- shell脚本全集
- shell脚本的初体验
- 条件测试:可以用test和[]或者[[]]进行比较
- shell脚本中28个特殊字符的作用简明总结
- Shell中的替换
- Shell中的字符串
- shell编程之脚本调试
- shell编程之条件语句
- shell编程之case语句
- shell编程之for循环语句
- shell编程之while循环语句
- shell编程之until循环语句
- shell编程之select循环与菜单语句
- shell编程之信号捕捉trap
- shell编程之循环控制语句continue
- shell编程之循环控制语句break
- shell编程之sleep命令
- shell编程之exit命令
- shell编程之循环控制shift命令
- shell编程之函数应用
- shell编程之return
- shell编程之数组
- shell编程之expect
- shell编程之sshpass
- 如何在编写 SHELL 显示多个信息,echo或者 EOF
- Living Example:统计当前系统的使用率
- Living Example:为root用户编写登陆脚本
- Living Example:用户登录脚本详情
- Living Example:监控每天固定时间的网络状态并生成csv文件发送到自己的邮箱的小脚本
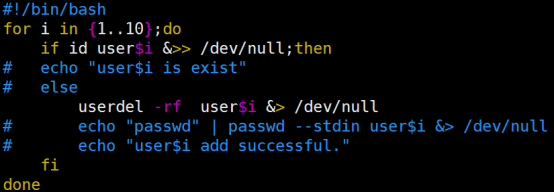
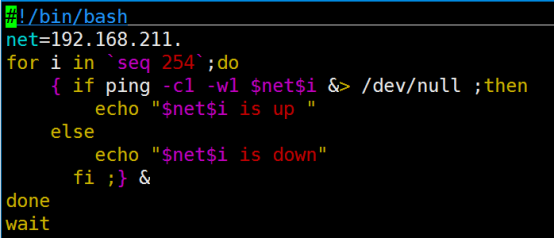
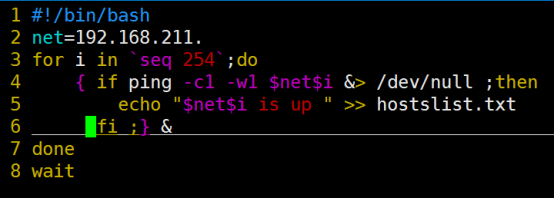
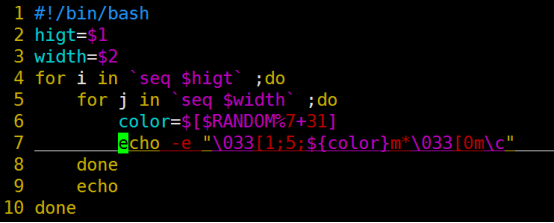
- Living Example:几个shell初学者必会脚本
- Living Example:调用系统的function里的action动作
- 用户登录系统次数、用户登录系统时长
- 通用java服务启动脚本
shell脚本全集
shell脚本的初体验
1、编写简单的脚本:
命令:vim pp.sh 然后在文件中写入如下内容。
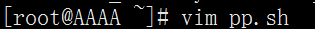
#!/bin/bash
cal
date
ls /
说明:shell脚本一般结尾用.sh表示
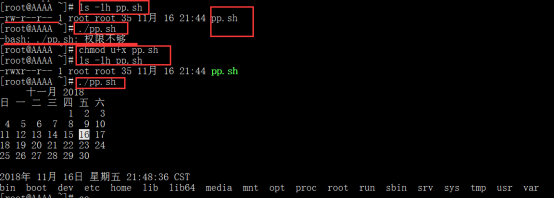
2、执行脚本的4种方法:
必须在脚本文件夹下执行命令 ,以下4种方法:
1、在当前路径直接执行命令 ./pp.sh (脚本需要执行权限才行)
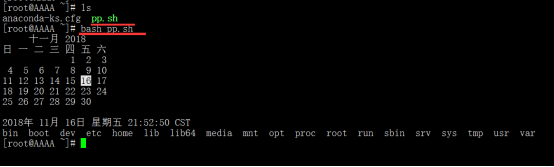
2、bash pp.sh (脚本不需要执行权限都行)
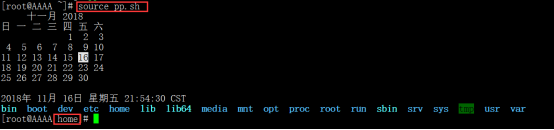
3、source pp.sh (脚本不需要执行权限都行)
(前面1、2种方法都是打开一个子shell运行的,第3种就是在当前shell里面运行的)
4、sh pp.sh (脚本不需要执行权限都行)
说明:2、4方法是一样的
3、read -p 的用法:就是要输入内容才往下面继续执行
-r 允许输入包含反斜线
-t 表示设置提示信息与等待时间(单位默认认为秒)eg:-t time
-n 限定输入的字符数 eg:-n 字符个数
-s 不会显输入的内容 (-s 需要在-p前面)
-p \'test\' 打印提示(test),等待输入,并将输入存在REPLY中。
一般read命令可以结合"-p" "-t"
eg:read -t 5 -n 5 -p "请输入你想输入的内容"
eg:read -t 5 -n 5 -s -p "请输入你想输入的内容"
设置定义功能是否开启:set -/+ (-是开启这个功能,+是关闭这个功能)
开启跟踪功能:set -/+x
(-x,是开启跟踪功能;+x,是关闭跟踪功能,写脚本的时候可以用。)
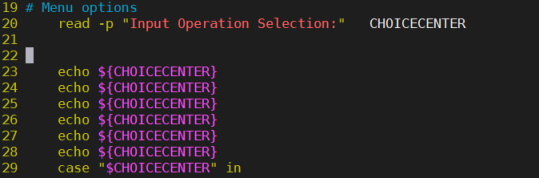
这里的CHICECENTER就是你要传入的信息,CHICECENTER就是一个变量了,你可以用这个变量来作判断。
4、#!/bin/bash的作用
答:#!/bin/bash是shell脚本的第一行,称为释伴(shebang)行。这里#符号叫做hash,而!
叫做 bang。它的意思是命令通过 /bin/bash 来执行。
注意事项
1)开头加解释器:#!/bin/bash
2)语法缩进,建议使用四个空格;多加注释说明。
3)命名建议规则:变量名大写、局部变量小写,函数名小写,名字体现出实际作用。
4)默认变量是全局的,在函数中变量local指定为局部变量,避免污染其他作用域。
5)有两个命令能帮助我调试脚本:set -e 遇到执行非0时退出脚本,set-x打印执行过程。
6)写脚本一定先测试再到生产上。
条件测试:可以用test和[]或者[[]]进行比较
test 条件表达式
[ 条件表达式 ] (括号两端必须有空格)
eg:
[root@test opt]# [ -f /etc/passwd ]
[root@test opt]# echo $?
0
[root@test opt]# [ -d /etc/passwd ]
[root@test opt]# echo $?
1
预定义变量:(又称为特殊变量)
$# 表示命令行中位置参数的个数
$0 表示当前执行的脚本或程序的名称
$* 表示所有位置参数的内容
$? 表示前一条命令执行后的状态,返回值为0表示执行正确,返回值任何非0值均表示执行出现异常。
Notice:$0属于预定义变量而不是位置变量
位置变量
[13、shell位置变量]
加减乘除
+ 加
- 减
* 乘
/ 除
% 取摸
== 等于
awk -F: '($3%2==0) {print$1"======"$3}' /etc/passwd
运算:
bc 可以计算小数
expr 只能计算正整数
let
$(())
$[]
[root@test6 ]#a=1
[root@test6 ]#b=3
[root@test6 ]#expr $a + $b
4
[root@test6 ]#expr $((a+b))
4
[root@test tmp]# expr $[a + b]
8
-------------------------------------------
[root@test6 ]#let c=$a+$b
[root@test6 ]#echo $c
4
-----------------------------------------------
[root@test6 ]#echo $(($a+$b))
4
-----------------------------------------------
[root@test6 ]#echo $[$a+$b]
4
expr-->表达式计算工具(只能做正整数的运算)
expr命令是一款表达式计算工具,使用它完成表达式的求值操作。
expr的常用运算符:
加法运算:+
减法运算:-
乘法运算:\*
除法运算:/
求摸(取余)运算:%
Grammar
expr (Option) (参数)
Option
--help:显示指令的帮助信息;
--version:显示指令版本信息。
参数
表达式:要求值的表达式。
Living Example
result=`expr 2 + 3`
result=$(expr $no1 + 5)
let-->是bash中用于计算的工具
let命令是bash中用于计算的工具,提供常用运算符还提供了方幂**运算符。在变量的房屋计算中不需要加上$来表示变量,如果表达式的值是非0,那么返回的状态值是0;否则,返回的状态值是1。
Grammar
let arg [arg ...] #arg代表运算式
用法
自加操作let no++
自减操作let no--
简写形式let no+=10,let no-=20,分别等同于let no=no+10,let no=no-20
Living Example
help let
---------------------------------------------------
#!/bin/bash
let a=5+4 b=9-3
echo $a $b
#!/bin/bash
let "t1 = ((a = 5 + 3, b = 7 - 1, c = 15 - 4))"
echo "t1 = $t1, a = $a, b = $b"
bc 计算器 (默认是进入交互模式)
bc命令是一种支持任意精度的交互执行的计算器语言。bash内置了对整数四则运算的支持,但是并不支持浮点运算,而bc命令可以很方便的进行浮点运算,当然整数运算也不再话下。
Grammar
bc (Option) (参数)
Option
-i:强制进入交互式模式;
-l:定义使用的标准数学库;
-w:对POSIX bc的扩展给出警告信息;
-q:不打印正常的GNU bc环境信息;
-v:显示指令版本信息;
-h:显示指令的帮助信息。
参数
文件:指定包含计算任务的文件。
Living Example
算术操作高级运算bc命令它可以执行浮点运算和一些高级函数:
echo "1.212*3" | bc
3.636
设定小数精度(数值范围)
echo "scale=2;3/8" | bc
0.37
参数scale=2是将bc输出结果的小数位设置为2位。
进制转换
#!/bin/bash
abc=192
echo "obase=2;$abc" | bc
执行结果为:11000000,这是用bc将十进制转换成二进制。
#!/bin/bash
abc=11000000
echo "obase=10;ibase=2;$abc" | bc
执行结果为:192,这是用bc将二进制转换为十进制。
计算平方和平方根:
echo "10^10" | bc
echo "sqrt(100)" | bc

进入交互式模式
整数值比较:
-eq(equal)是A=B的意思
-ne(not equal)是A不等于B的意思
-gt(greater than)是A大于B的意思
-ge(greater or equal)是A大于或等于B的意思
-lt(lesser than)是A小于B的意思
-le(lesser or equal)是A小于或等于B的意思
例如:
test $aa -eq $bb 或者[ $aa -gt $bb ]
test 3 -eq 6 &&echo right || echo error
或者[ 3 -gt 6 ] &&echo right || echo error
说明:[[]]这个里面可以用"<、>、="运算符合,而[]这个只能用英文缩写
字符串比较
= A字符串与B字符串相同
!= A字符串与B字符串不相同,其中"!"符号表示取反
-z 检查字符串是否为空,对应未定义或赋予空值的变量将视为空串
-n 检查字符串是否不为空。
= 等于 应用于:整型或字符串比较 如果在[] 中,只能是字符串
!=不等于 应用于:整型或字符串比较 如果在[] 中,只能是字符串
< 小于 应用于:整型比较 在[] 中,不能使用 表示字符串
> 大于 应用于:整型比较 在[] 中,不能使用 表示字符串
比较两个字符串是否相等的办法是:
比较两个字符串是否相等的办法是:
if [ "$test"x = "test"x ]; then
这里的关键有几点:
1 使用单个等号
2 注意到等号两边各有一个空格:这是unix shell的要求
3 注意到"$test"x最后的x,这是特意安排的,因为当$test为空的时候,上面的表达式就变成了x = testx,显然是不相等的。而如果没有这个x,表达式就会报错:[: =: unary operator expected
逻辑测试:&& || !
