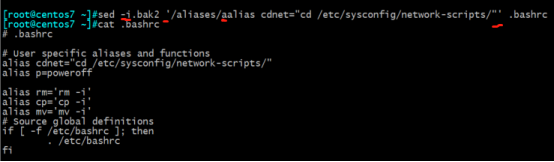
2、子命令i
子命令i和a使用上基本上一样,只不过是在指定行上边插入指定行的内容。
例子1:
sed 'a A' message
说明:将message文件中每一行上边都插入添加一行内容是A。
例子2:
sed '1,2a A' message
说明:将message文件中1-2行的上边插入添加一行内容是A
例子3:
sed '1,2a A\nB\nC' message
说明:将message文件中1-2行的上边分别添加3行,3行内容分别是A、B、C,这里使用了\n,插入多行内容都可以按照这种方式来实现。
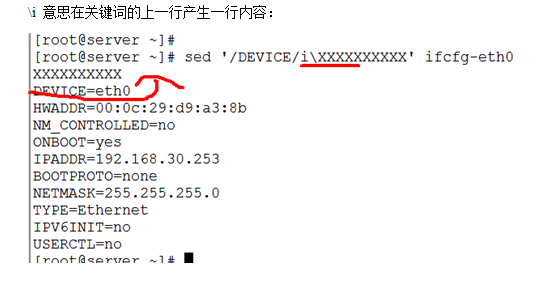
3、子命令c
子命令c是表示把指定的行内容替换为自己需要的行内容。
例子1:
sed 'c A' messge
说明:将message文件中所有的行内容都分别替换为A行内容。
例子2:
sed '1,2c AAA' messge
说明:将message文件中1-2行的内容替换为A,Notice这里说的是将1-2行所有的内容只替换为一个A内容,也就是1-2行内容变成了一行,定址如果连续就是这种情况。如果想把1-2行分别替换为A,可以参考下个例子的方式。
例子3:
sed '1,2c A\nA' messge
说明:将message中1-2行内容分别替换为了A,需要在替换内容上手动加换行\n,这样当然也可以将一行内容替换为多行内容。
例子4:
sed -i.bak '/^#PermitRootLogin/cPermitRootLogin no' /etc/ssh/sshd_config
修改ssh相关配置(以#PermitRootLogin开头的行替换为PermitRootLogin no)
sed -i.bak -e '/^#Port/cPort 22' -e '/^#PermitRootLogin/cPermitRootLogin no'
4、子命令d
子命令d表示删除指定的行内容,比较简单,更容易理解。
(如果删除首行sed '1d' messge)(如果删除末行sed '$d' messge)
例子1:
sed 'd' message
说明:将message所有行全部删除,因为没有加定址表达式,所以平时如果需要删除指定行内容,需要在子命令前加定址表达式。
例子2:
sed '1,3d' message
说明:将message文件中1-3行内容删除
5、子命令s
子命令s为替换子命令,是平时sed使用的最多的子命令,没有之一。因为支持正则表达式,功能变得强大无比,下边来详细地说说子命令s的使用方法。
基本语法:单引号与双引号的区别就是双引号可以引用变量的指,而单引号不能
'[address]s/pattern/replacement/flags file'
'[address]s+pattern+replacement+flags file'
'[address]s@pattern@replacement@flags file'
'[address]s#pattern#replacement#flags file'
解释:[address]范围s /pattern老字符/replacement新字符/flags标记
s字符串替换,替换的时候可以把/换成其它的符号,比如=,replacement部分用下列字符会有特殊含义:
>>> &:用正则表达式匹配的内容进行替换
>>> \n:回调参数
>>> \(\):保存被匹配的字符以备反向引用\n时使用,最多9个标签,标签书序从左到右
替换标记Flags
>>> n:可以是1-512,表示第n次出现的情况进行替换
>>> g:全局更改
>>> p:打印模式空间的内容
>>> w file:写入到一个文件file中


eg:
sed 's/root/haha/g' /etc/passwd
eg:
eg:去掉#号
[root@CentOS6]#sed -e '/^#NameVirtualHost/s/#//' -e '/^#<VirtualHost \*:80/,/^#<\/VirtualHost/s/#//' /etc/httpd/conf/httpd.conf
eg:取文件或目录名
echo "/etc/sysconfig/network" | sed -r 's@(.*\/)([^/]+\/?$)@\2@'
##安装jumpser是取版本号 (多次修改可以用分号分隔)
Version=$(curl -s 'https://api.github.com/repos/jumpserver/installer/releases/latest' | grep "tag_name" | head -n 1 | awk -F ":" '{print $2}' | sed 's/\"//g;s/,//g;s/ //g')
#如果修改值是变量,则需要用双引号囊括
function config_installer() {
cd /opt/jumpserver-installer-$Version
JMS_Version=$(curl -s 'https://api.github.com/repos/jumpserver/jumpserver/releases/latest' | grep "tag_name" | head -n 1 | awk -F ":" '{print $2}' | sed 's/\"//g;s/,//g;s/ //g')
if [ ! "$JMS_Version" ]; then
echo -e "[\033[31m ERROR \033[0m] Network Failed (请检查网络是否正常或尝试重新执行脚本)"
exit 1
fi
sed -i "s/VERSION=.*/VERSION=$JMS_Version/g" /opt/jumpserver-installer-$Version/static.env
./jmsctl.sh install
}
eg:替换多个字符(必须把替换的内容放在中括号里面)
who -u am i 2>/dev/null |awk '{print $NF}'
who -u am i 2>/dev/null |awk '{print $NF}' |sed -e 's/[()]//g'
在Linux中使用 sed 命令时,#& 表示匹配到的整个模式(pattern)本身。具体解释如下:
#: 在sed中,#表示将其后的内容作为注释,直到行尾。&: 表示匹配到的整个模式(或者可以理解为找到的文本)。
因此,#& 结合起来的意思是,把匹配到的文本(整个模式)作为注释的一部分。
例如,假设有一个文件 example.txt 内容如下:
apple
banana
cherry
如果我们使用 sed 命令来处理这个文件,比如将每行的文本加上前缀 fruit:,可以这样做:
sed 's/.*/fruit: &/' example.txt
这个命令的含义是,对于每一行(.* 匹配每一行的内容),用 fruit: 加上匹配到的整行文本(&)。输出结果会是:
fruit: apple
fruit: banana
fruit: cherry
现在如果我们在 sed 命令中使用 #&:
sed 's/.*/#&/' example.txt
这个命令的含义是,对于每一行,把匹配到的整行文本作为注释的一部分。输出结果会是:
#apple
#banana
#cherry
因此,#& 可以用来在 sed 处理的文本中将匹配到的内容作为注释的一部分插入。
6、子命令y
子命令y表示字符替换,可以替换多个字符,只能替换字符不能替换字符串,且不支持正则表达式,具体使用方法看例子。
例子1:
sed 'y/ ab/AB/' messge
说明:把message中所有a字符替换为A符号,所有b字符替换为B符号。
强调一下,这里的替换源字符个数和目的字符个数必须相等;字符不支持正则表达式;源字符和目标字符每个字符需要一一对应。
7、子命令=
子命令=,可以将行号打印出来。
例子:
sed '1,2=' messge
结果:
1
nihao
2
hello world
说明:将指定行的上边显示行号。
打印所以行数:
# sed = sed.txt
8、子命令r
子命令r,类似于a,也是将内容追加到指定行的后边,只不过r是将指定文件内容读取并追加到指定行下边。
例子1:
sed '2r a.txt' messge
说明:将a.txt文件内容读取并插入到message文件第2行的下边。
9、子命令!
模式空间中匹配行取反
sed -n '/^root/!P' /etc/passwd (显示除以root开头的行)