逻辑符:&& || ! 这3种连接符
&& 逻辑的与(表示而且)
|| 逻辑的或(表示或者)
! 逻辑否(表示不)
-a表示且
-o表示或者
--------------------------------------------------------------------
逻辑运算符:
&&:
用逻辑运算符&&。由于每个命令会返回一个返回值,命令a && b的执行方式是:
(1)bash 先执行 a
(2)如果a失败了(返回结果不是0),那么根据short circuiting,第二个命令b就不会被执行。
(3)如果a成功了(返回结果是0),那么第二个命令b就会接着被执行。
例子:
$ mkdir /tmp/good && cd /tmp/good # 只有当mkdir(创建目录)成功,cd才会被执行
||:
$ mkdir /tmp/good || echo "failed to create folder /tmp/good" # 如果mkdir不成功, echo就会被执行。
------------------------------------------------------------------------------------------------
()多命令group
()内部有多个命令时, 可以统一操作这些命令的stdout和stderr
[root@test ~]# (echo "123" ; echo ".com") > 1.txt
[root@test ~]# cat 1.txt
123
.com
[root@test ~]# (echo "123" , echo ".com") > 1.txt
[root@test ~]# cat 1.txt
123 , echo .com
[root@test ~]# (echo "123" echo ".com") > 1.txt
[root@test ~]# cat 1.txt
123 echo .com
文件测试:
Test 用法
-d 文件名 如果文件存在并且是目录,返回true
-e 文件名 如果文件存在,返回true
-f 文件名 如果文件存在并且是普通文件,返回true
-r 文件名 如果文件存在并可读,返回true
-s 文件名 如果文件存在并且不为空,返回true
-w 文件名 如果文件存在并可写,返回true
-x 文件名 如果文件存在并可执行,返回true
-L 文件名 如果文件存在并为链接文件,返回true
-b 侦测是否为一个『 block 档案』
-c 侦测是否为一个『 character 档案』
-S 侦测是否为一个『 socket 标签档案』
-nt:判断文件A是否比文件B新
-ot:判断文件A是否比文件B旧
-ef:判断两个文件是否为同一个文件,用来判断两个文件是否指向同一个inode
Living Example:
[root@test ~]# [ -d /tmp/grub2.cfg ]
[root@test ~]# echo $?
1
[root@test ~]# [ -d /etc/ ] && echo "yes"
yes
[root@test ~]# echo $?
0 (&&表示所有条件必须成立)
[root@test ~]# test new.txt -nt www.txt && echo 1 || echo 0
0
Living Example:
[root@test ~]# [ -d /tmp/grub2.cfg ]
[root@test ~]# echo $?
关于程序的逻辑卷标
关于程序的逻辑卷标
-G 侦测是否由 GID 所执行的程序所拥有
-O 侦测是否由 UID 所执行的程序所拥有
-p 侦测是否为程序间传送信息的 name pipe 或是 FIFO (老实说,这个不太懂!)
关于档案的属性侦测
-r 侦测是否为可读的属性
-w 侦测是否为可以写入的属性
-x 侦测是否为可执行的属性
-u 侦测是否具有『 SUID 』的属性
-g 侦测是否具有『 SGID 』的属性
-k 侦测是否具有『 sticky bit 』的属性
总结(test、[]、[[]])
https://mp.weixin.qq.com/s/ZUrVFSfRQyEi9-uo89s8uw
1、test 命令
test
shell环境中测试条件表达式工具
补充说明
test命令 是shell环境中测试条件表达式的实用工具。
语法
test(选项)
选项
-b<文件>:如果文件为一个块特殊文件,则为真;
-c<文件>:如果文件为一个字符特殊文件,则为真;
-d<文件>:如果文件为一个目录,则为真;
-e<文件>:如果文件存在,则为真;
-f<文件>:如果文件为一个普通文件,则为真;
-g<文件>:如果设置了文件的SGID位,则为真;
-G<文件>:如果文件存在且归该组所有,则为真;
-k<文件>:如果设置了文件的粘着位,则为真;
-O<文件>:如果文件存在并且归该用户所有,则为真;
-p<文件>:如果文件为一个命名管道,则为真;
-r<文件>:如果文件可读,则为真;
-s<文件>:如果文件的长度不为零,则为真;
-S<文件>:如果文件为一个套接字特殊文件,则为真;
-u<文件>:如果设置了文件的SUID位,则为真;
-w<文件>:如果文件可写,则为真;
-x<文件>:如果文件可执行,则为真。
实例
linux中shell编程中的test常见用法:
判断表达式
if test #表达式为真
if test ! #表达式为假
test 表达式1 –a 表达式2 #两个表达式都为真
test 表达式1 –o 表达式2 #两个表达式有一个为真
test 表达式1 ! 表达式2 #条件求反
判断字符串
test -n 字符串 #字符串的长度非零
test -z 字符串 #字符串的长度是否为零
test 字符串1=字符串2 #字符串是否相等,若相等返回true
test 字符串1!=字符串2 #字符串是否不等,若不等返回false
判断整数
test 整数1 -eq 整数2 #整数相等
test 整数1 -ge 整数2 #整数1大于等于整数2
test 整数1 -gt 整数2 #整数1大于整数2
test 整数1 -le 整数2 #整数1小于等于整数2
test 整数1 -lt 整数2 #整数1小于整数2
test 整数1 -ne 整数2 #整数1不等于整数2
判断文件
test File1 –ef File2 两个文件是否为同一个文件,可用于硬连接。主要判断两个文件是否指向同一个inode。
test File1 –nt File2 判断文件1是否比文件2新
test File1 –ot File2 判断文件1比是否文件2旧
test -b file #文件是否块设备文件
test -c File #文件并且是字符设备文件
test -d File #文件并且是目录
test -e File #文件是否存在 (常用)
test -f File #文件是否为正规文件 (常用)
test -g File #文件是否是设置了组id
test -G File #文件属于的有效组ID
test -h File #文件是否是一个符号链接(同-L)
test -L File #文件是否是一个符号链接(同-h)
test -k File #文件是否设置了Sticky bit位
test -b File #文件存在并且是块设备文件
test -o File #文件的属于有效用户ID
test -p File #文件是一个命名管道
test -r File #文件是否可读
test -s File #文件是否是非空白文件
test -t FD #文件描述符是在一个终端打开的
test -u File #文件存在并且设置了它的set-user-id位
test -w File #文件是否存在并可写
test -x File #文件属否存在并可执行
使用方法:test EXPRESSION
如:
[root@localhost ~]# test 1 = 1 && echo 'ok'
ok
[root@localhost ~]# test -d /etc/ && echo 'ok'
ok
[root@localhost ~]# test 1 -eq 1 && echo 'ok'
ok
[root@localhost ~]# if test 1 = 1 ; then echo 'ok'; fi
ok
注意:所有字符 与逻辑运算符直接用“空格”分开,不能连到一起。
2、精简表达式
[] 表达式
[root@localhost ~]# [ 1 -eq 1 ] && echo 'ok'
ok
[root@localhost ~]# [ 2 < 1 ] && echo 'ok'
-bash: 2: No such file or directory
[root@localhost ~]# [ 2 < 1 ] && echo 'ok'
[root@localhost ~]# [ 2 -gt 1 -a 3 -lt 4 ] && echo 'ok'
ok
[root@localhost ~]# [ 2 -gt 1 && 3 -lt 4 ] && echo 'ok'
-bash: [: missing `]'
注意:在[] 表达式中,常见的>,<需要加转义字符,表示字符串大小比较,以acill码 位置作为比较。 不直接支持<>运算符,还有逻辑运算符|| && 它需要用-a[and] –o[or]表示
[[]] 表达式
[root@localhost ~]# [ 1 -eq 1 ] && echo 'ok'
ok
[root@localhost ~]$ [[ 2 < 3 ]] && echo 'ok'
ok
[root@localhost ~]$ [[ 2 < 3 && 4 > 5 ]] && echo 'ok'
ok
注意:[[]] 运算符只是[]运算符的扩充。能够支持<,>符号运算不需要转义符,它还是以字符串比较大小。里面支持逻辑运算符:|| &&
3、性能比较
bash的条件表达式中有三个几乎等效的符号和命令:test,[]和[[]]。通常,大家习惯用if [];then这样的形式。而[[]]的出现,根据ABS所说,是为了兼容><之类的运算符。以下是比较它们性能,发现[[]]是最快的。
$ time (for m in {1..100000}; do test -d .;done;)
real 0m0.658s
user 0m0.558s
sys 0m0.100s
$ time (for m in {1..100000}; do [ -d . ];done;)
real 0m0.609s
user 0m0.524s
sys 0m0.085s
$ time (for m in {1..100000}; do [[ -d . ]];done;)
real 0m0.311s
user 0m0.275s
sys 0m0.036s
不考虑对低版本bash和对sh的兼容的情况下,用[[]]是兼容性强,而且性能比较快,在做条件运算时候,可以使用该运算符
Linux Shell 中 ()、(())、[]、[[]]、{} 的作用
https://mp.weixin.qq.com/s/MEfTpLb-tneI4vYg5qSayw
一、小括号,圆括号()
1、单小括号 ()
①命令组。括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用。括号中多个命令之间用分号隔开,最后一个命令可以没有分号,各命令和括号之间不必有空格。
②命令替换。等同于cmd,shell扫描一遍命令行,发现了

③用于初始化数组。如:array=(a b c d)
2、双小括号 (( ))
①整数扩展。这种扩展计算是整数型的计算,不支持浮点型。((exp))结构扩展并计算一个算术表达式的值,如果表达式的结果为0,那么返回的退出状态码为1,或者是\"假\",而一个非零值的表达式所返回的退出状态码将为0,或者是\"true\"。若是逻辑判断,表达式exp为真则为1,假则为0。

③单纯用 (( )) 也可重定义变量值,比如 a=5; ((a++)) 可将 $a 重定义为6

二、中括号,方括号[]
1、单中括号 []
①bash 的内部命令,[和test是等同的。如果我们不用绝对路径指明,通常我们用的都是bash自带的命令。if/test结构中的左中括号是调用test的命令标识,右中括号是关闭条件判断的。这个命令把它的参数作为比较表达式或者作为文件测试,并且根据比较的结果来返回一个退出状态码。if/test结构中并不是必须右中括号,但是新版的Bash中要求必须这样。
②Test和[]中可用的比较运算符只有==和!=,两者都是用于字符串比较的,不可用于整数比较,整数比较只能使用-eq,-gt这种形式。无论是字符串比较还是整数比较都不支持大于号小于号。如果实在想用,对于字符串比较可以使用转义形式,如果比较\"ab\"和\"bc\":[ab < bc ],结果为真,也就是返回状态为0。[ ]中的逻辑与和逻辑或使用-a 和-o 表示。
③字符范围。用作正则表达式的一部分,描述一个匹配的字符范围。作为test用途的中括号内不能使用正则。
④在一个array 结构的上下文中,中括号用来引用数组中每个元素的编号。
2、双中括号[[ ]]
①[[是 bash 程序语言的关键字。并不是一个命令,[[ ]] 结构比[]结构更加通用。在[[和]]之间所有的字符都不会发生文件名扩展或者单词分割,但是会发生参数扩展和命令替换。
②支持字符串的模式匹配,使用=~操作符时甚至支持shell的正则表达式。字符串比较时可以把右边的作为一个模式,而不仅仅是一个字符串,比如[[ hello == hell? ]],结果为真。[[ ]] 中匹配字符串或通配符,不需要引号。
③使用[[ ... ]]条件判断结构,而不是[ ...],能够防止脚本中的许多逻辑错误。比如,&&、||、<和>操作符能够正常存在于[[ ]]条件判断结构中,但是如果出现在[]结构中的话,会报错。比如可以直接使用if [[ $a != 1 && $a != 2 ]], 如果不适用双括号, 则为if [ $a -ne 1] && [ $a != 2 ]或者if [ $a -ne 1 -a $a != 2 ]
④bash把双中括号中的表达式看作一个单独的元素,并返回一个退出状态码。
例子:
if ($i<5)
if [ $i -lt 5 ]
if [ $a -ne 1 -a $a != 2 ]
if [ $a -ne 1] && [ $a != 2 ]
if [[ $a != 1 && $a != 2 ]]
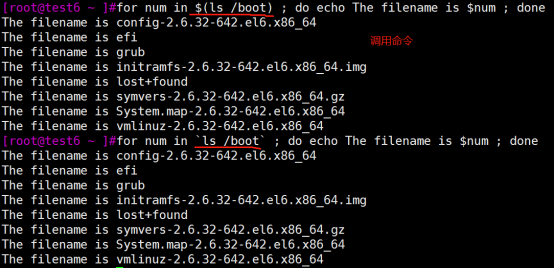
for i in $(seq 0 4);do echo $i;done
for i in `seq 0 4`;do echo $i;done
for ((i=0;i<5;i++));do echo $i;done
for i in {0..4};do echo $i;done
三、大括号、花括号 {}
1、常规用法
①大括号拓展。(通配(globbing))将对大括号中的文件名做扩展。在大括号中,不允许有空白,除非这个空白被引用或转义。
第一种:对大括号中的以逗号分割的文件列表进行拓展。如 touch {a,b}.txt 结果为a.txt 和b.txt。
第二种:对大括号中以点点(..)分割的顺序文件列表起拓展作用,如:touch {a..d}.txt 结果为a.txt b.txt c.txt d.txt
# ls {ex1,ex2}.sh
ex1.sh ex2.sh
# ls {ex{1..3},ex4}.sh
ex1.sh ex2.sh ex3.sh ex4.sh
# ls {ex[1-3],ex4}.sh
ex1.sh ex2.sh ex3.sh ex4.sh
②代码块,又被称为内部组,这个结构事实上创建了一个匿名函数。与小括号中的命令不同,大括号内的命令不会新开一个子shell运行,即脚本余下部分仍可使用括号内变量。括号内的命令间用分号隔开,最后一个也必须有分号。{}的第一个命令和左括号之间必须要有一个空格。
2、几种特殊的替换结构
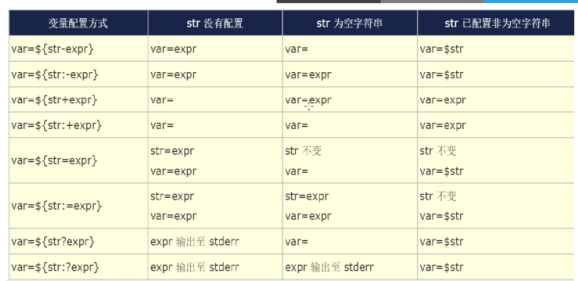
${var:-string},${var:+string},${var:=string},${var:?string}
①${var:-string}和${var:=string}:若变量var为空,则用在命令行中用string来替换${var:-string},否则变量var不为空时,则用变量var的值来替换${var:-string};对于${var:=string}的替换规则和${var:-string}是一样的,所不同之处是${var:=string}若var为空时,用string替换${var:=string}的同时,把string赋给变量var:${var:=string}很常用的一种用法是,判断某个变量是否赋值,没有的话则给它赋上一个默认值。
② ${var:+string}的替换规则和上面的相反,即只有当var不是空的时候才替换成string,若var为空时则不替换或者说是替换成变量 var的值,即空值。(因为变量var此时为空,所以这两种说法是等价的)
③${var:?string}替换规则为:若变量var不为空,则用变量var的值来替换${var:?string};若变量var为空,则把string输出到标准错误中,并从脚本中退出。我们可利用此特性来检查是否设置了变量的值。
补充扩展:在上面这五种替换结构中string不一定是常值的,可用另外一个变量的值或是一种命令的输出。
3、四种模式匹配替换结构
模式匹配记忆方法:
#是去掉左边(在键盘上#在$之左边)
%是去掉右边(在键盘上%在$之右边)
#和%中的单一符号是最小匹配,两个相同符号是最大匹配。
${var%pattern},${var%%pattern},${var#pattern},${var##pattern}
第一种模式:${variable%pattern},这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最短的匹配模式
第二种模式:${variable%%pattern},这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最长的匹配模式
第三种模式:${variable#pattern} 这种模式时,shell在variable中查找,看它是否一给的模式pattern开始,如果是,就从命令行把variable中的内容去掉左边最短的匹配模式
第四种模式:${variable##pattern} 这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最长的匹配模式
这四种模式中都不会改变variable的值,其中,只有在pattern中使用了*匹配符号时,%和%%,#和##才有区别。结构中的pattern支持通配符,*表示零个或多个任意字符,?表示仅与一个任意字符匹配,[...]表示匹配中括号里面的字符,[!...]表示不匹配中括号里面的字符。
# var=testcase
# echo $var
testcase
# echo ${var%s*e}
testca
# echo $var
testcase
# echo ${var%%s*e}
te
# echo ${var#?e}
stcase
# echo ${var##?e}
stcase
# echo ${var##*e}
# echo ${var##*s}
e
# echo ${var##test}
case
4、字符串提取和替换
${var:num},${var:num1:num2},${var/pattern/pattern},${var//pattern/pattern}
第一种模式:${var:num},这种模式时,shell在var中提取第num个字符到末尾的所有字符。若num为正数,从左边0处开始;若num为负数,从右边开始提取字串,但必须使用在冒号后面加空格或一个数字或整个num加上括号,如${var:-2}、${var:1-3}或${var:(-2)}。
第二种模式:${var:num1:num2},num1是位置,num2是长度。表示从$var字符串的第$num1个位置开始提取长度为$num2的子串。不能为负数。
第三种模式:${var/pattern/pattern}表示将var字符串的第一个匹配的pattern替换为另一个pattern。
第四种模式:${var//pattern/pattern}表示将var字符串中的所有能匹配的pattern替换为另一个pattern。
[root@centos ~]# var=/home/centos
[root@centos ~]# echo $var
/home/centos
[root@centos ~]# echo ${var:5}
/centos
[root@centos ~]# echo ${var: -6}
centos
[root@centos ~]# echo ${var:(-6)}
centos
[root@centos ~]# echo ${var:1:4}
home
[root@centos ~]# echo ${var/o/h}
/hhme/centos
[root@centos ~]# echo ${var//o/h}
/hhme/cenths
###安装jumpserver时运用到的花括号
cd /opt
if [ ! -d "/opt/jumpserver-installer-$Version" ]; then
wget -qO jumpserver-installer-$Version.tar.gz https://github.com/jumpserver/installer/releases/download/$Version/jumpserver-installer-$Version.tar.gz || {
rm -rf /opt/jumpserver-installer-$Version.tar.gz
echo -e "[\033[31m ERROR \033[0m] Failed to download jumpserver-installer (下载 jumpserver-installer 失败, 请检查网络是否正常或尝试重新执行脚本)"
exit 1
}
tar -xf /opt/jumpserver-installer-$Version.tar.gz -C /opt || {
rm -rf /opt/jumpserver-installer-$Version
echo -e "[\033[31m ERROR \033[0m] Failed to unzip jumpserver-installe (解压 jumpserver-installer 失败, 请检查网络是否正常或尝试重新执行脚本)"
exit 1
}
rm -rf /opt/jumpserver-installer-$Version.tar.gz
fi
四、符号$后的括号
(1)${a} 变量a的值, 在不引起歧义的情况下可以省略大括号。
(2)$(cmd)命令替换,和`cmd`效果相同,结果为shell命令cmd的输,过某些Shell版本不支持$()形式的命令替换, 如tcsh。
(3)$((expression)) 和`exprexpression`效果相同,计算数学表达式exp的数值, 其中exp只要符合C语言的运算规则即可,甚至三目运算符和逻辑表达式都可以计算
五、使用
多条命令执行
多条命令执行
(1)单小括号,(cmd1;cmd2;cmd3) 新开一个子shell顺序执行命令cmd1,cmd2,cmd3, 各命令之间用分号隔开, 最后一个命令后可以没有分号。括号两边不能有空格
(ls;cd /)
(2)单大括号,{ cmd1;cmd2;cmd3;} 在当前shell顺序执行命令cmd1,cmd2,cmd3, 各命令之间用分号隔开, 最后一个命令后必须有分号, 第一条命令和左括号之间必须用空格隔开。对{}和()而言, 括号中的重定向符只影响该条命令, 而括号外的重定向符影响到括号中的所有命令。第一个单花括号必须有空格,最后一个单花括号可有可无无空格
{ ls;cd /;}
{ ls;cd /tmp/;}
shell脚本中28个特殊字符的作用简明总结
https://www.cnblogs.com/qiulinzhang/p/9513943.html
https://www.jb51.net/article/49176.htm
1 、#
注释作用, #! 除外
此外, 在参数替换 echo ${PATH#*:} 这里不表示注释, 数制转换, 不表示注释echo $((2#101011))
2 、;
命令行分隔符, 可以在一行中写多个命令. echo hello; echo there
3、 ;;
终止 case 选项
case "$variable" in
abc) echo "$variable = abc";;
xyz) echo "$variable = xyz";;
esac
4、 .
隐藏文件前缀
.命令等价于source
. 表示当前目录 .. 表示上一级目录
正则表达式中作为单个字符匹配
5、 "" ''
双引号, 单引号, 其中双引号中可以引用变量, 而单引号中不行,它们的作用是组织特殊字符
6、 \
转义字符
\cmd => 强制执行命令\cp a b
7、 /
文件名分隔符, 除法操作
8、 `(Esc 下边的按钮)
后置引用, 命令替换
9、 :
空命令,等价于\"NOP\"(no op,一个什么也不干的命令)。也可以被认为与shell的内建命令true作用相同。\":\"命令是一个bash的内建命令,它的退出码(exit status)是(0)。
也可被认为是 shell 内建命令 true 作用相同,
例如: 死循环
while :
do
echo "1"
done
等价于:
while true
do
echo "1"
done
在 if/then 语句中做占位符:
condition=5
if [ $condition -gt 0 ] #gt表示greater than,也就是大于,同样有-lt(小于),-eq(等于
then : # 这里的冒号表示什么都不做, 引出分支
else
do other thing
fi
在一个 2 元命令中提供一个占位符.
在和 >(重定向操作符)一起使用时, 清空文件, 并没有修改文件的权限, 例如: (如果文件不存在, 将会创建文件)
: > data.log 等同于 cat /dev/null > data.log
# Package removal, not upgrade
systemctl --no-reload disable node_exporter.service > /dev/null 2>&1 || :
systemctl stop node_exporter.service > /dev/null 2>&1 || :
10、 !
取反操作符!= 不等于
11、 *
万能匹配符, 正则表达式中
数学乘法
** 幂运算
12、 ?
测试操作
正则表达式中, ? 匹配任意单个字符
13、 $
变量符号
正则表达式中 行结束符
${} 参数替换
$*,$@ 位置参数
$? 退出状态
$$ 进程ID
14、 ()
命令组, (a=hello; echo $a), 在 () 中的命令列表将作为一个子 shell来运行. 在() 中的变量, 由于在子shell中,所以对于脚本剩下的部分是不可用的.
数组初始化: array=(element1, element2, element3)
15、 {xxx,yyy,zzz}
大括号扩展
cat {file1,file2,file3} > combined_file,将file1,file2,file3合并在一起并重定向到commbined_file中.
大括号中不能有空格
16、 {}
代码块. 事实上, 这个结构创建了一个匿名的函数. 但是与函数不同的是,在其中声明的变量, 对于脚本的其他部分的代码来说还是可见的.