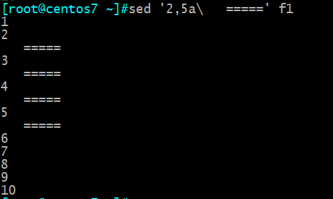
10、子命令w
把f1文件里面的2至5行放到f2文件里
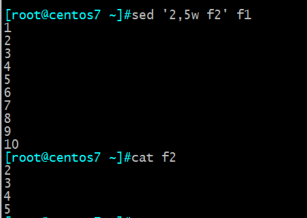
11、高级子命令
高级子命令比较少,但是比较复杂,平时用的也会相对少些,却也很重要,有的内容处理不用高级子命令是完成不了的。

n:读入下一行到模式空间,例:’4{n;d}’ 删除第5行。
N:追加下一行到模式空间,再把当前行和下一行同时应用后面的命令。
P:输出多行模式空间的第一部分,直到第一个嵌入的换行符位置。在执行完脚本的最后一个命令之后,模式空间的内容自动输出。P命令经常出现在N命令之后和D命令之前。
D:删除模式空间中第一个换行符的内容。它不会导致读入新的输入行,相反,它返回到脚本的顶端,将这些指令应用与模式空间剩余的内容。这3个命令能建立一个输入、输出循环,用来维护两行模式空间,但是一次只输出一行。
例子1:
sed ‘N;$!P;D’ file
#说明:删除文件倒数第二行
例子2:
sed ‘N;$!P;$!D;$d’ file
# 说明:删除文件最后两行
例子3:打印偶数行或奇数行
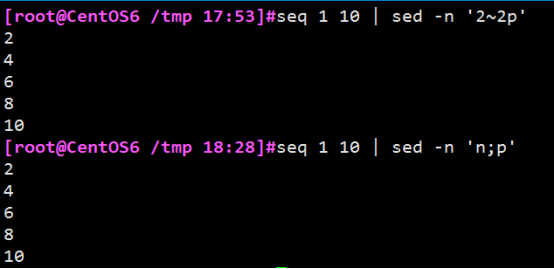
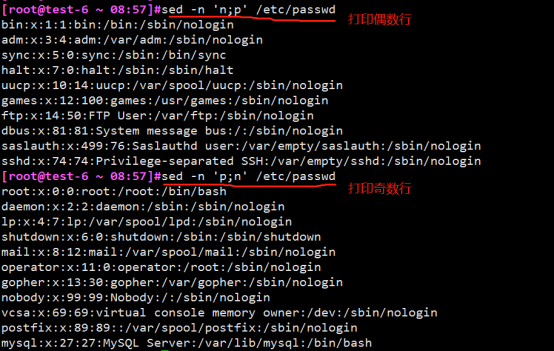
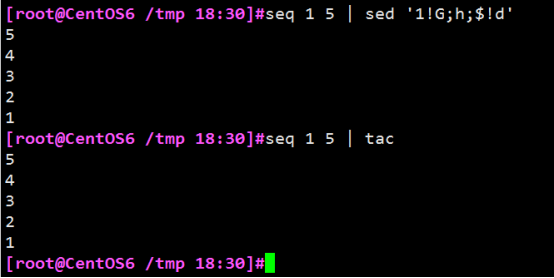
例子4:使文件倒叙
Living Example用法 (没有实际操作过)
测试文件:
# cat message
hello 123 world
例子1:
sed ‘s/hello/HELLO/’ message
说明:将message每行包含的第一个hello的字符串替换为HELLO,这是最基本的用法。
例子2:
sed -r ‘s/[a-z]+ [0-9]+ [a-z]+/A/’ message
结果:A
说明:使用了扩展正则表达式,需要加-rOption。
例子3:
sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/\1\2\3/’ message
结果:hello 123 world
说明:再看下一个例子就明白了。
例子4:
sed -r 's/([a-z]+)( [0-9]+ )([a-z]+)/\1\2\3/' message
结果:world 123 hello
说明:\1表示正则第一个分组结果,\2表示正则匹配第二个分组结果,\3表示正则匹配第三个分组结果。
例子5:
sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/&/’ message
结果:hello 123 world
说明:&表示正则表达式匹配的整个结果集。
例子6:
sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/111&222/’ message
结果:111hello 123 world222
说明:在匹配结果前后分别加了111、222。
例子7:
sed -r ‘s/.*/111&222/’ message
说明:在message文件中每行的首尾分别加上111、222。
例子8:
sed ‘s/i/A/g’ message
说明:把message文件中每行的所有i字符替换为A,默认不加g标记时只替换每行的第一个字符。
例子9:
sed ‘s/i/A/2’ message
说明:把message文件中每行的第2个i字符替换为A。
例子10:
sed -n ‘s/i/A/p’ message
说明:加-p标记会把被替换的行打印出来,再加上-nOption会关闭模式空间打印模式,因此该命令的效果就是只显示被替换修改的行。
例子11:
ed -n 's/a/A/w b.txt' messge
说明:把message文件中内容的每行第一个字符i替换为A,然后把修改内容另存为b.txt文件。
例子12:
sed -n ‘s/i/A/i’ message
说明:把message文件中每一行的第一个i或I字符替换为A字符,也即是忽略大小写。
sed练习
分支和测试 (没有理解到)
分支命令用于无条件转移,测试命令用于有条件转移。
1、分支branch
跳转的位置与标签相关联。
如果有标签则跳转到标签所在的后面行继续执行。
如果没有标签则跳转到脚本的结尾处。
标签:以冒号开始后接标签名,不要在标签名前后使用空格。
2、跳转到标签指定位置
测试文件:
grep seker /etc/passwd
seker:x:500:500::/home/seker:/bin/bash
例子1:
grep seker /etc/passwd | sed ‘:top;s/seker/blues/;/seker/b top;s/5/555/’
结果:blues:x:55500:500::/home/blues:/bin/bash
选择执行
例子2:
grep ‘seker’ /etc/passwd | sed ‘s/seker/blues/;/seker/b end;s/5/555/;:end;s/5/666/’
结果:blues:x:66600:500::/home/seker:/bin/bash
测试命令,如果前一个替换命令执行成功则跳转到脚本末尾(case结构)
例子3:
grep ‘seker’ /etc/passwd | sed ‘s/seker/ABC;t;s/home/DEF/;t;s/bash/XYZ/’
结果:ABC:x:500:500::/home/seker:/bin/bash
例子4:
grep ‘zorro’ /etc/passwd | sed ‘s/seker/ABC/;t;s/home/DEF/;t;s/bash/XYZ’
结果:zorro:x:500:500::/DEF/zorro:/bin/bash
与标签关联,跳转到标签位置。
例子5:
grep ‘seker’ /etc/passwd | sed ‘s/seker/ABC/;t end;s/home/DEF/;t;end;s/bash/XYZ’
结果:ABC:x:500:500::/home/seker:/bin/XYZ
sed实战练习
Living Example1:删除文件每行的第二个字符。
sed -r 's/(.*)(.)$/\1/'
Living Example2:删除文件每行的最后一个字符。
sed -r 's/(.*)(.)$/\1/' file.txt (实践了的)
Living Example3:删除文件每行的倒数第2个单词。
sed -r ‘s/(.*)([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]*$)/\1\2\4\5/’ /etc/passwd
Living Example4:交换每行的第一个字符和第二个字符。
sed -r ‘s/(.)(.)(.*)/\2\1\3/’ /etc/passwd
Living Example5:交换每行的第一个单词和最后一个单词。
sed -r ‘s/([a-Z]+)([^a-Z]+)(.*)([^a-Z]+)([a-Z]+)([^a-Z]*$)/\5\2\3\4\1\6/’ /etc/passwd
Living Example6:删除一个文件中所有的数字。
sed 's/[0-9]//g' file.txt (实践了的)
Living Example7:用制表符替换文件中出现的所有空格。
sed -r ‘s/ +/\t/g’ /etc/passwd
Living Example8:把所有大写字母用括号()括起来。
sed -r ‘s/([A-Z])/(\1)/g’ /etc/passwd
Living Example9:打印每行3次。
sed ‘p;p’ /etc/passwd
Living Example10:隔行删除
sed ‘0~2{=;d}’ /etc/passwd
Living Example11:把文件从第22行到第33行复制到56行后面。
sed ‘22h;23,33H;56G’ /etc/passwd
Living Example12:把文件从第22行到第33行移动到第56行后面。
sed ‘22{h;d};23,33{H;d};56g’ /etc/passwd
Living Example13:只显示每行的第一个单词。
sed -r ‘s/([a-Z]+)([^a-Z]+)(.*)/\1/’ /etc/passwd
Living Example14:打印每行的第一个单词和第三个单词。
sed -r ‘s/([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]+)(.*)/\1\t\5/’ /etc/passwd
Living Example15:将格式为mm/yy/dd的日期格式换成 mm;yy;dd
date '+%m/%y/%d' | sed 's/\//;/g'
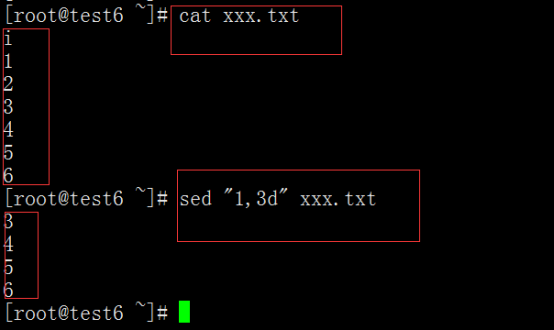
sed "1,3d" 文件名:删除那几行
这个就表示删除1-3行 d:表示删除 (但是不能对原文件进行更改)
sed ”/adm/ixxxxxxxxxxxxxxxxxxxxxxxxxxxxx” xx
表示在xx这个文件里面,有adm的这一行的下面一行添加xxxxxxxxxxxxxxxxxx。 (-c 是删除这一行,-i:是下一行 -a:是上一行)

Living Example用法
例子1:
# cat test.txt
11111
22222
33333
44444
sed ‘{1h;2,3H;4G}’ test.txt
结果:
22222
44444
22222
解释说明:略。懒得写了。
例子2:
sed ‘{1h;2x;3g;$G}’ test.txt
结果:
11111
44444
解释说明:略。
sed ‘{1!G;h;$!d}’ test.txt
结果:
44444
33333
22222
11111
awk(awk外面用单引号,里面用双引号)
http://www.cnblogs.com/ginvip/p/6352157.html
https://www.cnblogs.com/xudong-bupt/p/3721210.html
awk简介:
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk 是一种很棒的语言,它适合文本处理和报表生成,其Grammar较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。 awk 是三剑客的老大,利剑出鞘,必会不同凡响。
awk工作原理
awk '{pattern + action}' {filenames}
-F fs指定分隔符 (默认是用空格做分隔符)
-v 赋值一个用户自定义变量
-f 指定脚本文件,从脚本中读取awk命令
尽管操作可能会很复杂,但Grammar总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。