# 代码块中的内容, 外部访问, I/O重定向
#!/bin/bash
File=/etc/fstab
# 在这个代码块中的变量, 外部也可以访问
{
read line1
read line2
} < $File
echo "First line in $File is"
echo "$line1"
echo
echo "Second line in $File is"
echo "$line2"
exit 0
# 将一个代码块的结果保存到文件
17、 {} \;
路径名, 一般都是在 find 命令中使用, 注意; 用来结束find 命令序列的 -exec
18、 []
test
数组元素, 例如 array[1]=abc
字符范围, 在正则表达式中使用
19、 [[]]
test 表达式本身放在[] 里
20 、 (())
数学计算扩展
21、 >& >>& >> <
重定向
scriptname > filename 重定向脚本的输出到文件中, 覆盖原有内容
command &> filename 重定向 stdout 和 stderr 到文件中
command >&2 重定向 stdout 和 stderr
scriptname >> filename 重定向脚本输出到文件中, 添加到文件尾端,如果没有文件, 则创建这个文件.
22、 << <<<
重定向, << 用在"here document", <<< 用在"here string"
23、 \<, \>
正则表达式中的单词边界grep '\<the\>' testfile
24、 |
管道, 分析前边命令的输出, 并将输出作为后边命令的输入
25、 >|
强制重定向
26、 ||
逻辑或
27、 &
后台运行命令, 一个命令后边跟一个&, 将表示在后台运行
#!/bin/bash
for i in 1 2 3 4 5 6 7 8 9 10
do
echo -n "$i"
done&
注意, for 循环的最后一个 done&
28、 &&
逻辑与
Shell中的替换
转义符:
在echo中可以用于的转义符有:
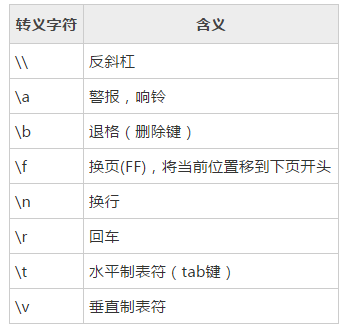
使用 echo 命令的 -E 选项禁止转义,默认也是不转义的; 使用 -n选项可以禁止插入换行符;
使用 echo 命令的 -e 选项可以对转义字符进行替换。
另外,Notice,经过我的实验,得到:
echo "\\" #得到 \
echo -e "\\" #得到 \
echo "\\\\" #得到 \\
echo -e "\\" #得到 \
命令替换:
它的意思就是说我们把一个命令的输出赋值给一个变量,方法为把命令用反引号(在Esc下方)引起来. 比如:
[root@test6 /opt 07:58:34]#directory=`pwd`
[root@test6 /opt 07:59:29]#echo $directory
/opt
在命令中调用date命令输出值
[root@test-6 ~]# echo `date`
2018年 12月 03日 星期一 19:13:35 CST
调用里面的内容:
[root@test-6 ~]# echo $(date)
2018年 12月 03日 星期一 19:14:51 CST
变量替换:
可以根据变量的状态(是否为空、是否定义等)来改变它的值.

eg:

Shell中的字符串
字符串处理
基于模式取子串
${var#*strings} 其中 strings 可以是指定的任意字符
功能: 自左而右,查找var变量所存储的字符串中,第一次出现的word,删除字符串开头至第一次出现 strings 字符之间的所有字符
${var#*strings} 同上,贪婪模式型,不同的是,删除字符串开头至最后一次由strings指定的字符之间的所有内容
例子:
[root@VM-16-16-centos ~ 13:15:45]# file="var/log/messages"
[root@VM-16-16-centos ~ 13:17:07]# echo "${file#*/}"
log/messages
[root@VM-16-16-centos ~ 13:17:17]# echo "${file##*/}"
messages
${var%strings*} 其中 strings 可以是指定的任意字符
功能:从右到左,在var变量存储的字符串中,找到第一次出现的 strings ,删除字符串的最后一个字符向左至第一次出现 strings 之间的所有字符
[root@VM-16-16-centos ~ 13:03:34]# file="/var/log/messages"
[root@VM-16-16-centos ~ 13:05:03]# echo "${file%/*}"
/var/log
$(var%%strings*]): 同上,只不过删除字符串最右侧的字符向左至最后一次出现strings字符之间的所以字符
例子:
[root@VM-16-16-centos ~ 12:34:15]# url=http://www.baidu.com:80
[root@VM-16-16-centos ~ 13:00:58]# echo ${url##*:}
80
[root@VM-16-16-centos ~ 12:59:53]# echo ${url%%:*}
http
查找替换
${var/pattern/substr} 查找var所表示的字符串中,第一次被pattern所匹配到的字符串,以substr替换
${var//pattern/substr} 查找var所表示的字符串中,所有能被pattern所匹配到的字符串,以substr替换
${var/#pattern/substr} 查找var所表示的字符串中,行首被pattern所匹配到的字符串,以substr替换
${var/%pattern/substr} 查找var所表示的字符串中,行尾被pattern所匹配到的字符串,以substr替换
查找并删除
${var/pattern} 删除var所表示的字符串中第一次被pattern所匹配到的字符串
${var//pattern} 删除var所表示的字符串中所有能被pattern所匹配到的字符串
${var/#pattern} 删除var所表示的字符串中行首被pattern所匹配到的字符串
${var/%pattern} 删除var所表示的字符串中行尾被pattern所匹配到的字符串
字符大小替换
${var^^} 把var中的 所有小写字母替换为大写字母
${var,,} 把var中的 所有小写字母替换为大写字母
示例:
[root@VM-16-16-centos ~ 14:37:55]# aa='asdasd' | echo ${aa^^}
ASDASD
[root@VM-16-16-centos ~ 14:38:04]# aa='ASDASD' | echo ${aa,,}
asdasd
创建临时文件
mktemp命令:创建并显示临时文件,可以避免冲突
# mktemp --help
Usage: mktemp [OPTION]... [TEMPLATE]
Create a temporary file or directory, safely, and print its name.
TEMPLATE must contain at least 3 consecutive 'X's in last component.
If TEMPLATE is not specified, use tmp.XXXXXXXXXX, and --tmpdir is implied.
Files are created u+rw, and directories u+rwx, minus umask restrictions.
-d, --directory create a directory, not a file
-u, --dry-run do not create anything; merely print a name (unsafe)
-p DIR, --tmpdir[=DIR] 指定临时文件所存放目录位置
示例:后缀必须至少有三个大写XXX
[root@VM ~ 11:26:34]# mktemp /tmp/tmpfileXXX
/tmp/tmpfilePpc
[root@VM ~ 11:27:04]# mktemp -d /tmp/tmpdirXXXXXX
/tmp/tmpdirBPddC7
[root@VM ~ 11:27:14]# mktemp --tmpdir=`mktemp -d /tmp/tmpdirXXXXXX` dirtmpfileXXXXXX
/tmp/tmpdirSvZW9X/dirtmpfilew4PVea
[root@VM ~ 11:28:33]# ll /tmp/tmp*
-rw------- 1 root root 0 Jun 28 11:27 /tmp/tmpfilePpc
/tmp/tmpdirBPddC7:
total 0
/tmp/tmpdirSvZW9X:
total 0
-rw------- 1 root root 0 Jun 28 11:27 dirtmpfilew4PVea
获取字符串(字符串切片):
${#var} 返回字符串变量var的长度
${var:offset} 返回字符串变量var中从第offset个字符后(不包括第offset个字符)的字符开始,offset的取值在0到${#var}-1之间。(bash4.2后,允许为负值)
${var:offset:number} 返回字符串变量var中从第offset个字符后(不包括第offset个字符)的字符开始,长度为number的部分
${var: -length} 取字符串的最右侧几个字符。注意:冒号后必须有一个空白字符
${var:offset:-length} 从最左侧跳过offset字符,一直向右取到距离最右侧length个字符之前的内容
${var: -length:offset} 先从最右侧向左取到length个字符开始,在向右取到距离最右侧offset个字符之间的内容。注意:-length前有一个空格
拼接字符串:
country="China"
[root@test-7 ~]# echo hello,$country
hello,Chian
[root@test-7 ~]# echo "hello,$country"
hello,Chian
获取字符串长度:
[root@test-7 ~]# string="asdfghjkl"
[root@test-7 ~]# echo ${string:1:4}
bcd
[root@test-6 ~]#var="nihao haha memeda"
[root@test-6 ~]#echo "${#var}"
17
替换字符串
[root@test-6]#var="nihao haha memeda"
[root@test-6]#echo "${var/nihao/dajiahao}"
dajiahao haha memeda
查找字符串:
string="huawei is a great company"
echo `expr index "$string" is`
3
shell编程之脚本调试
echo
echo命令是最有用的调试脚本工具之一,一般在可能出现问题的脚本中加入echo命令,采用分段排查的方式。
除了echo命令之外,bash shell也有相应的参数可以调试脚本。
使用sh/bash命令参数调试
sh/bash [-nvx] 脚本名
常用参数具体含义为:
- -n:不会执行脚本,仅仅查询脚本Grammar是否有问题,如果没有Grammar问题就不会显示任何内容,如果有就会报错。
- -v:在执行脚本前,先将脚本内容输出到屏幕上然后执行脚本,如果有错误,也会给出错误提示
- -x:将执行的脚本内容输出到屏幕上,这是个对调试很有用的参数
当脚本文件较长时,可以使用set命令指定调试一段脚本
set指令设置所使用shell的执行方式,可依照不同的需求来做设置
语法
set [+-abCdefhHklmnpPtuvx]
参数说明:
-
-a 标示已修改的变量,以供输出至环境变量。
-
-b 使被中止的后台程序立刻回报执行状态。
-
-C 转向所产生的文件无法覆盖已存在的文件。
-
-d Shell预设会用杂凑表记忆使用过的指令,以加速指令的执行。使用-d参数可取消。
-
-e 若指令传回值不等于0,则立即退出shell。
-
-f 取消使用通配符。
-
-h 自动记录函数的所在位置。
-
-H Shell 可利用\"!\"加<指令编号>的方式来执行history中记录的指令。
-
-k 指令所给的参数都会被视为此指令的环境变量。
-
-l 记录for循环的变量名称。
-
-m 使用监视模式。
-
-n 检查脚本语法,而不实际执行。
-
-p 启动优先顺序模式。
-
-P 启动-P参数后,执行指令时,会以实际的文件或目录来取代符号连接。
-
-t 执行完随后的指令,即退出shell。
-
-o 查看某个功能是否开启
-
-o pipefail 控制在管道符执行过程中有错误立即退出
-
-u 当执行时使用到未定义过的变量立即退出。
-
-v 显示shell所读取的输入值。
-
-x 执行指令后,会先显示该指令及所下的参数。
-
+<参数> 取消某个set曾启动的参数
Tips : Linux Shell 编程中
原文链接:https://blog.csdn.net/u010003835/java/article/details/79936072
1) 若程序 异常(返回 非 true)值, 程序会继续向下执行。
2)对于一些变量 VAR= 若忘记设置值,可能会导致 rm -rf ${VAR} 变为rm -rf /.这是非常危险的操作。
**所以一个好的做法是在 每个 shell 中添加 **
set -ue
nounset -u #在扩展一个没有的设置的变量的时候,显示错误的信息
errexit -e #如果一个命令返回一个非0退出状态值(失败),就退出. 之后出现的代码,一旦出现了返回值非零,整个脚本就会立即退出
set -o errexit #当然如果只有一个参数,也可以这么设置
参考:https://mp.weixin.qq.com/s/QcmTUPD3wnWv_3zl1_FURg
写过很多 bash 脚本的人都知道,bash 的坑不是一般的多。其实 bash本身并不是一个很严谨的语言,但是很多时候也不得不用。以下总结了一些编写可靠的bash 脚本的小 tips。
0. set -x -e -u -o pipefail
在写脚本时,在一开始(Shebang 之后)加上下面这一句,或者它的缩略版,能避免很多问题,更重要的是能让很多隐藏的问题暴露出来:
set -xeuo pipefail
下面说明每个参数的作用,以及一些例外的处理方式 :
-x :在执行每一个命令之前把经过变量展开之后的命令打印出来。这个对于 debug 脚本、输出 Log 时非常有用。正式运行的脚本也可以不加。
-e :遇到一个命令失败(返回码非零)时,立即退出。bash跟其它的脚本语言最大的不同点之一,应该就是遇到异常时继续运行下一条命令。这在很多时候会遇到意想不到的问题。加上-e ,会让 bash 在遇到一个命令失败时,立即退出。如果有时确实需要忽略个别命令的返回码,可以用|| true 。如:some_cmd || true # 即使some_cmd失败了,仍然会继续运行some_cmd || RET=$? # 或者可以这样来收集some_cmd的返回码,供后面的逻辑判断使用,但是在管道串起多条命令的情况下,只有最后一条命令失败时才会退出。如果想让管道中任意一条命令失败就退出,就要用后面提到的-o pipefail 了。
加-e 有时候可能会不太方便,动不动就退出。但还是应该坚持所谓的fail-fast原则,也就是有异常时停止正常运行,而不是继续尝试运行可能存在缺陷的过程。如果有命令可以明确忽略异常,那可以用上面提到的|| true 等方式明确地忽略之。
-u :试图使用未定义的变量,就立即退出。如果在 bash里使用一个未定义的变量,默认是会展开成一个空串。有时这种行为会导致问题,比如:rm -rf $MYDIR/data如果 MYDIR 变量因为某种原因没有赋值,这条命令就会变成 rm -rf /data。这就比较搞笑了。使用 -u 可以避免这种情况。但有时候在已经设置了-u后,某些地方还是希望能把未定义变量展开为空串,可以这样写:${SOME_VAR:-}#
bash变量展开语法,可以参考:https://www.gnu.org/software/bash/manual/html_node/Shell-Parameter-Expansion.html
-o pipefail :只要管道中的一个子命令失败,整个管道命令就失败。pipefail 与-e结合使用的话,就可以做到管道中的一个子命令失败,就退出脚本。
1. 防止重叠运行
在一些场景中,我们通常不希望一个脚本有多个实例在同时运行。比如用 crontab周期性运行脚本时,有时不希望上一个轮次还没运行完,下一个轮次就开始运行了。这时可以用flock 命令来解决。flock通过文件锁的方式来保证独占运行,并且还有一个好处是进程退出时,文件锁也会自动释放,不需要额外处理
用法 1:假设你的入口脚本是 myscript.sh,可以新建一个脚本,通过 flock 来运行它:
# flock --wait 超时时间 -e 锁文件 -c "要执行的命令"
# 例如:
flock --wait 5 -e "lock_myscript" -c "bash myscript.sh"
用法 2:也可以在原有脚本里使用 flock。可以把文件打开为一个文件描述符,然后使用 flock 对它上锁(flock 可以接受文件描述符参数)。
exec 123<>lock_myscript # 把lock_myscript打开为文件描述符123
flock --wait 5 123 || { echo 'cannot get lock, exit'; exit 1; }
2. 意外退出时杀掉所有子进程
我们的脚本通常会启动好多子脚本和子进程,当父脚本意外退出时,子进程其实并不会退出,而是继续运行着。如果脚本是周期性运行的,有可能发生一些意想不到的问题。
在 stackoverflow 上找到的一个方法,原理就是利用 trap 命令在脚本退出时kill掉它整个进程组。把下面的代码加在脚本开头区,实测管用:
trap "trap - SIGTERM && kill -- -$$" SIGINT SIGTERM EXIT
不过如果父进程是用 SIGKILL (kill -9) 杀掉的,就不行了。因为 SIGKILL时,进程是没有机会运行任何代码的。
3. timeout 限制运行时间
有时候需要对命令设置一个超时时间。这时可以使用timeout命令,用法很简单:
timeout 600s some_command arg1 arg2
命令在超时时间内运行结束时,返回码为 0,否则会返回一个非零返回码。timeout 在超时时默认会发送 TERM 信号,也可以用-s 参数让它发送其它信号。
4. 连续管道时,考虑使用tee 将中间结果落盘,以便查问题
有时候我们会用到把好多条命令用管道串在一起的情况。如cmd1 | cmd2 | cmd3 | ...这样会让问题变得难以排查,因为中间数据我们都看不到。
如果改成这样的格式:
cmd1 > out1.dat
cat out1 | cmd2 > out2.dat
cat out2 | cmd3 > out3.dat
性能又不太好,因为这样 cmd1, cmd2, cmd3 是串行运行的,这时可以用 tee命令:
cmd1 | tee out1.dat | cmd2 | tee out2.dat | cmd3 > out3.dat
shell编程之条件语句
单分支的if语句
单分支if语句的执行流程:首先判断条件测试操作的结果,如果返回值为0,表示条件成立,则执行then后面的命令序列,一直到遇见fi结束判断为止,继续执行其他脚本代码;如果返回值不为0,则忽略then后面的命令序列,直接调至fi行以后执行其他脚本代码。
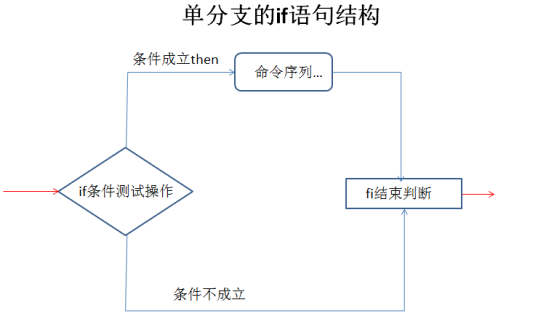
Living Example1:判断光盘挂载点目录是否存在,如果不存在,则新建此目录
vim chkmountdir.sh
#!/bin/bash
MOUNT_DIR="/media/cdrom/"
if [ ! -d $MOUNT_DIR ]
then
mkdir -p $MOUNT_DIR
fi
[root@test media]# bash /root/chkmountdir.sh #执行脚本:脚本前面加bash,脚本无执行权限也可以执行
Living Example2: (这种其实不好,fi过后if语句已经结束了,所有sudo这一条命令不属于if语句)
#!/bin/bash
if [ "$USER" != "root" ] (Notice:中括号里面有4个空格)
then
fdisk -l /dev/sda
echo "错误:非root用户,权限不足!"
fi
sudo fdisk -l /dev/sda
[root@test ~]# sh /opt/chkifroot.sh
#!/bin/bash
if [ $1 -eq 1 ] ; then
# Initial installation
systemctl preset node_exporter.service >/dev/null 2>&1 || :
fi
双分支的if语句
双分支if语句的执行流程:首先判断条件测试操作结果,如果条件成立,则执行then后面的命令序列,忽略else及后面的命令序列2,直到遇见fi结束判断;如果条件不成立,则忽略then及后面的命令序列1,直接跳至else后面的命令序列2并执行,直到遇间fi结束判断。
格式:
if 条件测试操作
then
命令序列1
else
命令序列2
fi
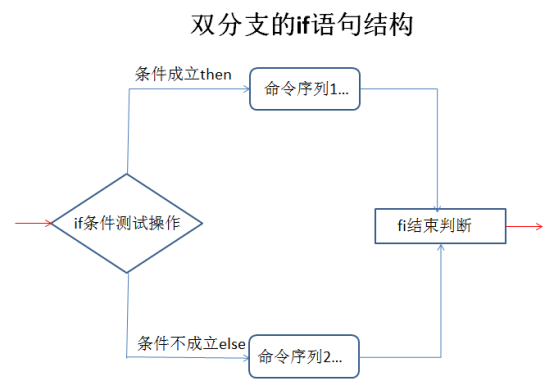
多分支的if语句
多分支if语句的执行流程:首先判断条件测试操作1的结果,如果条件1成立,则执行命令序列1,然后跳至fi结束判断;如果条件1不成立,则继续判断条件测试操作2的结果,如果条件2成立,则执行命令序列2,然后跳至fi结束判断......如果所有的条件都不满足,则执行else后面的命令序列n,直到遇见fi结束判断。
格式:
if 条件测试操作1
then
命令序列1
elif 条件测试操作2
then
命令序列2
else
命令序列3
fi
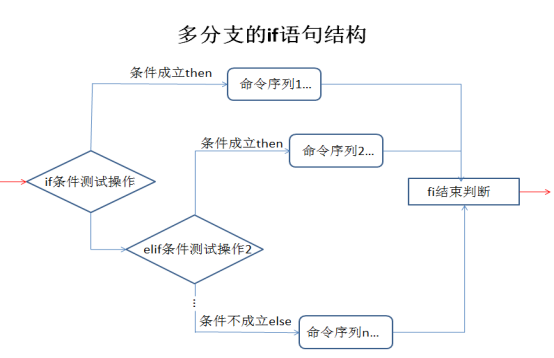
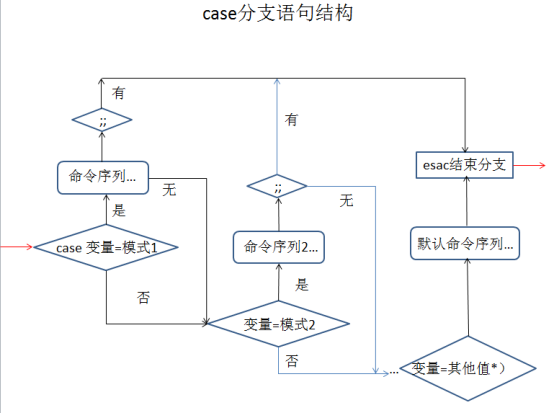
shell编程之case语句
case语句的执行流程:首先使用"变量"与模式1进行比较,若取值相同则执行模式1后的命令序列,直到遇见双分号";;"后跳转至esac,表示结束分支;若与模式1不相匹配,则继续与模式2进行比较,若取值相同则执行模式2后的命令序列,直到遇见双分号";;"后跳转至esac,表示结束分支......以此类推,若找不到任何匹配的值,则执行默认模式"*)"后的命令序列,直到遇见esac后的结束分支。
使用case分支语句是,有几个值得Notice的特点如下所述:
-
case首行行尾必须为单词"in",每一模式必须以右括号")"
-
双分号";;"表示命令序列的结束
-
模式字符串中,可以用方括号表示一个连续的范围,如"[0-9]";还可以用竖杆符号"|"表示或。如:"A|B"
-
最后的"*)"表示默认模式,其中的*相当于通配符
-
最后以esac 结束

case "$KEY" in #行尾必须有 in
[a-z]|[A-Z])
echo "您输入的是字母"
;;
[0-9])
echo "请输入的是数字"
;;
*)
echo "您输入的是非字母或者数字"
esac
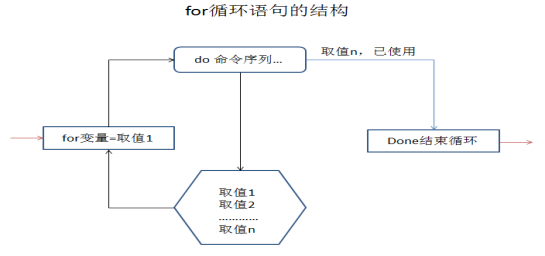
shell编程之for循环语句
for循环语句的Grammar结构如下所示:
for 变量名 in 取值列表
do
命令序列
done
for语句的执行流程:首先将列表中的第1个取值赋给变量,并执行do...done循环体中的命令序列;然后将列表中的第2个取值赋给变量,并执行循环体中的命令序列......一次类推,直到列表中的所有取值用完,最后将跳至done语句,表示结束循环。
(6)"变量 + echo命令"生成数据,中间用空格隔开。例如:
id="3AVC0 E1HTK2 17Y9Y"
for i in `echo "$id"`;do
echo $i
done



-EOF
# cat testeof.sh #为了格式的美观,可以这样写
#!/bin/bash
for i in {1..2} ;do
cat >> test.log <<-EOF
aaa
bbb
ccc
EOF
done
# cat testeof.sh #输入文件
#!/bin/bash
for i in {1..2} ;do
cat >> test.log << EOF
aaa
bbb
ccc
EOF
done
[root@Gitlab-9 ~]# cat test.log
aaa
bbb
ccc
aaa
bbb
ccc
aaa
bbb
ccc
[root@Gitlab-9 ~]# bash testeof.sh
[root@Gitlab-9 ~]# cat test.log
aaa
bbb
ccc
aaa
bbb
ccc
aaa
bbb
ccc
aaa
bbb
ccc
aaa
bbb
ccc
shell编程之while循环语句
while语句的执行流程:首先判断while后的条件测试操作结果,如果条件成立,则执行do...done循环体中的命令序列;返回while后再次判断条件测试结果,如果条件依然成立,则继续执行循环体;再次返回到while后,判断条件测试结果......如此循环,直到while后的条件测试结果不在成立为止,最后跳转到done语句,表示循环结束,如下图所示。
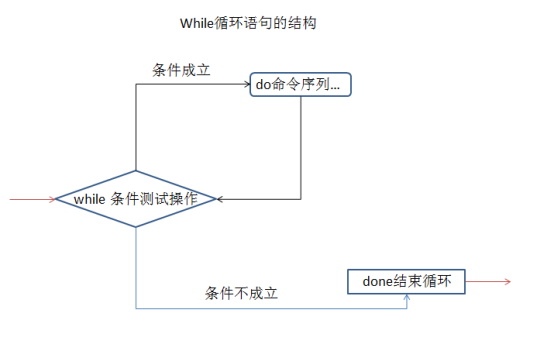
使用while循环语句时,有两个特殊的条件测试操作,即TRUE(真)和FALSE(假)。使用TRUE作为条件时,表示条件永远成立,循环体内的命令序列将无限执行下去,除非强制终止脚本(或者通过exit语句退出脚本);反之,若使用FALSE作为条件,则循环体将不会被执行。这两个特殊条件也可以用在if语句的条件测试中。
# 死循环
while true; do
循环内容
done
until false;do
循环内容
done
# while循环的特殊用法(遍历文件的每一行)
while read line ;do
循环内容
done < /path/filename
说明: 依次读取/path/filename文件中的每一行,且将行内容复制给变量line
shell编程之until循环语句
until condition;do
循环内容
done
进入条件: condition为false
退出条件: condition为true
until who | grep root &> /dev/null ; do sleep 1 ;done; echo "find root login"
shell编程之select循环与菜单语句
select variable in list
do
循环体命令
done
注意:
1、select循环主要用于创建菜单,按数字顺序排列的菜单项将显示在标准错误上,并显示PS3提示符,等待用户输入
2、用户输入菜单列表中的某个数字,执行相应的命令
3、用户输入被保存在内置变量REPLY中
select 与 case
1、select是个无限循环,因此要记住用break命令退出循环,或者exit命令终止脚本。也可以按Ctrl + c 退出循环
2、select 经常和case联合使用
3、与for循环类似,可以省略in list,此时使用位置参数
# cat select.sh
#!/bin/bash
PS3="please choose the menu(1-3): "
select menu in install remove reinstall
do
case $menu in
install)
echo "$REPLY: $menu"
break
;;
remove)
echo "$REPLY: $menu"
break
;;
reinstall)
echo "$REPLY: $menu"
break
;;
*)
echo "$menu is empty"
;;
esac
done
shell编程之信号捕捉trap
trap '触发指令'信号
自定义进程收到系统发出的指定信号后,将执行触发指令,而不会执行原操作
trap '' 信号
忽略信号的操作
trap '-' 信号
恢复原信号的操作
trap -p 信号
列出自定义信号操作
# cat trap.sh
#!/bin/bash
trap 'echo "signal:SIGINT"' int