使用方法及格式:

















awk命令:
FILENAME 当前输入文件的名
$0 表示整个当前行的文本内容
$n 当前记录的第n个字段,比如:为$1表示第一个字段
-F "[:#/]" 定义三个分隔符
FS 输入字段分隔符(默认是空格或者多个连续的空格或者tab);与-v连用
NF 表示字段数,在执行过程中对应于当前的字段数,NF:列的个数。($NF表示最后一列,$(NF-1)表示倒数第二,列以此类推)
NR 表示每行的记录号,在执行过程中对应于当前的行号,多文件记录递增
FNR 各文件分别计数的行号
OFS 输出字段分隔符(默认值是一个空格)
\t 制表符
\n 换行符
~ 匹配
!~ 不匹配
N 显示宽度
- 左对齐 (默认是右对齐)
再次说明, awk 对输入文件中的每一行都执行这个脚本。





注意
花括号是用单引号括起来的
'{print $2}'
Living Example1:-F"字符"单个字符作为分隔符(如果是以空格做分隔符,可以不写-F)
[root@web ~]# echo AA BB CC DD | awk '{print $2}' (默认空格做分隔符)
BB

[root@web ~]# echo " AA|BB|CC|DD" | awk -F "|" '{print $2}' (”|”做分隔符)
BB

[root@web ~]# echo "AA,BB,CC,DD" | awk -F, '{print $2}' (”,”做分隔符)
BB

[root@web ~]# awk -F: '{print $1}' /etc/passwd #(打印passwd,第一列用户名)

Living Example2:和-F"[ :]"多个字符做分隔符和多个分隔符
[root@web ~]# echo "12AxAdskfiellf" | awk -F "kf" '{print $1}' #(多个字符做分隔符)
12AxAds
[root@web ~]# echo "12AxAdskfiellf" | awk 'BEGIN {FS="kf"} {print $1}' #(这个也是多个字符)
12AxAds
# awk的-F参数可以指定新的记录分隔符,有些时候可能需求指定多个分隔符,比如下面的内容
width:720 height:360
#如果需要取出width和height后面的值的话,一般会这样做,即做两次awk操作
# echo "width:720 height:360" | awk '{print $1;print $2}' | awk -F: '{print $2}'
720
360
# 其实呢,通过在awk中指定两个记录分隔符(空格和:),即可一次性的提取出width和height后面的值,在awk中支持多个记录分隔符的写法如下
# echo "width:720 height:360" | awk -F'[ :]' '{print $2,$4}'
720 360
# 不过,一般像下面这样写,多一个加号表明将连续出现的记录分隔符当做一个来处理
# echo "width:720 height:360" | awk -F'[ :]+' '{print $2,$4}'
720 360
# ip add | grep eth | grep inet | awk -F "[ /]+" '{print $3}' #取IP地址
# ip addr | grep eth |awk 'NR==2 {print $2}' | sed 's@/24@@g'
Living Example3、关系运算符

Living Example4、$NF表示最后一列
[root@web ~]# echo "one two three four" | awk '{print $NF}'
Four #(取最后一行)
[root@web ~]# echo "one two three four" | awk '{print $(NF- 2)}'
two #(这个也是取最后一行,记住做运算的时候要加括号)

Living Example5、打印出passwd文件中UID小于10的用户名和它的登录使用的shell
[root@web ~]# awk -F: '$3<10{print $1 $NF}' /etc/passwd
root/bin/bash
bin/sbin/nologin
daemon/sbin/nologin
adm/sbin/nologin
lp/sbin/nologin
sync/bin/sync
shutdown/sbin/shutdown
halt/sbin/halt
mail/sbin/nologin
[root@web ~]# awk -F: '$3<10{print $1 "<======>" $NF}' /etc/passwd
root<======>/bin/bash
bin<======>/sbin/nologin
daemon<======>/sbin/nologin
adm<======>/sbin/nologin
lp<======>/sbin/nologin
sync<======>/bin/sync
shutdown<======>/sbin/shutdown
halt<======>/sbin/halt
mail<======>/sbin/nologin
[root@web ~]# awk -F: '$3<10{print $1 "\t" $NF}' /etc/passwd
root /bin/bash
bin /sbin/nologin #("\t"表示tab)必须用双引号,因为有斜杠“\“
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
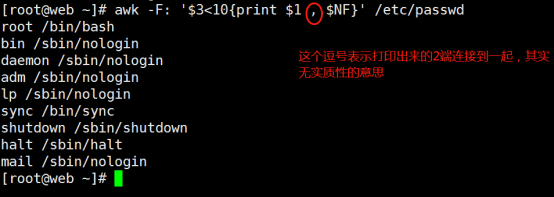
Living Example6、打印出系统中UID大于100且登录shell是/bin/bash的用户
[root@web ~]# awk -F: '$3>100 && $NF=="/bin/bash"{print $1 $NF}' /etc/passwd
penng/bin/bash
[root@web ~]# awk -F: '$3>100 && $NF=="/bin/bash"{print $1 , $NF}' /etc/passwd
penng /bin/bash
Living Example7、打印行号大于等于3且行号小于等于6的行 (NR)
[root@web ~]# awk -F: '(NR>=3&&NR<=6){print NR,$0}' /etc/passwd
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
[root@web ~]# #(需要条件是要用括号,NR表示行号)

Living Example8、查出行号小于等于5且包括bin/bash的行
[root@web ~]# awk -F: '{if($3<=5 && $NF ~ "bin/bash"){print $1,$NF}}' /etc/passwd
root /bin/bash
Living Example9、打印已root开头的行
[root@web ~]# awk -F: '/^root/{print $0}' /etc/passwd

Living Example10、使用awk查出包括root字符的行,有以下3种方法
第一种、
[root@web ~]# awk -F: '/root/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@web ~]# awk -F: '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@web ~]# awk -F: '/root/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin



第二种、
Living Example11、使用3种方法去除首行
1、grep -v 取反 \^Kernel 表示以这个Kernel开头
[root@web ~]# route -n | grep -v ^Kernel
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.79.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
0.0.0.0 192.168.79.2 0.0.0.0 UG 0 0 0 eth0

2、sed 1d 删除第一行
[root@web ~]# route -n | sed 1d
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.79.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
0.0.0.0 192.168.79.2 0.0.0.0 UG 0 0 0 eth0

3、利用行号,在取反
NR==n 表示打印第n行
NR!=n 表示不打印第n行
[root@web ~]# route -n | awk 'NR!=1 {print $0}'
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.79.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
0.0.0.0 192.168.79.2 0.0.0.0 UG 0 0 0 eth0

Living Example12、NR,NF,$NF,"\t",$0 (综合应用)
awk -F: '{print NR,NF,$NF,"\t",$0}' /etc/passwd //依次打印行号,字段数,最后字段值,制表符,每行内容
Living Example13、条件表达式
例:如果UID大于10,则输出user=> 用户名,否则输出pass=>用户名
[root@web ~]# awk -F: '{if($3<10){print "user=>"$1}else{print "pass=>" $1}}' /etc/passwd


Living Example14、格式化输出
输出passwd文件中第一列的内容
[root@web ~]# awk -F: '{printf "%s\n",$1}' /etc/passwd
在输出的字母前面添加自定义字符串 USERNAME:
[root@web ~]# awk -F: '{printf "USERNAME: %s\n",$1}' /etc/passwd
[root@test-6 /tmp 14:32]#awk -F: '{printf "%-20s====%10d\n",$1,$3}' /etc/passwd
Living Example15、awk引用变量 (很少使用)
[root@web ~]# var="test"
[root@web ~]# awk 'BEGIN{print "'$var'"}'
test
综合例子
[root@test-6]#df -h | awk '$0 ~ /^\/dev\/s/ {print $0}'
[root@test-6]#df -h | awk -F% '$0 ~ /^\/dev\/s/ {print $1}' | awk '$5<=10'
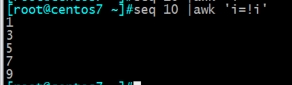
打印奇数行
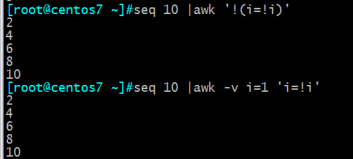
打印偶数行
100以内的正整数求和
[root@test-6]#awk 'BEGIN{for(i=1;i<=100;i++)sum+=i;print sum}'
5050
统计httpd访问的IP地址情况
[root@test-6]#awk '/^[0-9]/{ip[$1]++}END{for(i in ip){print i,ip[i]}}' /var/log/httpd/access_log
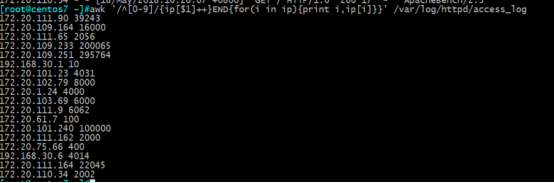
脚本实现:

取访问IP地址前10的IP地址


管道:"|"
利用Linux所提供的管道符"|"将两个命令隔开,管道符左边命令的输出就会作为管道符右边命令的输入。连续使用管道意味着第一个命令的输出会作为第二个命令的输入,第二个命令的输出又会作为第三个命令的输入,依此类推。
Notice:管道左边命令的输入作为管道右边命令的输入(命令的输入是一定的),不是参数,并不是所有命令都支持管道
Living Example1:
[root@redhat7-min tmp]# echo "321qazwsxedc123" | tr 'a-z' 'A-Z' > 4个命令综合应用.txt
[root@redhat7-min tmp]# cat 4个命令综合应用.txt
321QAZWSXEDC123
Living Example2:ifconfig eth0 | grep “inet addr”