trap -p
for((i=0;i<=10;i++))
do
sleep 1
echo $i
done
trap '' int
trap -p
for((i=11;i<=20;i++))
do
sleep 1
echo $i
done
trap '-' int
trap -p
for((i=21;i<=30;i++))
do
sleep 1
echo $i
done
shell编程之循环控制语句continue
用于循环体中
continue [N] 表示提前结束第N层的本轮循环,而直接进入下一轮判断,最内层为第1层
while condition1; do
cmd1
……
if condition2; then
continue
fi
cmdN
done
跳过某些次循环,然后在执行接下来的循环
for i in {1..10};do
if [ $i -eq 5 ] ;then
continue;
fi
echo i=$i
done
shell编程之循环控制语句break
用于循环体中
break [N] 表示提前结束第N层的本轮循环,最内层为第1层
while condition1; do
cmd1
……
if condition2; then
break
fi
cmdN
done
for i in {1..10};do
if [ $i -eq 5 ] ;then
break;
fi
echo i=$i
done
shell编程之sleep命令
sleep NUM(睡眠NUM秒)
shell编程之exit命令
退出整个脚本
exit NUMber
shell编程之循环控制shift命令
shift [N] 用于将参数列表list左移指定次数,缺省为左移一次 参数列表list一旦移动,做左端的那个参数就是从列表中删除。while循环遍历位置参数列表时,常用到shift
# 示例1:
#!/bin/bash
until [ -z "$1" ]
do
useradd $1
echo "$1 is created"
shift
done
echo "done"
# cat doit.sh
#!/bin/bash
while [ $# -gt 0 ] # or (( $# > 0 ))
do
echo $*
shift
done
[root@VM-16-16-centos ~ 17:42:45]# bash doit.sh 1 2 3 4
1 2 3 4
2 3 4
3 4
4
shell编程之函数应用
shell函数定义的基本格式如下,其中[function]是可选的,表示该函数的功能,这个是可以省略掉的;函数名后面加一个(),里面是没有内容的;而我们执行的命令序列放在{}里面的,[return X]的作用是当命令序列执行完后返回给系统一个值,该项也是可以省略的。若有时候我们调用的函数很多,那么我们可以一次写好几个。
查看函数:[root@CentOS6 ~ 13:27]#declare -f
删除函数:unset 函数名
# 语法1:
function 函数名(){
命令序列
[return x]
}
函数名
# 语法1:
function 函数名 {
命令序列
[return x]
}
函数名
# 语法1:
函数名(){
命令序列
[return x]
}
函数名
函数的退出状态码:
1、默认取决于函数中执行的最后一条命令的退出状态码
2、自定义退出状态码,格式如下:
1、return 从函数中返回,用最后状态命令决定返回值
2、return 0 表示正确返回
3、return 1-255 表示错误返回
fork炸弹是一种恶意程序,它内部是一个不断在fork进程的无限循环,实质是一个简单的递归程序。由于程序是递归的,如果没有任何限制,这会导致这个简单的程序迅速耗尽系统里的所以资源
函数实现fork炸弹:
:(){ :|:& };:
bomb() { bomb | bomb & }; bomb
脚本实现fork炸弹:
cat bomb.sh
#!/bin/bash
./$0|./$0&
shell编程之return
参考:https://www.linuxidc.com/Linux/2018-12/155951.htm
https://zhidao.baidu.com/question/116528967.html
1、终止一个函数.
2、return命令允许带一个整型参数, 这个整数将作为函数的"退出状态
码"返回给调用这个函数的脚本, 并且这个整数也被赋值给变量$?
3、命令格式:return value
shell编程之数组
变量: 存储单个元素的内存空间
数组:存储多个元素的连续的内存空间,相当于多个变量的集合
数组名和索引:
索引:编号从0开始,属于数值索引
注意:索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash4.0版本之后开始支持了。bash的 数组支持稀疏格式(索引不连续)
声明数组:
declare -a ARRAY_NAME
declare -A ARRAY_NAME #关联数组
注意:两者不可以相互转换
数组赋值:
数组元素的赋值
1、一次只赋值一个元素
ARRAT_NAME[INDEX]=VALUE
weekdays[0]="Sunday"
weekdays[4]="Thursday"
2、一次赋值全部元素,空格隔开
ARRAY_NAME=("VAL1" "VAL2" ……)
3、只赋值特定元素
ARRAY_NAME=([0]="VAL1" [6]="VAL2",……)
4、交互式数组值对赋值
read -a ARRAY
显示所有数组:declare -a
引用数组:
引用数组元素:
${ARRAY_NAME[INDEX]}
注意:省略[INDEX]表示引用下标为0的元素
引用数组所有元素:
${ARRAY_NAME[*]}
${ARRAY_NAME[@]}
数组的长度(数组中元素的个数):
${#ARRAY_NAME[*]}
${#ARRAY_NAME[@]}
删除数组中的某元素:导致稀疏格式
unset ADDAY[INDEX]
删除整个数组:
unset ARRAY
遍历存在以下三种方式:
(1)${数组名[@]}、${数组名[*]}均可以获得所有元素(不管是元素列表,还是一整个字符串),使用for循环遍历即可
(2)带数组下标的遍历,当需要使用到数组的下标时,可以使用${!数组名[@]}
(3)while循环:根据元素的个数遍历,但对于稀疏数组,可能会丢失数据
数组数据处理:
引用数组中的元素:
数组切片:${ARRAY[@]:offset:number}
offset:要跳过的元素个数
number:要取出的元素个数
取偏移量之后的所以元素
${ARRAY[@]:offset}
向数组中追加元素:
ARRAY[${#ARRAY[*]}]=value
关联数组:
declare -A ARRAT_NAME
ARRAY_NAME=([index_name1]='val1' [index_name2]='val2' ……)
注意:关联数组必须先声明在调用
#找出最大值和最小值
#!/bin/bash
declare -a num
declare -i max
for i in {0..9}
do
num[$i]=$[$RANDOM%10]
done
echo ${num[*]}
max="${num[0]}"
for j in ${num[@]}
do
if [ $max -le $j ]
then
max=$j
fi
done
echo "max is:$max"
----------------------------------------------------------------
#!/bin/bash
declare -a rand
for ((i=0;i<10;i++))
do
rand[$i]=$RANDOM
if [ $i -eq 0 ]
then
max=${rand[$i]}
min=$max
else
[ $max -lt ${rand[$i]} ] && { max=${rand[$i]};continue; }
[ $min -gt ${rand[$i]} ] && min=${rand[$i]}
fi
done
echo "${rand[*]}"
echo "max is : $max"
echo "min is : $min"
shell编程之expect
参考:http://www.51niux.com/?id=55
Expect是Unix系统中用来进行自动化控制和测试的软件工具,由Don Libes制作,作为Tcl脚本语言的一个扩展,应用在交互式软件中如telnet,ftp,passwd,fsck,rlogin,tip,ssh等等。该工具利用Unix伪终端包装其子进程,允许任意程序通过终端接入进行自动化控制;也可利用Tk工具,将交互程序包装在X11的图形用户界面中。
一般将expect脚本的后缀命名为".exp"
# 安装
yum install expect -y
# expect 语法
expect [选项] [-c cmds] [args]
# 选项
-c : 从命令行执行expect脚本,默认expect是交互执行的
| 选项 | 作用 |
|---|---|
-c |
命令行执行expect脚本,默认expect是交互执行的,可多次使用 |
-d |
debug模式,可以在运行时输出一些诊断信息,与在脚本开始处使用exp_internal 1相似。 |
-D |
启用交换调式器,可设一整数参数。 |
-f |
从文件读取命令,仅用于使用#!时。如果文件名为"-",则从stdin读取(使用"./-"从文件名为-的文件读取)。 |
-i |
交互式输入命令,使用"exit"或"EOF"退出输入状态 |
-- |
标示选项结束(如果你需要传递与expect选项相似的参数给脚本时),可放到#!行:#!/usr/bin/expect -- |
-v |
显示expect版本信息 |
# 常用命令
spawn 新建一个新进程,这个进程的交互由expect控制
expect 等待接受进程返回的字符串,直到超时时间,根据规则决定下一步操作
send 发送字符串给expect控制的进程
set 设定变量为某个值
exp_continue 重新执行expect命令分支
[lindex $argv 0] 获取expect脚本的第1个参数
[lindex $argv 1] 获取expect脚本的第2个参数
set timeout -1 设置超时方式为永远等待
set timeout 30 设置超时时间为30秒
interact 将脚本的控制权交给用户,用户可继续输入命令
expect eof 等待spawn进程结束后退出信号eof
| 命令参数 | 作用 |
|---|---|
| spawn | 新建一个新进程,执行后面的命令或程序。需要进入到expect环境才可以执行,不能直接在shell环境下直接执行 |
| set timeout n | 设置超时时间,表示该脚本代码需在n秒钟内完成,如果超过,则退出。用来防止ssh远程主机网络不可达时卡住及在远程主机执行命令宕住。如果设置为-1表示不会超时 |
| set | 定义变量. |
| $argv | expect脚本可以接受bash的外部传参,可以使用[ lindex $argv n ]n为0表示第一个传参,为1表示第二个传参,以此类推 |
| expect | 从交互程序进程中指定接收信息, 如果匹配成功, 就执行send的指令交互;否则等待timeout秒后自动退出expect语句 |
| send | 如果匹配到expect接受到的信息,就将send中的指令交互传递,执行交互动作。结尾处加上\r表示如果出现异常等待的状态可以进行核查 |
| exp_continue | 表示循环式匹配,通常匹配之后都会退出语句,但如果有exp_continue则可以不断循环匹配,输入多条命令,简化写法。 |
| exit | 退出expect脚本 |
| expect eof | spawn进程结束后会向expect发送eof,接收到eof代表该进程结束 |
| interact | 执行完代码后保持交互状态,将控制权交给用户。没有该命令执行完后自动退出而不是留在远程终端上 |
| puts | 输出变量 |
#用法
#单一分支
# vim test.exp
#!/usr/bin/expect
set timeout 20
set password 123456
spawn ssh root@192.168.137.7
expect "*assword:" { send "$password\r" }
expect eof # 注意:就算这里是interact也不会以保持交互状态
#多分支模式写法
# vim test.exp
#!/usr/bin/expect
set timeout 20
set password 123456
spawn ssh root@192.168.137.7
expect {
"(yes/no)?" { send "yes\r"; exp_continue }
"*assword:" { send "$password\r" }
}
expect eof # 注意:就算这里是interact也不会以保持交互状态
# shell脚本调用expect进行免密登录
#!/bin/bash
ip=$1
user=root
passwd="dasdas"
expect << EOF
spawn ssh ${user}@${ip}
# \n表示换行
expect {
"yes/no" {send "yes\n";exp_continue }
"password" { send "$passwd\n" }
}
#expect "]#" { send "exit\n" }
expect eof
#interact
EOF
./Script_name target_IP
# shell脚本调用expect进行传输ssh-key进行免密登录
[root@test ~/.ssh]#cat SSH_secret_free_login_ssh-copy-id
#!/bin/bash
for line in $(cat ./service_list);do
echo $line
ip=${line}
user=root
passwd="qaz!fss321"
expect << EOF
spawn /usr/bin/ssh-copy-id -i /root/.ssh/id_rsa.pub ${user}@${ip}
expect {
"yes/no" {send "yes\n";exp_continue }