Living Example3:ls | grep a 查看当前目录下名称包含a的文件或文件夹
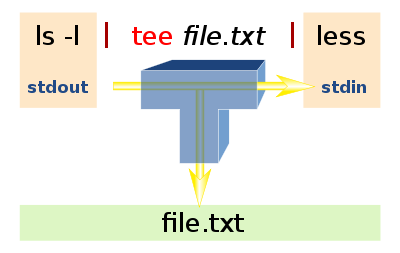
tee 把数据重定向到给定文件和屏幕上
tee命令用于将数据重定向到文件,另一方面还可以提供一份重定向数据的副本作为后续命令的stdin。
简单的说就是把数据重定向到给定文件和屏幕上。
存在缓存机制,每1024个字节将输出一次。若从管道接收输入数据,应该是缓冲区满,才将数据转存到指定的文件中。若文件内容不到1024个字节,则接收完从标准输入设备读入的数据后,将刷新一次缓冲区,并转存数据到指定文件。
Grammar
tee(Option)(参数)
Option
-a:追加;
-i:强制保存,忽略中断(interrupt)信号
参数
文件:指定输出重定向的文件。
Living Example:
[root@CentOS6 ~]# cat /etc/passwd | tail -1 | tee www.txt
jack:x:1888:502:market lisi:/home/jack:/bin/bash
[root@CentOS6 ~]# cat /etc/passwd | tail -1
jack:x:1888:502:market lisi:/home/jack:/bin/bash
[root@CentOS6 ~]# ls
www.txt
[root@CentOS6 ~]# cat www.txt
jack:x:1888:502:market lisi:/home/jack:/bin/bash
在终端打印stdout同时重定向到文件中:
ls | tee out.txt
1.sh
1.txt
2.txt
eee.tst
EEE.tst
one
out.txt
string2
www.pdf
WWW.pdf
WWW.pef
[root@localhost text]# ls | tee out.txt | cat -n
1 1.sh
2 1.txt
3 2.txt
4 eee.tst
5 EEE.tst
6 one
7 out.txt
8 string2
9 www.pdf
10 WWW.pdf
11 WWW.pef
xargs是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具
xargs命令是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具。
它擅长将标准输入数据转换成命令行参数,xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。
xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。 xargs的默认命令是echo,空格是默认定界符。这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。
xargs 是构建单行命令的重要组件之一。xargs 一般是和管道一起使用
例如:大多数 Linux命令都会产生输出:文件列表、字符串列表等。但如果要使用其他某个命令并将前一个命令的输出作为参数该怎么办?例如,file 命令显示文件类型(可执行文件、ascii文本等);你能处理输出,使其仅显示文件名,目前你希望将这些名称传递给 ls -l命令以查看时间戳记。xargs 命令就是用来完成此项工作的。
命令格式:
somecommand |xargs -item command
参数:
- -a file 从文件中读入作为 stdin
- -e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
-
-p 当每次执行一个argument的时候询问一次用户。
-
-n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
-
-t 表示先打印命令,然后再执行。
-
-i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。
-
-r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。
-
-s num 命令行的最大字符数,指的是 xargs 后面那个命令的最大命令行字符数。
-
-L num 从标准输入一次读取 num 行送给 command 命令。
-
-l 同 -L。
-
-d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。
-
-x exit的意思,主要是配合-s使用。。
-
-P 修改最大的进程数,默认是1,为0时候为as many as it can ,这个例子我没有想到,应该平时都用不到的吧
| -e[EOFString] | 废弃的标志。请使用 -E 标志。将 EOFString 参数用作逻辑 EOF 字符串。如果不指定 -e 或 -E 标志, 则假定下划线(_)为逻辑 EOF 字符串。如果不指定 EOFString 参数,则禁用逻辑 EOF 字符串 能力,且下划线按照字面含义使用。xargs 命令读取标准输入直到达到 EOF 或指定的字符串。 |
|---|---|
| -E EOFString | 指定逻辑 EOF 字符串以替换缺省的下划线(_)。 xargs 命令读取标准输入直到达到 EOF 或指定的字符串。 |
| -i[ReplaceString] | 废弃的标志。请使用 -I(大写 i)标志。*如果没有指定 ReplaceString 参数, 则使用字符串 "{}"。*注:-I(大写 i)和 -i 标志是互相排斥的;最后指定的标志生效。 |
| -I ReplaceString | (大写 i)。插入标准输入的每一行作为 Command 参数的自变量,把它插入每个发生 ReplaceString 的 Argument 中。ReplaceString 不能在超过 5 个自变量中使用。 在每个标准输入行开始的空字符被忽略。 每个 Argument 能包含一个或多个 ReplaceString,但不能大于 255 字节。-I 标志同样打开 -x 标志。注:-I(大写 i)和 -i 标志是互相排斥的;最后指定的标志生效。 |
| -l[Number] | (小写的 L)。废弃的标志。请使用 -L 标志。如果没有指定 Number 参数,使用缺省值 1。-l 标志同样打开 -x 标志。注: -L、-I(小写的 L)和 -n 标志是互相排斥的;最后指定的标志生效。 |
| -L Number | 用从标准输入读取的指定行数的非空参数运行 Command 命令。如果保留少于指定的 Number,Command 参数 的最后调用可以有少数几个参数行。行以第一个换行字符结束,除非该行的最后一个字符是一个空格 或制表符。后续的空格表示延续至下一个非空行。注: -L、-I(小写的 L)和 -n 标志是互相排斥的;最后指定的标志生效。 |
| -n Number | 运行 Command 参数,且使用尽可能多的标准输入自变量,直到 Number 参数指定的最大值。如果满足以下条件,则 xargs 命令使用 更少的自变量:1. 如果积累的命令行长度超出了 由 -s Size 标志指定的字节。2. 最后的迭代有少于 Number(但是非 零)的自变量保留。注: -L、-I(小写的 L)和 -n 标志是互相排斥的;最后指定的标志生效。 |
| -p | 询问是否运行 Command 参数。 它显示构造的命令行,后跟一个 ?...(问号和省略号)提示。输入肯定的、特定于语言环境的响应 以运行 Command 参数。 任何其它响应都会引起 xargs 命令 跳过那个特定的参数调用。每个调用都将询问您。 -p 标志同样打开 -t 标志。 |
| -s Size | 设置构造的 Command 行的最大 总大小。Size 参数必须是正整数。如果满足以下条件,则使用更少的自变量:1. 自变量的总数超出 -n 标志指定的自变量数。2. 总行数超出 -L 或 -I(小 写 L)标志指定的行数。3. 累积由 Size 参数指定的字节数之前达到 EOF。 |
| -t | 启用跟踪方式,并在运行之前将构造的 Command 行回送到标准错误。 |
| -x | 如果有任何 Command 行大于 -s Size 标志指定的字节数,停止运行 xargs 命令。如果指定 -I(大写 i)或 -l(小写 L)标志,则打开 -x 标志。如果 没有指定 -i、-I(大写 i)、-l(小写 L)、-L 或 -n 标志,则 Command 行的总长度必须 在 -s Size 标志指定的限制内。 |
| -d | 定义定界符(默认为空格) |
示例1:
find . -type f -name "*.log" | xargs -i cp {} /tmp/k/
find . -type f -name "*.log" | xargs -I {} cp {} /tmp/n/
结果出来了,
加-i 参数直接用 {}就能代替管道之前的标准输出的内容;
加 -I 参数 需要事先指定替换字符
示例2:redis-cli在shell下 执行命令处理数据
# 把redis key从1库移动到9库
redis-cli -h 127.0.0.1 -a 123456!Iq' -n 1 keys '*player_*' | xargs -i redis-cli -h 127.0.0.1 -a 123456!Iq' -n 1 move {} 9
示例3: 批量load docker镜像
ls . | xargs -n 1 -i docker load -i {}
ls . | xargs -n 1 -I {} docker load -i {}
示例3:
1、在整个系统中查找内存信息转储文件(core dump) ,然后把结果保存到/tmp/core.log 文件中:
$ find / -name "core" -print | xargs echo "" > /tmp/core.log
2、当一个目录下文件太多时,直接用rm * 命令会报参数过长,用如下方法可以全部删除
$ls | xargs rm
# 列出all目录下所有文件名带'2018/03'的文件
$ find all -type f |grep '2018/03'
all/2018/0305 all/2018/0308
# 统计这些文件的行数。实际执行的命令是 " wc -l all/2018/0305 all/2018/0308"
$ find all -type f |grep '2018/03' | xargs wc -l
716 all/2018/0305
719 all/2018/0308
1435 total
# 实际执行的命令是 "wc -l all/2018/0305" 和 "wc -l all/2018/0308" 两条。
$ find all -type f |grep '2018/03' | xargs -I {} wc -l {}
716 all/2018/0305
719 all/2018/0308
3、xargs用作替换工具,读取输入数据重新格式化后输出
定义一个测试文件,内有多行文本数据:
cat test.txt
a b c d e f g
h i j k l m n
o p q
r s t
u v w x y z
多行输入单行输出:
cat test.txt | xargs
a b c d e f g h i j k l m n o p q r s t u v w x y z
-n选项多行输出:
cat test.txt | xargs -n3
a b c
d e f
g h i
j k l
m n o
p q r
s t u
v w x
y z
-d选项可以自定义一个定界符:
echo "nameXnameXnameXname" | xargs -dX
name name name name
结合-n选项使用:
echo "nameXnameXnameXname" | xargs -dX -n2
name name
name name
4、读取stdin,将格式化后的参数传递给命令
假设一个命令为 sk.sh 和一个保存参数的文件arg.txt:
#!/bin/bash
#sk.sh命令内容,打印出所有参数。
echo $*
arg.txt文件内容:
cat arg.txt
aaa
bbb
ccc
xargs的一个选项-I,使用-I指定一个替换字符串{},这个字符串在xargs扩展时会被替换掉,当-I与xargs结合使用,每一个参数命令都会被执行一次:
cat arg.txt | xargs -I {} ./sk.sh -p {} -l
-p aaa -l
-p bbb -l
-p ccc -l
复制所有图片文件到 /data/images 目录下:
ls *.jpg | xargs -n1 -I cp {} /data/images
xargs结合find使用
用rm 删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long. 用xargs去避免这个问题:
find . -type f -name "*.log" -print0 | xargs -0 rm -f
xargs -0将\0作为定界符。
统计一个源代码目录中所有php文件的行数:
find . -type f -name "*.php" -print0 | xargs -0 wc -l
查找所有的jpg 文件,并且压缩它们:
find . -type f -name "*.jpg" -print | xargs tar -czvf images.tar.gz
xargs其他应用
假如你有一个文件包含了很多你希望下载的URL,你能够使用xargs下载所有链接:
cat url-list.txt | xargs wget -c
子Shell(Subshells)
运行一个shell脚本时会启动另一个命令解释器.,就好像你的命令是在命令行提示下被解释的一样,类似于批处理文件里的一系列命令。每个shell脚本有效地运行在父shell(parent shell)的一个子进程里。这个父shell是指在一个控制终端或在一个xterm窗口中给你命令指示符的进程。
cmd1 | ( cmd2; cmd3; cmd4 ) | cmd5
如果cmd2 是cd /,那么就会改变子Shell的工作目录,这种改变只是局限于子shell内部,cmd5则完全不知道工作目录发生的变化。子shell是嵌在圆括号()内部的命令序列,子Shell内部定义的变量为局部变量。
子shell可用于为一组命令设定临时的环境变量:
COMMAND1
COMMAND2
COMMAND3
(
IFS=:
PATH=/bin
unset TERMINFO
set -C
shift 5
COMMAND4
COMMAND5
exit 3 # 只是从子shell退出。
)
# 父shell不受影响,变量值没有更改。
COMMAND6
COMMAND7
Notice:find命令把匹配到的文件传递给xargs命令,而xargs命令每次只获取一部分文件而不是全部,不像-exec选项那样。这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去
exec -->用于调用并执行指令的命令
http://www.linuxidc.com/Linux/2017-07/145372.htm
exec命令通常用在shell脚本程序中,可以调用其他的命令。如果在当前终端中使用命令,则当指定的命令执行完毕后会立即退出终端。
exec解释:
-exec 参数后面跟的是 command 命令,它的终止是以“”为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。
{} 花括号代表前面find查找出来的文件名。
使用find时,只要把想要的操作写在一个文件里,就可以用exec来配合find 查找,很方便的。在有些操作系统中,只允许 -exec 选项执行诸如 ls 或 ls -l 这样的命令。大多数用户使用着一些Option是为了查找旧文件并删除它们。建议再真正执行 rm 命令删除文件之前,最好先用 ls 命令看一下,确认他们是所要删除的文件。 exec 选项后面跟随着所要执行的命令或脚本,然后是一对儿{},一个空格和一个\,最后是一个分号。为了使用 exec 选项,必须要同时使用 print 选项。如果验证一下 find 命令,会发现该命令只输出从当前路径起的相对路径及文件名。
Living Example1:ls -l 命令放在 find 命令的 -exec 选项中
命令:
find . -type f -exec ls -l {} \; find 命令匹配到了当前目录下的所有普通文件,并在 -exec 选项中使用 ls -l 命令将它们列出。
这个命令有点坑,不过确实很好用,说它坑是因为我输入的时候 收到提示:find 遗漏 -exec 的参数,^^
解决:1.注意是一对儿{},一个空格和一个\,最后是一个分号
3. 在 \; 使用 “\;” '\;' 这样把它们引起来。【“引起来”,感觉怪别扭的,不过想不出来怎么描述】
Living Example2:在目录中查找更改时间在n 日以前的文件并删除它们
命令:
find . -type f -mtime +14 -exec rm {} \; 在 shell 中用任何方式删除文件之前,应当先查看相应的文件,一定要小心,当使用诸如 mv 或 rm 命令时,可以使用-exec Option的安全模式,他将对每个匹配到的文件进行操作之前提示你。
Living Example3:在目录中查找更改时间在n日以前的文件并删除它们,在删除之前先给出提示
命令:
find . -name "*.log" -mtime +5 -ok rm {} \; 查找当前目录中所有以 .log 结尾的,更改时间在 5 日以上的文件,并删除它们,并且在删除之前先给出提示。按y 键确定,n 键 取消。
Living Example4: -exec 中使用 grep 命令