"password" { send "$passwd\n" }
}
#expect "]#" { send "exit\n" }
expect eof
interact
EOF
sleep 6
done
cat ./service_list
192.168.137.7
shell编程之sshpass
sshpass用于免密执行Linux相关命令
如何在编写 SHELL 显示多个信息,echo或者 EOF
echo 'xxxxxx'
echo 'xxxxxx'
或者
cat << EOF
+--------------------------------------------------------------+
| === Welcome to Bash Shell === |
+--------------------------------------------------------------+
EOF
Living Example:统计当前系统的使用率
[root@CentOS6 ~]# vim user_cache.sh (内容如下)
#!/bin/bash
echo "当前系统内存使用百分比为:"
USEFREE=`free -m | grep -i mem | awk '{print $3/$2*100 "%"}'`
echo -e "内存使用百分比:\e[31m${USEFREE}\e[0m"
[root@CentOS6 ~]# bash user_cache.sh (运行脚本)
当前系统内存使用百分比为:
内存使用百分比:86.0204%
Living Example:为root用户编写登陆脚本
vim /root/welcome.sh
#!/bin/bash
#此脚本用于显示进程数,登陆的用户数与用户名,根分区的磁盘使用率
echo "已开启进程数:$(($(ps aux | wc -l)-1))"
echo "已登录用户数:$(who | wc -l)"
echo -e "已登录的用户账号:\n$(who | awk '{print $1}')"
echo "根分区磁盘使用率:$(df -h | grep "/$" | awk '{print $4}')"
#echo "根分区磁盘使用率:"`df -h | grep "/$" | awk '{print $4}'`
修改/roo/.bash_profile,调用welcome.sh
Living Example:用户登录脚本详情
#系统基础检测
cat > /etc/profile.d/system-info.sh << 'EOF'
#/bin/bash
#Copyright (c) [2019] Huawei Technologies Co., Ltd.
#generic-release is licensed under the Mulan PSL v1.
#You can use this software according to the terms and conditions of the Mulan PSL v1.
#You may obtain a copy of Mulan PSL v1 at:
# http://license.coscl.org.cn/MulanPSL
#THIS SOFTWARE IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR
#IMPLIED, INCLUDING BUT NOT LIMITED TO NON-INFRINGEMENT, MERCHANTABILITY OR FIT FOR A PARTICULAR
#PURPOSE.
#See the Mulan PSL v1 for more details.
# Welcome
welcome=$(uname -r)
# Memory
memory_total=$(free -m | awk '/Mem:/ { printf($2)}')
if [ $memory_total -gt 0 ]
then
memory_usage=$(free -m | awk '/Mem:/ { printf("%3.1f%%", $3/$2*100)}')
else
memory_usage=0.0%
fi
# Swap memory
swap_total=$(free -m | awk '/Swap:/ { printf($2)}')
if [ $swap_total -gt 0 ]
then
swap_mem=$(free -m | awk '/Swap:/ { printf("%3.1f%%", $3/$2*100)}')
else
swap_mem=0.0%
fi
# Usage
usageof=$(df -h / | awk '/\// {print $(NF-1)}')
# System load
load_average=$(awk '{print $1}' /proc/loadavg)
# WHO I AM
whoiam=$(whoami)
# Time
time_cur=$(date)
# Processes
processes=$(ps aux | wc -l)
# echo "已开启进程数:$(($(ps aux | wc -l)-1))"
# Users
user_num=$(users | wc -w)
# Ip address
ip_pre=$(/sbin/ip a|grep inet|grep -v 127.0.0.1|grep -v inet6 | awk '{print $2}' | head -1)
ip_address=${ip_pre%/*}
echo -e "\n"
echo -e "Welcome to $welcome\n"
echo -e "System information as of time: \t$time_cur\n"
echo -e "User who has logged in: \t$(who | awk '{print $1}')"
echo -e "System load: \t\033[0;33;40m$load_average\033[0m"
echo -e "Processes: \t$processes"
echo -e "Memory used: \t$memory_usage"
echo -e "Swap used: \t$swap_mem"
echo -e "Disk Usage On: \t$usageof"
echo -e "Root disk availability: \t$(df -h | grep "/$" | awk '{print $4}')"
echo -e "IP address: \t$ip_address"
echo -e "Users online: \t$user_num"
echo -e "User who has logged in: \t$(who | awk '{print $1}' | xargs echo)"
if [ "$whoiam"=="root" ]
then
echo -e "\n"
else
echo -e "To run a command as administrator(user \"root\"),use \"sudo <command>\"."
fi
umask 0077
EOF
umask 0077 是一个设置文件权限的 umask 命令。umask 命令用于确定新创建文件和目录的默认权限。
在 Linux 系统上,文件和目录都有一组权限来控制对其的访问和操作。umask 值通过与默认权限进行按位与运算,来确定不应该设置的权限位。在这种情况下,0077 表示关闭其他用户的读、写和执行权限,同时关闭组用户的读、写和执行权限,只保留文件所有者的读、写和执行权限。
具体来说,对于新创建的普通文件,默认权限是 -rw-rw-rw-(八进制表示为 0666),而对于新创建的目录,默认权限是 rwxrwxrwx(八进制表示为 0777)。应用 umask 0077 后,普通文件的权限将变为 0600(只有文件所有者有读写权限),目录的权限将变为 0700(只有目录所有者有读写执行权限)。
可以在 Shell 中直接运行 umask 0077 来临时更改当前会话的 umask 值。如果想使此更改永久生效,可以将 umask 0077 添加到 Shell 配置文件(如 ~/.bashrc 或 /etc/profile)中。
请注意,在更改 umask 值时要小心,确保您理解这样做可能会对系统的安全性和功能产生的影响。建议在修改系统文件之前进行适当的测试和备份。
Living Example:监控每天固定时间的网络状态并生成csv文件发送到自己的邮箱的小脚本
#!/bin/bash
tname=`date +%Y-%-m-%-d`
echo ${tname}
dstat -tnf --output /tmp/eths_${tname}.csv 1 40 #显示时间的分页网卡状态,因为我的服务器有5块网卡,自动生成一个eths_(每天日期).csv的文件
echo "今天的备份" | mail -a /tmp/eths_${tname}.csv -s "今天的备份文件" xxxx@qq.com #发送文件到我得邮箱
#最后把这个脚本写进周期计划任务就行了,每天十点发送邮件给我:
crontab -e
0 10 * * * /usr/src/脚本名字.sh >/dev/null 2>&1
Living Example:几个shell初学者必会脚本
#!/bin/bash
declare -i sum=0
for i in {1..5};do
# let sum=sum+i
let sum+=i
done
echo $sum
unset sum (这一步可有可无,就是清除变量)
-----------------------------------------------------------------------------------------
#!/bin/bash
for ((sum=0,i=1;i<=100;i++))
do
let sum+=i
done
echo sum=$sum
-----------------------------------------------------------------------------------------
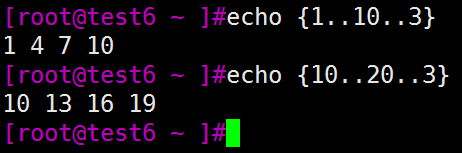
[root@test opt]# sum=0;for i in {1..100..3};do let sum=sum+i;done;echo sum=$sum
sum=1717
-----------------------------------------------------------------------------------------
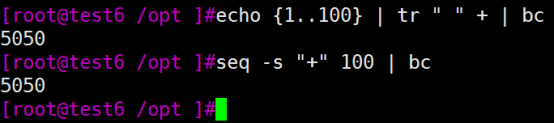
[root@test-6 /script]#echo {1..100} | tr -s " " "+" | bc
5050
-----------------------------------------------------------------------------------------
sum=`seq -s "+" 1 2 100 | bc`
echo "奇数之和为:$sum"
-----------------------------------------------------------------------------------------
#求整体之和
sumall=`awk 'BEGIN{for(i=1;i<=100;i++)sum+=i;print sum}'`
echo "整体之和为:$sumall"
-----------------------------------------------------------------------------------------
[root@CentOS-6-2 /script 16:52]#cat haha.txt
2
3
4
[root@CentOS-6-2 /script 16:52]#awk '{sum=sum+$1};END{print sum}' haha.txt
9
[root@CentOS-6-2 /script 16:52]#awk '{sum+=$1};END{print sum}' haha.txt
9
2. [root@master sh]# cat test2.sh #计算开机率
#!/bin/bash
success=0
fail=0
for((i=1;i<50;i++));do
IP="172.16.80.$i"
ping -c1 $IP > /dev/null 2>&1
if [ $? -eq 0 ] ;then
let success=$success+1
else
let fail=$fail+1
fi
done
echo "computer start ratio $(($success*100/50))%"
echo "computer close ratio $(($fail*100/50))%"
====================================
#!/bin/bash
declare -a net
net=(192.168.{136,137}.{1..100})
for i in ${net[@]}
do
{ if ping -c4 -i 0.2 -W3 $i &> /dev/null ;then
echo "$i is up "
else
echo "$i is down"
fi ; } &
done > /tmp/net.txt
wait
echo "`cat /tmp/net.txt | grep "up"`"
echo -e "Number of starts:`cat /tmp/net.txt | fgrep "up" | wc -l`\nEverything else is down"
=============网路畅通性===============
3.[root@master sh]# cat test3.sh (乘法口诀表)
#!/bin/bash
#1*1=1
#1*2=2 2*2=4
#1*3=3 2*3=6 3*3=9
#1*4=4 2*4=8 3*4=12 4*4=16
#.............................
#
#实质被乘数就是行数。乘数的变化:乘数永远小于等于行数。
#乘数是number1 被乘数是line
#
for((line=1;line<=9;line++));do
for((number1=1;number1<=line;number1++));do
echo -n "$number1*$line=$[$number1*$line] "
done
echo
done
=====================================
#!/bin/bash
for i in {1..9};do
for ((j=1;j<=i;j++));do
let C=$j*$i
echo -ne "$j*$i=$C\t"
done
echo ""
done
=====================================
#!/bin/bash
for i in `seq 9`
do
for j in `seq $i`
do
echo -ne "$j*$i=$(($i*$j))\t"
done
echo ""
done
=====================================
4. [root@master ~]# cat ./tree1.sh
#!/bin/bash
#三角形:
# 三角形的总行数为total_line(5).
# 每行中有“total_line 减当前行数”个空格,假设当前行为current_line
# 每行中有"当前行*2-1" 个星(star)
total_line=5
for((line=1;line<=total_line;line++));do
for((k=1;k<=total_line-line;k++));do
echo -n " "
done
for((s=1;s<=line*2-1;s++));do
echo -n '*'
done
echo
done
total_line=4
for((line=1;line<=total_line;line++));do
for((k=1;k<=3;k++));do
echo -n " "
done
for((s=1;s<=3;s++));do
echo -n '*'
done
echo
done
Living Example:调用系统的function里的action动作
#!/bin/bash
. /etc/init.d/functions
case $1 in
start)
echo "starting..."
action "starting true" /bin/true
;;
stop)
echo "stop"
action "stop" /bin/false
;;
*)
echo "hahaa"
;;
esac
用户登录系统次数、用户登录系统时长
参考:https://mp.weixin.qq.com/s/b6eF96ZFJHgLkSq3gI4PSw
作为一名 Linux程序员,每天都要跟服务器打交道,那么想要找到谁在摸鱼,只要关注他的两个指标就行:
Linux系统给我们提供了大量非常实用的命令,当然有一些命令可以用来查看系统各用户在系统上登录的次数,以及使用系统总时间。用户的这些信息是保存在 /var/log/wtmp 文件里,所以我们就可以通过一些简单的命令把我们想要的信息提取出来。这些信息就是摸鱼的证据!
使用 last 命令获取用户登录信息
一个可以实现这个目的的命令就是last 命令。这个命令可以列出用户登录的详细信息,可供我们进行追溯。它的典型输出如下:
[root@VM-16-16-centos ~ 18:01:02]# last | head -5 | tr -s " "
root pts/2 118.122.119.70 Tue Jun 28 11:33 still logged in
root pts/1 118.122.119.70 Tue Jun 28 11:26 still logged in
root pts/0 118.122.119.70 Tue Jun 28 11:05 - 13:20 (02:14)
root pts/0 101.206.168.66 Sun Jun 26 21:20 - 21:39 (00:18)
root pts/0 118.122.119.70 Fri Jun 24 12:15 - 18:43 (06:27)
在上面这行命令中,tr -s " "表示将多个空格合并为一个,这样可以节约篇幅。如果没有加上 tr 命令的话,它的输出会类似下面这样:
[root@VM-16-16-centos ~ 18:01:15]# last | head -5
root pts/2 118.122.119.70 Tue Jun 28 11:33 still logged in
root pts/1 118.122.119.70 Tue Jun 28 11:26 still logged in
root pts/0 118.122.119.70 Tue Jun 28 11:05 - 13:20 (02:14)
root pts/0 101.206.168.66 Sun Jun 26 21:20 - 21:39 (00:18)
root pts/0 118.122.119.70 Fri Jun 24 12:15 - 18:43 (06:27)
像上面那样 last 命令没有跟任何参数的话,它会列出所有用户的登录信息。如果你只想看某个用户登录情况,那么只需在last 后面跟上具体的用户名即可,即:
last username
这里还加了head -5命令,它的作用是只列出 last 命令结果的前 5条信息。如果不加这个命令的话,那么出来的结果将很长,我们可以用 wc 命令稍微瞧一眼:
last | wc -l
所以,通过 last 命令可以看到每个人的登录情况,摸鱼的小伙伴们,请接招!
第一招:统计每个用户登录次数
在last命令的结果里,用户每登录一次,就会产生一条记录,所以这里我们就可以使用这些记录来统计每个用户登录的次数。
[root@ ~]# for user in `ls /home` ;do echo -ne "$user\t"; last $user | wc -l ;done
lighthouse 13
在上面的命令里,我们先获取 home 目录下所有用户,然后依次使用last命令获取他们的登录情况,再使用wc命令统计他们的登录次数。
当然,为了查看大家的登录次数,每次都要敲这么长的一条命令,那真的很让人抓狂。所以一个比较好的办法就是将这条命令直接写成shell 脚本,下次我们想用的时候就可以直接运行它了。
我们可以新建一个 show_user_logins.sh 脚本,然后使用 vim 写入以下内容:
# cat show_user_logins.sh
#!/bin/bash
echo -n "Logins since: "
who /var/log/wtmp | head -1 | awk '{print $3}'
echo "================="
for user in `ls /home`
do
echo -ne "$user\t"
last $user | wc -l
done
写完之后按 :wq 保存退出。再之后使用命令 chmod +xshow_user_logins.sh 使这个脚本具有可执行属性。
一切准备就绪后我们就可以运行这个脚本,可以看到得到的结果跟我们在命令行里手动敲的命令结果一致。
通过第一招,摸鱼的小伙伴已经浮出水面,并受到重重一击:但作为资深摸鱼专家,我肯定知道,用户每登录一次就会有一次记录,那么多登几次就会显得自己很勤快,所以使用这种方法很容易躲避追击。
不急,我还有第二招,想在我眼皮底下摸鱼没那么容易!
第二招:统计每个用户登录时长
last命令只能统计用户的登录记录,但不能统计用户的登录时长。如果想统计每个用户的登录时长,那么就要使用另一个命令了:ac 命令。ac 命令使用方法很简单,只需在 ac 后面跟上你想统计的用户即可,如下:
# 安装
yum provides */ac
yum install -y psacct
[root@ ~ 16:10:47]# ac root
total 418.73
这个结果表示用户 root在这台电脑上的总登录时长是 31.61 小时(ac命令统计出来的结果默认单位是小时 )
我们可以仿照上面写出统计每个用户登录时长的命令:
[root@ ~ 16:11:45]# for user in `ls /home`;do ac $user |sed "s/total/$user\t/" ;done
lighthouse 0.45
同样地,这里先获取 home 目录下所有用户名,然后再将这些用户名作为参数传给ac 命令,就可以统计出来所有每个用户的登录时长了。
我们可以从上面的 ac 命令结果看到,它的执行结果都是 total +时长 ,如果所有用户的结果都这样,那么我们就无法区别谁是谁了。所以我们在这里再使用 sed 命令,将total 替换为具体的用户名,以作区分。
这里还有个小小的瑕疵,就是每个用户名之前会空出几个空格,虽然不影响结果,但看起来有点别扭,我们可以再使用一个 sed 命令将其去掉。
# for user in `ls /home`; do ac $user | sed "s/^\t//" | sed "s/total/$user\t/" ;done
lighthouse 0.45
同样地,我们可以将以上命令写成脚本,后面就可以更方便使用。这里我们所使用的脚本名称是 show_user_hours.sh ,当然你可以自定义。
# cat show_user_hours.sh
#!/bin/bash
echo -n "hours online since: "
who /var/log/wtmp | head -1 | awk '{print $3}'
echo "==============================="
for user in `ls /home`; do ac $user | sed "s/^\t//" | sed "s/total/$user\t/" ;done
脚本的执行结果如下,同样与手敲命令结果一致:
通过第二招,摸鱼的小伙伴已经无处遁形,并受到了 1万 点伤害
通用java服务启动脚本
# cat xxxx.sh
#!/bin/bash
# chkconfig: 345 85 15
# description: xxxx service
#
# xxx Start up the xxxx server daemon
#
# source function library
. /etc/rc.d/init.d/functions
#定义配置文件路径
INITFILE=/usr/local/icbc/config/icbc-service.yml
#程序名
ProgramName="xxxx.jar"
#定义命令
CMD="/usr/java/jdk1.8.0_251/bin/java -jar /usr/local/jar/${ProgramName} --spring.config.location=${INITFILE} -Xms4G -Xmx4G"
pidN=`ps aux | grep ${ProgramName} | grep -v grep | awk '{print $2}' | wc -l`
pid=`ps aux | grep ${ProgramName} | grep -v grep | awk '{print $2}'`
start()
{
status
while true; do
nohup $CMD >/dev/null 2>&1 &
echo "${ProgramName} is running background..."
sleep 10
pidN=`ps aux | grep ${ProgramName} | grep -v grep | awk '{print $2}' | wc -l`
if [ $pidN -ge 1 ];then
pid=`ps aux | grep ${ProgramName} | grep -v grep | awk '{print $2}'`
action "start ${ProgramName} true. pid=${pid}" /bin/true
break
else
action "start ${ProgramName} Failed." /bin/false
fi
done
}
stop()
{
pid=`ps aux | grep ${ProgramName} | grep -v grep | awk '{print $2}'`
if [ ! -z ${pid} ];then
echo $pid
kill -9 `ps aux | grep ${ProgramName} | grep -v grep | awk '{print $2}' | xargs echo`
action "stop ${ProgramName} true" /bin/true
else
action "${ProgramName} stopped" /bin/true
fi
}
status()
{
if [ $pidN -ge 1 ];then
action "${ProgramName} already started. pid=${pid}" /bin/true
exit 0
else
action "${ProgramName} Program not started." /bin/true
fi
}
case "$1" in
start)
start
;;
stop)
stop
;;
status)
status
;;
*)
echo $"Usage: $0 {start|stop|status}"
esac
nohup $CMD & &> /dev/null 这样还是能让nohup的结果输出
是的,nohup 命令用于在后台运行命令,并防止其受到终端关闭或断开连接的影响。然而,&> /dev/null 这一部分并不能完全抑制输出,因为它只会将命令的标准输出和错误输出重定向到 /dev/null 文件,而不会吸收 nohup 命令本身的输出。
如果你希望完全抑制 nohup 命令的所有输出,可以使用以下形式:
nohup $CMD >/dev/null 2>&1 &
这里的 >/dev/null 将标准输出重定向到 /dev/null,2>&1 则将标准错误输出重定向到与标准输出相同的位置(即/dev/null),最后的 & 使命令在后台运行。
你需要保留 nohup 命令的输出日志,可以将输出重定向到一个文件中。例如:
#保存本次的
nohup $CMD > /path/to/logfile.log 2>&1 &
#保存所有的
nohup $CMD >> /path/to/logfile.log 2>&1 &
这将把 nohup 命令及其执行的命令的标准输出和错误输出都重定向到指定的日志文件 /path/to/logfile.log 中。通过这种方式,你可以在日志文件中查看执行结果,而不会在终端上显示。
免责声明: 本文部分内容转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。