命令:find /etc -name "passwd" -exec grep "root" {} \;
任何形式的命令都可以在 -exec 选项中使用。 在上面的例子中我们使用 grep 命令。find命令首先匹配所有文件名为“passwd”的文件,然后执行 grep 命令查看这些文件中是否存在一个 root 用户。
Living Example5:查找文件并移动到指定目录
命令:find . -name "*.log" -exec mv {} .. \; .. 是路径名
Living Example6:用exec选项执行 cp 命令
命令: find . -name "*.log" -exec cp {} test3 \;
一不小心又中招了,test3 是个目录,不然cp 不进去。
cut -->以某种方式按照文件的列进行分割
cut命令用来显示行中的指定部分,删除文件中指定字段。cut经常用来显示文件的内容,类似于下的type命令。
说明:该命令有两项功能,其一是用来显示文件的内容,它依次读取由参数file所指明的文件,将它们的内容输出到标准输出上;其二是连接两个或多个文件,如cut fl f2 > f3将把文件fl和几的内容合并起来,然后通过输出重定向符">"的作用,将它们放入文件f3中。
当文件较大时,文本在屏幕上迅速闪过(滚屏),用户往往看不清所显示的内容。因此,一般用more等命令分屏显示。为了控制滚屏,可以按Ctrl+S键,停止滚屏;按Ctrl+Q键可以恢复滚屏。按Ctrl+C(中断)键可以终止该命令的执行,并且返回Shell提示符状态。
缺点:只能指定一个分隔符 cut: 分界符必须是单个字符
Grammar
cut (Option) (参数)
Option:
-d:指定字段的分隔符,默认的字段分隔符为"TAB";
-f NUM:显示指定字段的内容;df连用功能很强大
--output-delimiter=<字段分隔符>:指定输出内容是的字段分割符;(默认是冒号)
-c:仅显示行中指定范围的字符;
-b:仅显示行中指定直接范围的内容;
-n:与"-b"Option连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
范围控制:
n:只有第n项
n-:从第n项一直到行尾
n-m:从第n项到第m项(包括m)
-m:从一行的开始到第m项(包括m)
-:从一行的开始到结束的所有项
Living Example
[root@test6 /tmp 03:10:08]#tail -1 /etc/passwd | cut -d":" --output-delimiter="---" -f1,4
4---505
cat /etc/passwd | cut -b1-3 #取每行的第1-3字字节
[root@test-6 ~]# cat /etc/passwd | cut -d: -f1 (第一段)
cat /etc/passwd | cut -b1-3,5-7,8 #取每行的第1-3,5-7,8的字节(后面的数字会先进行从小到大的排列) 需要事先知道具体字节,很容易出错
cat song.txt |cut -nb 1,2,3#当 -b 添加 -n 后则不会分割多字节 (我的系统是utf-8,所以需要用三个字节来表示一个汉字)
cat /etc/passwd | cut -c1,3 #适用于中文
cat /etc/passwd | cut -d : -f 3 #以:分割,取第三段
cat /etc/passwd | cut -d '' #以空格进行分割,且是一个空格
[root@CentOS6 ~]# who | cut -c1-9 以字符取
root
root
root
root
[root@CentOS6 ~]# df | tr -s " " % | cut -d"%" -f 3 取出used这一列
cut -d: -f1 /etc/passwd # 查看系统所有用户
cut -d: -f1 /etc/group # 查看系统所有组
产生如下的文件
[root@test tmp]# printf "3\ta\tb\n1\tc\td\n2\te\tf\n" > /tmp/1.tmp
[root@test tmp]# cat 1.tmp
3 a b
1 c d
2 e f
只显示文件的第1列和第3列:
[root@test tmp]# cut -f1,3 /tmp/1.tmp
3 b
1 d
2 f
[root@test tmp]#
如果使用-b参数,指定的列是按照字节来计算的:
[root@test tmp]# cut -b1 /tmp/1.tmp
3
1
2
缺点: 有的时候分隔符很难确定
paste-->将多个文件按照列队列进行合并
paste命令用于将多个文件按照列队列进行合并。
Grammar
paste (Option) (参数)
Option
-s或--serial串列进行而非平行处理。
-d<间隔字符>或--delimiters=<间隔字符>:用指定的间隔字符取代跳格字符;
参数
文件列表:指定需要合并的文件列表。
Living Example:
如果你想把两个文件按照对应的每行放在同一行上,可以用paste,比如:
data1文件为
1
2
3
data2的文件为
zhang
zhc
hongchangfirst
那么你想要得到
1 zhang
2 zhc
3 hongchangfirst
那么你这样就也可以,
paste data1 data2
默认使用tab键作为份分隔符,还可以自定义分隔符,如用=号:
paste -d'=' data1 data2
split 分割文件
split命令可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志等。
将输入内容拆分为固定大小的分片并输出到"前缀aa"、"前缀ab",...;
默认以 1000行为拆分单位,默认前缀为"x"。如果不指定文件,或者文件为"-",则从标准输入读取数据。
Option
长选项必须使用的参数对于短选项时也是必需使用的。
-b, --bytes=大小 指定每个输出文件的字节大小
-a, --suffix-length=N 指定后缀长度为N (默认为2)
-C, --line-bytes=大小 指定每个输出文件里最大行字节大小
-d, --numeric-suffixes 使用数字后缀代替字母后缀
-l, --lines=数值 指定每个输出文件有多少行
--verbose 在每个输出文件打开前输出文件特征
--help 显示此帮助信息并退出
--version 显示版本信息并退出
SIZE 可以是一个可选的整数,后面跟着以下单位中的一个:
KB 1000,K 1024,MB 1000*1000,M 1024*1024,还有 G、T、P、E、Z、Y。
Living Example:
生成一个大小为100KB的测试文件:
[root@localhost split]# dd if=/dev/zero bs=100k count=1 of=date.file
1+0 records in
1+0 records out
102400 bytes (102 kB) copied, 0.00043 seconds, 238 MB/s
使用split命令将上面创建的date.file文件分割成大小为10KB的小文件:
[root@localhost split]# split -b 10k date.file
[root@localhost split]# ls
date.file xaa xab xac xad xae xaf xag xah xai xaj
文件被分割成多个带有字母的后缀文件,如果想用数字后缀可使用-d参数,同时可以使用-a length来指定后缀的长度:
[root@localhost split]# split -b 10k date.file -d -a 3
[root@localhost split]# ls
date.file x000 x001 x002 x003 x004 x005 x006 x007 x008 x009
为分割后的文件指定文件名的前缀:
[root@localhost split]# split -b 10k date.file -d -a 3 split_file
[root@localhost split]# ls
date.file split_file000 split_file001 split_file002 split_file003 split_file004 split_file005 split_file006 split_file007 split_file008 split_file009
使用-l选项根据文件的行数来分割文件,例如把文件分割成每个包含10行的小文件:
split -l 10 date.file
split -b 10k /etc/services /root/文件名字
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。